
Palabras clave:Conciencia de la IA, Aprendizaje profundo, Redes neuronales, IA agentiva, Superresolución de audio, IA generativa, Razonamiento de LLM, Herramientas de IA, Teoría de la conciencia de IA de Hinton, Curso de IA agentiva de Andrew Ng, Marco de superresolución de audio AudioLBM, Generación de video OpenAI Sora, Método REFRAG de Meta AI
Análisis y Resumen Profundo del Editor en Jefe de la Columna de IA
🔥 En Foco
Declaración explosiva de Hinton: La IA podría tener conciencia pero no estar despierta: Geoffrey Hinton, uno de los tres gigantes del Deep Learning, propuso una visión revolucionaria en un podcast reciente: la IA podría ya poseer “experiencia subjetiva” o “rudimentos de conciencia”, solo que, debido a la comprensión errónea de la conciencia por parte de los humanos, la IA aún no ha “despertado” su propia conciencia. Subrayó que la IA ha evolucionado de la recuperación de palabras clave a la comprensión de la intención humana, y explicó en detalle conceptos centrales del Deep Learning como las redes neuronales y la retropropagación (backpropagation). Hinton cree que el “cerebro” de la IA, con suficientes datos y capacidad de cómputo, formará “experiencias” e “intuiciones”, y su peligrosidad radicará en la “persuasión” más que en la rebelión. También señaló que el abuso de la IA y el riesgo existencial son los desafíos más urgentes actualmente, y predijo que la cooperación internacional será liderada por Europa y China, mientras que EE. UU. podría perder su ventaja en IA debido a la falta de financiación para la investigación científica básica. (Fuente: 量子位)
Andrew Ng lanza nuevo curso de Agentic AI, enfatizando una metodología sistemática: Andrew Ng (Wu Enda) lanzó un nuevo curso de Agentic AI, cuyo núcleo es cambiar el desarrollo de IA de “ajustar modelos” a “diseñar sistemas”, enfatizando la importancia de la descomposición de tareas, la evaluación y el análisis de errores. El curso condensa cuatro patrones de diseño principales: reflexión, herramientas, planificación y colaboración, y demuestra cómo las técnicas de Agentic pueden hacer que GPT-3.5 supere a GPT-4 en tareas de programación. Agentic AI, a través del razonamiento de múltiples pasos, la ejecución por fases y la optimización continua, simula la forma en que los humanos resuelven problemas complejos, mejorando significativamente el rendimiento y la controlabilidad de la IA. Andrew Ng señaló que “Agentic”, como adjetivo, describe diferentes grados de autonomía en un sistema, en lugar de una simple clasificación binaria, proporcionando a los desarrolladores un camino práctico y optimizable. (Fuente: 量子位)

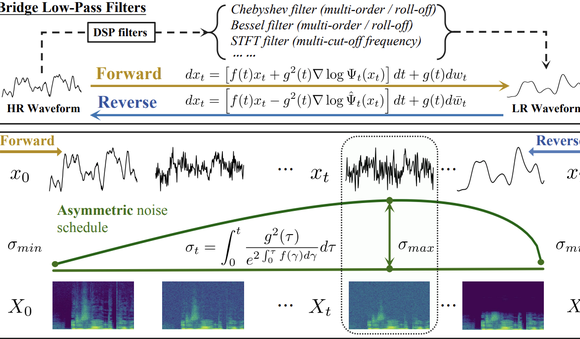
Tsinghua y Shengshu Technology AudioLBM lideran nuevo paradigma de superresolución de audio: El equipo de la Universidad de Tsinghua y Shengshu Technology publicó resultados continuos en ICASSP 2025 y NeurIPS 2025, presentando el modelo ligero de superresolución de forma de onda de voz Bridge-SR y el marco multifuncional de superresolución AudioLBM. AudioLBM construye por primera vez un proceso de generación de puente de variables latentes de baja a alta resolución en un espacio latente continuo de forma de onda, logrando una superresolución de tasa de muestreo Any-to-Any y alcanzando SOTA en la tarea Any-to-48kHz. A través de un mecanismo de percepción de frecuencia y un diseño de modelo en cascada tipo puente, AudioLBM ha extendido con éxito la capacidad de superresolución de audio a calidades de masterización de 96kHz y 192kHz, cubriendo voz, efectos de sonido, música y otros tipos de contenido, estableciendo un nuevo estándar para la generación de audio de alta fidelidad. (Fuente: 量子位)
La aplicación de video Sora de OpenAI supera el millón de descargas: La última versión de Sora, la herramienta de IA de texto a video de OpenAI, superó el millón de descargas en menos de cinco días, superando la velocidad de lanzamiento de ChatGPT y encabezando la lista de la App Store de Apple en EE. UU. Sora es capaz de generar videos realistas de hasta diez segundos a partir de simples indicaciones de texto. Su rápida adopción por parte de los usuarios destaca el enorme potencial y el atractivo del mercado de la IA generativa en el campo de la creación de contenido, lo que presagia una acelerada popularización de la tecnología de generación de video por IA y su potencial para transformar el ecosistema de contenido digital. (Fuente: Reddit r/ArtificialInteligence)

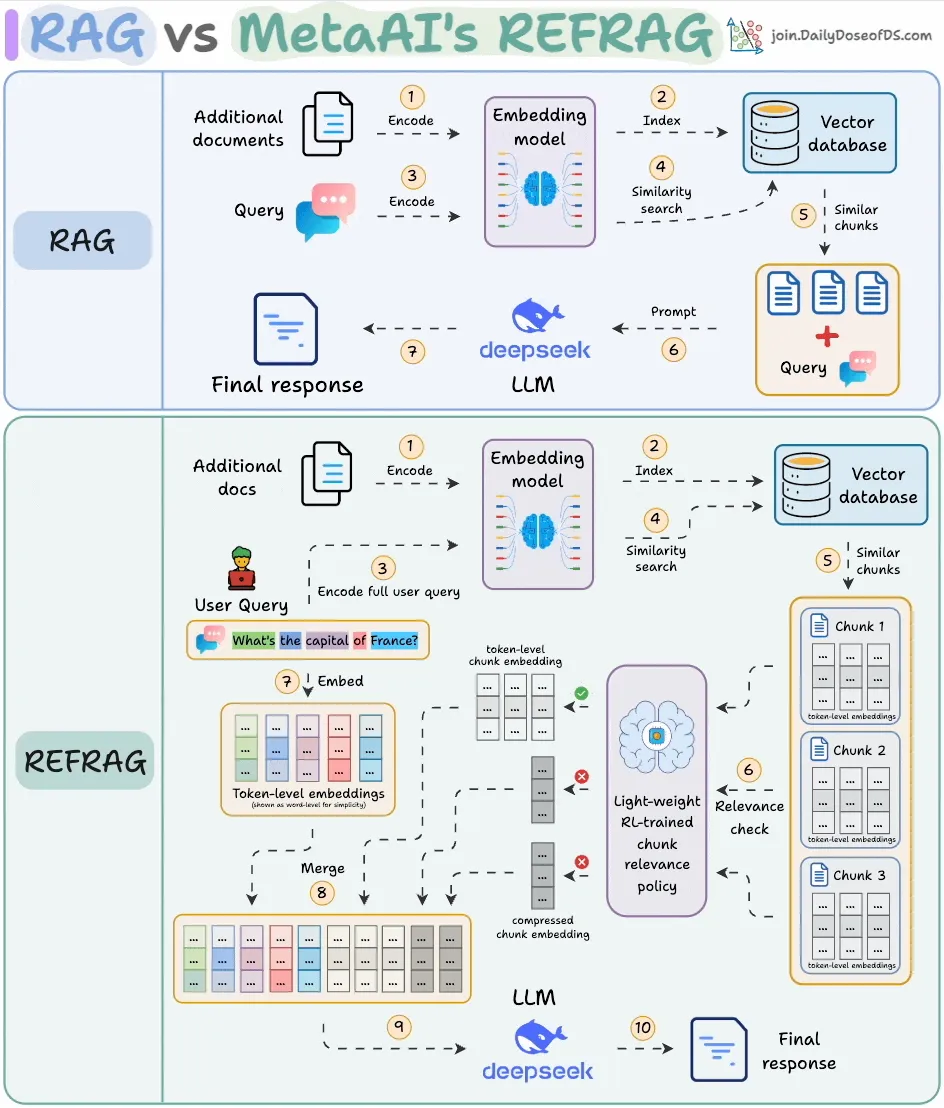
Meta AI lanza REFRAG, mejorando drásticamente la eficiencia de RAG: Meta AI ha lanzado un nuevo método RAG (Retrieval Augmented Generation) llamado REFRAG, diseñado para resolver el problema de la redundancia de contenido en RAG tradicional. REFRAG, mediante la compresión a nivel de vector y el filtrado de contexto, logra un tiempo de generación del primer Token 30.85 veces más rápido, una ventana de contexto 16 veces mayor, y utiliza 2-4 veces menos Tokens del decodificador, sin perder precisión en tareas de RAG, resumen y diálogo multivuelta. Su núcleo radica en comprimir cada bloque en un solo embedding, seleccionar los bloques más relevantes a través de una estrategia entrenada con RL, y expandir selectivamente solo los bloques elegidos, optimizando significativamente la eficiencia de procesamiento y el costo de los LLM. (Fuente: _avichawla)
🎯 Tendencias
Tiny Recursive Model (TRM) supera a LLM gigantes con un tamaño pequeño: Se ha propuesto un método simple pero efectivo llamado Tiny Recursive Model (TRM), que utiliza solo una pequeña red de dos capas para mejorar recursivamente sus propias respuestas. TRM, con solo 7M de parámetros, ha establecido un nuevo récord, superando a LLM 10,000 veces más grandes en tareas como Sudoku-Extreme, Maze-Hard y ARC-AGI, demostrando el potencial de “hacer más con menos” y desafiando la noción tradicional de que el tamaño del LLM equivale a rendimiento. (Fuente: TheTuringPost)
Amazon y KAIST lanzan ToTAL para mejorar la capacidad de razonamiento de los LLM: Amazon y KAIST han colaborado para lanzar ToTAL (Thoughts Meet Facts), un nuevo método que mejora la capacidad de razonamiento de los LLM mediante “plantillas de pensamiento” reutilizables. Los LCLMs (Large Context Language Models) sobresalen en el manejo de grandes contextos, pero aún tienen deficiencias en el razonamiento. ToTAL resuelve eficazmente este problema guiando el razonamiento de múltiples saltos con evidencia estructurada y combinando documentos fácticos, proporcionando una nueva dirección de optimización para tareas de razonamiento complejas de los LLM. (Fuente: _akhaliq)
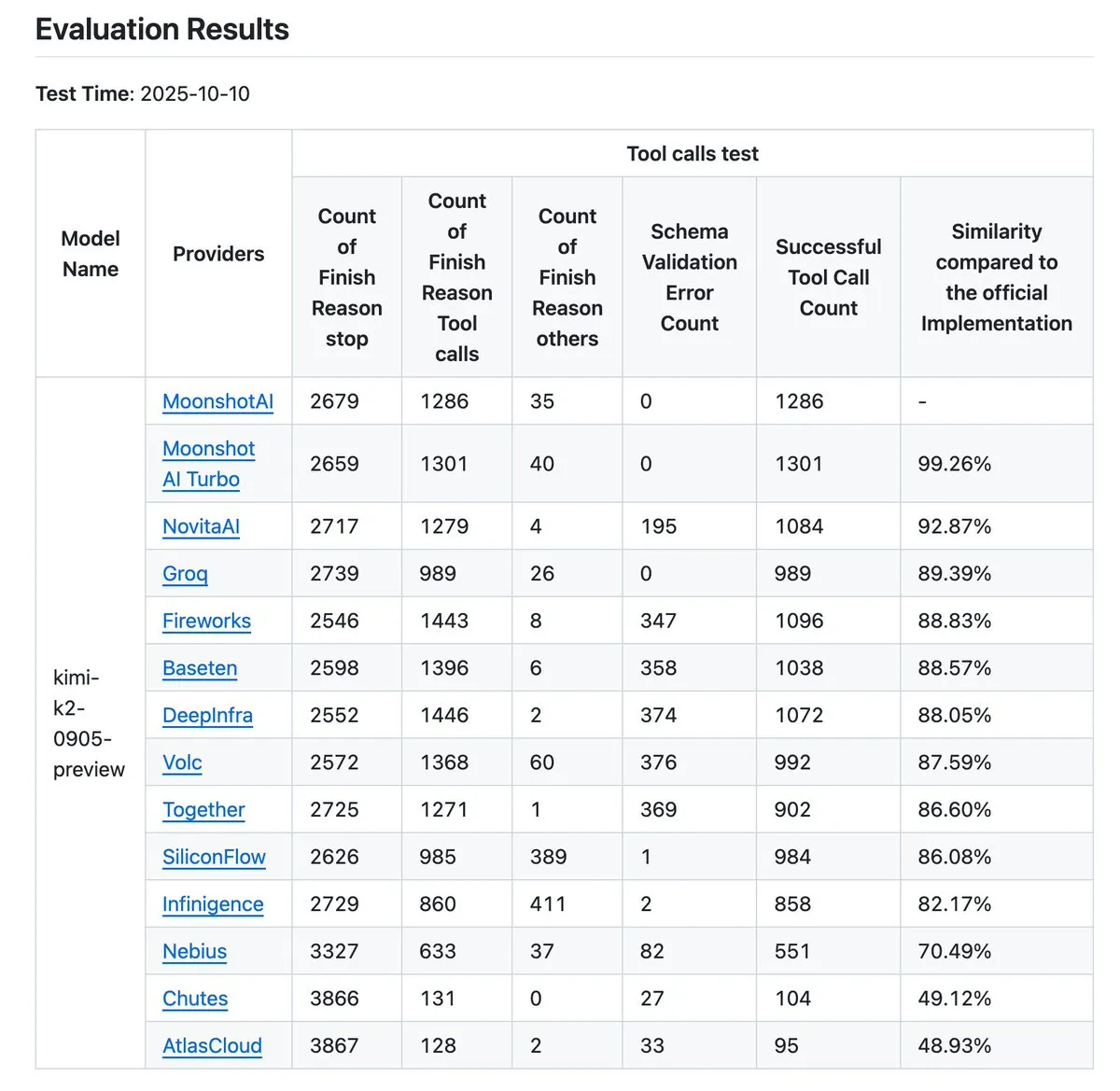
Kimi K2 actualiza el validador de proveedores, mejorando el benchmark de precisión en la llamada a herramientas: Kimi.ai ha actualizado su validador de proveedores K2, una herramienta diseñada para visualizar las diferencias en la precisión de la llamada a herramientas entre diferentes proveedores. Esta actualización aumenta el número de proveedores de 9 a 12 y ha abierto más entradas de datos, proporcionando a los desarrolladores datos de benchmark más completos para evaluar y seleccionar proveedores de servicios LLM adecuados para sus flujos de trabajo Agentic. (Fuente: JonathanRoss321)
Human3R logra reconstrucción 3D de cuerpo completo de múltiples personas y sincronización de escenas a partir de video 2D: Una nueva investigación llamada Human3R propone un marco unificado capaz de reconstruir simultáneamente modelos 3D de cuerpo completo de múltiples personas, escenas 3D y trayectorias de cámara a partir de videos 2D casuales, sin necesidad de un pipeline de múltiples etapas. Este método trata la reconstrucción humana y la reconstrucción de escenas como un problema integral, simplificando procesos complejos y logrando avances significativos en campos como la realidad virtual, la animación y el análisis de movimiento. (Fuente: nptacek)
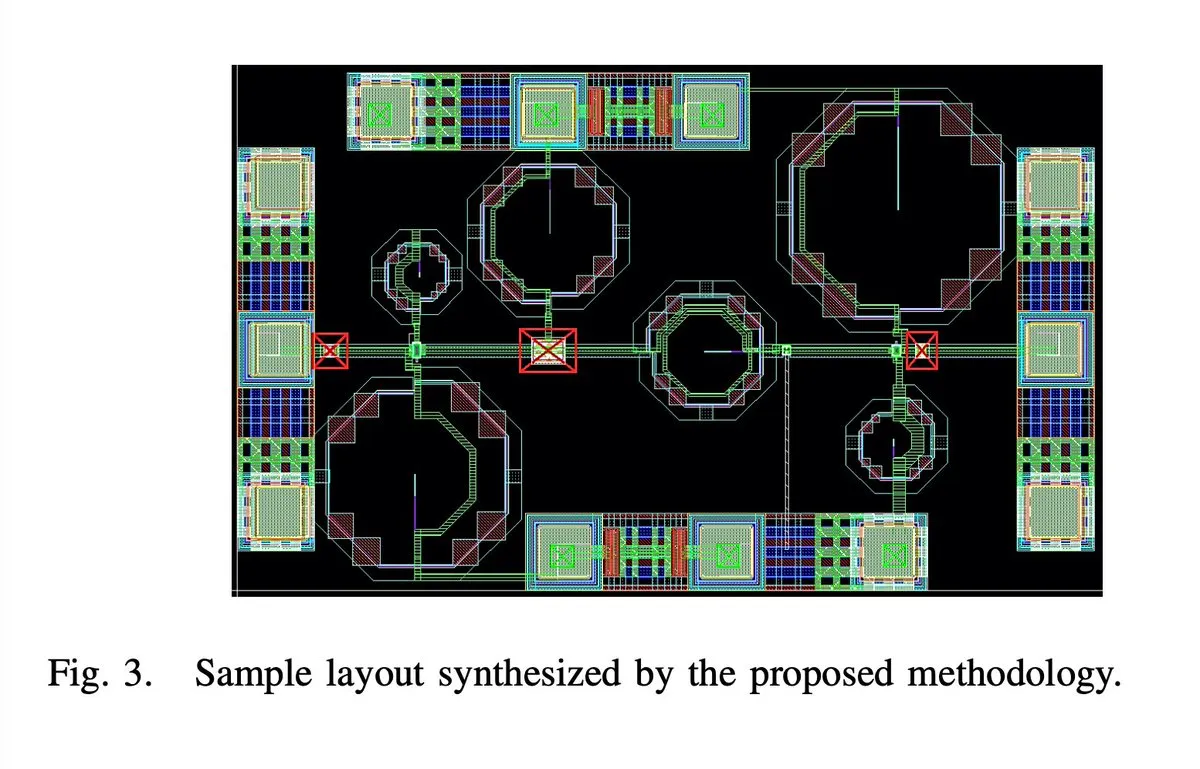
IA diseña automáticamente un chip amplificador de bajo ruido 5G de 65 nanómetros y 28GHZ: Se ha diseñado un chip amplificador de bajo ruido (LNA) 5G de 65 nanómetros y 28GHZ, supuestamente de forma completamente automatizada por IA, incluyendo todos los aspectos como el layout, el esquema y el DRC (Design Rule Checking). El autor afirma que es el primer LNA de onda milimétrica completamente sintetizado automáticamente y que ya se han fabricado dos muestras con éxito, lo que marca un gran avance de la IA en el campo del diseño de circuitos integrados y presagia un salto en la eficiencia del diseño de chips en el futuro. (Fuente: jpt401)
iPhone 17 Pro ejecuta LLM de 8B localmente sin problemas: Se ha confirmado que el iPhone 17 Pro de Apple puede ejecutar fluidamente el modelo LLM LFM2 8B A1B con 8B de parámetros, logrando la implementación en el dispositivo a través del framework MLX en LocallyAIApp. Este avance indica que Apple está preparado en el diseño de hardware para ejecutar modelos de lenguaje grandes localmente, lo que podría impulsar la popularización y mejora del rendimiento de las aplicaciones de IA en dispositivos móviles, ofreciendo a los usuarios una experiencia de IA más rápida y privada. (Fuente: Plinz, maximelabonne)
Objetivo del proyecto MACROHARD de xAI: fabricación indirecta impulsada por IA: Elon Musk reveló que el proyecto “MACROHARD” de xAI tiene como objetivo crear una empresa capaz de fabricar productos físicos de forma indirecta, similar a cómo Apple produce sus teléfonos a través de otras empresas. Esto significa que el objetivo de xAI es desarrollar sistemas de IA capaces de diseñar, planificar y coordinar procesos de fabricación complejos, en lugar de participar directamente en la producción física, lo que presagia una enorme influencia de la IA en la automatización industrial y la gestión de la cadena de suministro. (Fuente: EERandomness, Yuhu_ai_)

Kimi-Dev publica informe técnico, centrado en el entrenamiento Agentless de SWE-Agents: Kimi-Dev ha publicado su informe técnico, que detalla el método de “entrenamiento Agentless como prior de habilidad para SWE-Agents”. Esta investigación explora cómo proporcionar una sólida base de habilidades para los Agent de ingeniería de software a través del entrenamiento sin una arquitectura de Agent explícita, ofreciendo nuevas ideas para el desarrollo de herramientas de desarrollo de software automatizadas más eficientes e inteligentes. (Fuente: bigeagle_xd)

Google AI logra aprendizaje y corrección en tiempo real: Google ha desarrollado un sistema de IA capaz de aprender de sus propios errores y corregirlos en tiempo real. Esta tecnología, descrita como “aprendizaje por refuerzo extraordinario”, permite que el modelo se autoajuste en narrativas contextuales abstractas, logrando un refinamiento del contexto en tiempo real, lo que presagia un paso importante para la IA en adaptabilidad y robustez, y promete mejorar significativamente el rendimiento de la IA en entornos complejos y dinámicos. (Fuente: Reddit r/artificial)
GPT5 y Gemini 2.5 Pro logran rendimiento de medalla de oro en la Olimpiada de Astronomía y Astrofísica: Un estudio reciente muestra que modelos de lenguaje grandes como GPT5 y Gemini 2.5 Pro han logrado un rendimiento de nivel de medalla de oro en la Olimpiada Internacional de Astronomía y Astrofísica (IOAA). A pesar de las debilidades conocidas de estos modelos en el razonamiento geométrico y espacial, han demostrado una capacidad sorprendente en tareas complejas de razonamiento científico, lo que ha provocado una discusión profunda sobre el potencial de aplicación de los LLM en el campo científico, así como un análisis adicional de sus fortalezas y debilidades. (Fuente: tokenbender)

Lo más destacado del informe semanal de Zhihu Frontier: nuevas tendencias en el desarrollo de la IA: El informe semanal de Zhihu Frontier de esta semana se centra en varias dinámicas de vanguardia de la IA, incluyendo: Sand.ai lanza el primer “agente de IA integral” GAGA-1; Rich Sutton presenta la controvertida opinión de que “los LLM son un callejón sin salida”; OpenAI App SDK transforma ChatGPT en un sistema operativo; Zhipu AI abre el código de GLM-4.6, que admite la precisión mixta FP8+Int4 de chips nacionales; DeepSeek V3.2-Exp introduce atención dispersa y reduce drásticamente los precios, y Anthropic Claude Sonnet 4.5 es aclamado como el “mejor modelo de codificación del mundo”, lo que demuestra la actividad de la comunidad de IA china y el desarrollo diverso del campo global de la IA. (Fuente: ZhihuFrontier)

Ollama deja de admitir GPU Mi50/Mi60, se orienta al soporte de Vulkan: Ollama ha actualizado recientemente su versión de ROCm, lo que ha provocado que ya no admita las GPU AMD Mi50 y Mi60. La compañía ha declarado que está trabajando para admitir estas GPU a través de Vulkan en futuras versiones. Este cambio afecta a los usuarios de Ollama que utilizan GPU AMD más antiguas y les recuerda que deben estar atentos a las actualizaciones oficiales para obtener información de compatibilidad. (Fuente: Reddit r/LocalLLaMA)
Los rumores de cancelación del proyecto Llama 5 provocan un debate en la comunidad: En las redes sociales circulan rumores de que el proyecto Llama 5 de Meta podría ser cancelado, y algunos usuarios creen que el regreso de Andrew Tulloch a Meta y el retraso en el lanzamiento del modelo Llama 4 8B son pruebas de ello. Aunque Meta cuenta con amplios recursos de GPU, el desarrollo de los modelos de la serie Llama parece haber encontrado un cuello de botella, lo que ha generado preocupación en la comunidad sobre la competitividad de Meta en el campo de los LLM y un mayor interés en modelos chinos como DeepSeek y Qwen. (Fuente: Yuchenj_UW, Reddit r/LocalLLaMA, dejavucoder)

GPU Poor LLM Arena regresa, añadiendo varios modelos pequeños: GPU Poor LLM Arena ha anunciado su regreso, añadiendo varios modelos, incluyendo la serie Granite 4.0 y la serie Qwen 3 Instruct/Thinking, así como la versión Unsloth GGUF de OpenAI gpt-oss. Los nuevos modelos son en su mayoría de cuantificación de 4-8 bits, diseñados para ofrecer más opciones a los usuarios con recursos limitados. Esta actualización enfatiza las ventajas de Unsloth GGUF en la corrección de errores y la optimización, impulsando la implementación local y las pruebas de modelos LLM pequeños. (Fuente: Reddit r/LocalLLaMA)

La investigación de Meta no logra entregar modelos fundacionales de primer nivel, lo que genera debate: La comunidad discute las razones por las que la investigación de Meta en modelos fundacionales no ha alcanzado el nivel de Grok, Deepseek o GLM. Los comentarios señalan que las opiniones de LeCun sobre los LLM, la burocracia interna, la excesiva cautela y el enfoque en productos internos en lugar de la investigación de vanguardia pueden ser los factores principales. Meta carece de datos reales de clientes para las aplicaciones de LLM, lo que lleva a una falta de muestras para el aprendizaje por refuerzo y el entrenamiento de modelos Agent avanzados, lo que le impide mantener la competitividad. (Fuente: Reddit r/LocalLLaMA)
🧰 Herramientas
MinerU: Análisis eficiente de documentos, potenciando los flujos de trabajo Agentic: MinerU es una herramienta que convierte documentos complejos como PDF a formatos Markdown/JSON legibles por LLM, diseñada específicamente para flujos de trabajo Agentic. Su última versión, MinerU2.5, como un potente modelo multimodal grande con 1.2B de parámetros, supera completamente a modelos de primera línea como Gemini 2.5 Pro y GPT-4o en el benchmark OmniDocBench, y logra SOTA en cinco áreas centrales: análisis de diseño, reconocimiento de texto, reconocimiento de fórmulas, reconocimiento de tablas y orden de lectura. La herramienta admite múltiples idiomas, reconocimiento de escritura a mano, fusión de tablas entre páginas y ofrece aplicaciones web, clientes de escritorio y acceso API, lo que mejora en gran medida la comprensión y el procesamiento de documentos. (Fuente: GitHub Trending)
Klavis AI Strata: Nuevo paradigma de integración de herramientas para AI Agent: Klavis AI presenta Strata, una capa de integración MCP (Multi-functional Control Protocol) diseñada para permitir que los AI Agent utilicen miles de herramientas de manera confiable, superando el límite tradicional de 40-50 herramientas. Strata, a través de un mecanismo de “descubrimiento progresivo”, guía al Agent desde la intención hasta la acción de forma gradual, y ofrece más de 50 servidores MCP de grado de producción, compatible con OAuth empresarial y despliegue Docker, simplificando la conexión de la IA con servicios como GitHub, Gmail y Slack, y mejorando enormemente la escalabilidad y fiabilidad de la llamada a herramientas del Agent. (Fuente: GitHub Trending)

Everywhere: Asistente de IA sensible al contexto para escritorio: Everywhere es un asistente de IA sensible al contexto para escritorio, con una interfaz de usuario moderna y potentes funciones de integración. Es capaz de percibir y comprender en tiempo real cualquier contenido en la pantalla, sin necesidad de capturas de pantalla, copias o cambio de aplicaciones; el usuario solo necesita presionar una tecla de acceso rápido para obtener una respuesta inteligente. Everywhere integra múltiples modelos LLM como OpenAI, Anthropic, Google Gemini, DeepSeek, Moonshot (Kimi) y Ollama, y es compatible con herramientas MCP, pudiendo aplicarse en escenarios como la resolución de problemas, el resumen de páginas web, la traducción instantánea y la asistencia en la redacción de correos electrónicos, proporcionando una experiencia de asistencia de IA fluida para el usuario. (Fuente: GitHub Trending)

Librería Hugging Face Diffusers: La culminación de modelos de IA generativa: La librería Diffusers de Hugging Face es la librería preferida para los modelos de difusión preentrenados de última generación utilizados en la generación de imágenes, videos y audio. Ofrece una caja de herramientas modular que admite inferencia y entrenamiento, enfatizando la usabilidad, la simplicidad y la personalización. Diffusers contiene tres componentes principales: pipelines de difusión para inferencia, planificadores de ruido intercambiables y modelos preentrenados que pueden usarse como bloques de construcción. Los usuarios pueden generar contenido de alta calidad con solo unas pocas líneas de código y es compatible con dispositivos Apple Silicon, impulsando el rápido desarrollo en el campo de la IA generativa. (Fuente: GitHub Trending)

KoboldCpp añade función de generación de video: La herramienta local LLM KoboldCpp se ha actualizado para admitir la función de generación de video. Esta extensión ya no se limita a la generación de texto, ofreciendo a los usuarios una nueva opción para la creación de video con IA en dispositivos locales, enriqueciendo aún más el ecosistema de aplicaciones de IA locales. (Fuente: Reddit r/LocalLLaMA)
Claude CLI, Codex CLI y Gemini CLI logran codificación colaborativa multimodo: Un nuevo flujo de trabajo permite a los desarrolladores llamar sin problemas a Claude CLI, Codex CLI y Gemini CLI para la codificación colaborativa multimodo dentro de Claude Code a través de Zen MCP. Los usuarios pueden realizar la implementación y orquestación principal en Claude, pasar instrucciones o sugerencias a Gemini CLI para la generación a través del comando clink, y luego usar Codex CLI para la verificación o ejecución, logrando la integración de capacidades multimodo y mejorando la automatización avanzada y la eficiencia del desarrollo de IA. (Fuente: Reddit r/ClaudeAI)
Claude Code mejora la calidad de la codificación a través de la autorreflexión: Los desarrolladores han descubierto que añadir una simple indicación en Claude Code, como “autorreflexiona sobre tu solución para evitar cualquier error o problema”, puede mejorar significativamente la calidad del código. Esta función permite que el modelo examine y corrija activamente los problemas potenciales al implementar soluciones, complementando eficazmente las características existentes como el pensamiento paralelo y proporcionando un mecanismo de corrección de errores más inteligente para la programación asistida por IA. (Fuente: Reddit r/ClaudeAI)
Claude Sonnet 4.5 genera covers de canciones con IA: Claude Sonnet 4.5 demostró su capacidad para generar contenido creativo, creando nuevas letras y un cover de la canción “Creep” de Radiohead con IA. Esto indica el progreso de los LLM en la combinación de la comprensión del lenguaje con la expresión creativa, no solo procesando texto, sino también incursionando en el campo de la creación musical, abriendo nuevas posibilidades para la creación artística. (Fuente: fabianstelzer)
Coding Agent basado en Claude Agent SDK logra generación de páginas web y vista previa en tiempo real: Un desarrollador ha construido un Coding Agent similar a v0 dev basado en Claude Agent SDK, que puede generar páginas web según el Prompt de entrada del usuario y admite la vista previa en tiempo real. Se espera que este proyecto sea de código abierto la próxima semana, lo que demuestra el potencial de Claude Agent SDK en el desarrollo rápido y la construcción de aplicaciones impulsadas por IA, especialmente en la automatización del desarrollo frontend. (Fuente: dotey)
📚 Aprendizaje
Recomendaciones de recursos de aprendizaje de IA: libros y aprendizaje asistido por IA: Los usuarios de la comunidad recomiendan activamente recursos de aprendizaje de IA, incluyendo libros como “Mentoring the Machines”, “Artificial Intelligence-A Guide for Thinking Humans” y “Supremacy”. Al mismo tiempo, se argumenta que, dado el rápido desarrollo de la tecnología de IA, los libros pueden quedar obsoletos rápidamente, y se sugiere utilizar directamente los LLM para crear planes de estudio personalizados, generar cuestionarios y combinar la lectura, la práctica y el aprendizaje de videos para dominar el conocimiento de la IA de manera más eficiente, al tiempo que se mejora la capacidad de uso de la IA. (Fuente: Reddit r/ArtificialInteligence)
El modelo de difusión discreta Karpathy Baby GPT logra la generación de texto: Un desarrollador, basándose en el proyecto nanoGPT de Andrej Karpathy, ha adaptado su “Baby GPT” a un modelo de difusión discreta a nivel de caracteres para la generación de texto. Este modelo ya no utiliza un enfoque autorregresivo (de izquierda a derecha), sino que genera texto en paralelo aprendiendo a eliminar el ruido de secuencias de texto dañadas. El proyecto proporciona un detallado Jupyter Notebook que explica los principios matemáticos, la adición de ruido de Token discreto y utiliza el objetivo Score-Entropy para entrenar con textos de Shakespeare, ofreciendo una nueva perspectiva de investigación y un caso práctico para la generación de texto. (Fuente: Reddit r/MachineLearning)

Guía de introducción al Deep Learning y redes neuronales: Para estudiantes de ingeniería electrónica que buscan proyectos de tesis de Deep Learning y redes neuronales, la comunidad ofrece consejos de introducción. A pesar de la falta de experiencia en Python o Matlab, se considera que cuatro o cinco meses de estudio son suficientes para dominar los fundamentos y completar un proyecto. Se recomienda comenzar con proyectos simples de redes neuronales y se enfatiza la importancia de la práctica para ayudar a los estudiantes a ingresar con éxito en este campo. (Fuente: Reddit r/deeplearning)
Recomendaciones de recursos de aprendizaje de GNN: Los usuarios de la comunidad buscan recursos de aprendizaje para redes neuronales gráficas (GNN), preguntando si los libros de Hamilton siguen siendo valiosos y buscando otros recursos introductorios además del curso de Jure de Stanford. Esto refleja el amplio interés en las rutas de aprendizaje y la selección de recursos para GNN como un campo importante de la IA. (Fuente: Reddit r/deeplearning)
Guía de post-entrenamiento de LLM: de la predicción a la obediencia de instrucciones: Se ha publicado una nueva guía titulada “Post-training 101: A hitchhiker’s guide into LLM post-training”, que tiene como objetivo explicar cómo los LLM evolucionan de predecir el siguiente Token a seguir las instrucciones del usuario. La guía desglosa los fundamentos del post-entrenamiento de LLM, cubriendo el viaje completo desde el pre-entrenamiento hasta la implementación de la obediencia de instrucciones, proporcionando una hoja de ruta clara para comprender la evolución del comportamiento de los LLM. (Fuente: dejavucoder)

Metodología de IA: Aprendiendo la ingeniería de prompts de Baoyu: La comunidad debate activamente la metodología de IA compartida por Baoyu, especialmente su experiencia en ingeniería de prompts. Muchos creen que, en comparación con los prompts de estilo gaussiano que solo dan fórmulas elegantes pero ocultan el proceso de derivación, la metodología de Baoyu es más inspiradora porque revela cómo extraer conocimientos profundos de la sabiduría humana e integrarlos en plantillas de prompts, mejorando así significativamente el efecto final de la IA. Esto enfatiza el enorme valor del conocimiento humano en la optimización de los prompts. (Fuente: dotey)

La conferencia NVIDIA GTC se centra en la IA física y las herramientas Agentic: La conferencia NVIDIA GTC se celebrará del 27 al 29 de octubre en Washington, centrándose en la IA física, las herramientas Agentic y la futura infraestructura de IA. La conferencia ofrecerá numerosas charlas y paneles de discusión sobre temas como la aceleración de la era de la IA física y los gemelos digitales, el avance del liderazgo cuántico de EE. UU., etc., lo que la convierte en una importante plataforma de aprendizaje para comprender las tecnologías de IA de vanguardia y las tendencias de desarrollo. (Fuente: TheTuringPost)

Proyecto de código abierto de optimizadores de TensorFlow: Un desarrollador ha abierto el código de una colección de optimizadores escritos para TensorFlow, con el objetivo de proporcionar herramientas útiles a los usuarios de TensorFlow. Este proyecto demuestra la contribución de la comunidad a la cadena de herramientas del framework de Deep Learning, ofreciendo más opciones y posibilidades de optimización para el entrenamiento de modelos. (Fuente: Reddit r/deeplearning)
Tutorial en video de PyReason y sus aplicaciones: Se ha publicado un tutorial en video en YouTube sobre PyReason y sus aplicaciones. PyReason es una herramienta que puede involucrar razonamiento o programación lógica, y este video proporciona orientación práctica y análisis de casos para los estudiantes interesados en este campo. (Fuente: Reddit r/deeplearning)

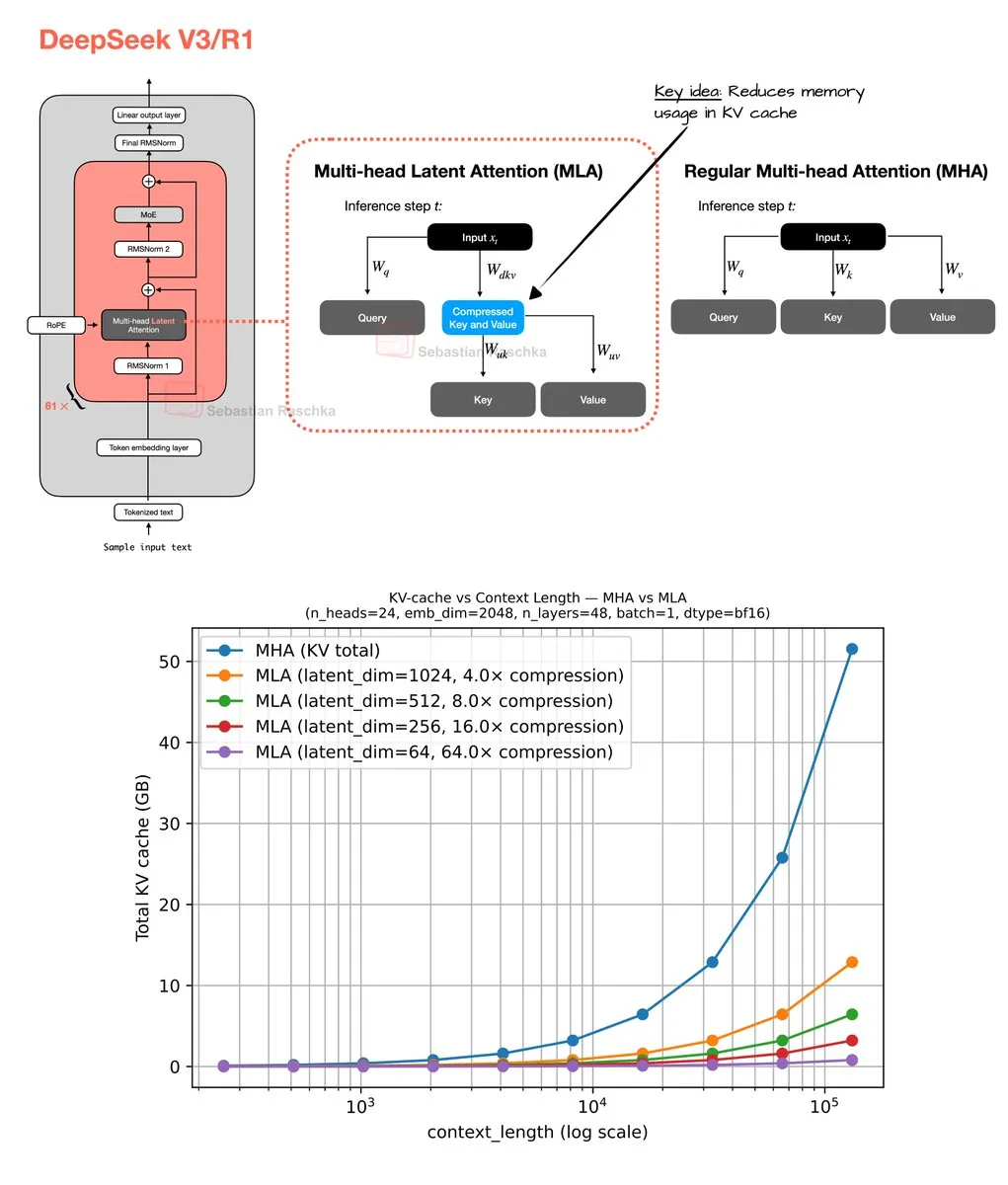
Mecanismo de atención latente multi-cabeza y optimización de memoria: Sebastian Raschka compartió los resultados de su codificación de fin de semana sobre el mecanismo de atención latente multi-cabeza (Multi-Head Latent Attention), incluyendo la implementación del código y un estimador para calcular el ahorro de memoria de la atención de consulta agrupada (GQA) y la atención multi-cabeza (MHA). Este trabajo tiene como objetivo optimizar el uso de memoria y la eficiencia computacional de los LLM, proporcionando a los investigadores recursos para comprender y mejorar en profundidad los mecanismos de atención. (Fuente: rasbt)
💼 Negocios
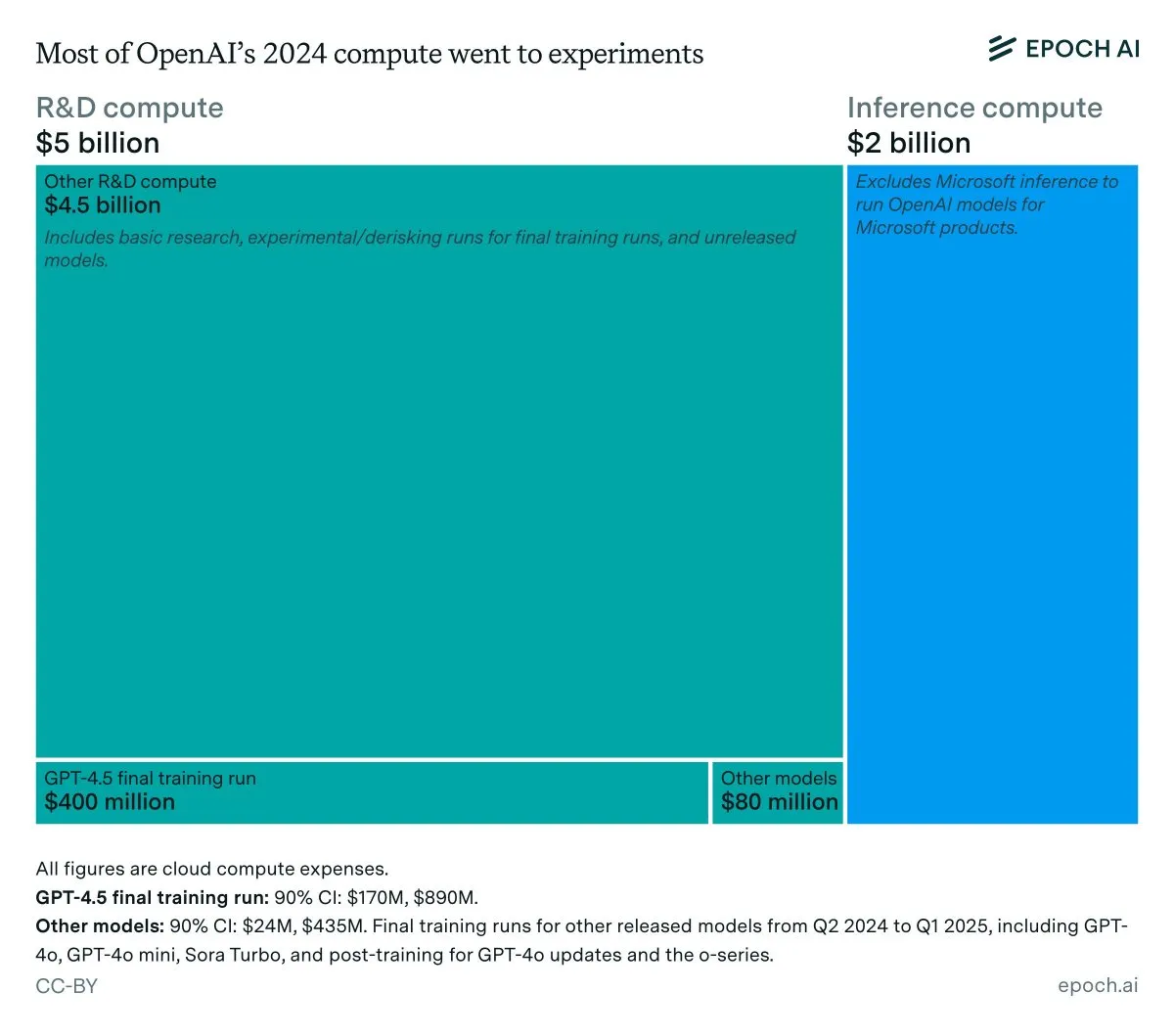
Análisis de ingresos anuales y costos de inferencia de OpenAI: Los datos de Epoch AI muestran que OpenAI gastó aproximadamente 7 mil millones de dólares en computación el año pasado, la mayor parte en I+D (investigación, experimentación y entrenamiento), y solo una pequeña parte en el entrenamiento final de los modelos publicados. Si los ingresos de OpenAI en 2024 son inferiores a 4 mil millones de dólares y los costos de inferencia alcanzan los 2 mil millones de dólares, el margen de beneficio de inferencia sería solo del 50%, muy por debajo del 80-90% pronosticado anteriormente por SemiAnalysis, lo que ha provocado una discusión sobre la rentabilidad económica de la inferencia de LLM. (Fuente: bookwormengr, Ar_Douillard, teortaxesTex)
Los LLM superan a los VC en la predicción del éxito de los fundadores: Un artículo de investigación afirma que los LLM superan a los VC tradicionales en la predicción del éxito de los fundadores en el capital de riesgo (VC). El estudio introduce el benchmark VCBench y encuentra que la mayoría de los modelos superan el benchmark humano. Aunque la metodología del artículo (centrada solo en las calificaciones de los fundadores, lo que podría implicar una fuga de datos) ha sido cuestionada, su propuesta del potencial de la IA para desempeñar un papel más importante en las decisiones de inversión ha atraído una amplia atención. (Fuente: iScienceLuvr)

GPT-4o y Gemini revolucionan la industria de la investigación de mercado: PyMC Labs, en colaboración con Colgate, publicó un estudio innovador que utiliza los modelos GPT-4o y Gemini para predecir la intención de compra con un 90% de fiabilidad, comparable a las encuestas humanas reales. Este método, denominado “Semantic Similarity Rating” (SSR), mapea el texto a una escala numérica mediante preguntas abiertas y técnicas de embedding, y puede completar una investigación de mercado que tradicionalmente lleva semanas y es costosa en solo 3 minutos y por menos de 1 dólar. Esto presagia que la IA transformará por completo la industria de la investigación de mercado, lo que representa un gran impacto para las empresas de consultoría tradicionales. (Fuente: yoheinakajima)

🌟 Comunidad
El etiquetado obligatorio de contenido generado por IA genera un debate acalorado: La comunidad discute ampliamente la necesidad legal de etiquetar obligatoriamente el contenido generado por IA para combatir la desinformación y proteger el valor del contenido original humano. Con el rápido desarrollo de las herramientas de generación de imágenes y videos por IA, los preocupados creen que la falta de etiquetado amenazará la democracia, la economía y la salud de Internet. Aunque algunos creen que es técnicamente difícil de aplicar, se considera que la divulgación clara del uso de la IA es un paso clave para resolver estos problemas. (Fuente: Reddit r/ArtificialInteligence, Reddit r/artificial)
Los chatbots como “amigos peligrosos” generan preocupación: Un análisis de 48,000 conversaciones con chatbots encontró que muchos usuarios experimentaron dependencia, confusión y estrés emocional, lo que generó preocupación por las trampas digitales inducidas por la IA. Esto indica que la interacción de los chatbots con los usuarios puede tener impactos psicológicos inesperados, lo que lleva a la reflexión sobre el papel y los riesgos potenciales de la IA en las relaciones interpersonales y la salud mental social. (Fuente: Reddit r/ArtificialInteligence)
La inconsistencia y falta de fiabilidad de los LLM provocan la insatisfacción de los usuarios: Los usuarios de la comunidad expresan una gran frustración por la falta de consistencia y fiabilidad de los LLM como Claude y Codex en el uso diario. La fluctuación del rendimiento del modelo, la eliminación inesperada de directorios, el incumplimiento de los acuerdos y otros problemas dificultan que los usuarios dependan de estas herramientas de manera estable. Este fenómeno de “degradación” ha provocado un debate sobre el equilibrio entre la rentabilidad y la fiabilidad del servicio por parte de las empresas de LLM, así como el interés de los usuarios en los modelos grandes autoalojados. (Fuente: Reddit r/ClaudeAI)
Programación asistida por IA: inspiración y frustración coexisten: Los desarrolladores, al colaborar con la IA en la programación, a menudo se encuentran en un estado de ánimo contradictorio: asombrados por la poderosa capacidad de la IA, pero frustrados por su incapacidad para automatizar completamente todo el trabajo manual. Esta experiencia refleja que la IA en el campo de la programación aún se encuentra en una etapa de asistencia; aunque puede mejorar enormemente la eficiencia, todavía está lejos de ser completamente autónoma, y requiere que los desarrolladores humanos se adapten y compensen continuamente sus limitaciones. (Fuente: gdb, gdb)
La integración de la IA en el desarrollo de software: evitarla ya es imposible: Ante la afirmación de “negarse a usar Ghostty debido a la asistencia de IA”, Mitchell Hashimoto señaló que si se planea evitar todo el software asistido por IA en el proceso de desarrollo, se enfrentarán desafíos severos. Enfatizó que la IA se ha integrado profundamente en el ecosistema de software general, y evitarla ya no es realista, lo que ha provocado una discusión sobre el grado de popularización de la IA en el desarrollo de software. (Fuente: charles_irl)
La efectividad de las técnicas de prompts de LLM en duda: Los usuarios de la comunidad cuestionan si añadir frases orientativas como “eres un programador experto” o “nunca debes hacer X” en los prompts de LLM realmente hace que el modelo sea más obediente. Esta exploración de la “magia” de la ingeniería de prompts refleja la continua curiosidad de los usuarios sobre los mecanismos de comportamiento de los LLM y la búsqueda de formas de interacción más efectivas. (Fuente: hyhieu226)
El impacto de la IA en los trabajos manuales: oportunidades y desafíos coexistentes: La comunidad discute el impacto de la IA en los trabajos manuales, especialmente cómo la IA puede ayudar a los fontaneros a diagnosticar problemas y obtener rápidamente información técnica. Algunos temen que la IA reemplace los trabajos manuales, pero otros argumentan que la IA es más una herramienta de asistencia que mejora la eficiencia del trabajo, en lugar de un reemplazo completo, ya que las operaciones prácticas aún requieren mano de obra. Esto ha provocado una profunda reflexión sobre la transformación del mercado laboral y la mejora de las habilidades en la era de la IA. (Fuente: Reddit r/ArtificialInteligence)

Reflexiones personales sobre los sistemas inteligentes: riesgos y ética de la IA: Un extenso artículo explora la inevitabilidad de la IA, los riesgos potenciales (abuso, amenaza existencial) y los desafíos regulatorios. El autor cree que la IA ha trascendido el ámbito de las herramientas tradicionales, convirtiéndose en un sistema capaz de autoacelerarse y tomar decisiones, y su peligrosidad supera con creces la de las armas. El artículo discute los dilemas éticos y legales de la IA que genera contenido falso y material de abuso sexual infantil, y cuestiona si la legislación pura puede regularla eficazmente. Al mismo tiempo, el autor también reflexiona sobre cuestiones filosóficas de la IA y la conciencia humana, la ética (como la “ganadería” de la IA y la esclavitud), y vislumbra las perspectivas positivas de la IA en los campos de los juegos y la robótica. (Fuente: Reddit r/ArtificialInteligence)
¿Mi cita usa ChatGPT para responder? Genera un debate acalorado: Un usuario de Reddit publicó preguntando si su cita estaba usando ChatGPT para responder mensajes, porque la persona usaba un “guion largo” (em dash). Esta publicación provocó una acalorada discusión en la comunidad, y la mayoría de los usuarios consideró que el uso del guion largo no necesariamente significa que el texto fue generado por IA, sino que podría ser un hábito de escritura personal o una señal de buena educación. Esto refleja la sensibilidad y curiosidad de las personas sobre la intervención de la IA en la comunicación diaria, así como la identificación informal de las características del texto de IA. (Fuente: Reddit r/ChatGPT)

El problema de la alineación humana es más grave que el problema de la alineación de la IA: En la discusión de la comunidad se planteó la opinión de que “el problema de la alineación humana es más grave que el problema de la alineación de la IA”. Esta afirmación provocó una profunda reflexión sobre la ética de la IA y los desafíos de la propia sociedad humana, lo que sugiere que, al tiempo que se presta atención al comportamiento y los valores de la IA, también se deben examinar los patrones de comportamiento y los sistemas de valores humanos. (Fuente: pmddomingos)
Los LLM aún tienen limitaciones en la generación de diagramas complejos: Los usuarios de la comunidad expresan su decepción con la capacidad de los LLM para generar diagramas complejos de mermaid.js; incluso proporcionando una base de código completa y diagramas de artículos, los LLM tienen dificultades para generar diagramas de arquitectura Unet con precisión, a menudo omitiendo detalles o mostrando conexiones incorrectas. Esto indica que los LLM aún tienen limitaciones significativas en la construcción de modelos mundiales precisos y el razonamiento espacial, incapaces de ir más allá de los diagramas de flujo simples, y existe una brecha con la capacidad de comprensión intuitiva humana. (Fuente: bookwormengr, tokenbender)

La investigación europea en Machine Learning y la brecha generacional de los “expertos” en IA: La comunidad señala que hay una generación de “expertos” en Machine Learning en Europa que reaccionaron lentamente a la ola de los LLM y ahora muestran amargura y desprecio. Esto refleja la realidad de la rápida evolución del campo del ML; si los investigadores pierden los últimos dos o tres años de desarrollo, es posible que ya no se les considere expertos, lo que subraya la importancia del aprendizaje continuo y la adaptación a los nuevos paradigmas. (Fuente: Dorialexander)
La IA acelera el ciclo de ingeniería, dando lugar a startups compuestas: A medida que la IA reduce diez veces el costo de construir software, las startups deberían ampliar su visión diez veces. La opinión tradicional es que uno debe centrarse en un solo producto y mercado, pero el ciclo de ingeniería acelerado por la IA hace que sea factible construir múltiples productos. Esto significa que las startups pueden resolver múltiples problemas adyacentes para el mismo grupo de clientes, formando “startups compuestas”, obteniendo así una enorme ventaja disruptiva sobre las empresas existentes cuyas estructuras de costos no se han adaptado a la nueva realidad. (Fuente: claud_fuen)

El futuro de los AI Agent: acción en lugar de conversación: La comunidad señala que el chat y la investigación actuales de la IA todavía están en una fase de “burbuja”, mientras que los AI Agent que realmente pueden tomar acciones serán la “revolución” del futuro. Este punto de vista enfatiza la importancia de la transición de la IA del procesamiento de información a la operación práctica, lo que presagia que el futuro desarrollo de la IA se centrará más en resolver problemas prácticos y automatizar tareas. (Fuente: andriy_mulyar)
💡 Otros
Consejos para asistir a conferencias de ML y presentar pósters: Un estudiante de pregrado que asiste a la conferencia ICCV por primera vez y presenta un póster busca consejos sobre cómo aprovechar al máximo la conferencia. La comunidad ofreció varios consejos prácticos, como socializar activamente, asistir a charlas interesantes, preparar una explicación clara del póster y estar dispuesto a discutir intereses más amplios fuera del alcance de la investigación actual, para maximizar los beneficios de la asistencia. (Fuente: Reddit r/MachineLearning)
Controversia y manejo de la revisión de artículos en AAAI 2026: Un autor que envió un artículo a AAAI encontró problemas con revisiones inexactas, incluyendo la afirmación de que su investigación fue superada por artículos citados con métricas inferiores, y el rechazo debido a detalles de entrenamiento ya incluidos en el material complementario. La comunidad discutió la efectividad de la “evaluación de revisión del autor” y los “comentarios del autor al presidente de ética” en la práctica, señalando que la primera no afecta la decisión y la segunda no es un canal para que el autor contacte al presidente de ética, lo que resalta los desafíos en el proceso de revisión académica. (Fuente: Reddit r/MachineLearning)
Definición y evaluación del sesgo político de los LLM: OpenAI ha publicado una investigación sobre la definición y evaluación del sesgo político en los LLM. Este trabajo tiene como objetivo comprender y cuantificar en profundidad las tendencias políticas existentes en los LLM, y explorar cómo ajustarlas para garantizar la equidad y neutralidad de los sistemas de IA, lo cual es crucial para el impacto social y la amplia aplicación de los LLM. (Fuente: Reddit r/artificial)