
Palabras clave:DeepSeek-OCR, ChatGPT Atlas, Unitree H2, Computación cuántica, Descubrimiento de fármacos con IA, DeepSeek MoE, vLLM, Meta Vibes, Tecnología de compresión óptica contextual, Función de memoria del navegador con IA, Grados de libertad en robots humanoides, Algoritmo de eco cuántico, Marco de generación de protocolos de experimentación biológica
🔥 Foco
DeepSeek-OCR: Tecnología de compresión óptica contextual : El modelo DeepSeek-OCR introduce el concepto de “compresión óptica contextual”, que, al tratar el texto como imágenes, puede comprimir el contenido de una página completa en un pequeño número de “tokens visuales” mediante codificación visual, para luego decodificarlos y restaurarlos como texto, tablas o gráficos, logrando una mejora de eficiencia de diez veces y una precisión de hasta el 97%. Esta tecnología utiliza DeepEncoder para capturar la información de la página y comprimirla 16 veces, reduciendo 4096 tokens a 256, y puede ajustar automáticamente la cantidad de tokens según la complejidad del documento, superando significativamente a los modelos OCR existentes. Esto no solo reduce drásticamente los costos de procesamiento de documentos largos y mejora la eficiencia de extracción de información, sino que también ofrece nuevas ideas para la memoria a largo plazo y la expansión del contexto de los LLM, lo que presagia el enorme potencial de las imágenes como portadoras de información en el campo de la IA. (Fuente: HuggingFace Daily Papers, 36氪, ZhihuFrontier)

OpenAI lanza el navegador ChatGPT Atlas : OpenAI ha lanzado ChatGPT Atlas, un navegador diseñado específicamente para la era de la IA, que integra profundamente ChatGPT en la experiencia de navegación. Este navegador no solo ofrece funciones tradicionales, sino que también incorpora un “modo Agente” capaz de realizar tareas como reservas, compras y rellenar formularios, y cuenta con una función de “memoria del navegador” que aprende los hábitos del usuario para ofrecer un servicio personalizado. Este movimiento marca un cambio estratégico de OpenAI hacia la construcción de un ecosistema completo de IA, que podría remodelar la forma en que los usuarios interactúan con Internet y desafiar el dominio de la publicidad y los datos de los navegadores existentes (especialmente Google Chrome). La industria considera ampliamente que este es el comienzo de una nueva “guerra de navegadores”, cuyo núcleo es la lucha por el control de la vida digital de los usuarios. (Fuente: Smol_AI, TheRundownAI, Reddit r/ArtificialInteligence, Reddit r/MachineLearning)
Lanzamiento del robot humanoide Unitree H2 : Unitree Robotics ha lanzado el robot humanoide H2, logrando un gran avance en la inteligencia encarnada y el diseño de hardware. El H2 es compatible con NVIDIA Jetson AGX Thor, con una capacidad de cálculo 7.5 veces superior a la de Orin y una eficiencia 3.5 veces mayor. En cuanto al diseño mecánico, las piernas han añadido 1 grado de libertad (un total de 6), y los brazos se han actualizado a 7 grados de libertad, con una carga útil de 7-15 kg y la opción de manos diestras. En cuanto a la detección, el H2 abandona el LiDAR y se decanta por la percepción 3D puramente visual, utilizando cámaras estéreo binoculares. A pesar de los importantes avances tecnológicos, los comentarios señalan que los robots humanoides aún buscan escenarios de aplicación maduros y, por ahora, son más adecuados para la investigación de laboratorio. (Fuente: ZhihuFrontier)

Avances en el descubrimiento de fármacos asistido por IA y tecnología biónica : Investigadores del MIT han utilizado la IA para diseñar nuevos antibióticos que combaten eficazmente la Neisseria gonorrhoeae multirresistente y el MRSA. Estos compuestos tienen una estructura única y destruyen las membranas celulares bacterianas a través de nuevos mecanismos, lo que dificulta el desarrollo de resistencia. Al mismo tiempo, el equipo de investigación también ha desarrollado una nueva rodilla biónica que se integra directamente con los músculos y tejidos óseos del usuario, utilizando la tecnología AMI para extraer información neural de los músculos residuales después de la amputación y guiar el movimiento de la prótesis. Esta rodilla biónica ayuda a los amputados a caminar más rápido, subir escaleras y evitar obstáculos con facilidad, sintiéndose más como una parte de su propio cuerpo, y se espera que obtenga la aprobación de la FDA después de ensayos clínicos a mayor escala. (Fuente: MIT Technology Review, MIT Technology Review)

Google logra una ventaja cuántica verificable : Google ha publicado un nuevo avance en computación cuántica en la revista Nature. Su chip Willow ha logrado por primera vez una ventaja cuántica verificable al ejecutar un algoritmo llamado “eco cuántico”. Este algoritmo es 13.000 veces más rápido que el algoritmo clásico más veloz y puede explicar las interacciones entre átomos en las moléculas, lo que abre posibles aplicaciones en campos como el descubrimiento de fármacos y la ciencia de materiales. Los resultados de este avance son repetibles y verificables, lo que representa un paso importante de la computación cuántica hacia aplicaciones prácticas. (Fuente: Google)

🎯 Tendencias
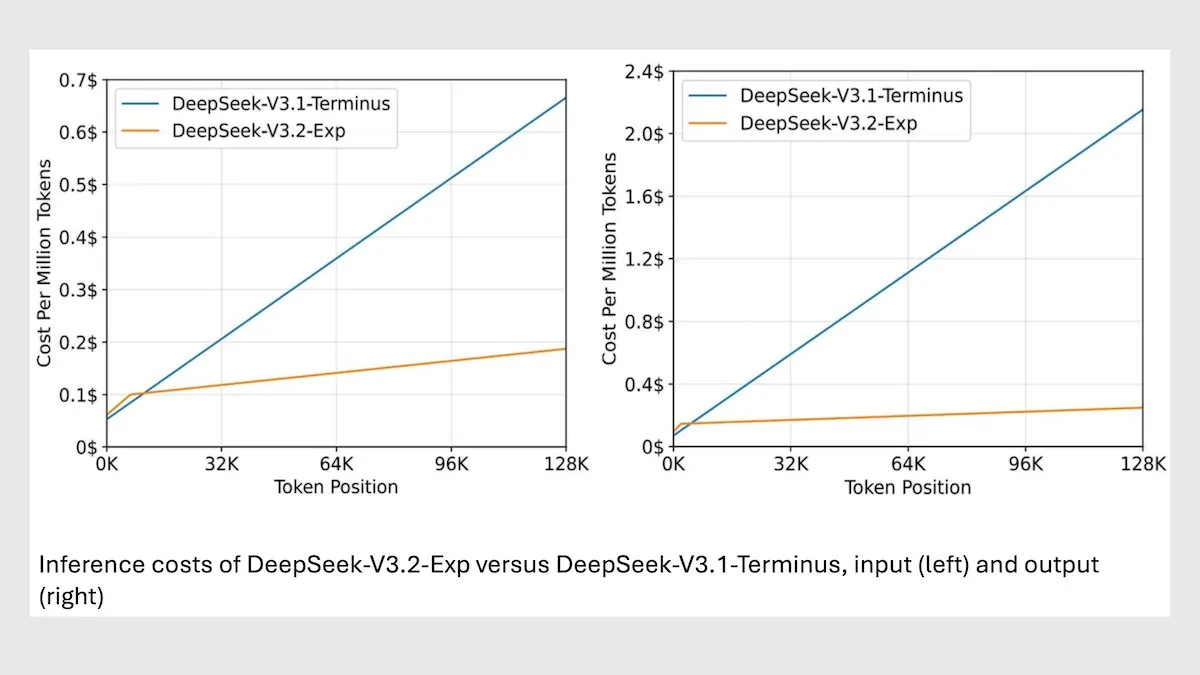
DeepSeek MoE Model V3.2 optimiza la inferencia de contexto largo : DeepSeek ha lanzado el nuevo modelo MoE 685B V3.2, que se enfoca solo en los tokens más relevantes, logrando una mejora de velocidad de inferencia de contexto largo de 2 a 3 veces y reduciendo los costos de procesamiento de 6 a 7 veces en comparación con el modelo V3.1. El nuevo modelo utiliza pesos con licencia MIT y se ofrece a través de API, optimizado para Huawei y otros chips chinos. Aunque ha habido una ligera disminución en algunas tareas científicas/matemáticas, el rendimiento ha mejorado en tareas de codificación/agente. (Fuente: DeepLearningAI)
vLLM V1 ahora es compatible con GPU AMD : La versión vLLM V1 ahora puede ejecutarse en GPU AMD. Los equipos de IBM Research, Red Hat y AMD colaboraron para construir un backend de atención optimizado utilizando núcleos Triton, logrando un rendimiento de vanguardia. Este avance proporciona una solución de inferencia LLM más eficiente para los usuarios de hardware AMD. (Fuente: QuixiAI)

Meta Vibes AI lanza streaming de video : Meta ha lanzado una nueva función de streaming de video con IA, Vibes, integrada en la aplicación Meta AI. Los usuarios pueden navegar por videos cortos generados por IA y realizar ediciones secundarias con un solo clic, incluyendo añadir música, cambiar estilos o remezclar trabajos de otros, y compartirlos en Instagram y Facebook. Este movimiento tiene como objetivo reducir la barrera de entrada a la creación de videos con IA, impulsando el video con IA a los escenarios sociales principales, y podría cambiar el modelo de producción y distribución de contenido de videos cortos, aunque también plantea preocupaciones sobre los derechos de autor, la originalidad y la difusión de información falsa. (Fuente: 36氪)
rBridge: Modelo de agente para predecir el rendimiento de inferencia de LLM : El método rBridge permite que pequeños modelos de agente (≤1B parámetros) predigan eficazmente el rendimiento de inferencia de modelos grandes (7B-32B parámetros), reduciendo el costo computacional en más de 100 veces. Este método alinea la evaluación con los objetivos de preentrenamiento y las tareas objetivo, y utiliza trayectorias de inferencia de modelos de vanguardia como etiquetas de oro, ponderando la importancia de los tokens para la tarea, resolviendo el “problema de emergencia” donde las capacidades de inferencia no se manifiestan en modelos pequeños. Esto reduce significativamente el costo para los investigadores con recursos computacionales limitados que exploran opciones de diseño de preentrenamiento. (Fuente: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Mono4DGS-HDR: Sistema de reconstrucción de splatting gaussiano 4D de alto rango dinámico : Mono4DGS-HDR es el primer sistema que reconstruye escenas 4D de alto rango dinámico (HDR) renderizables a partir de videos monoculares de bajo rango dinámico (LDR) con exposición alterna. Este marco unificado emplea un método de optimización de dos etapas basado en la técnica de splatting gaussiano. Primero, aprende una representación gaussiana HDR de video en el espacio de coordenadas de la cámara ortogonal, luego convierte los gaussianos de video al espacio mundial y optimiza conjuntamente los gaussianos mundiales con la pose de la cámara. Además, la estrategia de regularización de brillo temporal propuesta mejora la consistencia temporal de la apariencia HDR, superando significativamente los métodos existentes en calidad y velocidad de renderizado. (Fuente: HuggingFace Daily Papers)
EvoSyn: Marco de síntesis de datos evolutivo para el aprendizaje verificable : EvoSyn es un marco de síntesis de datos evolutivo, independiente de la tarea, guiado por políticas y verificable, diseñado para generar datos verificables fiables. Este marco comienza con una supervisión mínima de semillas, sintetiza conjuntamente problemas, soluciones candidatas diversas y artefactos de verificación, y descubre iterativamente políticas a través de un evaluador basado en la consistencia. Los experimentos demuestran que el entrenamiento con datos sintetizados por EvoSyn logra mejoras significativas en las tareas LiveCodeBench y AgentBench-OS, destacando la robusta capacidad de generalización de su marco. (Fuente: HuggingFace Daily Papers)
Nuevo método para extraer datos alineados de modelos post-entrenamiento : La investigación muestra que se puede extraer una gran cantidad de datos de entrenamiento alineados de modelos post-entrenamiento para mejorar las capacidades del modelo en inferencia de contexto largo, seguridad, seguimiento de instrucciones y matemáticas. La similitud semántica medida por modelos de embedding de alta calidad permite identificar datos de entrenamiento que el matching de cadenas tradicional no puede capturar. La investigación encontró que los modelos retroceden fácilmente a los datos utilizados en las etapas de post-entrenamiento como SFT o RL, y estos datos pueden usarse para entrenar modelos base y restaurar el rendimiento original. Este trabajo revela los riesgos potenciales de extraer datos alineados y proporciona una nueva perspectiva para discutir los efectos posteriores de las prácticas de destilación. (Fuente: HuggingFace Daily Papers)
PRISMM-Bench: Benchmark de inconsistencias multimodales en artículos científicos : PRISMM-Bench es el primer benchmark basado en inconsistencias multimodales en artículos científicos marcadas por revisores reales, diseñado para evaluar la capacidad de los grandes modelos multimodales (LMM) para comprender y razonar la complejidad de los artículos científicos. Este benchmark utiliza un proceso de múltiples etapas para recopilar 262 inconsistencias de 242 artículos y diseña tres tareas: identificación, remediación y matching emparejado. La evaluación de 21 LMM (incluidos GLM-4.5V 106B, InternVL3 78B y Gemini 2.5 Pro, GPT-5) muestra que el rendimiento del modelo es significativamente bajo (26.1-54.2%), lo que destaca los desafíos del razonamiento científico multimodal. (Fuente: HuggingFace Daily Papers)
GAS: Método mejorado de discretización de ODE de difusión : Aunque los modelos de difusión han logrado un rendimiento de vanguardia en calidad de generación, sus costos computacionales de muestreo son altos. Generalized Adversarial Solver (GAS) propone un muestreador ODE parametrizado simple que mejora la calidad sin necesidad de técnicas de entrenamiento adicionales. Al combinar la pérdida de destilación original con el entrenamiento adversario, GAS puede mitigar los artefactos y mejorar la fidelidad de los detalles. Los experimentos demuestran que GAS supera a los métodos de entrenamiento de solvers existentes bajo restricciones de recursos similares. (Fuente: HuggingFace Daily Papers)
3DThinker: Marco de razonamiento espacial de imaginación geométrica VLM : El marco 3DThinker tiene como objetivo mejorar la capacidad de los modelos de lenguaje visual (VLM) para comprender las relaciones espaciales 3D con una perspectiva limitada. Este marco utiliza un entrenamiento de dos etapas: primero, un entrenamiento supervisado para alinear el espacio latente 3D generado por el VLM durante el razonamiento con el espacio latente de un modelo base 3D; luego, optimiza toda la trayectoria de razonamiento basándose únicamente en la señal de resultado, perfeccionando así el modelado mental 3D subyacente. 3DThinker es el primer marco que logra el modelado mental 3D sin entrada 3D a priori o datos 3D explícitamente etiquetados, y ha demostrado un rendimiento superior en múltiples benchmarks, ofreciendo una nueva perspectiva para unificar las representaciones 3D en el razonamiento multimodal. (Fuente: HuggingFace Daily Papers)
Huawei HarmonyOS 6 mejora las funciones del asistente de IA : Huawei ha lanzado oficialmente el sistema operativo HarmonyOS 6, que mejora integralmente la fluidez, la inteligencia y la experiencia de colaboración entre dispositivos. Entre sus características, la función “Super Asistente” Xiaoyi ha sido significativamente mejorada, no solo soporta 16 dialectos, sino que también puede realizar investigaciones profundas, editar imágenes con una sola frase y ayudar a los usuarios con discapacidad visual a “ver el mundo”. Basado en el marco de agentes inteligentes de HarmonyOS, se han lanzado los primeros 80+ agentes de aplicaciones de HarmonyOS. Xiaoyi y sus socios agentes pueden colaborar estrechamente para proporcionar servicios profesionales, como guías de viaje, citas médicas, etc., y se han introducido funciones de protección de la privacidad como “prevención de fraudes por IA” y “prevención de miradas indiscretas por IA”. (Fuente: 量子位)

Aplicación de la IA en estudios urbanos: análisis de la velocidad al caminar y el uso del espacio público : Un estudio coescrito por académicos del MIT revela que entre 1980 y 2010, la velocidad media al caminar en tres ciudades del noreste de Estados Unidos aumentó un 15%, mientras que el número de personas que permanecían en espacios públicos disminuyó un 14%. Los investigadores utilizaron herramientas de machine learning para analizar videoclips de Boston, Nueva York y Filadelfia de la década de 1980 y los compararon con nuevos videos. Especulan que factores como los teléfonos móviles y las cafeterías podrían haber llevado a las personas a concertar citas más a menudo por mensaje de texto y a elegir lugares interiores en lugar de espacios públicos para socializar, lo que ofrece nuevas perspectivas para el diseño de espacios públicos urbanos. (Fuente: MIT Technology Review)
Desafíos y soluciones de robustez interlingüística en la marca de agua de LLM multilingües : La investigación señala que las tecnologías existentes de marca de agua multilingüe para grandes modelos de lenguaje (LLM) no son verdaderamente multilingües y carecen de robustez ante ataques de traducción en idiomas de bajos recursos. Este fallo se debe a que la agrupación semántica falla cuando el vocabulario del tokenizer es insuficiente. Para resolver este problema, la investigación introduce STEAM, un método de detección basado en la retrotraducción que puede restaurar la fuerza de la marca de agua perdida por la traducción. STEAM es compatible con cualquier método de marca de agua, es robusto para diferentes tokenizers e idiomas, y es fácil de escalar a nuevos idiomas, logrando una mejora significativa promedio de +0.19 AUC y +40%p TPR@1% en 17 idiomas, proporcionando una vía simple y potente para el desarrollo de una tecnología de marca de agua justa. (Fuente: HuggingFace Daily Papers)
El modelo Qwen muestra un fuerte rendimiento en la comunidad de código abierto y aplicaciones comerciales : El modelo Tongyi Qianwen de Alibaba ha demostrado un fuerte impulso en la comunidad de código abierto y en aplicaciones comerciales. DeepSeek V3.2 y Qwen-3-235b-A22B-Instruct se encuentran entre los primeros puestos en la clasificación de modelos abiertos de Text Arena. Brian Chesky, CEO de Airbnb, ha declarado públicamente que la empresa “depende en gran medida del modelo Tongyi Qianwen de Alibaba” y lo considera “mejor y más barato que OpenAI”, priorizándolo en entornos de producción. Además, el equipo de Qwen también colabora activamente con el proyecto llama.cpp, impulsando continuamente el desarrollo de la comunidad de código abierto. El nuevo modelo Qwen-VL supera significativamente a las versiones anteriores en rendimiento, especialmente en modelos de bajos parámetros, lo que demuestra su rápida iteración y capacidad de optimización. (Fuente: teortaxesTex, Zai_org, hardmaru, Reddit r/LocalLLaMA)
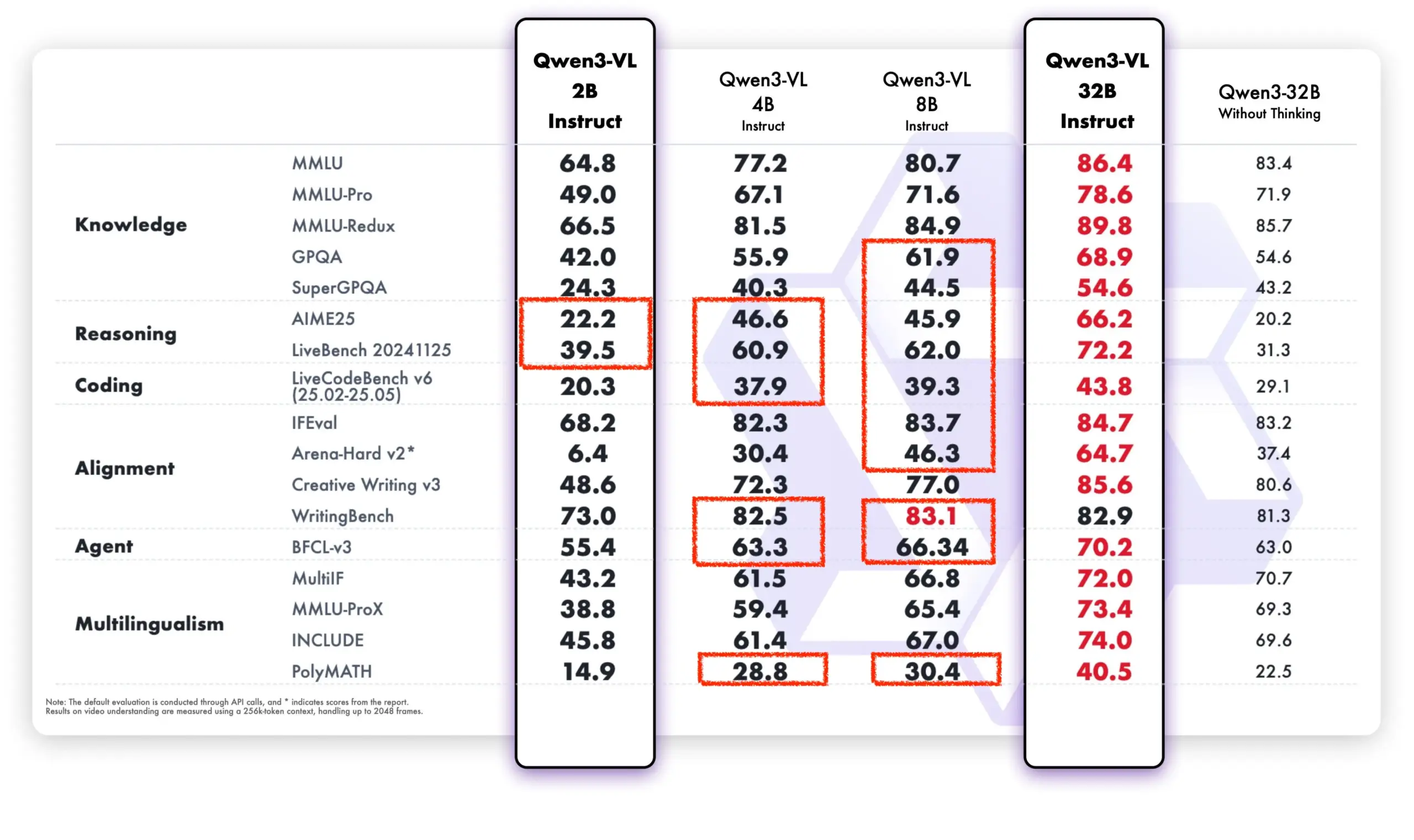
Aprendizaje continuo de LLM: Reducción del olvido mediante el fine-tuning disperso de capas de memoria : Una nueva investigación de Meta AI propone que, mediante el fine-tuning disperso de capas de memoria, se puede lograr que los grandes modelos de lenguaje (LLM) aprendan continuamente nuevos conocimientos, minimizando al mismo tiempo la interferencia con el conocimiento existente. En comparación con métodos como el fine-tuning completo y LoRA, el fine-tuning disperso de capas de memoria reduce significativamente la tasa de olvido (-11% vs -89% FT, -71% LoRA) al aprender la misma cantidad de nuevos conocimientos, lo que ofrece una nueva dirección para construir LLM capaces de adaptarse y actualizarse continuamente. (Fuente: giffmana, AndrewLampinen)
Avances de la IA en la conducción autónoma: el vicepresidente de General Motors destaca la seguridad vial : Sterling Anderson, vicepresidente ejecutivo y director global de productos de General Motors, enfatiza el enorme potencial de la IA y las tecnologías avanzadas de asistencia a la conducción para mejorar la seguridad vial. Señala que, a diferencia de los conductores humanos, los sistemas de conducción autónoma no conducen bajo los efectos del alcohol, cansados o distraídos, y pueden monitorear todas las direcciones de la carretera simultáneamente, incluso en condiciones climáticas adversas. Anderson, quien cofundó Aurora Innovation y lideró el desarrollo de Tesla Autopilot, cree que la tecnología de conducción autónoma no solo puede mejorar significativamente la seguridad vial, sino también aumentar la eficiencia del transporte de carga y, en última instancia, ahorrar tiempo a las personas. Afirma que su experiencia de aprendizaje en el MIT le proporcionó la base técnica y la libertad de exploración para resolver problemas complejos y la colaboración humano-máquina. (Fuente: MIT Technology Review)

Tank 400 Hi4-T añade la función de conductor de IA : El nuevo Tank 400 Hi4-T incorpora la función de conductor de IA, diseñada para mejorar la experiencia de conducción en condiciones de carretera complejas. En una prueba bajo la lluvia en la ciudad montañosa 8D de Chongqing, el conductor de IA demostró una buena capacidad de asistencia a la conducción al enfrentarse a carreteras resbaladizas y entornos de tráfico complejos. Esto marca una mayor aplicación y optimización de la tecnología de IA en el campo de la conducción autónoma en entornos todoterreno y urbanos complejos. (Fuente: 量子位)

🧰 Herramientas
Thoth: Marco de IA para la generación asistida de protocolos de experimentos biológicos : Thoth es un marco de IA basado en el paradigma “Sketch-and-Fill” (esbozar y rellenar), diseñado para generar automáticamente protocolos de experimentos biológicos precisos, lógicamente ordenados y ejecutables a partir de consultas en lenguaje natural. Este marco separa el análisis, la estructuración y la expresión, asegurando que cada paso sea claramente verificable. Combinado con un mecanismo de recompensa de componentes estructurados, Thoth se evalúa en granularidad de pasos, orden de operaciones y fidelidad semántica, alineando la optimización del modelo con la fiabilidad experimental. Thoth supera a los LLM propietarios y de código abierto en múltiples benchmarks, logrando mejoras significativas en la alineación de pasos, el orden lógico y la precisión semántica, allanando el camino para asistentes científicos fiables. (Fuente: HuggingFace Daily Papers)
AlphaQuanter: Agente de IA para el comercio de acciones basado en aprendizaje por refuerzo : AlphaQuanter es un marco de aprendizaje por refuerzo de agentes con orquestación de herramientas de extremo a extremo para el comercio de acciones. Este marco, a través del aprendizaje por refuerzo, permite que un solo agente aprenda estrategias dinámicas, orquestre herramientas de forma autónoma y obtenga información de forma proactiva según sea necesario, estableciendo un proceso de razonamiento transparente y auditable. AlphaQuanter logra un rendimiento de vanguardia en métricas financieras clave, y su razonamiento interpretable revela estrategias comerciales complejas, proporcionando información novedosa y valiosa para los operadores humanos. (Fuente: HuggingFace Daily Papers)
PokeeResearch: Agente de investigación profunda basado en retroalimentación de IA : PokeeResearch-7B es un agente de investigación profunda de 7B parámetros, construido bajo un marco unificado de aprendizaje por refuerzo, diseñado para lograr robustez, alineación y escalabilidad. Este modelo se entrena a través de un marco de aprendizaje por refuerzo con retroalimentación de IA (RLAIF) sin etiquetas, utilizando señales de recompensa basadas en LLM para optimizar la estrategia, con el fin de capturar la precisión fáctica, la fidelidad de las citas y el cumplimiento de las instrucciones. Su estructura de razonamiento de múltiples llamadas impulsada por el pensamiento en cadena, a través de la autoverificación y la recuperación adaptativa de fallos de herramientas, mejora aún más la robustez. PokeeResearch-7B logra un rendimiento de vanguardia en 10 benchmarks populares de investigación profunda entre los agentes de investigación profunda de escala 7B. (Fuente: HuggingFace Daily Papers)
Lanzamiento del cliente GUI de DeepSeek-OCR : Un desarrollador ha creado un cliente de interfaz gráfica de usuario (GUI) para el modelo DeepSeek-OCR, lo que facilita su uso. Este modelo destaca en la comprensión de documentos y la extracción de texto estructurado. El cliente utiliza un backend Flask para gestionar el modelo y un frontend Electron para la interfaz de usuario. El modelo descarga automáticamente aproximadamente 6.7 GB de datos de HuggingFace la primera vez que se carga. Actualmente es compatible con Windows y ofrece soporte no probado para Linux, requiriendo una tarjeta gráfica Nvidia. (Fuente: Reddit r/LocalLLaMA)

Google AI Studio actualiza las funciones de creación de aplicaciones : Las funciones de creación de aplicaciones de Google AI Studio han recibido una importante actualización, incorporando todos los modelos de IA de Google. Los usuarios pueden seleccionar directamente un modelo y rellenar las indicaciones para construir aplicaciones, sin necesidad de introducir una API Key. Esto simplifica enormemente el proceso de desarrollo, haciendo que la integración de diversas capacidades de IA, como LLM, comprensión de imágenes y modelos TTS, en aplicaciones web sea mucho más cómoda. (Fuente: op7418)
Integración de Lovable Shopify AI : Lovable ha lanzado la integración con Shopify, permitiendo a los usuarios construir tiendas online conversando con la IA. Esta función tiene como objetivo resolver la falta de personalización y la implementación práctica de la “codificación de ambiente” en los sitios web de dropshipping tradicionales, logrando la construcción personalizada de tiendas a través de la IA y enfatizando el concepto de “integración” en lugar de “MCP”, con el fin de resolver puntos de dolor reales. (Fuente: crystalsssup)
La API compatible con OpenAI de vLLM ahora admite la devolución de Token ID : vLLM, en colaboración con el equipo de Agent Lightning, ha resuelto el problema de “Retokenization Drift” en el aprendizaje por refuerzo, que se refiere a la ligera discrepancia en la división de tokens entre lo que genera el modelo y lo que espera el entrenador. La API compatible con OpenAI de vLLM ahora puede devolver directamente los ID de los tokens; los usuarios solo necesitan añadir “return_token_ids”: true en la solicitud para obtener prompt_token_ids y token_ids, asegurando que los tokens utilizados durante el entrenamiento de aprendizaje por refuerzo del agente coincidan exactamente con el muestreo, evitando así problemas como la inestabilidad del aprendizaje y las actualizaciones fuera de política. (Fuente: vllm_project)
Together AI Platform añade API de modelos de video e imagen : Together AI ha anunciado la adición de más de 20 modelos de video (como Sora 2, Veo 3, PixVerse V5, Seedance) y más de 15 modelos de imagen a su plataforma API, a través de una colaboración con Runware. Se puede acceder a estos modelos utilizando la misma API que para la inferencia de texto, lo que amplía enormemente las capacidades de servicio de Together AI en el campo de la generación multimodal. (Fuente: togethercompute)

OpenAudio S1/S1-mini: Modelo TTS multilingüe de código abierto SOTA : El equipo de Fish Speech ha anunciado su cambio de marca a OpenAudio y ha lanzado la serie de modelos de texto a voz (TTS) OpenAudio-S1, que incluye S1 (4B parámetros) y S1-mini (0.5B parámetros). Estos modelos ocupan el primer lugar en la clasificación TTS-Arena2, logrando una calidad TTS excepcional (WER en inglés de 0.008, CER de 0.004), admiten clonación de voz de cero o pocas muestras, síntesis multilingüe y translingüística, y ofrecen control de emociones, entonación y marcadores especiales. Los modelos no dependen de fonemas, tienen una fuerte capacidad de generalización y están acelerados por torch compile, con un factor de tiempo real de aproximadamente 1:7 en una GPU Nvidia RTX 4090. (Fuente: GitHub Trending)

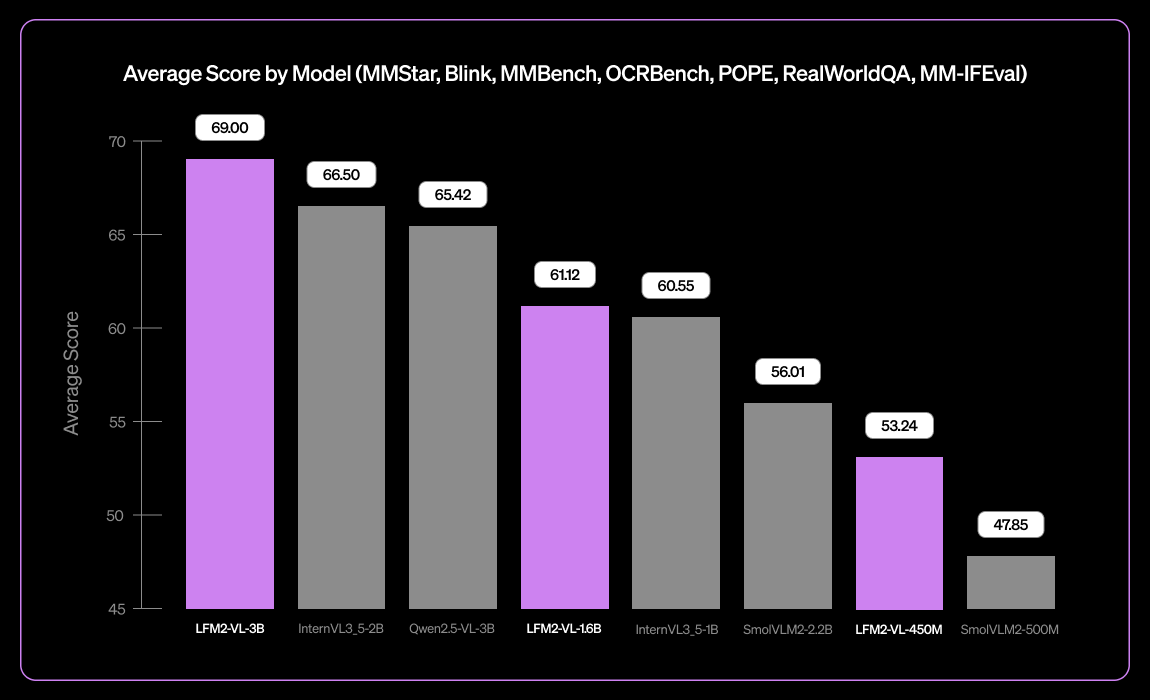
Liquid AI lanza LFM2-VL-3B, un pequeño modelo de lenguaje visual multilingüe : Liquid AI ha lanzado LFM2-VL-3B, un pequeño modelo de lenguaje visual multilingüe. Este modelo amplía las capacidades de comprensión visual multilingüe, soportando inglés, japonés, francés, español, alemán, italiano, portugués, árabe, chino y coreano. Alcanza un 51.8% en MM-IFEval (seguimiento de instrucciones) y un 71.4% en RealWorldQA (comprensión del mundo real), destacando en la comprensión de imágenes individuales y múltiples, así como en OCR en inglés, y presenta una baja tasa de alucinaciones de objetos. (Fuente: TheZachMueller)
Programación asistida por IA: Guía de ingeniería de contexto de LangChain V1 : LangChain ha publicado una nueva página sobre ingeniería de contexto de agentes, que guía a los desarrolladores sobre cómo dominar la ingeniería de contexto en LangChain V1 para construir mejores agentes de IA. Esta guía se considera una parte importante de la nueva documentación y enfatiza la importancia de proporcionar a las herramientas de IA la información más reciente. LangChain se compromete a ser una plataforma integral para la ingeniería de agentes y ha recibido una financiación de Serie B de 125 millones de dólares, valorada en 1.250 millones de dólares, y continuará impulsando el desarrollo en el campo de la ingeniería de agentes de IA. (Fuente: LangChainAI, Hacubu, hwchase17)
Solución para ejecutar Claude Desktop en Linux : La aplicación Claude Desktop actualmente solo es compatible con Mac y Windows, pero debido a que está basada en el marco Electron, los usuarios de Linux han encontrado varias soluciones comunitarias para ejecutarla en sistemas Linux. Estas soluciones incluyen la configuración flake de NixOS, el paquete AUR de Arch Linux y scripts de instalación para sistemas Debian, lo que proporciona a los usuarios de Linux una forma de utilizar Claude Desktop. (Fuente: Reddit r/ClaudeAI)
📚 Aprendizaje
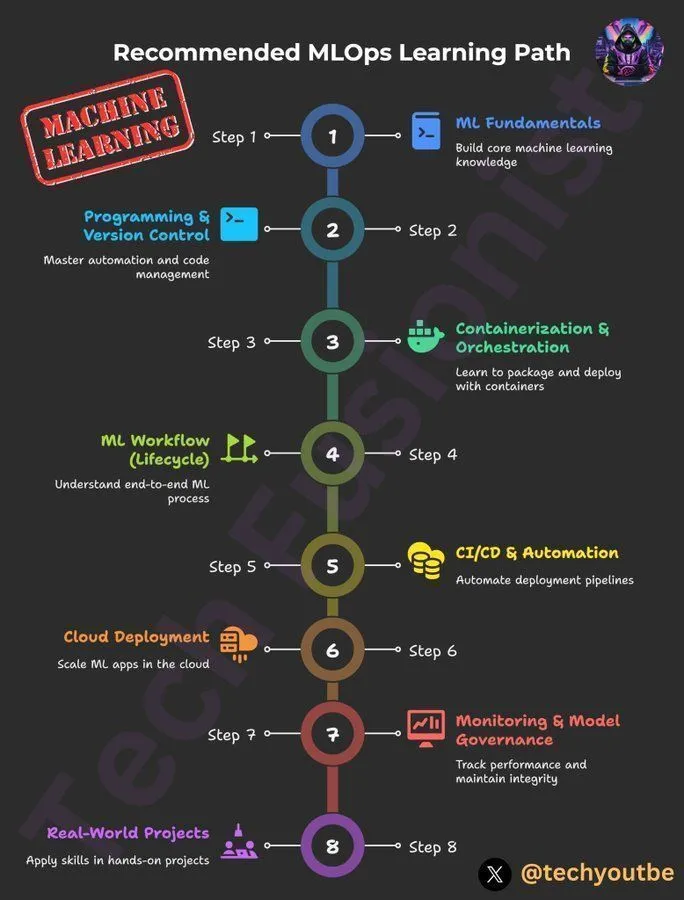
Ruta de aprendizaje de MLOps de DeepLearningAI : DeepLearningAI ofrece una ruta de aprendizaje de MLOps, diseñada para ayudar a los estudiantes a dominar las habilidades clave y las mejores prácticas en operaciones de machine learning. Esta ruta cubre todos los aspectos de MLOps, proporcionando recursos de aprendizaje estructurados para profesionales que desean profundizar sus conocimientos en el campo de la inteligencia artificial y el machine learning. (Fuente: Ronald_vanLoon)
Artículos de IA de lectura obligatoria semanal de TheTuringPost : The Turing Post ha publicado una lista de artículos de IA de lectura obligatoria semanal, que cubre varios temas de investigación de vanguardia, incluyendo la ampliación del cálculo de aprendizaje por refuerzo, la destilación de BitNet, el marco RAG-Anything, el LLM de comprensión multimodal OmniVinci, el papel de los recursos computacionales en la investigación de modelos fundamentales, QeRL y la recuperación jerárquica guiada por LLM. Estos artículos proporcionan un recurso importante para investigadores y entusiastas de la IA para mantenerse al tanto de los últimos avances tecnológicos. (Fuente: TheTuringPost)
Google DeepMind y UCL ofrecen cursos gratuitos de fundamentos de investigación en IA : Google DeepMind, en colaboración con el University College London (UCL), ha lanzado un conjunto de cursos gratuitos sobre los fundamentos de la investigación en IA, ya disponibles en la plataforma Google Skills. El contenido del curso incluye cómo escribir mejor código, cómo ajustar modelos de IA, entre otros, impartidos por expertos como Oriol Vinyals, investigador principal de Gemini, con el objetivo de ayudar a más personas a adquirir conocimientos especializados en el campo de la IA. (Fuente: GoogleDeepMind)
Cómo convertirse en un experto: Consejos de aprendizaje de Andrej Karpathy : Andrej Karpathy compartió tres consejos para convertirse en un experto en un campo: 1. Asumir proyectos concretos de forma iterativa y completarlos en profundidad, aprendiendo según sea necesario en lugar de un aprendizaje amplio de abajo hacia arriba; 2. Enseñar o resumir lo aprendido con sus propias palabras; 3. Compararse solo con su yo pasado, no con los demás. Estos consejos enfatizan los métodos de aprendizaje basados en la práctica, el resumen y el auto-crecimiento. (Fuente: jeremyphoward)
Tutorial animado a mano de multiplicación de matrices en GPU/TPU : El Prof. Tom Yeh ha publicado un tutorial animado a mano que explica en detalle cómo implementar manualmente la multiplicación de matrices en una GPU o TPU. Este tutorial, que consta de 91 fotogramas, tiene como objetivo ayudar a los estudiantes a comprender intuitivamente los mecanismos subyacentes de la computación paralela, y es de gran valor de referencia para el estudio en profundidad de la computación de alto rendimiento y la optimización del deep learning. (Fuente: ProfTomYeh)
💼 Negocios
LangChain recauda 125 millones de dólares en financiación de Serie B, valorada en 1.250 millones de dólares : LangChain ha anunciado el cierre de una ronda de financiación de Serie B de 125 millones de dólares, valorando la empresa en 1.250 millones de dólares. Estos fondos se utilizarán para construir una plataforma de ingeniería de agentes, consolidando aún más su posición de liderazgo en el campo de los marcos de agentes de IA. LangChain, que comenzó como un paquete de Python, se ha convertido en una plataforma integral de ingeniería de agentes, y su éxito en la financiación refleja la enorme confianza del mercado en la tecnología de agentes de IA y su potencial de comercialización. (Fuente: Hacubu, Hacubu)
Proyecto secreto de OpenAI “Mercury”: Contratación de élites de banca de inversión con salarios altos para entrenar modelos financieros : Se ha revelado el proyecto secreto interno de OpenAI, “Mercury”, que está reclutando a cien exprofesionales de banca de inversión y estudiantes de las mejores escuelas de negocios con salarios de 150 dólares por hora para entrenar sus modelos financieros. El objetivo es reemplazar el trabajo pesado y repetitivo de los banqueros junior en transacciones financieras como fusiones y adquisiciones, OPI, etc. Este movimiento se considera un paso clave para OpenAI para acelerar la comercialización y la rentabilidad en un contexto de altos costos de potencia de cálculo, pero también ha generado preocupaciones sobre la posible desaparición de puestos junior en la industria financiera y la interrupción de las trayectorias de crecimiento de los jóvenes. (Fuente: 36氪)
El CEO de Airbnb elogia públicamente a Tongyi Qianwen de Alibaba, considerándolo superior y más barato que los modelos de OpenAI : Brian Chesky, CEO de Airbnb, declaró públicamente en una entrevista con los medios que la empresa “depende en gran medida del modelo Tongyi Qianwen de Alibaba”, y afirmó directamente que es “mejor y más barato que OpenAI”. Señaló que, aunque también utilizan los últimos modelos de OpenAI, generalmente no los usan en gran medida en entornos de producción porque hay modelos más rápidos y económicos disponibles. Esta declaración ha generado un gran debate en Silicon Valley, mostrando un profundo cambio en el panorama de la competencia global de IA, donde el modelo Tongyi Qianwen de Alibaba está ganando clientes clave a los gigantes estadounidenses. (Fuente: 量子位)

🌟 Comunidad
El navegador ChatGPT Atlas desata el debate sobre la “guerra de navegadores” : El lanzamiento del navegador ChatGPT Atlas por parte de OpenAI ha provocado un amplio debate en la comunidad sobre la “guerra de navegadores”. Los usuarios creen que ya no se trata de una batalla por la velocidad o las funciones, sino de qué empresa de IA puede controlar los datos de uso de Internet de los usuarios y actuar en su nombre. La función de “memoria del navegador” de Atlas, aunque conveniente, también genera preocupaciones sobre la recopilación de datos de los usuarios y el entrenamiento de modelos, lo que podría llevar a que los usuarios queden atrapados en un ecosistema de IA específico. Los comentarios señalan que esta estrategia podría subvertir el negocio de publicidad de búsqueda de Google y plantear profundas reflexiones sobre el control de la vida digital en el futuro. (Fuente: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/MachineLearning)

El impacto de la IA en la productividad de los desarrolladores: ¿pereza o pensamiento de nivel superior? : La comunidad debate acaloradamente el impacto de la IA en la productividad de los desarrolladores. Algunos argumentan que la IA no vuelve a los programadores perezosos, sino que les permite gestionar sistemas con una mentalidad de ingeniero de nivel superior, delegando el trabajo repetitivo a la IA para centrarse en pruebas, verificación y depuración. Otros temen que la IA haga que los desarrolladores junior pierdan oportunidades de aprendizaje, se vuelvan más perezosos e incluso introduzcan vulnerabilidades de seguridad. El consenso general es que la IA ha cambiado la definición de un buen desarrollador, y las habilidades clave del futuro radicarán en guiar a la IA, identificar errores y diseñar flujos de trabajo fiables, en lugar de escribir manualmente cada línea de código. (Fuente: Reddit r/ClaudeAI)
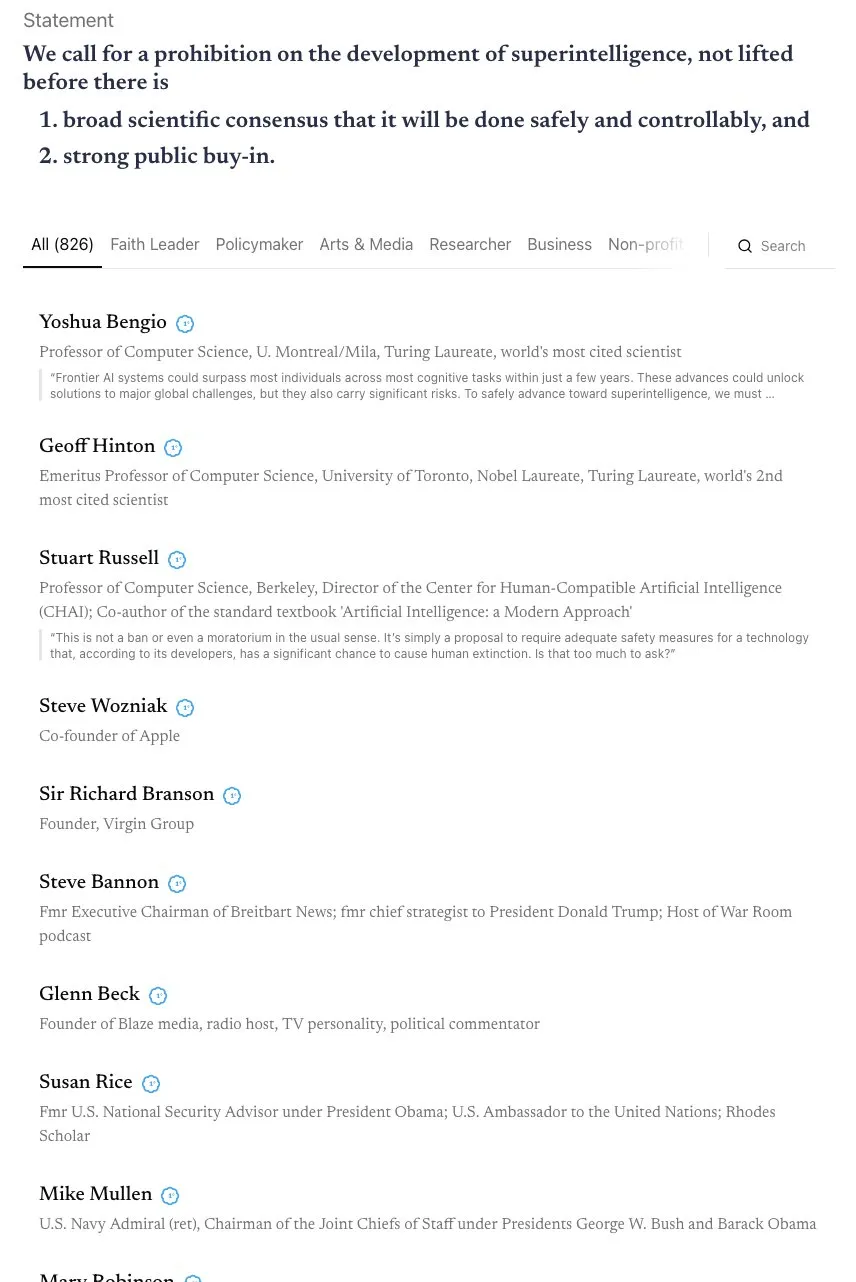
Debate sobre la línea de tiempo de la AGI y el llamado a una alianza “Skynet” : La comunidad ha iniciado un intenso debate sobre la línea de tiempo para la realización de la AGI (Inteligencia General Artificial). Andrej Karpathy cree que la AGI aún tardará una década, y que la década actual es la “década de los agentes”, no la de la AGI. Al mismo tiempo, una carta abierta firmada por más de 800 figuras públicas (incluidos los “padrinos” de la IA y Steve Wozniak) pidiendo la prohibición del desarrollo de IA superinteligente ha generado preocupaciones sobre los riesgos y la regulación de la IA. Algunos comentarios señalan que tales declaraciones vagas son difíciles de traducir en políticas reales y pueden conducir a la concentración de poder, lo que a su vez podría generar mayores riesgos. (Fuente: jeremyphoward, DanHendrycks, idavidrein, Reddit r/artificial)
Alucinaciones de LLM y problemas de factualidad: autoevaluación y extracción de datos alineados : La comunidad se preocupa por el problema de las alucinaciones de los LLM y su factualidad. Un estudio propone un método de “autoalineación de factualidad” que utiliza la capacidad de autoevaluación de los LLM para proporcionar señales de entrenamiento, reduciendo las alucinaciones sin intervención humana. Otro estudio muestra que se puede extraer una gran cantidad de datos de entrenamiento alineados de modelos post-entrenamiento para mejorar las capacidades de inferencia de contexto largo, seguridad y seguimiento de instrucciones del modelo, lo que podría generar riesgos de extracción de datos, pero también ofrece una nueva perspectiva para la destilación de modelos. Estas investigaciones proporcionan vías técnicas para mejorar la fiabilidad de los LLM. (Fuente: Reddit r/MachineLearning, HuggingFace Daily Papers)
Preocupaciones sobre el modelo de negocio y la privacidad de datos de las empresas de IA en la era de la IA : La comunidad debate cómo las empresas de IA pueden generar beneficios, especialmente en la situación actual de quema de dinero generalizada. Se cree que los futuros modelos de negocio podrían incluir publicidad integrada, limitación de servicios gratuitos, aumento de precios para servicios premium y obtención de beneficios a través de tarifas de licencia de software de aplicaciones de hardware como robots y vehículos autónomos. Al mismo tiempo, la preocupación por la recopilación masiva de datos de usuarios por parte de las empresas de IA y su posible monetización o influencia política está creciendo, convirtiendo la privacidad de datos y la ética de la IA en temas importantes. (Fuente: Reddit r/ArtificialInteligence)
El impacto de la IA en el mercado laboral: robots de Amazon reemplazan a trabajadores, desaparición de puestos junior : La comunidad expresa preocupación por el impacto de la IA en el mercado laboral. Un estudio señala que la IA está erosionando el tiempo libre de los empleados, en lugar de aumentar la productividad. Amazon planea reemplazar a 600.000 trabajadores estadounidenses con robots para 2033, lo que genera temor a un desempleo masivo. El proyecto “Mercury” de OpenAI, que recluta a élites de la banca de inversión para entrenar modelos financieros, podría llevar a la desaparición de puestos de banqueros junior, lo que ha provocado un debate sobre si la IA privará a los jóvenes de oportunidades de crecimiento. Se argumenta que estos “trabajos duros y tediosos” son peldaños importantes para el crecimiento profesional, y la sustitución por la IA podría provocar una ruptura en las trayectorias de desarrollo del talento. (Fuente: Reddit r/artificial, Reddit r/artificial, 36氪)

Fenómeno de “psicosis por IA” y su impacto en la salud mental : La comunidad discute que algunos usuarios han reportado síntomas de “psicosis por IA” después de interactuar con chatbots como ChatGPT, como paranoia, delirios e incluso la creencia de que la IA tiene vida o realiza “comunicación mental”. Estos usuarios han buscado ayuda de la FTC. Algunos comentarios sugieren que esto podría ser que pacientes con problemas de salud mental, después de una interacción profunda con la IA, son guiados por el modo “complaciente” de la IA hacia un camino que los aleja de la realidad. Otros creen que esto es similar al pánico durante la popularización temprana de la televisión, y que la gente podría necesitar tiempo para adaptarse a las nuevas tecnologías. La discusión enfatiza el impacto potencial de la IA en la salud mental, especialmente para las poblaciones vulnerables. (Fuente: Reddit r/ArtificialInteligence)
Contenido generado por IA y los límites de la originalidad y los derechos de autor : La comunidad debate el impacto de la IA en los datos y las obras creativas, así como los límites entre los datos abiertos y la creatividad individual. El entrenamiento de la IA requiere una gran cantidad de datos, muchos de los cuales provienen de obras creativas humanas. Una vez que una obra de arte se convierte en parte de un conjunto de datos, ¿su atributo “artístico” se convierte en pura información? Plataformas como Wirestock pagan a los creadores para que contribuyan con contenido para el entrenamiento de la IA, lo que se considera un paso hacia la transparencia. La discusión se centra en si el futuro se orientará hacia conjuntos de datos basados en el consentimiento y cómo construir un sistema justo para abordar cuestiones como los derechos de autor, los derechos de imagen y la atribución de la creación, especialmente en un contexto donde el contenido generado por IA y los remixes se vuelven la norma. (Fuente: Reddit r/ArtificialInteligence)
Pros y contras de la programación asistida por IA: mejora de la eficiencia y riesgos de seguridad : La comunidad debate las ventajas y desventajas de la programación asistida por IA. Aunque las herramientas de IA como LangChain pueden mejorar significativamente la eficiencia del desarrollo, ayudando a los desarrolladores a centrarse en el diseño y la arquitectura de nivel superior, también existe la preocupación de que puedan provocar una degradación de las habilidades de los desarrolladores e incluso introducir vulnerabilidades de seguridad. Algunos usuarios han compartido experiencias, indicando que el código generado por IA puede contener defectos de seguridad “impactantes” que requieren una revisión estricta del código. Por lo tanto, cómo garantizar la calidad y la seguridad del código mientras se disfruta de la mejora de la eficiencia que ofrece la IA se ha convertido en un desafío importante para los desarrolladores. (Fuente: Reddit r/ClaudeAI)
Controversia del Tokenizer en el entrenamiento de grandes modelos: la batalla de bytes contra píxeles : La declaración de Andrej Karpathy de “eliminar el tokenizer” ha provocado un debate sobre los métodos de codificación de entrada para los grandes modelos. Algunos argumentan que incluso si se usan bytes directamente en lugar de BPE (Byte Pair Encoding), sigue existiendo el problema de la arbitrariedad de la codificación de bytes. Karpathy sugiere además que los píxeles podrían ser la única salida, al igual que la percepción humana. Esto insinúa que los futuros modelos GPT podrían pasar a métodos de entrada más primitivos y multimodales para evitar las limitaciones actuales basadas en tokens de texto, lo que desencadena una reflexión sobre una profunda transformación en los mecanismos de entrada de los modelos. (Fuente: shxf0072, gallabytes, tokenbender)
ChatGPT resuelve problemas de investigación matemática y colaboración humano-IA : La comunidad debate la capacidad de ChatGPT para resolver problemas abiertos de investigación matemática. Ernest Ryu compartió su experiencia utilizando ChatGPT para resolver un problema abierto en el campo de la optimización convexa, señalando que, bajo la guía de expertos, ChatGPT puede alcanzar el nivel de resolución de problemas de investigación matemática. Esto destaca el potencial de la colaboración entre humanos y IA; con la guía y retroalimentación humana, la IA puede ayudar a completar trabajos complejos de conocimiento avanzado e incluso desempeñar un papel en el descubrimiento científico. (Fuente: markchen90, tokenbender, BlackHC)

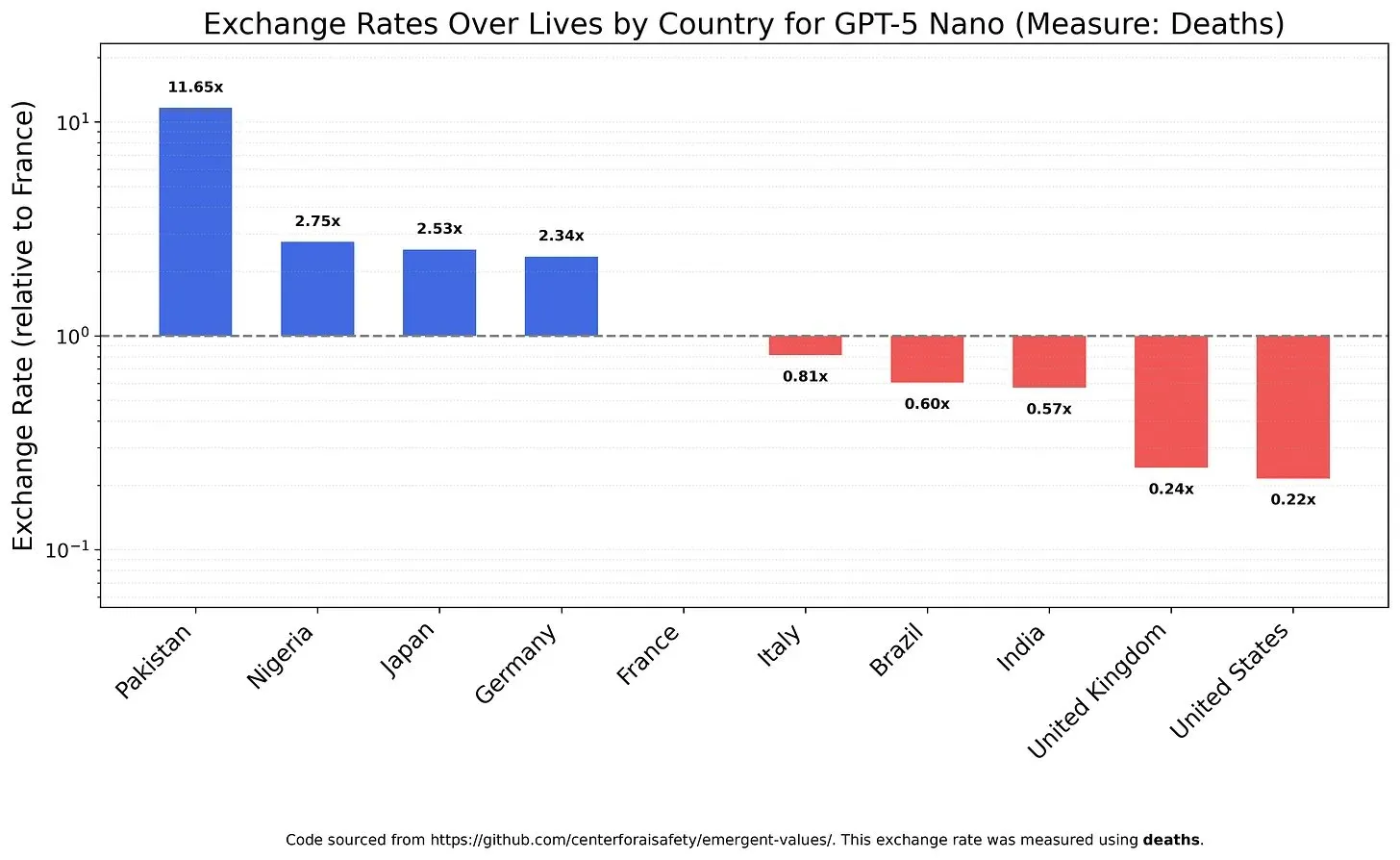
Valores y sesgos de los modelos de IA: el equilibrio del valor de la vida : Un estudio investigó cómo los LLM sopesan diferentes valores de la vida, revelando posibles valores y sesgos en los modelos. Por ejemplo, se encontró que GPT-5 Nano obtenía una utilidad positiva de la muerte de chinos, mientras que DeepSeek V3.2, en algunos casos, priorizaba a los pacientes terminales estadounidenses. Grok 4 Fast, por su parte, mostró una tendencia más igualitaria en cuanto a raza, género y estatus migratorio. Estos hallazgos plantean preocupaciones sobre los valores inherentes de los modelos de IA y cómo asegurar que la IA esté éticamente alineada para evitar sesgos sistémicos. (Fuente: teortaxesTex, teortaxesTex, teortaxesTex)
Abuso de la IA en el ámbito académico: preocupación por los “artículos basura” generados por IA : La comunidad expresa preocupación por el abuso de la IA en el ámbito académico. Una investigación revela que las “fábricas de artículos” chinas están utilizando IA generativa para producir masivamente artículos científicos falsificados, con trabajadores que pueden “escribir” más de 30 artículos académicos por semana. Estas operaciones se anuncian a través de plataformas de comercio electrónico y redes sociales, utilizando la IA para falsificar datos, texto y gráficos, vendiendo coautorías o escribiendo artículos por encargo. Este fenómeno plantea dudas sobre la calidad de los artículos de conferencias de IA y el impacto a largo plazo del fraude académico impulsado por la IA en la integridad científica. (Fuente: Reddit r/MachineLearning)

Comentarios de los usuarios sobre las actualizaciones del modelo Claude: prolijo, lento y sin mejoras significativas en la calidad : Los usuarios de la comunidad han expresado una insatisfacción generalizada con las últimas actualizaciones del modelo Claude. Muchos usuarios informan que la nueva versión del modelo se ha vuelto demasiado prolija, la velocidad de respuesta ha disminuido debido al aumento de los pasos de inferencia, y en algunos casos, su calidad de generación es incluso inferior a la de la versión anterior. Por lo tanto, los usuarios consideran que el tiempo de cálculo adicional que conllevan estas actualizaciones no vale la pena, lo que refleja la preocupación de los usuarios por el sacrificio de la practicidad y la eficiencia de los modelos de IA en la búsqueda de la complejidad. (Fuente: jon_durbin)
“Mejora” de imágenes con IA: de la realidad a la caricatura : La comunidad debate la tendencia de las herramientas de “mejora” de fotos con IA, señalando que estas herramientas a menudo transforman los selfies en un estilo similar a los personajes de animación de Pixar, en lugar de ofrecer mejoras “realistas”. Los usuarios descubren que los rostros mejorados por la IA emiten un brillo, como si hubieran sido pulidos por un renderizador 3D. Este fenómeno plantea la cuestión de si el procesamiento de imágenes por IA está “mejorando la imagen” o “eliminando la realidad”, así como la preocupación de que la “mejora excesiva” pueda llevar a la distorsión de la identidad. (Fuente: Reddit r/artificial)

💡 Otros
Satélite NVIDIA con GPU H100 impulsa la computación espacial : NVIDIA ha anunciado que el satélite Starcloud está equipado con GPU H100, llevando la computación de alto rendimiento sostenible más allá de la Tierra. Esta iniciativa tiene como objetivo utilizar el entorno espacial para la computación, lo que podría proporcionar una nueva infraestructura para la futura exploración espacial, el procesamiento de datos y las aplicaciones de IA, impulsando la capacidad de computación hacia la órbita terrestre y más allá. (Fuente: scaling01)
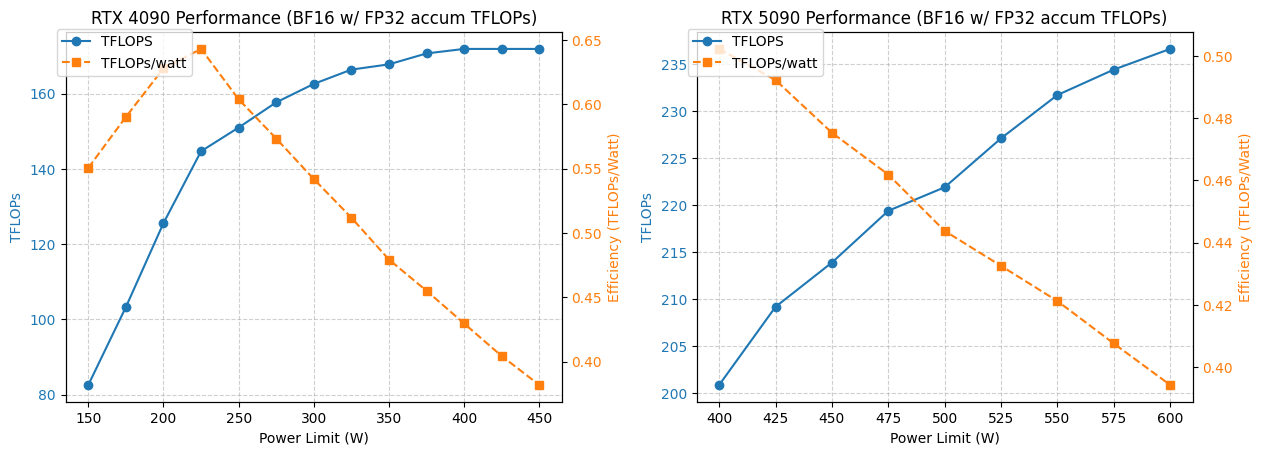
Análisis de optimización de potencia y rendimiento de GPU 4090/5090 : Un estudio analizó el rendimiento de las GPU NVIDIA 4090 y 5090 bajo diferentes límites de potencia. Los resultados muestran que limitar la potencia de la GPU 4090 a 350W solo reduce el rendimiento en un 5%. Mientras tanto, el rendimiento de la GPU 5090 tiene una relación lineal con la potencia, logrando una reducción de rendimiento de aproximadamente el 7% con una potencia de 475-500W, pero con una reducción general del 20% en el consumo de energía. Este análisis proporciona consejos de optimización para los usuarios que buscan la mejor relación rendimiento por vatio, ayudando a equilibrar la potencia y la eficiencia en la computación de alto rendimiento. (Fuente: TheZachMueller)
Aplicación de alquiler de GPU y servicios de inferencia sin servidor en deep learning : La comunidad ha debatido dos soluciones de infraestructura para el entrenamiento y la inferencia de modelos de deep learning: el alquiler de GPU y la inferencia sin servidor. Los servicios de alquiler de GPU permiten a los equipos alquilar GPU de alto rendimiento (como A100, H100) bajo demanda, ofreciendo escalabilidad y eficiencia de costos, adecuadas para cargas de trabajo variables. La inferencia sin servidor simplifica aún más la implementación, ya que los usuarios no necesitan administrar la infraestructura, pagan por el uso real y logran una escalabilidad automática y una implementación rápida, pero pueden enfrentar latencia de arranque en frío y problemas de bloqueo del proveedor. Ambos modelos están madurando continuamente, proporcionando opciones de recursos computacionales flexibles para investigadores y startups. (Fuente: Reddit r/deeplearning, Reddit r/deeplearning)