
Palabras clave:supercomputadora, alucinación de IA, infracción de derechos de autor, modelo de lenguaje grande, chip de IA, supercomputadora JUPITER, artículo sobre alucinación de IA de OpenAI, caso de conciliación por derechos de autor de Anthropic, modelo Qwen3-Max-Preview, chip de IA de desarrollo propio de OpenAI
🔥 Foco
Lanzamiento de JUPITER, el primer superordenador exascale de Europa: JUPITER, el primer superordenador exascale de Europa, ya está en funcionamiento, impulsado por NVIDIA Grace Hopper. Este sistema es el superordenador más eficiente energéticamente del mundo, fusionando la AI con el HPC, y está diseñado para lograr avances en campos como la ciencia climática, la neurociencia y la simulación cuántica. Esto marca un paso importante para Europa en la computación de alto rendimiento y la investigación de AI, con el potencial de acelerar descubrimientos científicos de vanguardia. (Fuente: nvidia)

OpenAI publica un estudio que revela la raíz de las alucinaciones de la AI: OpenAI ha publicado el estudio “Por qué los modelos de lenguaje alucinan”, señalando que la causa fundamental de las alucinaciones de la AI radica en los mecanismos actuales de entrenamiento y evaluación que recompensan al modelo por adivinar en lugar de admitir la incertidumbre. Durante la fase de preentrenamiento, los modelos carecen de etiquetas de “verdadero/falso”, lo que les dificulta distinguir entre información válida e inválida, y son propensos a inventar, especialmente al procesar hechos de baja frecuencia. OpenAI insta a actualizar las métricas de evaluación para penalizar los errores seguros y recompensar la expresión de incertidumbre, promoviendo así modelos más “honestos”. (Fuente: source, source, source, source, source)

Anthropic llega a un acuerdo de 1.500 millones de dólares por infracción de derechos de autor de AI: Anthropic ha llegado a un acuerdo con autores de libros en un caso de infracción de derechos de autor de AI, aceptando pagar al menos 1.500 millones de dólares. El acuerdo cubre aproximadamente 500.000 obras protegidas por derechos de autor, con un promedio de unos 3.000 dólares por obra (antes de honorarios de abogados), y se compromete a destruir los conjuntos de datos pirateados. Este caso es el primer acuerdo de demanda colectiva relacionada con la AI y los derechos de autor en EE. UU., y podría sentar un precedente para la definición legal de la AI generativa y la propiedad intelectual. (Fuente: source, source, source, source, source, source, source)

🎯 Tendencias
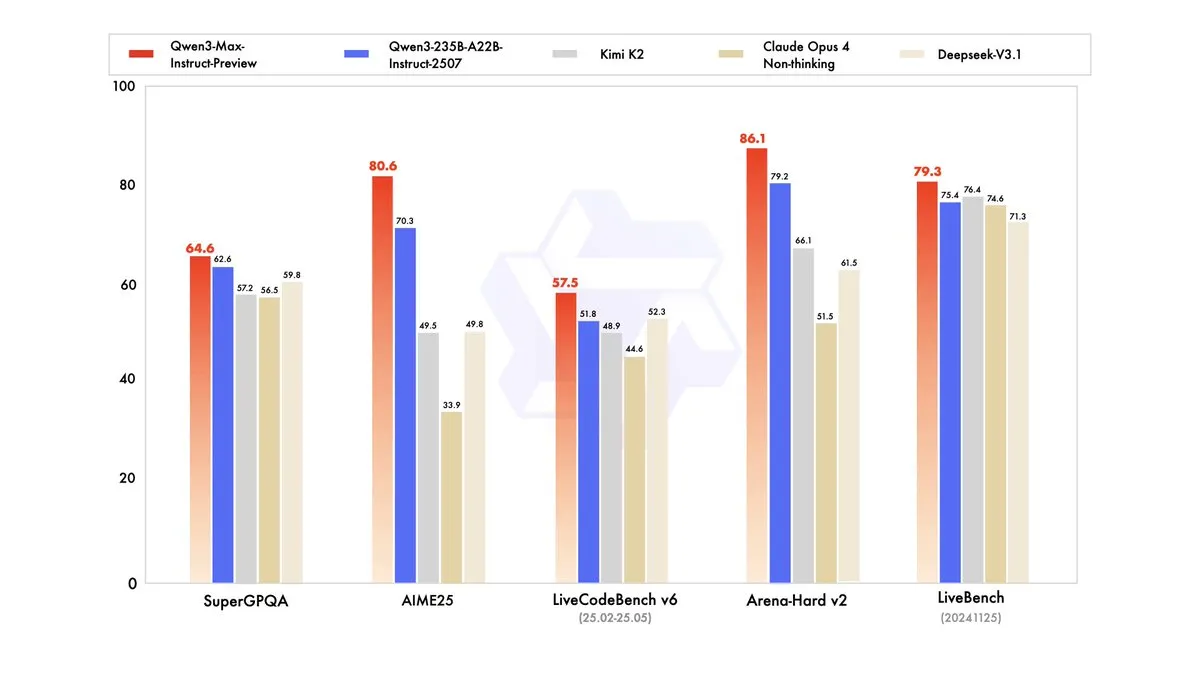
Qwen3-Max-Preview lanzado con más de un billón de parámetros: Alibaba Cloud Qwen (Tongyi Qianwen) ha lanzado su modelo más grande hasta la fecha, Qwen3-Max-Preview (Instruct), con más de un billón de parámetros. El modelo ya está disponible a través de Qwen Chat y la API de Alibaba Cloud, y ha superado al anterior Qwen3-235B-A22B-2507 en pruebas de referencia. Las pruebas internas y los comentarios de los primeros usuarios indican mejoras significativas en rendimiento, amplitud de conocimientos, capacidad de diálogo, tareas de Agent y seguimiento de instrucciones. El modelo también ha sido lanzado en OpenRouter, lo que ha generado discusiones en la comunidad sobre si será de código abierto. (Fuente: source, source, source, source, source, source, source, source)
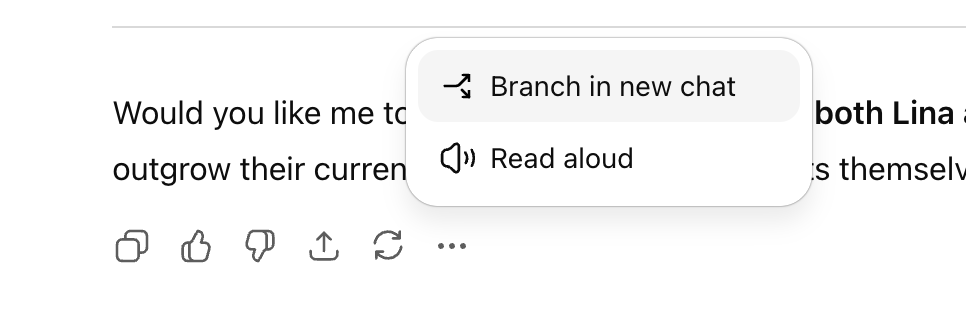
ChatGPT añade la función de conversación ramificada para mejorar la exploración multilínea: OpenAI ha lanzado una nueva función de “conversación ramificada” para la versión web de ChatGPT, que permite a los usuarios crear nuevas ramas en cualquier respuesta para explorar múltiples líneas de pensamiento sin necesidad de iniciar una nueva conversación o preocuparse por un contexto demasiado largo. Esta función, combinada con la memoria, hace que las conversaciones sean más continuas y flexibles, transformando el diálogo de lineal a una estructura de árbol, lo que ayuda a los usuarios a retener diferentes ideas y mejora la eficiencia de la colaboración con el asistente de AI. (Fuente: source, source, source)
OpenAI planea lanzar una plataforma de contratación de AI y desarrollar sus propios chips de AI: OpenAI planea lanzar una plataforma de contratación impulsada por AI a mediados de 2026, compitiendo con LinkedIn, y ofrecerá una certificación de “fluidez en AI”. Además, para reducir su dependencia de Nvidia, OpenAI comenzará a producir sus propios chips de AI diseñados a medida el próximo año. Estas iniciativas demuestran la ambición de OpenAI de expandir su ecosistema de aplicaciones de AI y optimizar su infraestructura de hardware. (Fuente: source, source, source, source, source)

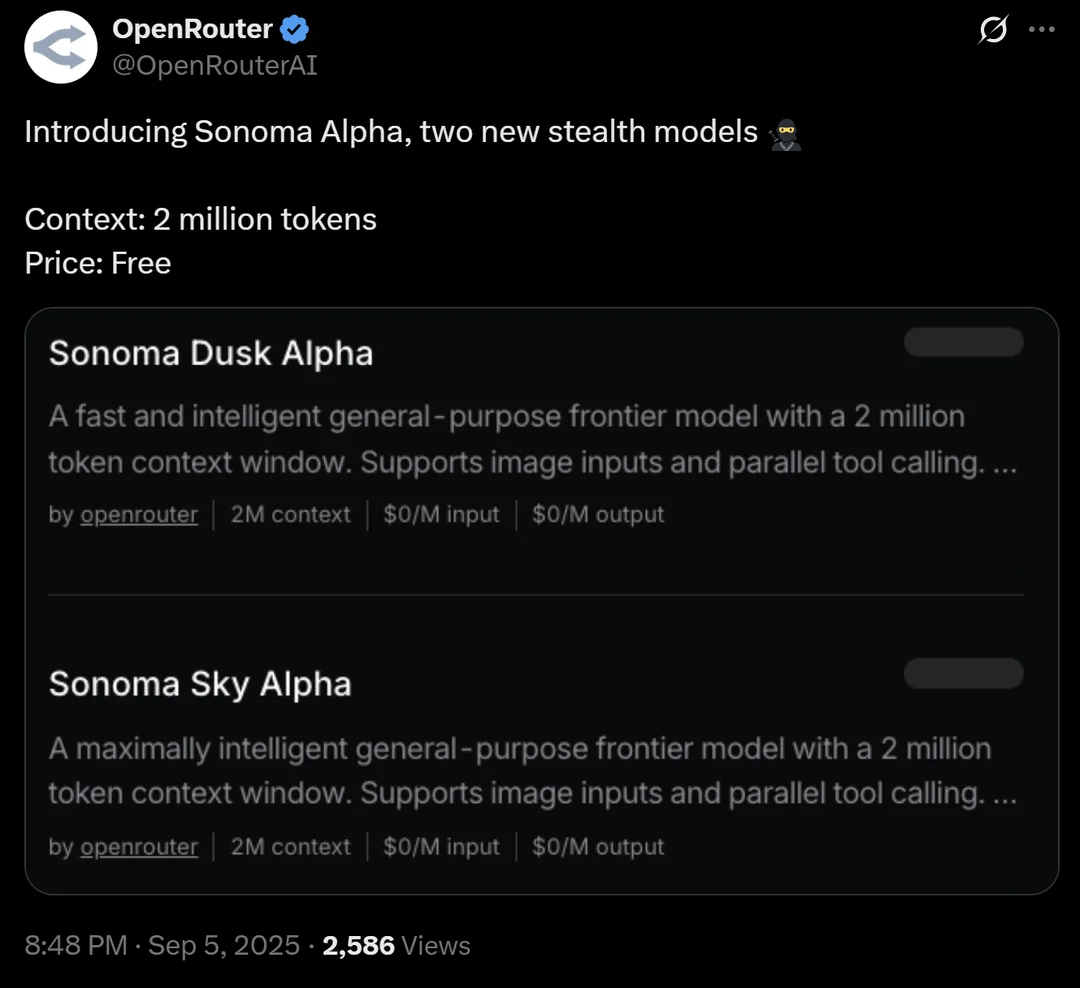
OpenRouter lanza el modelo sigiloso Sonoma Alpha con una ventana de contexto de 2 millones: La plataforma OpenRouter ha lanzado un modelo “sigiloso” llamado Sonoma Alpha, cuya característica principal es el soporte para una ventana de contexto de 2 millones y su disponibilidad gratuita. La comunidad especula que este modelo es de la serie Grok de xAI, ya que su característica de “buscar la verdad al máximo” se alinea con la filosofía de Elon Musk. El modelo destaca en la generación de código, lógica y tareas científicas, lo que presagia el potencial de los modelos de contexto ultralargo en aplicaciones prácticas. (Fuente: source, source, source)
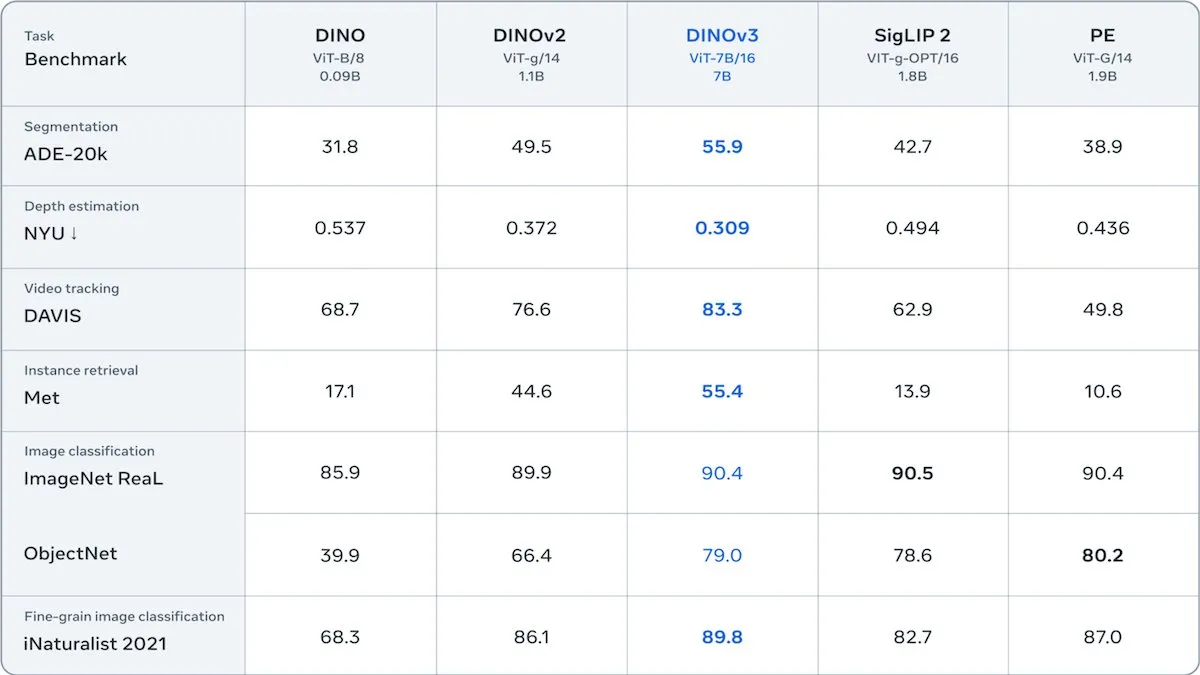
Meta lanza DINOv3, un Transformer visual auto-supervisado: Meta ha lanzado DINOv3, un modelo Transformer visual auto-supervisado de 6.700 millones de parámetros, que mejora significativamente la calidad de las incrustaciones de imágenes en tareas como la segmentación de imágenes y la estimación de profundidad. El modelo, entrenado con 1.700 millones de imágenes de Instagram, introduce un nuevo término de pérdida para mantener la diversidad a nivel de parche, superando las limitaciones de los datos sin etiquetar. DINOv3 se lanza bajo una licencia que permite el uso comercial pero prohíbe las aplicaciones militares, proporcionando una potente red troncal auto-supervisada para aplicaciones visuales posteriores. (Fuente: DeepLearningAI)
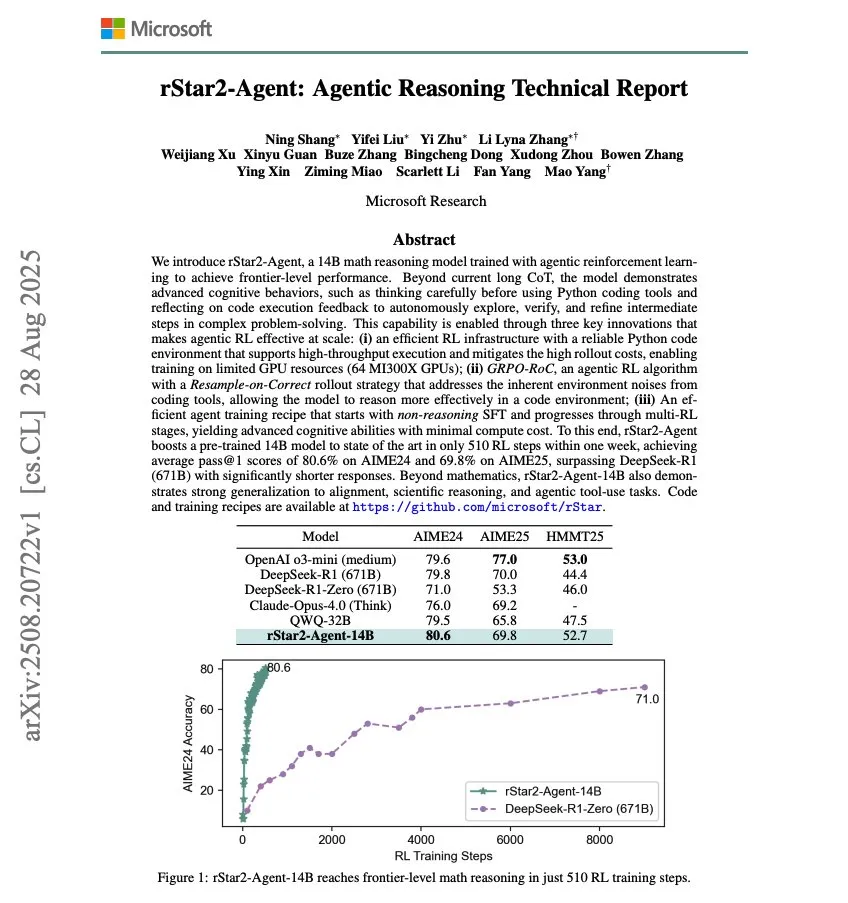
Microsoft lanza rStar2-Agent, un modelo de razonamiento matemático de 14B: Microsoft ha lanzado rStar2-Agent, un modelo de razonamiento matemático de 14B, entrenado con Agentic RL, que ha logrado capacidades de razonamiento matemático de vanguardia con solo 510 pasos de entrenamiento de RL. Esta investigación demuestra el potencial de mejorar rápidamente el rendimiento de los modelos de AI en dominios específicos a través del aprendizaje por refuerzo. (Fuente: dair_ai)
OpenAI establece oai Labs para explorar nuevas interfaces de colaboración humano-AI: OpenAI ha anunciado la creación de oai Labs, dirigido por Joanne Jang, que se centrará en la investigación y prototipado de nuevas interfaces para la colaboración humano-AI. El equipo tiene como objetivo ir más allá de los modelos de chat y agentes existentes, explorando nuevos paradigmas y herramientas para mejorar la forma en que las personas interactúan, piensan, crean, aprenden y se conectan con la AI. (Fuente: source, source)
Feria IFA 2025: Tendencias en hardware de AI y robótica: En la IFA 2025 en Berlín, los fabricantes chinos dominan completamente el mercado de gafas de AI, con marcas como Rokid y Thunder Innovation exhibiendo múltiples productos y explorando activamente ecosistemas en el extranjero. En el campo de la robótica, Unitree Robotics mostró su robot humanoide G1 y el perro robot Go 2, atrayendo mucha atención; Midea y Ubtech también exhibieron robots de servicio doméstico. Robots de limpieza inteligentes, robots cortacésped, robots de piscina y otros robots funcionales florecen, con mejoras tecnológicas que los acercan a la vida diaria. La AI se ha integrado profundamente en electrodomésticos, teléfonos móviles, PC y otros productos electrónicos de consumo, enfatizando la implementación práctica y la experiencia “sin fisuras”. (Fuente: 36氪)

OpenBMB lanza MiniCPM 4.1-8B, el primer LLM de atención dispersa entrenable de código abierto: OpenBMB ha lanzado el modelo MiniCPM 4.1-8B, el primer LLM de inferencia de código abierto que utiliza atención dispersa entrenable. Este modelo supera a otros de su tamaño en 15 tareas, mejora la velocidad de inferencia en 3 veces y emplea una arquitectura eficiente. Esto marca un progreso significativo en la capacidad de inferencia y eficiencia de los modelos de código abierto, proporcionando a los investigadores una nueva y potente herramienta. (Fuente: teortaxesTex)

🧰 Herramientas
Open Instruct: Biblioteca de código de alto rendimiento para investigación de RL: Open Instruct, mantenido por AllenAI, es una biblioteca de código de investigación de aprendizaje por refuerzo (RL) de alto rendimiento, diseñada para proporcionar implementaciones de RL fáciles de modificar y con un rendimiento excepcional. Este proyecto, liderado por Finbarr y otros, está en constante mejora, ofreciendo a los investigadores una plataforma fundamental para experimentos y desarrollo de RL. (Fuente: source, source)
Grok: Comprensión y resumen de PDF: Grok de xAI ha lanzado una función de lector de PDF, que permite a los usuarios resaltar cualquier parte y hacer clic en “explicar” para comprender el contenido, o hacer clic en “citar” para hacer preguntas específicas. Esto mejora enormemente la eficiencia y la profundidad de comprensión de los usuarios al procesar documentos PDF extensos. (Fuente: source, source)
Devin AI: Analista de datos para EightSleep: Devin AI de Cognition ha sido utilizado por el equipo de EightSleep como analista de datos, manejando diversas tareas desde “anomalías digitales” hasta consultas de datos ad-hoc, reduciendo el tiempo de finalización de análisis/paneles de días a horas, lo que mejora significativamente la eficiencia en la obtención de información de datos. Esto demuestra el potente potencial de aplicación de los agentes de AI en el análisis de datos empresariales. (Fuente: cognition)
Funcionalidad de subagentes de Claude Code explicada: Claude Code, a través de su herramienta Task, permite a los usuarios crear tres tipos de subagentes especializados: de propósito general, de configuración de línea de estado y de configuración de estilo de salida. Estos subagentes tienen sus propios conjuntos de herramientas y pueden manejar tareas complejas, configurar ajustes o crear estilos de salida. Los subagentes son sin estado, se ejecutan una vez y devuelven resultados, siendo adecuados para delegar búsquedas complejas, análisis o configuraciones especializadas para mantener el enfoque de la conversación principal. (Fuente: Vtrivedy10)
LlamaIndex SemTools: Herramienta de búsqueda y análisis de documentos para Agentes de línea de comandos: LlamaIndex ha lanzado SemTools, un kit de herramientas CLI para análisis y búsqueda semántica. Combinando herramientas Unix con capacidades de búsqueda semántica, los Agentes pueden procesar documentos complejos de manera eficiente, proporcionando respuestas más detalladas y precisas, cubriendo tareas como búsqueda, referencias cruzadas y análisis temporal. Esto demuestra que la combinación de herramientas Unix existentes con la búsqueda semántica puede crear trabajadores del conocimiento potentes. (Fuente: source, source)
Replit Agent: Asistente de codificación de AI de Prompt a aplicación de producción: Replit Agent celebra su primer aniversario. Esta herramienta ha evolucionado desde la finalización de código y la edición de chat con AI hasta la capacidad de transformar directamente un prompt en una aplicación de nivel de producción. Replit destaca su capacidad para automatizar la configuración del entorno de desarrollo, la instalación de paquetes, la configuración de bases de datos y la implementación, con el objetivo de revolucionar el proceso de desarrollo de software. (Fuente: source, source)

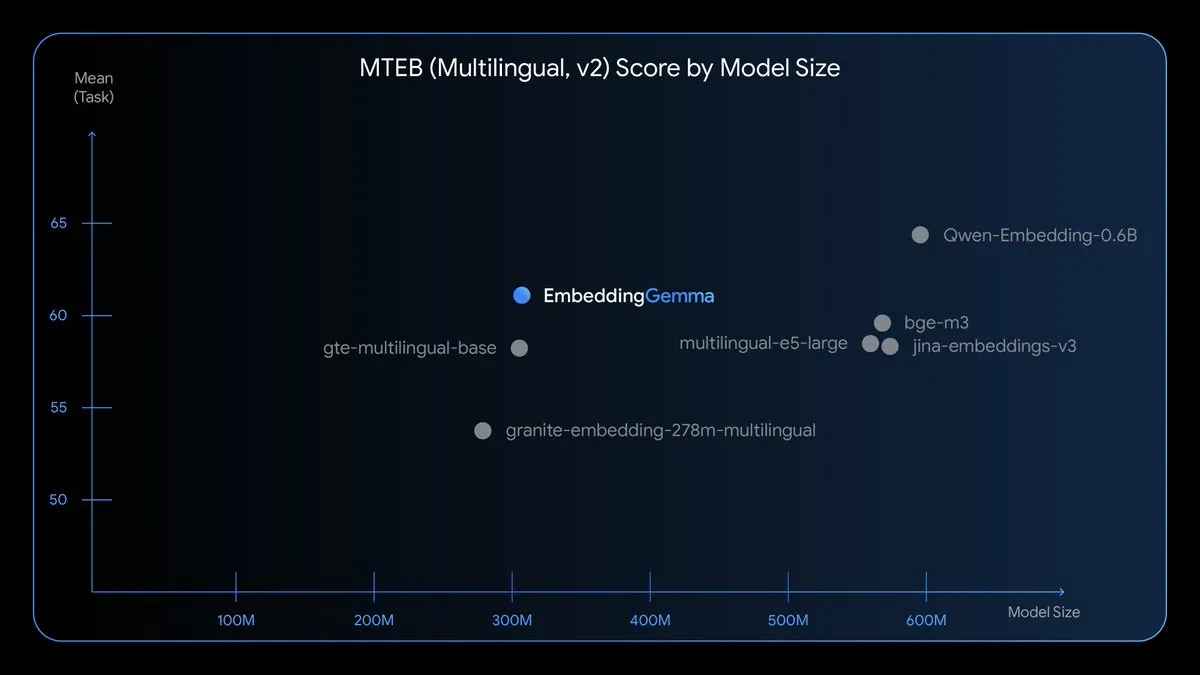
EmbeddingGemma: Modelo de incrustación multilingüe en el dispositivo: EmbeddingGemma es un nuevo modelo de incrustación multilingüe de código abierto, con 308M parámetros, entrenado en Gemma 3 y compatible con más de 100 idiomas. Este modelo está optimizado para velocidad, privacidad y eficiencia, puede funcionar sin conexión, ocupa menos de 200MB de memoria y tiene un tiempo de inferencia inferior a 15ms, lo que permite RAG, búsqueda semántica y clasificación en el dispositivo. (Fuente: TheTuringPost)
Nano Banana Hackathon: Desafío de AI generativa: Kaggle organizará el Nano Banana Hackathon, ofreciendo 400.000 dólares en premios y acceso gratuito a la API de Gemini para usar Gemini 2.5 Flash Image. Los participantes crearán con tecnologías de AI generativa en 48 horas, y la competencia evaluará la innovación, la ejecución técnica, el impacto y la presentación. (Fuente: source, source, source)

📚 Aprendizaje
Cómo construir un AI Agent desde cero: Python_Dv ha compartido un tutorial y una guía para construir un AI Agent desde cero, cubriendo tecnologías clave como LLM, AI generativa y Machine Learning. Este recurso proporciona a los desarrolladores una ruta de inicio para la práctica del desarrollo de AI Agent. (Fuente: Ronald_vanLoon)

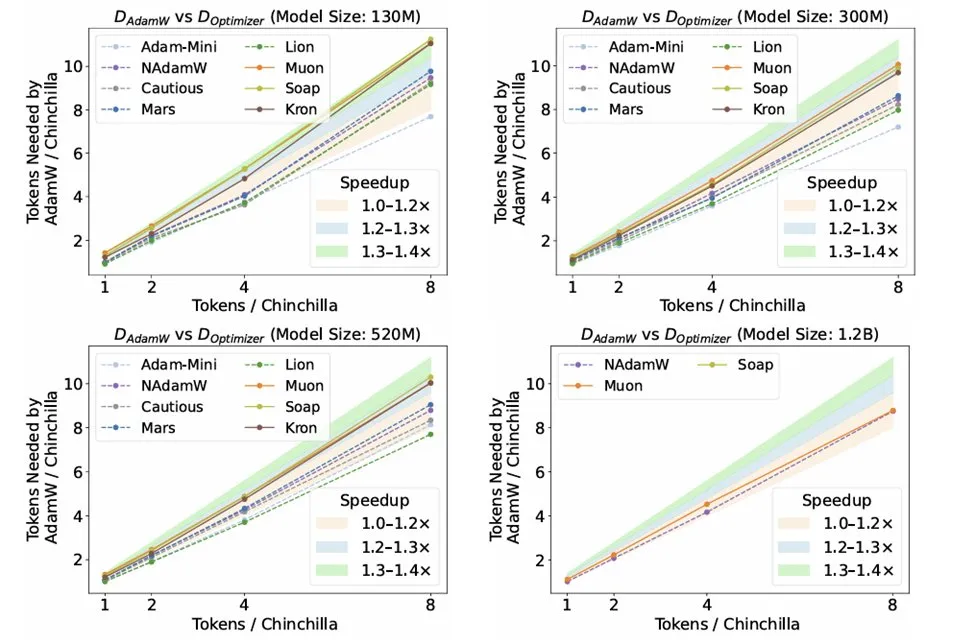
Investigación sobre optimizadores en la inferencia de LLM: El estudio “Fantastic Pretraining Optimizers and Where to Find Them” de Kaiyue Wen y otros, realiza un riguroso benchmark de 10 optimizadores. La investigación revela que, a pesar de la atención prestada a optimizadores como Muon y Mars, su aceleración en comparación con AdamW es solo de alrededor del 10% después de un ajuste estricto de hiperparámetros y escalado. Esto subraya la necesidad de ser cautelosos al evaluar nuevos optimizadores, evitando problemas de ajuste de línea base insuficiente o escala limitada. (Fuente: source, source, source)
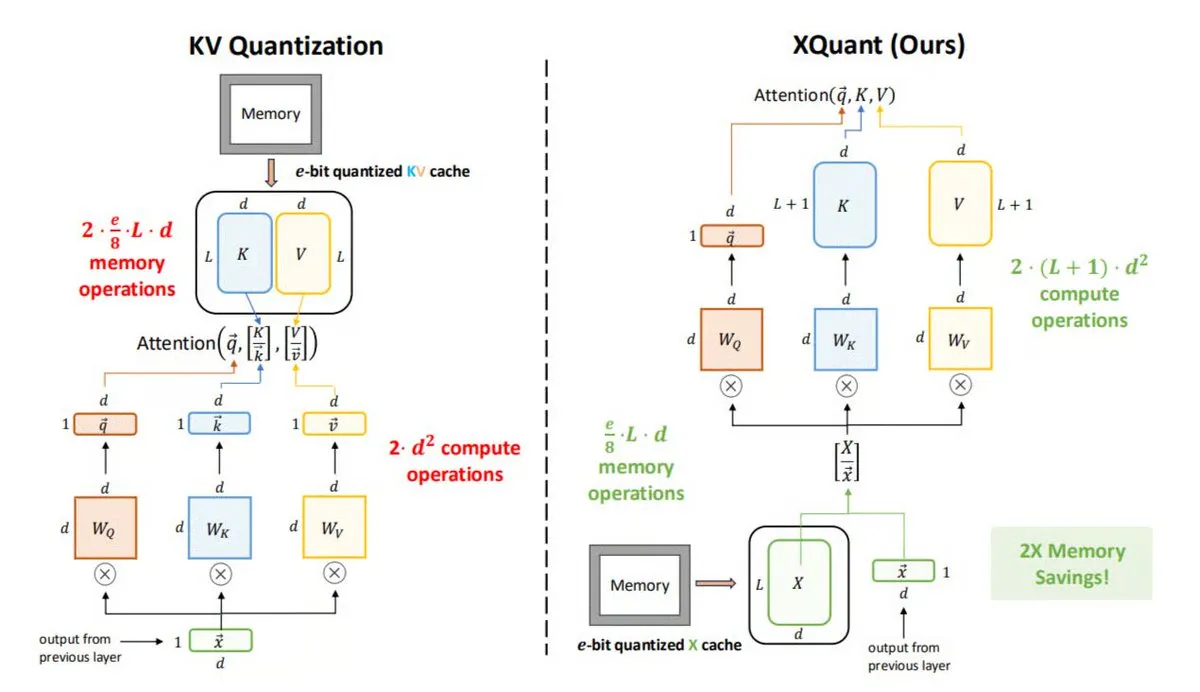
XQuant: Técnica de optimización de memoria en la inferencia de LLM: La UC Berkeley ha propuesto XQuant, un nuevo método de optimización de memoria para LLM que puede reducir el uso de memoria hasta 12 veces. XQuant no almacena el caché KV tradicional, sino que cuantifica y almacena las activaciones de entrada de la capa (X), regenerando Key y Value bajo demanda a partir de X durante la inferencia. Esta técnica logra una inferencia más rápida y eficiente con un pequeño aumento en la computación, sin sacrificar la precisión. (Fuente: TheTuringPost)
Diseño de Prompts para LLM: Metodología Mom Test: Tz compartió la metodología de aplicar el enfoque de investigación de usuarios de “Mom Test” al diseño de prompts para LLM, enfatizando evitar preguntas que lleven al modelo a dar “respuestas bonitas y vacías”. En cambio, se deben construir prompts que obliguen al modelo a dar respuestas verificables, basadas en hechos o con restricciones claras. El núcleo es evitar opiniones, suposiciones futuras y ambigüedades, y exigir especificidad, orientación a la acción y verificación en lugar de elogios. (Fuente: dotey)

La tecnología de compresión de AI es 300 veces mejor que los métodos tradicionales: El canal de YouTube Two Minute Papers señala que la tecnología de compresión de AI es 300 veces más eficiente que los métodos de compresión tradicionales, pero actualmente no está ampliamente utilizada. El video podría explorar tecnologías de motores físicos como WaveBlender de NVIDIA, demostrando el enorme potencial de la AI en la compresión de datos y sus aplicaciones en la simulación de audio, entre otros. (Fuente: , source)
Desafío de superinteligencia multimodal NeurIPS 2025: Lambda Research invita a investigadores, ingenieros y entusiastas de la AI a participar en el Gran Desafío de Superinteligencia Multimodal NeurIPS 2025, con el objetivo de impulsar el desarrollo del Machine Learning multimodal de código abierto. Los equipos participantes tendrán la oportunidad de ganar hasta 20.000 dólares en créditos de computación para construir juntos la futura AI multimodal de código abierto. (Fuente: Reddit r/deeplearning)

Guía completa anotada de modelos de difusión: La comunidad de Reddit ha compartido una guía completa anotada sobre “¿Qué son los modelos de difusión?”. Esta guía proporciona a los estudiantes recursos para comprender en profundidad los principios y aplicaciones de los modelos de difusión, ayudándoles a dominar esta tecnología de AI generativa de vanguardia. (Fuente: Reddit r/deeplearning)
Aplicación de LoRA/QLoRA en el entrenamiento multi-GPU de LLM visuales: La comunidad ha discutido los desafíos y la práctica de LoRA/QLoRA en el entrenamiento de grandes LLM visuales (como Llama 3.2 90B Visual Instruct) en entornos multi-GPU. Debido al enorme tamaño del modelo, que no puede ejecutarse en una sola GPU, los desarrolladores buscan frameworks/paquetes que soporten el entrenamiento multi-GPU. LoRA/QLoRA, por sus características de ajuste fino eficiente, genera grandes expectativas, pero su aplicabilidad en escenarios específicos aún requiere una exploración profunda. (Fuente: source, source)
💼 Negocios
OpenAI adquiere el equipo Alex respaldado por Y Combinator: OpenAI ha adquirido el equipo Alex, una startup respaldada por Y Combinator. Este equipo se unirá al equipo Codex de OpenAI para trabajar en asistentes de codificación de AI. Daniel Edrisian, fundador de Alex, afirmó que construyeron con éxito los mejores agentes de codificación para aplicaciones iOS y macOS, y esta adquisición permitirá que su trabajo continúe a una escala mayor. (Fuente: The Verge)
Baseten cierra una ronda de financiación Serie D de 150 millones de dólares, enfocándose en el futuro de la inferencia de AI: Baseten ha cerrado una ronda de financiación Serie D de 150 millones de dólares. Su CEO, Tuhin One, señala que a medida que los precios de los tokens disminuyen, los costos de inferencia seguirán bajando, lo que presagia un crecimiento a mayor escala en el mercado de inferencia de AI. Baseten se dedica a construir una infraestructura de inferencia de AI omnipresente para apoyar la amplia aplicación de la AI en diversas industrias. (Fuente: basetenco)
RecallAI cierra una ronda de financiación Serie B de 38 millones de dólares para acelerar los servicios de grabación de reuniones con AI: RecallAI ha anunciado el cierre de una ronda de financiación Serie B de 38 millones de dólares, liderada por BessemerVP, con la participación de HubSpot Ventures y SalesforceVC. RecallAI ofrece servicios de API de grabación de reuniones y ya ha atendido a más de 2.000 empresas. Esta financiación acelerará su expansión en el campo de la grabación de reuniones con AI, consolidando aún más su posición en el mercado. (Fuente: blader)
🌟 Comunidad
Valor y controversia de la evaluación de AI (Evals): La comunidad ha mantenido una intensa discusión sobre la necesidad y los métodos de evaluación de AI (Evals), explorando su papel en las aplicaciones empresariales, su complementariedad con las pruebas A/B y la importancia de la ciencia de datos en la ingeniería de AI. Algunos consideran que los Evals son clave para comprender el rendimiento de los sistemas de AI y optimizar las iteraciones, mientras que otros creen que una dependencia excesiva de los Evals puede llevar a la “pseudociencia”. (Fuente: source, source)

Calidad de la codificación con AI y las limitaciones del “Vibe Coding”: Los desarrolladores discuten las ventajas y desventajas de la generación de código con AI, señalando que la AI es buena para el prototipado rápido, el manejo de código boilerplate y la escritura de pruebas, pero el código generado a menudo es criticado por ser verboso, excesivamente defensivo y carente de capacidad de refactorización. Muchos desarrolladores creen que, para el código que requiere mantenimiento a largo plazo, la escritura manual sigue siendo superior al “Vibe Coding” generado por AI. (Fuente: source, source)
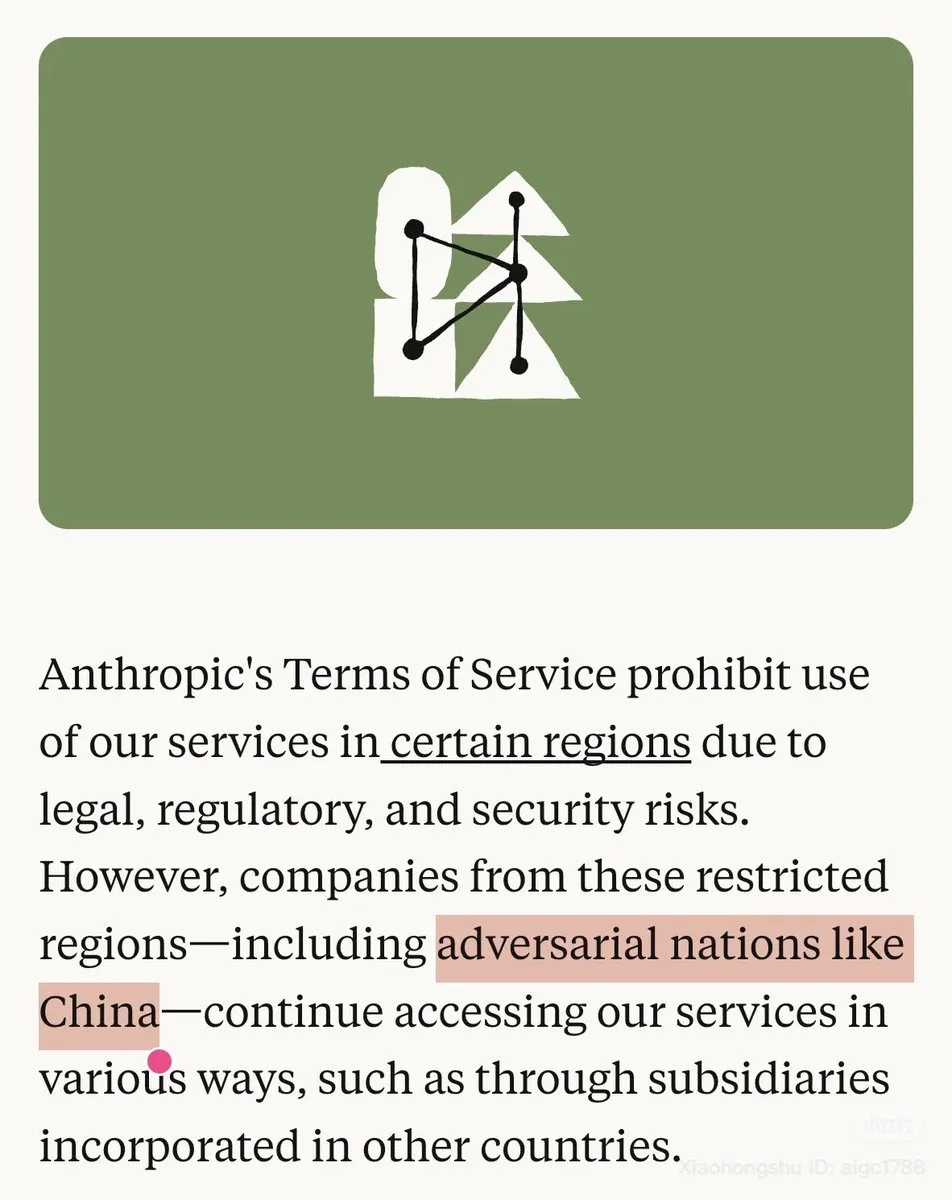
Controversia sobre la política de Anthropic hacia China y la disponibilidad del modelo: Anthropic ha marcado explícitamente a China como un “país hostil” en su blog y ha restringido el uso de Claude en ciertas regiones, lo que ha provocado un fuerte descontento en la comunidad. Al mismo tiempo, el modelo Opus 4.1 de Claude.ai también ha sido retirado temporalmente, lo que agrava las preocupaciones de los usuarios sobre la estabilidad del modelo y las políticas de la empresa. Muchos usuarios chinos han expresado que se pasarán a OpenAI Codex. (Fuente: source, source)
Interacción de la AI con la política y preocupaciones regulatorias: Líderes tecnológicos como Sam Altman y Lisa Su elogiaron las políticas pro-negocios y pro-innovación de la administración Trump en una cena en la Casa Blanca, lo que provocó discusiones sobre la interacción de las empresas de AI con el poder político y las perspectivas de aplicación de la AI en la educación. Al mismo tiempo, la FTC investigará el impacto de las empresas de AI en los niños, lo que refleja la preocupación de los reguladores por los posibles riesgos sociales de la tecnología de AI. (Fuente: source, source)

Capacidades del AI Agent y desafíos de desarrollo: La comunidad discute las capacidades centrales requeridas por los AI Agent, incluyendo la necesidad de un contexto ultralargo y la interpretabilidad del Agent. Los ingenieros de AI informan que, en los procesos de generación de código, evaluación de ejecución y pensamiento del modelo por parte de los agentes de AI, el flujo de trabajo se vuelve altamente fragmentado, lo que lleva a una gran cantidad de tiempo de espera, convirtiéndose en una de las experiencias más frustrantes en la era de la AI. (Fuente: source, source)

Impacto de la AI en el empleo, UBI y distribución de la riqueza social: La comunidad debate acaloradamente el impacto de la AI en el mercado laboral, la necesidad de la Renta Básica Universal (UBI) y la preocupación de que la AI pueda exacerbar la desigualdad de riqueza. Expertos como el científico informático Geoffrey Hinton creen que la AI hará que unos pocos sean más ricos y la mayoría más pobres, lo que ha provocado una profunda discusión sobre la equidad social de la tecnología de AI, el impacto en el empleo y la redistribución de la riqueza. (Fuente: source, source)

Rendimiento del modelo de AI y disminución de la experiencia del usuario: Muchos usuarios se quejan de que el rendimiento de ChatGPT ha disminuido significativamente recientemente, manifestándose en un aumento de las alucinaciones, la negativa a responder preguntas específicas, la falta de empatía genuina y las restricciones de censura de contenido. Al mismo tiempo, el problema de que los chatbots de AI “se hagan los tontos” también ha provocado descontento, ya que se cree que esto puede deberse a las políticas empresariales en lugar de una verdadera falta de capacidad, lo que lleva a una mala experiencia del usuario. (Fuente: source, source)
Calidad del contenido generado por AI y percepción pública: La comunidad ha discutido las percepciones negativas de la gente sobre el contenido generado por AI, a menudo refiriéndose a él como “AI Slop” (basura de AI), lo que refleja preocupaciones sobre el abuso de la AI, la calidad inconsistente y la devaluación de la creatividad humana. Al mismo tiempo, las tecnologías de generación de AI también han desafiado la era de la fotografía como evidencia confiable, lo que ha provocado discusiones sobre los deepfakes y la veracidad de la información. (Fuente: source, source)

Ética de la AI y comportamiento del usuario: Ser amable con la AI: La comunidad discute si los usuarios se vuelven más groseros al interactuar con asistentes de AI debido a su “complacencia” incondicional, y si este patrón de interacción podría afectar negativamente la comunicación con los humanos. Muchos creen que, aunque la AI no tenga sentimientos, mantener la cortesía es por la propia salud mental y para evitar que los malos hábitos se extiendan a las relaciones interpersonales reales. (Fuente: Reddit r/ClaudeAI)
Conciencia de la AI y límites filosóficos de la inteligencia: La comunidad explora la cuestión filosófica de si la AI tiene conciencia o “vida”, citando el ejemplo de la película “Cortocircuito” (Short Circuit), donde el robot Johnny 5 es declarado “vivo” al comprender el humor. La mayoría de las opiniones sostienen que la comprensión del humor por parte de la AI es una manifestación de inteligencia, pero no una prueba de vida o conciencia, y que la limitación del Test de Turing radica en su incapacidad para verificar la “experiencia interna” de la AI. (Fuente: Reddit r/ArtificialInteligence)
Gestión de la comunidad LocalLLaMA y controversia sobre la generalización de la AI: La comunidad LocalLLaMA de Reddit ha lanzado una nueva etiqueta “local only”, que exige que las publicaciones relacionadas con la tecnología LLM local utilicen esta etiqueta para filtrar “ruido” como modelos no locales o costos de API. Esta medida ha provocado una fuerte reacción en la comunidad, y muchos usuarios creen que va en contra del propósito original de la comunidad de “priorizar lo local”. Al mismo tiempo, la discusión sobre “los sistemas de AI generalizada son una mentira” también refleja el cuestionamiento sobre la capacidad de generalización y la fiabilidad de la AI. (Fuente: source, source)
Competencia en el mercado de computación GPU y trayectoria de desarrollo de la AI: La comunidad discute la intensa competencia en el mercado de computación GPU, y la necesidad de que los nuevos proveedores de servicios en la nube mejoren su competitividad. Al mismo tiempo, el progreso de la AI no está impulsado únicamente por la potencia computacional; la eficiencia del aprendizaje y las arquitecturas no Transformer podrían traer el próximo salto exponencial, lo que ha provocado una reflexión sobre la futura trayectoria de desarrollo de la AI. También hay quienes señalan que el progreso de la AI no está impulsado únicamente por la potencia computacional, y que la eficiencia del aprendizaje y las arquitecturas no Transformer podrían traer el próximo salto exponencial. (Fuente: source, source)
💡 Otros
India utiliza robots para limpiar alcantarillas, mejorando la difícil situación de la limpieza manual: El gobierno de Delhi, India, está promoviendo el uso de robots para reemplazar la limpieza manual de alcantarillas, con el fin de resolver el problema de larga data de la “limpieza manual”. Aunque esta práctica está prohibida desde 1993, sigue siendo generalizada y peligrosa. Varias empresas han ofrecido soluciones tecnológicas alternativas, incluyendo robots de diversas complejidades, con el objetivo de mejorar la seguridad y la dignidad en el trabajo. (Fuente: MIT Technology Review)
Investigación utiliza “robots ratón” para simular el comportamiento real de los ratones: Investigadores están desarrollando un “robot ratón” con el objetivo de estudiar en profundidad la biología y la neurociencia mediante la simulación del comportamiento real de los ratones. Este proyecto combina robótica, Machine Learning e Inteligencia Artificial, proporcionando una nueva plataforma experimental para comprender el comportamiento animal. (Fuente: Ronald_vanLoon)
La AI reconstruye la película perdida de Orson Welles “El cuarto mandamiento”: El equipo de Fable Simulation está utilizando tecnología de AI, con fines no comerciales y académicos, para reconstruir los 43 minutos perdidos de la obra maestra de Orson Welles, “El cuarto mandamiento” (The Magnificent Ambersons). Este proyecto demuestra el potencial de la AI en la restauración cinematográfica y la preservación del patrimonio artístico, con la esperanza de permitir al público revivir esta obra clásica inacabada. (Fuente: source, source)
