
Mots-clés:AI, Agent, protocole A2A de Google, TPU v7 pour l’IA, modèles de raisonnement mathématique, outils de traduction vidéo KrillinAI, benchmark BrowseComp d’OpenAI
🔥 Focus
Google lance le protocole A2A et la septième génération de TPU, accélérant l’ère des AI Agents et de l’inférence : Google a lancé le protocole open source Agent2Agent (A2A), visant à permettre la communication et la collaboration sécurisées entre les AI Agents de différents fournisseurs et frameworks. Il complète plutôt qu’il ne remplace le protocole MCP (MCP connecte les Agents aux outils, A2A connecte les Agents entre eux). A2A suit des principes tels que la découverte de capacités, la gestion des tâches, la collaboration et la négociation de l’expérience utilisateur, et a déjà reçu le soutien de plus de 50 partenaires. Parallèlement, Google a dévoilé la septième génération de TPU (Ironwood/TPU v7), spécialement optimisée pour l’inférence AI. Sa puissance de calcul FP8 atteint 4614 TFlops, avec 192 Go de HBM par puce et une bande passante de 7,2 TBps, offrant une efficacité énergétique doublée par rapport à la génération précédente. Le cluster le plus puissant (9216 puces) atteint une puissance de calcul de 42,5 ExaFlops. Ces développements visent à soutenir les modèles de type « réflexion » comme Gemini et les applications d’AI Agents de nouvelle génération, marquant le passage de l’IA d’une approche réactive à une génération proactive d’insights. (Source: 36氪, 36氪, 微信公众号, 微信公众号, 微信公众号, 微信公众号)

MCP devient le pivot de l’écosystème des AI Agents, Alibaba et Tencent l’adoptent pleinement : Le Model Context Protocol (MCP) devient rapidement l’interface standard pour connecter les AI Agents aux outils externes et aux sources de données, salué comme l' »USB » de l’écosystème AI. Alibaba Cloud a lancé le premier service MCP du secteur couvrant l’ensemble du cycle de vie sur sa plateforme Bailian, intégrant le calcul de fonctions, plus de 200 grands modèles et plus de 50 services MCP, permettant la création rapide d’Agents en 5 minutes. Tencent Cloud a également publié une « Suite de développement AI » prenant en charge l’hébergement de plugins MCP. En découplant l’hôte, le serveur et le client, MCP réduit les coûts de développement répétitifs et améliore l’interconnectivité des outils AI, ce qui est crucial pour réaliser une collaboration complexe entre Agents. Bien qu’il soit confronté à des défis précoces tels qu’un écosystème immature et une chaîne d’outils incomplète, avec le soutien croissant d’OpenAI, Google, Microsoft, Amazon et des géants chinois, MCP devrait accélérer l’explosion des applications AI et le développement industriel. (Source: 36氪)
L’IA réalise une avancée majeure aux Olympiades de Mathématiques : Les résultats de la deuxième Olympiade de Mathématiques pour l’IA (AI Mathematical Olympiad – Progress Prize 2) montrent des progrès significatifs de l’IA dans la résolution de problèmes mathématiques complexes. Le meilleur modèle a obtenu un score élevé de 34/50 lors d’un test composé de problèmes entièrement nouveaux, avec des ressources de calcul limitées (coût inférieur à 1 dollar par problème) et nécessitant des réponses entières exactes (0-999). Ce résultat dépasse de loin les estimations précédentes basées sur l’évaluation humaine, qui jugeaient que les LLM ne pouvaient atteindre qu’environ 5% de réussite. Même un modèle dérivé relativement basique de DeepSeek R1 a obtenu 28/50. Ces résultats indiquent que les capacités de raisonnement mathématique de l’IA, en particulier pour les problèmes de niveau olympique nécessitant une résolution créative, progressent rapidement et ne se limitent pas à la simple reconnaissance de formes ou à la mémorisation de données. (Source: Reddit r/MachineLearning)
SenseTime lance SenseNova V6, un modèle multimodal MoE de 600 milliards de paramètres : SenseTime Technology a lancé la sixième génération de son grand modèle, SenseNova V6. Adoptant une architecture Mixture of Experts (MoE) de 600 milliards de paramètres, il prend en charge nativement les entrées multimodales (texte, image, vidéo) et leur traitement fusionné. Ce modèle affiche d’excellentes performances dans plusieurs benchmarks purement textuels et multimodaux, surpassant GPT-4.5 et Gemini 2.0 Pro. Ses capacités clés incluent un raisonnement puissant (raisonnement profond multimodal et linguistique dépassant o1, Gemini 2.0 flash-thinking), une interaction forte (compréhension audio/vidéo en temps réel, expression émotionnelle) et une mémoire longue (supportant l’analyse de longues vidéos, comme l’inférence directe sur plusieurs minutes de contenu vidéo). Les technologies clés comprennent l’entraînement fusionné multimodal natif, la synthèse de longues chaînes de pensée multimodales (supportant 64K tokens), l’apprentissage par renforcement mixte multimodal (RLHF+RFT), ainsi que la représentation unifiée et la compression dynamique pour les longues vidéos. SenseTime souligne que l’IA doit servir les applications quotidiennes et favoriser son déploiement dans divers secteurs. (Source: 微信公众号)
🎯 Tendances
Google Gemini 2.5 Flash bientôt disponible, axé sur l’inférence efficace : Lors de la conférence Cloud Next ’25, Google a annoncé le modèle Gemini 2.5 Flash. En tant que version allégée du modèle phare Gemini 2.5 Pro, Flash se concentrera sur la fourniture de capacités d’inférence rapides et à faible coût. Sa particularité réside dans sa capacité à ajuster dynamiquement la profondeur d’inférence en fonction de la complexité de l’invite, évitant ainsi un calcul excessif pour les questions simples. Les développeurs pourront personnaliser la profondeur d’inférence pour contrôler les coûts. Le modèle devrait être bientôt disponible sur Vertex AI, visant à répondre aux besoins des applications quotidiennes sensibles à la vitesse de réponse. (Source: 微信公众号, X)

ByteDance publie le rapport technique de Seed-Thinking-v1.5, aux fortes capacités de raisonnement : ByteDance a dévoilé les détails techniques de son modèle de raisonnement Seed-Thinking-v1.5, entraîné par apprentissage par renforcement. Le rapport montre que le modèle excelle dans plusieurs benchmarks, surpassant DeepSeek-R1 et approchant les niveaux de Gemini-2.5-Pro et O3-mini-high, avec un score de 40% au test ARC-AGI. Le modèle possède 200 milliards de paramètres au total et 20 milliards de paramètres activés. Les poids du modèle n’ont pas encore été publiés, mais ses excellentes capacités de raisonnement et son nombre relativement faible de paramètres activés ont attiré l’attention de la communauté. (Source: X)

ChatGPT améliore sa fonction mémoire, peut citer tout l’historique des conversations : OpenAI a annoncé une mise à niveau de la fonction mémoire de ChatGPT, permettant au modèle de citer l’ensemble de l’historique des conversations de l’utilisateur pour fournir des réponses plus personnalisées. Cette amélioration vise à exploiter les préférences et les intérêts de l’utilisateur pour améliorer l’aide à la rédaction, les suggestions, l’apprentissage, etc. Lorsque l’utilisateur démarre une nouvelle conversation, ChatGPT utilisera naturellement ces souvenirs. L’utilisateur conserve un contrôle total sur cette fonctionnalité et peut désactiver la citation de l’historique dans les paramètres, désactiver complètement la fonction mémoire, ou utiliser le mode de conversation temporaire. La fonctionnalité a commencé à être déployée auprès des utilisateurs Plus et Pro (sauf dans certaines régions) et couvrira bientôt les utilisateurs des versions Team, Enterprise et Education. (Source: X, X)
OpenAI publie un podcast sur les coulisses du développement de GPT-4.5 : Sam Altman et les membres clés de l’équipe OpenAI, Alex Paino, Dan Selsam et Amin Tootoonchian, ont enregistré un podcast explorant le processus de développement de GPT-4.5 et ses orientations futures. L’équipe a révélé que le développement de GPT-4.5 marque un passage de l’optimisation de l’efficacité de calcul à l’optimisation de l’efficacité des données, avec pour objectif d’atteindre une intelligence dix fois supérieure à celle de GPT-4. Le podcast a discuté de l’importance du mécanisme de « compression » dans l’apprentissage non supervisé (proche de l’induction de Solomonoff), a souligné la nécessité d’évaluer avec précision les performances du modèle et d’éviter la mémorisation par cœur, et a partagé les expériences de dépassement des défis techniques et l’importance du moral de l’équipe. (Source: X, X)
Perplexity intègre Gemini 2.5 Pro, prévoit d’intégrer Grok 3 et WhatsApp : Le moteur de recherche AI Perplexity a annoncé avoir intégré le dernier modèle de Google, Gemini 2.5 Pro, pour ses utilisateurs Pro, et invite les utilisateurs à le comparer avec des modèles tels que Sonar, GPT-4o, Claude 3.7 Sonnet, DeepSeek R1 et O3. De plus, le PDG de Perplexity, Aravind Srinivas, a confirmé qu’après avoir reçu de nombreux retours positifs des utilisateurs, le développement d’une intégration de Perplexity avec WhatsApp allait commencer. Parallèlement, le modèle Grok 3 devrait également être bientôt pris en charge sur la plateforme Perplexity. (Source: X, X, X)

La série de modèles Qwen3 d’Alibaba en préparation, mais la sortie prendra encore du temps : La communauté attend avec impatience la prochaine génération de modèles Qwen3 d’Alibaba, y compris les versions non open source, Qwen3-8B et Qwen3-MoE-15B-A2B. Cependant, selon une réponse d’un développeur Qwen sur les réseaux sociaux, la sortie de Qwen3 n’est pas une question « d’heures », et nécessite encore plus de temps de préparation. Cela indique qu’Alibaba développe activement la nouvelle génération de modèles, mais le calendrier de sortie spécifique n’est pas encore déterminé. (Source: X, Reddit r/LocalLLaMA)

Des modèles mystérieux à haute performance « Dragontail » et « Quasar Alpha » apparaissent sur LM Arena, suscitant des spéculations : Sur la plateforme LMSYS Chatbot Arena (LM Arena), des modèles anonymes nommés « Dragontail » et « Quasar Alpha » sont apparus. Dans leurs interactions avec les utilisateurs, ils ont montré des performances comparables, voire supérieures sur certains problèmes mathématiques, aux modèles de pointe (comme o3-mini-high, Claude 3.7 Sonnet). La communauté spécule que « Dragontail » pourrait être une variante du prochain Qwen3 ou de Gemini 2.5 Flash, tandis que « Quasar Alpha » est supposé par certains utilisateurs être un modèle de la série o4-mini d’OpenAI. L’apparition de ces modèles anonymes reflète le rôle de l’arène de modèles comme plateforme de test et d’évaluation des performances des modèles de pointe. (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
La démo du modèle Kimi-VL-A3B-Thinking de Moonshot AI est en ligne sur Hugging Face : Moonshot AI a mis en ligne une démonstration interactive (Demo) de son modèle multimodal Kimi-VL-A3B-Thinking sur Hugging Face Spaces. Les utilisateurs peuvent désormais expérimenter publiquement ce modèle. Les premiers tests montrent que le modèle possède des capacités d’OCR et de reconnaissance d’images en ligne, mais peut avoir des performances limitées sur certaines tâches nécessitant une vaste base de connaissances (comme comprendre l’humour d’un mème spécifique), ce qui pourrait être lié à la taille du modèle. (Source: X, X)

AMD organisera un événement AI pour lancer de nouveaux GPU pour data centers : AMD prévoit d’organiser un événement intitulé « Advancing AI 2025 », au cours duquel de nouveaux GPU destinés aux data centers seront annoncés. Ce lancement se concentrera sur les applications AI, et non sur les cartes graphiques pour le jeu. Cette initiative montre l’investissement continu d’AMD sur le marché du matériel AI, avec l’intention de concurrencer Nvidia dans le domaine des accélérateurs AI dominé par ce dernier. (Source: Reddit r/artificial)
🧰 Outils
Firecrawl : Outil open source pour convertir des sites web en données utilisables par les LLM : Lancé par Mendable AI, Firecrawl est un puissant outil open source (écrit en TypeScript) conçu pour scraper, crawler et convertir des sites web entiers en Markdown ou en données structurées prêtes pour les LLM via une seule API. Il gère les proxies, les mécanismes anti-bots, le rendu de contenu dynamique, etc., et prend en charge le crawl personnalisé (par exemple, exclure des balises, crawl authentifié), l’analyse de médias (PDF, DOCX) et l’interaction avec les pages (cliquer, faire défiler, saisir). Il fournit une API, des SDK Python/Node/Go/Rust, et est déjà intégré dans divers frameworks LLM (Langchain, Llama Index, Crew.ai) et plateformes low-code (Dify, Langflow, Flowise). Firecrawl propose un service API hébergé ainsi qu’une version open source exécutable localement. (Source: GitHub)
KrillinAI : Outil de traduction et de doublage vidéo basé sur les grands modèles : KrillinAI est un projet open source écrit en Go qui utilise de grands modèles linguistiques (LLM) pour fournir des services de traduction et de doublage vidéo de niveau professionnel. Il prend en charge le déploiement complet en un clic et peut gérer l’ensemble du workflow, du téléchargement vidéo (supportant yt-dlp et l’upload local), la génération de sous-titres haute précision (Whisper), la segmentation et l’alignement intelligents des sous-titres (LLM), la traduction multilingue, le remplacement de terminologie, le doublage IA et le clonage vocal (CosyVoice), jusqu’à la synthèse vidéo (adaptation automatique au format horizontal/vertical). Il vise à générer du contenu adapté aux plateformes comme YouTube, TikTok, Bilibili, etc. Le projet propose une version bureau pour Win/Mac et une version non-bureau (Web UI), et prend en charge le déploiement Docker. (Source: GitHub)
Second Me : Construire un « soi IA » localisé et personnalisé : Second Me est un projet open source visant à construire un « jumeau numérique » ou un « soi IA » de l’utilisateur à l’aide de modèles AI exécutés localement. Il met l’accent sur la confidentialité (exécution entièrement locale) et la personnalisation, en utilisant une modélisation hiérarchique de la mémoire (HMM) et une structure « Me-alignment » pour simuler l’identité, les souvenirs, les valeurs et le mode de raisonnement de l’utilisateur. Le projet prend en charge le déploiement Docker (macOS, Windows, Linux) et une interface API compatible OpenAI, et explore actuellement le support de l’entraînement MLX. La communauté est active et a contribué à l’intégration d’un bot WeChat, au support multilingue, etc. Sa vision est de faire de l’IA une extension des capacités de l’utilisateur, plutôt qu’un appendice de la plateforme. (Source: Reddit r/LocalLLaMA)

EasyControl : Injection conditionnelle de type LoRA pour les modèles Diffusion basés sur l’architecture DiT : EasyControl est un nouveau framework open source récemment publié, visant à résoudre le manque de plugins matures (comme LoRA) pour les nouveaux modèles Diffusion basés sur l’architecture DiT (Diffusion Transformer). Il fournit un module léger d’injection conditionnelle qui permet aux utilisateurs d’ajouter facilement des capacités de contrôle similaires à LoRA aux modèles DiT, réalisant des tâches telles que le transfert de style. Le projet montre les résultats d’un modèle entraîné avec 100 visages asiatiques et leurs images correspondantes de style Ghibli (générées par GPT-4o), et prend déjà en charge l’intégration avec ComfyUI. (Source: X)

XplainMD : Pipeline IA explicable biomédical fusionnant GNN et LLM : XplainMD est un pipeline AI open source de bout en bout, spécialement conçu pour les graphes de connaissances biomédicaux. Il combine des réseaux neuronaux de graphes (R-GCN) pour la prédiction de liens multi-relationnels (tels que les relations médicament-maladie, gène-phénotype), utilise GNNExplainer pour l’explicabilité du modèle, visualise les sous-graphes de prédiction via PyVis, et utilise le modèle LLaMA 3.1 8B Instruct pour l’explication en langage naturel et la vérification de plausibilité des prédictions. L’ensemble du processus est déployé dans une application Gradio interactive, visant à fournir des prédictions tout en expliquant le « pourquoi », renforçant ainsi la fiabilité et l’utilisabilité de l’IA dans des domaines sensibles comme la médecine de précision. (Source: Reddit r/deeplearning, Reddit r/MachineLearning)
LaMPlace : Nouvelle méthode basée sur l’IA pour l’optimisation de la disposition des macro-cellules de puce : Des chercheurs de l’Université des Sciences et Technologies de Chine, du Huawei Noah’s Ark Lab et de l’Université de Tianjin ont proposé LaMPlace, une méthode d’optimisation de la disposition des macro-cellules de puce basée sur l’IA. Cette méthode utilise un prédicteur de métriques structuré (utilisant des polynômes de Laurent pour modéliser l’impact de la distance inter-macro sur les métriques inter-étapes comme WNS/TNS) et un mécanisme de génération de masque apprenable pour guider les décisions de placement dès les étapes précoces de la disposition, afin d’optimiser les performances finales de la puce (PPA). LaMPlace vise à déplacer les objectifs d’optimisation des métriques intermédiaires faciles à calculer (comme la longueur de fil, la densité) vers les objectifs de conception finaux, réalisant une « optimisation shift-left » et améliorant l’efficacité de la conception. Cette méthode a été sélectionnée pour une présentation orale à l’ICLR 2025. (Source: 微信公众号)
Google lance l’Agent Development Kit (ADK) et Firebase Studio : Dans le cadre de ses efforts pour promouvoir l’écosystème des AI Agents, Google a lancé l’Agent Development Kit (ADK), un framework de développement pour la construction de systèmes multi-agents. ADK prend en charge plusieurs fournisseurs de modèles (Gemini, GPT-4o, Claude, Llama, etc.), fournit des outils CLI, la gestion des Artifacts, AgentTool (appel inter-Agents), etc., et prend en charge le déploiement sur Agent Engine ou Cloud Run. Parallèlement, Google a également lancé Firebase Studio, un outil de programmation AI dans le cloud, intégrant le modèle Gemini, qui prend en charge le développement d’applications couvrant tout le cycle, du codage IA à la compilation/build et au déploiement de services cloud. (Source: 微信公众号, Reddit r/LocalLLaMA)
OpenFOAMGPT : Utiliser des grands modèles chinois pour réduire les coûts de simulation CFD : L’Université d’Exeter (Royaume-Uni) et une équipe de l’Université Beihang ont mis à jour le projet OpenFOAMGPT, qui vise à permettre aux utilisateurs de piloter des simulations de mécanique des fluides numérique (CFD) en langage naturel. La nouvelle version intègre avec succès les grands modèles chinois DeepSeek V3 et Qwen 2.5-Max, maintenant des performances proches de GPT-4o/o1 tout en réduisant les coûts jusqu’à 100 fois. De plus, l’équipe a également réalisé un déploiement localisé en utilisant le modèle QwQ-32B (dans un environnement mono-GPU), offrant aux chercheurs et aux PME chinoises une solution de CFD assistée par IA plus économique et pratique, abaissant ainsi la barrière d’entrée professionnelle. (Source: 微信公众号)
Slop Forensics Toolkit : Outil d’analyse du contenu répétitif dans les sorties LLM : Une nouvelle boîte à outils open source a été publiée pour analyser le « slop » – c’est-à-dire les mots et phrases excessivement répétés – dans les sorties des grands modèles linguistiques (LLM). L’outil utilise l’analyse stylométrique pour identifier le vocabulaire et les n-grammes apparaissant plus fréquemment que dans l’écriture humaine, construisant ainsi le « profil de slop » du modèle. Il s’inspire également des méthodes de bioinformatique, considérant les caractéristiques lexicales comme des « mutations » pour inférer des arbres de similarité entre différents modèles. L’outil vise à aider les chercheurs à comprendre et comparer les caractéristiques génératives des différents LLM et la contamination potentielle des données ou les biais d’entraînement. (Source: Reddit r/MachineLearning)
Le framework d’inférence vLLM ajoute le support pour les TPU Google : Le populaire framework open source d’inférence et de service pour grands modèles vLLM a annoncé l’ajout du support pour les TPU Google. Combinée à la sortie récente de la septième génération de TPU de Google (Ironwood), cette mise à jour signifie que les développeurs peuvent utiliser vLLM pour une inférence et un déploiement efficaces de modèles sur le matériel AI haute performance de Google. Cela contribue à étendre l’écosystème logiciel des TPU, offrant aux utilisateurs plus de choix matériels. (Source: X)

📚 Apprentissage
CUHK, Tsinghua et d’autres proposent le framework SICOG, explorant de nouvelles voies pour l’auto-évolution des grands modèles : Face à la dépendance des grands modèles envers des données de pré-entraînement de haute qualité et à l’épuisement des ressources de données, des institutions comme l’Université Chinoise de Hong Kong (CUHK), l’Université Tsinghua et d’autres ont proposé le framework SICOG (Self-Improving Systematic Cognition). Ce framework construit un mécanisme d’auto-évolution tripartite « amélioration post-entraînement – optimisation de l’inférence – renforcement par ré-pré-entraînement ». Il utilise la « description en chaîne » (CoD) pour améliorer la perception visuelle structurée, la « chaîne de pensée structurée » (CoT) pour améliorer le raisonnement multimodal, et exploite une boucle fermée de données auto-générées et un filtrage par cohérence pour obtenir une amélioration continue des capacités cognitives du modèle avec zéro annotation manuelle. Les expériences prouvent que SICOG peut améliorer significativement les performances du modèle sur plusieurs tâches, réduire les hallucinations et montrer une bonne scalabilité, offrant de nouvelles pistes pour résoudre le goulot d’étranglement du pré-entraînement et avancer vers une IA à apprentissage autonome. (Source: 微信公众号)
OpenAI publie et rend open source le benchmark BrowseComp pour évaluer la capacité de navigation web des AI Agents : OpenAI a publié et rendu open source le benchmark BrowseComp (Browsing Competition). Ce benchmark vise à évaluer la capacité des AI Agents à naviguer sur Internet pour trouver des informations difficiles à localiser, semblable à une chasse au trésor en ligne pour Agents. OpenAI estime que ce type de test capture les capacités clés de navigation de type recherche approfondie des agents intelligents, ce qui est essentiel pour évaluer le niveau d’intelligence des Agents de navigation web avancés. (Source: X, X)
Une étude révèle que les modèles de raisonnement généralisent mieux sur les tâches de codage OOD : Une nouvelle étude (arXiv:2504.05518v1) compare la capacité de généralisation des modèles de raisonnement et des modèles non basés sur le raisonnement à travers des expériences sur des tâches de codage. Les résultats montrent que les modèles de raisonnement ne subissent pas de baisse significative de performance lors du transfert de tâches intra-distribution vers des tâches hors distribution (OOD) ; tandis que les modèles non basés sur le raisonnement montrent une baisse de performance. Cela suggère que les modèles de raisonnement ne sont pas de simples reconnaisseurs de formes ; ils peuvent apprendre et généraliser à des tâches en dehors de leur distribution d’entraînement, possédant de plus fortes capacités d’abstraction et d’application. (Source: Reddit r/ArtificialInteligence)
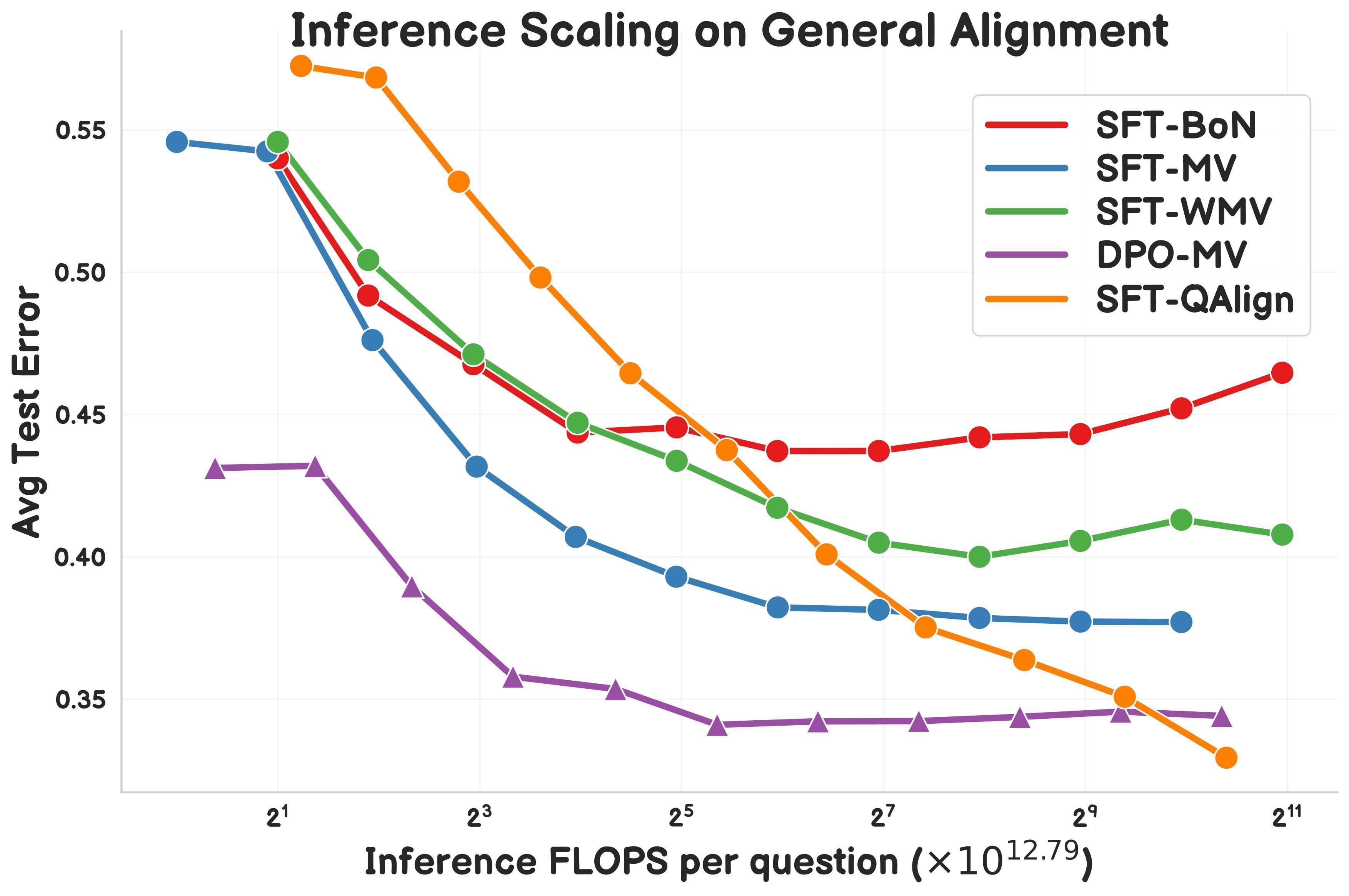
Une étude propose QAlign : une méthode d’alignement au moment du test basée sur MCMC : Gonçalo Faria et al. proposent QAlign, une nouvelle méthode d’alignement au moment du test (test-time alignment) qui utilise le Monte Carlo par Chaîne de Markov (MCMC) pour améliorer les performances des modèles linguistiques sans avoir à les réentraîner. L’étude montre que QAlign surpasse en performance les modèles affinés par DPO (Direct Preference Optimization) (à budget de calcul d’inférence égal) et peut surmonter les limitations de l’échantillonnage traditionnel Best-of-N (qui a tendance à sur-optimiser le modèle de récompense) et du vote majoritaire (incapable de découvrir des réponses uniques). QAlign pourrait être utilisé pour des scénarios tels que la génération de données de haute qualité. (Source: X)
Yann LeCun réitère les limitations des LLM auto-régressifs : Lors d’une récente présentation, Yann LeCun, scientifique en chef de l’IA chez Meta, a réaffirmé son point de vue sur les limitations de l’architecture actuelle dominante des grands modèles linguistiques auto-régressifs (Auto-Regressive), estimant que ce modèle est « voué à l’échec » (doomed). Il pense que cette approche de prédiction mot par mot limite la capacité du modèle à effectuer une planification réelle et un raisonnement profond. Bien que les modèles auto-régressifs soient actuellement l’état de l’art (SOTA), LeCun et d’autres chercheurs explorent activement des alternatives, telles que l’architecture de prédiction par enchâssement conjoint (JEPA), dans l’espoir de réaliser des systèmes d’IA plus proches de l’intelligence humaine. (Source: Reddit r/MachineLearning)
LlamaIndex démontre la construction d’un Agent de génération de rapports en combinaison avec Google Cloud : Jerry Liu, fondateur de LlamaIndex, a montré lors du Google Cloud Next ’25 comment combiner les workflows LlamaIndex et les bases de données Google Cloud (telles que BigQuery, AlloyDB) pour construire un Agent de génération de rapports. Cet Agent est capable d’analyser des documents SOP (en utilisant LlamaParse), une base de données de tutoriels, des données juridiques, etc., pour générer des guides d’intégration personnalisés pour les nouveaux employés. Cela illustre que l’architecture d’Agent basée sur la connaissance nécessite des capacités robustes d’accès et de traitement des données, et démontre le rôle de LlamaIndex dans la construction de telles applications d’Agent. (Source: X)

Un chercheur partage le moteur Symbolic Compression et le format de fichier .sym : Un chercheur indépendant a rendu open source un moteur nommé Symbolic Compression et son format de fichier correspondant .sym. Ce projet prétend pouvoir compresser en extrayant les règles récursives et la logique structurelle derrière les séquences (comme les nombres premiers, la suite de Fibonacci) (basé sur sa loi proposée de Miller : κ(x) = ((ψ(x) – x)/x)²), plutôt qu’en compressant simplement les données brutes. Il vise à stocker et prédire l’apparition de la structure elle-même, offrant un format similaire à JSON mais pour la logique récursive. Le projet comprend des outils CLI et une fonctionnalité de compression multi-régions. (Source: Reddit r/MachineLearning)

💼 Affaires
La tarification de l’API Grok-3 annoncée, à partir de 0,3 $/million de tokens : xAI a officiellement ouvert au public l’API de la série Grok 3, adoptant une stratégie de tarification à plusieurs niveaux. Grok 3 (Beta), destiné aux applications d’entreprise, est tarifé à 3 $/million de tokens en entrée et 15 $/million de tokens en sortie ; le Grok 3 Mini (Beta) léger est tarifé à 0,3 $/million de tokens en entrée et 0,5 $/million de tokens en sortie. Les deux offrent également une version à réponse rapide (fast-beta) à un prix plus élevé. Cette stratégie de tarification le place en concurrence, en termes de coût, avec des modèles tels que Google Gemini 2.5 Pro, le forfait Anthropic Claude Max (minimum 100 $) et Meta Llama 4 Maverick (environ 0,36 $/million de tokens). (Source: 微信公众号)
Rapport IA de Stanford : La puissance d’Alibaba en IA classée troisième mondialement, l’écart Chine-USA se réduit : Le dernier « Rapport sur l’indice de l’intelligence artificielle 2025 » de l’Université de Stanford montre que parmi les contributions mondiales aux grands modèles importants, Google et OpenAI se classent premiers ex aequo avec 7 modèles chacun, tandis qu’Alibaba se classe troisième mondialement et premier en Chine avec 6 modèles (série Qwen). Le rapport souligne que l’écart de performance des modèles entre la Chine et les États-Unis s’est considérablement réduit, passant de 17,5 points de pourcentage (benchmark MMLU) fin 2023 à 0,3 point de pourcentage fin 2024. La famille de modèles Qwen d’Alibaba (plus de 200 modèles déjà open source) est devenue la plus grande série de modèles open source au monde, avec plus de 100 000 modèles dérivés. Le rapport mentionne également que les besoins en puissance de calcul pour l’entraînement des modèles chinois de premier plan (tels que Qwen2.5, DeepSeek-V3) sont généralement inférieurs à ceux des modèles américains similaires, ce qui témoigne d’une plus grande efficacité. (Source: 微信公众号)
Les entreprises chinoises d’IA médicale cherchent à percer face aux droits de douane et aux barrières techniques : Confrontées à de multiples pressions, notamment l’augmentation des droits de douane américains et le monopole technologique (par exemple, les géants du GPS contrôlant les interfaces de données d’imagerie), les entreprises chinoises de technologie médicale accélèrent la substitution nationale et la transformation intelligente. United Imaging Healthcare (联影医疗) maintient une R&D interne pour ses technologies clés, lançant des équipements haut de gamme tels que la résonance magnétique 5.0T, et développant de grands modèles médicaux et des agents intelligents. Mindray (迈瑞医疗), via sa stratégie « Équipement + IT + IA », construit un écosystème numérique intelligent (comme la plateforme Ruiying Cloud++ intégrant DeepSeek) et pénètre en profondeur le marché international. Diasys (德适生物), quant à elle, entre dans la médecine de précision avec son grand modèle d’imagerie médicale iMedImage®, participe à l’élaboration des normes industrielles et réalise une concurrence différenciée. Ces entreprises, propulsées par l’IA, visent à percer dans les technologies clés, la chaîne d’approvisionnement et l’acceptation clinique, afin de remodeler le paysage du marché. (Source: 微信公众号)
🌟 Communauté
L’application de l’IA dans l’éducation suscite des discussions : La communauté discute de la manière dont l’intelligence artificielle (IA) pourrait transformer l’éducation grâce à des plans d’apprentissage personnalisés. L’IA a le potentiel d’adapter le contenu et les méthodes pédagogiques aux besoins individuels, au rythme et au style d’apprentissage de chaque élève, permettant une éducation personnalisée et améliorant l’efficacité et les résultats de l’apprentissage. (Source: X)

L’ingénierie complexe derrière l’éditeur Cursor attire l’attention : La communauté mentionne que la réalisation de l’éditeur de code AI Cursor n’est pas une tâche aisée. Son objectif principal est d’éviter que l’utilisateur ait à copier-coller manuellement du code, ce qui a nécessité d’importantes optimisations de l’expérience utilisateur et des innovations techniques, notamment l’invention de nouveaux paradigmes d’édition de code, le développement interne du modèle d’édition rapide FastApply et du modèle de prédiction de complétion de code Fusion, ainsi que l’implémentation d’un RAG à deux niveaux localement et côté serveur pour optimiser le traitement du contexte. Ces efforts montrent la profondeur technique requise pour construire une expérience de programmation IA fluide. (Source: X)
Un outil de triche IA soulève des discussions sur l’éthique et les systèmes de recrutement : Roy Lee, un étudiant de l’Université de Columbia, a développé un outil IA « Interview Coder » pour tricher lors d’entretiens de programmation, obtenant des offres de plusieurs entreprises de premier plan avant d’être expulsé de l’école. Il a ensuite gagné 2,2 millions de dollars en 50 jours en vendant cet outil. L’outil peut fonctionner de manière invisible et générer des réponses en simulant le style de codage humain. L’incident a suscité un large débat : d’une part, de nombreux développeurs expriment leur mécontentement face aux entretiens de programmation rigides et déconnectés de la réalité (comme le bachotage LeetCode) ; d’autre part, l’augmentation rapide du phénomène de triche par IA (certains rapports indiquent une augmentation de 2% à 10%) remet en question l’efficacité des entretiens techniques actuels, pourrait forcer les entreprises à remodeler leurs systèmes de recrutement et soulève des discussions sur les limites éthiques de ce qui constitue la « triche » à l’ère de l’IA. (Source: 36氪)
Émergence d’applications innovantes d’Agents généraux : De récentes compétitions hackathon d’Agents (comme flowith, openmanus) ont vu émerger de nombreuses applications innovantes. Catégorie développement/design : un Agent peut générer automatiquement un projet complet (maxcode) incluant le code front-end, back-end et la structure de la base de données à partir d’une esquisse d’UI, ou collecter des informations de manière autonome, déterminer un style et générer un site web personnel. Catégorie analyse/décision : un Agent peut calculer le meilleur emplacement sur un vol pour observer les aurores boréales, ou effectuer une optimisation auto-itérative de stratégies de trading quantitatif (Yilu Xiangbei – 一鹿向北). Catégorie services personnalisés : un Agent peut recommander intelligemment des lieux de rencontre (Jarvis-CafeMeet), analyser les données de Douban (豆瓣) pour générer un « rapport de goût », ou servir les utilisateurs âgés via interaction vocale (老奶奶教你用OpenManus – Grandma teaches you OpenManus). Catégorie création artistique : un Agent peut générer de l’art numérique dans un style spécifique, générer une danse à partir de musique, personnaliser des pinceaux de peinture, générer en temps réel de la musique programmable (strudel-manus), etc. Ces exemples démontrent l’énorme potentiel des Agents dans divers domaines. (Source: 微信公众号)
Andrew Ng commente l’impact des droits de douane américains sur le développement de l’IA : Andrew Ng a exprimé son inquiétude face à l’imposition généralisée de droits de douane élevés par les États-Unis, estimant que cela nuirait aux relations avec les alliés, entraverait l’économie mondiale, créerait de l’inflation et aurait un impact négatif sur le développement de l’IA. Il souligne que si la libre circulation des idées et des logiciels (en particulier open source) pourrait ne pas être trop affectée, les droits de douane limiteraient l’accès au matériel AI (serveurs, refroidissement, équipements réseau), augmenteraient les coûts de construction des data centers et affecteraient indirectement l’approvisionnement en puissance de calcul en impactant les importations d’équipements électriques. Bien que les droits de douane puissent légèrement stimuler la demande intérieure de robots et d’automatisation, cela serait difficilement suffisant pour compenser les faiblesses du secteur manufacturier. Il appelle la communauté AI à maintenir la coopération et les échanges internationaux. (Source: X)
Discussion animée sur l’application de l’IA dans le soutien à la santé mentale : De plus en plus d’utilisateurs partagent leurs expériences d’utilisation d’outils AI comme ChatGPT pour le conseil psychologique et le soutien émotionnel. Beaucoup déclarent que l’IA offre un espace sûr et sans jugement pour se confier, permet d’obtenir un retour immédiat et des conseils utiles, et peut même, dans certains cas, mieux faire sentir écouté et compris qu’un thérapeute humain, produisant ainsi des effets positifs de catharsis émotionnelle. Bien que les utilisateurs reconnaissent généralement que l’IA ne peut pas remplacer complètement les thérapeutes professionnels agréés, en particulier pour traiter les problèmes psychologiques graves, elle montre un potentiel énorme pour fournir un soutien de base, gérer le stress quotidien et explorer initialement les problèmes personnels, et est appréciée pour son accessibilité et son faible coût. (Source: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
La qualification du contenu traduit par IA suscite des discussions : La communauté a débattu de la question suivante : si l’IA (comme ChatGPT) est utilisée pour traduire une histoire écrite par un humain, son contenu doit-il être considéré comme une création humaine ou une création IA ? Un point de vue est que si l’IA sert uniquement d’outil de traduction, sans altérer la pensée, la structure et le ton originaux, le contenu reste essentiellement une création humaine. Cependant, les détecteurs de texte IA pourraient le marquer comme généré par IA en analysant les motifs textuels. Cela soulève des questions sur la définition du rôle de l’IA dans le processus créatif, les limitations des détecteurs d’IA et comment préserver le style original dans la traduction. (Source: Reddit r/ArtificialInteligence)
Un utilisateur signale des problèmes avec Gemini 2.5 Pro dans le traitement de longs contextes : L’utilisateur Nathan Lambert a constaté, en testant Gemini 2.5 Pro, que le modèle rencontrait des erreurs de connexion lors du traitement de requêtes avec des entrées de contexte très longues. Le phénomène observé est que le modèle semble régénérer presque tous les tokens d’entrée pendant l’inférence, entraînant des coûts d’inférence extrêmement élevés et finalement un échec. De plus, il a souligné l’impossibilité de partager l’historique de chat Gemini lorsque l’erreur se produit. Ces retours soulignent les problèmes potentiels de stabilité et d’efficacité des modèles actuels lors du traitement de contextes ultra-longs. (Source: X)

La communauté réagit mal à la sortie de Llama 4, mettant en doute ses performances et son ouverture : La sortie de la série de modèles Llama 4 par Meta a suscité de nombreuses discussions et critiques négatives au sein de la communauté. Les utilisateurs estiment généralement que, bien que le modèle Maverick dispose d’une fenêtre de contexte allant jusqu’à 10 millions de tokens et offre des performances acceptables en matière d’appel de fonctions, son nombre total de paramètres de 400 milliards (17 milliards de paramètres activés) n’a pas apporté l’amélioration attendue des performances d’inférence, se révélant même moins bon que des modèles comme QwQ 32B. De plus, sa licence restrictive, l’absence de document technique et de carte système, ainsi que les soupçons de « gonflage de score » sur des benchmarks comme LMSYS, ont nui à la réputation de Meta dans la communauté open source. La communauté exprime sa déception quant à l’incapacité de Meta à maintenir l’ouverture et la position de leader de Llama 3. (Source: Reddit r/LocalLLaMA)

Le plan Claude Pro est accusé d’être une dégradation déguisée, les utilisateurs se plaignent de l’augmentation des restrictions d’utilisation : Avec le lancement par Anthropic du forfait Max plus cher (prétendant offrir 5 ou 20 fois l’utilisation du plan Pro), de nombreux utilisateurs de Claude Pro dans la communauté signalent qu’ils ressentent que les limites d’utilisation du plan Pro lui-même sont devenues plus strictes et qu’il est plus facile d’atteindre la limite. Les utilisateurs supposent qu’Anthropic a peut-être réduit le quota réel disponible du plan Pro pour inciter les utilisateurs à passer au plan Max. Cet ajustement opaque et la dégradation perçue du service ont provoqué le mécontentement des utilisateurs, surtout lorsque le modèle Claude lui-même a encore des problèmes de mémoire de fenêtre contextuelle. (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

La communauté OpenWebUI discute des fonctionnalités et des problèmes : Les utilisateurs d’OpenWebUI discutent des fonctionnalités de l’outil et des problèmes rencontrés au sein de la communauté. Un utilisateur demande s’il est possible d’intégrer Nextcloud comme option de stockage cloud supplémentaire. Un autre utilisateur signale un problème lors de l’utilisation de la fonction de base de connaissances : lors du téléchargement de plusieurs documents, le LLM ne semble référencer que le premier. Un autre utilisateur rencontre une erreur de timeout en essayant de se connecter à un endpoint API OpenAI compatible Gemini. Ces discussions reflètent les besoins et les préoccupations des utilisateurs concernant l’extensibilité et la stabilité de l’outil. (Source: Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
La communauté Suno AI échange des astuces d’utilisation et des problèmes : La communauté des utilisateurs de Suno AI est active, les discussions portent notamment sur : comment exclure des instruments spécifiques (comme la batterie, les claviers) lors de l’utilisation de la fonction Cover pour isoler les instruments solos ; la recherche de conseils pour générer un style musical spécifique (comme le Trip Hop) ; le signalement de problèmes avec la fonction d’invitation d’amis qui ne permet pas d’obtenir des crédits ; la discussion sur les problèmes de droits d’auteur des paroles, par exemple si des phrases spécifiques (comme « You’re Dead ») déclenchent des restrictions de droits d’auteur ; et le partage de cas d’utilisation créative de Suno, comme la création de musique de fond pour un personnage de D&D. (Source: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)
💡 Autres
Exploration de la génération par IA de « photos accidentelles » : Des utilisateurs de la communauté essaient d’utiliser l’IA pour générer des photos qui semblent avoir été prises involontairement, avec une composition aléatoire, voire un léger flou ou une surexposition. Cette exploration vise à défier la tendance de l’IA à générer des images parfaites, en imitant le hasard et l’imperfection de la photographie humaine, et démontre la capacité de l’IA à comprendre et simuler des styles photographiques spécifiques (y compris le style « mauvaise photo »). (Source: Reddit r/ChatGPT)

Potentiel de l’IA dans la gestion de la chaîne d’approvisionnement : La discussion souligne le potentiel de l’intelligence artificielle (IA) pour améliorer la traçabilité et la transparence de la chaîne d’approvisionnement. En utilisant l’apprentissage automatique et l’analyse de données, l’IA peut aider les entreprises à mieux surveiller le flux de marchandises, prédire les risques d’interruption, optimiser la gestion des stocks et fournir aux consommateurs des informations plus fiables sur l’origine des produits. (Source: X)

Exploration de l’application de l’IA dans la gestion des ressources humaines : La communauté discute de la possibilité d’adopter des avatars IA (Avatars) pour la gestion des ressources humaines. Cela pourrait inclure l’utilisation de l’IA pour la présélection lors des entretiens initiaux, la formation des employés, les réponses aux questions sur les politiques, voire le soutien émotionnel, dans le but d’améliorer l’efficacité des processus RH et l’expérience employé. (Source: X)

La Banque d’Angleterre avertit que l’IA pourrait déclencher une crise de marché : La Banque d’Angleterre a émis un avertissement indiquant que les logiciels d’intelligence artificielle pourraient être utilisés pour manipuler les marchés, voire créer intentionnellement une crise de marché à des fins lucratives. Cela soulève des inquiétudes quant à la réglementation et au contrôle des risques de l’application de l’IA dans le domaine financier. (Source: Reddit r/artificial)

Nouvelle méthode d’IA générative pour créer des formes 3D réalistes : Des chercheurs du MIT ont développé une nouvelle méthode d’IA générative capable de créer des formes tridimensionnelles plus réalistes. Ceci revêt une importance significative pour des domaines tels que la conception de produits, la réalité virtuelle, le développement de jeux et l’impression 3D, faisant progresser la technologie de génération de modèles 3D complexes à partir d’images 2D ou de descriptions textuelles. (Source: X)

La consommation d’énergie et le coût de l’inférence IA considérablement réduits : Des rapports indiquent que de nouvelles avancées technologiques ont permis de réduire la consommation d’énergie des tâches d’inférence AI (mesurée en énergie MAC) de 100 fois et les coûts de 20 fois. Cette amélioration de l’efficacité est cruciale pour la faisabilité et la rentabilité des modèles AI sur les appareils périphériques, mobiles et dans les déploiements cloud à grande échelle. (Source: X)

Discussion sur l’impact de l’IA sur la cognition humaine : La communauté discute de l’impact potentiel de la dépendance excessive à l’IA sur le cerveau humain, certains citant un titre d’article affirmant que cela pourrait rendre le cerveau « Atrophié Et Mal Préparé ». Cela reflète les préoccupations concernant la dégradation potentielle des fonctions cognitives humaines essentielles comme la pensée critique, la mémoire, la résolution de problèmes après la généralisation des outils IA. (Source: X)

Perspectives et inquiétudes concernant les futurs modes de travail pilotés par l’IA : La communauté discute en citant le point de vue d’un article prédisant que d’ici 2025, l’IA réécrira les règles du travail, mettant potentiellement fin aux modes de travail actuels. Cela suscite des discussions et des inquiétudes sur l’impact de l’automatisation par l’IA sur le marché de l’emploi, l’évolution des compétences requises et les nouveaux modèles de collaboration homme-machine. (Source: X)
