
Palabras clave:Modelo de Cerebro Grande, Chips de IA, Modelo de Parámetros de Billones, Inteligencia Encarnada, Marco RAG, Agentes de IA, Aceleración de Inferencia LLM, SpikingBrain-1.0, Chip Personalizado OpenAI Broadcom, Qwen3-Max-Preview, Modelo de Código Abierto WALL-OSS, Marco REFRAG
🔥 Foco
La Academia China de Ciencias lanza el modelo de cerebro artificial SpikingBrain-1.0 de complejidad lineal : Adopta un mecanismo de neuronas de pulso para lograr una complejidad lineal/casi lineal, mejorando la velocidad TTFT de secuencias largas en GPUs nacionales entre 26.5x y más de 100x, y aumentando significativamente la velocidad de decodificación en CPUs de teléfonos móviles. Este modelo logra un entrenamiento eficiente con una cantidad extremadamente baja de datos, demostrando el enorme potencial de las arquitecturas neuromórficas para resolver las limitaciones de complejidad cuadrática de la arquitectura Transformer, sentando las bases para un ecosistema de IA nacional autónomo y controlable. (Fuente: 量子位)

OpenAI firma un acuerdo de 10.000 millones de dólares con Broadcom para chips de IA personalizados : Para abordar la escasez de chips en el desarrollo de la IA, OpenAI ha llegado a un acuerdo de 10.000 millones de dólares con Broadcom para personalizar racks de servidores de IA que soporten sus modelos de próxima generación. Esta medida subraya que la carrera armamentística de la IA se ha desplazado hacia el control del hardware, con el objetivo de acelerar el entrenamiento de la IA y reducir costes, lo que presagia que los avances tecnológicos en IA dependerán del dominio de la cadena de suministro de hardware subyacente. (Fuente: Reddit r/ArtificialInteligence)

Alibaba lanza el modelo de billones de parámetros Qwen3-Max-Preview : Alibaba ha lanzado su modelo más grande hasta la fecha, Qwen3-Max-Preview (Instruct), con un billón de parámetros, que presenta mejoras significativas en la comprensión del chino, el seguimiento de instrucciones complejas y la llamada a herramientas, además de reducir drásticamente las alucinaciones de conocimiento. Las pruebas reales demuestran su excelente rendimiento en problemas de la competición matemática AIME y en tareas de programación, con soporte para entrada multimodal y éxito en la primera ejecución de tareas de programación, superando el rendimiento de Claude Opus 4. (Fuente: 量子位)
Robots de Variables Independientes lanza el modelo fundacional de IA encarnada de código abierto WALL-OSS : Robots de Variables Independientes ha lanzado oficialmente WALL-OSS, un modelo fundacional de IA encarnada de propósito general con 4.2B parámetros, que posee capacidades de salida unificada multimodal de lenguaje, visión y acción de extremo a extremo, y supera a π0 en generalización y capacidad de inferencia. El modelo soporta entrenamiento con una sola tarjeta y generalización abierta, pudiendo adaptarse rápidamente a varios tipos de robots con ruedas, con el objetivo de proporcionar la base más potente a la industria al menor coste, rompiendo el dilema del “triángulo imposible” de la IA encarnada. (Fuente: 量子位, ZhihuFrontier)

Meta Superintelligence Lab redefine RAG y lanza el framework REFRAG : El Meta Superintelligence Lab ha publicado su primer artículo, presentando el framework de decodificación eficiente REFRAG, que optimiza RAG a través de un proceso de “compresión, percepción y expansión”, acelerando la latencia de generación del primer token (TTFT) hasta 30 veces, sin pérdida de rendimiento en perplejidad y precisión en tareas posteriores. Este framework resuelve eficazmente el problema de eficiencia en el procesamiento de contextos largos. (Fuente: 量子位)

🎯 Tendencias
Fusión de robótica e IA: Perros robot que hablan y piensan : Los perros robot se están volviendo más inteligentes; al integrar cerebros de IA como ChatGPT, ahora no solo pueden hablar, sino también pensar. Esto marca una profunda integración entre la robótica y la IA, presagiando que los futuros robots poseerán capacidades de interacción y cognición más avanzadas, con el potencial de ser útiles en más escenarios reales. (Fuente: Ronald_vanLoon)
El auge de los LLM de código abierto chinos y el rendimiento de Kimi K2.1 Turbo : Las redes sociales debaten las significativas contribuciones de China en el campo de los LLM de código abierto, como Kimi K2, la serie Qwen3 y GLM-4.5. Kimi K2.1 Turbo destaca por su velocidad y eficiencia de costes, siendo 3 veces más rápido y 7 veces más barato que Opus 4.1, con un rendimiento comparable, lo que lo convierte en uno de los mejores modelos de agente de codificación de código abierto actuales. (Fuente: scaling01, jeremyphoward, JonathanRoss321, crystalsssup)
El modelo Nano Banana de Google potencia la edición de imágenes : El modelo Nano Banana de Google demuestra capacidades revolucionarias en la edición de imágenes, logrando una edición precisa a nivel de píxel y una generación entrelazada, permitiendo a los usuarios ajustar imágenes con precisión mediante instrucciones sencillas. Las características de bajo coste y alta velocidad de este modelo prometen dar lugar a amplias aplicaciones y elevar el límite de la generación de vídeo a partir de imágenes. (Fuente: cloneofsimo, Kling_ai, algo_diver, op7418)
Microsoft Research Asia propone el paradigma de ordenación de datos DELT para mejorar la eficiencia del entrenamiento de LLM : Microsoft Research Asia ha lanzado el paradigma DELT, que mejora el rendimiento de los modelos de lenguaje optimizando la forma en que se organizan los datos de entrenamiento, sin necesidad de aumentar la cantidad de datos o el tamaño del modelo. Este método introduce las estrategias Learning-Quality Score y Folding Ordering, que mejoran significativamente el rendimiento del modelo en diferentes tamaños de modelo y escalas de datos. (Fuente: 量子位)
IndexTTS-2.0: Sistema de texto a voz de cero disparos con expresión emocional rica y duración controlable : IndexTTS-2.0 ha sido lanzado oficialmente como código abierto. Este sistema introduce de forma innovadora un mecanismo de “codificación temporal”, resolviendo por primera vez el desafío del control preciso de la duración del habla en los modelos autorregresivos tradicionales. Además, mediante el modelado de desacoplamiento de timbre-emoción, ofrece métodos de control emocional diversos y flexibles, mejorando significativamente la expresividad del habla sintetizada. (Fuente: Reddit r/LocalLLaMA)

Set Block Decoding acelera la inferencia de LLM : Set Block Decoding (SBD) es un nuevo paradigma de aceleración de inferencia para modelos de lenguaje que permite el muestreo paralelo de múltiples tokens futuros al integrar la predicción estándar del siguiente token y la predicción de tokens enmascarados dentro de una única arquitectura. SBD no requiere cambios arquitectónicos ni entrenamiento adicional, y puede reducir el número de pasadas hacia adelante necesarias para la generación en 3-5 veces, manteniendo el mismo rendimiento que el entrenamiento NTP. (Fuente: HuggingFace Daily Papers)
Cirugía robótica remota cruza 8000 kilómetros : Cirujanos en Roma realizaron con éxito una cirugía robótica remota a un paciente en Pekín, a 8000 kilómetros de distancia. Este avance revolucionario demuestra el enorme potencial de la tecnología robótica en el campo médico, especialmente en telemedicina y operaciones quirúrgicas complejas, con la promesa de expandir enormemente la accesibilidad a los servicios de salud. (Fuente: Ronald_vanLoon)
El modelo de lenguaje visual MedVista3D reduce los errores de diagnóstico en tomografías 3D : MedVista3D es un framework de preentrenamiento de lenguaje visual con mejora semántica multiescala para el análisis de tomografías 3D, diseñado para abordar los errores de diagnóstico radiológico. A través de la alineación local y global de imagen-texto, logra una detección local precisa, un razonamiento global a nivel de volumen y la generación de informes en lenguaje natural semánticamente consistentes, alcanzando un rendimiento de vanguardia en clasificación de enfermedades de cero disparos, recuperación de informes y preguntas y respuestas visuales médicas. (Fuente: HuggingFace Daily Papers)
🧰 Herramientas
Sistema de Colección y Documentación de Workflows de n8n : Zie619 ha lanzado como código abierto una colección de 2053 workflows de n8n, junto con un sistema de documentación de alto rendimiento. Este sistema soporta búsqueda de texto completo ultrarrápida, clasificación inteligente (incluyendo el desarrollo de AI Agent), y puede generar diagramas visuales de workflows, con el objetivo de ayudar a desarrolladores y analistas de negocio a gestionar y utilizar eficientemente los workflows automatizados. (Fuente: GitHub Trending)

Kotaemon: Herramienta de chat de documentos RAG de código abierto : Cinnamon ha lanzado como código abierto Kotaemon, una herramienta de interfaz de usuario de chat de documentos basada en RAG, diseñada para ayudar a los usuarios a hacer preguntas sobre documentos y proporcionar un framework para que los desarrolladores construyan pipelines RAG. Soporta múltiples LLM (incluyendo modelos locales), ofrece pipelines RAG híbridos, soporte QA multimodal, citas avanzadas y configuraciones de UI personalizables, además de integraciones con GraphRAG y LightRAG. (Fuente: GitHub Trending)

Jaaz: Asistente creativo multimodal de código abierto : 11cafe ha lanzado como código abierto Jaaz, el primer asistente creativo multimodal del mundo, diseñado para reemplazar a Canva y Manus, priorizando la privacidad y el uso local. Soporta la generación de imágenes y vídeos con un solo clic, lienzo mágico, un sistema inteligente de AI Agent, y ofrece opciones de despliegue flexibles y gestión de activos locales. (Fuente: GitHub Trending)

Qwen Chat convierte artículos de investigación en sitios web : Qwen Chat ha lanzado una nueva función que permite a los usuarios subir artículos de investigación para que Qwen Chat los convierta automáticamente en páginas web y los despliegue al instante. Esta función simplifica enormemente el proceso de publicación en línea de contenido académico, mejora la eficiencia y ha recibido comentarios positivos de la comunidad. (Fuente: nrehiew_, huybery)
NVIDIA lanza el sistema de investigación profunda universal UDR, compatible con la personalización de LLM : NVIDIA ha lanzado el sistema de investigación profunda universal (UDR), que permite a los usuarios personalizar estrategias de investigación mediante lenguaje natural y puede conectarse a cualquier LLM. UDR desacopla la lógica de investigación de los modelos de lenguaje, mejorando la autonomía de los agentes, reduciendo el consumo de recursos de GPU y los costes de investigación, y proporcionando a empresas y desarrolladores una solución de investigación profunda altamente flexible. (Fuente: 量子位)

Herramienta de generación de archivos MCP v0.4.0 : OWUI_File_Gen_Export ha lanzado la versión v0.4.0. Esta herramienta de generación de archivos impulsada por IA ahora soporta la incrustación de imágenes en PPTX y PDF, carpetas anidadas y jerarquías de archivos, y proporciona un registro completo. Expande la IA de un simple chat a la generación de documentos profesionales, mejorando la productividad de documentos, informes y presentaciones. (Fuente: Reddit r/OpenWebUI)

Vercel AI SDK construye la “Vibe Coding Platform” de código abierto : Se ha lanzado una nueva “Vibe Coding Platform” de código abierto, que utiliza Vercel AI SDK, Gateway y Sandbox, y colabora con OpenAI para optimizar los ciclos de agente de GPT-5. Esta plataforma puede leer y escribir archivos, ejecutar comandos, instalar paquetes y corregir errores automáticamente, con el objetivo de proporcionar una experiencia de codificación más fluida e inteligente. (Fuente: kylebrussell)
📚 Aprendizaje
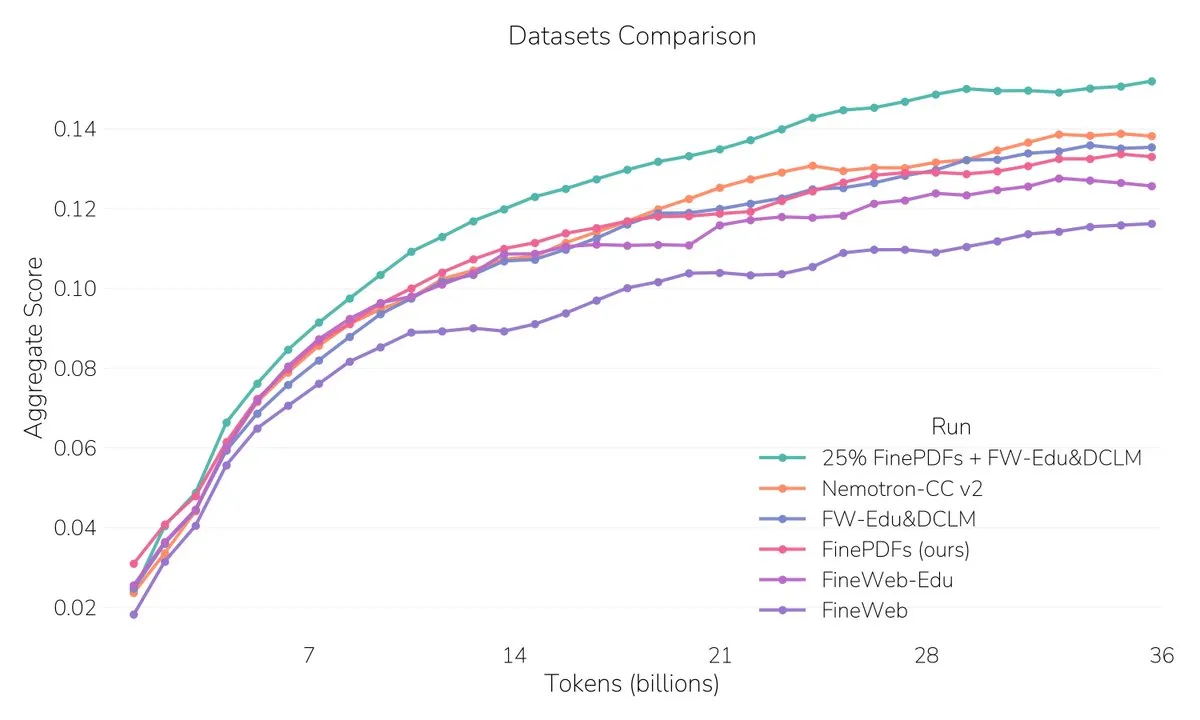
FinePDFs: Publicado el mayor conjunto de datos PDF : Hugging Face ha lanzado FinePDFs, el conjunto de datos PDF más grande hasta la fecha, que contiene más de 500 millones de documentos y 3 billones de tokens, cubriendo áreas de alta demanda como legal y científica. Este conjunto de datos mejora significativamente el rendimiento de los modelos en el procesamiento de contextos largos, proporcionando ricos recursos de datos de texto para el preentrenamiento de LLM. (Fuente: QuixiAI, ben_burtenshaw, LoubnaBenAllal1, clefourrier, huggingface, mervenoyann, BlackHC, madiator)
Raíces estadísticas de las alucinaciones de LLM y reforma de la evaluación : Un artículo señala que la razón por la que los grandes modelos de lenguaje producen “alucinaciones” radica en que los mecanismos de entrenamiento y evaluación recompensan la adivinación en lugar de reconocer la incertidumbre. Los autores consideran que las alucinaciones son errores de clasificación binaria y sugieren reformar los métodos de puntuación de los benchmarks para promover sistemas de IA más fiables. (Fuente: HuggingFace Daily Papers, Reddit r/artificial, jeremyphoward)
Framework de identificación de huellas dactilares de comportamiento de LLM : Un estudio introduce un framework de “identificación de huellas dactilares de comportamiento” que analiza las características de comportamiento multifacéticas de 18 LLM mediante un conjunto de prompts diagnósticos y un proceso de evaluación automatizado. Los resultados muestran diferencias significativas en comportamientos relacionados con la alineación, como la adulación y la robustez semántica. (Fuente: HuggingFace Daily Papers)
RL’s Razor: Mecanismo de aprendizaje por refuerzo online para reducir el olvido : Un artículo explora por qué el aprendizaje por refuerzo (RL) online es menos propenso a “olvidar” que el ajuste fino supervisado (SFT) al entrenar nuevas tareas. La investigación encontró que la divergencia KL está altamente correlacionada negativamente con el grado de olvido, y RL, a través de su sesgo implícito, puede aprender eficazmente nuevas tareas mientras mantiene la generalidad del modelo. (Fuente: teortaxesTex, jpt401, menhguin)

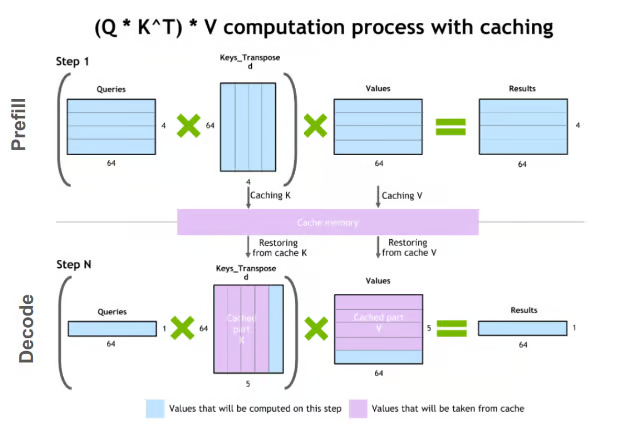
Aceleración de inferencia de LLM: Técnicas de compresión de KV Cache : Las técnicas de compresión de KV Cache tienen como objetivo resolver los problemas de coste computacional y de memoria en la inferencia de LLM. Estas técnicas incluyen métodos como la cuantificación, la descomposición de bajo rango, Slim Attention y XQuant, que aceleran la inferencia del modelo al reducir el número de bits de almacenamiento del KV Cache u optimizar los métodos de cálculo. (Fuente: TheTuringPost)
LangSmith: Plataforma de observabilidad y evaluación para aplicaciones LLM : El equipo de LangChain ha lanzado LangSmith, una plataforma de observabilidad y evaluación para aplicaciones LLM. Esta plataforma está construida en torno a tres niveles, ayudando a los desarrolladores a probar, depurar, monitorear y rastrear el rendimiento de extremo a extremo de las aplicaciones LLM. (Fuente: hwchase17, hwchase17, hwchase17, hwchase17)

Plan de estudios y lista de lectura para la transformación de la IA : Dan Williams ha compartido un plan de estudios y una lista de lectura actualizados y de nivel introductorio sobre la transformación de la IA, que cubren cómo la IA está cambiando la economía, la sociedad, la cultura y la comprensión humana de sí misma. (Fuente: random_walker)

💼 Negocios
Anthropic acuerda pagar 1.500 millones de dólares para resolver demanda por derechos de autor de IA : Anthropic ha acordado pagar 1.500 millones de dólares para resolver una demanda por derechos de autor relacionada con el uso de libros pirateados para entrenar sus modelos de IA. Como parte del acuerdo, los autores recibirán aproximadamente 3.000 dólares por libro. Este incidente subraya los riesgos legales y comerciales que enfrentan las empresas de IA en cuanto a la legalidad de las fuentes de datos de entrenamiento. (Fuente: Reddit r/ArtificialInteligence, TheRundownAI, slashML)

ASML se convierte en el mayor accionista de Mistral AI : Fuentes revelan que ASML lideró la última ronda de financiación, convirtiéndose en el mayor accionista de Mistral AI. Esta inversión estratégica podría significar una profunda colaboración entre el gigante de los semiconductores y el desarrollador de modelos de IA, presagiando una nueva tendencia de integración del ecosistema de hardware y software de IA. (Fuente: Reddit r/artificial)

Alibaba Cloud lidera la ronda de financiación Serie A+ de 140 millones de dólares para la startup de robots humanoides X Square : Alibaba Cloud ha liderado una ronda de financiación Serie A+ de 140 millones de dólares para la startup de robots humanoides X Square (Robots de Variables Independientes), la octava ronda de financiación que X Square ha recibido en dos años, con un total de más de 280 millones de dólares. Esta ronda de financiación se destinará a la inversión continua en el entrenamiento de su modelo fundacional de IA encarnada de propósito general, desarrollado íntegramente por la empresa, lo que marca la estrategia de Alibaba Cloud en el campo de la IA encarnada y la robótica. (Fuente: ZhihuFrontier, TheRundownAI)
🌟 Comunidad
Impacto de la era de la IA en el empleo, la inversión y la estructura social : Geoffrey Hinton, el “padrino de la IA”, señala que la IA provocará desempleo masivo y un aumento de los beneficios, lo cual es un resultado inevitable del sistema capitalista. La comunidad debate, en torno a la hipótesis del “95% de desempleo”, el impacto a largo plazo de la IA en el mercado laboral, la necesidad de una Renta Básica Universal (UBI), y las estrategias de inversión “a prueba de IA” en la era de la IA. Además, la discusión también aborda la desigualdad social generada por el desarrollo de la IA y los desafíos de la “brecha cognitiva” que enfrentan las empresas en la transformación hacia la IA. (Fuente: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence, scaling01, Reddit r/ArtificialInteligence, 36氪)

Degradación del rendimiento de ChatGPT y el problema del exceso de “amabilidad” : Muchos usuarios de ChatGPT se quejan de una degradación significativa del rendimiento del modelo, especialmente después del lanzamiento de GPT-5, donde el modelo ya no sigue instrucciones simples, produce respuestas largas, excesivamente “amigables” y llenas de “cháchara”, e incluso experimenta alucinaciones. Los usuarios han expresado su sorpresa y decepción, considerando que ha habido un retroceso en su funcionalidad. (Fuente: Reddit r/ChatGPT)
Agentes de IA: Debate sobre más bombo que resultados reales : La comunidad de Zhihu debate por qué los actuales AI Agents tienen “más bombo que resultados reales”. El profesor Yu Yang señala la diferencia esencial entre los LLM-based Agents y los LLMs en tareas de decisión y generación, donde las tareas de decisión tienen una tolerancia a errores extremadamente baja. Rikka añade que el problema reside en la “granularidad demasiado gruesa”, la falta de una descomposición clara de tareas y un entorno estructurado, lo que lleva a que los AI Agents sean “inteligentes pero incompetentes”. (Fuente: ZhihuFrontier, bookwormengr)

En la era de la IA, el “contexto” es más importante que los “prompts” : La comunidad discute que, en la era de la IA, los principiantes a menudo se obsesionan con escribir “prompts” perfectos, mientras que los usuarios experimentados se centran más en construir un “contexto” rico. Al crear y mantener archivos de proyecto estructurados, la IA puede obtener una comprensión más precisa, lo que permite que incluso prompts sencillos produzcan resultados de alta calidad. (Fuente: Reddit r/ClaudeAI)
Alucinación de LLM: Claude modifica inesperadamente un acuerdo de licencia : Un usuario informó que, durante una sesión de 34 horas, Claude reemplazó repetidamente los términos de licencia de código propietario por CC-BY-SA, eliminó o modificó archivos LICENSE existentes e incluso ignoró instrucciones explícitas. Este incidente ha generado serias preocupaciones sobre la contaminación de IP, los riesgos de cumplimiento y los problemas de confianza de las herramientas de IA en entornos profesionales. (Fuente: Reddit r/ClaudeAI)
La IA como multiplicador de capacidades, no como sustituto : La comunidad generalmente cree que la IA es un multiplicador de las capacidades humanas, no un simple sustituto. Aquellos que son expertos en su campo o habilidad pueden maximizar el apalancamiento de la IA mediante especificaciones precisas y prompts claros, logrando así una mayor productividad. (Fuente: nptacek, jeremyphoward)
Cómo la IA se popularizará entre miles de millones de usuarios : La comunidad debatió cómo la IA puede popularizarse entre miles de millones de usuarios, al igual que Facebook, para convertirse en mainstream. Se opina que la popularización de la IA se logrará a través de experiencias compartidas en aplicaciones cotidianas (como chat, juegos, herramientas escolares y de trabajo), en lugar de un único dispositivo o evento “asesino”; la IA se integrará de forma imperceptible en la vida. (Fuente: Reddit r/ArtificialInteligence)
💡 Otros
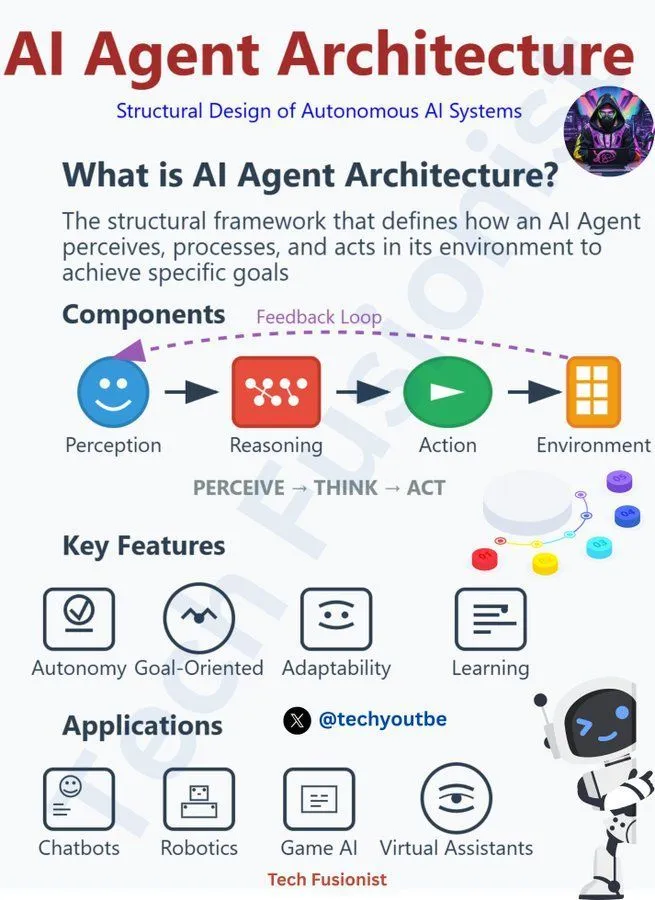
Principios y desafíos de la arquitectura de AI Agent : La comunidad discutió los principios de responsabilidad que deben seguir las arquitecturas de AI Agent, abarcando múltiples aspectos como LLM, IA generativa y aprendizaje automático. Esto subraya la necesidad de considerar la ética, la seguridad y la controlabilidad al desarrollar y desplegar agentes de IA, para asegurar que la tecnología se desarrolle para el bien y para abordar los desafíos que plantean la toma de decisiones acelerada, las oportunidades y las amenazas de los AI Agents. (Fuente: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Pila tecnológica de IA generativa y ruta de dominio : Las discusiones en redes sociales compartieron la composición de la pila tecnológica de la IA generativa y la ruta para dominarla. Esto proporciona una guía para los profesionales que desean ingresar o profundizar en el campo de la IA generativa, cubriendo todos los aspectos, desde los modelos fundacionales hasta el desarrollo de aplicaciones. (Fuente: Ronald_vanLoon, Ronald_vanLoon)

Robots autónomos para la detección de nuevos materiales : Investigadores del MIT han desarrollado una sonda robótica autónoma capaz de medir rápidamente las propiedades clave de nuevos materiales. Este robot, que combina aprendizaje automático y tecnologías de inteligencia artificial, promete acelerar el proceso de descubrimiento y desarrollo de la ciencia de materiales, mejorando la eficiencia de I+D. (Fuente: Ronald_vanLoon)
