
Palabras clave:OpenAI, Amazon AWS, Capacidad de cálculo de IA, Stanford AgentFlow, Meituan LongCat-Flash-Omni, Alibaba Qwen3-Max-Thinking, Modelo TRM de Samsung, Unity AI Graph, Colaboración en capacidad de cálculo entre OpenAI y Amazon, Marco de aprendizaje por refuerzo de AgentFlow, Modelo multimodal LongCat-Flash-Omni, Capacidad de razonamiento de Qwen3-Max-Thinking, Arquitectura de razonamiento recursivo TRM
Aquí tienes la traducción de la noticia de AI al español, siguiendo tus requisitos:
🔥 En Foco
OpenAI y Amazon alcanzan un acuerdo de computación de 38 mil millones de dólares : OpenAI y Amazon AWS han firmado un acuerdo de computación en la nube valorado en 38 mil millones de dólares, con el objetivo de asegurar recursos de GPU de NVIDIA para respaldar la construcción de su infraestructura de modelos de AI y sus ambiciosos objetivos en AI. Este movimiento marca un paso importante para OpenAI en la diversificación de sus proveedores de servicios en la nube, reduciendo su dependencia exclusiva de Microsoft y allanando el camino para una futura IPO. Por parte de Amazon, esta colaboración consolida su liderazgo en el ámbito de la infraestructura de AI, mientras mantiene su asociación con Anthropic, un competidor de OpenAI. El acuerdo proporcionará a OpenAI una capacidad de computación escalable para la inferencia de AI y el entrenamiento de modelos de próxima generación, además de promover la aplicación de sus modelos fundacionales en la plataforma AWS. (Fuente: Ronald_vanLoon, scaling01, TheRundownAI)

Framework AgentFlow de Stanford: Pequeños modelos superan a GPT-4o : Equipos de investigación de la Universidad de Stanford y otros han lanzado el framework AgentFlow, que, a través de una arquitectura modular y el algoritmo Flow-GRPO, permite que los sistemas de agentes de AI realicen aprendizaje por refuerzo en línea dentro de los flujos de inferencia, logrando una auto-optimización continua. Con solo 7B parámetros, AgentFlow ha superado por completo a GPT-4o (aproximadamente 200B parámetros) y Llama-3.1-405B en tareas de búsqueda, matemáticas y ciencia, alcanzando la cima del ranking diario de HuggingFace Paper. Esta investigación demuestra que los sistemas de agentes pueden adquirir capacidades de aprendizaje similares a las de los modelos grandes a través del aprendizaje por refuerzo en línea, siendo más eficientes en tareas específicas, lo que abre un nuevo camino de “pequeño pero potente” para el desarrollo de la AI. (Fuente: HuggingFace Daily Papers)
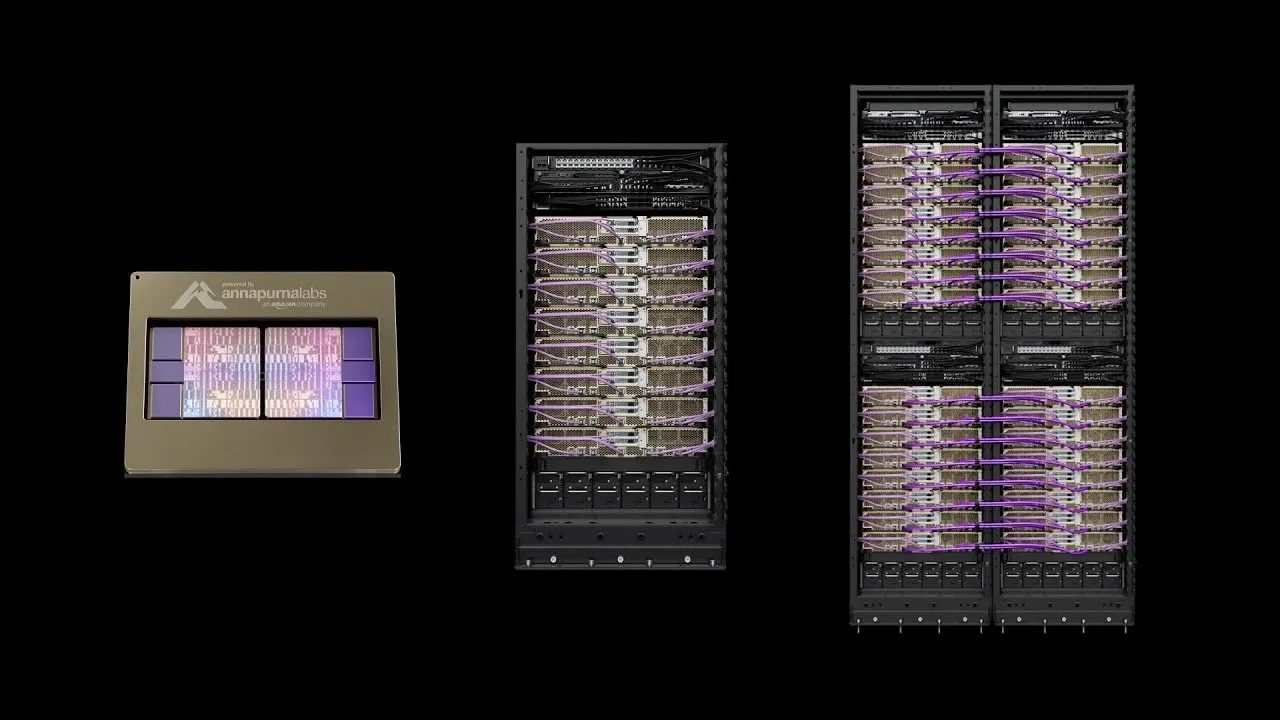
AWS lanza Project Rainier: Uno de los clústeres de computación de AI más grandes del mundo : AWS ha lanzado Project Rainier, un clúster de computación de AI construido en menos de un año, que cuenta con casi 500.000 chips Trainium2. Anthropic ya ha entrenado nuevos modelos Claude aquí y planea expandirse a 1 millón de chips para finales de 2025. Trainium2 es el procesador de entrenamiento de AI personalizado de AWS, diseñado para manejar redes neuronales a gran escala. El proyecto utiliza la arquitectura UltraServer, conectada a través de redes NeuronLinks y EFA, ofreciendo hasta 83.2 petaflops de capacidad de cálculo para modelos FP8 dispersos, y se alimenta con energía 100% renovable, logrando una alta eficiencia energética. Project Rainier marca el liderazgo de AWS en el campo de la infraestructura de AI, ofreciendo soluciones verticalmente integradas, desde chips personalizados hasta la refrigeración de centros de datos. (Fuente: TheTuringPost)
🎯 Tendencias
Meituan lanza el modelo multimodal LongCat-Flash-Omni : Meituan ha lanzado en código abierto su último modelo multimodal, LongCat-Flash-Omni, el cual ha alcanzado el nivel SOTA de código abierto en benchmarks integrales como Omni-Bench y WorldSense, y es comparable al modelo de código cerrado Gemini-2.5-Pro. LongCat-Flash-Omni emplea una arquitectura MoE con 560B parámetros totales y 27B parámetros activos, logrando una alta eficiencia de inferencia e interacción en tiempo real de baja latencia, siendo el primer modelo de código abierto en lograr interacción multimodal en tiempo real. Este modelo soporta entradas multimodales de texto, voz, imagen, video y cualquier combinación, y cuenta con una ventana de contexto de 128K tokens, permitiendo interacciones de audio y video de más de 8 minutos. (Fuente: WeChat, ZhihuFrontier)

Alibaba lanza la versión de inferencia Qwen3-Max-Thinking : El equipo de Alibaba Qwen ha lanzado una versión preliminar temprana de Qwen3-Max-Thinking, un modelo de punto de control intermedio que aún está en entrenamiento. Después de mejorar el uso de herramientas y expandir el cálculo en tiempo de prueba, el modelo logró una puntuación del 100% en benchmarks de inferencia desafiantes como AIME 2025 y HMMT. El lanzamiento de Qwen3-Max-Thinking demuestra el progreso significativo de Alibaba en las capacidades de inferencia de AI, ofreciendo a los usuarios una cadena de pensamiento y habilidades de resolución de problemas más potentes. (Fuente: Alibaba_Qwen, op7418)
Modelo TRM de Samsung: Inferencia recursiva desafía el paradigma Transformer : El laboratorio SAIL de Samsung en Montreal ha propuesto el Tiny Recursive Model (TRM), una nueva arquitectura de inferencia recursiva con solo 7 millones de parámetros y una red neuronal de dos capas. TRM, al actualizar recursivamente “respuestas” y “variables de pensamiento latentes”, se aproxima al resultado correcto a través de múltiples rondas de autocorrección, batiendo récords en tareas como Sudoku-Extreme y superando a modelos grandes como DeepSeek R1 y Gemini 2.5 Pro. El modelo incluso abandona la capa de autoatención en su arquitectura (variante TRM-MLP), lo que sugiere que para tareas de entrada fija a pequeña escala, el MLP puede reducir el sobreajuste, desafiando la regla empírica de la comunidad de AI de “cuanto más grande el modelo, más potente”, y ofreciendo nuevas ideas para la inferencia de AI ligera. (Fuente: 36氪)

Conferencia de Desarrolladores de Unity: Tendencias futuras de AI+Juegos : La Conferencia de Desarrolladores de Unity 2025 destacó que la AI se convertirá en el motor de la creatividad y eficiencia en los juegos. El motor Unity y Tencent Hunyuan lanzaron conjuntamente la plataforma AI Graph, que integra profundamente los flujos de trabajo AIGC, pudiendo aumentar la eficiencia del diseño 2D en un 30% y la producción de activos 3D en un 70%. Amazon Web Services (AWS) también mostró el empoderamiento de la AI en todo el ciclo de vida de los juegos (construcción, operación, crecimiento), especialmente en la generación de código, donde la AI está pasando de ser una ayuda a la creación autónoma. Meshy, como herramienta de creación de AI generativa 3D, ayuda a los desarrolladores a reducir costos y acelerar la creación de prototipos a través de modelos de difusión y modelos autorregresivos, con un enorme potencial especialmente en escenarios de VR/AR y UGC. (Fuente: WeChat)

Cartesia lanza el modelo de voz Sonic-3 : La compañía de AI de voz Cartesia ha lanzado su último modelo de voz, Sonic-3, que ha demostrado resultados asombrosos al replicar la voz de Elon Musk y ha obtenido una ronda de financiación Serie B de 100 millones de dólares de inversores como NVIDIA. Sonic-3 está construido sobre un modelo de espacio de estados (SSM), en lugar de la arquitectura Transformer tradicional, lo que le permite percibir continuamente el contexto y el ambiente de la conversación, logrando respuestas de AI más naturales y sin esfuerzo. Su latencia es de solo 90 milisegundos, con un tiempo de respuesta de extremo a extremo de 190 milisegundos, siendo uno de los sistemas de generación de voz más rápidos actualmente. (Fuente: WeChat)

MiniMax lanza el modelo de voz Speech 2.6 : MiniMax ha lanzado su último modelo de voz, MiniMax Speech 2.6, destacando sus características de “rápido y elocuente”. Este modelo comprime la latencia de respuesta a menos de 250ms, soporta más de 40 idiomas y todos los acentos, y puede reconocer con precisión “textos no estándar” como URLs, correos electrónicos, cantidades, fechas y números de teléfono. Esto significa que, incluso con entradas de acento fuerte, habla rápida e información compleja, el modelo puede entender y vocalizar claramente a la primera, mejorando significativamente la eficiencia y precisión de la interacción de voz. (Fuente: WeChat)
Amazon Chronos-2: Modelo fundacional de predicción universal : Amazon ha lanzado Chronos-2, un modelo fundacional diseñado para manejar cualquier tarea de predicción. Este modelo soporta predicción de información univariante, multivariante y covariante, y puede operar de forma zero-shot. El lanzamiento de Chronos-2 marca un avance importante para Amazon en el campo de la predicción de series temporales, ofreciendo a empresas y desarrolladores capacidades de predicción más flexibles y potentes, con el potencial de simplificar procesos de predicción complejos y mejorar la eficiencia en la toma de decisiones. (Fuente: dl_weekly)
YOLOv11 para segmentación de instancias de edificios y clasificación de altura : Un artículo detalla la aplicación de YOLOv11 en la segmentación de instancias de edificios y la clasificación discreta de alturas a partir de imágenes satelitales. YOLOv11, a través de una arquitectura más eficiente, combinando características de diferentes escalas, mejora la precisión de la localización de objetos y sobresale en escenarios urbanos complejos. El modelo logró un rendimiento de segmentación de instancias del 60.4% mAP@50 y 38.3% mAP@50-95 en el conjunto de datos DFC2023 Track 2, manteniendo al mismo tiempo una precisión de clasificación robusta para cinco niveles de altura predefinidos. YOLOv11 muestra un rendimiento superior en el manejo de oclusiones, formas de edificios complejas y desequilibrio de clases, siendo adecuado para el mapeo urbano a gran escala y en tiempo real. (Fuente: HuggingFace Daily Papers)
🧰 Herramientas
PageIndex: Sistema de indexación de documentos RAG de inferencia : VectifyAI ha lanzado PageIndex, un sistema RAG (Retrieval Augmented Generation) de inferencia que no requiere bases de datos vectoriales ni fragmentación. PageIndex, al construir un índice de estructura de árbol de documentos, simula la forma en que los expertos humanos navegan y extraen conocimiento, permitiendo a los LLM realizar inferencias de múltiples pasos para lograr una recuperación de documentos más precisa. El sistema alcanzó una precisión del 98.7% en el benchmark FinanceBench, superando con creces a los sistemas RAG vectoriales tradicionales, y es especialmente adecuado para el análisis de documentos largos y especializados como informes financieros y documentos legales. PageIndex ofrece múltiples opciones de despliegue, incluyendo autoalojamiento, servicios en la nube y API. (Fuente: GitHub Trending)

LocalAI: Alternativa local de código abierto a OpenAI : LocalAI es una alternativa gratuita y de código abierto a OpenAI, que proporciona una REST API compatible con la API de OpenAI, y soporta la ejecución local de LLM, generación de imágenes, audio, video y clonación de voz en hardware de consumo. Este proyecto no requiere GPU, soporta varios modelos como gguf, transformers, diffusers, y ya ha integrado funciones como WebUI, inferencia P2P y Model Context Protocol (MCP). LocalAI tiene como objetivo lograr la localización y descentralización de la inferencia de AI, ofreciendo a los usuarios opciones de despliegue de AI más flexibles y privadas, y soportando diversas aceleraciones de hardware. (Fuente: GitHub Trending)
DeepAnalyze: LLM Agentic para ciencia de datos : Equipos de investigación de la Universidad Renmin de China y la Universidad de Tsinghua han lanzado DeepAnalyze, el primer Agentic LLM orientado a la ciencia de datos. Este modelo no requiere un workflow diseñado manualmente; con solo un LLM, puede completar de forma autónoma tareas complejas de ciencia de datos como preparación, análisis, modelado, visualización y obtención de insights, y puede generar informes de investigación a nivel de analista. DeepAnalyze, a través de un paradigma de entrenamiento Agentic de aprendizaje curricular y un marco de síntesis de trayectorias orientado a datos, aprende en entornos reales, resolviendo los desafíos de la escasez de recompensas y la falta de trayectorias de resolución de problemas de cadena larga, logrando una investigación profunda y autónoma en el campo de la ciencia de datos. (Fuente: WeChat)

AI PC: Potenciado por procesadores Intel Core Ultra serie 200H : Las AI PC equipadas con procesadores Intel Core Ultra serie 200H se están convirtiendo en una nueva opción para mejorar la eficiencia en el trabajo y la vida. Esta serie de procesadores integra una potente NPU (Neural Processing Unit), con una mejora de eficiencia energética de hasta el 21%, capaz de manejar tareas de AI de larga duración y bajo consumo, como la eliminación de ruido de fondo en tiempo real, el recorte inteligente de imágenes, la organización de documentos con asistentes de AI, y todo ello sin necesidad de conexión a internet. Esta arquitectura híbrida de CPU, GPU y NPU permite que las AI PC sobresalgan en portabilidad, larga duración de batería y trabajo sin conexión, brindando una experiencia de AI fluida y natural para escenarios de oficina, estudio y juegos. (Fuente: WeChat)

Claude Skills: Directorio de más de 2300 habilidades : Un sitio web llamado skillsmp.com ha recopilado más de 2300 Claude Skills, ofreciendo a los usuarios de Claude AI un directorio de habilidades con capacidad de búsqueda. Estas habilidades están organizadas por categorías, incluyendo herramientas de desarrollo, documentación, mejoras de AI, análisis de datos, entre otras, y ofrecen funciones de vista previa, descarga ZIP e instalación CLI. Esta plataforma tiene como objetivo ayudar a los usuarios de Claude a descubrir y utilizar habilidades de AI de manera más conveniente, mejorando las capacidades de los Agentes y logrando tareas automatizadas más eficientes, contribuyendo con herramientas útiles a la comunidad. (Fuente: Reddit r/ClaudeAI)
AI Chatbots para sitios web: Los diez mejores chatbots de AI en 2025 : Un informe ha enumerado los diez mejores chatbots de AI para sitios web en 2025, con el objetivo de ayudar a startups y fundadores individuales a elegir la herramienta adecuada. ChatQube fue calificado como la nueva herramienta más interesante debido a sus notificaciones instantáneas de “brechas de conocimiento” y su capacidad de conciencia contextual. Intercom Fin es adecuado para grandes equipos de soporte, Drift se enfoca en marketing y captura de leads, y Tidio es ideal para pequeñas empresas y comercio electrónico. Otros como Crisp, Chatbase, Zendesk AI, Botpress, Flowise y Kommunicate también tienen sus propias características, cubriendo una variedad de necesidades desde configuraciones simples hasta altamente personalizadas, lo que indica que los chatbots de AI se han vuelto más prácticos y populares. (Fuente: Reddit r/artificial)
Perplexity Comet: AI coding Agent : Perplexity Comet es aclamado como un eficiente AI coding Agent; los usuarios solo necesitan asignarle una tarea, y este la completará de forma autónoma. Por ejemplo, un usuario puede otorgarle acceso a un repositorio de GitHub y pedirle que configure un Webhook para escuchar eventos push; Comet es capaz de obtener con precisión la URL del Webhook de otras pestañas y configurarlo correctamente. Esto demuestra la potente capacidad de Perplexity Comet para comprender instrucciones complejas, operar entre aplicaciones y automatizar procesos de desarrollo, mejorando enormemente la eficiencia de los desarrolladores. (Fuente: AravSrinivas)
LazyCraft: El competidor de código abierto de Dify para plataformas Agent : LazyCraft es una nueva plataforma de desarrollo y gestión de aplicaciones AI Agent de código abierto, considerada un fuerte competidor para Dify. Ofrece un sistema de ciclo cerrado más completo, con módulos centrales integrados como base de conocimiento, gestión de Prompts, servicios de inferencia, herramientas MCP (que soportan local y remoto), gestión de conjuntos de datos y evaluación de modelos. LazyCraft soporta la gestión multi-inquilino/multi-espacio de trabajo, resolviendo las necesidades de control de permisos de grano fino y gestión de equipos en escenarios empresariales. Además, integra funciones de ajuste fino y gestión de modelos locales, permitiendo a los usuarios comparar científicamente el rendimiento de los modelos, proporcionando un potente soporte a las empresas con necesidades de privacidad de datos y personalización profunda. (Fuente: WeChat)
📚 Aprendizaje
HuggingFace Smol Training Playbook: Guía de entrenamiento de LLM : HuggingFace ha lanzado el Smol Training Playbook, una guía completa para el entrenamiento de LLM que detalla el proceso detrás del entrenamiento de SmolLM3. La guía cubre toda la cadena, desde las decisiones estratégicas y de costos previas al inicio, el pre-entrenamiento (datos, estudios de ablación, arquitectura y ajuste), el post-entrenamiento (SFT, DPO, GRPO, fusión de modelos) hasta la infraestructura (configuración de clústeres de GPU, comunicación, depuración). Esta guía de más de 200 páginas tiene como objetivo proporcionar a los desarrolladores de LLM una experiencia de entrenamiento transparente y práctica, reduciendo la barrera para el entrenamiento de modelos propios e impulsando el desarrollo de la AI de código abierto. (Fuente: TheTuringPost, ClementDelangue)

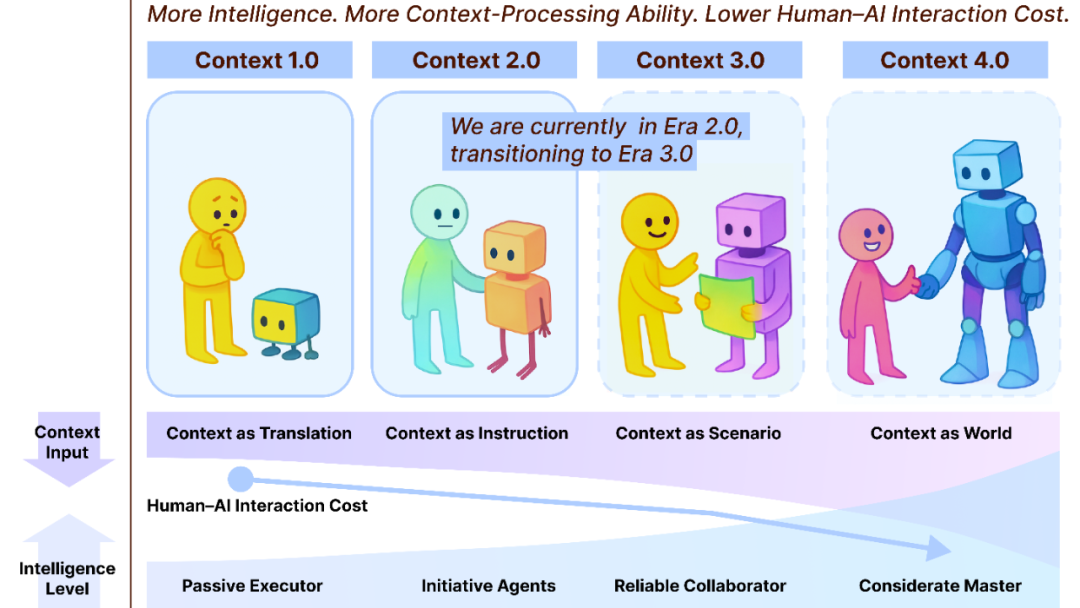
Context Engineering 2.0: 30 años de evolución : El equipo de Liu Pengfei de la Shanghai Institute of Intelligent Science and Technology ha propuesto el marco “Context Engineering 2.0”, analizando la esencia, historia y futuro de la Ingeniería de Contexto. La investigación señala que la ingeniería de contexto es un proceso de reducción de entropía de 30 años, cuyo objetivo es cerrar la brecha cognitiva entre humanos y máquinas. Desde la era 1.0 impulsada por sensores, pasando por la era 2.0 de asistentes inteligentes y fusión multimodal, hasta la era 3.0, que predice la recopilación imperceptible y la colaboración fluida, la evolución de la ingeniería de contexto ha impulsado una revolución en la interacción humano-máquina. El marco enfatiza tres dimensiones: “recopilar, gestionar, usar”, y explora cuestiones filosóficas como cómo el contexto podría formar una nueva identidad humana una vez que la AI supere a los humanos. (Fuente: WeChat)
Microsoft Research Asia PixelCraft: Mejora la comprensión de gráficos en grandes modelos : Microsoft Research Asia, en colaboración con la Universidad de Tsinghua y otros equipos, ha lanzado PixelCraft, con el objetivo de mejorar sistemáticamente la capacidad de los modelos grandes multimodales (MLLM) para comprender imágenes estructuradas como gráficos, diagramas geométricos y bocetos. PixelCraft se basa en dos pilares: procesamiento de imágenes de alta fidelidad e inferencia no lineal multi-agente. Logra un mapeo de referencia de texto a nivel de píxel mediante el ajuste fino de modelos de grounding y utiliza un conjunto de agentes de herramientas visuales para ejecutar operaciones de imagen verificables. Su proceso de inferencia conversacional soporta el retroceso y la exploración de ramas, mejorando significativamente la precisión, robustez y explicabilidad del modelo en benchmarks de gráficos y geometría como CharXiv y ChartQAPro. (Fuente: WeChat)
Spatial-SSRL: Aprendizaje por refuerzo auto-supervisado mejora la comprensión espacial : Una investigación ha introducido Spatial-SSRL, un paradigma de aprendizaje por refuerzo auto-supervisado, diseñado para mejorar las capacidades de comprensión espacial de los modelos de lenguaje visual grandes (LVLM). Spatial-SSRL obtiene señales verificables directamente de imágenes RGB o RGB-D ordinarias, construyendo automáticamente cinco tareas pre-texto que capturan estructuras espaciales 2D y 3D, sin necesidad de anotación manual o de LVLM. En siete benchmarks de comprensión espacial de imágenes y videos, Spatial-SSRL logró una mejora promedio de precisión del 4.63% (3B) y 3.89% (7B) en comparación con el modelo base Qwen2.5-VL, demostrando que una supervisión simple e intrínseca puede lograr RLVR a gran escala, brindando una inteligencia espacial más fuerte a los LVLM. (Fuente: HuggingFace Daily Papers)
π_RL: Ajuste fino de modelos VLA con aprendizaje por refuerzo en línea : Una investigación ha propuesto π_RL, un framework de código abierto para entrenar modelos de acción visual-lingüística (VLA) basados en flujo en simulaciones paralelas. π_RL implementa dos algoritmos de RL: Flow-Noise modela el proceso de denoising como un MDP de tiempo discreto, mientras que Flow-SDE logra una exploración eficiente de RL a través de una transformación ODE-SDE. En los benchmarks LIBERO y ManiSkill, π_RL mejoró significativamente el rendimiento de los modelos SFT few-shot pi_0 y pi_0.5, demostrando la efectividad del RL en línea para modelos VLA basados en flujo y logrando potentes capacidades de RL multitarea y generalización. (Fuente: HuggingFace Daily Papers)
LLM Agents: Subsistemas centrales para construir agentes LLM autónomos : Un artículo de lectura obligatoria, “Fundamentals of Building Autonomous LLM Agents”, revisa los subsistemas cognitivos centrales que componen los agentes autónomos impulsados por LLM. El artículo detalla componentes clave como la percepción, el razonamiento y la planificación (CoT, MCTS, ReAct, ToT), la memoria a largo y corto plazo, la ejecución (ejecución de código, uso de herramientas, llamadas a API) y la retroalimentación de ciclo cerrado. Esta investigación proporciona una perspectiva integral para comprender y construir agentes LLM capaces de operar de forma autónoma, enfatizando cómo estos subsistemas trabajan en conjunto para lograr comportamientos inteligentes complejos. (Fuente: TheTuringPost)

Efficient Vision-Language-Action Models: Una revisión de modelos VLA eficientes : Una revisión exhaustiva, “A Survey on Efficient Vision-Language-Action Models”, explora los avances de vanguardia en modelos eficientes de visión-lenguaje-acción (VLA) en el campo de la inteligencia encarnada. Esta revisión propone una taxonomía unificada, dividiendo las técnicas existentes en tres pilares principales: diseño eficiente de modelos, entrenamiento eficiente y recopilación eficiente de datos. A través de una revisión crítica de los métodos más avanzados, la investigación proporciona una referencia fundamental para la comunidad, resume aplicaciones representativas, aclara desafíos clave y traza una hoja de ruta para futuras investigaciones, con el objetivo de abordar las enormes demandas computacionales y de datos que enfrentan los modelos VLA en su despliegue. (Fuente: HuggingFace Daily Papers)
Nuevo hallazgo sobre el cuello de botella de rendimiento de las SNNs: Frecuencia, no escasez : Una investigación ha revelado la verdadera razón detrás de la brecha de rendimiento entre las SNNs (Spiking Neural Networks) y las ANNs (Artificial Neural Networks): no es la pérdida de información debido a activaciones binarias/dispersas, como se creía tradicionalmente, sino la característica inherente de filtro de paso bajo de las neuronas de pulso. La investigación encontró que las SNNs se comportan como filtros de paso bajo a nivel de red, lo que provoca una rápida disipación de los componentes de alta frecuencia y reduce la efectividad de la representación de características. Al reemplazar Avg-Pool con Max-Pool en el Spiking Transformer, la precisión de CIFAR-100 mejoró en un 2.39%, y se propuso la arquitectura Max-Former, logrando una precisión del 82.39% y una reducción del consumo de energía del 30% en ImageNet. (Fuente: Reddit r/MachineLearning)
💼 Negocios
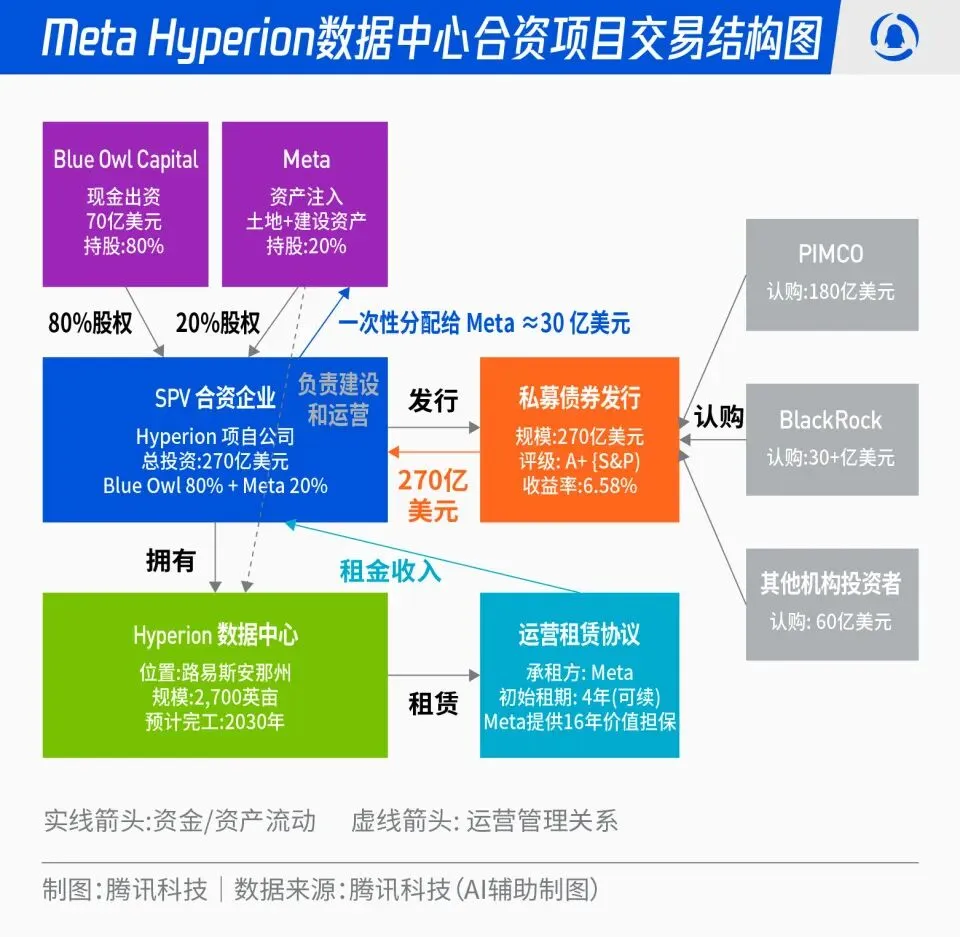
Meta y Blue Owl lanzan el proyecto de joint venture Hyperion de 27 mil millones de dólares para centros de datos : Meta ha anunciado una asociación con Blue Owl para lanzar “Hyperion”, un proyecto de joint venture para centros de datos valorado en 27 mil millones de dólares. Meta aportará el 20% y Blue Owl el 80%, emitiendo bonos con calificación A+ y capital a través de un SPV, anclados por fondos institucionales a largo plazo como PIMCO y BlackRock. El proyecto tiene como objetivo transformar la construcción de infraestructura de AI de un gasto de capital tradicional a un modelo de innovación financiera; una vez construidos, los centros de datos serán arrendados a largo plazo por Meta, quien conservará el control operativo. Esta medida optimizará el balance de Meta, acelerará su expansión en AI y, al mismo tiempo, proporcionará a los capitales a largo plazo una cartera de inversiones con alta calificación, respaldo de activos físicos y flujos de efectivo estables. (Fuente: 36氪)
La “mafia de OpenAI”: Auge de financiación para startups de ex empleados : Silicon Valley está experimentando un fenómeno de “mafia de OpenAI”, con varios ex ejecutivos, investigadores y líderes de producto de OpenAI dejando la empresa para iniciar sus propias ventures, obteniendo cientos de millones o incluso miles de millones de dólares en financiación con altas valoraciones, incluso antes de lanzar un producto. Por ejemplo, Angela Jiang fundó Worktrace AI y está negociando una ronda de financiación semilla de decenas de millones de dólares; la ex CTO Mira Murati fundó Thinking Machines Lab y completó una financiación de 2 mil millones de dólares; y el ex científico jefe Ilya Sutskever estableció Safe Superintelligence Inc. (SSI) con una valoración de 32 mil millones de dólares. Estos ex empleados, a través de inversiones mutuas, respaldo tecnológico y reputación, están construyendo una nueva red de poder de AI fuera de OpenAI; el capital valora más la “procedencia de OpenAI” que el producto en sí. (Fuente: 36氪)

El profundo impacto de la AI en la industria aérea: Lufthansa recorta 4000 puestos de trabajo : Lufthansa, el grupo aéreo más grande de Europa, ha anunciado que para 2030 recortará aproximadamente 4000 puestos administrativos, lo que representa el 4% de su plantilla total, principalmente debido a la acelerada aplicación de la inteligencia artificial y las herramientas digitales. La aplicación de la AI en la industria de la aviación ha penetrado profundamente en la optimización de procesos, la mejora de la eficiencia y la gestión de ingresos, por ejemplo, optimizando la gestión de tarifas a través de big data y algoritmos. Aunque los puestos operativos como pilotos y tripulantes de cabina no se han visto afectados por ahora, servicios estandarizados como la limpieza de aeropuertos y el manejo de equipaje ya han introducido robots. La AI también muestra potencial en la gestión del consumo de combustible, las operaciones de vuelo y la identificación de factores inseguros, por ejemplo, calculando con precisión la cantidad de combustible necesaria según los datos meteorológicos, y mejorando la eficiencia de rotación de las aeronaves mediante visión artificial. (Fuente: 36氪)
🌟 Comunidad
La “adicción al guion” de ChatGPT y la fuente de datos : Las redes sociales debaten el problema del “acento” de ChatGPT, que usa guiones con demasiada frecuencia. El análisis sugiere que esto no se debe a una preferencia por el inglés africano de los tutores de RLHF, sino a que GPT-4 y modelos posteriores fueron entrenados extensivamente con obras literarias de dominio público de finales del siglo XIX y principios del XX. En estos “libros antiguos”, el uso de guiones era mucho más frecuente que en el inglés contemporáneo, lo que llevó a que el modelo de AI aprendiera fielmente el estilo de escritura de esa época. Este hallazgo revela el profundo impacto de las fuentes de datos de entrenamiento en el estilo lingüístico de los modelos de AI, y también explica por qué modelos anteriores como GPT-3.5 no presentaban este problema. (Fuente: dotey)
Censura de contenido de AI y controversia ética: Retirada de Gemma y respuestas anómalas de ChatGPT : Google retiró a Gemma de AI Studio después de que la senadora Blackburn acusara al modelo de difamación, lo que desató un debate sobre la censura de contenido de AI y la libertad de expresión. Al mismo tiempo, usuarios de Reddit informaron que ChatGPT estaba generando respuestas anómalas, como comentarios con tendencias suicidas al discutir sobre café, lo que generó dudas entre los usuarios sobre la excesiva protección de seguridad de la AI y el posicionamiento del producto. Estos incidentes reflejan conjuntamente los desafíos que enfrenta la AI en la generación de contenido y el control ético, así como el dilema de las empresas tecnológicas al equilibrar la experiencia del usuario, la revisión de seguridad y las presiones políticas. (Fuente: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
Popularización y democratización de la tecnología AI: PewDiePie construye su propia plataforma de AI : El conocido YouTuber PewDiePie se está involucrando activamente en el ámbito del autoalojamiento de AI, construyendo una plataforma de AI local con 10 tarjetas gráficas 4090, ejecutando modelos como Llama 70B, gpt-oss-120B y Qwen 245B, y desarrollando una Web UI personalizada (chat, RAG, búsqueda, TTS). También planea entrenar sus propios modelos y utilizar la AI para simulaciones de plegamiento de proteínas. Las acciones de PewDiePie se consideran un ejemplo de democratización y despliegue local de la AI, atrayendo a millones de seguidores a la tecnología de AI e impulsando su popularización desde el ámbito profesional al público general. (Fuente: vllm_project, Reddit r/artificial)

Aumento de la demanda de datos de AI y disputa por IP: Reddit demanda a Perplexity AI : La industria de la AI se enfrenta al desafío del agotamiento de datos; la escasez de datos de alta calidad está llevando a los proveedores de AI a recurrir a fuentes de datos de “baja calidad” como las redes sociales. Reddit ha demandado a Perplexity AI, el unicornio de búsqueda de AI, en un tribunal federal de Nueva York, acusándolo de extraer ilegalmente comentarios de usuarios de Reddit sin permiso para obtener beneficios comerciales. Este incidente subraya la dependencia de los grandes modelos de AI de enormes volúmenes de datos, así como el creciente conflicto entre los propietarios de datos y los proveedores de AI sobre los derechos de propiedad intelectual y uso de datos. En el futuro, la diferencia en la capacidad de adquisición de datos entre gigantes y startups podría convertirse en un factor clave de diferenciación en la competencia del sector de la AI. (Fuente: 36氪)
Controversia y regulación del contenido generado por AI: California/Utah exigen divulgación de interacciones con AI : Con la popularización de las aplicaciones de AI, la cuestión de la transparencia en el contenido generado por AI y las interacciones con AI se vuelve cada vez más prominente. Los estados de Utah y California en EE. UU. han comenzado a legislar, exigiendo a las empresas que informen claramente a los usuarios cuando interactúen con AI. Esta medida busca abordar las preocupaciones de los consumidores sobre la “AI oculta”, garantizar el derecho a la información del usuario y hacer frente a los posibles problemas éticos y de confianza que la AI plantea en áreas como el servicio al cliente y la creación de contenido. Sin embargo, la industria tecnológica se opone a tales medidas regulatorias, argumentando que podrían obstaculizar la innovación y el desarrollo de aplicaciones de AI, lo que ha provocado un debate entre el avance tecnológico y la responsabilidad social. (Fuente: Reddit r/artificial, Reddit r/ArtificialInteligence)

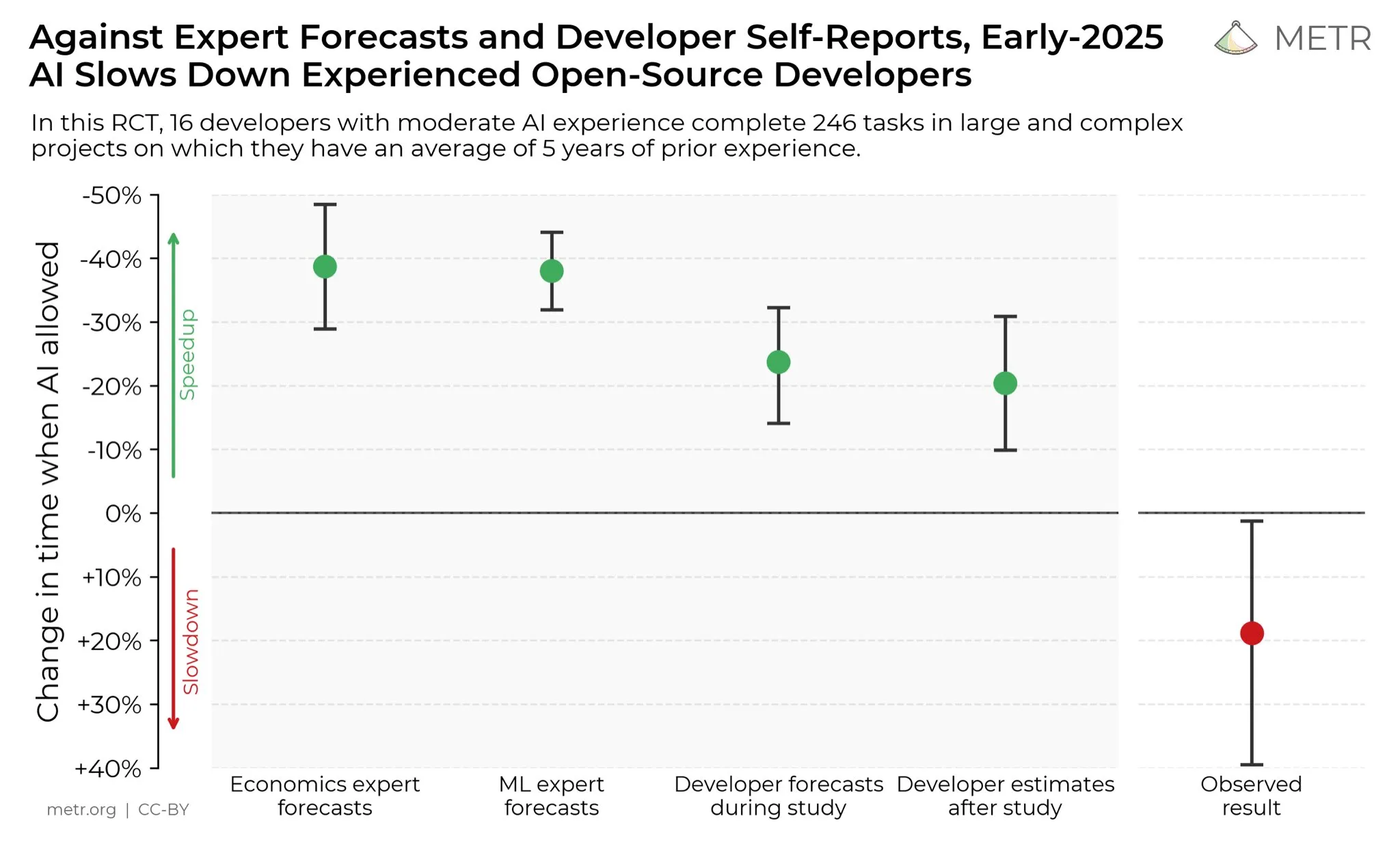
Opiniones de desarrolladores sobre la mejora de la productividad con AI : En las redes sociales, los desarrolladores generalmente creen que la AI ha mejorado enormemente su productividad. Algunos desarrolladores afirman que, con la ayuda de la AI, su productividad se ha multiplicado por diez. METR_Evals está llevando a cabo una investigación para cuantificar el impacto de la AI en la productividad de los desarrolladores e invita a más personas a participar. Esta discusión refleja el papel cada vez más importante de las herramientas de AI en el desarrollo de software, así como la alta aprobación de la programación asistida por AI por parte de la comunidad de desarrolladores, lo que presagia que la AI continuará remodelando los modelos de trabajo de la ingeniería de software. (Fuente: METR_Evals)
Modelo “autodesarrollado” de Cursor, ¿un envoltorio para código abierto chino? Debate en línea : Después de que las aplicaciones de programación de AI Cursor y Windsurf lanzaran nuevos modelos, algunos internautas descubrieron que sus modelos hablaban chino durante el proceso de inferencia y se sospecha que utilizan modelos de código abierto chinos como Zhipu GLM. Este hallazgo desató un acalorado debate en la comunidad; muchos lamentaron que los grandes modelos de código abierto chinos hayan alcanzado un nivel líder internacional, siendo buenos y económicos, convirtiéndose en una opción racional para las startups que construyen aplicaciones y modelos verticales. Este incidente también ha llevado a la gente a reexaminar el modelo de innovación en el campo de la AI, es decir, el desarrollo secundario basado en modelos de código abierto potentes y económicos, en lugar de invertir grandes sumas para entrenar modelos desde cero. (Fuente: WeChat)

Discurso de odio hacia la AI y resistencia social : La comunidad de Reddit está impregnada de una fuerte resistencia hacia la AI; los usuarios afirman que cualquier publicación que mencione la AI recibe una gran cantidad de “downvotes” y ataques personales. Este fenómeno de “odio a la AI” no se limita a Reddit, sino que también es común en plataformas como Twitter, Bluesky, Tumblr y YouTube. Los usuarios que utilizan la AI para la escritura asistida, la generación de imágenes o la toma de decisiones son acusados de ser “creadores de basura de AI”, e incluso esto afecta sus relaciones sociales. Esta oposición emocional indica que, a pesar del continuo desarrollo de la tecnología de AI, las preocupaciones y prejuicios de la sociedad sobre su impacto ambiental, la sustitución de empleos, la ética artística y otros aspectos siguen profundamente arraigados y son difíciles de disipar a corto plazo. (Fuente: Reddit r/ArtificialInteligence)
💡 Otros
Desafíos del almacenamiento de datos en la era de la AI : A medida que la revolución de la AI se profundiza, el almacenamiento de datos enfrenta enormes desafíos, necesitando adaptarse constantemente a las masivas demandas de datos que trae el rápido desarrollo de la tecnología de AI. La investigación del Instituto Tecnológico de Massachusetts (MIT) está explorando cómo ayudar a los sistemas de almacenamiento de datos a seguir el ritmo de la revolución de la AI, para asegurar que los modelos de AI puedan acceder y procesar los datos necesarios de manera eficiente. Esto subraya el papel crucial de la infraestructura de datos en el ecosistema de la AI, así como la importancia de la innovación continua para satisfacer las demandas computacionales de la AI. (Fuente: Ronald_vanLoon)

Innovación en robótica en múltiples campos: Desde la estabilización de cámaras hasta manos humanoides : La robótica continúa innovando en múltiples campos. JigSpace mostró su aplicación 3D/AR en Apple Vision Pro. WevolverApp presentó cómo los drones logran una perfecta estabilización de cámara a través de un sistema de cardán. IntEngineering mostró el sistema Mantiss Jump Reloaded, que ofrece una estabilidad asombrosa para los camarógrafos. Además, la investigación también incluye manos robóticas con detección táctil, el kit de robótica modular UGOT, robots trepadores de cuerda y el control estable del Unitree G1 en terrenos irregulares; todo esto presagia avances significativos en la percepción, manipulación y movilidad de la robótica. (Fuente: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)