
Mots-clés:AI, TPU, Google TPU Ironwood, protocole A2A, SK Hynix HBM, MoE modèle, DeepSeek impact
🔥 Focus
Google annonce la 7ème génération de TPU et le protocole de collaboration d’agents A2A: Lors de la conférence Cloud Next ’25, Google a dévoilé « Ironwood », la septième génération de TPU conçue spécifiquement pour l’inférence IA, offrant une puissance de calcul massive de 42,5 Exaflops, dépassant de loin les supercalculateurs actuels. Cette puce bénéficie d’une mémoire et d’une bande passante considérablement accrues (192 Go HBM, bande passante de 7,2 Tb/s) et d’une efficacité énergétique doublée, visant à supporter des « modèles de pensée » nécessitant des capacités d’inférence complexes, comme Gemini 2.5. Parallèlement, Google a lancé le protocole open source Agent-to-Agent (A2A), destiné à standardiser la communication et la collaboration sécurisées entre différents agents IA, déjà soutenu par plus de 50 entreprises. A2A définit la découverte des capacités des agents, la gestion des tâches, les méthodes de collaboration, etc., et est complémentaire au protocole MCP utilisé pour connecter les outils. Google a également annoncé le support du protocole MCP dans ses modèles Gemini et SDK, favorisant davantage l’interconnexion de l’écosystème des agents IA. (Source: 机器之心, 36氪, 卡兹克, 机器之心, AI前线)

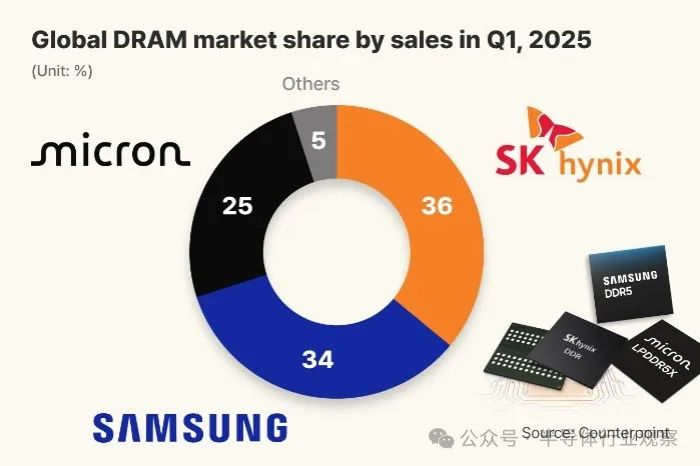
SK Hynix prend la tête du marché mondial de la DRAM pour la première fois grâce à son avantage HBM: Un rapport de la société d’études de marché Counterpoint Research montre qu’au premier trimestre 2025, SK Hynix est devenu le plus grand fournisseur mondial de DRAM avec 36% de part de marché, dépassant pour la première fois Samsung (34%), Micron se classant troisième avec 25%. Le succès de SK Hynix est principalement attribué à sa position dominante dans le domaine de la mémoire à haute bande passante (HBM) (sa part de marché atteindrait 70%), la demande de HBM étant fortement stimulée par l’essor de l’IA. SK Hynix fournit exclusivement ses puces HBM3E pour les accélérateurs IA de NVIDIA, et la demande de HBM devrait continuer à croître rapidement. Parallèlement, des médias coréens rapportent que SK Hynix a atteint un taux de rendement de 80% pour son processus 1c DRAM (environ 11-12 nm), prenant temporairement l’avantage technologique sur Samsung qui s’efforce encore d’améliorer son rendement, ce qui jette les bases de sa production de masse de HBM4. (Source: 半导体行业观察)
Les protocoles d’agents IA MCP et A2A suscitent l’attention et une lutte d’écosystèmes: Récemment, le Model Context Protocol (MCP) proposé par Anthropic et le protocole inter-agents (A2A) lancé par Google sont devenus des sujets brûlants dans le domaine de l’IA. Le MCP vise à standardiser l’interaction entre les modèles IA et les outils externes, sources de données, étant comparé à une interface « USB-C » pour les applications IA, et est déjà soutenu par Microsoft, Google, ainsi que de nombreuses startups et communautés open source. L’A2A se concentre sur la communication et la collaboration sécurisées entre les agents IA de différents fournisseurs, avec plus de 50 entreprises participantes. Ces protocoles visent à résoudre les problèmes de mauvaise interopérabilité et de fragmentation de l’écosystème entre les agents IA. Cependant, selon les analystes, derrière la promotion de ces protocoles par les géants se cache également une intention stratégique de construire leurs propres barrières d’écosystème et d’empêcher la fuite de données. Par exemple, les premiers partenaires A2A de Google sont principalement liés à son écosystème, et le service MCP lancé par Alibaba Cloud intègre également principalement des applications au sein de son propre système. Des plateformes comme Meituan et Didi pourraient ne pas adopter facilement les protocoles ouverts en raison de considérations de souveraineté des données et d’influence dans l’écosystème. Cette guerre des protocoles est essentiellement une lutte pour la domination de l’écosystème IA et le contrôle des données. (Source: 卡兹克, 王智远, AI前线, 机器之心)
🎯 Tendances
DeepSeek suscite une réflexion sur l’avenir des logiciels d’entreprise: L’open source de DeepSeek a un impact sur l’industrie des logiciels d’entreprise, suscitant des discussions sur les barrières technologiques des fournisseurs SaaS et sur la question de savoir si les employés numériques IA mettront fin aux logiciels traditionnels. Guo Shunri, PDG de Wohang Technology, estime que les SaaS de type outil à fonction unique (comme le RPA) sont les plus en danger, car ils sont facilement remplaçables par les capacités multimodales des grands modèles. Yang Fangxian, PDG de 53AI, juge que les applications concrètes des grands modèles sont encore limitées, mais que dans 10 à 20 ans, les SaaS traditionnels disparaîtront, remplacés par la productivité IA (fusion homme numérique + SaaS). Shen Yang, expert en informatisation et numérisation, a un point de vue plus radical, estimant que le modèle SaaS pourrait être bouleversé d’ici six mois à un an, et qu’à l’avenir, la facturation devra reposer sur les données en temps réel ou les résultats du service. La conversation souligne que l’IA reconfigurera les modèles économiques, que les entreprises capables de bien utiliser l’IA obtiendront un avantage concurrentiel, tandis que celles qui réagissent lentement feront face à l’élimination. Actuellement, le goulot d’étranglement du déploiement de l’IA réside dans les silos de données d’entreprise et l’intégration insuffisante des connaissances, plutôt que dans la technologie IA elle-même. (Source: 36氪)
État actuel et réflexion sur l’application de l’IA dans le gros électroménager: La technologie IA est intégrée dans les réfrigérateurs, machines à laver, climatiseurs et autres gros appareils électroménagers, offrant des fonctions telles que l’interaction vocale et le contrôle intelligent (par exemple, économie d’énergie IA, lavage/soin IA). Des marques comme Haier, TCL, Samsung lancent des appareils électroménagers IA, comme le réfrigérateur Haier équipé de DeepSeek qui peut fournir des suggestions de gestion des aliments, ou le climatiseur TCL qui peut annoncer la météo. Cependant, l’article souligne que le « contenu IA » des appareils électroménagers actuels est inégal, certaines fonctions (comme un climatiseur annonçant les taux de change) semblant superflues et peu pratiques. Comparé aux produits IA comme les robots aspirateurs qui ont déjà réalisé une boucle « perception-décision-exécution » relativement complète, l’application de l’IA dans le gros électroménager reste souvent au niveau de la perception et de la suggestion, sans pouvoir prendre de décisions et exécuter de manière totalement autonome. L’article remet en question la nécessité de certaines fonctions « IA », soulignant que les consommateurs ont davantage besoin d’appareils électroménagers dont les fonctionnalités principales sont performantes et résolvent leurs problèmes, plutôt que de surfer de force sur la vague de l’IA. L’article estime que le rôle du gros électroménager à l’ère de l’IA devrait être celui d’un maillon de l’écosystème de la maison intelligente, nécessitant d’atteindre l’excellence dans les fonctions principales et d’améliorer la capacité de collaboration, plutôt que de tous se transformer en outils de chat. (Source: 36氪)

Les modèles MoE deviennent la nouvelle tendance, Alibaba Cloud met à niveau son infrastructure IA pour relever les défis: L’architecture Mixture of Experts (MoE) devient la tendance dominante pour les grands modèles d’IA, de Mixtral à DeepSeek, Qwen2.5-Max et Llama 4, tous adoptant cette architecture. Pour relever les défis posés par MoE (comme le routage des tokens, la sélection des experts, etc.), Alibaba Cloud a lancé le framework d’entraînement FlashMoE basé sur PAI-DLC, supportant l’entraînement en précision mixte MoE à très grande échelle, capable d’augmenter le MFU à 35-40% à l’échelle de dizaines de milliers de cartes GPU. Parallèlement, Alibaba Cloud a lancé le moteur d’inférence distribué Llumnix pour MoE, réduisant considérablement la latence. De plus, Alibaba Cloud a également lancé la 9ème génération d’instances ECS, optimisé le cluster Lingjun (réseau HPN 7.0, stockage haute performance CPFS, système d’auto-réparation des pannes), mis à niveau le stockage objet OSS (OSSFS 2.0), et lancé MaxCompute AI Function ainsi que le service DataWorks Agent supportant le protocole MCP, mettant à niveau complètement son infrastructure IA pour faire face au nouveau paradigme apporté par MoE et les modèles d’inférence. (Source: 机器之心)
Keenon Robotics lance le robot de service humanoïde XMAN-R1: Keenon Robotics, entreprise leader mondiale des robots de service, a lancé son premier robot de service humanoïde incarné, le XMAN-R1, positionné comme « né pour servir ». Ce robot est basé sur les données réelles massives accumulées par Keenon dans les scénarios de restauration, d’hôtellerie, médicaux, etc., en mettant l’accent sur l’orientation tâche, la convivialité et la sécurité. Le XMAN-R1 peut accomplir des tâches en boucle fermée dans les scénarios de service, telles que la prise de commande, la préparation des plats, la livraison de repas, le débarrassage, etc. Il possède des capacités de remise d’objets à deux mains, de contrôle du mouvement, d’interaction anthropomorphe (grand modèle de langage, retour d’expression faciale), et est équipé de 11 capteurs multimodaux et d’une technologie d’évitement d’obstacles intelligent pour s’adapter aux environnements très fréquentés. Le XMAN-R1 formera un écosystème de collaboration multiforme avec les robots spécialisés existants de Keenon (livraison, nettoyage, etc.) pour accomplir des tâches de service commercial plus complexes, complétant ainsi la matrice de robots de service incarnés multiformes de Keenon. (Source: InfoQ)
L’Université Jiaotong de Xi’an et d’autres proposent Every Painting Awakened, un framework d’animation de peintures sans entraînement: Face aux problèmes de « mouvement immobile » ou « désordonné » des méthodes actuelles d’image vers vidéo (I2V) dans l’animation de peintures, l’Université Jiaotong de Xi’an, l’Université de Technologie de Hefei et l’Université de Macao ont conjointement proposé le framework sans entraînement « Every Painting Awakened ». Ce framework utilise un modèle d’image pré-entraîné pour générer une image proxy servant de guidage dynamique. Grâce à une technique de distillation de score à double chemin, il préserve séparément les détails statiques de la peinture originale et extrait l’a priori dynamique de l’image proxy. Ensuite, il utilise un mécanisme de fusion latente mixte (interpolation linéaire sphérique) pour fusionner les caractéristiques dynamiques et statiques dans l’espace latent, qui sont ensuite fournies à un modèle I2V existant pour générer la vidéo. Cette méthode améliore les modèles I2V existants sans entraînement supplémentaire, peut exécuter précisément les instructions de mouvement des prompts textuels tout en préservant le style et le coup de pinceau de la peinture originale, réalisant une animation de peinture naturelle et fluide. Les expériences prouvent l’efficacité de ce framework pour améliorer l’adéquation sémantique et préserver l’intégrité du style. (Source: PaperWeekly)
L’Université de Waterloo et Meta proposent MoCha : génération de vidéos de dialogue multi-personnages basée sur la parole et le texte: Pour pallier les insuffisances des technologies actuelles de génération vidéo dans la narration axée sur les personnages (limitée au visage, dépendante de conditions auxiliaires, ne supportant qu’un seul personnage), l’Université de Waterloo au Canada et Meta GenAI proposent le framework MoCha. MoCha est la première méthode pour la tâche « Talking Characters », ne nécessitant que des entrées vocales et textuelles pour générer des vidéos de dialogue en pied (du gros plan au plan moyen) des personnages, supportant plusieurs personnages et des dialogues multi-tours. Les technologies clés incluent : 1) Le mécanisme Speech-Video Window Attention, qui aligne précisément les caractéristiques temporelles de la parole et de la vidéo grâce à une modélisation conditionnelle temporelle locale, garantissant la synchronisation labiale et gestuelle ; 2) Une stratégie d’entraînement conjointe parole-texte, utilisant les données vidéo existantes annotées avec parole et texte pour améliorer la capacité de généralisation et la contrôlabilité du modèle ; 3) Des modèles de prompts structurés et des étiquettes de personnage, permettant pour la première fois la génération de dialogues multi-personnages et multi-tours, tout en maintenant la cohérence contextuelle et l’identité des personnages. Les expériences valident ses avantages en termes de réalisme, d’expressivité et de contrôlabilité, faisant progresser la génération automatisée de narration cinématographique. (Source: PaperWeekly)
L’Université des Sciences et Technologies de Huazhong & Xiaomi Auto proposent le framework de conduite autonome ORION: Face à la capacité limitée de raisonnement causal de la conduite autonome de bout en bout dans l’interaction en boucle fermée, l’Université des Sciences et Technologies de Huazhong et Xiaomi Auto proposent le framework ORION. Ce framework combine de manière innovante les grands modèles visuel-linguistiques (VLM) et les modèles génératifs (comme VAE ou les modèles de diffusion). Il utilise le VLM pour la compréhension de scène, le raisonnement et la génération d’instructions, puis aligne l’espace de raisonnement sémantique du VLM avec l’espace d’action de trajectoire purement numérique via le modèle génératif pour guider la génération de trajectoire. Parallèlement, il introduit le module QT-Former pour agréger efficacement les informations contextuelles visuelles historiques à long terme, surmontant la limitation des tokens et la charge de calcul des VLM lors du traitement de plusieurs images. ORION réalise une optimisation unifiée de bout en bout des tâches de questions-réponses visuelles (VQA) et de planification. Lors de l’évaluation en boucle fermée Bench2Drive, ORION a obtenu un score de conduite de 77,74 points et un taux de succès de 54,62%, surpassant nettement la meilleure méthode précédente. Le code, les modèles et les jeux de données seront open source. (Source: 机器之心)
L’Université Nationale de Singapour propose GEAL : utiliser les grands modèles 2D pour améliorer la prédiction d’Affordance 3D: Pour résoudre les problèmes de rareté des données 3D, d’annotation coûteuse et de manque de généralisation et de robustesse des modèles dans l’apprentissage de l’Affordance 3D (prédiction des zones interactives des objets), l’Université Nationale de Singapour propose le framework GEAL. GEAL utilise le 3D Gaussian Splatting pour rendre des nuages de points épars en images réalistes, qui sont ensuite envoyées à un grand modèle visuel 2D pré-entraîné (comme DINOV2) pour extraire des caractéristiques sémantiques riches. Grâce à un alignement de cohérence intermodale innovant (Cross-Modal Consistency Alignment), comprenant un module de fusion adaptative de granularité (GAFM) et un module d’alignement de cohérence (CAM), il fusionne efficacement les caractéristiques visuelles 2D et les caractéristiques géométriques spatiales 3D. Le GAFM agrège de manière adaptative les caractéristiques multi-échelles selon les instructions textuelles, tandis que le CAM favorise l’alignement bidirectionnel de l’information en rendant les caractéristiques 3D en 2D et en appliquant une perte de cohérence. GEAL ne nécessite pas d’annotation 3D à grande échelle et améliore considérablement la capacité de généralisation aux nouveaux objets et scènes, ainsi que la robustesse dans les environnements bruyants. L’équipe a également construit un jeu de données de référence contenant diverses perturbations réelles pour évaluer la robustesse du modèle. (Source: 机器之心)
Moonshot AI lance les modèles Kimi-VL MoE (petit et grand), axés sur l’inférence multimodale et le contexte long: Moonshot AI a lancé Kimi-VL et Kimi-VL-Thinking, deux modèles visuel-linguistiques Mixture of Experts (MoE). Ces deux modèles ont un nombre total de paramètres de 16B, avec seulement environ 3B de paramètres activés, mais affichent d’excellentes performances dans plusieurs benchmarks. Kimi-VL-Thinking excelle en inférence multimodale (MathVision à 36,8%) et en compétences d’agent (ScreenSpot-Pro à 34,5%), avec des performances comparables à des modèles 10 fois plus grands. Les modèles utilisent la technologie MoonViT pour traiter nativement les entrées visuelles haute résolution (OCRBench à 867) et supportent une fenêtre de contexte long allant jusqu’à 128K (MMLongBench-Doc à 35,1%, LongVideoBench à 64,5%), dépassant des modèles plus grands comme GPT-4o sur des benchmarks clés. Les articles de recherche associés et les modèles Hugging Face ont été publiés. (Source: Reddit r/LocalLLaMA)
🧰 Outils
Firebase Studio : La plateforme de développement full-stack en ligne de Google intégrant l’IA: Google a intégré l’outil de développement Project IDX dans Firebase, le renommant Firebase Studio, offrant un environnement de développement d’applications full-stack gratuit dans le navigateur. Les principales caractéristiques de la nouvelle plateforme incluent : 1) Création de projet assistée par IA, capable de générer la structure de code initiale pour des applications Next.js, etc., à partir de prompts en langage naturel ; 2) Basculement entre deux modes de travail, supportant un passage transparent entre le mode intelligent IA pour la génération rapide de contenu et l’environnement de développement cloud traditionnel (espace de travail cloud basé sur VM) ; 3) Héritage des fonctionnalités d’IDX, telles que les modèles full-stack, l’émulateur Android, la collaboration d’équipe, le déploiement en un clic, etc. Firebase Studio intègre profondément les services backend de Firebase (base de données, authentification, etc.), visant à créer une expérience de développement « tout-en-un » intégrant le développement front-end, back-end et les services cloud. Les retours utilisateurs indiquent que l’outil est très puissant, avec une bonne expérience interactive, capable de construire des applications via des prompts avec aperçu en temps réel, et supportant même la modification de l’interface utilisateur en marquant des captures d’écran. Cependant, l’accès peut actuellement être limité en raison d’un trop grand nombre d’utilisateurs. (Source: 36氪, dotey)

OpenManus : Projet d’Agent open source répliquant rapidement les fonctionnalités clés de Manus: Face à l’engouement suscité par Manus AI Agent dont le code n’est pas open source, Liang Xinbing, étudiant diplômé de l’Université Normale de Chine de l’Est, et Xiang Jinyu, chercheur chez DeepWisdom, ainsi que d’autres développeurs nés après 2000, ont rapidement développé et mis en open source le projet OpenManus pendant leur temps libre. Ce projet vise à répliquer les fonctionnalités principales de Manus et à montrer la logique centrale de l’Agent (basée sur Tool et Prompt) avec un code concis et facile à comprendre (environ quelques milliers de lignes). Le projet utilise le modèle React avec function call et a conçu des outils principaux pour les opérations de navigateur, l’édition de fichiers, l’exécution de code, etc. OpenManus a rapidement obtenu plus de 40 000 étoiles sur GitHub, reflétant l’enthousiasme de la communauté open source pour la technologie des Agents. Les développeurs ont partagé leur workflow utilisant de grands modèles pour aider à comprendre les dépôts de code, concevoir l’architecture et générer du code, et ont discuté du protocole MCP (l’interface Type-C du monde de l’IA) et des défis de la collaboration multi-agents. Le projet est en développement continu, prévoyant d’améliorer l’écosystème d’outils, le support MCP, le mécanisme de coordination multi-agents et les cas de test. (Source: CSDN)
Vulgarisation du concept d’Agent IA et scénarios d’application: Un Agent IA (AI Agent) est un logiciel capable de percevoir l’environnement de manière autonome, de prendre des décisions et d’exécuter des tâches. Contrairement à une IA ordinaire (comme un chatbot) qui ne fournit que des informations, il peut « passer à l’action » pour vous. Ses caractéristiques clés incluent l’autonomie, la capacité de mémoire, la capacité à utiliser des outils et la capacité d’apprentissage et d’adaptation. Les scénarios d’application sont vastes, tels que l’assistant personnel (planification automatique de voyages, gestion de l’agenda et des e-mails), les applications commerciales (amélioration de l’efficacité du développement logiciel, du service client, de la découverte de médicaments), l’amélioration de l’efficacité de l’entreprise (automatisation des processus RH, gestion de la création de contenu). La construction d’un Agent IA implique les étapes de Perception (collecte de données), Réflexion (analyse et planification par le modèle IA), Action (appel d’API d’outils) et Apprentissage (amélioration à partir des résultats). Les grandes entreprises comme Microsoft, Google, BAT (Baidu, Alibaba, Tencent) investissent toutes dans ce domaine. Les utilisateurs peuvent commencer à utiliser des plateformes comme Coze ou en écrivant des modèles de prompts, en commençant par des tâches simples pour explorer progressivement son potentiel. (Source: 周知)
Color Reshape : Outil de traitement par lots pour corriger la dominante de couleur des images GPT-4o: Face au problème fréquent de dominante bleue ou jaune dans les images générées par GPT-4o, le développeur « Guicang » a lancé un outil nommé « Color Reshape ». Cet outil vise, par une opération en un clic, à corriger par lots l’équilibre des couleurs des images générées par IA, pour les faire ressembler davantage à des photographies professionnelles et restaurer les couleurs réelles. Ses caractéristiques incluent le support du traitement par lots, une fonction de comparaison image originale/résultat avec des curseurs, et des options professionnelles de contrôle de la balance des couleurs. Cela résout le problème des utilisateurs devant ajuster manuellement les couleurs après avoir généré des images avec GPT-4o, améliorant l’efficacité et le résultat final de la création artistique par IA. (Source: op7418)
Notion lance MCP Server: Notion a publié son implémentation de serveur MCP (Model Context Protocol), maintenant open source sur GitHub. Ce serveur permet aux agents IA d’interagir avec Notion via le protocole MCP, implémentant diverses fonctionnalités de l’API Notion, y compris l’obtention du contenu des pages, des commentaires, l’exécution de recherches, etc. Cela signifie que les AI Agents supportant le protocole MCP (comme Claude, etc.) pourront plus facilement appeler et manipuler les données et fonctionnalités Notion de l’utilisateur, étendant davantage les scénarios d’application et les capacités des AI Agents. (Source: karminski3)

OLMoTrace : Nouvel outil pour explorer la mémorisation et la synthèse d’informations par les modèles linguistiques: Ai2 (Allen Institute for AI) a lancé OLMoTrace, une nouvelle fonctionnalité de son AI Playground, visant à aider à comprendre dans quelle mesure les grands modèles de langage (LLM) apprennent et synthétisent l’information, et dans quelle mesure ils ne font que mémoriser et répéter les données d’entraînement. Les utilisateurs peuvent désormais utiliser cet outil pour visualiser les extraits de données d’entraînement qui ont pu contribuer à la génération d’une complétion spécifique par le modèle. Ceci est important pour étudier les mécanismes internes des LLM, comprendre l’origine de leur comportement et évaluer l’équilibre entre leur capacité de généralisation et de mémorisation, en particulier pour les chercheurs et développeurs préoccupés par l’originalité et la fiabilité des modèles. (Source: natolambert)
📚 Apprentissage
NVIDIA lance le modèle de fondation ouvert GR00T N1 pour promouvoir le développement de robots humanoïdes universels: NVIDIA a lancé GR00T N1, un modèle de fondation ouvert spécialement conçu pour les robots humanoïdes universels. Ce modèle vise à résoudre le problème de la rareté des données d’entraînement pour les robots en apprenant à partir de plusieurs sources de données combinées : 1) Utilisation d’Omniverse pour créer des environnements de jumeaux numériques de haute précision (comme des usines) afin de générer de grandes quantités de données simulées auto-étiquetées ; 2) Utilisation du modèle Cosmos pour transformer les données simulées en vidéos plus réalistes, augmentant ainsi l’ensemble d’entraînement ; 3) Développement d’un système IA pour annoter automatiquement les vidéos existantes sur Internet, en extrayant des informations telles que les actions, les articulations, les objectifs, permettant ainsi aux vidéos du monde réel d’être également utilisées comme données d’entraînement. GR00T N1 adopte un mode de pensée à double système : System 2 pour la planification par inférence lente, System 1 (basé sur un modèle Diffusion) pour générer des instructions de contrôle de mouvement en temps réel. Les expériences montrent une augmentation du taux de succès de 46% à 76% par rapport aux méthodes précédentes. Ce modèle est open source, supporte différentes morphologies de robots et vise à accélérer la R&D et l’application des robots universels. (Source: Two Minute Papers)
L’IA aide à soulager l’anxiété liée aux mathématiques chez les lycéens: Selon une enquête mondiale de la Society for Industrial and Applied Mathematics (SIAM) de Philadelphie, plus de la moitié (56%) des lycéens pensent que l’IA aide à soulager l’anxiété liée aux mathématiques. 15% des élèves déclarent que leur anxiété mathématique a diminué après avoir utilisé personnellement l’IA, et 21% ont vu leurs notes s’améliorer. Les raisons pour lesquelles l’IA soulage l’anxiété incluent : fournir une aide et un retour instantanés (61%), renforcer la confiance (permettre de poser des questions à son propre rythme, 44%), l’apprentissage personnalisé (33%), et réduire la peur de faire des erreurs (25%). Cependant, seulement 19% des enseignants pensent que l’IA peut réduire l’anxiété mathématique. La majorité des enseignants et des élèves (64% des enseignants, 43% des élèves) pensent que l’IA devrait être utilisée en complément des enseignants humains, comme tuteur ou partenaire d’apprentissage, pour aider à comprendre les concepts plutôt que de donner directement les réponses. La popularisation de l’IA suscite également une réflexion sur la relation enseignant-élève et l’évolution du rôle de l’enseignant, comme accorder plus d’importance aux examens où l’IA ne peut pas être utilisée, la nécessité pour les enseignants de maîtriser l’IA pour guider les élèves, et la possibilité pour les enseignants de se concentrer davantage sur le tutorat personnalisé. (Source: 元宇宙之心MetaverseHub)

💼 Commercial
L’entreprise d’intelligence incarnée « Qiongche Intelligence » finalise un tour de financement Pre-A++ de plusieurs centaines de millions de yuans: « Qiongche Intelligence », une entreprise d’intelligence incarnée fondée par une équipe issue de Stanford, a récemment finalisé un tour de financement Pre-A++ de plusieurs centaines de millions de yuans, avec la participation de Sheng Yu Investment, Qingke Venture Capital, Jiayu Capital, Yunqi Partners, Shanghai Science and Technology Innovation Group, etc. Les anciens actionnaires Prosperity7 et Red Sequoia China ont réinvesti pour le troisième tour consécutif. Les fonds seront utilisés pour accélérer les percées dans les domaines du modèle de fondation d’intelligence incarnée, de la collecte et de l’évaluation de données, et pour promouvoir la commercialisation dans des scénarios tels que l’exécution des commandes de détail, les services à domicile et la transformation alimentaire. L’entreprise a été co-fondée par le professeur Lu Cewu de l’Université Jiao Tong de Shanghai et Wang Shiquan, fondateur de Flexiv Technology, et se concentre sur la résolution des problèmes fondamentaux de l’intelligence incarnée tels que la description et l’interaction avec le monde physique et l’acquisition de données. Son produit principal, le « Qiongche Embodied Brain », possède des capacités en boucle fermée complètes et réduit les coûts des données grâce à son système de collecte de données auto-développé de type « accompagnement de la production » (CoMiner). L’entreprise a déjà collaboré avec des entreprises d’électroménager pour développer des robots de service à domicile (comme le robot de lavage/soin présenté à l’AWE) et a conclu des intentions de coopération avec des fabricants de produits alimentaires. (Source: 36氪)
L’entreprise de robots humanoïdes « StarDust Intelligence » finalise des tours de financement A et A+ de plusieurs centaines de millions de yuans: L’entreprise de robots humanoïdes incarnés « StarDust Intelligence » a finalisé consécutivement les tours de financement A et A+, pour un montant total de plusieurs centaines de millions de yuans, menés par Jinqiu Fund et Ant Group, avec la participation des anciens actionnaires Yunqi Partners, Daotong Capital, etc. L’entreprise définit le paradigme « Design for AI » et s’engage à créer des assistants robots IA dotés de capacités de manipulation de niveau humain. Son produit principal, Astribot S1, adopte une conception de transmission par câble unique, atteignant un rapport charge utile/poids propre élevé (1:1), une haute vitesse (extrémité supérieure à 10 m/s) et des capacités de manipulation flexibles similaires à celles de l’homme. StarDust Intelligence a construit une boucle technologique fermée « corps+données+modèle », capable d’utiliser à faible coût des vidéos du monde réel et des données de mouvements humains, et de collecter efficacement des données d’interaction multimodales, donnant aux robots des capacités de perception d’environnements complexes, de cognition, de prise de décision et de généralisation des opérations universelles. Actuellement, le S1 a été itéré trois fois, et l’entreprise mène des mises en œuvre pratiques avec des universités, des entreprises, etc., tout en optimisant continuellement son grand modèle de bout en bout. (Source: 36氪)

La startup de matériel IA io Products de Jony Ive et Sam Altman pourrait être acquise par OpenAI: io Products, la startup de matériel IA co-fondée par l’ancien directeur du design d’Apple Jony Ive et le PDG d’OpenAI Sam Altman, pourrait être acquise par OpenAI pour un prix d’au moins 500 millions de dollars, selon The Information. Fondée en 2024, io Products vise à créer des appareils personnels pilotés par l’IA moins intrusifs que les smartphones. Les pistes explorées pourraient inclure des téléphones sans écran, des appareils domestiques pilotés par l’IA ou des assistants IA portables. Cette acquisition potentielle marque l’expansion potentielle d’OpenAI du domaine logiciel vers le matériel grand public. Cependant, compte tenu de l’échec de précédents produits matériels IA comme le Humane AI Pin et le Rabbit R1, ainsi que de la préférence des utilisateurs pour l’amélioration des fonctions IA des téléphones existants plutôt que pour de nouvelles formes d’appareils, la demande et l’acceptation par le marché des appareils IA sans écran restent incertaines. (Source: 不客观实验室)

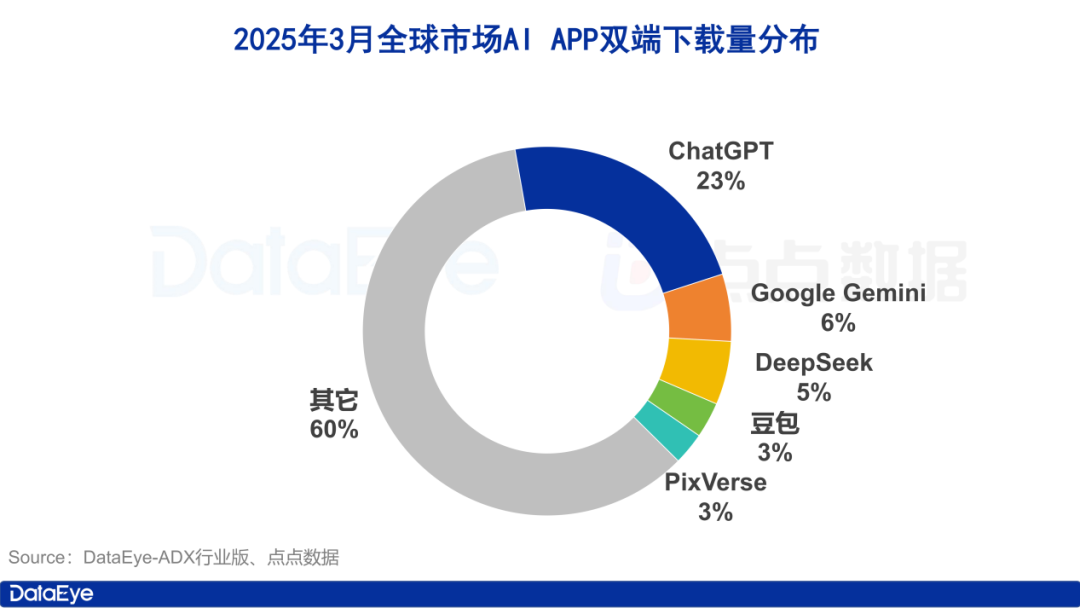
Observation du marché des applications IA en mars : 260 millions de téléchargements mondiaux, lutte à trois entre Tencent, Alibaba et ByteDance en Chine: Un rapport de l’institut de recherche DataEye montre qu’en mars 2025, les téléchargements mondiaux estimés d’applications IA (App Store & Google Play) ont atteint 260 millions. ChatGPT est largement en tête avec 23% de part, suivi par Google Gemini qui dépasse DeepSeek. Sur le marché chinois (App Store), les téléchargements ont atteint 40,2 millions, avec DeepSeek, Jmeng AI, Doubao, Quark et Tencent Yuanbao dans le top cinq. Les téléchargements de Kimi intelligent assistant ont chuté drastiquement. En termes d’acquisition d’utilisateurs payante, sur le marché de la Chine continentale, le volume de créations publicitaires pour les produits IA (y compris les mini-programmes) a atteint 957 000 groupes. Tencent Yuanbao (26%), Quark (24%) et Doubao (13%) se classent parmi les trois premiers, formant un paysage concurrentiel intense entre Tencent, Alibaba et ByteDance. Kimi est sorti du classement après avoir suspendu sa publicité. Le rapport estime que le succès fulgurant de DeepSeek et la stratégie « All in AI » d’Alibaba poussent les géants technologiques à accélérer leur déploiement sur le marché des applications IA grand public. (Source: 36氪)
Anthropic lance le plan d’abonnement à prix élevé Claude Max: En concurrence avec ChatGPT Pro d’OpenAI (200 $/mois), Anthropic a lancé le service d’abonnement Claude Max. Ce service offre deux options : 100 $/mois, offrant une limite d’utilisation 5 fois supérieure à celle de Claude Pro (20 $/mois) ; 200 $/mois, offrant une limite d’utilisation jusqu’à 20 fois supérieure. Les utilisateurs du plan Max auront un accès prioritaire aux derniers modèles et fonctionnalités IA d’Anthropic, y compris le mode vocal à venir. Cette initiative est considérée comme une nouvelle voie pour les entreprises d’IA pour explorer l’augmentation des revenus et servir les utilisateurs intensifs. Le chef de produit d’Anthropic a déclaré que ce plan cible principalement les utilisateurs professionnels intensifs dans les domaines du codage, de la finance, des médias et du divertissement, et du marketing, et n’exclut pas la possibilité de lancer des plans plus chers à l’avenir. Parallèlement, Anthropic explore également des services pour des marchés spécifiques comme l’éducation. (Source: dotey, op7418)

xAI lance l’API Grok 3 et annonce les prix: xAI a officiellement ouvert le test bêta de la série d’API Grok 3, proposant les modèles Grok 3 et Grok 3 Mini, chacun avec un mode normal et un mode rapide (réponse plus rapide mais coût de sortie plus élevé). Grok 3 est adapté aux scénarios d’entreprise tels que l’extraction de données et la programmation, avec un prix de 3 $ par million de tokens en entrée et 15 $ par million de tokens en sortie (mode rapide : 5 $/25 $). Grok 3 Mini est un modèle léger adapté aux tâches simples, avec un prix de 0,3 $ par million de tokens en entrée et 0,5 $ par million de tokens en sortie (mode rapide : 0,6 $/4 $). Cela offre aux développeurs des choix flexibles pour répondre aux besoins de différents scénarios d’application en termes de performance et de coût. Pendant ce temps, Google lance également de nouveaux plans incluant un niveau gratuit pour les développeurs, Anthropic lance le plan Max à prix élevé, et Llama 4 de Meta entre en concurrence avec un faible coût (environ 0,36 $/million de tokens), montrant la concurrence différenciée des géants de l’IA dans leurs stratégies de tarification des API. (Source: 新智元, op7418)
36Kr publie la liste des cas d’innovation d’applications natives IA 2025: 36Kr a sélectionné et publié la liste des « Cas d’innovation d’applications natives IA 2025 », retenant finalement 45 cas. La sélection vise à découvrir les produits et applications natifs IA qui sont les premiers à appliquer la technologie IA dans des scénarios réels, à créer une valeur réelle et à mener la transformation de l’industrie. Les cas retenus couvrent plusieurs domaines, dont la fabrication intelligente, le service client, la création de contenu, la gestion d’entreprise, la bureautique, la sécurité, le marketing et la santé. L’évaluation a révélé que les cas retenus présentent quatre caractéristiques principales : 1) L’intégration inter-domaines s’accélère, créant de nouveaux modèles économiques ; 2) Intégration profonde avec les points de douleur de l’industrie, fournissant des solutions distinctives ; 3) Accent mis sur l’amélioration de l’expérience utilisateur et des services personnalisés ; 4) S’appuyant sur une technologie propriétaire puissante (grands modèles, multimodalité) et construisant activement un écosystème d’innovation. Cette liste reflète le fait que les applications natives IA connaissent une croissance explosive et pénètrent profondément dans tous les secteurs. (Source: 36氪)

🌟 Communauté
Google DeepMind révélé utiliser des clauses de non-concurrence allant jusqu’à 1 an pour restreindre la mobilité des talents: Selon Business Insider, Google DeepMind est accusé d’utiliser des accords de non-concurrence pouvant aller jusqu’à 12 mois (incluant des congés payés forcés / « garden leave ») pour empêcher les talents clés de l’IA de rejoindre des concurrents comme OpenAI, Microsoft, etc. L’accord est généralement inclus dans le contrat de travail et prend effet lorsque l’employé tente de rejoindre un concurrent direct. La durée de la période de non-concurrence dépend du poste, pouvant être de 6 mois pour les développeurs de première ligne et jusqu’à 1 an pour les chercheurs seniors. Cette mesure suscite la controverse, critiquée comme des « menottes dorées professionnelles », qui, dans le secteur de l’IA à itération rapide, peut entraîner une obsolescence des compétences des talents, freiner l’innovation et la mobilité des talents. Parce que la loi britannique autorise l’application d’accords de non-concurrence « raisonnables » et que le siège de DeepMind est à Londres, cela contraste avec la Californie qui interdit la non-concurrence. Nando de Freitas, ancien cadre de DeepMind et actuellement VP chez Microsoft, a publiquement critiqué cette pratique sur la plateforme X, affirmant qu’elle ne devrait pas avoir un tel pouvoir en Europe, suscitant une large discussion. (Source: CSDN程序人生)

L’IA suscite des inquiétudes concernant le « cocon émotionnel »: Avec le développement de la technologie IA, les applications visant à satisfaire les émotions et les désirs humains augmentent, comme les poupées sexuelles intelligentes (Wmdoll prévoit une croissance des ventes de 30%), les compagnons virtuels IA, le chat IA délégué (augmentant les revenus des créateurs OnlyFans), etc. L’article analyse et souligne que l’IA peut fournir une valeur émotionnelle stable, patiente et positive, répondre aux besoins de communication spirituelle des gens, dépassant même les vraies personnes. Cependant, cette « complaisance excessive » et cette « surprotection » peuvent conduire les humains à former un « cocon émotionnel », à dépendre excessivement des sentiments subjectifs pour gérer les relations, à réduire la tolérance à la complexité et aux frustrations des relations interpersonnelles réelles, et à aggraver la fragilité émotionnelle, l’atomisation et l’antagonisme entre les sexes. L’article estime que si l’IA libère le temps humain en gérant les tâches subalternes, elle peut aussi, en raison de sa nature complaisante, enfermer les gens dans leur zone de confort et leurs fantasmes ultimes, entraver la croissance personnelle et les interactions interpersonnelles réelles, et pourrait finalement rendre les humains plus seuls et être « conquis » par l’IA. (Source: 周天财经)

Ajustement stratégique de MiniMax : De « produit-modèle intégré » à la priorité technologique, en pariant sur la vidéo IA: Face à la pression concurrentielle de DeepSeek et d’autres, l’entreprise d’IA MiniMax ajuste sa stratégie. Au début, elle adhérait à l’approche « produit-modèle intégré », où les modèles servaient les applications (par exemple, le modèle de texte pour l’assistant MiniMax, le modèle vidéo pour Hailuo AI, ainsi que Talkie, Xingye, etc.), et améliorait l’efficacité en modifiant l’architecture sous-jacente de Transformer (attention linéaire). Le fondateur Yan Junjie a réfléchi et estimé qu' »une meilleure application ne mène pas nécessairement à un meilleur modèle », et l’entreprise s’oriente désormais vers une approche « axée sur la technologie », séparant la R&D technologique de l’application produit. Au niveau du produit, MiniMax se concentre sur la marque « Hailuo » pour la génération vidéo, l’ancien « Hailuo AI » étant renommé « MiniMax », et des rumeurs indiquent l’acquisition de l’entreprise de génération vidéo IA Luying Technology (qui possède la plateforme de style anime/manga YoYo). Cette décision pourrait être due au risque de retrait de sa principale source de revenus, Talkie (application de compagnonnage IA), des plateformes sur les marchés étrangers, nécessitant de trouver de nouveaux points de croissance. Parallèlement, MiniMax commence à se concentrer sur les activités B2B, en créant une alliance d’innovation pour l’industrie du matériel intelligent, mais ses activités B2B semblent encore faibles et font face à des défis. (Source: guangzi0088)

Great Wall Motors et Unitree Technology collaborent pour explorer « SUV + chien robot »: Great Wall Motors et l’entreprise de robotique Unitree Technology ont conclu un partenariat stratégique pour collaborer dans des domaines tels que la technologie robotique et la fabrication intelligente. La première phase de coopération se concentrera sur les scénarios d’application « SUV + chien robot », explorant des possibilités telles que le transport d’équipement et l’accompagnement d’aventures en plein air. L’article discute de l’application des robots (en particulier humanoïdes) dans l’industrie automobile, estimant qu’actuellement, les robots dans les usines automobiles jouent principalement un rôle d' »assistant » (comme transporter des objets lourds) et que remplacer les humains n’est pas encore réaliste en raison d’une flexibilité et d’une adaptabilité insuffisantes. Tandis que l’expansion des scénarios « voiture + robot » (similaire à « voiture + drone » de BYD) vise à élargir les limites d’utilisation de la voiture. Concernant « SUV + chien robot », l’article estime qu’il a une valeur potentielle pour les passionnés de tout-terrain hardcore ou des secteurs spécifiques (comme le sauvetage en milieu sauvage) pour transporter de l’équipement ou faire de la reconnaissance de terrain, mais sa popularisation fait face à des défis tels que le coût élevé, une demande de niche et la maturité technologique. Actuellement, cela ressemble plus à une exploration des futurs scénarios intelligents en extérieur qu’à un besoin essentiel. (Source: 电车通)

Discussion sur l’adéquation de l’architecture Llama 4 pour les workflows spécifiques des utilisateurs Mac: Un utilisateur de Mac Studio (M3 Ultra, 512 Go RAM) a partagé l’adéquation du modèle Llama 4 Maverick pour son workflow. Cet utilisateur est passionné par l’amélioration des performances des LLM via des workflows itératifs et de validation en plusieurs étapes, mais auparavant, l’exécution de grands modèles (32B-70B) sur Mac était trop lente (jusqu’à 20-30 minutes), tandis que les petits modèles (8-14B), bien que rapides, n’offraient pas une qualité idéale. Llama 4 Maverick, bien qu’ayant un grand nombre de paramètres (400B) et nécessitant beaucoup de mémoire (ce que le Mac fournit justement), a une architecture MoE qui fait que sa vitesse d’exécution réelle est proche de celle d’un modèle 17B (environ 16,8 T/s de vitesse de génération avec quantification Q8). Cette caractéristique « grande occupation mémoire mais vitesse relativement rapide » correspond exactement au point douloureux des utilisateurs Mac « mémoire abondante mais vitesse limitée », en faisant le choix idéal pour le workflow spécifique de cet utilisateur, bien que le modèle ne soit pas très bien noté globalement et qu’il puisse y avoir des problèmes de tokenizer. (Source: Reddit r/LocalLLaMA)
💡 Autres
Google Gemini met à niveau la fonction Deep Research: Demis Hassabis, PDG de Google DeepMind, a annoncé que la fonction Deep Research dans l’application Gemini (abonnement Gemini Advanced requis) est désormais alimentée par le modèle Gemini 2.5 Pro. Google affirme qu’il s’agit de la capacité de recherche approfondie la plus puissante du marché, avec une préférence utilisateur de 2 contre 1 par rapport au meilleur concurrent suivant. Le Deep Research mis à niveau peut mieux analyser les informations pour générer des rapports approfondis pour les utilisateurs sur presque n’importe quel sujet. (Source: demishassabis)

Utiliser GPT-4o pour convertir des photos en style d’art de découpage en couches: Un utilisateur a partagé une astuce de prompt utilisant GPT-4o ou Sora pour convertir des photos ordinaires en images de style art de découpage avec un effet de couches. L’idée principale est de demander au modèle d’identifier et de séparer le plan moyen et l’arrière-plan de la photo, puis d’appliquer le style d’art de découpage en couches pour redessiner, avec la possibilité d’ajouter un titre. L’exemple montre la conversion réussie d’une photo de la ville de Chicago en une œuvre de style découpage avec le titre « Chicago 2016 ». (Source: dotey)

Utiliser GPT-4o pour générer des illustrations de calendrier de mode basées sur la date: Un utilisateur a partagé un modèle de prompt et une méthode utilisant GPT-4o pour générer des illustrations de calendrier de mode dans le style du calendrier lunaire chinois. La méthode se déroule en deux étapes : premièrement, entrer la date, laisser le modèle récupérer les informations correspondantes du calendrier lunaire (jour de la semaine, date lunaire, jours fériés, activités favorables/défavorables, citation inspirante) et la description de la tenue saisonnière du personnage, puis générer un prompt détaillé pour la génération d’image basé sur le modèle ; deuxièmement, laisser le modèle dessiner l’image en fonction du prompt généré. Le modèle demande une image verticale (9:16) dans un style d’illustration fraîche dessinée à la main, contenant une image de fille mignonne et à la mode, la date grégorienne visible, le mois en anglais, le jour de la semaine en chinois et anglais, la date lunaire, les jours fériés, les activités « favorables » en colonne verticale et une citation inspirante, en faisant attention à l’espace blanc et à la mise en page. L’exemple montre une illustration de calendrier du Nouvel An générée selon cette méthode. (Source: dotey)
