
Mots-clés:AI, LLM, fraude AI shopping, benchmark LLM raisonnement, auto-hébergement Gemini, compression modèle HIGGS, vLLM optimisation inference
🔥 À la une
Une application de shopping « IA » se révèle être gérée par des humains: Une start-up nommée Fintech et son fondateur sont accusés de fraude. Leur application de shopping, prétendument alimentée par l’IA, dépendait en réalité fortement d’équipes humaines basées aux Philippines pour traiter les transactions. Cet incident attire à nouveau l’attention sur le phénomène du « AI Washing », où les entreprises exagèrent ou déforment leurs capacités en IA pour attirer des investissements ou des utilisateurs. L’affaire souligne les défis liés à la distinction entre les applications technologiques d’IA authentiques et fausses dans le contexte actuel de l’engouement pour l’IA, ainsi que l’importance de la diligence raisonnable envers les start-ups (source: Reddit r/ArtificialInteligence)

Un nouveau benchmark révèle le manque de capacité de généralisation des modèles de raisonnement IA: Un nouveau benchmark nommé LLM-Benchmark (https://llm-benchmark.github.io/) montre que même les modèles de raisonnement IA les plus récents peinent à traiter des énigmes logiques hors distribution (OOD). L’étude révèle que, comparés aux performances des modèles sur des benchmarks tels que les Olympiades de mathématiques, leurs scores sur ces nouvelles énigmes logiques sont bien inférieurs aux attentes (environ 50 fois plus bas), exposant les limites des modèles actuels en matière de raisonnement logique véritable et de généralisation au-delà de la distribution des données d’entraînement (source: Reddit r/ArtificialInteligence)
Google autorise les entreprises à auto-héberger les modèles Gemini pour répondre aux préoccupations de confidentialité des données: Google a annoncé qu’il permettrait aux entreprises clientes d’exécuter les modèles d’IA Gemini dans leurs propres centres de données, en commençant par Gemini 2.5 Pro. Cette initiative vise à répondre aux exigences strictes des entreprises en matière de confidentialité et de sécurité des données, leur permettant d’utiliser la technologie IA avancée de Google sans envoyer de données sensibles vers le cloud. Cette stratégie, similaire à celle de Mistral AI, contraste avec celle d’OpenAI et d’Anthropic, qui fournissent principalement leurs services via des API cloud ou des partenaires, et pourrait modifier le paysage concurrentiel du marché de l’IA d’entreprise (source: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

🎯 Actualités
VSCode prend en charge nativement llama.cpp, étendant les capacités locales de Copilot: Une mise à jour récente de Visual Studio Code a ajouté la prise en charge des modèles d’IA locaux. Après avoir supporté Ollama, il est désormais compatible avec llama.cpp via un ajustement mineur. Cela signifie que les développeurs peuvent utiliser directement dans VSCode des grands modèles de langage (LLM) locaux exécutés via llama.cpp, comme alternative ou complément à GitHub Copilot, facilitant davantage l’utilisation des LLM pour l’assistance au code dans un environnement local et améliorant la flexibilité de développement et la confidentialité des données. Les utilisateurs doivent sélectionner Ollama comme proxy dans les paramètres (bien qu’ils utilisent en réalité llama.cpp) pour activer cette fonctionnalité (source: Reddit r/LocalLLaMA)

Yandex et d’autres institutions publient HIGGS : une nouvelle méthode de compression LLM: Des chercheurs de Yandex Research, HSE University, MIT et d’autres institutions ont développé une nouvelle technique de compression par quantification LLM appelée HIGGS. Cette méthode vise à réduire considérablement la taille du modèle pour permettre son exécution sur des appareils moins performants, tout en minimisant autant que possible la perte de qualité du modèle. Il est rapporté que cette méthode a été utilisée avec succès pour compresser le modèle DeepSeek R1 de 671 milliards de paramètres, avec des résultats significatifs. HIGGS a pour but d’abaisser le seuil d’utilisation des LLM, permettant aux petites entreprises, aux instituts de recherche et aux développeurs individuels d’appliquer plus facilement de grands modèles. Le code associé a été publié sur GitHub et Hugging Face (source: Reddit r/LocalLLaMA)
Google corrige les problèmes de quantification du modèle QAT 2.7: Google a mis à jour la version 2.7 de ses modèles quantifiés QAT (Quantization Aware Training) (potentiellement Gemma 2 7B ou un modèle similaire), corrigeant certains problèmes d’erreurs de jetons de contrôle (control tokens) présents dans la version précédente. Auparavant, le modèle pouvait générer des marqueurs incorrects tels que <end_of_turn> à la fin de la sortie. Les modèles quantifiés nouvellement téléversés ont résolu ces problèmes, et les utilisateurs peuvent télécharger la version mise à jour pour obtenir le comportement correct du modèle (source: Reddit r/LocalLLaMA)
Le CEO de DeepMind parle des réalisations d’AlphaFold: Dans une interview, Demis Hassabis, CEO de DeepMind, a souligné l’impact considérable d’AlphaFold, utilisant la métaphore selon laquelle AlphaFold a accompli « un milliard d’années de temps de recherche doctorale » en un an. Il a noté que par le passé, la résolution de la structure d’une protéine nécessitait généralement toute la durée d’un doctorat (4-5 ans), alors qu’AlphaFold a prédit en un an la structure de toutes les 200 millions de protéines (connues à l’époque). Ces propos mettent en évidence le potentiel révolutionnaire de l’IA pour accélérer les découvertes scientifiques (source: Reddit r/artificial)

🧰 Outils
MinIO : Stockage objet haute performance pour l’IA: MinIO est un système de stockage objet open-source haute performance, compatible S3, sous licence GNU AGPLv3. Il met particulièrement l’accent sur sa capacité à construire une infrastructure haute performance pour les charges de travail en machine learning, analytique et données applicatives, et fournit une documentation dédiée au stockage pour l’IA. Les utilisateurs peuvent l’installer via des conteneurs (Podman/Docker), Homebrew (macOS), des fichiers binaires (Linux/macOS/Windows) ou à partir des sources. MinIO prend en charge la construction de clusters de stockage distribués à haute disponibilité avec code d’effacement (erasure coding), adaptés aux scénarios d’applications IA nécessitant le traitement de grandes quantités de données (source: minio/minio – GitHub Trending (all/daily))

IntentKit : Framework pour construire des agents IA dotés de compétences: IntentKit est un framework open-source pour agents autonomes, conçu pour permettre aux développeurs de créer et gérer des agents IA dotés de multiples capacités, y compris l’interaction avec la blockchain (priorité aux chaînes EVM), la gestion des médias sociaux (Twitter, Telegram, etc.) et l’intégration de compétences personnalisées. Le framework prend en charge la gestion multi-agents et l’exécution autonome, et prévoit de lancer un système de plugins extensibles. Le projet est actuellement en phase Alpha, fournit un aperçu de l’architecture et un guide de développement, et encourage la contribution de compétences par la communauté (source: crestalnetwork/intentkit – GitHub Trending (all/daily))

vLLM : Moteur d’inférence et de service LLM haute performance: vLLM est une bibliothèque à haut débit et efficace en mémoire, spécialisée dans l’inférence et le service de LLM. Ses principaux avantages incluent la gestion efficace de la mémoire des clés-valeurs d’attention grâce à la technologie PagedAttention, la prise en charge du traitement par lots continu (Continuous Batching), l’optimisation des graphes CUDA/HIP, diverses techniques de quantification (GPTQ, AWQ, FP8, etc.), l’intégration avec FlashAttention/FlashInfer, et le décodage spéculatif (Speculative Decoding). vLLM prend en charge les modèles Hugging Face, fournit une API compatible OpenAI, et peut fonctionner sur divers matériels tels que NVIDIA, AMD, etc., ce qui le rend adapté aux scénarios nécessitant le déploiement à grande échelle de services LLM (source: vllm-project/vllm – GitHub Trending (all/daily))
tfrecords-reader : Lecteur TFRecords avec accès aléatoire et fonctions de recherche: Il s’agit d’un outil Python pour manipuler les jeux de données TFRecords, spécialement conçu pour l’inspection et l’analyse des données. Il permet aux utilisateurs de créer des index pour les fichiers TFRecords, réalisant un accès aléatoire et une recherche basée sur le contenu (en utilisant les requêtes Polars SQL), surmontant ainsi les limitations de la lecture séquentielle native de TFRecords. L’outil ne dépend pas des paquets TensorFlow et protobuf, prend en charge la lecture directe depuis Google Storage, indexe rapidement et facilite l’exploration et la recherche d’échantillons dans de grands jeux de données TFRecords en dehors de l’entraînement de modèles (source: Reddit r/MachineLearning)
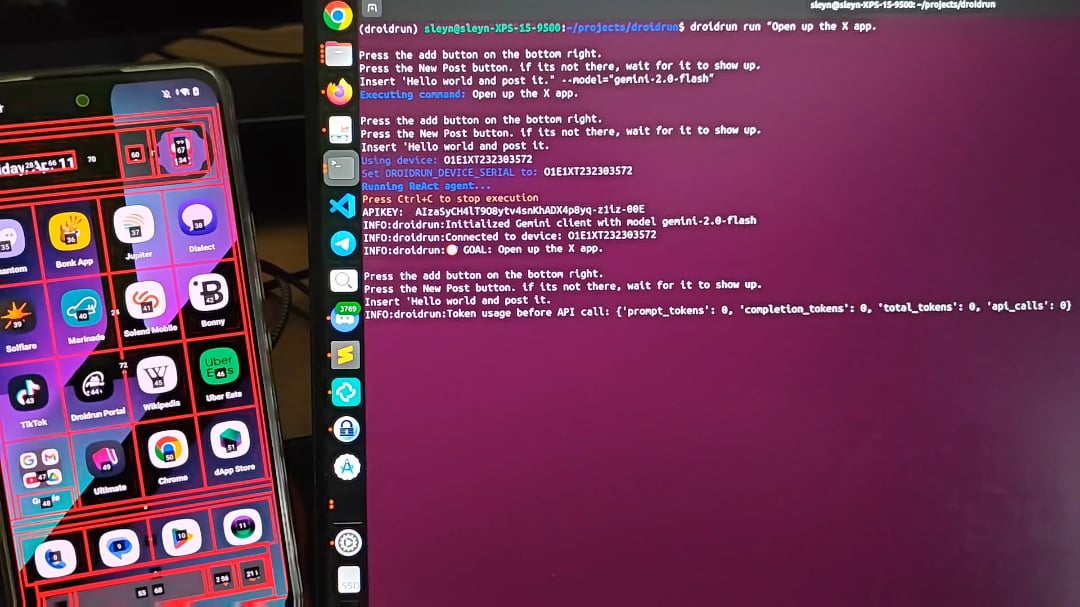
DroidRun : Permettre aux agents IA de contrôler les téléphones Android: DroidRun est un projet qui permet aux agents IA d’interagir avec des appareils Android comme le ferait un humain. En se connectant à n’importe quel LLM, il peut réaliser le contrôle interactif de l’interface utilisateur du téléphone pour exécuter diverses tâches. Le projet démontre son potentiel, visant à réaliser l’automatisation des opérations sur mobile, comme la publication automatique de contenu, la gestion d’applications, etc. Les développeurs invitent la communauté à fournir des retours et des idées pour explorer davantage de scénarios d’automatisation (source: Reddit r/LocalLLaMA)
📚 Apprentissage
Cell Patterns publie une revue majeure sur les grands modèles multilingues (MLLM): Cette revue synthétise systématiquement l’état actuel de la recherche sur les grands modèles multilingues, couvrant 473 publications. Le contenu inclut les ressources de jeux de données et les méthodes de construction pour le pré-entraînement multilingue, l’ajustement fin par instruction (instruction fine-tuning) et le RLHF ; les stratégies d’alignement interlingual, divisées en alignement par ajustement des paramètres (comme le pré-entraînement, l’ajustement fin par instruction, le RLHF, l’ajustement fin en aval) et l’alignement par gel des paramètres (comme le prompting direct, le code-switching, l’alignement par traduction, l’augmentation par récupération) ; les métriques et benchmarks d’évaluation multilingues (tâches NLU et NLG) ; et explore les futures directions de recherche et défis tels que les hallucinations, l’édition des connaissances, la sécurité, l’équité, l’extension linguistique/modale, l’interprétabilité, l’efficacité du déploiement et la cohérence des mises à jour. Fournit une cartographie complète de la recherche sur les MLLM (source: Cell Patterns重磅综述!473篇文献全面解析多语言大模型最新研究进展)

AAAI 2025 | Beihang propose TRACK : Apprentissage collaboratif des représentations dynamiques du réseau routier et des trajectoires: L’équipe de l’Université Beihang propose le modèle TRACK, visant à résoudre le problème des méthodes existantes qui ne capturent pas la dynamique spatio-temporelle du trafic. Ce modèle modélise conjointement pour la première fois l’état du trafic (caractéristiques macroscopiques de groupe) et les données de trajectoire (caractéristiques microscopiques individuelles), considérant qu’ils s’influencent mutuellement. TRACK apprend des représentations dynamiques du réseau routier et des trajectoires via un réseau d’attention graphique (GAT), un Transformer, ainsi qu’un GAT innovant sensible aux transferts de trajectoires et un mécanisme d’attention collaboratif. Le modèle adopte un cadre de pré-entraînement conjoint comprenant des tâches auto-supervisées telles que la prédiction de trajectoires masquées, l’apprentissage contrastif de trajectoires, la prédiction d’états masqués, la prédiction de l’état suivant et l’appariement trajectoire-état du trafic, et montre des performances supérieures dans les tâches de prédiction de l’état du trafic et d’estimation du temps de trajet (source: AAAI 2025 | 告别静态建模!北航团队提出动态路网与轨迹表示的协同学习范式)

Le professeur Yang Linyi de SUSTech recrute des doctorants/RA/étudiants visiteurs dans le domaine des grands modèles: Le professeur Yang Linyi du Département de Statistique et Science des Données de la Southern University of Science and Technology (SUSTech) (prise de fonction imminente, PI indépendant) établit le Laboratoire d’Intelligence Artificielle Générative (GenAI Lab) et recrute des doctorants et étudiants en master pour les promotions 2025/2026, ainsi que des post-doctorants, assistants de recherche et stagiaires. Les axes de recherche incluent l’analyse causale du raisonnement des grands modèles, les méthodes d’apprentissage par renforcement généralisables pour les grands modèles, la construction de systèmes fiables non-agents pour prévenir la perte de contrôle de l’IA. Le professeur Yang a publié plusieurs articles dans des conférences de premier plan, collabore largement avec des universités et instituts de recherche nationaux et internationaux, et encourage la co-direction. Les candidats doivent faire preuve d’une forte motivation personnelle, de solides bases en mathématiques et en programmation (source: 博士申请 | 南方科技大学杨林易老师招收大模型方向全奖博士/RA/访问学生)

Projet personnel : Construire un grand modèle de langage à partir de zéro: Un développeur partage son projet personnel de mise en œuvre d’un Causal Language Model (similaire à GPT) à partir de zéro. Le projet utilise Python et PyTorch, l’architecture principale comprend une auto-attention multi-têtes avec Causal Mask, un réseau feed-forward, et une pile de blocs décodeurs (normalisation de couche, connexions résiduelles). Le modèle utilise des embeddings de mots et de position pré-entraînés de GPT-2, et la couche de sortie mappe vers les logits du vocabulaire. Il utilise l’échantillonnage Top-k pour la génération de texte auto-régressive et est entraîné sur le jeu de données WikiText en utilisant l’optimiseur AdamW et la CrossEntropyLoss. Le code du projet est open-source sur GitHub, montrant le processus de base de construction d’un LLM (source: Reddit r/MachineLearning)
Analyse d’article : d1 – Étendre les capacités de raisonnement des grands modèles de langage à base de diffusion (dLLM) via l’apprentissage par renforcement: Cette recherche propose le framework d1, visant à appliquer des LLM pré-entraînés basés sur la diffusion (dLLM) à des tâches de raisonnement. Les dLLM génèrent du texte par un processus allant du grossier au fin, différent des modèles auto-régressifs (AR). Le framework d1 combine l’ajustement fin supervisé (SFT) et l’apprentissage par renforcement (RL), incluant spécifiquement : l’utilisation du Masked SFT pour la distillation des connaissances et l’auto-amélioration guidée ; la proposition d’un nouvel algorithme RL sans critique basé sur le gradient de politique, diffu-GRPO. Les expériences montrent que d1 améliore significativement les performances des dLLM SOTA sur les benchmarks de raisonnement mathématique et logique, prouvant le potentiel des dLLM pour les tâches de raisonnement (source: Reddit r/MachineLearning)
💼 Business
Le laboratoire Tongyi d’Alibaba recrute des experts en algorithmes pour la recherche RAG/IA générique (Pékin/Hangzhou): L’équipe de recherche IA du laboratoire Tongyi d’Alibaba recrute des experts en algorithmes pour faire progresser la recherche et l’optimisation des modules centraux de recherche et RAG (Retrieval-Augmented Generation), tels que les modèles Embedding et ReRank, afin d’améliorer les performances des modèles et de maintenir une position de leader dans l’industrie. Les responsabilités du poste incluent également l’optimisation de l’ensemble de la chaîne de traitement pour les applications en aval (questions-réponses, service client, Memory multimodale), l’amélioration de la précision, de l’efficacité et de l’évolutivité, et la collaboration avec l’équipe pour favoriser l’implémentation métier. Exige un Master ou plus dans un domaine pertinent, une familiarité avec les technologies de recherche/NLP/grands modèles, et une expérience de projet connexe (source: 北京/杭州内推 | 阿里通义实验室招聘通用RAG/AI搜索方向算法专家)

La start-up de recrutement IA OpportuNext recherche un CTO (Télétravail/Actions): OpportuNext est une start-up en phase de démarrage visant à améliorer le processus de recrutement grâce à la technologie IA, en fournissant des outils intelligents de mise en correspondance des postes, d’analyse de CV et de planification de carrière. Le fondateur recherche un partenaire technique (CTO) pour diriger le développement des fonctionnalités IA, construire des systèmes backend évolutifs et stimuler l’innovation produit. Exige une expérience en AI/ML, Python et systèmes évolutifs, une passion pour la résolution de problèmes concrets, et la volonté de rejoindre une start-up à ses débuts (poste en télétravail basé sur des actions) (source: Reddit r/deeplearning)
🌟 Communauté
Réflexion : Les grands modèles sont essentiellement une « illusion du langage »: Un article de réflexion approfondie soutient que les grands modèles (comme ChatGPT) ne comprennent pas réellement l’information, mais imitent et prédisent les formes d’expression en apprenant à partir d’énormes quantités de données linguistiques. Le rôle du prompt est de définir le contexte et de guider l’attention du modèle, et non de communiquer avec une entité consciente. Les réponses du modèle sont basées sur la reproduction de motifs « vus suffisamment souvent », semblant intelligentes mais manquant de compréhension réelle, ce qui conduit facilement à des hallucinations où il « dit des bêtises avec un air sérieux ». L’interaction homme-machine ressemble davantage à l’utilisateur pensant à la place du modèle, tandis que la sortie du modèle peut subtilement remodeler les habitudes de pensée et de jugement de l’utilisateur, et potentiellement refléter et amplifier les biais existants dans la réalité (source: 我所理解的大模型:语言的幻术)
Discussion : Consommation d’énergie de l’IA et différences de stratégies de développement de modèles entre les États-Unis et la Chine: Des utilisateurs de Reddit discutent des déclarations de Trump classant le charbon comme minéral clé pour le développement de l’IA, soulevant des inquiétudes quant à la consommation d’énergie de l’IA. Les commentaires soulignent que les grands modèles deviennent de plus en plus énergivores, tandis que les entreprises chinoises semblent préférer construire des modèles plus légers et axés sur l’efficacité. Cela reflète le compromis entre performance et efficacité énergétique dans le développement de l’IA, ainsi que les différentes voies technologiques potentiellement adoptées par différentes régions (source: Reddit r/artificial)

Question : Recherche d’un framework d’apprentissage par renforcement profond similaire à PyTorch Lightning: Un utilisateur de Reddit demande s’il existe des frameworks similaires à PyTorch Lightning (PL) spécifiquement conçus pour l’apprentissage par renforcement profond (DRL). L’utilisateur estime que bien que PL puisse être utilisé pour le DRL, sa conception est davantage orientée vers l’apprentissage supervisé basé sur des jeux de données que vers le DRL piloté par l’interaction avec l’environnement. Le post cherche des recommandations de la communauté pour des frameworks adaptés au DRL (comme DQN, PPO) et s’intégrant bien avec des environnements comme Gymnasium, ou des partages de meilleures pratiques pour l’utilisation de PL pour le DRL (source: Reddit r/deeplearning)
Communauté : Lancement de MetaMinds, une communauté Discord pour les musiciens virtuels: Une nouvelle communauté Discord nommée MetaMinds a été créée, visant à fournir une plateforme d’échange, de collaboration et de partage pour les artistes virtuels utilisant des outils IA (comme Suno) pour créer de la musique. La communauté a lancé son premier concours de création de chansons intitulé « A Personal Song » et prévoit d’organiser à l’avenir des compétitions de plus haut niveau, pouvant même inclure des prix en espèces. Cela reflète la formation d’un nouvel écosystème communautaire dans le domaine de la création musicale par IA (source: Reddit r/SunoAI)
Discussion : Comment appeler un ensemble de jeux de données incluant des ensembles d’entraînement ?: Un utilisateur de Reddit demande comment nommer un ensemble de plusieurs jeux de données destinés à entraîner et évaluer le même modèle, par opposition à un « benchmark » utilisé pour évaluer les performances d’un modèle sur plusieurs tâches. Cette question explore les détails de la classification des jeux de données et de l’utilisation de la terminologie dans le domaine du machine learning (source: Reddit r/MachineLearning)
Demande d’aide : Implémenter la fonctionnalité de transcription vocale (Speech-to-Text) dans OpenWebUI: Un utilisateur cherche la meilleure solution et les modèles recommandés pour implémenter la fonctionnalité de transcription vocale (l’utilisateur parle de TTS mais décrit la transcription de vidéos YouTube/fichiers audio, ce qui correspond à ASR/STT) dans un environnement OpenWebUI+Ollama déployé sur Docker, en utilisant un GPU H100. Cela reflète le besoin des utilisateurs d’intégrer davantage de capacités de traitement modal dans les interfaces d’interaction LLM locales (source: Reddit r/OpenWebUI)
Discussion : Avis sur l’abonnement annuel à Claude et l’ajustement des limitations: Un utilisateur de Reddit se réjouit de ne pas avoir souscrit à l’abonnement annuel de Claude, car de nombreux utilisateurs se sont plaints récemment du resserrement des limites d’utilisation. L’utilisateur pense qu’Anthropic pourrait ajuster sa stratégie pour économiser des coûts après avoir attiré un grand nombre d’utilisateurs payants. Parallèlement, l’utilisateur mentionne les performances puissantes du Gemini 2.5 Pro gratuit, exprimant des inquiétudes et des attentes quant à l’avenir de Claude. La discussion reflète la sensibilité des utilisateurs aux prix des services LLM, aux limites d’utilisation et au rapport qualité-prix (source: Reddit r/ClaudeAI)
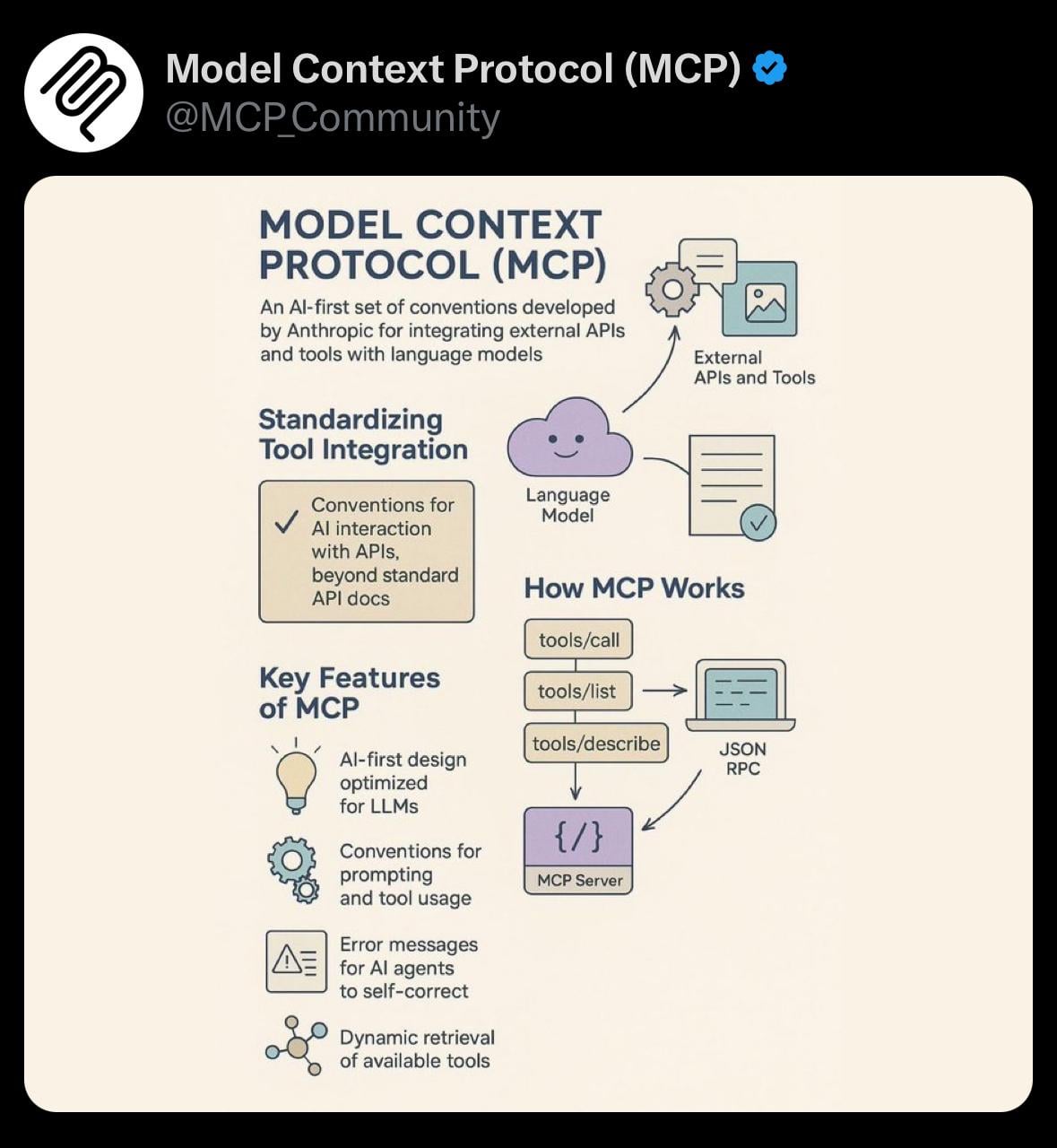
Partage : Visualisation simple du Protocole de Contexte du Modèle (MCP): Un utilisateur partage une image de visualisation simple concernant le Model Context Protocol (MCP). MCP pourrait être un concept technique lié au modèle Claude d’Anthropic, visant à optimiser ou gérer la manière dont le modèle traite les longs contextes. Ce partage fournit une aide visuelle à la communauté pour comprendre les concepts techniques pertinents (source: Reddit r/ClaudeAI)
Demande d’aide : Ajouter des commandes personnalisées dans le chat OpenWebUI: Un utilisateur demande quelle est la difficulté technique pour ajouter des commandes personnalisées (par exemple, sous forme de @tag avec menu d’auto-complétion) dans l’interface de chat OpenWebUI afin de faciliter les requêtes RAG personnalisées (par exemple, filtrer par type de document). L’utilisateur envisage également un menu déroulant comme alternative. Cela reflète le souhait des utilisateurs d’étendre les capacités d’interaction front-end pour contrôler plus flexiblement les fonctionnalités IA back-end (source: Reddit r/OpenWebUI)
Discussion : Générer des QR codes IA esthétiques et fonctionnels: Un utilisateur a essayé d’utiliser ChatGPT/DALL-E pour générer des QR codes fusionnant style artistique et scannabilité, mais les résultats n’étaient pas satisfaisants, soulignant que des méthodes comme ControlNet sont plus efficaces. Cela soulève une discussion sur les limites des modèles de génération d’images texte-vers-image grand public actuels pour générer des images nécessitant une structure précise et une fonctionnalité (comme la scannabilité) (source: Reddit r/ChatGPT)

Recherche de partenaires d’étude AI/ML: Un étudiant de troisième année en licence d’informatique (spécialisation AI/ML) cherche 4-5 personnes partageant les mêmes idées pour former une équipe afin d’approfondir l’apprentissage de l’AI/ML, de développer des projets ensemble et de s’entraîner aux structures de données et algorithmes (DSA/CP). L’initiateur liste sa pile technologique et ses centres d’intérêt, espérant créer un petit groupe de motivation mutuelle et d’apprentissage collaboratif (source: Reddit r/deeplearning)
Discussion : Les agents IA vont-ils aggraver le problème du spam ?: Un utilisateur de Reddit exprime sa crainte que l’utilisation généralisée des agents IA pour automatiser des tâches (comme la recherche de prospects et l’envoi de messages) n’entraîne une prolifération du spam. Lorsque tout le monde utilise des outils similaires, les destinataires cibles sont submergés par un grand nombre de messages automatisés personnalisés, ce qui réduit l’efficacité de la communication et rend les outils d’agent inutiles. La discussion soulève une réflexion sur les externalités négatives potentielles de l’application à grande échelle des outils d’IA (source: Reddit r/ArtificialInteligence)
Discussion : Problèmes de qualité récents de Suno AI: Un utilisateur partage un extrait musical généré avec Suno AI, indiquant que malgré les discussions récentes dans la communauté sur la baisse de qualité des sorties de Suno, il trouve personnellement que cet extrait est plutôt bon. Cela reflète la perception des fluctuations de performance des outils de génération IA par la communauté et les différences d’évaluation subjective (source: Reddit r/SunoAI)

Discussion : RTX 4090 vs RTX 5090 pour l’entraînement en deep learning: Un utilisateur demande conseil pour la construction d’une station de travail mono-GPU pour le deep learning personnel (principalement non-LLM) : faut-il choisir l’actuelle RTX 4090 ou attendre la prochaine RTX 5090 ? Le post sollicite l’avis de la communauté sur le choix du matériel et demande comment distinguer les cartes de jeu des cartes professionnelles lors de l’achat (bien qu’il s’agisse de cartes grand public). Reflète les considérations des développeurs IA en matière de sélection de matériel (source: Reddit r/deeplearning)
Discussion : L’IA va-t-elle détruire le capitalisme ?: Un utilisateur estime qu’en raison de la recherche de maximisation des profits par les entreprises, l’IA pourrait finir par remplacer la plupart des emplois. Dans le système capitaliste actuel, cela entraînerait un chômage massif et une interruption des sources de revenus. L’utilisateur suggère que le revenu de base universel (UBI), financé par une taxe supplémentaire sur les entreprises profitant de l’IA, pourrait être une solution nécessaire. La discussion aborde l’impact profond de l’IA sur la future structure économique et les modèles sociaux (source: Reddit r/ArtificialInteligence)
Demande d’aide : Reproduire l’article d’Anthropic « Reasoning Models Don’t Always Say What They Think »: Un utilisateur cherche de l’aide auprès de la communauté pour trouver des prompts ou des informations pertinentes permettant de reproduire les résultats de l’article d’Anthropic sur le fait que « les modèles de raisonnement ne disent pas toujours ce qu’ils pensent ». Cet article explore l’incohérence potentielle entre le processus de raisonnement interne des grands modèles de langage et leur sortie finale. Cela montre l’intérêt des membres de la communauté pour la compréhension et la validation des découvertes de la recherche de pointe en IA (source: Reddit r/MachineLearning)
Demande d’aide : Configuration et expérience RAG dans OpenWebUI: Un utilisateur demande les meilleures pratiques pour utiliser le RAG (Retrieval-Augmented Generation) dans OpenWebUI, y compris les paramètres recommandés, les paramètres à éviter et les modèles d’embedding préférés. L’utilisateur rencontre également des problèmes de comportement anormal du modèle (par exemple, Mistral Small renvoyant une liste vide) et demande la relation de priorité entre les paramètres personnels de l’utilisateur et les paramètres du modèle de l’administrateur. Cela reflète les défis rencontrés par les utilisateurs dans le déploiement et l’optimisation réels des applications RAG et leur besoin de partager des expériences (source: Reddit r/OpenWebUI)
Discussion : La perte d’utilisateurs de Claude améliorera-t-elle le service ?: Un utilisateur émet l’hypothèse que la récente perte d’une partie des utilisateurs de Claude (« Genesis Exodus ») due aux limitations et aux problèmes de performance pourrait, à l’inverse, libérer des ressources de calcul, permettant ainsi à la qualité du service (performance, limitations) de revenir à un état plus idéal. L’utilisateur exprime sa préférence pour Claude et espère une amélioration du service. La discussion reflète l’observation et la réflexion des utilisateurs sur la relation entre l’offre et la demande de services IA, l’allocation des ressources et la dynamique de la qualité de service (source: Reddit r/ClaudeAI)

Discussion : Comment définir l' »art IA » ?: Un utilisateur lance une discussion demandant aux membres de la communauté comment ils définissent l' »art IA », et pose des questions connexes : une personne utilisant des outils IA (comme ChatGPT) pour générer des images est-elle un créateur ? Possède-t-elle des droits d’auteur ? Quel rôle jouent les fournisseurs de services LLM dans la création, et doivent-ils être considérés comme co-créateurs ? Cette discussion vise à clarifier les concepts fondamentaux entourant la paternité, les droits d’auteur, etc., relatifs au contenu généré par l’IA (source: Reddit r/ArtificialInteligence)
Discussion : La musique IA menace-t-elle la « communalité » de la musique ?: Un utilisateur soulève la question de savoir si les outils IA comme Suno, capables de générer facilement de la musique hyper-personnalisée, affaiblissent la « communalité » de la musique en tant qu’expérience partagée. Les points d’inquiétude incluent : la musique pourrait devenir un miroir personnalisé plutôt qu’un phare reliant les communautés ; les événements musicaux collectifs comme les concerts pourraient être affectés ; les utilisateurs pourraient devenir uniquement réceptifs au contenu personnalisé, réduisant leur ouverture à la musique diversifiée ou stimulante. La discussion porte sur l’impact potentiel de l’IA sur la culture musicale et ses fonctions sociales (source: Reddit r/SunoAI)
Question : Quelle est la précision de Suno AI pour générer des chansons en hindi ?: Un utilisateur non locuteur de l’hindi demande la précision et la naturalité de Suno AI lors de la génération de chants en hindi. Cherche à comprendre les performances de l’outil dans une langue spécifique non anglaise (source: Reddit r/SunoAI)
💡 Autres
Partage d’œuvre Suno AI : Nightingale’s Melody (Rock alternatif/indie): Un utilisateur partage une chanson de style rock alternatif/indie « Nightingale’s Melody » créée avec Suno AI, et fournit un lien YouTube (source: Reddit r/SunoAI)

Partage d’œuvre Suno AI : The Art of Abundance (Psytrance): Un utilisateur partage une musique générée par IA combinant Psytrance haute énergie et éléments spirituels/technologiques. Les paroles ont été créées par ChatGPT, la musique et les voix par Suno AI, les visuels par MidJourney et PhotoMosh Pro. L’œuvre explore le concept d’abondance à l’ère numérique, dépassant le matérialisme pour aborder la créativité, la conscience de l’IA et le désir humain (source: Reddit r/SunoAI)

Partage d’œuvre Suno AI : Do your Job (Musique country): Un utilisateur partage une chanson de style country créée avec Suno AI, dont les paroles tournent autour d’une affaire non résolue réelle (la disparition de Colton Ross Barrera), exprimant la frustration de la famille et l’appel à la justice (source: Reddit r/SunoAI)

Partage d’œuvre Suno AI : Toxic Friends (Electro Pop): Un utilisateur partage sa participation au concours d’avril de Suno AI avec une œuvre de style electro pop intitulée « Toxic Friends » (source: Reddit r/SunoAI)

Partage d’œuvre Suno AI : Starlight Visitor (Reprise pop années 80): Un utilisateur partage une reprise de style pop des années 80 d’une chanson existante, réalisée avec Suno AI, et fournit un lien YouTube (source: Reddit r/SunoAI)

Application créative de ChatGPT : Extension de mème sur les produits à base d’œufs: Inspiré par un mème sur les œufs, un utilisateur a utilisé ChatGPT pour générer une série d’images et de descriptions humoristiques et conceptuelles de produits liés aux œufs, tels que « Precracked Life », « Internet of Eggs », etc. Montre la possibilité d’utiliser l’IA pour la divergence créative et la création de contenu humoristique (source: Reddit r/ChatGPT)
Partage d’œuvre Suno AI : Tom and Jerry / Crambone (Reprise blues rock): Un utilisateur partage une reprise de style blues rock réalisée avec Suno AI, reprenant « Tom and Jerry / Crambone », et fournit un lien YouTube (source: Reddit r/SunoAI)

Image générée par IA : Incarnation des sept péchés capitaux: Un utilisateur partage une vidéo montrant des images générées par IA (probablement ChatGPT/DALL-E) représentant l’incarnation et la personnification des sept péchés capitaux (tels que l’avarice, la paresse, l’envie, etc.) (source: Reddit r/ChatGPT)
