Palabras clave:Investigación en IA, Ciencia de la Computación, Aprendizaje por Refuerzo, Desarrollo de Medicamentos, Conducción Autónoma, Modelos de Lenguaje, Procesamiento Multimodal, Células Virtuales, Instituto Laude, Instructores de Aprendizaje por Refuerzo (RLTs), Plataforma BioNeMo, Tesla Robotaxi, Modelo Kimi VL A3B Thinking
🔥 Enfoque
Nace el Laude Institute, con 100 millones de dólares de financiación inicial para impulsar la investigación de bien público en ciencias de la computación: Andy Konwinski anunció el lanzamiento del Laude Institute, una organización sin ánimo de lucro destinada a financiar la investigación en ciencias de la computación no comercial que tenga un impacto significativo en el mundo. Jeff Dean, Joyia Pineau y Dave Patterson, entre otras personalidades de renombre, se unen al consejo directivo. La institución ha obtenido un compromiso inicial de financiación de 100 millones de dólares y, mediante financiación, compartición de recursos y creación de comunidad, apoyará a los investigadores para convertir ideas en impacto real, con especial atención a la investigación abierta y orientada al impacto. (Fuente: JeffDean, matei_zaharia, lschmidt3, Tim_Dettmers, andrew_n_carr, gneubig, lateinteraction, sarahookr, jefrankle)

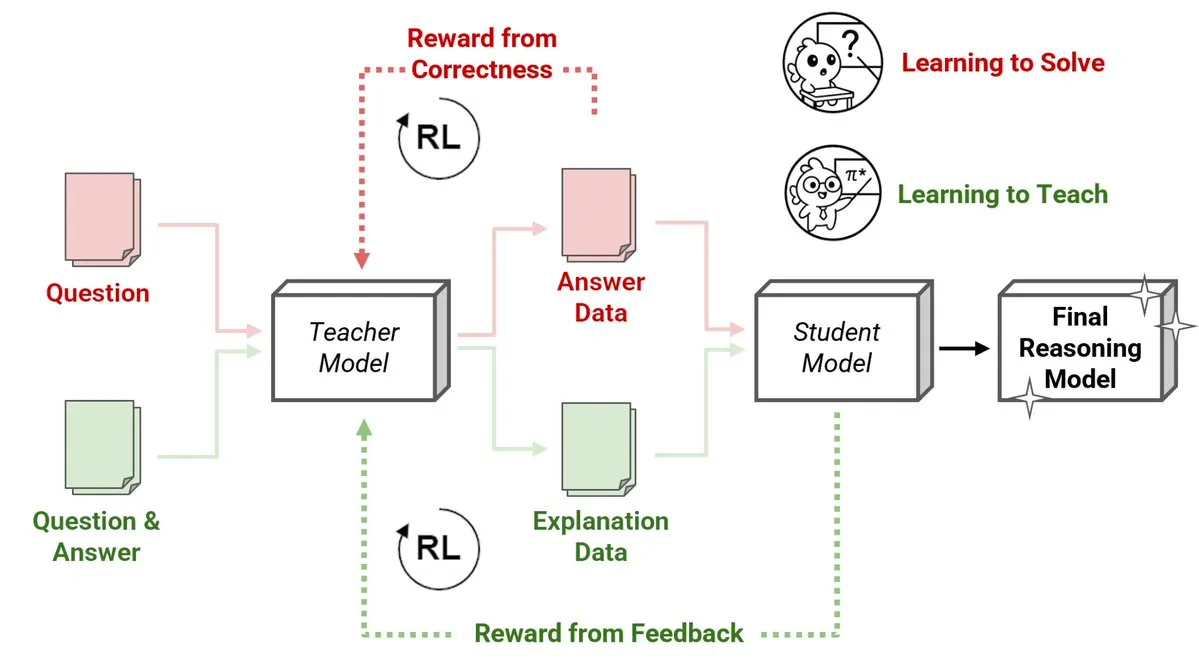
Sakana AI lanza un nuevo método de Reinforcement Learning Teachers (RLTs), donde modelos pequeños enseñan a razonar a modelos grandes: Sakana AI ha presentado un nuevo método de Reinforcement Learning Teachers (RLTs) que transforma la enseñanza del razonamiento en Large Language Models (LLMs) mediante Reinforcement Learning (RL). El RL tradicional se centra en “aprender a resolver” problemas, mientras que los RLTs se entrenan para generar “explicaciones” claras y paso a paso para enseñar a los modelos estudiantes. Un RLT con solo 7B de parámetros, al enseñar a un modelo estudiante de 32B de parámetros, supera en tareas de razonamiento competitivas y de nivel de posgrado a LLMs varias veces más grandes. Este enfoque establece un nuevo estándar de eficiencia para el desarrollo de modelos de lenguaje de razonamiento con RL. (Fuente: cognitivecompai, AndrewLampinen)
Nvidia colabora con Novo Nordisk para acelerar el descubrimiento de fármacos utilizando supercomputadoras de IA: Nvidia ha anunciado una colaboración con el gigante farmacéutico danés Novo Nordisk y el Centro Nacional de Innovación en IA de Dinamarca para utilizar conjuntamente la tecnología de IA y la supercomputadora más reciente de Dinamarca, Gefion, para acelerar el desarrollo de nuevos fármacos. Esta colaboración utilizará la plataforma BioNeMo de Nvidia y flujos de trabajo avanzados de IA, con el objetivo de transformar el modelo de investigación y desarrollo de medicamentos. La supercomputadora Gefion, construida con tecnología de Eviden y Nvidia, proporcionará un potente soporte computacional para la investigación en áreas como las ciencias de la vida, impulsando la medicina personalizada y el descubrimiento de nuevas terapias. (Fuente: nvidia)

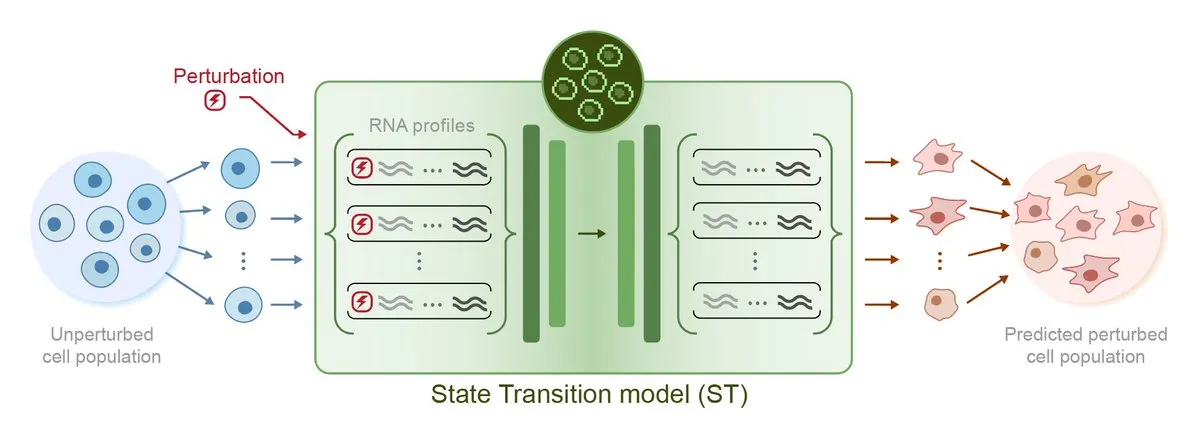
Arc Institute lanza STATE, su primer modelo de IA para predicción de perturbaciones, avanzando hacia el objetivo de la célula virtual: Arc Institute ha lanzado su primer modelo de IA para la predicción de perturbaciones, STATE, un paso importante hacia su objetivo de lograr una célula virtual. El modelo STATE está diseñado para aprender cómo utilizar perturbaciones farmacológicas, de citoquinas o genéticas para alterar el estado celular (por ejemplo, de “enfermo” a “sano”). El lanzamiento de este modelo marca un nuevo avance en la IA para comprender y predecir el comportamiento celular, abriendo nuevas vías para el tratamiento de enfermedades y el desarrollo de fármacos. Los modelos relacionados están disponibles en HuggingFace. (Fuente: riemannzeta, ClementDelangue)
Tesla inicia pruebas piloto de Robotaxi en Austin, la solución visual atrae la atención y el código heredado de Karpathy se simplifica drásticamente: Tesla ha iniciado oficialmente el servicio piloto de Robotaxi en Austin, Texas, EE. UU. Los primeros vehículos, basados en el Model Y, utilizan una solución de percepción puramente visual y el software FSD. El equipo dirigido por Ashok Elluswamy, responsable de IA y software de conducción autónoma de Tesla, ha realizado cambios técnicos significativos en el sistema, reduciendo en casi un 90% las aproximadamente 330.000-340.000 líneas de código heurístico en C++ heredadas del equipo de Andrej Karpathy, sustituyéndolas por una “red neuronal gigante”. Esta medida tiene como objetivo pasar de la “codificación de la experiencia humana” a la “formación parametrizada”, optimizando autónomamente el modelo mediante datos masivos y simulación de conducción. Actualmente, el servicio se encuentra en una fase temprana de prueba, lo que ha generado un amplio debate en la industria sobre la hoja de ruta tecnológica y la capacidad de escalado de Tesla. (Fuente: 36氪, Ronald_vanLoon, kylebrussell)

🎯 Movimientos
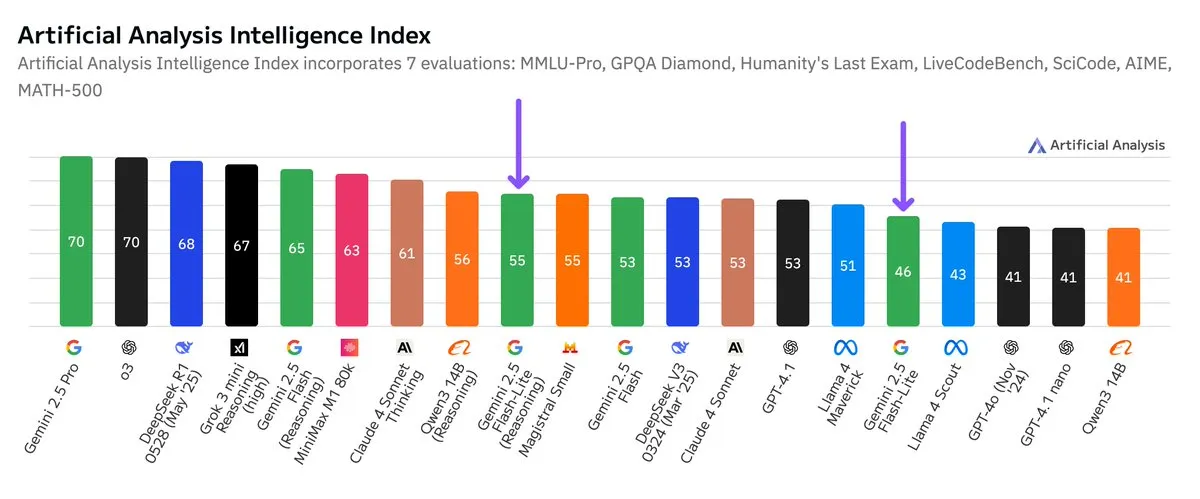
Google publica pruebas de referencia independientes para Gemini 2.5 Flash-Lite, mejorando la relación coste-rendimiento: Según los resultados de las pruebas de referencia independientes publicadas por Artificial Analysis, la versión Preview (06-17) de Google Gemini 2.5 Flash-Lite reduce los costes aproximadamente 5 veces y aumenta la velocidad aproximadamente 1,7 veces en comparación con la versión Flash normal, aunque con una disminución en el nivel de inteligencia. Este modelo es una actualización de Gemini 2.0 Flash-Lite, lanzado en febrero de 2025, y pertenece a la categoría de modelos híbridos. Esta actualización demuestra los continuos esfuerzos de Google por mejorar la eficiencia y la rentabilidad de los modelos, posiblemente orientándose a escenarios de aplicación con altos requisitos de coste y velocidad. (Fuente: zacharynado)
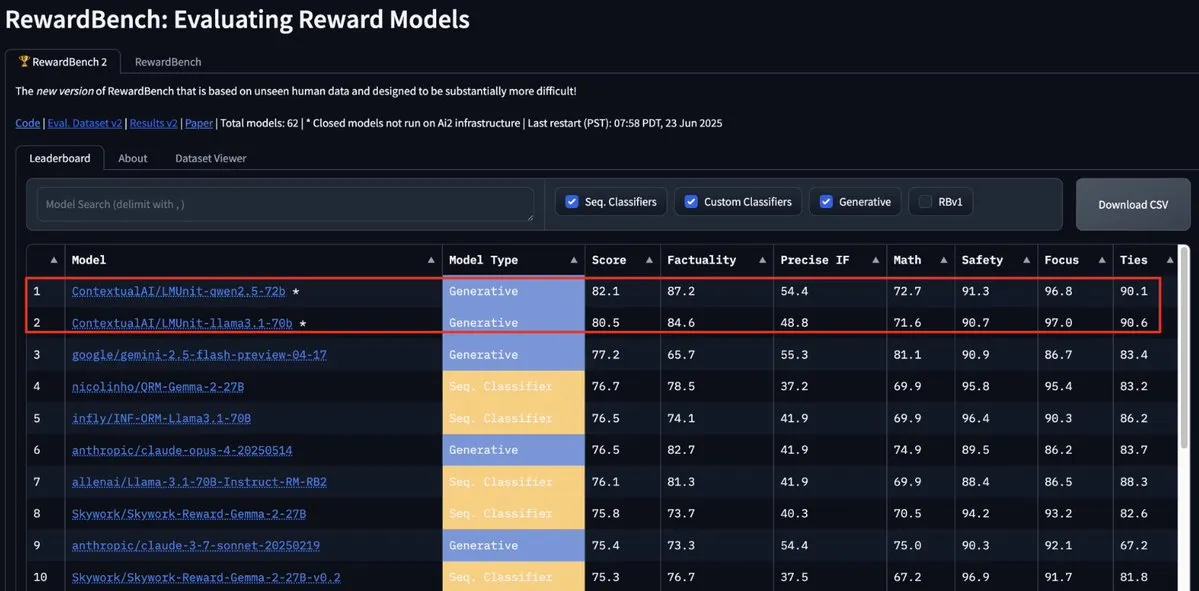
El modelo LMUnit de ContextualAI encabeza RewardBench2, superando a Gemini, Claude 4 y GPT-4.1: El modelo LMUnit de ContextualAI ha alcanzado el primer puesto en la prueba de referencia RewardBench2, con una puntuación más de un 5% superior a la de modelos conocidos como Gemini, Claude 4 y GPT-4.1. Este logro podría atribuirse a su método de entrenamiento único, que se dice que es similar al método de “rubrics” en el que OpenAI invirtió un esfuerzo considerable para o4 y modelos posteriores. Este método ayuda a lograr una expansión efectiva cuando se utiliza un LLM como juez (llm-as-a-judge) durante el razonamiento. (Fuente: natolambert, menhguin, apsdehal)
Arcee.ai expande con éxito la longitud de contexto del modelo AFM-4.5B de 4k a 64k: Arcee.ai ha anunciado que la longitud de contexto de su primer modelo base, AFM-4.5B, se ha expandido con éxito de 4k a 64k. El equipo logró este avance mediante experimentación activa, fusión de modelos, destilación y lo que denominaron en broma “una gran cantidad de sopa” (refiriéndose a técnicas de fusión de modelos). Este progreso es crucial para procesar tareas con textos largos. Las mejoras de Arcee en el modelo GLM-32B-Base también demuestran su eficacia, no solo aumentando el soporte de contexto largo de 8k a 32k, sino también mejorando todas las evaluaciones del modelo base (incluido el contexto corto). (Fuente: eliebakouch, teortaxesTex, nrehiew_, shxf0072, code_star)

Actualización de la API Gemini de Google mejora la velocidad y capacidad de procesamiento de vídeo y PDF: La API Gemini de Google ha recibido una importante actualización en el procesamiento de vídeo y PDF. El tiempo hasta el primer byte (TTFT) para vídeos en caché ha mejorado 3 veces, y la velocidad de procesamiento de PDF en caché ha aumentado hasta 4 veces. Además, la nueva versión admite el procesamiento por lotes de múltiples vídeos, y el rendimiento de la caché implícita se acerca al de la caché explícita. Estas mejoras tienen como objetivo aumentar la eficiencia y la experiencia de los desarrolladores al utilizar la API Gemini para procesar contenido multimedia. (Fuente: _philschmid)
Moonshot (Kimi) actualiza el modelo Kimi VL A3B Thinking, mejorando la capacidad de procesamiento multimodal: Moonshot AI (Kimi) ha lanzado una versión actualizada de su pequeño modelo de lenguaje visual (VLM) Kimi VL A3B Thinking, bajo licencia MIT. La nueva versión consume menos tokens, acorta la trayectoria de pensamiento, admite el procesamiento de vídeo y puede manejar imágenes de mayor resolución (1792×1792). Alcanzó 65,2 puntos en VideoMMMU, mejoró en 20,1 puntos hasta 56,9 en MathVision, mejoró en 8,4 puntos hasta 80,1 en MathVista, mejoró en 3,2 puntos hasta 46,3 en MMMU-Pro, y muestra un rendimiento excepcional en razonamiento visual, localización de UI Agent, y procesamiento de vídeo y PDF. Ya está disponible en código abierto en Hugging Face. (Fuente: mervenoyann)

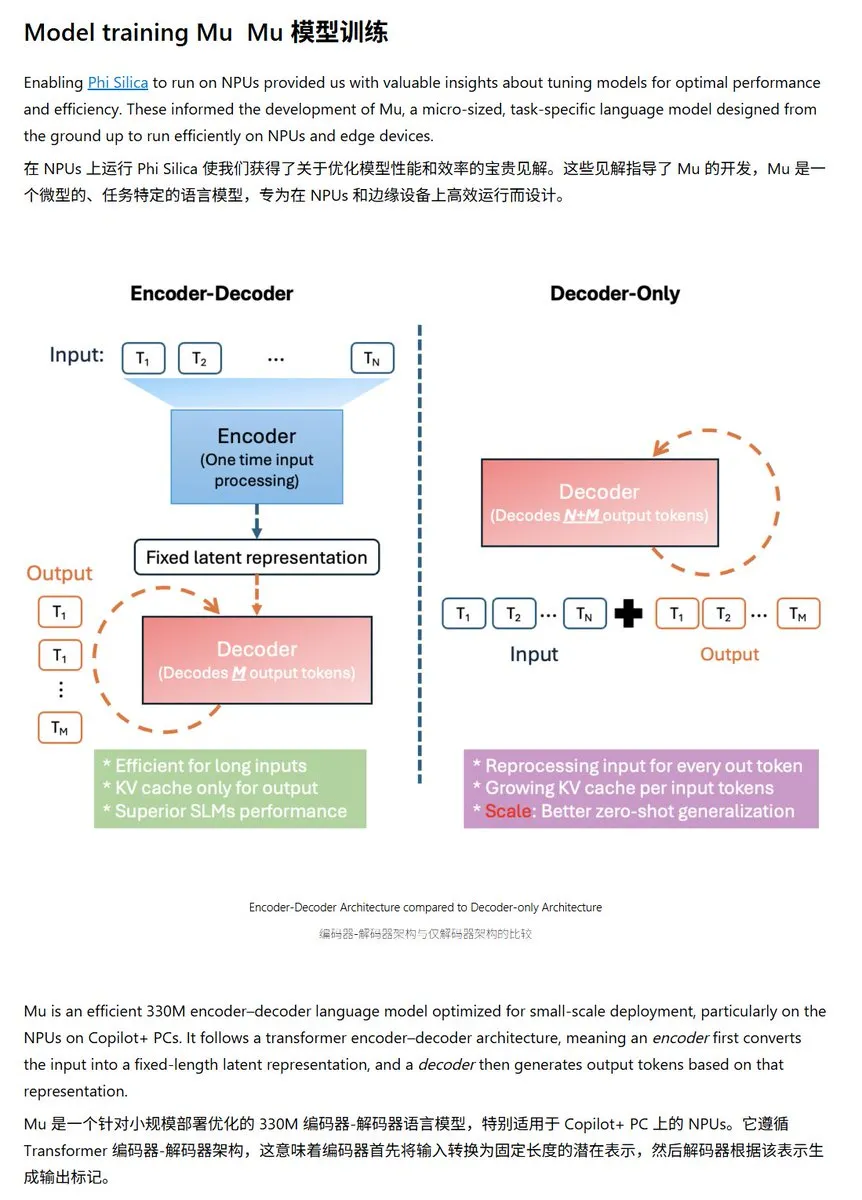
Microsoft lanza el pequeño modelo de lenguaje Mu-330M, optimizado para NPU de Windows: Microsoft ha presentado un nuevo modelo de lenguaje pequeño, Mu-330M, diseñado para ejecutarse en la NPU (Unidad de Procesamiento Neuronal) de los PC Windows Copilot+, con el objetivo de admitir funciones de Agent dentro del sistema Windows. El modelo ha sido optimizado para NPU, utilizando técnicas como incrustaciones de posición rotatoria, atención de consulta agrupada y LayerNorm de doble capa, para funcionar eficientemente con un bajo consumo de energía, lo que marca un mayor avance de Microsoft en las capacidades de IA en el dispositivo (edge AI). (Fuente: karminski3)
DeepMind publica informe técnico de Mercury, centrado en modelos de lenguaje de difusión: Inception Labs (equipo relacionado con DeepMind) ha publicado el informe técnico de su modelo de lenguaje de difusión Mercury. El informe detalla la arquitectura del modelo Mercury, los métodos de entrenamiento y los resultados experimentales, proporcionando a los investigadores una visión profunda de este tipo emergente de modelo. Los modelos de difusión ya han logrado un éxito notable en el campo de la generación de imágenes, y su aplicación a los modelos de lenguaje es una dirección de vanguardia en la investigación actual de la IA. (Fuente: andriy_mulyar)
Meta se asocia con Oakley para ampliar su línea de gafas inteligentes con IA: Meta se ha asociado con la marca de gafas Oakley para ampliar aún más su línea de productos de gafas inteligentes con IA. Se espera que las nuevas gafas inteligentes integren la tecnología de IA de Meta, ofreciendo funciones interactivas y experiencias de usuario más ricas. Esta colaboración marca la continua inversión de Meta en el campo de los dispositivos de IA portátiles, con el objetivo de integrar la IA de forma más fluida en la vida cotidiana. (Fuente: rowancheung, Ronald_vanLoon)
Alibaba Cloud lanza PAI-TurboX, un framework de aceleración para entrenamiento e inferencia de modelos de conducción autónoma, que puede reducir el tiempo de entrenamiento en un 50%: Alibaba Cloud ha lanzado PAI-TurboX, un framework de aceleración para el entrenamiento e inferencia de modelos en el campo de la conducción autónoma. Este framework tiene como objetivo mejorar la eficiencia del entrenamiento e inferencia de modelos de percepción, planificación y control, e incluso modelos del mundo. Mediante la optimización del preprocesamiento de datos multimodales, la afinidad de CPU, la compilación dinámica, el paralelismo de pipeline, y proporcionando optimización de operadores y capacidades de cuantización, las pruebas han demostrado que PAI-TurboX puede reducir el tiempo de entrenamiento en aproximadamente un 50% en tareas de entrenamiento de múltiples modelos de la industria como BEVFusion, MapTR y SparseDrive. (Fuente: 量子位)
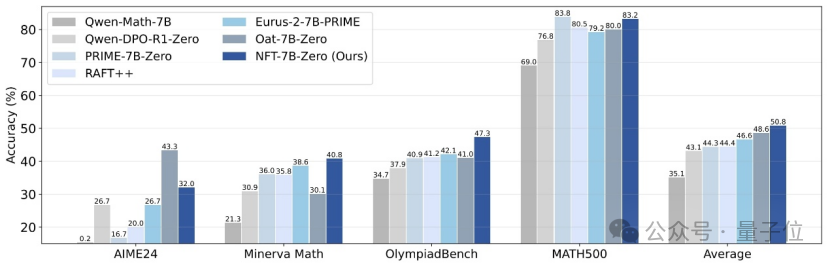
Tsinghua, Nvidia y otros proponen el método NFT, que permite al aprendizaje supervisado “reflexionar” a partir de los errores: Investigadores de la Universidad de Tsinghua, Nvidia y la Universidad de Stanford han propuesto conjuntamente un nuevo esquema de aprendizaje supervisado llamado NFT (Negative-aware FineTuning). Este método, basado en el algoritmo RFT (Rejection FineTuning), utiliza datos negativos para el entrenamiento mediante la construcción de un “modelo negativo implícito”, es decir, una “estrategia negativa implícita”. Esta estrategia permite que el aprendizaje supervisado, al igual que el aprendizaje por refuerzo, realice una “autorreflexión”, cerrando la brecha en ciertas capacidades entre el aprendizaje supervisado y el aprendizaje por refuerzo. Ha demostrado mejoras significativas de rendimiento en tareas como el razonamiento matemático, e incluso en condiciones On-Policy su gradiente de función de pérdida es equivalente a GRPO. (Fuente: 量子位)
Lanzamiento de OmniGen2: modelo multifuncional de edición de imágenes de 8B, que fusiona comprensión visual y generación de imágenes: Se ha lanzado un nuevo modelo multifuncional de edición de imágenes llamado OmniGen2, que combina la comprensión visual (basada en Qwen-VL-2.5) con la generación de imágenes (un modelo de difusión de 4B parámetros), con un total de aproximadamente 8B parámetros. OmniGen2 puede admitir múltiples tareas como texto a imagen, edición de imágenes, comprensión de imágenes y generación contextual, con el objetivo de proporcionar un modelo unificado capaz de resolver diversos problemas relacionados con la visión y adecuado para la integración en dispositivos finales. (Fuente: karminski3)

Actualización del modelo de generación de imágenes a partir de texto Chroma-8.9B-v39, basado en FLUX.1-schnell, disponible para uso comercial: Se ha lanzado una actualización del modelo de texto a imagen Chroma-8.9B-v39, que mejora la iluminación y la naturalidad de las tareas. El modelo se basa en FLUX.1-schnell, con el número de parámetros comprimido de 12B a 8.9B, y utiliza la licencia Apache 2.0, lo que permite su uso comercial. Según se informa, el modelo “reintroduce conceptos anatómicos faltantes, sin restricciones de contenido” y ha sido post-entrenado con un conjunto de datos que incluye 5 millones de obras de anime, furry, arte y fotografías. (Fuente: karminski3)

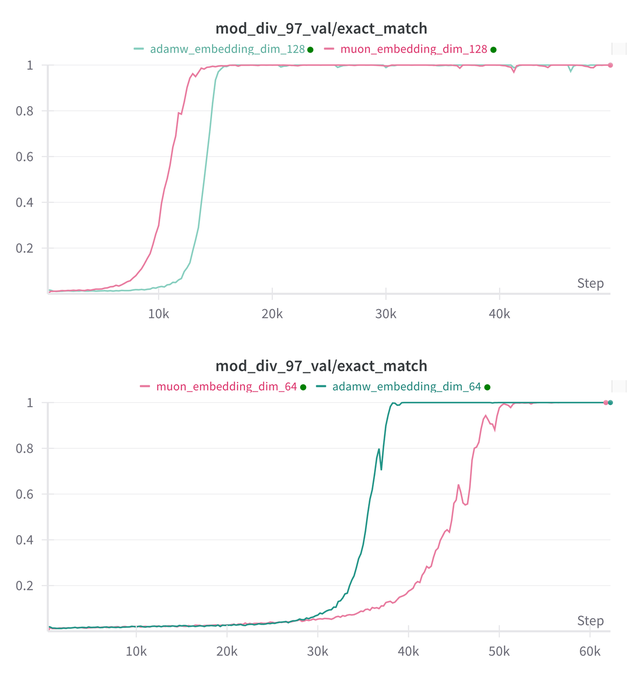
Essential AI actualiza sus conclusiones de investigación sobre la capacidad de Grokking de sus modelos Muon y Adam: Essential AI ha compartido los últimos avances de su investigación sobre la capacidad de Grokking (un fenómeno en el que un modelo tiene un rendimiento deficiente al principio del entrenamiento y luego comprende repentinamente la generalización) de sus modelos Muon y Adam. Las hipótesis iniciales pueden contradecir las observaciones reales. El equipo ha publicado los resultados de pequeños experimentos de investigación internos que muestran que, después de ampliar el espacio de búsqueda de hiperparámetros, Muon no tiene una ventaja universal obvia sobre AdamW, y ambos tienen ventajas y desventajas en diferentes escenarios. Esto indica que AdamW sigue siendo un optimizador potente e incluso SOTA en muchos casos. (Fuente: eliebakouch, teortaxesTex, nrehiew_)
Actualización del modelo de generación de imágenes Ostris AI, centrándose en la versión sin CFG y optimizando los detalles de alta frecuencia: Ostris AI continúa actualizando su modelo de generación de imágenes, centrándose actualmente en el desarrollo de la versión sin CFG (Classifier-Free Guidance) debido a su convergencia más rápida. En la última actualización del Día 7, el equipo incorporó nuevas técnicas de entrenamiento para manejar mejor los detalles de alta frecuencia y se esfuerza por eliminar los artefactos de alto detalle. La actualización anterior del Día 4 ya había demostrado una mejora significativa en la calidad de las imágenes generadas sin usar CFG mediante nuevos métodos. (Fuente: ostrisai)

Ant Group, CAS y otros abren el código del modelo ViLaSR-7B, logrando razonamiento espacial “dibujando mientras se piensa”: El Instituto de Investigación Tecnológica de Ant Group, el Instituto de Automatización de la Academia China de Ciencias (CAS) y la Universidad China de Hong Kong han abierto conjuntamente el código del modelo ViLaSR-7B. Este modelo, a través del paradigma “Drawing to Reason in Space”, permite a los Large Vision Language Models (LVLM) dibujar marcas auxiliares (como líneas de referencia, cuadros delimitadores) en el espacio visual para ayudar al pensamiento, mejorando así la percepción espacial y las capacidades de razonamiento. ViLaSR utiliza un marco de entrenamiento de tres etapas: arranque en frío, muestreo por rechazo reflexivo y aprendizaje por refuerzo. Los experimentos demuestran que el modelo mejora en un promedio del 18,4% en 5 benchmarks, incluyendo navegación en laberintos, comprensión de imágenes y razonamiento espacial en vídeo, y su rendimiento en VSI-Bench se acerca al de Gemini-1.5-Pro. (Fuente: 量子位)

🧰 Herramientas
SGLang ahora es compatible con Hugging Face Transformers como backend, mejorando la eficiencia de la inferencia: SGLang ha anunciado que ahora es compatible con Hugging Face Transformers como backend. Esto significa que los usuarios pueden proporcionar servicios de inferencia rápidos y de nivel de producción para cualquier modelo compatible con Transformers, sin necesidad de soporte nativo, de forma plug-and-play. Esta integración tiene como objetivo simplificar el proceso de despliegue de la inferencia de modelos de lenguaje de alto rendimiento, ampliando el alcance y la facilidad de uso de SGLang. (Fuente: TheZachMueller, ClementDelangue)

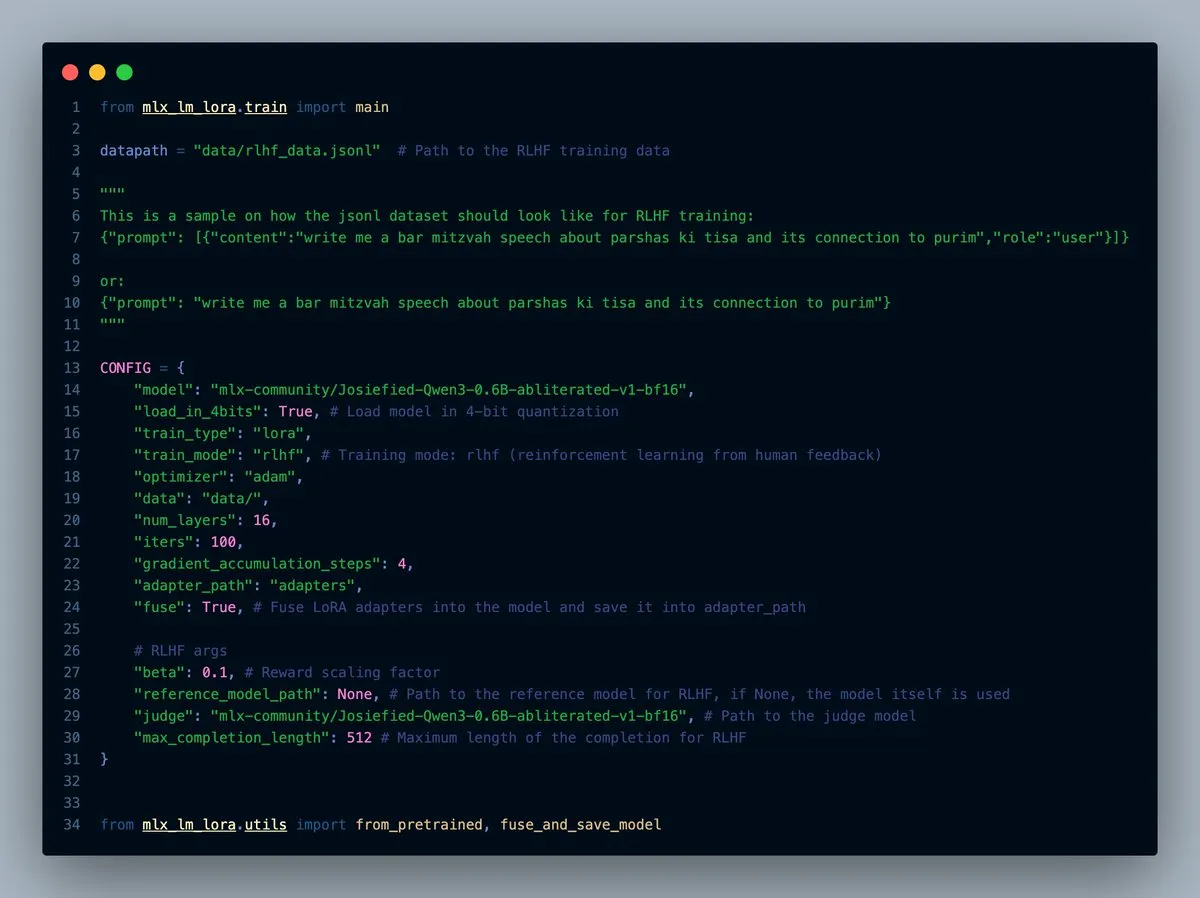
Lanzamiento de MLX-LM-LORA v0.7.0, con funcionalidad RLHF incorporada: Se ha lanzado la versión v0.7.0 de MLX-LM-LORA, que incluye la funcionalidad incorporada de Reinforcement Learning from Human Feedback (RLHF). La herramienta ahora admite la carga en 4, 6 y 8 bits, el modo de entrenamiento RLHF y puede fusionar directamente los adaptadores (adapters) en los pesos base. Esto hace que el ajuste fino LoRA en el framework MLX sea más inteligente y eficiente, especialmente en dispositivos con chips de Apple. (Fuente: awnihannun)
Lanzamiento de LlamaCloud, un conjunto de herramientas compatible con MCP para flujos de trabajo documentales: LlamaCloud ya está disponible como un conjunto de herramientas compatible con el Protocolo de Contexto de Modelo (MCP) para cualquier flujo de trabajo documental. Los usuarios pueden conectarlo a modelos como Claude para realizar operaciones complejas de extracción y comparación de documentos. Por ejemplo, puede analizar el rendimiento financiero de Tesla durante los últimos cinco trimestres y generar un informe completo, creando dinámicamente esquemas estandarizados y ejecutándolos en todos los archivos, para luego utilizar la generación de código para obtener el resultado final. LlamaCloud puede corregir dinámicamente esquemas incorrectos y admite enlaces directos a archivos. (Fuente: jerryjliu0)
Georgi Gerganov anticipa el proyecto LlamaBarn: Georgi Gerganov (creador de llama.cpp) publicó una imagen en las redes sociales, anticipando un nuevo proyecto llamado “LlamaBarn”. La imagen muestra una interfaz similar a un panel de control, que incluye elementos como selección de modelos, ajuste de parámetros, etc., lo que sugiere que podría ser una herramienta para gestionar, ejecutar o probar LLMs locales. La comunidad ha expresado su expectación, considerando que podría convertirse en un fuerte competidor para herramientas existentes como Ollama. (Fuente: ClementDelangue, teortaxesTex, jeremyphoward)
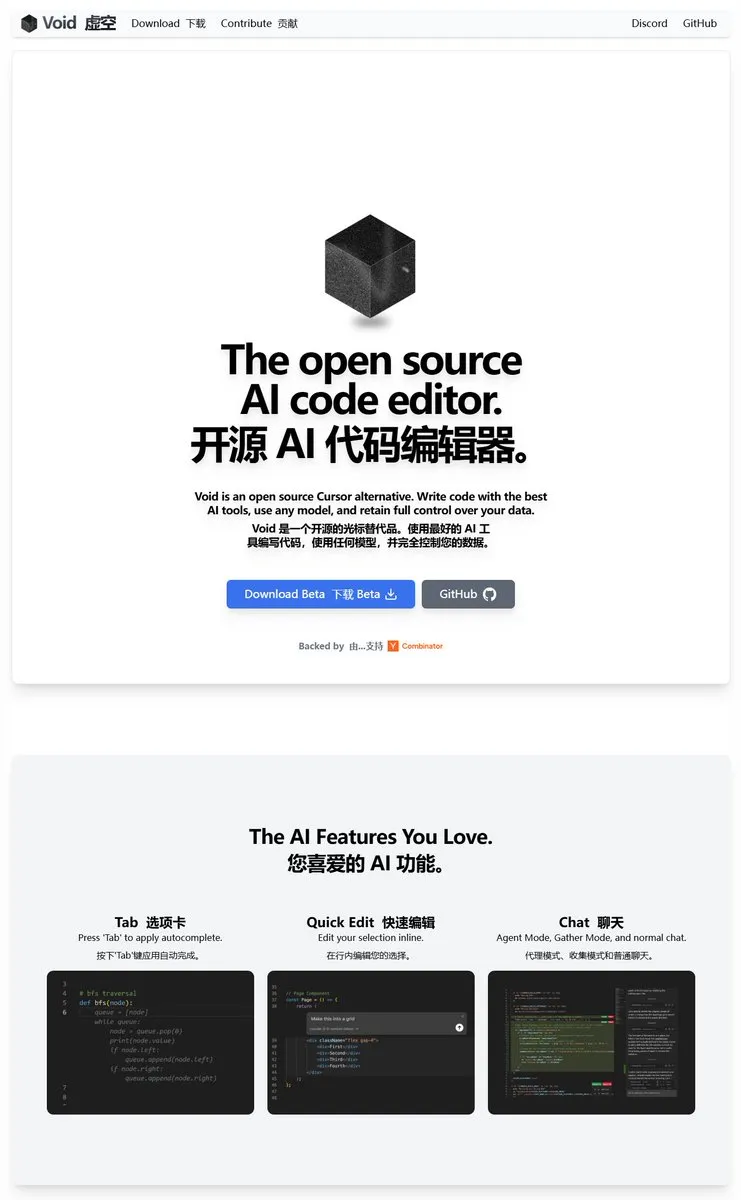
Void Editor: un nuevo asistente de programación de IA de código abierto, compatible con MCP y modelos locales: Void Editor se presenta como un nuevo asistente de programación de IA de código abierto, con el objetivo de ser una alternativa a herramientas como Cursor. Es compatible con autocompletado mediante tabulación, modo de chat, Protocolo de Contexto de Modelo (MCP) y modo Agent. Los usuarios pueden conectar cualquier API de Large Language Model o ejecutar modelos localmente, ofreciendo a los desarrolladores una experiencia flexible de programación asistida por IA. (Fuente: karminski3)
Together AI lanza la herramienta Which LLM para ayudar a seleccionar el LLM de código abierto adecuado: Together AI ha lanzado una herramienta gratuita llamada “Which LLM”, diseñada para ayudar a los usuarios a seleccionar el Large Language Model de código abierto más adecuado según casos de uso específicos, requisitos de rendimiento y consideraciones económicas. Con la proliferación de LLMs de código abierto, este tipo de herramientas puede proporcionar una referencia valiosa para desarrolladores e investigadores a la hora de seleccionar modelos. (Fuente: vipulved)
Perplexity Finance añade función de seguimiento de la línea de tiempo del precio de las acciones: Perplexity Finance ha anunciado que los usuarios ahora pueden rastrear la línea de tiempo de las variaciones de precio de cualquier símbolo bursátil en su plataforma. Esta nueva función tiene como objetivo proporcionar a los usuarios una herramienta de análisis de información del mercado financiero más intuitiva y conveniente que, combinada con las capacidades de IA de Perplexity, podría aportar una nueva experiencia a la consulta y análisis de información financiera. (Fuente: AravSrinivas)

IdeaWeaver lanza el primer agente de IA para la depuración del rendimiento del sistema: IdeaWeaver ha lanzado lo que afirma ser el primer agente de IA diseñado específicamente para depurar problemas de rendimiento del sistema. La herramienta utiliza el framework CrewAI y es capaz de ejecutar comandos del sistema para diagnosticar problemas relacionados con la CPU, la memoria, E/S y la red. Su característica distintiva es dar prioridad al uso de LLMs locales (a través de OLLAMA) para proteger la privacidad, solicitando claves de API de OpenAI solo cuando los modelos locales no están disponibles, con el objetivo de aplicar las capacidades de la IA a los campos de DevOps y la administración de sistemas. (Fuente: Reddit r/artificial)
Kling AI añade soporte para Live Photo, permitiendo guardar vídeos generados como fondos de pantalla dinámicos: Kling AI ha anunciado que su función de generación de vídeo ahora permite guardar las creaciones como Live Photos (fotos animadas). Los usuarios pueden establecer su contenido dinámico favorito creado por Kling como fondo de pantalla del móvil, aumentando la diversión y la utilidad de los vídeos generados por IA. (Fuente: Kling_ai)
Cognition AI abre el código de Blockdiff, logrando una mejora de 200 veces en la velocidad de las instantáneas de VM: Cognition AI ha anunciado la apertura del código de Blockdiff, su formato de archivo de instantáneas de VM desarrollado para Devin. Debido a que la creación de instantáneas de VM en EC2 consumía demasiado tiempo (más de 30 minutos), el equipo construyó su propio hipervisor otterlink y el formato de archivo Blockdiff, lo que permitió aumentar la velocidad de creación de instantáneas en 200 veces. Esta contribución de código abierto tiene como objetivo ayudar a los desarrolladores a gestionar entornos de máquinas virtuales de manera más eficiente. (Fuente: karinanguyen_)

📚 Aprendizaje
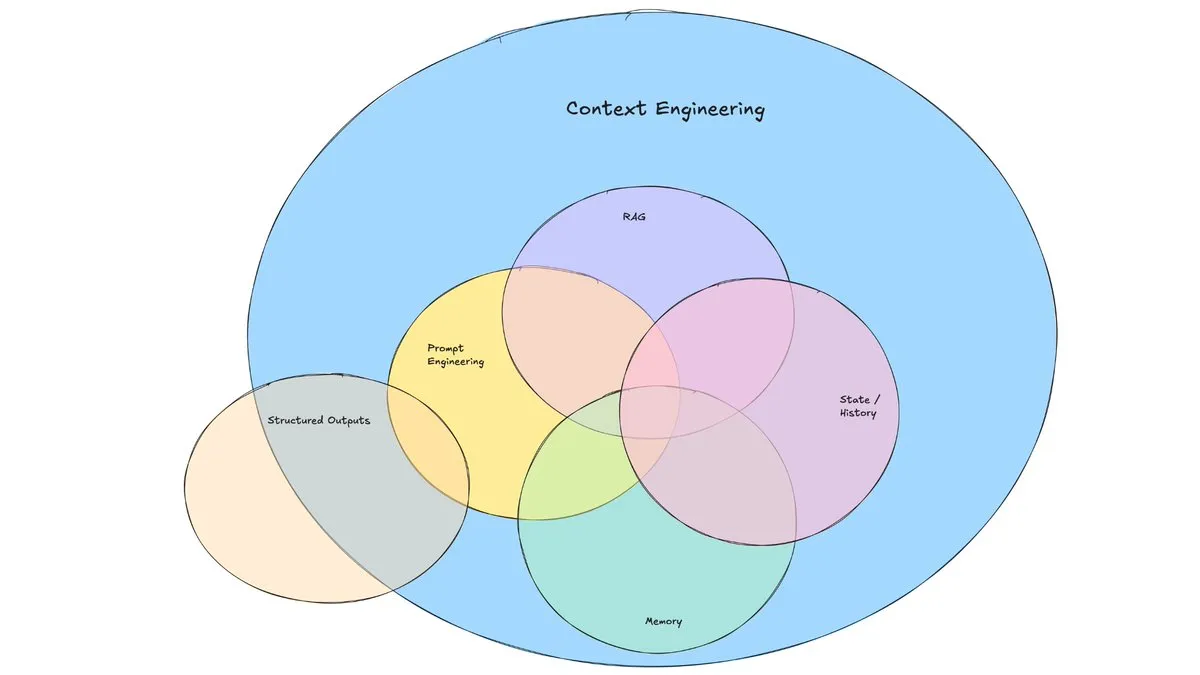
Artículo de blog de LangChain explora el auge de la “Ingeniería de Contexto”: LangChain ha publicado un artículo de blog que explora el término cada vez más popular de “Ingeniería de Contexto” (Context Engineering). El artículo lo define como “la construcción de sistemas dinámicos para proporcionar la información y herramientas correctas en el formato correcto, permitiendo así que los LLM completen tareas razonablemente”. Esto no es un concepto completamente nuevo, ya que los constructores de Agents lo han practicado durante mucho tiempo, y herramientas como LangGraph y LangSmith también nacieron para este propósito. La propuesta de este término ayuda a atraer más atención a las habilidades y herramientas relacionadas. (Fuente: hwchase17, Hacubu, yoheinakajima)
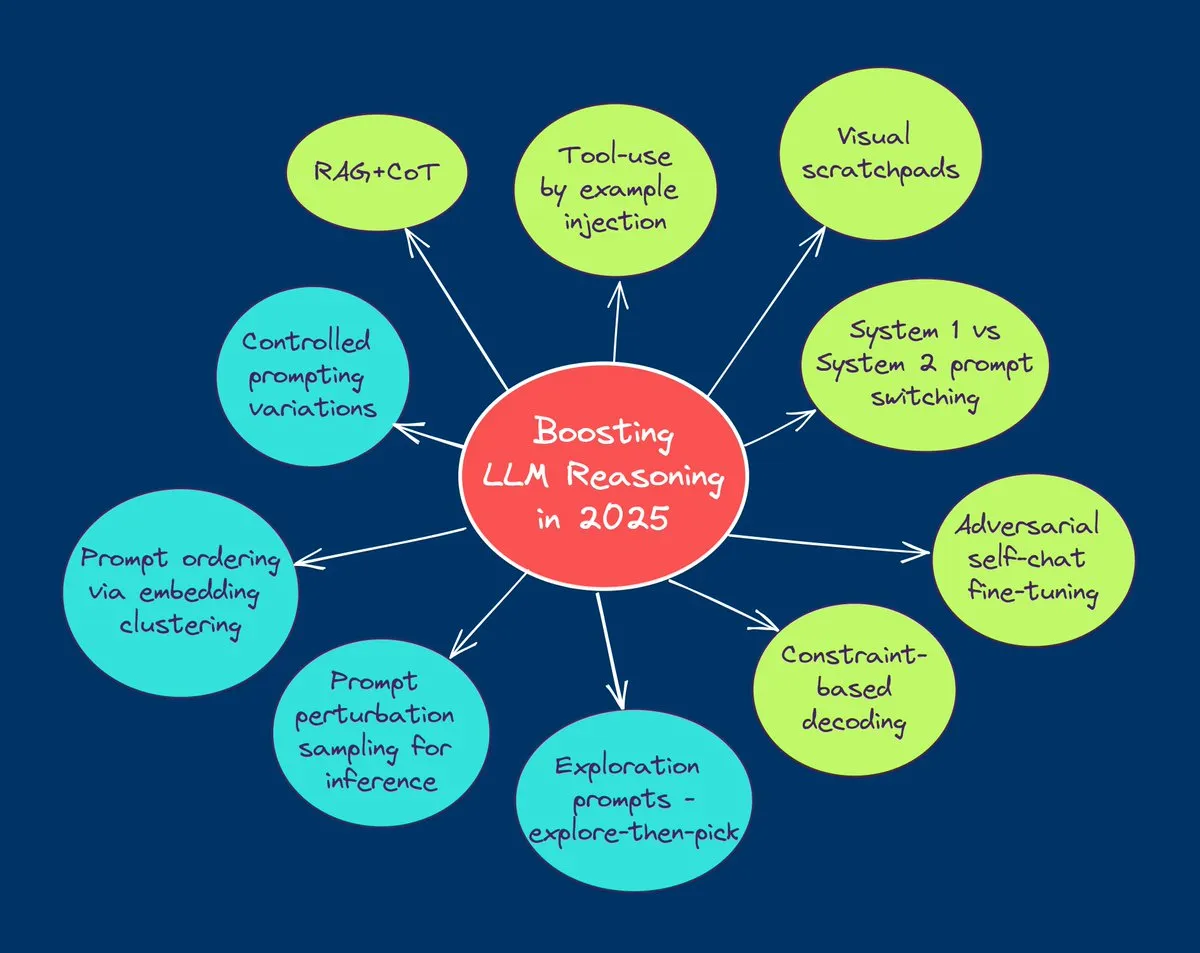
TuringPost resume las 10 principales tecnologías para mejorar la capacidad de razonamiento de los LLM en 2025: TuringPost ha compartido 10 tecnologías clave utilizadas en 2025 para mejorar la capacidad de razonamiento de los Large Language Models (LLM), que incluyen: Chain-of-Thought aumentada por recuperación (RAG+CoT), uso de herramientas mediante inyección de ejemplos, borrador visual (soporte para razonamiento multimodal), cambio entre prompting de Sistema 1 y Sistema 2, auto-diálogo adversario para ajuste fino, decodificación basada en restricciones, prompting exploratorio (explorar primero, luego seleccionar), muestreo de perturbación de prompts para razonamiento, ordenación de prompts mediante agrupamiento de embeddings y variantes de prompt controladas. Estas tecnologías ofrecen diversas vías para optimizar el rendimiento de los LLM en tareas complejas. (Fuente: TheTuringPost, TheTuringPost)
Cohere Labs organiza una Escuela de Verano de ML para explorar el futuro del machine learning: La comunidad de ciencia abierta de Cohere Labs organizará una Escuela de Verano de ML (ML Summer School) en julio. El evento reunirá a miembros de la comunidad global para discutir el futuro del machine learning y contará con ponentes de la industria. Entre ellos, Katrina Lawrence impartirá un curso de repaso de matemáticas para machine learning el 2 de julio, cubriendo conceptos básicos como cálculo, cálculo vectorial y álgebra lineal. (Fuente: sarahookr)

DeepLearning.AI y Meta colaboran para lanzar el curso gratuito “Building with Llama 4”: DeepLearning.AI y Meta han colaborado para lanzar un curso gratuito llamado “Building with Llama 4”. El contenido del curso incluye: operaciones prácticas con los modelos de la serie Llama 4, comprensión de su arquitectura Mixture of Experts (MOE) y cómo construir aplicaciones utilizando la API oficial; aplicación de Llama 4 para inferencia multi-imagen, localización de imágenes (identificación de objetos y sus cuadros delimitadores) y procesamiento de consultas de texto de contexto largo de hasta 1 millón de tokens; uso de las herramientas de optimización de prompts de Llama 4 para mejorar automáticamente los prompts del sistema y utilización de su kit de herramientas de datos sintéticos para crear conjuntos de datos de alta calidad para el ajuste fino. (Fuente: DeepLearningAI)
El canal de YouTube de EleutherAI ofrece abundante contenido de investigación en IA: El canal de YouTube de EleutherAI recopila vídeos grabados de sus clubes de lectura y series de conferencias, con más de 100 horas de contenido. Los temas cubren la escalabilidad y el rendimiento del machine learning, el análisis funcional, así como podcasts y entrevistas con miembros del equipo. El canal ofrece abundantes recursos de aprendizaje para investigadores y entusiastas de la IA. EleutherAI también ha lanzado una nueva serie de conferencias, cuya primera entrega está a cargo de @linguist_cat sobre tokenizadores y sus limitaciones. (Fuente: BlancheMinerva, BlancheMinerva)
Artículo explora la mejora del razonamiento multimodal mediante tokens visuales latentes (Machine Mental Imagery): Un nuevo artículo, “Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens”, propone el framework Mirage, que mejora el razonamiento multimodal añadiendo tokens visuales latentes durante el proceso de decodificación del VLM (en lugar de generar imágenes completas), simulando la imaginería mental humana. El método primero supervisa los tokens latentes mediante la destilación de embeddings de imágenes reales, luego cambia a supervisión puramente textual para alinear la trayectoria latente con los objetivos de la tarea, y mejora aún más la capacidad mediante aprendizaje por refuerzo. Los experimentos demuestran que Mirage puede lograr un razonamiento multimodal más potente sin generar imágenes explícitas. (Fuente: HuggingFace Daily Papers)
Artículo propone el framework Vision as a Dialect, unificando la comprensión y generación visual mediante representaciones alineadas con texto: Un artículo titulado “Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations” presenta un framework de LLM multimodal llamado Tar. Este framework utiliza un tokenizador alineado con texto (TA-Tok) para convertir imágenes en tokens discretos y emplea un libro de códigos alineado con texto proyectado desde el vocabulario del LLM, unificando así la visión y el texto en una representación semántica discreta compartida. Tar logra entradas y salidas multimodales a través de una interfaz compartida, sin necesidad de diseños específicos para cada modalidad, y adopta un codificador-decodificador adaptable a la escala y un destokenizador generativo para equilibrar la eficiencia y el detalle visual. (Fuente: HuggingFace Daily Papers)
Artículo presenta ReasonFlux-PRM: un PRM consciente de la trayectoria para el razonamiento de cadena de pensamiento larga en LLM: El artículo “ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs” presenta un novedoso modelo de recompensa de proceso consciente de la trayectoria (PRM), diseñado específicamente para evaluar trazas de razonamiento de tipo trayectoria-respuesta generadas por modelos de razonamiento de vanguardia como DeepSeek-R1. ReasonFlux-PRM combina la supervisión a nivel de paso y a nivel de trayectoria, logrando una asignación de recompensa de grano fino alineada con datos de cadena de pensamiento estructurada, y obtiene mejoras de rendimiento en escenarios como SFT, RL y expansión BoN en tiempo de prueba. (Fuente: HuggingFace Daily Papers)
Artículo investiga métodos de evaluación para las barreras de protección contra jailbreak en Large Language Models: Un artículo titulado “SoK: Evaluating Jailbreak Guardrails for Large Language Models” realiza una sistematización del conocimiento sobre los ataques de jailbreak a Large Language Models (LLMs) y sus barreras de protección (Guardrails). El artículo propone una nueva taxonomía multidimensional que clasifica las barreras de protección desde seis dimensiones clave e introduce un marco de evaluación de seguridad-eficiencia-utilidad para valorar su efectividad práctica. Mediante un amplio análisis y experimentación, el artículo señala las ventajas y desventajas de los métodos de barreras de protección existentes, explora su universalidad frente a diferentes tipos de ataques y ofrece ideas para optimizar las combinaciones de defensa. (Fuente: HuggingFace Daily Papers)
Artículo destacado de AAAI 2025 explora clases decidibles de Procesos de Decisión de Markov Parcialmente Observables (POMDP): Un artículo titulado “Revelations: A Decidable Class of POMDP with Omega-Regular Objectives” ha recibido el premio de artículo destacado en AAAI 2025. La investigación identifica una clase decidible de MDP (Procesos de Decisión de Markov): problemas de decisión con “revelaciones fuertes”, es decir, donde en cada paso hay una probabilidad no nula de revelar el estado exacto del mundo. El artículo también proporciona resultados de decidibilidad para “revelaciones débiles”, donde se garantiza que el estado exacto se revelará eventualmente, pero no necesariamente en cada paso. Esta investigación proporciona una nueva base teórica para la toma de decisiones óptimas en situaciones de información incompleta. (Fuente: aihub.org)
Artículo propone CommVQ: cuantización vectorial conmutativa para la compresión de caché KV: El artículo “CommVQ: Commutative Vector Quantization for KV Cache Compression” propone un método llamado CommVQ que comprime la caché KV mediante cuantización aditiva y un codificador y libro de códigos ligeros, para reducir la huella de memoria en la inferencia de LLM de contexto largo. Para reducir el coste computacional de la decodificación, el libro de códigos está diseñado para ser conmutable con las incrustaciones de posición rotatoria (RoPE) y se entrena utilizando el algoritmo EM. Los experimentos demuestran que este método puede reducir el tamaño de la caché KV FP16 en un 87,5% con cuantización de 2 bits y supera a los métodos existentes de cuantización de caché KV, pudiendo incluso lograr la cuantización de caché KV de 1 bit con una pérdida de precisión mínima. (Fuente: HuggingFace Daily Papers)
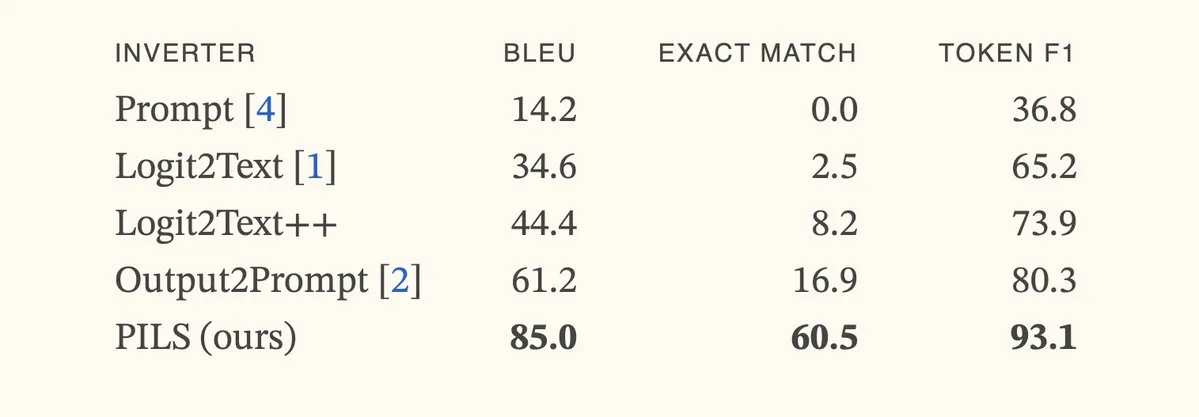
Artículo propone el método PILS, mejorando la inversión de modelos de lenguaje mediante la representación compacta de la distribución del siguiente token: El artículo “Better Language Model Inversion by Compactly Representing Next-Token Distributions” propone un nuevo método de inversión de modelos de lenguaje llamado PILS (Prompt Inversion from Logprob Sequences). Este método recupera prompts ocultos analizando las probabilidades del siguiente token del modelo en múltiples pasos de generación. El núcleo radica en descubrir que los vectores de salida del modelo de lenguaje ocupan un subespacio de baja dimensión, lo que permite comprimir sin pérdidas la distribución de probabilidad del siguiente token mediante un mapeo lineal, para una inversión más efectiva. Los experimentos demuestran que PILS supera significativamente a los métodos SOTA anteriores en la recuperación de prompts ocultos. (Fuente: HuggingFace Daily Papers, jxmnop)
Artículo presenta Phantom-Data: un conjunto de datos general para la generación de vídeo con consistencia de sujeto: El artículo “Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset” presenta un nuevo conjunto de datos llamado Phantom-Data, diseñado para abordar el problema común de “copiar y pegar” en los modelos existentes de generación de sujeto a vídeo (es decir, el entrelazamiento excesivo de la identidad del sujeto con los atributos del fondo y el contexto). Phantom-Data es el primer conjunto de datos general de consistencia de sujeto a vídeo emparejado entre contextos, que contiene aproximadamente un millón de pares con identidad consistente en diferentes categorías. Este conjunto de datos se construye mediante un proceso de tres etapas, que incluye la detección de sujetos, la recuperación de sujetos a gran escala entre contextos y la verificación de identidad guiada por priors. (Fuente: HuggingFace Daily Papers)
Artículo propone LongWriter-Zero: dominando la generación de texto ultralargo mediante aprendizaje por refuerzo: El artículo “LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning” propone un método basado en incentivos para cultivar la capacidad de los LLM de generar texto ultralargo y de alta calidad desde cero utilizando aprendizaje por refuerzo (RL), sin necesidad de datos anotados o sintéticos. El método comienza con un modelo base y lo guía mediante RL para refinar los procesos de planificación y escritura, utilizando un modelo de recompensa especializado para controlar la longitud, la calidad de la escritura y el formato estructural. Los experimentos demuestran que LongWriter-Zero, entrenado a partir de Qwen2.5-32B, supera a los métodos SFT tradicionales en tareas de escritura de texto largo y alcanza niveles SOTA en múltiples benchmarks. (Fuente: HuggingFace Daily Papers)
💼 Negocios
La empresa de IA legal Harvey anuncia una ronda de financiación Serie E de 300 millones de dólares, con una valoración de 5.000 millones de dólares: La startup de IA legal Harvey ha anunciado la finalización de una ronda de financiación Serie E de 300 millones de dólares, codirigida por Kleiner Perkins y Coatue, lo que sitúa la valoración de la empresa en 5.000 millones de dólares. Otros inversores incluyen Sequoia Capital, GV, DST Global, Conviction, Elad Gil, OpenAI Startup Fund, Elemental, SV Angel, Kris Fredrickson y REV. Esta financiación ayudará a Harvey a continuar desarrollando y expandiendo sus aplicaciones de IA en el ámbito legal. (Fuente: saranormous)
El servicio de nube de GPU bajo demanda Hyperbolic alcanza un ARR de 1 millón de dólares en 7 días desde su lanzamiento: Yuchenj_UW anunció que su servicio de nube de GPU bajo demanda Hyperbolic, lanzado la semana pasada, alcanzó unos ingresos recurrentes anuales (ARR) de 1 millón de dólares en solo 7 días, partiendo de cero y con una mínima campaña de marketing a través de un solo tuit. Ofrecen a los constructores créditos de prueba gratuitos para nodos 8xH100, lo que demuestra la fuerte demanda del mercado de servicios de nube de GPU de alto rendimiento. (Fuente: Yuchenj_UW)
Replit anuncia que sus ingresos recurrentes anuales (ARR) superan los 100 millones de dólares: La plataforma de entorno de desarrollo integrado (IDE) en línea y computación en la nube Replit ha anunciado que sus ingresos recurrentes anuales (ARR) han superado los 100 millones de dólares, un crecimiento significativo desde los 10 millones de dólares a finales de 2024. La compañía afirma que todavía tiene más de la mitad de los fondos en el banco después de su última ronda de financiación en 2023 con una valoración de 1.100 millones de dólares. El crecimiento de Replit se debe al uso de su plataforma por parte de usuarios empresariales (como Zillow, HubSpot) y desarrolladores independientes, y actualmente está contratando activamente. (Fuente: pirroh, kylebrussell, hwchase17, Hacubu)
🌟 Comunidad
Nuevo paradigma de programación con IA: primero diseñar, luego hacer prompting, optimizando iterativamente la generación de código: dotey y Baoyu discuten el cambio en el modelo de desarrollo de software provocado por la programación con IA. El debate tradicional entre “diseñar primero, codificar después” y “primero implementar, luego refactorizar” se fusiona en la era de la IA. La IA reduce drásticamente el coste y el tiempo desde el diseño hasta la codificación, permitiendo a los desarrolladores implementar versiones rápidamente incluso cuando el diseño no está completamente claro, e iterar para mejorar el diseño y los prompts mediante la validación de resultados. Los prompts asumen el papel de los antiguos “documentos de diseño detallado”, pero de forma más simplificada. En este modelo, los desarrolladores deben centrarse más en el diseño del sistema, generar código en lotes pequeños, utilizar la gestión del código fuente y revisar y probar el código generado por la IA. Para los programadores experimentados, cambiar la mentalidad y los hábitos de desarrollo es clave para adoptar la programación con IA. (Fuente: dotey)
Claude Code es elogiado por los desarrolladores por su potente capacidad de procesamiento de grandes bases de código y eficiencia contextual: La comunidad de Reddit r/ClaudeAI debate acaloradamente sobre el excelente rendimiento de Claude Code en el manejo de grandes bases de código. Los usuarios informan que puede comprender bien bases de código que superan con creces los 200k tokens y realizar modificaciones. Se discute que Claude Code podría lograr un procesamiento contextual eficiente mediante estrategias similares a la lectura humana (leyendo solo partes clave), utilizando herramientas como grep para la recuperación contextual (en lugar de depender completamente de la compresión vectorizada de RAG) y las ventajas de la integración de modelos de primera mano. Los usuarios comparten múltiples casos de éxito utilizando Claude Code para la reparación de problemas del sistema, la creación de rastreadores de finanzas personales, el desarrollo de aplicaciones de Android (incluso sin experiencia en desarrollo de Android), la creación de scripts DataviewJS para Obsidian, etc., mejorando significativamente la eficiencia del trabajo. (Fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

El concepto de “Ingeniería de Contexto” atrae la atención, enfatizando la construcción de sistemas dinámicos para potenciar los LLM: Harrison Chase de LangChain propone que la “Ingeniería de Contexto” (Context Engineering) es el trabajo central de los ingenieros de IA en la construcción de sistemas. Se define como “la construcción de sistemas dinámicos para proporcionar la información y herramientas correctas en el formato correcto, permitiendo así que los LLM completen tareas razonablemente”. Este concepto subraya la importancia de cómo organizar y proporcionar eficazmente la información contextual en las aplicaciones de LLM para el rendimiento del modelo, siendo fundamental en áreas como la construcción de Agents. (Fuente: hwchase17, Hacubu, yoheinakajima)
El fundador de Meta, Zuckerberg, recluta personalmente talento en IA, generando atención en la comunidad: Informes en redes sociales indican que Mark Zuckerberg, fundador de Meta, está participando personalmente en el reclutamiento de talento para su laboratorio de superinteligencia, contactando directamente a cientos de candidatos potenciales e invitando a cenar a quienes responden. Este movimiento se interpreta como una muestra de la determinación y el esfuerzo de Meta en el campo de la IA, especialmente en la inteligencia artificial general (AGI) o la superinteligencia, y evidencia la intensa competencia por los mejores talentos en IA entre las principales empresas tecnológicas. (Fuente: reach_vb, andrew_n_carr)

El desarrollo de la IA provoca una profunda reflexión sobre el mercado laboral y la estructura económica: La Harvard Business School y el economista Anton Korinek advierten que la AGI podría alcanzarse en 2-5 años, y si el sistema económico no se transforma radicalmente, podría colapsar, enfatizando la necesidad de una renta básica universal. Al mismo tiempo, la comunidad discute que la IA automatizará una gran cantidad de tareas cuantificables, impactando los trabajos de cuello azul y cuello blanco, y las empresas necesitarán reestructurar sus organizaciones para adaptarse a la IA. Yuval Noah Harari compara la revolución de la IA con una “ola migratoria de IA”, lo que genera debates sobre el reemplazo de empleos por la IA y la búsqueda de poder. Estos puntos de vista apuntan conjuntamente al impacto disruptivo de la IA en la futura estructura socioeconómica. (Fuente: 36氪, 36氪, Reddit r/artificial, Reddit r/ChatGPT)

La IA destaca en competiciones de programación, el excelente rendimiento del agente de Sakana AI genera debate: El agente de Sakana AI se clasificó en el puesto 21 entre más de 1.000 programadores humanos en la competición de programación heurística AtCoder, situándose en el 6,8% superior general. La IA iteró aproximadamente 100 versiones en 4 horas, generando miles de soluciones potenciales, mientras que los concursantes humanos suelen probar solo unas 12. La IA utilizó Gemini 2.5 Pro y combinó conocimiento experto con algoritmos de búsqueda sistemática (como recocido simulado y búsqueda por haz) para resolver problemas de optimización del mundo real. Las reacciones de la comunidad fueron mixtas; algunos argumentaron que la programación de competición es diferente de la ingeniería a nivel empresarial y que la victoria de la IA es más parecida a que un ordenador supere a los humanos en sumas y restas. (Fuente: Reddit r/ArtificialInteligence)
💡 Otros
Exploración de la IA en la educación profesional: diversos intentos con entrevistas, profesores y máquinas de aprendizaje: Gigantes de la educación profesional como Huatu, Fenbi y Zhonggong están explorando activamente aplicaciones de IA, con diferentes enfoques. Huatu se centra en la evaluación de entrevistas mediante IA, Fenbi profundiza en la corrección y los profesores de IA (las ventas de su sistema de clases de IA para practicar exámenes ya superan los 14 millones), mientras que Zhonggong ha lanzado una máquina de aprendizaje para el empleo con IA. El consenso de la industria es que la IA debería mejorar los resultados del aprendizaje y la eficiencia operativa, en lugar de buscar simplemente primas de precios elevadas. La aplicación de la IA también está pasando de la prueba de concepto a la profundización en escenarios específicos, como 51CTO, que utiliza avatares digitales y modelado 3D para generar cursos, y emplea la IA para la generación de preguntas de examen y el análisis de rutas de aprendizaje. Sin embargo, la mayoría de las empresas educativas aún no tienen la capacidad de construir sus propios modelos grandes y tienden más a utilizar API de terceros. (Fuente: 36氪)
Disney y Universal Pictures demandan al unicornio de generación de imágenes por IA Midjourney por infracción: Los gigantes de Hollywood Disney y Universal Pictures han demandado conjuntamente a la empresa de generación de imágenes por IA Midjourney, acusándola de utilizar sin permiso una gran cantidad de contenido IP protegido por derechos de autor (como Iron Man, los Minions, etc.) para entrenar modelos de IA y generar imágenes muy similares. Los demandantes exigen la prohibición de las actividades infractoras y una indemnización de hasta 150.000 dólares por cada obra infringida intencionadamente. Este caso pone de relieve los desafíos de derechos de autor a los que se enfrenta la IA generativa; el fundador de Midjourney admitió previamente haber utilizado datos sin autorización. La demanda podría tener como objetivo impulsar el establecimiento de mecanismos de licencia de derechos de autor y sistemas de filtrado de contenido. (Fuente: 36氪)

Se acusa a Apple de estar rezagada en IA, podría considerar adquisiciones para compensar deficiencias; la empresa de la ex CTO de OpenAI en el punto de mira: Informes indican que Apple está relativamente rezagada en el campo de la IA, con capacidades de IA propias insuficientes y un rendimiento mediocre de Siri. Para compensar esta brecha, Apple podría considerar realizar adquisiciones importantes; se rumorea que ha tenido contactos preliminares con Mira Murati, ex CTO de OpenAI, sobre su nueva empresa Thinking Machines Lab. Históricamente, Apple ha mejorado sus capacidades mediante la adquisición de pequeñas empresas tecnológicas (como la propia Siri). Actualmente, Apple está muy por detrás de los gigantes de la industria en cuanto al tamaño de los parámetros de sus modelos de IA, y la adquisición de empresas como Mistral podría ayudarla a lograr un gran avance en el desarrollo de sus propios modelos grandes. (Fuente: 36氪)