
Mots-clés:Llama 4, GPT-4o, performance de Llama 4, controverses Llama 4, GPT-4o style Ghibli, droits d’auteur GPT-4o, applications créatives GPT-4o
🔥 Pleins feux
Controverse autour de la sortie de Llama 4, performances jugées décevantes et soupçons de manipulation des classements: Meta a lancé la série de modèles Llama 4 (Scout, Maverick, Behemoth), utilisant une architecture MoE et supportant jusqu’à 10 millions de tokens de contexte. Cependant, les tests de la communauté révèlent des performances inférieures aux attentes dans des tâches comme le codage et la rédaction de textes longs, voire inférieures à celles de DeepSeek R1, Gemini 2.5 Pro et certains modèles open source existants. L’image promotionnelle officielle est critiquée pour être « optimisée pour la conversation », soulevant des doutes sur une éventuelle manipulation des classements (benchmark). De plus, les exigences élevées en matière de puissance de calcul rendent difficile l’exécution locale pour les utilisateurs ordinaires. Des fuites suggèrent des problèmes lors de l’entraînement interne et une interdiction d’utilisation par les entités de l’UE en raison de la conformité à l’EU AI Act. Bien que les capacités du modèle de base soient correctes, l’absence d’innovations majeures (comme le maintien du DPO au lieu du PPO/GRPO) fait que le lancement est considéré comme ayant reçu un accueil mitigé, voire décevant (Sources: AI科技评论, YouTube, YouTube, ylecun, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
La génération d’images « style Ghibli » par GPT-4o devient virale, repoussant les frontières créatives mais soulevant des controverses sur le droit d’auteur: Le modèle GPT-4o d’OpenAI a déclenché une vague de création sur les réseaux sociaux mondiaux grâce à sa puissante capacité à générer des images dans le « style Ghibli ». Les utilisateurs transforment des classiques du cinéma comme « La Légende de Zhen Huan », « Titanic » et des photos personnelles dans ce style. Cette fonctionnalité abaisse le seuil de la création artistique et favorise la démocratisation de l’expression visuelle. Cependant, sa reproduction précise de styles artistiques spécifiques a également suscité des controverses sur le droit d’auteur. Des voix s’élèvent pour demander si OpenAI a utilisé les œuvres du Studio Ghibli pour l’entraînement sans autorisation, soulignant à nouveau la zone grise juridique concernant le droit d’auteur des données d’entraînement de l’IA et les défis posés à l’originalité (Source: 36氪)

🎯 Tendances
Lancement du modèle de langage à diffusion Dream-7B, performances comparables aux modèles autorégressifs de même taille: L’Université de Hong Kong et Huawei Noah’s Ark Lab proposent un nouveau modèle de langage à diffusion, Dream-7B. Ce modèle montre des performances comparables, voire supérieures, aux meilleurs modèles autorégressifs de taille similaire comme Qwen2.5 7B et LLaMA3 8B dans les capacités générales, le raisonnement mathématique et les tâches de programmation. Il présente également des avantages uniques en matière de planification et de flexibilité d’inférence (par exemple, génération dans n’importe quel ordre). La recherche a utilisé des techniques telles que l’initialisation des poids à partir de modèles autorégressifs et le réarrangement adaptatif du bruit au niveau du token basé sur le contexte pour un entraînement efficace, démontrant le potentiel des modèles de diffusion dans le traitement du langage naturel (Source: AINLPer)
Publication du rapport AI Index 2025 de Stanford HAI, révélant le paysage concurrentiel mondial de l’IA: Le rapport annuel de Stanford HAI indique que les États-Unis restent en tête pour le nombre de modèles d’IA de pointe (40), mais la Chine rattrape rapidement (15, représentée par DeepSeek), et de nouveaux acteurs comme la France entrent en lice. Le rapport souligne l’essor des poids open source et des modèles multimodaux (comme Llama, DeepSeek), ainsi que l’amélioration de l’efficacité de l’entraînement de l’IA et la tendance à la baisse des coûts. Parallèlement, l’application et l’investissement dans l’IA en entreprise atteignent des records, mais s’accompagnent d’une augmentation des risques éthiques (abus, défaillance des modèles). Le rapport considère les données synthétiques comme essentielles et note que le raisonnement complexe reste un défi (Sources: Wired, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/MachineLearning)

OpenAI lance la nouvelle API Responses, base pour la construction d’Agents: Le PDG d’OpenAI, Sam Altman, a mis en avant la nouvelle API Responses. Cette API est positionnée comme la nouvelle primitive de base de l’API OpenAI, fruit de deux ans d’expérience en conception d’API, et servira de fondation pour la construction de la prochaine génération d’AI Agents (Source: sama)
Une étude révèle que les LLM peuvent identifier leurs propres erreurs: Une étude rapportée par VentureBeat montre que les grands modèles de langage (LLMs) ont la capacité de reconnaître les erreurs qu’ils commettent. Cette découverte pourrait avoir des implications pour l’auto-correction des modèles, l’amélioration de leur fiabilité et la confiance dans l’interaction homme-machine (Source: Ronald_vanLoon)

Les agents IA autonomes suscitent intérêt et inquiétude: Un article de FastCompany explore l’essor des agents IA autonomes, considérés comme la prochaine vague de développement de l’IA. Tout en reconnaissant leurs capacités étonnantes, l’article souligne également les risques potentiels et les aspects préoccupants, suscitant une réflexion sur la direction et la sécurité de cette technologie (Source: Ronald_vanLoon)

NVIDIA utilise des données synthétiques pour faire progresser la technologie de conduite autonome: Sawyer Merritt a partagé une vidéo de NVIDIA montrant comment l’entreprise utilise des données synthétiques pour entraîner et améliorer sa technologie de conduite entièrement autonome. Cela démontre l’importance croissante des données synthétiques pour résoudre les problèmes de rareté des données réelles, de coût élevé de l’annotation et de difficulté à couvrir les cas limites, devenant une ressource clé pour l’entraînement des modèles d’IA dans des domaines comme la conduite autonome (Source: Ronald_vanLoon)
Gemini 2.5 Pro se distingue dans l’évaluation MathArena USAMO: Oriol Vinyals de Google DeepMind a noté que Gemini 2.5 Pro a obtenu un score de 24,4% au benchmark MathArena USAMO (Olympiade Mathématique des États-Unis), devenant le premier modèle à obtenir un score significatif dans ce test de raisonnement mathématique de haute difficulté. Cela démontre ses fortes capacités en raisonnement mathématique et les progrès rapides de l’IA dans la résolution de problèmes complexes (Source: OriolVinyalsML)

Démonstration de technologie de contrôle de robot humanoïde: Ilir Aliu a fait la démonstration de la capacité à contrôler un robot humanoïde complet, ce qui implique généralement des technologies d’IA complexes telles que la planification de mouvement, le contrôle de l’équilibre, la perception et l’interaction, un axe de recherche important dans le domaine de l’intelligence incarnée (Source: Ronald_vanLoon)
Rumeur : le modèle Qwen supportera bientôt MCP: Selon une image partagée par karminski3, le grand modèle Qwen d’Alibaba prévoirait de supporter le MCP (Model Context Protocol). Cela signifierait que Qwen pourrait mieux s’intégrer avec des clients comme Cursor, en utilisant des outils externes (comme la navigation web, l’exécution de code) pour améliorer ses capacités (Source: karminski3)

Le modèle de deep learning VarNet atteint l’état de l’art (SOTA) dans la détection des mutations cancéreuses: Une étude publiée dans Nature Communications présente un framework de deep learning de bout en bout nommé VarNet. Entraîné sur des centaines de génomes complets de cancer, ce framework détecte les variations somatiques avec une haute précision, sans nécessiter d’ajustement manuel de règles heuristiques, et atteint les meilleures performances actuelles sur plusieurs benchmarks (Source: Reddit r/MachineLearning)

Exploration de mécanismes extensibles d’utilisation d’outils par les Agents: Face aux limitations des méthodes actuelles d’utilisation d’outils par les Agents (préchargement statique ou codage en dur), des chercheurs explorent des modèles d’utilisation d’outils dynamiques et découvrables. L’idée est que l’Agent interroge un registre d’outils externe pendant l’exécution, sélectionne et utilise dynamiquement des outils en fonction de son objectif, de manière similaire à un développeur parcourant la documentation d’une API. Différentes pistes de mise en œuvre sont discutées, comme l’exploration manuelle, la sélection automatique par correspondance floue, ou l’assistance par un LLM externe, visant à améliorer la flexibilité, l’extensibilité et la capacité d’adaptation autonome des Agents (Source: Reddit r/artificial)

Lancement du premier modèle RP à raisonnement multi-tours QwQ-32B-ArliAI-RpR-v1: ArliAI a lancé le modèle RpR (RolePlay with Reasoning) basé sur Qwen QwQ-32B. Ce modèle est présenté comme le premier modèle de raisonnement multi-tours correctement entraîné pour le jeu de rôle (RP) et l’écriture créative. Il utilise les datasets de la série RPMax et exploite le modèle de base QwQ pour générer des processus de raisonnement pour les données RP. Des méthodes d’entraînement spécifiques (comme les paragraphes indépendants du template) garantissent que le modèle ne dépend pas des blocs de raisonnement présents dans le contexte lors du raisonnement, visant à améliorer la cohérence et l’intérêt des longues conversations (Source: Reddit r/LocalLLaMA)

Les modèles de la série Qwen3 sont supportés par le framework d’inférence vLLM: Le framework d’inférence et de service LLM haute performance vLLM a fusionné le support pour les modèles à venir de la série Qwen3, incluant Qwen3-8B et Qwen3-MoE-15B-A2B. Cela annonce la sortie imminente des modèles Qwen3 et permet à la communauté d’utiliser vLLM pour déployer et exécuter efficacement ces nouveaux modèles (Source: Reddit r/LocalLLaMA)

🧰 Outils
Serveur Firecrawl MCP : Doter les LLM de puissantes capacités de web scraping: mendableai a rendu open source le serveur Firecrawl MCP. Cet outil implémente le Model Context Protocol (MCP), permettant aux clients LLM comme Cursor et Claude d’appeler les fonctions de web scraping, de crawl, de recherche et d’extraction de Firecrawl. Il supporte l’API cloud ou une instance auto-hébergée, et offre des fonctionnalités telles que le rendu JS, la découverte d’URL, les réessais automatiques, le traitement par lots, la limitation de débit, la surveillance des quotas, etc., améliorant considérablement la capacité des LLM à traiter et analyser les informations web en temps réel (Source: mendableai/firecrawl-mcp-server – GitHub Trending (all/monthly))
LlamaParse introduit un nouvel agent de mise en page piloté par VLM: LlamaIndex a lancé un nouvel agent de mise en page au sein de LlamaParse. Cet agent utilise des modèles visuels-linguistiques (VLM) avancés pour analyser les documents, capable de détecter tous les blocs sur une page (tableaux, graphiques, paragraphes) et de décider dynamiquement comment analyser chaque partie dans le format correct. Cela améliore considérablement la précision de l’analyse de documents et de l’extraction d’informations, en particulier en réduisant l’omission d’éléments comme les tableaux et les graphiques, et supporte des références visuelles précises (Source: jerryjliu0)

Hugging Face propose des services d’inférence Llama 4 via Together AI: Les utilisateurs peuvent désormais exécuter directement l’inférence sur la page du modèle Llama 4 de Hugging Face, un service fourni par Together AI. Cela offre aux développeurs et chercheurs un moyen pratique d’expérimenter et de tester les modèles Llama 4 sans avoir à les déployer eux-mêmes (Source: huggingface)
Un Agent IA utilisant Llama 4 pour simuler les tweets de célébrités: Karan Vaidya a présenté un Agent IA qui utilise le dernier modèle Llama 4 Scout de Meta, combiné avec des outils comme Composio, LlamaIndex, Groq, Exa, pour imiter le ton et le style de personnalités du monde de la tech comme Elon Musk, Sam Altman, Naval Ravikant, et générer des tweets à la demande (Source: jerryjliu0)
Lancement de Docext, outil open source d’intelligence documentaire locale: Nanonets a rendu open source Docext, un outil d’intelligence documentaire local (on-premise) basé sur des modèles visuels-linguistiques (VLM). Il n’a pas besoin de moteur OCR ou d’API externe et peut extraire directement des données structurées (champs et tableaux) à partir d’images de documents (comme des factures, des passeports). Il supporte les modèles personnalisés, les documents multi-pages, le déploiement via API REST, et fournit une interface web Gradio, en mettant l’accent sur la confidentialité des données et le contrôle local (Source: Reddit r/MachineLearning)
![[P] Docext: Open-Source, On-Prem Document Intelligence Powered by Vision-Language Models](https://external-preview.redd.it/AzAUcQsq5hLIWBdbljeo3gS5MBu9Hz6rtRM5jlgXne8.jpg?auto=webp&s=e6feffd0636e518c24e01ca133e5f83696a1fdaa)
Lancement du modèle open source texte-parole OuteTTS 1.0: OuteTTS 1.0 est un modèle texte-parole (TTS) open source basé sur l’architecture Llama, avec des améliorations significatives en qualité de synthèse vocale et en clonage vocal. La nouvelle version supporte 20 langues et fournit les poids du modèle aux formats SafeTensors et GGUF (llama.cpp), ainsi que la bibliothèque d’exécution Github correspondante, facilitant le déploiement et l’utilisation locale par les utilisateurs (Source: Reddit r/LocalLLaMA)

Un utilisateur utilise Claude pour scraper et créer un site d’emplois à distance: Un utilisateur a partagé comment il a utilisé le modèle Claude d’Anthropic pour scraper 10 000 offres d’emploi à distance et créer un site agrégateur gratuit d’emplois à distance nommé BetterRemoteJobs.com. Cela illustre le potentiel des LLM pour l’automatisation de la collecte d’informations et le développement rapide de prototypes (Source: Reddit r/ClaudeAI)

Partage d’un conteneur Docker pour MCPO: L’utilisateur flyfox666 a créé et partagé un conteneur Docker pour MCPO (Model Context Protocol Orchestrator), facilitant le déploiement et l’utilisation d’outils ou de services supportant MCP. MCPO est généralement utilisé pour coordonner l’interaction entre les LLM et les outils externes (comme les navigateurs, les exécuteurs de code) (Source: Reddit r/OpenWebUI)

📚 Apprentissage
Meta publie le Llama Cookbook : le guide officiel pour construire avec Llama: Meta a lancé le Llama Cookbook (anciennement llama-recipes), une bibliothèque de guides officiels conçue pour aider les développeurs à démarrer et à utiliser la série de modèles Llama (y compris les derniers Llama 4 Scout et Llama 3.2 Vision). Le contenu couvre l’inférence, le fine-tuning, le RAG, ainsi que des cas d’utilisation de bout en bout (comme un assistant e-mail, NotebookLlama, Text-to-SQL), et inclut des exemples d’intégrations tierces et d’IA responsable (Llama Guard) (Source: meta-llama/llama-cookbook – GitHub Trending (all/daily))
Publication de la première revue systématique sur le Test-Time Scaling (TTS): Des chercheurs de plusieurs institutions (CityU HK, McGill, Renmin University Gaoling) ont publié la première revue systématique sur l’extension en phase d’inférence des grands modèles (Test-Time Scaling, TTS). L’article propose un cadre d’analyse quadridimensionnel (Quoi/Comment/Où/Dans quelle mesure) et examine systématiquement les techniques TTS telles que CoT, Self-Consistency, la recherche, la vérification, DeepSeek-R1/o1, etc. L’objectif est de fournir une perspective unifiée, des critères d’évaluation et une orientation pour le développement de ce domaine clé visant à surmonter les goulots d’étranglement du pré-entraînement (Source: AI科技评论)
Cours sur les Diffusion Models et implémentation PyTorch: Xavier Bresson partage ses notes de cours sur les Diffusion Models, expliqués à partir des premiers principes statistiques, et fournit des notebooks PyTorch d’accompagnement, incluant le code pour implémenter des Diffusion Models à partir de zéro avec Transformer et UNet (Source: ylecun)

Guide pour construire des applications RAG avec LangChain et DeepSeek-R1: La communauté LangChain a partagé un guide expliquant comment utiliser DeepSeek-R1 (un modèle open source de type OpenAI) et les outils de traitement de documents de LangChain pour construire des applications RAG (génération augmentée par récupération). Le guide montre des implémentations locales et cloud (Source: LangChainAI)

Analyse d’article : Generative Verifiers – La modélisation de récompense comme prédiction du prochain token: Un article intitulé « Generative Verifiers » propose une nouvelle approche pour les modèles de récompense (Reward Model, RM). Au lieu que le RM ne produise qu’un score scalaire, il génère du texte explicatif (similaire à CoT) pour aider à la notation. Ce RM « anthropomorphisé » peut intégrer des techniques d’ingénierie de prompt, améliorer la flexibilité, et pourrait devenir une direction importante pour l’amélioration du RLHF à l’ère des grands modèles de raisonnement (LRM) (Source: dotey)

Le dataset OpenThoughts2 populaire sur Hugging Face: Ryan Marten souligne que le dataset OpenThoughts2 est devenu le dataset tendance numéro 1 sur Hugging Face. Cela indique généralement que le dataset a reçu une large attention et utilisation au sein de la communauté, potentiellement pour l’entraînement de modèles, l’évaluation ou d’autres objectifs de recherche (Source: huggingface)

L’ajout de connexions résiduelles accélère significativement l’entraînement de RepLKNet-XL: Un utilisateur Reddit rapporte qu’après avoir ajouté des connexions résiduelles (Skip Connections) à son modèle RepLKNet-XL, la vitesse d’entraînement a été multipliée par 6. Sur une RTX 5090, le temps pour 20 000 itérations est passé de 2,4 heures à 24 minutes ; sur une RTX 3090, le temps pour 9 000 itérations est passé de 10 heures 28 minutes à 1 heure 47 minutes. Cela confirme à nouveau l’importance des connexions résiduelles dans l’entraînement des réseaux profonds (Source: Reddit r/deeplearning)
Neural Graffiti : Ajout d’une couche de neuroplasticité aux Transformers: L’utilisateur babycommando propose une technique expérimentale nommée « Neural Graffiti », visant à insérer une « couche de graffiti » inspirée de la neuroplasticité entre les couches Transformer et la couche de projection de sortie. L’objectif est d’influencer la génération de tokens en fonction des expériences d’interaction passées, donnant au modèle une « personnalité » évolutive au fil du temps. Cette couche ajuste la sortie en fusionnant la mémoire historique. Le projet est open source et une démo est disponible (Source: Reddit r/LocalLLaMA)
💼 Affaires
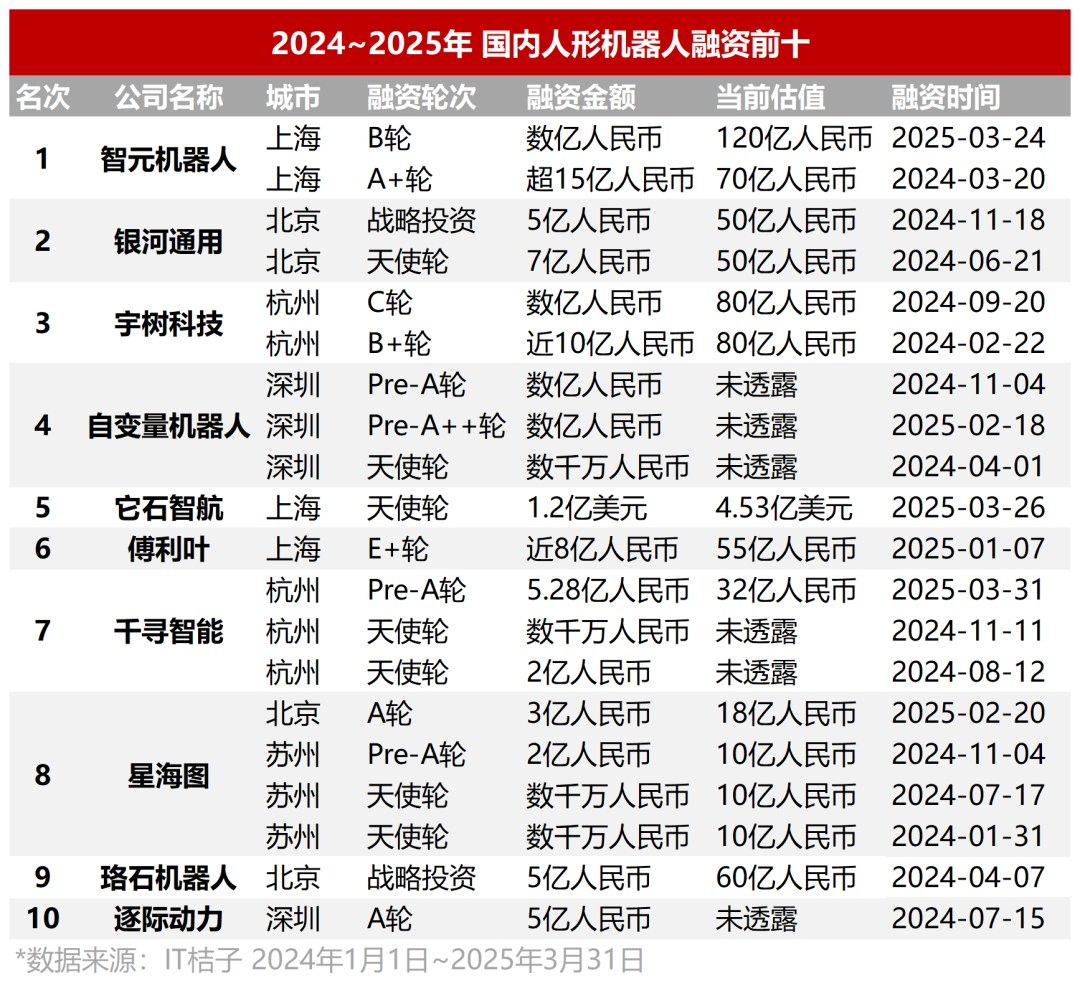
Surchauffe des investissements dans les robots humanoïdes, valorisations élevées des projets précoces, voie de commercialisation encore remise en question: Au T1 2024-2025, le financement dans le domaine des robots humanoïdes en Chine a explosé. Les tours d’amorçage de dizaines de millions sont devenus la norme, près de la moitié des projets ont levé plus de 100 millions de yuans, avec des valorisations dépassant généralement 100 millions, voire 500 millions. Des projets phares comme Itastek Robotics ont obtenu des centaines de millions de dollars de financement quelques mois après leur création. Les fonds d’État sont devenus des moteurs importants. Cependant, malgré cet engouement, la voie de commercialisation reste floue. Les coûts élevés (de centaines de milliers à plusieurs millions), et la difficulté de déploiement dans des scénarios d’application (actuellement concentrés sur l’industrie, la santé, etc. en ToB) sont les principaux défis. Des investisseurs comme Zhu Xiaohu ont commencé à se retirer, et l’effondrement de CloudMinds Robotics a également tiré la sonnette d’alarme, présentant un secteur contrasté. Les constructeurs automobiles (BYD, Xpeng, Xiaomi, etc.) entrent en jeu, cherchant des synergies technologiques et de nouveaux points de croissance (Sources: 36氪, 36氪)
Concurrence intense sur le marché des lunettes intelligentes IA entre la Chine et les États-Unis, avec des stratégies différentes: Les lunettes intelligentes IA sont considérées comme une plateforme informatique de nouvelle génération potentielle, intensifiant la concurrence entre les géants technologiques chinois et américains. Les fabricants américains comme Meta (Ray-Ban Meta, Hypernova), Amazon, Apple ciblent le marché haut de gamme, s’appuyant sur leur marque et leur écosystème, avec des prix élevés. En revanche, les fabricants chinois comme Xiaomi, Huawei (via Shanji Technology) adoptent une stratégie de rapport qualité-prix, utilisant leurs avantages en matière de chaîne d’approvisionnement et d’innovation localisée pour abaisser considérablement la barrière d’entrée sur le marché (par exemple, le Shanji A1 à 999 yuans), visant le marché de masse. La technologie optique, la puissance de calcul côté terminal, la consommation d’énergie et l’écosystème de scénarios sont des défis clés. Les ventes mondiales devraient dépasser 30 millions d’unités d’ici 2027, la Chine représentant près de la moitié du marché (Source: 36氪)

Le PDG d’Anthropic craint qu’un krach boursier n’entrave les progrès de l’IA: Dans une interview, le PDG d’Anthropic, Dario Amodei, a mentionné qu’outre la géopolitique (comme le conflit dans le détroit de Taiwan) et les goulots d’étranglement des données, des perturbations majeures des marchés financiers pourraient également freiner le développement de l’IA. Il a expliqué que si un krach boursier ébranlait la confiance dans les perspectives de la technologie IA, cela pourrait affecter la capacité de financement d’entreprises comme OpenAI et Anthropic, réduisant ainsi les fonds et la puissance de calcul disponibles pour entraîner les grands modèles, créant une prophétie auto-réalisatrice et ralentissant les progrès de l’IA (Source: YouTube)
Le PDG de Shopify oblige tous les employés à adopter l’IA, l’intégrant au travail quotidien et aux performances: Un e-mail interne du PDG de Shopify, Tobi Lütke, exige que tous les employés de l’entreprise apprennent et appliquent l’IA. Les mesures spécifiques incluent : l’intégration de l’application de l’IA dans l’évaluation des performances et l’évaluation par les pairs ; l’utilisation obligatoire de l’IA pendant la « phase de prototypage GSD » (GSD Prototype phase) ; avant de demander de nouvelles ressources humaines ou matérielles, les départements doivent d’abord prouver pourquoi l’objectif ne peut pas être atteint avec l’IA. Cette initiative vise à intégrer profondément l’IA dans la culture et les processus opérationnels de l’entreprise, afin d’améliorer l’efficacité et la capacité d’innovation (Sources: dotey, AravSrinivas)
Fauna Robotics lève 30 millions de dollars pour développer des robots adaptés aux espaces humains: Fauna Robotics a annoncé avoir levé 30 millions de dollars lors d’un tour de financement mené par Kleiner Perkins, Quiet Capital et Lux Capital. L’entreprise se consacre au développement de robots capables de fonctionner de manière flexible dans les espaces de vie et de travail humains, ce qui nécessite généralement des capacités avancées de perception, de navigation, d’interaction et de manipulation, étroitement liées à l’intelligence incarnée et à l’IA (Source: ylecun)

Anthropic et Northeastern University s’associent pour promouvoir l’IA responsable dans l’enseignement supérieur: Anthropic a établi un partenariat avec Northeastern University aux États-Unis, visant à intégrer l’innovation en IA responsable dans l’enseignement, la recherche et les opérations de l’enseignement supérieur. Dans le cadre de cette collaboration, Northeastern University promouvra l’utilisation de Claude for Education d’Anthropic au sein de son réseau mondial, fournissant des outils d’IA aux étudiants et au personnel (Source: Reddit r/ArtificialInteligence)

🌟 Communauté
Interview de Sam Altman : L’IA comme outil d’autonomisation, pas de remplacement, optimiste quant à l’avenir des Agents: Dans une interview, le PDG d’OpenAI, Sam Altman, a réagi aux sujets d’actualité. Il estime que la popularité des images style Ghibli générées par GPT-4o prouve une fois de plus la valeur de la technologie pour abaisser le seuil de la création. Concernant les accusations d’être une simple « coquille vide », il affirme que la plupart des entreprises qui ont changé le monde étaient initialement considérées comme de simples repackagings, l’essentiel étant de créer une valeur utilisateur unique. Il prédit que l’IA augmentera considérablement la productivité des programmeurs (potentiellement par 10) et provoquera une explosion de la demande de logiciels via le « paradoxe de Jevons ». Il est optimiste quant à la transition des AI Agents d’outils passifs à des exécutants actifs, en particulier dans le domaine de la programmation. Il conseille aux professionnels d’adopter l’IA, car à une époque où la stagnation équivaut à un suicide professionnel, il faut privilégier les environnements permettant d’être exposé aux technologies de pointe (Source: 量子位)

La prédiction d’une superintelligence IA d’ici 2027 suscite des débats, jugée trop optimiste: Un rapport intitulé « AI-2027 », co-écrit par d’anciens chercheurs d’OpenAI, prédit que l’IA atteindra des capacités de codage surhumaines début 2027, accélérant ainsi son propre développement et menant à la naissance d’une superintelligence. Le rapport dépeint des scénarios où des AI Agents agissent de manière autonome (piratage, auto-réplication). Cependant, cette prédiction est contestée. Les critiques estiment qu’elle sous-estime la complexité du monde réel, les limites des benchmarks, les barrières des données/codes propriétaires et les risques de sécurité. Ils soutiennent que même si l’IA excelle dans certains benchmarks, la réalisation de tâches complexes de manière totalement autonome et fiable (en particulier celles impliquant une interaction avec le monde physique ou des domaines sensibles à la sécurité) reste un défi immense, et que le calendrier prédit est probablement trop agressif (Source: YouTube)
Un utilisateur partage des prompts pour la génération d’images IA: Dotey a partagé deux ensembles de prompts pour la génération d’images IA (adaptés à des outils comme Sora ou GPT-4o) : un pour créer une figurine de collection 3D mignonne et détaillée basée sur une photo (style chaleureux et romantique), et un autre pour transformer les personnes d’une photo en style boîte de figurine Funko Pop. Des descriptions détaillées et des exigences de style sont fournies, accompagnées d’images d’exemple (Source: dotey)

Claude 3.7 Sonnet critiqué pour introduire des modifications non pertinentes dans le code: Un utilisateur Reddit signale que lors de l’utilisation de Claude 3.7 Sonnet pour modifier du code, le modèle a tendance à modifier du code ou des fonctionnalités non liés qui ne font pas partie de la demande, causant des ruptures inattendues. L’utilisateur indique que Claude 3.5 Sonnet se comportait mieux à cet égard, et pouvait même corriger les erreurs de la version 3.7 via git diff. L’utilisateur cherche des prompts efficaces pour contraindre le comportement de la version 3.7 et éviter ce type de problème (Source: Reddit r/ClaudeAI)
Les principaux LLM échouent aux tâches de planification sous contraintes: Un utilisateur Reddit rapporte avoir demandé à ChatGPT, Grok et Claude de créer un calendrier de rotation de basketball répondant à des contraintes spécifiques (nombre de joueurs, temps de jeu égal, limites de jeu consécutif, restrictions sur les combinaisons de joueurs spécifiques). Tous les modèles ont affirmé avoir satisfait les conditions, mais une vérification manuelle a révélé des erreurs de comptage et l’incapacité à exécuter correctement toutes les contraintes. Cela met en évidence les limites actuelles des LLM dans le traitement de la satisfaction de contraintes complexes et des tâches de planification précises (Source: Reddit r/ArtificialInteligence)
Un utilisateur se plaint de performances incohérentes sur son compte Claude Pro, soupçonnant une limitation ou une dégradation: Un utilisateur de Claude Pro signale des performances très différentes entre deux comptes payants à son nom. L’un des comptes (le compte d’origine) est presque inutilisable pour les tâches de génération de code long, s’arrêtant souvent après avoir généré quelques lignes de code après avoir cliqué sur « Continuer », comme s’il était intentionnellement limité ou endommagé. Le nouveau compte n’a pas ce problème. L’utilisateur soupçonne une limitation ou une dégradation de service opaque en arrière-plan et exprime une forte insatisfaction quant à la fiabilité du produit payant (Source: Reddit r/ClaudeAI)
Discussion : Comment les LLM comprennent-ils les invites de jeu de rôle ?: Un utilisateur Reddit demande comment les grands modèles de langage (LLM) comprennent et exécutent des instructions comme « jouer le rôle de » (par exemple, jouer le rôle d’une grand-mère). L’utilisateur suppose que cela est lié au fine-tuning et se demande si les développeurs doivent pré-coder ou préparer des données d’entraînement spécifiques pour un grand nombre de rôles, ainsi que la relation entre l’entraînement général et le fine-tuning pour des rôles spécifiques (Source: Reddit r/ArtificialInteligence)

Discussion satirique : Remplacer la pensée personnelle par l’IA pour gagner en « efficacité » et en « calme »: Un post sur Reddit préconise, sur un ton satirique, d’externaliser complètement la pensée personnelle, la prise de décision, l’expression d’opinions, etc., à l’IA. L’auteur prétend que cela élimine l’anxiété, améliore l’efficacité et, de manière inattendue, donne aux autres l’impression que vous êtes devenu « sage » et « calme », alors qu’en réalité vous n’êtes qu’une « marionnette de chair » du LLM. Le post a suscité des discussions sur la valeur de la pensée, la dépendance à l’IA et la subjectivité humaine (Source: Reddit r/ChatGPT)
Discussion : Pourquoi le grand public n’utilise-t-il pas encore largement l’IA ?: Un utilisateur Reddit lance une discussion sur les raisons pour lesquelles, malgré l’omniprésence du sujet de l’IA, de nombreuses personnes extérieures au monde de la technologie ne l’utilisent toujours pas activement dans leur travail ou leur vie quotidienne. Les raisons possibles évoquées incluent : ne pas réaliser qu’ils l’utilisent déjà (par exemple, Siri, algorithmes de recommandation), le scepticisme envers la technologie (boîte noire, confidentialité, emplois), une interface utilisateur peu conviviale (nécessitant des connaissances en ingénierie de prompt), une culture du lieu de travail qui ne l’a pas encore adoptée, etc. Cela a suscité une réflexion sur le fossé d’adoption de l’IA (Source: Reddit r/ArtificialInteligence)
Un utilisateur partage des techniques de prompt pour une recherche approfondie avec Claude 3.7: Un utilisateur Reddit partage une structure de prompt détaillée visant à faire en sorte que Claude 3.7 Sonnet simule l’outil Deep Research d’OpenAI pour une recherche approfondie collaborative. La méthode force l’utilisation de points de contrôle (arrêt après avoir recherché 5 sources pour demander la permission) et combine des outils MCP comme Playwright (navigation web), mcp-reasoner (raisonnement), youtube-transcript (transcription vidéo), pour guider le modèle dans une collecte et une analyse d’informations structurées et par étapes (Source: Reddit r/ClaudeAI)
Un utilisateur partage son workflow et ses astuces pour utiliser efficacement Claude Pro: Un utilisateur de Claude Pro partage son expérience d’utilisation efficace de Claude dans des scénarios de codage, visant à réduire les problèmes liés aux limites de tokens et aux mauvaises performances du modèle. Les astuces incluent : fournir un contexte de code précis via des fichiers .txt, définir des instructions de projet concises, utiliser davantage le mode concise de l’Extended Thinking, exiger explicitement le format de sortie, modifier le prompt pour déclencher une nouvelle branche en cas de problème plutôt que d’itérer continuellement, et garder les conversations courtes en ne fournissant que les informations nécessaires. L’auteur estime qu’en optimisant le workflow, on peut utiliser efficacement Claude Pro (Source: Reddit r/ClaudeAI)
Débat philosophique sur la conscience des LLM: Sur Reddit, un utilisateur cite le « Je pense, donc je suis » de Descartes, arguant que puisque les grands modèles de langage (LLM) capables d’effectuer un raisonnement peuvent être « conscients » de leur propre « pensée » (processus de raisonnement), ils satisfont à la définition de la conscience et sont donc conscients. Ce point de vue assimile la fonction de raisonnement des LLM à la conscience de soi, suscitant un débat philosophique sur la définition de la conscience, le fonctionnement des LLM et la différence entre la simulation et la possession réelle de la conscience (Source: Reddit r/artificial)
Discussion : Seriez-vous prêt à voler dans un avion entièrement piloté par l’IA ?: Un utilisateur Reddit lance un sondage et une discussion demandant si les gens seraient prêts à voler dans un avion entièrement piloté par l’IA, sans pilote humain dans le cockpit. La discussion aborde le niveau de confiance dans la technologie actuelle de pilotage automatique, la fiabilité de l’IA dans des domaines spécifiques (comme l’aviation), la question de la responsabilité et l’évolution de l’acceptation par le public avec les développements technologiques futurs (Source: Reddit r/ArtificialInteligence)
💡 Divers
Le centre d’intérêt de la branche à but non lucratif d’OpenAI pourrait se déplacer: Avec le développement commercial et la valorisation en flèche d’OpenAI (rumeur de 300 milliards de dollars), le rôle de sa branche à but non lucratif initialement créée pour contrôler l’AGI et utiliser ses bénéfices pour le bien de toute l’humanité semble évoluer. Des commentaires suggèrent que le centre d’intérêt de cette branche pourrait être passé de la gouvernance ambitieuse de l’AGI à des activités philanthropiques plus traditionnelles, comme le soutien à des œuvres caritatives locales, suscitant des discussions sur son intention initiale et ses promesses (Source: YouTube)
L’IA pilotée par l’intention pour le support client: Un article de T-Mobile Business explore l’utilisation de l’IA pilotée par l’intention pour améliorer l’expérience du support client. L’IA peut prédire et résoudre proactivement les problèmes, gérer un grand volume d’interactions et assister les agents humains pour fournir un support plus empathique. En identifiant l’intention du client, l’IA peut répondre plus précisément à ses besoins et optimiser les processus de service (Source: Ronald_vanLoon)
Le défi pour l’IA d’identifier le contenu généré par l’IA: DeltalogiX discute d’un défi intéressant auquel l’IA est confrontée : identifier le contenu généré par d’autres IA. Avec l’amélioration des capacités de l’IA à générer du texte, des images, de l’audio, etc., il devient de plus en plus difficile de distinguer la création humaine de la création machine, ce qui pose de nouvelles exigences techniques pour la modération de contenu, la protection du droit d’auteur, la vérification de l’authenticité de l’information, etc. (Source: Ronald_vanLoon)

Le succès de la GenAI dépend d’une stratégie de données de haute qualité: Un article de Forbes souligne qu’une stratégie de données générique ne convient pas à toutes les applications GenAI. Pour assurer le succès des projets GenAI, il faut élaborer des stratégies ciblées de qualité des données en fonction des scénarios d’application spécifiques, en se concentrant sur la pertinence, l’exactitude, l’actualité et la diversité des données, afin d’éviter que le modèle ne produise des biais ou des sorties erronées (Source: Ronald_vanLoon)

L’IA au service des plans de traitement médical personnalisé: Une illustration d’Antgrasso met en évidence le potentiel de l’IA dans l’élaboration de plans de traitement médical personnalisé. En analysant les données génomiques, les antécédents médicaux, le mode de vie et d’autres informations multidimensionnelles des patients, l’IA peut aider les médecins à concevoir des plans de traitement plus précis et plus efficaces, favorisant le développement de la médecine de précision (Source: Ronald_vanLoon)

L’IA redéfinit l’efficacité et la rapidité de la chaîne d’approvisionnement: Un article de Nicochan33 explore comment l’intelligence artificielle redéfinit l’efficacité et la rapidité de la chaîne d’approvisionnement en optimisant les prévisions, la planification d’itinéraires, la gestion des stocks, l’alerte précoce des risques, etc., la rendant plus agile et intelligente (Source: Ronald_vanLoon)

Un utilisateur affirme avoir développé un améliorateur universel de raisonnement pour LLM: Un utilisateur Reddit affirme avoir développé une méthode qui améliore significativement la capacité de raisonnement des LLM (prétendant une amélioration de 15-25 points de « QI ») sans nécessiter de fine-tuning, et qui pourrait fonctionner comme une couche d’alignement transparente. L’utilisateur cherche à obtenir un brevet et sollicite l’avis de la communauté sur les voies de développement futures (licence, collaboration, open source, etc.) (Source: Reddit r/deeplearning)
Manifeste du projet OAK – Open Agentic Knowledge: Un manifeste pour un projet nommé OAK (Open Agentic Knowledge) est apparu sur GitHub. Bien que le contenu spécifique ne soit pas détaillé, le nom suggère que le projet pourrait viser à créer un cadre ou un standard ouvert pour que les AI Agents utilisent et partagent des connaissances, afin de promouvoir l’amélioration de leurs capacités et leur interopérabilité (Source: Reddit r/ArtificialInteligence)
