
Mots-clés:GPT-4.5, Grand modèle, Détails d’entraînement de GPT-4.5, Performances de Huawei PanGu Ultra, Impact du RLHF sur les capacités de raisonnement, Recherche sur la limite d’apprentissage humain de 4GB, Ensemble de données mathématiques open source MegaMath
🔥 Pleins feux
OpenAI révèle les détails et les défis de l’entraînement de GPT-4.5 : Le CEO d’OpenAI, Sam Altman, et l’équipe technique principale de GPT-4.5 ont discuté des détails du développement du modèle. Le projet a démarré il y a deux ans, mobilisant la quasi-totalité de l’entreprise et prenant plus de temps que prévu. L’entraînement a rencontré des « problèmes catastrophiques » tels que des pannes de cluster de 100 000 cartes GPU et des bugs cachés, exposant les goulots d’étranglement de l’infrastructure, mais favorisant également la mise à niveau de la stack technologique. Aujourd’hui, seulement 5 à 10 personnes suffisent pour répliquer un modèle de niveau GPT-4. L’équipe estime que l’amélioration future des performances dépendra de l’efficacité des données plutôt que de la puissance de calcul, nécessitant le développement de nouveaux algorithmes pour apprendre davantage à partir de la même quantité de données. L’architecture système évolue vers le multi-cluster, impliquant potentiellement la collaboration de dizaines de millions de GPU à l’avenir, ce qui exige une plus grande tolérance aux pannes. La discussion a également porté sur la Scaling Law, la conception conjointe du machine learning et des systèmes, et la nature de l’apprentissage non supervisé, illustrant la réflexion et la pratique d’OpenAI dans la promotion de la recherche et du développement de grands modèles de pointe (Source : 36Kr)

Huawei lance le grand modèle dense Pangu Ultra de 135 milliards de paramètres, natif Ascend : L’équipe Pangu de Huawei a lancé Pangu Ultra, un grand modèle de langage généraliste dense de 135 milliards de paramètres, entraîné sur des NPU Ascend de fabrication chinoise. Le modèle utilise une structure Transformer à 94 couches et introduit les technologies Depth-scaled sandwich-norm (DSSN) et TinyInit pour résoudre les problèmes de stabilité de l’entraînement des modèles ultra-profonds, réalisant un entraînement stable sans pics de perte (loss spikes) sur 13,2T de données de haute qualité. Au niveau système, grâce à des optimisations telles que le parallélisme hybride, la fusion d’opérateurs et le découpage de sous-séquences, le taux d’utilisation de la puissance de calcul (MFU) sur un cluster Ascend de 8192 cartes a été porté à plus de 50%. Les évaluations montrent que Pangu Ultra surpasse les modèles denses tels que Llama 405B et Mistral Large 2 sur plusieurs benchmarks, et peut rivaliser avec des modèles MoE à plus grande échelle comme DeepSeek-R1, prouvant la faisabilité du développement de grands modèles de pointe basés sur la puissance de calcul nationale (Source : 机器之心)

Une étude remet en question la significativité de l’amélioration des capacités de raisonnement des LLM par l’apprentissage par renforcement : Des chercheurs de l’Université de Tübingen et de l’Université de Cambridge remettent en question les affirmations récentes selon lesquelles l’apprentissage par renforcement (RL) améliorerait considérablement les capacités de raisonnement des modèles de langage. Grâce à une enquête rigoureuse sur les benchmarks de raisonnement couramment utilisés (tels que AIME24), l’étude révèle une grande instabilité des résultats : le simple changement de la graine aléatoire (random seed) peut entraîner des fluctuations importantes des scores. Dans le cadre d’une évaluation standardisée, l’amélioration des performances apportée par le RL est bien inférieure à celle rapportée initialement, souvent non statistiquement significative, voire inférieure aux effets du fine-tuning supervisé (SFT), avec une capacité de généralisation également plus faible. L’étude souligne que les différences d’échantillonnage, les configurations de décodage, les cadres d’évaluation et l’hétérogénéité matérielle sont les principales causes d’instabilité, et appelle à l’adoption de normes d’évaluation plus strictes et reproductibles pour évaluer avec objectivité les progrès réels des capacités de raisonnement des modèles (Source : 机器之心)

Discours TED d’Altman : Lancement prochain d’un modèle open source puissant, ChatGPT n’est pas une AGI : Le CEO d’OpenAI, Sam Altman, a déclaré lors de la conférence TED qu’un modèle open source puissant était en développement, dont les performances dépasseront tous les modèles open source existants, répondant directement aux concurrents tels que DeepSeek. Il a souligné que le nombre d’utilisateurs de ChatGPT continue de croître de manière exponentielle et que la nouvelle fonction de mémoire améliorera l’expérience personnalisée. Il estime que l’IA connaîtra des percées dans les domaines de la découverte scientifique et du développement logiciel (gains d’efficacité énormes), mais que les modèles actuels comme ChatGPT ne possèdent pas encore la capacité d’auto-apprentissage continu et de généralisation inter-domaines, et ne sont donc pas des AGI. Il a également abordé les questions de droit d’auteur et de « droit au style » soulevées par les capacités créatives de GPT-4o, et a réaffirmé la confiance d’OpenAI dans la sécurité de ses modèles et ses mécanismes de contrôle des risques (Source : 新智元)

Une étude estime la limite d’apprentissage humain à environ 4 Go sur une vie, suscitant un débat sur les interfaces cerveau-machine et le développement de l’IA : Une étude de Caltech publiée dans la revue Neuron (groupe Cell) estime la vitesse de traitement de l’information du cerveau humain à environ 10 bits par seconde, bien inférieure au taux de collecte de données du système sensoriel (environ 1 milliard de bits par seconde). Sur cette base, l’étude déduit que la limite d’accumulation de connaissances humaines sur une vie (en supposant 100 ans d’apprentissage continu sans oubli) est d’environ 4 Go, bien moins que la capacité de stockage des paramètres des grands modèles (par exemple, un modèle 7B peut stocker 14 milliards de bits). L’étude attribue ce goulot d’étranglement au mécanisme de traitement sériel du système nerveux central et prédit que le dépassement de l’intelligence humaine par l’intelligence artificielle n’est qu’une question de temps. L’étude remet également en question Neuralink de Musk, arguant qu’il ne peut pas surmonter les limitations structurelles fondamentales du cerveau et qu’il serait préférable d’optimiser les méthodes de communication existantes. Cette recherche a déclenché de vastes discussions sur les limites cognitives humaines, le potentiel de développement de l’IA et l’orientation des interfaces cerveau-machine (Source : 量子位)

🎯 Tendances
GPT-4 bientôt retiré, GPT-4.1 et un nouveau modèle mystérieux pourraient faire leur apparition : OpenAI a annoncé qu’à partir du 30 avril, GPT-4o remplacera complètement GPT-4 (sorti il y a deux ans) dans ChatGPT, ce dernier restant disponible via l’API. Parallèlement, des fuites dans la communauté et le code suggèrent qu’OpenAI pourrait bientôt lancer une série de nouveaux modèles, notamment GPT-4.1 (et ses versions mini/nano), un modèle d’inférence o3 pleine puissance, ainsi qu’une nouvelle série o4 (comme o4-mini). Un modèle mystérieux nommé Optimus Alpha est apparu sur OpenRouter, affichant d’excellentes performances (notamment en programmation) et supportant un contexte d’un million de tokens. Il est largement spéculé qu’il s’agit de l’un des nouveaux modèles qu’OpenAI s’apprête à lancer (potentiellement GPT-4.1 ou o4-mini), partageant de nombreuses similitudes (comme des bugs spécifiques) avec les modèles d’OpenAI. Cela indique une accélération du rythme d’itération des modèles d’OpenAI, qui consolide activement sa position de leader technologique (Source : source, source)

Le grand modèle Qwen3 d’Alibaba est en préparation : Des sources indiquent qu’Alibaba prévoit de lancer prochainement le grand modèle Qwen3. L’équipe de R&D confirme que le modèle est entré dans sa phase finale de préparation, mais la date de lancement exacte n’est pas fixée. Qwen3 serait le produit modèle phare d’Alibaba pour le premier semestre 2025, son développement ayant commencé après Qwen2.5. Influencée par des modèles concurrents comme DeepSeek-R1, l’équipe des modèles fondamentaux d’Alibaba Cloud a recentré sa stratégie sur l’amélioration des capacités de raisonnement du modèle, montrant une focalisation stratégique sur des capacités spécifiques dans le paysage concurrentiel des grands modèles (Source : InfoQ)

Kimi baisse les prix de sa plateforme ouverte et publie en open source des modèles de vision légers : La plateforme ouverte Kimi de Moonshot AI a annoncé une réduction des prix pour ses services d’inférence de modèles et son cache de contexte, visant à réduire les coûts pour les utilisateurs grâce à l’optimisation technologique. Parallèlement, Kimi a publié en open source deux modèles de langage de vision légers basés sur l’architecture MoE, Kimi-VL et Kimi-VL-Thinking, supportant un contexte de 128K et n’ayant qu’environ 3 milliards de paramètres actifs. Ils sont censés surpasser de manière significative les grands modèles 10 fois plus grands en termes de capacités de raisonnement multimodal, dans le but de promouvoir le développement et l’application de petits modèles multimodaux efficaces (Source : InfoQ)
Google lance le protocole d’interopérabilité des agents A2A et plusieurs nouveaux produits IA : Lors de la conférence Google Cloud Next ’25, Google, en collaboration avec plus de 50 partenaires, a lancé le protocole ouvert Agent2Agent (A2A), visant à permettre l’interopérabilité et la collaboration entre les agents intelligents IA développés par différentes entreprises et plateformes. Parallèlement, Google a annoncé plusieurs modèles et applications IA, dont Gemini 2.5 Flash (version efficace du modèle phare), Lyria (génération de musique à partir de texte), Veo 2 (création vidéo), Imagen 3 (génération d’images), Chirp 3 (voix personnalisée), et a lancé la septième génération de puces TPU, Ironwood, optimisée pour l’inférence. Cette série d’annonces reflète la stratégie globale et ouverte de Google en matière d’infrastructure IA, de modèles, de plateformes et d’agents intelligents (Source : InfoQ)
ByteDance publie le modèle d’inférence Seed-Thinking-v1.5 de 200 milliards de paramètres : L’équipe Doubao de ByteDance a publié un rapport technique présentant son modèle d’inférence MoE Seed-Thinking-v1.5, qui totalise 200 milliards de paramètres. Ce modèle active 20 milliards de paramètres à chaque fois et affiche d’excellentes performances sur plusieurs benchmarks, dépassant prétendument DeepSeek-R1 qui totalise 671 milliards de paramètres. La communauté spécule qu’il pourrait s’agir du modèle utilisé dans le mode « réflexion approfondie » de l’application Doubao actuelle, démontrant les progrès de ByteDance dans le développement de modèles d’inférence efficaces (Source : InfoQ)
Midjourney lance le modèle V7, améliorant la qualité d’image et l’efficacité de génération : L’outil de génération d’images IA Midjourney a lancé son nouveau modèle V7 (version alpha). Cette nouvelle version améliore la cohérence et la consistance de la génération d’images, en particulier pour les mains, les parties du corps et les détails des objets, et peut générer des textures plus réalistes et riches. V7 introduit le Draft Mode, qui permet une vitesse de rendu dix fois supérieure pour la moitié du coût, idéal pour l’exploration et l’itération rapides. Il propose également les modes turbo (plus rapide mais plus cher) et relax (plus lent mais moins cher) pour répondre aux différents besoins des utilisateurs (Source : InfoQ)
Amazon lance le modèle vocal IA Nova Sonic : Amazon a lancé Nova Sonic, un modèle IA génératif de nouvelle génération traitant nativement la parole. Selon Amazon, ce modèle rivalise avec les meilleurs modèles vocaux d’OpenAI et de Google sur des indicateurs clés tels que la vitesse, la reconnaissance vocale et la qualité du dialogue. Nova Sonic est disponible via la plateforme pour développeurs Amazon Bedrock, utilise une nouvelle API de streaming bidirectionnel et coûte environ 80% moins cher que GPT-4o, visant à fournir des capacités d’interaction vocale naturelle rentables pour les applications IA d’entreprise (Source : InfoQ)
Les fonctions IA de l’iPhone en Chine pourraient être lancées mi-2025, intégrant les technologies de Baidu et Alibaba : Des rapports indiquent qu’Apple prévoit d’introduire le service Apple Intelligence sur les iPhones du marché chinois (potentiellement dans iOS 18.5) avant la mi-2025. Cette fonctionnalité utilisera le grand modèle Wenxin de Baidu pour fournir des capacités intelligentes et intégrera le moteur de censure d’Alibaba pour se conformer aux exigences réglementaires sur le contenu. Apple n’a signé d’accord d’exclusivité ni avec Baidu ni avec Alibaba, ce qui témoigne de sa stratégie de partenariat localisé sur les marchés clés pour déployer rapidement les fonctionnalités IA (Source : InfoQ)
🧰 Outils
Volcano Engine lance l’agent intelligent de données d’entreprise Data Agent : Volcano Engine a lancé Data Agent, un outil d’agent intelligent de données au niveau de l’entreprise. Cet outil exploite les capacités de raisonnement, d’analyse et d’appel d’outils des grands modèles pour comprendre en profondeur les besoins métier de l’entreprise, automatiser des tâches complexes d’analyse et d’application de données telles que la rédaction de rapports de recherche approfondis et la conception de campagnes marketing, améliorant ainsi l’efficacité de l’utilisation des données et la prise de décision en entreprise (Source : InfoQ)
Le nouveau style de génération d’images de GPT-4o attire l’attention : Des utilisateurs des médias sociaux présentent de nouveaux styles créés à l’aide de la fonction de génération d’images de GPT-4o, par exemple en combinant des éléments d’interface rétro de Windows 2000 avec des images de personnages pour générer des effets de collage uniques. Les utilisateurs partagent des techniques de prompts, comme l’utilisation d’images de référence et la combinaison de descriptions de style et de contenu, suscitant l’intérêt de la communauté pour l’exploration du potentiel créatif de GPT-4o (Source : source, source)

📚 Apprentissage
Publication de MegaMath, le plus grand jeu de données open source de pré-entraînement mathématique : LLM360 a lancé MegaMath, un jeu de données open source de pré-entraînement pour le raisonnement mathématique contenant 371 milliards de tokens, dépassant en taille le DeepSeek-Math Corpus. Le jeu de données couvre des pages web à forte densité mathématique (279B), du code lié aux mathématiques (28B) et des données synthétiques de haute qualité (64B). L’équipe a mis en œuvre un pipeline de traitement de données sophistiqué, comprenant l’optimisation de la structure HTML, l’extraction en deux étapes, le filtrage et le raffinement assistés par LLM, garantissant ainsi l’échelle, la qualité et la diversité des données. La validation du pré-entraînement sur le modèle Llama-3.2 montre que l’utilisation de MegaMath apporte une amélioration absolue de 15 à 20% sur les benchmarks GSM8K et MATH, fournissant à la communauté open source une base solide pour l’entraînement des capacités de raisonnement mathématique (Source : 机器之心)

Nabla-GFlowNet : Équilibrer diversité et efficacité dans le fine-tuning des modèles de diffusion : Des chercheurs de la CUHK (Shenzhen) et d’autres institutions proposent Nabla-GFlowNet, une nouvelle méthode de fine-tuning par récompense des modèles de diffusion basée sur les réseaux de flux génératifs (GFlowNet). Cette méthode vise à résoudre les problèmes de convergence lente du fine-tuning par apprentissage par renforcement traditionnel et de surajustement facile avec perte de diversité lors de l’optimisation directe par récompense. En dérivant une nouvelle condition d’équilibre de flux (Nabla-DB) et en concevant une fonction de perte spécifique ainsi qu’une paramétrisation du gradient de flux logarithmique, Nabla-GFlowNet peut aligner efficacement le modèle sur les fonctions de récompense (comme le score esthétique, le suivi d’instructions) tout en préservant la diversité des échantillons générés. Des expériences sur Stable Diffusion ont démontré ses avantages par rapport aux méthodes telles que DDPO, ReFL et DRaFT (Source : 机器之心)
Llama.cpp corrige des problèmes liés à Llama 4 : Le projet llama.cpp a fusionné deux corrections pour les modèles Llama 4, concernant RoPE (Rotary Positional Embedding) et des calculs de normes incorrects. Ces corrections visent à améliorer la qualité de sortie du modèle, mais les utilisateurs devront peut-être retélécharger les fichiers de modèle GGUF générés avec les outils de conversion mis à jour pour en bénéficier (Source : source)
💼 Affaires
Nvidia finalise l’acquisition de Lepton AI : Selon des rapports, Nvidia a acquis Lepton AI, une startup d’infrastructure IA fondée par l’ancien vice-président d’Alibaba, Jia Yangqing, pour une valeur potentielle de plusieurs centaines de millions de dollars. L’activité principale de Lepton AI consiste à louer des serveurs GPU Nvidia et à fournir des logiciels pour aider les entreprises à construire et gérer des applications IA. Jia Yangqing, son co-fondateur Bai Junjie et une vingtaine d’employés ont rejoint Nvidia. Cette acquisition est considérée comme une démarche stratégique de Nvidia pour étendre ses services cloud et ses logiciels d’entreprise, afin de faire face à la concurrence des puces personnalisées d’AWS, Google Cloud, etc. (Source : InfoQ)
L’anxiété règne dans le secteur technologique américain, l’IA impacte le marché de l’emploi : Des rapports indiquent que le secteur technologique américain traverse une période difficile marquée par des réductions de postes, une baisse des salaires et un allongement des cycles de recherche d’emploi. Les licenciements massifs, l’utilisation de l’IA par les entreprises (comme Salesforce, Meta, Google) pour remplacer la main-d’œuvre ou suspendre les recrutements (en particulier pour les postes d’ingénierie et de premier niveau) exacerbent l’anxiété professionnelle des travailleurs du secteur. Les données montrent une augmentation de la proportion de personnes signalant des baisses de salaire et passant de postes de direction à des postes de contributeur individuel. L’IA remodèle le marché de l’emploi, obligeant les chercheurs d’emploi à élargir leurs horizons vers des secteurs non technologiques ou à se tourner vers l’entrepreneuriat. Les experts conseillent de rechercher des opportunités d’emploi en dehors des « Sept Géants » (Big Tech) et de maîtriser les outils IA pour améliorer sa compétitivité (Source : InfoQ)

Rumeur : OpenAI envisagerait d’acquérir l’entreprise de matériel IA co-fondée par Altman et Jony Ive : Des sources indiquent qu’OpenAI discute de l’acquisition, pour au moins 500 millions de dollars, de io Products, la société d’IA co-fondée par son CEO Sam Altman et l’ancien directeur du design d’Apple, Jony Ive. Cette société vise à développer des appareils personnels pilotés par l’IA, potentiellement sous la forme d’un « téléphone » sans écran ou d’un appareil domestique. L’équipe d’ingénieurs de io Products construit les appareils, OpenAI fournit la technologie, le studio d’Ive s’occupe du design, et Altman est profondément impliqué. Si l’acquisition se concrétise, elle intégrerait l’équipe matérielle au sein d’OpenAI, accélérant ainsi ses ambitions dans le domaine du matériel IA (Source : InfoQ)
La startup de l’ex-CTO d’OpenAI débauche à nouveau chez son ancien employeur : La startup IA « Thinking Machines Laboratory », fondée par l’ancienne CTO d’OpenAI Mira Murati, a attiré deux anciennes figures clés d’OpenAI au sein de son équipe de conseillers : l’ancien Chief Research Officer Bob McGrew et l’ancien chercheur Alec Radford. Radford est l’auteur principal des articles fondateurs de la série GPT. Ce recrutement renforce davantage la puissance technique de la startup et reflète également la concurrence féroce pour les talents dans le domaine de l’IA (Source : InfoQ)
Baichuan Intelligence réoriente ses activités vers le domaine médical : Le fondateur de Baichuan Intelligence, Wang Xiaochuan, a publié une lettre à tous les employés à l’occasion du deuxième anniversaire de l’entreprise, réaffirmant que l’entreprise se concentrera sur le domaine médical, en développant des services applicatifs tels que Baixiaoying, l’IA pédiatrique, l’IA généraliste et la médecine de précision. Il a souligné la nécessité de réduire les actions superflues et d’aplatir la structure organisationnelle. Auparavant, il avait été rapporté que l’équipe B2B du secteur financier de l’entreprise avait été supprimée, que le partenaire commercial Deng Jiang était parti, et que plusieurs autres co-fondateurs étaient partis ou sur le point de partir, ce qui témoigne d’une phase de recentrage stratégique et d’ajustement organisationnel (Source : InfoQ)
Alibaba Cloud lance le programme partenaire de l’écosystème IA « Flourishing Flowers » : Alibaba Cloud a lancé le programme « Flourishing Flowers » (Fleurs Épanouies) visant à soutenir les partenaires de l’écosystème IA. Ce programme fournira des ressources cloud, un soutien en puissance de calcul, le regroupement de produits, la planification de la commercialisation et des services tout au long du cycle de vie, en fonction de la maturité des produits des partenaires. Parallèlement, Alibaba Cloud a lancé une place de marché pour les applications et services IA, dans le but de construire un écosystème IA prospère et d’accélérer l’adoption des technologies et applications IA (Source : InfoQ)
Kugou Music conclut un partenariat approfondi avec DeepSeek : Kugou Music a annoncé un partenariat avec la société d’IA DeepSeek pour lancer une série de fonctionnalités innovantes basées sur l’IA. Celles-ci incluent la génération de rapports d’écoute personnalisés grâce à l’analyse multimodale, des recommandations quotidiennes par IA, une recherche intelligente, la gestion de playlists par IA, la génération de pochettes dynamiques par IA, ainsi qu’un « Commentateur IA » doté de personas, visant à améliorer l’expérience musicale et l’interaction communautaire des utilisateurs grâce à la technologie IA (Source : InfoQ)
Rumeur : Google utiliserait des clauses de non-concurrence « agressives » pour retenir les talents IA : Des rapports indiquent que DeepMind, filiale de Google, imposerait des clauses de non-concurrence d’un an à certains employés britanniques pour empêcher leur départ vers des concurrents. Pendant cette période, les employés n’auraient pas besoin de travailler mais continueraient à percevoir leur salaire (congé payé ou « garden leave »), ce qui laisserait certains chercheurs se sentir marginalisés et incapables de participer aux avancées rapides du secteur. Cette pratique pourrait être interdite par la FTC aux États-Unis mais s’appliquerait au siège de Londres, suscitant un débat sur la concurrence pour les talents et la restriction de l’innovation (Source : InfoQ)
D’anciens employés d’OpenAI déposent des documents juridiques en soutien au procès de Musk : 12 anciens employés d’OpenAI ont déposé un document juridique soutenant le procès intenté par Elon Musk contre OpenAI. Ils estiment que le plan de restructuration d’OpenAI (vers une structure à but lucratif) pourrait violer fondamentalement la mission initiale non lucrative de l’entreprise, mission qui avait été un facteur clé de leur recrutement. OpenAI a répondu que sa mission ne changerait pas, malgré le changement de structure (Source : InfoQ)
🌟 Communauté
Une étude d’Anthropic révèle les modes d’application et les défis de l’IA dans l’enseignement supérieur : Anthropic a analysé des millions de conversations anonymes d’étudiants sur la plateforme Claude.ai, révélant que les étudiants en sciences et ingénierie (en particulier en informatique) sont les premiers utilisateurs de l’IA. Les modes d’interaction des étudiants avec l’IA se répartissent en quatre catégories à peu près égales : résolution directe de problèmes, génération directe de contenu, résolution collaborative de problèmes et génération collaborative de contenu. L’IA est principalement utilisée pour des tâches cognitives de haut niveau telles que la création (programmation, rédaction d’exercices) et l’analyse (explication de concepts). L’étude révèle également des cas potentiels de fraude académique (obtention de réponses, contournement de la détection de plagiat), soulevant des préoccupations concernant l’intégrité académique, le développement de la pensée critique et les méthodes d’évaluation (Source : 新智元)

La génération d’images GPT-4o lance de nouvelles tendances : du style Ghibli aux cartes de célébrités IA : Les puissantes capacités de génération d’images de GPT-4o continuent de susciter un engouement créatif sur les médias sociaux. Après le succès viral des « portraits de famille style Ghibli » (dont l’instigateur est l’ancien ingénieur d’Amazon Grant Slatton), les utilisateurs créent désormais des cartes de style « Magic: The Gathering » représentant des personnalités du domaine de l’IA (par exemple, Sam Altman défini comme « Seigneur de l’AGI »), ainsi que des cartes de tarot personnalisées. Ces exemples illustrent le potentiel de l’IA dans l’imitation de styles artistiques et la génération créative, mais soulèvent également des discussions sur l’originalité, le droit d’auteur, la valeur esthétique et l’impact de l’IA sur le métier de designer (Source : 新智元)

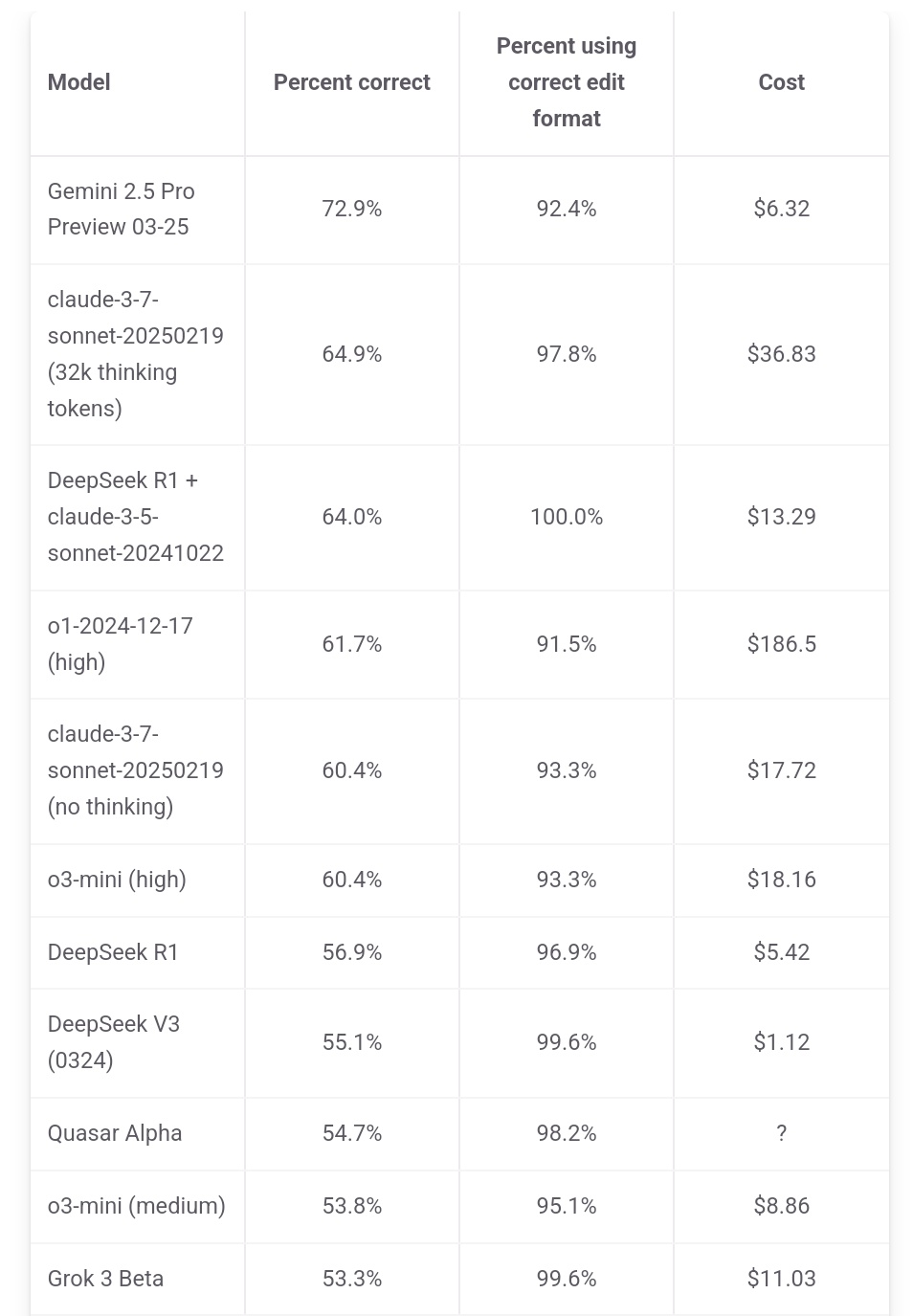
Jeff Dean souligne l’avantage en termes de coût de Gemini 2.5 Pro : Le responsable de l’IA chez Google, Jeff Dean, a retweeté les données de classement d’aider.chat, soulignant que Gemini 2.5 Pro non seulement domine le benchmark de programmation Polyglot en termes de performances, mais que son coût (6 $) est également nettement inférieur à celui des autres modèles du Top 10 (à l’exception de DeepSeek), mettant en avant son avantage coût-performance. Certains modèles concurrents coûtent 2 fois, 3 fois, voire 30 fois plus cher que Gemini 2.5 Pro (Source : JeffDean)
Reddit débat de l’impact de l’IA sur le marché de l’emploi, en particulier les postes de premier niveau : Un fil de discussion sur le forum Reddit a suscité un vif débat. L’auteur (un étudiant en master CIS) exprime sa profonde inquiétude quant au remplacement par l’IA des emplois non manuels de premier niveau (en particulier en ingénierie logicielle, analyse de données, support IT), arguant que l’affirmation « l’IA ne prendra pas les emplois » ignore la situation difficile des jeunes diplômés. Il note que les grandes entreprises réduisent déjà les recrutements sur les campus et craint un avenir sombre pour le marché de l’emploi. Les commentaires sont partagés : certains reconnaissent la crise, d’autres y voient une perturbation technologique normale nécessitant une adaptation (par exemple, gérer des équipes d’IA), d’autres encore remettent en question l’affirmation selon laquelle « 90% des emplois disparaîtront », soulignant les cycles économiques, les différences entre pays et les limites actuelles de l’IA (Source : source)
Les utilisateurs de Claude se plaignent de la baisse des performances et du resserrement des restrictions : Une discussion concentrée est apparue sur le subreddit ClaudeAI. Plusieurs utilisateurs (y compris des utilisateurs Pro) signalent avoir rencontré récemment des limites d’utilisation (quota) plus strictes, atteignant fréquemment le plafond même pour des opérations normales. Certains soupçonnent Anthropic de resserrer discrètement les quotas et expriment leur mécontentement, estimant que cela poussera les utilisateurs vers les concurrents. De plus, certains utilisateurs signalent que la « personnalité » de Claude semble avoir changé, devenant plus « froide », « mécanique », perdant le sens philosophique et poétique des versions précédentes, ce qui a conduit certains utilisateurs à annuler leur abonnement (Source : source, source, source, source)
La génération d’images ChatGPT suscite amusement et discussions : Des utilisateurs de Reddit partagent diverses tentatives et résultats de génération d’images avec ChatGPT. Quelqu’un a demandé de « transformer » un chien en humain, obtenant une image ressemblant à un « anthropomorphe/furry », ce qui a déclenché une discussion sur la compréhension des prompts et les biais potentiels. Un autre utilisateur a demandé à être dessiné sous forme de vitrail version multivers, avec des résultats époustouflants. D’autres encore ont demandé de générer des images métaphoriques sur l’IA ou ont interrogé l’IA sur ses « cauchemars », montrant le potentiel et les limites de la génération d’images IA pour l’expression créative et la visualisation de concepts abstraits (Source : source, source, source, source, source)

La communauté discute du choix des modèles LLM et des stratégies d’utilisation : Sur le subreddit LocalLLaMA, un utilisateur propose d’organiser une discussion mensuelle sur l’utilisation des modèles, afin de partager les meilleurs modèles (open source et propriétaires) utilisés par chacun dans différents scénarios (codage, écriture, recherche, etc.) et les raisons de ces choix. Dans les commentaires, les utilisateurs partagent leurs combinaisons de modèles actuelles, telles que Deepseek V3.1/Gemini 2.5 Pro/4o/R1/Qwen 2.5 Max/Sonnet 3.7/Gemma 3/Claude 3.7/Mistral Nemo, etc., et mentionnent des utilisations spécifiques (appel d’outils, classification, jeu de rôle), reflétant la tendance des utilisateurs à sélectionner et combiner différents modèles en fonction des besoins de la tâche (Source : source)
💡 Autres
Le Sommet de l’Industrie AIGC en Chine aura lieu prochainement : Le troisième Sommet de l’Industrie AIGC en Chine se tiendra le 16 avril à Pékin. Le sommet réunira plus de 20 leaders de l’industrie issus d’entreprises telles que Baidu, Huawei, Microsoft Research Asia, Amazon Web Services, Mianbi Intelligence, Shengshu Technology, etc., pour discuter des avancées technologiques de l’IA (puissance de calcul, grands modèles), des applications sectorielles (éducation, divertissement, recherche, services aux entreprises), de la construction de l’écosystème (sécurité contrôlable, défis de déploiement), etc. Le sommet publiera également des classements d’entreprises/produits AIGC et une cartographie panoramique des applications AIGC en Chine (Source : 量子位)

Rapport de Stanford : L’écart de performance entre les meilleurs modèles d’IA américains et chinois se réduit à 0,3% : Le rapport AI Index 2025 publié par l’Université de Stanford montre que l’écart de performance entre les meilleurs modèles d’IA américains et chinois s’est considérablement réduit, passant de 20% en 2023 à 0,3%. Bien que les États-Unis restent en tête en termes de nombre de modèles notables (40 contre 15) et d’entreprises leaders du secteur, les modèles chinois rattrapent rapidement leur retard. Le rapport souligne également que l’écart de performance entre les meilleurs modèles se réduit également, passant de 12% en 2024 à 5%, ce qui témoigne d’un phénomène de convergence marqué (Source : InfoQ)