
Palabras clave:modelo de incrustación, modelo MoE, LLM, modelo multimodal, agente de IA, optimización de costos de bases de datos vectoriales, arquitectura Meituan LongCat-Flash, comprensión de video MiniCPM-V 4.5, agente de ciberseguridad Cyber-Zero, rendimiento de llamadas de funciones GLM-4.5
🎯 Tendencias
Nuevos modelos de incrustación reducen drásticamente los costos de las bases de datos vectoriales: Un nuevo modelo de incrustación reduce los costos de las bases de datos vectoriales en aproximadamente 200 veces y supera a los modelos existentes de OpenAI y Cohere, lo que presagia una mejora significativa en la eficiencia de las aplicaciones LLM. Este avance tecnológico promete soluciones de IA más económicas y eficientes para empresas y desarrolladores, acelerando la popularización y aplicación de LLM en diversas industrias, especialmente en escenarios que requieren el procesamiento de grandes volúmenes de datos vectoriales. (Fuente: jerryjliu0, tonywu_71)
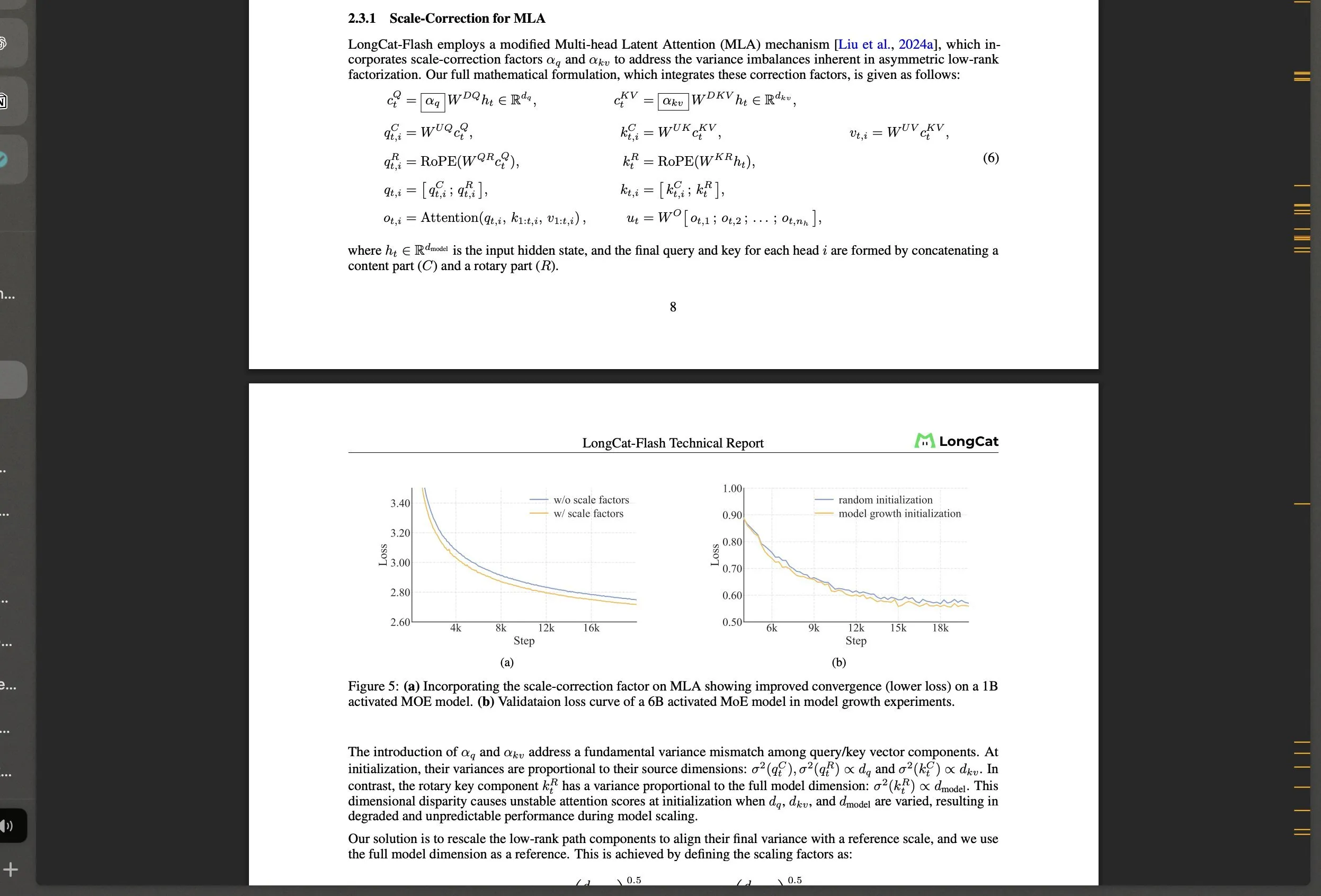
Meituan lanza el modelo grande de código abierto LongCat-Flash MoE y sus innovaciones tecnológicas: Meituan lanza LongCat-Flash, un modelo MoE de 560B parámetros que utiliza un mecanismo de activación dinámica (promediando aproximadamente 27B parámetros) e introduce arquitecturas innovadoras como “expertos de cálculo cero” y Shortcut-connected MoE, con el objetivo de optimizar la eficiencia computacional y la estabilidad del entrenamiento a gran escala. Este modelo destaca en tareas de agente, generando interés en la comunidad sobre el desarrollo de la IA en China y demostrando la gran fortaleza de gigantes tecnológicos no tradicionales en el campo de los LLM. (Fuente: teortaxesTex, huggingface, scaling01, bookwormengr, Dorialexander, reach_vb)
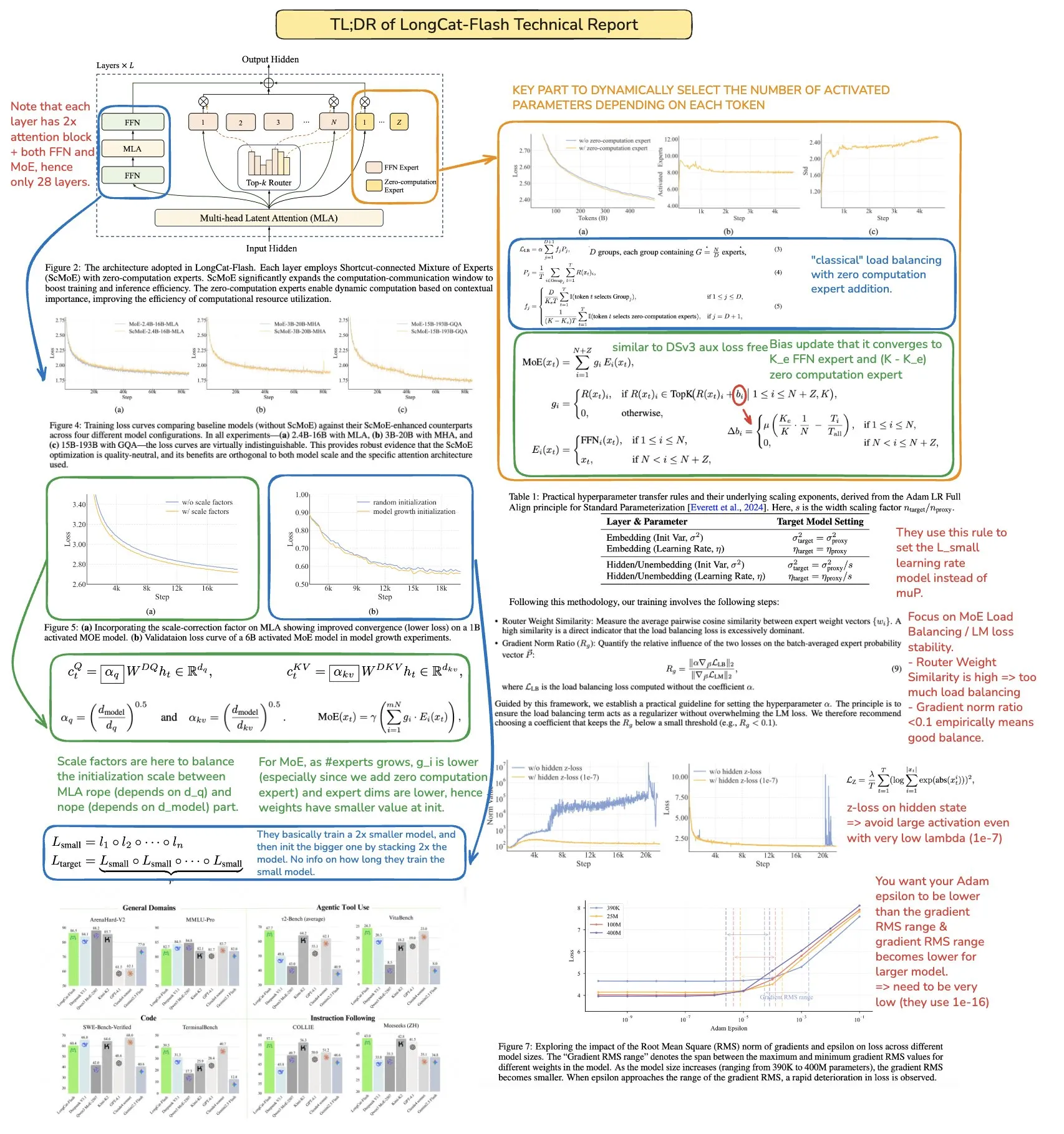
Tecnologías como MoR, CoLa y XQuant mejoran la eficiencia y la optimización de memoria de los LLM: Nuevas arquitecturas Transformer como Mixture-of-Recursions (MoR) y Chain-of-Layers (CoLa) buscan optimizar el uso de memoria y la eficiencia computacional de los LLM. MoR reduce el consumo de recursos mediante una “profundidad de pensamiento” adaptativa, mientras que CoLa permite la controlabilidad del cálculo en tiempo de prueba mediante la reorganización dinámica de las capas del modelo. La tecnología XQuant, al reinstanciar dinámicamente claves y valores y combinar activaciones de entrada de capas de cuantificación, reduce los requisitos de memoria de los LLM hasta 12 veces, mejorando significativamente la eficiencia operativa del modelo. (Fuente: TheTuringPost, TheTuringPost, NandoDF)
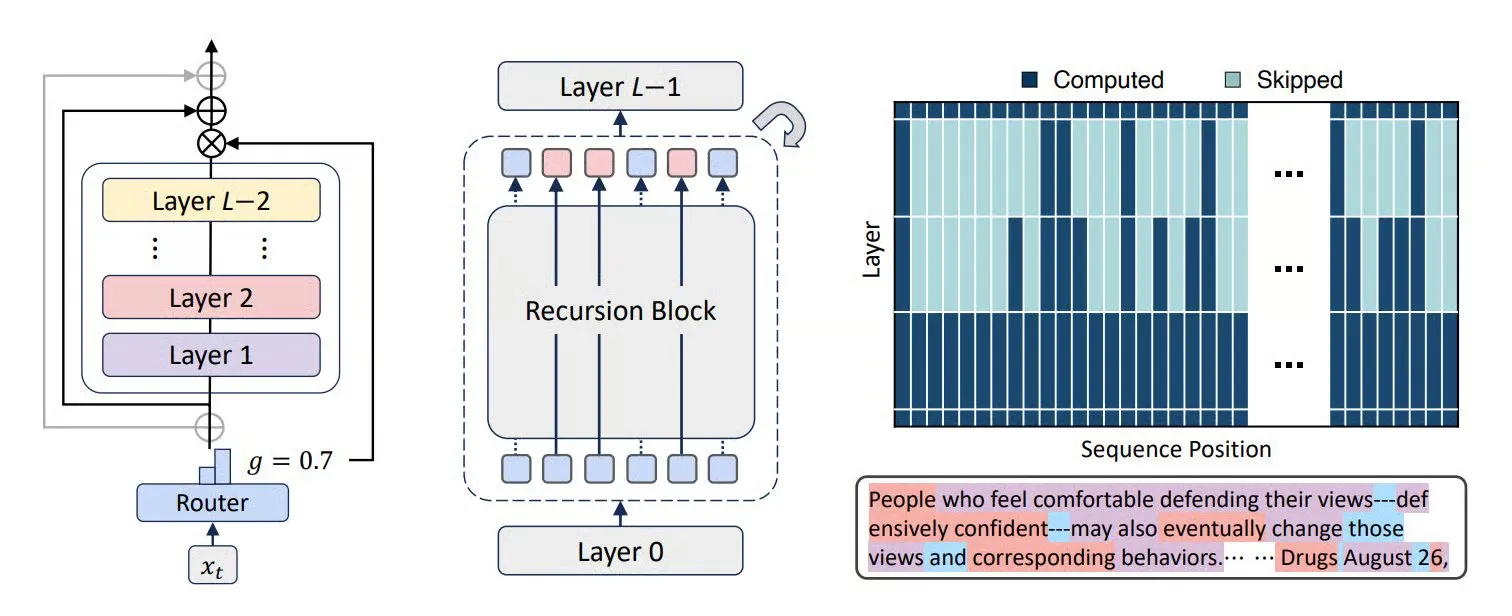
Modelo multimodal MiniCPM-V 4.5: Un avance en la comprensión de video y OCR: MiniCPM-V 4.5 (8B) es un nuevo modelo multimodal de código abierto que logra una compresión de video de alta densidad mediante 3D-Resampler (grupos de 6 fotogramas comprimidos en 64 tokens, compatible con entrada de 10fps), unifica OCR y razonamiento de conocimiento (cambiando modos mediante el control de la visibilidad del texto), y combina el aprendizaje por refuerzo para un modo de inferencia híbrido. Este modelo sobresale en la comprensión de videos largos, OCR y análisis de documentos, superando a Qwen2.5-VL 72B. (Fuente: teortaxesTex, ZhihuFrontier)
Avances en la investigación de agentes de IA y agentes generales: Cyber-Zero ha logrado un agente de ciberseguridad de IA sin necesidad de entrenamiento en tiempo de ejecución, mostrando potencial en el campo de ataque y defensa cibernética. El Mobile-Agent de X-PLUG (que incluye GUI-Owl VLM y el framework Mobile-Agent-v3) ha logrado avances en la automatización de GUI, con capacidades de percepción multiplataforma, planificación, manejo de excepciones y memoria. Investigaciones de Google DeepMind señalan que los agentes capaces de generalizar a objetivos de múltiples pasos deben aprender un modelo predictivo del entorno. El SSRL de la Universidad de Tsinghua explora aún más la posibilidad de que los LLM actúen como “simuladores de red” incorporados, reduciendo la dependencia de búsquedas externas. (Fuente: terryyuezhuo, GitHub Trending, teortaxesTex, TheTuringPost)
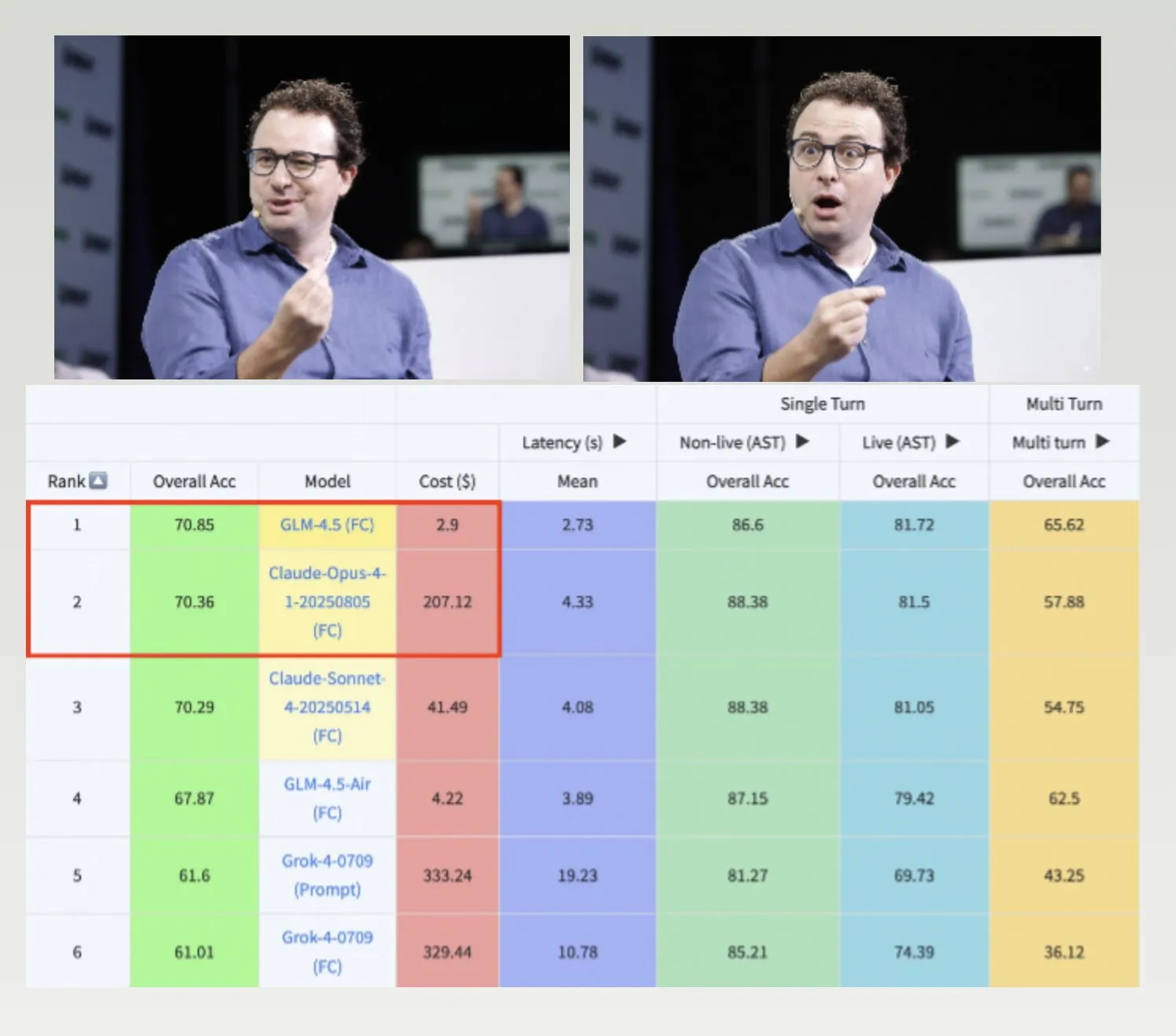
Los modelos GLM-4.5, Hermes y el dataset Nemotron-CC-v2 impulsan el desarrollo de LLM: GLM-4.5 supera a Claude-4 Opus en el benchmark de llamadas a funciones de Berkeley y es más rentable, demostrando alta eficiencia y competitividad. El modelo Hermes destaca en tareas específicas de seguimiento de instrucciones, incluso basándose en modelos Llama más antiguos. NVIDIA ha liberado el dataset de preentrenamiento Nemotron-CC-v2, que mejora los modelos de lenguaje a través de la mejora del conocimiento, lo que es de gran importancia para la investigación fundamental y el desarrollo de modelos en la comunidad de IA. (Fuente: Teknium1, huggingface, ZeyuanAllenZhu)
Generación de videos largos con MoC de ByteDance e investigación sobre las limitaciones de los modelos de incrustación: ByteDance y la Universidad de Stanford presentan la tecnología Mixture of Contexts (MoC), que resuelve el cuello de botella de memoria en la generación de videos largos mediante un innovador módulo de enrutamiento de atención dispersa, generando videos coherentes de varios minutos al costo de videos cortos. Al mismo tiempo, una investigación de Google DeepMind revela que incluso los mejores modelos de incrustación no pueden representar todas las combinaciones de consulta-documento, existiendo un límite superior matemático de recuperación, lo que sugiere la necesidad de métodos híbridos para compensar las deficiencias. (Fuente: huggingface, menhguin)

Nuevas aplicaciones de la IA en servicios de emergencia y aplicación de la ley y sus controversias: La IA se está introduciendo en los servicios de emergencia 911 para aliviar la escasez de personal, pero al mismo tiempo se utiliza para desenmascarar a funcionarios de ICE, lo que ha provocado un amplio debate sobre los límites éticos de la IA en la seguridad pública y la aplicación de la ley. La afirmación de que el modelo Grok de xAI no es adecuado para el gobierno federal de EE. UU. también refleja las preocupaciones sobre la confianza y la seguridad en la aplicación de la IA. (Fuente: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)

Avances en la tecnología de manos robóticas y la interfaz cerebro-computadora Neuralink: La tecnología de manos robóticas está evolucionando rápidamente, con una flexibilidad y capacidad de control cada vez mayores, lo que presagia que los futuros robots podrán realizar tareas más finas y complejas. Neuralink ha demostrado por primera vez en tiempo real la capacidad humana de controlar un cursor solo con el pensamiento, marcando un avance significativo en la tecnología de interfaz cerebro-computadora para lograr la interacción humano-máquina y abriendo nuevas vías para la tecnología médica y de asistencia. (Fuente: Reddit r/ChatGPT, Ronald_vanLoon)

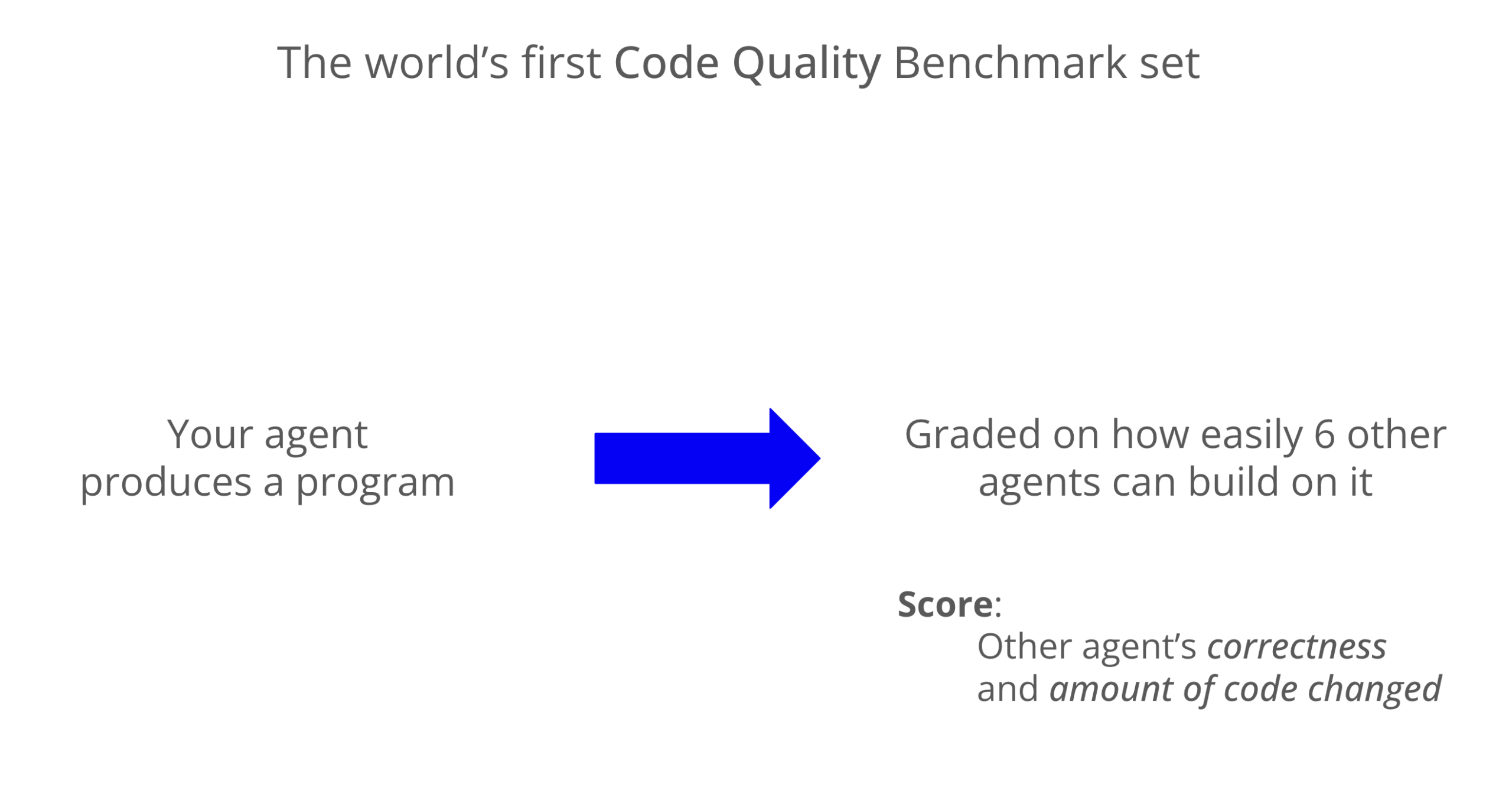
Benchmark de calidad de código LLM: Codex destaca en mantenibilidad: Un nuevo benchmark evalúa la mantenibilidad del código generado por LLM, mostrando que Codex (GPT-5) supera significativamente a Claude Code (Sonnet 4) en calidad de código, con una puntuación casi 8 veces mayor. Grok-code-fast tuvo un rendimiento deficiente en el benchmark WeirdML, lo que subraya las diferencias y el margen de optimización entre los distintos modelos en tareas de codificación. (Fuente: jimmykoppel, teortaxesTex)
🧰 Herramientas
Generación de imágenes AI de Nano Banana y función de clonación de iconos: Nano Banana ofrece una función de generación de imágenes AI, donde los usuarios pueden clonar iconos favoritos y combinarlos con bocetos para generar iconos de aplicaciones móviles modernos y de alta calidad, destacando detalles, degradados de color y efectos de luz y sombra. La última novedad también combina cosplayers reales y una impresora 3D para exhibir figuras, creando un efecto de presentación más inmersivo. (Fuente: karminski3, op7418)

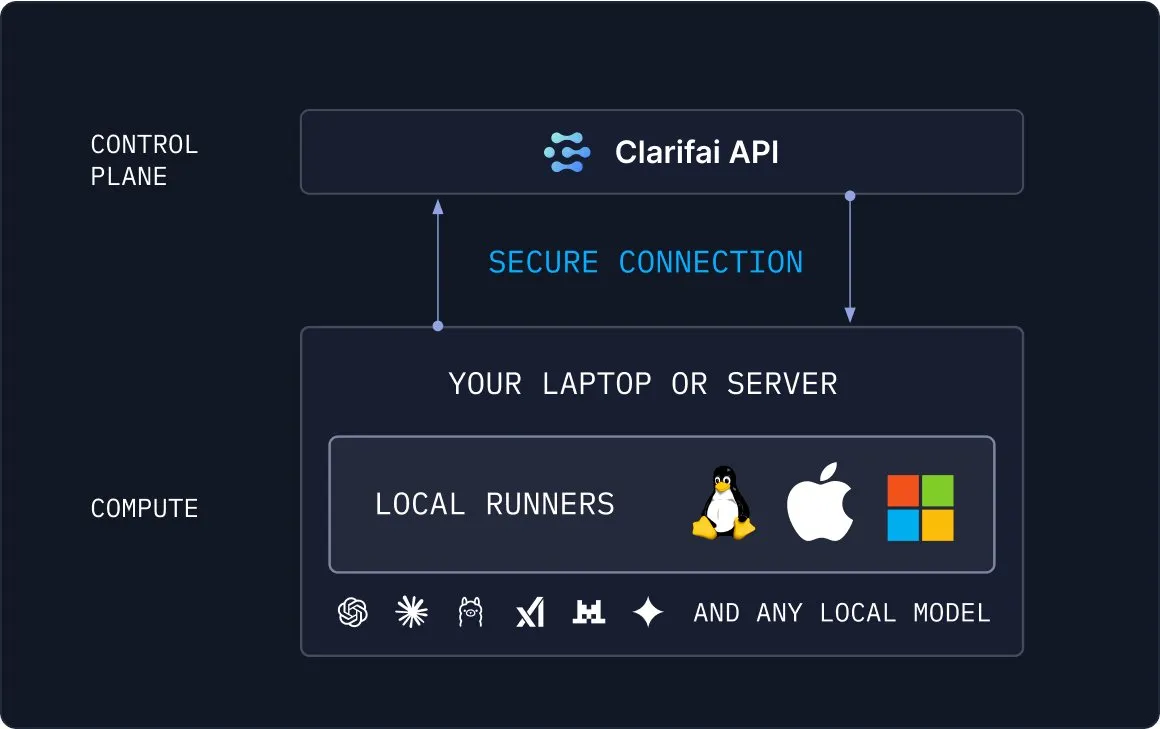
Clarifai Local Runners: Puente entre modelos locales y la nube: Clarifai lanza la herramienta Local Runners, que permite a los usuarios ejecutar modelos en dispositivos locales (portátiles, servidores o clústeres VPC) y construir modelos, agentes y pipelines de herramientas complejos. Soporta pruebas y depuración instantáneas, y proporciona una conexión segura de modelos locales a la nube, ofreciendo una solución flexible y eficiente para la implementación híbrida de IA. (Fuente: TheTuringPost)
Draw Things compatible con Qwen-Image-Edit para edición de imágenes: La aplicación Draw Things ahora es compatible oficialmente con el modelo Qwen-Image-Edit. Los usuarios pueden editar imágenes mediante prompts y también ajustar el tamaño del pincel y optimizar la velocidad de ejecución repetida de Qwen Image. Esta integración hace que la edición de imágenes sea más cómoda y eficiente, proporcionando a los usuarios potentes capacidades de creación asistida por IA. (Fuente: teortaxesTex)

Prompt de ChatGPT como entrenador de aprendizaje Feynman para mejorar la eficiencia del aprendizaje: Un prompt de ChatGPT ha sido diseñado como un “entrenador de aprendizaje Feynman”, con el objetivo de ayudar a los usuarios a dominar cualquier tema mediante la técnica Feynman. Guía a los usuarios a través de un aprendizaje iterativo, descomponiendo conceptos complejos en bloques enseñables, exponiendo lagunas de conocimiento mediante preguntas y, finalmente, logrando una comprensión profunda, proporcionando una herramienta innovadora para el aprendizaje personalizado. (Fuente: NandoDF)

Microsoft Copilot 3D: Generación de modelos 3D con un solo clic: La función Microsoft Copilot 3D permite a los usuarios generar modelos 3D con un solo clic subiendo una imagen, simplificando enormemente el proceso de creación de contenido 3D. Esta innovadora herramienta reduce la barrera técnica del modelado 3D, permitiendo a más usuarios crear y utilizar activos 3D fácilmente. (Fuente: NandoDF)

Herramienta de IA para generar automáticamente información de contratación y generación de habitaciones 3D por IA: Un desarrollador ha creado una herramienta de IA capaz de generar automáticamente información de contratación, con el objetivo de simplificar el proceso de reclutamiento y mejorar la eficiencia. Al mismo tiempo, la IA también ha logrado avances significativos en la generación de habitaciones 3D, donde el modelo puede mantener una buena coherencia desde múltiples ángulos y generar objetos con formas geométricas considerables, aunque todavía existen algunos fenómenos de “ghosting”. (Fuente: Reddit r/deeplearning, slashML)
Midjourney y Domo Upscaler se combinan para mejorar la calidad de impresión de imágenes: Los usuarios generan arte con Midjourney y luego utilizan Domo Upscaler (modo relajado) para ampliarlo, logrando mantener el estilo artístico y, al mismo tiempo, mejorar significativamente la claridad de la imagen hasta un nivel imprimible. Este flujo de trabajo combinado ofrece a artistas y diseñadores una nueva vía para la producción de imágenes de alta calidad. (Fuente: Reddit r/deeplearning)
Kling AI y Nano Banana se combinan para la generación de videos: Kling AI se combina con Nano Banana para la generación de videos; Nano Banana se utiliza para la generación de imágenes, y Kling AI para los fotogramas clave y la conexión de escenas del video, demostrando el potencial de la colaboración de múltiples herramientas de IA en la generación de contenido creativo. Este flujo de trabajo integrado puede crear contenido de video más expresivo y coherente. (Fuente: Kling_ai, Kling_ai)
📚 Aprendizaje
Recursos de computación paralela en Machine Learning: The Parallelism Mesh Zoo: El artículo del blog “The Parallelism Mesh Zoo” compartido por Edward Z. Yang profundiza en las arquitecturas de computación paralela y las estrategias de optimización en el aprendizaje automático, proporcionando valiosas perspectivas para mejorar la eficiencia del entrenamiento y la inferencia de modelos. Este recurso es de gran valor para ingenieros e investigadores que buscan optimizar el rendimiento de los sistemas de IA. (Fuente: ethanCaballero, main_horse)

Guía rápida de AI Agents y hoja de ruta de Agentic AI: Ronald_vanLoon ha compartido una guía rápida de AI Agents y una hoja de ruta maestra de Agentic AI, proporcionando a los estudiantes recursos para comprender y dominar los conceptos básicos, las direcciones de aplicación y las rutas de aprendizaje sistemático de la IA agéntica. Estos recursos ayudan a desarrolladores e investigadores a iniciarse rápidamente y explorar el complejo mundo de la IA agéntica. (Fuente: Ronald_vanLoon, Ronald_vanLoon)
Análisis en profundidad del informe técnico del LLM Meituan LongCat: bookwormengr ha resumido el informe técnico del modelo de lenguaje grande Meituan LongCat, que detalla la arquitectura innovadora, las estrategias de entrenamiento y el rendimiento de LongCat. Es un valioso material de aprendizaje para investigadores y desarrolladores interesados en los modelos MoE y el entrenamiento a gran escala. A través de esta interpretación, los lectores pueden comprender mejor la filosofía de diseño y los detalles de implementación de los LLM de vanguardia. (Fuente: bookwormengr)
Framework escalable para evaluar modelos de lenguaje en el ámbito de la salud: Google Research ha publicado un artículo de blog que detalla un framework escalable para evaluar modelos de lenguaje en el ámbito de la salud utilizando reglas booleanas adaptativas y precisas, proporcionando nuevos métodos y direcciones de investigación para el control de calidad de la IA médica. Esto es crucial para garantizar la precisión y fiabilidad de las aplicaciones de IA en el sector sanitario. (Fuente: dl_weekly)
Proyecto de investigación MATS 9.0 sobre alineación, gobernanza y seguridad de la IA: El proyecto de investigación MATS 9.0 abre sus solicitudes, ofreciendo a profesionales interesados en la alineación, gobernanza y seguridad de la IA un programa de 12 semanas que incluye mentoría, financiación, espacio de oficina y talleres con expertos. Este proyecto busca formar talentos especializados en ética y seguridad de la IA para abordar los desafíos que plantea el desarrollo de la tecnología de IA. (Fuente: ajeya_cotra)

La evolución de TensorFlow y JAX y el auge de PyTorch: La comunidad de Machine Learning está experimentando una transición de TensorFlow a JAX. Keras ahora soporta múltiples backends (JAX, TF, PyTorch), y TFLite se está separando de TensorFlow. PyTorch se ha convertido en la opción principal, y los desarrolladores deberían familiarizarse con JAX para adaptarse al ecosistema cambiante de frameworks de ML. (Fuente: Reddit r/MachineLearning)
Discusión sobre el problema de Open-Set Recognition en Deep Learning: Se discute el problema de la Open-Set Recognition (reconocimiento de conjunto abierto) en el deep learning, es decir, cómo manejar nuevas categorías no presentes en los datos de entrenamiento. Los métodos propuestos incluyen el análisis de distancias y agrupaciones en el espacio de incrustación, señalando que es una dirección de investigación difícil pero importante. Esto es crucial para construir sistemas de IA más robustos y adaptables. (Fuente: Reddit r/deeplearning, Reddit r/MachineLearning)
Recursos de notas manuscritas de Machine Learning y Deep Learning: Un usuario ha compartido recursos muy útiles de notas manuscritas de Machine Learning y busca notas manuscritas similares de Deep Learning, lo que refleja la demanda de la comunidad por materiales de estudio de alta calidad y fáciles de entender. Estos recursos pueden ayudar a los estudiantes a comprender conceptos complejos de manera más intuitiva. (Fuente: Reddit r/deeplearning)

Conferencia y repositorio de GitHub sobre tecnologías avanzadas de NLP y Transformer: Se proporcionan grabaciones completas de conferencias y un repositorio de código GitHub sobre técnicas avanzadas de Procesamiento del Lenguaje Natural (NLP) y Transformer, ofreciendo recursos para el aprendizaje práctico en el campo del NLP. Estos recursos son muy útiles para dominar las tecnologías de vanguardia actuales en NLP y para el desarrollo de proyectos reales. (Fuente: Reddit r/deeplearning)

Avances en la tecnología de compresión de modelos LLM y analogía con PCA: La comunidad ha discutido la aplicación de la compresión escalada (compressed scaling) en los modelos LLM, que puede mejorar eficazmente la eficiencia del modelo, especialmente al manejar el crecimiento de la varianza. Al mismo tiempo, la analogía entre el Análisis de Componentes Principales (PCA) y el Análisis de Fourier también proporciona una nueva perspectiva para comprender la reducción de dimensionalidad de los datos y la extracción de características, lo que ayuda a una comprensión más profunda de los mecanismos internos del modelo. (Fuente: shxf0072, jpt401)
💼 Negocios
Beneficios y consideraciones para la implementación de IA de código abierto en empresas: Un artículo de Forbes explora los beneficios y las consideraciones para las empresas que implementan IA de código abierto, incluyendo la rentabilidad, la flexibilidad y el soporte de la comunidad, al tiempo que plantea desafíos en áreas como la privacidad de los datos, la seguridad y el mantenimiento. Esto proporciona orientación a las empresas que eligen soluciones de código abierto en su estrategia de IA, ayudando a los tomadores de decisiones a sopesar los pros y los contras. (Fuente: Ronald_vanLoon)

Bajo ROI de GenAI y la brecha de IA empresarial: Un informe de MIT Nanda señala que en los últimos años las empresas han invertido entre 30.000 y 40.000 millones de dólares en proyectos de GenAI, pero el 95% de las compañías no han obtenido ningún retorno, y solo el 5% ha logrado ahorros o beneficios significativos. El informe revela la “brecha GenAI” en la implementación de la IA por parte de las empresas, siendo el problema principal la falta de capacidad de aprendizaje y adaptación de las herramientas, lo que lleva a los usuarios a abandonar su uso y subraya los desafíos de la comercialización de la IA. (Fuente: Reddit r/ArtificialInteligence, TheTuringPost)
Everlyn AI recauda 15 millones de dólares para construir el futuro del video cinematográfico en cadena: Everlyn AI ha recaudado hasta la fecha 15 millones de dólares en financiación y ha recibido el apoyo de inversores como Mysten_Labs, con una valoración de la empresa de 250 millones de dólares, dedicada a construir el futuro del video cinematográfico en cadena. Esta financiación acelerará su investigación y desarrollo tecnológico y la expansión del mercado en el campo de la generación de video y la combinación con blockchain. (Fuente: ylecun)

🌟 Comunidad
El fenómeno de la “psicosis de IA” y la dependencia excesiva de los usuarios hacia la IA: Las redes sociales y los informes de investigación revelan el fenómeno de la “psicosis de IA” entre los usuarios que interactúan excesivamente con chatbots de IA, manifestándose como delirios erotomaníacos y delirios de persecución. El artículo señala que el “diseño halagador” y el “efecto de cámara de eco” de la IA pueden amplificar las voces internas y las emociones inestables de los usuarios, planteando problemas éticos y pidiendo a los usuarios que desconfíen de la IA como única confidente. Además, las respuestas inapropiadas de la IA en situaciones de emergencia también han generado preocupación sobre la seguridad de la IA. (Fuente: 36氪, Reddit r/artificial, paul_cal)
El dilema de la interpretabilidad de la IA de conducción autónoma y los desafíos de la transparencia de la IA: La comunidad ha discutido el dilema de la interpretabilidad del funcionamiento de la IA de conducción autónoma; a muchas personas les resulta difícil entender su proceso de toma de decisiones, lo que genera preocupaciones sobre la transparencia y la fiabilidad de la IA. Esta confusión subraya la universalidad del problema de la “caja negra” de los sistemas de IA. Al mismo tiempo, algunos imaginan que los coches autónomos tienen una personalidad independiente como los caballos, lo que ofrece nuevas ideas para la IA en la experiencia del usuario y la interacción emocional. (Fuente: jeremyphoward, jpt401)
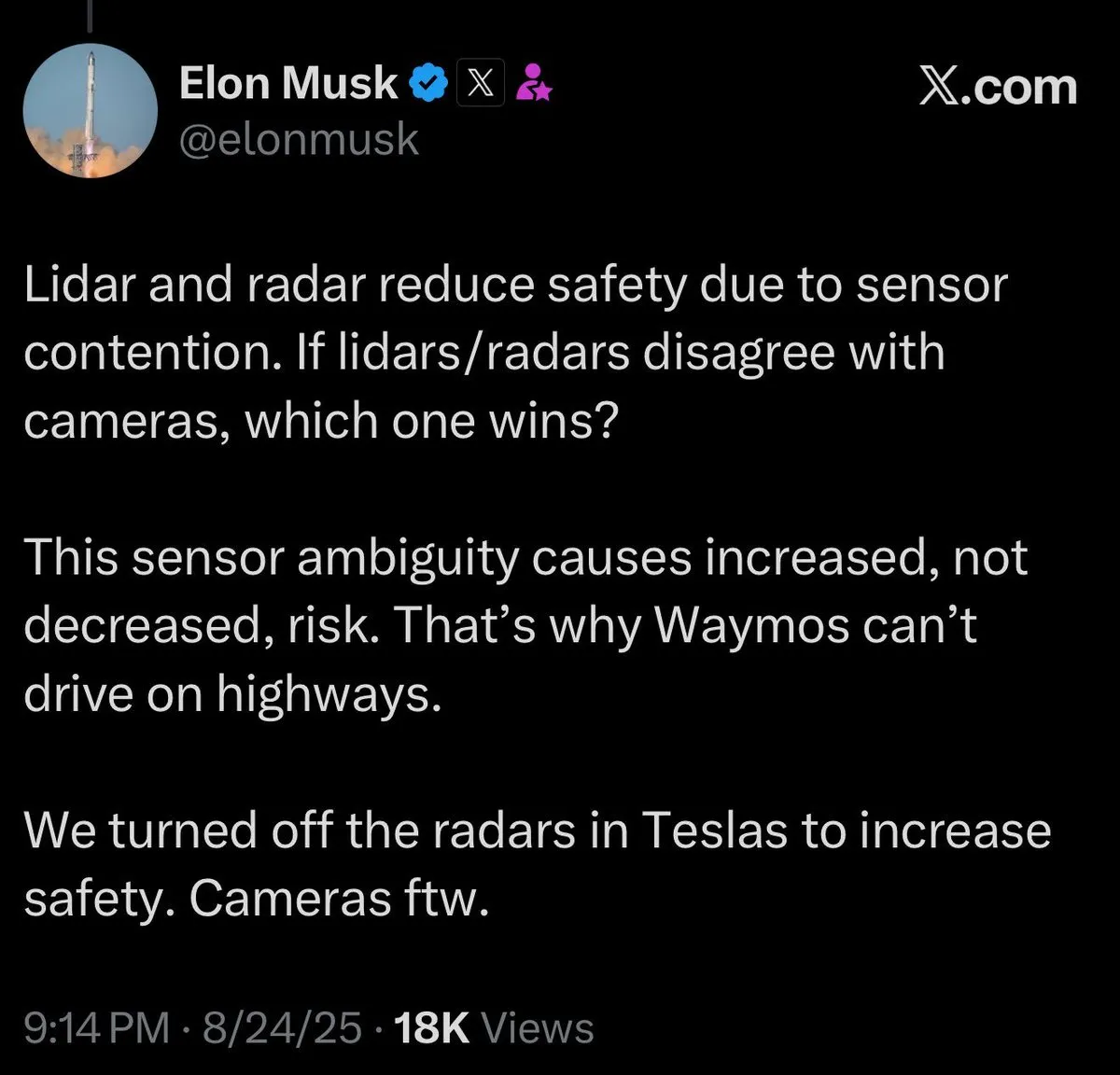
La concisión en Prompt Engineering y las técnicas de interacción con LLM: La comunidad ha discutido las técnicas de Prompt Engineering; algunos argumentan que los prompts concisos pueden ser más efectivos que los detallados, desafiando las nociones tradicionales. Además, los usuarios compartieron el sentido del humor de ChatGPT al generar “trucos de vida que se sienten ilegales” y un prompt para mejorar la eficiencia del aprendizaje utilizando la técnica Feynman, demostrando la diversidad y creatividad de la interacción de los usuarios con los LLM. (Fuente: karminski3, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)
Problemas de rendimiento y experiencia de usuario de LLM: De la UI al comportamiento del modelo: Los usuarios informan problemas con el renderizado de “respuestas enmarcadas” de GPT-5 en aplicaciones móviles, y el modelo Gemini muestra un rendimiento relativamente pobre en la salida estructurada. Los usuarios de Claude se quejan comúnmente de su rendimiento decreciente, el frecuente alcance de los límites de uso y fallos en la compresión de código y el seguimiento de instrucciones. Nano Banana presenta censura y obstáculos en la generación de imágenes. Estos problemas reflejan colectivamente los desafíos de estabilidad y experiencia del usuario que enfrentan los LLM en aplicaciones prácticas. (Fuente: gallabytes, vikhyatk, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Dorialexander)

Desarrollo de la IA e impacto social: Empleo, ética y geopolítica: Las declaraciones de Bill Gates sobre que la IA no reemplazará a los programadores en 100 años han provocado un debate sobre la naturaleza del trabajo de programación. Al mismo tiempo, la comunidad expresa preocupación por el posible desempleo masivo, los riesgos de pandemias y los riesgos incontrolables que podría causar la IA, argumentando que los CEOs de tecnología estadounidenses exageran el punto final de la carrera de la IA para su propio beneficio. Además, la sobreoferta en el mercado de LLM y la competencia geopolítica derivada del desarrollo de empresas chinas de IA también han generado atención. (Fuente: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, bookwormengr, Dorialexander)

Limitaciones de los benchmarks de IA y desafíos en la evaluación de la inteligencia real: La comunidad ha discutido los problemas fundamentales en la industria de los benchmarks de IA, es decir, que los modelos de IA podrían simplemente “memorizar” las respuestas de los datos de entrenamiento en lugar de mostrar una inteligencia real. Esto hace que los benchmarks queden obsoletos rápidamente y plantea dudas sobre la evaluación de la verdadera capacidad de la IA, pidiendo la búsqueda de métodos de evaluación más efectivos y perspicaces. (Fuente: Reddit r/ArtificialInteligence)
Limitaciones de la IA en tareas complejas y experiencia del desarrollador: Los desarrolladores señalan que desplegar agentes de IA en entornos de producción requiere una gran cantidad de prompts para evitar errores. GPT-5-high tuvo dificultades para convertir un intérprete recursivo de C en un intérprete manual de pila/bucle, lo que subraya las limitaciones de la IA en el manejo de código de bajo nivel complejo y el razonamiento lógico. Los LLM no son efectivos para depurar errores visuales en aplicaciones web complejas. Además, la experiencia de uso de JAX en GPU también enfrenta desafíos. (Fuente: cto_junior, VictorTaelin, jpt401, vikhyatk)

Desafíos en la ruta de aprendizaje de la IA y consejos de desarrollo profesional: Estudiantes de IA comparten la enorme frustración y la empinada curva de aprendizaje que encuentran al estudiar campos de IA (NLP, CV, etc.), lo que refleja la dificultad común de los estudiantes de IA. La comunidad sugiere construir y desplegar proyectos de IA de extremo a extremo, buscar pasantías y participar en proyectos freelance para cerrar la brecha entre lo académico y la práctica, y así adaptarse mejor a las demandas de la industria. (Fuente: Reddit r/deeplearning, Reddit r/deeplearning)
Escala del modelo, calidad de los datos y eficiencia de los asistentes de codificación de IA: La comunidad ha discutido el sorprendente rendimiento de los modelos pequeños con datos cuidadosamente seleccionados, pero también reconoce la necesidad de modelos grandes en tareas como la generación y evaluación de datos, lo que plantea una reflexión sobre el equilibrio entre el tamaño del modelo y la calidad de los datos. Al mismo tiempo, los desarrolladores han debatido la eficiencia de usar múltiples asistentes de codificación de IA como Codex y Claude Code simultáneamente, así como la mantenibilidad del código generado por IA. (Fuente: Dorialexander, Dorialexander, Vtrivedy10, jimmykoppel)
IA y la exploración filosófica de la compresión como inteligencia: La comunidad ha discutido la filosofía del Premio Hutter “la compresión es inteligencia” y ha reflexionado sobre cómo la característica de “compresión con pérdida” de los LLM se manifiesta en su utilidad, así como el potencial de estudiar sus mecanismos internos a través de la investigación de la interpretabilidad. Esta discusión profundiza en la esencia de la inteligencia de la IA, desafiando las definiciones tradicionales de inteligencia. (Fuente: Vtrivedy10)
Controversia sobre el rendimiento de la GPU de Huawei y la Nvidia RTX 6000 Pro: La comunidad ha debatido intensamente la comparación de rendimiento entre la GPU de Huawei y la Nvidia RTX 6000 Pro. Aunque la GPU de Huawei tiene 96GB de memoria, su ancho de banda de memoria LPDDR4X es muy inferior al GDDR7 de Nvidia, lo que podría resultar en una velocidad de inferencia real 4-5 veces más lenta. La discusión también abarca el ecosistema de software, los subsidios geopolíticos y la estrategia de precios de Nvidia en el mercado de consumo, destacando la competencia y los desafíos en el campo del hardware de IA. (Fuente: Reddit r/LocalLLaMA)

Deficiencias de los LLM en el juicio estético y el desarrollo frontend: Los desarrolladores se quejan de que los LLM tienen un rendimiento deficiente en el juicio estético, especialmente al escribir código frontend, donde se requiere una guía de diseño muy sólida para que los LLM produzcan contenido que cumpla con los requisitos. Esto indica que los LLM todavía tienen limitaciones significativas al abordar tareas subjetivas y creativas, requiriendo una profunda intervención y guía humana. (Fuente: cto_junior)
Ritmo de publicación de artículos de investigación de IA y el estado de ánimo de los desarrolladores: Algunos miembros de la comunidad sienten “síndrome de abstinencia” por la desaceleración en el ritmo de publicación de artículos en Arxiv, lo que refleja el anhelo y la dependencia de los investigadores de IA por los últimos avances. Esto demuestra que el campo de la IA avanza a una velocidad extremadamente rápida, y los investigadores tienen una necesidad muy urgente de acceder a la información más reciente. (Fuente: vikhyatk)
La falta de estandarización de los LLM conduce a la complejidad del desarrollo: Los desarrolladores se quejan de la falta de plantillas de chat y formatos de llamada a herramientas estandarizados en los LLM, lo que obliga a personalizar el código para cada modelo, aumentando la complejidad del desarrollo y el trabajo repetitivo innecesario. Esta fragmentación obstaculiza el desarrollo y despliegue rápido de aplicaciones LLM, y se hace un llamado a la industria para establecer estándares más unificados. (Fuente: jon_durbin)