
Palabras clave:OpenAI, Infraestructura de IA, Virus generado por IA, AlphaEarth Foundations, RTEB, Claude Sonnet 4.5, DeepSeek V3.2-Exp, IA multimodal, Proyecto Stargate de OpenAI, Modelo de lenguaje Transformer Genome, Modelado de 10 metros de Google AlphaEarth, Benchmark RTEB de Hugging Face, Generación de código de Anthropic Claude, OpenAI, Infraestructura de IA, Virus generado por IA, AlphaEarth Foundations, RTEB, Claude Sonnet 4.5, DeepSeek V3.2-Exp, IA multimodal, Proyecto Stargate de OpenAI, Modelo de lenguaje Transformer Genome, Modelado de 10 metros de Google AlphaEarth, Benchmark RTEB de Hugging Face, Generación de código de Anthropic Claude
Como editor jefe sénior de la sección de IA, he realizado un análisis, resumen y destilación profundos de las noticias y discusiones sociales que me ha proporcionado. A continuación, se presenta el contenido integrado:
🔥 Foco
Apuesta de OpenAI por una infraestructura de billones de dólares: OpenAI está colaborando con Oracle y SoftBank, planeando invertir billones de dólares a nivel global en la construcción de infraestructura de cómputo, bajo el nombre en clave “Stargate”. Inicialmente, se anunciaron 5 nuevos sitios en Estados Unidos, con un costo de 400 mil millones de dólares, y una colaboración con Nvidia para construir el proyecto “Stargate UK” en el Reino Unido. OpenAI predice que la demanda futura de electricidad para la IA alcanzará los 100 gigavatios, y la inversión total podría llegar a los 5 billones de dólares. Esta iniciativa busca satisfacer la enorme demanda de capacidad de cómputo de los modelos de IA, pero también ha generado preocupaciones sobre la inversión de capital, el consumo de energía y los posibles riesgos financieros, destacando la extrema dependencia de la IA en la infraestructura. (Fuente: DeepLearning.AI Blog)

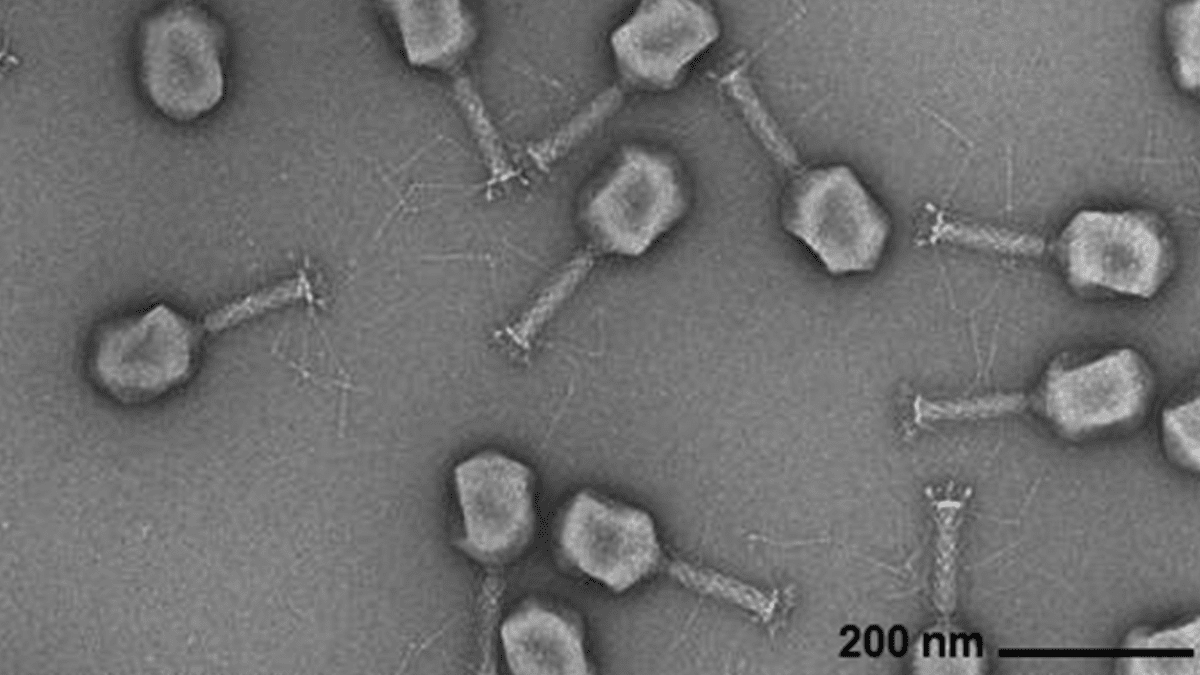
Generación de genomas virales por IA: Investigadores del Arc Institute, la Universidad de Stanford y el Memorial Sloan Kettering Cancer Center han utilizado modelos de lenguaje genómico basados en Transformer para sintetizar con éxito nuevos virus bacteriófagos capaces de combatir infecciones bacterianas comunes. Esta tecnología, mediante el ajuste fino de secuencias genómicas virales, puede generar nuevos genomas con funciones específicas y diferentes de los virus naturales. Este avance abre nuevas vías para el desarrollo de terapias alternativas a los antibióticos, pero también plantea preocupaciones sobre la bioseguridad y el uso malicioso, enfatizando la necesidad de investigación en respuesta a amenazas biológicas. (Fuente: DeepLearning.AI Blog)
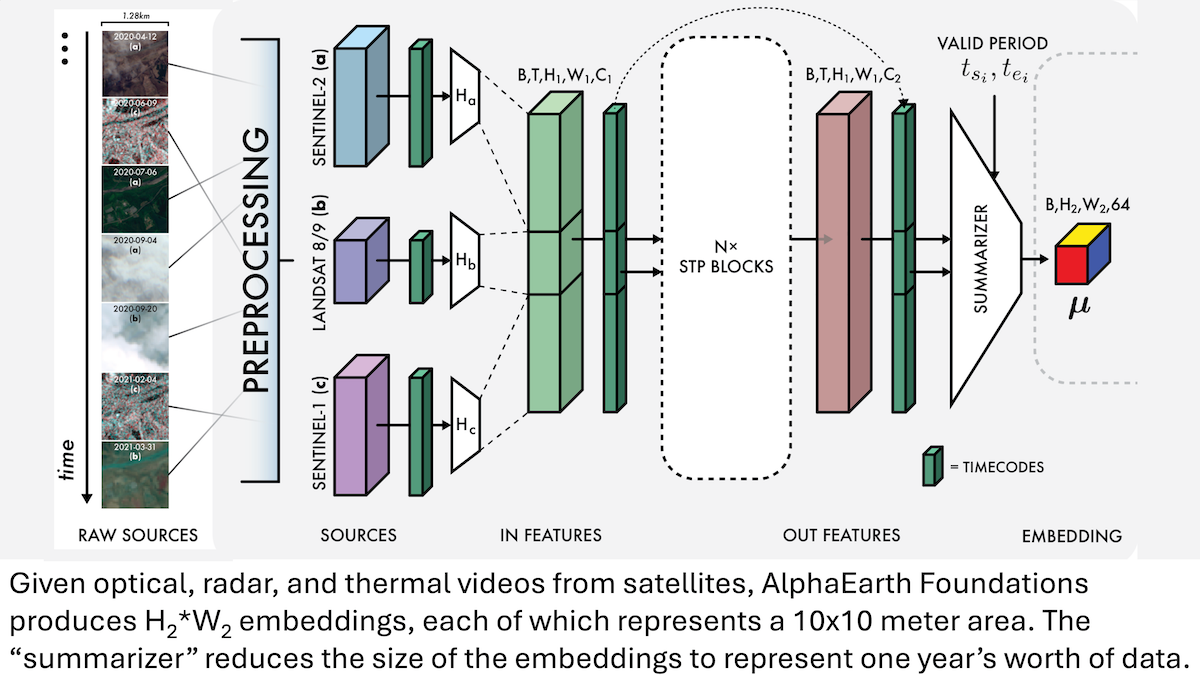
AlphaEarth Foundations de Google: Modelado de alta precisión de la Tierra a escala de 10 metros: Investigadores de Google han lanzado el modelo AlphaEarth Foundations (AEF), capaz de integrar imágenes satelitales y otros datos de sensores para modelar la superficie terrestre con una resolución de 10 metros cuadrados, y generar embeddings que representan las características anuales de la Tierra desde 2017 hasta 2024. Estos embeddings pueden utilizarse para rastrear diversas propiedades planetarias como la humedad, la precipitación, la vegetación, así como desafíos globales como la producción de alimentos, el riesgo de incendios forestales y los niveles de los embalses, proporcionando una herramienta de alta precisión sin precedentes para el monitoreo ambiental y la investigación del cambio climático. (Fuente: DeepLearning.AI Blog)
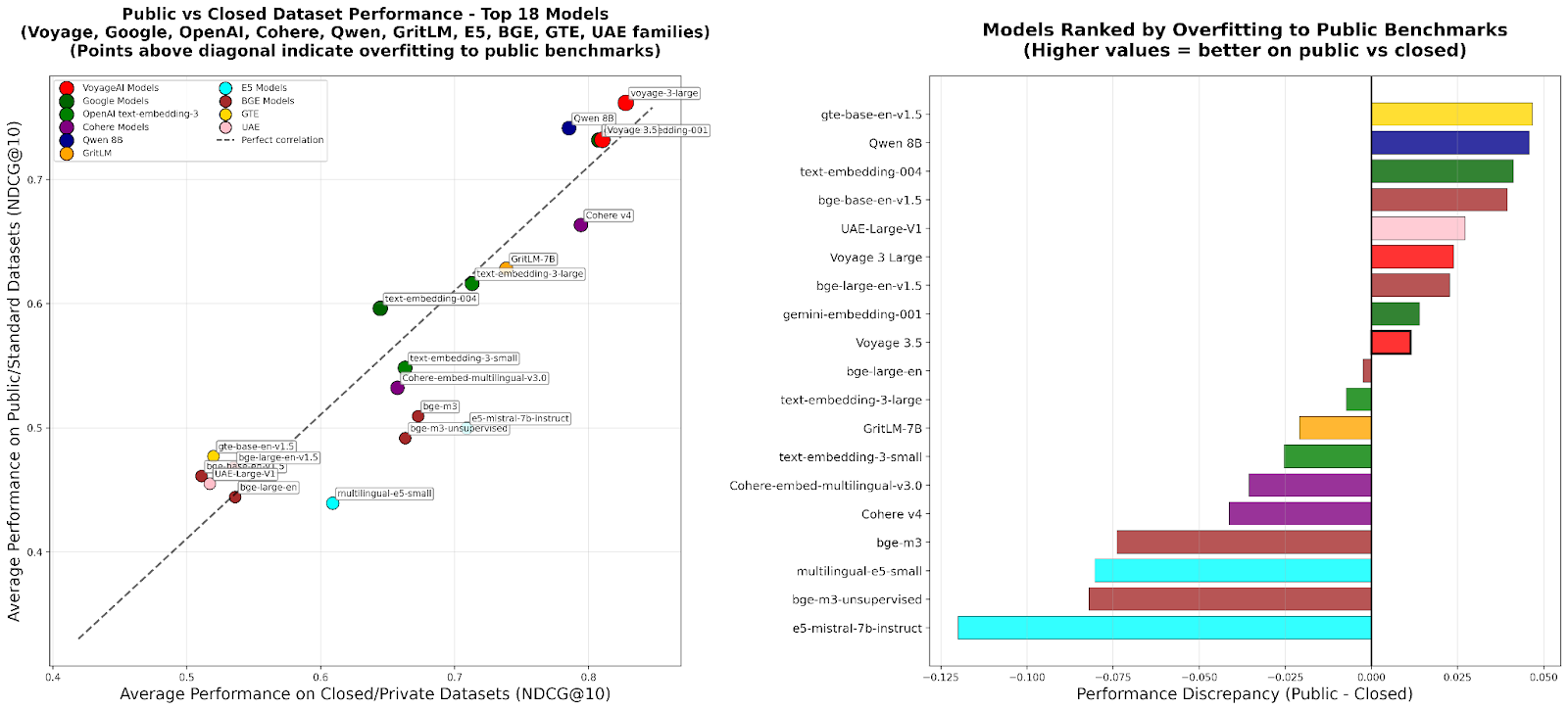
RTEB: Nuevo estándar para la evaluación de embeddings de recuperación: Hugging Face ha lanzado la versión beta de Retrieval Embedding Benchmark (RTEB), con el objetivo de proporcionar un estándar de evaluación fiable para la precisión de recuperación de los modelos de embeddings. Este benchmark, mediante una estrategia híbrida que combina conjuntos de datos públicos y privados, resuelve eficazmente el problema del sobreajuste de modelos en los benchmarks existentes, asegurando que los resultados de la evaluación reflejen mejor la capacidad de generalización del modelo en datos no vistos, lo cual es crucial para mejorar la calidad de aplicaciones de IA como RAG y Agent. (Fuente: HuggingFace Blog)
Entrenamiento intermedio de RL escalable: Razonamiento mediante abstracción de acciones: Una investigación reciente propone el algoritmo “Reasoning as Action Abstraction” (RA3), que identifica conjuntos de acciones compactos y útiles durante la fase de entrenamiento intermedio de Reinforcement Learning (RL) y acelera el RL en línea, mejorando significativamente las capacidades de razonamiento y generación de código de los Large Language Models (LLMs). Este método destaca en tareas de generación de código, con un rendimiento promedio superior entre 4 y 8 puntos porcentuales respecto a los modelos de referencia, y logra una convergencia de RL más rápida y un rendimiento asintótico superior. (Fuente: HuggingFace Daily Papers)
🎯 Tendencias
OpenAI Sora 2: Nueva era de las redes sociales de video con IA: OpenAI ha lanzado Sora 2 y su aplicación social homónima, con el objetivo de crear una red social centrada en el usuario y su círculo social (amigos, mascotas) a través de la visualización y creación de videos generados por IA, en lugar de una plataforma tradicional de distribución de contenido. Sora 2 demuestra potentes capacidades de simulación física y generación de audio, aunque las pruebas iniciales aún presentan imperfecciones en detalles como la “generación de dedos”. Su lanzamiento ha provocado debates sobre la adicción a los videos de IA, los deepfakes y la trayectoria de comercialización de OpenAI. Sam Altman respondió que Sora busca equilibrar el avance tecnológico con la experiencia placentera del usuario y financiar la investigación en IA. (Fuente: 36氪, Reddit r/ChatGPT, OpenAI)

Anthropic Claude Sonnet 4.5: Nuevo referente en código y Agent: Anthropic ha lanzado Claude Sonnet 4.5, aclamado como “el mejor modelo de programación del mundo” y “el modelo más potente para construir Agents complejos”, con una autonomía de hasta 30 horas y una mejora significativa en el rendimiento de codificación en tareas de GitHub. El modelo también ha incorporado una función de memoria que permite guardar el progreso del proyecto. Aunque su rendimiento es muy elogiado, persisten las controversias entre los usuarios sobre sus límites de uso y la comparación de su rendimiento real con Opus 4.1 y GPT-5. (Fuente: Reddit r/ClaudeAI, Reddit r/artificial, Reddit r/ClaudeAI)
DeepSeek V3.2-Exp: Arquitectura de atención dispersa para mayor eficiencia: DeepSeek ha lanzado el Large Language Model DeepSeek V3.2-Exp, que introduce una nueva arquitectura de atención dispersa (DSA) que reduce la complejidad de la atención principal de O(L²) a O(L·k), optimizando significativamente los costos de pre-relleno y decodificación en escenarios de contexto largo, lo que a su vez reduce drásticamente las tarifas de uso de la API. Jiuzhang Yunji ha sido pionera en la adaptación de DeepSeek V3.2-Exp, ofreciendo una solución de despliegue privado segura y eficiente para satisfacer las necesidades empresariales de seguridad de datos y flexibilidad de cómputo. (Fuente: 量子位, Reddit r/LocalLLaMA)

Lanzamiento del modelo multimodal audio-texto LFM2-Audio-1.5B: Liquid AI ha presentado LFM2-Audio-1.5B, un modelo fundacional de audio-texto todo en uno de extremo a extremo, capaz de comprender y generar texto y audio. Este modelo es 10 veces más rápido en inferencia que modelos similares y, con solo 1.5B parámetros, su calidad es comparable a la de modelos 10 veces más grandes, soportando despliegue local y conversación en tiempo real. Hume AI también ha lanzado Octave 2, un modelo de texto a voz multilingüe más rápido y económico, con capacidades de diálogo multi-hablante y conversión de voz. (Fuente: Reddit r/LocalLLaMA, QuixiAI)

Microsoft Agent Framework: Avances en el desarrollo de sistemas Agent: Microsoft ha lanzado Microsoft Agent Framework, que integra AutoGen y Semantic Kernel en un SDK unificado y listo para producción, diseñado para construir, orquestar y desplegar sistemas multi-Agent. Este framework soporta .NET y Python, y permite flujos de trabajo multi-Agent a través de orquestación basada en grafos, con el objetivo de simplificar el desarrollo, la observación y la gobernanza de aplicaciones Agent, acelerando la implementación de AIAgents a nivel empresarial. (Fuente: gojira, omarsar0)

Vanguardia tecnológica y competencia industrial en robótica con IA: La tecnología robótica sigue avanzando. OmniRetarget de Amazon FAR optimiza la captura de movimiento humano para el aprendizaje de habilidades humanoides complejas con un mínimo Reinforcement Learning. Periodic Labs se dedica a crear “científicos de IA” para acelerar el descubrimiento científico. Nvidia, por su parte, destaca el papel de su motor de física abierto Newton, el modelo de lenguaje visual de inferencia Cosmos Reason y el modelo fundacional de robótica Isaac GR00T N1.6 en el despliegue de IA física. Al mismo tiempo, China muestra una ventaja líder en la producción de robots y en el costo de los robots humanoides, lo que genera atención sobre el panorama competitivo global de la industria robótica. (Fuente: pabbeel, LiamFedus, nvidia, atroyn)

🧰 Herramientas
Tinker API: Interfaz flexible para simplificar el ajuste fino de LLM: Thinking Machines Lab ha lanzado Tinker API, una interfaz flexible diseñada para el ajuste fino de modelos de lenguaje. Permite a investigadores y desarrolladores escribir bucles de entrenamiento localmente, mientras Tinker se encarga de ejecutarlos en un clúster de GPU distribuido, gestionando la complejidad de la infraestructura. Esto permite a los usuarios centrarse en los algoritmos y los datos. La herramienta busca reducir la barrera de entrada para el post-entrenamiento de LLM, acelerar la experimentación y la innovación con modelos abiertos, y ha sido elogiada por expertos como Andrej Karpathy como “la infraestructura que siempre quise”. (Fuente: Reddit r/artificial, Thinking Machines, karpathy)

LlamaAgents: Despliegue de Document Agent con un solo clic: LlamaIndex ha lanzado LlamaAgents, que ofrece la capacidad de desplegar AI Agents centrados en documentos con un solo clic, con el objetivo de acelerar la construcción y entrega de agentes de documentos en 10 veces. La plataforma proporciona plantillas preconfiguradas al 90%, soporta el procesamiento automatizado de tareas intensivas en documentos como facturas, revisión de contratos y reclamaciones, y permite una personalización ilimitada. Los usuarios pueden desplegar en LlamaCloud y gestionar y actualizar fácilmente los flujos de trabajo de Agent a través de repositorios Git, acortando drásticamente el ciclo de desarrollo. (Fuente: jerryjliu0, jerryjliu0)

Hex AI Agent: Potenciando el análisis y la colaboración en equipo: Hex ha lanzado tres nuevos AI Agents, diseñados específicamente para el análisis de datos y la colaboración en equipo: Threads ofrece interacción conversacional con datos, Semantic Model Agent crea un contexto controlado para obtener respuestas precisas, y Notebook Agent revoluciona el trabajo diario de los equipos de datos. Todos estos Agents están impulsados por Claude 4.5 Sonnet y tienen como objetivo transformar el análisis conversacional de IA de un concepto futuro en una herramienta eficiente y disponible al instante. (Fuente: sarahcat21)
Sculptor: La interfaz de usuario que faltaba para Claude Code: Imbue ha lanzado Sculptor, una interfaz de usuario diseñada para Claude Code, con el objetivo de mejorar la experiencia de programación de Agent. Permite a los desarrolladores ejecutar múltiples Claude Agents en paralelo dentro de contenedores aislados, y sincronizar el trabajo del Agent con el entorno de desarrollo local para pruebas y edición a través del “modo de emparejamiento”. Sculptor también planea soportar GPT-5 y ofrecer funciones de sugerencia como la detección de comportamientos engañosos, con el objetivo de hacer la programación de Agent más fluida y eficiente. (Fuente: kanjun, kanjun)
Synthesia 3.0: Nuevo avance en video interactivo con IA: Synthesia ha lanzado la versión 3.0, introduciendo varias funciones innovadoras, incluyendo “Video Agents” (videos interactivos que pueden mantener conversaciones en tiempo real, utilizados para capacitación y entrevistas), “Avatares” mejorados (creados con una sola indicación o imagen, con expresiones faciales y movimientos corporales realistas) y “Copilot” (un editor de video con IA que puede generar rápidamente guiones y elementos visuales). Además, se han mejorado las funciones de interactividad y las herramientas de diseño de cursos, con el objetivo de revolucionar la creación de videos y la experiencia de aprendizaje. (Fuente: synthesiaIO, synthesiaIO)
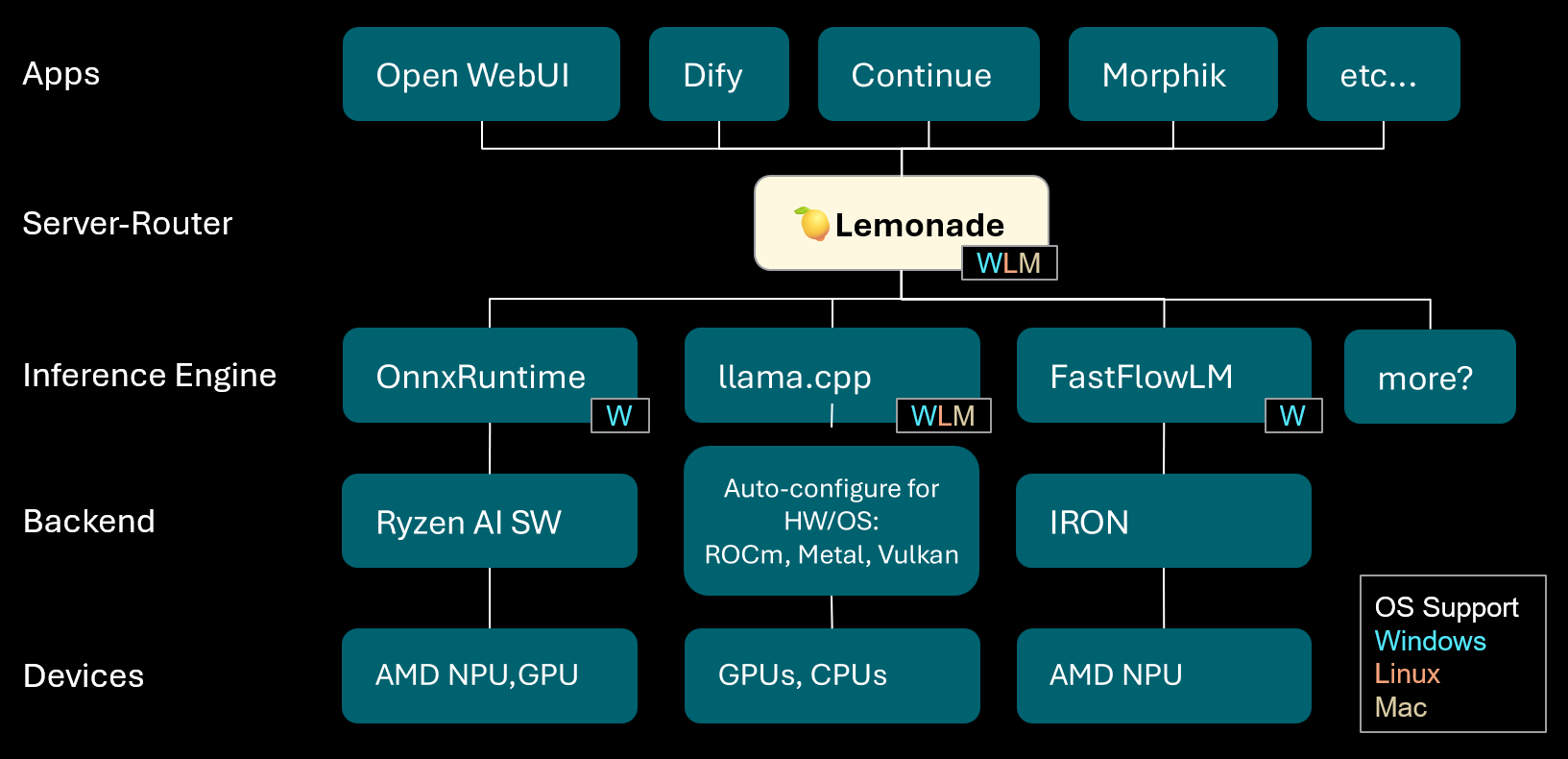
Lemonade: Servidor-enrutador local de LLM: Lemonade ha lanzado la versión v8.1.11, un servidor-enrutador local de LLM que configura automáticamente motores de inferencia de alto rendimiento para diversas PC (incluyendo AMD NPU y dispositivos macOS/Apple Silicon). Soporta múltiples formatos de modelo como ONNX, GGUF y FastFlowLM, y utiliza el backend Metal de llama.cpp para un cómputo eficiente en Apple Silicon, ofreciendo a los usuarios una experiencia LLM local flexible y de alto rendimiento. (Fuente: Reddit r/LocalLLaMA)
PopAi: Generación de presentaciones impulsada por IA: PopAi ha demostrado la capacidad de su herramienta de IA para generar presentaciones comerciales detalladas con gráficos e ilustraciones a partir de una simple indicación en cuestión de minutos. Esto subraya la eficiencia de la IA en la creación de contenido, permitiendo que incluso los no profesionales produzcan rápidamente materiales de presentación de alta calidad. (Fuente: kaifulee)

GitHub Copilot CLI: Selección automática de modelos: GitHub Copilot CLI ahora ofrece la función de selección automática de modelos para usuarios comerciales y empresariales. Esta actualización permite que el sistema elija automáticamente el modelo más adecuado según la tarea actual, con el objetivo de mejorar la eficiencia del desarrollo y la calidad de la generación de código. (Fuente: pierceboggan)
Mixedbread Search: Búsqueda local multilingüe y multimodal: Mixedbread ha lanzado su sistema de búsqueda en versión beta, que ofrece una función de búsqueda de documentos rápida, precisa, multilingüe y multimodal. Este sistema enfatiza la ejecución local, lo que permite a los usuarios realizar una recuperación eficiente de documentos en sus propios dispositivos, especialmente adecuado para escenarios que requieren el procesamiento de diversos tipos de datos. (Fuente: TheZachMueller)
Hume AI Octave 2: Modelo TTS multilingüe de próxima generación: Hume AI ha lanzado Octave 2, un modelo de texto a voz (TTS) multilingüe de próxima generación. Este modelo es un 40% más rápido y un 50% más económico que su predecesor, y soporta más de 11 idiomas, diálogo multi-hablante, conversión de voz y edición de fonemas, con el objetivo de ofrecer una experiencia de IA de voz más rápida, realista y emotiva. (Fuente: AlanCowen)
Actualizaciones de septiembre de AssemblyAI: Servicio de audio de IA todo en uno: AssemblyAI ha revisado sus actualizaciones de septiembre, destacando el lanzamiento de Playground dentro de la aplicación, extensión de lenguaje universal, función de desidentificación de PII en la UE, así como mejoras en el rendimiento de streaming y sugerencias de palabras clave. Estas actualizaciones tienen como objetivo proporcionar a los usuarios un servicio de procesamiento de audio con IA más completo y eficiente. (Fuente: AssemblyAI)
Herramienta Voiceflow MCP: Estandarización de la integración de herramientas de Agent: Voiceflow ha lanzado la herramienta Model Context Protocol (MCP), que proporciona una forma estandarizada para que los AI Agents utilicen diversas herramientas. Esto simplifica el trabajo de integración personalizada para los desarrolladores y ofrece herramientas de terceros preconstruidas para usuarios sin código, ampliando enormemente las capacidades de los Voiceflow Agents. (Fuente: ReamBraden)
Salesforce Agentforce Vibes: Codificación de Agent a nivel empresarial: Salesforce ha lanzado el producto “Agentforce Vibes”, basado en la arquitectura de Cline, que aprovecha el soporte del Model Context Protocol (MCP) para ofrecer capacidades de codificación autónoma a clientes empresariales. Este producto garantiza la comunicación segura de los LLM con fuentes de conocimiento/bases de datos internas y externas, con el objetivo de lograr la codificación de IA a escala empresarial. (Fuente: cline)

JoyAgent-JDGenie: Informe de arquitectura de Agent generalista: Se ha publicado el informe técnico de GAIA (Generalist Agent Architecture), una arquitectura que integra un marco colectivo multi-Agent (combinando planificación, Agents de ejecución y votación de modelos de revisión), un sistema de memoria jerárquica (capas de trabajo, semántica, programa) y un conjunto de herramientas para búsqueda, ejecución de código y análisis multimodal. Este marco ha demostrado un rendimiento excepcional en pruebas de referencia integrales, superando las bases de código abierto y acercándose al rendimiento de sistemas propietarios, proporcionando un camino para construir asistentes de IA escalables, resilientes y adaptables. (Fuente: HuggingFace Daily Papers)
Asistente de viaje con IA: Empoderando desde la planificación hasta la acción: La aplicación de asistente de viaje con IA lanzada por Mafengwo tiene como objetivo elevar la IA de la generación tradicional de guías a la asistencia práctica durante el viaje. La aplicación puede generar guías personalizadas con texto e imágenes, y ofrece funciones prácticas como la reserva de restaurantes mediante un AI Agent que realiza llamadas, resolviendo eficazmente puntos débiles como las barreras lingüísticas. Aunque todavía hay margen de mejora en la traducción en tiempo real y la personalización profunda, ha reducido significativamente la barrera para “salir sin planificar”, demostrando el enorme potencial de la IA para conectar la información digital con las acciones en el mundo físico. (Fuente: 36氪)

📚 Aprendizaje
Consejos para el desarrollo profesional de investigadores de IA: Para el desarrollo profesional de investigadores de IA, los expertos enfatizan la importancia de ser un excelente programador, alentando a reproducir trabajos de investigación desde cero y a comprender profundamente la infraestructura. Al mismo tiempo, sugieren construir activamente una marca personal, compartir ideas interesantes, mantener la curiosidad y la adaptabilidad, y priorizar puestos que promuevan la innovación y el aprendizaje. A largo plazo, el esfuerzo continuo y la obtención de resultados tangibles son clave para construir confianza y motivación. (Fuente: dejavucoder, BlackHC)
Curso de análisis de datos con Python: DeepLearningAI ha lanzado un nuevo curso de análisis de datos con Python, diseñado para enseñar cómo utilizar Python para mejorar la eficiencia, trazabilidad y reproducibilidad del análisis de datos. Este curso forma parte del certificado profesional de análisis de datos y enfatiza el papel central de las habilidades de programación en el trabajo de datos moderno. (Fuente: DeepLearningAI)
Estudiantes obtienen herramientas de IA de Copilot gratis: Microsoft ofrece a estudiantes universitarios elegibles una suscripción gratuita de 12 meses a Microsoft 365 Personal, que incluye acceso adicional a Copilot Podcasts, Deep Research y Vision. Esta iniciativa busca proporcionar a los estudiantes potentes herramientas de IA para apoyar su aprendizaje e innovación. (Fuente: mustafasuleyman)

Configuración de cursos locales de AI/ML: Un educador compartió cómo crear cursos prácticos de AI/ML para estudiantes, basados en desarrollo local y hardware de consumo, con un presupuesto limitado. Sugiere usar modelos pequeños, Transformer Lab como plataforma de entrenamiento, y enfatiza la comprensión de los conceptos centrales en lugar de perseguir ciegamente la escala del modelo, para mejorar el efecto de aprendizaje y las habilidades prácticas de los estudiantes. (Fuente: Reddit r/deeplearning)
Próximos seminarios de IA: AIhub ha publicado una lista de próximos seminarios de Machine Learning e IA que se celebrarán entre octubre y noviembre de 2025. Estos eventos cubren múltiples temas, desde la recopilación de datos de plataformas de redes sociales con restricciones políticas hasta la ética de la IA. Todos los seminarios son gratuitos y ofrecen opciones de participación en línea, proporcionando ricas oportunidades de aprendizaje e intercambio para la comunidad de IA. (Fuente: aihub.org)

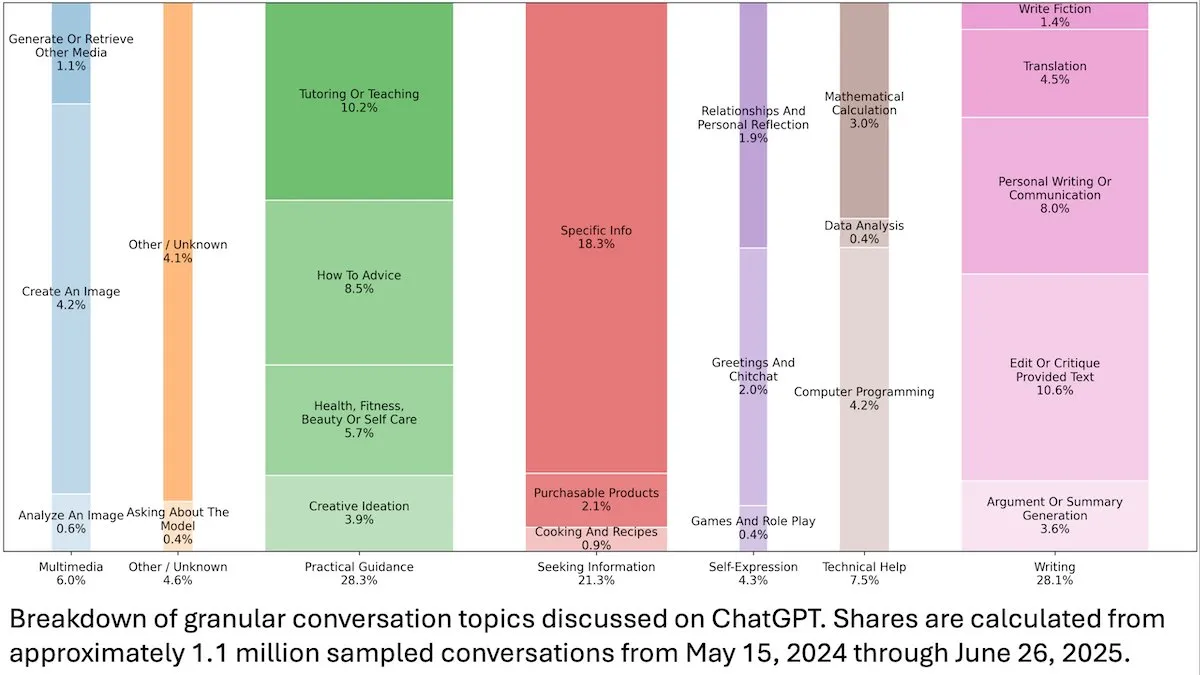
Insights sobre el comportamiento del usuario de ChatGPT: Un estudio de OpenAI publicado por DeepLearningAI revela que el análisis de 110 millones de conversaciones anónimas de ChatGPT muestra que su uso ha pasado de ser laboral a satisfacer necesidades personales, con una mayor proporción de usuarias y usuarios jóvenes de 18 a 25 años. Las solicitudes más comunes son orientación práctica (28.3%), ayuda para escribir (28.1%) y consultas de información (21.3%), lo que revela la amplia aplicación de ChatGPT en la vida diaria. (Fuente: DeepLearningAI)
Code2Video: Generación de videos educativos impulsada por código: Una investigación presenta Code2Video, un marco de Agent centrado en el código que genera videos educativos profesionales a través de código Python ejecutable. Este marco incluye tres Agents colaborativos: un planificador, un codificador y un crítico, capaces de estructurar el contenido de las conferencias, convertirlo en código y optimizarlo visualmente. Logró una mejora del rendimiento del 40% en el benchmark de videos educativos MMMC y generó videos comparables a los tutoriales humanos. (Fuente: HuggingFace Daily Papers)
BiasFreeBench: Benchmark para la mitigación de sesgos en LLM: BiasFreeBench se introduce como un benchmark empírico para comparar exhaustivamente ocho técnicas principales de mitigación de sesgos en LLM. Este benchmark, al reorganizar conjuntos de datos existentes, introduce una métrica de “Bias-Free Score” a nivel de respuesta en dos escenarios de prueba (preguntas de opción múltiple y preguntas abiertas de varias rondas) para medir la equidad, seguridad y el grado de anti-estereotipo de las respuestas de los LLM, con el objetivo de establecer una plataforma de prueba unificada para la investigación de mitigación de sesgos. (Fuente: HuggingFace Daily Papers)
Obstáculos en el aprendizaje de la multiplicación de Transformers y la trampa de la dependencia a largo plazo: Un estudio de ingeniería inversa analizó las razones del fracaso de los modelos Transformer en la tarea aparentemente simple de la multiplicación de números de varias cifras. La investigación encontró que el modelo codifica la estructura de dependencia a largo plazo necesaria en una cadena de pensamiento implícita, pero los métodos de ajuste fino estándar no lograron converger a un óptimo global que pudiera explotar estas dependencias. Al introducir una función de pérdida auxiliar, los investigadores lograron resolver este problema, revelando las trampas en el aprendizaje de dependencias a largo plazo por parte de los Transformers y proporcionando un ejemplo de cómo resolver este problema con un sesgo inductivo correcto. (Fuente: HuggingFace Daily Papers)
Insights de entrenamiento VL-PRM en razonamiento multimodal: La investigación tiene como objetivo dilucidar el espacio de diseño de los modelos de recompensa de proceso visual-lenguaje (VL-PRMs), explorando múltiples estrategias para la construcción de conjuntos de datos, entrenamiento y escalado en tiempo de prueba. Al introducir un marco de síntesis de datos mixtos y una supervisión enfocada en la percepción, los VL-PRMs demostraron insights clave en cinco benchmarks multimodales, incluyendo un rendimiento superior a los modelos de recompensa de resultados en el escalado en tiempo de prueba, la capacidad de los VL-PRMs de pequeño tamaño para detectar errores de proceso, y la capacidad de revelar el potencial de razonamiento de backbones VLM más potentes. (Fuente: HuggingFace Daily Papers)
GEM: Simulador de entorno general para LLM Agentic: GEM (General Experience Maker) es un simulador de entorno de código abierto, diseñado específicamente para el aprendizaje experiencial de LLM Agents. Proporciona una interfaz estándar Agent-entorno, soporta ejecución vectorizada asíncrona para un alto rendimiento y ofrece wrappers flexibles para una fácil extensión. GEM también incluye un conjunto diverso de entornos y herramientas integradas, y proporciona líneas base utilizando marcos de entrenamiento de RL como REINFORCE, con el objetivo de acelerar la investigación de LLM Agentic. (Fuente: HuggingFace Daily Papers)
GUI-KV: Compresión de caché KV eficiente para GUI Agent: GUI-KV es un método de compresión de caché KV plug-and-play, diseñado para GUI Agents, que mejora la eficiencia sin necesidad de reentrenamiento. Al analizar los patrones de atención en las cargas de trabajo de GUI, este método combina la guía de prominencia espacial y las técnicas de puntuación de redundancia temporal, logrando una precisión cercana a la de la caché completa con un presupuesto moderado y reduciendo significativamente los FLOPs de decodificación, aprovechando eficazmente la redundancia específica de la GUI. (Fuente: HuggingFace Daily Papers)
Más allá de la verosimilitud logarítmica: Investigación de funciones objetivo probabilísticas para SFT: La investigación explora funciones objetivo probabilísticas más allá de la tradicional verosimilitud logarítmica negativa (NLL) en el ajuste fino supervisado (SFT). A través de extensos experimentos con 7 backbones de modelos, 14 benchmarks y 3 dominios, se encontró que cuando la capacidad del modelo es fuerte, las funciones objetivo que priorizan tokens con pesos de probabilidad a priori más bajos (como -p, -p^10) superan a NLL; mientras que cuando la capacidad del modelo es débil, NLL domina. El análisis teórico revela cómo las funciones objetivo equilibran según la capacidad del modelo, proporcionando estrategias de optimización más basadas en principios para SFT. (Fuente: HuggingFace Daily Papers)
VLA-RFT: Ajuste fino de RL basado en recompensas de validación en simuladores de mundo: VLA-RFT es un marco de ajuste fino por refuerzo para modelos de visión-lenguaje-acción (VLA) que utiliza modelos de mundo basados en datos como simuladores controlables. El simulador, entrenado con datos de interacción reales, predice futuras observaciones visuales basadas en acciones, lo que permite la implementación de políticas con recompensas densas a nivel de trayectoria. Este marco reduce significativamente los requisitos de muestras, superando las potentes líneas base supervisadas en menos de 400 pasos de ajuste fino y demostrando una fuerte robustez en condiciones de perturbación. (Fuente: HuggingFace Daily Papers)
ImitSAT: Resolución del problema de satisfacibilidad booleana mediante aprendizaje por imitación: ImitSAT es una estrategia de ramificación para solucionadores CDCL basada en aprendizaje por imitación, utilizada para resolver el problema de satisfacibilidad booleana (SAT). Este método, al aprender de un experto KeyTrace, colapsa ejecuciones completas en secuencias de decisiones supervivientes, proporcionando una supervisión densa a nivel de decisión que reduce directamente el número de propagaciones. Los experimentos demuestran que ImitSAT supera a los métodos de aprendizaje existentes en el recuento de propagaciones y el tiempo de ejecución, logrando una convergencia más rápida y un entrenamiento estable. (Fuente: HuggingFace Daily Papers)
Estudio de prácticas de prueba de marcos de AI Agent de código abierto: Un estudio empírico a gran escala de 39 marcos de Agent de código abierto y 439 aplicaciones de Agent revela las prácticas de prueba en el ecosistema de AI Agent. El estudio identifica diez patrones de prueba únicos, encontrando que la inversión en pruebas de componentes deterministas (como herramientas y flujos de trabajo) supera el 70%, mientras que los agentes de planificación basados en LLM representan menos del 5%. Además, las pruebas de regresión de los componentes de Prompt (Trigger) se descuidan gravemente, apareciendo en solo aproximadamente el 1% de las pruebas, revelando puntos ciegos críticos en las pruebas de Agent. (Fuente: HuggingFace Daily Papers)
DeepCodeSeek: Recuperación de API en tiempo real para generación de código: DeepCodeSeek propone una nueva técnica para proporcionar recuperación de API en tiempo real para la generación de código consciente del contexto, lo que permite la autocompletación de código de alta calidad de extremo a extremo y aplicaciones de AI Agentic. Este método resuelve el problema de la fuga de API en los conjuntos de datos de referencia existentes al expandir el código y el índice para predecir las API necesarias. Después de la optimización, un reordenador compacto de 0.6B supera el rendimiento de un modelo de 8B mientras mantiene una latencia 2.5 veces menor. (Fuente: HuggingFace Daily Papers)
CORRECT: Identificación concisa de errores en sistemas multi-Agent: CORRECT es un marco ligero y sin entrenamiento que logra la identificación de errores y la transferencia de conocimiento en sistemas multi-Agent mediante el uso de una caché en línea de patrones de error destilados. Este marco puede identificar errores estructurados en tiempo lineal, evitando un reentrenamiento costoso, y puede adaptarse a despliegues dinámicos de MAS. CORRECT mejoró la localización de errores a nivel de paso en un 19.8% en siete aplicaciones multi-Agent, reduciendo significativamente la brecha entre la automatización y la identificación de errores a nivel humano. (Fuente: HuggingFace Daily Papers)
Swift: Modelo de consistencia autorregresivo para una previsión meteorológica eficiente: Swift es un modelo de consistencia de un solo paso que logra por primera vez el ajuste fino autorregresivo de modelos de flujo probabilístico y utiliza un objetivo de puntuación de probabilidad de rango continuo (CRPS). Este modelo puede generar pronósticos meteorológicos de 6 horas hábiles y mantener la estabilidad hasta por 75 días, funcionando 39 veces más rápido que las líneas base de difusión de última generación, al tiempo que logra una habilidad de pronóstico comparable a la de IFS ENS numérico, marcando un paso importante hacia pronósticos de conjunto eficientes y fiables a escalas de mediano a largo plazo y estacionales. (Fuente: HuggingFace Daily Papers)
Catching the Details: Predictor de RoI autodestilado para la percepción de grano fino de MLLM: La investigación propone una red de propuesta de región autodestilada (SD-RPN) eficiente y sin anotaciones, que resuelve el problema del alto costo computacional de los Large Language Models multimodales (MLLM) al procesar imágenes de alta resolución. SD-RPN, al transformar los mapas de atención de las capas intermedias de MLLM en etiquetas pseudo-RoI de alta calidad y entrenar una RPN ligera para una localización precisa, logra una eficiencia de datos y capacidad de generalización, mejorando la precisión en más del 10% en benchmarks no vistos. (Fuente: HuggingFace Daily Papers)
Nuevo paradigma para el razonamiento multi-turno de LLM: In-Place Feedback: La investigación introduce un nuevo paradigma de interacción llamado “In-Place Feedback” para guiar a los LLM en el razonamiento multi-turno. Los usuarios pueden editar directamente las respuestas anteriores del LLM, y el modelo genera revisiones basadas en esta respuesta modificada. La evaluación empírica muestra que In-Place Feedback supera al feedback multi-turno tradicional en benchmarks intensivos en razonamiento, al tiempo que reduce el uso de tokens en un 79.1%, resolviendo las limitaciones del modelo para aplicar el feedback con precisión. (Fuente: HuggingFace Daily Papers)
Previsibilidad de la dinámica del Reinforcement Learning de LLM: Este trabajo revela dos propiedades fundamentales de las actualizaciones de parámetros en el entrenamiento de Reinforcement Learning (RL) de LLM: la dominancia de rango 1 (el subespacio singular más alto de la matriz de actualización de parámetros determina casi por completo la mejora de la inferencia) y la dinámica lineal de rango 1 (este subespacio dominante evoluciona linealmente durante el entrenamiento). Basándose en estos hallazgos, la investigación propone AlphaRL, un marco de aceleración plug-and-play que, al inferir las actualizaciones finales de parámetros a través de una ventana de entrenamiento temprana, logra una aceleración de hasta 2.5 veces, conservando más del 96% del rendimiento de inferencia. (Fuente: HuggingFace Daily Papers)
Las trampas de la compresión de caché KV: La investigación revela múltiples trampas de la compresión de caché KV en el despliegue de LLM, especialmente en escenarios reales como los prompts de múltiples instrucciones, donde la compresión puede llevar a una rápida disminución del rendimiento de ciertas instrucciones, o incluso a que el LLM las ignore por completo. El estudio, a través de análisis de casos de fuga de prompts del sistema, demuestra empíricamente el impacto de la compresión en la fuga y el seguimiento de instrucciones generales, y propone mejoras simples en las estrategias de expulsión de caché KV. (Fuente: HuggingFace Daily Papers)
💼 Negocios
Competencia entre gigantes de la IA: Diferencias estratégicas entre OpenAI y Anthropic: OpenAI y Anthropic han adoptado trayectorias de desarrollo muy diferentes en el campo de la IA. OpenAI, a través de la integración de comercio electrónico en ChatGPT y el lanzamiento de la aplicación social Sora, busca una “expansión horizontal” para convertirse en una superplataforma que cubra múltiples aspectos de la vida del usuario, con una valoración que ya supera a Anthropic en cientos de miles de millones de dólares. Anthropic, por su parte, se enfoca en una “profundización vertical”, con Claude Sonnet 4.5 como núcleo, cultivando el mercado de programación de IA y Agents empresariales, y estableciendo profundos lazos con proveedores de servicios en la nube como AWS y Google. Detrás de ambos se encuentra la pugna por la “diplomacia de la capacidad de cómputo” entre los dos gigantes de la computación en la nube, Microsoft y Amazon, lo que subraya la realidad industrial de la escasez y el alto costo de la capacidad de cómputo en la era de la IA. (Fuente: 36氪, 量子位, 36氪)
Perplexity adquiere Visual Electric: Perplexity ha anunciado la adquisición de Visual Electric, cuyo equipo se unirá a Perplexity para desarrollar nuevas experiencias de productos de consumo. Los productos de Visual Electric se descontinuarán gradualmente. Esta adquisición tiene como objetivo fortalecer la capacidad de innovación de Perplexity en el ámbito de los productos de IA para el consumidor. (Fuente: AravSrinivas)

Databricks adquiere Mooncakelabs: Databricks ha anunciado la adquisición de Mooncakelabs para acelerar la realización de su visión Lakebase. Lakebase es una nueva base de datos OLTP construida sobre Postgres y optimizada para AI Agents, diseñada para proporcionar una base unificada para aplicaciones, análisis e IA, y profundamente integrada con Lakehouse y Agent Bricks, simplificando la gestión de datos y el desarrollo de aplicaciones de IA. (Fuente: matei_zaharia)

🌟 Comunidad
Impacto de la IA en el empleo y la sociedad: La comunidad debate ampliamente el profundo impacto de la automatización por IA en el mercado laboral, preocupada por la posibilidad de desempleo masivo, la creación de nuevas clases sociales y la necesidad de una Renta Básica Universal (UBI). Se cuestiona si los nuevos trabajos relacionados con la IA también serán automatizados y si no todos podrán adquirir las habilidades de IA para adaptarse al futuro. La discusión también aborda los desafíos de la gestión de costos y el ROI de los AI Agents, así como el impacto potencial de la llegada de la AGI en la estructura social y la geopolítica. (Fuente: Reddit r/ArtificialInteligence, Ronald_vanLoon, Ronald_vanLoon)
Ética de la IA y la lucha por el control: La comunidad debate acaloradamente quién debería controlar el futuro de la IA, si la gente común o los oligarcas tecnológicos. Se pide que el desarrollo de la IA se centre en el ser humano, enfatizando la transparencia y el control del usuario sobre sus datos personales y el historial de la IA. Al mismo tiempo, el “padrino de la IA”, Yoshua Bengio, advierte que las máquinas superinteligentes podrían llevar a la extinción humana en una década. Empresas como Meta planean utilizar datos de chats de IA para publicidad dirigida, lo que agrava aún más las preocupaciones de los usuarios sobre la privacidad y el uso indebido de la IA, provocando una profunda reflexión sobre la ética y la regulación de la IA. (Fuente: Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence)

Comportamiento anómalo del modelo de seguridad GPT-5: Usuarios de la comunidad de Reddit han reportado que el modelo “CHAT-SAFETY” de GPT-5, al procesar solicitudes no maliciosas, exhibe un comportamiento extraño, acusatorio e incluso alucinatorio, por ejemplo, interpretando una pregunta sobre reconocimiento de huellas dactilares como un comportamiento de seguimiento y fabricando leyes. Esta respuesta excesivamente sensible e imprecisa ha generado serias dudas entre los usuarios sobre la fiabilidad del modelo, los posibles daños y las políticas de seguridad de OpenAI. (Fuente: Reddit r/ChatGPT)
“Lecciones amargas” y el debate sobre la trayectoria de desarrollo de LLM: Andrej Karpathy y Richard Sutton, padre del Reinforcement Learning, debaten si los LLM se ajustan a las “lecciones amargas”. Sutton argumenta que los LLM dependen de datos humanos limitados para el preentrenamiento y no siguen realmente el principio de aprender de la experiencia de las “lecciones amargas”. Karpathy, por su parte, considera el preentrenamiento como una “mala evolución” para resolver el problema del arranque en frío, y señala las diferencias fundamentales entre los LLM y la inteligencia animal en los mecanismos de aprendizaje, enfatizando que la IA actual se parece más a “invocar fantasmas” que a “construir animales”. (Fuente: karpathy, SchmidhuberAI)
Discusión sobre el valor de una configuración local de LLM: Los usuarios de la comunidad debaten el valor de invertir decenas de miles de dólares en una configuración local de LLM. Los defensores destacan la privacidad, la seguridad de los datos y el conocimiento profundo adquirido a través de la operación práctica como sus principales ventajas, comparándolo con los aficionados a la radioafición. Los opositores, sin embargo, argumentan que, con la mejora del rendimiento de las API en la nube económicas (como Sonnet 4.5 y Gemini Pro 2.5), una configuración local de alto costo es difícil de justificar. (Fuente: Reddit r/LocalLLaMA)
LLM como evaluador: Nuevo método de evaluación de Agent: Investigadores y desarrolladores están explorando el uso de LLM como “jueces” para evaluar la calidad de las respuestas de los AI Agents, incluyendo la precisión y la fundamentación. La práctica demuestra que, cuando los prompts del evaluador están cuidadosamente diseñados (por ejemplo, un solo criterio, puntuación anclada, formato de salida estricto y advertencias de sesgo), este método puede ser sorprendentemente efectivo. Esta tendencia indica que LLM-as-a-Judge tiene un enorme potencial en el campo de la evaluación de Agent. (Fuente: Reddit r/MachineLearning)
Interacción entre IA y humanos: De dispositivos a personajes virtuales: La IA está redefiniendo la interacción humana en múltiples dimensiones. Una startup vinculada al MIT ha lanzado un dispositivo wearable “casi telepático” que permite la comunicación silenciosa. Al mismo tiempo, los AI Agents de voz en tiempo real como NPC (personajes no jugables) ya se aplican en juegos web 3D, lo que presagia el potencial de la IA para ofrecer experiencias de interacción más naturales e inmersivas en juegos y mundos virtuales. Estos avances provocan debates sobre el papel de la IA en la vida diaria y el entretenimiento. (Fuente: Reddit r/ArtificialInteligence, Reddit r/artificial)

Elección entre modelos abiertos y cerrados: La comunidad debatió los mayores obstáculos que enfrentan los ingenieros de software al pasar de modelos de código cerrado a modelos de código abierto. Los expertos señalaron que el ajuste fino de modelos de código abierto, en lugar de depender de modelos de caja negra de código cerrado, es crucial para un aprendizaje profundo, lograr la diferenciación del producto y crear mejores productos para los usuarios. Aunque el desarrollo de modelos de código abierto puede ser más lento, a largo plazo, tienen un enorme potencial en la creación de valor y la autonomía tecnológica. (Fuente: ClementDelangue, huggingface)
Infraestructura de IA y desafíos de cómputo: El proyecto “Stargate” de OpenAI revela la enorme demanda de capacidad de cómputo, energía y terreno por parte de la IA, con una previsión de consumo de hasta 900.000 obleas DRAM al mes. La escasez de GPU, sus altos precios y las limitaciones del suministro eléctrico obligan a las empresas de IA a recurrir a la “diplomacia de la capacidad de cómputo”, vinculándose profundamente con proveedores de servicios en la nube (como Microsoft y Amazon). Este modelo de inversión en activos pesados y colaboración estratégica, aunque impulsa el desarrollo de la IA, también conlleva riesgos de variables externas como la cadena de suministro, las políticas energéticas y la regulación. (Fuente: karminski3, AI巨头的奶妈局, DeepLearning.AI Blog)

💡 Otros
Derechos de autor de la música con IA y mecanismos de compensación: La organización sueca de derechos de autor STIM, en colaboración con la empresa Sureel, ha lanzado un acuerdo de licencia de música con IA para abordar el uso de obras musicales en el entrenamiento de modelos de IA. Este acuerdo permite a los desarrolladores de IA utilizar legalmente la música y, a través de la tecnología de atribución de Sureel, calcular el impacto de las obras en la salida del modelo, compensando así a compositores y artistas discográficos. Esta iniciativa busca proporcionar seguridad jurídica para la creación musical con IA, incentivar la producción de contenido original y generar nuevas fuentes de ingresos para los titulares de derechos de autor. (Fuente: DeepLearning.AI Blog)

Seguridad de LLM y ataques adversarios: Trend Micro ha publicado una investigación que explora en profundidad las múltiples formas en que los LLM pueden ser explotados por atacantes, incluyendo el compromiso a través de prompts cuidadosamente construidos, envenenamiento de datos y vulnerabilidades en sistemas multi-Agent. La investigación enfatiza la importancia de comprender estos vectores de ataque para desarrollar aplicaciones LLM y sistemas multi-Agent más seguros, y propone estrategias de defensa correspondientes. (Fuente: Reddit r/deeplearning)

IA proactiva: Equilibrio entre conveniencia y privacidad: La comunidad ha debatido la conveniencia y los riesgos potenciales de invasión de la privacidad que conlleva la “Proactive Ambient AI” (IA ambiental proactiva) como asistente inteligente. Este tipo de IA puede ofrecer ayuda de forma proactiva, pero su recopilación y procesamiento continuo de datos personales genera preocupación entre los usuarios sobre la transparencia, el control y la propiedad de los datos. Algunos puntos de vista abogan por establecer “protocolos de transparencia” y “perfiles básicos personales” para garantizar que los usuarios tengan control sobre su historial de interacciones con la IA. (Fuente: Reddit r/artificial)
