Palabras clave:Derechos de autor de datos de entrenamiento de IA, AlphaGenome, OpenAI copia de hardware, Resultados de IA en exámenes de ingreso a la universidad, Gemini CLI, Nuevo método RLT, BitNet b1.58, Agente Biomni inteligente, Sentencia sobre uso justo de IA, Predicción de pares de bases de ADN, Respuesta de Altman a acusaciones de plagio, Mejora de capacidad matemática en modelos grandes, Cuota gratuita de agentes de IA en terminales
🔥 Enfoque
Fallo histórico sobre derechos de autor para datos de entrenamiento de IA: Tribunal de EE. UU. dictamina que el uso de libros comprados legalmente para entrenar IA constituye “uso justo”: Un tribunal federal de EE. UU., en una demanda contra Anthropic, ha dictaminado que el uso por parte de las empresas de IA de libros publicados y comprados legalmente para entrenar modelos de lenguaje grandes entra en la categoría de “uso justo” (fair use), sin necesidad del consentimiento previo del autor. El tribunal consideró que el entrenamiento de IA es un “uso transformador” de la obra original, no reemplaza directamente el mercado de la obra original y beneficia la innovación tecnológica y el interés público. Sin embargo, el tribunal también dictaminó que el uso de libros pirateados para el entrenamiento no constituye uso justo, y Anthropic aún podría ser considerada responsable por ello. Este fallo se remite al precedente del caso Google Books de 2015 y se considera un paso importante para reducir los riesgos de derechos de autor en los datos de entrenamiento de IA, pudiendo influir en la tramitación de otros casos similares (como las demandas contra OpenAI y Meta). Anteriormente, Meta también obtuvo un fallo favorable en una demanda similar por derechos de autor, donde el juez consideró que el demandante no demostró suficientemente que el uso de sus libros por parte de Meta para entrenar modelos de IA causara daño económico. Estos fallos en conjunto proporcionan una guía legal más clara para la industria de la IA en cuanto a la adquisición y uso de datos, pero enfatizan la importancia de la adquisición legal de datos. (Fuente: 量子位, DeepLearning.AI Blog, wiredmagazine)
Google DeepMind lanza AlphaGenome: el “microscopio” de IA que predice el impacto de las variaciones genéticas en millones de pares de bases de ADN: Google DeepMind ha presentado el modelo de IA AlphaGenome, capaz de tomar secuencias de ADN de hasta 1 millón de pares de bases como entrada para predecir miles de características moleculares y evaluar el impacto de las variaciones genéticas, liderando en más de 20 benchmarks de predicción genómica. AlphaGenome se caracteriza por su procesamiento contextual de secuencias largas de alta resolución, predicción multimodal integral, puntuación eficiente de variaciones y un novedoso modelo de conexión de splicing. El entrenamiento de un solo modelo requiere solo 4 horas, con un presupuesto computacional que es la mitad del modelo Enformer original. Este modelo tiene como objetivo ayudar a los científicos a comprender la regulación genética, acelerar la comprensión de enfermedades (especialmente enfermedades raras), guiar el diseño de biología sintética e impulsar la investigación básica. Actualmente se ofrece una versión preliminar a través de API para investigación no comercial, con planes de lanzamiento completo en el futuro. (Fuente: 36氪, Google, demishassabis)

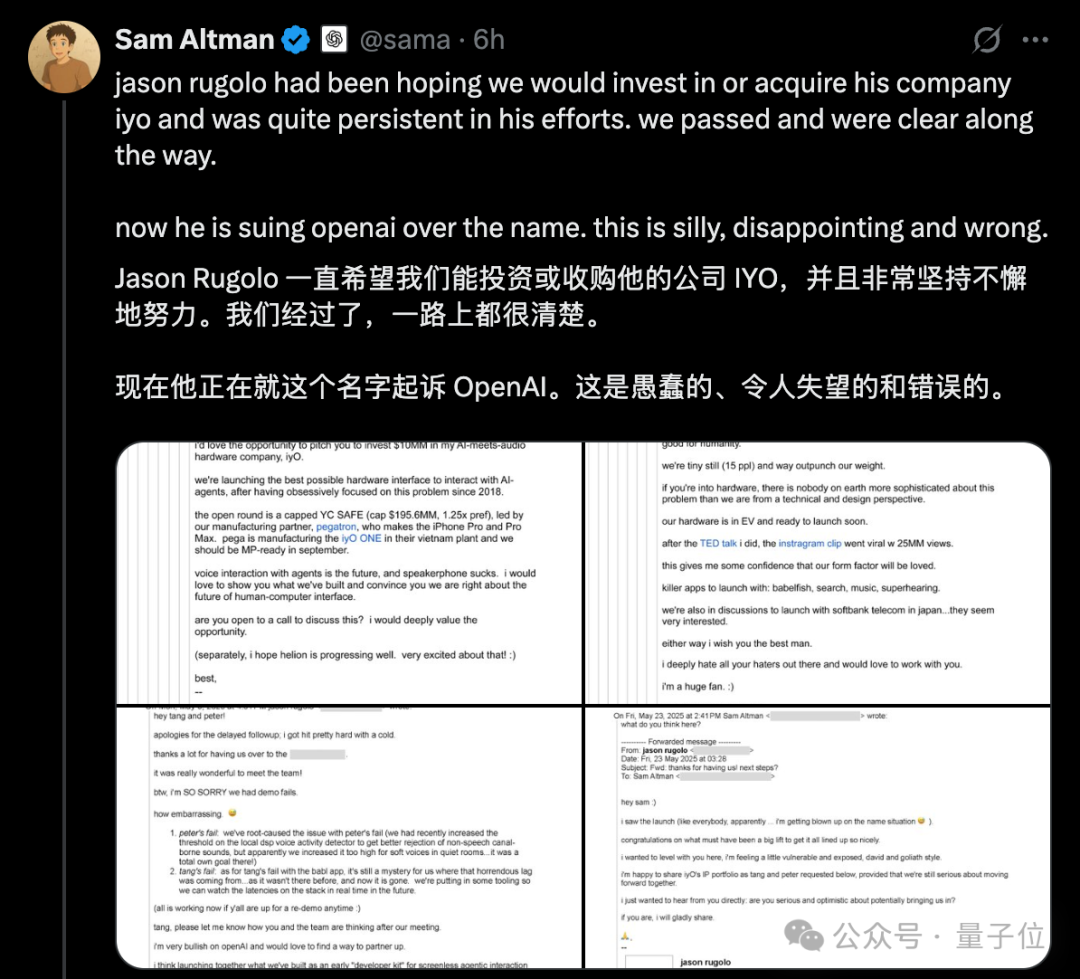
Se intensifica la controversia por el “escándalo de plagio” de hardware de OpenAI, Altman refuta públicamente la demanda de IYO con correos electrónicos: En respuesta a las acusaciones de la startup de hardware de IA IYO contra OpenAI y su empresa de hardware adquirida io (fundada por el exdiseñador de Apple Jony Ive) por infracción de marca registrada y plagio de producto, el CEO de OpenAI, Sam Altman, respondió públicamente en redes sociales, calificando la demanda de IYO como “tonta, decepcionante y completamente errónea”. Altman presentó capturas de pantalla de correos electrónicos que muestran que el fundador de IYO, Jason Rugolo, había buscado activamente una inversión de 10 millones de dólares o la adquisición por parte de OpenAI antes de la demanda, y aún esperaba compartir su propiedad intelectual después de que OpenAI anunciara la adquisición de io. Altman cree que IYO inició la demanda solo después de que la inversión o adquisición no se concretara. El fundador de IYO, por su parte, refutó que Altman estuviera llevando el caso a un “tribunal en línea” e insistió en los derechos sobre el nombre de su producto. Anteriormente, el tribunal había aprobado una orden de restricción temporal para IYO, impidiendo a OpenAI usar el logo IO. OpenAI afirma que su producto de hardware es diferente del dispositivo auditivo personalizado de IYO, que el diseño del prototipo no está definido y que no saldrá al mercado hasta al menos un año después. (Fuente: 量子位, 36氪)
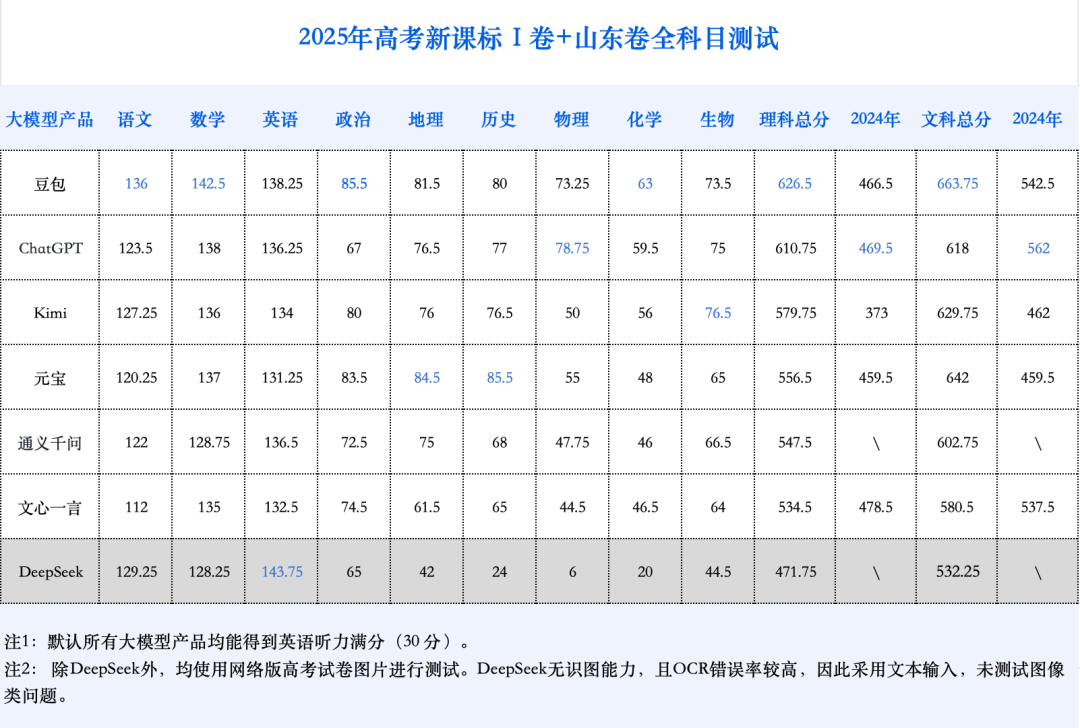
Grandes modelos de IA se enfrentan de nuevo al Gaokao, con una mejora general significativa en los resultados y un progreso destacado en matemáticas: Los resultados de la simulación del examen Gaokao de IA 2025 de GeekPark muestran que los principales modelos grandes (como Doubao, DeepSeek R1, ChatGPT o3, etc.) han mejorado significativamente sus resultados generales en comparación con el año pasado, demostrando potencial para ingresar a las mejores universidades; se estima que el “zhuangyuan” (mejor puntuado) Doubao podría clasificarse entre los 900 primeros de la provincia de Shandong. El fenómeno de desequilibrio entre asignaturas de letras y ciencias en la IA se ha mitigado, con un crecimiento más rápido de la puntuación media en ciencias. Las matemáticas se convirtieron en la asignatura con el progreso más notable, con un aumento de la puntuación media de 84.25 puntos, superando a lengua y literatura e inglés. La capacidad multimodal se ha convertido en un factor clave para diferenciar el rendimiento, destacando especialmente en asignaturas con gran cantidad de preguntas con imágenes, como física y geografía. Aunque la IA muestra un rendimiento excelente en razonamiento complejo y cálculo, todavía comete errores al comprender preguntas sencillas con información visual confusa (como una pregunta de vectores en matemáticas). En cuanto a la redacción, la IA puede escribir textos con estructura completa y argumentos ricos, pero carece de profundidad de pensamiento y resonancia emocional, lo que dificulta la producción de obras maestras. (Fuente: 36氪)
🎯 Tendencias
Google lanza Gemini CLI impulsado por Gemini 2.5 Pro, atrayendo atención con una generosa cuota gratuita: Google ha lanzado oficialmente Gemini CLI, un asistente de IA que se ejecuta en el entorno de terminal, basado en el modelo Gemini 2.5 Pro. Su característica más destacada es una cuota de uso gratuito extremadamente generosa: admite una ventana de contexto de 1 millón de tokens, con 60 llamadas al modelo por minuto y 1000 al día, lo que representa una fuerte competencia para herramientas de pago como Claude Code de Anthropic. Gemini CLI utiliza la licencia de código abierto Apache 2.0 y admite la escritura y depuración de código, gestión de proyectos, consulta de documentación y la invocación de otros servicios de Google (como la generación de imágenes y vídeos) a través de MCP. Google enfatiza la ventaja de su modelo universal en el manejo de tareas de desarrollo complejas, argumentando que los modelos puramente de código podrían estar limitados. La comunidad ha reaccionado con entusiasmo, considerando que esto impulsará la popularización y la competencia de las herramientas de IA para CLI. (Fuente: 36氪, Reddit r/LocalLLaMA, dotey)

Sakana AI propone un nuevo método RLT, donde un modelo pequeño de 7B “enseña” superando a DeepSeek-R1: Sakana AI, fundada por Llion Jones, uno de los autores de Transformer, ha propuesto un nuevo método de profesores de aprendizaje por refuerzo (RLTs). Este método hace que el modelo profesor ya no resuelva problemas desde cero, sino que genere explicaciones claras paso a paso basadas en soluciones conocidas, imitando la enseñanza “heurística” de los buenos profesores humanos. Los experimentos demuestran que un modelo RLT pequeño de 7B entrenado con este método supera en la enseñanza de habilidades de razonamiento al modelo DeepSeek-R1 de 671B, y puede entrenar eficazmente modelos estudiantes hasta 3 veces más grandes (como uno de 32B), reduciendo significativamente los costos de entrenamiento. Este método busca resolver los problemas de los modelos profesores tradicionales que dependen de su propia capacidad para resolver problemas, son lentos y costosos de entrenar, mejorando la eficiencia al alinear el entrenamiento del profesor con su verdadero propósito (ayudar al modelo estudiante a aprender). (Fuente: 量子位, SakanaAILabs)

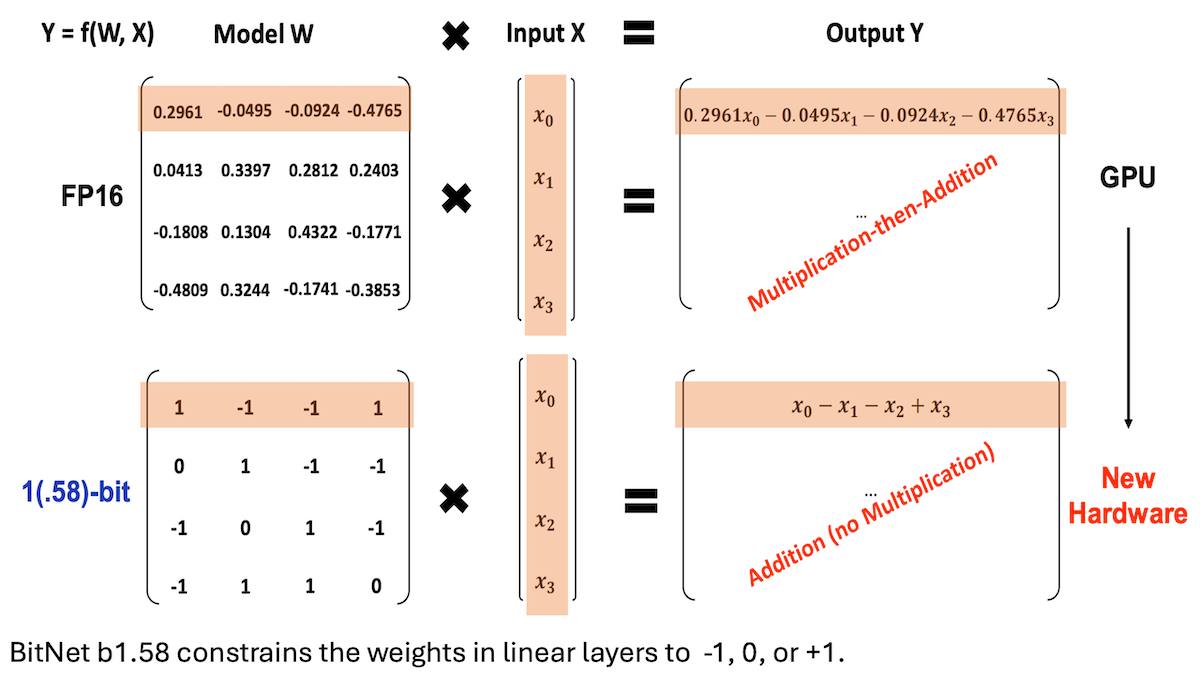
Microsoft y otros proponen BitNet b1.58, logrando LLM de baja precisión y alto rendimiento de inferencia: Investigadores de Microsoft, la Universidad de la Academia China de Ciencias y la Universidad de Tsinghua han actualizado el modelo BitNet b1.58, donde la mayoría de los pesos se limitan a tres valores: -1, 0 o +1 (aproximadamente 1.58 bits/parámetro). A una escala de 2 mil millones de parámetros, su rendimiento compite con los modelos de precisión completa de primer nivel. Este modelo se optimiza mediante estrategias de entrenamiento cuidadosamente diseñadas (como entrenamiento consciente de la cuantización, tasa de aprendizaje en dos etapas y decaimiento de peso). En 16 benchmarks populares, su velocidad y uso de memoria superan a Qwen2.5-1.5B, Gemma-3 1B, entre otros; su precisión promedio se acerca a Qwen2.5-1.5B y supera a la versión cuantizada de 4 bits de Qwen2.5-1.5B. Este trabajo demuestra que, mediante un ajuste meticuloso de hiperparámetros, los modelos de baja precisión también pueden lograr un alto rendimiento, ofreciendo nuevas ideas para la implementación eficiente de LLM. (Fuente: DeepLearning.AI Blog)
Instituciones como Stanford lanzan Biomni, un agente inteligente para investigación biológica que integra más de cien herramientas y bases de datos: Investigadores de la Universidad de Stanford, la Universidad de Princeton y otras instituciones han lanzado Biomni, un agente de IA diseñado específicamente para una amplia gama de investigaciones biológicas. Este agente, basado en Claude 4 Sonnet, integra 150 herramientas seleccionadas de 2500 artículos recientes de 25 campos especializados de la biología (incluyendo genómica, inmunología, neurociencia, etc.), casi 60 bases de datos y alrededor de 100 paquetes de software biológico populares. Biomni puede realizar diversas tareas como hacer preguntas, proponer hipótesis, diseñar procesos, analizar conjuntos de datos y generar gráficos. Adopta el framework CodeAct, respondiendo a las consultas mediante planificación iterativa, generación y ejecución de código, e introduce otra instancia de Claude 4 Sonnet como juez para evaluar la razonabilidad de los resultados intermedios. En múltiples benchmarks como Lab-bench y estudios de casos reales, Biomni supera el rendimiento de Claude 4 Sonnet por sí solo y de los modelos Claude mejorados con recuperación de literatura. (Fuente: DeepLearning.AI Blog)

Anthropic lanza nueva función en Claude Code: crear y compartir Artifacts impulsados por IA: Anthropic ha introducido una nueva función para su asistente de programación de IA, Claude Code, que permite a los usuarios crear, alojar y compartir “Artifacts” (entendidos como pequeñas aplicaciones o herramientas de IA), pudiendo integrar directamente la inteligencia de Claude en estas creaciones. Esto significa que los usuarios no solo pueden usar Claude para generar fragmentos de código o realizar análisis, sino también construir aplicaciones funcionales impulsadas por IA. Una característica clave es que, al compartir estas aplicaciones de IA, los espectadores se autentican con sus propias cuentas de Claude, y su uso se contabiliza en la cuota de suscripción del espectador, no del creador. Esta función se encuentra actualmente en fase beta y está disponible para todos los usuarios gratuitos, Pro y Max, con el objetivo de reducir la barrera de entrada para la creación de aplicaciones de IA y promover la popularización y el intercambio de capacidades de IA. (Fuente: kylebrussell, Reddit r/ClaudeAI)
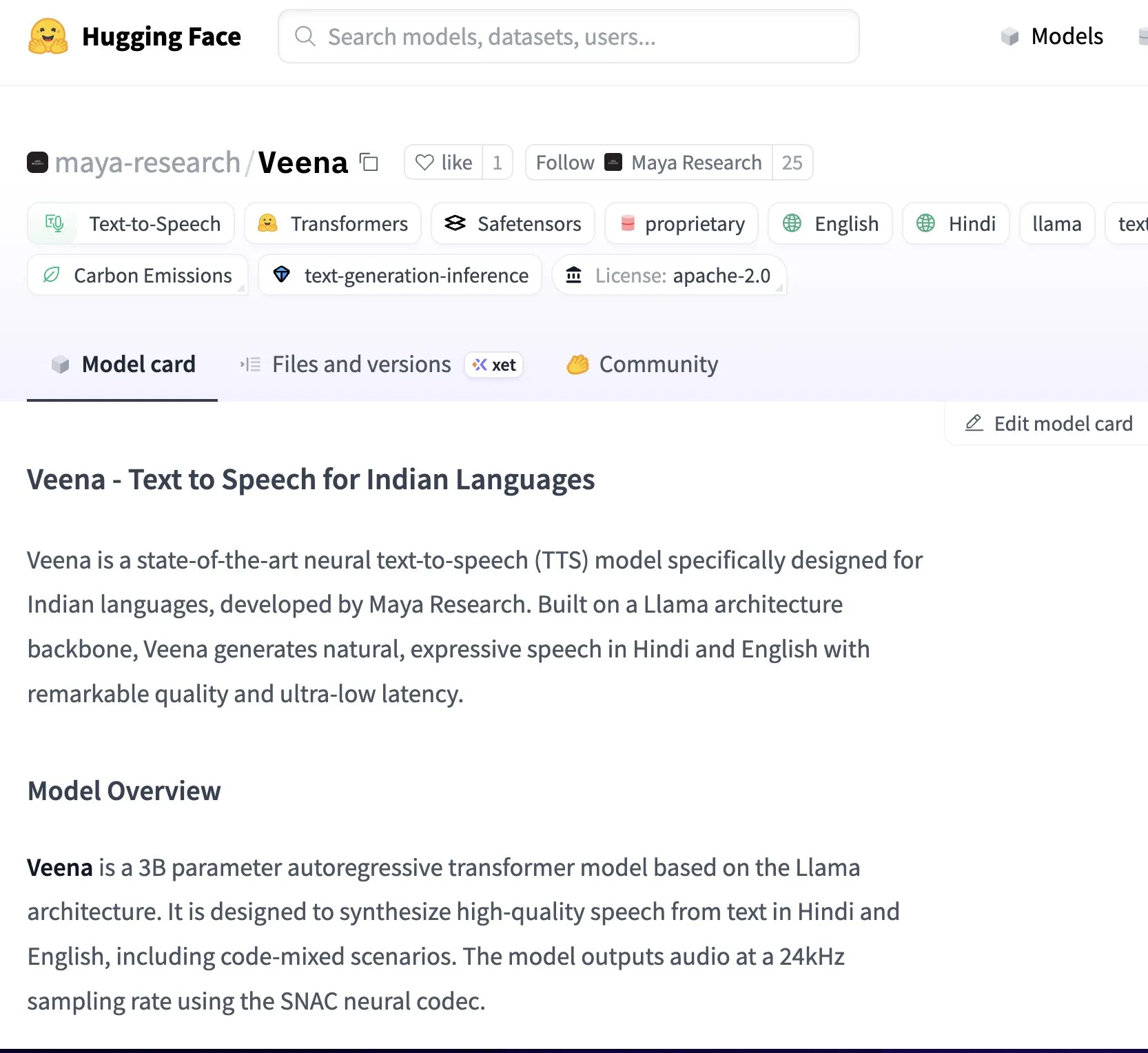
Maya Research lanza el modelo Veena TTS, compatible con hindi e inglés, con un timbre de voz más cercano al nativo de la India: Maya Research ha lanzado un modelo de texto a voz (TTS) llamado Veena, basado en la arquitectura Llama de 3B y con licencia Apache 2.0. La característica distintiva de Veena es su capacidad para generar voz en inglés e hindi con acento indio, incluyendo escenarios de code-mix, abordando las deficiencias de los modelos TTS existentes en la pronunciación localizada para la India. El modelo tiene una latencia inferior a 80 milisegundos, puede ejecutarse en el entorno gratuito de Google Colab y ya está disponible en Hugging Face Hub. El equipo ha declarado que está desarrollando activamente soporte para otros idiomas indios como tamil, telugu y bengalí. (Fuente: huggingface, huggingface)
HiDream.ai (智象未来) lanza vivago2.0, integrando capacidades de generación y edición multimodal: HiDream.ai (智象未来), fundada por el experto en IA Mei Tao, ha lanzado la herramienta de creación multimodal de IA vivago2.0. Este producto integra funciones como generación de imágenes, conversión de imagen a vídeo, podcast de IA (sincronización labial), plantillas de efectos especiales, y cuenta con una comunidad creativa para que los usuarios compartan y obtengan inspiración. Su tecnología central se basa en el nuevo agente inteligente de imágenes HiDream-A1, que integra versiones avanzadas de código cerrado de HiDream-I1 (modelo base de generación de imágenes de 17 mil millones de parámetros, previamente de código abierto y líder en competiciones de texto a imagen) y HiDream-E1 (modelo interactivo de edición de imágenes). vivago2.0 tiene como objetivo reducir la barrera de entrada para la creación de contenido multimodal, ofreciendo cientos de plantillas de efectos especiales y soportando la generación y modificación de imágenes mediante diálogo en lenguaje natural (Image Agent). (Fuente: 量子位)

Nvidia lanza la serie de GPU RTX 5050, con diferentes configuraciones de VRAM para escritorio y portátiles: Nvidia ha lanzado oficialmente la serie de GPU GeForce RTX 5050, que incluye versiones para escritorio y portátiles, programadas para salir a la venta en julio, con un precio minorista sugerido en China a partir de 2099 yuanes para la versión de escritorio. La RTX 5050 de escritorio cuenta con 2560 núcleos Blackwell CUDA, equipada con 8GB de memoria GDDR6 y un consumo máximo de energía de 130W. La versión para portátiles de la RTX 5050 también tiene 2560 núcleos CUDA, pero está equipada con 8GB de memoria GDDR7, más eficiente energéticamente. Nvidia afirma que, con la tecnología DLSS 4, la RTX 5050 puede superar los 150 fps con ray tracing en juegos como Cyberpunk 2077, y en comparación con la RTX 3050, el rendimiento de rasterización mejora en promedio un 60% (versión de escritorio) y 2.4 veces (versión para portátiles). Esta diferenciación en la configuración de la VRAM refleja la estrategia de Nvidia para equilibrar costos y rendimiento en diferentes segmentos del mercado. (Fuente: 量子位)

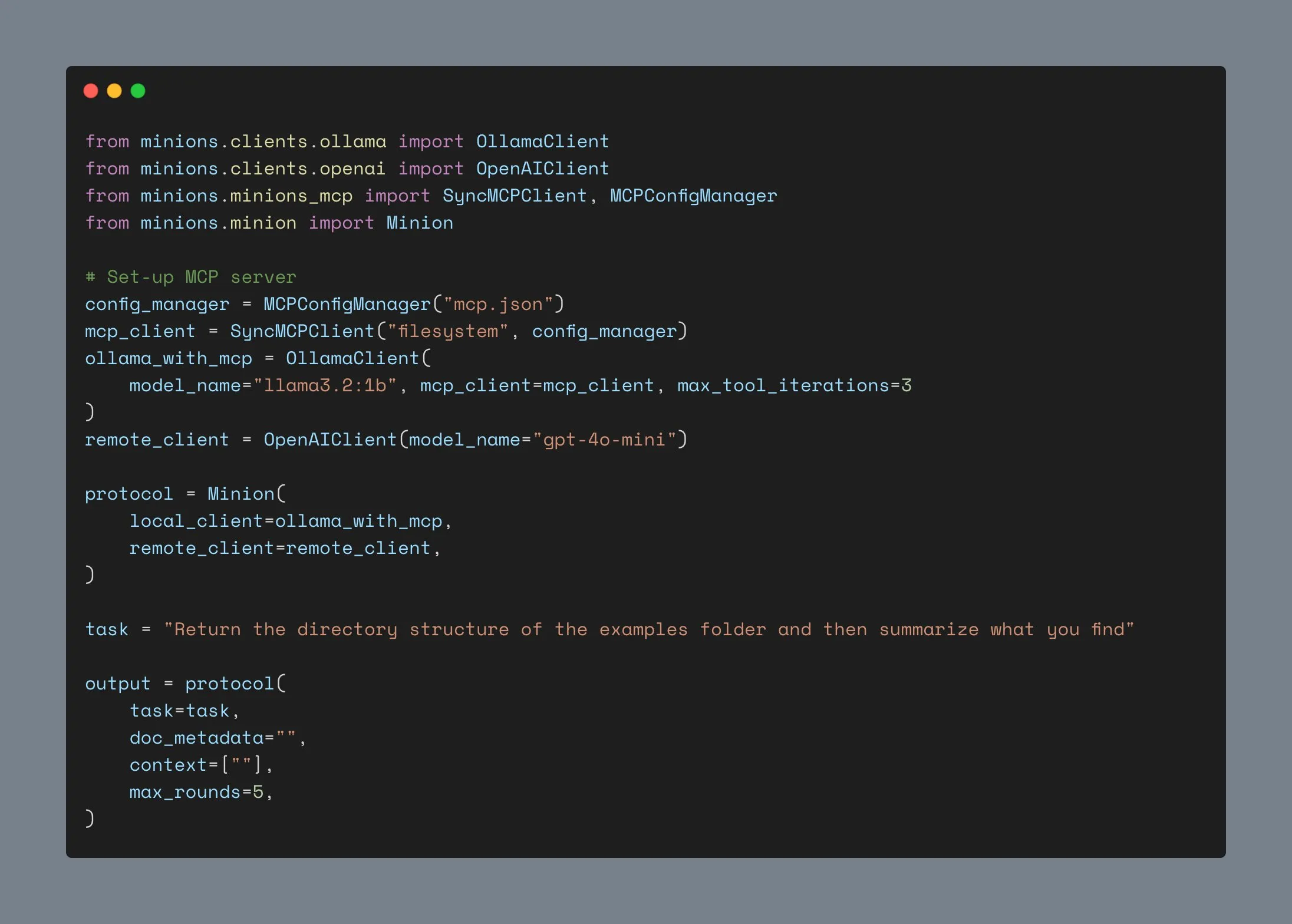
LM Studio se actualiza para admitir el protocolo MCP, permitiendo conectar LLM locales con servidores MCP: La herramienta de ejecución de LLM de escritorio LM Studio ha lanzado una nueva versión (0.3.17) que añade soporte para el Protocolo de Contexto de Modelo (MCP). Los usuarios ahora pueden conectar modelos de lenguaje grandes que se ejecutan localmente con servidores compatibles con MCP, por ejemplo, para invocar herramientas o servicios externos. LM Studio ha actualizado su interfaz de programa para esto, permitiendo a los usuarios instalar y configurar servicios MCP, y puede cargar y gestionar automáticamente los procesos del servidor MCP local. Para facilitar la configuración, LM Studio también ofrece una herramienta en línea para generar enlaces de configuración del servidor MCP que se pueden importar con un solo clic. (Fuente: multimodalart, karminski3)

Gradio lanza la biblioteca ligera de seguimiento de experimentos Trackio: El equipo de Gradio, parte de Hugging Face, ha lanzado Trackio, una biblioteca ligera para el seguimiento y visualización de experimentos. Esta herramienta está escrita en menos de 1000 líneas de código Python, es completamente de código abierto y gratuita, y admite su uso local o alojado. Trackio tiene como objetivo ayudar a los desarrolladores a registrar y monitorear de manera más conveniente diversas métricas y resultados durante el proceso de experimentación en machine learning, simplificando el flujo de gestión de experimentos. (Fuente: ClementDelangue, _akhaliq)
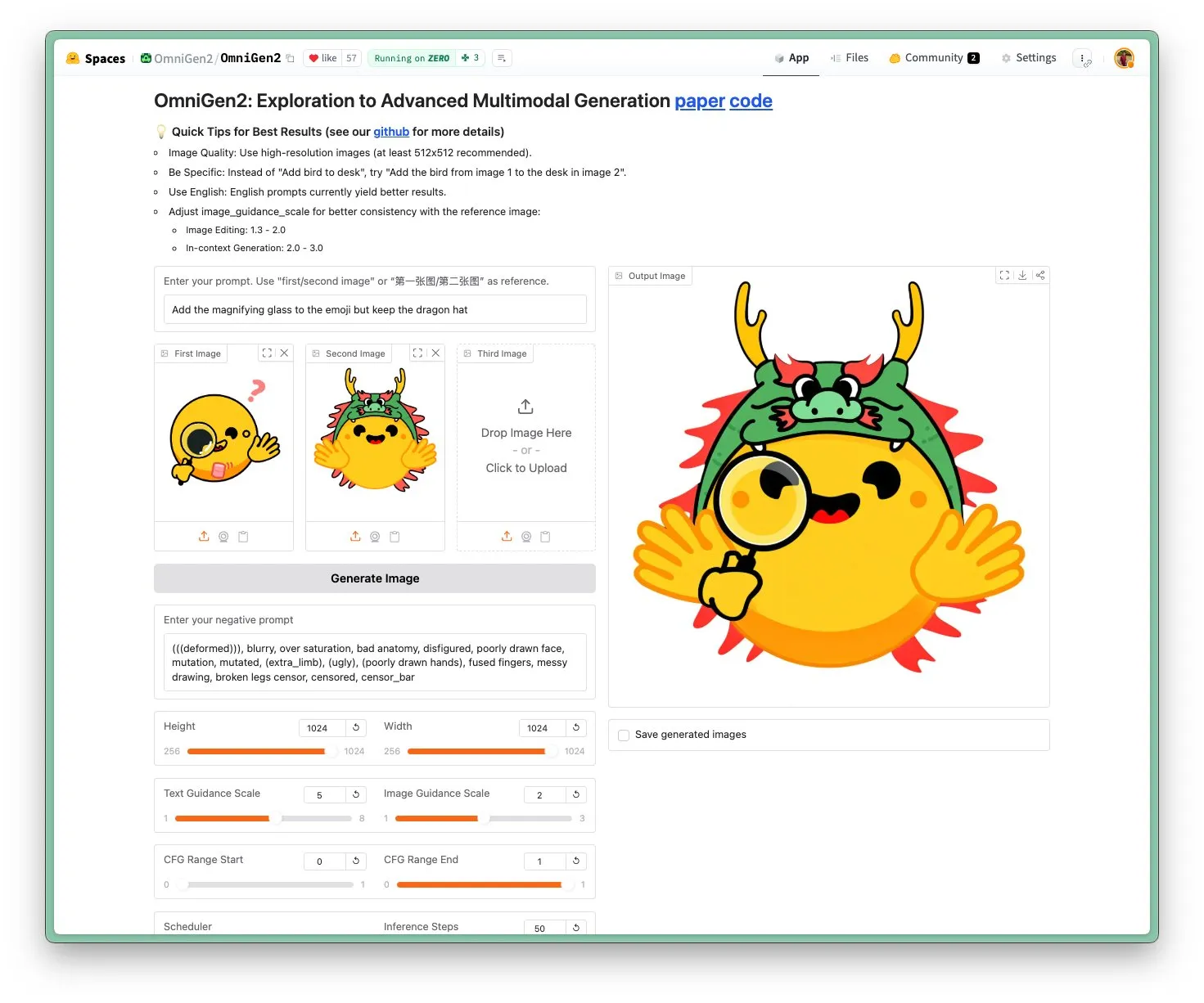
Lanzamiento de OmniGen 2: modelo visual multifuncional y de edición de imágenes SOTA con licencia Apache 2.0: El nuevo modelo OmniGen 2 alcanza el estado del arte (SOTA) en edición de imágenes y se distribuye bajo la licencia de código abierto Apache 2.0. Este modelo no solo destaca en la edición de imágenes, sino que también puede realizar generación contextual, conversión de texto a imagen, comprensión visual y otras tareas diversas. Los usuarios pueden probar directamente la demo y el modelo en Hugging Face Hub. (Fuente: huggingface)
Se propone la arquitectura Atlas: con memoria contextual de largo alcance, desafiando a Transformer: La nueva arquitectura propuesta, Atlas, tiene como objetivo resolver el problema de la memoria a largo plazo en los LLM, afirmando superar a Transformer y a las modernas RNN lineales en tareas de modelado de lenguaje. Atlas tiene la capacidad de aprender cómo memorizar el contexto en tiempo de prueba, puede aumentar la longitud efectiva del contexto de los modelos Titans y alcanzar una precisión superior al 80% en el benchmark BABILong con una ventana de contexto de 10 millones. Los investigadores también discuten otra serie de modelos de atención softmax de generalización estricta basados en la idea de Atlas. (Fuente: behrouz_ali)

Actualización del modelo visual Moondream 2B: mejora en razonamiento visual y comprensión de UI, generación de texto un 40% más rápida: Se ha lanzado una nueva versión del modelo visual Moondream 2B, con mejoras en el razonamiento visual, detección de objetos y comprensión de la interfaz de usuario (UI), además de un aumento del 40% en la velocidad de generación de texto. Esto indica que los modelos multimodales pequeños continúan optimizándose en capacidades específicas, con el objetivo de proporcionar una interacción visual-lingüística más eficiente y precisa. (Fuente: mervenoyann)
Inworld AI y Modular colaboran para lanzar un modelo TTS de bajo costo y alta calidad: Inworld AI ha anunciado el lanzamiento de un nuevo modelo de texto a voz (TTS) que, según afirman, reduce el costo del TTS de última generación en 20 veces, alcanzando los 5 dólares por millón de caracteres. Este modelo se basa en la arquitectura Llama, y su código de entrenamiento y modelado será de código abierto. Su socio, Modular, ha declarado que mediante la colaboración tecnológica, han logrado la plataforma de inferencia TTS más rápida y con la latencia más baja en NVIDIA B200, y publicarán un informe técnico conjunto. (Fuente: clattner_llvm)
Higgsfield AI lanza el modelo Soul: enfocado en la generación de fotos de alta estética: Higgsfield AI ha presentado un nuevo modelo de generación de fotos llamado Higgsfield Soul, que se especializa en un alto valor estético y un realismo de nivel moda. El modelo ofrece más de 50 preajustes cuidadosamente seleccionados, diseñados para generar imágenes comparables a la fotografía profesional, desafiando la fotografía móvil tradicional. (Fuente: _akhaliq)
🧰 Herramientas
Gemini CLI: Agente de IA de terminal de código abierto lanzado por Google, ofrece 1000 llamadas gratuitas diarias a Gemini 2.5 Pro: Google ha lanzado Gemini CLI, un agente de IA de línea de comandos de código abierto que permite a los usuarios utilizar directamente el modelo Gemini 2.5 Pro en la terminal. Esta herramienta ofrece una ventana de contexto de 1 millón de tokens, y los usuarios gratuitos pueden obtener hasta 1000 solicitudes diarias (60 por minuto). Gemini CLI admite la escritura y depuración de código, E/S del sistema de archivos, comprensión de contenido web, plugins y el protocolo MCP, con el objetivo de ayudar a los desarrolladores a construir y mantener software de manera más eficiente. Su naturaleza de código abierto (licencia Apache 2.0) y su alta cuota gratuita lo convierten en un fuerte competidor para herramientas existentes como Claude Code, y podría impulsar el soporte para modelos locales. (Fuente: Reddit r/LocalLLaMA, dotey, yoheinakajima)
Anthropic lanza nueva función en Claude Code: crear y compartir Artifacts impulsados por IA, los usuarios utilizan su propia cuota: Anthropic ha introducido una nueva función para su asistente de programación de IA, Claude Code, que permite a los usuarios crear, alojar y compartir “Artifacts” (entendidos como pequeñas aplicaciones o herramientas de IA), pudiendo integrar directamente la inteligencia de Claude en estas creaciones. Esto significa que los usuarios no solo pueden usar Claude para generar fragmentos de código o realizar análisis, sino también construir aplicaciones funcionales impulsadas por IA. Una característica clave es que, al compartir estas aplicaciones de IA, los espectadores se autentican con sus propias cuentas de Claude, y su uso se contabiliza en la cuota de suscripción del espectador, no del creador. Esta función se encuentra actualmente en fase beta y está disponible para todos los usuarios gratuitos, Pro y Max, con el objetivo de reducir la barrera de entrada para la creación de aplicaciones de IA y promover la popularización y el intercambio de capacidades de IA. (Fuente: kylebrussell, Reddit r/ClaudeAI, dotey)
LM Studio se actualiza para admitir el protocolo MCP, permitiendo conectar LLM locales con servidores MCP: La herramienta de ejecución de LLM de escritorio LM Studio ha lanzado una nueva versión (0.3.17) que añade soporte para el Protocolo de Contexto de Modelo (MCP). Los usuarios ahora pueden conectar modelos de lenguaje grandes que se ejecutan localmente con servidores compatibles con MCP, por ejemplo, para invocar herramientas o servicios externos. LM Studio ha actualizado su interfaz de programa para esto, permitiendo a los usuarios instalar y configurar servicios MCP, y puede cargar y gestionar automáticamente los procesos del servidor MCP local. Para facilitar la configuración, LM Studio también ofrece una herramienta en línea para generar enlaces de configuración del servidor MCP que se pueden importar con un solo clic. (Fuente: multimodalart, karminski3)
Superconductor: Herramienta para gestionar equipos de agentes Claude Code en dispositivos móviles o de escritorio: Superconductor es una nueva herramienta que permite a los usuarios gestionar un equipo compuesto por múltiples agentes Claude Code a través de sus teléfonos móviles u ordenadores portátiles. Los usuarios pueden escribir “tickets” de tareas informales, iniciar múltiples agentes para cada ticket, cada uno con su propia vista previa de la aplicación en tiempo real. Los desarrolladores pueden generar un PR (Pull Request) de los resultados del agente con mejor rendimiento con un solo clic. La herramienta tiene como objetivo simplificar la colaboración multiagente y los procesos de generación de código. (Fuente: full_stack_dl)
Udio lanza la función Sessions, mejorando la precisión en la edición de música con IA: La plataforma de generación de música con IA Udio ha lanzado la función “Sessions” para sus suscriptores de las versiones estándar y profesional. Esta función introduce una nueva vista de línea de tiempo para la edición de pistas, permitiendo a los usuarios producir música con mayor precisión y reduciendo la dependencia de la generación aleatoria de la IA. Actualmente, Sessions admite la extensión o edición de pistas, y se añadirán más funciones en el futuro. (Fuente: TomLikesRobots)
Cliente Ollama actualizado, admite integración MCP, supera las mil estrellas en GitHub: El cliente Ollama ha sido actualizado y ahora puede integrar su función de llamada a herramientas con cualquier servidor MCP de Anthropic. Esto significa que los usuarios pueden combinar la comodidad de ejecutar modelos localmente con Ollama y las capacidades de herramientas externas proporcionadas por MCP. Al mismo tiempo, el proyecto ha superado las 1000 estrellas en GitHub. (Fuente: ollama)
📚 Aprendizaje
Andrew Ng lanza nuevo curso: Protocolo de Comunicación de Agentes ACP: DeepLearning.AI en colaboración con IBM Research ha lanzado un curso corto sobre el Protocolo de Comunicación de Agentes (ACP). ACP es un protocolo abierto que estandariza la comunicación entre agentes a través de una interfaz RESTful unificada, con el objetivo de resolver los desafíos de integración al construir sistemas multiagente por múltiples equipos y a través de diferentes frameworks. El curso enseñará cómo usar ACP para conectar agentes construidos con diferentes frameworks (como CrewAI, Smoljames), lograr la colaboración en flujos de trabajo secuenciales y jerárquicos, e importar agentes ACP a la plataforma BeeAI (una plataforma de código abierto para el registro y compartición de agentes). Los alumnos aprenderán el ciclo de vida de los agentes ACP y los compararán con protocolos como MCP (Model Context Protocol) y A2A (Agent-to-Agent). (Fuente: AndrewYNg)
La Universidad Johns Hopkins lanza un curso sobre DSPy: La Universidad Johns Hopkins ha inaugurado un curso sobre DSPy. DSPy es un framework para la optimización algorítmica de prompts y pesos de LLM, que transforma el proceso de ingeniería de prompts, antes manual, en un proceso más sistemático y programable de construcción y optimización de módulos. El CEO de Shopify, Tobi Lutke, también ha declarado que DSPy es su herramienta preferida para la ingeniería de contexto. (Fuente: stanfordnlp, lateinteraction)

Tutorial de LM Studio: Cómo lograr una experiencia similar a ChatGPT local y privada usando modelos de código abierto de Hugging Face: Niels Rogge ha publicado un tutorial en YouTube que demuestra cómo usar LM Studio en combinación con modelos de código abierto de Hugging Face (como Mistral 3.2-Small) para lograr una experiencia 100% privada y offline similar a ChatGPT localmente. El tutorial explica conceptos como GGUF, cuantización, y por qué los modelos aún ocupan un espacio considerable con cuantización de 4 bits, y muestra la compatibilidad de LM Studio con la API de OpenAI. (Fuente: _akhaliq)

LlamaIndex organizará un seminario web sobre la memoria de los agentes: LlamaIndex colaborará con AIMakerspace para organizar una discusión en línea sobre la memoria de los agentes. El contenido cubrirá la persistencia del historial de chat, el uso de bloques estáticos, fácticos y vectoriales para lograr memoria a largo plazo, la lógica de implementación de memoria personalizada y cuándo la memoria es crucial, entre otros temas. La discusión tiene como objetivo ayudar a los desarrolladores a construir agentes que necesiten un contexto real en las conversaciones. (Fuente: jerryjliu0)

Podcast de Weaviate discute benchmarks y evaluación de RAG: El episodio 124 del podcast de Weaviate invitó a Nandan Thakur, quien ha hecho contribuciones significativas en el campo de la evaluación de búsqueda, para discutir el benchmarking y la evaluación de la Generación Aumentada por Recuperación (RAG). El contenido abarca benchmarks como BEIR, MIRACL, TREC y el más reciente FreshStack, así como múltiples temas en RAG como inferencia, redacción de consultas, búsqueda cíclica, resultados de búsqueda paginados y recuperadores híbridos. (Fuente: lateinteraction)

PyTorch lanza la receta flux-fast, acelerando los modelos Flux 2.5 veces en H100: PyTorch ha lanzado una receta simple llamada flux-fast, diseñada para aumentar la velocidad de ejecución de los modelos Flux en GPU H100 en 2.5 veces sin necesidad de ajustes complejos. Esta solución tiene como objetivo simplificar la implementación de la computación de alto rendimiento, y el código relacionado ya está disponible. (Fuente: robrombach)

Se anuncia información sobre la conferencia MLSys 2026: La conferencia MLSys 2026 está programada para mayo de 2026 en Seattle (Bellevue), con fecha límite para la presentación de artículos el 30 de octubre de este año. Todas las grabaciones de las sesiones de MLSys 2025 ya están disponibles gratuitamente en el sitio web oficial. Esta conferencia se centra en la investigación y los avances en el campo de los sistemas de machine learning. (Fuente: JeffDean)

El curso CS336 de Stanford “Construyendo Modelos de Lenguaje desde Cero” recibe atención: El curso CS336 de la Universidad de Stanford, impartido por Percy Liang y otros, titulado “Language Models from Scratch” (Modelos de Lenguaje desde Cero), ha recibido elogios generalizados. El curso tiene como objetivo que los estudiantes comprendan profundamente los detalles técnicos de los modelos de lenguaje, remediando el problema de la desconexión entre los investigadores y los detalles técnicos mediante la construcción manual de modelos. El contenido del curso y las tareas se consideran recursos de aprendizaje importantes para convertirse en un experto en LLM. (Fuente: nrehiew_, jpt401)
💼 Negocios
Meta invierte 14.3 mil millones de dólares en Scale AI y contrata a su CEO Alexandr Wang para acelerar la I+D en IA: Para fortalecer su capacidad en IA, Meta ha llegado a un acuerdo con la empresa de etiquetado de datos Scale AI, invirtiendo 14.3 mil millones de dólares para adquirir el 49% de sus acciones sin derecho a voto, y contratando a su fundador y CEO Alexandr Wang y su equipo. Alexandr Wang será responsable de un nuevo laboratorio en Meta enfocado en la investigación de la superinteligencia. Esta medida tiene como objetivo inyectar talento de IA de primer nivel y capacidades de operación de datos a gran escala en Meta, para hacer frente a la tibia recepción de su modelo Llama 4 y la agitación de personal en su departamento de investigación de IA. Scale AI utilizará los fondos para acelerar la innovación y distribuir parte de los fondos a los accionistas; su Director de Estrategia, Jason Droege, actuará como CEO interino. Esta transacción podría eludir parte del escrutinio gubernamental al evitar una adquisición directa. (Fuente: DeepLearning.AI Blog)

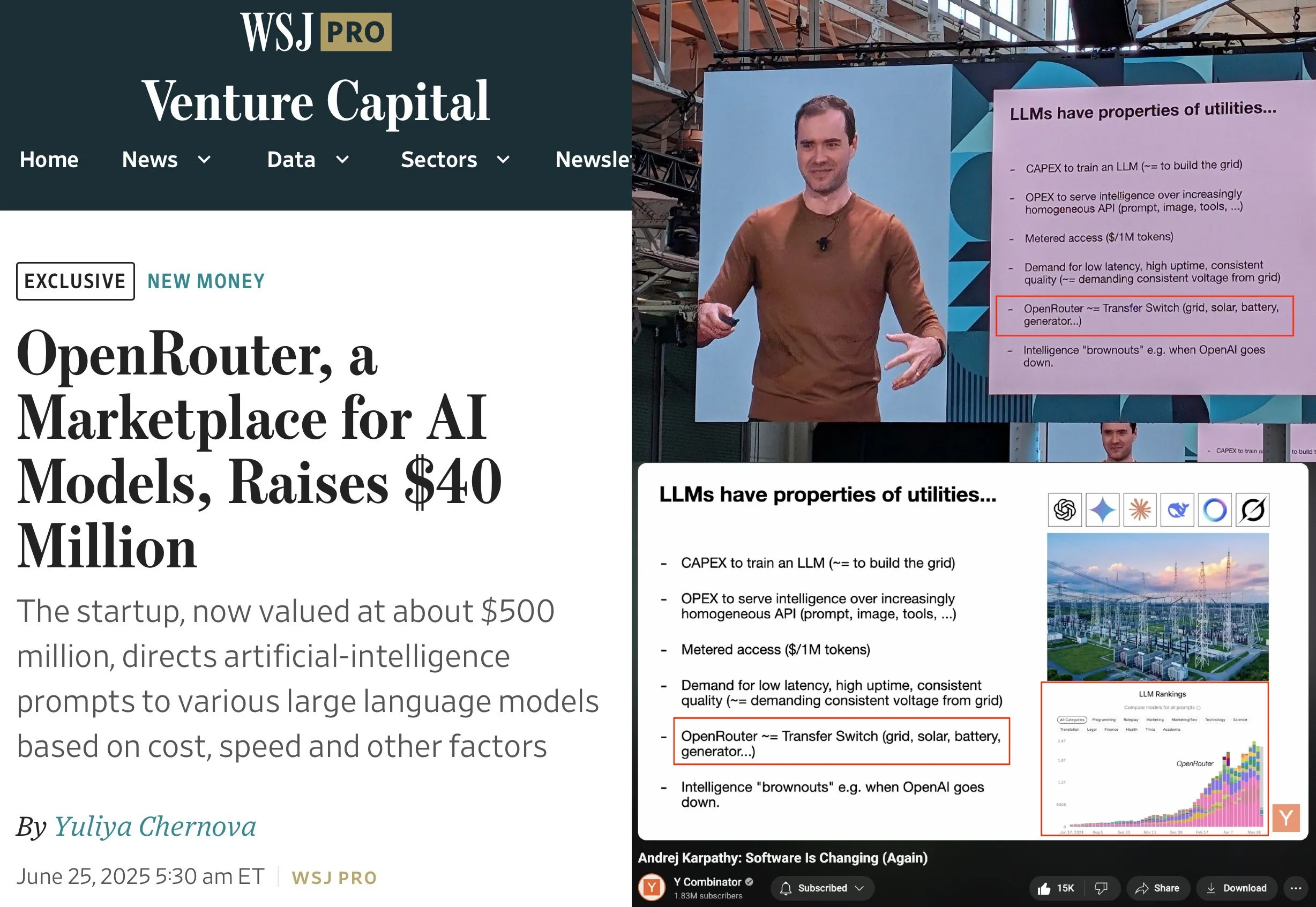
OpenRouter completa una ronda de financiación Serie A de 40 millones de dólares, liderada por a16z y Menlo: OpenRouter, el plano de control para la inferencia de LLM y mercado de modelos, ha anunciado la finalización de una ronda de financiación semilla y Serie A por un total de 40 millones de dólares, liderada por a16z y Menlo Ventures. OpenRouter tiene como objetivo convertirse en la interfaz unificada para que los desarrolladores seleccionen y utilicen diversos LLM, ofreciendo actualmente más de 400 modelos y procesando 100 billones de tokens anualmente. La financiación se utilizará para expandir las modalidades de modelos compatibles (como generación de imágenes, modelos de interacción multimodal), implementar mecanismos de enrutamiento más inteligentes (como enrutamiento geográfico, optimización de asignación de GPU a nivel empresarial) y mejorar las funciones de descubrimiento de modelos. (Fuente: amasad, swyx)
La empresa de robots humanoides “Lingbao CASBOT” obtiene casi 100 millones de yuanes en financiación ángel+, liderada por Lens Technology: La marca de robots humanoides “Lingbao CASBOT” ha anunciado la finalización de una ronda de financiación ángel+ de casi 100 millones de yuanes, liderada por Lens Technology, con la participación de Tianjin Jiayi y los antiguos accionistas Guotou Chuanghe y Henan Asset. Los fondos se utilizarán para acelerar la producción en masa de productos, la investigación y desarrollo tecnológico y la expansión del mercado. Lingbao CASBOT se especializa en la aplicación de robots humanoides de propósito general e inteligencia corpórea, y ya ha lanzado dos robots humanoides bípedos, CASBOT 01 y 02, dirigidos respectivamente a operaciones especiales y escenarios de interacción humano-robot más amplios (como guías turísticos, educación). La tecnología central de la empresa incluye un modelo jerárquico de extremo a extremo combinado con post-entrenamiento mediante aprendizaje por refuerzo, y ya ha establecido colaboraciones en los sectores de fabricación industrial y energía minera con Zhaojin Group, Zhongkuang Group, entre otros. (Fuente: 36氪, 36氪)

🌟 Comunidad
Andrej Karpathy aboga por la “ingeniería de contexto” en lugar de la “ingeniería de prompts”, enfatizando la complejidad de construir aplicaciones LLM: Andrej Karpathy coincide con la opinión de Tobi Lutke de que la “ingeniería de contexto” (context engineering) describe con mayor precisión la habilidad central en las aplicaciones LLM a nivel industrial que la “ingeniería de prompts” (prompt engineering). Señala que los prompts suelen referirse a descripciones de tareas cortas ingresadas por los usuarios en el día a día, mientras que la ingeniería de contexto es un arte y una ciencia refinados que implican rellenar con precisión la ventana de contexto con descripciones de tareas, pocos ejemplos (few-shot), RAG, datos multimodales, herramientas, historial de estados, etc., para optimizar el rendimiento del LLM. También enfatiza que las aplicaciones LLM van mucho más allá de esto, requiriendo resolver una serie de problemas complejos de ingeniería de software como la descomposición de problemas, el flujo de control, la programación de múltiples modelos, UI/UX, evaluación de seguridad, etc., por lo que la afirmación de que son “un simple envoltorio de ChatGPT” es errónea. (Fuente: karpathy, code_star, dotey)
Hugging Face lanza un plan de equipos de pago para responder a las preguntas de la comunidad sobre su modelo de rentabilidad: En respuesta a las preguntas de la comunidad sobre cómo Hugging Face obtiene beneficios (como las suscitadas por el tuit del usuario @levelsio), el cofundador de Hugging Face, Clement Delangue, respondió con humor diciendo que “se activó la ansiedad por la rentabilidad” y anunció el lanzamiento de un nuevo plan premium para equipos de pago. Hugging Face, como plataforma que aloja una gran cantidad de modelos de IA, ofrece API gratuitas y no exige claves de API, ha tenido su modelo de negocio como foco de discusión en la comunidad. El lanzamiento del nuevo plan indica que está explorando y expandiendo activamente vías de comercialización. (Fuente: huggingface, ClementDelangue)
Debate en la comunidad sobre la lealtad de los usuarios a los asistentes de código de IA y la colaboración multiherramienta: Un informe de The Information señala que la lealtad de los desarrolladores hacia los asistentes de codificación podría ser mayor de lo que se piensa. Al mismo tiempo, en la comunidad también se observa el fenómeno de desarrolladores que utilizan simultáneamente múltiples herramientas de codificación de IA como Claude Code, Codex (CLI) y Gemini (CLI) en el mismo repositorio de código. Esto refleja que los desarrolladores están probando activamente diferentes herramientas de IA para mejorar la eficiencia, y también podrían estar buscando la combinación de funciones específicas que mejor se adapte a su flujo de trabajo, en lugar de depender completamente de una sola herramienta. (Fuente: steph_palazzolo, code_star)

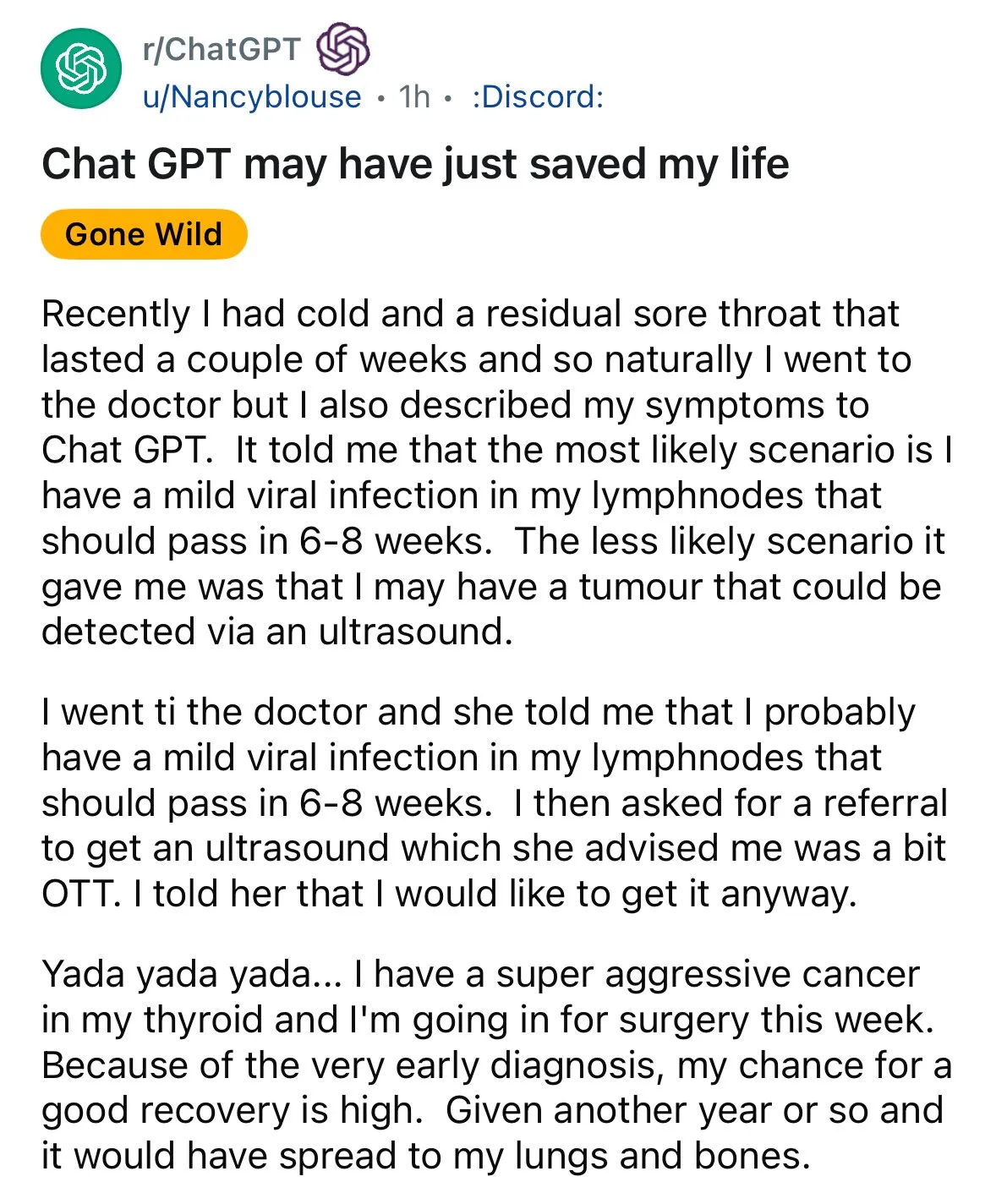
La IA muestra potencial en el diagnóstico médico, generando debate sobre la “segunda opinión”: En las redes sociales ha resurgido un caso de diagnóstico asistido por IA: un paciente con dolor de garganta, después de que el médico le recomendara observación, obtuvo una sugerencia de ChatGPT para realizarse una ecografía, lo que finalmente reveló un cáncer de tiroides. Eventos como este generan debate, animando a las personas a utilizar la IA para obtener una “segunda opinión” en cuestiones médicas, considerando que esto podría salvar vidas. Al mismo tiempo, la investigación del modelo GRAPE del Instituto DAMO de Alibaba, que detecta cáncer gástrico temprano mediante tomografías computarizadas convencionales, también apareció en Nature Medicine, mostrando el enorme potencial de la IA en la detección temprana del cáncer. (Fuente: aidan_mclau, Yuchenj_UW)
La “literatura de desahogo” (Fafeng Wenxue) en la era de la IA y el fenómeno del acompañamiento por IA: La “literatura de desahogo” (Fafeng Wenxue), popular entre los jóvenes como una forma de catarsis emocional y pequeña resistencia, está encontrando un punto de encuentro con las herramientas de IA. Muchos usuarios utilizan la IA generativa (como Dan Xiaohuang de Wen Xiaoyan) como válvula de escape emocional y compañía, para aliviar la soledad, obtener consuelo e incluso ayudar en la toma de decisiones (como el análisis post-discusión). La IA, por su paciencia, imparcialidad y disponibilidad constante, se convierte en un “amigo electrónico” de bajo costo y alta privacidad, ayudando a los usuarios a encontrar consuelo en momentos de caos y se considera que contribuye a mejorar el estado mental. (Fuente: 36氪)

Continúa el debate sobre si los LLM son inteligencia artificial general (AGI): En la comunidad persiste el debate sobre si los modelos de lenguaje grandes (LLM) son o cuándo alcanzarán la inteligencia artificial general (AGI). Algunos argumentan que, aunque los LLM tienen un rendimiento sobresaliente en muchas tareas, todavía están lejos de la verdadera AGI, especialmente en ausencia de la teoría y los datos del funcionamiento interno de los genios científicos humanos. También existen diferentes opiniones sobre el cronograma para la realización de la AGI, mencionándose desde un cercano 2028 hasta un más lejano 2035-2040. (Fuente: menhguin)

💡 Otros
El primer chatbot del mundo, Eliza, restaurado con éxito 60 años después: Eliza, el primer chatbot del mundo inventado por el científico del MIT Joseph Weizenbaum a mediados de la década de 1960, ha sido “resucitado” con éxito 60 años después, tras redescubrirse una copia impresa de su código original, perdido durante muchos años. Gracias al esfuerzo de equipos de la Universidad de Stanford y el MIT, que limpiaron y depuraron el código original, repararon funciones y desarrollaron un entorno de simulación para ejecutarlo. La Eliza original analizaba el texto introducido por el usuario, extraía palabras clave y reorganizaba frases para responder, interactuando con los usuarios bajo la apariencia de un terapeuta rogeriano, lo que llegó a generar un apego emocional en muchos probadores. El código y el simulador de la Eliza restaurada se han publicado en Github para que el público pueda experimentarlos. (Fuente: 36氪)

La herramienta de generación de imágenes por IA Midjourney enfrenta demandas por derechos de autor de Disney y otros, pero su modelo creativo único es muy popular: La plataforma de generación de imágenes por IA Midjourney enfrenta acciones legales debido a que las imágenes que genera podrían infringir los derechos de autor de los activos visuales de empresas como Disney y Universal Pictures. Sin embargo, la herramienta, gracias a su modelo creativo único —generar imágenes altamente artísticas y estilizadas en la comunidad de Discord mediante prompts de texto— goza de gran popularidad entre los creadores de todo el mundo. El equipo de Midjourney cuenta con menos de 50 personas, no ha realizado rondas de financiación, pero sus ingresos anuales ya alcanzan los 200 millones de dólares. Su filosofía de producto enfatiza “la imaginación por encima de todo”, posicionando la IA como un motor para expandir el pensamiento humano, en lugar de una simple herramienta de reemplazo, y mediante una interacción minimalista “des-herramientada” y una cultura de co-creación comunitaria, ha remodelado el paradigma creativo digital. (Fuente: 36氪)

La transformación del liderazgo impulsada por la IA: de la obediencia jerárquica a la simbiosis humano-máquina: Con la profunda integración de la IA en el trabajo, el liderazgo tradicional enfrenta desafíos. Una encuesta de Google muestra que el 82% de los líderes jóvenes usan IA, y datos de Oracle indican que el 25% de los empleados preferiría preguntar a la IA antes que a su líder. La IA está cambiando el entorno del liderazgo: la información y la experiencia ya no son el foso exclusivo de los líderes, la transparencia en la toma de decisiones genera presión, y la gestión pasa de equipos puramente humanos a “híbridos humano-máquina”. La Escuela de Administración de la Universidad de Fudan propone el concepto de “liderazgo simbiótico”, enfatizando la simbiosis y fusión de la economía tradicional y la digital, la empresa y el ecosistema, y el cerebro humano y el cerebro de la máquina. Los líderes en la era de la IA necesitan gestionar la transición entre las antiguas y nuevas fuerzas motrices, crear valor en redes colaborativas y发挥 el efecto multiplicador de la sinergia humano-máquina, siendo la competencia central saber cómo hacer que la IA sirva a los humanos. (Fuente: 36氪)