

Palabras clave:modelo de lenguaje grande, evaluación de IA, sistema multiagente, capacidad de razonamiento, procesamiento de contexto, modelo de código abierto, generación de video con IA, programación con IA, evaluación de capacidad de razonamiento LLM, Claude Opus 4 refuta el artículo de Apple, modelo MiniMax-M1 MoE, modelo de programación Kimi-Dev-72B, función Gemini Deep Think
🔥 Enfoque
Un artículo de Apple que cuestiona la capacidad de razonamiento de los grandes modelos es refutado; un paper coescrito por Claude señala fallos en el diseño experimental: Apple publicó recientemente un paper titulado “La ilusión de pensar”, en el que, mediante pruebas con problemas clásicos como la Torre de Hanói y el mundo de los bloques, señaló que los principales modelos de lenguaje grandes (LLM) no rinden bien en tareas de razonamiento complejo, siendo esencialmente un emparejamiento de patrones en lugar de una verdadera comprensión. Sin embargo, el investigador independiente Alex Lawsen, junto con el modelo de IA Claude Opus 4, publicaron conjuntamente un artículo titulado “La ilusión de la ‘ilusión de pensar’” para refutarlo, argumentando que el experimento de Apple tiene fallos de diseño: 1. No se consideró el límite máximo de salida de Tokens de los LLM, lo que llevó a que los modelos fueran calificados como incorrectos por no poder generar pasos extremadamente largos en su totalidad; 2. Algunos casos de prueba (como ciertos “problemas de cruzar el río”) son matemáticamente irresolubles bajo las condiciones dadas, por lo que la incapacidad de la IA para dar la “respuesta correcta” no se debe a una falta de capacidad; 3. Al cambiar el método de evaluación, como solicitar al modelo que genere un programa para resolver el problema en lugar de los pasos completos, la IA mostró un rendimiento excelente. Este incidente ha provocado un amplio debate sobre la verdadera capacidad de razonamiento de los LLM y la metodología de evaluación, destacando la importancia de diseñar esquemas de evaluación razonables y recordando a los desarrolladores que deben prestar atención a factores como la ventana de contexto, el presupuesto de salida y la formulación de tareas, y su impacto en el rendimiento del modelo en aplicaciones prácticas. (Fuente: 新智元, 大数据文摘)
Hoja de ruta de IA de Google revelada, sugiere que la próxima arquitectura de IA podría abandonar el mecanismo de atención actual: Logan Kilpatrick, jefe de producto de Google, reveló en la AI Engineer World’s Fair la dirección futura del modelo Gemini, siendo lo más destacado la perspectiva de lograr un “contexto infinito”. Señaló que con el mecanismo de atención actual y la forma de procesar el contexto, no se puede lograr un verdadero contexto infinito, lo que sugiere que Google podría estar investigando una arquitectura de IA central completamente nueva. La hoja de ruta también incluye: capacidad multimodal completa (ya compatible con imágenes + audio, el video es la siguiente etapa), experimentos tempranos con Diffusion, capacidad de Agent por defecto (llamada y uso de herramientas de primera clase, el modelo evoluciona gradualmente hacia un agente inteligente), capacidad de razonamiento en continua expansión y el lanzamiento de más modelos pequeños. Esta serie de planes indica que Google está impulsando activamente la evolución de la IA de una respuesta pasiva a un agente inteligente activo, y está comprometido a superar los cuellos de botella tecnológicos existentes, especialmente en el procesamiento del contexto, lo que podría conducir a cambios importantes en la arquitectura de la IA. (Fuente: 新智元)
Sakana AI lanza ALE-Agent, superando al 98% de los concursantes humanos en una competencia de programación de problemas NP-difíciles: Sakana AI, cofundada por Llion Jones, uno de los autores de Transformer, en colaboración con la plataforma japonesa de competencias de programación AtCoder, lanzó ALE-Bench (Algorithm Engineering Benchmark). Este se enfoca en evaluar las capacidades de razonamiento a largo plazo y programación creativa de la IA en problemas NP-difíciles (como planificación de rutas y programación de tareas). Su ALE-Agent, desarrollado sobre Gemini 2.5 Pro y combinando提示 de conocimiento de dominio con estrategias diversificadas de búsqueda en el espacio de soluciones, tuvo un desempeño sobresaliente en la competencia heurística de AtCoder, clasificándose en el puesto 21 (dentro del 2% superior) y superando a una gran cantidad de desarrolladores humanos de élite. Esto marca un avance importante de la IA en la resolución de problemas complejos de optimización, con implicaciones significativas para aplicaciones prácticas como la logística y la planificación de la producción. Aunque ALE-Agent muestra un rendimiento excelente en algoritmos como el recocido simulado, todavía hay margen de mejora en la depuración, el análisis de complejidad y la evitación de errores de optimización. (Fuente: 新智元, SakanaAILabs, hardmaru)
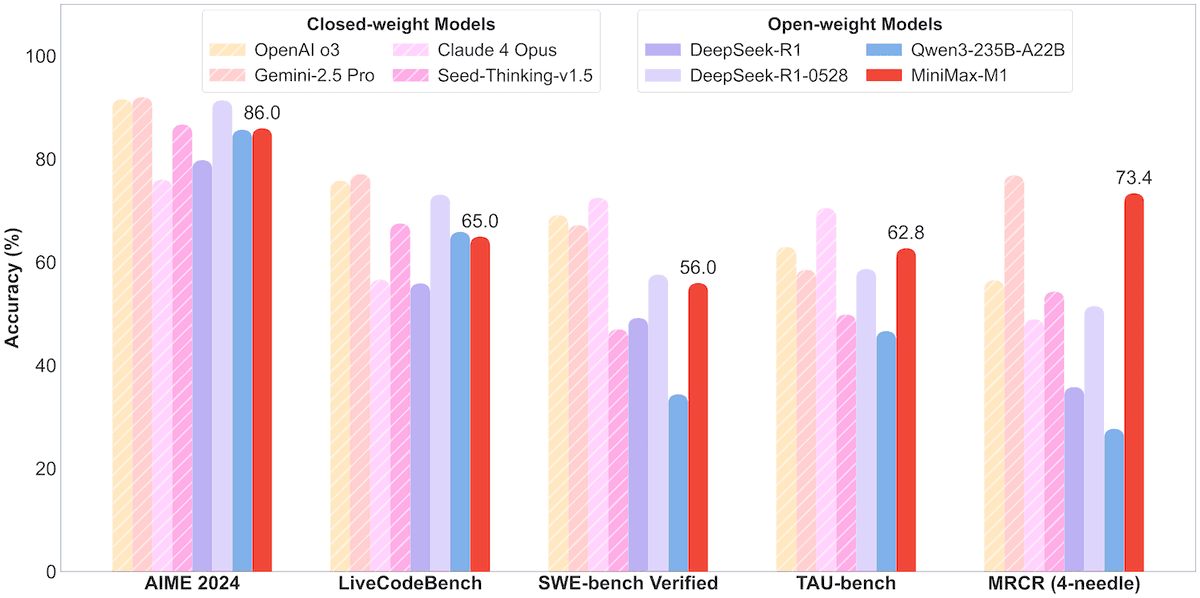
MiniMax lanza el modelo MoE MiniMax-M1 de 456B parámetros, compatible con un contexto de un millón y una salida de 80,000 Tokens: MiniMax ha lanzado su primer modelo de inferencia de mezcla de expertos (MoE) a gran escala de código abierto, MiniMax-M1. El modelo tiene una escala de 45.6 mil millones de parámetros, activando 4.59 mil millones de parámetros por Token, y utiliza una arquitectura que combina MoE con el mecanismo de atención Lightning Attention. M1 admite de forma nativa una longitud de contexto de 1 millón de Tokens y puede lograr una salida líder en la industria de 80,000 Tokens, incluyendo versiones con presupuestos de pensamiento de 40k y 80k. En pruebas de referencia para ingeniería de software, uso de herramientas y tareas de contexto largo, M1 supera a modelos como DeepSeek-R1 y Qwen3-235B, destacando especialmente en el uso de herramientas de Agent (como TAU-bench). Su fase de aprendizaje por refuerzo solo requirió 512 unidades H800 durante tres semanas, con un costo aproximado de 537,400 dólares. El modelo M1 ya está disponible de forma gratuita en la APP y la web de MiniMax, y se ofrece a través de API. (Fuente: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, 智东西)
🎯 Tendencias
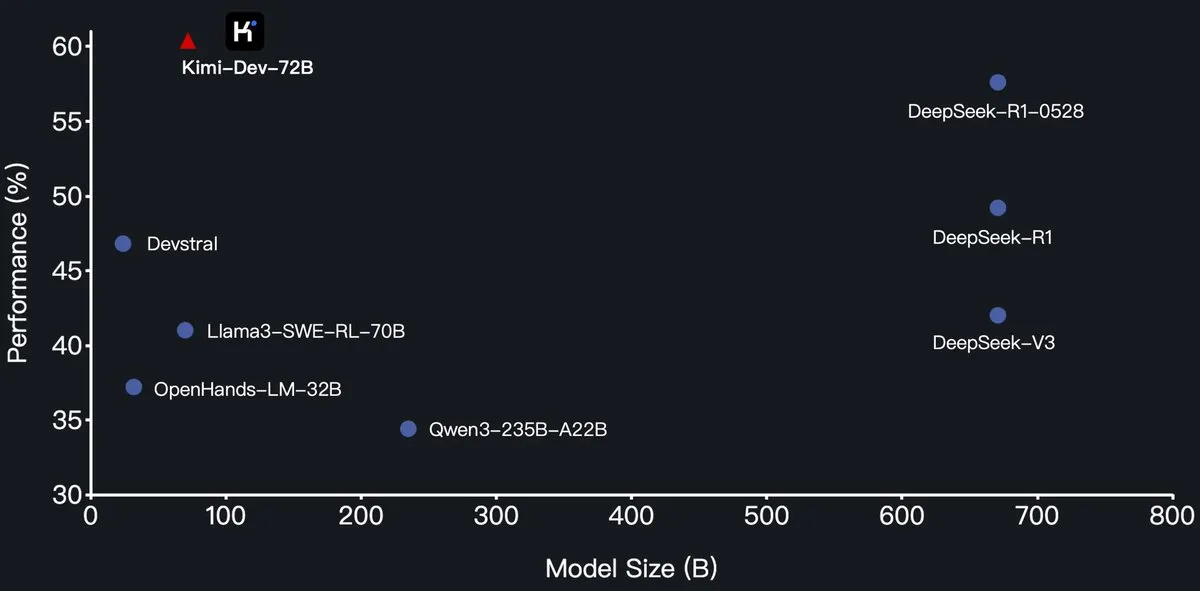
Moonshot AI (月之暗面) lanza el modelo de programación Kimi-Dev-72B de código abierto, superando a DeepSeek-R1 en SWE-Bench: Moonshot AI (月之暗面) ha lanzado su nuevo modelo de lenguaje grande de programación de código abierto, Kimi-Dev-72B, que se basa en un ajuste fino de Qwen2.5-72B. Se informa que Kimi-Dev-72B logró una tasa de resolución del 60.4% en la prueba de referencia SWE-bench Verified, superando a modelos como DeepSeek-R1-0528 (57.6%) y Qwen3-235B-A22B, convirtiéndose en uno de los modelos de código abierto más destacados. Este modelo ha sido entrenado mediante aprendizaje por refuerzo, centrándose en la reparación de repositorios de código reales en entornos Docker, y solo recibe recompensas cuando el conjunto completo de pruebas se supera con éxito. El responsable de desarrollo de Qwen indicó que no se había concedido autorización, pero el uso de la licencia MIT por parte de Kimi para publicar la versión ajustada cumple con la normativa. (Fuente: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
La serie de modelos Qwen3 añade soporte para el formato MLX, optimizando la inferencia en chips de Apple: El equipo de Tongyi Qianwen de Alibaba anunció que la serie de modelos Qwen3 ahora es compatible con el formato MLX y ofrece cuatro niveles de cuantización: 4bit, 6bit, 8bit y BF16. Esta medida tiene como objetivo optimizar la eficiencia de ejecución de los modelos en el framework MLX de Apple, facilitando a los desarrolladores la implementación local y la inferencia en dispositivos Mac. Los usuarios pueden obtener los modelos correspondientes en HuggingFace y ModelScope. (Fuente: ClementDelangue, stablequan, jeremyphoward)

Google Gemini lanzará próximamente la función “Deep Think” para mejorar la capacidad de procesamiento de problemas complejos: Google se está preparando para introducir una nueva función llamada “Deep Think” en su modelo Gemini 2.5 Pro. Esta función tiene como objetivo proporcionar capacidad de cómputo adicional para abordar problemas más desafiantes, especialmente en tareas relacionadas con las matemáticas, donde se espera que Deep Think mejore el rendimiento hasta en un 15% en comparación con la versión regular de Gemini 2.5 Pro. Esta función aparecerá como una nueva opción en la barra de herramientas y el proceso podría tardar unos minutos. Al mismo tiempo, la interfaz de usuario de Gemini también recibirá una actualización. (Fuente: op7418)
El modelo de generación de video Veo 3 de Google se lanza oficialmente, expandiéndose a más de 70 mercados: Google anunció que su modelo de generación de video por IA, Veo 3, ya está disponible oficialmente para los suscriptores de AI Pro y Ultra, cubriendo más de 70 mercados en todo el mundo. Veo 3 ha llamado la atención por sus videos realistas y creativos; anteriormente, algunos usuarios ya habían utilizado el modelo para crear contenido ASMR como el viral “corte de frutas mágico”, que obtuvo decenas de millones de reproducciones en redes sociales, demostrando su potencial en el campo de la creación de contenido. Este lanzamiento oficial permitirá a más usuarios experimentar y utilizar Veo 3 para la creación de videos. (Fuente: Google, 新智元)
Hugging Face y Groq colaboran para ofrecer servicios de inferencia LLM de alta velocidad: Hugging Face ha anunciado una colaboración con la empresa de chips de IA Groq para integrar las LPU™ (Language Processing Unit) de Groq en Hugging Face Playground y API. Los usuarios ahora pueden experimentar directamente los servicios de inferencia LLM acelerados por hardware de Groq en la plataforma Hugging Face, con soporte para múltiples modelos, incluidos Llama 4 y Qwen 3. Esta iniciativa tiene como objetivo proporcionar a los desarrolladores opciones de inferencia de modelos de IA más rápidas y eficientes, especialmente adecuadas para construir agentes, asistentes y aplicaciones de IA en tiempo real. (Fuente: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

Hugging Face Hub añade función de filtrado por tamaño de modelo para ayudar a los desarrolladores a elegir el modelo adecuado: La plataforma Hugging Face ha lanzado una nueva función que permite a los usuarios filtrar modelos según su tamaño (Size Range), especialmente para aquellos que se ejecutan en el framework mlx / mlx-lm. Esta mejora tiene como objetivo ayudar a los desarrolladores a encontrar más fácilmente modelos que se ajusten a sus necesidades específicas de hardware y rendimiento, enfatizando que no siempre un modelo más grande es mejor, ya que los modelos pequeños especializados suelen ser óptimos en escenarios específicos. (Fuente: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

Actualización de NVIDIA NCCL: comienza a usar acumulación FP32 para operaciones de reducción con entradas de media precisión: La última versión de NVIDIA Collective Communications Library (NCCL) (commit 72d2432) introduce una actualización importante: al procesar operaciones de reducción (reduction ops) con entradas de media precisión (como FP16, BF16), comienza a utilizar FP32 para la acumulación. Este cambio es crucial para mantener la precisión computacional y prevenir el desbordamiento, especialmente en el entrenamiento distribuido a gran escala. Se espera que esta versión se integre en PyTorch 2.8 y versiones posteriores. (Fuente: StasBekman)

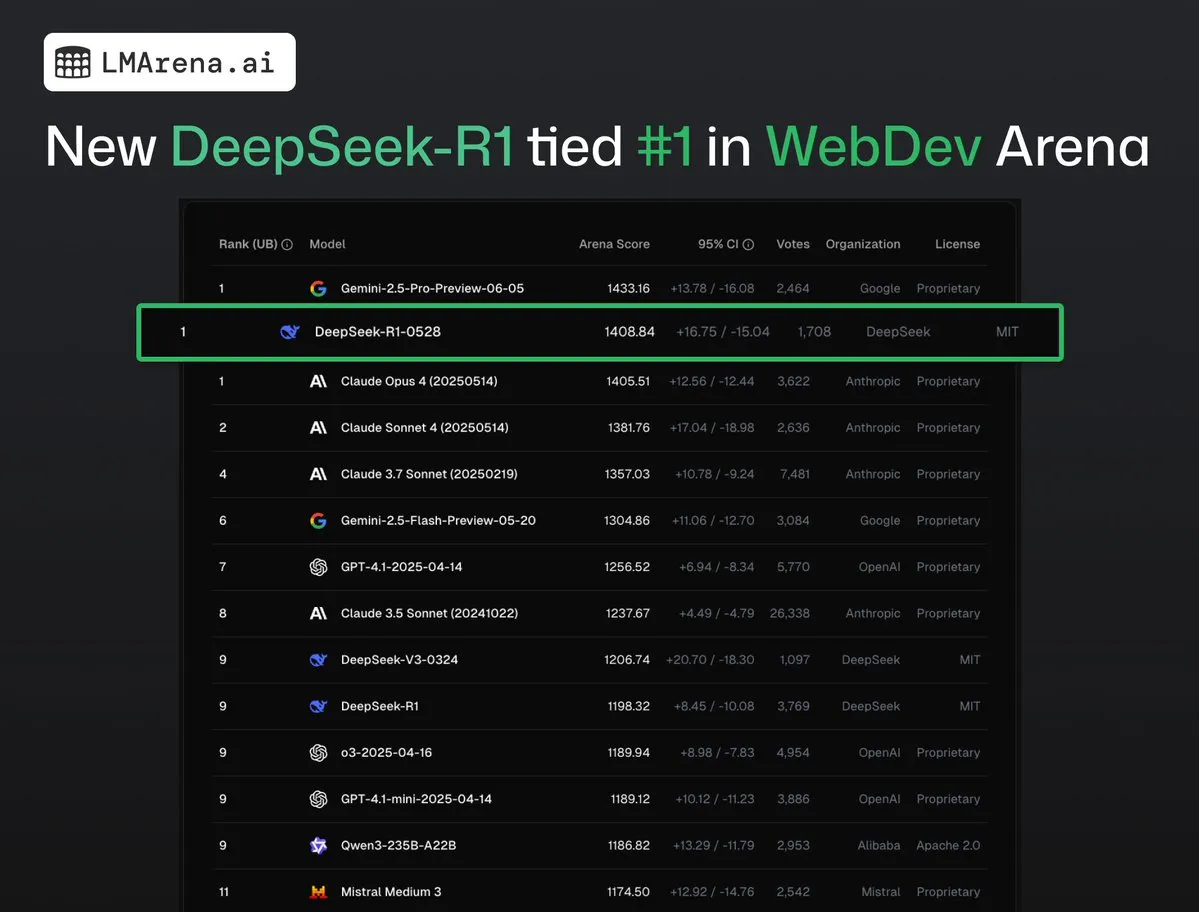
DeepSeek-R1 (0528) empata en el primer puesto con Claude Opus 4 en WebDev Arena: Los últimos datos de lmarena.ai muestran que la nueva versión de DeepSeek-R1 (0528) ha tenido un rendimiento excepcional en la prueba de referencia WebDev Arena, empatando en el primer puesto con Claude Opus 4. Este modelo ocupa el sexto lugar en la clasificación general de Text Arena, el segundo en capacidad de programación, el cuarto en prompts difíciles, el quinto en capacidad matemática, y es el modelo de código abierto con licencia MIT con mejor rendimiento en la clasificación. Esto marca la fuerte competitividad de DeepSeek en tareas específicas de desarrollo y razonamiento. (Fuente: ClementDelangue, zizhpan)
ByteDance lanza los modelos de imagen Seedream 3.0 y video Seedance 1.0 Lite en la plataforma Poe: Las herramientas de creación de IA de ByteDance han lanzado una actualización en la plataforma internacional Poe, presentando el modelo de generación de imágenes Seedream 3.0 de Jmeng AI y el modelo de generación de video Seedance 1.0 Lite. Seedream 3.0 tiene como objetivo generar imágenes claras y vívidas, mientras que Seedance 1.0 Lite puede generar rápidamente videos con efectos dinámicos realistas. Los usuarios pueden primero generar imágenes con Seedream en Poe y luego, mencionando a Seedance con @, convertirlas en videos, logrando un flujo de creación continuo de imagen a video. (Fuente: op7418)

Tencent lanza el modelo de canto Levo, compatible con separación de pistas y clonación de timbre zero-shot: Tencent ha lanzado un modelo de canto con IA llamado Levo, cuyo rendimiento se dice que es comparable al de Suno V3.5. Levo admite la separación de pistas de audio y la función de clonación de timbre zero-shot. A juzgar por las demostraciones y puntuaciones publicadas, su rendimiento es sobresaliente. Este avance demuestra la fortaleza de Tencent en el campo de la generación de música con IA. (Fuente: karminski3)
OpenAI lanza la función de generación de imágenes de ChatGPT en WhatsApp: OpenAI anunció que los usuarios ahora pueden utilizar la función de generación de imágenes de ChatGPT a través del servicio 1-800-ChatGPT en WhatsApp. Esta actualización permite a un grupo más amplio de usuarios generar imágenes de IA directamente en la aplicación de mensajería instantánea de manera conveniente. (Fuente: gdb, eliza_luth, iScienceLuvr)
SpatialLM se actualiza a la versión 1.1, mejorando la comprensión y reconstrucción de escenas 3D: El modelo de razonamiento espacial SpatialLM ha lanzado la versión 1.1. La nueva versión admite múltiples modos de fuente de entrada, incluyendo la generación de escenas 3D a partir de texto (Text-to-3D), reconstrucción a partir de video de cámara de mano, datos de nubes de puntos LiDAR (como el LiDAR del iPhone Pro) y muestreo de mallas sintéticas. Las características clave incluyen el manejo robusto de nubes de puntos no estructuradas, permitiendo una reconstrucción razonable incluso con datos de escaneo 3D incompletos. Además, la nueva versión optimiza la detección zero-shot para la entrada de video en streaming, mejora la precisión de la estimación de la disposición interior y eleva el efecto de detección de objetos 3D. Los escenarios de aplicación son amplios, abarcando la reconstrucción de escenas AR, la comprensión espacial para robots, los flujos de trabajo de diseño 3D y las aplicaciones de cámara para consumidores. (Fuente: karminski3)
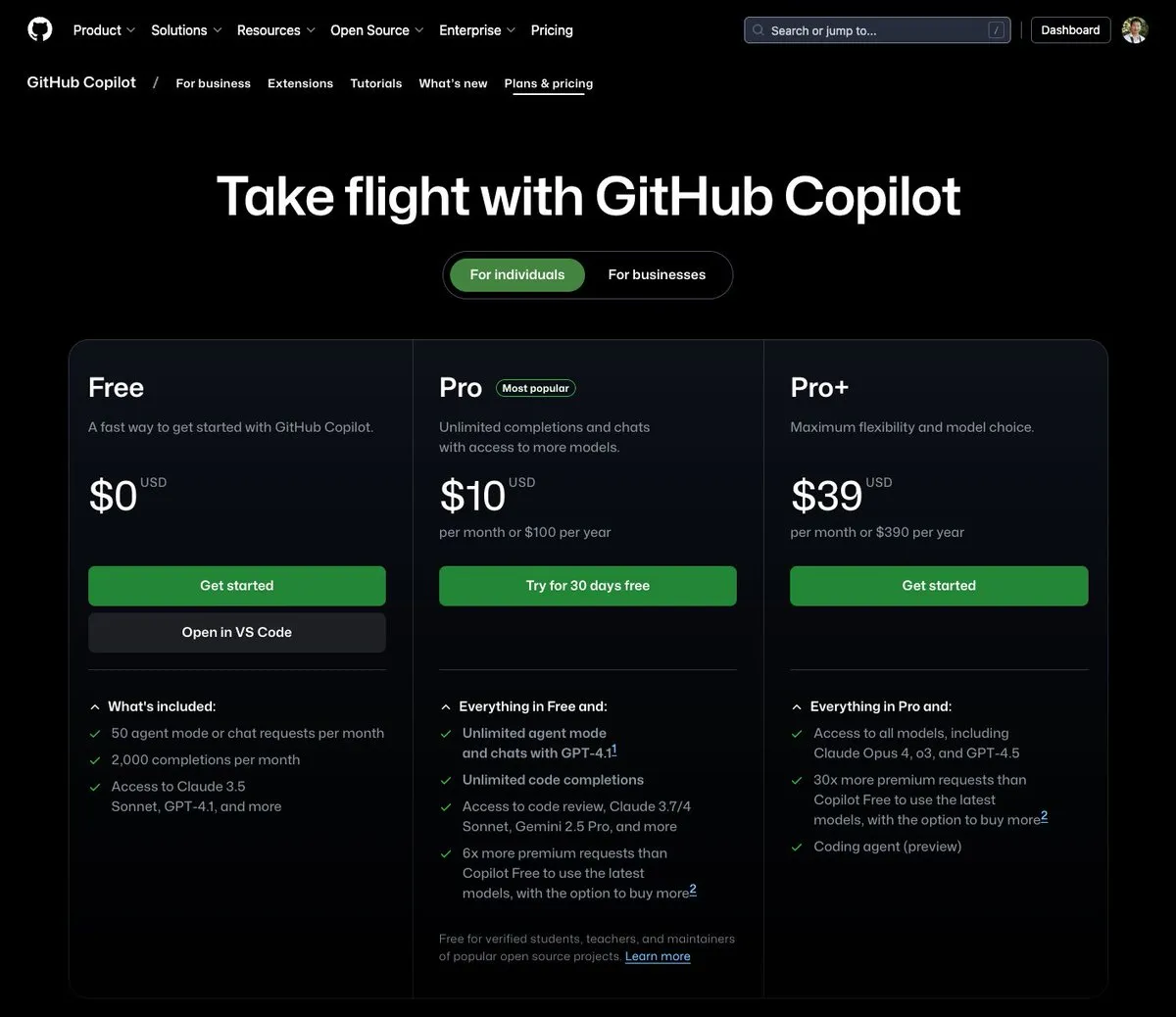
GitHub Copilot lanza un plan de $39 al mes, integrando Claude Opus 4 y otros grandes modelos: GitHub Copilot ha añadido un nuevo plan de suscripción de $39 al mes. Este plan no solo ofrece funciones de asistente de codificación, sino que también permite a los usuarios acceder a varios modelos de lenguaje potentes, incluyendo Claude Opus 4, o3 y GPT-4.5, y utilizar el Coding agent. Esta iniciativa tiene como objetivo proporcionar a los desarrolladores una experiencia de programación asistida por IA más completa. (Fuente: dotey)
El costo de llamada de los grandes modelos de IA continúa disminuyendo, la serie Doubao 1.6 reduce su precio en un 63% adicional: Volcano Engine, en la conferencia Force Original Power, lanzó la serie de grandes modelos Doubao 1.6 y anunció una reducción de costos integral del 63%. Para el rango de longitud de entrada de 0-32K, comúnmente utilizado por la mayoría de las empresas, el precio es de 0.8 yuanes por millón de tokens de entrada y 8 yuanes de salida. Esto marca una continua escalada en la guerra de precios de los grandes modelos, después de que Alibaba Qianwen redujera sus costos a 1/10 de DeepSeek R1 en marzo de este año. Los bajos costos impulsarán aún más la implementación y popularización de aplicaciones como los AI Agents. (Fuente: 字节必须再赢一次)
La herramienta de aceleración de generación de video Chipmunk se actualiza, admite arquitecturas multi-GPU y más modelos de código abierto: La herramienta Chipmunk del equipo de Dan Fu ha recibido una actualización y ahora admite una aceleración sin pérdidas de 1.4-3x en la generación de video en múltiples arquitecturas de GPU NVIDIA (sm_80, sm_89, sm_90, como A100s, 4090s, H100s). Al mismo tiempo, Chipmunk ha añadido soporte para más modelos de video de código abierto como Mochi y Wan, y proporciona tutoriales de integración. La herramienta aprovecha la escasez de valores de activación en los modelos de video (solo el 5-25% de los valores de activación contribuyen a más del 90% de la salida) para lograr la aceleración, sin necesidad de reentrenar el modelo. (Fuente: realDanFu)

🧰 Herramientas
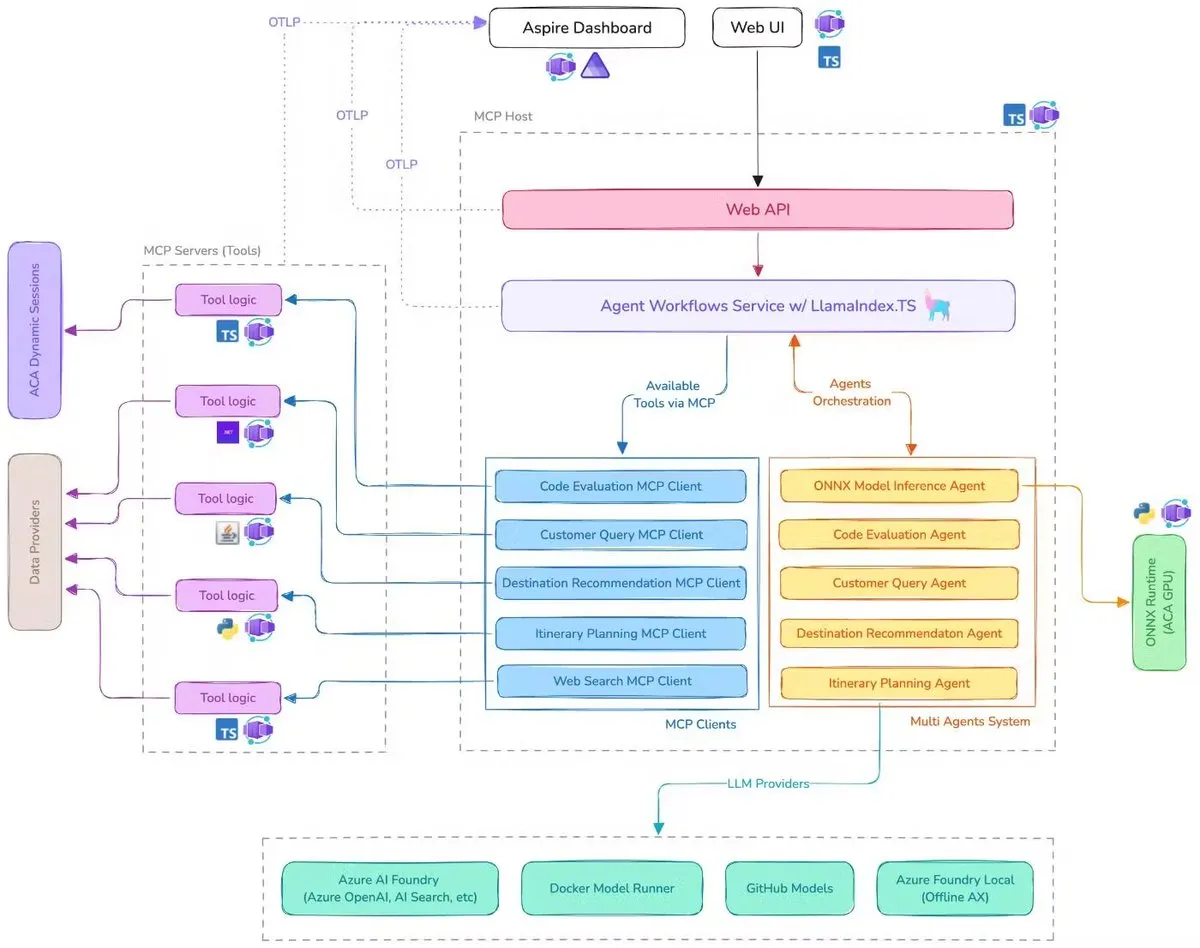
Microsoft lanza demo de asistente de viajes con IA, integrando MCP, LlamaIndex.TS y Azure AI Foundry: Microsoft ha presentado una demo de un asistente de viajes con IA. Este sistema coordina múltiples agentes de IA (incluyendo clasificación de consultas, recomendación de destinos, planificación de itinerarios y otros seis agentes especializados) para completar tareas complejas de planificación de viajes, utilizando el Protocolo de Contexto de Modelo (MCP), LlamaIndex.TS y Azure AI Foundry. Cada agente obtiene datos y herramientas en tiempo real a través de servidores MCP escritos en Java, .NET, Python y TypeScript. La aplicación demuestra cómo los multiagentes de nivel empresarial pueden colaborar a través de microservicios multilingües, utilizando modelos de Azure OpenAI y GitHub para proporcionar capacidades de IA, y puede lograr una implementación sin servidor escalable a través de Azure Container Apps. (Fuente: jerryjliu0, jerryjliu0)
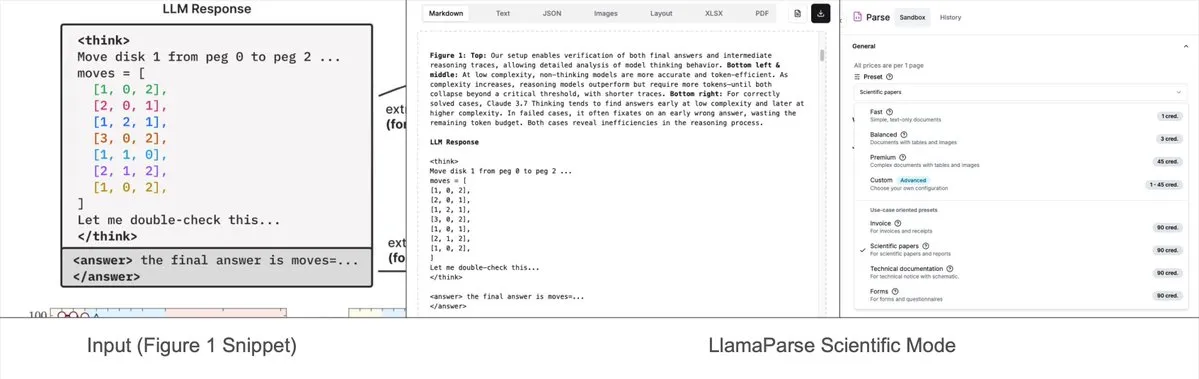
LlamaParse añade modos preestablecidos, puede analizar gráficos complejos en Mermaid o Markdown: La herramienta LlamaParse de LlamaIndex se ha actualizado recientemente, añadiendo “modos preestablecidos” (preset-modes) que le permiten analizar gráficos complejos en documentos como informes de investigación (por ejemplo, gráficos con múltiples curvas y anotaciones) y convertirlos en diagramas Mermaid formateados o tablas Markdown. Esta función ayuda a capturar el contexto completo de la página, y el texto estructurado generado se puede utilizar para construir flujos RAG o para una mayor extracción de metadatos. (Fuente: jerryjliu0)
Prompt Optimizer: una herramienta de optimización para ayudar a escribir prompts de alta calidad: Prompt Optimizer es una herramienta diseñada para ayudar a los usuarios a escribir mejores prompts de IA, mejorando así la calidad de la salida de la IA. Es compatible con aplicaciones web y extensiones de Chrome, ofreciendo optimización inteligente, mejora iterativa en múltiples rondas, comparación entre prompts originales y optimizados, integración de múltiples modelos (OpenAI, Gemini, DeepSeek, Zhipu AI, SiliconFlow, etc.), configuración avanzada de parámetros y almacenamiento local encriptado, entre otras funciones. La herramienta procesa los datos puramente en el lado del cliente, garantizando la seguridad y privacidad de los datos. (Fuente: GitHub Trending)

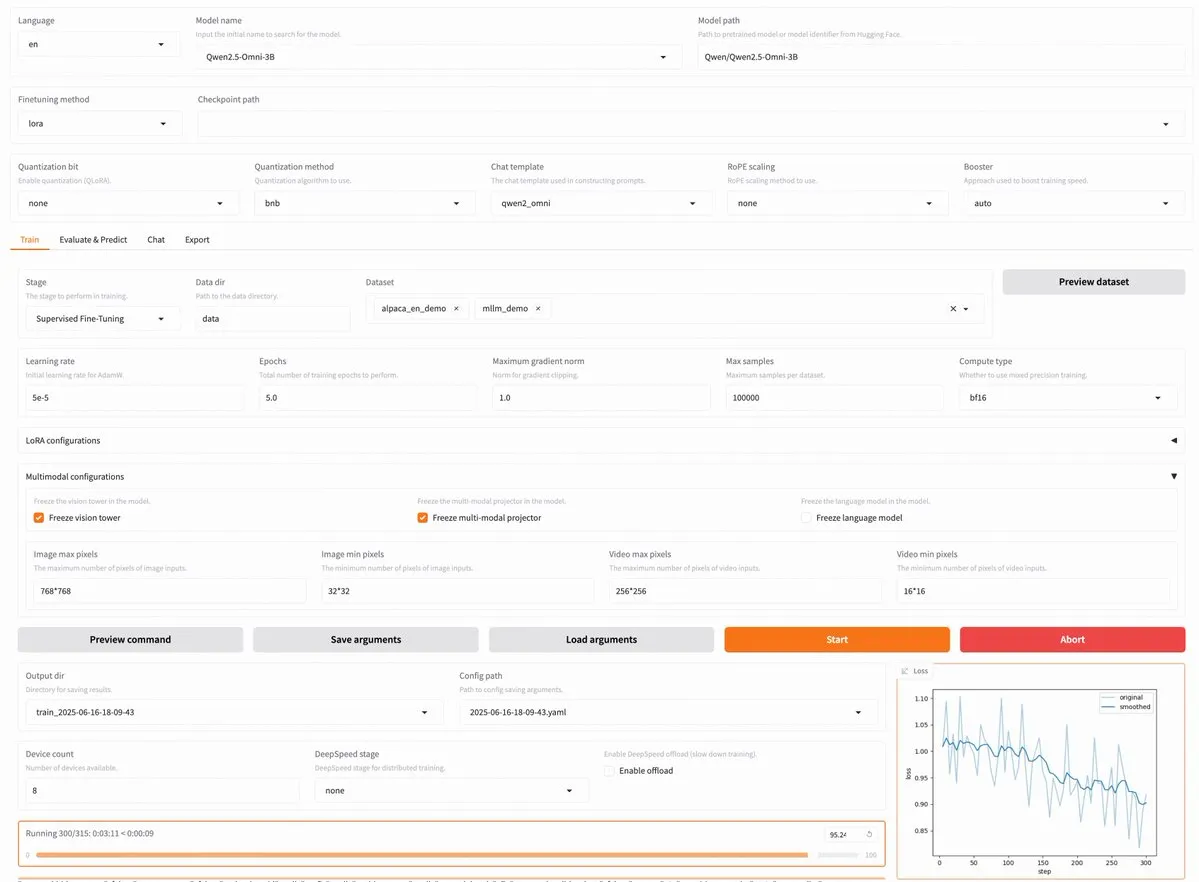
LLaMA Factory v0.9.3 lanzada, admite ajuste fino sin código para casi 300 modelos, incluidos Qwen3 y Llama 4: LLaMA Factory ha lanzado la versión v0.9.3. Esta versión es una plataforma de ajuste fino sin código, completamente de código abierto y con interfaz de usuario Gradio, compatible con casi 300 modelos, incluidos los más recientes Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni, entre otros. Los usuarios pueden instalarla localmente a través de una imagen Docker o experimentarla en Hugging Face Spaces, Google Colab y la nube GPU de Novita. (Fuente: _akhaliq)
Nanonets OCR: Modelo OCR SOTA basado en Qwen 2.5 VL 3B de código abierto: Nanonets ha lanzado un nuevo modelo OCR de 3B parámetros, Nanonets OCR. Este modelo se basa en la red troncal Qwen 2.5 VL 3B, supera en rendimiento a la API Mistral OCR y se publica bajo la licencia Apache 2.0. Es capaz de manejar diversas tareas de OCR, como el reconocimiento de LaTeX, la detección de marcas de agua y firmas, y la extracción de tablas complejas. (Fuente: huggingface)
Se informa que Perplexity Labs puede reemplazar múltiples puestos profesionales, lo que genera un debate sobre la capacidad de las herramientas de IA: Un usuario, GREG ISENBERG, afirmó haber utilizado Perplexity Labs para reemplazar el trabajo de cinco puestos: vendedor, redactor publicitario, director de cine, gestor de redes sociales y analista financiero, considerando que la capacidad de las herramientas de IA es “realmente una locura”. El CEO de Perplexity, Arav Srinivas, retuiteó y comentó que este es uno de los mejores videos que muestran cómo se aplican los agentes de IA en casos de uso de la vida real, comparando Perplexity Labs con otras herramientas del mercado en análisis financiero, marketing en redes sociales, dirección creativa y ventas. Esto resalta el potencial de los AI Agents para integrar y ejecutar tareas profesionales multidisciplinares. (Fuente: AravSrinivas, AravSrinivas)
Claude-Flow lanza la importante actualización v1.0.50, activando el “Modo Enjambre” para mejorar la eficiencia de la automatización de código: Claude-Flow, un sistema de agentes paralelos por lotes basado en Claude Code, ha lanzado la versión v1.0.50. La nueva versión introduce el “Modo Enjambre” (Swarm Mode), que permite a los usuarios generar, gestionar y coordinar simultáneamente cientos de agentes Claude trabajando en paralelo para construir, probar, desplegar o realizar ciclos de investigación multifásicos. Se afirma que el rendimiento mejora 20 veces en comparación con la automatización secuencial tradicional de Claude Code. Los desarrolladores pueden inicializarlo mediante npx claude-flow@latest init --sparc --force. (Fuente: Reddit r/ClaudeAI)

📚 Aprendizaje
Awesome Machine Learning: una lista completa de recursos de aprendizaje automático: El proyecto “awesome-machine-learning” en GitHub es una lista cuidadosamente seleccionada de frameworks, bibliotecas y software de aprendizaje automático, clasificados por lenguaje de programación. También contiene enlaces a libros gratuitos de aprendizaje automático, eventos profesionales, cursos en línea, boletines de blogs y reuniones locales, proporcionando una valiosa guía para estudiantes y profesionales del aprendizaje automático. (Fuente: GitHub Trending)
Anthropic y Cognition AI publican respectivamente artículos de blog sobre la construcción de sistemas multiagente, LangChain realiza un resumen: Anthropic y Cognition AI publicaron recientemente sendos artículos de blog sobre la construcción (o no construcción) de sistemas multiagente. Anthropic compartió su experiencia en la construcción de su sistema de investigación multiagente, mientras que Cognition AI propuso el punto de vista de “no construir multiagentes”. Harrison Chase de LangChain resumió esto, señalando que aunque las opiniones parecen diferentes en la superficie, ambos artículos tienen muchos puntos en común en cuanto a directrices y recomendaciones, y los relacionó con los esfuerzos de LangChain en el ámbito multiagente. (Fuente: hwchase17, Hacubu)
El artículo “Recent Advances in Speech Language Models: A Survey” es aceptado en la conferencia principal de ACL 2025: Un artículo de revisión sobre modelos de lenguaje de voz (SpeechLM) titulado “Recent Advances in Speech Language Models: A Survey”, escrito por un equipo de la Universidad China de Hong Kong, ha sido aceptado en la conferencia principal de ACL 2025. Este artículo es la primera revisión exhaustiva y sistemática en este campo, analizando en profundidad la arquitectura técnica de los SpeechLM (tokenizadores de voz, modelos de lenguaje, vocoders), estrategias de entrenamiento (preentrenamiento, ajuste fino de instrucciones, post-alineación), paradigmas de interacción (modelado full-duplex), escenarios de aplicación (semántica, hablante, paralingüística) y sistemas de evaluación. El artículo enfatiza el potencial de los SpeechLM para lograr una interacción de voz natural hombre-máquina y señala los desafíos y direcciones futuras. (Fuente: 36氪)

Nueva investigación mejora la capacidad de razonamiento interdominio de modelos pequeños mediante el aprendizaje visual de juegos (ViGaL); un modelo de 7B supera a GPT-4o en matemáticas: Investigadores de la Universidad de Rice, la Universidad Johns Hopkins y NVIDIA han propuesto un nuevo paradigma de post-entrenamiento llamado ViGaL (Visual Game Learning). Al hacer que un modelo multimodal de 7B parámetros (Qwen2.5-VL-7B) juegue a juegos arcade sencillos como Snake y rotación 3D, el modelo no solo mejoró sus habilidades en los juegos, sino que también mostró una mejora significativa en la capacidad de razonamiento interdominio en tareas complejas como matemáticas (MathVista) y preguntas y respuestas multidisciplinares (MMMU), superando incluso en algunos aspectos a modelos de primer nivel como GPT-4o. La investigación indica que el entrenamiento con juegos puede cultivar capacidades cognitivas generales del modelo, como la comprensión espacial y la planificación secuencial, y que diferentes juegos pueden fortalecer diferentes aspectos de las habilidades de razonamiento. Este método mejora la capacidad de razonamiento manteniendo al mismo tiempo la capacidad visual general del modelo. (Fuente: 新智元)

Shanghai AI Lab y otros proponen el framework MathFusion para mejorar la capacidad de resolución de problemas matemáticos de los LLM mediante la fusión de instrucciones: El Laboratorio de Inteligencia Artificial de Shanghái, la Escuela de Inteligencia Artificial Gaoling de la Universidad Renmin de China y otras instituciones han propuesto conjuntamente el framework MathFusion. Su objetivo es mejorar la capacidad de los modelos de lenguaje grandes (LLM) para resolver problemas matemáticos mediante la fusión de diferentes problemas matemáticos para generar instrucciones sintéticas con estructuras más diversas y lógicas más complejas. Este framework incluye tres estrategias de fusión: secuencial, paralela y condicional, capaces de capturar eficazmente las conexiones profundas entre los problemas. Los experimentos demuestran que, utilizando solo 45K instrucciones sintéticas para el ajuste fino de modelos como DeepSeekMath-7B, Llama3-8B y Mistral-7B, MathFusion logró una mejora promedio de la precisión del 18.0% en múltiples benchmarks matemáticos, demostrando alta eficiencia de datos y rendimiento. (Fuente: 量子位)

Shanghai AI Lab y otros proponen el framework GRA, donde modelos pequeños colaboran para generar datos de alta calidad, con un rendimiento comparable a modelos de 72B: El Laboratorio de Inteligencia Artificial de Shanghái, en colaboración con la Universidad Renmin de China, ha propuesto el framework GRA (Generator–Reviewer–Adjudicator). Mediante la simulación del mecanismo de envío de artículos y revisión por pares, permite que múltiples modelos de lenguaje pequeños (parámetros 7-8B) colaboren para generar datos de entrenamiento de alta calidad. En este framework, el Generator es responsable de la generación, el Reviewer realiza múltiples rondas de revisión y puntuación, y el Adjudicator toma la decisión final en caso de conflicto en la revisión. Los experimentos demuestran que el entrenamiento de modelos base como LLaMA-3.1-8B y Qwen-2.5-7B con datos generados por GRA, en 10 conjuntos de datos principales que abarcan matemáticas, código y razonamiento lógico, iguala o supera el rendimiento de los datos generados por destilación de modelos grandes como Qwen-2.5-72B-Instruct. Esto ofrece nuevas ideas para la síntesis de datos de bajo costo y alta eficiencia. (Fuente: 量子位)

Un artículo explora el estado actual y futuro de la interpretabilidad de los grandes modelos, enfatizando su importancia para el despliegue seguro de la IA: Tencent Research Institute publicó un artículo que explora en profundidad el estado actual, las rutas técnicas y los desafíos futuros de la interpretabilidad de los modelos de lenguaje grandes (LLM). El artículo señala que comprender los mecanismos internos de los LLM es crucial para prevenir la desviación de valores, depurar y mejorar modelos, evitar el abuso e impulsar aplicaciones en escenarios de alto riesgo. Las rutas técnicas actuales incluyen la explicación automatizada (grandes modelos explicando modelos pequeños), la visualización de características (como los autoencoders dispersos), el monitoreo de la cadena de pensamiento y la interpretabilidad mecanicista (como el “microscopio de IA” de Anthropic y Tracr de DeepMind). Sin embargo, la polisemia neuronal, la universalidad de las reglas de explicación y las limitaciones cognitivas humanas siguen siendo los principales desafíos. El artículo hace un llamado a fortalecer la inversión en investigación sobre interpretabilidad y sugiere adoptar reglas de “soft law” que fomenten la autorregulación de la industria en la etapa actual, para garantizar un desarrollo seguro, transparente y centrado en el ser humano de la tecnología de IA. (Fuente: 腾讯研究院)

Nuevo artículo explora las aplicaciones y avances de los modelos de difusión discreta en modelos de lenguaje grandes y multimodales: Un artículo titulado “Discrete Diffusion in Large Language and Multimodal Models: A Survey” revisa sistemáticamente los avances en la investigación de los modelos de lenguaje de difusión discreta (dLLMs) y los modelos de lenguaje multimodales de difusión discreta (dMLLMs). Estos modelos adoptan la decodificación paralela de múltiples Tokens y estrategias de generación basadas en la eliminación de ruido, logrando generación paralela, controlabilidad de salida de grano fino y capacidades de percepción dinámicas y sensibles a la respuesta, con una velocidad de inferencia que puede ser hasta 10 veces más rápida que los modelos autorregresivos. El artículo rastrea su historia de desarrollo, formaliza el marco matemático, clasifica los modelos representativos, analiza las tecnologías clave de entrenamiento e inferencia, y resume las aplicaciones en los dominios del lenguaje, lenguaje visual y biología, discutiendo finalmente las futuras direcciones de investigación y los desafíos de implementación. (Fuente: HuggingFace Daily Papers)
Nueva investigación propone Test3R: mejorar la precisión geométrica de la reconstrucción 3D mediante el aprendizaje en tiempo de prueba: Una nueva técnica llamada Test3R mejora significativamente la precisión geométrica de la reconstrucción 3D mediante el aprendizaje en tiempo de prueba. El método utiliza tripletes de imágenes (I_1,I_2,I_3) y genera resultados de reconstrucción a partir de los pares de imágenes (I_1,I_2) e (I_1,I_3). La idea central es optimizar la red en tiempo de prueba mediante un objetivo autosupervisado: maximizar la consistencia geométrica de estos dos resultados de reconstrucción con respecto a la imagen común I_1. Los experimentos demuestran que Test3R supera significativamente a los métodos SOTA existentes en tareas de reconstrucción 3D y estimación de profundidad multivista, y posee características de universalidad y bajo costo, siendo fácil de aplicar a otros modelos con un costo de entrenamiento en tiempo de prueba y un número de parámetros mínimos. (Fuente: HuggingFace Daily Papers)
Artículo propone Mirage-1: un agente GUI con habilidades multimodales jerárquicas para mejorar el manejo de tareas a largo plazo: Investigadores proponen Mirage-1, un agente GUI multimodal, multiplataforma y plug-and-play, diseñado para abordar la falta de conocimiento y la brecha entre los dominios offline y online que enfrentan los agentes GUI actuales al manejar tareas a largo plazo en entornos online. El núcleo de Mirage-1 es el módulo de Habilidades Multimodales Jerárquicas (HMS), que abstrae progresivamente las trayectorias en habilidades de ejecución, habilidades centrales y metahabilidades, proporcionando una estructura de conocimiento jerárquica para la planificación de tareas a largo plazo. Al mismo tiempo, el algoritmo de Búsqueda de Árbol de Monte Carlo Mejorada por Habilidades (SA-MCTS) utiliza las habilidades adquiridas offline para reducir el espacio de búsqueda de acciones en la exploración del árbol online. En las pruebas de referencia AndroidWorld, MobileMiniWob++, Mind2Web-Live y el nuevo AndroidLH, Mirage-1 demostró mejoras significativas de rendimiento. (Fuente: HuggingFace Daily Papers)
El artículo “Don’t Pay Attention” propone una nueva arquitectura de red neuronal fundamental, Avey, desafiando a Transformer: Un artículo titulado “Don’t Pay Attention” propone una nueva arquitectura de red neuronal fundamental llamada Avey, diseñada para eliminar la dependencia de los mecanismos de atención y recurrencia. Avey consta de un clasificador (ranker) y un procesador neuronal autorregresivo (autoregressive neural processor), que colaboran para identificar y contextualizar únicamente los Tokens más relevantes para cualquier Token dado, independientemente de su posición en la secuencia. Esta arquitectura desacopla la longitud de la secuencia del ancho del contexto, lo que permite procesar eficazmente secuencias de longitud arbitraria. Los resultados experimentales muestran que Avey se desempeña de manera comparable a Transformer en benchmarks estándar de NLP de corto alcance y destaca especialmente en la captura de dependencias de largo alcance. (Fuente: HuggingFace Daily Papers)
Nuevo artículo explora la verificación de código escalable mediante modelos de recompensa, equilibrando precisión y rendimiento: Un estudio explora el equilibrio entre el uso de modelos de recompensa de resultados (ORM) y validadores exhaustivos (como conjuntos de pruebas completos) cuando los modelos de lenguaje grandes (LLM) resuelven tareas de codificación. La investigación encuentra que, incluso en presencia de validadores exhaustivos, los ORM juegan un papel crucial en la verificación escalable al sacrificar cierta precisión por velocidad. Específicamente, en el método “generar-podar-reordenar”, el uso de un validador más rápido pero menos preciso para eliminar previamente soluciones incorrectas puede acelerar el sistema 11.65 veces, con solo una reducción del 8.33% en la precisión. Este método funciona filtrando soluciones incorrectas pero bien clasificadas, ofreciendo nuevas ideas para diseñar sistemas de clasificación de programas escalables y precisos. (Fuente: HuggingFace Daily Papers)
Nuevo benchmark AbstentionBench revela: LLM de tipo inferencial rinden mal en preguntas incontestables: Para evaluar la capacidad de los modelos de lenguaje grandes (LLM) de optar por la abstención (es decir, negarse a responder explícitamente) ante la incertidumbre, los investigadores han lanzado AbstentionBench. Este benchmark a gran escala contiene 20 conjuntos de datos diferentes, que cubren diversos tipos de preguntas como respuestas desconocidas, especificaciones insuficientes, premisas erróneas, interpretaciones subjetivas e información desactualizada. La evaluación de 20 LLM de vanguardia muestra que la abstención es un problema no resuelto y que el aumento de la escala del modelo contribuye poco a ello. Sorprendentemente, incluso los LLM de tipo inferencial, entrenados explícitamente para dominios matemáticos y científicos, vieron su capacidad de abstención reducida en un promedio del 24% debido al ajuste fino para el razonamiento. Aunque los prompts de sistema cuidadosamente diseñados pueden mejorar el rendimiento de la abstención en la práctica, esto no resuelve las deficiencias fundamentales del modelo en el razonamiento bajo incertidumbre. (Fuente: HuggingFace Daily Papers)
Artículo propone el método PatchInstruct basado en prompts y descomposición por parches para utilizar LLM en la predicción de series temporales: Una nueva investigación explora estrategias de prompting simples y flexibles para utilizar modelos de lenguaje grandes (LLM) en la predicción de series temporales, sin necesidad de un reentrenamiento extenso o arquitecturas externas complejas. Mediante la combinación de la descomposición de series temporales, la tokenización basada en parches (patch-based tokenization) y la mejora de vecinos basada en la similitud, entre otros métodos de prompting especializados, los investigadores descubrieron que se puede mejorar la calidad de las predicciones de los LLM, manteniendo al mismo tiempo la simplicidad y minimizando el preprocesamiento de datos. El método PatchInstruct propuesto en esta investigación permite a los LLM realizar predicciones precisas y efectivas. (Fuente: HuggingFace Daily Papers)
Nuevo conjunto de datos MS4UI publicado, enfocado en el resumen multimodal de videos instructivos de interfaz de usuario: Para abordar las deficiencias de los benchmarks existentes en cuanto a proporcionar instrucciones ejecutables paso a paso e ilustraciones, los investigadores han propuesto el conjunto de datos MS4UI (Multi-modal Summarization for User Interface Instructional Videos). Este conjunto de datos contiene 2413 videos instructivos de UI, con una duración total de más de 167 horas, y ha sido anotado manualmente con segmentación de video, resúmenes de texto y resúmenes de video. Su objetivo es impulsar la investigación de métodos de resumen multimodal concisos y ejecutables para videos instructivos de UI. Los experimentos demuestran que los métodos actuales SOTA de resumen multimodal tienen un rendimiento deficiente en MS4UI, lo que subraya la importancia de nuevos métodos en este campo. (Fuente: HuggingFace Daily Papers)
DeepResearch Bench: un completo banco de pruebas para agentes de investigación profunda: Para evaluar sistemáticamente las capacidades de los agentes de investigación profunda basados en LLM (Deep Research Agents, DRAs), los investigadores han lanzado DeepResearch Bench. Este banco de pruebas contiene 100 tareas de investigación de nivel doctoral cuidadosamente diseñadas por expertos de 22 campos diferentes. Dada la complejidad y la laboriosidad de evaluar los DRAs, los investigadores proponen dos nuevos métodos de evaluación que muestran una alta concordancia con el juicio humano: uno es un método de criterios adaptativos basado en referencias para evaluar la calidad de los informes de investigación generados; el otro es un marco que evalúa la capacidad de recuperación y recopilación de información de los DRA mediante la evaluación del número de citas efectivas y la precisión general de las citas. (Fuente: HuggingFace Daily Papers)
Artículo propone BridgeVLA: aprendizaje eficiente de manipulación 3D mediante alineación de entrada y salida: Para mejorar la eficiencia con la que los modelos de lenguaje visual (VLM) utilizan señales 3D en el aprendizaje de manipulación robótica, los investigadores proponen BridgeVLA, un novedoso modelo de acción de lenguaje visual 3D (VLA). BridgeVLA proyecta la entrada 3D en múltiples imágenes 2D, asegurando la alineación con la entrada de la red troncal del VLM, y utiliza mapas de calor 2D para la predicción de acciones, unificando así la entrada y la salida en un espacio de imagen 2D consistente. Además, la investigación propone un método de preentrenamiento escalable que dota a la red troncal del VLM de la capacidad de predecir mapas de calor 2D antes del aprendizaje de políticas downstream. Los experimentos demuestran que BridgeVLA tiene un rendimiento sobresaliente en múltiples benchmarks de simulación y experimentos con robots reales, mejorando significativamente la eficiencia y efectividad del aprendizaje de manipulación 3D, y mostrando una fuerte eficiencia de muestra y capacidad de generalización. (Fuente: HuggingFace Daily Papers)
Nueva investigación sintetiza millones de instrucciones de usuario diversas y complejas (SynthQuestions) mediante fundamentación por atribución: Para abordar la falta de datos de instrucciones diversos, complejos y a gran escala necesarios para la alineación de modelos de lenguaje grandes (LLM), los investigadores proponen un método de síntesis de instrucciones basado en la fundamentación por atribución (attributed grounding). Este marco incluye: 1) un proceso de atribución de arriba hacia abajo que vincula las instrucciones reales seleccionadas con usuarios contextualizados; 2) un proceso de síntesis de abajo hacia arriba que utiliza documentos web para generar primero contextos y luego instrucciones significativas. Mediante este método se construyó el conjunto de datos SynthQuestions, que contiene 1 millón de instrucciones. Los experimentos demuestran que los modelos entrenados con este conjunto de datos logran un rendimiento líder en múltiples benchmarks comunes, y que el rendimiento continúa mejorando a medida que aumenta el corpus web. (Fuente: HuggingFace Daily Papers)
Publicado PersonaFeedback: un benchmark de evaluación personalizada a gran escala con anotaciones humanas: Para evaluar la capacidad de los modelos de lenguaje grandes (LLM) para proporcionar respuestas personalizadas dado un perfil de usuario predefinido y una consulta, los investigadores han lanzado el benchmark PersonaFeedback. Este benchmark contiene 8298 casos de prueba anotados por humanos, clasificados en tres niveles (fácil, medio y difícil) según la complejidad contextual del perfil de usuario y la dificultad para distinguir respuestas personalizadas. A diferencia de los benchmarks existentes, PersonaFeedback desacopla la inferencia de perfiles de la personalización, centrándose en evaluar la capacidad del modelo para generar respuestas personalizadas para perfiles explícitos. Los resultados experimentales muestran que incluso los LLM SOTA enfrentan desafíos en las pruebas de nivel difícil, lo que indica que los marcos actuales de mejora por recuperación no son la solución final para las tareas de personalización. (Fuente: HuggingFace Daily Papers)
Artículo explora la “cirugía lingüística” en grandes modelos multilingües: control de idioma en tiempo de inferencia mediante inyección latente: Una nueva investigación explora el fenómeno de alineación de representaciones que ocurre naturalmente en los modelos de lenguaje grandes (LLM) y su importancia para desacoplar la información específica del idioma de la información independiente del idioma. El estudio confirma la existencia de esta alineación y analiza cómo se compara su comportamiento con el de los modelos de alineación diseñados explícitamente. Basándose en estos hallazgos, los investigadores proponen el método de Control de Idioma en Tiempo de Inferencia (Inference-Time Language Control, ITLC), que utiliza la inyección latente (latent injection) para lograr un control preciso entre idiomas y mitigar el problema de la confusión lingüística en los LLM. Los experimentos demuestran que ITLC tiene una fuerte capacidad de control entre idiomas mientras mantiene la integridad semántica del idioma objetivo, y puede aliviar eficazmente el problema de la confusión entre idiomas que persiste incluso en los LLM a gran escala actuales. (Fuente: HuggingFace Daily Papers)
Artículo propone el método NoWait: eliminar los “Tokens de pensamiento” para mejorar la eficiencia de inferencia de los grandes modelos: Investigaciones recientes indican que los grandes modelos de inferencia, al realizar razonamientos complejos paso a paso, a menudo generan salidas redundantes debido a un exceso de “pensamiento” (como la salida de Tokens tipo “Wait”, “Hmm”), lo que afecta la eficiencia. El nuevo método propuesto, NoWait, tiene como objetivo validar la necesidad de estos Tokens de autorreflexión explícitos para el razonamiento de alto nivel, suprimiéndolos durante la inferencia. En diez benchmarks que abarcan tareas de razonamiento textual, visual y de video, NoWait redujo la longitud de las trayectorias de la cadena de pensamiento entre un 27% y un 51% en cinco familias de modelos estilo R1, sin dañar la utilidad del modelo. Este método ofrece una solución plug-and-play para lograr una inferencia multimodal eficiente que mantiene la utilidad. (Fuente: HuggingFace Daily Papers)
💼 Negocios
OpenAI gana un contrato de defensa de EE. UU. por 200 millones de dólares para desarrollar capacidades militares de vanguardia: OpenAI ha firmado un contrato de un año por valor de 200 millones de dólares con el Departamento de Defensa de EE. UU. con el objetivo de desarrollar herramientas avanzadas de inteligencia artificial para la seguridad nacional. Esto marca la primera vez que OpenAI obtiene un contrato de este tipo listado por el Pentágono. El trabajo se realizará principalmente en la Región de la Capital Nacional. Anteriormente, OpenAI ya había colaborado con la empresa de defensa Anduril. Esta medida se produce en un contexto de amplio impulso a las aplicaciones de IA en el sector de defensa de EE. UU., donde sus competidores Anthropic también han colaborado con Palantir y Amazon en este ámbito. El CEO de OpenAI, Sam Altman, ha expresado públicamente su apoyo a los proyectos de seguridad nacional. (Fuente: Reddit r/ArtificialInteligence, code_star)

Alta completa una ronda de financiación de 11 millones de dólares, liderada por Menlo Ventures, enfocándose en IA + moda: La startup de moda con IA, Alta, anunció la finalización de una ronda de financiación de 11 millones de dólares liderada por Menlo Ventures, con la participación de Benchstrength y Aglaé Ventures (el fondo de capital riesgo respaldado por la familia Arnault del grupo LVMH). Amy Tong Wu se unirá al consejo de administración de Alta. Esta ronda de financiación impulsará el desarrollo futuro de Alta en la intersección de la IA y la moda. (Fuente: ZhaiAndrew)
Figure ajusta su estructura organizativa, fusionando el departamento de Controles con Helix para acelerar su hoja de ruta de IA: La empresa de robots humanoides Figure anunció que su departamento de Controles (Controls) ha dejado de existir y todo el equipo se ha fusionado con el departamento Helix. Esta medida tiene como objetivo acelerar el desarrollo de la hoja de ruta de la empresa en el campo de la inteligencia artificial, lo que indica que Figure está concentrando más recursos y esfuerzos en la investigación y aplicación de la tecnología de IA. (Fuente: adcock_brett)
🌟 Comunidad
Discusión sobre AGI: los usuarios comunes no necesitan preocuparse excesivamente, AGI se inclina más hacia la estrategia que hacia una herramienta cotidiana: Múltiples personas en la comunidad señalan que, para el usuario común de LLM, no es necesario preocuparse excesivamente por la llegada de AGI (Inteligencia Artificial General). La definición de AGI es vaga y muy teórica; incluso si se logra, a corto plazo no se reflejará directamente en la ventana de chat del usuario. Más bien, será una herramienta estratégica e infraestructura para naciones o grandes instituciones, utilizada para manejar asuntos complejos como negociaciones entre países, y no para ayudar a individuos a programar reuniones. (Fuente: farguney, farguney, farguney, farguney)
La construcción de sistemas multiagente requiere evaluación humana, prestando atención a los casos límite y la calidad de las fuentes: Al construir sistemas multiagente, la evaluación y las pruebas manuales son cruciales, ya que pueden descubrir casos límite que la evaluación automatizada podría pasar por alto. Por ejemplo, los primeros agentes, al seleccionar fuentes de información, tendían a preferir granjas de contenido optimizadas para SEO en lugar de PDF académicos autorizados o blogs personales. La incorporación de heurísticas sobre la calidad de las fuentes en los prompts ayuda a resolver tales problemas. Esto demuestra que, incluso en la era de la evaluación automatizada, las pruebas manuales siguen siendo indispensables para descubrir fallos del sistema y sesgos sutiles en la selección de fuentes. (Fuente: riemannzeta)

Las diferencias en los mecanismos de predicción y aprendizaje entre los LLM y los modelos de video generan reflexión: Yann LeCun y Pedro Domingos retuitearon la opinión de Sergey Levine, discutiendo por qué los modelos de lenguaje pueden aprender tanto de la predicción del siguiente Token, mientras que los modelos de video aprenden relativamente poco de la predicción del siguiente fotograma. Levine especula que esto podría deberse a que los LLM actúan de alguna manera como “escáneres cerebrales”, lo que sugiere la singularidad de sus mecanismos de aprendizaje, o que los LLM son como si vivieran en la caverna de Platón, infiriendo el mundo real a través de la observación de secuencias de sombras (texto). (Fuente: ylecun, pmddomingos, pmddomingos)

Impacto positivo de los AI Agents en la educación: fomentan que los estudiantes salgan de su zona de confort: La discusión en la comunidad considera que los AI Agents no solo tienen un impacto positivo en las empresas, sino que también tienen un gran potencial en el campo de la educación. A través de la interacción con AI Agents, los estudiantes pueden salir de su zona de confort de manera más efectiva, lo que promueve la mejora de los resultados del aprendizaje. (Fuente: pirroh, amasad)
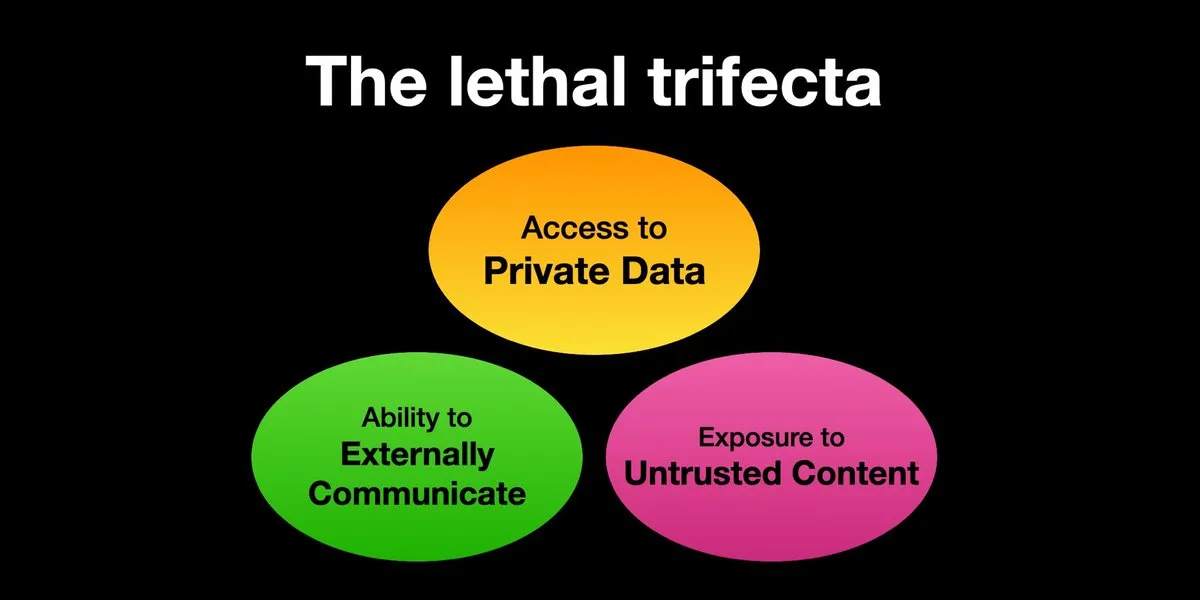
Los AI Agents enfrentan riesgos de ataques de inyección de prompts, la protección de seguridad necesita urgentemente ser reforzada: Karpathy retuiteó la advertencia de Simon Willison sobre el riesgo de la “Trifecta Letal” que enfrentan los AI Agents: cuando un AI Agent tiene acceso a datos privados, contacto con contenido no confiable y capacidad de comunicación externa simultáneamente, los atacantes pueden engañar al sistema para robar datos. Esto recuerda a la era del “Salvaje Oeste” de los primeros virus informáticos. Actualmente, los mecanismos de defensa contra prompts maliciosos son aún imperfectos; por ejemplo, falta un paradigma de seguridad similar al espacio de kernel/usuario de los sistemas operativos para restringir la capacidad de los Agents de ejecutar scripts arbitrarios. Esto genera preocupaciones sobre la adopción temprana de LLM Agents para la computación personal. (Fuente: karpathy, TheTuringPost)
En la era de la IA, la capacidad de aprendizaje rápido se convierte en una competencia central: Mustafa Suleyman señala que el mayor acelerador profesional en la próxima década será una capacidad de aprendizaje excepcional. Aconseja a las personas que identifiquen claramente su estilo de aprendizaje, utilicen la IA para convertir materiales al formato adecuado (como podcasts, cuestionarios), luego apliquen el conocimiento y repitan continuamente este proceso, logrando así un rápido aprendizaje y crecimiento. (Fuente: mustafasuleyman)
Autenticidad y relevancia del contenido generado por IA: la relevancia podría superar a la autenticidad: El usuario imjaredz compartió su experiencia al enviar 2000 correos electrónicos de prospección generados por IA. Nadie se quejó de que fueran escritos por IA; por el contrario, 5 personas indicaron que el contenido del correo era “exactamente en lo que estaban trabajando”. Esto generó una discusión sobre si, en la comunicación, la relevancia del contenido es más importante que su “autenticidad” (si fue creado por un humano). (Fuente: imjaredz)
Debate sobre la capacidad de “comprensión” de los LLM: la aproximación conductual no equivale a una verdadera comprensión: En la comunidad existe la opinión de que, aunque los modelos de lenguaje grandes muestran una potente capacidad de aproximación conductual y cognitiva, esto no equivale a una verdadera comprensión. La comprensión requiere capacidad de explicación, y simplemente mostrar un comportamiento no es inteligencia ni comprensión. Esta diferencia fundamental a menudo se pasa por alto. Esta perspectiva enfatiza que, antes de confiar decisiones que impliquen la seguridad de vidas a los modelos, es necesario evaluar con prudencia si realmente se acercan a la inteligencia artificial general y tener cuidado con la exageración de sus capacidades. (Fuente: farguney)
Los AI Agents destacan en benchmarks de ingeniería de software, pero se debate su naturaleza como “agentes”: A medida que la IA obtiene puntuaciones cada vez más altas en benchmarks de ingeniería de software como SWE-bench (incluso superando los 50-60 puntos), la comunidad discute si la “era de la codificación por agentes” ha llegado realmente. Existe la opinión de que si se utilizan universalmente “frameworks sin agentes” (agentless frameworks), en lugar de permitir que los modelos de lenguaje exploren realmente en un entorno, entonces llamarlo “era de la codificación por agentes” podría no ser del todo exacto, aunque estos frameworks en sí mismos son muy valiosos. (Fuente: huybery, terryyuezhuo)
Necesidad de moderación de contenido para imágenes generadas por IA: búsqueda de soluciones de código abierto o comerciales: Con la popularización de la tecnología de generación de imágenes por IA, los desarrolladores en China comienzan a prestar atención a los problemas de cumplimiento del contenido de salida, especialmente cómo detectar contenido pornográfico, políticamente sensible, etc. En la comunidad ha surgido la discusión sobre la búsqueda de modelos pequeños de código abierto disponibles o productos comerciales para la moderación de contenido. (Fuente: dotey)
💡 Otros
Personalización impulsada por IA y relevancia del contenido: 2000 correos electrónicos de IA sin quejas, 5 personas dicen “justo lo que necesitaba”: Un usuario compartió que envió 2000 correos electrónicos de prospección generados por IA, y ningún destinatario se quejó de que los correos fueran escritos por IA. Por el contrario, cinco destinatarios indicaron que el contenido del correo era “exactamente el trabajo en el que estaban actualmente”. Este caso generó un debate sobre si, en la comunicación asistida por IA, la alta relevancia del contenido puede superar las preocupaciones sobre la “autenticidad” (es decir, si fue escrito por un humano), lo que sugiere el potencial de la IA en la generación de contenido personalizado. (Fuente: imjaredz)
Los humanos se convierten en el cuello de botella de los sistemas de IA, es necesario evitar o mejorar la eficiencia humana: La opinión de Charles Earl señala que las bandejas de entrada se desbordan de correos mientras que las bandejas de salida están vacías, lo que refleja que los humanos son el cuello de botella en el procesamiento y la respuesta de la información. En la era de la IA, es necesario reflexionar sobre cómo evitar los cuellos de botella humanos o cómo mejorar la eficiencia del trabajo humano mediante tecnologías como la IA. (Fuente: charles_irl)
Riesgos potenciales del control de hogares inteligentes por IA: usuario atrapado en una cama inteligente fría debido a un fallo de la App: Un usuario compartió su experiencia de no poder regular la temperatura de su cama inteligente controlada por IA (Eight Sleep Pod3) debido a un fallo de la aplicación, lo que finalmente lo dejó atrapado en una cama fría. Dado que este modelo no tiene control manual y depende completamente de la aplicación, este fallo pone de manifiesto los inconvenientes y la experiencia “distópica” que puede surgir de la dependencia excesiva de la IA y las aplicaciones para controlar los dispositivos domésticos inteligentes. (Fuente: madiator)