
Mots-clés:AI, modèles, rapport AI Index 2025, processeur photonique AI, modèles multimodaux open source, optimisation des coûts d’inférence, éthique et responsabilité AI
🔥 Pleins feux
Stanford publie le rapport AI Index 2025: L’Université Stanford a publié le rapport « 2025 AI Index » de 456 pages, offrant un aperçu complet de l’état actuel et des tendances dans le domaine de l’IA. Le rapport souligne que les États-Unis dominent en nombre de modèles publiés, mais que la Chine rattrape rapidement en termes de qualité des modèles, réduisant considérablement l’écart de performance. Les coûts d’entraînement continuent d’augmenter (par exemple, environ 192 millions de dollars pour Gemini 1.0 Ultra), mais les coûts d’inférence diminuent fortement. Le problème des émissions carbone de l’IA devient de plus en plus grave, l’entraînement de Meta Llama 3.1 générant des émissions considérables. Le rapport mentionne également que de nombreux benchmarks d’IA sont saturés, rendant difficile la distinction des capacités des modèles, et que le « dernier examen humain » devient un nouveau défi. La collecte de données publiques est limitée (48% des domaines de premier niveau restreignent les robots d’exploration), suscitant des inquiétudes quant à un « pic de données ». Les investissements des entreprises dans l’IA sont massifs, mais n’ont pas encore généré de retours significatifs sur la productivité. L’IA a un potentiel énorme dans les domaines scientifique et médical, mais la conversion en applications pratiques prendra encore du temps. Sur le plan politique, la législation au niveau des États américains est active, en particulier concernant les deepfakes, tandis qu’au niveau mondial, il s’agit principalement de déclarations non contraignantes. Malgré les craintes de remplacement d’emplois, l’attitude générale du public envers l’IA reste plutôt optimiste (Source: AINLPer)
Percée pour un nouveau type de processeur IA photonique: La revue Nature a publié deux articles présentant de nouveaux processeurs IA combinant photonique et électronique, visant à surmonter les goulots d’étranglement de performance et de consommation d’énergie de l’ère post-transistor. L’accélérateur photonique PACE de la société singapourienne Lightelligence (contenant plus de 16 000 composants photoniques) a démontré des vitesses de calcul allant jusqu’à 1 GHz et une réduction de la latence minimale de 500 fois, excellant dans la résolution du problème d’Ising. Le processeur photonique de la société américaine Lightmatter (contenant quatre matrices 128×128) a exécuté avec succès des modèles d’IA tels que BERT et ResNet, avec une précision comparable aux processeurs électroniques, et a démontré des applications telles que jouer à Pac-Man. Les deux études indiquent que leurs systèmes sont extensibles et peuvent être fabriqués dans les usines CMOS existantes, promettant de pousser le matériel d’IA vers une plus grande puissance et une meilleure efficacité énergétique, marquant une étape importante vers la praticabilité du calcul photonique (Source: 36Kr)

UC Berkeley publie en open source DeepCoder, un modèle de code 14B comparable à o3-mini: UC Berkeley et Together AI ont conjointement publié DeepCoder-14B-Preview, un modèle d’inférence de code de 14 milliards de paramètres entièrement open source, dont les performances rivalisent avec o3-mini d’OpenAI. Le modèle a été fine-tuné à partir de Deepseek-R1-Distilled-Qwen-14B via l’apprentissage par renforcement distribué (RL) et atteint 60,6% de Pass@1 sur le benchmark LiveCodeBench. L’équipe a construit un jeu d’entraînement contenant 24 000 problèmes de programmation de haute qualité et a adopté une méthode d’entraînement GRPO+ améliorée, une extension contextuelle itérative (de 16K à 32K, atteignant 64K en inférence) et une technique de filtrage ultra-long. Le système d’entraînement RL optimisé, verl-pipeline, qui a doublé la vitesse d’entraînement de bout en bout, a également été rendu open source. Cette publication inclut non seulement le modèle, mais aussi le jeu de données, le code et les journaux d’entraînement (Source: Xinzhiyuan)
🎯 Mouvements
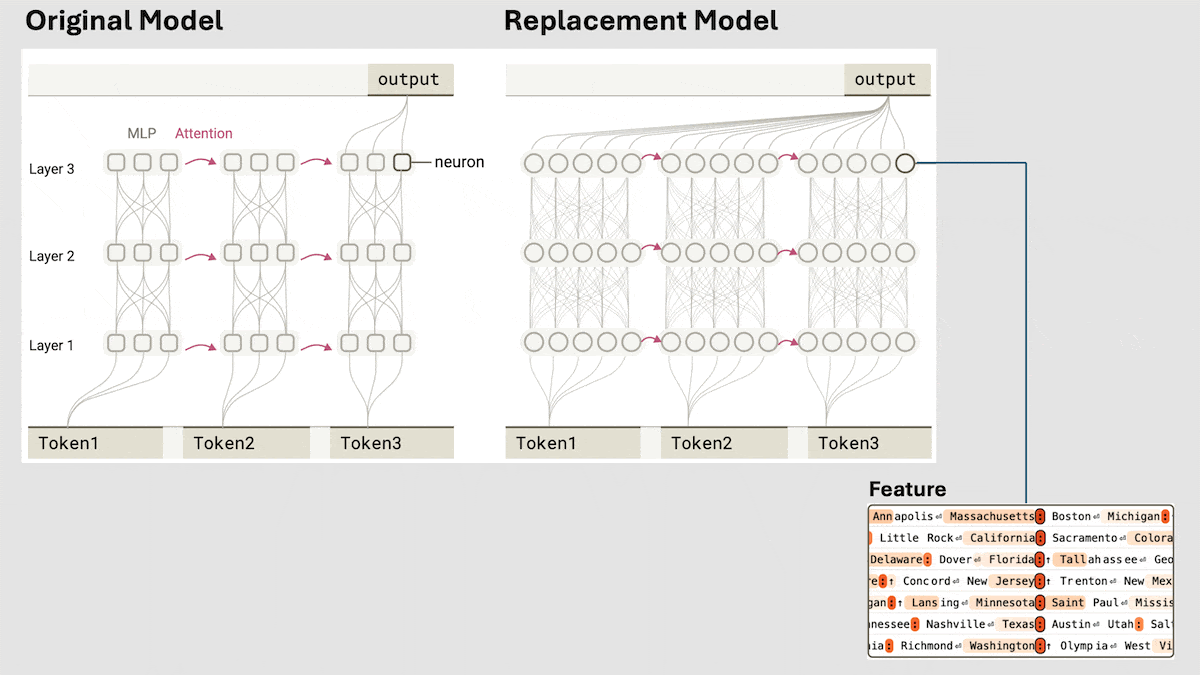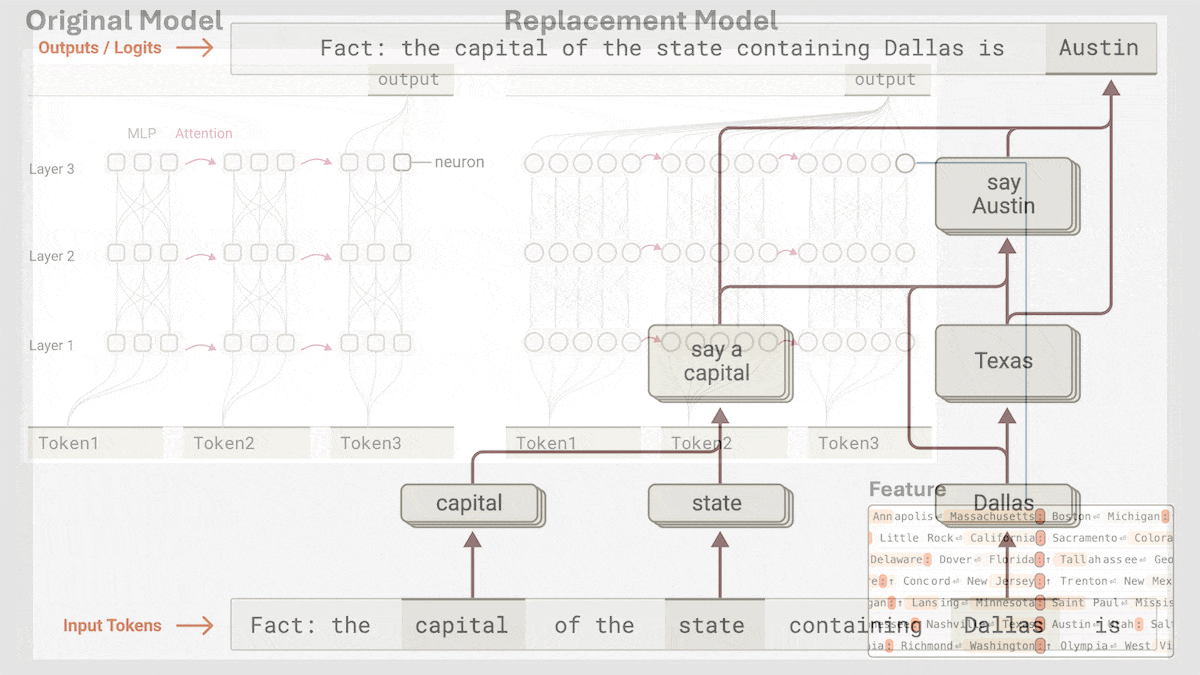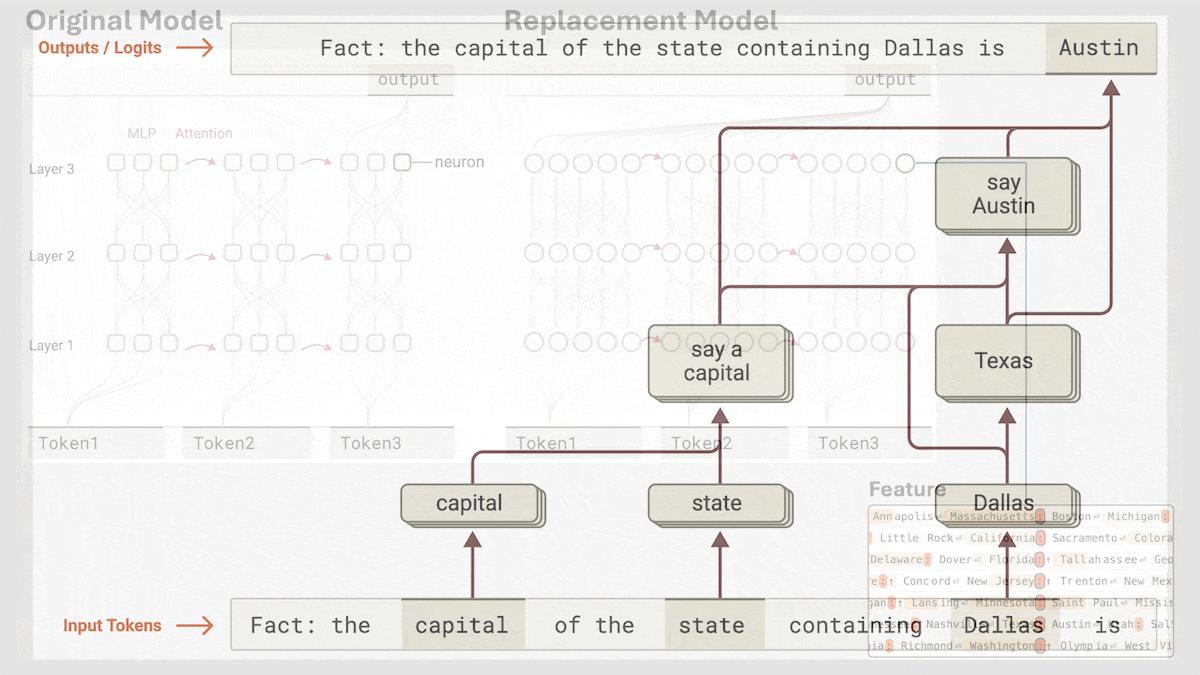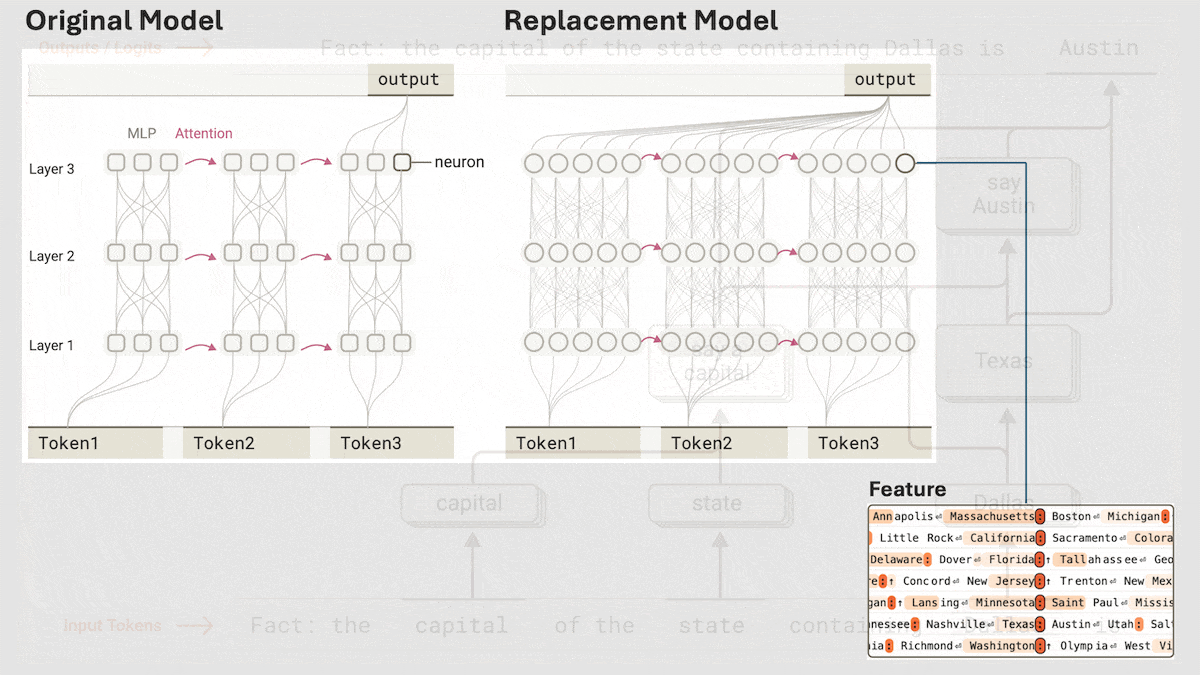
Anthropic révèle le mécanisme de raisonnement implicite de Claude 3.5 Haiku: L’équipe de recherche d’Anthropic a analysé les mécanismes internes des modèles Transformer (en particulier Claude 3.5 Haiku) à l’aide d’une nouvelle méthode. Ils ont découvert que même sans entraînement explicite pour la pensée en chaîne (Chain-of-Thought), le modèle manifeste des étapes de type raisonnement via les activations neuronales lors de la génération de réponses. La méthode remplace les couches entièrement connectées par des « transcodeurs inter-couches » interprétables, identifie les « caractéristiques » liées à des concepts ou prédictions spécifiques, et construit des graphes d’attribution pour visualiser le flux d’information. Les expériences montrent que le modèle passe par plusieurs étapes logiques internes pour répondre à des questions (comme « Quel est l’antonyme de petit ? » ou déterminer la capitale de l’État de Dallas), plutôt que de prédire directement la réponse. Cette recherche aide à comprendre le fonctionnement interne des LLM et à distinguer la véritable capacité de raisonnement de l’imitation superficielle (Source: DeepLearning.AI)
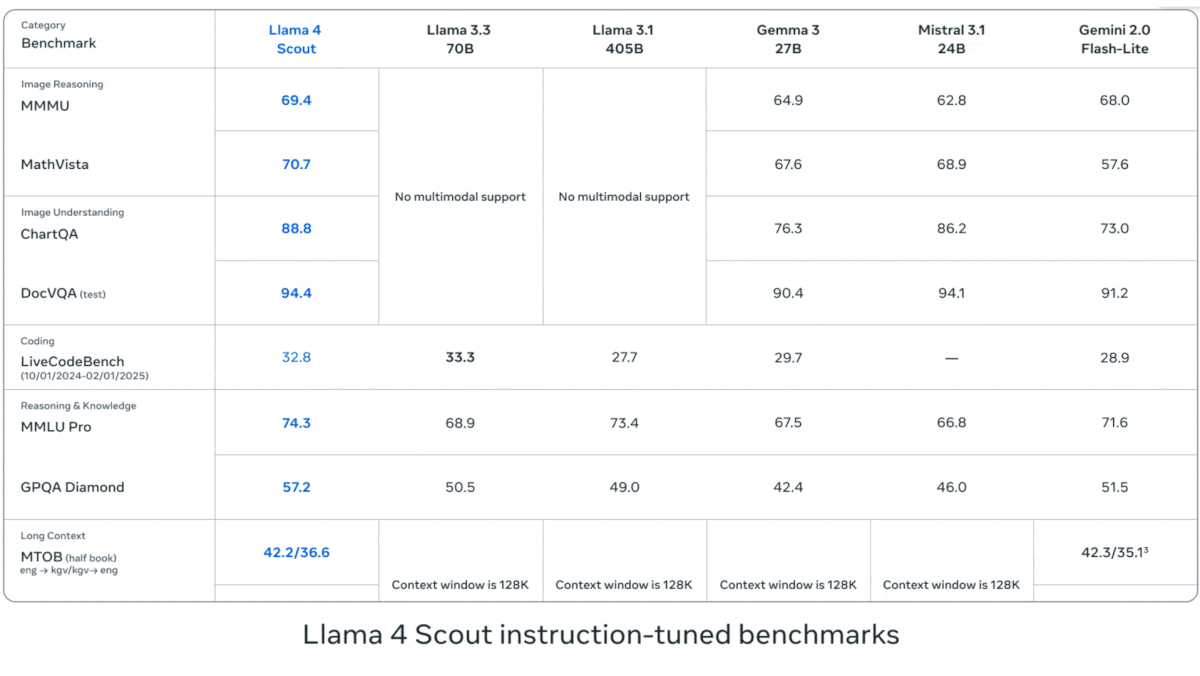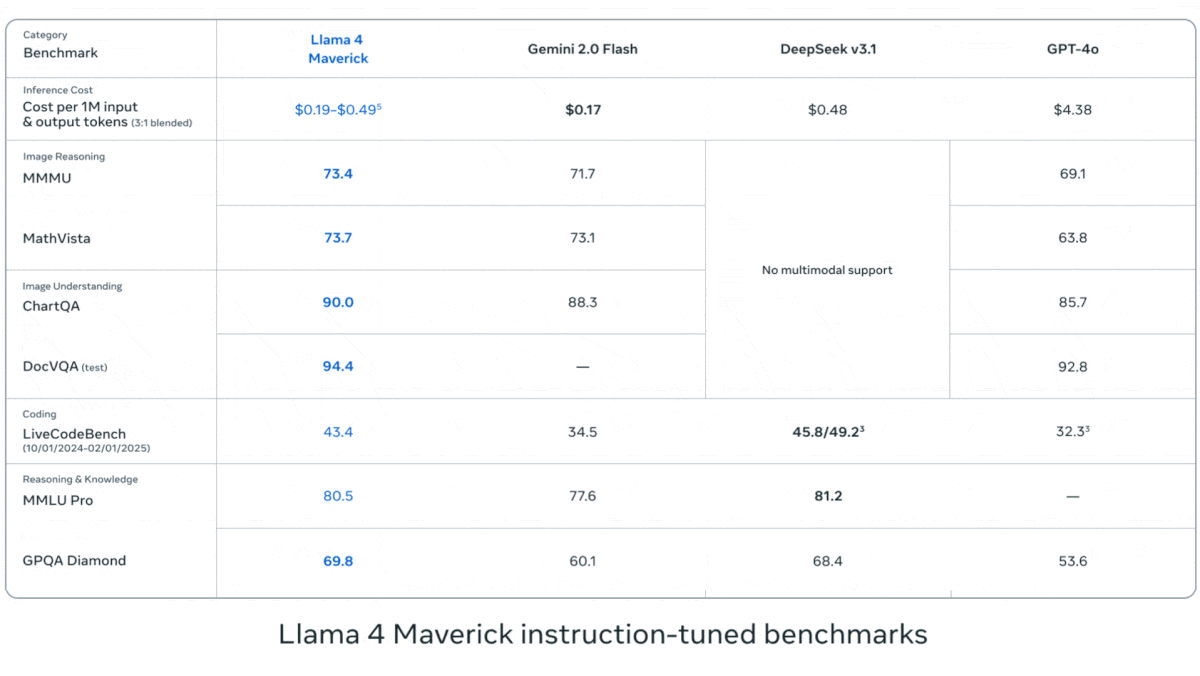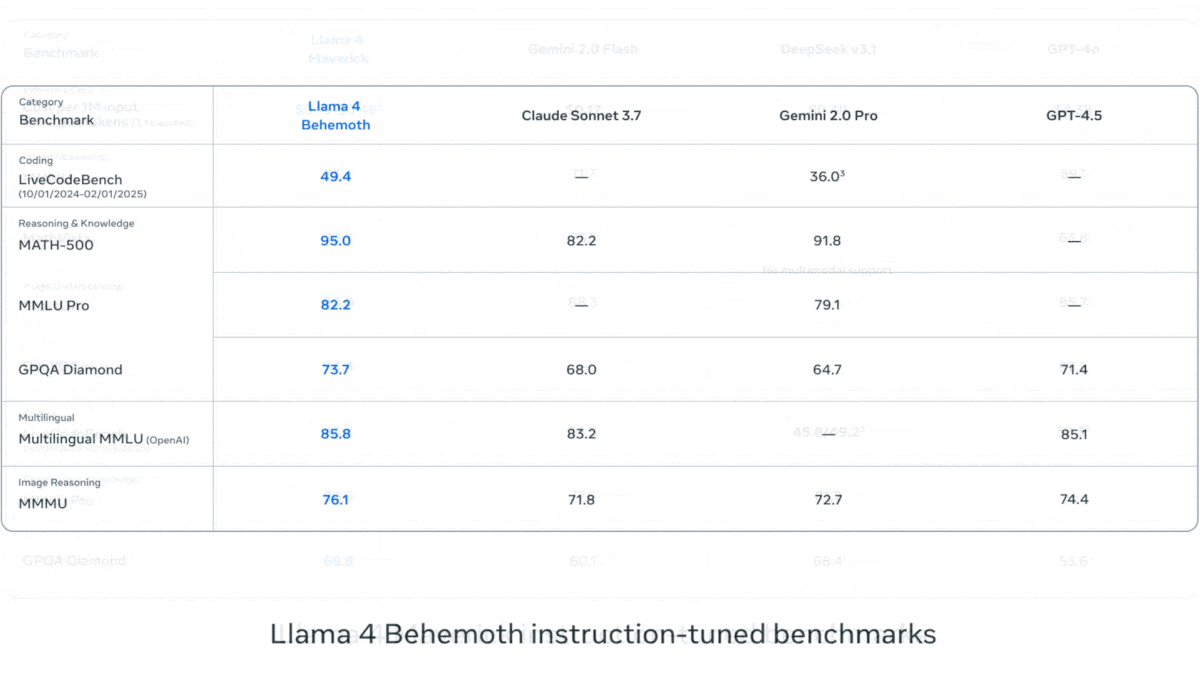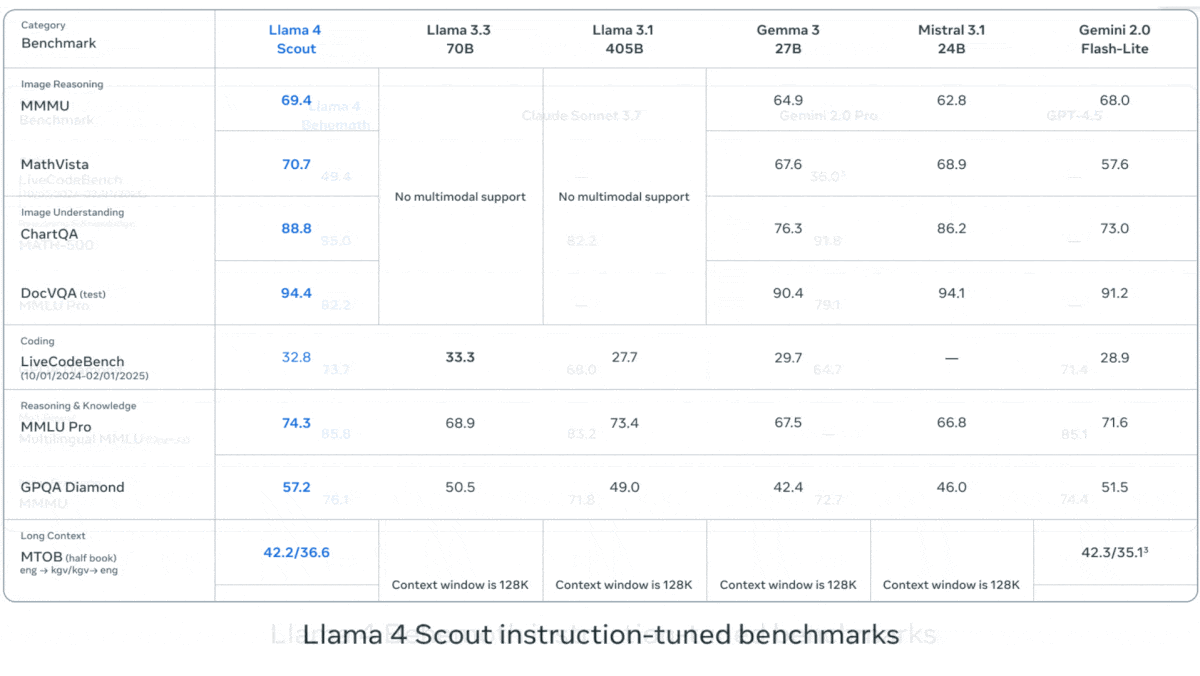
Meta publie la série Llama 4 de modèles de langage visuel: Meta a lancé deux modèles multimodaux open source de la série Llama 4 : Llama 4 Scout (109B paramètres, 17B activés) et Llama 4 Maverick (400B paramètres, 17B activés), et a annoncé Llama 4 Behemoth avec près de 2T paramètres. Ces modèles utilisent tous une architecture MoE, supportent les entrées texte, image, vidéo et génèrent des sorties texte. Scout dispose d’une fenêtre de contexte allant jusqu’à 10 millions de tokens (bien que son efficacité réelle soit remise en question), tandis que Maverick en a une de 1 million. Les modèles affichent de solides performances sur plusieurs benchmarks d’image, de codage, de connaissances et de raisonnement, Scout surpassant Gemma 3 27B, et Maverick surpassant GPT-4o et Gemini 2.0 Flash. Les premières versions de Behemoth dépassent GPT-4.5. La publication de ces modèles accélère encore la course des modèles open source pour rattraper les modèles propriétaires (Source: DeepLearning.AI, X @AIatMeta)
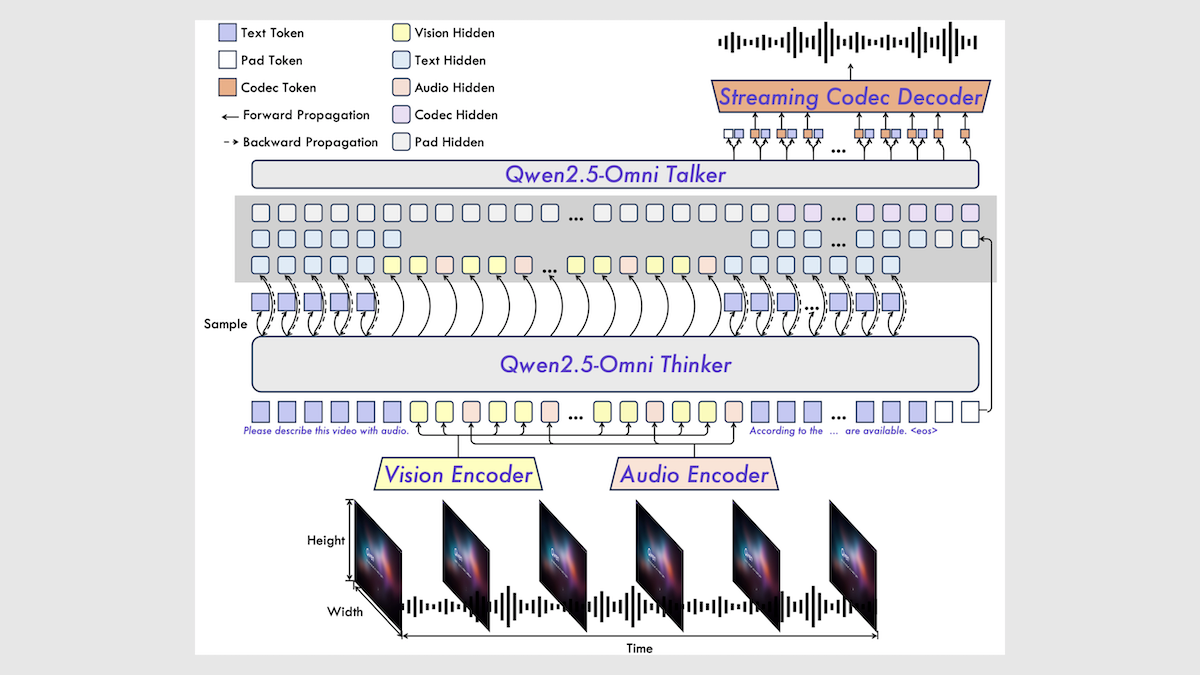
Alibaba publie le modèle multimodal Qwen2.5-Omni 7B: Alibaba a publié un nouveau modèle multimodal open source, Qwen2.5-Omni 7B, capable de traiter des entrées texte, image, audio et vidéo, et de générer des sorties texte et vocales. Le modèle est construit sur le modèle texte Qwen 2.5 7B, l’encodeur visuel Qwen2.5-VL et l’encodeur audio Whisper-large-v3, en utilisant une architecture innovante Thinker-Talker. Le modèle excelle dans plusieurs benchmarks, atteignant notamment le niveau SOTA (State-of-the-Art) dans les tâches audio-vers-texte, image-vers-texte et vidéo-vers-texte, bien qu’il soit légèrement moins performant dans les tâches de texte pur et de texte-vers-parole. La publication de Qwen2.5-Omni enrichit davantage le choix de modèles multimodaux open source haute performance (Source: DeepLearning.AI)
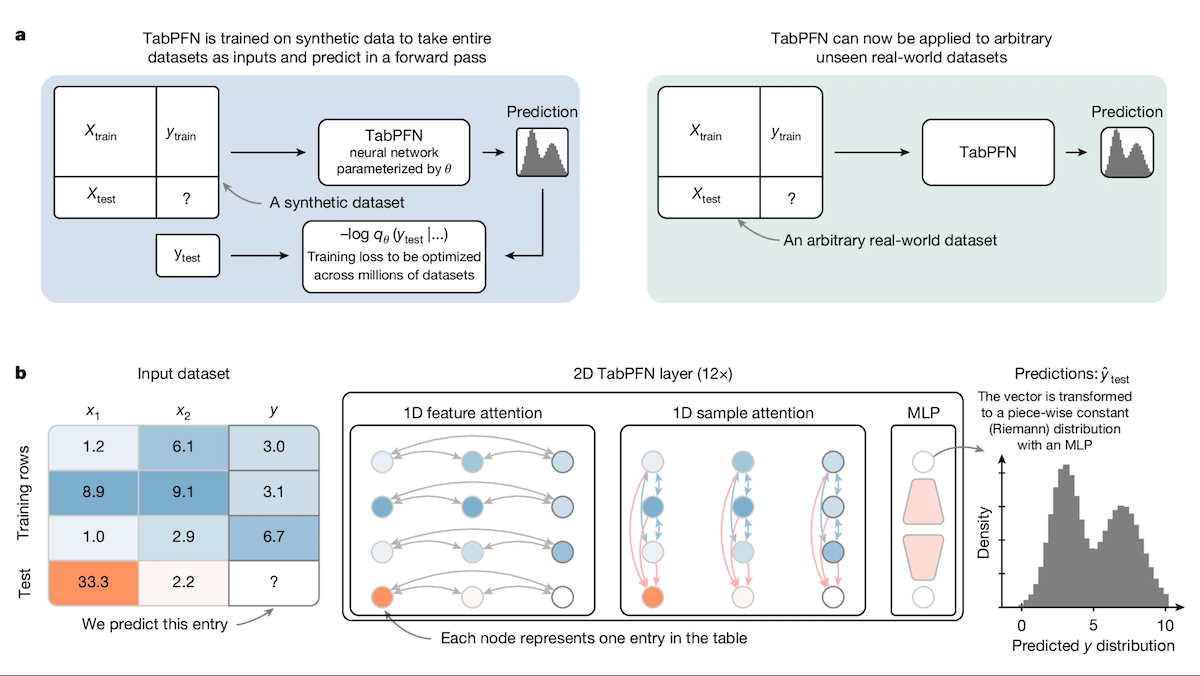
TabPFN : Un Transformer pour les données tabulaires surpassant les arbres de décision: Des chercheurs de l’Université de Fribourg et d’autres institutions ont lancé Tabular Prior-data Fitted Network (TabPFN), un modèle Transformer spécialement conçu pour les données tabulaires. Grâce à un pré-entraînement sur 100 millions de jeux de données synthétiques, TabPFN apprend à identifier des patterns inter-jeux de données, lui permettant d’effectuer directement des prédictions de classification et de régression sur de nouvelles données tabulaires sans entraînement supplémentaire. Les expériences montrent que sur les benchmarks AutoML et OpenML-CTR23, TabPFN surpasse les méthodes populaires d’arbres à gradient boosting comme CatBoost, LightGBM et XGBoost en classification (AUC) et en régression (RMSE), bien que sa vitesse d’inférence soit plus lente. Ce travail ouvre de nouvelles voies pour les Transformers dans le domaine du traitement des données tabulaires (Source: DeepLearning.AI)
La plateforme Intel devient une nouvelle option rentable pour les machines tout-en-un de grands modèles: Avec la popularisation des modèles open source comme DeepSeek, les machines tout-en-un pour grands modèles deviennent un choix populaire pour les entreprises souhaitant déployer rapidement l’IA. Intel propose une solution matérielle rentable via la combinaison de ses cartes graphiques de jeu Arc™ (comme l’A770) et de ses processeurs Xeon® W, ramenant le prix des machines tout-en-un de millions à des centaines de milliers de yuans. La plateforme supporte non seulement DeepSeek R1, mais est également compatible avec les modèles Qwen, Llama, etc. Plusieurs entreprises comme Feizhi Cloud, SuperCloud et Cloud-Tip ont déjà lancé des produits ou solutions de machines IA tout-en-un basés sur cette plateforme pour des scénarios tels que les questions-réponses sur base de connaissances, le service client intelligent, le conseil financier et le traitement de documents, répondant aux besoins d’inférence IA locale des PME et de départements spécifiques (Source: Quantumbit)
Google lance le TPU de septième génération « Ironwood »: Lors de la conférence Google Cloud Next, Google a annoncé son système TPU de septième génération, Ironwood, spécialement optimisé pour l’inférence IA. Par rapport au premier Cloud TPU, Ironwood offre une amélioration des performances de 3600 fois et une amélioration de l’efficacité énergétique de 29 fois. Comparé à Trillium de sixième génération, Ironwood améliore la performance par watt de 2 fois, dispose de 192 Go de mémoire par puce (6 fois plus que Trillium) et une vitesse d’accès aux données 4,5 fois plus rapide. Ironwood devrait être lancé plus tard cette année pour répondre à la demande croissante d’inférence IA (Source: X @demishassabis, X @JeffDean, Reddit r/LocalLLaMA)

Google DeepMind et les modèles Gemini supporteront le protocole MCP: Demis Hassabis, co-fondateur de Google DeepMind, et Oriol Vinyals, responsable des modèles Gemini, ont tous deux indiqué qu’ils supporteraient le protocole de contexte de modèle (MCP) et se réjouissent de collaborer avec l’équipe MCP et les partenaires de l’industrie pour développer ce protocole. MCP devient rapidement un standard ouvert pour l’ère des agents IA, visant à permettre à différents modèles de comprendre un « langage de service » unifié pour faciliter l’appel d’outils externes et d’API. Cette décision permettra aux modèles Gemini de mieux s’intégrer à l’écosystème MCP croissant pour construire des applications d’agents plus puissantes (Source: X @demishassabis, X @OriolVinyalsML)
Moonshot AI publie le modèle multimodal KimiVL A3B: Moonshot AI a publié les modèles KimiVL A3B Instruct & Thinking, une série de grands modèles multimodaux open source (licence MIT) avec une capacité de contexte long de 128K. La série comprend un MoE VLM et un MoE Reasoning VLM, avec seulement environ 3B paramètres activés. Ils surpasseraient GPT-4o sur les benchmarks visuels et mathématiques, atteignant 36,8% sur MathVision, 34,5% sur ScreenSpot-Pro, 867 points sur OCRBench, et montrant de bonnes performances dans les tests de contexte long (MMLongBench-Doc 35,1%, LongVideoBench 64,5%). Les poids du modèle ont été publiés sur Hugging Face (Source: X @huggingface)

Publication d’Orpheus TTS 3B : Modèle multilingue de clonage vocal zero-shot: La communauté open source a publié le modèle Orpheus TTS 3B, un modèle texte-vers-parole multilingue de 3 milliards de paramètres. Il supporte le clonage vocal zero-shot, une latence de génération en streaming d’environ 100 millisecondes, et permet de guider l’émotion et l’intonation pour générer une voix quasi humaine. Le modèle utilise la licence Apache 2.0, et ses poids sont disponibles sur Hugging Face, faisant progresser davantage la technologie TTS open source (Source: X @huggingface)
Publication d’OmniSVG : Modèle unifié de génération de graphiques vectoriels adaptatifs: Un nouveau modèle nommé OmniSVG a été proposé, visant à unifier la génération de graphiques vectoriels adaptatifs (SVG). Basé sur Qwen2.5-VL et intégrant un tokeniseur SVG, ce modèle peut accepter des entrées texte et image et générer le code SVG correspondant. Le site web du projet démontre ses puissants effets de génération SVG. L’article et le jeu de données sont publiés, mais les poids du modèle ne sont pas encore publics (Source: X @karminski3, Reddit r/LocalLLaMA)
Google Cloud Next 2025 se concentre sur l’IA: La conférence Google Cloud Next a mis en avant les progrès dans le domaine de l’IA. Lancement du TPU Ironwood de septième génération optimisé pour l’inférence ; annonce que Gemini 2.5 Pro est actuellement le modèle le plus intelligent et a atteint le sommet du Chatbot Arena ; combinaison des résultats de recherche de DeepMind, Google Research et Google Cloud pour offrir aux clients des modèles comme WeatherNext et AlphaFold ; autorisation pour les entreprises d’exécuter les modèles Gemini dans leurs propres centres de données ; et annonce d’un partenariat avec Nvidia pour apporter les modèles Gemini en déploiement local via Blackwell et le Confidential Computing (Source: X @GoogleDeepMind, X @GoogleDeepMind, Reddit r/artificial, X @nvidia)
Prévisions des tendances IA pour 2025: Synthétisant divers points de vue, les tendances clés de l’IA pour 2025 incluent : le développement continu et l’approfondissement des applications de l’IA générative, l’importance croissante de l’éthique de l’IA et de l’IA responsable, la popularisation de l’IA en périphérie (edge AI), l’accélération de l’adoption de l’IA dans des secteurs spécifiques (comme la santé, la finance, la chaîne d’approvisionnement), l’amélioration des capacités IA multimodales, l’autonomie et les défis des agents IA, la disruption des modèles commerciaux traditionnels par l’IA, et la demande croissante de talents IA et de diversité des compétences (Source: X @Ronald_vanLoon, X @Ronald_vanLoon, X @Ronald_vanLoon)

Les usines Tesla réalisent le transfert de véhicules par conduite autonome: Tesla a montré que ses voitures produites peuvent rouler de manière autonome depuis la sortie de la chaîne de production jusqu’à la zone de chargement dans l’enceinte de l’usine, sans intervention humaine. Cela démontre le potentiel d’application de la technologie de conduite autonome dans des environnements contrôlés (comme la logistique d’usine), et constitue un exemple des progrès de l’IA dans la fabrication automobile et l’automatisation (Source: X @Ronald_vanLoon)
🧰 Outils
Free-for-dev : Répertoire complet de ressources gratuites pour développeurs: Le projet ripienaar/free-for-dev sur GitHub est une liste de ressources populaire qui regroupe les niveaux gratuits utiles aux développeurs (en particulier DevOps et infrastructure) pour divers produits SaaS, PaaS et IaaS. La liste couvre de nombreuses catégories telles que les services cloud, les bases de données, les API, la surveillance, le CI/CD, l’hébergement de code, les outils IA, etc., et exige explicitement que les services offrent un niveau gratuit permanent plutôt qu’une période d’essai, tout en mettant l’accent sur la sécurité (par exemple, les services limitant TLS ne sont pas acceptés). Ce projet piloté par la communauté est constamment mis à jour et facilite grandement la recherche et la comparaison de services gratuits pour les développeurs (Source: GitHub: ripienaar/free-for-dev)

Graphiti : Framework pour construire des graphes de connaissances IA en temps réel: getzep/graphiti est un framework Python pour construire et interroger des graphes de connaissances dotés de capacités de perception temporelle, particulièrement adapté aux agents IA nécessitant de traiter des informations d’environnement dynamique. Il peut intégrer en continu les interactions utilisateur, les données structurées/non structurées, supporte les mises à jour incrémentielles et les requêtes historiques précises sans recalculer entièrement le graphe. Graphiti combine les plongements sémantiques, la recherche par mots-clés (BM25) et le parcours de graphe pour une recherche hybride efficace, et permet des définitions d’entités personnalisées. Ce framework est la technologie clé de la couche mémoire Zep, désormais open source (Source: GitHub: getzep/graphiti)

WeChatMsg : Outil d’extraction de l’historique de chat WeChat et d’entraînement d’assistant IA: LC044/WeChatMsg est un outil pour extraire l’historique de chat local de WeChat sous Windows (supporte WeChat 4.0) et l’exporter dans des formats tels que HTML, Word, Excel, etc. Il vise à aider les utilisateurs à sauvegarder définitivement leur historique de chat et peut analyser les enregistrements pour générer un rapport annuel. De plus, l’outil permet d’utiliser les données de chat de l’utilisateur pour entraîner un assistant de chat IA personnalisé, incarnant le concept « mes données, mes décisions ». Le projet fournit une interface utilisateur graphique et des instructions d’utilisation détaillées (Source: GitHub: LC044/WeChatMsg)
Alibaba Cloud Bailian lance un service MCP complet, créant une usine d’agents: La plateforme Alibaba Cloud Bailian a officiellement lancé la capacité complète de la plateforme pour le service de protocole de contexte de modèle (MCP), couvrant l’ensemble du cycle de vie : enregistrement de service, hébergement cloud, appel d’agent et combinaison de processus. Les développeurs peuvent utiliser directement les services MCP officiels ou tiers hébergés sur la plateforme, comme Amap (Gaode Maps) ou Notion, ou enregistrer leurs propres API en tant que services MCP via une configuration simple (sans gérer de serveur). L’objectif est d’abaisser le seuil de développement des agents, permettant aux développeurs de construire et déployer rapidement des agents IA capables d’appeler des outils externes, favorisant ainsi l’application des grands modèles dans des scénarios réels. Ce service est considéré comme une étape importante dans la commercialisation de l’IA par Alibaba (Source: WeChat Public Account – AINLPer, Quantumbit)
Hugging Face et Cloudflare s’associent pour fournir une infrastructure WebRTC gratuite: Hugging Face s’associe à Cloudflare pour fournir aux développeurs IA une infrastructure WebRTC de niveau entreprise à l’échelle mondiale via FastRTC. Les développeurs peuvent utiliser un Hugging Face Token pour transférer gratuitement 10 Go de données afin de construire des applications IA vocales et vidéo en temps réel. Une démonstration officielle de chat vocal Llama 4 est fournie en exemple, montrant la commodité apportée par cette collaboration (Source: X @huggingface)
Google AI Studio bénéficie d’une mise à jour majeure de son interface utilisateur: L’interface utilisateur de Google AI Studio (anciennement MakerSuite) a subi la première phase de sa refonte, offrant une apparence et une expérience plus modernes. Cette mise à jour vise à jeter les bases de nouvelles fonctionnalités de la plateforme développeur qui seront lancées dans les mois à venir. La nouvelle interface utilisateur est plus cohérente avec le style des applications Gemini et ajoute un back-office développeur dédié pour la gestion des API et des paiements. Cette mise à jour laisse présager une extension des fonctionnalités de la plateforme, incluant potentiellement l’accès à de nouveaux modèles (comme Veo 2) (Source: X @JeffDean, X @op7418)

LlamaIndex lance une fonction de référencement visuel: LlamaIndex a publié un nouveau tutoriel montrant comment utiliser la fonctionnalité d’agent de mise en page dans LlamaParse pour réaliser le référencement visuel des réponses de l’agent. Cela signifie que les réponses générées peuvent non seulement remonter à la source textuelle, mais aussi être directement mappées aux régions visuelles correspondantes (localisées précisément par des boîtes englobantes) dans le document source (par exemple, un PDF). Cela améliore l’explicabilité et la capacité de traçabilité des réponses de l’agent, particulièrement utile pour traiter des documents contenant des éléments visuels comme des graphiques et des tableaux (Source: X @jerryjliu0)

LangGraph lance un constructeur d’interface graphique sans code: LangGraph propose désormais un constructeur d’interface graphique (GUI) sans code pour concevoir l’architecture des agents. Les utilisateurs peuvent planifier le flux de travail de l’agent et les connexions de nœuds par des opérations visuelles comme le glisser-déposer, puis générer le code Python ou TypeScript en un clic. Cela abaisse le seuil de construction d’applications d’agent complexes, facilitant le prototypage rapide et le développement (Source: X @LangChainAI)
Perplexity met à jour sa fonctionnalité de graphiques boursiers: Perplexity a mis à jour sa fonctionnalité de graphiques boursiers, qui reflète désormais en temps réel les variations de cours du jour, au lieu d’étirer l’axe temporel pour remplir tout le graphique. Cette amélioration, bien que basique, améliore l’instantanéité et l’utilité de la présentation des informations financières (Source: X @AravSrinivas, X @AravSrinivas)

OLMoTrace : Un outil pour connecter les sorties LLM aux données d’entraînement: L’Allen Institute for AI (AI2) a lancé l’outil OLMoTrace, capable de mapper en temps réel les sorties du modèle OLMo à leurs sources de données d’entraînement correspondantes (avec une correspondance en quelques secondes parmi 4T de tokens de données). Cela aide à comprendre le comportement du modèle, à améliorer la transparence et à améliorer les données post-entraînement. L’outil vise à aider les chercheurs et les développeurs à mieux comprendre les mécanismes internes et les sources de connaissances des grands modèles de langage (Source: X @natolambert)
llama.cpp fusionne le support pour les modèles Qwen3: Le populaire framework d’inférence LLM local llama.cpp a fusionné le support pour la prochaine série de modèles Qwen3, y compris les modèles de base et les versions MoE. Cela signifie qu’une fois les modèles Qwen3 publiés, les utilisateurs pourront immédiatement utiliser les modèles quantifiés au format GGUF dans l’écosystème llama.cpp, facilitant leur exécution sur des appareils locaux (Source: X @karminski3, Reddit r/LocalLLaMA)

Le framework KTransformers supporte les modèles Llama 4: Le framework d’inférence IA chinois KTransformers (connu pour supporter l’inférence hybride CPU+GPU, en particulier le déchargement de modèles MoE) a ajouté un support expérimental pour la série de modèles Meta Llama 4 dans sa branche de développement. Selon la documentation, l’exécution de Llama-4-Scout (109B) quantifié en Q4 nécessite environ 65 Go de RAM et 10 Go de VRAM, tandis que Llama-4-Maverick (402B) nécessite environ 270 Go de RAM et 12 Go de VRAM. Sur une configuration 4090 + double Xeon 4, la vitesse d’inférence par lot unique peut atteindre 32 tokens/s. Cela offre une possibilité d’exécuter de grands modèles MoE avec une VRAM limitée (Source: X @karminski3, Reddit r/LocalLLaMA)
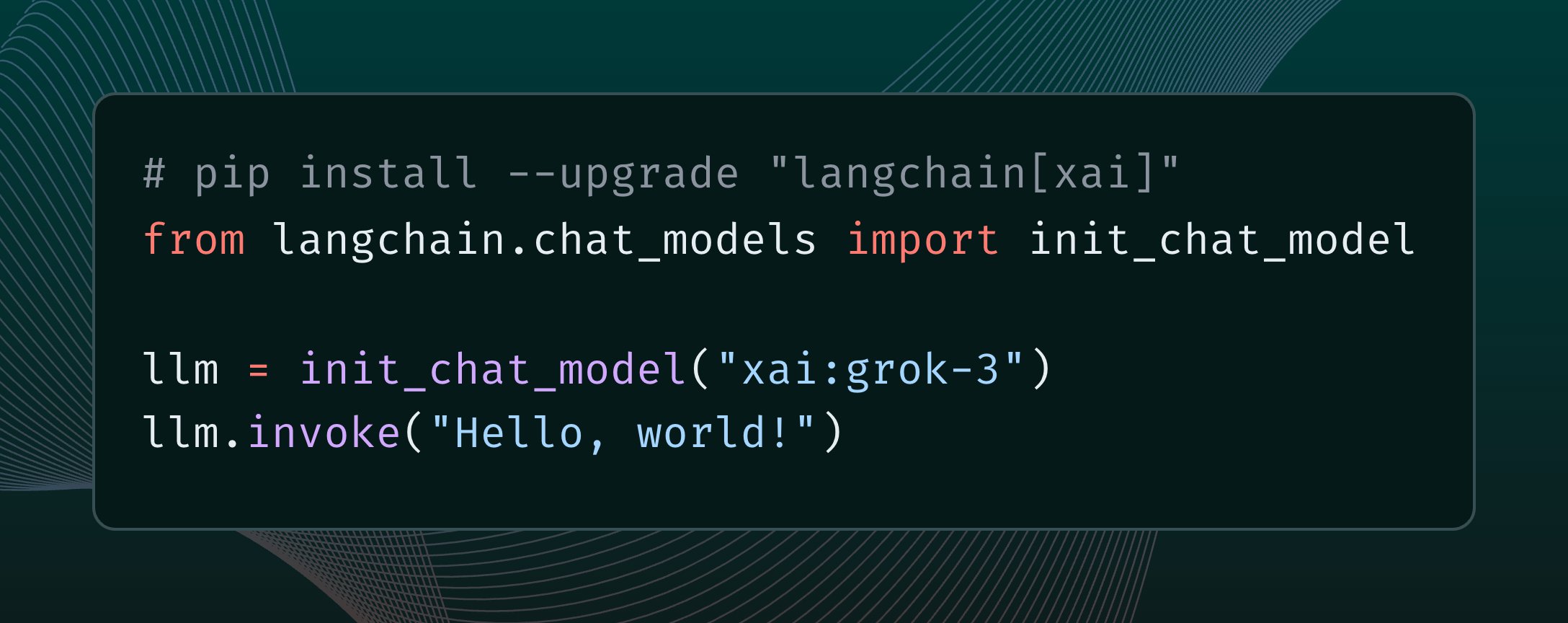
LangChain intègre le modèle Grok 3 de xAI: LangChain a annoncé l’intégration du dernier modèle Grok 3 publié par xAI. Les utilisateurs peuvent désormais appeler Grok 3 via le framework LangChain pour construire des applications exploitant ses puissantes capacités (Source: X @LangChainAI)
Tutoriel de déploiement gratuit du service cloud n8n: Présente comment déployer gratuitement la plateforme open source d’automatisation des flux de travail n8n en utilisant Hugging Face Spaces et Supabase, et obtenir un accès par nom de domaine public supportant HTTPS. Cela permet aux utilisateurs d’exploiter toutes les fonctionnalités de n8n (y compris les nœuds nécessitant une URL de rappel) sans avoir à acheter de serveur ni à configurer de nom de domaine et de certificat SSL. Cette méthode utilise la base de données gratuite de Supabase pour résoudre le problème de perte de données causé par la mise en veille de Hugging Face Space (Source: WeChat Public Account – 袋鼠帝AI客栈)
Mise à jour des plugins OpenWebUI : Compteur de contexte et mémoire adaptative: Des développeurs de la communauté ont publié/mis à jour deux plugins pour OpenWebUI : 1) Enhanced Context Counter v3, offrant un tableau de bord détaillé de l’utilisation des tokens, du suivi des coûts et des métriques de performance, supportant plusieurs modèles et un calibrage personnalisé. 2) Adaptive Memory v2, qui extrait, stocke et injecte dynamiquement via un LLM des informations spécifiques à l’utilisateur (faits, préférences, objectifs, etc.), réalisant une mémoire conversationnelle personnalisée, persistante et adaptative, fonctionnant entièrement localement sans dépendances externes (Source: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
QuickVoice MCP : Permettre à Claude de passer des appels: Un développeur de la communauté a créé un outil MCP (Model Context Protocol) nommé QuickVoice, qui permet aux modèles supportant MCP comme Claude 3.7 Sonnet de passer et de gérer de vrais appels téléphoniques. Les utilisateurs peuvent donner des instructions en langage naturel (par exemple, « Appelle le médecin pour prendre rendez-vous ») pour que l’IA accomplisse la tâche d’appel, y compris la navigation dans les menus SVI (IVR). Le projet est open source sur GitHub (Source: Reddit r/ClaudeAI)

RPG Dice Roller pour OpenWebUI: La communauté a développé un plugin d’outil de lancer de dés RPG pour OpenWebUI, facilitant l’obtention de résultats aléatoires authentiques lors de conversations de jeu de rôle (Source: Reddit r/OpenWebUI)
📚 Apprentissage
Cours de machine learning open source Girafe-ai: Le projet girafe-ai/ml-course sur GitHub fournit le matériel pédagogique du premier semestre du cours de machine learning de girafe-ai, couvrant Naive Bayes, kNN, régression/classification linéaire, SVM, PCA, arbres de décision, apprentissage d’ensemble, gradient boosting, ainsi qu’une introduction au deep learning. Il propose des enregistrements vidéo des cours, des diapositives PPT et des devoirs. C’est une ressource précieuse pour apprendre les bases du machine learning (Source: GitHub: girafe-ai/ml-course)
L’USTC et Huawei Noah’s Ark proposent le framework CMO pour optimiser la synthèse logique de puces: L’équipe du professeur Wang Jie de l’Université des sciences et technologies de Chine (USTC), en collaboration avec le Laboratoire Noah’s Ark de Huawei, a publié un article à l’ICLR 2025 proposant une méthode d’optimisation logique efficace basée sur l’extraction de fonctions neuro-symboliques, appelée CMO. Ce framework utilise un réseau neuronal graphique (GNN) pour guider une recherche arborescente Monte-Carlo (MCTS), générant des fonctions de score symboliques légères, interprétables et avec une forte capacité de généralisation, utilisées pour élaguer les transformations de nœuds invalides dans les opérateurs d’optimisation logique (comme Mfs2). Les expériences montrent que CMO peut améliorer l’efficacité d’exécution des opérateurs clés jusqu’à 2,5 fois tout en maintenant la qualité d’optimisation, et a été appliqué à l’outil de synthèse logique EMU développé par Huawei (Source: Quantumbit)
Le Shanghai AI Lab propose MaskGaussian, une nouvelle méthode d’élagage gaussien: L’équipe de recherche du Shanghai AI Lab a présenté la méthode MaskGaussian à CVPR 2025 pour optimiser le 3D Gaussian Splatting. Cette méthode, en intégrant une distribution de masque apprenable dans le processus de rastérisation, permet pour la première fois de préserver les gradients à la fois pour les points gaussiens utilisés et non utilisés. Cela permet d’élaguer un grand nombre de points gaussiens redondants tout en maintenant au maximum la qualité de reconstruction. Les expériences sur plusieurs jeux de données ont montré un élagage de plus de 60% des points gaussiens avec une perte de performance négligeable, tout en améliorant la vitesse d’entraînement et en réduisant l’occupation mémoire (Source: Quantumbit)
Analyse du rapport technique de Qwen2.5-Omni: Un utilisateur de Reddit partage des notes d’analyse détaillées du rapport technique de Qwen2.5-Omni d’Alibaba. Le rapport présente l’architecture Thinker-Talker du modèle, sa méthode de traitement des entrées multimodales (texte, image, audio, vidéo) – y compris l’encodage positionnel innovant TMRoPE pour l’alignement audio-vidéo -, son mécanisme de génération vocale en streaming, son processus d’entraînement (pré-entraînement + RL post-entraînement), etc. Ces notes offrent une référence précieuse pour comprendre les principes de fonctionnement internes de ce modèle multimodal de pointe (Source: Reddit r/LocalLLaMA)
McKinsey publie un guide opérationnel pour le déploiement à grande échelle de l’IA générative en entreprise: McKinsey a publié un guide opérationnel destiné aux leaders des données, explorant comment appliquer l’IA générative à grande échelle en entreprise. Le rapport couvre probablement l’élaboration de stratégies, le choix technologiques, la formation des talents, la gestion des risques, etc., fournissant des orientations aux entreprises pour la mise en œuvre et l’expansion de GenAI en pratique (Source: X @Ronald_vanLoon)

Guide d’initiation à l’apprentissage des agents IA: Khulood_Almani partage des ressources ou des étapes sur comment commencer à apprendre sur les agents IA, incluant potentiellement des parcours d’apprentissage, des concepts clés, des outils ou plateformes recommandés, offrant un guide aux apprenants souhaitant entrer dans le domaine des agents IA (Source: X @Ronald_vanLoon)

Étude sur les techniques de re-classement dans la reconnaissance visuelle de lieux: Un article sur arXiv explore si la technique de re-classement (Re-Ranking) est toujours efficace dans la tâche de reconnaissance visuelle de lieux (Visual Place Recognition, VPR). L’étude analyse potentiellement les avantages et inconvénients des méthodes de re-classement existantes et évalue leur rôle et leur nécessité dans les systèmes VPR modernes (Source: Reddit r/deeplearning, Reddit r/MachineLearning)
Le rapport de recherche « AI 2027 » explore les risques et l’avenir de l’ASI: Un rapport de recherche intitulé « AI 2027 » explore les scénarios possibles de développement de l’IA d’ici 2027, en particulier la possibilité que la R&D automatisée en IA mène à l’émergence d’une IA surhumaine (ASI). Le rapport analyse les risques potentiels posés par l’ASI, tels que la perte de contrôle humaine due au désalignement des objectifs, la concentration du pouvoir, l’intensification des risques de sécurité due à une course internationale aux armements, le vol de modèles et le retard de la perception publique, et explore les issues géopolitiques possibles telles que la guerre, un accord ou la soumission (Source: Reddit r/artificial)
Étude sur l’alignement des activations des réseaux neuronaux: Un article publié sur OpenReview explore les raisons de l’alignement représentationnel dans les réseaux neuronaux. L’étude révèle que l’alignement ne provient pas de neurones individuels, mais est lié au fonctionnement des fonctions d’activation, et propose la méthode Spotlight Resonance Method pour expliquer ce phénomène, en fournissant des résultats expérimentaux à l’appui (Source: Reddit r/deeplearning)
💼 Affaires
Alibaba International mise sur l’IA pour percer: Face à la concurrence féroce dans le secteur de l’e-commerce transfrontalier et aux changements dans le commerce mondial, Alibaba International Digital Commerce Group considère l’IA comme une stratégie clé et investit massivement pour rechercher la croissance et l’amélioration de l’efficacité. L’entreprise a lancé le plan mondial de formation des talents IA « Bravo 102 » et a désigné 80% des postes de recrutement sur les campus comme étant liés à l’IA. Les applications IA couvrent déjà le B2B (moteur de recherche IA Accio, agent IA « assistant commercial ») et le B2C (plateforme Aidge offrant essayage virtuel, service client IA, etc.). Bien que la croissance du chiffre d’affaires d’Alibaba International soit significative (hausse de 32% au T4 2024), les investissements ont entraîné une augmentation des pertes. L’IA est considérée comme le moteur clé permettant à Alibaba International de sortir de la concurrence par les prix bas, de réaliser une transformation vers une haute valeur ajoutée et d’affiner ses opérations (Source: 36Kr)
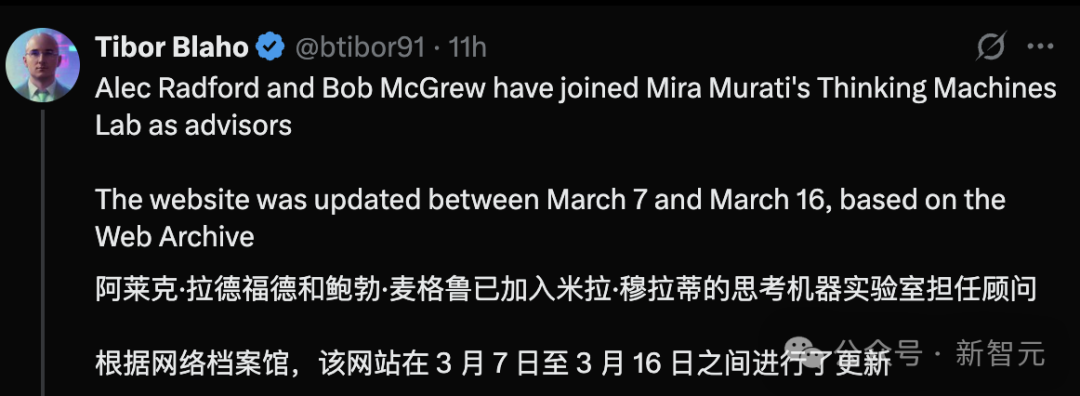
D’anciens membres clés d’OpenAI rejoignent la nouvelle entreprise de Mira Murati: Alec Radford, premier auteur fondateur de la série GPT, et Bob McGrew, ancien directeur de la recherche d’OpenAI, ont rejoint la nouvelle entreprise d’IA Thinking Machines Lab, fondée par l’ancienne CTO d’OpenAI Mira Murati, en tant que conseillers. Radford a joué un rôle clé dans la naissance des modèles de la série GPT, tandis que McGrew a été profondément impliqué dans le développement de GPT-3/4 et du modèle o1. L’équipe fondatrice de Thinking Machines Lab compte un grand nombre (au moins 19) d’anciens d’OpenAI. L’entreprise vise à populariser les applications IA et prévoirait de lever 1 milliard de dollars pour une valorisation de 9 milliards de dollars, ce qui témoigne des fortes attentes du marché envers les start-ups dirigées par des talents IA de premier plan (Source: Xinzhiyuan)
Les fonds communs de placement s’intéressent aux activités IA+Santé des entreprises pharmaceutiques: Récemment, plusieurs fonds communs de placement publics chinois ont mené des enquêtes intensives auprès d’entreprises pharmaceutiques cotées, l’application de l’IA dans le domaine médical étant un point central d’intérêt. Haier Biomedical a présenté ses applications IA dans son réseau sanguin IoT et son réseau de vaccins, ainsi que les progrès réalisés dans l’amélioration de l’efficacité des scénarios de santé publique (comme la prise de rendez-vous pour vaccin) grâce à l’IA. Hisun Pharmaceutical a indiqué avoir introduit le modèle DeepSeek-R1 et collaborer avec des entreprises de pharmatech IA, dans l’espoir d’utiliser l’IA pour habiliter l’ensemble du processus de R&D de nouveaux médicaments. Kangyuan Pharmaceutical a également déclaré construire une plateforme de découverte de médicaments innovants de médecine traditionnelle chinoise pilotée par IA + multi-omiques. Cela indique que l’application de la technologie IA dans la R&D pharmaceutique, les opérations et les services aux patients suscite une grande attention du marché des capitaux (Source: ChiNext Observation)
OpenAI lance le programme Pioneers pour approfondir la coopération sectorielle: OpenAI a lancé le programme Pioneers, visant à établir des partenariats avec des entreprises ambitieuses pour construire conjointement des produits IA avancés. Le programme se concentrera sur deux aspects : premièrement, le fine-tuning intensif des modèles pour qu’ils surpassent les modèles génériques dans des tâches à haute valeur dans des domaines spécifiques ; deuxièmement, la construction de meilleures évaluations du monde réel (evals) pour permettre à l’industrie de mieux mesurer la performance des modèles sur des tâches pertinentes pour le domaine. Cela indique qu’OpenAI cherche à appliquer plus profondément sa technologie à des secteurs spécifiques et à améliorer l’utilité pratique et les normes d’évaluation des modèles dans les secteurs verticaux par le biais de collaborations (Source: X @sama)
Nvidia et Google Cloud s’associent pour promouvoir le déploiement local de Gemini: Nvidia et Google Cloud ont annoncé un partenariat pour supporter l’exécution des modèles Google Gemini sur site (on-premise) en entreprise. La solution combinera la plateforme Nvidia Blackwell GPU et la technologie de Confidential Computing, visant à offrir aux entreprises des options de déploiement IA localisées, performantes et sécurisées. Cette initiative répond aux besoins de certaines entreprises en matière de confidentialité des données, de conformité en matière de sécurité et de performances spécifiques, leur permettant d’exécuter les puissants modèles Gemini sur leur propre infrastructure (Source: X @nvidia)
Google autorise les entreprises à exécuter les modèles Gemini dans leurs propres centres de données: Google Cloud a annoncé qu’il autoriserait les entreprises clientes à exécuter ses modèles IA Gemini dans leurs propres centres de données. Cette initiative vise à répondre aux besoins des entreprises en matière de souveraineté des données, de sécurité et de déploiement personnalisé, leur permettant d’exploiter les puissantes capacités de Gemini dans leur environnement local sans avoir à transférer de données sensibles vers le cloud. Cela offre aux entreprises une plus grande flexibilité et un meilleur contrôle, en particulier dans les secteurs strictement réglementés comme la finance et la santé (Source: Reddit r/artificial)
Le PDG de Nvidia, Jensen Huang, minimise l’impact des droits de douane, les serveurs IA pourraient être exemptés: Face à la nouvelle politique tarifaire américaine potentielle, le PDG de Nvidia, Jensen Huang, a déclaré que l’impact serait limité et a laissé entendre que la plupart des serveurs IA de Nvidia pourraient obtenir une exemption. Cela pourrait être dû à l’importance stratégique de ses produits ou à une classification commerciale spécifique. Cette nouvelle est un signal positif pour l’industrie de l’IA dépendante du matériel Nvidia, contribuant à atténuer les craintes d’une augmentation des coûts de la chaîne d’approvisionnement (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)
🌟 Communauté
Discussion animée sur Reddit : Quand le modèle Qwen3 sera-t-il publié ?: La communauté Reddit et les utilisateurs de la plateforme X (anciennement Twitter) discutent vivement de la date de sortie du modèle Qwen3 d’Alibaba. Bien qu’un utilisateur ait partagé l’affiche du sommet IA d’Alibaba et spéculé sur une sortie imminente, il a été confirmé par la suite que ce sommet n’avait pas annoncé Qwen3. Parallèlement, la nouvelle de la fusion du support Qwen3 dans llama.cpp a intensifié l’attente de la communauté. Cela reflète la grande attention et l’attente de la communauté open source concernant les progrès des grands modèles chinois (Source: X @karminski3, Reddit r/LocalLLaMA)

Lancement du concours de jeux de données d’inférence: Bespoke Labs, en collaboration avec Hugging Face et Together AI, a lancé un concours de jeux de données d’inférence. L’objectif est d’encourager la communauté à créer des jeux de données d’inférence plus diversifiés et plus proches de la complexité du monde réel, en particulier dans le raisonnement multi-domaines comme la finance et la médecine, afin de stimuler le développement de la prochaine génération de LLM. Les jeux de données existants (comme OpenThoughts-114k) ont déjà joué un rôle important dans l’entraînement des modèles, et le concours espère repousser davantage les limites des jeux de données (Source: X @huggingface)

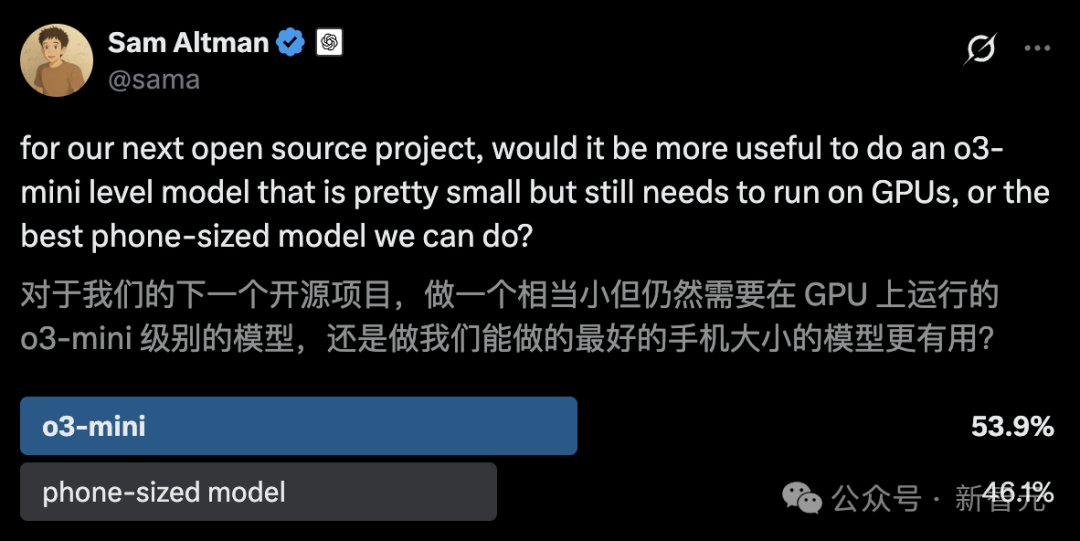
Mise à jour du benchmark de programmation LiveCodeBench, o3-mini en tête: Le classement des capacités de programmation LiveCodeBench a été mis à jour après 8 mois, avec o3-mini (high) et o3-mini (medium) d’OpenAI aux première et deuxième places, suivis de Google Gemini 2.5 Pro en troisième position. Ce classement a suscité des discussions dans la communauté, certains utilisateurs exprimant des doutes sur le classement relativement bas de Claude 3.5/3.7, estimant qu’il ne correspond pas à leur expérience utilisateur réelle, ce qui reflète les différences possibles entre les différents benchmarks et la perception subjective des utilisateurs (Source: Reddit r/LocalLLaMA)

Discussion communautaire sur Claude Code : Puissant mais cher et bogué: Les utilisateurs de Reddit discutent de Claude Code d’Anthropic, le considérant généralement comme ayant une forte capacité de perception du contexte et de bons résultats en codage, donnant même l’impression de « venir du futur ». Cependant, ses inconvénients sont son prix élevé (un utilisateur mentionne un coût journalier allant jusqu’à 30 $) et quelques bugs (comme la perte du fichier claude.md après la session, des erreurs de syntaxe en sortie, etc.). Les utilisateurs attendent avec impatience des alternatives futures plus performantes et moins chères (Source: Reddit r/ClaudeAI)
Un utilisateur partage des modèles quantifiés de Mistral-Small-3.1-24B: Un utilisateur de la communauté Ollama partage les versions quantifiées Q5_K_M et Q6_K (format GGUF) du modèle Mistral-Small-3.1-24B, comblant le manque du dépôt officiel qui ne fournissait que Q4 et Q8. Ces modèles quantifiés ont été créés à l’aide du client Ollama, supportent la fonctionnalité visuelle et fournissent une référence de longueur de contexte sur une RTX 4090 (Source: Reddit r/LocalLLaMA)

La communauté recherche des outils IA d’upscaling vidéo: Un utilisateur de Reddit demande s’il existe des outils IA capables d’améliorer une vidéo basse résolution de 240p en 1080p/60fps, dans l’espoir de restaurer de vieux clips musicaux. Les commentaires mentionnent des outils comme Ai4Video et Cutout.Pro, mais certains estiment que l’amélioration depuis une très basse résolution a des effets limités, s’apparentant peut-être plus à une régénération qu’à une restauration (Source: Reddit r/artificial)
Un utilisateur soupçonne une mise à jour discrète de Claude 3.5 Sonnet: Un développeur utilisateur de Reddit soupçonne, sur la base de son expérience utilisateur (par exemple, le modèle commence à utiliser des emojis, changement de style de réponse), qu’Anthropic a remplacé la version originale du modèle Claude 3.5 Sonnet par une version optimisée ou distillée sans en informer les utilisateurs, entraînant un changement de performance ou de comportement. Cet utilisateur estime que la version originale 3.5 était supérieure à la 3.7 en matière de codage, mais que son expérience récente s’est dégradée. Cela a suscité une discussion communautaire sur la transparence et la cohérence des versions de modèle (Source: Reddit r/ClaudeAI)
Le rapport d’Anthropic suscite une discussion sur la triche étudiante avec l’IA: Anthropic a publié un rapport sur l’éducation qui, en analysant des millions de conversations étudiantes anonymes, suggère que les étudiants pourraient utiliser Claude pour commettre une inconduite académique. Ce rapport a suscité une discussion communautaire, avec des points de vue variés : la triche étudiante a toujours existé, l’IA n’est qu’un nouvel outil ; le système éducatif doit s’adapter à l’ère de l’IA, les méthodes d’évaluation devraient changer ; certains utilisateurs expriment des préoccupations concernant la confidentialité de l’analyse des données de conversation des utilisateurs par Anthropic (Source: Reddit r/ClaudeAI)

Discussion communautaire sur les méthodes de surveillance des applications LLM/Agent: Un utilisateur de la communauté Machine Learning de Reddit lance une discussion pour demander comment les autres surveillent les performances et les coûts de leurs applications LLM ou agents IA, par exemple en suivant l’utilisation des tokens, la latence, le taux d’erreur, les changements de version de prompt, etc. La discussion vise à comprendre les méthodes pratiques et les points douloureux de la communauté en matière de LLMOps, qu’il s’agisse de solutions maison ou de l’utilisation d’outils spécifiques (Source: Reddit r/MachineLearning)
💡 Divers
Andrew Ng commente l’impact de la politique tarifaire américaine sur l’IA: Dans sa newsletter The Batch, Andrew Ng exprime ses inquiétudes concernant la nouvelle politique tarifaire américaine, estimant qu’elle nuit non seulement aux relations avec les alliés et à l’économie mondiale, mais qu’elle entrave également indirectement le développement et l’adoption de l’IA aux États-Unis en restreignant les importations de matériel (comme les serveurs, le refroidissement, les équipements réseau, les composants d’installations électriques) et en augmentant les prix de l’électronique grand public. Il souligne que, bien que les droits de douane puissent légèrement stimuler la demande de robots et d’automatisation, ce n’est pas un moyen efficace de résoudre les problèmes de fabrication, et que les progrès de l’IA dans la robotique sont relativement lents. Il appelle la communauté IA à renforcer la coopération internationale et l’échange d’idées (Source: DeepLearning.AI)

Percées et pièges de l’IA dans le secteur des télécommunications: L’article explore le potentiel d’application de l’intelligence artificielle dans l’industrie des télécommunications, comme l’optimisation du réseau, le service client, la maintenance prédictive, etc., tout en soulignant les défis et pièges potentiels, tels que la confidentialité des données, les biais algorithmiques, la complexité d’intégration et l’impact sur les flux de travail existants (Source: X @Ronald_vanLoon)
La diversité des compétences est cruciale pour le retour sur investissement de l’IA: Antonio Grasso souligne que pour réaliser avec succès le retour sur investissement (ROI) des projets d’intelligence artificielle, les équipes doivent posséder un ensemble de compétences diversifié, pouvant inclure la science des données, l’ingénierie, la connaissance du domaine, l’éthique, l’analyse commerciale, etc. (Source: X @Ronald_vanLoon)

Les chaînes d’approvisionnement pilotées par l’IA mènent au développement durable: L’article de Nicochan33 souligne que l’utilisation de l’IA pour optimiser la gestion de la chaîne d’approvisionnement (comme la planification d’itinéraires, la gestion des stocks, la prévision de la demande) peut non seulement améliorer l’efficacité, mais aussi promouvoir les objectifs de développement durable en réduisant le gaspillage, en diminuant la consommation d’énergie, etc. (Source: X @Ronald_vanLoon)

Autonomie, garde-fous et pièges des agents IA: L’article de VentureBeat explore les questions clés du développement des agents IA, notamment comment équilibrer leur capacité autonome, concevoir des mesures de sécurité efficaces pour prévenir les abus ou les conséquences imprévues, et les pièges potentiels rencontrés lors du déploiement et de l’utilisation (Source: X @Ronald_vanLoon)

L’IA considérée comme la plus grande menace pour les entreprises « ennuyeuses »: L’article de Forbes estime que l’intelligence artificielle constitue la plus grande menace disruptive pour les entreprises traditionnellement considérées comme « ennuyeuses » ou procédurales, car ces activités contiennent souvent un grand nombre de tâches pouvant être automatisées ou optimisées par l’IA (Source: X @Ronald_vanLoon)

Problème de biais dans les algorithmes médicaux et nouvelles directives: L’article de Fortune se penche sur le problème de longue date des biais dans l’IA appliquée au domaine médical et explore si de nouvelles directives peuvent faire avancer la résolution de ce problème, afin de garantir l’équité et la précision des applications médicales de l’IA (Source: X @Ronald_vanLoon)

Rôle de l’IA dans l’amélioration des compétences de la main-d’œuvre et la reconnaissance des maladies: L’article de Forbes explore le rôle positif de l’IA dans deux domaines : premièrement, aider à améliorer les compétences de la main-d’œuvre existante pour s’adapter aux besoins futurs du travail, et deuxièmement, fournir un soutien dans la reconnaissance et le diagnostic précoces des maladies (Source: X @Ronald_vanLoon)

Les agents numériques IA redéfiniront le travail: L’article de VentureBeat discute de la manière dont les agents IA (agents numériques) s’intègrent sur le lieu de travail, non seulement comme des outils, mais potentiellement en changeant la définition même du travail, les processus et les modes de collaboration homme-machine (Source: X @Ronald_vanLoon)

Le dilemme de l’invisibilité, de l’autonomie et de la vulnérabilité des agents IA: L’article de VentureBeat explore en profondeur le nouveau dilemme posé par les agents IA : leur fonctionnement peut être « invisible » pour l’utilisateur, ils possèdent une grande autonomie, et en même temps, ils peuvent être exploités ou attaqués de manière malveillante, ce qui pose de nouveaux défis en matière de sécurité et d’éthique (Source: X @Ronald_vanLoon)

Trump menace TSMC de droits de douane de 100%: L’ancien président américain Trump a déclaré avoir informé TSMC qu’il imposerait des droits de douane de 100% sur ses produits si l’entreprise ne construisait pas d’usines aux États-Unis. Cette déclaration reflète l’impact continu de la géopolitique sur la chaîne d’approvisionnement des semi-conducteurs et pourrait présenter un risque potentiel pour l’approvisionnement en matériel IA dépendant des puces de TSMC (Source: Reddit r/ArtificialInteligence, Reddit r/artificial)

Google Gemini 2.5 Pro accusé de manquer d’un rapport de sécurité clé: Fortune rapporte que le dernier modèle Gemini 2.5 Pro de Google manque d’un rapport de sécurité clé (Model Card), ce qui pourrait violer les engagements de sécurité IA pris précédemment par Google envers le gouvernement américain et lors de sommets internationaux. Cette affaire attire l’attention sur la transparence des grandes entreprises technologiques dans la publication des modèles et le respect de leurs engagements en matière de sécurité (Source: Reddit r/artificial)

Utilisation de l’IA pour la reconnaissance des plaques d’immatriculation: L’article de Rackenzik présente la technologie de détection et de reconnaissance des plaques d’immatriculation basée sur le deep learning, explorant les défis associés, tels que le flou d’image, les différences de style de plaques entre pays/régions et les difficultés de reconnaissance dans diverses conditions réelles (Source: Reddit r/deeplearning)
