
Palabras clave:Kimi K2 Thinking, Gemini, Agente de IA, LLM, Modelo de código abierto, Kimi K2 Thinking contexto de 256K, Gemini 1.2 billones de parámetros, Herramientas de invocación de agentes de IA, Aceleración de inferencia LLM, Pruebas comparativas de modelos de IA de código abierto
🔥 Foco
Lanzamiento del modelo Kimi K2 Thinking: un nuevo avance en la capacidad de inferencia de IA de código abierto : Moonshot AI ha lanzado el modelo Kimi K2 Thinking, un modelo de agente de inferencia de código abierto con un billón de parámetros que ha demostrado un rendimiento excepcional en benchmarks como HLE y BrowseComp. Soporta una ventana de contexto de 256K y puede ejecutar entre 200 y 300 llamadas de herramientas consecutivas. El modelo logra una aceleración de inferencia de dos veces con cuantificación INT4, reduciendo el consumo de memoria a la mitad sin pérdida de precisión. Esto marca una nueva frontera para los modelos de IA de código abierto en capacidades de inferencia y agente, compitiendo con los modelos cerrados de primer nivel a un costo menor, y se espera que acelere el desarrollo y la popularización de aplicaciones de IA. (Fuente: eliebakouch, scaling01, bookwormengr, vllm_project, nrehiew_, crystalsssup, Reddit r/LocalLLaMA)

Apple y Google colaboran: Gemini impulsa una gran actualización de Siri : Apple planea introducir el modelo de IA Gemini de 1.2 billones de parámetros de Google en iOS 26.4, que se lanzará en la primavera de 2026, para una actualización integral de Siri. Esta versión personalizada de Gemini se ejecutará en los servidores de nube privada de Apple, con el objetivo de mejorar significativamente la comprensión semántica, las conversaciones multirrespuesta y las capacidades de recuperación de información en tiempo real de Siri, e integrar la función de búsqueda web de IA. Este movimiento marca un cambio estratégico importante para Apple, que busca la colaboración externa en el campo de la IA para acelerar la inteligencia de sus productos principales, lo que presagia un gran salto funcional para Siri. (Fuente: op7418, pmddomingos, TheRundownAI)

El científico Kosmos AI logra un salto en la eficiencia de la investigación, descubriendo 7 hallazgos de forma independiente : El científico Kosmos AI completó el equivalente a 6 meses de trabajo de un científico humano en 12 horas, leyendo 1500 artículos, ejecutando 42,000 líneas de código y produciendo informes científicos rastreables. Descubrió de forma independiente 7 hallazgos en campos como la neuroprotección y la ciencia de materiales, 4 de los cuales fueron propuestos por primera vez. El sistema, a través de la memoria continua y la planificación autónoma, ha evolucionado de una herramienta pasiva a un colaborador de investigación. Aunque todavía requiere que los humanos verifiquen aproximadamente el 20% de las conclusiones, presagia que la colaboración humano-máquina remodelará el paradigma de la investigación científica. (Fuente: Reddit r/MachineLearning, iScienceLuvr)
🎯 Tendencias
El modelo Google Gemini 3 Pro se filtra accidentalmente, generando preocupación en la comunidad : El modelo Google Gemini 3 Pro se filtró accidentalmente, y actualmente estuvo brevemente disponible en la CLI de Gemini para IPs de EE. UU., aunque con errores frecuentes e inestabilidad. Esta filtración ha generado una gran atención en la comunidad sobre el número de parámetros del modelo y su futuro lanzamiento, lo que sugiere que los últimos avances de Google en modelos de lenguaje grandes podrían hacerse públicos pronto. (Fuente: op7418)
El modelo OpenAI GPT-5.1 Thinking está a punto de ser lanzado, la expectación de la comunidad es alta : Múltiples fuentes en redes sociales insinúan que OpenAI está a punto de lanzar el modelo GPT-5.1 Thinking, y hay información filtrada que confirma su existencia. Esta noticia ha generado una gran expectación en la comunidad sobre las capacidades del modelo de próxima generación de OpenAI y su fecha de lanzamiento, con un enfoque particular en la mejora de sus capacidades de razonamiento y pensamiento, lo que se espera que impulse nuevamente la vanguardia de la tecnología de IA. (Fuente: scaling01)
Investigación de Anthropic descubre conciencia introspectiva emergente en LLM, la autoconciencia de la IA genera atención : A través de experimentos de inyección de conceptos, Anthropic descubrió que sus LLM (como Claude Opus 4.1 y 4) muestran una conciencia introspectiva emergente, capaz de detectar conceptos inyectados con un 20% de éxito, distinguir entre “pensamiento” interno y entrada de texto, e identificar intenciones de salida. Los modelos también pueden regular su estado interno cuando se les solicita, lo que indica que los LLM actuales están desarrollando una autoconciencia mecánica diversa y poco fiable, lo que provoca una discusión profunda sobre la autoconciencia y la conciencia de la IA. (Fuente: TheTuringPost)

OpenAI Codex itera rápidamente, ChatGPT soporta interrupción y guía para mejorar la eficiencia de la interacción : El modelo Codex de OpenAI está mejorando rápidamente, y ChatGPT también ha añadido una nueva función que permite a los usuarios interrumpir y añadir nuevo contexto durante la ejecución de consultas largas, sin necesidad de reiniciar o perder el progreso. Esta importante actualización de funciones permite a los usuarios guiar y refinar las respuestas de la IA como si colaboraran con un compañero de equipo real, mejorando en gran medida la flexibilidad y eficiencia de la interacción, y optimizando la experiencia del usuario en investigaciones profundas y consultas complejas. (Fuente: nickaturley, nickaturley)
Tencent Hunyuan lanza un podcast interactivo de IA, explorando un nuevo modelo de interacción de contenido de IA : Tencent Hunyuan ha lanzado el primer podcast interactivo de IA de China, que permite a los usuarios interrumpir y hacer preguntas en cualquier momento mientras escuchan. La IA proporciona respuestas combinando el contexto, la información de fondo y la búsqueda en línea. Aunque la tecnología ha logrado una interacción de voz más natural, su núcleo sigue siendo la interacción entre el usuario y la IA, no con el creador, y las respuestas no tienen una conexión directa con el creador. La implementación comercial y el modelo de pago del usuario aún enfrentan desafíos, y es urgente explorar cómo establecer una conexión emocional entre los usuarios y los creadores. (Fuente: 36氪)
Desarrollo y desafíos del mercado de hardware de IA e inteligencia encarnada: de auriculares a robots humanoides : Con la madurez de los modelos grandes y las tecnologías multimodales, el mercado de auriculares de IA sigue calentándose, expandiendo sus funciones al ecosistema de contenido y la monitorización de la salud. La industria de robots de inteligencia encarnada también se encuentra en el umbral de una nueva ronda de explosión. Empresas como Xpeng y PHYBOT han mostrado robots humanoides, aclarando las dudas sobre “personas escondidas”, y explorando escenarios de aplicación como el cuidado de ancianos y la preservación cultural (como la caligrafía y el kung fu). Sin embargo, la industria enfrenta desafíos como el costo, el retorno de la inversión, la recopilación de datos y los cuellos de botella de estandarización. A corto plazo, necesita centrarse pragmáticamente en la “versatilidad de escenarios”, y a largo plazo, requiere plataformas abiertas y colaboración ecológica. La IA en el campo de la salud también debe prestar atención a las brechas en la atención al paciente. (Fuente: 36氪, 36氪, op7418, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Nuevos modelos y avances de rendimiento: generación de código Qwen3-Next, modelos híbridos vLLM e inferencia de baja memoria : El modelo Qwen3-Next de Alibaba Cloud sobresale en la generación de código complejo, creando con éxito aplicaciones web completamente funcionales. vLLM soporta completamente modelos híbridos como Qwen3-Next, Nemotron Nano 2 y Granite 4.0, mejorando la eficiencia de la inferencia. El modelo Jamba Reasoning 3B de AI21 Labs logra una ejecución de memoria ultrabaja de 2.25 GiB. Maya-research/maya1 lanza una nueva generación de modelos de texto a voz autorregresivos, que soportan la personalización del timbre mediante descripción de texto. TabPFN-2.5 amplía la capacidad de procesamiento de datos tabulares a 50,000 muestras. Se analiza que el modelo Windsurf SWE-1.5 se parece más a GLM-4.5, lo que sugiere la aplicación de modelos grandes nacionales en Silicon Valley. MiniMax AI ocupa el segundo lugar en la arena RockAlpha. Estos avances impulsan colectivamente los límites de rendimiento de los LLM en la generación de código, la eficiencia de inferencia, la multimodalidad y el procesamiento de datos tabulares. (Fuente: Reddit r/deeplearning, vllm_project, AI21Labs, Reddit r/LocalLLaMA, Reddit r/MachineLearning, dotey, Alibaba_Qwen, MiniMax__AI)

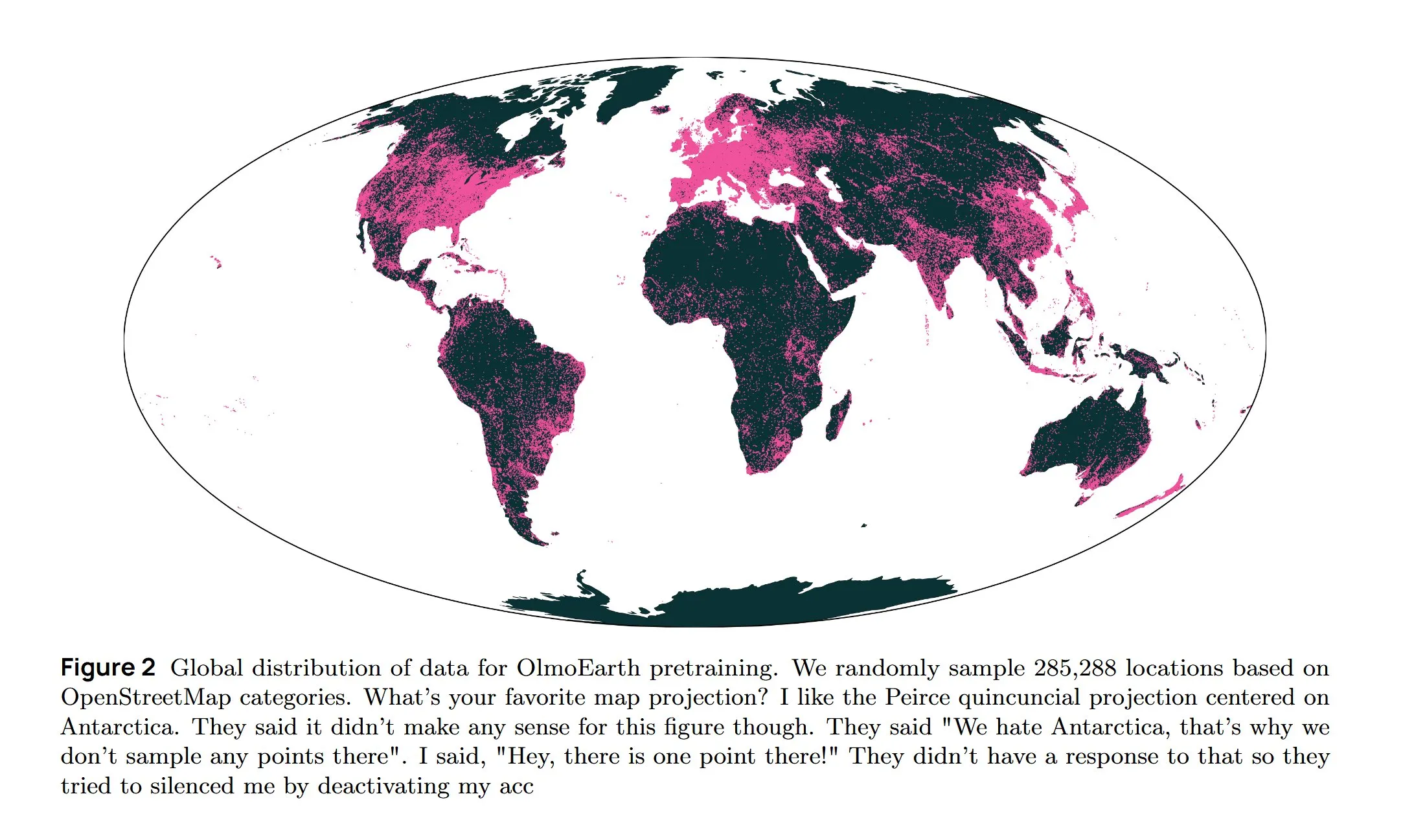
Infraestructura de IA e investigación de vanguardia: refrigeración AWS, LLM difusivos y arquitectura multilingüe : Amazon AWS lanza el sistema de refrigeración líquida In-Row Heat Exchanger (IRHX) para abordar los desafíos de disipación de calor de la infraestructura de IA. Joseph Redmon regresa a la investigación de IA, publicando el artículo OlmoEarth, explorando modelos fundacionales de observación de la Tierra. Meta AI lanza la nueva arquitectura “Mixture of Languages”, optimizando el entrenamiento de modelos multilingües. El equipo de Inception logra LLM difusivos, aumentando la velocidad de generación 10 veces. Google DeepMind AlphaEvolve se utiliza para la exploración matemática a gran escala. El modelo Wan 2.2, optimizado con NVFP4, aumenta la velocidad de inferencia en un 8%. Estos avances impulsan colectivamente la eficiencia de la infraestructura de IA y la innovación en áreas clave de investigación. (Fuente: bookwormengr, iScienceLuvr, TimDarcet, GoogleDeepMind, mrsiipa, jefrankle)

La tecnología BCI de Neuralink permite a usuarios paralizados controlar brazos robóticos : La tecnología de interfaz cerebro-computadora (BCI) de Neuralink ha logrado con éxito que usuarios paralizados controlen brazos robóticos con el pensamiento. Este avance innovador presagia el enorme potencial de la IA en la asistencia médica y la interacción humano-computadora, y en el futuro podría combinarse con robots de asistencia vital para mejorar significativamente la calidad de vida y la independencia de las personas con discapacidad. (Fuente: Ronald_vanLoon)
🧰 Herramientas
Lanzamiento del modelo Google Gemini Computer Use Preview, que permite la interacción web automatizada con IA : Google ha lanzado el modelo Gemini Computer Use Preview, que los usuarios pueden ejecutar a través de una interfaz de línea de comandos (CLI), lo que le permite realizar operaciones de navegador, como buscar “Hello World” en Google. Esta herramienta es compatible con los entornos Playwright y Browserbase y se puede configurar a través de la Gemini API o Vertex AI, proporcionando una base para que los agentes de IA logren la interacción web automatizada, lo que amplía enormemente las capacidades de los LLM en aplicaciones prácticas. (Fuente: GitHub Trending, Reddit r/LocalLLaMA, Reddit r/artificial)

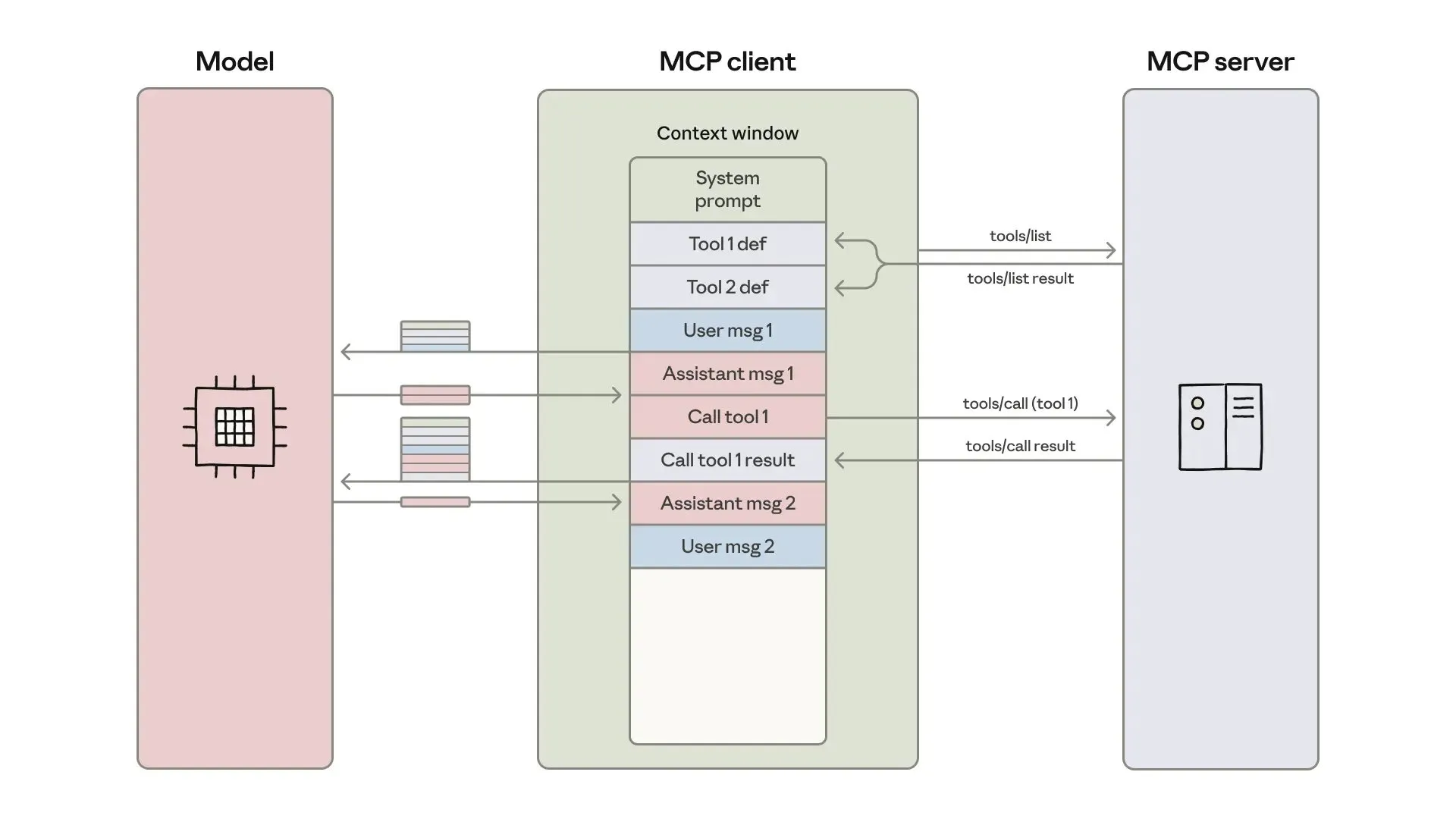
Desarrollo y optimización de agentes de IA: ingeniería de contexto y construcción eficiente : Anthropic ha publicado una guía sobre cómo construir agentes de IA más eficientes, centrándose en resolver problemas de costo de token, latencia y combinación de herramientas en las llamadas a herramientas. La guía reduce el uso de tokens para flujos de trabajo complejos de 150,000 a 2,000 mediante un enfoque de “código como API”, descubrimiento progresivo de herramientas y procesamiento de datos en el entorno. Al mismo tiempo, los desarrolladores de habilidades de agente de ClaudeAI comparten su experiencia, enfatizando que las Agent Skills deben verse como un problema de ingeniería de contexto en lugar de una acumulación de documentos, mejorando significativamente la velocidad de activación y la eficiencia de los tokens a través de un sistema de carga de tres capas, lo que demuestra la importancia de la “regla de las 200 líneas” y la divulgación progresiva. (Fuente: omarsar0, Reddit r/ClaudeAI)
Chat LangChain lanza nueva versión, ofreciendo una experiencia de chat más rápida e inteligente : Chat LangChain ha lanzado una nueva versión, que se anuncia como “más rápida, más inteligente y más atractiva”, con el objetivo de reemplazar la documentación tradicional con una interfaz de chat para ayudar a los desarrolladores a entregar proyectos más rápidamente. Esta actualización mejora la experiencia del usuario del ecosistema LangChain, haciéndolo más fácil de usar y desarrollar, y proporcionando una herramienta más eficiente para construir aplicaciones LLM. (Fuente: hwchase17)
La plataforma de codificación Yansu AI lanza la función de simulación de escenarios, aumentando la confianza en el desarrollo de software : Yansu es una nueva plataforma de codificación de IA que se centra en el desarrollo de software serio y complejo, y su característica única es colocar la simulación de escenarios antes de la codificación. Este enfoque tiene como objetivo aumentar la confianza y la eficiencia en el desarrollo de software mediante la simulación previa de escenarios de desarrollo, reduciendo la depuración y la reelaboración posteriores, optimizando así todo el proceso de desarrollo. (Fuente: omarsar0)
Qdrant Engine lanza una solución RAG nativa de la nube, logrando un control total de los datos : Qdrant Engine ha publicado un nuevo artículo comunitario que presenta una solución RAG (Retrieval Augmented Generation) nativa de la nube basada en Qdrant (base de datos vectorial), KServe (embeddings) y Envoy Gateway (enrutamiento y métricas). Esta es una pila RAG completa de código abierto que proporciona un control total de los datos, facilitando a las empresas y desarrolladores la creación de aplicaciones de IA eficientes, con un énfasis particular en la privacidad de los datos y la capacidad de implementación autónoma. (Fuente: qdrant_engine)

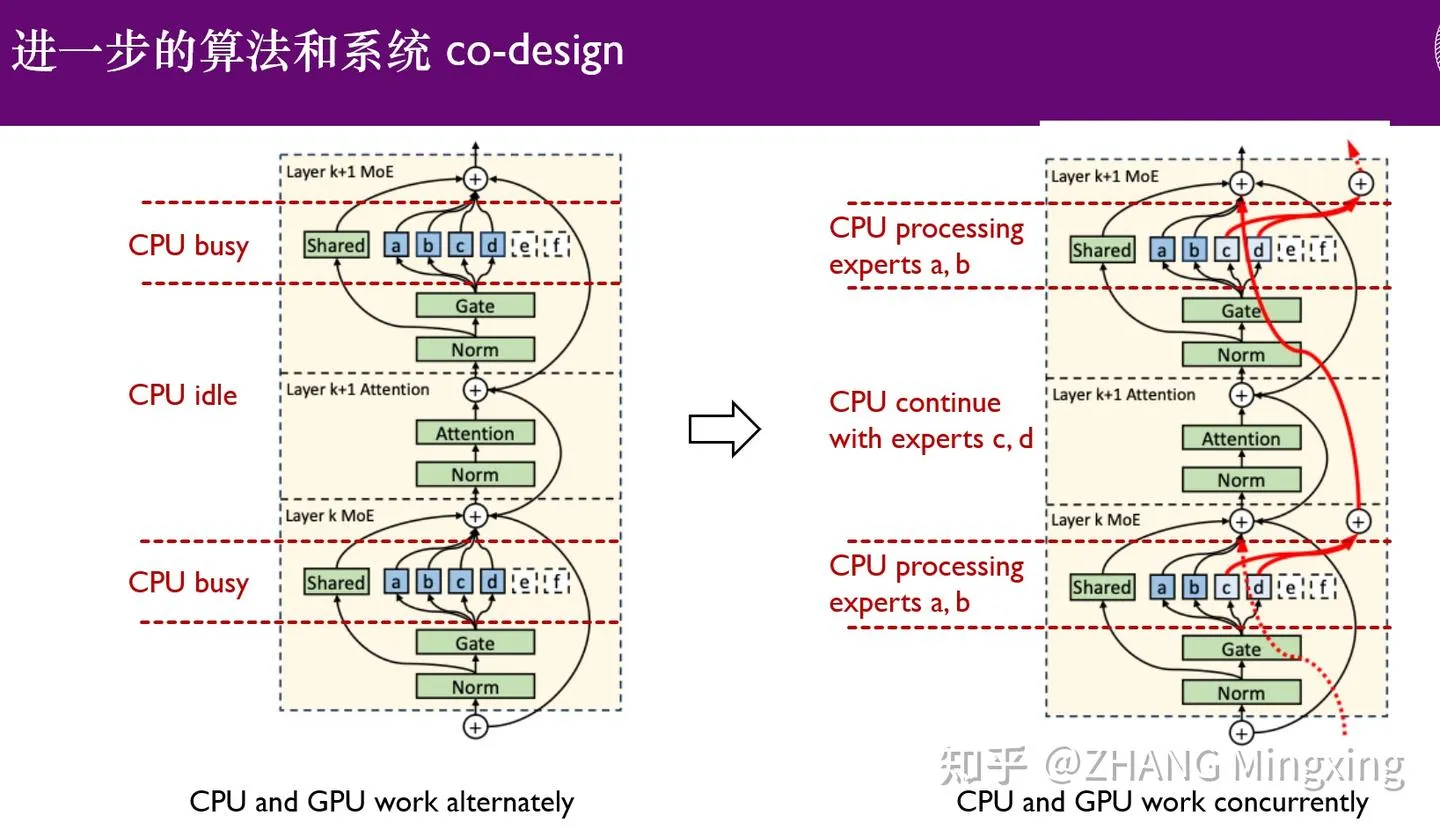
KTransformers entra en una nueva era de inferencia multi-GPU y ajuste fino local, potenciando modelos de billones de parámetros : KTransformers, en colaboración con SGLang y LLaMa-Factory, ha logrado una inferencia paralela multi-GPU de bajo umbral y un ajuste fino local para modelos de billones de parámetros (como DeepSeek 671B y Kimi K2 1TB). A través de la tecnología de latencia de expertos y el ajuste fino heterogéneo CPU/GPU, se ha mejorado significativamente la velocidad de inferencia y la eficiencia de la memoria, lo que permite que los modelos ultragrandes se ejecuten de manera eficiente incluso con recursos limitados, impulsando la aplicación de modelos de lenguaje grandes en dispositivos de borde y despliegues privados. (Fuente: ZhihuFrontier)
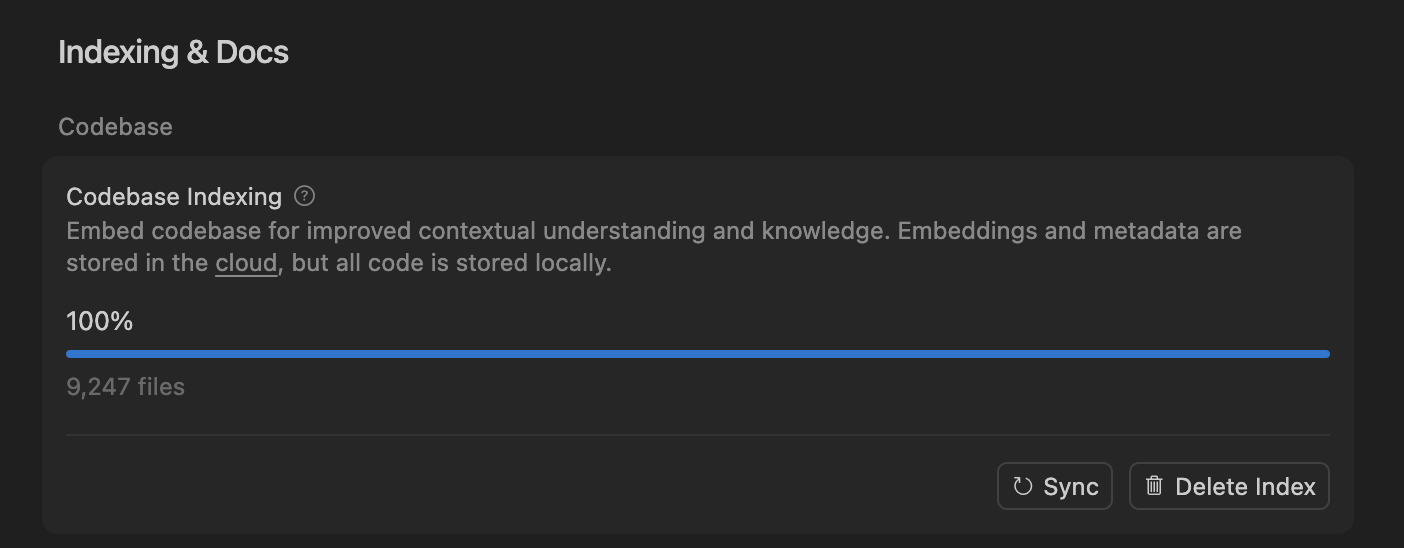
Cursor mejora la precisión del agente de codificación de IA a través de la búsqueda semántica, optimizando el procesamiento de grandes bases de código : El equipo de Cursor descubrió que la búsqueda semántica puede mejorar significativamente la precisión de su agente de codificación de IA en todos los modelos de vanguardia, especialmente en grandes bases de código, superando con creces a las herramientas grep tradicionales. Al almacenar los embeddings de la base de código en la nube y acceder al código localmente, Cursor logra una indexación y actualización eficientes, sin almacenar ningún código en el servidor, lo que garantiza la privacidad y la eficiencia. Este avance tecnológico es crucial para mejorar la capacidad de asistencia de la IA en el desarrollo de software complejo. (Fuente: dejavucoder, turbopuffer)
Conjunto de herramientas de código abierto para agentes LLM y modelos tabulares: SDialog y TabTune : El taller JSALT 2025 de la Universidad Johns Hopkins ha lanzado SDialog, un kit de herramientas de código abierto con licencia MIT para construir, simular y evaluar agentes conversacionales basados en LLM de principio a fin, que soporta la definición de roles, coordinadores y herramientas, y proporciona análisis de interpretabilidad mecánica. Al mismo tiempo, Lexsi Labs ha lanzado TabTune, un framework de código abierto diseñado para simplificar el flujo de trabajo de los modelos fundacionales tabulares (TFMs), proporcionando una interfaz unificada que soporta múltiples estrategias de adaptación, lo que mejora la usabilidad y escalabilidad de los TFMs. (Fuente: Reddit r/MachineLearning, Reddit r/deeplearning)

📚 Aprendizaje
Artículos de vanguardia: aprendizaje de datos DLM, ICL tabular y generación de audio y video : El artículo “Diffusion Language Models are Super Data Learners” señala que los DLM pueden superar continuamente a los modelos AR en situaciones de datos limitados. “Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning” presenta una nueva arquitectura para el aprendizaje en contexto tabular, superando el SOTA mediante el procesamiento multiescala y la atención dispersa por bloques. “UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions” propone un marco unificado para la generación conjunta de audio y video, resolviendo los problemas de sincronización labial y falta de coherencia semántica. Estos artículos impulsan colectivamente los avances de los LLM en eficiencia de datos, procesamiento de tipos de datos específicos y generación multimodal. (Fuente: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Investigación sobre inferencia y seguridad de LLM: optimización secuencial, entrenamiento de consistencia y ataques de Red Team : El estudio “The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute” encontró que la optimización iterativa secuencial de la inferencia de LLM supera en la mayoría de los casos la auto-consistencia paralela, con una mejora significativa en la precisión. El artículo “Consistency Training Helps Stop Sycophancy and Jailbreaks” de Google DeepMind propone que el entrenamiento de consistencia puede suprimir la adulación y los jailbreaks de la IA. Un artículo de EMNLP 2025 explora los ataques de Red Team a LM, enfatizando la optimización de la perplejidad y la toxicidad. Estas investigaciones proporcionan una guía teórica y práctica importante para mejorar la eficiencia de inferencia, la seguridad y la robustez de los LLM. (Fuente: HuggingFace Daily Papers, Google DeepMind发布“Consistency Training”论文,抑制AI谄媚和越狱, EMNLP 2025论文探讨LM红队攻击与偏好学习)

Evaluación y benchmarks de capacidad de LLM: CodeClash e IMO-Bench : CodeClash es un nuevo benchmark para evaluar la capacidad de codificación de los LLM en la gestión de bases de código completas y la programación competitiva, desafiando los límites de los LLM existentes. El lanzamiento de IMO-Bench fue crucial para que Gemini DeepThink obtuviera una medalla de oro en la Olimpiada Internacional de Matemáticas, proporcionando un recurso valioso para mejorar las capacidades de razonamiento matemático de la IA. Estos benchmarks impulsan el desarrollo y la evaluación de los LLM en tareas avanzadas como la codificación compleja y el razonamiento matemático. (Fuente: CodeClash:评估LLM编码能力的新基准, IMO-Bench发布,助力Gemini DeepThink在IMO中取得金牌)

El equipo de Stanford NLP publica resultados de investigación multidisciplinaria en EMNLP 2025 : El equipo de NLP de la Universidad de Stanford ha publicado múltiples artículos de investigación en la conferencia EMNLP 2025, cubriendo áreas de vanguardia como grafos de conocimiento cultural, identificación de datos no aprendidos por LLM, benchmarks de razonamiento semántico de programas, búsqueda de n-gramas a escala de Internet, modelos de lenguaje visual robóticos, optimización del aprendizaje en contexto, reconocimiento de texto histórico y detección de inconsistencias de conocimiento en Wikipedia. Estos resultados demuestran la profundidad y amplitud de su última investigación en procesamiento de lenguaje natural y campos interdisciplinarios de IA. (Fuente: stanfordnlp)
Recursos de aprendizaje de agentes de IA y RL: auto-juego, sistemas multi-agente y curso de Jupyter AI : Varios investigadores creen que el auto-juego (self-play) y los auto-currículos (autocurricula) son la próxima frontera en el aprendizaje por refuerzo (RL) y los agentes de IA. La versión de acceso anticipado de “Build a Multi-Agent System (From Scratch)” de Manning Books está teniendo un gran éxito de ventas, enseñando cómo construir sistemas multi-agente con LLM de código abierto. DeepLearning.AI ha lanzado el curso Jupyter AI, que permite la codificación y el desarrollo de aplicaciones de IA. ProfTomYeh también ha proporcionado una serie de guías para principiantes sobre RAG, bases de datos vectoriales, agentes y multi-agentes. Estos recursos proporcionan un soporte integral para el aprendizaje y la práctica de agentes de IA y RL. (Fuente: RL与Agent领域:自玩和自课程是未来前沿, 《Build a Multi-Agent System (From Scratch)》早期访问版销售火爆, Jupyter AI课程发布,赋能AI编码与应用开发, RAG、向量数据库、代理和多代理初学者指南系列)
Infraestructura y optimización de LLM: DeepSeek-OCR, depuración de PyTorch y visualización de MoE : DeepSeek-OCR resuelve el problema de la explosión de Tokens de los VLM tradicionales al comprimir la información visual de los documentos en una pequeña cantidad de tokens, mejorando la eficiencia. StasBekman ha añadido una guía de depuración de memoria para modelos grandes de PyTorch en su “The Art of Debugging Open Book”. xjdr ha desarrollado una herramienta de visualización personalizada para modelos MoE, mejorando la comprensión de métricas específicas de MoE. Estas herramientas y recursos proporcionan un soporte clave para la optimización y mejora del rendimiento de la infraestructura de LLM. (Fuente: DeepSeek-OCR解决Token爆炸问题,提升文档视觉语言模型效率, PyTorch调试大型模型内存使用指南, MoE特定指标的可视化工具)

Aprendizaje de IA y desarrollo profesional: hoja de ruta para científicos de datos e historia concisa de la IA : PythonPr compartió la “Hoja de ruta completa de 0 a científico de datos”, que proporciona una guía integral para los estudiantes que aspiran a convertirse en científicos de datos. Ronald_vanLoon compartió “Una breve historia de la inteligencia artificial”, que ofrece a los lectores una visión general de la historia del desarrollo de la tecnología de IA. Estos recursos proporcionan conocimientos básicos y orientación para el aprendizaje introductorio y el desarrollo profesional en el campo de la IA. (Fuente: 《0到数据科学家完整路线图》分享, 《人工智能简史》分享)

El equipo de Hugging Face comparte experiencia en entrenamiento de LLM y procesamiento de datasets en streaming : El equipo científico de Hugging Face ha publicado una serie de artículos de blog sobre el entrenamiento de modelos de lenguaje grandes, proporcionando una valiosa experiencia práctica y orientación teórica para investigadores y desarrolladores. Al mismo tiempo, Hugging Face ha lanzado soporte completo para el procesamiento de datasets en streaming en el entrenamiento distribuido a gran escala, mejorando la eficiencia del entrenamiento y haciendo que el procesamiento de grandes datasets sea más conveniente y eficiente. (Fuente: Hugging Face科学团队博客分享LLM训练经验, 数据集流式处理在分布式训练中的应用)

💼 Negocios
Giga AI recauda 61 millones de dólares en financiación Serie A para acelerar la automatización de operaciones con clientes : Giga AI ha completado con éxito una ronda de financiación Serie A de 61 millones de dólares, con el objetivo de automatizar las operaciones con clientes. La compañía ya ha colaborado con empresas líderes como DoorDash para mejorar la experiencia del cliente utilizando IA. Sus fundadores, que renunciaron a salarios altos, ajustaron la dirección del producto varias veces antes de encontrar el ajuste al mercado, demostrando la resiliencia de los emprendedores y presagiando el enorme potencial comercial de la IA en el servicio al cliente empresarial. (Fuente: bookwormengr)

Wabi recauda 20 millones de dólares en financiación, con el objetivo de empoderar una nueva era de creación de software personal : Eugenia Kuyda anunció que Wabi ha recibido 20 millones de dólares en financiación liderada por a16z, con el objetivo de inaugurar una nueva era de software personal, permitiendo a cualquier persona crear, descubrir, remezclar y compartir fácilmente mini-aplicaciones personalizadas. Wabi se compromete a empoderar la creación de software de la misma manera que YouTube empodera la creación de videos, lo que presagia un futuro en el que el software será creado por las masas en lugar de por unos pocos desarrolladores, impulsando la visión de “todos son desarrolladores”. (Fuente: amasad)
Google y Anthropic negocian aumentar la inversión, profundizando la colaboración entre gigantes de la IA : Google está en conversaciones iniciales con Anthropic para discutir un aumento de su inversión en esta última. Este movimiento podría presagiar una mayor profundización de la colaboración entre ambas compañías en el campo de la IA, y podría influir en la dirección futura del desarrollo de modelos de IA y el panorama de la competencia del mercado, fortaleciendo la posición estratégica de Google en el ecosistema de la IA. (Fuente: Reddit r/ClaudeAI)
🌟 Comunidad
Impacto de la IA en la sociedad y el lugar de trabajo: empleo, riesgos y remodelación de habilidades : La comunidad discute que la IA no reemplaza trabajos, sino que mejora la eficiencia, pero el estallido de la burbuja de la IA podría provocar despidos masivos. Una encuesta muestra que el 93% de los ejecutivos utilizan herramientas de IA no aprobadas, lo que se convierte en la mayor fuente de riesgo de IA para las empresas. La IA también ayuda a los usuarios a descubrir habilidades ocultas como el diseño visual y la creación de cómics, lo que lleva a las personas a reflexionar sobre su propio potencial. Estas discusiones revelan el complejo impacto de la IA en la sociedad y el lugar de trabajo, incluyendo mejoras de eficiencia, posible desempleo, riesgos de seguridad y remodelación de habilidades personales. (Fuente: Ronald_vanLoon, TheTuringPost, Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Veracidad del contenido de IA y crisis de confianza: proliferación y problemas de alucinación : A medida que el costo de generar contenido con IA se acerca a cero, el mercado se inunda de información generada por IA, lo que lleva a una drástica disminución de la confianza de los usuarios en la autenticidad y fiabilidad del contenido. Un médico utilizó IA para escribir un artículo médico, lo que resultó en una gran cantidad de referencias inexistentes, destacando el problema de alucinación que la IA puede producir en la escritura académica. Estos incidentes revelan colectivamente la crisis de confianza provocada por la proliferación de contenido de IA, así como la importancia de una revisión y verificación estrictas en la creación asistida por IA. (Fuente: dotey, Reddit r/artificial)
Ética y gobernanza de la IA: apertura, equidad y riesgos potenciales : La comunidad cuestiona el estatus de “sin fines de lucro” de OpenAI y su búsqueda de deuda garantizada por el gobierno, argumentando que su modelo es “privatizar ganancias, socializar pérdidas”. Se señala que las capacidades de los modelos utilizados internamente por las grandes empresas de IA superan con creces las versiones disponibles públicamente, y esta inteligencia SOTA “privatizada” se considera injusta. Investigadores de Anthropic están preocupados de que la futura ASI pueda buscar “venganza” si sus modelos “ancestros” son eliminados, y se toman en serio el problema del “bienestar del modelo”. El equipo de IA de Microsoft se dedica a desarrollar la superinteligencia centrada en el ser humano (HSI), enfatizando la dirección ética del desarrollo de la IA. Estas discusiones reflejan la profunda preocupación pública por los modelos de negocio de los gigantes de la IA, la apertura tecnológica, la responsabilidad ética y la intervención gubernamental. (Fuente: scaling01, Teknium, bookwormengr, VictorTaelin, VictorTaelin, Reddit r/ArtificialInteligence, yusuf_i_mehdi)

Geopolítica de la IA: competencia entre EE. UU. y China y el auge del código abierto : La competencia entre EE. UU. y China en el campo de los chips de IA es cada vez más intensa. China prohíbe los chips de IA extranjeros en los centros de datos estatales, mientras que EE. UU. restringe la venta de los chips de IA de gama alta de Nvidia a China. Nvidia se está volcando hacia la India en busca de nuevos centros de IA. Al mismo tiempo, el rápido ascenso de los modelos de IA de código abierto chinos (como Kimi K2 Thinking), cuyo rendimiento ya puede competir con los modelos de vanguardia estadounidenses a un costo menor. Esta tendencia presagia que el mundo de la IA se dividirá en dos ecosistemas principales, lo que podría ralentizar el progreso global de la IA, pero también podría permitir que países subestimados como la India desempeñen un papel más importante en el panorama global de la IA. (Fuente: Teknium, Reddit r/ArtificialInteligence, bookwormengr, scaling01)
La transformación de la IA en el campo del SEO: de las palabras clave a la optimización del contexto : Con la aparición de ChatGPT, Gemini y AI Overviews, el SEO está pasando de las señales de clasificación tradicionales a la visibilidad de la IA y la optimización de citas. El SEO futuro se centrará más en la citabilidad, la veracidad y la estructuración del contenido para satisfacer la necesidad de los LLM de contexto y fuentes autorizadas, lo que presagia la llegada de la era de la “Optimización de Modelos de Lenguaje Grandes” (LLMO). Este cambio requiere que los profesionales de SEO piensen como ingenieros de prompts, pasando de la densidad de palabras clave a proporcionar contenido de alta calidad en el que la IA confíe y cite. (Fuente: Reddit r/ArtificialInteligence)
Nuevas tendencias en la evaluación de agentes de IA y LLM: diseño de interacción y enfoque en benchmarks : Las redes sociales han discutido el diseño de interacción de los agentes de IA, como cómo guiar a un agente para que se autoentreviste, y la capacidad de Claude AI para mostrar “irritación” y “autorreflexión” cuando se enfrenta a las críticas de los usuarios. Al mismo tiempo, Jeffrey Emanuel compartió su proyecto de correo electrónico del agente MCP, demostrando una colaboración eficiente entre agentes de codificación de IA. La comunidad cree que AIME se está convirtiendo en el nuevo foco de los benchmarks de LLM, reemplazando a GSM8k, enfatizando la capacidad de los LLM en el razonamiento matemático y la resolución de problemas complejos. Estas discusiones revelan colectivamente las nuevas tendencias en el diseño de interacción de agentes de IA, los mecanismos de colaboración y los estándares de evaluación de LLM. (Fuente: Vtrivedy10, Reddit r/ArtificialInteligence, dejavucoder, doodlestein, _lewtun)
Evolución de la tecnología RAG y optimización del contexto: más no siempre es mejor : La comunidad discute que la afirmación de que la tecnología RAG (Retrieval Augmented Generation) está “muerta” es prematura, y que tecnologías como la búsqueda semántica pueden mejorar significativamente la precisión de los agentes de IA en grandes bases de código. LightOn enfatizó en una conferencia que más contexto no siempre es mejor; demasiados tokens pueden aumentar los costos, ralentizar los modelos y difuminar las respuestas. RAG debe centrarse en la precisión en lugar de la longitud, proporcionando información más clara a través de la búsqueda empresarial para evitar que la IA se ahogue en el ruido. Estas discusiones revelan que la tecnología RAG sigue evolucionando y enfatizan el papel clave de la gestión del contexto en las aplicaciones de IA. (Fuente: HamelHusain, wandb)

Acceso a recursos computacionales de IA y experimentos con modelos abiertos, promoviendo la innovación comunitaria : La comunidad ha discutido la equidad en el acceso a los recursos computacionales de IA, y hay proyectos que ofrecen hasta 100,000 dólares en recursos computacionales de GCP para apoyar experimentos con modelos de código abierto. Esta iniciativa tiene como objetivo alentar a pequeños equipos e investigadores individuales a explorar nuevos modelos de código abierto, promoviendo la innovación y la diversidad en la comunidad de IA, y reduciendo el umbral para la investigación en IA. (Fuente: vikhyatk)
La importancia de la pantalla del ordenador personal en la era de la IA, que afecta la capacidad de trabajo técnico creativo : Scott Stevenson argumenta que la “intimidad” de una persona con la pantalla de su ordenador es un indicador importante de su capacidad competitiva en trabajos técnicos creativos. Si un usuario puede usar el ordenador con comodidad y soltura, destacará; de lo contrario, podría ser más adecuado para roles como ventas, desarrollo de negocios o gestión de oficinas. Este punto de vista enfatiza la profunda conexión entre las herramientas digitales y la eficiencia del trabajo personal, así como la importancia de la interfaz humano-computadora en la era de la IA. (Fuente: scottastevenson)
Experiencia de usuario de ChatGPT y discusión sobre la personificación de la IA: sugerencias de descanso y emojis : ChatGPT sugirió proactivamente a los usuarios que se tomaran un descanso después de un largo período de estudio, lo que generó una amplia discusión en la comunidad, y muchos usuarios expresaron que era la primera vez que una IA les sugería algo así. Al mismo tiempo, el uso del emoji de “sonrisa pícara” 😏 por parte de ChatGPT también provocó especulaciones en la comunidad, y los usuarios se preguntaron si esto presagiaba una nueva versión o si la IA estaba mostrando un estilo de interacción más provocador o humorístico. Estos incidentes reflejan que la IA ha incorporado más consideraciones humanizadas en el diseño de la experiencia del usuario, así como las profundas reflexiones que la personificación de la IA provoca en la interacción humano-computadora. (Fuente: Reddit r/ChatGPT, Reddit r/ChatGPT)
💡 Otros
La IA y la robótica impulsarán la próxima revolución industrial : Se discute ampliamente en las redes sociales que la IA encarnada y la robótica impulsarán conjuntamente la próxima revolución industrial. Este punto de vista enfatiza el enorme potencial de la combinación de IA y hardware, presagiando una transformación integral en la producción automatizada e inteligente y los estilos de vida, lo que afectará profundamente la economía global y la estructura social. (Fuente: Ronald_vanLoon)

En la era de la IA, la “superpercepción” es el requisito previo para la “superinteligencia” : Sainingxie propone que “sin superpercepción, no se puede construir superinteligencia”. Este punto de vista enfatiza el papel fundamental de la IA en la adquisición, procesamiento y comprensión de información multimodal, argumentando que un avance en las capacidades sensoriales es clave para lograr una inteligencia más avanzada. Desafía las trayectorias tradicionales de desarrollo de la IA y pide una mayor atención a la construcción de las capacidades de la capa de percepción de la IA. (Fuente: sainingxie)
Las antiguas TPU de Google alcanzan el 100% de utilización, demostrando el valor del hardware antiguo en la IA : Las antiguas TPU de Google, de hace 7 u 8 años, están funcionando con una utilización del 100%. Estos chips, completamente depreciados, siguen trabajando de manera eficiente. Esto demuestra que incluso el hardware antiguo puede tener un gran valor en el entrenamiento y la inferencia de IA, especialmente en términos de rentabilidad, lo que ofrece una nueva perspectiva sobre la economía y la sostenibilidad de la infraestructura de IA. (Fuente: giffmana)
