
Palabras clave:OpenAI, LLM de razonamiento, Olimpiada Internacional de Matemáticas, ChatGPT Agent, Kimi K2, conjunto de datos de entrenamiento de IA, privacidad de datos personales, neutralidad política de los modelos de IA, rendimiento a nivel de medalla de oro en la IMO, conjunto de datos DataComp CommonPool, inteligencia de agentes LLM, orden ejecutiva de IA de la Casa Blanca, arquitectura MoE
🔥 Enfoque
El LLM experimental de razonamiento de OpenAI obtiene una medalla de oro en la Olimpiada Internacional de Matemáticas: El último LLM experimental de razonamiento de OpenAI logró un rendimiento a nivel de medalla de oro en la Olimpiada Internacional de Matemáticas (IMO) de 2025, resolviendo 5 de 6 problemas. El modelo funcionó bajo las mismas reglas que los humanos, incluido un límite de tiempo de 4,5 horas por problema, y no utilizó ninguna herramienta, generando pruebas en lenguaje natural. Esto marca un gran avance para la IA en el razonamiento matemático y presagia el potencial de la IA en el descubrimiento científico. (Fuente: gdb, scaling01, dmdohan, SebastienBubeck, markchen90, npew, MillionInt, cloneofsimo, bookwormengr, tokenbender)

El conjunto de datos de entrenamiento de IA CommonPool contiene millones de datos personales: Una investigación descubrió que DataComp CommonPool, un gran conjunto de datos de entrenamiento de IA de código abierto, contiene millones de imágenes de pasaportes, tarjetas de crédito, certificados de nacimiento y otros documentos que contienen información de identificación personal. Los investigadores auditaron el 0,1% de los datos de CommonPool y encontraron miles de imágenes con información de identificación personal, estimando que el número de estas imágenes en todo el conjunto de datos podría llegar a cientos de millones. Esto plantea preocupaciones sobre la protección de la privacidad en los datos de entrenamiento de IA y hace un llamado a la comunidad de aprendizaje automático para que reconsidere la práctica del web scraping indiscriminado. (Fuente: MIT Technology Review)

🎯 Tendencias
OpenAI lanza el asistente personal ChatGPT Agent: OpenAI lanzó ChatGPT Agent, un asistente personal que puede realizar tareas en nombre del usuario mediante la construcción de su propia “computadora virtual”. Esto marca un paso significativo en la inteligencia de agentes LLM, pero la función aún se encuentra en sus primeras etapas y las tareas pueden tardar un tiempo en completarse. (Fuente: MIT Technology Review, The Verge, Wired)
La Casa Blanca prepara una orden ejecutiva que exige que los modelos de IA sean “políticamente neutrales y libres de sesgos”: La Casa Blanca está preparando una orden ejecutiva que exige que los modelos de IA sean “políticamente neutrales y libres de sesgos”. El cumplimiento determinará la elegibilidad para contratos federales, lo cual es un gran problema para todos los laboratorios de IA. Se espera que la orden ejecutiva se publique la próxima semana. (Fuente: WSJ, MIT Technology Review, natolambert)

Kimi K2: Un modelo de inteligencia de agente con capacidad de uso de herramientas: Publicado por Kimi_Moonshot, Kimi K2 es un modelo de inteligencia de agente con capacidad de uso de herramientas. Se destaca en el uso de herramientas, matemáticas, codificación y tareas de varios pasos, y actualmente es el modelo de código abierto número uno en Arena, y el quinto en la clasificación general. Kimi K2 adopta una arquitectura Mixture-of-Experts (MoE) a gran escala similar a DeepSeek-V3, con 1 billón de parámetros totales y 32 mil millones de parámetros activos. (Fuente: TheTuringPost)

🧰 Herramientas
El servidor GitHub MCP conecta las herramientas de IA con la plataforma GitHub: El servidor GitHub MCP permite que las herramientas de IA se conecten directamente a la plataforma GitHub, lo que permite a los agentes de IA, asistentes y chatbots leer repositorios y archivos de código, administrar problemas y PR, analizar código y automatizar flujos de trabajo, todo a través de la interacción en lenguaje natural. (Fuente: GitHub Trending)
ik_llama.cpp: Una bifurcación de llama.cpp con mejor rendimiento de CPU: ik_llama.cpp es una bifurcación de llama.cpp con mejor rendimiento de CPU y GPU/CPU híbrida, nuevos tipos de cuantificación SOTA, soporte Bitnet de primera clase, DeepSeek mejorado a través de MLA, FlashMLA, operaciones MoE fusionadas y tensor patching, y empaquetado de cuantificación intercalado por filas para inferencia GPU/CPU híbrida, entre otras cosas. (Fuente: GitHub Trending)
📚 Aprendizaje
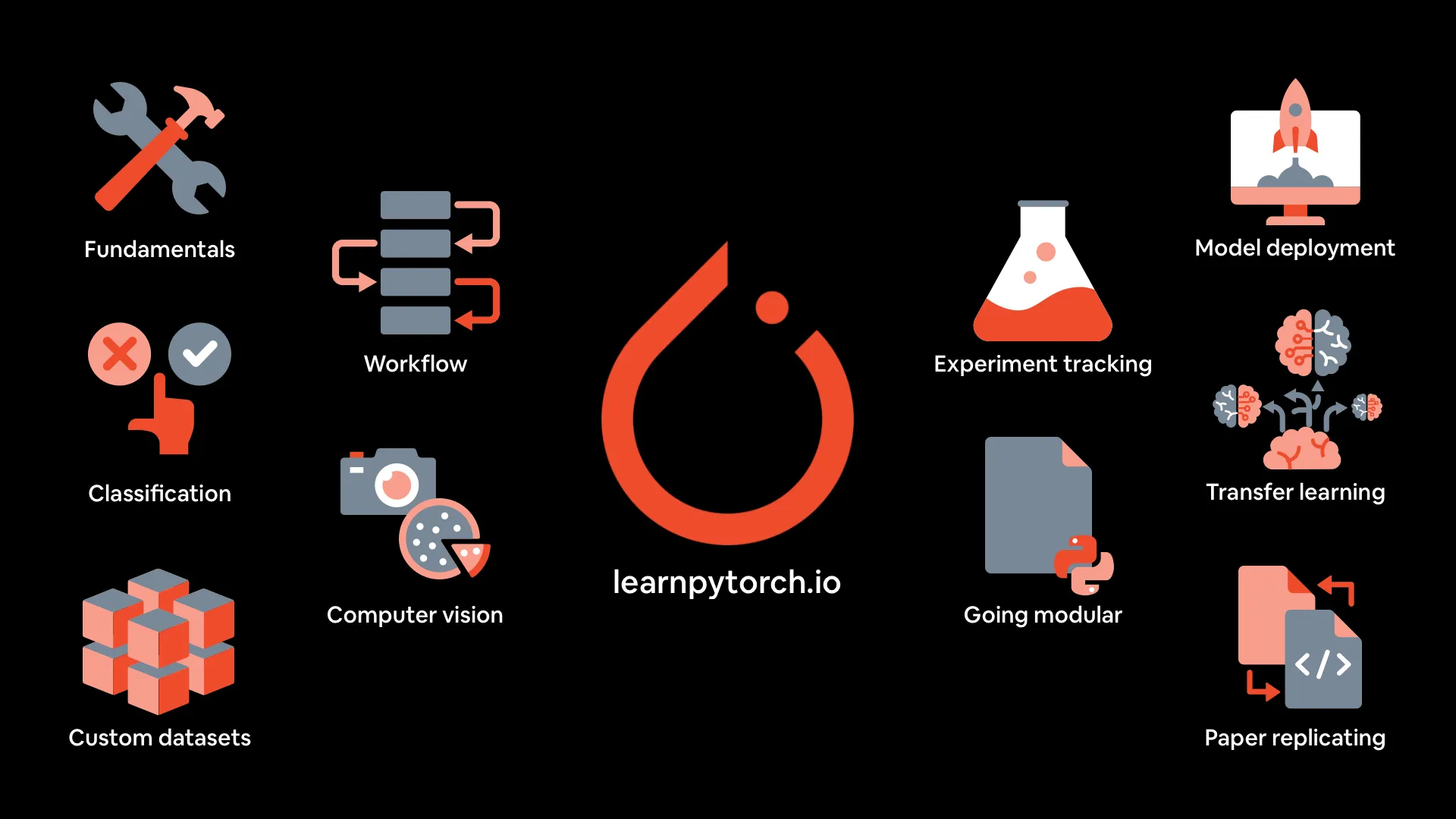
Materiales del curso de aprendizaje profundo de PyTorch: mrdbourke/pytorch-deep-learning proporciona los materiales del curso “Aprendizaje profundo de PyTorch desde cero”, incluyendo una versión de libro en línea, videos de las primeras cinco secciones en YouTube, ejercicios y clases adicionales. El curso se centra en la práctica y la experimentación con código, cubriendo los fundamentos de PyTorch, el flujo de trabajo, la clasificación de redes neuronales, la visión por computadora, conjuntos de datos personalizados, el aprendizaje por transferencia, el seguimiento de experimentos y la implementación de modelos. (Fuente: GitHub Trending)
MIT Press ofrece tres libros gratuitos sobre algoritmos y aprendizaje automático: MIT Press ofrece tres libros gratuitos sobre teoría de algoritmos y algoritmos centrales de aprendizaje automático: The Algorithm Design Manual, Algorithms for Decision Making y Algorithms for Verification. Estos libros son excelentes para profundizar en los algoritmos y el aprendizaje automático. (Fuente: TheTuringPost, TheTuringPost)

Los Transformers basados en energía son aprendices y pensadores escalables: Un artículo explora los Energy-Based Transformers (EBT), un nuevo tipo de Modelo Basado en Energía (EBM) que aprende a verificar explícitamente la compatibilidad entre las entradas y las predicciones candidatas, reformulando el problema de predicción como una optimización sobre este verificador, lo que permite “pensar” aprendiendo únicamente a partir del aprendizaje no supervisado. (Fuente: )

🌟 Comunidad
Lecciones aprendidas sobre la ingeniería de contexto para LLMs: El equipo de ManusAI compartió las lecciones aprendidas sobre la construcción de ingeniería de contexto para agentes de IA, señalando la importancia del almacenamiento en caché KV, el sistema de archivos, el seguimiento de errores, etc., en el diseño de agentes. (Fuente: dotey, AymericRoucher, vllm_project)
Comparación del rendimiento en el mundo real de Kimi K2 y Gemini: ClementDelangue y jeremyphoward retuitearon la publicación de pash, señalando que Kimi K2 superó a Gemini en tareas del mundo real, y proporcionaron datos gráficos relevantes. (Fuente: ClementDelangue, jeremyphoward)
El resultado de la medalla de oro de OpenAI en la IMO fue una sorpresa: El logro del LLM de OpenAI al obtener una medalla de oro en la IMO tomó a muchos por sorpresa, lo que provocó una amplia discusión en la comunidad. (Fuente: kylebrussell, VictorTaelin)
💼 Negocios
Anthropic limita el uso de Claude Code: Anthropic limitó el uso de Claude Code sin informar a los usuarios, lo que provocó quejas de los usuarios y preocupaciones sobre los productos cerrados. (Fuente: jeremyphoward, HamelHusain)
Meta se niega a firmar el pacto europeo de IA: Meta se negó a firmar el pacto europeo de IA, alegando que es excesivamente intervencionista y obstaculizará el desarrollo de la IA. (Fuente: Reddit r/artificial, Reddit r/ArtificialInteligence)
💡 Otros
Cómo ejecutar un LLM en tu computadora portátil: MIT Technology Review publicó una guía sobre cómo ejecutar un modelo de lenguaje grande (LLM) en tu computadora portátil, proporcionando pasos y consejos para ejecutar un LLM localmente para usuarios preocupados por la privacidad, que desean liberarse del control de las grandes empresas de LLM o que disfrutan experimentando con cosas nuevas. (Fuente: MIT Technology Review, MIT Technology Review)
Una breve historia de los “bebés de tres padres”: MIT Technology Review repasó la historia de los “bebés de tres padres”, presentando los diferentes enfoques de la tecnología, las controversias y los últimos avances en la investigación, incluido el nacimiento de ocho bebés en un ensayo en el Reino Unido. (Fuente: MIT Technology Review, MIT Technology Review)
Cómo encontrar valor en los agentes de IA desde el primer día: Este artículo explora cómo las empresas pueden encontrar valor en los agentes de IA, sugiriendo que las empresas adopten una mentalidad iterativa, comiencen con “ganancias rápidas” y casos de uso incrementales, y prioricen la interoperabilidad para prepararse para futuros sistemas multiagente. (Fuente: MIT Technology Review)