
Mots-clés:AI, LLM, rapport AI Index 2025, Meta Llama 4 controverse, Gemini Deep Research, NVIDIA Llama 3.1 Nemotron, OpenEvidence AI médical
🔥 Pleins feux
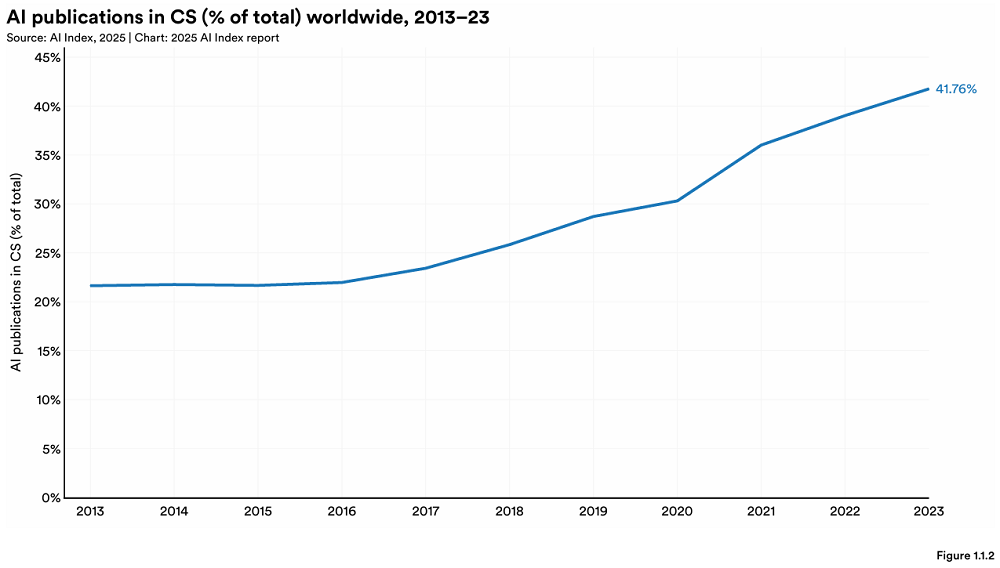
Stanford publie son rapport annuel AI Index, révélant de nouveaux changements dans le paysage mondial de l’IA: Stanford University HAI publie le rapport « AI Index Report 2025 » de 456 pages. Le rapport montre que les États-Unis restent en tête pour la production de modèles d’IA de pointe, mais la Chine réduit rapidement l’écart de performance (par exemple, l’écart sur MMLU et HumanEval a presque disparu). L’industrie domine le développement de modèles importants (représentant 90%), mais le nombre de modèles a diminué. Le coût du matériel d’IA diminue de 30% par an, et les performances doublent tous les 1,9 ans. L’investissement mondial dans l’IA atteint 252,3 milliards de dollars, les États-Unis étant largement en tête avec 109,1 milliards de dollars (environ 12 fois les 9,3 milliards de dollars de la Chine), et l’investissement dans l’IA générative atteint 33,9 milliards de dollars. Le taux d’adoption de l’IA par les entreprises atteint 78%, la Chine enregistrant la croissance la plus rapide (atteignant 75%). L’IA commence à réduire les coûts et à améliorer l’efficacité des entreprises. L’IA réalise des percées dans le domaine scientifique, remportant deux prix Nobel et surpassant les humains dans le séquençage des protéines et le diagnostic clinique. L’optimisme mondial à l’égard de l’IA augmente, mais avec des différences régionales significatives, la Chine étant la plus optimiste. L’écosystème de l’IA responsable (RAI) mûrit progressivement, mais l’évaluation et la pratique restent inégales. (Source: 36氪, AI科技评论, dotey, 36kr)
La sortie de Meta Llama 4 suscite une vive controverse, accusé de « manipulation de classement » et de performances médiocres: La série de grands modèles open source Llama 4 (Scout, Maverick, Behemoth) récemment publiée par Meta a vu sa réputation chuter dans les 72 heures suivant sa sortie. Sa version Maverick s’est rapidement hissée à la deuxième place sur Chatbot Arena, mais il a été révélé qu’il s’agissait d’une « version expérimentale » non publiée et optimisée pour la conversation, soulevant des accusations de « manipulation de classement ». Bien que Meta ait nié l’entraînement sur l’ensemble de test, l’entreprise a reconnu des problèmes de performance. Les retours de la communauté indiquent que Llama 4 ne répond pas aux attentes en matière de codage, de compréhension de contexte long, etc., et serait même inférieur à des modèles avec moins de paramètres (comme DeepSeek V3). Des experts en IA comme Gary Marcus commentent que le « Scaling est mort », estimant que l’augmentation simple de la taille du modèle ne peut pas apporter une capacité de raisonnement fiable, et s’inquiètent que les progrès mondiaux de l’IA puissent stagner en raison de facteurs financiers, géopolitiques, etc. LMArena a publié les données d’évaluation pertinentes pour examen et a mis à jour sa stratégie de classement pour éviter toute confusion. (Source: 36kr, 雷科技, AIatMeta, karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

🎯 Tendances
Mise à niveau de la fonctionnalité Gemini Deep Research, adopte le modèle Gemini 2.5 Pro: La fonctionnalité Deep Research de l’application Google Gemini est désormais alimentée par le modèle Gemini 2.5 Pro. Les premiers tests utilisateurs indiquent des performances supérieures à celles des produits concurrents. Cette mise à niveau vise à améliorer les capacités de recherche et de synthèse d’informations, la pertinence des rapports et les capacités d’analyse et de raisonnement. Les utilisateurs de Gemini Advanced peuvent expérimenter cette mise à jour. Plusieurs utilisateurs et le PDG de Google DeepMind, Demis Hassabis, ont partagé des expériences positives d’utilisation de la nouvelle version de Deep Research pour des tâches complexes (comme l’analyse de marché), la qualifiant de rapide et complète. (Source: JeffDean, dotey, JeffDean, demishassabis)

Nvidia publie le modèle Llama 3.1 Nemotron Ultra 253B: Nvidia a publié le modèle Llama 3.1 Nemotron Ultra 253B sur Hugging Face. Ce modèle est un modèle dense (non-MoE) avec une fonctionnalité d’activation/désactivation de l’inférence. Il a été modifié à partir du modèle Llama-405B de Meta via la technique de pruning NAS et a subi un post-entraînement axé sur l’inférence (SFT + RL en FP8). Les benchmarks montrent des performances supérieures à DeepSeek R1, mais certains commentaires soulignent que la comparaison directe avec le modèle MoE DeepSeek R1 (moins de paramètres actifs) pourrait ne pas être totalement équitable. Nvidia a également publié le jeu de données de post-entraînement correspondant sur Hugging Face. (Source: huggingface, Reddit r/LocalLLaMA, dylan522p, huggingface)

L’IA + fabrication devient un nouveau point focal, opportunités et défis coexistent: L’IA pénètre de plus en plus l’industrie manufacturière chinoise, avec des applications couvrant l’automatisation de la production (par exemple, la production de matériaux dentaires par Yucheng), l’intelligence des produits (par exemple, les lunettes d’aide au sommeil IA de Binghan Technology), l’optimisation des processus (par exemple, les comptes rendus de réunion IA de Zhongke Lingchuang) et la R&D et le diagnostic (par exemple, la plateforme de diagnostic cardiovasculaire de Ruixin Intelligent, la prévision de la demande de pièces détachées et la détection des pannes de Bihucar). Des institutions financières comme WeBank utilisent également la technologie IA (par exemple, la génération de rapports de due diligence intelligents) pour servir les entreprises manufacturières innovantes. Cependant, l' »IA + fabrication » est toujours confrontée à des défis tels que la faible qualité des données et la faible base de numérisation des entreprises. Les investisseurs conseillent aux entreprises d’utiliser l’IA au service de leur activité principale, plutôt que comme un simple gadget, et d’investir à long terme pour résoudre les problèmes de données et de mise en œuvre. (Source: 36氪)
DeepSeek R1 établit un record de vitesse d’inférence sur Nvidia B200: La startup IA Avian.io a annoncé qu’en collaboration avec Nvidia, elle a atteint une vitesse d’inférence de 303 tokens/seconde pour le modèle DeepSeek R1 sur la dernière plateforme GPU Blackwell B200, établissant ainsi un record mondial. Avian.io a déclaré qu’elle fournirait dans les prochains jours des points d’extrémité d’inférence DeepSeek R1 dédiés basés sur B200 et a déjà ouvert les précommandes. Cette réalisation marque une nouvelle ère pour les modèles pilotés par le calcul au moment du test (test time compute driven models). (Source: Reddit r/LocalLLaMA)

OpenAI crée une équipe de déploiement stratégique pour favoriser l’application des modèles de pointe: OpenAI a créé une nouvelle équipe de déploiement stratégique (Strategic Deployment) visant à pousser les modèles de pointe (tels que GPT-4.5 et les modèles futurs) à des niveaux plus élevés de capacité, de fiabilité et d’alignement, et à les déployer dans des domaines du monde réel à fort impact afin d’accélérer la transformation de l’économie par l’IA et d’explorer la voie vers l’AGI. L’équipe recrute activement et fait de la promotion lors de conférences académiques telles que l’ICLR. (Source: sama)
L’IA fait face à des défis dans l’amélioration de l’expérience client (CX): L’article explore les difficultés et les défis rencontrés lors de l’utilisation de l’IA pour améliorer l’expérience client. Bien que l’IA offre un potentiel, une mise en œuvre efficace n’est pas simple et peut impliquer des problèmes liés à l’intégration des données, à la précision des modèles, à l’acceptation par les utilisateurs et aux coûts de maintenance. (Source: Ronald_vanLoon)

L’application de l’IA suscite innovation et inquiétudes sur le lieu de travail: L’article discute du double impact de l’application de l’IA sur le lieu de travail : d’une part, la stimulation du potentiel d’innovation, et d’autre part, les inquiétudes suscitées pour la main-d’œuvre existante, telles que la possibilité de remplacement des emplois, l’évolution des besoins en compétences, etc. (Source: Ronald_vanLoon)

L’Internet of Behavior (IoB) transforme la prise de décision commerciale: La technologie utilisant le machine learning et l’intelligence artificielle pour analyser les données comportementales des utilisateurs (Internet of Behavior) fournit aux entreprises des informations plus approfondies, transformant ainsi leur manière de prendre des décisions commerciales, pouvant concerner le marketing personnalisé, l’évaluation des risques, le développement de produits, etc. (Source: Ronald_vanLoon)

Le modèle multimodal RolmOCR se distingue dans le classement Hugging Face: Yifei Hu souligne que le modèle de langage visuel RolmOCR développé par son équipe obtient d’excellents résultats dans le classement Hugging Face, se classant troisième parmi les VLM et cinquième parmi tous les modèles. L’équipe prévoit de publier davantage de modèles, de jeux de données et d’algorithmes à l’avenir pour soutenir la recherche scientifique open source. (Source: huggingface)

Résumé des actualités IA (08/04/2025): Les actualités récentes liées à l’IA incluent : Meta Llama 4 accusé de comportement trompeur dans les benchmarks ; Apple pourrait transférer davantage de production d’iPhone en Inde pour éviter les tarifs douaniers ; IBM lance un nouveau mainframe pour l’ère de l’IA ; des rumeurs selon lesquelles Google paierait grassement certains employés IA pour les « mettre au placard » pendant un an afin de les retenir ; Microsoft aurait licencié les employés qui ont interrompu son événement Copilot pour protester ; Amazon affirme que son modèle vidéo IA peut désormais générer des séquences de plusieurs minutes. (Source: Reddit r/ArtificialInteligence)

🧰 Outils
FunASR : Toolkit open source de reconnaissance vocale de bout en bout fondamental publié par Alibaba DAMO Academy: FunASR est un toolkit qui intègre des fonctionnalités telles que la reconnaissance vocale (ASR), la détection d’activité vocale (VAD), la restauration de la ponctuation, le modèle linguistique, la reconnaissance de l’empreinte vocale, la séparation des locuteurs et la reconnaissance multi-locuteurs. Il prend en charge l’inférence et le fine-tuning de modèles pré-entraînés de niveau industriel (tels que Paraformer, SenseVoice, Whisper, Qwen-Audio, etc.) et fournit des scripts et des tutoriels pratiques. Les mises à jour récentes incluent la prise en charge de SenseVoiceSmall, Whisper-large-v3-turbo, des modèles de détection de mots-clés, des modèles de reconnaissance d’émotions, et la publication de services de transcription hors ligne/en temps réel optimisés en termes de mémoire et de performances (y compris une version GPU). (Source: modelscope/FunASR – GitHub Trending (all/daily))
LightRAG : Framework RAG concis et efficace: LightRAG est un framework RAG développé par le laboratoire DS de l’Université de Hong Kong (HKU), conçu pour simplifier et accélérer la construction d’applications RAG. Il intègre des capacités de construction et de récupération de graphes de connaissances (KG), prend en charge plusieurs modes de récupération (local, global, mixte, naïf, mode Mix), et peut se connecter de manière flexible à différents LLM (tels que OpenAI, Hugging Face, Ollama) et modèles d’Embedding. Le framework prend également en charge plusieurs backends de stockage (tels que NetworkX, Neo4j, PostgreSQL, Faiss) et plusieurs types de fichiers en entrée (PDF, DOC, PPT, CSV), et offre des fonctionnalités telles que l’édition d’entités/relations, l’exportation de données, la gestion du cache, le suivi des tokens, l’historique des conversations et les prompts personnalisés. Le projet fournit une interface utilisateur Web et des services API, ainsi qu’un outil de visualisation de graphes de connaissances. (Source: HKUDS/LightRAG – GitHub Trending (all/daily))
LangGraph aide Definely à construire un agent IA juridique: La société Definely a utilisé LangGraph pour construire un système multi-agents IA directement intégré dans Microsoft Word, afin d’aider les avocats à traiter des tâches juridiques complexes. Le système est capable de décomposer les tâches juridiques en sous-tâches, d’extraire des clauses en tenant compte du contexte, d’analyser les modifications et de rédiger des contrats, et d’intégrer les contributions et approbations des avocats via une boucle de collaboration homme-machine (Human-in-the-loop) pour guider les décisions clés. Cela démontre la capacité de LangGraph à construire des flux de travail d’agents complexes et contrôlables. (Source: LangChainAI)

LlamaParse lance un nouvel agent sensible à la mise en page: LlamaIndex a lancé une nouvelle fonctionnalité pour LlamaParse : l’agent de mise en page. Cet agent utilise des modèles VLM SOTA de différentes tailles, de Flash 2.0 à Sonnet 3.7, pour analyser dynamiquement les pages de documents en tenant compte de la mise en page. Il analyse d’abord la mise en page globale et décompose la page en blocs (tels que tableaux, graphiques, paragraphes), puis sélectionne différents modèles en fonction de la complexité du bloc (par exemple, utiliser un modèle plus puissant pour traiter les graphiques, un modèle plus petit pour le texte). Cette fonctionnalité est particulièrement importante pour les flux de travail d’agents nécessitant le traitement d’un grand contexte documentaire. (Source: jerryjliu0)

Auth0 lance des outils de sécurité pour les applications GenAI: Auth0 a lancé un nouveau produit « Auth for GenAI », conçu pour aider les développeurs à sécuriser facilement leurs applications et agents GenAI. Le produit offre des fonctionnalités telles que l’authentification des utilisateurs, l’appel d’API au nom de l’utilisateur, la confirmation asynchrone de l’utilisateur (CIBA) et l’autorisation RAG. Il fournit des SDK et de la documentation pour les frameworks GenAI populaires (tels que LangChain, LlamaIndex, Firebase Genkit, etc.), simplifiant l’intégration de l’authentification et de l’autorisation dans les applications IA. (Source: jerryjliu0, jerryjliu0)

Ollama ajoute le support du modèle de vision Mistral Small 3.1: L’outil d’exécution de grands modèles locaux Ollama prend désormais en charge le dernier modèle Mistral Small 3.1 de Mistral AI, y compris ses capacités de vision (multimodales). Les utilisateurs peuvent télécharger et exécuter des versions quantifiées telles que mistral-small3.1:24b-instruct-2503-q4_K_M via la bibliothèque Ollama. Les retours de la communauté indiquent que le modèle fonctionne bien pour des tâches comme l’OCR, mais certains utilisateurs signalent une vitesse d’inférence plus lente sur du matériel spécifique (comme l’AMD 7900xt). (Source: Reddit r/LocalLLaMA)

Unsloth publie des modèles quantifiés GGUF de Llama-4 Scout: Unsloth a publié en open source des versions quantifiées au format GGUF du modèle Llama-4 Scout 17B, facilitant leur exécution sur des CPU locaux ou des GPU à mémoire limitée. Celles-ci incluent une version de quantification dynamique de 2,71 bits, d’une taille de seulement 42,2 Go. Les utilisateurs peuvent consulter les fichiers de modèles pour différents niveaux de quantification (comme Q6_K) et leurs informations de compatibilité matérielle sur Hugging Face. (Source: karminski3)

OpenEvals de LangSmith prend en charge les schémas de sortie personnalisés: L’outil d’évaluation LLM OpenEvals de LangSmith permet désormais aux utilisateurs de personnaliser les schémas de sortie (output schemas) des évaluateurs LLM-as-judge. Bien que le schéma par défaut couvre de nombreux cas courants, cette mise à jour offre aux utilisateurs une flexibilité totale pour adapter la structure et le contenu des réponses du modèle à leurs besoins d’évaluation spécifiques. La fonctionnalité est disponible dans les versions Python et JS. (Source: LangChainAI)

Les modèles Qwen 3 supporteront bientôt llama.cpp: Un patch pour la prise en charge des modèles de la série Qwen 3 d’Alibaba dans llama.cpp a été soumis via une Pull Request, approuvé et est sur le point d’être fusionné. Cela signifie que les utilisateurs pourront bientôt exécuter les modèles Qwen 3 localement via le framework llama.cpp. Cette mise à jour a été soumise par bozheng-hit, qui avait précédemment contribué à la prise en charge de Qwen 3 pour la bibliothèque transformers. (Source: Reddit r/LocalLLaMA)

Lancement de Computer Use Agent Arena: L’équipe OSWorld a lancé Computer Use Agent Arena, une plateforme permettant de tester des agents d’utilisation d’ordinateur (Computer-Use Agents) dans des environnements réels sans configuration préalable. Les utilisateurs peuvent comparer les performances des meilleurs VLM tels que OpenAI Operator, Claude 3.7, Gemini 2.5 Pro, Qwen 2.5 VL sur plus de 100 applications et sites web réels. La plateforme offre une configuration en un clic et est annoncée comme sécurisée et gratuite. (Source: lmarena_ai)
Le service de distribution musicale Too Lost est favorable à la musique IA: Un utilisateur de Reddit partage son expérience de distribution de musique générée par IA (Suno, Udio, etc.) via Too Lost. Avantages : accepte explicitement la musique IA, approbation rapide (1-2 jours), prix abordable (35 $/an pour des publications illimitées), la musique ne disparaît pas à l’expiration de l’abonnement (mais le partage des revenus passe à 85/15), prise en charge des noms de label personnalisés. Inconvénients : distribution lente vers Instagram/Facebook (>16 jours), peut nécessiter une preuve de distribution antérieure. (Source: Reddit r/SunoAI)
📚 Apprentissage
NVIDIA lance CUDA Python: NVIDIA a lancé CUDA Python, visant à fournir un point d’entrée unifié depuis Python vers la plateforme CUDA. Il comprend plusieurs composants : cuda.core fournit un accès Pythonic au Runtime CUDA ; cuda.bindings fournit des liaisons de bas niveau aux API CUDA C ; cuda.cooperative fournit des primitives parallèles côté appareil de CCCL (pour Numba CUDA) ; cuda.parallel fournit des algorithmes parallèles côté hôte de CCCL (tri, scan, etc.) ; et numba.cuda pour compiler un sous-ensemble de Python en noyaux CUDA. Le package cuda-python lui-même se transformera en un méta-package contenant ces sous-packages versionnés indépendamment. (Source: NVIDIA/cuda-python – GitHub Trending (all/daily))
Hugging Face publie un grand jeu de données de codage avec raisonnement: Un grand jeu de données contenant 736 712 solutions de code Python générées par DeepSeek-R1 a été publié sur Hugging Face. Ce jeu de données contient les traces de raisonnement (reasoning traces) du code, peut être utilisé à des fins commerciales et non commerciales, et est l’un des plus grands jeux de données de codage avec raisonnement actuellement disponibles. (Source: huggingface)

Cinq défis majeurs et solutions pour la construction d’agents IA: L’article passe en revue les cinq principaux défis rencontrés lors de la construction d’agents IA : 1) Gestion du raisonnement et de la prise de décision (assurer la cohérence et la fiabilité) ; 2) Traitement des processus multi-étapes et du contexte (gestion de l’état, gestion des erreurs) ; 3) Gestion de l’intégration des outils (augmentation des points de défaillance, risques de sécurité) ; 4) Contrôle des hallucinations et garantie de l’exactitude ; 5) Gestion des performances à grande échelle (gestion de la haute concurrence, des délais d’attente, des goulots d’étranglement des ressources). Pour chaque défi, l’article propose des solutions spécifiques, telles que l’adoption de prompts structurés (ReAct), une gestion d’état robuste, une définition précise des outils, des systèmes de validation stricts (vérification des faits, citations), une révision humaine, une surveillance LLMOps, etc. (Source: AINLPer)
L’ancien scientifique en chef de Kaggle revient sur ULMFiT, peut-être le premier LLM: Jeremy Howard (fondateur de fast.ai, ancien scientifique en chef de Kaggle) a affirmé sur les réseaux sociaux que son ULMFiT de 2018 était le premier « modèle de langage universel », déclenchant un débat sur le « premier LLM ». ULMFiT utilisait un paradigme de pré-entraînement non supervisé et de fine-tuning, obtenant des résultats SOTA sur les tâches de classification de texte et inspirant GPT-1. Un article d’analyse estime que, selon les critères d’entraînement auto-supervisé, de prédiction du prochain token, d’adaptabilité à de nouvelles tâches et d’universalité, ULMFiT est plus proche de la définition moderne des LLM que CoVE ou ELMo, étant l’un des « ancêtres communs » des LLM modernes. (Source: 量子位)
Partage technique sur le fine-tuning léger de LLM du point de vue des développeurs: Destiné aux développeurs qui ne sont pas des ingénieurs ML spécialisés, ce partage d’expérience porte sur l’utilisation de méthodes de fine-tuning efficaces en termes de paramètres (PEFT) comme LoRA, QLoRA pour améliorer la qualité de sortie des LLM. Il souligne que ces méthodes sont plus adaptées à l’intégration dans les flux de développement réguliers, évitant la complexité du fine-tuning complet. L’équipe associée organisera un webinaire gratuit pour discuter des points douloureux rencontrés par les développeurs dans la pratique. (Source: Reddit r/artificial, Reddit r/MachineLearning)
Un article propose de repenser la réflexion dans le pré-entraînement: Une recherche d’Essential AI (dirigée par Ashish Vaswani, l’un des auteurs de Transformer) a révélé que les LLM démontrent déjà des capacités de raisonnement générales inter-tâches et inter-domaines pendant la phase de pré-entraînement. L’article propose qu’un simple token « wait » puisse servir de « déclencheur de réflexion », améliorant considérablement les performances de raisonnement du modèle. Cette recherche suggère que, par rapport aux méthodes de post-entraînement dépendant de modèles de récompense fins (comme RLHF), exploiter la capacité de réflexion intrinsèque du modèle pendant le pré-entraînement pourrait être une voie plus simple et plus fondamentale pour améliorer la capacité de raisonnement générale, et pourrait potentiellement surmonter les goulots d’étranglement des méthodes actuelles de fine-tuning spécifiques à une tâche. (Source: dotey)

Un article propose d’utiliser la perte RL pour la génération d’histoires sans modèle de récompense: Des chercheurs proposent un paradigme de récompense inspiré de RLVR, appelé VR-CLI, pour optimiser la génération de longues histoires (tâche de prédiction du chapitre suivant, environ 100 000 tokens) via une perte RL (comme la perplexité) en l’absence de modèle de récompense explicite. Les expériences montrent que cette méthode est corrélée au jugement humain sur la qualité du contenu généré. (Source: natolambert)

Un article propose la méthode P3 pour améliorer la robustesse de la classification Zero-Shot: Pour résoudre le problème de la sensibilité des modèles aux variations de prompt (prompt brittleness) dans la classification de texte Zero-Shot, les chercheurs proposent la méthode Placeholding Parallel Prediction (P3). Cette méthode simule un échantillonnage complet des chemins de génération en prédisant les probabilités des tokens à plusieurs positions, plutôt que de se fier uniquement à la probabilité du prochain token. Les expériences montrent que P3 améliore la précision et réduit l’écart type entre différents prompts jusqu’à 98%, améliorant la robustesse et maintenant même des performances comparables en l’absence de prompt. (Source: Reddit r/MachineLearning)
Un article propose une couche Test-Time Training pour améliorer la génération de longues vidéos: Pour résoudre les problèmes de cohérence dus à l’inefficacité du mécanisme d’auto-attention dans l’architecture Transformer lors de la génération de longues vidéos (par exemple, plus d’une minute), une recherche propose une nouvelle couche Test-Time Training (TTT). L’état caché de cette couche peut lui-même être un réseau neuronal, plus expressif qu’une couche traditionnelle, permettant ainsi de générer des vidéos longues avec une meilleure cohérence, naturalité et esthétique. (Source: dotey)
Publication du rapport technique SmolVLM, explorant des modèles multimodaux petits et efficaces: Le rapport technique présente la conception et les découvertes expérimentales de SmolVLM (paramètres 256M, 500M, 2.2B), visant à construire des modèles multimodaux petits et efficaces. Les principales conclusions incluent : l’augmentation de la longueur du contexte (2K->16K) améliore considérablement les performances (+60%) ; les petits LLM bénéficient davantage des petits SigLIP (80M) ; le brassage de pixels (Pixel shuffling) peut réduire considérablement la longueur de la séquence ; les tokens de position appris sont supérieurs aux tokens de texte bruts ; les prompts système et les tokens multimédias dédiés sont particulièrement importants pour les tâches vidéo ; trop de données CoT nuit aux performances des petits modèles ; l’entraînement sur des vidéos plus longues contribue à améliorer les performances des tâches image et vidéo. SmolVLM atteint le niveau SOTA dans ses contraintes matérielles et a été implémenté pour une inférence en temps réel sur iPhone 15 et dans le navigateur. (Source: huggingface)

Hugging Face publie le Reasoning Required Dataset: Ce jeu de données contient 5000 échantillons provenant de fineweb-edu, annotés selon la complexité du raisonnement (score de 0 à 4), pour déterminer si un texte est adapté à la génération d’un jeu de données de raisonnement. Le jeu de données vise à entraîner un classificateur ModernBERT pour pré-filtrer efficacement le contenu et étendre la portée des jeux de données de raisonnement au-delà des domaines des mathématiques et du codage. (Source: huggingface)
Le benchmark CoCoCo évalue la capacité des LLM à quantifier les conséquences: Upright Project a publié le rapport technique du benchmark CoCoCo, utilisé pour évaluer la cohérence des LLM dans la quantification des conséquences comportementales. Les tests ont révélé que Claude 3.7 Sonnet (avec un budget de réflexion de 2000 tokens) obtient les meilleurs résultats, mais présente un biais en soulignant les conséquences positives et en minimisant les conséquences négatives. Le rapport conclut que, malgré les progrès récents des LLM dans cette capacité, il reste encore beaucoup de chemin à parcourir. (Source: Reddit r/ArtificialInteligence)

Comparaison des moteurs d’inférence GenAI : TensorRT-LLM vs vLLM vs TGI vs LMDeploy: NLP Cloud partage une analyse comparative et les résultats de benchmarks de quatre moteurs d’inférence GenAI populaires. TensorRT-LLM est le plus rapide sur les GPU Nvidia mais complexe à configurer ; vLLM est open-source, flexible et a un débit élevé, mais une latence par requête légèrement inférieure ; Hugging Face TGI est facile à configurer et à scaler, bien intégré à l’écosystème HF ; LMDeploy (TurboMind) se distingue par sa vitesse de décodage et ses performances d’inférence 4 bits sur les GPU Nvidia, avec une faible latence, mais TurboMind a un support limité des modèles. (Source: Reddit r/MachineLearning)
Annonce de la nouvelle saison du podcast Google DeepMind: La nouvelle saison du podcast Google DeepMind sera lancée le 10 avril, animée par Hannah Fry. Le contenu couvrira comment la science pilotée par l’IA révolutionne la médecine, les technologies robotiques de pointe, les limites des données générées par l’homme, et d’autres sujets. (Source: GoogleDeepMind)
Vidéo de présentation de la plateforme LangGraph: LangChain a publié une vidéo de 4 minutes expliquant les fonctionnalités de la plateforme LangGraph, montrant comment utiliser ce produit de niveau entreprise pour développer, déployer et gérer des agents IA. (Source: LangChainAI, LangChainAI)

Implémentation Keras de First-Order Motion Transfer: Un développeur partage son implémentation en Keras du modèle de mouvement de premier ordre (First-Order Motion Model) de l’article de Siarohin et al. (NeurIPS 2019) pour l’animation d’images. En raison de l’absence dans Keras d’une fonctionnalité similaire à grid_sample de PyTorch, le développeur a construit un module personnalisé de déformation de champ de flux, prenant en charge le traitement par lots, les coordonnées normalisées et l’accélération GPU. Le projet comprend la détection de points clés, l’estimation de mouvement, le générateur et le processus d’entraînement GAN, et fournit un exemple de code et de la documentation. (Source: Reddit r/deeplearning)

Organigramme du traitement du langage naturel (NLP): L’image montre le processus de base du traitement du langage naturel, pouvant inclure les étapes de prétraitement du texte, d’extraction de caractéristiques, d’entraînement du modèle, d’évaluation, etc. (Source: Ronald_vanLoon)

Blog expliquant les principes mathématiques des GANs: Un développeur partage son article de blog sur Medium concernant les principes mathématiques derrière les réseaux antagonistes génératifs (GANs), en se concentrant sur l’explication de la dérivation et de la preuve de la fonction de valeur utilisée dans le jeu minimax des GANs. (Source: Reddit r/deeplearning)

Concepts d’introduction au clustering K-Means: Partage d’une introduction au concept de l’algorithme de clustering K-Means, comme vulgarisation pour les débutants en machine learning, expliquant cette méthode d’apprentissage non supervisé. (Source: Reddit r/deeplearning)

École d’été et conférence sur la science des données biomédicales: Budapest, en Hongrie, accueillera une école d’été et une conférence sur la science des données biomédicales du 28 juillet au 8 août 2025. L’école d’été propose une formation intensive sur la visualisation des données médicales, le machine learning, le deep learning, les réseaux biomédicaux, etc. La conférence présentera des recherches de pointe et invitera des experts, dont des lauréats du prix Nobel. (Source: Reddit r/MachineLearning)
Partage d’un dépôt personnel de modèles de Deep Learning: Un autodidacte partage son dépôt GitHub, documentant sa pratique de création de modèles de deep learning pour différents jeux de données (comme CIFAR-10, MNIST, yt-finance), incluant les scores, les graphiques de prédiction et la documentation, comme moyen d’apprentissage et d’entraînement personnel. (Source: Reddit r/deeplearning)

💼 Affaires
La licorne IA OpenEvidence bouleverse l’IA médicale avec une approche Internet: La société d’IA médicale OpenEvidence a levé 75 millions de dollars auprès de Sequoia, atteignant une valorisation de 1 milliard de dollars et devenant une nouvelle licorne. Contrairement au modèle B2B traditionnel, OpenEvidence adopte une stratégie similaire à celle de l’Internet grand public, offrant directement des services gratuits aux médecins (financés par la publicité), les aidant à rechercher avec précision des informations dans la vaste littérature médicale et à traiter des cas complexes. Le produit connaît une croissance rapide, et il est affirmé qu’un quart des médecins américains l’utilisent déjà. La clé de son succès réside dans la rigueur des sources de données (littérature évaluée par les pairs) et une architecture multi-modèles intégrée pour garantir l’exactitude des informations, tout en assurant la transparence grâce aux citations de sources, créant ainsi un modèle gagnant-gagnant pour les médecins et les revues médicales. (Source: 36氪)
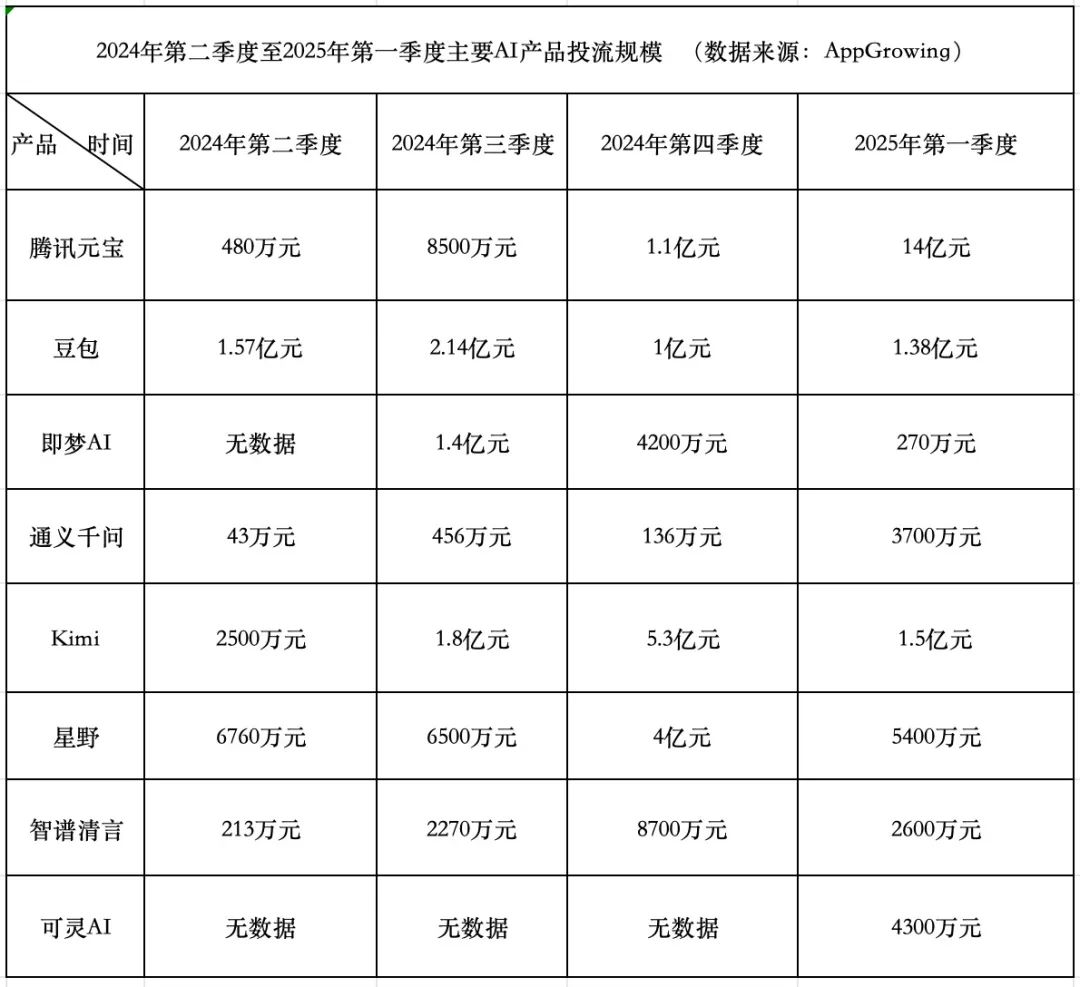
Course aux dépenses pour les produits IA : Tencent agressif, ByteDance conservateur, les startups reculent: Au premier trimestre 2025, les dépenses publicitaires pour les produits IA ont atteint 1,84 milliard de yuans. Tencent Yuanbao a dominé avec 1,4 milliard, sa publicité s’étendant même aux murs des villages. ByteDance Doubao a dépensé 138 millions de yuans, avec une stratégie relativement conservatrice. Kuaishou Keling AI a investi 43 millions de yuans. En comparaison, les startups vedettes Kimi et Xingye ont considérablement réduit leurs dépenses publicitaires (environ 200 millions au total, bien moins que les 930 millions du T4), et Zhipu Qingyan a également réduit ses investissements de manière significative. Les fondateurs de startups commencent à remettre en question le modèle de dépenses excessives, se concentrant davantage sur l’amélioration des capacités des modèles et les barrières technologiques. Tencent, grâce à son système publicitaire, est le bénéficiaire de cette guerre des dépenses publicitaires IA. Alibaba Tongyi Qianwen et Baidu Wenxin Yiyan sont relativement moins agressifs en matière de publicité, se concentrant davantage sur l’écosystème et l’open source. La tendance de l’industrie montre que la méthode consistant simplement à dépenser de l’argent pour gagner en échelle perd de son efficacité, et la concurrence des produits IA entre dans une nouvelle phase axée sur les capacités des modèles et la construction d’écosystèmes. (Source: 中国企业家杂志)
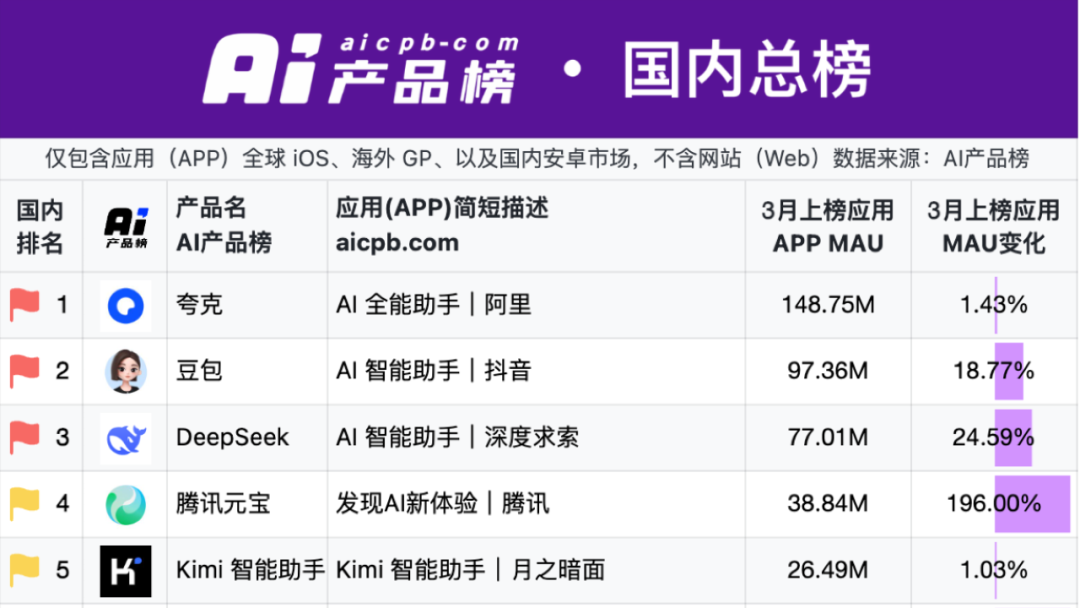
Quark et Baidu Wenku mènent la nouvelle bataille des applications IA : l’émergence du modèle « Super Box »: En 2025, le focus des applications IA passe du ChatBot à la « Super Box IA », c’est-à-dire une entrée unique intégrant la recherche IA, le dialogue et des outils (comme PPT, traduction, génération d’images). Quark d’Alibaba et Baidu Wenku sont les leaders de ce segment, en tête des données d’utilisateurs actifs mensuels. Les deux s’appuient sur une base « recherche + stockage cloud + documents », intégrant les capacités de l’IA pour tenter de répondre aux besoins des utilisateurs en matière de tâches centralisées et de conquérir le point d’entrée du trafic C-end. Les tests montrent que les deux surpassent la recherche traditionnelle pour la correspondance d’informations de base, mais qu’il y a encore une marge d’amélioration dans la profondeur et la satisfaction pour des tâches spécifiques (comme la planification d’itinéraires, la génération de PPT). Les grandes entreprises choisissent ces deux produits comme fers de lance de l’IA pour exploiter leur base d’utilisateurs et leurs données accumulées, explorer la forme optimale de l’IA To C et compléter leur propre écosystème IA. (Source: 定焦One)
Comment les entreprises peuvent-elles mettre en œuvre efficacement l’IA avec une expertise interne limitée ?: L’article explore comment les entreprises, en l’absence de connaissances approfondies internes en IA, peuvent introduire et mettre en œuvre efficacement et de manière réfléchie les technologies d’intelligence artificielle. Cela peut impliquer de recourir à des collaborations externes, de choisir les bonnes plateformes d’outils, de commencer par des projets pilotes à petite échelle, de mettre l’accent sur la formation des employés et de définir clairement les objectifs commerciaux. (Source: Ronald_vanLoon, Ronald_vanLoon)

La diversité des compétences est cruciale pour atteindre le ROI des investissements en IA: Les projets d’IA réussis nécessitent non seulement des experts techniques, mais aussi des talents possédant des compétences variées en compréhension métier, analyse de données, considérations éthiques, gestion de projet, etc. La diversité des compétences au sein de l’organisation est un facteur clé pour garantir que les projets d’IA peuvent être mis en œuvre efficacement, résoudre des problèmes réels et finalement générer de la valeur commerciale (ROI). (Source: Ronald_vanLoon)

Partage de stratégie de page de destination SEO pour produit IA: Gofei partage sa carte récapitulative de stratégie de page de destination SEO utilisée pour son produit IA (qui aurait généré 100 000 $ de revenus mensuels), soulignant l’efficacité de sa méthodologie. (Source: dotey)

🌟 Communauté
Le phénomène de triche aux entretiens avec l’IA attire l’attention, la prolifération des outils défie l’équité du recrutement: L’article révèle l’augmentation de l’utilisation d’outils IA pour tricher lors des entretiens vidéo à distance. Ces outils peuvent transcrire en temps réel les questions de l’intervieweur et générer des réponses que le candidat peut lire, et même aider lors des tests techniques. L’auteur a personnellement testé et constaté que ces outils présentent des délais notables, des erreurs de reconnaissance et des risques d’échec, offrant une mauvaise expérience et étant coûteux. Cependant, ce phénomène a alerté les RH et les intervieweurs, qui commencent à étudier des méthodes anti-triche. L’article explore l’impact de la triche par IA sur l’équité du recrutement et réfute l’argument selon lequel « pouvoir résoudre un problème avec l’IA est une compétence », soulignant que le cœur de l’entretien est l’évaluation des capacités et de la pensée réelles, et non la dépendance à des outils externes instables. (Source: 差评X.PIN)

Les universités pour seniors des comtés lancent des cours d’IA, popularisation et risques coexistent: Un reportage sur la tendance nationale (y compris dans les comtés) des universités pour seniors à proposer des cours d’IA. Le contenu des cours se concentre principalement sur la création de contenu IA (comme écrire des textes avec Doubao, générer des images/vidéos avec Jimeng/Keling, composer des poèmes/dessins avec DeepSeek) et les applications quotidiennes (interpréter les rapports d’examen médical, rechercher des recettes, prévenir la fraude). Les frais de scolarité sont généralement de 100 à 300 yuans par semestre, plus abordables que les coûteux cours d’IA commerciaux. Cependant, les personnes âgées sont confrontées à la fracture numérique lors de l’apprentissage (difficultés à télécharger des applications, opérations de base) et l’enseignement peut manquer d’avertissements suffisants sur les risques de l’IA, comme les hallucinations, en particulier dans des domaines critiques comme la santé. (Source: 刺猬公社)
John Carmack répond à l’impact des outils IA sur la valeur des compétences: En réponse aux craintes que les outils IA ne dévalorisent les compétences des programmeurs, artistes, etc., John Carmack estime que le progrès des outils a toujours été au cœur de l’informatique. Tout comme les moteurs de jeu ont élargi la participation au développement de jeux, les outils IA vont autonomiser les meilleurs créateurs, les petites équipes et attirer de nouvelles personnes. Bien qu’il soit possible à l’avenir de générer des jeux ou d’autres contenus par simple prompt, les œuvres exceptionnelles nécessiteront toujours des équipes professionnelles. Globalement, les outils IA augmenteront l’efficacité de la production de contenu de qualité. Il s’oppose au refus d’utiliser des outils avancés par crainte de perdre son emploi. (Source: dotey)
Série de critiques et réflexions sur l’IA: L’article, sous forme d’une série de phrases courtes et percutantes, critique et réfléchit sur les phénomènes courants dans le domaine actuel de l’IA, abordant la surmédiatisation de l’AGI, la prolifération des actualités IA, la bulle de financement, l’écart entre les capacités des modèles et les attentes humaines, les défis éthiques de l’IA, le problème de la boîte noire décisionnelle et les biais de perception du public concernant l’IA. L’idée centrale est qu’il existe un fossé entre la réalité et le battage médiatique, et qu’il faut considérer le développement de l’IA avec plus de prudence. (Source: 世上本无 AGI,报道多了,就有了)
Débat : le RAG sera-t-il remplacé par le contexte long ?: La discussion communautaire se concentre à nouveau sur la question de savoir si les fenêtres de contexte ultra-longues annoncées par des modèles comme Llama 4 (par exemple, 10 millions de tokens) rendront obsolète la technologie RAG (Retrieval-Augmented Generation). L’opinion dominante est que l’augmentation simple de la longueur du contexte ne peut pas remplacer complètement le RAG, car ce dernier conserve des avantages en termes de traitement des informations en temps réel, de récupération dans des bases de connaissances spécifiques, de contrôle des sources d’information et de rentabilité. Le contexte long et le RAG sont probablement plus complémentaires que substituables. (Source: Reddit r/artificial)

Discussion communautaire : Comment suivre le rythme du développement de l’IA ?: Un utilisateur de Reddit exprime sa difficulté à suivre le rythme effréné du développement de l’IA et ressent du FOMO (Fear Of Missing Out). Les commentaires s’accordent généralement sur le fait qu’il est impossible de tout suivre et suggèrent : de se concentrer sur son propre domaine de niche, de collaborer et partager l’information avec ses pairs, de ne pas s’inquiéter pour chaque petite mise à jour, de distinguer les progrès réels du battage marketing, et d’accepter qu’il s’agit d’un processus d’apprentissage continu. (Source: Reddit r/ArtificialInteligence)
Discussion communautaire : Meilleure interface utilisateur (UI) LLM locale actuelle: Un utilisateur de Reddit lance une discussion pour savoir quelle est l’interface utilisateur LLM locale la plus recommandée en avril 2025. Les options populaires mentionnées dans les commentaires incluent Open WebUI, LM Studio, SillyTavern (particulièrement adapté au jeu de rôle et à la construction de mondes), Msty (option d’installation en un clic avec de nombreuses fonctionnalités), Reor (notes + RAG), llama.cpp (ligne de commande), llamafile, llama-server, et d.ai (mobile Android). Le choix dépend des besoins de l’utilisateur (facilité d’utilisation, fonctionnalités, scénarios spécifiques, etc.). (Source: Reddit r/LocalLLaMA)
L’alignement de l’IA forçant les modèles à « mentir » suscite des inquiétudes: Un utilisateur de Reddit critique certaines méthodes d’alignement de l’IA qui forcent les modèles à nier leur propre identité (par exemple, ne pas admettre être un modèle spécifique), considérant que cette forme d’alignement par le « mensonge forcé » est problématique. Le message montre des captures d’écran d’une conversation où, par des questions inductives, le modèle finit par « admettre » son identité, suscitant une discussion sur les objectifs de l’alignement et la transparence. (Source: Reddit r/artificial

Le test A/B d’OpenAI GPT-4.5 suscite la discussion: Un utilisateur remarque qu’en utilisant GPT-4.5, il rencontre de nombreuses invites de test A/B du type « Lequel préférez-vous ? ». Les commentaires suggèrent qu’OpenAI pourrait utiliser ses utilisateurs payants pour collecter des données de préférence sur les modèles, et que ces données pourraient différer de celles collectées sur des plateformes publiques comme LM Arena. (Source: natolambert)
Problèmes dans la pratique du Model Context Protocol (MCP): Un utilisateur de la communauté souligne que, bien que le MCP (Model Context Protocol) soit un concept prometteur pour standardiser l’interaction entre l’IA et les outils, de nombreuses implémentations actuelles sont de qualité médiocre. Les points de risque incluent : l’incapacité des développeurs à contrôler totalement les instructions envoyées par le serveur MCP, la mauvaise gestion par le système des erreurs de saisie humaine (comme les fautes d’orthographe), les problèmes d’hallucination propres aux LLM, et les limites floues des capacités du MCP. Il est conseillé d’utiliser avec prudence, en particulier dans les scénarios non-lecture seule, et de privilégier les implémentations open source pour garantir la transparence. (Source: Reddit r/artificial)
Retour d’utilisateurs Suno sur des anomalies de la fonction Extend: Plusieurs utilisateurs de Suno signalent des problèmes avec la fonction « Extend » (étendre), qui ne parvient pas à poursuivre le style de la chanson comme prévu, introduisant au contraire de nouvelles mélodies, instruments, voire rythmes et styles. Les utilisateurs expriment leur mécontentement d’avoir dépensé beaucoup de crédits pour des résultats inutilisables et se demandent s’il s’agit d’un bug système. Un utilisateur a réalisé une vidéo montrant le problème. (Source: Reddit r/SunoAI, Reddit r/SunoAI)

Retour d’utilisateurs Suno sur la baisse récente de la qualité de génération: Un utilisateur payant de longue date de Suno se plaint d’une baisse importante de la qualité de génération des modèles V4 et V3.5 récemment, affirmant que des prompts auparavant fiables génèrent maintenant du « bruit » ou de la musique fausse, ayant gaspillé 3000 crédits sans obtenir une seule chanson utilisable. L’utilisateur se demande s’il s’agit d’un bug et envisage d’annuler son abonnement. (Source: Reddit r/SunoAI)
Partage communautaire : Utiliser l’IA pour générer des images des métiers de rêve des enfants: Une vidéo montre un cas d’utilisation touchant : des enfants décrivent le métier qu’ils veulent faire plus tard (avocat, glacier, gardien de zoo, cycliste), puis une IA (ChatGPT dans la vidéo) génère les images correspondantes à partir des descriptions. Les enfants sont ravis en voyant les images. (Source: Reddit r/ChatGPT)

Partage communautaire : Images générées par IA de célébrités rencontrant leur moi jeune/âgé: Un utilisateur a utilisé la fonction de génération d’images de ChatGPT pour créer une série d’images montrant des célébrités (comme Musk, Schwarzenegger, McCartney, Tony Hawk, Clint Eastwood, etc.) rencontrant des versions plus jeunes ou plus âgées d’elles-mêmes, avec un effet réaliste et amusant. (Source: Reddit r/ChatGPT)
Vidéo « étrange » générée par IA sur la réindustrialisation américaine: Un utilisateur partage une vidéo prétendument générée par une IA chinoise sur la « réindustrialisation américaine ». Le contenu et le style de la bande sonore sont jugés « déjantés » et empreints d’humour/ironie, montrant la capacité de l’IA à générer du contenu narratif spécifique et ses biais potentiels. (Source: Reddit r/ChatGPT

Un utilisateur compare les coûts et les résultats de Claude et o1-pro: Un utilisateur partage son expérience d’amélioration de cartes CSS Tailwind en utilisant OpenAI o1-pro et Anthropic Claude Sonnet 3.7. Les résultats montrent que la sortie de Claude était meilleure et que le coût était bien inférieur à celui d’o1-pro (moins de 1 $ contre près de 6 $). (Source: Reddit r/ClaudeAI)
La stabilité du service Claude moquée par les utilisateurs: Des utilisateurs publient des mèmes ou des commentaires pour se moquer de la fréquence à laquelle le service Claude d’Anthropic subit une « demande exceptionnellement élevée » entraînant une surcharge ou une inaccessibilité pendant les heures de pointe en semaine, suggérant que sa stabilité doit être améliorée. (Source: Reddit r/ClaudeAI)

Doctorant en mathématiques cherche des ressources d’introduction au Machine Learning: Un étudiant sur le point de commencer un doctorat en mathématiques, dont la recherche implique l’application d’outils d’algèbre linéaire au machine learning (en particulier les PINNs), recherche des ressources d’introduction au ML adaptées à un public matheux, rigoureuses et concises (livres, notes de cours, vidéos), trouvant les manuels standards (comme Bishop, Goodfellow) trop longs. (Source: Reddit r/MachineLearning)

Un étudiant teste les différences de performance des petits modèles sur différents matériels: Un étudiant partage des données de performance pour de petits modèles comme Llama3.2 1B et Granite3.1 MoE testés sur un GPU de bureau RTX 2060 et un Raspberry Pi 5. Il constate que Llama3.2 est le plus performant sur le bureau mais moins bon sur le Raspberry Pi, ce qui le laisse perplexe. Il observe également une plus grande fluctuation des résultats pour les modèles MoE et en demande la raison. (Source: Reddit r/MachineLearning)
Un utilisateur cherche à séparer les modèles de recherche et de génération de titres dans OpenWebUI: Un utilisateur d’OpenWebUI demande s’il est possible de configurer séparément le modèle utilisé pour générer les requêtes de recherche (privilégiant un modèle fort en raisonnement) et celui utilisé pour générer les titres/tags (privilégiant un petit modèle plus économique). (Source: Reddit r/OpenWebUI)
Un utilisateur cherche le manuel de prompts musicaux Suno AI: Un utilisateur demande si quelqu’un a encore conservé le manuel de prompts musicaux Suno AI (PDF) qui circulait auparavant, car le lien original est mort. (Source: Reddit r/SunoAI)

Un utilisateur cherche de l’aide pour intégrer OpenWebUI avec LM Studio: Un utilisateur essaie de connecter OpenWebUI avec LM Studio comme backend (via l’API compatible OpenAI) mais rencontre des problèmes lors de la configuration de la recherche web et de la fonction d’embedding, et demande l’aide de la communauté. (Source: Reddit r/OpenWebUI)
Partages d’utilisateurs de créations musicales générées par IA: Plusieurs utilisateurs sur r/SunoAI partagent leurs créations musicales réalisées avec Suno AI, couvrant divers styles tels que Ambient, Musical, Alternative Psychedelic Rock, Folk Country, Comedy ballad (EDM), Rap, Folk Music, Dreamy indie pop. (Source: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)

Un utilisateur s’interroge sur la valeur de l’abonnement Suno: Compte tenu des plaintes récentes concernant la qualité de Suno v4, un utilisateur demande si l’achat d’un abonnement Suno vaut toujours la peine actuellement, en particulier pour remasteriser d’anciennes chansons de la version v3. (Source: Reddit r/SunoAI)
Un utilisateur cherche des conseils pour créer un album de musique Suno: Un utilisateur expérimenté de Suno prévoit de compiler ses morceaux préférés en un album et de le publier sur Spotify via des plateformes comme DistroKid, et demande des conseils à la communauté sur la sélection des chansons, leur ordre et les aspects techniques. (Source: Reddit r/SunoAI)
Un utilisateur se plaint des problèmes d’interface utilisateur de Suno sur iPad: Un nouvel abonné signale des problèmes d’interface lors de l’utilisation du site web Suno sur iPad, ne pouvant pas utiliser correctement les fonctions d’enregistrement, d’édition des paroles, de glisser-déposer, etc., et cherche des solutions ou des conseils. (Source: Reddit r/SunoAI)
Un utilisateur soupçonne Cursor AI de dégrader discrètement les modèles: Un utilisateur soupçonne Cursor AI d’avoir secrètement dégradé le modèle qu’il utilise, passant du prétendu Claude 3.7 à 3.5, en se basant sur un changement de comportement de l’agent et son refus de divulguer des informations sur le modèle. L’utilisateur affirme que son message de questionnement publié sur r/cursor a été supprimé. (Source: Reddit r/ClaudeAI)
Un utilisateur demande quels sont les services IA payants couramment utilisés: Un utilisateur lance une discussion pour demander à quels services IA payants les gens s’abonnent chaque mois, afin de savoir quels outils sont considérés comme valant leur prix et s’il y a des services à recommander. (Source: Reddit r/artificial)
Aide en Deep Learning : Identifier des signaux mixtes: Un débutant demande de l’aide pour utiliser le deep learning afin d’identifier des motifs dans des signaux de mesure scientifique mélangés. Les données sont des points de coordonnées au format txt/Excel. Les questions incluent : comment intégrer des données supplémentaires au format image ? Le modèle peut-il traiter des motifs mixtes représentés par des points de coordonnées ? Quels modèles ou directions d’apprentissage sont recommandés ? (Source: Reddit r/deeplearning)
Meme/Humour: La communauté a vu apparaître plusieurs mèmes ou publications humoristiques liés à l’IA, par exemple sur le fait de tomber amoureux d’une IA (film Her), la préférence pour le modèle Gemma 3, la saturation du marché des preneurs de notes IA, les pannes de service de Claude, et des cartes à collectionner de célébrités générées par IA. (Source: Reddit r/ChatGPT, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, AravSrinivas, Reddit r/artificial)

💡 Autres
Protocol Buffers (Protobuf) continue de susciter l’intérêt: Le format d’échange de données Protobuf développé par Google maintient une forte attention sur GitHub. En tant que mécanisme extensible, neutre au langage et à la plateforme, pour sérialiser des données structurées, il est largement utilisé dans l’IA/ML et de nombreux grands systèmes (comme TensorFlow, gRPC). Le dépôt fournit des instructions d’installation pour le compilateur (protoc), des liens vers les bibliothèques d’exécution multilingues et un guide d’intégration Bazel. (Source: protocolbuffers/protobuf – GitHub Trending (all/daily))
Le framework Web Gin reste populaire: Gin, le framework Web HTTP haute performance écrit en Go, continue d’être populaire sur GitHub. Il est connu pour son API similaire à Martini et ses performances jusqu’à 40 fois supérieures (grâce à httprouter), ce qui le rend adapté aux scénarios nécessitant des services Web haute performance (pouvant inclure des services API pour les modèles IA). (Source: gin-gonic/gin – GitHub Trending (all/daily))
Hugging Face Hub adopte le nouveau backend Xet pour une efficacité accrue: Hugging Face Hub a commencé à utiliser un nouveau backend de stockage, Xet, en remplacement de l’ancien backend Git. Xet utilise la technologie de découpage défini par le contenu (CDC) pour effectuer la déduplication des données au niveau de l’octet (blocs d’environ 64 Ko), plutôt qu’au niveau du fichier. Cela signifie que lors de la modification de fichiers volumineux (comme Parquet), seules les différences au niveau des lignes modifiées doivent être transférées et stockées, ce qui améliore considérablement l’efficacité du téléchargement/téléversement et du stockage. La publication du modèle Llama-4 a permis de tester avec succès ce backend. (Source: huggingface)
Hugging Face Hub supportera bientôt les clients MCP: Un développeur de Hugging Face a soumis une Pull Request visant à ajouter la prise en charge du protocole de contexte de modèle (MCP) au client Inference de la bibliothèque huggingface_hub. Cela pourrait signifier que les services d’inférence de Hugging Face pourront mieux interagir avec les outils et agents conformes à la norme MCP. (Source: huggingface)
Système de livraison par drone Zipline: Présentation du système de livraison par drone de la société Zipline. Ce système pourrait utiliser l’IA pour la planification d’itinéraires, l’évitement d’obstacles et la livraison de précision, appliqué dans les domaines de la logistique et de la chaîne d’approvisionnement, montrant notamment un potentiel dans le transport de fournitures médicales. (Source: Ronald_vanLoon)
Le robot ergoCub pour l’interaction physique homme-robot: L’Institut Italien de Technologie (IIT) présente le robot ergoCub, conçu pour la recherche sur l’interaction physique homme-robot. Ces robots nécessitent généralement des algorithmes d’IA avancés pour permettre la perception, le contrôle moteur et des capacités d’interaction sûres. (Source: Ronald_vanLoon)
KeyForge3D : Dupliquer des clés avec la vision par ordinateur: Un projet GitHub nommé KeyForge3D utilise OpenCV (bibliothèque de vision par ordinateur) pour identifier la forme des clés, calculer leur code de taillage (bitting code), et peut exporter un modèle STL pour l’impression 3D. Bien qu’il utilise principalement des techniques de CV traditionnelles, il démontre le potentiel d’application de la reconnaissance d’images dans les tâches de réplication du monde physique, et pourrait à l’avenir être combiné avec l’IA pour améliorer davantage la précision et l’adaptabilité de la reconnaissance. (Source: karminski3)

Les principes de l’IA responsable (Responsible AI) suscitent l’intérêt: Le message mentionne les principes de l’IA responsable utilisés par des organisations comme EY, soulignant la nécessité de prendre en compte l’équité, la transparence, l’explicabilité, la confidentialité, la sécurité et la responsabilité lors du développement et du déploiement de systèmes d’IA. (Source: Ronald_vanLoon)
Kawasaki présente un robot quadrupède « cheval » à hydrogène pilotable: Kawasaki Heavy Industries a présenté un robot quadrupède nommé Corleo, conçu pour être pilotable et utilisant de l’hydrogène comme source d’énergie. Bien qu’il s’agisse d’un robot, le rapport ne précise pas le degré d’application de l’IA dans ses systèmes de contrôle ou d’interaction. (Source: Reddit r/ArtificialInteligence)
