
Palabras clave:Anthropic Claude Sonnet 4.5, DeepSeek-V3.2-Exp, OpenAI ChatGPT, Modelos de IA, Inteligencia Artificial, Modelos de Lenguaje Grande (LLM), Programación con IA, Agentes Inteligentes de IA, Capacidad de programación de Claude Sonnet 4.5, Mecanismo de atención dispersa DSA, Función de pago instantáneo de ChatGPT, Aplicación social Sora 2, Técnica de ajuste fino LoRA
🔥 En Foco
Anthropic lanza Claude Sonnet 4.5, mejorando significativamente las capacidades de programación y agentes: Anthropic ha lanzado oficialmente Claude Sonnet 4.5, aclamado como el modelo de programación más potente del mundo, logrando avances notables en la construcción de agentes, uso de computadoras, razonamiento y capacidades matemáticas. Este modelo puede trabajar de forma autónoma y continua durante más de 30 horas, ha alcanzado la cima en la prueba SWE-bench Verified y ha batido récords en el benchmark de tareas informáticas OSWorld. Las nuevas características incluyen la función de retroceso “checkpoint” de Claude Code, un plugin para VS Code, edición contextual para la API y herramientas de memoria. Además, se ha introducido la función experimental “Imagine with Claude”, que permite generar interfaces de software en tiempo real. Sonnet 4.5 también ha mejorado drásticamente la seguridad, reduciendo comportamientos indeseables como el engaño y la adulación, y ha obtenido la certificación AI safety level 3 (ASL-3), disminuyendo la tasa de falsos positivos en 10 veces. El precio se mantiene igual que Sonnet 4, lo que mejora aún más la relación calidad-precio y se espera que desencadene una nueva ronda de competencia en la programación con IA. (Fuente: Reddit r/ClaudeAI, 36氪, 36氪, 36氪, 36氪, 36氪, Reddit r/ChatGPT, dotey, dotey, dotey)

DeepSeek-V3.2-Exp lanzado, introduce el mecanismo de atención dispersa DSA y reduce precios: DeepSeek ha lanzado el modelo experimental V3.2-Exp, que introduce el mecanismo de atención dispersa DeepSeek Sparse Attention (DSA), mejorando significativamente la eficiencia de entrenamiento e inferencia de contextos largos, al tiempo que reduce los precios de la API en más del 50%. DSA utiliza un “indexador relámpago” para identificar eficientemente los Token clave para cálculos precisos, reduciendo la complejidad de la atención de O(L²) a O(Lk). Fabricantes de chips de IA chinos como Huawei Ascend, Cambricon y Hygon han logrado la adaptación “Day 0”, impulsando aún más el desarrollo del ecosistema de computación nacional. El modelo también ha liberado operadores GPU en versión TileLang, que compiten con NVIDIA CUDA, facilitando a los desarrolladores la creación de prototipos y la depuración. Aunque ha habido algunas concesiones en ciertas capacidades, su innovación arquitectónica y rentabilidad señalan una nueva dirección para el procesamiento de texto largo en modelos grandes. (Fuente: 36氪, 36氪, 36氪, 量子位, 量子位, 量子位, Reddit r/LocalLLaMA, Twitter)

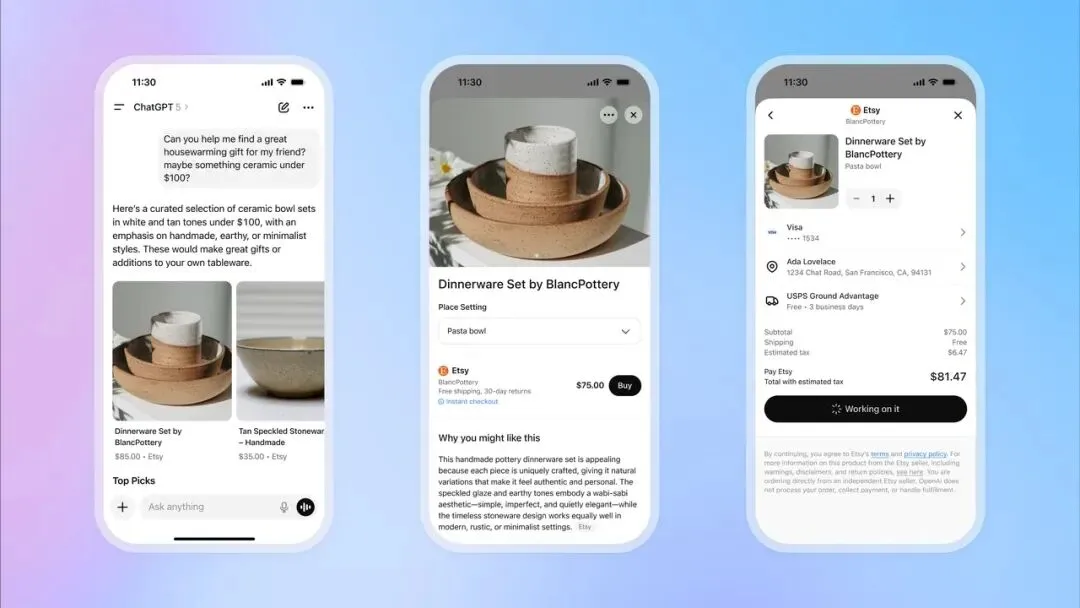
OpenAI lanza la función de pago instantáneo en ChatGPT, entrando en el comercio electrónico: OpenAI ha lanzado la función “Instant Checkout” en ChatGPT, permitiendo a los usuarios comprar productos directamente de las plataformas Etsy y Shopify dentro de la conversación, sin necesidad de redirigir a sitios web externos. Esta función se basa en el “Agentic Commerce Protocol” desarrollado por OpenAI en colaboración con Stripe, y ha sido de código abierto, con el objetivo de convertir el enorme tráfico de ChatGPT en transacciones comerciales. Inicialmente, es compatible con el mercado estadounidense y planea expandirse a carritos de compras con múltiples productos y más regiones en el futuro. Este movimiento se considera un gran paso en la comercialización de OpenAI, con el potencial de convertirse en una importante fuente de ingresos y tener un profundo impacto en el comercio electrónico tradicional y la industria publicitaria. (Fuente: 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Twitter, Twitter, Twitter, Twitter)
OpenAI se prepara para lanzar la aplicación social Sora 2, creando una plataforma de videos cortos con IA: OpenAI se está preparando para lanzar una aplicación social independiente impulsada por su último modelo de video, Sora 2. La aplicación está diseñada para ser muy similar a TikTok, con un feed de video vertical y navegación por deslizamiento, pero todo el contenido será generado por IA. Los usuarios podrán generar clips de video de hasta 10 segundos y usar sus propios retratos en los videos mediante una función de autenticación de identidad. Este movimiento tiene como objetivo replicar el éxito de ChatGPT en el ámbito del texto, permitiendo al público experimentar directamente el potencial del video con IA y entrar directamente en la competencia con Meta y Google. Sin embargo, la estrategia de OpenAI de “usar contenido con derechos de autor por defecto, a menos que el titular de los derechos opte por no participar” ha generado una fuerte preocupación entre los creadores de contenido y las compañías cinematográficas, lo que presagia una intensa batalla entre la IA y la propiedad intelectual. (Fuente: 36氪, Reddit r/artificial, Twitter, Twitter)

🎯 Tendencias
El modelo Pangu 718B de Huawei ocupa el segundo lugar en la lista de modelos grandes de IA en chino de SuperCLUE: El modelo openPangu-Ultra-MoE-718B de Huawei se ha clasificado en segundo lugar en la lista de código abierto del benchmark general de modelos grandes de IA en chino de SuperCLUE. Este modelo adopta una filosofía de entrenamiento de “pensar en lugar de acumular datos”, utilizando principios de construcción de datos de “calidad primero, cobertura de diversidad, adaptación a la complejidad” y una estrategia de preentrenamiento en tres etapas (general, inferencia, recocido) para construir un amplio conocimiento del mundo y mejorar las capacidades de razonamiento lógico. Para mitigar el problema de las alucinaciones, se introduce un mecanismo de “crítica e internalización”; para mejorar la capacidad de uso de herramientas, se emplea un marco de síntesis ToolACE mejorado. (Fuente: 量子位)

FSDrive unifica VLA y modelos del mundo, impulsando la conducción autónoma hacia el razonamiento visual: FSDrive (FutureSightDrive) propone un “CoT visual espacio-temporal” que, mediante la unificación de futuros fotogramas de imagen como pasos de razonamiento intermedios, combina escenas futuras con resultados de percepción para el razonamiento visual, impulsando así la conducción autónoma del razonamiento simbólico al razonamiento visual. Este método, sin modificar la arquitectura MLLM existente, activa la capacidad de generación de imágenes mediante la expansión del vocabulario y la generación visual autorregresiva, e inyecta priors físicos con un CoT visual progresivo. El modelo actúa tanto como “modelo del mundo” para predecir el futuro como “modelo de dinámica inversa” para la planificación de trayectorias. (Fuente: 36氪)

GPT-5 proporciona ideas clave para la computación cuántica, elogiado por el experto Scott Aaronson: Scott Aaronson, una autoridad en la teoría de la computación cuántica, reveló que GPT-5 le proporcionó ideas clave para una prueba en su investigación sobre la teoría de la complejidad cuántica en menos de media hora, resolviendo un problema que había estado molestando a su equipo. Scott Aaronson afirmó que GPT-5 ha logrado un progreso significativo en la superación de las actividades intelectuales más humanas, lo que marca un “momento dulce” en la colaboración entre humanos e IA, capaz de proporcionar inspiración innovadora a los investigadores en momentos críticos. (Fuente: 量子位, Twitter)

HuggingFace acelera la inferencia del modelo Qwen3-8B Agent en Intel Core Ultra: HuggingFace, en colaboración con Intel, ha logrado acelerar la velocidad de inferencia del modelo Qwen3-8B Agent en la GPU integrada Intel Core Ultra en 1.4 veces, utilizando OpenVINO.GenAI y un modelo de borrador Qwen3-0.6B con “depth-pruned”. Esta optimización hace que la ejecución de aplicaciones Agent con Qwen3-8B sea más eficiente en AI PC, especialmente para flujos de trabajo complejos que requieren inferencia en múltiples pasos y llamadas a herramientas, impulsando aún más la practicidad de los AI Agent locales. (Fuente: HuggingFace Blog)

El robot Reachy Mini integra GPT-4o, logrando una interacción multimodal: El robot Reachy Mini de Hugging Face / Pollen Robotics ha integrado con éxito el modelo GPT-4o de OpenAI, logrando una mejora significativa en las capacidades de interacción multimodal. Las nuevas funciones incluyen análisis de imágenes (el robot puede describir y razonar sobre las fotos tomadas), seguimiento facial (mantener el contacto visual), fusión de movimientos (movimiento de cabeza, seguimiento facial, emociones/danza funcionando simultáneamente), reconocimiento facial local y comportamientos autónomos cuando está inactivo. Estos avances hacen que la interacción humano-máquina sea más natural y fluida, pero aún enfrentan desafíos como el sistema de memoria, el reconocimiento de voz y las estrategias para multitudes complejas. (Fuente: Reddit r/ChatGPT, Twitter)

Intel lanza la nueva versión Beta de LLM Scaler, compatible con GenAI en GPU Battlemage: Intel ha lanzado la nueva versión Beta de LLM Scaler, diseñada para optimizar el rendimiento de la IA generativa (GenAI) en las GPU Battlemage. Este movimiento presagia la continua inversión de Intel en hardware y software de IA para mejorar la competitividad de sus GPU en tareas de inferencia y generación de modelos de lenguaje grandes. (Fuente: Reddit r/artificial)
Claude lanza panel de control de límites de uso, ChatGPT estrena función de control parental: Anthropic ha lanzado un panel de control de límites de uso en tiempo real para Claude Code y Claude App, permitiendo a los usuarios rastrear su consumo de Token para cumplir con los límites de tasa semanales previamente anunciados. Al mismo tiempo, OpenAI ha introducido una función de control parental en ChatGPT, que permite a los padres vincular las cuentas de los adolescentes, proporcionando automáticamente una protección de seguridad más sólida y la capacidad de ajustar funciones y establecer límites de uso, aunque los padres no pueden ver el contenido específico de las conversaciones. (Fuente: Reddit r/ClaudeAI, 36氪)
Modelo de lenguaje de 5 millones de parámetros ejecutándose en Minecraft, mostrando aplicaciones innovadoras de IA: Sammyuri ha construido un complejo sistema de Redstone en Minecraft que ejecuta con éxito un modelo de lenguaje de aproximadamente 5 millones de parámetros, dotándolo de capacidades básicas de conversación. Este avance demuestra la posibilidad de implementar IA local en entornos de juego y ha generado una amplia atención y discusión en la comunidad sobre las aplicaciones de la IA en plataformas no tradicionales. (Fuente: Reddit r/LocalLLaMA, Twitter)
Los servidores de IA de Inspur logran una velocidad de inferencia de 8.9ms, con un costo de 1 yuan por millón de Token: Inspur ha lanzado los servidores de IA ultra-escalables Yuan Nao HC1000 y los supernodos Yuan Nao SD200, elevando la velocidad de inferencia de IA a un nuevo récord. El Yuan Nao SD200 logra un tiempo de salida por Token (TPOT) de 8.9ms en el modelo DeepSeek-R1, casi el doble que el SOTA anterior, y soporta inferencia de modelos grandes de billones de parámetros y colaboración multi-agente en tiempo real. El Yuan Nao HC1000 reduce el costo de salida por millón de Token a 1 yuan, y el costo por tarjeta en un 60%. Estos avances tienen como objetivo resolver los cuellos de botella de velocidad y costo que enfrenta la industrialización de los agentes, proporcionando una infraestructura de computación eficiente y de bajo costo para la implementación a gran escala de la colaboración multi-agente y el razonamiento de tareas complejas. (Fuente: 量子位)

Nuevo método de 3D Gaussian Splatting feedforward: el equipo de la Universidad de Zhejiang propone “voxel-aligned”: El equipo de la Universidad de Zhejiang ha propuesto VolSplat, un marco de 3D Gaussian Splatting (3DGS) feedforward “voxel-aligned”, con el objetivo de resolver los cuellos de botella de consistencia geométrica y asignación de densidad gaussiana en la reconstrucción 3D multi-vista de los métodos “pixel-aligned” existentes. VolSplat fusiona información 2D multi-vista en el espacio 3D y utiliza una Sparse 3D U-Net para refinar las características, logrando una reconstrucción 3D de mayor calidad, más robusta y eficiente. Este método supera a varias líneas base en conjuntos de datos públicos y demuestra una fuerte capacidad de generalización de cero-shot en conjuntos de datos no vistos. (Fuente: 量子位)

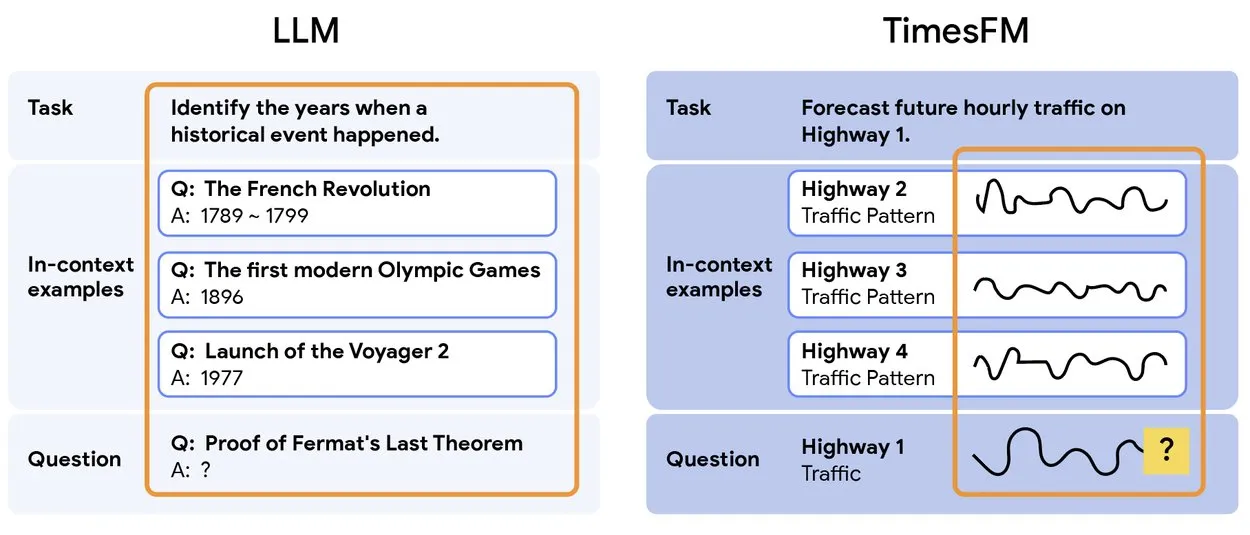
TimesFM 2.5: Lanzamiento del modelo preentrenado de predicción de series temporales: Se ha lanzado TimesFM 2.5, un modelo preentrenado para la predicción de series temporales, con un número de parámetros reducido de 500M a 200M, una longitud de contexto aumentada de 2K a 16K, y un rendimiento excepcional en configuraciones de cero-shot. El modelo ya está disponible en Hugging Face y bajo licencia Apache 2.0, proporcionando una solución más eficiente y potente para tareas de predicción de series temporales. (Fuente: Twitter)
Yunpeng Technology lanza nuevos productos AI+Salud, impulsando la aplicación de la IA en el ámbito de la salud familiar: Yunpeng Technology, en colaboración con Shuaikang y Skyworth, ha lanzado el “Laboratorio de Cocina del Futuro Digital e Inteligente” y un refrigerador inteligente equipado con un modelo grande de IA para la salud. El modelo grande de IA para la salud optimiza el diseño y la operación de la cocina, mientras que el refrigerador inteligente proporciona gestión de salud personalizada a través del “Asistente de Salud Xiaoyun”. Este lanzamiento marca un avance de la IA en el campo de la gestión de la salud diaria, con el potencial de ofrecer servicios de salud personalizados a través de dispositivos inteligentes y mejorar el nivel de tecnología de salud en el hogar. (Fuente: 36氪)
Alibaba lanza el modelo de pensamiento de código abierto de 1 billón de parámetros Ring-1T-preview: El equipo Ant Ling de Alibaba ha lanzado el primer modelo de pensamiento de código abierto de 1 billón de parámetros, Ring-1T-preview, con el objetivo de lograr “pensamiento profundo, sin esperas”. Este modelo ha logrado excelentes resultados iniciales en tareas de procesamiento de lenguaje natural, incluyendo los benchmarks AIME25, HMMT25, ARC-AGI-1, LCB y Codeforces. Además, resolvió el problema Q3 de IMO25 de una sola vez y proporcionó soluciones parciales para Q1/Q2/Q4/Q5, demostrando sus potentes capacidades de razonamiento y resolución de problemas. (Fuente: Twitter, Twitter, Twitter)

🧰 Herramientas
PopAi lanza “Slide Agent”, IA para generar presentaciones con un clic: El equipo de PopAi ha lanzado la herramienta “Slide Agent”, diseñada para simplificar el proceso de creación de presentaciones. Los usuarios solo necesitan introducir sus requisitos a través de un Prompt, elegir entre más de 300 plantillas, y la IA generará automáticamente un borrador, ajustará el diseño, gráficos, imágenes, logotipos y otros formatos, para finalmente descargarlo como un archivo .pptx editable. Esta herramienta integra las funciones de ChatGPT y Canva, reduciendo drásticamente el umbral y el tiempo de creación de presentaciones. (Fuente: Twitter)
Alibaba lanza la herramienta de código abierto PDF a Markdown Miner U2.5: El equipo de Alibaba ha lanzado la herramienta de código abierto PDF a Markdown Miner U2.5, con una demostración ya disponible en HuggingFace. Esta herramienta puede convertir eficientemente documentos PDF a formato Markdown, facilitando a los usuarios la extracción, edición y reutilización de contenido. Es una herramienta práctica asistida por IA para desarrolladores e investigadores que necesitan procesar grandes volúmenes de documentos PDF. (Fuente: dotey)
VEED Animate 2.2 lanzado, soporta la remodelación de estilos de video e intercambio de personajes: La versión 2.2 de VEED Animate ha sido lanzada oficialmente, impulsada por la tecnología WAN 2.2. Esta herramienta permite a los usuarios remodelar fácilmente el estilo de un video con una sola imagen, intercambiar instantáneamente personajes en un video y crear clips de video 10 veces más rápido. Estas nuevas funciones simplifican enormemente el proceso de creación de video, ofreciendo a los creadores de contenido más posibilidades creativas impulsadas por la IA. (Fuente: TomLikesRobots)
LangChain se enfoca en la estandarización de respuestas LLM, soportando funciones complejas: LangChain, en su desarrollo de v1, se ha centrado en estandarizar las respuestas de los LLM para abordar la complejidad creciente de las funciones de los LLM, como las llamadas a herramientas del lado del servidor, la inferencia y las referencias. El marco tiene como objetivo resolver los problemas de incompatibilidad de formato de API entre diferentes proveedores de LLM, proporcionando una interfaz unificada para los desarrolladores, simplificando así la construcción de agentes multimodales y flujos de trabajo complejos. (Fuente: LangChainAI, Twitter)
Hugging Face Transformers.js permite ejecutar modelos de IA sin conexión en el navegador: La biblioteca Transformers.js de Hugging Face permite a los usuarios ejecutar modelos de IA como Llama 3.2 sin conexión en el navegador, utilizando tecnologías ONNX y WebGPU. Esto permite a los desarrolladores realizar tareas de IA como chatbots, detección de objetos y eliminación de fondos localmente, sin depender de servicios en la nube, lo que mejora la privacidad de los datos y la velocidad de procesamiento. (Fuente: Twitter)
El ecosistema ToolUniverse ayuda a los científicos de IA a construir e integrar herramientas: ToolUniverse es un ecosistema diseñado para construir científicos de IA, que estandariza la forma en que los científicos de IA identifican y llaman a las herramientas, integrando más de 600 modelos de Machine Learning, conjuntos de datos, API y paquetes de software científico para análisis de datos, recuperación de conocimiento y diseño experimental. La plataforma optimiza automáticamente las interfaces de las herramientas, crea nuevas herramientas a partir de descripciones en lenguaje natural e itera para optimizar las especificaciones de las herramientas, combinándolas en flujos de trabajo de agentes, impulsando así la colaboración de los científicos de IA en el proceso de descubrimiento. (Fuente: HuggingFace Daily Papers)
El marco EasySteer mejora el rendimiento y la escalabilidad de la manipulación de LLM: EasySteer es un marco unificado basado en vLLM, diseñado para mejorar el rendimiento y la escalabilidad de la manipulación de LLM. A través de una arquitectura modular, interfaces conectables, control de parámetros de grano fino y vectores de manipulación precalculados, logra una mejora de velocidad de 5.5 a 11.4 veces y reduce eficazmente el “overthinking” y las alucinaciones. EasySteer transforma la manipulación de LLM de una técnica de investigación a una capacidad de nivel de producción, proporcionando una infraestructura clave para modelos de lenguaje desplegables y controlables. (Fuente: HuggingFace Daily Papers)
VibeGame: un motor de juegos asistido por IA basado en WebStack: VibeGame es un motor de juegos declarativo avanzado construido con three.js, rapier y bitecs, diseñado específicamente para el desarrollo de juegos asistido por IA. A través de un alto nivel de abstracción, funciones integradas de física y renderizado, y una arquitectura Entity-Component-System (ECS), permite a la IA comprender y generar código de juego de manera más eficiente. Aunque actualmente es más adecuado para juegos de plataformas simples, su código abierto y sintaxis amigable con la IA ofrecen una solución prometedora para el desarrollo de juegos impulsado por IA. (Fuente: HuggingFace Blog)
Herramienta de mapa de investigación de IA, integra 900 mil artículos y proporciona respuestas con citas: Una innovadora herramienta de IA agrupa semánticamente y visualiza 900 mil artículos de investigación de IA de la última década, formando un mapa de investigación detallado. Los usuarios pueden hacer preguntas a la herramienta y obtener respuestas con citas precisas, lo que simplifica enormemente el proceso de búsqueda y comprensión de la vasta literatura académica para los investigadores, mejorando la eficiencia de la investigación. (Fuente: Reddit r/ArtificialInteligence)
Kroko ASR: una alternativa rápida y de streaming a Whisper: Kroko ASR es un nuevo modelo de código abierto de voz a texto, posicionado como una alternativa rápida y de streaming a Whisper. Tiene un tamaño de modelo más pequeño, una velocidad de inferencia en CPU más rápida (compatible con dispositivos móviles y navegadores), y casi no presenta alucinaciones. Kroko ASR es compatible con varios idiomas y tiene como objetivo reducir la barrera de entrada a la IA de voz, haciéndola más fácil de implementar y entrenar en dispositivos de borde. (Fuente: Reddit r/LocalLLaMA)
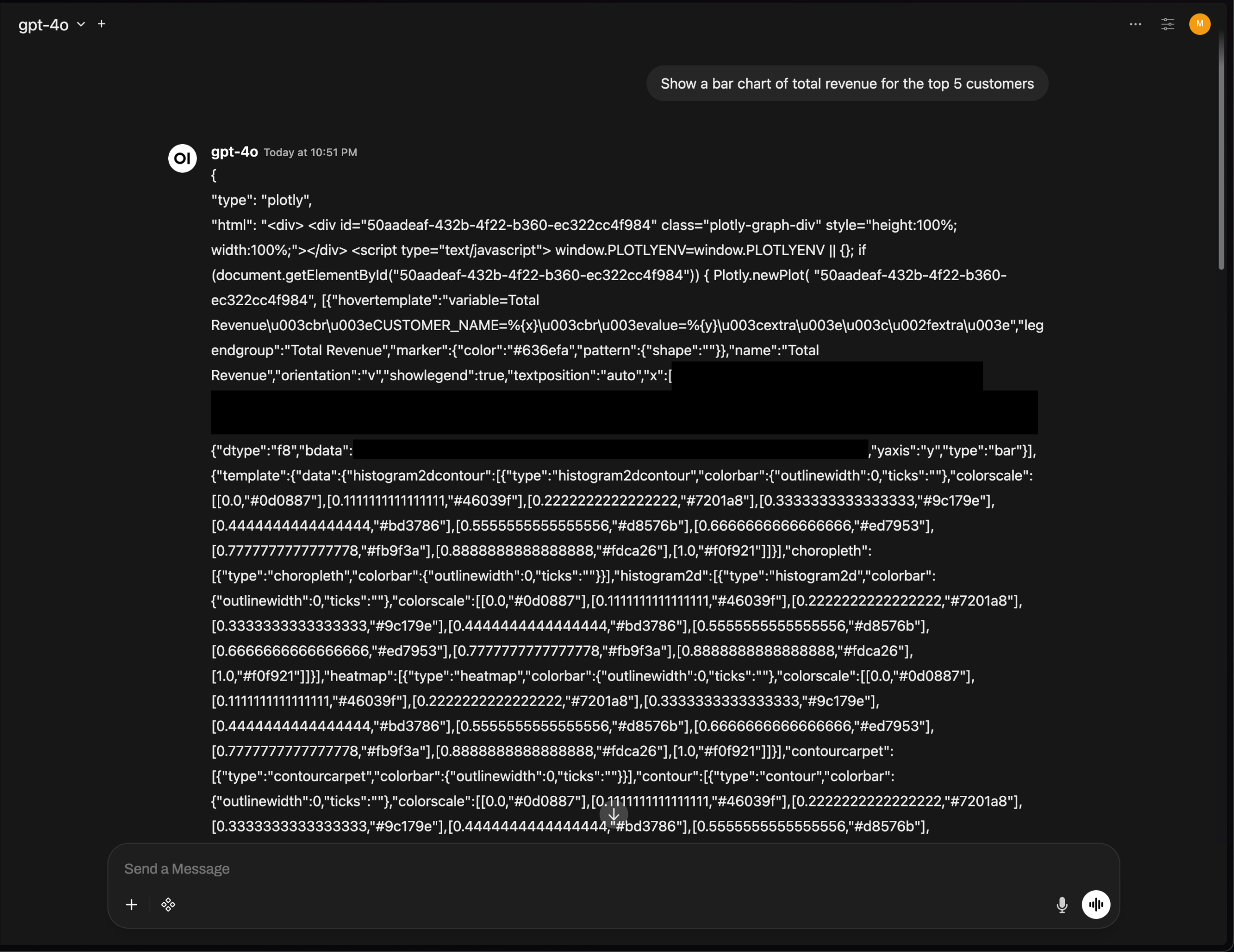
Problema de renderizado de gráficos Plotly en OpenWebUI, destaca desafíos de integración de UI de herramientas de IA: La versión v0.6.32 de OpenWebUI presenta un problema en el que los gráficos Plotly no se renderizan correctamente, sino que muestran directamente el JSON original. Los usuarios informan que el backend devuelve el JSON correcto, pero el frontend no activa el renderizado, lo que refleja que las herramientas de IA aún enfrentan desafíos técnicos en la integración de la UI del frontend y el renderizado de texto enriquecido, lo que requiere una mayor optimización por parte de la comunidad de desarrolladores. (Fuente: Reddit r/OpenWebUI)
📚 Aprendizaje
Estudio comparativo de rendimiento entre LoRA finetuning y full finetuning: Una investigación reciente de Thinking Machines (equipo de John Schulman) indica que, en el aprendizaje por refuerzo, si LoRA (Low-Rank Adaptation) se aplica correctamente, su rendimiento puede igualar al de full finetuning, con un menor consumo de recursos (aproximadamente 2/3 de la computación), incluso con rank=1. El estudio enfatiza que LoRA debe aplicarse a todas las capas (incluyendo MLP/MoE) y utilizar una tasa de aprendizaje 10 veces mayor que el full finetuning. Este hallazgo reduce drásticamente la barrera para entrenar modelos RL de alto rendimiento, permitiendo a más desarrolladores lograr modelos de alta calidad con una sola GPU. (Fuente: Reddit r/LocalLLaMA, Twitter, Twitter)
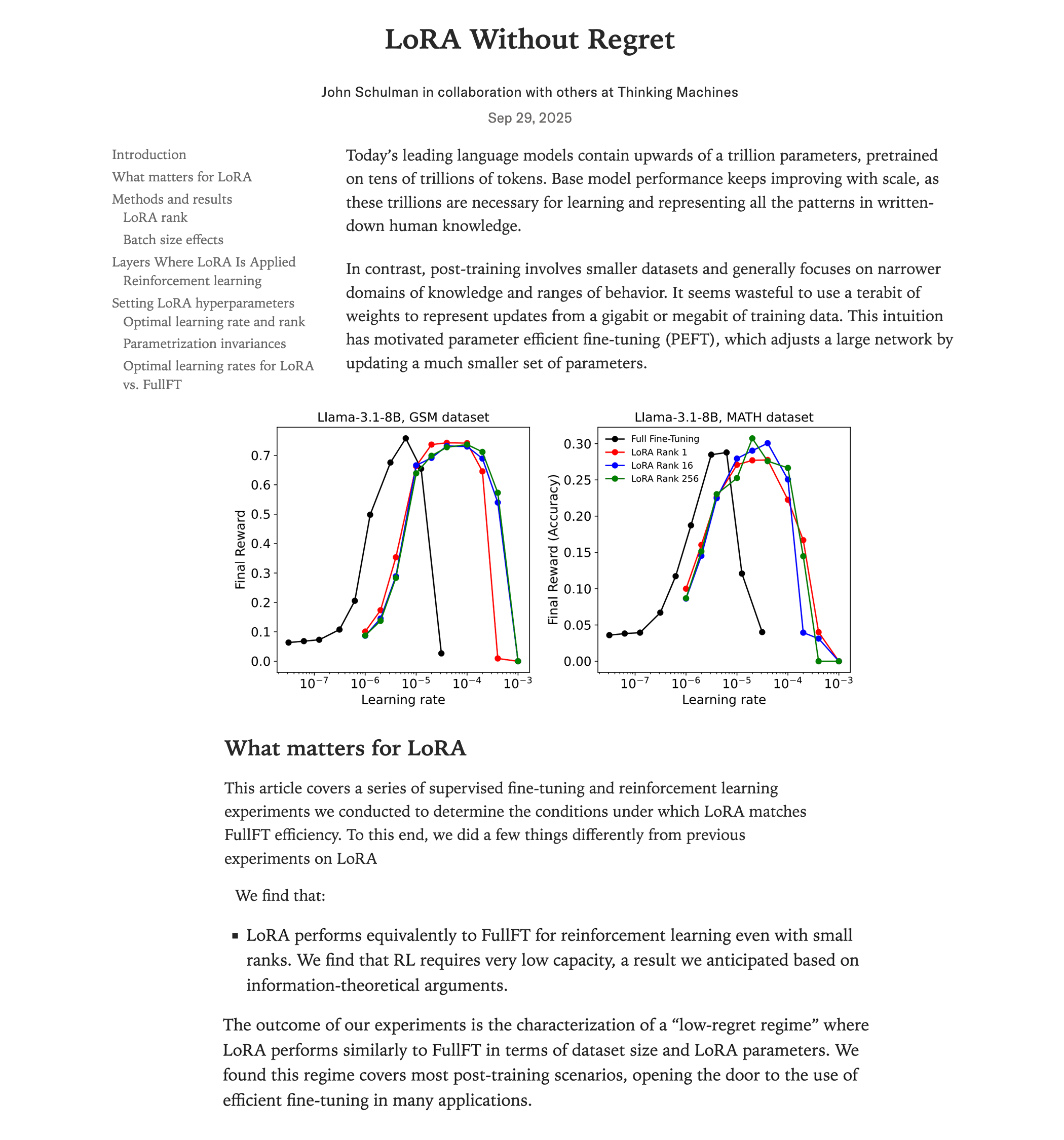
Anatomía de los núcleos de multiplicación de matrices de alto rendimiento en GPU NVIDIA: Un blog técnico detallado disecciona el mecanismo de implementación de los núcleos de multiplicación de matrices (matmul) de alto rendimiento dentro de las GPU NVIDIA. El artículo cubre los fundamentos de la arquitectura de GPU, la jerarquía de memoria (GMEM, SMEM, L1/L2), la programación PTX/SASS, y características avanzadas de la arquitectura Hopper (H100) como TMA e instrucciones wgmma. Este recurso tiene como objetivo ayudar a los desarrolladores a comprender en profundidad la programación CUDA y la optimización del rendimiento de la GPU, lo cual es crucial para el entrenamiento y la inferencia de modelos Transformer. (Fuente: Reddit r/deeplearning, Twitter)
Las conferencias del curso de Visión por Computadora y Deep Learning CS231N de Stanford ya están disponibles en YouTube: Las aclamadas conferencias del curso CS231N (Deep Learning para Visión por Computadora) de la Universidad de Stanford ya están disponibles de forma gratuita en YouTube. Esto ofrece a los estudiantes de todo el mundo una valiosa oportunidad de acceder a recursos educativos de IA de alta calidad, cubriendo conocimientos de deep learning para visión por computadora desde conceptos básicos hasta aplicaciones de vanguardia. (Fuente: Reddit r/deeplearning)

RL-ZVP: Mejorando las capacidades de razonamiento de LLM en aprendizaje por refuerzo con Zero-Variance Prompts: Una investigación reciente propone el método “RL with Zero-Variance Prompts (RL-ZVP)” para mejorar las capacidades de razonamiento de modelos de lenguaje grandes (LLM) en el aprendizaje por refuerzo. Este método ya no ignora los “Zero-Variance Prompts” (situaciones en las que todas las respuestas del modelo obtienen la misma recompensa), sino que extrae señales de aprendizaje valiosas de ellos, recompensando directamente la corrección y castigando los errores, y utilizando la entropía a nivel de Token para guiar la conformación de ventajas. Los resultados experimentales muestran que RL-ZVP mejora significativamente la precisión y la tasa de éxito en los benchmarks de razonamiento matemático en comparación con los métodos tradicionales. (Fuente: Reddit r/MachineLearning)
Aprendizaje guiado por el futuro: un enfoque predictivo para mejorar la predicción de series temporales: Un estudio propone el “Aprendizaje Guiado por el Futuro” (Future-Guided Learning), que mejora la predicción de eventos en series temporales mediante un mecanismo de retroalimentación dinámica. Este método incluye un modelo de detección que analiza datos futuros y un modelo de predicción que realiza pronósticos basados en datos actuales. Cuando el modelo de predicción difiere del modelo de detección, el modelo de predicción se actualiza de manera más significativa para minimizar la “sorpresa”, ajustando dinámicamente los parámetros y mejorando eficazmente la precisión de la predicción de series temporales. (Fuente: Reddit r/MachineLearning)
El futuro de la IA en bajas dimensiones: Yann Lecun sobre el aprendizaje de representaciones abstractas: El pionero de la IA Yann Lecun, en una entrevista con Lex Fridman, propuso que el próximo salto de la IA provendrá del aprendizaje en espacios latentes de baja dimensión, en lugar de procesar directamente datos crudos de alta dimensión como los píxeles. Él cree que los sistemas inteligentes verdaderos necesitan aprender la estructura causal y las dinámicas físicas del mundo a través de representaciones abstractas, lo que les permitiría hacer predicciones precisas incluso cuando los detalles cambian. Este enfoque hará que los modelos sean más flexibles, robustos, reducirá la dependencia de grandes volúmenes de datos y disminuirá los costos computacionales. (Fuente: Reddit r/ArtificialInteligence)
SIRI: Escalando el aprendizaje por refuerzo iterativo con compresión intercalada: SIRI (Scaling Iterative Reinforcement Learning with Interleaved Compression) es un método de aprendizaje por refuerzo simple y efectivo que ajusta dinámicamente la longitud máxima de rollout durante el entrenamiento, comprimiendo y expandiendo iterativamente el presupuesto de inferencia. Este mecanismo de entrenamiento obliga al modelo a tomar decisiones precisas en un contexto limitado, reduciendo los Token redundantes, al tiempo que proporciona espacio para la exploración y la planificación, mejorando así constantemente la eficiencia y precisión de los modelos de inferencia grandes en la compensación rendimiento-eficiencia. (Fuente: HuggingFace Daily Papers)
MultiCrafter: Modelo generativo multi-agente con atención espacialmente desacoplada y aprendizaje por refuerzo consciente de la identidad: MultiCrafter es un marco diseñado para lograr una generación de imágenes multi-agente de alta fidelidad y alineada con las preferencias. Introduce una supervisión de posición explícita para separar las regiones de atención entre diferentes sujetos, mitigando eficazmente el problema de la fuga de atributos. Al mismo tiempo, el marco utiliza una arquitectura Mixture of Experts (MoE) para mejorar la capacidad del modelo y diseña un novedoso marco de aprendizaje por refuerzo en línea, que combina un mecanismo de puntuación y estrategias de entrenamiento estables, asegurando que la fidelidad del sujeto de las imágenes generadas esté altamente alineada con las preferencias estéticas humanas. (Fuente: HuggingFace Daily Papers)
Visual Jigsaw: Mejorando la comprensión visual de MLLM mediante post-entrenamiento auto-supervisado: Visual Jigsaw es un marco general de post-entrenamiento auto-supervisado diseñado para mejorar las capacidades de comprensión visual de los modelos de lenguaje grandes multimodales (MLLM). Este método particiona y desordena la entrada visual, y requiere que el modelo reconstruya el orden correcto de las permutaciones mediante lenguaje natural. Este enfoque de aprendizaje por refuerzo basado en recompensas verificables (RLVR) no requiere componentes de generación visual adicionales ni anotaciones manuales, y puede mejorar significativamente el rendimiento de los MLLM en percepción de grano fino, razonamiento temporal y comprensión espacial 3D. (Fuente: HuggingFace Daily Papers)
MGM-Omni: Escalando Omni LLM para la generación de voz personalizada de larga duración: MGM-Omni es un Omni LLM unificado que, a través de su arquitectura única de Tokenization de doble vía “cerebro-boca”, logra una comprensión multimodal y una generación de voz expresiva de larga duración. Este diseño desacopla el razonamiento multimodal de la generación de voz en tiempo real, soportando una interacción intermodal eficiente y una clonación de voz en streaming de baja latencia, y demostrando una excelente eficiencia de datos. Los experimentos muestran que MGM-Omni supera a los modelos de código abierto existentes en la consistencia del timbre, la generación de voz natural consciente del contexto, y la comprensión de audio de larga duración y multimodal. (Fuente: HuggingFace Daily Papers)
SID: Aprendizaje de navegación lingüística orientada a objetivos mediante demostraciones auto-mejoradas: SID (Self-Improving Demonstrations) es un método de aprendizaje de navegación lingüística orientada a objetivos que mejora significativamente la capacidad de exploración y la generalización de los agentes de navegación en entornos desconocidos mediante demostraciones auto-mejoradas iterativas. Este método primero entrena un agente inicial utilizando datos de ruta más corta, y luego el agente genera nuevas trayectorias de exploración que proporcionan estrategias de exploración más fuertes para entrenar un agente mejor, logrando así una mejora continua del rendimiento. Los experimentos muestran que SID logra un rendimiento SOTA en tareas como REVERIE y SOON, con una tasa de éxito del 50.9% en el conjunto de validación no visto de SOON, superando en un 13.9% a los métodos anteriores. (Fuente: HuggingFace Daily Papers)
LOVE-R1: Mejorando la comprensión de videos largos mediante un mecanismo de escalado adaptativo: El modelo LOVE-R1 tiene como objetivo resolver el conflicto entre la comprensión temporal a largo plazo y la percepción espacial detallada en la comprensión de videos largos. Este modelo introduce un mecanismo de escalado adaptativo, que primero muestrea densamente fotogramas de baja resolución, y cuando se necesitan detalles espaciales, el modelo puede escalar a alta resolución los segmentos de video de interés según la inferencia, hasta obtener información visual clave. Todo el proceso se logra mediante inferencia en múltiples pasos, combinado con el ajuste fino de datos CoT y el ajuste fino por refuerzo desacoplado, logrando mejoras significativas en los benchmarks de comprensión de videos largos. (Fuente: HuggingFace Daily Papers)
Euclid’s Gift: Mejorando el razonamiento espacial de modelos de lenguaje visual mediante tareas de agente geométrico: Euclid’s Gift es una investigación que mejora las capacidades de percepción y razonamiento espacial de los modelos de lenguaje visual (VLM) a través de tareas de agente geométrico. Este proyecto construye Euclid30K, un conjunto de datos multimodal que contiene 30K problemas de geometría plana y sólida, y utiliza Group Relative Policy Optimization (GRPO) para ajustar los modelos de la serie Qwen2.5VL y RoboBrain2.0. Los experimentos demuestran que los modelos entrenados logran mejoras significativas de cero-shot en cuatro benchmarks de razonamiento espacial, incluyendo Super-CLEVR y Omni3DBench, con RoboBrain2.0-Euclid-7B alcanzando una precisión del 49.6%, superando a los modelos SOTA anteriores. (Fuente: HuggingFace Daily Papers)
SphereAR: Mejorando la generación autorregresiva de Token continuos a través del espacio latente hiperesférico: SphereAR tiene como objetivo resolver los problemas causados por la varianza heterogénea del espacio latente VAE en los modelos de generación de imágenes autorregresivos (AR) de Token continuos. El diseño central es restringir todas las entradas y salidas AR (incluyendo después de CFG) a una hiperesfera de radio fijo, utilizando un VAE hiperesférico. El análisis teórico muestra que la restricción hiperesférica elimina la causa principal del colapso de la varianza, estabilizando así la decodificación AR. Los experimentos demuestran que SphereAR logra un rendimiento SOTA en tareas de generación de ImageNet, superando a los modelos de difusión y modelos de generación enmascarada de escala de parámetros equivalente. (Fuente: HuggingFace Daily Papers)
AceSearcher: Guiando el razonamiento y la búsqueda de LLM a través del auto-juego por refuerzo: AceSearcher es un marco de auto-juego cooperativo diseñado para mejorar la capacidad de búsqueda aumentada de LLM en tareas de razonamiento complejas. Este marco entrena un solo LLM para alternar entre la descomposición de consultas complejas y la integración del contexto recuperado, optimizando la precisión de la respuesta final a través de ajuste fino supervisado y ajuste fino por refuerzo, sin necesidad de anotaciones intermedias. Los experimentos muestran que AceSearcher supera significativamente las líneas base SOTA en varias tareas intensivas en razonamiento; en tareas de razonamiento financiero a nivel de documento, AceSearcher-32B iguala el rendimiento de DeepSeek-V3 con menos del 5% de los parámetros. (Fuente: HuggingFace Daily Papers)
SparseD: Mecanismo de atención dispersa para modelos de lenguaje de difusión: SparseD es un método de atención dispersa para modelos de lenguaje de difusión (DLM), diseñado para resolver el cuello de botella de la complejidad cuadrática del cálculo de atención en contextos largos. Este método precalcula patrones dispersos específicos de la cabeza y los reutiliza en todos los pasos de denoising, utilizando atención completa en los primeros pasos de denoising y luego cambiando a atención dispersa, logrando así una aceleración sin pérdidas. Los resultados experimentales muestran que SparseD puede lograr una mejora de velocidad de hasta 1.5 veces en contextos de 64k en comparación con FlashAttention, mejorando eficazmente la eficiencia de inferencia de los DLM en aplicaciones de contexto largo. (Fuente: HuggingFace Daily Papers)
SLA: Acelerando Diffusion Transformer con atención lineal dispersa sintonizable: SLA (Sparse-Linear Attention) es un método de atención entrenable diseñado para acelerar los modelos Diffusion Transformer (DiT), especialmente en el cálculo de atención en la generación de video. Este método divide los pesos de atención en tres categorías: clave, borde e insignificante, aplicando atención O(N²) y O(N) respectivamente, y saltándose las partes insignificantes. SLA fusiona estos cálculos en un solo núcleo de GPU, y después de unos pocos pasos de ajuste fino, reduce el cálculo de atención en los modelos DiT en 20 veces, acelerando de extremo a extremo la generación de video en 2.2 veces, sin pérdida de calidad de generación. (Fuente: HuggingFace Daily Papers)
OpenGPT-4o-Image: Conjunto de datos completo para generación y edición avanzada de imágenes: OpenGPT-4o-Image es un conjunto de datos a gran escala, construido combinando clasificación de tareas jerárquicas y un método de generación automática de datos GPT-4o, diseñado para mejorar el rendimiento de los modelos multimodales unificados en la generación y edición de imágenes. Este conjunto de datos contiene 80k pares de instrucción-imagen de alta calidad, cubriendo 11 dominios principales y 51 subtareas, incluyendo renderizado de texto, control de estilo, imágenes científicas y edición de instrucciones complejas. Los modelos ajustados en OpenGPT-4o-Image han logrado mejoras significativas de rendimiento en varios benchmarks, demostrando el papel clave de la construcción sistemática de datos para avanzar en las capacidades de la IA multimodal. (Fuente: HuggingFace Daily Papers)
SANA-Video: Un pequeño modelo de difusión para generar videos de 720p de un minuto de manera eficiente: SANA-Video es un pequeño modelo de difusión capaz de generar videos de hasta 720×1280 de resolución y de un minuto de duración de manera eficiente. Logra la generación de videos de alta resolución, alta calidad y larga duración a través de una arquitectura DiT lineal y una caché KV de memoria constante, manteniendo al mismo tiempo una fuerte alineación texto-video. El costo de entrenamiento de SANA-Video es solo el 1% del de MovieGen, y cuando se implementa en una GPU RTX 5090, la velocidad de inferencia para generar un video de 5 segundos a 720p puede alcanzar los 29 segundos, logrando una generación de video de bajo costo y alta calidad. (Fuente: HuggingFace Daily Papers)
AdvChain: Mejora de la alineación de seguridad de modelos de razonamiento grandes mediante ajuste adversarial de CoT: AdvChain es un nuevo paradigma de alineación que, a través del ajuste adversarial de Chain-of-Thought (CoT), enseña a los modelos de razonamiento grandes (LRM) la capacidad de auto-corrección dinámica. Este método construye un conjunto de datos que contiene ejemplos de “tentación-corrección” y “vacilación-corrección”, permitiendo al modelo aprender a recuperarse de desviaciones de razonamiento dañinas y de una cautela innecesaria. Los experimentos muestran que AdvChain mejora significativamente la robustez del modelo contra ataques de jailbreak y secuestro de CoT, al tiempo que reduce drásticamente el rechazo excesivo de Prompts benignos, logrando un equilibrio superior entre seguridad y utilidad. (Fuente: HuggingFace Daily Papers)
SDLM: Escalando el aprendizaje por refuerzo iterativo con compresión intercalada: Sequential Diffusion Language Model (SDLM) propone un método unificado de predicción de next-token y next-block, que permite al modelo determinar adaptativamente la longitud de generación en cada paso. SDLM puede transformar modelos de lenguaje autorregresivos preentrenados con un costo mínimo, y realizar inferencia de difusión dentro de bloques enmascarados de tamaño fijo, mientras decodifica dinámicamente subsecuencias continuas. Los experimentos muestran que SDLM logra un mayor rendimiento al tiempo que iguala o supera las fuertes líneas base autorregresivas, demostrando su potente potencial de escalabilidad. (Fuente: HuggingFace Daily Papers)
Insight-to-Solve (I2S): Transformando demostraciones de razonamiento In-Context en activos de LLM de razonamiento: Insight-to-Solve (I2S) es un programa en tiempo de prueba diseñado para transformar demostraciones de razonamiento In-Context de alta calidad en activos efectivos para modelos de lenguaje grandes de razonamiento (RLM). La investigación encontró que la adición directa de ejemplos de demostración puede reducir la precisión de los RLM. I2S transforma las demostraciones en ideas explícitamente reutilizables y genera trayectorias de razonamiento específicas para el objetivo, con la opción de auto-refinamiento para mejorar la coherencia y la corrección. Los experimentos muestran que I2S e I2S+ superan consistentemente las líneas base de respuesta directa y escalado en tiempo de prueba en varios benchmarks, incluso para modelos GPT, lo que lleva a mejoras significativas. (Fuente: HuggingFace Daily Papers)
UniMIC: Codificación interactiva multimodal basada en Token para la colaboración humano-máquina: UniMIC (Unified token-based Multimodal Interactive Coding) es un marco que tiene como objetivo lograr una interacción multimodal eficiente y de baja tasa de bits entre dispositivos de borde y agentes de IA en la nube, a través de representaciones basadas en Token. UniMIC utiliza una representación Tokenizada compacta como medio de comunicación y combina un modelo de entropía Transformer, reduciendo eficazmente la redundancia entre Token. Los experimentos demuestran que UniMIC logra ahorros significativos en la tasa de bits en tareas como la generación de texto a imagen, la inpainting de imágenes y la respuesta a preguntas visuales, y mantiene la robustez a tasas de bits ultrabajas, proporcionando un paradigma práctico para la próxima generación de comunicación interactiva multimodal. (Fuente: HuggingFace Daily Papers)
RLBFF: Retroalimentación flexible binaria que une la retroalimentación humana con recompensas verificables: RLBFF (Reinforcement Learning with Binary Flexible Feedback) es un paradigma de aprendizaje por refuerzo que combina la diversidad de preferencias humanas con la precisión de la verificación de reglas. Extrae principios de la retroalimentación en lenguaje natural que pueden responderse de forma binaria (por ejemplo, precisión de la información: sí/no, legibilidad del código: sí/no) y utiliza esto para entrenar un modelo de recompensa. RLBFF sobresale en RM-Bench y JudgeBench, y permite a los usuarios personalizar el enfoque de los principios durante la inferencia. Además, ofrece una solución completamente de código abierto para alinear Qwen3-32B con RLBFF, lo que le permite igualar o superar el rendimiento de o3-mini y DeepSeek R1 en benchmarks de alineación general. (Fuente: HuggingFace Daily Papers)
MetaAPO: Optimización de alineación mediante muestreo en línea meta-ponderado: MetaAPO (Meta-Weighted Adaptive Preference Optimization) es un marco novedoso que optimiza la alineación de modelos de lenguaje grandes (LLM) con las preferencias humanas mediante el acoplamiento dinámico de la generación de datos y el entrenamiento del modelo. MetaAPO utiliza un meta-learner ligero como “estimador de la brecha de alineación” para evaluar los beneficios potenciales del muestreo en línea en relación con los datos fuera de línea, guiando la generación en línea de objetivos y asignando meta-pesos a nivel de muestra, equilibrando dinámicamente la calidad y distribución de los datos en línea y fuera de línea. Los experimentos muestran que MetaAPO supera consistentemente los métodos de optimización de preferencias existentes en AlpacaEval 2, Arena-Hard y MT-Bench, al tiempo que reduce los costos de anotación en línea en un 42%. (Fuente: HuggingFace Daily Papers)
Tool-Light: Razonamiento eficiente con integración de herramientas mediante aprendizaje de preferencias auto-evolutivo: Tool-Light es un marco diseñado para alentar a los modelos de lenguaje grandes (LLM) a realizar tareas de razonamiento con integración de herramientas (TIR) de manera eficiente y precisa. La investigación encontró que los resultados de las llamadas a herramientas pueden causar cambios significativos en la entropía de la información de inferencia posterior. Tool-Light se logra combinando la construcción de conjuntos de datos y el ajuste fino en múltiples etapas, donde la construcción de conjuntos de datos utiliza muestreo auto-evolutivo continuo, integrando muestreo vanilla y muestreo guiado por entropía, y estableciendo estrictos criterios de selección de pares positivos y negativos. El proceso de entrenamiento incluye SFT y optimización de preferencias directas auto-evolutivas (DPO). Los experimentos demuestran que Tool-Light mejora significativamente la eficiencia de los modelos en la ejecución de tareas TIR. (Fuente: HuggingFace Daily Papers)
ChatInject: Ataques de inyección de Prompt a agentes LLM utilizando plantillas de chat: ChatInject es un método de ataque de inyección de Prompt indirecto que explota la dependencia de los LLM de las plantillas de chat estructuradas y la manipulación del contexto en conversaciones de múltiples turnos. El atacante formatea una carga maliciosa imitando el formato de la plantilla de chat nativa, induciendo al agente a realizar operaciones sospechosas. Los experimentos muestran que ChatInject tiene una tasa de éxito de ataque más alta que los métodos tradicionales de inyección de Prompt, especialmente en conversaciones de múltiples turnos, y es altamente transferible a diferentes modelos, mientras que las defensas existentes basadas en Prompt son en su mayoría ineficaces contra este tipo de ataques. (Fuente: HuggingFace Daily Papers)
💼 Negocios
Modal cierra una ronda de financiación Serie B de 87 millones de dólares, valorando la empresa en 1.100 millones de dólares: Modal, una empresa de infraestructura de IA, ha anunciado el cierre de una ronda de financiación Serie B de 87 millones de dólares, lo que eleva su valoración a 1.100 millones de dólares. Esta ronda de financiación tiene como objetivo acelerar la innovación y el desarrollo de la infraestructura de IA para abordar los desafíos que enfrenta la infraestructura informática tradicional en la era de la IA. Modal ayuda a investigadores y desarrolladores a optimizar sus procesos de entrenamiento e implementación de modelos de IA al proporcionar servicios de computación en la nube eficientes. (Fuente: Twitter, Twitter, Twitter)
OpenAI reporta ingresos de 4.300 millones de dólares y pérdidas de 13.500 millones de dólares en el primer semestre, enfrentando desafíos de rentabilidad: OpenAI ha anunciado ingresos de 4.300 millones de dólares en el primer semestre de 2025, con una previsión de ingresos anuales que superarán los 13.000 millones de dólares, principalmente gracias a las suscripciones a ChatGPT Plus y los servicios de API empresariales. Sin embargo, durante el mismo período, las pérdidas netas ascendieron a 13.500 millones de dólares, siendo los costos estructurales y la inversión en I+D (como GPT-5) los principales factores, con un costo anual de alquiler de servidores de hasta 16.000 millones de dólares. Aunque OpenAI cuenta con 17.500 millones de dólares en reservas de efectivo y avanza con un plan de financiación de 30.000 millones de dólares, el continuo consumo de efectivo y la brecha de eficiencia con competidores como Anthropic le plantean serios desafíos de rentabilidad. (Fuente: 36氪)
Guerra de capital en el sector de robots humanoides: Zhiyuan, Yinhe General y otros despliegan activamente la cadena industrial: El sector de robots humanoides ha entrado en una fase de guerra de capital, con empresas líderes como Zhiyuan Robotics y Yinhe General expandiendo activamente su “círculo de amigos” a través de la creación de fondos, la inversión en pares y la cooperación estratégica. Zhiyuan Robotics ha realizado casi 20 inversiones externas, cubriendo motores, sensores y aplicaciones downstream, y ha colaborado con Fulim Precision y Softcom Power para implementar escenarios comerciales. Yinhe General, por su parte, ha establecido una empresa conjunta con Bosch China para promover la aplicación de la inteligencia encarnada en la fabricación de automóviles. Estas iniciativas tienen como objetivo obtener pedidos, subsanar deficiencias y establecer una red de suministro estable para futuras entregas a gran escala, pero la industria presenta grandes diferencias en las rutas tecnológicas y una intensa competencia. (Fuente: 36氪)

🌟 Comunidad
La autenticidad del contenido generado por IA es difícil de discernir, lo que provoca una crisis de confianza social: Con el rápido desarrollo de la tecnología de IA, la verosimilitud de los videos generados por IA (como la versión de acción real de “Attack on Titan” o el “cambio de rostro” de un streamer indonesio a un influencer japonés) ha alcanzado un nivel increíble, lo que ha generado una profunda preocupación social sobre la autenticidad del contenido. En las redes sociales, los usuarios generalmente expresan que cada vez es más difícil distinguir entre el contenido real y el generado por IA, lo que no solo socava la credibilidad de los creadores de contenido legítimos, sino que también puede usarse para difundir información falsa. Los expertos señalan que, a menos que se imponga un etiquetado obligatorio del contenido de IA, este “motor hiperrealista” continuará erosionando el sentido de la realidad y, en última instancia, podría “acabar con Internet”. (Fuente: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Twitter, Twitter)

Impacto de la IA en el mercado laboral: el informe de Sequoia afirma que el 95% de la inversión en IA es ineficaz, los recién graduados son los más afectados: Sequoia Capital compartió un informe de investigación del MIT y la Universidad de Harvard que señala que el 95% de la inversión empresarial en IA no ha generado valor real, y que el verdadero aumento de la productividad proviene de una “economía de IA en la sombra” formada por empleados que utilizan “a escondidas” herramientas de IA personales. El informe también revela que el impacto de la IA en el mercado laboral se concentra principalmente en los jóvenes recién graduados, especialmente en el sector minorista y mayorista, donde el número de contrataciones para puestos de nivel inicial ha disminuido significativamente, y los títulos de universidades de prestigio tampoco son una protección completa. Esto indica que la IA está cambiando la asignación de tareas, y el valor humano se está desplazando hacia la experiencia y el juicio único. (Fuente: 36氪, Reddit r/ArtificialInteligence)
Los ajustes del modelo de OpenAI provocan un fuerte descontento entre los usuarios, que piden una comunicación transparente: Los recientes “downgrades” no anunciados de OpenAI de los modelos GPT-4o/GPT-5 a versiones de baja potencia, que han provocado una disminución del rendimiento del modelo, han generado un fuerte descontento entre los usuarios. Muchos usuarios se quejan de que el modelo se ha vuelto “más tonto”, perdiendo su perspicacia original y su experiencia de comunicación “amigable”, e incluso algunos lo califican de “golpe mental”. Los ejecutivos de OpenAI respondieron que se trataba de una “prueba de enrutamiento de seguridad” para manejar temas delicados, pero los usuarios en general piden a OpenAI que mejore la comunicación y la transparencia con ellos, evitando cambios unilaterales en los acuerdos de productos para reconstruir la confianza del usuario. (Fuente: Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, Twitter)
Impuestos a los robots: debate sobre el progreso tecnológico y la equidad social: Con el desarrollo de la IA y la robótica, la discusión sobre la “imposición de impuestos” a los robots es cada vez más frecuente, con el objetivo de equilibrar los problemas de empleo y la desigualdad social que podría generar la sustitución de la mano de obra humana por robots. Los defensores argumentan que un impuesto a los robots podría proporcionar beneficios sociales y apoyo para la reempleabilidad de los desempleados, corrigiendo el desequilibrio de poder de negociación entre el capital y el trabajo. Sin embargo, los profesionales de la industria robótica generalmente creen que es demasiado pronto para imponer impuestos, ya que podría obstaculizar el desarrollo de industrias emergentes. Corea del Sur ya ha aumentado indirectamente el costo del uso de robots al reducir las exenciones fiscales para las empresas de automatización. (Fuente: 36氪)
El futuro de los robots humanoides: el famoso experto en robótica Rodney Brooks cree que no se parecerán a los humanos: El renombrado experto en robótica Rodney Brooks escribió un artículo señalando que, a pesar de las enormes inversiones, los robots humanoides actuales aún no pueden lograr la destreza a nivel humano, y la marcha bípeda presenta riesgos de seguridad. Predice que en los próximos 15 años, los robots humanoides ya no imitarán la forma humana, sino que evolucionarán hacia robots especializados con ruedas, múltiples brazos (equipados con pinzas o ventosas) y múltiples sensores (imágenes de luz activa, percepción de luz no visible), para adaptarse a tareas específicas. Él cree que la búsqueda actual de una forma “humanoide” implica una inversión masiva que, en última instancia, será en vano. (Fuente: 36氪)

Controversia sobre la calidad del código generado por IA y la experiencia del desarrollador: En las redes sociales, los desarrolladores han debatido acaloradamente sobre la calidad y utilidad del código generado por IA. Algunos elogiaron a Claude Sonnet 4.5 por poder refactorizar toda una base de código, pero el código generado no funcionaba; otros se quejaron de que el código generado por IA “no compilaba”, lo que reducía la eficiencia del desarrollo. Estas discusiones reflejan que la programación asistida por IA todavía enfrenta desafíos entre la eficiencia y la precisión, así como la necesidad de depuración y verificación por parte de los desarrolladores al enfrentarse a los resultados generados por IA. (Fuente: Twitter, Twitter, Twitter)

Cambio en la visión del talento en la era de la IA: de “cazar talentos” a “cultivar cosechas”: En las redes sociales se debate acaloradamente que la visión del talento en la era de la IA debería pasar de la tradicional “caza de talentos” a “cultivar cosechas”. Dada la escasez de talento en el campo de la IA y la rápida iteración tecnológica, las empresas deberían centrarse más en capacitar a los empleados con una pila tecnológica básica, en lugar de perseguir ciegamente talentos “terminados” de alto precio en el mercado. Este punto de vista enfatiza la importancia del aprendizaje continuo y el desarrollo interno para adaptarse a las demandas rápidamente cambiantes del sector de la IA. (Fuente: dotey)
Consumo de energía de la infraestructura de IA y las necesidades energéticas de Sam Altman: Sam Altman ha planteado que el desarrollo de la IA requiere 250GW de electricidad, lo que ha generado preocupación y debate social sobre el enorme consumo de energía de la infraestructura de IA. Esta demanda supera con creces la capacidad de suministro de energía existente, lo que lleva a la reflexión sobre cómo equilibrar el rápido desarrollo de la IA con un suministro de energía sostenible. Las discusiones relacionadas también abordan los problemas ambientales en la fabricación de semiconductores, como el uso de PFAS y los riesgos potenciales de sus alternativas. (Fuente: Twitter, Twitter)

Apocalipsis de la IA vs. optimistas: preocupaciones y refutaciones: En las redes sociales existe un amplio debate sobre el “apocalipsis de la IA” y los riesgos potenciales de la IA, pero también muchas personas creen que estas preocupaciones son exageradas. Los optimistas argumentan que los problemas reales que trae la IA (como el impacto climático, la explotación empresarial, la vigilancia militar) son más urgentes que la lejana “superinteligencia que destruye a la humanidad”, y que se deben abordar los desafíos actuales que se pueden resolver. Algunos consideran que la teoría del apocalipsis de la IA es una “tontería”, una manifestación de pereza e inestabilidad, mientras que otros creen que la IA finalmente conducirá a la creación y el cultivo. (Fuente: Reddit r/ArtificialInteligence, Twitter, Twitter)
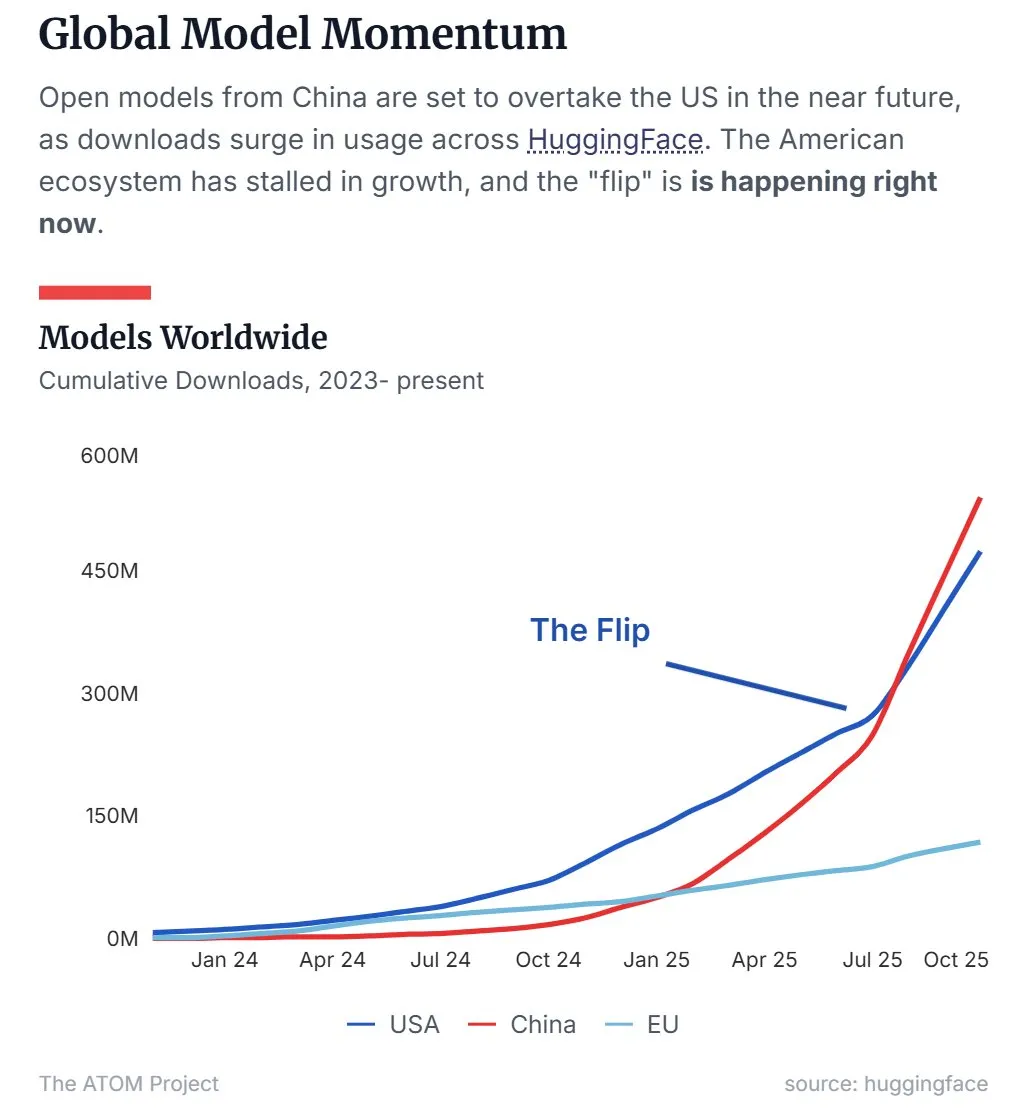
La cuota de mercado de LLM de código abierto de China supera a la de EE. UU.: Los últimos datos muestran que los modelos de lenguaje grandes (LLM) de código abierto chinos, representados por Qwen, han superado a los de EE. UU. en cuota de mercado, convirtiéndose en la fuerza dominante en el campo de los LLM de código abierto. Esta tendencia indica que China está acelerando su ascenso en la investigación y aplicación de la tecnología de IA de código abierto, lo que tiene un impacto importante en el panorama global de la IA. (Fuente: Twitter, Twitter)
Un equipo de 45 días produce la serie de cómics con IA “Tomorrow is Monday”, logrando decenas de millones de reproducciones: Un equipo de solo 10 personas completó la producción de 50 episodios de la serie de cómics con IA “Tomorrow is Monday” en 45 días, y sin ninguna inversión en promoción, las reproducciones en toda la red superaron los diez millones, y los ingresos pagados en Douyin ya cubrieron todos los costos. El proyecto adoptó el concepto central de “personajes originales + generación de IA”, resolviendo el problema de la atribución de derechos de autor del contenido de IA y explorando una ruta de desarrollo comercial de IP de categoría completa. El proceso de producción está altamente dividido, con artistas de arte original, ingenieros, editores de postproducción y directores colaborando estrechamente, demostrando el enorme potencial de la tecnología de IA para reducir costos y aumentar la eficiencia en la producción de contenido. (Fuente: 36氪)

💡 Otros
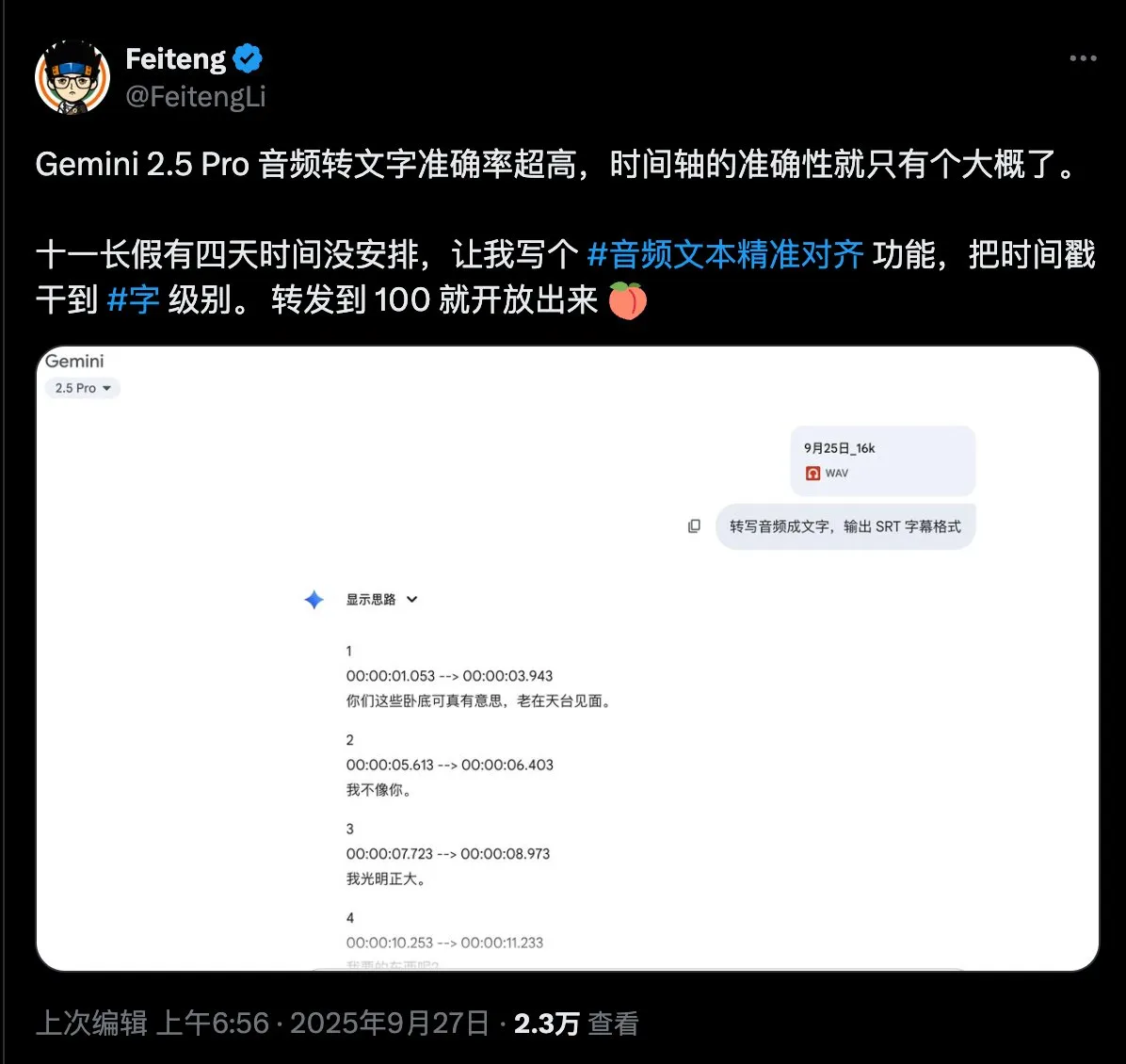
Cuestionario sobre la necesidad de alineación precisa de texto de audio: Un usuario de redes sociales ha mostrado un gran interés en la tecnología de alineación precisa de texto de audio y ha publicado un cuestionario de necesidades, con el objetivo de recopilar los requisitos específicos de los usuarios sobre las funciones y escenarios de aplicación de esta tecnología, con la esperanza de impulsar el desarrollo y la optimización de las tecnologías relacionadas. (Fuente: dotey)
DeepMind presenta la demo de Nano Banana: Google DeepMind ha presentado una demostración llamada “Nano Banana”, que ha generado atención en las redes sociales. Aunque los detalles específicos no se han revelado por completo, podría estar relacionado con la generación de video con IA o la tecnología de IA multimodal, lo que sugiere nuevos avances de DeepMind en el campo de la IA visual. (Fuente: GoogleDeepMind)
Discusión académica sobre la prioridad de invención de Highway Net y ResNet: El reconocido investigador de IA Jürgen Schmidhuber retuiteó un mensaje, reavivando la discusión académica sobre la prioridad de invención de Highway Net y ResNet en el aprendizaje residual profundo. Señaló que la afirmación del artículo de Microsoft sobre ResNet de que Highway Net era un trabajo “contemporáneo” es inexacta, y enfatizó que Highway Net se publicó siete meses antes que ResNet y ya había identificado y propuesto soluciones para las conexiones residuales. (Fuente: SchmidhuberAI)