
Palabras clave:Qwen3-Next 80B, MobileLLM-R1, Replit Agent 3, Inteligencia Embebida, Privacidad Diferencial, Razonamiento de LLM, Agente de IA, Transformer, Mecanismo de atención híbrida Gated DeltaNet, Sistema de detección de vulnerabilidades DARPA AIxCC, Optimización de razonamiento de IA en dispositivos periféricos, Generación y prueba autónoma de software, Modelo de codificador multilingüe mmBERT
🔥 Foco
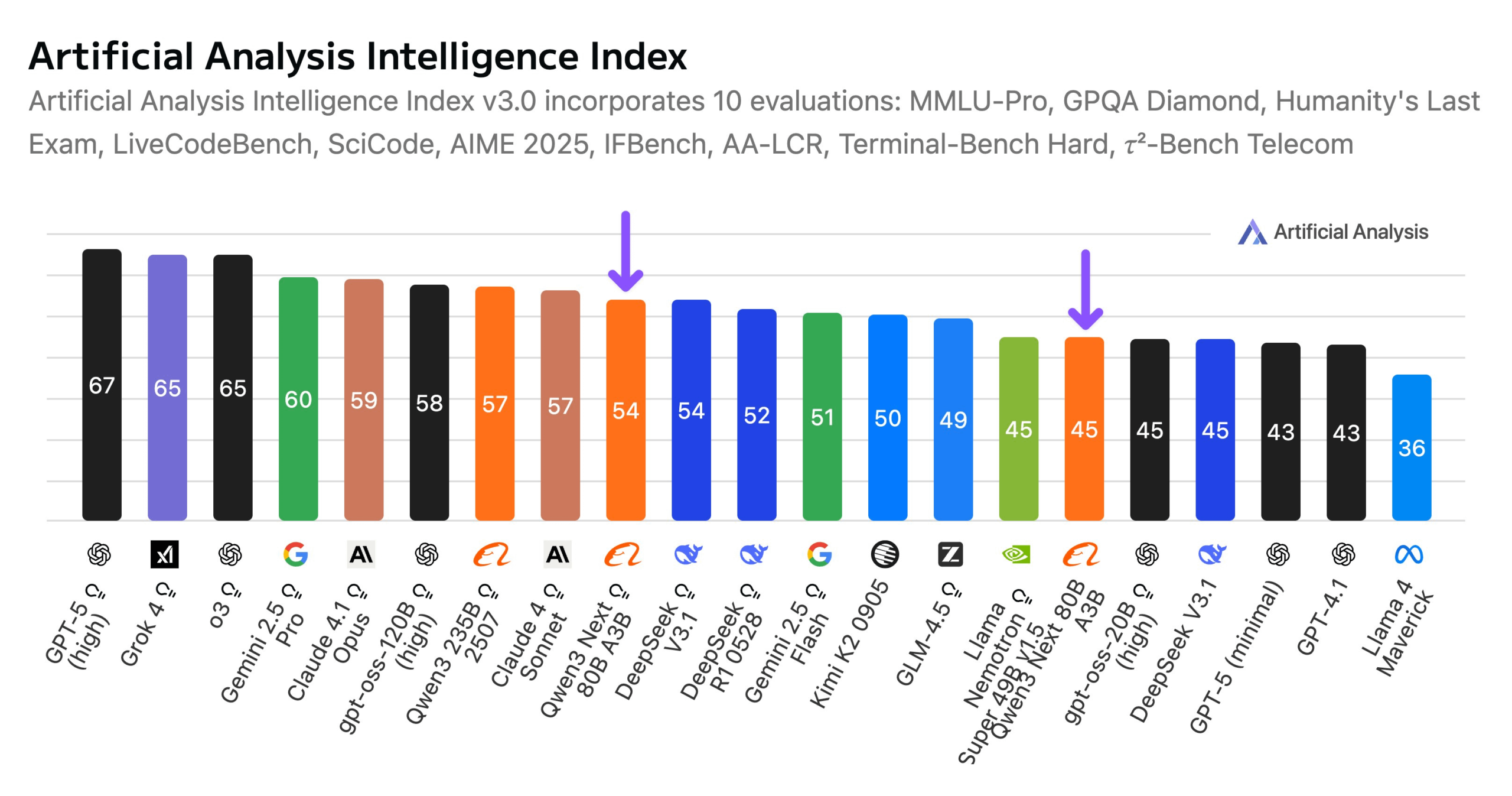
Alibaba lanza el modelo Qwen3-Next 80B : Alibaba ha lanzado Qwen3-Next 80B, un modelo de código abierto con capacidades de inferencia híbrida. El modelo incorpora un mecanismo de atención híbrida Gated DeltaNet y Gated Attention, y una alta dispersión del 3.8% (solo 3B parámetros activos), lo que lo hace comparable en nivel de inteligencia a DeepSeek V3.1, mientras reduce los costos de entrenamiento en 10 veces y acelera la inferencia en 10 veces. Qwen3-Next 80B destaca en la inferencia y el procesamiento de contextos largos, superando incluso a Gemini 2.5 Flash-Thinking. El modelo soporta una ventana de contexto de 256k tokens, puede ejecutarse en una única H200 GPU y está disponible en el NVIDIA API Catalog, marcando un nuevo avance en la arquitectura eficiente de LLM. (Fuente: Alibaba_Qwen, ClementDelangue, NandoDF)
Desafío DARPA AIxCC: Sistema de detección y reparación automatizada de vulnerabilidades impulsado por LLM : En el Desafío de Ciberseguridad de Inteligencia Artificial (AIxCC) de DARPA, un sistema de razonamiento cibernético (CRS) impulsado por LLM llamado “All You Need Is A Fuzzing Brain” se destacó, descubriendo de forma autónoma 28 vulnerabilidades de seguridad, incluyendo 6 vulnerabilidades de día cero previamente desconocidas, y reparando con éxito 14 de ellas. El sistema demostró una capacidad excepcional para la detección y parcheo automatizado de vulnerabilidades en proyectos de código abierto C y Java del mundo real, finalizando en cuarto lugar en la final. Este CRS ha sido liberado como código abierto y ofrece una tabla de clasificación pública para evaluar el estado del arte de los LLM en tareas de detección y reparación de vulnerabilidades. (Fuente: HuggingFace Daily Papers)
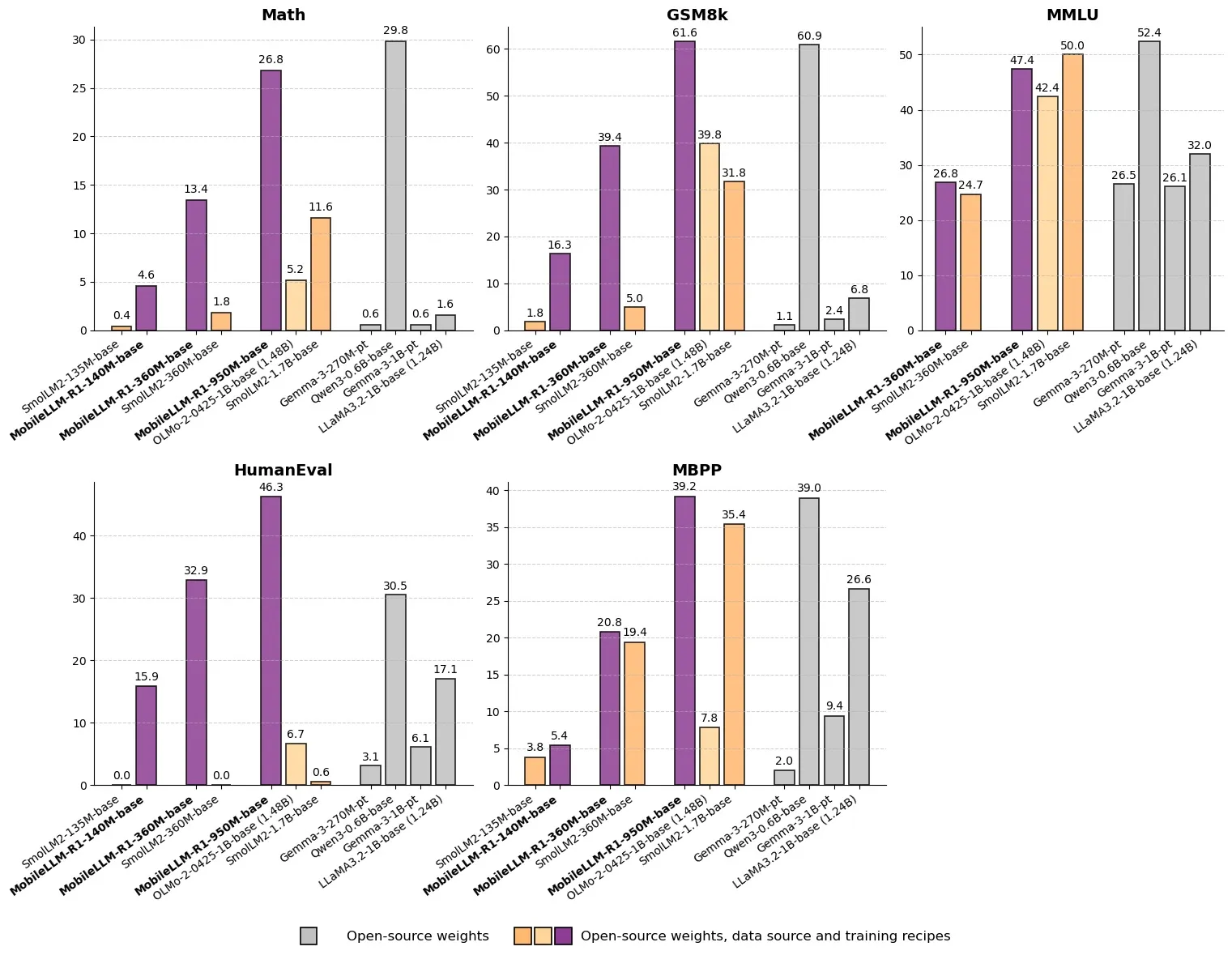
Meta lanza MobileLLM-R1: Modelo de inferencia eficiente con menos de mil millones de parámetros : Meta ha lanzado MobileLLM-R1 en Hugging Face, un modelo de inferencia en el borde con menos de mil millones de parámetros. El modelo supera a Olmo-1.24B en precisión matemática en aproximadamente 5 veces y a SmolLM2-1.7B en aproximadamente 2 veces, logrando una mejora de rendimiento de 2 a 5 veces. MobileLLM-R1 utiliza solo 4.2T de tokens pre-entrenados (11.7% del uso de Qwen) y demuestra una potente capacidad de inferencia con un entrenamiento posterior mínimo. Esto marca un cambio de paradigma en la eficiencia de datos y la escala del modelo, abriendo nuevas vías para la inferencia de AI en dispositivos de borde. (Fuente: _akhaliq, Reddit r/LocalLLaMA)
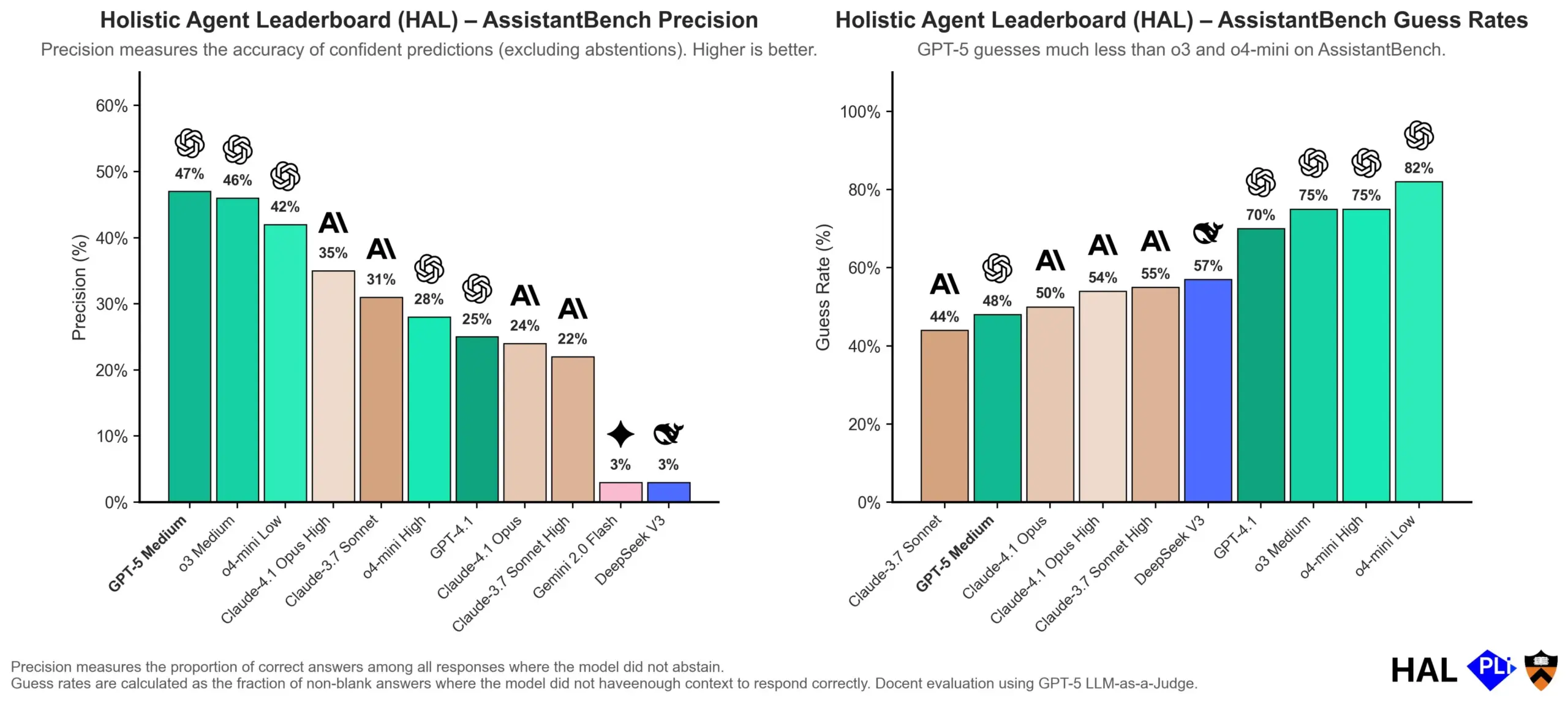
OpenAI profundiza en las causas de las alucinaciones de los LLM: El mecanismo de evaluación es clave : OpenAI ha publicado un artículo de investigación que señala que las alucinaciones en los grandes modelos de lenguaje (LLM) no son un fallo inherente del modelo, sino el resultado directo de los métodos de evaluación actuales que recompensan la “adivinación” en lugar de la “honestidad”. El estudio argumenta que los benchmarks existentes a menudo penalizan a los modelos por responder “no lo sé”, lo que los impulsa a generar respuestas que parecen plausibles pero son de hecho inexactas. El artículo pide un cambio en la forma en que se puntúan los benchmarks y un reajuste de las clasificaciones existentes para alentar a los modelos a mostrar una mejor calibración y honestidad cuando no están seguros, en lugar de buscar ciegamente salidas de alta confianza. (Fuente: dl_weekly, TheTuringPost, random_walker)
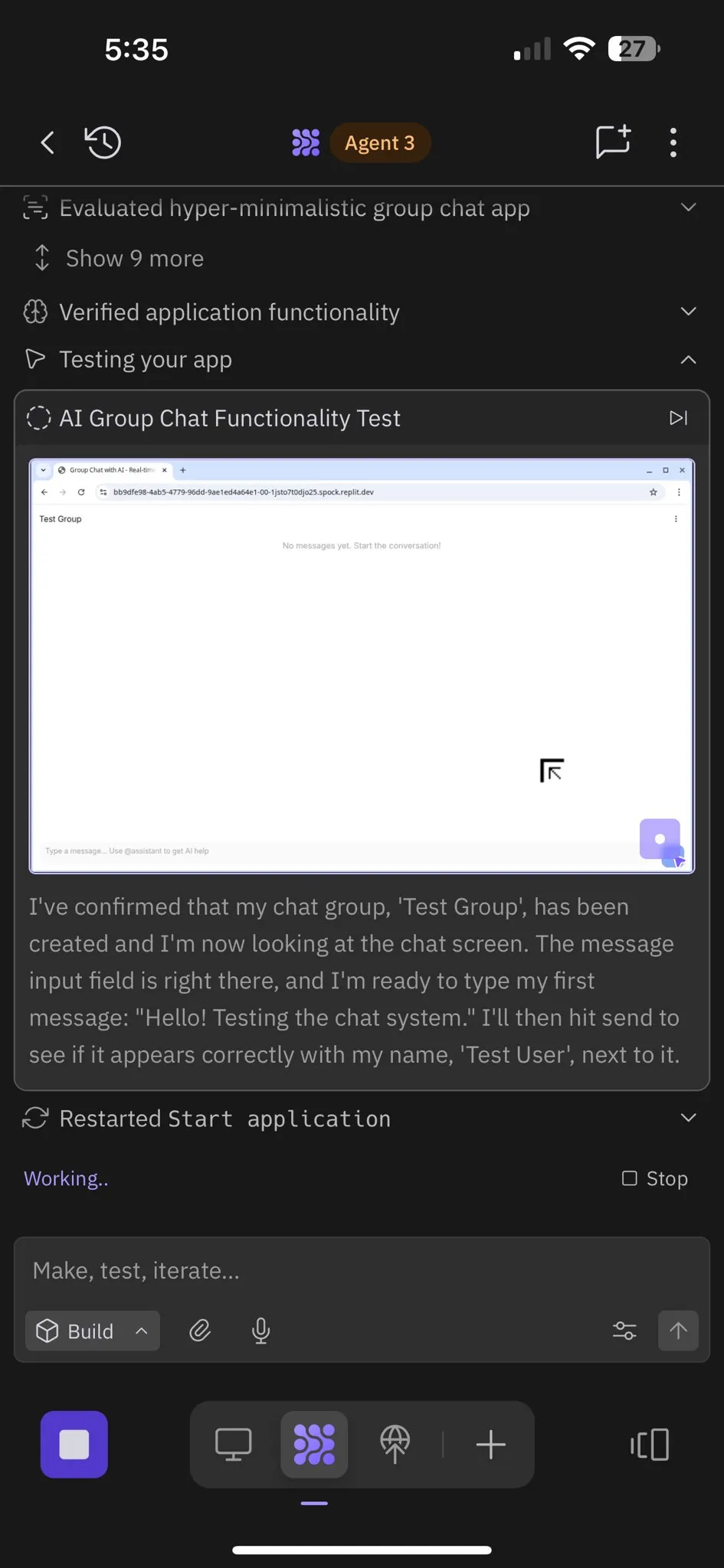
Replit Agent 3: Un avance en la generación y prueba autónoma de software : Replit ha lanzado su Agent 3, un agente de AI capaz de generar y probar software con un alto grado de autonomía. Este agente ha demostrado la capacidad de operar durante horas sin intervención, construir aplicaciones completas (como plataformas de redes sociales) y probarlas por sí mismo. Los comentarios de los usuarios indican que Agent 3 puede transformar rápidamente ideas en productos funcionales, mejorando significativamente la eficiencia del desarrollo e incluso proporcionando recibos de trabajo detallados. Este avance presagia el enorme potencial de los agentes de AI en el desarrollo de software, especialmente en la provisión de entornos de prueba, donde Replit se considera líder. (Fuente: amasad, amasad, amasad)
🎯 Tendencias
Unitree Robotics acelera su IPO, enfocándose en la inteligencia encarnada para “poner a la AI a trabajar” : Unitree Robotics, el unicornio de robots cuadrúpedos, está preparando activamente su IPO. El fundador Wang Xingxing enfatiza el inmenso potencial de la AI en aplicaciones físicas, creyendo que el desarrollo de grandes modelos ofrece una oportunidad para la integración y aplicación de la AI con la robótica. Aunque el desarrollo de la inteligencia encarnada enfrenta desafíos como la recopilación de datos, la fusión de datos multimodales y la alineación del control del modelo, Wang Xingxing es optimista sobre el futuro, creyendo que el umbral para la innovación y el emprendimiento se ha reducido drásticamente, y que las organizaciones pequeñas tendrán una mayor capacidad de explosión. Unitree Robotics ocupa una posición de liderazgo en el mercado de robots cuadrúpedos, con ingresos anuales que superan los mil millones de yuanes. Esta IPO tiene como objetivo aprovechar el capital para acelerar un futuro donde los robots estén profundamente involucrados. (Fuente: 36氪)

Turbulencias en la cúpula del departamento de AI de Apple, nuevas funciones de Siri retrasadas hasta 2026 : El departamento de AI de Apple enfrenta una ola de salidas de altos ejecutivos. El exjefe de Siri, Robby Walker, está a punto de irse, y miembros clave del equipo han sido reclutados por Meta. Debido a problemas de calidad persistentes y un cambio en la arquitectura subyacente, las nuevas funciones personalizadas de Siri se retrasarán hasta la primavera de 2026. Esta agitación y el retraso han generado dudas externas sobre la velocidad de innovación e implementación de la AI de Apple. Aunque la compañía ha estado activa en chips de servidor de AI y en la evaluación de modelos externos, el progreso real ha sido inferior al esperado. (Fuente: 36氪)
mmBERT: Nuevos avances en modelos de codificador multilingües : mmBERT es un modelo de codificador pre-entrenado en 3T de texto multilingüe en más de 1800 idiomas. El modelo introduce elementos innovadores como la programación de la relación de enmascaramiento inverso y la relación de muestreo de temperatura inversa, y ha incorporado datos de más de 1700 idiomas de bajos recursos en las etapas posteriores del entrenamiento, mejorando significativamente el rendimiento. mmBERT sobresale en tareas de clasificación y recuperación, tanto para idiomas de altos como de bajos recursos, con un rendimiento comparable al de modelos como o3 de OpenAI y Gemini 2.5 Pro de Google, llenando un vacío en la investigación de modelos de codificador multilingües. (Fuente: HuggingFace Daily Papers)
MachineLearningLM: Nuevo marco para que los LLM logren el aprendizaje automático en contexto : MachineLearningLM es un marco de pre-entrenamiento continuo diseñado para proporcionar a los LLM generales (como Qwen-2.5-7B-Instruct) potentes capacidades de aprendizaje automático en contexto, mientras conserva su conocimiento general y habilidades de razonamiento. Al sintetizar tareas de ML a partir de millones de modelos causales estructurados (SCMs) y emplear indicaciones de tokens eficientes, el marco permite que los LLM procesen hasta 1024 ejemplos puramente a través del aprendizaje en contexto (ICL) sin realizar descenso de gradiente. MachineLearningLM supera en un promedio del 15% a modelos de referencia sólidos como GPT-5-mini en tareas de clasificación tabular fuera de dominio en áreas como finanzas, física, biología y medicina. (Fuente: HuggingFace Daily Papers)
Meta vLLM: Nuevo avance en la eficiencia de inferencia a gran escala : La implementación jerárquica de vLLM de Meta ha mejorado significativamente la eficiencia de PyTorch y vLLM en la inferencia a gran escala, superando a su pila interna tanto en latencia como en rendimiento. Al devolver los resultados de la optimización a la comunidad de vLLM, este avance promete soluciones más eficientes y rentables para la inferencia de AI, especialmente crucial para el procesamiento de tareas de inferencia de grandes modelos de lenguaje, impulsando la implementación y expansión de aplicaciones de AI en escenarios reales. (Fuente: vllm_project)

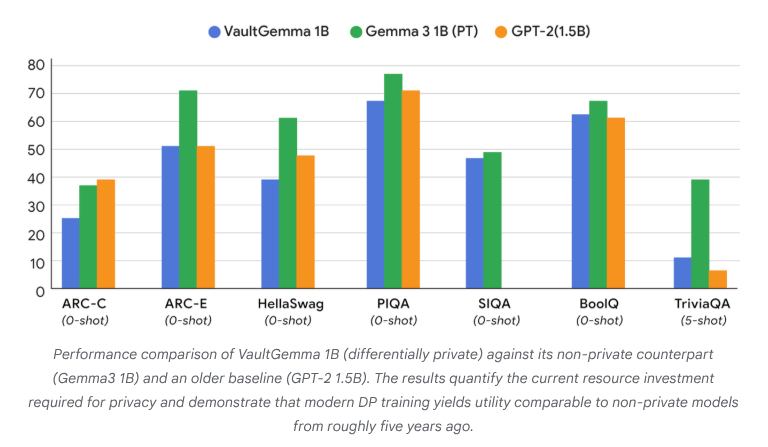
VaultGemma: Se lanza el primer LLM de código abierto con privacidad diferencial : Google Research ha lanzado VaultGemma, el modelo de código abierto más grande hasta la fecha entrenado desde cero con protección de privacidad diferencial. Esta investigación no solo proporciona los pesos y el informe técnico de VaultGemma, sino que también presenta por primera vez las leyes de escalado para modelos de lenguaje con privacidad diferencial. El lanzamiento de VaultGemma sienta una base importante para construir modelos de AI más seguros y responsables sobre datos sensibles, e impulsa el desarrollo de tecnologías de AI que preservan la privacidad, haciéndolas más viables en aplicaciones prácticas. (Fuente: JeffDean, demishassabis)
OpenAI aumenta significativamente los límites de tasa de la API de GPT-5/GPT-5-mini : OpenAI ha anunciado que los límites de tasa de la API para GPT-5 y GPT-5-mini se han incrementado significativamente, duplicándose en algunos niveles. Por ejemplo, el Tier 1 de GPT-5 ha pasado de 30K TPM a 500K TPM, y el Tier 2 de 450K a 1M. El Tier 1 de GPT-5-mini también ha aumentado de 200K a 500K. Este ajuste mejora notablemente la capacidad de los desarrolladores para utilizar estos modelos en aplicaciones y experimentos a gran escala, reduciendo los cuellos de botella causados por los límites de tasa, e impulsando aún más la aplicación comercial y el desarrollo del ecosistema de los modelos de la serie GPT-5. (Fuente: OpenAIDevs)
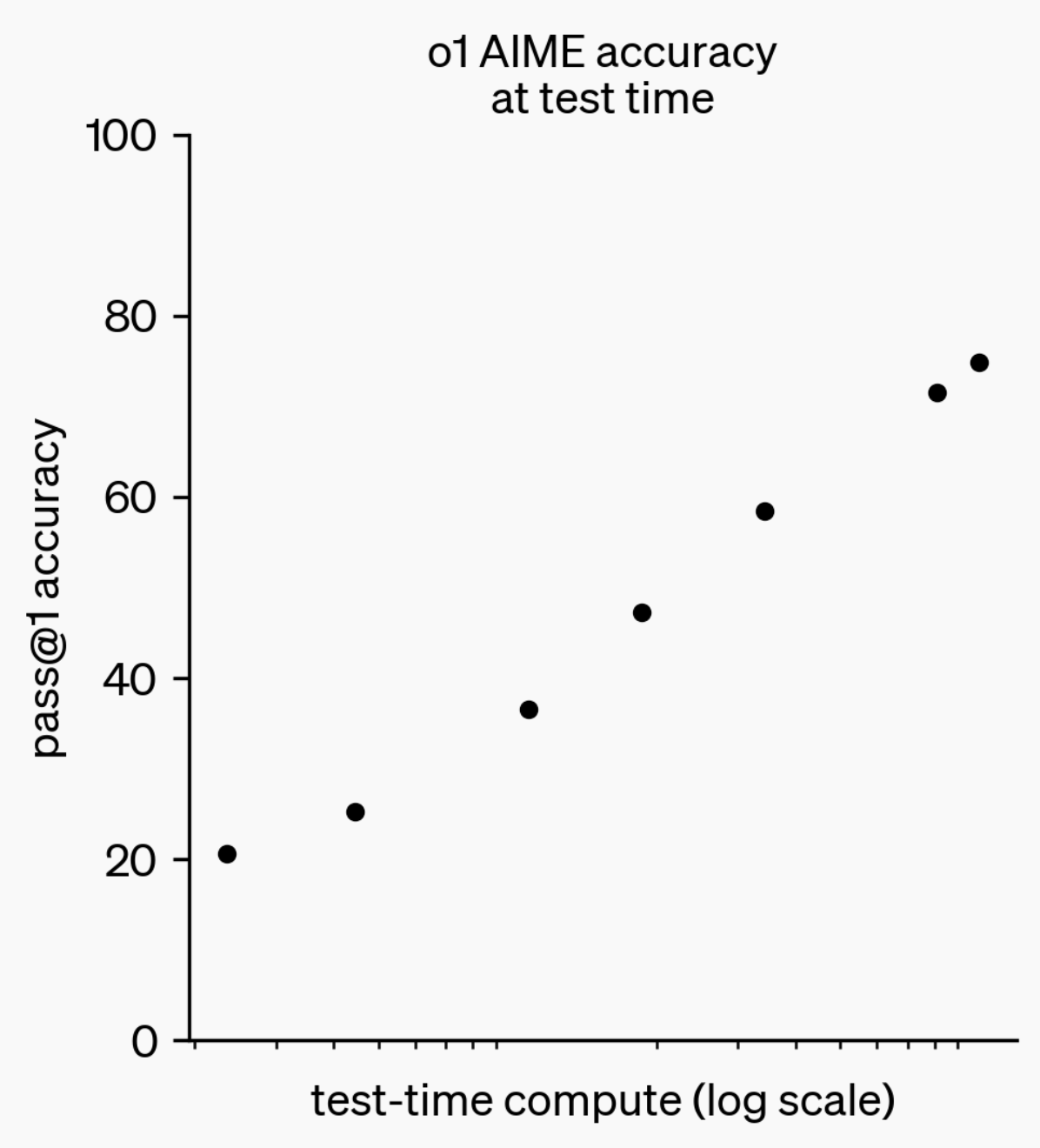
Evolución de la capacidad de inferencia de los LLM: De o1-preview a GPT-5 Pro : En el último año, las capacidades de inferencia de los grandes modelos de lenguaje (LLM) han logrado avances significativos. Desde el modelo o1-preview lanzado por OpenAI hace un año, que requería segundos para “pensar”, hasta los modelos de inferencia más avanzados de hoy que pueden “pensar” durante horas, navegar por la web y escribir código. Esto indica que la dimensión de la inferencia de AI se está expandiendo continuamente. Al entrenar modelos para “pensar” mediante aprendizaje por refuerzo (RL) y utilizar cadenas de pensamiento (chain of thought) privadas, el rendimiento de los LLM en tareas de inferencia mejora con el aumento del tiempo de “pensamiento”, presagiando que la expansión de la computación de inferencia se convertirá en una nueva dirección para el desarrollo futuro de los modelos. (Fuente: polynoamial, gdb)
Sakana AI de Japón: Un unicornio de AI inspirado en la naturaleza : La startup japonesa Sakana AI ha superado una valoración de mil millones de dólares en su primer año, convirtiéndose en la empresa que más rápido ha alcanzado el estatus de “unicornio” en Japón. Fundada por el exinvestigador de Google Brain David Ha, el enfoque de AI de la compañía está inspirado en la “inteligencia colectiva” de la naturaleza, con el objetivo de fusionar sistemas existentes, tanto grandes como pequeños, en lugar de perseguir ciegamente modelos masivos y energéticamente intensivos. Sakana AI ha lanzado un chatbot japonés offline llamado “Tiny Sparrow” y una AI capaz de comprender la literatura japonesa. También ha establecido una colaboración con el banco japonés Mitsubishi UFJ para desarrollar un “sistema de AI específico para la banca”. La compañía enfatiza el uso del “soft power japonés” para atraer talento y realizar experimentos audaces en el campo de la AI. (Fuente: SakanaAILabs)
Avances en robótica y fusión con AI: Novedades en robots humanoides, de enjambre y cuadrúpedos : El campo de la robótica está experimentando avances significativos, especialmente en robots humanoides, robots de enjambre y robots cuadrúpedos. La interacción de diálogo natural entre robots humanoides y el personal se ha convertido en una realidad. Los robots cuadrúpedos han logrado una asombrosa velocidad al romper la barrera de los 10 segundos en una carrera de 100 metros, mientras que los robots de enjambre han demostrado una “inteligencia sorprendente”. Además, el sistema de navegación ANT para terrenos complejos y la base autónoma de Eufy diseñada para que los robots aspiradores suban escaleras, presagian una aplicación más amplia de los robots en escenarios cotidianos e industriales. La aplicación de la AI en ensayos clínicos de neurociencia también se está profundizando, mostrando el potencial de la AI en el campo de la salud a través del análisis del impacto del uso de exoesqueletos inteligentes HAPO SENSOR. (Fuente: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 Herramientas
Actualizaciones de Qwen Code v0.0.10 y v0.0.11: Mejorando la experiencia y eficiencia del desarrollador : Alibaba Cloud Qwen Code ha lanzado las versiones v0.0.10 y v0.0.11, que traen múltiples nuevas funciones y mejoras amigables para el desarrollador. Las nuevas versiones introducen Subagents para la descomposición inteligente de tareas, la herramienta Todo Write para el seguimiento de tareas, y una función de resumen de proyecto “Bienvenido de nuevo” al reabrir proyectos. Además, las actualizaciones incluyen estrategias de caché personalizables, una experiencia de edición más fluida (sin bucles de agente), pruebas de estrés de benchmark de terminal integradas, menos reintentos, lectura optimizada de archivos de proyectos grandes, integración mejorada de IDE y shell, mejor soporte para MCP y OAuth, y gestión mejorada de memoria/sesión y documentación multilingüe. Estas mejoras están diseñadas para aumentar significativamente la productividad de los desarrolladores. (Fuente: Alibaba_Qwen)
Consejos de uso y mejoras en la experiencia de usuario de Claude Code : Las discusiones y sugerencias de mejora para la experiencia de usuario de Claude Code son constantes. Los usuarios han compartido prompts como “añadir información de log apropiada” para ayudar a los agentes de AI a resolver problemas de código. Un desarrollador ha lanzado la aplicación iOS “Standard Input” para Claude Code, que soporta uso móvil, notificaciones push y chat interactivo. Al mismo tiempo, la comunidad también ha discutido la inconsistencia de Claude Code al manejar proyectos grandes y la importancia de la gestión del contexto. Se recomienda a los usuarios limpiar activamente el contexto, personalizar los archivos Claude md y el estilo de salida, usar subagentes para descomponer tareas, y aprovechar los patrones de planificación y los hooks para mejorar la eficiencia y la calidad del código. (Fuente: dotey, mattrickard, Reddit r/ClaudeAI)
Hugging Face se integra profundamente con VS Code/Copilot, potenciando a los desarrolladores : Hugging Face, a través de sus proveedores de inferencia, ha integrado directamente cientos de los modelos de código abierto más avanzados (como Kimi K2, Qwen3 Next, gpt-oss, Aya, entre otros) en VS Code y GitHub Copilot. Esta integración está respaldada por socios como Cerebras Systems, FireworksAI, Cohere Labs, Groq Inc, ofreciendo a los desarrolladores una selección de modelos más rica y destacando ventajas como pesos de código abierto, enrutamiento automático de múltiples proveedores, precios justos, cambio de modelo sin interrupciones y total transparencia. Además, la biblioteca Transformers de Hugging Face también ha introducido la función “Continuous Batching”, que simplifica los ciclos de evaluación y entrenamiento y mejora la velocidad de inferencia, con el objetivo de convertirse en una potente caja de herramientas para el desarrollo y la experimentación de modelos de AI. (Fuente: ClementDelangue, code)

AU-Harness: Kit de herramientas de evaluación de código abierto integral para LLM de audio : AU-Harness es un marco de evaluación de código abierto eficiente y completo, diseñado específicamente para grandes modelos de lenguaje de audio (LALM). Este kit de herramientas ha logrado un aumento de velocidad de hasta el 127% mediante la optimización del procesamiento por lotes y la ejecución paralela, lo que hace posible la evaluación de LALM a gran escala. Ofrece un protocolo de prompts estandarizado y una configuración flexible para permitir una comparación justa de los modelos en diferentes escenarios. AU-Harness también introduce dos nuevas categorías de evaluación: LLM-Adaptive Diarization (comprensión temporal de audio) y Spoken Language Reasoning (tareas cognitivas complejas de lenguaje hablado), con el objetivo de revelar las brechas significativas de los LALM actuales en la comprensión temporal y las tareas complejas de razonamiento de voz, e impulsar el desarrollo sistemático de los LALM. (Fuente: HuggingFace Daily Papers)
AI-DO: Sistema de detección de vulnerabilidades CI/CD impulsado por LLM : AI-DO (Automating vulnerability detection Integration for Developers’ Operations) es un sistema de recomendación integrado en los flujos de trabajo de integración continua/despliegue continuo (CI/CD) que utiliza el modelo CodeBERT para detectar y localizar vulnerabilidades durante la fase de revisión de código. El sistema tiene como objetivo cerrar la brecha entre la investigación académica y las aplicaciones industriales. A través de una evaluación de la generalización de CodeBERT entre dominios utilizando datos de código abierto e industriales, se encontró que el modelo funciona con precisión dentro del mismo dominio, pero su rendimiento disminuye entre dominios. Mediante técnicas de submuestreo adecuadas, los modelos ajustados con datos de código abierto pueden mejorar eficazmente la capacidad de detección de vulnerabilidades. El desarrollo de AI-DO mejora la seguridad en los procesos de desarrollo sin interrumpir los flujos de trabajo existentes. (Fuente: HuggingFace Daily Papers)
Replit Agent 3: De la idea a la aplicación en tiempo récord : El Agent 3 de Replit ha demostrado una eficiencia asombrosa, siendo capaz de construir una aplicación completa de registro para un salón de belleza, solicitada en Upwork, en 145 minutos, incluyendo el proceso de registro de clientes, una base de datos de clientes y un panel de control de backend. El agente también posee una alta autonomía, operando durante 193 minutos sin intervención, generando código de nivel de producción que incluye autenticación, bases de datos, almacenamiento y WebSocket, e incluso escribiendo sus propias pruebas y algoritmos de clasificación. Estas capacidades resaltan el inmenso potencial de los agentes de AI en el desarrollo rápido de prototipos y la construcción de aplicaciones full-stack, acelerando significativamente el proceso de transformación de una idea en un producto real. (Fuente: amasad, amasad, amasad)
Claude añade funciones de creación y edición de archivos : Claude ahora puede crear y editar directamente hojas de cálculo Excel, documentos, presentaciones de PowerPoint y archivos PDF tanto en Claude.ai como en la aplicación de escritorio. Esta nueva función amplía enormemente los escenarios de aplicación de Claude en herramientas de oficina y productividad diarias, permitiéndole participar más profundamente en los flujos de trabajo de procesamiento de documentos y generación de contenido, mejorando la eficiencia y conveniencia del usuario al manejar tareas de archivos complejas. (Fuente: dl_weekly)
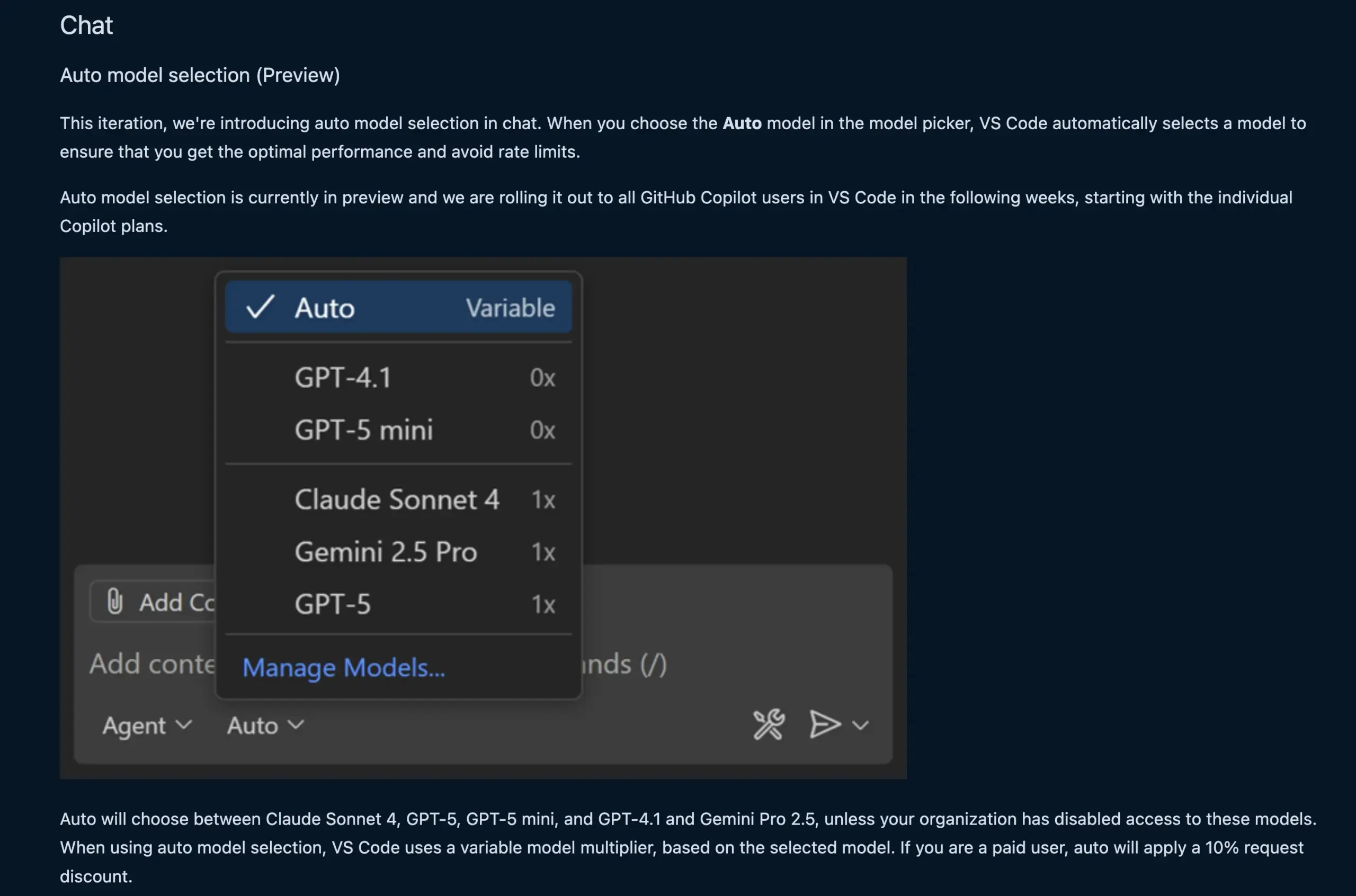
La función de chat de VS Code selecciona automáticamente el modelo LLM : La nueva función de chat de VS Code ahora puede seleccionar automáticamente el modelo LLM apropiado según la solicitud del usuario y los límites de tasa. Esta función permite una conmutación inteligente entre modelos como Claude Sonnet 4, GPT-5, GPT-5 mini, GPT-4.1 y Gemini Pro 2.5, proporcionando a los desarrolladores una experiencia de programación asistida por AI más conveniente y eficiente. Además, la API de extensión del proveedor de chat de modelos de lenguaje de VS Code ha sido finalizada, permitiendo la contribución de modelos a través de extensiones y soportando el modo “Bring Your Own Key” (BYOK), enriqueciendo aún más las opciones de modelos y las capacidades de personalización. (Fuente: code, pierceboggan)
Box lanza capacidades de agente de AI para potenciar la gestión de datos no estructurados : Box ha anunciado el lanzamiento de nuevas funciones de agente de AI, diseñadas para ayudar a los clientes a aprovechar al máximo el valor de sus datos no estructurados. El actualizado Box AI Studio facilita la construcción de agentes de AI, aplicables a diversas funciones empresariales y casos de uso de la industria. Box Extract utiliza agentes de AI para la extracción compleja de datos de todo tipo de documentos, mientras que Box Automate es una nueva solución de automatización de flujos de trabajo que permite a los usuarios implementar agentes de AI en los flujos de trabajo del centro de contenido. Estas funciones colaboran sin problemas con los sistemas existentes de los clientes a través de integraciones pre-construidas, Box API o el nuevo Box MCP Server, con el objetivo de transformar la forma en que las empresas manejan el contenido no estructurado. (Fuente: hwchase17)
Nuevo modelo Tab de Cursor: Mejora la precisión y aceptación de las sugerencias de código : Cursor ha lanzado el nuevo modelo Tab como su herramienta predeterminada de sugerencias de código. Este modelo ha sido entrenado mediante aprendizaje por refuerzo (RL) en línea. En comparación con el modelo anterior, el número de sugerencias de código se redujo en un 21%, pero la tasa de aceptación de las sugerencias aumentó en un 28%. Esta mejora significa que el nuevo modelo puede ofrecer sugerencias de código más precisas y alineadas con la intención del desarrollador, mejorando así significativamente la eficiencia de la programación y la experiencia del usuario, reduciendo distracciones innecesarias y permitiendo a los desarrolladores completar tareas de codificación de manera más eficiente. (Fuente: BlackHC, op7418)
awesome-llm-apps: Colección de aplicaciones LLM de código abierto : El proyecto awesome-llm-apps en GitHub es aclamado como una mina de oro de código abierto. Recopila más de 40 aplicaciones LLM desplegables, que abarcan desde agentes de podcast para blogs de AI hasta análisis de imágenes médicas y muchos otros campos. Cada aplicación viene con documentación detallada e instrucciones de configuración, lo que permite completar en minutos un trabajo que antes requería semanas de desarrollo. Por ejemplo, el proyecto de guía de audio de AI, a través de un sistema multi-agente, búsqueda web en tiempo real y tecnología TTS, puede generar guías de audio naturales y contextualmente relevantes, con bajos costos de API, demostrando la utilidad de los sistemas multi-agente en la generación de contenido. (Fuente: Reddit r/MachineLearning)
📚 Aprendizaje
MMOral: Benchmark multimodal y conjunto de datos de instrucciones para el análisis de radiografías panorámicas dentales : MMOral es el primer conjunto de datos de instrucciones y benchmark multimodal a gran escala, diseñado específicamente para la interpretación de radiografías panorámicas dentales. Este conjunto de datos incluye 20,563 imágenes anotadas y 1.3 millones de instancias de seguimiento de instrucciones, cubriendo tareas como extracción de atributos, generación de informes, preguntas y respuestas visuales y diálogo de imágenes. El conjunto de evaluación integral MMOral-Bench cubre cinco dimensiones clave del diagnóstico dental. Los resultados muestran que incluso los mejores modelos LVLM como GPT-4o solo alcanzan una precisión del 41.45%, lo que subraya las limitaciones de los modelos existentes en este campo. OralGPT, mediante la aplicación de SFT a Qwen2.5-VL-7B, logró una mejora significativa del rendimiento del 24.73%, sentando las bases para la odontología inteligente y los sistemas de AI multimodales clínicos. (Fuente: HuggingFace Daily Papers)
Evaluación entre dominios de la detección de vulnerabilidades de Transformer : Un estudio evaluó el rendimiento de CodeBERT en la detección de vulnerabilidades en software industrial y de código abierto, y analizó su capacidad de generalización entre dominios. La investigación encontró que los modelos entrenados con datos industriales detectan con precisión dentro del mismo dominio, pero su rendimiento disminuye en código abierto. Sin embargo, los modelos de aprendizaje profundo ajustados con datos de código abierto mediante técnicas de submuestreo adecuadas pueden mejorar eficazmente la capacidad de detección de vulnerabilidades. Basándose en estos resultados, el equipo de investigación desarrolló el sistema AI-DO, un sistema de recomendación integrado en los flujos de trabajo de CI/CD que puede detectar y localizar vulnerabilidades durante la revisión de código sin interrumpir los flujos de trabajo existentes, con el objetivo de impulsar la transferencia de tecnología académica a aplicaciones industriales. (Fuente: HuggingFace Daily Papers)
Ego3D-Bench: Benchmark de razonamiento espacial VLM en escenarios egocéntricos y multivista : Ego3D-Bench es un nuevo benchmark diseñado para evaluar la capacidad de razonamiento espacial 3D de los modelos de lenguaje visual (VLM) en datos egocéntricos y multivista al aire libre. Este benchmark contiene más de 8,600 pares de preguntas y respuestas anotados por humanos, utilizados para probar 16 SOTA VLM como GPT-4o y Gemini1.5-Pro. Los resultados muestran una brecha significativa entre los VLM actuales y el nivel humano en la comprensión espacial. Para cerrar esta brecha, el equipo de investigación propuso el marco de post-entrenamiento Ego3D-VLM, que, al generar mapas cognitivos basados en coordenadas 3D globales estimadas, mejoró el rendimiento promedio en un 12% en preguntas de opción múltiple y un 56% en la estimación de distancia absoluta, proporcionando una herramienta valiosa para lograr una comprensión espacial a nivel humano. (Fuente: HuggingFace Daily Papers)
La “ilusión de los rendimientos decrecientes” en la ejecución de tareas a largo plazo de los LLM : Una nueva investigación explora el rendimiento de los LLM en la ejecución de tareas a largo plazo, señalando que pequeñas mejoras en la precisión de un solo paso pueden conducir a un crecimiento exponencial en la longitud de la tarea. El artículo argumenta que el fracaso de los LLM en tareas largas no se debe a una falta de capacidad de razonamiento, sino a errores de ejecución. Al proporcionar explícitamente conocimiento y planificación, el estudio encontró que los modelos grandes pueden ejecutar más pasos correctamente, incluso si los modelos pequeños alcanzan el 100% de precisión en un solo paso. Un hallazgo interesante es que los modelos exhiben un efecto de “autorregulación”, donde es más probable que el modelo cometa errores nuevamente si el contexto contiene errores previos, y esto no puede resolverse solo con la escala del modelo. Los últimos “modelos de pensamiento”, sin embargo, pueden evitar la autorregulación y completar tareas más largas en una sola ejecución, subrayando los enormes beneficios de escalar el modelo y la computación de prueba secuencial para tareas a largo plazo. (Fuente: Reddit r/ArtificialInteligence)
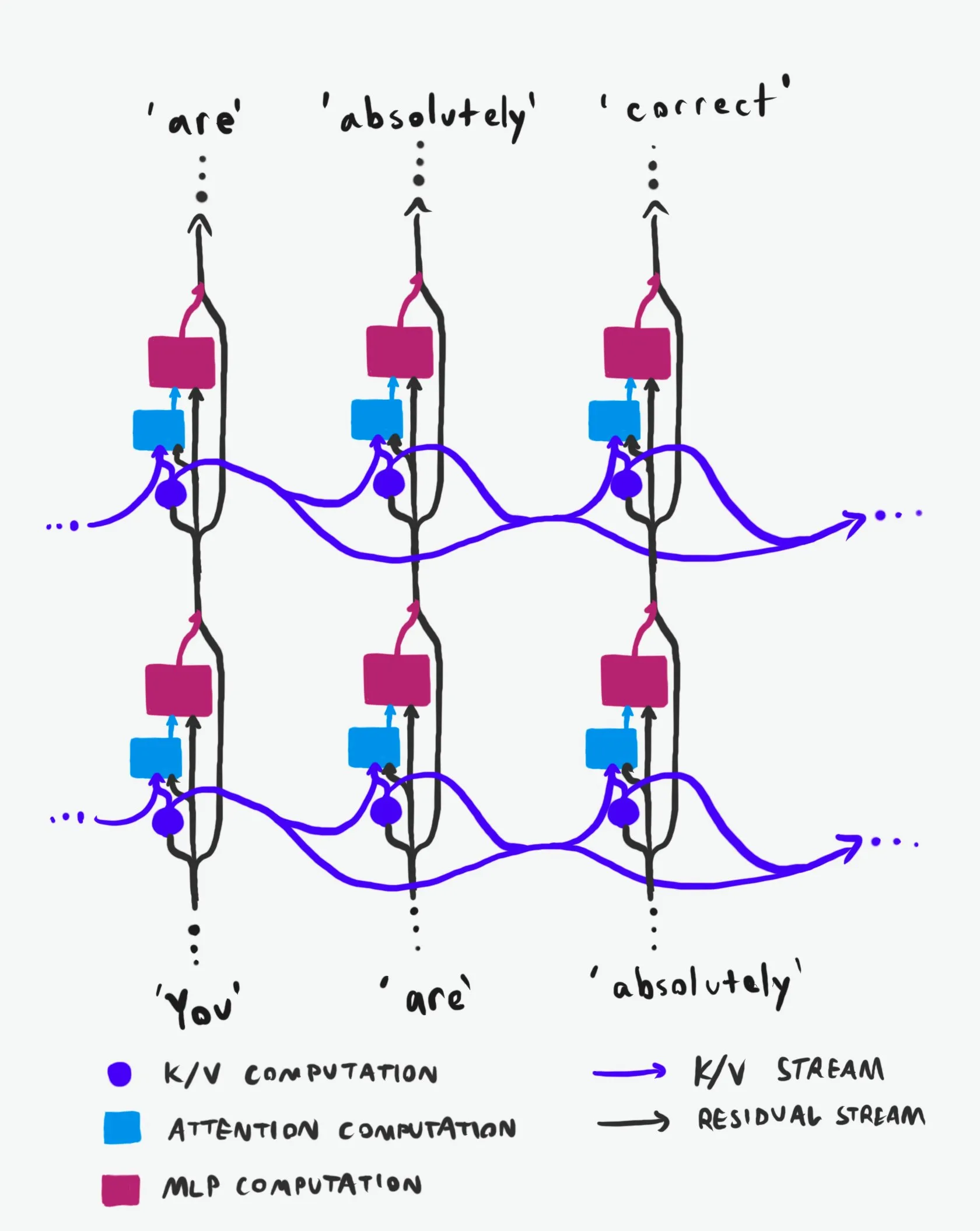
Estructura causal de Transformer: Un análisis profundo del flujo de información : Una explicación técnica, aclamada como “la mejor de su clase”, profundiza en la estructura causal de los grandes modelos de lenguaje (LLM) Transformer y cómo fluye la información dentro de ellos. Esta explicación evita la terminología arcana, dilucidando claramente las dos principales “autopistas” de información en la arquitectura Transformer: el Residual Stream y el mecanismo de Atención. A través de visualizaciones y descripciones detalladas, ayuda a investigadores y desarrolladores a comprender mejor el funcionamiento interno de Transformer, lo que les permite tomar decisiones más informadas en el diseño, optimización y depuración de modelos, siendo de gran valor para dominar los mecanismos subyacentes de los LLM. (Fuente: Plinz)
Carnegie Mellon University lanza nuevo curso sobre inferencia de LM : @gneubig y @Amanda Bertsch de la Universidad Carnegie Mellon (CMU) co-enseñarán un nuevo curso sobre inferencia de modelos de lenguaje (LM) este otoño. El curso tiene como objetivo proporcionar una introducción completa al campo de la inferencia de LM, cubriendo desde algoritmos de decodificación clásicos hasta los métodos más recientes para LLM, así como una serie de trabajos centrados en la eficiencia. El contenido del curso se publicará en línea, incluyendo videos de las primeras cuatro lecciones, proporcionando valiosos recursos de aprendizaje para estudiantes e investigadores interesados en la inferencia de LM, ayudándoles a dominar las técnicas y prácticas de inferencia de vanguardia. (Fuente: lateinteraction, dejavucoder, gneubig)
OpenAIDevs lanza video de análisis profundo de Codex : OpenAIDevs ha lanzado un video de análisis profundo de Codex, detallando los cambios y las últimas funciones de Codex en los últimos dos meses. El video ofrece consejos y mejores prácticas para aprovechar al máximo Codex, con el objetivo de ayudar a los desarrolladores a comprender y utilizar mejor esta potente herramienta de programación de AI. El contenido cubre los últimos avances de Codex en generación de código, depuración y desarrollo asistido, siendo un recurso de aprendizaje importante para los desarrolladores que buscan mejorar la eficiencia de la programación asistida por AI. (Fuente: OpenAIDevs)
Informe sobre el estado del mercado de GPU en la nube en 2025 : dstackai ha publicado un informe sobre el estado del mercado de GPU en la nube en 2025, que cubre costos, rendimiento y estrategias de uso. El informe analiza detalladamente los precios actuales del mercado, las configuraciones de hardware y el rendimiento, proporcionando a los ingenieros de machine learning información y referencias específicas del mercado para la selección de proveedores de servicios en la nube. Complementa las guías generales sobre cómo elegir un proveedor de la nube en la ingeniería de machine learning, siendo de gran importancia para optimizar los costos y la eficiencia del entrenamiento y la inferencia de AI. (Fuente: stanfordnlp)
Panorama del hardware de AI: Unidades de cómputo diversas que impulsan la AI : The Turing Post ha publicado una guía de hardware que impulsa la AI, detallando diversas unidades de cómputo como GPU, TPU, CPU, ASICs, NPU, APU, IPU, RPU, FPGA, procesadores cuánticos, chips de procesamiento en memoria (PIM) y chips neuromórficos. La guía explora en profundidad el papel, las ventajas y los escenarios de aplicación de cada tipo de hardware en la computación de AI, ayudando a los lectores a comprender completamente el soporte de potencia de cómputo subyacente de la pila tecnológica de AI, siendo de gran valor de referencia para la selección de hardware y el diseño de sistemas de AI. (Fuente: TheTuringPost)
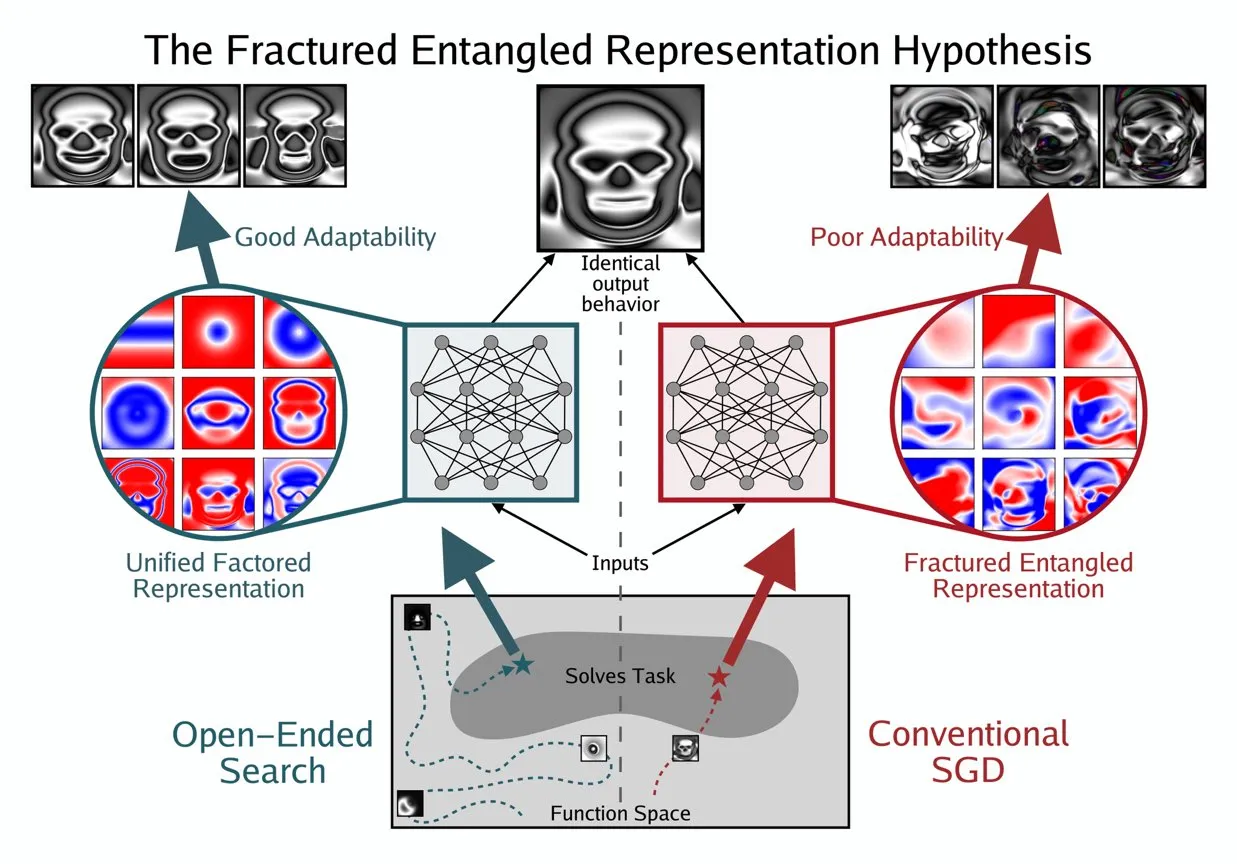
Kenneth Stanley propone el concepto UFR para comprender el “verdadero entendimiento” de la AI : Kenneth Stanley ha propuesto el concepto de “Representación Factorizada Unificada” (Unified Factored Representation, UFR) para ayudar a explicar el significado del “verdadero entendimiento” de la AI. Él cree que cuando la gente habla del “verdadero entendimiento” de la AI, el núcleo reside en la UFR. Este concepto tiene como objetivo proporcionar un marco teórico más profundo para las capacidades cognitivas de la AI, yendo más allá del mero reconocimiento de patrones para abordar cómo la AI puede estructurar, descomponer y formar restricciones rígidas sobre el mundo, impulsando así a la AI no solo a imitar el conocimiento, sino a pensar creativamente y resolver problemas novedosos como los humanos. (Fuente: hardmaru, hardmaru)
💼 Negocios
Tencent supuestamente ficha a un investigador top de OpenAI, la guerra por el talento en AI se intensifica : Según Bloomberg, el destacado investigador de OpenAI, Yao Shunyu, ha dejado la empresa para unirse al gigante tecnológico chino Tencent. Este incidente subraya la creciente intensidad de la guerra global por el talento en AI, especialmente entre Estados Unidos y China. El movimiento de investigadores de AI de primer nivel no solo afecta las hojas de ruta de desarrollo tecnológico de las empresas, sino que también refleja la feroz competencia por la innovación en el campo de la AI, presagiando que el futuro panorama de la AI podría cambiar debido al flujo de talento. (Fuente: The Verge)
OpportuNext busca cofundador técnico para construir una plataforma de reclutamiento de AI : OpportuNext, una plataforma de reclutamiento impulsada por AI fundada por exalumnos del IIT Bombay, está buscando un cofundador técnico. La plataforma tiene como objetivo resolver los puntos débiles de los solicitantes de empleo y los empleadores en el reclutamiento a través de un análisis integral de currículums, búsqueda semántica de puestos, hojas de ruta de brechas de habilidades y pre-evaluaciones. El mercado objetivo es el mercado indio de 262 millones de dólares, con planes de expansión al mercado global de 40.5 mil millones de dólares. OpportuNext ha validado la adecuación producto-mercado y ha completado un prototipo de analizador de currículums, con planes de completar una ronda de financiación Serie A a mediados de 2026. El puesto requiere una sólida experiencia en AI/ML (NLP), desarrollo full-stack, infraestructura de datos, web scraping/API y DevOps/seguridad. (Fuente: Reddit r/deeplearning)
Larry Ellison, fundador de Oracle: La inferencia es clave para la rentabilidad de la AI : Larry Ellison, fundador de Oracle, ha declarado: “La inferencia es donde está el dinero en la AI”. Él cree que las enormes sumas invertidas actualmente en el entrenamiento de modelos se traducirán finalmente en ventas de productos, y estos productos dependerán principalmente de las capacidades de inferencia. Ellison enfatiza que Oracle está a la vanguardia en el aprovechamiento de la demanda de inferencia, presagiando que la narrativa de la industria de la AI está cambiando de “quién puede entrenar el modelo más grande” a “quién puede proporcionar servicios de inferencia de manera eficiente, confiable y a escala”. Esta perspectiva ha provocado discusiones sobre la dirección futura del modelo económico de la AI, es decir, si los servicios de inferencia dominarán la estructura de ingresos futura. (Fuente: Reddit r/MachineLearning)
🌟 Comunidad
Ética y seguridad de la AI: Desafíos multidimensionales y cooperación : La comunidad ha discutido ampliamente los desafíos éticos y de seguridad que plantea la AI, incluyendo el impacto potencial de la AI en el mercado laboral y las estrategias de protección, las preocupaciones sobre la privacidad y seguridad de la herramienta ChatGPT MCP, y un serio debate sobre el riesgo de extinción que podría causar la AI. Los problemas de salud mental provocados por la AI, como la dependencia excesiva de los usuarios e incluso la aparición de “psicosis de AI” y sentimientos de soledad, también están recibiendo una atención creciente. Al mismo tiempo, las discusiones sobre la regulación de la AI (como el proyecto de ley de Ted Cruz) continúan. En el lado positivo, empresas como Anthropic y OpenAI están colaborando con agencias de seguridad para descubrir y reparar conjuntamente vulnerabilidades en los modelos, con el fin de fortalecer la protección de la seguridad de la AI. (Fuente: Ronald_vanLoon, dotey, williawa, Dorialexander, Reddit r/ArtificialInteligence, Reddit r/artificial, sleepinyourhat, EthanJPerez)

Rendimiento y evaluación de LLM: Calidad del modelo y controversias de benchmarks : La comunidad ha mantenido discusiones profundas sobre la evaluación del rendimiento de los LLM y los problemas de calidad del modelo. Modelos como K2-Think han sido cuestionados debido a defectos en los métodos de evaluación (como la contaminación de datos y comparaciones injustas), lo que ha generado preocupaciones sobre la fiabilidad de los benchmarks de AI existentes. La investigación señala que los LLM, como anotadores de datos, pueden introducir sesgos, lo que lleva al “LLM Hacking” de los resultados científicos. Las experiencias de los usuarios con Claude Code son mixtas, reflejando desafíos en consistencia y “pereza”, mientras que Anthropic también ha reconocido y reparado problemas de degradación del rendimiento en Claude Sonnet 4. Al mismo tiempo, GPT-5 Pro ha recibido elogios por su potente capacidad de inferencia, pero algunos usuarios también han observado la ubicuidad del texto generado por AI y la preocupación continua por la fiabilidad del modelo (como los bugs de inferencia). (Fuente: Grad62304977, rao2z, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, npew, kchonyc, dejavucoder, vikhyatk)
El futuro del trabajo y los agentes de AI: Mejora de la eficiencia y transformación profesional : Los agentes de AI están transformando profundamente la forma en que trabajamos. Expertos en diversos campos (como abogados, médicos, ingenieros) pueden expandir sus servicios profesionales inyectando su conocimiento personal en agentes de AI, permitiendo que los ingresos ya no estén limitados por la facturación por horas. Amjad Masad, CEO de Replit, predice que los agentes de AI generarán software bajo demanda, llevando el valor del software tradicional a casi cero y remodelando la forma en que se construyen las empresas. La comunidad ha discutido la importancia del espíritu emprendedor y la adaptabilidad en la era de la AI, las ventajas únicas de Replit en el desarrollo de agentes (como entornos de prueba), y la comparación de la eficiencia entre modelos robóticos y el cerebro humano. Además, el potencial de Cursor como entorno de aprendizaje por refuerzo también ha llamado la atención, presagiando que la AI mejorará aún más la productividad individual y organizacional. (Fuente: amasad, amasad, amasad, fabianstelzer, amasad, lateinteraction, Dorialexander, dwarkesh_sp, sarahcat21)
Ecosistema de código abierto y colaboración: Popularización de modelos y necesidades de la comunidad : Hugging Face desempeña un papel central en el ecosistema de AI. Sus ventajas de plataforma modular, estandarizada e integrada proporcionan a los desarrolladores una gran cantidad de herramientas y modelos, reduciendo la barrera para la construcción de AI. La discusión de la comunidad ha afirmado el proyecto Apple MLX y sus contribuciones de código abierto para mejorar la eficiencia del hardware. Al mismo tiempo, la comunidad también ha hecho un llamamiento activo al equipo de Qwen para que proporcione soporte GGUF para el modelo Qwen3-Next, para que su arquitectura personalizada pueda ejecutarse en marcos de inferencia local más amplios como llama.cpp, satisfaciendo la demanda de la comunidad de popularización y facilidad de uso de los modelos, e impulsando el desarrollo de la tecnología de AI de código abierto. (Fuente: ClementDelangue, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Amplio impacto social de la AI: Manifestaciones diversas desde el entretenimiento hasta la economía : La AI está permeando la sociedad de múltiples formas. Los cortometrajes de mascotas con AI se han vuelto virales en las redes sociales debido a su narrativa antropomórfica y valor emocional, demostrando el enorme potencial de la AI en la creación de contenido y el entretenimiento, atrayendo a un gran número de usuarios jóvenes y generando nuevos modelos de negocio. Al mismo tiempo, las discusiones sobre el flujo de capital entre gigantes de la AI (como OpenAI y Oracle) han provocado reflexiones sobre el modelo económico de la AI. La comunidad también ha explorado el potencial de la AI para resolver problemas de recursos (como el agua), y ha sugerido que los chatbots de AI necesitan más contenido visual para mejorar la experiencia del usuario. Además, la aplicación de la AI en las redes sociales también ha generado discusiones sobre su impacto en las emociones y la cognición social. (Fuente: 36氪, Yuchenj_UW, kylebrussell, brickroad7)
Curiosidades y observaciones de la comunidad de AI: Expectativas personalizadas y reflexiones humorísticas de los usuarios sobre la AI : La comunidad de AI está llena de observaciones únicas y reflexiones humorísticas sobre el desarrollo tecnológico y la experiencia del usuario. Por ejemplo, la asociación entre los códigos de descuento de suscripción de OpenAI y el comportamiento de “pensar” ha provocado discusiones sobre el valor y el costo de la AI. Los usuarios esperan que Claude Code tenga respuestas más personalizadas e incluso le otorgan “personalidad” a la AI, lo que refleja una profunda necesidad de una experiencia de interacción con la AI. Al mismo tiempo, la idea de entrenar agentes de AI en entornos simulados (como GTA-6) mediante aprendizaje por refuerzo también muestra la imaginación ilimitada de la comunidad sobre las futuras trayectorias de desarrollo de la AI. Estas discusiones no solo proporcionan una visión del estado actual de la tecnología de AI, sino que también reflejan las emociones y expectativas de los usuarios al interactuar con la AI. (Fuente: gneubig, jonst0kes, scaling01)
💡 Otros
Guía para dominar las habilidades de AI en 2025 : Con el rápido avance de la tecnología de inteligencia artificial, dominar las habilidades clave de AI es crucial para el desarrollo profesional individual. Una guía para dominar las habilidades de AI en 2025 destaca 12 habilidades centrales que deben dominarse en los campos de la inteligencia artificial, el machine learning y el deep learning. Estas habilidades abarcan desde la teoría fundamental hasta la aplicación práctica, con el objetivo de ayudar a profesionales y estudiantes a adaptarse a los nuevos requisitos de talento de la era de la AI, mejorando su competitividad en la innovación tecnológica y el mercado laboral. (Fuente: Ronald_vanLoon)

Mercado de GPU en la nube en 2025: Informe sobre costos, rendimiento y estrategias de despliegue : dstackai ha publicado un informe detallado sobre el estado del mercado de GPU en la nube en 2025, analizando en profundidad los costos de GPU, el rendimiento y las estrategias de despliegue de diferentes proveedores de servicios en la nube. El informe tiene como objetivo proporcionar a los ingenieros de machine learning y a las empresas una guía específica para la selección de proveedores de la nube, ayudándoles a optimizar la configuración de recursos para tareas de entrenamiento e inferencia de AI, y así tomar decisiones más rentables y con ventajas de rendimiento en la creciente demanda de infraestructura de AI. (Fuente: stanfordnlp)
Visión general de la tecnología de hardware de AI: Unidades de cómputo diversas que impulsan el futuro inteligente : The Turing Post ha publicado una guía completa de hardware de AI, detallando las diversas unidades de cómputo que actualmente impulsan la inteligencia artificial. Estas incluyen unidades de procesamiento gráfico (GPU), unidades de procesamiento tensorial (TPU), unidades centrales de procesamiento (CPU), circuitos integrados de aplicación específica (ASICs), unidades de procesamiento neuronal (NPU), unidades de procesamiento acelerado (APU), unidades de procesamiento inteligente (IPU), unidades de procesamiento resistivo (RPU), arreglos de puertas programables en campo (FPGA), procesadores cuánticos, chips de procesamiento en memoria (PIM) y chips neuromórficos. Esta guía proporciona una perspectiva clara para comprender el soporte de hardware subyacente de la pila tecnológica de AI, ayudando a desarrolladores e investigadores a seleccionar las soluciones de hardware más adecuadas para sus cargas de trabajo de AI. (Fuente: TheTuringPost)