
Mots-clés:AI, LLM, rapport AI 2025, modèles open source, DeepSeek performance, évaluation des modèles LLM, coût de l’inférence AI
🔥 Focus
Stanford publie le rapport AI Index 2025, révélant les tendances clés de l’industrie : L’Institut pour l’IA centrée sur l’humain (HAI) de l’Université de Stanford publie son huitième rapport annuel AI Index (456 pages), suivant de manière exhaustive le développement mondial de l’IA en 2024. Le rapport ajoute de nouveaux contenus sur le matériel d’IA, les coûts d’inférence, les pratiques d’IA responsable en entreprise et les applications de l’IA dans les sciences et la médecine. Les tendances clés incluent : 1) Amélioration significative des performances de l’IA sur des benchmarks difficiles comme MMMU ; 2) Intégration croissante de l’IA dans la vie quotidienne, y compris la santé et les transports ; 3) Investissements et taux d’adoption record par les entreprises, les États-Unis investissant bien plus que la Chine, mais l’écart de performance des modèles chinois se réduit rapidement (l’écart entre les meilleurs modèles américains et chinois sur des benchmarks comme MMLU est réduit à 0,3 % – 1,7 %) ; 4) Les modèles open-source/petits comme DeepSeek se rapprochent des performances des modèles fermés/grands, avec une baisse drastique des coûts d’inférence (réduction de 280 fois en deux ans) ; 5) Renforcement mondial de la réglementation de l’IA et augmentation des investissements ; 6) Accélération de la démocratisation de l’éducation à l’IA mais ressources inégales ; 7) Augmentation rapide des incidents de sécurité liés à l’IA, pratiques d’IA responsable inégales ; 8) Optimisme croissant envers l’IA au niveau mondial mais avec de grandes disparités régionales. Le rapport souligne le potentiel transformateur de l’IA et la nécessité d’orienter son développement. (Source : 36Kr, New Zhiyuan, MetaverseHub, Ji Qizhi Xin)

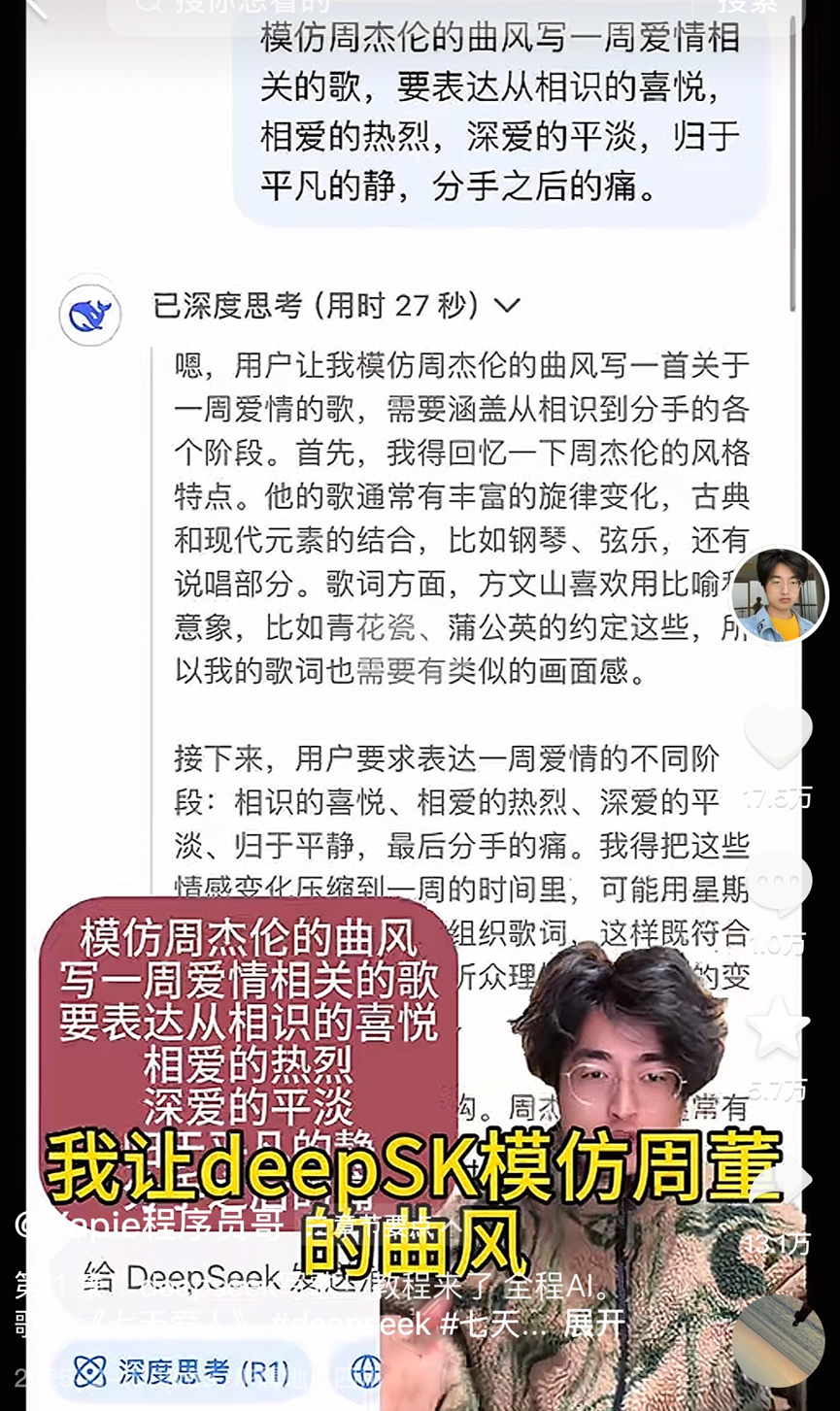
La popularité explosive de la création musicale par IA suscite la controverse, le phénomène « Seven Day Lover » révèle l’engouement excessif et les défis du secteur : La chanson « Seven Day Lover » générée par IA, imitant le style de Jay Chou, est devenue virale de manière inattendue, atteignant les classements de tendances et de musique, et ses droits d’auteur ont été rapidement vendus, déclenchant un engouement pour la création musicale par IA. De nombreux amateurs affluent sur les plateformes, utilisant des outils d’IA pour produire des chansons en masse, certaines plateformes lançant également des activités connexes. Cependant, derrière cette prospérité se cachent de nombreux problèmes : la qualité des nombreuses chansons IA est inégale, qualifiée de « déchets musicaux » ; elles reposent sur l’imitation et l’assemblage, manquant de véritable innovation ; la propriété des droits d’auteur est floue, les États-Unis ayant clairement indiqué que la création par IA n’est pas protégée par le droit d’auteur, et des plateformes comme Tencent Music soulignent également les risques juridiques ; la monétisation commerciale est difficile, à l’exception de quelques succès viraux, la plupart des chansons IA génèrent des revenus dérisoires, et les plateformes renforcent leur contrôle. Les professionnels de l’industrie craignent que l’IA ne menace les emplois des musiciens débutants et s’inquiètent davantage de la « déprocessualisation » de la création entraînant une paresse intellectuelle et un déclin esthétique chez l’homme. (Source : 36Kr)
Le modèle Llama 4 pris dans une controverse de « falsification » après sa sortie, l’écart entre le classement Arena et les performances réelles suscite la polémique : Le dernier modèle open-source de Meta, Llama 4, a obtenu un score élevé sur Chatbot Arena, dépassant DeepSeek-V3 pour devenir le numéro un des modèles open-source. Cependant, de nombreux tests utilisateurs rapportent de mauvaises performances en programmation, raisonnement et écriture créative, bien en deçà des attentes et de son classement Arena. Par la suite, l’arène des grands modèles (LMArena) a officiellement indiqué que la version fournie par Meta pour les tests Arena était une version expérimentale personnalisée pour optimiser les préférences humaines (Llama-4-Maverick-03-26-Experimental), et non la version standard publiée sur Hugging Face, et que Meta n’avait pas clairement signalé cette différence. LMArena a publié plus de 2000 enregistrements de confrontations, montrant que le style de réponse de cette version expérimentale (par exemple, plus amical, utilisation d’émojis) pourrait être un facteur important influençant le classement, et mettra en ligne la version HF de Llama 4 pour une réévaluation. Le responsable de Meta Gen AI a nié l’entraînement sur l’ensemble de test, affirmant que la différence de performance provenait de problèmes de stabilité de déploiement. Cet incident a déclenché une large discussion et des doutes au sein de la communauté sur les performances de Llama 4, la transparence de Meta et la fiabilité de la méthode d’évaluation de LMArena. (Source : Quantum Bit, Ji Qizhi Xin, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Le phénomène DeepSeek attire l’attention de l’industrie, la conférence chinoise sur l’IA générative explore de nouvelles opportunités : L’ascension de DeepSeek est considérée comme un tournant clé pour l’industrie de l’IA générative en Chine et dans le monde. Son modèle open-source à haute efficacité et faible coût catalyse l’engouement pour la R&D des modèles d’inférence et de l’infrastructure IA, et insuffle un nouvel élan à l’IA embarquée (edge AI) et à la mise en œuvre de la puissance de calcul nationale. Lors de la Conférence chinoise sur l’IA générative 2025, plus de 50 experts de l’industrie, du monde universitaire et de la recherche ont discuté des changements induits par DeepSeek, du raisonnement profond, du multimodal, des modèles du monde (world models), de l’infrastructure IA, des applications AIGC, des Agents et de l’intelligence incarnée (embodied intelligence). Les participants estiment que DeepSeek réduit considérablement les coûts de déploiement pour les entreprises (certaines applications ont vu leurs coûts chuter de 90 % après la transition), démontrant l’activité et la capacité de mise en œuvre rapide de la Chine dans la communauté open-source. La conférence a également abordé la nécessité de nouveaux terminaux pour l’explosion des applications IA, les défis de la mise en œuvre des Agents, les percées des clusters de calcul nationaux, le développement de l’intelligence physique, les voies de commercialisation de l’IA, soulignant le rôle de plus en plus important de la Chine dans le paysage mondial de l’IA. (Source : 36Kr, Ronald_vanLoon)

🎯 Tendances
L’Agentic AI considérée comme la prochaine grande percée : L’Agentic AI (IA agentique) devient un moteur clé de la transformation dans les domaines commercial et technologique. Contrairement à l’IA traditionnelle qui exécute des tâches spécifiques, l’Agentic AI peut définir de manière autonome des objectifs, élaborer des plans et exécuter des tâches complexes en plusieurs étapes, agissant davantage comme un employé numérique autonome. Elles peuvent intégrer plusieurs outils et sources de données, effectuer des raisonnements et prendre des décisions, promettant des changements disruptifs dans des domaines tels que le service client, l’analyse de données et le développement de logiciels. Avec le développement technologique, l’Agentic AI entraînera une transformation profonde des modèles opérationnels des entreprises et des modes d’interaction homme-machine. (Source : Ronald_vanLoon)

Nvidia publie le modèle Llama-Nemotron-Ultra 253B, avec poids et données open-source : Nvidia lance Llama-Nemotron-Ultra, un modèle dense de 253 milliards de paramètres obtenu en entraînant un Llama-3.1-405B après élagage NAS et optimisation de l’inférence. Ce modèle se concentre sur l’amélioration des capacités d’inférence, utilise le post-entraînement SFT et RL (précision FP8), et met en open-source les poids et les données de post-entraînement. La contribution continue de Nvidia aux travaux de post-entraînement open-source est saluée par la communauté. (Source : natolambert)

La série de modèles Qwen3 pourrait être publiée, incluant des versions 8B et 15B MoE : D’après les informations d’une PR fusionnée dans le dépôt de code vLLM, Alibaba s’apprêterait à publier la nouvelle série de modèles Qwen3. Actuellement, les versions possibles connues incluent Qwen3-8B et Qwen3-MoE-15B-A2B. La communauté spécule que la version 8B pourrait être un modèle multimodal, tandis que la version 15B serait un modèle MoE (Mixture of Experts) axé sur le texte. Les utilisateurs espèrent des améliorations de performances avec ces nouveaux modèles ; si le MoE 15B atteint le niveau de Qwen2.5-Max, ce serait considéré comme un succès significatif. (Source : karminski3)

Runway lance Gen-4 Turbo, la vitesse de génération vidéo considérablement améliorée : Runway a publié son dernier modèle de génération vidéo, Gen-4 Turbo. Le principal atout du nouveau modèle réside dans sa vitesse de génération, affirmant pouvoir générer une vidéo de 10 secondes en 30 secondes, une accélération significative par rapport aux versions précédentes. Cela rend Gen-4 Turbo particulièrement adapté aux scénarios d’application nécessitant une itération rapide et une exploration créative. La mise à jour est déployée pour tous les plans utilisateurs. (Source : op7418)
Google Gemini Live est lancé, permettant une interaction visuelle et vocale en temps réel : Google annonce le lancement officiel de la fonctionnalité Gemini Live, d’abord sur les appareils Pixel 9 et Samsung Galaxy S25, puis pour les utilisateurs de Gemini Advanced sur Android. Cette fonctionnalité permet aux utilisateurs de partager le contenu de leur écran ou une vue en temps réel via la caméra et de dialoguer vocalement avec Gemini, permettant la compréhension du contenu visuel et des interactions telles que poser des questions, résoudre des problèmes, faire du brainstorming, etc. Cela marque une avancée importante pour Google dans l’expérience d’interaction IA multimodale, concrétisant davantage la vision du Project Astra. (Source : op7418, JeffDean, demishassabis)
HiDream publie le modèle d’image open-source HiDream-I1 de 17 milliards de paramètres : L’équipe HiDream AI a publié et mis en open-source son modèle de génération d’images de 17 milliards de paramètres, HiDream-I1. D’après les premières images présentées, la qualité des images générées par ce modèle est acceptable. Le code du modèle est disponible sur GitHub pour que les développeurs et les chercheurs puissent l’utiliser et l’explorer. (Source : op7418)

La vague open-source des grands modèles s’accélère, exploration du modèle économique « 2.0 » : En 2025, l’essor des modèles open-source représenté par DeepSeek pousse Meta, Alibaba, Tencent, etc., à accélérer leurs démarches open-source, et même les anciens partisans du « fermé » comme OpenAI et Baidu commencent à changer de cap. Les moteurs de l’open-source incluent la demande d’intelligence embarquée (edge intelligence), les besoins de personnalisation sectorielle, l’accélération de la division du travail écosystémique et le franchissement d’un seuil technologique critique. L’open-source abaisse les barrières pour les développeurs et les PME, favorisant la démocratisation technologique et l’innovation. Cependant, open-source ne signifie pas gratuit ; la maintenance et la localisation ont toujours un coût. Les principaux acteurs explorent des modèles de commercialisation 2.0, tels que « modèle de base open-source + services API commerciaux à valeur ajoutée » (comme DeepSeek, Zhipu AI), « version communautaire open-source + version entreprise dédiée » (comme Alibaba Cloud Qwen) et « modèle open-source + monétisation via la plateforme cloud » (comme Meta Llama). Le cœur de la stratégie est « attirer via l’open-source, monétiser via les services », en réalisant des profits grâce à l’écosystème, la personnalisation et les services cloud. (Source : First New Voice)

🧰 Outils
Augment Code : Plateforme de codage IA conçue pour les projets complexes : Augment Code est lancé, se positionnant comme la première plateforme de codage IA capable de comprendre en profondeur les grandes bases de code complexes, spécialement conçue pour la collaboration en équipe. Elle offre une capacité de traitement de contexte allant jusqu’à 200K tokens, une mémoire persistante (apprenant le style de code, l’historique de refactoring, les normes d’équipe) et une intégration profonde avec des outils (VS Code, JetBrains, Vim, GitHub, Linear, Notion, etc.). Son agent principal peut non seulement écrire du code, mais aussi exécuter des commandes terminal, créer des PR complètes, générer de la documentation et des cas de test sensibles au contexte. Augment se classe premier au classement SWE-bench Verified (en combinaison avec Claude Sonnet 3.7 et o1) et est déjà utilisé par des entreprises comme Webflow et Kong. La plateforme est actuellement gratuite et vise à résoudre les difficultés des développeurs lors du traitement de grandes bases de code héritées. (Source : AI Jinxiu Sheng)
Cloudflare lance le service AutoRAG pour simplifier la création d’applications RAG : Cloudflare a lancé AutoRAG, un service visant à simplifier le développement d’applications de génération augmentée par récupération (RAG). Les développeurs peuvent utiliser ce service pour transformer automatiquement des sources de données (telles que des documents, des sites web) en bases de connaissances interrogeables par de grands modèles, sans avoir à gérer manuellement l’indexation des données et la logique de récupération. Pendant la phase de bêta publique, AutoRAG est gratuit, avec une limite de 10 instances par compte, chaque instance pouvant traiter jusqu’à 100 000 fichiers. Cette initiative abaisse le seuil d’entrée pour la création d’applications IA basées sur des connaissances spécifiques. (Source : karminski3)

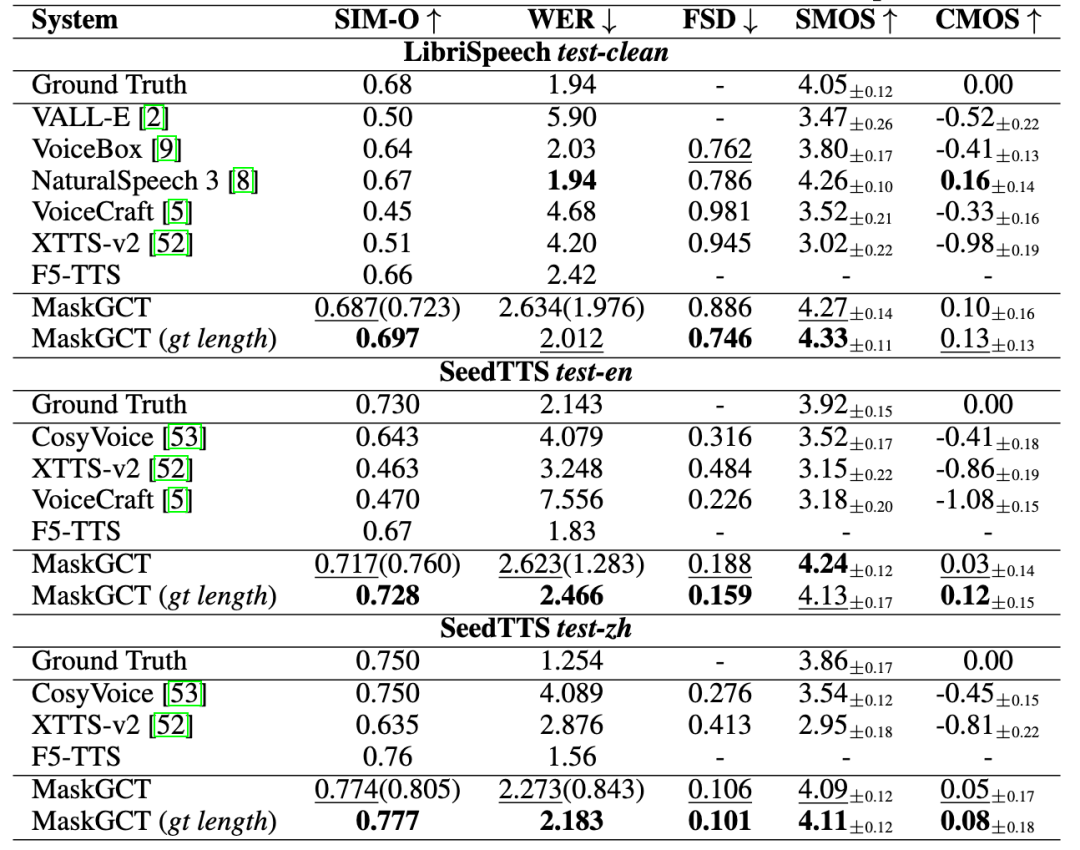
Quwan Technology lance « Quwan QianYin », offrant une solution complète de processus vocal IA : Quwan Technology lance le produit vocal IA « Quwan QianYin (All Voice Lab) », basé sur le modèle MaskGCT développé conjointement avec CUHK (Shenzhen). Ce produit intègre des fonctions telles que la synthèse vocale à partir de texte, la traduction vidéo, la synthèse multilingue, l’effacement des sous-titres, etc. Sa particularité est l’automatisation complète du processus de traduction vidéo, avec une capacité de traitement quotidienne de plus de 1000 minutes, améliorant l’efficacité de 10 fois. L’effet de génération vocale est riche en émotions et comparable à une voix humaine réelle. Quwan QianYin vise à répondre aux besoins de diffusion interlinguistique à grande échelle grâce à ses capacités industrielles, et est déjà utilisé dans des domaines tels que l’exportation de mini-séries (réduction des coûts, croissance des utilisateurs), les actualités, le tourisme culturel, les livres audio, se positionnant comme une « infrastructure de contenu mondiale ». (Source : 36Kr)
Exa : Moteur de recherche conçu spécifiquement pour les Agents IA : Exa se positionne comme « l’API Bing de l’ère LLM », un moteur de recherche spécialement conçu pour les Agents IA, visant à permettre à l’IA d’accéder et de comprendre efficacement les informations d’Internet. Contrairement à la recherche humaine, Exa peut traiter des requêtes en langage naturel plus complexes, fournir des résultats plus complets et prendre en charge des requêtes à haut débit et faible latence. Ses API principales incluent la recherche rapide, l’acquisition de contenu (crawler), la recherche de liens similaires, etc. Exa propose également la fonctionnalité Websets, permettant aux utilisateurs de structurer les informations d’Internet en utilisant des critères de filtrage en langage naturel. La société a reçu des investissements de Lightspeed, Nvidia, etc., avec un ARR dépassant les 10 millions de dollars, son principal concurrent étant Brave Search. (Source : AI Explorer)
Un outil IA permet de résumer visuellement les historiques de discussion WeChat : En utilisant une combinaison d’outils IA, il est possible d’exporter les historiques de discussion de groupe ou privés WeChat et de générer des rapports visuels. Les étapes comprennent : 1) Utiliser un outil tiers (comme Liuhen MemoTrace) pour exporter l’historique de discussion WeChat en fichier TXT (attention aux risques de sécurité des données) ; 2) Entrer le fichier TXT et un modèle de Prompt spécifique (contenant du code de style) dans un grand modèle prenant en charge le traitement de longs textes (comme Gemini 2.5 Pro dans AI Studio) pour générer du code HTML ; 3) Convertir le code HTML généré en un lien web partageable via un service en ligne (comme yourware.so), ou utiliser un outil en ligne (comme cloudconvert.com) pour le convertir directement en image. Cette méthode permet de transformer de longues conversations en rapports structurés et clairs, incluant des citations quotidiennes et des nuages de mots, facilitant la révision et le partage. (Source : Kazk)
Le modèle d’image Jimm AI 3.0 est entièrement déployé : Jimm AI annonce que la version 3.0 de son modèle de génération d’images a terminé les tests et est maintenant entièrement déployée. La nouvelle version devrait présenter des améliorations en termes de qualité d’image, de diversité de styles et de compréhension sémantique. Des utilisateurs (comme 歸藏) ont déjà partagé des tests détaillés et des collections de prompts pour l’utilisation du modèle 3.0 dans différents domaines de conception (comme les images pour les opérations IA), montrant ses effets de génération. (Source : op7418)

VIBE Chat : Site de chat amusant avec arrière-plans aléatoires : Un site web nommé VIBE Chat offre une expérience de chat originale, générant une image d’arrière-plan différente de manière aléatoire pour chaque session. Le site est basé sur le modèle Gemini 2.0 Flash, et les utilisateurs peuvent l’utiliser pour des tâches telles que la programmation, le code ou le contenu étant affichés directement dans l’interface de chat. Les tests montrent qu’il peut générer du code pour des jeux simples comme Flappy Bird et Tetris. (Source : karminski3)
Un développeur crée un assistant GPT dédié à SunoAI : Un développeur a créé un GPT personnalisé nommé « Hook & Harmony Studio », conçu pour assister le processus de création musicale avec Suno AI. Cet outil peut, à partir d’un concept de chanson fourni par l’utilisateur, générer un titre unique, des paroles structurées (avec indications d’instruments et de chant), des suggestions de tags de style conformes à Suno, filtrer les clichés et, en option, générer des prompts pour les visuels de la chanson. Il vise à simplifier la création de paroles et l’exploration de styles, et formate automatiquement le tout pour une utilisation dans le mode projet de Suno. (Source : Reddit r/SunoAI)
Code to Prompt Generator : Outil simplifiant la conversion de code en prompts LLM : Un développeur a mis en open-source un petit outil nommé « Code to Prompt Generator », visant à simplifier la création de prompts LLM à partir de dépôts de code. Il peut scanner automatiquement les dossiers de projet pour générer une arborescence de fichiers (en excluant les fichiers non pertinents), permettre aux utilisateurs d’inclure sélectivement des fichiers/répertoires, afficher le nombre de tokens en temps réel, sauvegarder et réutiliser des instructions (Meta Prompts), et copier le prompt final en un clic. L’outil utilise un frontend Next.js et un backend Flask, et fonctionne sur plusieurs plateformes. (Source : Reddit r/ClaudeAI)
Publication des versions GGUF de Llama 4, supportant l’exécution locale : Suite à l’intégration du support de Llama 4 (actuellement texte uniquement) dans llama.cpp, les développeurs de la communauté (comme bartowski, unsloth, lmstudio-community) ont rapidement publié des versions quantifiées GGUF du modèle Llama 4 Scout. Ces versions utilisent des stratégies de quantification optimisées comme imatrix, visant à équilibrer la taille du modèle et les performances, permettant aux utilisateurs d’exécuter Llama 4 sur du matériel local. Des versions avec différentes largeurs de bits (par exemple, IQ1_S 1.78bit, Q4_K_XL 4.5bit) sont disponibles pour répondre aux besoins de différentes configurations matérielles. Les utilisateurs peuvent trouver ces fichiers GGUF sur Hugging Face. (Source : Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

📚 Apprentissage
Microsoft et CUHK proposent ImageGen-CoT pour améliorer la compréhension contextuelle de la peinture IA : Pour résoudre les lacunes des modèles de peinture IA dans la compréhension des descriptions textuelles complexes et des relations contextuelles (comme la migration de la texture « pomme en cuir » vers « boîte en cuir »), les chercheurs de Microsoft Research Asia et de l’Université chinoise de Hong Kong (CUHK) proposent le framework ImageGen-CoT. Cette méthode introduit une étape de raisonnement en chaîne de pensée (Chain-of-Thought, CoT) avant la génération d’images, permettant au modèle de réfléchir d’abord aux informations clés et d’organiser la logique avant de créer. En construisant un jeu de données ImageGen-CoT de haute qualité et en effectuant un fine-tuning, les performances du modèle (comme SEED-X) sur la tâche T2I-ICL sont considérablement améliorées (CoBSAT amélioré de 89%, DreamBench++ amélioré de 114%). Ce framework adopte un raisonnement en deux étapes et explore plusieurs stratégies d’extension au moment du test (CoT unique, CoT multiples, extension mixte), l’extension mixte donnant les meilleurs résultats. (Source : 36Kr, New Zhiyuan)

Un article propose un nouveau paradigme de routage LLM et le benchmark RouterEval : Face aux problèmes de monopole de la puissance de calcul, de coûts élevés et de voie technologique unique dans la recherche sur les grands modèles, les chercheurs proposent le paradigme de routage LLM (Routing LLM), qui utilise un routeur intelligent (Router) pour attribuer dynamiquement les tâches à plusieurs petits modèles (open-source) afin qu’ils collaborent. Pour soutenir cette recherche, l’article met en open-source le benchmark complet RouterEval, contenant 200 millions d’enregistrements de performances de plus de 8500 LLM sur 12 benchmarks courants. Ce benchmark transforme le problème de routage en une tâche de classification standard, permettant la recherche sur un seul GPU, voire sur un ordinateur portable. L’étude révèle que grâce au routage intelligent (même avec seulement 3 à 10 modèles candidats), la combinaison de plusieurs modèles faibles peut surpasser les performances des meilleurs modèles monolithiques (comme GPT-4), démontrant un effet de « Model-level Scaling Up ». Ce travail offre une nouvelle approche pour atteindre une IA haute performance à faible coût. (Source : New Zhiyuan)
L’équipe de Jiawei Han et Jimeng Sun de l’UIUC met en open-source DeepRetrieval, utilisant le RL pour optimiser les requêtes des moteurs de recherche : Pour résoudre le problème de la faible qualité des requêtes initiales des utilisateurs entraînant des résultats de recherche d’informations médiocres, l’équipe de l’UIUC propose le framework DeepRetrieval. Ce système utilise l’apprentissage par renforcement (RL) pour entraîner un LLM à optimiser les requêtes initiales des utilisateurs (langage naturel, expressions booléennes ou SQL), les adaptant mieux aux caractéristiques de moteurs de recherche spécifiques (comme PubMed, BM25, bases de données SQL), maximisant ainsi l’efficacité de la recherche sans modifier les systèmes de recherche existants. Les expériences montrent que DeepRetrieval (modèle de seulement 3B) améliore considérablement les performances de recherche (recherche documentaire améliorée de 10 fois, dépasse GPT-4o sur la tâche Evidence-Seeking, précision d’exécution SQL améliorée), surpassant de loin les méthodes basées sur SFT. L’étude souligne que la capacité d’exploration du RL est supérieure à l’apprentissage par imitation du SFT, permettant de découvrir de meilleures stratégies de requête. (Source : Ji Qizhi Xin)
L’Institut d’Automatisation de l’Académie Chinoise des Sciences et d’autres proposent Vision-R1, utilisant l’apprentissage par renforcement pour améliorer la capacité de localisation visuelle des VLM : Face aux problèmes des grands modèles visuo-linguistiques (VLM) dans les tâches de détection d’objets et de localisation visuelle, tels que les erreurs de format, le faible taux de rappel et la précision insuffisante, l’Institut d’Automatisation de l’Académie Chinoise des Sciences et l’équipe de Zidong Taichu proposent le framework Vision-R1. Cette méthode s’inspire du succès du modèle linguistique R1 et introduit l’apprentissage par renforcement basé sur des règles (Rule-Based RL) dans les tâches de localisation visuelle. En concevant des fonctions de récompense au niveau de la tâche basées sur des métriques d’évaluation visuelle (exactitude du format, taux de rappel, précision IoU) et en adoptant une stratégie d’ajustement progressif des règles (récompenses différenciées, seuils progressifs par étape), sans dépendre de données de préférences humaines ni de modèles de récompense, elle améliore considérablement les performances de modèles comme Qwen2.5-VL sur des jeux de données tels que COCO et ODINW pour la détection d’objets (jusqu’à 50% d’amélioration), sans affecter fondamentalement les capacités générales de questions-réponses. Le code et le modèle sont open-source. (Source : Ji Qizhi Xin)
CalibQuant : Solution de quantification du KV Cache à 1 bit pour améliorer le débit des modèles multimodaux : Pour résoudre le problème de l’occupation excessive de la mémoire GPU par le KV Cache lors du traitement d’entrées visuelles à grande échelle par les grands modèles multimodaux (MLLM), limitant ainsi le débit, les chercheurs proposent la solution CalibQuant. Cette solution réalise une quantification extrême à 1 bit du KV Cache, combinant des techniques de post-mise à l’échelle (Post-Scaling) et de calibration (Calibration) conçues spécifiquement pour les caractéristiques de redondance du KV Cache visuel. La post-mise à l’échelle optimise l’ordre de calcul de la déquantification pour améliorer l’efficacité, tandis que la calibration ajuste les scores d’attention pour atténuer la distorsion des valeurs extrêmes introduite par la quantification à 1 bit. Les expériences montrent que CalibQuant peut réduire considérablement la mémoire et les coûts de calcul sur des modèles comme LLaVA et InternVL-2.5, permettant une augmentation du débit jusqu’à 10 fois, tout en ne perdant quasiment aucune performance du modèle. Cette méthode est plug-and-play et ne nécessite aucune modification du modèle original. (Source : PaperWeekly)
CVPR 2025 | SeqAfford : Réaliser un raisonnement séquentiel sur l’affordance 3D : Pour résoudre la difficulté actuelle de l’IA à comprendre et exécuter des instructions complexes impliquant plusieurs objets et étapes, les chercheurs proposent le framework SeqAfford. Ce framework combine pour la première fois la vision 3D avec les grands modèles linguistiques multimodaux (MLLM) pour le raisonnement séquentiel sur l’affordance 3D. En construisant le premier jeu de données Sequential 3D Affordance contenant plus de 180 000 paires d’instructions-nuages de points pour le fine-tuning, et en introduisant un mécanisme de raisonnement basé sur des tokens de segmentation (
GitHub héberge une collection de ressources de serveurs MCP : Un dépôt GitHub nommé awesome-mcp-servers rassemble et met en open-source plus de 300 serveurs MCP (Model Capability Protocol) pour les Agents IA. Ces serveurs couvrent des projets de production et expérimentaux, offrant aux développeurs une riche collection d’outils et d’interfaces pour faciliter l’interaction des Agents IA avec des services externes et des sources de données, favorisant ainsi le développement de l’écosystème des Agents. (Source : Reddit r/ClaudeAI)

Le professeur Fei Liu de l’Université Emory recrute des doctorants et stagiaires en grands modèles/NLP/GenAI : Fei Liu, professeure associée au département d’informatique de l’Université Emory aux États-Unis, recrute des doctorants avec bourse complète pour l’automne 2025. Les axes de recherche portent sur les capacités de raisonnement, de planification et de prise de décision des grands modèles linguistiques (LLM) en tant qu’agents intelligents, ainsi que sur les applications de l’IA dans des domaines tels que l’éducation et la santé. Les étudiants intéressés par ces domaines sont également invités à postuler pour des stages à distance ou des collaborations. Les candidats doivent avoir une formation en informatique ou dans un domaine connexe, d’excellentes compétences en programmation, et ceux ayant des publications de recherche ou de solides bases mathématiques seront privilégiés. (Source : AI Qiu Zhi)
Publication d’un guide de construction d’Agents IA : SuccessTech Services a publié un guide étape par étape expliquant comment construire des agents de grands modèles linguistiques (LLM). Ce guide couvre probablement les concepts de base des agents, la conception de l’architecture, le choix des outils, le processus de développement ainsi que des cas d’utilisation pratiques, offrant une introduction aux développeurs souhaitant créer des applications IA autonomes. (Source : Reddit r/OpenWebUI)

HKUST publie le code de Dream 7B, axé sur le raisonnement des modèles Diffusion : L’équipe NLP de l’Université des sciences et technologies de Hong Kong (HKUST) a rendu public le dépôt GitHub de son modèle de raisonnement pour les modèles Diffusion, Dream 7B, précédemment publié. Ce modèle vise à permettre aux LLM de comprendre et d’exécuter des instructions liées aux modèles Diffusion. La publication du code permet aux chercheurs de reproduire et d’étudier davantage ce modèle. (Source : Reddit r/LocalLLaMA)

💼 Affaires
Lingxin Qiaoshou lève un financement d’amorçage de niveau 100 millions de yuans pour développer la main robotique la plus dextre au monde : La société d’intelligence incarnée « Lingxin Qiaoshou » a finalisé un tour de financement d’amorçage de plus de 100 millions de yuans, mené par Sequoia Seed Fund et d’autres. L’entreprise se concentre sur une plateforme « main dextre + intelligence cloud ». Sa série de mains dextres auto-développées Linker Hand atteint 25-30 degrés de liberté pour la version industrielle et jusqu’à 42 pour la version recherche (la plus élevée au monde, dépassant les 24 de Shadow Hand et les 22 d’Optimus), avec des capacités de perception de haute précision (fusion multi-capteurs) et de manipulation. L’entreprise utilise deux structures, à tringlerie et à câble-tendon, et a atteint la production de masse, combinée à une intelligence cloud (entraînée sur le grand jeu de données DexSkill-Net) pour l’apprentissage et le contrôle. Les produits présentent des avantages en termes de coût (environ 50 000 RMB, bien inférieur aux 1,5 million de RMB de Shadow Hand) et de durabilité, ont déjà été achetés par des universités de premier plan comme l’Université de Pékin et l’Université Tsinghua, et sont appliqués dans des scénarios médicaux, industriels, etc. (Source : 36Kr)

Google paierait des salaires élevés en « congé de jardinage » à des employés IA pour les empêcher de rejoindre des concurrents : Selon des rapports, Google, afin d’empêcher des talents clés de l’IA de partir chez des concurrents comme OpenAI, aurait versé à certains employés démissionnaires des salaires élevés pendant une période pouvant aller jusqu’à un an (potentiellement des centaines de milliers de dollars), à condition qu’ils ne rejoignent pas d’entreprises concurrentes pendant cette période. Cette pratique, connue sous le nom de « gardening leave » (congé de jardinage), bien que courante dans des secteurs comme la finance, est plus rare dans l’industrie technologique, en particulier pour les chercheurs et ingénieurs IA qui ne sont pas des cadres supérieurs. Cela reflète l’extrême rareté des meilleurs talents en IA et la guerre acharnée pour les talents entre les géants de la technologie. (Source : Reddit r/ArtificialInteligence)

Le PDG de Shopify souligne que les employés doivent utiliser efficacement l’IA : Le PDG de Shopify, Tobias Lütke, exige que les employés, avant d’envisager d’augmenter la taille de leur équipe, réfléchissent d’abord à la manière d’utiliser les outils d’IA pour améliorer l’efficacité et résoudre les problèmes. Il considère l’IA comme un levier clé pour augmenter la productivité, et les employés devraient activement apprendre et l’intégrer dans leurs flux de travail quotidiens. Cette déclaration reflète la grande importance accordée par le monde de l’entreprise à l’amélioration de l’efficacité du travail grâce à l’IA, ainsi que les attentes envers les employés pour qu’ils s’adaptent aux nouvelles exigences de l’ère de l’IA. (Source : bushaicave.com)
36Kr lance l’appel à candidatures pour les « 2025 AI Partner Innovation Awards » : Pour découvrir et encourager les produits, solutions et entreprises innovants dans le domaine de l’IA, et promouvoir l’application de l’IA dans divers secteurs, 36Kr lance le concours « 2025 AI Partner Innovation Awards ». L’appel à candidatures couvre trois grandes catégories de produits/solutions non logiciels : innovation générale (bureautique, services aux entreprises, analyse de données, etc.), innovation sectorielle (finance, santé, éducation, industrie, etc.) et innovation terminale (matériel intelligent, automobile, robotique, etc.). La sélection sera basée sur quatre dimensions : innovation technique, efficacité de l’application, expérience utilisateur et valeur sociale, évaluées par un jury d’experts. La période d’inscription s’étend du 13 mars au 7 avril, et les résultats seront annoncés le 18 avril. (Source : 36Kr)

Lancement de l’élaboration de la première norme nationale pour le déploiement privé de grands modèles d’IA : Face aux problèmes rencontrés par les entreprises lors du déploiement privé de grands modèles d’IA, tels que l’inadéquation technique, les processus non standardisés et le manque de systèmes d’évaluation, le Centre de normalisation Zhihe, en collaboration avec le Troisième Institut de Recherche du Ministère de la Sécurité Publique et d’autres unités, lance l’élaboration de la norme de groupe « Guide pour la mise en œuvre technique et l’évaluation du déploiement privé de grands modèles d’intelligence artificielle ». Cette norme vise à couvrir l’ensemble du processus, de la sélection du modèle à l’optimisation continue, en passant par la planification des ressources, la mise en œuvre du déploiement et l’évaluation de la qualité, intégrant les aspects techniques, de sécurité, d’évaluation et les études de cas. Elle est élaborée conjointement par les utilisateurs de modèles, les fournisseurs de services techniques, les évaluateurs de qualité. La norme sollicite la participation d’unités de rédaction issues d’entreprises de grands modèles d’IA, de fournisseurs de services techniques, de fournisseurs de matériel, d’entreprises de cloud computing, de fournisseurs de services de sécurité, de fournisseurs de services de données, d’entreprises d’applications sectorielles, d’organismes de test et d’évaluation, d’organismes juridiques de conformité et d’organismes de développement durable. (Source : Construction de la normalisation Zhihe)
🌟 Communauté
Le contenu généré par IA suscite des inquiétudes concernant les « hallucinations » et la fiabilité de l’information : Plusieurs utilisateurs et médias rapportent que les grands modèles linguistiques, y compris DeepSeek, présentent le phénomène de « dire des bêtises avec un air sérieux », c’est-à-dire des hallucinations d’IA. L’IA peut inventer des faits inexistants, citer des sources erronées (comme l’origine de poèmes, d’articles de loi, d’informations sur des artefacts culturels), voire fabriquer des données (comme le « taux de mortalité des personnes nées dans les années 80″). Ce phénomène provient de données d’entraînement obsolètes, erronées ou biaisées, des angles morts de connaissance du modèle et du manque de capacité de vérification en temps réel. Les utilisateurs doivent se méfier de l’exactitude du contenu généré par l’IA, effectuer des vérifications croisées et une révision humaine, en particulier dans des contextes sérieux comme les études ou le travail. Une dépendance excessive peut entraîner la propagation d’informations erronées, exacerbant les défis de l' »ère post-vérité ». Le test d’hallucination Vectara HHEM montre également un taux d’hallucination élevé pour DeepSeek-R1. (Source : Zinc Scale)
La génération d’art par IA suscite à nouveau la controverse : à partir du succès viral du style Ghibli : La nouvelle fonctionnalité d’image de GPT d’OpenAI générant des images dans le style Ghibli a connu un grand succès, au point que le PDG Sam Altman a changé sa photo de profil pour ce style, stimulant les téléchargements et les revenus de ChatGPT. Cependant, cela a également ravivé la controverse sur l’éthique et les droits d’auteur de l’art généré par IA. Hayao Miyazaki lui-même s’était clairement opposé aux images générées par machine. Des professionnels d’Hollywood (comme Alex Hirsch, créateur de « Gravity Falls », et Zelda Williams, fille de Robin Williams) ont exprimé leur vif mécontentement, considérant cela comme un vol des créations des artistes, manquant d’âme. Altman a répondu qu’il s’agissait d’une « démocratisation de la création », une grande victoire pour la société. L’article estime que, bien que l’IA puisse imiter le style graphique, elle peut difficilement reproduire la narration complexe, le système esthétique et l’humanisme contenus dans les œuvres de Ghibli. La plupart des contenus générés par IA auront du mal à devenir des classiques, mais certaines collaborations homme-machine ou outils d’assistance réussiront. (Source : APPSO, Reddit r/artificial)

Point de vue : La structure cognitive humaine est l’avantage concurrentiel clé à l’ère de l’IA : L’article réfute l’idée que la popularisation des outils d’IA dévalorise les créateurs, arguant que l’expression et la création sont en soi des besoins humains intrinsèques et des « comportements de consommation », dont la valeur réside dans le processus et pas seulement dans le résultat. L’IA est un outil, incapable de remplacer la cognition et l’émotion uniques de l’homme. La « structure cognitive » du cerveau humain, formée par des milliards d’années d’évolution, est essentielle, et le développement de l’IA passe également d’une approche axée sur les données à une approche axée sur la cognition (imitant les processus cognitifs humains). Par conséquent, l’avantage concurrentiel futur ne réside pas dans le « travail », mais dans la « structure cognitive » ou le « point d’ancrage » pour interagir avec l’IA – c’est-à-dire une perspective unique, une expérience profonde et des liens authentiques établis avec les autres. Les créateurs devraient se concentrer sur le perfectionnement de leur partie unique, devenir des points de référence stables dans le déluge d’informations, fournir un sens de l’orientation et de la valeur pour eux-mêmes et les autres, et contrer l' »augmentation de l’entropie » potentiellement induite par l’IA. (Source : Wang Zhiyuan)
Point de vue : Les applications IA présentent de nouvelles barrières basées sur les relations et la confiance : En réponse à l’affirmation de Zhu Xiaohu selon laquelle « les applications IA n’ont pas de barrières », l’article propose une réfutation, arguant qu’à l’ère de l’IA, les barrières des applications sont passées des barrières technologiques traditionnelles à de nouvelles barrières basées sur les relations et la confiance. Les applications IA ne visent plus seulement l’échelle des utilisateurs, mais peuvent générer des profits sur des marchés verticaux en offrant des expériences personnalisées. Même les applications « coquilles » peuvent construire des avantages concurrentiels en établissant des liens profonds avec les utilisateurs (l’IA vous comprend mieux à mesure que vous l’utilisez), grâce au lien de confiance entre l’IP du créateur et les utilisateurs, et à l’optimisation continue via une boucle de données fermée (entraînement sur les données sectorielles + données personnelles). Il est conseillé aux entrepreneurs de se concentrer sur des domaines verticaux, de créer des expériences uniques, de construire des boucles de données fermées et d’établir des liens émotionnels. (Source : Zhou Zhi)
Les escroqueries aux « formations accélérées » en IA ciblent les pensions de retraite des personnes âgées : Des cours en ligne arborant des slogans tels que « monétisation rapide grâce à l’IA », « gagnez plus de 10 000 yuans par mois », ciblent précisément les personnes âgées via les plateformes de vidéos courtes. Ces cours utilisent souvent l’enseignement gratuit comme appât, des vidéos de personnes numériques, de fausses identités d' »experts », et exploitent l’anxiété liée à la retraite ou les mythes de l’enrichissement rapide pour attirer les personnes âgées dans des groupes. Ensuite, par le biais d’un marketing de type lavage de cerveau (comme la publication de captures d’écran de revenus, la création d’un sentiment d’urgence pour les places limitées), ils incitent les personnes âgées à payer des frais de scolarité élevés (de plusieurs milliers à plus de dix mille yuans). Le contenu des cours est souvent constitué de connaissances de base sur la gestion des médias sociaux reconditionnées, et les promesses d’enseignement des compétences en IA, de remboursement pour les commandes reçues, de tutorat individuel sont pour la plupart de fausses publicités. Le service après-vente est inexistant et les remboursements sont difficiles. De nombreux jeunes ont déjà partagé sur les réseaux sociaux les expériences de leurs proches qui ont failli être ou ont été victimes de ces escroqueries, appelant à la vigilance. (Source : Bao Bian)

Karpathy : Les LLM bouleversent le parcours traditionnel de diffusion technologique, autonomisant les individus : Andrej Karpathy écrit que le modèle de diffusion technologique des grands modèles linguistiques (LLM) est radicalement différent de celui des technologies transformationnelles historiques (généralement descendantes : gouvernement -> entreprises -> individus). Les LLM se sont démocratisés presque du jour au lendemain, à faible coût (voire gratuitement) et à grande vitesse, sur les appareils de chacun, apportant des avantages disproportionnés aux individus ordinaires, tandis que l’impact sur les entreprises et les gouvernements est relativement en retard. C’est parce que les LLM peuvent fournir des connaissances de niveau quasi-expert dans de vastes domaines, comblant les lacunes des connaissances individuelles. En comparaison, les organisations, en raison de leurs avantages intrinsèques inadaptés aux capacités des LLM, de la complexité élevée des problèmes, de l’inertie interne, etc., bénéficient dans une mesure limitée. Il estime que la distribution future de l’IA est actuellement étonnamment équilibrée, un véritable « pouvoir au peuple ». Mais si l’argent peut acheter une IA significativement meilleure à l’avenir, le paysage pourrait à nouveau changer. (Source : op7418)
Un PDG d’application IA de 18 ans rejeté par plusieurs universités prestigieuses suscite le débat : Zach Yadegari, 18 ans, a cofondé pendant ses années de lycée l’application de suivi des calories par IA Cal AI, qui a dépassé les 3 millions de téléchargements et génère des revenus annuels de plusieurs millions de dollars. Malgré un GPA de 4.0, un score ACT élevé et une expérience entrepreneuriale impressionnante, il a été rejeté par 15 des 18 universités de premier plan auxquelles il a postulé, dont Harvard, Stanford, MIT, etc. L’affaire a suscité une large attention et discussion sur les réseaux sociaux. L’essai d’admission de Yadegari, qu’il a rendu public, avoue qu’il n’avait initialement pas l’intention d’aller à l’université, mais qu’il a changé d’avis après avoir reconnu la valeur de la vie universitaire. Les raisons de son rejet suscitent des spéculations : certains pensent que l’essai semblait « arrogant » ou suggérait un risque élevé d’abandon, affectant les taux d’obtention de diplôme importants pour les universités prestigieuses ; d’autres critiquent les problèmes du système d’admission universitaire ou évoquent une discrimination à l’encontre des candidats d’origine asiatique (analogie avec le cas Stanley Zhong). Yadegari lui-même dit espérer être perçu comme sincère. (Source : 36Kr, AI Frontline)
Débat communautaire : L’IA est-elle une bénédiction ou une malédiction ? : Une discussion sur les avantages et les inconvénients de la technologie IA a émergé sur Reddit. Un utilisateur considère l’IA comme une bénédiction technologique, permettant de réaliser rapidement des idées créatives (comme générer des images de scènes spécifiques), et ne comprend pas pourquoi certaines personnes (en particulier les non-créateurs) lui sont hostiles. Ce point de vue souligne la valeur de l’IA pour répondre aux besoins de création personnels, instantanés et à faible coût. Cela reflète une vision positive au sein de la communauté sur la capacité des outils IA à autonomiser la créativité individuelle, tout en reflétant également la controverse générale et les différentes attitudes envers la technologie IA dans la société. (Source : Reddit r/artificial)
Débat communautaire : Le protocole MCP deviendra-t-il l' »Internet » des Agents IA ? : Avec le développement du MCP (Model Capability Protocol), la communauté commence à discuter de son potentiel. Certains pensent que le MCP, en fournissant des interfaces standardisées pour permettre aux LLM d’interagir avec des outils externes et des sources de données, pourrait devenir l’infrastructure de base connectant divers Agents et services IA, à l’instar d’Internet connectant différents ordinateurs et sites web. Cela laisse présager que l’écosystème futur des Agents IA pourrait être basé sur le MCP pour réaliser l’interopérabilité et la collaboration. (Source : Reddit r/ClaudeAI)

💡 Autres
Les trois géants de Microsoft discutent de 50 ans et de l’avenir avec AI Copilot : À l’occasion du 50e anniversaire de Microsoft, les trois générations de PDG, Bill Gates, Steve Ballmer et Satya Nadella, ont eu une conversation avec l’assistant IA Copilot. Gates a évoqué ses prévisions initiales sur la valeur des logiciels et la baisse des coûts de calcul, et a réfléchi au fait qu’il aurait dû gérer plus tôt les relations avec le gouvernement. Ballmer et Nadella ont tous deux souligné l’importance de l’IA, Ballmer estimant qu’il fallait approfondir les activités autour de la technologie IA de base, tandis que Nadella prédit que l’IA deviendra un outil intelligent omniprésent, un « produit de consommation courante ». Au cours de la conversation, Copilot a également « taquiné » avec humour les trois dirigeants, comme le fait que le « visage pensif » de Gates pourrait provoquer un « écran bleu » chez l’IA. Cette conversation montre la réflexion des dirigeants de Microsoft sur l’histoire et leur consensus sur un avenir piloté par l’IA. (Source : Tencent Technology)

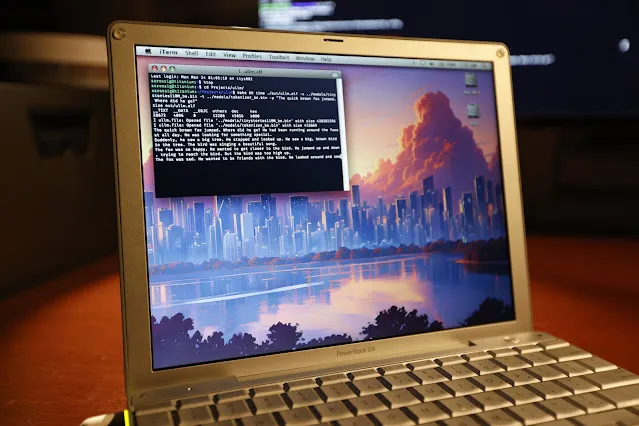
Exécution réussie de l’inférence LLM sur un PowerBook G4 vieux de 20 ans : L’ingénieur logiciel Andrew Rossignol a réussi à exécuter l’inférence du grand modèle Llama 2 de Meta (version TinyStories 110M) sur un ordinateur portable Apple PowerBook G4 vieux de 20 ans (processeur PowerPC G4 à 1,5 GHz, 1 Go de RAM). Il a porté le projet open-source llama2.c et l’a modifié pour l’architecture PowerPC (traitement big-endian, alignement mémoire), et a également utilisé l’extension vectorielle AltiVec (opérations de multiplication-accumulation fusionnées) pour augmenter la vitesse d’inférence d’environ 10% (de 0,77 token/s à 0,88 token/s). Bien que la vitesse ne soit qu’environ 1/8 de celle d’un CPU moderne, cela prouve qu’il est possible d’exécuter des modèles d’IA modernes même sur du matériel très ancien et aux ressources limitées. (Source : 36Kr, AI Frontline)
Discussion : Pourquoi avons-nous besoin de modèles du monde (World Models) ? : L’article explore la nécessité des modèles du monde (World Models), les considérant comme essentiels pour surmonter les limites actuelles des grands modèles linguistiques (LLM) (telles que le manque de compréhension du monde physique, de mémoire persistante, de capacités de raisonnement et de planification). Les modèles du monde visent à permettre à l’IA de construire une simulation interne de l’environnement, comme le font les humains, pour comprendre les lois physiques (comme la gravité, les collisions) et les relations causales, afin d’effectuer des prédictions et de prendre des décisions. L’article retrace l’évolution des modèles du monde, du concept en sciences cognitives à la modélisation computationnelle (combinant RL/DL, comme l’article « World Models » de DeepMind) puis à l’ère des grands modèles (combinant Transformer et multimodalité, comme Genie, PaLM-E). L’avantage principal des modèles du monde réside dans leur capacité de prédiction causale et de raisonnement contrefactuel, ainsi que leur capacité de généralisation inter-tâches, ce qui diffère fondamentalement de la nature des LLM qui prédisent sur la base de probabilités d’association dans de grands corpus textuels. Bien que les modèles du monde soient prometteurs, ils font encore face à des défis en termes de puissance de calcul, de capacité de généralisation et de données. (Source : Naojiti)

Nouvelle percée dans la détection de dangers par IA : Holmes-VAU réalise la compréhension d’anomalies dans les longues vidéos à plusieurs niveaux : Face aux lacunes des méthodes actuelles de compréhension des anomalies vidéo (VAU) dans le traitement des longues vidéos et des anomalies temporelles complexes, des institutions comme l’Université des sciences et technologies de Huazhong proposent le modèle Holmes-VAU et le jeu de données HIVAU-70k. Ce jeu de données contient plus de 70 000 instructions à différentes échelles temporelles (niveau vidéo, niveau événement, niveau clip), construit via un moteur de données semi-automatique, favorisant la compréhension globale des anomalies dans les vidéos longues et courtes par le modèle. Parallèlement, l’échantillonneur temporel axé sur les anomalies (Anomaly-focused Temporal Sampler – ATS) proposé peut échantillonner de manière dynamique et clairsemée les images clés en fonction du score d’anomalie, réduisant efficacement les informations redondantes et améliorant la précision et l’efficacité de l’analyse des anomalies dans les longues vidéos. Les expériences prouvent que Holmes-VAU surpasse considérablement les grands modèles multimodaux généraux dans les tâches de compréhension des anomalies vidéo à différentes granularités temporelles. (Source : Quantum Bit)
IA et durabilité : La question de l’empreinte carbone attire l’attention : Avec la croissance exponentielle de la taille des modèles d’IA et du volume de calcul pour l’entraînement, leur consommation d’énergie et leurs émissions de carbone deviennent des problèmes de plus en plus importants. Le rapport AI Index de Stanford souligne que, malgré l’amélioration de l’efficacité énergétique du matériel, la consommation globale d’énergie continue d’augmenter. Par exemple, l’entraînement du modèle Llama 3.1 de Meta est estimé générer près de 9000 tonnes de dioxyde de carbone. Bien que des modèles comme DeepSeek aient réalisé des percées en matière d’efficacité énergétique, l’empreinte carbone globale de l’industrie de l’IA reste un défi sérieux. Cela pousse les entreprises d’IA à explorer des solutions énergétiques zéro carbone comme l’énergie nucléaire et suscite des discussions sur la durabilité du développement de l’IA. (Source : Ronald_vanLoon, Ji Qizhi Xin)
