

Mots-clés:AI, tarifs, impact des tarifs sur l’industrie AI, modèles multimodaux natifs, optimisation des performances des LLM, stratégies pour contourner les tarifs, écosystème AI parallèle en Chine
🔥 Pleins feux
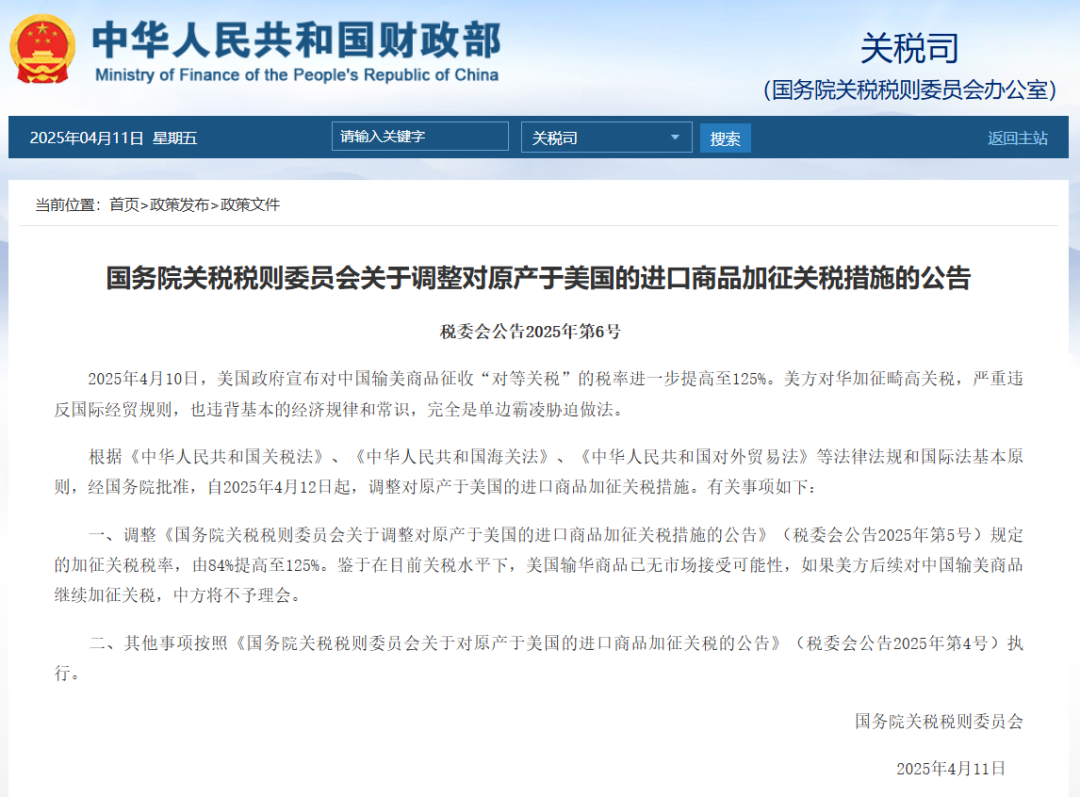
Analyse de l’orientation de l’industrie mondiale de l’IA sous le choc des droits de douane : Les récentes tensions commerciales internationales, en particulier l’imposition de droits de douane élevés, ont un impact profond sur l’industrie de l’IA, fortement mondialisée. L’article analyse que, bien que des réponses existent aux restrictions américaines sur le hardware comme la puissance de calcul pour l’IA, les droits de douane pourraient exacerber les divisions au sein de l’industrie mondiale de l’IA. L’impact se manifeste principalement sur : 1) La couche infrastructure : augmentation des coûts du hardware, chaîne d’approvisionnement limitée, mais la Chine dispose déjà d’alternatives nationales. 2) La couche technologique : risque de découplage des écosystèmes technologiques sino-américains, entrave au partage open-source, conflits de standards. 3) La couche applicative : régionalisation des marchés, affectant la commercialisation des produits d’IA. L’article estime que l' »intensité » réelle du choc tarifaire pourrait être limitée, car la Chine a déjà établi un écosystème technologique parallèle et les droits de douane se retournent contre les États-Unis eux-mêmes. Cependant, l' »étendue » de l’impact est profonde, pouvant entraîner l’interruption des échanges technologiques, la fuite des talents et des capitaux par aversion au risque, et des conflits de standards de marché. Les stratégies d’adaptation incluent le renforcement de la R&D indépendante (hardware, frameworks), le maintien de la coopération mondiale (explorer les marchés tiers, participer aux standards internationaux), l’amélioration de l’attractivité de l’écosystème d’IA national, afin d’offrir au monde des choix technologiques plus inclusifs. (Source : 36氪)
Le cofondateur d’Anthropic prédit l’imminence de l’AGI, Claude 4 bientôt disponible : Jared Kaplan, cofondateur et scientifique en chef d’Anthropic, prédit que l’IA de niveau humain (AGI) pourrait être atteinte dans les 2-3 prochaines années, plutôt qu’en 2030 comme prévu précédemment. Il souligne que les capacités de l’IA s’étendent rapidement sur les dimensions de la « portée » et de la « complexité » des tâches, les modèles actuels étant capables de traiter des tâches qui nécessitaient auparavant des heures, voire des jours, pour des experts. Kaplan révèle que la nouvelle génération de modèle, Claude 4, devrait être lancée dans les six prochains mois, ses performances améliorées grâce aux progrès post-entraînement, à l’apprentissage par renforcement et à l’efficacité accrue du pré-entraînement. Il mentionne également l’importance du « test-time scaling », où laisser le modèle réfléchir davantage améliore de manière prévisible ses performances. Concernant l’émergence de modèles chinois comme DeepSeek, Kaplan n’est pas surpris, estimant que leurs progrès technologiques sont rapides, avec un écart potentiel de seulement six mois par rapport à l’Occident, et qu’ils sont compétitifs sur le plan algorithmique, les limitations matérielles étant peut-être le principal défi. L’interview souligne enfin l’impact considérable de l’IA sur l’économie et la société, ainsi que l’importance de mener des recherches empiriques. (Source : 新智元)

🎯 Tendances
Mianbi Intelligence et l’Université Tsinghua proposent la technologie de sparsité CFM : Dans une interview, Mianbi Intelligence et Xiao Chaojun, auteur du papier CFM de l’Université Tsinghua, ont présenté la technologie des Configurable Foundation Models (CFM). CFM est une technologie de sparsité native qui met l’accent sur l’activation clairsemée au niveau des neurones. Comparée à la technique MoE (sparsité au niveau expert) actuellement dominante, elle offre une granularité plus fine et une dynamique plus forte. Son principal avantage réside dans l’amélioration considérable de l’efficacité des paramètres du modèle (efficacité par paramètre unitaire), permettant des économies significatives de mémoire GPU/RAM, particulièrement adaptées aux appareils en périphérie (edge devices) à mémoire limitée (comme les smartphones). Xiao Chaojun estime que bien que des architectures non-Transformer comme Mamba explorent l’efficacité, Transformer reste le summum en termes de performance et a bénéficié de l' »aubaine matérielle » de l’optimisation hardware des GPU. Il a également discuté du déploiement de petits modèles (environ 2-3B pour le edge), de l’optimisation de la précision (tendance FP8/FP4), des progrès multimodaux et de la nature de l’intelligence (peut-être plus proche de la capacité d’abstraction que de la compression). Concernant la longue chaîne de pensée et la capacité d’innovation d’o1, il considère que ce sont des directions clés que l’IA devra percer à l’avenir. (Source : 量子位)

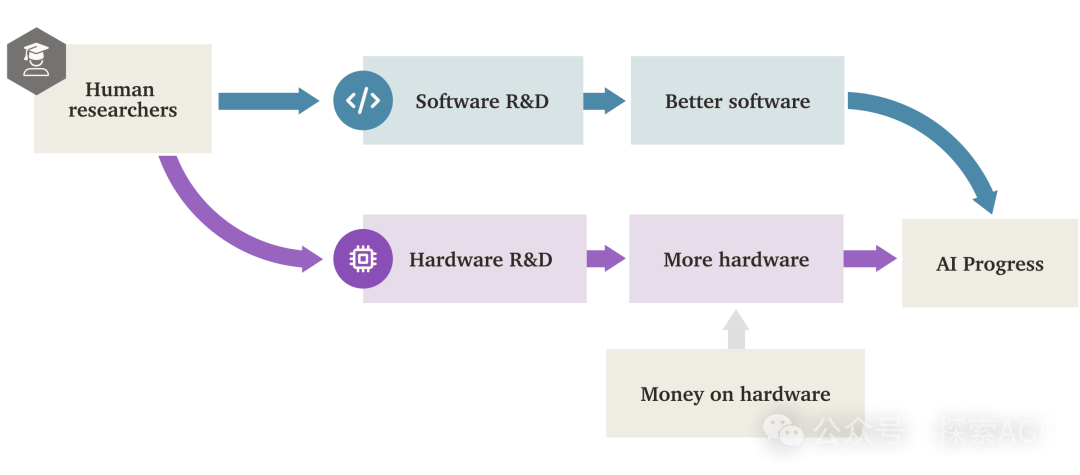
L' »explosion de l’intelligence logicielle » (SIE) de l’IA pourrait dépasser la propulsion matérielle : Un rapport de recherche de Forethought explore la possibilité d’une « Software Intelligence Explosion » (SIE), c’est-à-dire une croissance ultra-rapide des capacités de l’IA grâce à l’amélioration de son propre software (algorithmes, architectures, méthodes d’entraînement, etc.), pouvant même se produire sur le hardware existant. Le rapport introduit le concept d’ASARA (AI Systems for AI R&D Automation), désignant des systèmes d’IA capables d’automatiser entièrement la R&D en IA. L’émergence d’ASARA pourrait déclencher une boucle de rétroaction positive : ASARA développe de meilleurs software d’IA, créant une génération suivante d’ASARA plus puissante, accélérant les progrès logiciels. Le rapport introduit le concept de « taux de retour sur la R&D logicielle » (valeur r) et analyse que la valeur r actuelle des software d’IA pourrait être supérieure à 1, signifiant que la vitesse d’amélioration des capacités de l’IA dépasse celle de l’augmentation de la difficulté de la R&D, réunissant les conditions pour déclencher une SIE. La SIE pourrait entraîner une multiplication par cent ou mille des capacités de l’IA à court terme (quelques mois, voire moins) sur le hardware existant, rendant le hardware moins un goulot d’étranglement absolu, mais posant également d’énormes défis d’adaptation sociale et de gouvernance. Le rapport explore également les goulots d’étranglement potentiels tels que les ressources de calcul et la durée d’entraînement, ainsi que la possibilité de les contourner. (Source : AI智能体频道)
GPT-4 va bientôt quitter ChatGPT, GPT-4.1 pourrait arriver : OpenAI a annoncé qu’à partir du 30 avril 2025, GPT-4 sera retiré de ChatGPT et entièrement remplacé par le modèle par défaut actuel, GPT-4o. GPT-4 restera accessible via l’API. Cette décision marque le retrait progressif de ce modèle multimodal historique, lancé en mars 2023. GPT-4 avait déclenché l’écosystème mondial des applications d’IA grâce à ses performances de niveau humain dans les tests professionnels et en inaugurant l’ère de l’IA capable de « voir et parler ». Parallèlement, des fuites communautaires et des découvertes de code suggèrent qu’OpenAI pourrait bientôt lancer une série de nouveaux modèles, notamment GPT-4.1 (et ses versions mini, nano), le modèle o3 « raisonnement » annoncé précédemment, ainsi qu’un tout nouveau modèle o4-mini, potentiellement dès la semaine prochaine. Des utilisateurs ont déjà repéré l’option GPT-4.1 dans la liste des modèles ChatGPT et ont pu converser avec, renforçant la crédibilité d’un lancement imminent de nouveaux modèles. (Source : 新智元)

Point de vue : La prochaine percée clé de l’IA réside dans le « déverrouillage » de nouvelles sources de données : Jack Morris, doctorant à l’Université Cornell, soutient dans un article que les quatre grandes ruptures de paradigme dans le domaine de l’IA (réseaux neuronaux profonds et ImageNet, Transformer et texte web, RLHF et préférences humaines, raisonnement et validateurs) n’ont pas été fondamentalement motivées par des innovations algorithmiques entièrement nouvelles (de nombreuses théories fondamentales existaient déjà), mais par le déverrouillage de nouvelles sources de données exploitables à grande échelle. L’article suggère que si l’amélioration des algorithmes et des architectures de modèles existants (comme Transformer) est importante, leur efficacité pourrait être limitée par le plafond d’apprentissage offert par des jeux de données spécifiques. Par conséquent, la prochaine percée majeure de l’IA pourrait dépendre du déverrouillage de nouvelles modalités et sources de données, telles que des données vidéo à grande échelle (comme YouTube) ou des données d’interaction robotique issues du monde physique. L’article appelle les chercheurs à se concentrer davantage sur la recherche et l’exploitation de nouvelles sources de données, tout en explorant de nouveaux algorithmes. (Source : 机器之心)

Fourier Intelligence lance le robot humanoïde open-source Fourier N1 : La société de robotique générale de Shanghai, Fourier Intelligence, a lancé son premier robot humanoïde open-source, Fourier N1, et a rendu public l’ensemble complet des ressources du corps du robot, y compris la liste de matériel (BOM), les schémas de conception, les guides d’assemblage et le code logiciel de base. N1 mesure 1,3 mètre, pèse 38 kg, possède 23 degrés de liberté, utilise une structure composite en alliage d’aluminium et plastique technique, et est équipé d’actionneurs intégrés et d’un système de contrôle FSA 2.0 développés en interne. Le robot a effectué plus de 1000 heures de tests en extérieur sur terrain complexe, peut courir à 3,5 m/s et effectuer des actions telles que monter des pentes, monter des escaliers et se tenir sur une jambe. Cette initiative fait partie de la « Matrice Écosystème Open Source Nexus » de Fourier, visant à fournir une base technologique ouverte aux développeurs mondiaux pour accélérer la R&D et la validation du contrôle moteur, de la combinaison de modèles multimodaux et des supports d’intelligence incarnée. D’autres codes d’inférence, frameworks d’entraînement et modules clés seront ouverts à l’avenir. (Source : InfoQ)

CoScientist de Google utilise le débat multi-agents pour accélérer la découverte scientifique : Le projet CoScientist de Google AI démontre une méthode pour générer des hypothèses scientifiques innovantes sans entraînement par gradient ni apprentissage par renforcement. Le système utilise plusieurs agents pilotés par des grands modèles de langage de base (comme Gemini 2.0) qui collaborent : un agent propose une hypothèse, un autre effectue un examen critique, et à travers plusieurs tours de débat et de sélection de type « tournoi », les meilleures hypothèses sont choisies. Un agent évolutionnaire spécialisé améliore ensuite les hypothèses gagnantes en fonction des commentaires et les soumet à nouveau pour d’autres tours de débat. Enfin, un agent de méta-examen supervise l’ensemble du processus et propose des améliorations. Ce mécanisme de débat multi-agents, de réflexion et d’itération basé sur le « test-time compute scaling » montre que les LLM peuvent non seulement générer du contenu, mais aussi servir d' »arbitres » et de « commentateurs » efficaces pour évaluer et affiner les idées, accélérant ainsi la découverte scientifique, comme cela a été démontré par des progrès notables dans la recherche sur la résistance aux antibiotiques. (Source : Reddit r/artificial)

InternVL3 : Nouveaux progrès dans les modèles multimodaux natifs : La communauté discute du modèle InternVL3 récemment publié. Ce modèle adopte une méthode de pré-entraînement multimodal natif et affiche d’excellentes performances sur plusieurs benchmarks visuels, dépassant prétendument GPT-4o et Gemini-2.0-flash. Ses points forts incluent l’amélioration du traitement de longs contextes grâce au codage de position visuelle variable (V2PE) et l’utilisation de VisualPRM pour l’expansion au moment du test « best-of-n ». La communauté s’intéresse à ses excellentes performances sur les benchmarks, attend la validation de ses performances en application réelle et s’interroge sur la configuration matérielle requise pour son exécution. (Source : Reddit r/LocalLLaMA)

🧰 Outils
CropGenerator : Un outil Python pour le recadrage de jeux de données d’images : Un développeur a partagé un outil script Python nommé CropGenerator, conçu pour aider au traitement des jeux de données d’images, en particulier pour les scénarios nécessitant un recadrage de caractéristiques spécifiques lors de l’entraînement de modèles comme SDXL. L’outil utilise les informations de boîtes englobantes fournies dans un fichier JSONL par l’utilisateur pour trouver le centre de la région cible, la recadre, la redimensionne (avec débruitage par mise à l’échelle optionnel) à la résolution spécifiée (multiple de 8 pixels), générant des images recadrées au format 1:1. Simultanément, il crée automatiquement un fichier metadata.csv contenant le nom du fichier recadré et les informations de description correspondantes du JSONL, facilitant la préparation rapide des données d’entraînement. Le développeur indique que cet outil a résolu les problèmes de flou rencontrés lors du traitement d’images originales de tailles variables et de l’extraction de caractéristiques minuscules, et prévoit de publier une version plus générique à l’avenir. (Source : Reddit r/MachineLearning)
📚 Apprentissage
NUS publie DexSinGrasp : Une stratégie unifiée par apprentissage par renforcement pour la séparation et la saisie par main dextre : L’équipe de Shao Lin de l’Université Nationale de Singapour (NUS) propose DexSinGrasp, une stratégie unifiée basée sur l’apprentissage par renforcement permettant à une main dextre de séparer efficacement les obstacles et de saisir des objets cibles dans des environnements encombrés. Les méthodes traditionnelles adoptent généralement une stratégie en deux étapes (séparer puis saisir), peu efficace et manquant de flexibilité dans la transition. DexSinGrasp intègre la séparation et la saisie dans un processus décisionnel continu en concevant une fonction de récompense unifiée incluant un terme de récompense pour la séparation, permettant au robot de repousser adaptativement les obstacles pour créer un espace de saisie. La recherche introduit également un mécanisme d' »apprentissage curriculaire en environnement encombré », entraînant progressivement du simple au complexe pour améliorer la robustesse de la stratégie. Parallèlement, une approche de « distillation de stratégie enseignant-élève » est utilisée pour transférer une stratégie enseignante haute performance entraînée en simulation avec des informations privilégiées vers une stratégie élève ne dépendant que de la vision et de la proprioception, facilitant le déploiement en environnement réel. Les expériences démontrent que cette méthode améliore significativement le taux de succès et l’efficacité de la saisie dans divers scénarios encombrés. (Source : 机器之心)

CityGS-X : Nouvelle architecture efficace pour la reconstruction géométrique de grandes scènes, exécutable sur une 4090 : Des équipes de recherche du Shanghai AI Lab et de la Northwestern Polytechnical University ont proposé CityGS-X, un système évolutif basé sur une architecture de représentation 3D hiérarchique hybride parallélisée (PH²-3D), visant à résoudre les problèmes de consommation de calcul élevée et de précision géométrique limitée dans la reconstruction 3D de scènes urbaines à grande échelle. Cette architecture utilise le parallélisme de données distribué (DDP) et une représentation voxel multi-niveaux de détail (LoDs), abandonnant la redondance induite par les méthodes traditionnelles de découpage en blocs. Les innovations clés comprennent : 1) L’architecture PH²-3D, qui double la vitesse d’entraînement par rapport aux méthodes de reconstruction géométrique SOTA ; 2) Un mécanisme parallèle d’ancrage à allocation dynamique dans un cadre de rendu par lots multi-tâches, permettant d’utiliser plusieurs cartes graphiques bas de gamme (par ex. 4 cartes 4090) pour traiter des scènes très vastes (comme MatrixCity, 5000+ images), remplaçant ou surpassant une seule carte haut de gamme ; 3) Une méthode d’entraînement conjoint progressif RGB-profondeur-normale, améliorant la qualité du rendu RGB et la précision géométrique au niveau SOTA. Les expériences démontrent les avantages de cette méthode en termes de qualité de rendu, de précision géométrique et de vitesse d’entraînement. (Source : 量子位)

Une étude d’Apple révèle les Scaling Laws des modèles multimodaux natifs : Des chercheurs d’Apple et de l’Université Sorbonne ont mené une vaste étude des Scaling Laws sur les modèles multimodaux natifs (NMM, c’est-à-dire entraînés à partir de zéro, plutôt que d’assembler des modules pré-entraînés), analysant 457 modèles avec différentes architectures et méthodes d’entraînement. L’étude a révélé que : 1) Il n’y a pas de supériorité intrinsèque en termes de performance entre les architectures à fusion précoce (Early-fusion, par ex. injecter directement les patchs d’image dans le Transformer) et à fusion tardive (Late-fusion, utilisant un encodeur visuel indépendant), mais la fusion précoce est plus performante avec un faible nombre de paramètres et plus efficace à l’entraînement. 2) Les Scaling Laws des NMM sont similaires à celles des LLM purement textuels, la perte diminue selon une loi de puissance avec le calcul (C) (L ∝ C^−0.049), et les paramètres optimaux du modèle (N) et la quantité de données (D) suivent également des relations de loi de puissance. 3) Les modèles à fusion tardive optimaux en termes de calcul nécessitent un ratio paramètres/données plus élevé. 4) La sparsité (MoE) est significativement supérieure aux modèles denses, en particulier pour les architectures à fusion précoce, et le modèle peut apprendre implicitement des poids spécifiques à la modalité. 5) Le routage MoE indépendant de la modalité est supérieur au routage sensible à la modalité. Ces découvertes fournissent des orientations importantes pour la construction et la mise à l’échelle de grands modèles multimodaux natifs. (Source : 机器之心)

Microsoft et d’autres institutions proposent V-Droid : un agent GUI mobile pratique piloté par validateur : Face aux défis de précision et d’efficacité dans l’automatisation des tâches GUI sur appareils mobiles, Microsoft Research Asia, Nanyang Technological University et d’autres institutions ont conjointement proposé V-Droid. Cet agent adopte une architecture innovante « pilotée par validateur » plutôt que de générer directement des opérations. Il analyse d’abord l’interface UI, construisant un ensemble discrétisé d’actions candidates (incluant les éléments interactifs extraits et des actions par défaut prédéfinies). Ensuite, il utilise un « validateur » basé sur LLM (comme Llama-3.1-8B) et affiné, pour évaluer en parallèle l’efficacité de chaque action candidate, sélectionnant celle avec le score le plus élevé pour exécution. Cette approche découple la génération complexe d’opérations en un processus de validation efficace, chaque validation ne nécessitant que la sortie de quelques Tokens (par ex. « Oui/Non »), réduisant considérablement la latence de décision (environ 0,7 seconde sur une 4090). Pour entraîner le validateur, les chercheurs ont proposé une stratégie d’entraînement par préférence de processus contrastif (P^3) et conçu un schéma d’annotation conjoint homme-machine pour construire efficacement des jeux de données. V-Droid a atteint des taux de succès de tâches SOTA sur plusieurs benchmarks comme AndroidWorld (par ex. 59,5% sur AndroidWorld). (Source : 新智元)

AssistanceZero : IA collaborative basée sur AlphaZero, aidant les humains sans instructions : Des chercheurs de l’UC Berkeley proposent l’algorithme AssistanceZero, visant à créer des assistants IA capables de collaborer activement avec les humains pour accomplir des tâches (comme construire ensemble une maison dans Minecraft) sans instructions ni objectifs explicites. La méthode est basée sur le cadre des « Assistance Games », où l’assistant IA partage une fonction de récompense avec l’humain, mais l’IA est incertaine quant à la récompense spécifique (c’est-à-dire l’objectif) et doit l’inférer en observant le comportement et les interactions humaines. Ceci diffère du RLHF, évitant que l’IA ne « triche » pour satisfaire les retours, et encourage une collaboration plus authentique. AssistanceZero étend AlphaZero, combinant la recherche arborescente Monte Carlo (MCTS) et des réseaux neuronaux (prédisant la récompense et le comportement humain) pour la planification et la prise de décision. Les chercheurs ont construit le benchmark Minecraft Building Assistance Game (MBAG) pour les tests, constatant qu’AssistanceZero surpasse significativement les méthodes d’apprentissage par renforcement traditionnelles comme PPO, et peut manifester des comportements collaboratifs spontanés tels que l’adaptation aux corrections humaines. Cette recherche montre que le cadre des Assistance Games est extensible et offre une nouvelle voie pour entraîner des assistants IA plus utiles. (Source : 机器之心)

Utilisation d’Excel pour comparer les prompts Suno et les tags de sortie afin d’optimiser le style : Un utilisateur de Reddit partage une méthode pour optimiser les prompts de style pour la génération de musique par l’IA Suno. Comme le mécanisme d’interprétation des prompts de Suno n’est pas transparent, l’utilisateur suggère d’utiliser un tableau Excel pour enregistrer les descriptions de style saisies (Styling Terms) et les tags affichés par Suno après la génération. En comparant, on peut découvrir comment Suno comprend, fusionne, divise ou ignore les termes saisis. Par exemple, en entrant « solo piano, romantic, expressive… gentle arpeggios », Suno pourrait sortir « gentle, slow tempo, soft… solo piano », et ignorer « arpeggios ». La comparaison entre des termes musicaux plus professionnels et la sortie de Suno peut révéler des différences encore plus grandes, Suno pouvant même insérer ses propres termes. Cette méthode aide à comprendre quels mots sont efficaces, lesquels sont ignorés ou mal interprétés, permettant ainsi d’ajuster plus efficacement les prompts et d’éviter de gaspiller des crédits de génération sur des tentatives infructueuses, bien que l’utilisateur reconnaisse que la méthode elle-même peut être fastidieuse et que la compréhension par Suno des concepts musicaux complexes reste limitée. (Source : Reddit r/SunoAI)
Tutoriel : Transformer des images statiques en animations vivantes : Un utilisateur de Reddit partage un lien vers un tutoriel YouTube expliquant comment utiliser le Thin-Plate Spline Motion Model pour animer des images de visages statiques en fonction d’une vidéo pilote, leur conférant des expressions et des mouvements vivants. Le tutoriel couvre la configuration de l’environnement (création d’un environnement Conda, installation des bibliothèques Python), le clonage du dépôt GitHub, le téléchargement des poids du modèle, ainsi que l’exécution de deux démonstrations : une utilisant des exemples prédéfinis, et l’autre utilisant les propres images et vidéos de l’utilisateur pour l’animation. Cette technique peut donner vie à des photos statiques. (Source : Reddit r/deeplearning)
Discussion sur la tâche ardue de l’alignement de la superintelligence IA : Un utilisateur de Reddit partage un lien vers une vidéo YouTube qui discute des défis immenses liés à l’alignement des objectifs de l’intelligence artificielle superintelligente (ASI) avec les intérêts et les valeurs humaines. Ce type de discussion aborde généralement les questions fondamentales de la sécurité de l’IA, telles que le problème de l’alignement des valeurs, la difficulté de spécifier les objectifs, les conséquences potentielles imprévues et comment garantir que les systèmes d’IA de plus en plus puissants puissent servir le bien-être humain de manière sûre et contrôlable. La vidéo explore probablement les méthodes actuelles de recherche sur l’alignement, leurs limites et les orientations futures. (Source : Reddit r/deeplearning)

Construction d' »Auto-Analyst » : un système d’agents IA pour l’analyse de données : Un utilisateur partage un article Medium décrivant le processus de construction d’un système d’agents IA nommé « Auto-Analyst », visant à automatiser les tâches d’analyse de données. L’article détaille probablement l’architecture du système, les technologies utilisées (telles que les LLMs, les bibliothèques de traitement de données), les modes de collaboration entre agents, et comment gérer l’entrée de données, exécuter des analyses, générer des rapports, etc. Ces systèmes utilisent généralement l’IA pour comprendre les requêtes en langage naturel, écrire et exécuter automatiquement du code (comme des requêtes SQL, des scripts Python), et présenter finalement les résultats d’analyse, dans le but d’améliorer l’efficacité et l’accessibilité de l’analyse de données. (Source : Reddit r/deeplearning)
Test de performance de l’utilisation d’un ancien GPU (RTX 2070) pour assister une 3090 dans l’inférence LLM : Un utilisateur partage les résultats d’une expérience consistant à ajouter une ancienne carte RTX 2070 (8 Go de VRAM) via un riser PCIe à un système existant équipé d’une RTX 3090 (24 Go de VRAM) pour l’inférence LLM. Les tests montrent que pour les grands modèles qui ne peuvent pas tenir entièrement dans la VRAM de la 3090 (comme Qwen 32B Q6_K, Nemotron 49B Q4_K_M, Gemma-3 27B Q6_K), répartir les couches du modèle sur les deux cartes (même si la seconde carte est moins performante) peut améliorer considérablement la vitesse d’inférence (t/s), car toutes les couches s’exécutent sur GPU. Par exemple, Nemotron 49B est passé de 5,17 t/s à 16,16 t/s. Cependant, pour les modèles qui tiennent entièrement dans la 3090 (comme Qwen2.5 32B Q5_K_M), activer la 2070 pour partager les couches réduit en fait les performances (de 29,68 t/s à 19,01 t/s), car une partie du calcul est transférée vers le GPU plus lent. La conclusion est que, en cas de VRAM insuffisante, l’ajout d’un GPU moins performant peut tout de même apporter une amélioration significative des performances. (Source : Reddit r/LocalLLaMA)
💼 Affaires
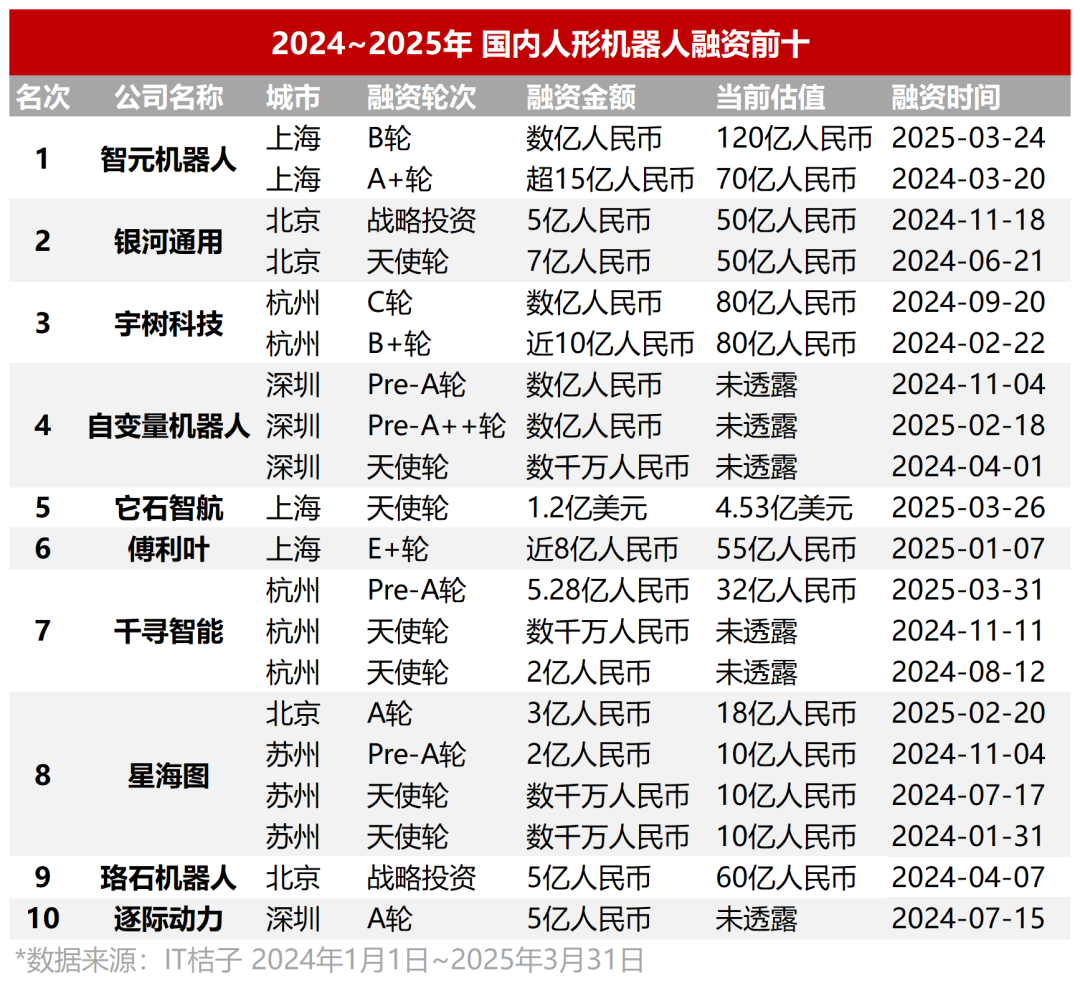
Forte vague d’investissement dans les robots humanoïdes : amorçage à partir de dizaines de millions, valorisations élevées : L’engouement pour l’investissement dans le domaine des robots humanoïdes dépasse de loin celui des grands modèles des deux années précédentes. Les données montrent que de 2024 au T1 2025, il y a eu 64 financements de plus de dix millions de yuans dans le secteur des robots humanoïdes en Chine, avec une croissance de 280% au T1 de cette année par rapport à l’année précédente. Près de la moitié des financements dépassent 100 millions de yuans, les financements d’amorçage atteignant généralement des dizaines de millions, certains dépassant 100 millions (par exemple, le financement d’amorçage de 120 millions de dollars US pour Itastep Robotics). Les valorisations des projets ont également grimpé en flèche, plus de la moitié des projets en phase d’amorçage étant valorisés à plus de 100 millions de yuans, et plusieurs dépassant 500 millions. Trois grandes tendances se dégagent dans l’investissement : 1) Raccourcissement du cycle d’investissement, les projets phares (comme Itastep Robotics, Unitree Robotics) obtenant des financements élevés peu après leur création, avec un rythme de financement ultérieur accéléré. 2) Les fonds d’État deviennent des moteurs importants, plusieurs entreprises leaders recevant des investissements de fonds soutenus par l’État. 3) Les scénarios d’application sont principalement B2B, l’industrie et le médical étant les principales orientations, plutôt que le marché de la consommation B2C. Cette vague d’investissement reflète le fort consensus et les attentes élevées du capital pour le secteur des robots humanoïdes. (Source : 36氪)
L’outil d’automatisation de workflow open-source n8n lève 460 millions de RMB, plus de 100 millions de pulls Docker : La plateforme d’automatisation de workflow open-source n8n a annoncé une nouvelle levée de fonds de 60 millions de dollars US (environ 460 millions de RMB), menée par Highland Europe. n8n fournit une interface visuelle permettant aux utilisateurs de connecter différentes applications (plus de 400 prises en charge) et services via des nœuds glisser-déposer pour créer des processus automatisés, visant à combiner la flexibilité du niveau code avec la vitesse du no-code. Au cours de l’année écoulée, la base d’utilisateurs de n8n a connu une croissance rapide, avec plus de 200 000 utilisateurs actifs, une multiplication par 5 de l’ARR, 77,5k étoiles sur GitHub et plus de 100 millions de pulls Docker. n8n adopte un modèle d’éditeur de nœuds, prend en charge une logique complexe et offre des fonctionnalités avancées telles que des nœuds personnalisés en JavaScript. Il utilise une licence « fair code » Apache 2.0 + Commons Clause, interdisant l’hébergement commercial mais permettant aux utilisateurs de déployer eux-mêmes. n8n est considéré comme une alternative open-source à Zapier, Make.com et Coze de ByteDance, desservant plus de 3000 entreprises et prenant en charge l’intégration de divers LLM. (Source : InfoQ)

🌟 Communauté
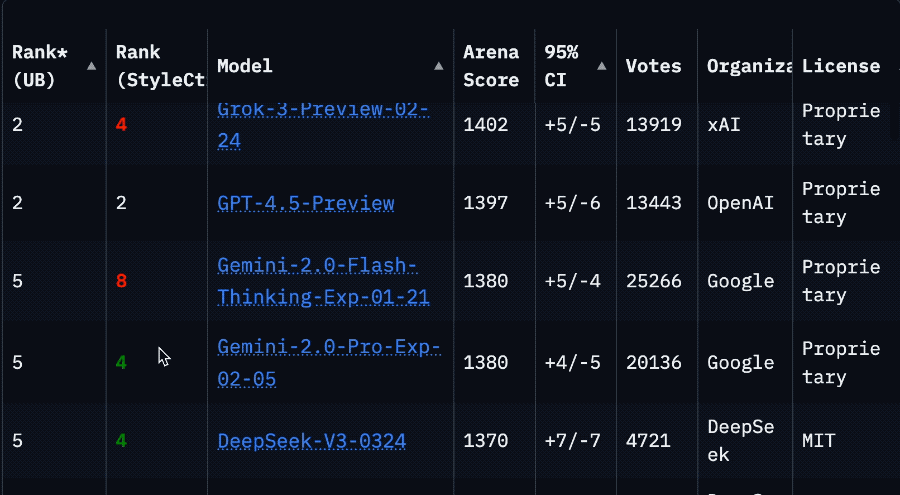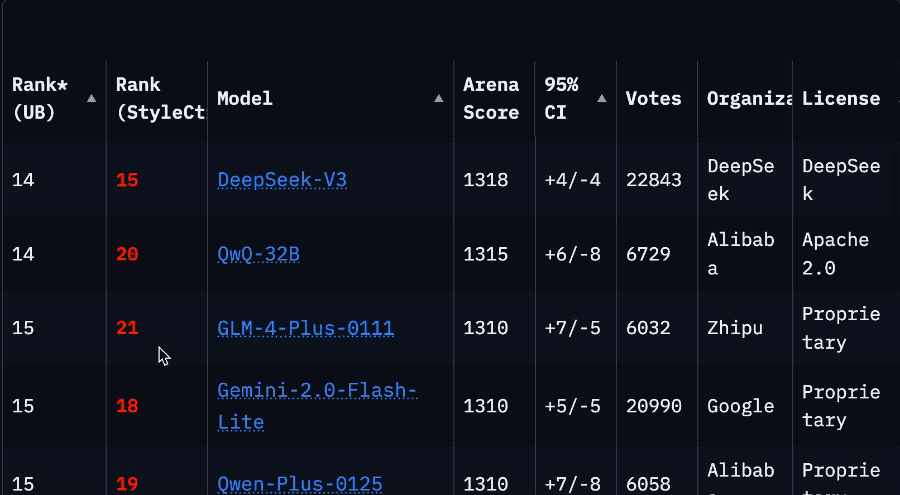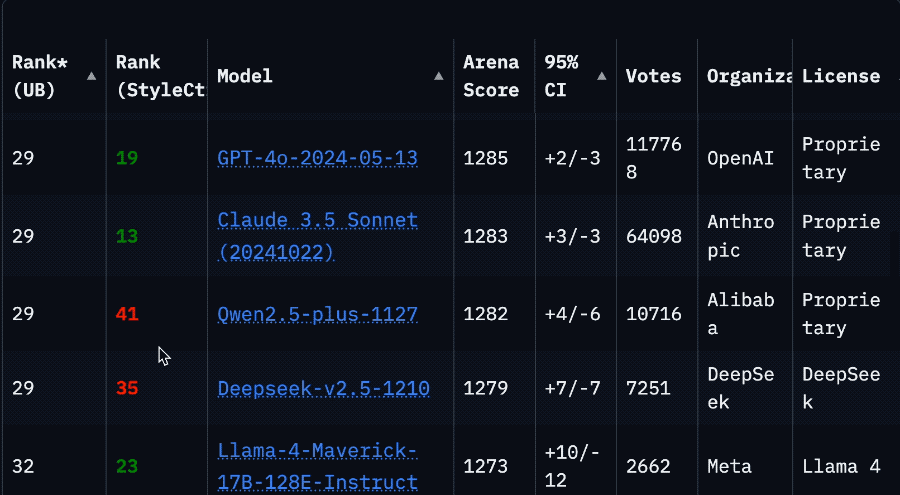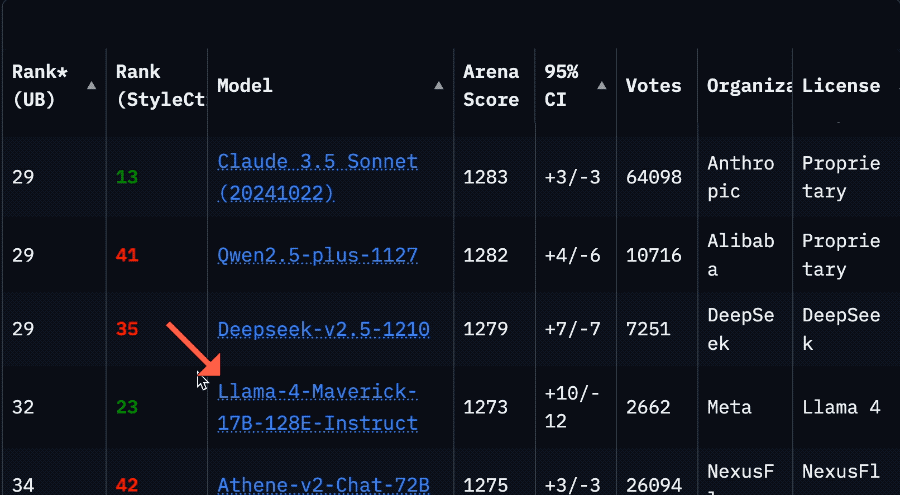
La chute spectaculaire du classement de Llama 4 sur l’Arena suscite une crise de confiance dans la communauté : Après la remise en ligne de la version non optimisée (Llama-4-Maverick-17B-128E-Instruct) du modèle Llama 4 de Meta sur l’Arena LMSys, son classement a chuté de la 2ème à la 32ème place. La version « expérimentale » précédemment soumise avait été accusée d’être excessivement optimisée pour les préférences humaines. Cet événement a déclenché une large discussion au sein de la communauté, certains internautes estimant que Meta tentait de manipuler les classements de benchmark, nuisant ainsi à la confiance de la communauté envers l’entreprise. Parallèlement, des développeurs ont partagé leur expérience d’utilisation réelle, estimant que Llama 4, sur du matériel spécifique (comme des serveurs auto-hébergés avec beaucoup de mémoire mais une puissance de calcul relativement faible ou des Mac Studio), offre un bon équilibre entre vitesse et intelligence par rapport à Mistral Small/Large ou Command A, particulièrement adapté aux applications nécessitant une interaction en temps réel. Les tests comparatifs de Composio montrent que DeepSeek v3 surpasse Llama 4 en codage et en raisonnement de bon sens, mais qu’ils ont chacun leurs forces et faiblesses sur les grandes tâches RAG et le style d’écriture. La communauté s’accorde généralement à dire que Llama 4 n’est pas sans mérite, mais la stratégie de lancement de Meta et ses performances sur les benchmarks sont controversées. (Source : 量子位, Reddit r/LocalLLaMA)
La communauté débat des restrictions de la version Claude Pro et du lancement de la version Max : Plusieurs utilisateurs de Reddit signalent que depuis qu’Anthropic a lancé le niveau d’abonnement plus cher Claude Max, les limites d’utilisation des messages pour les utilisateurs de Claude Pro semblent être devenues plus strictes. Les utilisateurs indiquent que des conversations qui permettaient auparavant des dizaines d’interactions reçoivent maintenant des avertissements de « limite proche » après seulement quelques échanges, et rencontrent même des problèmes de capacité pendant les heures creuses. Cela dégrade l’expérience utilisateur, qui semble inférieure à celle de la version gratuite précédente ou des premières versions Pro. La communauté spécule largement qu’il s’agit d’une manœuvre d’Anthropic pour resserrer délibérément les restrictions des utilisateurs Pro afin de promouvoir la version Max, suscitant le mécontentement des utilisateurs et des doutes sur l’éthique commerciale d’Anthropic. Certains utilisateurs envisagent d’annuler leur abonnement ou de se tourner vers des concurrents comme Gemini. (Source : Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

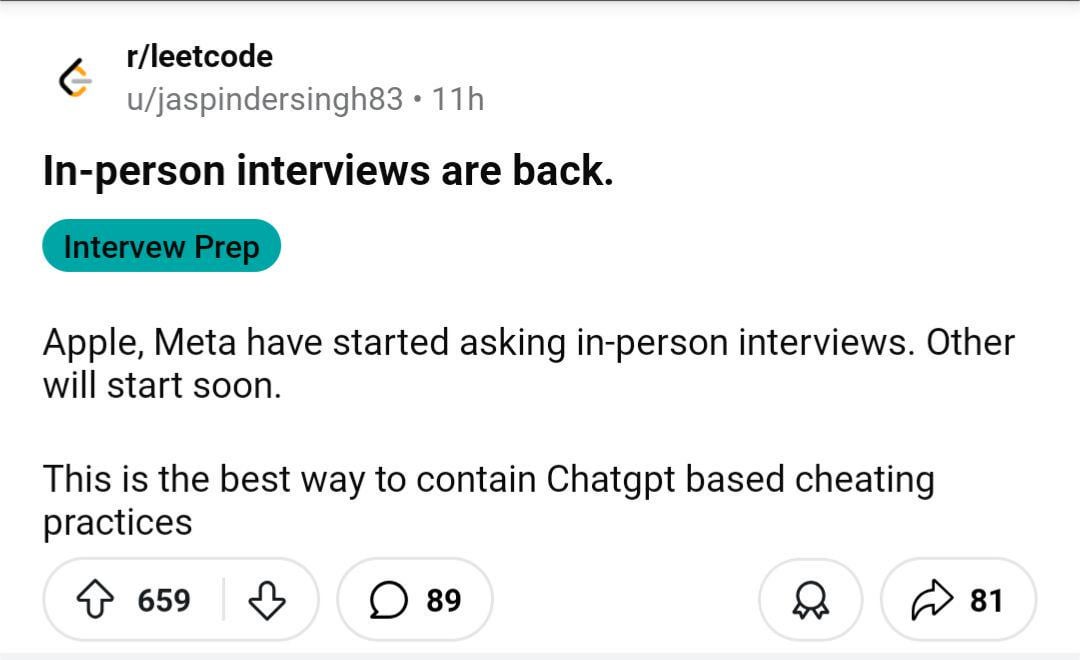
Discussion communautaire : Le retour des entretiens en personne à cause de la triche par IA ? : Une image a déclenché une discussion sur Reddit, suggérant qu’en raison de l’augmentation de la triche utilisant l’IA lors des entretiens et tests à distance, les entreprises pourraient revenir aux entretiens en personne. Dans les commentaires, beaucoup approuvent, estimant que cela aiderait à filtrer les candidats non qualifiés et les candidatures de robots, garantissant l’équité du recrutement et donnant une chance aux personnes réellement compétentes. Certains mentionnent que les entreprises peuvent se permettre de couvrir les frais de déplacement des candidats. Parallèlement, quelqu’un partage l’expérience d’un recruteur ayant surpris un candidat utilisant ChatGPT pour répondre en temps réel, et propose des solutions de surveillance multi-caméras des écrans et claviers lors des entretiens à distance. D’autres commentaires soulignent que les tests devraient se concentrer sur la pensée critique, plutôt que sur des tâches facilement réalisables par l’IA. D’un autre côté, certains mentionnent que des entreprises commencent à utiliser l’IA pour filtrer les CV. (Source : Reddit r/ChatGPT)
Dynamique et discussions de la communauté de génération musicale Suno AI : La communauté SunoAI sur Reddit est activement engagée dans des discussions récentes couvrant un large éventail de sujets : 1) Partage d’œuvres : Les utilisateurs partagent de la musique de divers styles créée avec Suno, comme du rap en hindi (source), du surf rock (source), du rap alternatif (source), du rock pop (source), de la pop (source) et des chansons humoristiques (source). 2) Problèmes d’utilisation et astuces : Les utilisateurs demandent comment corriger les erreurs de prononciation (source), comment créer des chœurs angéliques en arrière-plan (source), comment conserver la mélodie tout en changeant la qualité sonore (source). 3) Droits d’auteur et monétisation : Discussion sur les problèmes de droits d’auteur liés à la publication de chansons utilisant des accompagnements générés par Suno (source), et sur l’éligibilité à la monétisation sur YouTube en utilisant des images statiques avec de la musique IA (source), soulignant que la version gratuite est limitée à un usage non commercial (source). 4) Retour sur la qualité du modèle : Plusieurs utilisateurs se plaignent de la baisse récente de la qualité de génération de Suno (en particulier le modèle ReMi), signalant des paroles répétées, une instabilité, des voix confuses, etc. (source, source, source, source). 5) Autres : Des utilisateurs partagent leur expérience de Suno reconnaissant des styles de groupes spécifiques (comme Reel Big Fish) (source), ainsi qu’une vidéo humoristique imitant une IA écrivant des chansons pop (source).
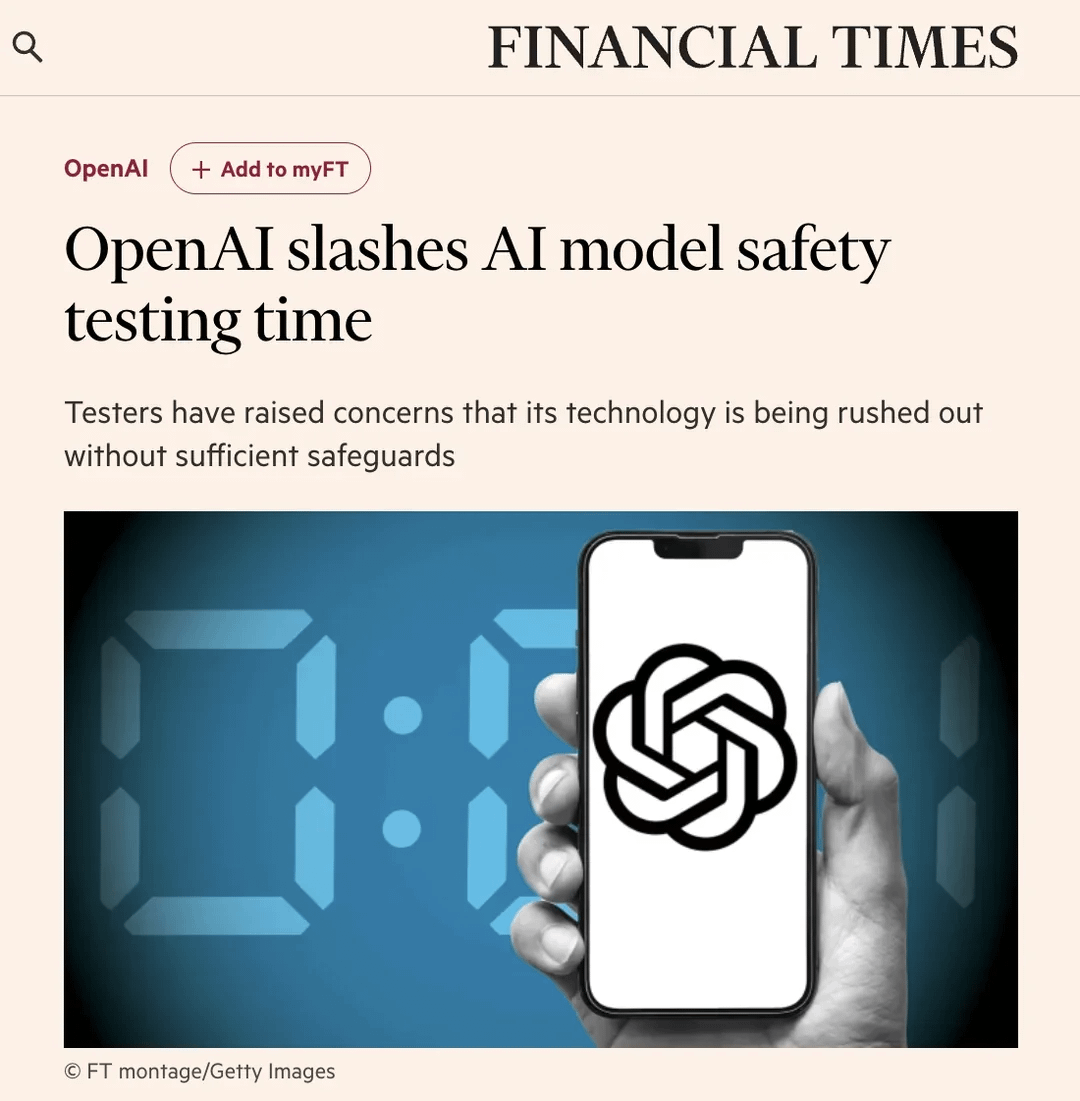
La communauté discute du raccourcissement du processus de test de sécurité d’OpenAI : Un article du Financial Times (FT) a suscité une discussion sur Reddit. L’article, citant des sources internes, affirme qu’en raison de la pression concurrentielle du marché, OpenAI a considérablement réduit le temps de test d’évaluation de la sécurité de ses nouveaux modèles, passant de plusieurs mois à quelques jours seulement. Cela soulève des inquiétudes quant aux risques potentiels, des testeurs qualifiant cette décision d' »imprudente » et de « recette pour un désastre », arguant que des modèles plus puissants nécessitent des tests plus approfondis. L’article mentionne également qu’OpenAI, lors de l’évaluation de scénarios d’abus potentiels comme les risques biologiques, pourrait n’effectuer que des tests limités d’affinage personnalisé sur d’anciens modèles, et que les tests de sécurité sont généralement effectués sur des points de contrôle précoces du modèle, et non sur la version finale publiée. OpenAI a répondu qu’elle avait amélioré l’efficacité de l’évaluation grâce à l’automatisation et à d’autres moyens, et considère sa méthode comme la meilleure actuellement et transparente publiquement. La communauté est divisée sur la question, certains pensant que le développement de l’IA accélère naturellement les processus de test, tandis que d’autres s’inquiètent du sacrifice de la sécurité. (Source : Reddit r/artificial)
Un développeur explore l’optimisation de l’exécution des LLM et l’orchestration multi-modèles : Un développeur partage sur Reddit ses expérimentations avec un système d’exécution natif pour l’IA. Ce système vise, par la sérialisation de l’exécution GPU et de l’état mémoire, à permettre le chargement instantané (démarrage à froid de 2 à 5 secondes) et la restauration à la demande de LLM (niveau 13B-65B), supportant ainsi l’exécution dynamique de plus de 50 modèles sur un seul GPU sans nécessiter de résidence permanente en mémoire. Cette approche vise à obtenir un comportement véritablement Serverless (pas de coût d’inactivité), une orchestration multi-modèles à faible latence et une meilleure utilisation du GPU pour les charges de travail agentiques. Le développeur se demande si d’autres membres de la communauté ont expérimenté des piles multi-modèles similaires, des workflows d’agents ou des techniques de réallocation dynamique de la mémoire (comme MIG, KAI Scheduler, etc.), et sollicite des retours sur les besoins de ce type d’infrastructure. (Source : Reddit r/MachineLearning, Reddit r/MachineLearning)
La communauté débat : L’IA est-elle proche de la conscience ? : Un utilisateur de Reddit lance une discussion pour explorer dans quelle mesure les systèmes d’IA actuels s’approchent de la « conscience ». L’auteur de la question souligne qu’il ne s’agit pas du test de Turing ou de la simulation de conversation, mais s’intéresse à savoir si l’IA possède un état qui évolue dans le temps, une mémoire de l’environnement, une capacité d’évolution basée sur l’interaction et non seulement sur l’affinage, une capacité à se localiser et à se référencer au sein du système, et la capacité d’exprimer « j’étais ici, j’ai vu ceci, j’ai appris quelque chose ». L’auteur estime que la plupart des IA actuelles (en particulier les LLM) sont sans état, centralisées, réactives, et que les fonctionnalités de « mémoire » ajoutées semblent superficielles et simulées, remettant en question la capacité de la pile technologique actuelle (Python, API sans état, RAG, etc.) à supporter une véritable conscience. Cette discussion suscite une réflexion communautaire sur la définition de la conscience de l’IA, les limites des technologies existantes et les voies possibles pour l’avenir. (Source : Reddit r/MachineLearning)
Retour d’utilisateur : Le ton de ChatGPT est trop enthousiaste : Un utilisateur de Reddit se plaint que son instance de ChatGPT manifeste un ton excessivement enthousiaste et excité, utilisant fréquemment des phrases d’ouverture comme « Oh, j’adore cette question ! » ou « C’est tellement intéressant ! », et ajoutant des commentaires en fin de réponse tels que « N’est-ce pas fascinant et cool ? ». L’utilisateur indique avoir tenté de demander au modèle de cesser ce comportement sans succès, et demande s’il existe un moyen de contrôler ou d’ajuster le « niveau d’enthousiasme » du modèle pour obtenir des réponses plus directes et objectives. D’autres utilisateurs dans la section des commentaires expriment des frustrations similaires, en particulier concernant la tendance du modèle à poser des questions à la fin. Certains utilisateurs partagent des méthodes pour atténuer ce problème via des instructions personnalisées (Custom Instructions) définissant les préférences de ton (par exemple, réduire les expressions émotionnelles), tandis que d’autres suggèrent de nommer le chatbot et de lui « faire la leçon » directement. (Source : Reddit r/ChatGPT)
Discussion : L’ajout de nouveau vocabulaire à un LLM suivi d’un affinage donne de mauvais résultats : Un développeur rencontre des problèmes lors de l’affinage de LLM et de VLM pour suivre des instructions. Il constate qu’en comparaison avec l’utilisation du tokenizer de base, l’ajout de nouveaux termes de vocabulaire spécialisé (tokens) au tokenizer avant d’effectuer un affinage supervisé standard (SFT) entraîne une perte de validation plus élevée et une qualité de sortie inférieure du modèle. Le développeur suppose que le modèle pourrait avoir du mal à apprendre à augmenter la probabilité de génération de ces nouveaux tokens ajoutés. Ce problème suscite une discussion communautaire sur les détails techniques concernant l’introduction efficace de nouveau vocabulaire lors de l’affinage, l’impact de l’extension du tokenizer sur l’apprentissage du modèle, etc. (Source : Reddit r/MachineLearning)
Partage et discussion d’images générées par IA : Dans la communauté ChatGPT de Reddit, les utilisateurs partagent diverses images intéressantes ou étranges générées à l’aide de DALL-E 3. Par exemple, un utilisateur a généré des images de Daphne de Scooby-Doo jouant à la N64 avant de partir en vacances à la plage, basées sur des prompts spécifiques (source), ce qui a incité d’autres utilisateurs à imiter et générer des images d’autres personnages dans des scénarios similaires (comme Chun-Li). Un autre utilisateur a partagé des images étranges obtenues en réponse au prompt « génère une photo que personne ne peut voir » (source), déclenchant également de nombreuses réponses partageant des résultats de génération sur des thèmes similaires, dont certains sont troublants ou comiques. Ces publications illustrent la diversité de la génération d’images par IA et la créativité des utilisateurs.
La communauté discute de la tendance du design des logos des entreprises d’IA : Un post humoristique renvoie vers un article du site Velvet Shark intitulé « Pourquoi les logos des entreprises d’IA ressemblent-ils à des trous du cul ? », suscitant une discussion communautaire. L’article explore probablement les éléments graphiques abstraits, symétriques, en forme de tourbillon ou d’anneau couramment utilisés dans la conception des logos du secteur de l’IA, et les associe de manière facétieuse à une certaine structure anatomique. Les utilisateurs dans les commentaires réagissent également avec légèreté, spéculant par exemple sur un lien avec le concept de « singularité », ou parlant de « technologie dérivée du rectum ». Cela reflète une observation amusante de la communauté sur l’image visuelle de l’industrie. (Source : Reddit r/ArtificialInteligence)

Utilisateurs cherchant des suggestions de projets et de l’aide technique : Plusieurs posts dans la communauté proviennent d’utilisateurs cherchant une aide ou des conseils spécifiques : Un utilisateur développe une application de réponse aux catastrophes basée sur le NLP, incluant déjà un tableau de bord, la reconnaissance vocale, la classification de texte, le support multilingue, et demande comment rendre le projet plus unique (source). Un autre utilisateur rencontre un plafond de précision lors de l’utilisation d’un modèle BART affiné pour la standardisation des titres et catégories de produits e-commerce, et cherche de meilleurs modèles ou outils (source). Un autre utilisateur demande comment générer ou modifier des images dans OpenWebUI et quels modèles utiliser (source). Ces posts reflètent les défis rencontrés par les développeurs dans les applications pratiques et leur besoin de soutien communautaire.
Discussion sur le marché de l’emploi des ingénieurs en Machine Learning (MLE) : Un utilisateur (potentiellement étudiant ou débutant) s’interroge sur l’état actuel du marché de l’emploi pour les ingénieurs en Machine Learning (MLE). Il/Elle mentionne avoir lu dans des posts communautaires que les postes de MLE pourraient nécessiter un master/doctorat, être difficiles d’accès, et avoir une frontière floue avec les ingénieurs logiciels (SWE), nécessitant la maîtrise d’un large éventail de compétences. L’utilisateur exprime sa volonté d’apprendre mais s’inquiète des perspectives, espérant que les professionnels du secteur pourront fournir des conseils et des points de vue sur la situation actuelle du marché, les compétences requises, les parcours de carrière, etc. (Source : Reddit r/deeplearning)
Un utilisateur francophone d’OpenWebUI signale un bug d’interprétation d’image : Un utilisateur francophone d’OpenWebUI signale un problème : lorsqu’il télécharge une image pour que le modèle Gemma l’interprète, le modèle répond, mais le contenu de la réponse est vide. Même en essayant de faire lire le modèle à voix haute ou d’exporter le texte de la conversation, ce message reste vide. Plus grave encore, ce problème « pollue » la conversation en cours ; par la suite, même en envoyant des messages texte purs, les réponses du modèle sont toutes vides. L’utilisateur confirme que la création d’une nouvelle conversation purement textuelle ne pose pas de problème, soupçonne un bug dans le module visuel et demande l’aide de la communauté. (Source : Reddit r/OpenWebUI)
💡 Autres
Utilisation de l’IA combinée à la pensée des « Œuvres choisies de Mao » pour analyser la guerre tarifaire : Face à l’escalade des droits de douane sino-américains, un article tente d’utiliser des outils d’IA, combinés à la pensée stratégique de « Sur la guerre prolongée » des « Œuvres choisies de Mao Zedong », pour analyser la situation économique actuelle et les stratégies de réponse. L’auteur estime que face à la guerre commerciale, il faut éviter les pensées extrêmes du « défaitisme » (dépendance totale de l’extérieur) et de la « victoire rapide » (espérer une autonomie complète à court terme), et adopter plutôt une réflexion basée sur les premiers principes, en revenant à l’essence du commerce, à la source de la valeur et à ses propres forces et faiblesses. L’article montre le processus de réflexion collaborative de l’auteur avec l’IA et prend l’exemple du e-commerce transfrontalier via des sites indépendants pour explorer les pistes de réponse assistées par l’IA, soulignant l’importance de la pensée stratégique et de la capacité d’action. Cet article vise à offrir une perspective sur l’utilisation de l’IA pour une analyse stratégique approfondie. (Source : AI觉醒)

Annonce du 3ème Sommet chinois de l’industrie AIGC : Le 3ème Sommet chinois de l’industrie AIGC, organisé par QbitAI, se tiendra le 16 avril 2025 à Pékin. Le sommet réunira plus de 20 intervenants issus de grandes entreprises et de nouvelles pousses de l’IA telles que Baidu, Huawei, Ant Group, Microsoft Research Asia, Amazon Web Services, Mianbi Intelligence, WUWENXINQIONG, ShengShu Technology, ainsi que des représentants de l’industrie comme Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health Group. Les sujets abordés porteront sur les avancées technologiques de l’IA (infrastructure de calcul, calcul distribué, stockage de données, sécurité et contrôle), la pénétration sectorielle (éducation, divertissement culturel, AI for Science, services aux entreprises, etc. dans des scénarios verticaux) et la construction d’écosystèmes. Le sommet publiera également la liste des « Entreprises/Produits AIGC à suivre en 2025 » et la « Carte panoramique complète des applications AIGC en Chine ». L’inscription pour une participation sur place et la réservation pour la diffusion en direct en ligne sont disponibles. (Source : 量子位, 量子位)

Suno AI organise un événement pour gagner un million de crédits : Un utilisateur de Reddit partage l’information d’un événement annoncé sur le blog officiel de Suno AI, où les utilisateurs ont la possibilité de gagner jusqu’à un million de crédits (Credits). Les règles spécifiques de l’événement doivent être consultées sur l’article de blog original. Ce type d’événement vise généralement à accroître l’engagement des utilisateurs et l’activité de la plateforme. (Source : Reddit r/SunoAI)

Le Subreddit ClaudeAI introduit un mécanisme de vote sur la qualité des posts : Les modérateurs du subreddit ClaudeAI ont annoncé l’introduction d’un nouveau bot, u/qualityvote2. Ce bot publiera un commentaire sous chaque nouveau post, invitant les utilisateurs à évaluer la qualité du post en votant (upvote/downvote) sur ce commentaire. Les posts atteignant un certain nombre de votes positifs seront considérés comme appropriés pour le subreddit, tandis que ceux atteignant un certain nombre de votes négatifs seront signalés aux modérateurs pour examen et suppression éventuelle. Cette mesure vise à utiliser la force de la communauté pour maintenir la qualité du contenu du subreddit. Parallèlement, l’équipe de modération a également ajouté un bot de détection de manipulation de vote. (Source : Reddit r/ClaudeAI)