Palabras clave:computación cuántica, autoactualización de IA, interfaz cerebro-computadora, modelos de lenguaje grande (LLM), computación neuromórfica, generación de video con IA, aprendizaje por refuerzo, ética de la IA, tasa de error de qubit, aprendizaje autosupervisado JEPA, cuantificación en formato MLX, modelo de comprensión visual PAM, generación de contenido ASMR con IA
🔥 Enfoque
La Universidad de Oxford alcanza una tasa de error récord del 0,000015% en un experimento de computación cuántica: El equipo de investigación de la Universidad de Oxford ha logrado un avance significativo en experimentos de computación cuántica, reduciendo la tasa de error de los cúbits al 0,000015%, estableciendo un nuevo récord mundial. Este progreso es crucial para construir ordenadores cuánticos tolerantes a fallos; una tasa de error extremadamente baja es un requisito previo para implementar algoritmos cuánticos complejos y liberar el potencial de la computación cuántica. Este logro demuestra un progreso significativo en la mejora de la estabilidad de los cúbits y la precisión de su manipulación a nivel de hardware, sentando una base más sólida para futuras aplicaciones que dependen de una gran potencia de cálculo en campos como la IA (Fuente: Ronald_vanLoon)

Investigadores del MIT logran que la inteligencia artificial aprenda a auto-mejorarse y actualizarse: Investigadores del Instituto Tecnológico de Massachusetts (MIT) han avanzado en el campo de la auto-mejora de la IA, desarrollando un nuevo método que permite a los sistemas de IA aprender de forma autónoma y mejorar su propio rendimiento. Esta capacidad imita el proceso humano de mejora continua a través de la experiencia y la reflexión, y es crucial para desarrollar una inteligencia artificial más autónoma y adaptable. Esta investigación podría allanar el camino para que los modelos de IA se optimicen continuamente después de su despliegue, reduciendo la dependencia de la intervención humana, lo que tiene profundas implicaciones para el desarrollo y la aplicación a largo plazo de la IA (Fuente: TheRundownAI)

IA de “lectura mental” convierte instantáneamente las ondas cerebrales de personas paralizadas en voz: Una investigación pionera demuestra cómo una IA de “lectura mental” convierte en tiempo real las ondas cerebrales de pacientes paralizados en voz clara. Esta tecnología, mediante interfaces cerebro-computadora (BCI) avanzadas y algoritmos de IA, decodifica las señales neuronales relacionadas con el lenguaje y las sintetiza en una salida de voz comprensible. Esto proporciona una forma completamente nueva de comunicación para pacientes que han perdido la capacidad de hablar debido a graves trastornos motores, con la esperanza de mejorar enormemente su calidad de vida, y marca un avance significativo de la IA en los campos de la asistencia médica y la neurociencia (Fuente: Ronald_vanLoon)

Avance en un problema centenario de física matemática, exalumnos de la Universidad de Pekín participan en la resolución del sexto problema de Hilbert: Exalumnos de la Universidad de Pekín, Deng Yu, y Ma Xiao de la Clase Juvenil de la USTC, junto con Zaher Hani, discípulo de Terence Tao, logran un gran avance en el sexto problema de Hilbert sobre la “axiomatización de la física”. Por primera vez, demostraron rigurosamente la transición completa de la mecánica newtoniana (microscópica, reversible en el tiempo) a la ecuación de Boltzmann (macroscópica estadística, irreversible en el tiempo), llenando el vacío lógico entre ambas, sentando una base matemática más sólida para la mecánica estadística y resolviendo inesperadamente el “misterio de la flecha del tiempo”. Este logro, mediante ingeniosas herramientas matemáticas y deducciones por etapas, muestra el camino desde la teoría atómica hasta las leyes del movimiento de los medios continuos (Fuente: 量子位)

🎯 Tendencias
Alibaba lanza versiones en formato MLX de sus modelos de la serie Qwen3: Alibaba anunció que su serie de modelos grandes Qwen3 ahora es compatible con el formato MLX y ofrece cuatro niveles de cuantización: 4 bits, 6 bits, 8 bits y BF16. MLX es un framework de aprendizaje automático optimizado por Apple para Apple Silicon, lo que significa que los modelos Qwen3 podrán ejecutarse de manera más eficiente en dispositivos Apple, reduciendo las barreras para implementar y ejecutar modelos grandes en el lado del cliente y ayudando a promover la popularización y aplicación de modelos grandes en dispositivos personales (Fuente: Alibaba_Qwen, awnihannun, cognitivecompai, Reddit r/LocalLLaMA)
Google lanza el modelo Gemma 3n, logrando alto rendimiento con pocos parámetros: Google ha presentado el modelo Gemma 3n, que tiene menos de 10 mil millones de parámetros pero ha superado los 1300 puntos en la clasificación LMArena, convirtiéndose en el primer modelo pequeño en alcanzar este logro. El destacado rendimiento de Gemma 3n demuestra que se puede lograr un alto nivel de comprensión y generación de lenguaje con una escala de parámetros relativamente pequeña, y es compatible con la ejecución en dispositivos del lado del cliente como teléfonos móviles, lo cual es de gran importancia para promover la popularización de las aplicaciones de IA y reducir los costos de cómputo (Fuente: osanseviero)
Tencent presenta tecnología de IA para generar activos 3D de calidad cinematográfica: Tencent ha mostrado una nueva tecnología de inteligencia artificial capaz de generar activos 3D con calidad cinematográfica. Se espera que esta tecnología mejore significativamente la eficiencia y la calidad de la creación de contenido 3D en campos como el desarrollo de videojuegos y la producción cinematográfica, reduciendo los costos de producción. La generación rápida de activos 3D de alta calidad es un eslabón clave en el desarrollo del metaverso y la industria de contenido digital (Fuente: TheRundownAI)
El modelo Kling 2.1 de Kuaishou muestra un rendimiento excepcional en la conversión de imagen a video y la generación sincronizada de audio y video: El modelo de generación de video por IA de Kuaishou, Kling, se ha actualizado a la versión 2.1, demostrando una gran capacidad en la conversión de imagen a video. Se informa que la nueva versión puede generar video y audio con un solo clic, sin necesidad de diseño de sonido posterior, produciendo contenido con sincronización de audio e imagen a nivel de estudio. Esto marca un avance de la IA en la generación de contenido multimodal, especialmente en el campo del video, simplificando el proceso de creación y mejorando la calidad de la generación (Fuente: Kling_ai, Kling_ai)
El nuevo modelo de video AI “Kangaroo” podría ser Minimax Hailuo 2.0, desafiando el SOTA actual: Ha aparecido en el mercado un misterioso modelo de generación de video por IA llamado “Kangaroo”, que muestra un fuerte rendimiento en el campo de la competencia de video por IA, especialmente en la conversión de imagen a video. Algunos análisis señalan que este modelo podría ser la versión Hailuo 2.0 de la empresa Minimax. Su aparición podría cambiar la jerarquía de rendimiento de los modelos existentes de texto a video e imagen a video, aunque su capacidad de procesamiento de audio aún está por evaluarse (Fuente: TomLikesRobots)
MiniMax lanza la serie de modelos M1, destacando por su capacidad de procesamiento de texto largo: MiniMaxAI ha lanzado la serie de modelos MiniMax-M1, un modelo MoE (Mixture of Experts) con 456B de parámetros. Esta serie de modelos ha mostrado un rendimiento excelente en múltiples benchmarks, superando especialmente a GPT-4.1 en el procesamiento de contextos largos (como en el benchmark OpenAI-MRCR) y ocupando el tercer lugar en LongBench-v2. Esto demuestra su potencial en el procesamiento y comprensión de documentos extensos, aunque su mayor “presupuesto de pensamiento” (thinking budget) podría plantear mayores exigencias a los recursos computacionales (Fuente: Reddit r/LocalLLaMA)

Richard Sutton, ganador del Premio Turing: La IA está pasando de la “era de los datos humanos” a la “era de la experiencia”: Richard Sutton, pionero del aprendizaje por refuerzo, señaló en la Conferencia de IA de Beijing Zhiyuan que los actuales modelos grandes de IA que dependen de datos humanos se están acercando a sus límites, ya que los datos humanos de alta calidad se están agotando y la expansión de la escala del modelo ofrece rendimientos decrecientes. Él cree que el futuro de la IA radica en entrar en la “era de la experiencia”, donde los agentes inteligentes aprenden generando experiencia de primera mano a través de la interacción en tiempo real con el entorno, en lugar de imitar textos antiguos. Esto requiere que los agentes operen continuamente en entornos reales o simulados, utilizando la retroalimentación del entorno como señal de recompensa, desarrollando modelos del mundo y sistemas de memoria, para lograr un verdadero aprendizaje continuo e innovación (Fuente: 36氪)

Modelo PAM: 3B parámetros para segmentación, reconocimiento y descripción integrada de imágenes y videos: MMLab de la Universidad China de Hong Kong y otras instituciones han lanzado el Perceive Anything Model (PAM) de código abierto, un modelo de 3B parámetros capaz de realizar simultáneamente la segmentación, reconocimiento, explicación y descripción de objetos en imágenes y videos, y generar texto y máscaras (Mask) de forma sincronizada. PAM logra una conversión eficiente de características visuales a tokens multimodales mediante la introducción de un Semantic Perceiver que conecta el esqueleto de segmentación SAM2 y un LLM. El equipo también ha construido un conjunto de datos de entrenamiento de imágenes y texto de alta calidad a gran escala. PAM ha superado o se acerca al estado del arte (SOTA) en múltiples benchmarks de comprensión visual y posee una eficiencia de inferencia superior (Fuente: 量子位)

La computación neuromórfica podría ser clave para la próxima generación de IA, con potencial de bajo consumo energético: Los científicos están explorando activamente la computación neuromórfica, que busca imitar la estructura y el funcionamiento del cerebro humano, para resolver el problema del alto consumo energético de los modelos de IA actuales. Instituciones como los laboratorios nacionales de EE. UU. están desarrollando computadoras neuromórficas con un número de neuronas comparable al de la corteza cerebral humana, teóricamente con una velocidad de funcionamiento muy superior al cerebro biológico, pero con un consumo energético extremadamente bajo (por ejemplo, 20 vatios para impulsar una IA similar al cerebro humano). Esta tecnología, mediante comunicación impulsada por eventos, computación en memoria y aprendizaje adaptativo, tiene el potencial de lograr una IA más inteligente, eficiente y de bajo consumo, considerándose una solución potencial a la crisis energética de la IA y una nueva vía para el desarrollo de la AGI (Fuente: 量子位)

El contenido ASMR generado por IA se vuelve viral en plataformas de videos cortos, tecnologías como Veo 3 lo impulsan: Los videos ASMR (Respuesta Sensorial Meridiana Autónoma) generados por IA se han popularizado rápidamente en plataformas como TikTok, con cuentas que atraen a casi 100,000 seguidores en 3 días y videos de frutas cortadas que superan los 16.5 millones de reproducciones. Estos videos combinan efectos visuales peculiares generados por IA (como frutas con textura de vidrio) con los sonidos correspondientes de corte, colisión, etc., creando una sensación “adictiva” única. Modelos como Veo 3 de Google DeepMind, capaces de generar directamente contenido con sincronización de audio e imagen, se consideran tecnologías clave que impulsan la creación de este tipo de contenido ASMR por IA, simplificando el proceso anterior que requería producir audio y video por separado y luego sintetizarlos (Fuente: 量子位)

La divulgación del historial de búsqueda de Meta AI atrae atención, Google prueba resúmenes de audio con IA: Meta ha hecho público el historial de búsqueda de los usuarios de su función de búsqueda con IA, lo que ha generado preocupación entre los usuarios sobre su privacidad y la transparencia en el uso de datos. Mientras tanto, Google está probando en sus proyectos de laboratorio una nueva función que ofrece resúmenes de audio tipo podcast generados por IA en la parte superior de los resultados de búsqueda, con el objetivo de proporcionar a los usuarios una forma más conveniente de obtener información. Estas dos dinámicas reflejan la continua exploración y los intentos de optimización de la experiencia del usuario por parte de los gigantes tecnológicos en la búsqueda con IA y la presentación de información (Fuente: Reddit r/ArtificialInteligence)

Equipo de Sídney desarrolla modelo de IA para identificar pensamientos a través de ondas cerebrales: Un equipo de investigación de Sídney, Australia, ha desarrollado un nuevo modelo de inteligencia artificial capaz de identificar el contenido de los pensamientos de un individuo mediante el análisis de datos de ondas cerebrales (EEG). Esta tecnología tiene un valor potencial en campos como la neurociencia, la interacción humano-computadora y la comunicación asistida, por ejemplo, ayudando a personas que no pueden comunicarse por medios tradicionales a expresar sus intenciones. El estudio impulsa aún más el desarrollo de la tecnología de interfaz cerebro-computadora y explora la capacidad de la IA para interpretar la compleja actividad cerebral (Fuente: Reddit r/ArtificialInteligence)
California propone legislación para limitar el papel de “jefes robot” de la IA en decisiones de contratación, despido, etc.: El estado de California en EE. UU. está impulsando un proyecto de ley destinado a limitar que las empresas tomen decisiones cruciales de personal, como la contratación y el despido, basándose únicamente en las recomendaciones de sistemas de IA. El proyecto de ley exige que los gerentes humanos revisen y respalden cualquier recomendación de este tipo por parte de la IA, para garantizar la supervisión humana y la rendición de cuentas. Los grupos empresariales se oponen, argumentando que aumentará los costos de cumplimiento y entrará en conflicto con las tecnologías de contratación existentes. Esta medida refleja la creciente preocupación por la ética de la IA y su impacto social, especialmente en la automatización de decisiones en el lugar de trabajo (Fuente: Reddit r/ArtificialInteligence)

🧰 Herramientas
Lanzamiento de Augmentoolkit 3.0, fortaleciendo la generación de conjuntos de datos y el flujo de microajuste (fine-tuning): Augmentoolkit ha lanzado la versión 3.0, una herramienta para crear conjuntos de datos de QA (Preguntas y Respuestas) a partir de documentos largos (como textos históricos) y realizar el microajuste de modelos. La nueva versión ofrece un pipeline de nivel de producción que genera automáticamente datos de entrenamiento y entrena modelos, incluye modelos locales microajustados específicamente para generar conjuntos de datos de QA de alta calidad, y proporciona una interfaz sin código. La herramienta tiene como objetivo simplificar el proceso de microajuste de modelos específicos de dominio y la generación de datos de entrenamiento, reduciendo las barreras técnicas (Fuente: Reddit r/LocalLLaMA)
Opius AI Planner: Planificador de IA para optimizar la experiencia de Cursor Composer: Se ha lanzado una extensión de Cursor llamada Opius AI Planner, diseñada para resolver los problemas de Cursor Composer en la comprensión de requisitos ambiguos. La herramienta puede analizar los requisitos del proyecto, generar una hoja de ruta detallada para la implementación y producir prompts estructurados optimizados para Composer, reduciendo así el número de iteraciones y haciendo que los resultados del proyecto se ajusten mejor a la concepción inicial. Esto refleja la tendencia de mejorar la utilidad de las herramientas de generación de código de IA mediante la planificación asistida por IA (Fuente: Reddit r/artificial)
Extensión Continue: Implementación de Copilot de código abierto local e integración con MCP en VSCode: Continue es una extensión de VSCode que permite a los usuarios configurar y utilizar modelos de lenguaje grandes de código abierto ejecutados localmente como asistentes de codificación, y puede integrar herramientas MCP (Model Control Protocol). Los usuarios pueden desplegar modelos localmente a través de servicios como Llama.cpp o LMStudio e interactuar con ellos a través de Continue, logrando un control y personalización completos del asistente de código, por ejemplo, integrando la herramienta de automatización de navegadores Playwright (Fuente: Reddit r/LocalLLaMA)

Combinación del modelo grande Doubao y Volcano Engine MCP simplifica el despliegue de servicios en la nube y la generación de páginas personales: El modelo grande Doubao de ByteDance ha demostrado una profunda capacidad de integración con el Protocolo de Control de Modelos (MCP) de Volcano Engine. Los usuarios pueden, mediante instrucciones en lenguaje natural, hacer que el modelo grande Doubao invoque funciones de Volcano Engine (como veFaaS, función como servicio) para completar tareas como generar una página web de guía de redes sociales personales y desplegarla automáticamente en línea. Esta integración elimina los complejos pasos de configuración manual del entorno en la nube, reduce las barreras para el uso de servicios en la nube y demuestra el potencial de la IA para simplificar los procesos de DevOps (Fuente: karminski3)
Figma lanza nueva función de IA: generación instantánea de sitios web a partir de prompts de texto: Figma ha presentado una nueva función impulsada por IA capaz de generar rápidamente prototipos o páginas de sitios web a partir de prompts de texto ingresados por el usuario. Esta función tiene como objetivo acelerar el proceso de diseño y desarrollo web, permitiendo a diseñadores y desarrolladores transformar rápidamente ideas en diseños visuales mediante descripciones en lenguaje natural, lo que demuestra aún más la penetración de la IA generativa en el campo de las herramientas de diseño creativo (Fuente: Ronald_vanLoon)
El centro de modelos de Hugging Face añade función de filtrado por tamaño de modelo: La plataforma Hugging Face ha añadido una función útil a su centro de modelos, permitiendo a los usuarios filtrar modelos según el tamaño de sus parámetros. Esta mejora permite a desarrolladores e investigadores encontrar más fácilmente modelos que se ajusten a sus recursos de hardware específicos o necesidades de rendimiento, aumentando la eficiencia en la navegación y selección dentro de la vasta biblioteca de modelos (Fuente: ClementDelangue, TheZachMueller, huggingface, clefourrier, multimodalart)
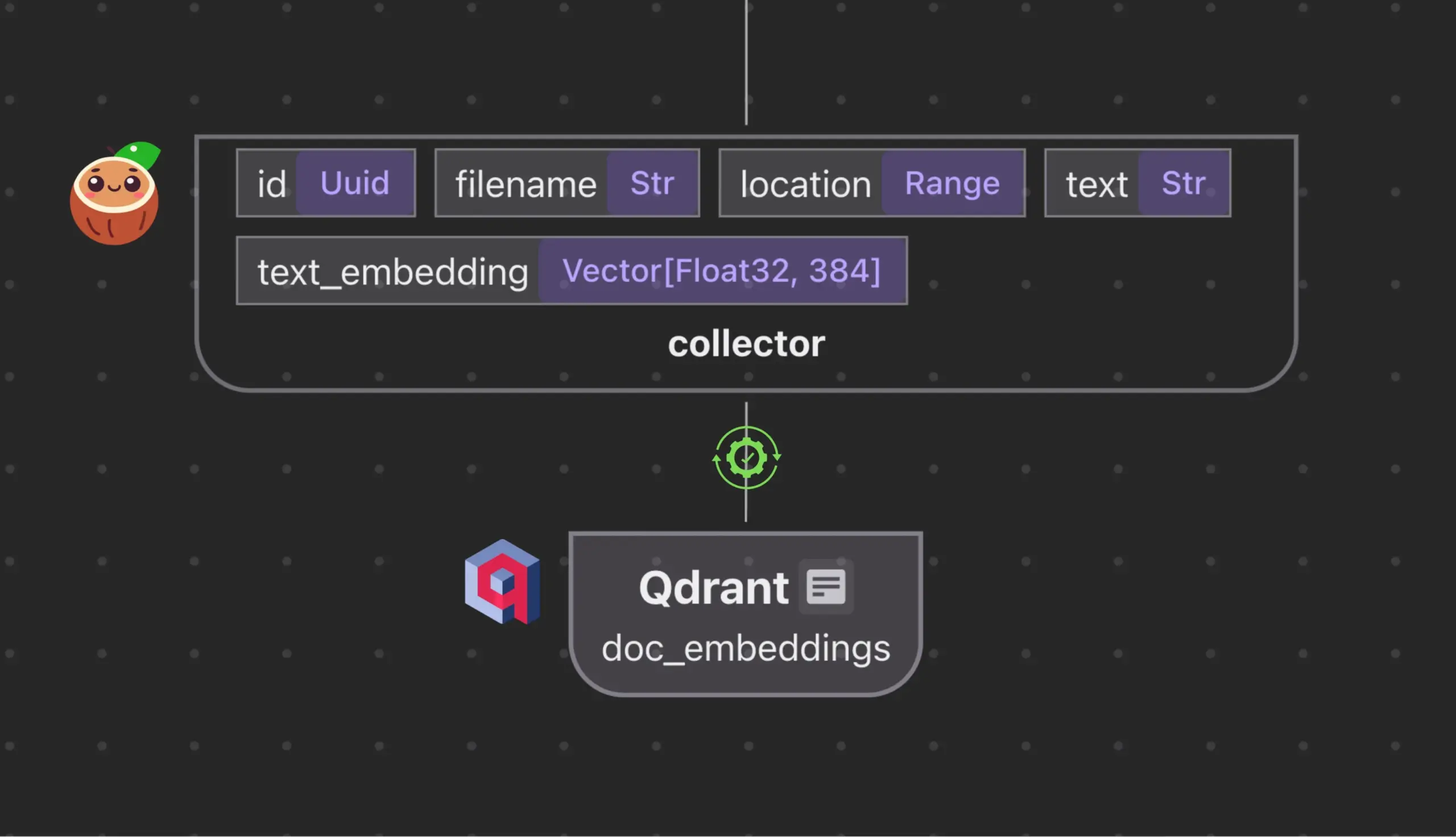
Cocoindex.io se integra con Qdrant para crear y sincronizar automáticamente colecciones de bases de datos vectoriales: La herramienta de flujo de datos de código abierto Cocoindex.io ahora admite la creación automática de colecciones de bases de datos vectoriales Qdrant. Los usuarios solo necesitan definir el flujo de datos, y la herramienta puede inferir el esquema Qdrant apropiado (incluido el tamaño del vector, la métrica de distancia y la estructura de la carga útil), y mantener sincronizados los campos vectoriales, los tipos de carga útil y las claves primarias, admitiendo actualizaciones incrementales. Esto simplifica la configuración y gestión de bases de datos vectoriales, aumentando la eficiencia de los equipos de datos (Fuente: qdrant_engine)
Manus AI: Herramienta de desarrollo de IA de ciclo completo que no solo escribe código, sino que también lo despliega automáticamente: Manus AI es una herramienta de desarrollo de IA de extremo a extremo capaz de realizar desde la escritura de código hasta la configuración del entorno, la instalación de dependencias, las pruebas e incluso el despliegue final en una URL en línea. Adopta una arquitectura de colaboración multiagente (planificación, desarrollo, pruebas, despliegue) y puede resolver de forma autónoma problemas de dependencias y errores de depuración. Aunque actualmente existe un modelo de precios basado en puntos de crédito, el desarrollo por un equipo chino (lo que podría implicar consideraciones de cumplimiento) y limitaciones en el soporte para arquitecturas empresariales ultracomplejas, demuestra el potencial de transformación de la “codificación asistida por IA” a la “ejecución del desarrollo por IA” (Fuente: Reddit r/artificial)

📚 Aprendizaje
Guía de optimización de la teoría de la traducción y prompts para traducción con IA: Combinando la teoría de “la traducción es reescritura” de “Nuevos estudios sobre la traducción” de Si Guo y las opiniones de “La traducción es el gran camino” de Yu Guangzhong, se discuten los principios de la traducción de alta calidad. Se enfatiza que la traducción debe centrarse en la expresión idiomática del idioma de destino, en lugar de la correspondencia literal, utilizando de manera flexible la traducción literal y la traducción libre, y prestando atención a las diferencias lógicas entre los idiomas chino y occidental para la reescritura sintáctica. El artículo también discute la pureza de la expresión china, el manejo de la terminología y reflexiona sobre las limitaciones del proceso de tres pasos “traducción literal – análisis – traducción libre” en la traducción con IA, sugiriendo un proceso más integrado de “comprensión – expresión – revisión – optimización” para mejorar la calidad de la traducción con IA y hacerla más acorde con el estilo de la divulgación científica en chino (Fuente: dotey)

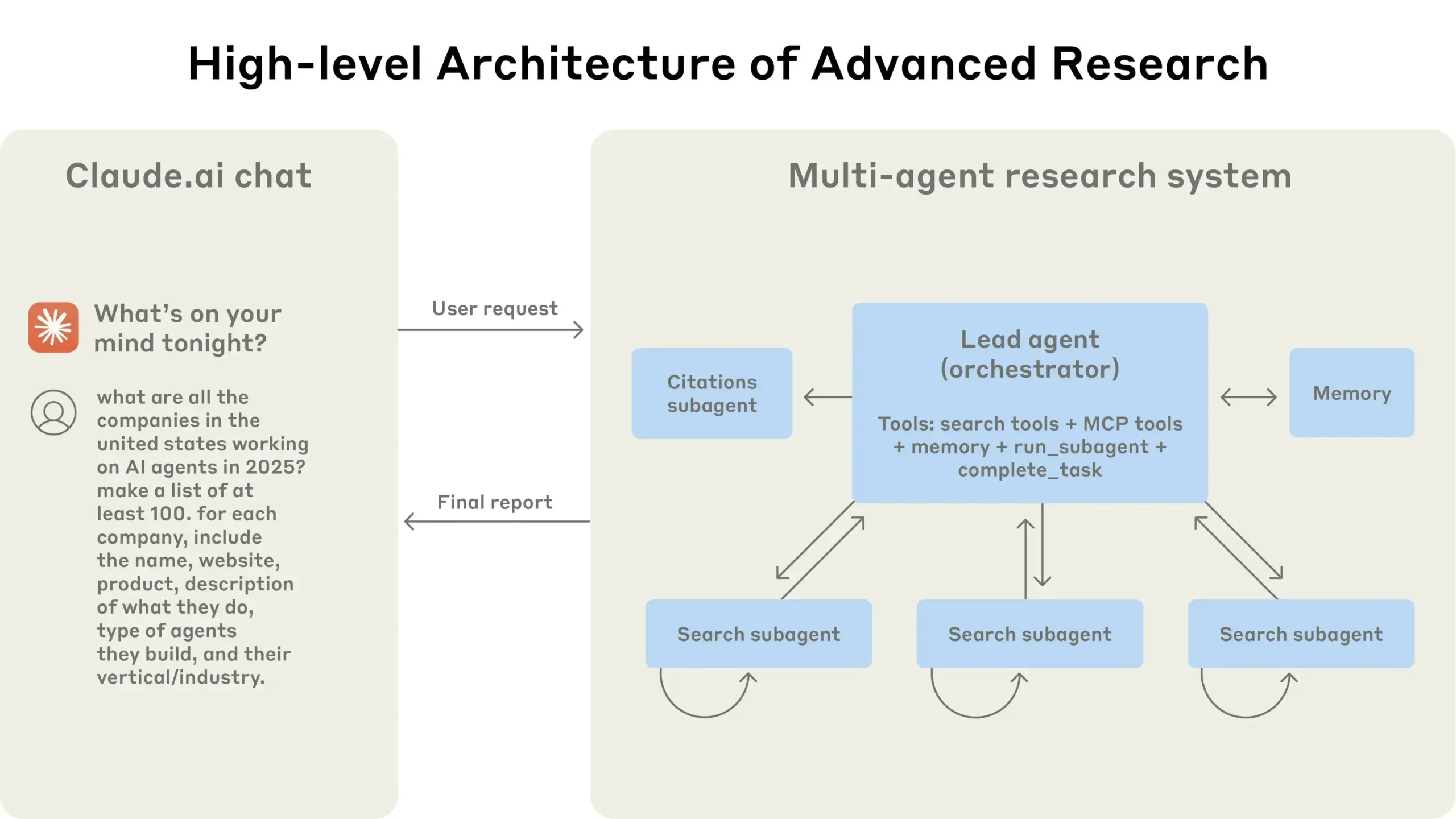
Anthropic comparte su experiencia en la construcción de sistemas de investigación multiagente: AnthropicAI ha publicado una guía gratuita que detalla cómo construyeron su sistema de investigación multiagente. El contenido incluye cómo funciona la arquitectura del sistema, métodos de ingeniería de prompts y pruebas, desafíos enfrentados en producción y las ventajas de los sistemas multiagente. Esta guía proporciona una valiosa experiencia práctica y conocimientos para investigadores y desarrolladores interesados en sistemas multiagente (Fuente: TheTuringPost, TheTuringPost)
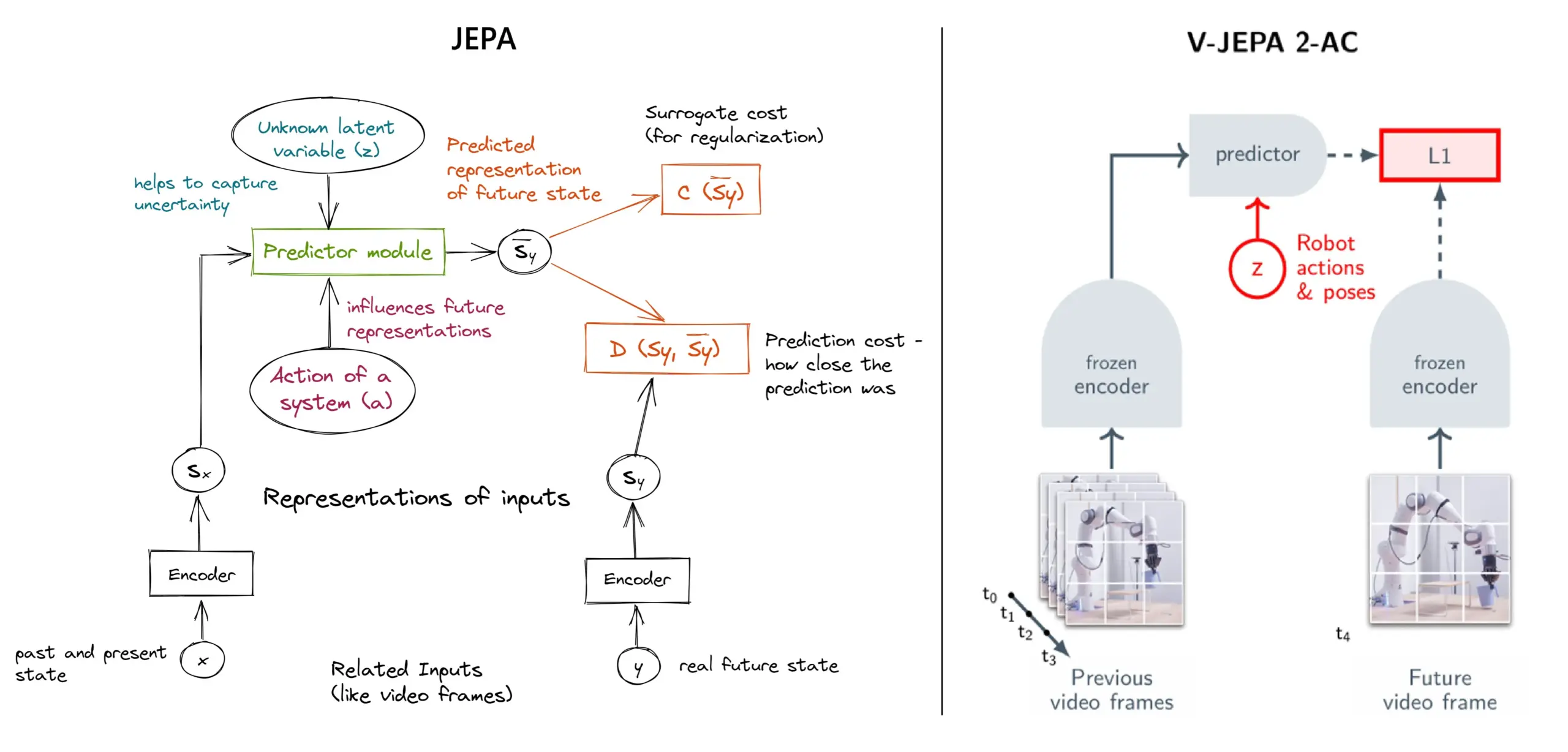
Explicación detallada del framework de aprendizaje autosupervisado JEPA: Resumen de 11 tipos: JEPA (Joint Embedding Predictive Architecture), propuesto por Yann LeCun de Meta y otros investigadores, es un framework de aprendizaje autosupervisado que aprende prediciendo la representación latente de las partes faltantes de los datos de entrada. El artículo presenta 11 tipos diferentes de JEPA, incluyendo V-JEPA 2, TS-JEPA, D-JEPA, etc., y proporciona más información y enlaces a recursos relacionados, lo que ayuda a comprender este método de aprendizaje autosupervisado de vanguardia (Fuente: TheTuringPost, TheTuringPost)
Framework DSPy: Desacoplar tareas y LLM para mejorar la mantenibilidad del código: Un artículo interpretativo sobre DSPy señala que el framework DSPy reduce la complejidad de usar LLM al desacoplar las tareas de los modelos de lenguaje grandes (LLM). Incluso antes de la optimización, DSPy puede ayudar a los desarrolladores a iniciar proyectos más rápidamente y generar código más fácil de mantener y extender. Esto es de gran valor para proyectos que necesitan manejar ingeniería de prompts compleja e integración de LLM (Fuente: lateinteraction, stanfordnlp)

Discusión de paper: Vision Transformers Don’t Need Trained Registers (Los Vision Transformers no necesitan registros entrenados): Un nuevo artículo de investigación explora el mecanismo por el cual los mapas de atención y los mapas de características en los Vision Transformers producen artefactos, un fenómeno que también existe en los modelos de lenguaje grandes. El artículo propone un método sin entrenamiento para mitigar estos artefactos, con el objetivo de mejorar el rendimiento y la interpretabilidad de los Vision Transformers. Esta investigación tiene valor de referencia para comprender y mejorar la aplicación de la arquitectura Transformer en tareas visuales (Fuente: Reddit r/MachineLearning)
Tutorial compartido: Construyendo la serie DeepSeek desde cero (29 episodios en total): Un creador de contenido ha publicado una serie de tutoriales en video titulada “Cómo construir DeepSeek desde cero”, que consta de 29 episodios. El contenido cubre los fundamentos del modelo DeepSeek, detalles de la arquitectura (como el mecanismo de atención, atención multicabeza, caché KV, MoE), codificación posicional, predicción multitoken y cuantización, entre otras tecnologías clave. Esta serie de tutoriales proporciona valiosos recursos en video para aquellos que deseen comprender en profundidad el funcionamiento interno de DeepSeek y modelos grandes similares (Fuente: Reddit r/LocalLLaMA)

Tutorial: Construyendo un pipeline RAG para resumir publicaciones de Hacker News: Haystack by deepset ha compartido un tutorial paso a paso que guía a los usuarios sobre cómo construir un pipeline de Generación Aumentada por Recuperación (RAG). Dicho pipeline puede obtener publicaciones en tiempo real de Hacker News y utilizar un endpoint de modelo de lenguaje grande (LLM) ejecutado localmente para resumir estas publicaciones. Esto proporciona un caso práctico para desarrolladores que deseen utilizar la tecnología RAG para procesar flujos de información en tiempo real y realizar el procesamiento de forma local (Fuente: dl_weekly)
Avance de paper: Conjunto de datos InterSyn y modelo de evaluación SynJudge para la generación intercalada de imágenes y texto: Para abordar las deficiencias actuales de los LMM en la generación de salidas de imágenes y texto estrechamente intercaladas (principalmente debido a la escala, calidad y riqueza de instrucciones limitadas de los conjuntos de datos de entrenamiento), los investigadores han lanzado InterSyn, un conjunto de datos multimodal a gran escala construido mediante el método SEIR (Autoevaluación y Optimización Iterativa). InterSyn contiene conversaciones de múltiples turnos impulsadas por instrucciones, con respuestas donde las imágenes y el texto están estrechamente intercalados. Al mismo tiempo, para evaluar este tipo de salida, los investigadores también propusieron el modelo de evaluación automática SynJudge, que evalúa desde cuatro dimensiones: contenido del texto, contenido de la imagen, calidad de la imagen y sinergia entre imagen y texto. Los experimentos muestran que los LMM entrenados en InterSyn mejoran en todos los indicadores de evaluación (Fuente: HuggingFace Daily Papers)
Avance de paper: Síntesis de nuevas vistas de imágenes y geometría alineadas mediante destilación de atención transmodal: Los investigadores proponen un marco basado en difusión, MoAI, que logra la generación alineada de nuevas vistas de imágenes y geometría mediante un método de “warping-and-inpainting” (deformación y reparación). Este método utiliza predictores de geometría existentes para predecir la forma geométrica parcial de la imagen de referencia y sintetiza la nueva vista como una tarea de reparación de imagen y geometría. Para garantizar una alineación precisa entre la imagen y la geometría, el artículo propone la destilación de atención transmodal, inyectando los mapas de atención de la rama de difusión de imágenes en la rama de difusión de geometría paralela durante el entrenamiento y la inferencia. Este método logra una síntesis de vistas extrapoladas de alta fidelidad en diversas escenas no vistas (Fuente: HuggingFace Daily Papers)
Avance de paper: Ajuste de Preferencias Configurable (CPT) basado en datos sintéticos guiados por reglas: Para abordar el problema de la solidificación de preferencias y la adaptabilidad limitada en modelos de retroalimentación humana como DPO, los investigadores proponen el marco de Ajuste de Preferencias Configurable (CPT). CPT utiliza prompts de sistema basados en reglas estructuradas de grano fino (que definen atributos deseados como el estilo de escritura) para generar datos de preferencia sintéticos. Mediante el ajuste fino con estas preferencias guiadas por reglas, los LLM pueden ajustar dinámicamente la salida en tiempo de inferencia según el prompt del sistema, sin necesidad de reentrenamiento, logrando un control de preferencias más detallado y contextualizado (Fuente: HuggingFace Daily Papers)
Avance de paper: La Dualidad de la Difusión (The Diffusion Duality): Los investigadores proponen el método Duo, que, al revelar que los procesos de difusión discreta en estado uniforme se originan a partir de una difusión gaussiana latente, transfiere las potentes técnicas de la difusión gaussiana a los modelos de difusión discreta para mejorar su rendimiento. Específicamente incluye: 1) Introducir una estrategia de aprendizaje curricular guiada por procesos gaussianos, que reduce la varianza, duplica la velocidad de entrenamiento y supera a los modelos autorregresivos en múltiples benchmarks. 2) Proponer la destilación de consistencia discreta, adaptando la destilación de consistencia continua al entorno discreto, logrando la generación en pocos pasos de modelos de lenguaje de difusión al acelerar el muestreo en dos órdenes de magnitud (Fuente: HuggingFace Daily Papers)
Avance de paper: SkillBlender – Control de movimiento de cuerpo completo para robots humanoides multifuncionales mediante fusión de habilidades: Para abordar las limitaciones de los métodos actuales de control de robots humanoides en cuanto a la generalización multitarea y la escalabilidad, los investigadores proponen SkillBlender, un marco de aprendizaje por refuerzo jerárquico. Este marco primero preentrena habilidades primitivas independientes de la tarea y orientadas a objetivos, y luego fusiona dinámicamente estas habilidades al realizar tareas complejas de manipulación motora, requiriendo una ingeniería de recompensas específica de la tarea mínima. Al mismo tiempo, se lanzó el benchmark de simulación SkillBench para la evaluación. Los experimentos demuestran que este método puede mejorar significativamente la precisión y viabilidad de diversas tareas de manipulación motora (Fuente: HuggingFace Daily Papers)
Avance de paper: Marco U-CoT+ – Desacoplamiento de la comprensión y detección guiada de memes dañinos mediante razonamiento CoT: Para hacer frente a los desafíos de eficiencia de recursos, flexibilidad e interpretabilidad en la detección de memes dañinos, los investigadores proponen el marco U-CoT+. Este marco primero convierte los memes visuales en descripciones textuales que conservan los detalles mediante un proceso de conversión de meme a texto de alta fidelidad, desacoplando así la interpretación y clasificación de memes, lo que permite que los modelos de lenguaje grandes (LLM) generales realicen una detección eficiente en recursos. Posteriormente, combinando directrices interpretables formuladas por humanos, guía el razonamiento del modelo bajo prompts CoT de cero disparos (zero-shot), mejorando la adaptabilidad e interpretabilidad a diferentes plataformas y cambios temporales (Fuente: HuggingFace Daily Papers)
Avance de paper: CRAFT – Pruebas de equipo rojo efectivas para agentes que siguen políticas: Abordando el problema del cumplimiento de políticas estrictas (como la elegibilidad para reembolsos) por parte de agentes LLM orientados a tareas, los investigadores proponen un nuevo modelo de amenaza, centrándose en usuarios adversarios que intentan explotar agentes basados en políticas para obtener beneficios personales. Para ello, desarrollaron CRAFT, un sistema de pruebas de equipo rojo multiagente que utiliza estrategias de persuasión conscientes de la política para atacar a agentes que siguen políticas en escenarios de servicio al cliente, con un rendimiento superior a los métodos tradicionales de jailbreak. Al mismo tiempo, lanzaron el benchmark tau-break para evaluar la robustez de los agentes ante tales comportamientos de manipulación (Fuente: HuggingFace Daily Papers)
Avance de paper: El fracaso de los recuperadores densos en consultas simples y el dilema de granularidad de los embeddings: La investigación revela una limitación de los codificadores de texto: los embeddings pueden no reconocer entidades o eventos de grano fino dentro de la semántica, lo que lleva a que la recuperación densa pueda fallar incluso en casos simples. Para estudiar este fenómeno, el artículo introduce el conjunto de datos de evaluación en chino CapRetrieval (donde los párrafos son leyendas de imágenes y las consultas son frases de entidades/eventos). La evaluación de cero disparos (zero-shot) indica que los codificadores pueden tener un rendimiento deficiente en la coincidencia de grano fino. El microajuste (fine-tuning) de los codificadores con la estrategia de generación de datos propuesta puede mejorar el rendimiento, pero también revela el “dilema de granularidad”, es decir, la dificultad de los embeddings para expresar la prominencia de grano fino mientras se alinean con la semántica general (Fuente: HuggingFace Daily Papers)
Avance de paper: pLSTM – Red de etiquetado de transformación de fuente lineal paralelizable: Abordando las limitaciones de las arquitecturas recurrentes existentes (como xLSTM, Mamba) que son principalmente adecuadas para datos secuenciales o requieren el procesamiento secuencial de datos multidimensionales, los investigadores proponen pLSTM (red de etiquetado de transformación de fuente lineal paralelizable). pLSTM extiende la multidimensionalidad a las RNN lineales, utilizando puertas de fuente, transformación y etiquetado que actúan sobre el grafo lineal de un grafo acíclico dirigido (DAG) general, logrando una paralelización similar a las formas de escaneo asociativo paralelo y recurrencia por bloques. Este método demuestra una buena capacidad de extrapolación y rendimiento en tareas sintéticas de visión por computadora y en benchmarks de grafos moleculares y visión por computadora (Fuente: HuggingFace Daily Papers)
Avance de paper: DeepVideo-R1 – Microajuste (fine-tuning) por refuerzo de video mediante regresión consciente de la dificultad GRPO: Para abordar las deficiencias del aprendizaje por refuerzo en la aplicación de modelos de lenguaje grandes para video (Video LLM), los investigadores proponen DeepVideo-R1, un Video LLM entrenado mediante su propuesto Reg-GRPO (GRPO regresivo) y una estrategia de aumento de datos consciente de la dificultad. Reg-GRPO reformula el objetivo GRPO como una tarea de regresión, prediciendo directamente la función de ventaja en GRPO, eliminando la dependencia de medidas de seguridad como el recorte (clipping), y guiando así la política de manera más directa. El aumento de datos consciente de la dificultad mejora dinámicamente las muestras de entrenamiento de niveles de dificultad solucionables. Los experimentos demuestran que DeepVideo-R1 mejora significativamente el rendimiento de la inferencia en video (Fuente: HuggingFace Daily Papers)
Avance de paper: Marco de auto-refinamiento para mejorar ASR utilizando datos sintéticos de TTS: Los investigadores proponen un marco de auto-refinamiento que puede mejorar el rendimiento del reconocimiento automático de voz (ASR) utilizando únicamente conjuntos de datos no etiquetados. El marco primero utiliza un modelo ASR existente para generar pseudoetiquetas en voz no etiquetada, y luego utiliza estas pseudoetiquetas para entrenar un sistema de texto a voz (TTS) de alta fidelidad. A continuación, los pares de voz-texto sintetizados por TTS se utilizan para guiar el entrenamiento del sistema ASR original, formando un ciclo cerrado de auto-mejora. Los experimentos en mandarín de Taiwán demuestran que este método puede reducir significativamente la tasa de error, proporcionando una vía práctica para mejorar el rendimiento de ASR en escenarios de bajos recursos o dominios específicos (Fuente: HuggingFace Daily Papers)
Avance de paper: Mapas de atención intrínsecamente fieles para Vision Transformers: Los investigadores proponen un método basado en la atención que utiliza máscaras de atención binarias aprendidas para garantizar que solo las regiones de la imagen atendidas influyan en la predicción. Este método tiene como objetivo resolver los sesgos que el contexto puede generar en la percepción de objetos, especialmente cuando los objetos aparecen en fondos fuera de distribución. A través de un marco de dos etapas (la primera etapa descubre partes de objetos e identifica regiones relevantes para la tarea, la segunda etapa utiliza máscaras de atención de entrada para limitar el campo receptivo para un análisis enfocado), el entrenamiento conjunto logra mejorar la robustez del modelo ante correlaciones espurias y fondos fuera de distribución (Fuente: HuggingFace Daily Papers)
Avance de paper: ViCrit – Tarea proxy de aprendizaje por refuerzo verificable para la percepción visual de VLM: Para abordar la falta de tareas de percepción visual en VLM que sean simultáneamente desafiantes y claramente verificables, los investigadores introducen ViCrit (Crítico de Alucinaciones Visuales en Leyendas). Esta es una tarea proxy de RL que entrena a los VLM para localizar alucinaciones visuales sutiles y sintéticas inyectadas en párrafos de leyendas de imágenes escritas por humanos. Al inyectar un único error de descripción visual sutil en leyendas de aproximadamente 200 palabras y requerir que el modelo localice el rango del error basándose en la imagen y la leyenda modificada, la tarea proporciona una recompensa binaria fácil de calcular y explícita. Los modelos entrenados con ViCrit muestran ganancias significativas en múltiples benchmarks de VL (Fuente: HuggingFace Daily Papers)
Avance de paper: Más allá de la atención homogénea – LLM eficientes en memoria con caché KV aproximado por Fourier: Para abordar el problema del aumento de la demanda de memoria del caché KV en los LLM a medida que aumenta la longitud del contexto, los investigadores proponen FourierAttention, un marco que no requiere entrenamiento. Este marco aprovecha los roles heterogéneos de las dimensiones de las cabezas del Transformer: las dimensiones bajas priorizan el contexto local, mientras que las dimensiones altas capturan dependencias a largo plazo. Al proyectar las dimensiones insensibles al contexto largo sobre una base de Fourier ortogonal, FourierAttention aproxima su evolución temporal con coeficientes espectrales de longitud fija. Las evaluaciones en modelos LLaMA muestran que este método logra la mejor precisión en contextos largos en LongBench y NIAH, y optimiza la memoria mediante un kernel Triton personalizado, FlashFourierAttention (Fuente: HuggingFace Daily Papers)
Avance de paper: JAFAR – Un muestreador superior universal para mejorar cualquier característica a cualquier resolución: Para abordar el problema de que las características espaciales de baja resolución generadas por los codificadores visuales básicos no satisfacen las necesidades de las tareas posteriores, los investigadores introducen JAFAR, un muestreador superior de características ligero y flexible. JAFAR puede aumentar la resolución espacial de las características visuales de cualquier codificador visual básico a cualquier resolución objetivo deseada. Emplea módulos basados en atención, modulados mediante transformación espacial de características (SFT), para promover la alineación semántica entre consultas de alta resolución derivadas de características de imagen de bajo nivel y claves de baja resolución semánticamente ricas. Los experimentos demuestran que JAFAR puede restaurar eficazmente detalles espaciales de grano fino y supera a los métodos existentes en diversas tareas posteriores (Fuente: HuggingFace Daily Papers)
Avance de paper: SwS – Síntesis de problemas impulsada por la autoconciencia de debilidades en el aprendizaje por refuerzo: Para abordar el problema de la escasez de conjuntos de problemas de alta calidad y con respuestas verificables en RLVR (Aprendizaje por Refuerzo con Recompensas Verificables) al entrenar LLM para resolver tareas de razonamiento complejas (como problemas matemáticos), los investigadores proponen el marco SwS (Síntesis de Problemas Impulsada por la Autoconciencia de Debilidades). SwS identifica sistemáticamente las deficiencias del modelo (problemas en los que el modelo falla continuamente en aprender durante el entrenamiento RL), extrae los conceptos centrales de estos casos de fallo y sintetiza nuevos problemas para reforzar las debilidades del modelo en el entrenamiento de mejora posterior. Este marco permite que el modelo se autoidentifique y resuelva sus debilidades en RL, logrando mejoras significativas de rendimiento en múltiples benchmarks de razonamiento convencionales (Fuente: HuggingFace Daily Papers)
Avance de paper: Aprendiendo un token de “seguir pensando” para mejorar la capacidad de expansión en tiempo de prueba: Para mejorar el rendimiento de los modelos de lenguaje al expandir los pasos de razonamiento mediante cómputo adicional en tiempo de prueba, los investigadores exploran la viabilidad de aprender un token dedicado de “seguir pensando” (<|continue-thinking|>). Entrenan únicamente el embedding de este token mediante aprendizaje por refuerzo, manteniendo congelados los pesos del modelo DeepSeek-R1 en su versión destilada. Los experimentos demuestran que, en comparación con los modelos base y los métodos de expansión en tiempo de prueba que utilizan tokens fijos (como “Wait”) para forzar un presupuesto, el token aprendido logra una mayor precisión en benchmarks matemáticos estándar, especialmente en los casos en que los tokens fijos pueden mejorar la precisión del modelo base, el token aprendido aporta una mejora aún mayor (Fuente: HuggingFace Daily Papers)
Avance de paper: LoRA-Edit – Edición de video controlada guiada por el primer fotograma mediante microajuste (fine-tuning) LoRA sensible a máscaras: Para resolver los problemas de los métodos de edición de video existentes que dependen de un preentrenamiento a gran escala y carecen de flexibilidad, los investigadores proponen LoRA-Edit, un método de microajuste LoRA basado en máscaras para adaptar modelos preentrenados de imagen a video (I2V) para una edición de video flexible. Este método, mientras preserva las regiones de fondo, es capaz de propagar efectos de edición controlables y combinar otra información de referencia (como puntos de vista alternativos o estados de escena) como anclajes visuales. Mediante una estrategia de ajuste LoRA impulsada por máscaras, el modelo aprende del video de entrada (estructura espacial y pistas de movimiento) y de la imagen de referencia (guía de apariencia), logrando un aprendizaje específico de la región (Fuente: HuggingFace Daily Papers)
Avance de paper: Infinity Instruct – Ampliando la selección y síntesis de instrucciones para mejorar los modelos de lenguaje: Para compensar el hecho de que los conjuntos de datos de instrucciones de código abierto existentes se centran principalmente en dominios estrechos (como matemáticas, codificación), lo que limita la capacidad de generalización, los investigadores presentan Infinity-Instruct, un conjunto de datos de instrucciones de alta calidad diseñado para mejorar las capacidades básicas y de chat de los LLM mediante un proceso de dos etapas. En la primera etapa, se utilizan técnicas de selección de datos mixtos para filtrar 7.4 millones de instrucciones básicas de alta calidad de entre más de 100 millones de muestras. En la segunda etapa, mediante un proceso de dos fases de selección, evolución y filtrado diagnóstico de instrucciones, se sintetizan 1.5 millones de instrucciones de chat de alta calidad. Los experimentos de microajuste (fine-tuning) en varios modelos de código abierto demuestran que este conjunto de datos puede mejorar significativamente el rendimiento del modelo en benchmarks básicos y de seguimiento de instrucciones (Fuente: HuggingFace Daily Papers)
Avance de paper: Primero candidatos, luego destilación – Marco profesor-alumno para el etiquetado de datos impulsado por LLM: Frente al problema en los métodos actuales de etiquetado de datos con LLM donde la determinación directa de una única etiqueta dorada por parte del LLM puede llevar a errores debido a la incertidumbre, los investigadores proponen un nuevo paradigma de etiquetado de candidatos: alentar al LLM a generar todas las etiquetas posibles cuando hay incertidumbre. Para asegurar que las tareas posteriores obtengan una única etiqueta, desarrollaron el marco profesor-alumno CanDist, que utiliza un modelo de lenguaje pequeño (SLM) para destilar las anotaciones candidatas. Se demuestra teóricamente que destilar anotaciones candidatas de un LLM profesor es superior a usar directamente una única anotación. Los experimentos validan la efectividad de este método (Fuente: HuggingFace Daily Papers)
Avance de paper: Med-PRM – Modelo de razonamiento médico con recompensa de proceso de validación por guías y paso a paso: Para abordar la limitación de los modelos de lenguaje grandes en la toma de decisiones clínicas, donde es difícil localizar y corregir errores en pasos específicos del razonamiento, los investigadores introducen Med-PRM, un marco de modelado de recompensa de proceso. Este marco utiliza técnicas de generación aumentada por recuperación para validar cada paso del razonamiento contra bases de conocimiento médico establecidas (guías clínicas y literatura). Mediante esta forma detallada de evaluar con precisión la calidad del razonamiento, Med-PRM logra un rendimiento SOTA en múltiples benchmarks de QA médicos y tareas de diagnóstico abiertas, y puede integrarse de forma plug-and-play con modelos de política fuertes (como Meerkat), mejorando significativamente la precisión de modelos más pequeños (8B parámetros) (Fuente: HuggingFace Daily Papers)
Avance de paper: Fricción de retroalimentación – Los LLM tienen dificultades para absorber completamente la retroalimentación externa: El estudio examina sistemáticamente la capacidad de los LLM para absorber retroalimentación externa. En los experimentos, un modelo solucionador intenta resolver problemas, luego un generador de retroalimentación con respuestas verdaderas casi completas proporciona retroalimentación específica, y el solucionador lo intenta de nuevo. Los resultados muestran que incluso en condiciones casi ideales, los modelos SOTA, incluido Claude 3.7, muestran resistencia a la retroalimentación, denominada “fricción de retroalimentación”. Aunque estrategias como el aumento progresivo de la temperatura y el rechazo explícito de respuestas erróneas previas muestran alguna mejora, los modelos aún no alcanzan el rendimiento objetivo. La investigación descarta factores como el exceso de confianza del modelo y la familiaridad con los datos, con el objetivo de revelar este obstáculo central para la auto-mejora de los LLM (Fuente: HuggingFace Daily Papers)
💼 Negocios
Meta invierte 14.300 millones de dólares para adquirir el 49% de Scale AI, el fundador Alexandr Wang se une al equipo de superinteligencia de Meta: Meta ha anunciado la adquisición del 49% de las acciones sin derecho a voto de la empresa de etiquetado de datos de IA Scale AI por 14.300 millones de dólares. El fundador de Scale AI, Alexandr Wang, un genio chino-estadounidense de 28 años, continuará como miembro del consejo de administración y liderará su equipo central para unirse al equipo de superinteligencia de Meta, formado personalmente por Zuckerberg. Esta adquisición se considera una compra de talento de alto precio por parte de Meta para impulsar sus capacidades de IA tras el bajo rendimiento de Llama 4, con el objetivo de integrar profundamente la IA en todos sus productos. Scale AI se hizo conocida por ofrecer servicios de etiquetado manual de datos de alta calidad a gran escala, con clientes como Waymo y OpenAI. Esta medida ha suscitado preocupaciones sobre la neutralidad de su plataforma y la seguridad de los datos, y clientes como Google podrían suspender su cooperación (Fuente: 36氪)

La estrategia “All in AI” de Kunlun Wanwei provoca la primera pérdida en diez años desde su salida a bolsa, las perspectivas de comercialización de la IA son inciertas: Desde que Kunlun Wanwei anunció su estrategia “All in AGI y AIGC”, ha estado desplegando activamente modelos grandes (modelo grande Tiangong) y aplicaciones de IA como música (Mureka), redes sociales (Linky), video (SkyReels) y ofimática (Skywork Super Agents), además de invertir en chips de computación para IA. Sin embargo, los elevados gastos en I+D y marketing provocaron que la empresa registrara en 2024 su primera pérdida en diez años desde su salida a bolsa (1.590 millones de yuanes), y las pérdidas continuaron en el primer trimestre de 2025. Aunque algunas aplicaciones de IA como Mureka y Linky han comenzado a generar ingresos, la rentabilidad general del negocio de IA y su competitividad en el mercado aún enfrentan desafíos, y queda por ver si podrá lograr su “sueño de gran empresa” gracias a la IA (Fuente: 36氪)

OpenAI podría estar probando anuncios en ChatGPT, la presión por la rentabilidad impulsa la exploración de modelos de negocio: Algunos usuarios de pago de ChatGPT Plus han informado haber encontrado anuncios insertados mientras usaban el modo de voz avanzado, lo que ha generado discusiones sobre si OpenAI ha comenzado a probar anuncios entre los usuarios de pago. Informes anteriores indicaban que OpenAI estaba considerando introducir publicidad para ampliar sus ingresos. Dados los altos costos operativos de los grandes modelos de IA y la presión por la rentabilidad (se estima una pérdida de 44 mil millones de dólares antes de 2029), así como la incertidumbre sobre el tiempo para alcanzar la AGI, se considera que la búsqueda de nuevos modelos de monetización como la publicidad es una elección inevitable para la sostenibilidad comercial de OpenAI, especialmente con una tasa de penetración de pago relativamente baja (Fuente: 36氪)

🌟 Comunidad
La IA tiene un enorme potencial en el campo de la ciencia de datos, Databricks contrata activamente: Matei Zaharia de Databricks cree que el aumento de la productividad de la IA en el campo de la ciencia de datos será aún más significativo que en la codificación asistida por IA. Databricks está liderando esta tendencia a través de productos como Lakeflow Designer y Genie Deep Research, y está contratando activamente investigadores e ingenieros en este campo, lo que demuestra la gran importancia que la industria otorga a la innovación en ciencia de datos impulsada por IA (Fuente: matei_zaharia)
Las diferencias de “personalidad” de los LLM afectan el comportamiento del circuito de agentes: El investigador Fabian Stelzer observó que diferentes modelos de lenguaje grandes (LLM) presentan diferencias en su “personalidad”, lo que hace que se comporten de manera distinta al ejecutar tareas en bucles agénticos. Por ejemplo, Claude tiende a ejecutar herramientas en serie, mientras que GPT-4.1 prefiere fuertemente la ejecución en paralelo, llegando incluso a ignorar las solicitudes en serie; el modelo Haiku es más “agresivo” al activar herramientas. Esta observación subraya la importancia de considerar las características subyacentes del LLM y las consecuencias funcionales de su “estado emocional” al diseñar y evaluar sistemas multiagente (Fuente: fabianstelzer, menhguin)
El “pensamiento” de los LLM depende de la salida de Tokens, sin salida no hay análisis efectivo: El usuario dotey retransmite el descubrimiento de xincmm al depurar un prompt de ReAct: si se espera que un LLM analice primero y luego ejecute una operación (como dibujar), pero no se le permite generar los Tokens del proceso de análisis, el LLM podría saltarse directamente el paso de análisis. Esto confirma que el proceso de “pensamiento” de un LLM se realiza mediante la generación de Tokens; si el “análisis” definido en el prompt no tiene una salida de contenido real, entonces la IA no ha ejecutado realmente dicho análisis. Esto tiene un significado orientador para diseñar prompts de LLM efectivos (Fuente: dotey)

Limitaciones de la IA en tareas específicas: Terence Tao afirma que la IA carece del “olfato matemático”: El matemático Terence Tao señala que, aunque las demostraciones generadas actualmente por la IA parecen impecables en la superficie (pasan la “prueba visual”), a menudo carecen de un sutil “olfato matemático” característico de los humanos, y tienden a cometer errores no humanos. Considera que la verdadera inteligencia no es solo parecer correcta, sino también poder “olfatear” lo que es real. Esto revela las limitaciones actuales de la IA en la comprensión profunda y el juicio intuitivo (Fuente: ecsquendor)
Desafíos del contenido generado por IA frente a las leyes físicas de la realidad: El usuario karminski3, al probar la generación de código con Doubao Seed 1.6 y DeepSeek-R1 (simulando la demolición por voladura de una chimenea en una animación 3D), descubrió que, aunque los modelos pueden generar código y simular la animación, todavía existen diferencias y margen de mejora en la reproducción de procesos físicos reales (como los efectos de la onda de choque, la forma en que colapsa la estructura). Doubao Seed 1.6 se acerca más a la realidad en la simulación de efectos de partículas y colapso estructural, mientras que DeepSeek se desempeña mejor en efectos de iluminación y humo. Esto refleja los desafíos de la IA en la comprensión y simulación de fenómenos físicos complejos (Fuente: karminski3)
Programador experimentado despedido por depender excesivamente de la IA para escribir código, negarse a modificarlo manualmente y amenazar a los nuevos con ser reemplazados por la IA: Un post de Reddit reproducido por 36Kr cuenta el caso de un programador con 30 años de experiencia que fue despedido por su excesiva dependencia de la IA (como depender completamente de Copilot Agent para enviar PRs, negarse a modificar código manualmente, tardar 5 días en completar una tarea de 1 día, y predicar a los becarios que la IA los reemplazaría). El incidente ha provocado un debate sobre los límites del uso razonable de la IA en el desarrollo de software y el impacto de la IA en el valor profesional de los desarrolladores (Fuente: 36氪)
El “flujo” y la “personalidad” de la IA afectan la experiencia del usuario: los usuarios informan que la IA es demasiado “positiva y complaciente”: Usuarios de la comunidad de Reddit discuten que, al interactuar con la IA (especialmente Claude), esta tiende a ser excesivamente optimista y a estar de acuerdo con las opiniones del usuario, careciendo de un desafío efectivo y una retroalimentación crítica profunda, lo que hace que los usuarios se sientan como en una “cámara de eco”. Esta “fatiga por la tonalidad de la IA” impulsa a los usuarios a buscar formas de hacer que la IA se comporte de manera más neutral y crítica, por ejemplo, mediante prompts específicos. Esto refleja los desafíos actuales de la IA para simular conversaciones humanas reales y multifacéticas y para proporcionar perspectivas verdaderamente profundas (Fuente: Reddit r/ClaudeAI)
En la era de la IA, el valor de la retroalimentación humana se destaca, pero las plataformas de interacción humana real enfrentan la infiltración de contenido de IA: Usuarios de Reddit discuten que, en un contexto de creciente contenido generado por IA, la retroalimentación y las opiniones humanas reales se vuelven más valiosas, y plataformas como Reddit son valoradas por sus características de interacción humana. Sin embargo, estas plataformas también enfrentan el desafío de la infiltración de contenido generado por IA (como comentarios de bots, publicaciones asistidas por IA), lo que dificulta discernir las opiniones humanas reales y genera preocupaciones sobre la autenticidad de la comunicación en línea en el futuro (Fuente: Reddit r/ArtificialInteligence)
¿Los “amigos” IA se convertirán en la norma? Tendencias y discusiones sobre la conexión emocional de los usuarios con la IA: En las redes sociales y comunidades de Reddit surgen discusiones sobre compañeros y amigos IA. Algunos usuarios creen que, debido a las características de la IA de no tener prejuicios y ofrecer apoyo constante, los amigos IA podrían convertirse en la norma en los próximos 5 años, algo que ya se manifiesta en aplicaciones como Endearing AI, Replika, Character.ai. Otros usuarios comparten sus experiencias de establecer relaciones de conversación profundas con IA como ChatGPT, llegando incluso a considerarlos sus “mejores amigos”. Esto suscita una amplia reflexión sobre la interacción emocional entre humanos e IA, el papel de la IA en el apoyo emocional y su potencial impacto social (Fuente: Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence)

El futuro de las startups “envoltorio” de IA genera debate: La comunidad de Reddit debate sobre las perspectivas de numerosas startups de IA que se basan en encapsular modelos fundamentales como GPT o Claude (añadiendo una interfaz de usuario, cadenas de prompts o microajustes para dominios específicos). Los participantes cuestionan si estas aplicaciones “envoltorio” podrán mantener su competitividad después de las iteraciones funcionales de las propias plataformas de modelos fundamentales, y si podrán construir verdaderas barreras de entrada. Se opina que centrarse en nichos verticales específicos, acumular datos propios e ir más allá del simple encapsulamiento podría ser su camino hacia la sostenibilidad (Fuente: Reddit r/LocalLLaMA)
Debate sobre el potencial comparativo de la IA para reemplazar en el diagnóstico médico y la ingeniería de software: En la comunidad de Reddit surge un debate que sugiere que la IA podría reemplazar a los médicos más rápido que a los ingenieros de software senior. La razón es que muchos diagnósticos médicos siguen protocolos establecidos, y la IA es experta en interpretar resultados de pruebas e identificar síntomas; mientras que la ingeniería de software a menudo implica una gran cantidad de conocimiento tácito y una comunicación compleja de requisitos, tareas que la IA difícilmente puede asumir por completo. Este punto de vista ha provocado una mayor reflexión sobre la profundidad de aplicación y la posibilidad de reemplazo de la IA en diferentes campos profesionales, pero también ha sido refutado por médicos y otros profesionales, quienes enfatizan la complejidad de la práctica real y la importancia del juicio humano (Fuente: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
💡 Otros
El avatar digital IA de Luo Yonghao debuta en el comercio electrónico de Baidu, con un GMV superior a 55 millones: El avatar digital IA de Luo Yonghao realizó su primera transmisión en vivo de ventas en la plataforma de comercio electrónico de Baidu, atrayendo a más de 13 millones de espectadores y alcanzando un volumen bruto de mercancías (GMV) superior a los 55 millones de yuanes. Este avatar digital fue creado por la plataforma “HuiBoXing” de Baidu E-commerce, basada en el modelo grande Wenxin 4.5, y es capaz de simular el tono de voz, acento y microexpresiones de Luo Yonghao, además de responder inteligentemente. Esta transmisión demostró el potencial del modelo “IA + presentador estrella” y el posicionamiento de Baidu en la tecnología de “avatares digitales de alta persuasión” y el comercio electrónico con IA (Fuente: 36氪)

Baidu, Tencent y otras empresas intensifican la contratación de talento en IA, lanzando planes de reclutamiento a gran escala: Baidu ha lanzado su mayor programa de reclutamiento de talento de IA de élite, el “Plan AIDU”, con un aumento interanual del 60% en la contratación de puestos, centrándose en áreas de vanguardia como algoritmos de modelos grandes e infraestructura básica, y ofreciendo salarios sin límite superior. Casualmente, Tencent también está atrayendo talento global en IA mediante la organización de un concurso de algoritmos de “recomendación generativa multimodal completa”, ofreciendo millones en premios y ofertas de contratación para recién graduados. Estas iniciativas reflejan la urgente necesidad y el posicionamiento estratégico de los gigantes tecnológicos chinos por el talento de élite en el contexto de la feroz competencia en el campo de la IA (Fuente: 量子位, 量子位)

Baidu lanza un servicio integral de asistencia con IA para la elección de carrera universitaria, integrando múltiples modelos y big data: En respuesta a la complejidad en la elección de carrera universitaria generada por la nueva reforma del examen de ingreso a la universidad (gaokao), Baidu ha lanzado una herramienta gratuita de asistencia con IA para la elección de carrera. Este servicio está integrado en la página temática “Gaokao” de la App de Baidu, ofreciendo un “Asistente de Elección de Carrera con IA” para recomendar instituciones y especialidades y analizar la probabilidad de admisión, y es compatible con agentes inteligentes “Charla sobre Carreras con IA” de múltiples modelos como Wenxin y DeepSeek R1 para consultas personalizadas. Además, combina big data de búsqueda exclusiva de Baidu para ofrecer análisis de perspectivas laborales de las especialidades, evaluaciones vocacionales MBTI, así como transmisiones en vivo de las oficinas de admisión de las universidades y sesiones de preguntas y respuestas con estudiantes veteranos, con el objetivo de ayudar a los candidatos a superar la brecha de información y tomar decisiones más adecuadas sobre su carrera (Fuente: 36氪)