
Palabras clave:IA, Modelo grande, Sistema multiagente, Claude, Transformer, Computación neuromórfica, LLM, Agente de IA, Sistema de investigación multiagente Claude, Método de entrenamiento híbrido Eso-LM, Supercomputadora neuromórfica, Tecnología Context Scaling, Tecnología de marca de agua SynthID
🔥 Enfoque
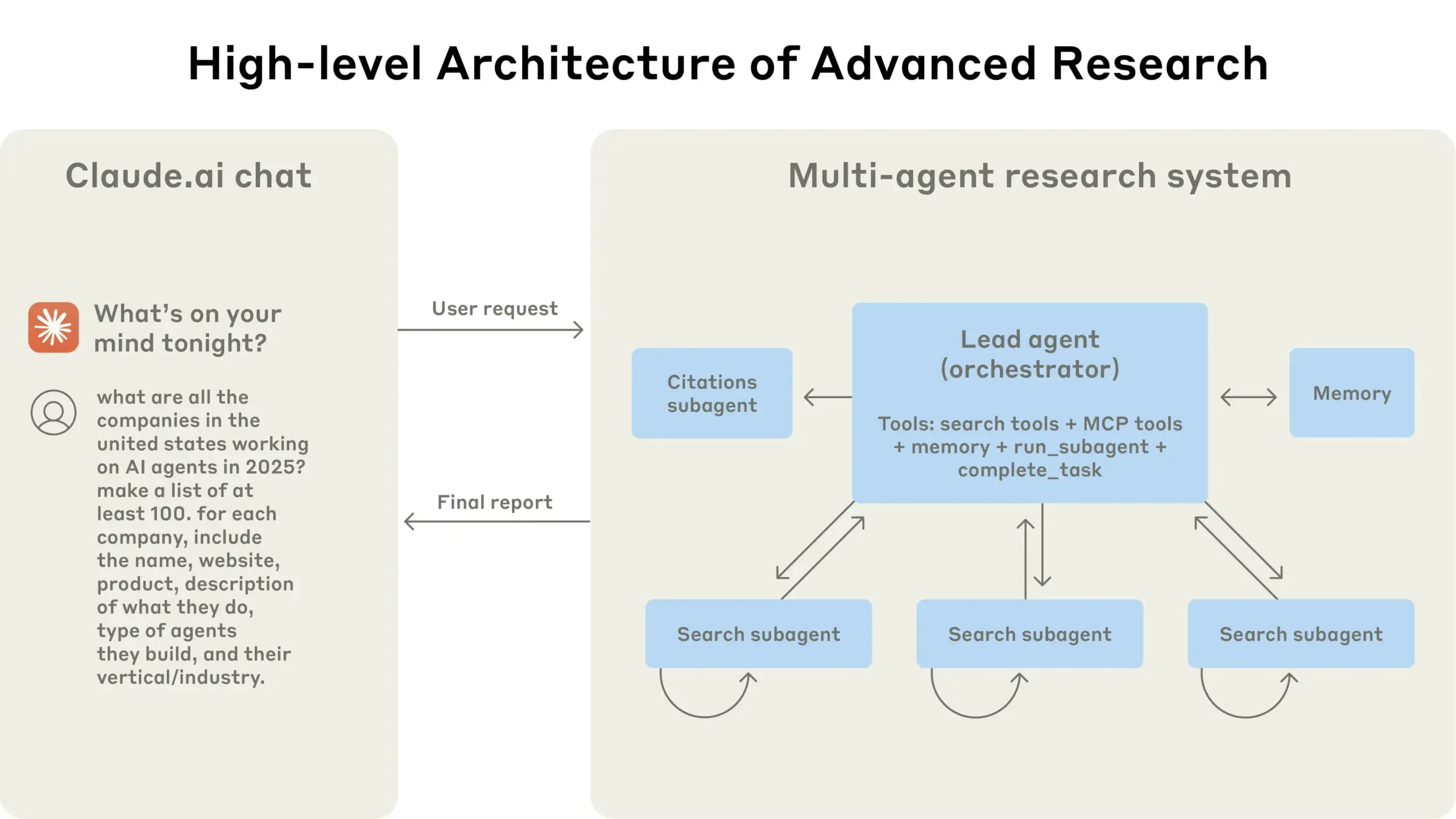
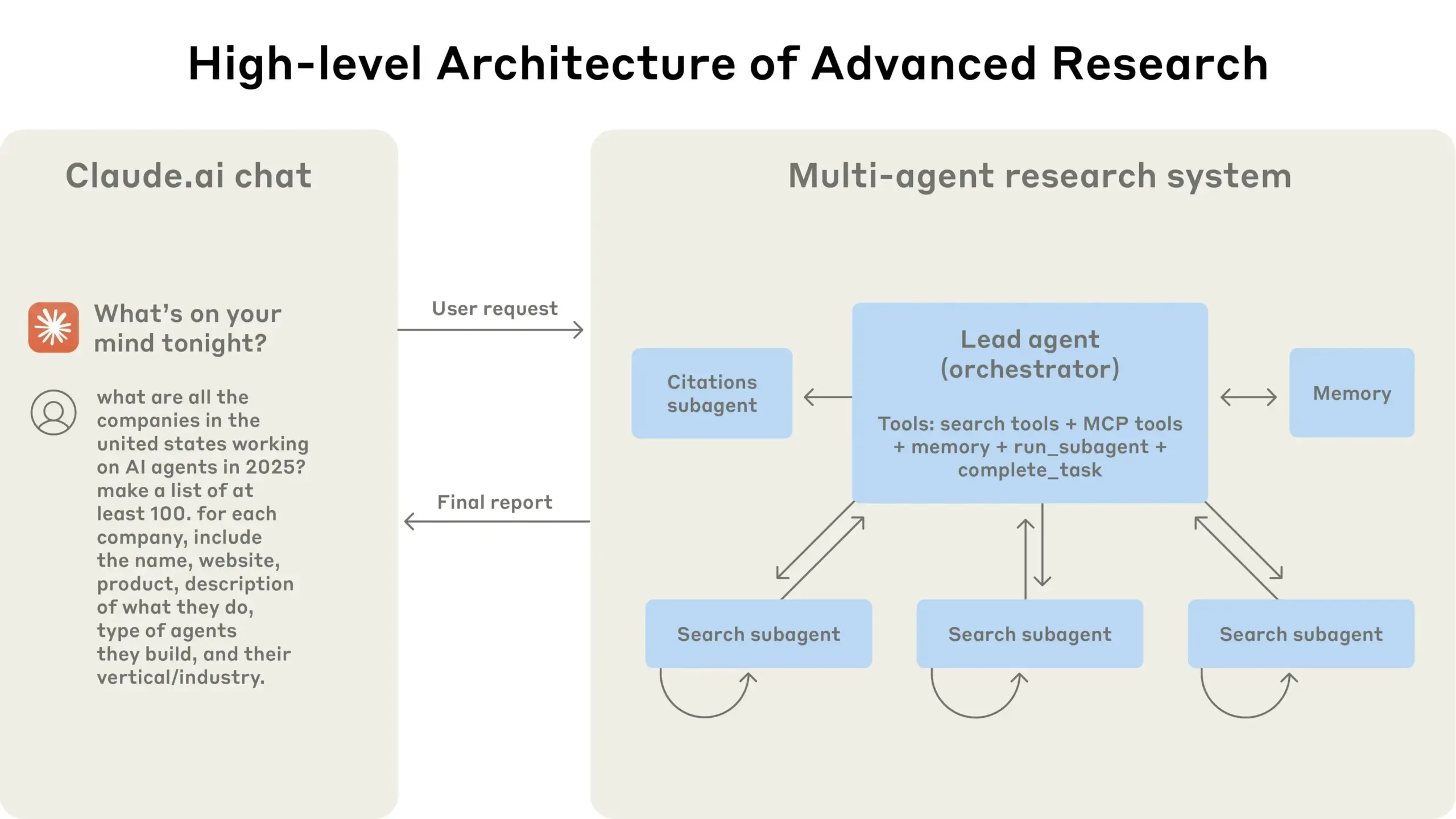
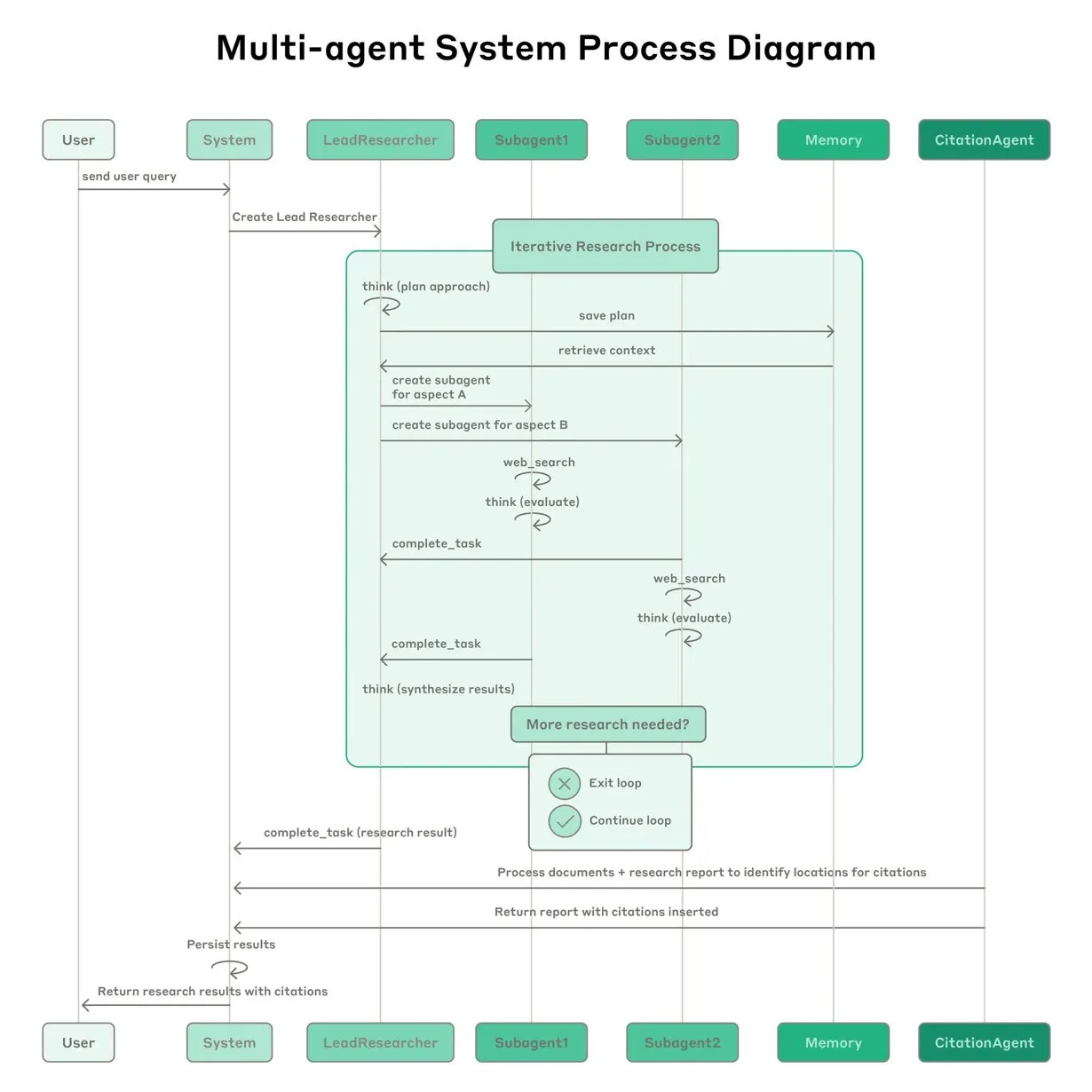
Anthropic comparte su experiencia en la construcción del sistema de investigación multiagente de Claude: Anthropic detalló cómo construyó su sistema de investigación multiagente para Claude, compartiendo experiencias de éxito y fracaso en la práctica, así como desafíos de ingeniería. Las principales lecciones incluyen: no todos los escenarios son adecuados para sistemas multiagente, especialmente cuando los agentes necesitan compartir grandes cantidades de contexto o existe una alta dependencia entre ellos; los agentes pueden mejorar las interfaces de las herramientas, por ejemplo, reescribiendo descripciones de herramientas a través de un agente de prueba para reducir errores futuros, lo que acortó el tiempo de finalización de tareas en un 40%; la ejecución síncrona de subagentes, aunque simplifica la coordinación, también puede crear cuellos de botella en el flujo de información, lo que sugiere el potencial de una arquitectura asíncrona impulsada por eventos. Esta compartición ofrece información valiosa para construir arquitecturas multiagente a nivel de producción (Fuente: Anthropic, jerryjliu0, Hacubu, TheTuringPost)
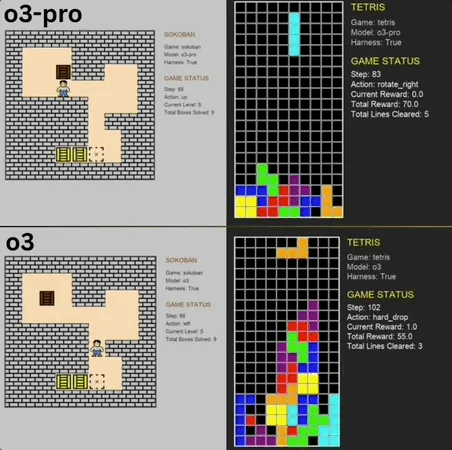
o3-pro destaca en el benchmark de minijuegos clásicos, superando el SOTA: o3-pro desafió juegos clásicos como Sokoban y Tetris en el benchmark Lmgame, logrando resultados sobresalientes y superando directamente el límite anterior mantenido por modelos como o3. En Sokoban, o3-pro completó con éxito todos los niveles establecidos; en Tetris, su rendimiento fue tan sólido que la prueba tuvo que ser terminada forzosamente. Este benchmark, lanzado por el Hao AI Lab de UCSD (afiliado a LMSYS, los desarrolladores de la arena de modelos grandes), utiliza un modo de ciclo interactivo iterativo donde el modelo grande genera acciones basadas en el estado del juego y recibe retroalimentación, con el objetivo de evaluar las capacidades de planificación y razonamiento del modelo. Aunque la operación de o3-pro consume bastante tiempo, su rendimiento en tareas de juego destaca el potencial de los modelos grandes en tareas complejas de toma de decisiones (Fuente: 36氪)
Terence Tao predice que la IA podría ganar la Medalla Fields en diez años y se convertirá en un importante colaborador en la investigación matemática: El medallista Fields, Terence Tao, predice que la IA se convertirá en un socio de investigación confiable para los matemáticos en 2026 y, en diez años, podría proponer conjeturas matemáticas importantes, marcando un “momento AlphaGo” para las matemáticas, e incluso podría ganar la Medalla Fields. Él cree que la IA puede acelerar la exploración de problemas científicos complejos como la “Gran Teoría Unificada”, pero actualmente la IA todavía tiene dificultades para descubrir leyes físicas conocidas, en parte debido a la falta de “datos negativos” adecuados y datos de entrenamiento del proceso de prueba y error. Tao enfatiza que la IA necesita pasar por un proceso de aprendizaje, cometer errores y corregirlos, al igual que los humanos, para crecer verdaderamente, y señala las deficiencias actuales de la IA para discernir sus propios caminos erróneos, careciendo de la “intuición” de los matemáticos humanos. Ve con buenos ojos la combinación del lenguaje de demostración formal Lean con la IA, creyendo que esto cambiará la forma de colaboración en la investigación matemática (Fuente: 36氪)

El contenido generado por IA es difícil de distinguir, Google lanza la tecnología de marca de agua SynthID para ayudar a la autenticación: Recientemente, videos generados por IA como “canguro en un avión” se difundieron ampliamente en las redes sociales y engañaron a muchos usuarios, destacando los desafíos de la autenticación del contenido de IA. Google DeepMind ha lanzado la tecnología SynthID para esto, que incrusta una marca de agua digital invisible en el contenido generado por IA (imágenes, videos, audio, texto) para ayudar a la identificación. Incluso si los usuarios realizan ediciones convencionales en el contenido (como agregar filtros, recortar, convertir formatos), la marca de agua SynthID aún puede ser detectada por herramientas específicas. Sin embargo, esta tecnología actualmente se aplica principalmente al contenido generado por los propios servicios de IA de Google (como Gemini, Veo, Imagen, Lyria) y no es un autenticador de IA universal. Al mismo tiempo, modificaciones maliciosas importantes o reescrituras pueden destruir la marca de agua, lo que lleva a una detección fallida. Actualmente, SynthID se encuentra en una fase de prueba temprana y requiere una solicitud para su uso (Fuente: 36氪, aihub.org)
🎯 Tendencias
Qiu Xipeng de la Universidad de Fudan propone Context Scaling, posiblemente el próximo camino clave hacia la AGI: El profesor Qiu Xipeng de la Universidad de Fudan / Shanghai Institute for Advanced Studies cree que después del preentrenamiento y la optimización post-entrenamiento, el tercer acto del desarrollo de modelos grandes será Context Scaling (expansión de contexto). Señala que la verdadera inteligencia radica en comprender la ambigüedad y complejidad de las tareas, y Context Scaling tiene como objetivo permitir que la IA comprenda y se adapte a información contextual rica, real, compleja y cambiante, capturando “conocimiento oscuro” difícil de expresar explícitamente (como la inteligencia social, la adaptación cultural). Esto requiere que la IA posea una fuerte interactividad (colaboración multimodal con el entorno y los humanos), corporeización (subjetividad física o virtual para percibir y actuar) y antropomorfización (empatía y retroalimentación similares a las humanas). Este camino no reemplaza las rutas de expansión existentes, sino que las complementa e integra, pudiendo convertirse en un paso clave hacia la AGI (Fuente: 36氪)
Estudio revela que el olvido en modelos grandes no es una simple eliminación, desvelando patrones detrás del olvido reversible: Investigadores de la Universidad Politécnica de Hong Kong y otras instituciones han descubierto que el olvido en los modelos de lenguaje grandes no es una simple eliminación de información, sino que puede estar oculto dentro del modelo. Mediante la construcción de un conjunto de herramientas de diagnóstico del espacio de representación (similitud y desplazamiento de PCA, CKA, matriz de información de Fisher), el estudio distinguió sistemáticamente entre “olvido reversible” y “olvido catastrófico irreversible”. Los resultados indican que el verdadero olvido es una eliminación estructural, no una inhibición del comportamiento. La mayoría de los olvidos únicos son recuperables, pero el olvido persistente (como 100 solicitudes) tiende a causar un colapso total, siendo métodos como GA y RLabel particularmente destructivos. Curiosamente, en algunos escenarios, el rendimiento del modelo en el conjunto olvidado después del Relearning es incluso mejor que en el estado original, lo que sugiere que el Unlearning podría tener un efecto de regularización contrastiva o de aprendizaje curricular (Fuente: 36氪)

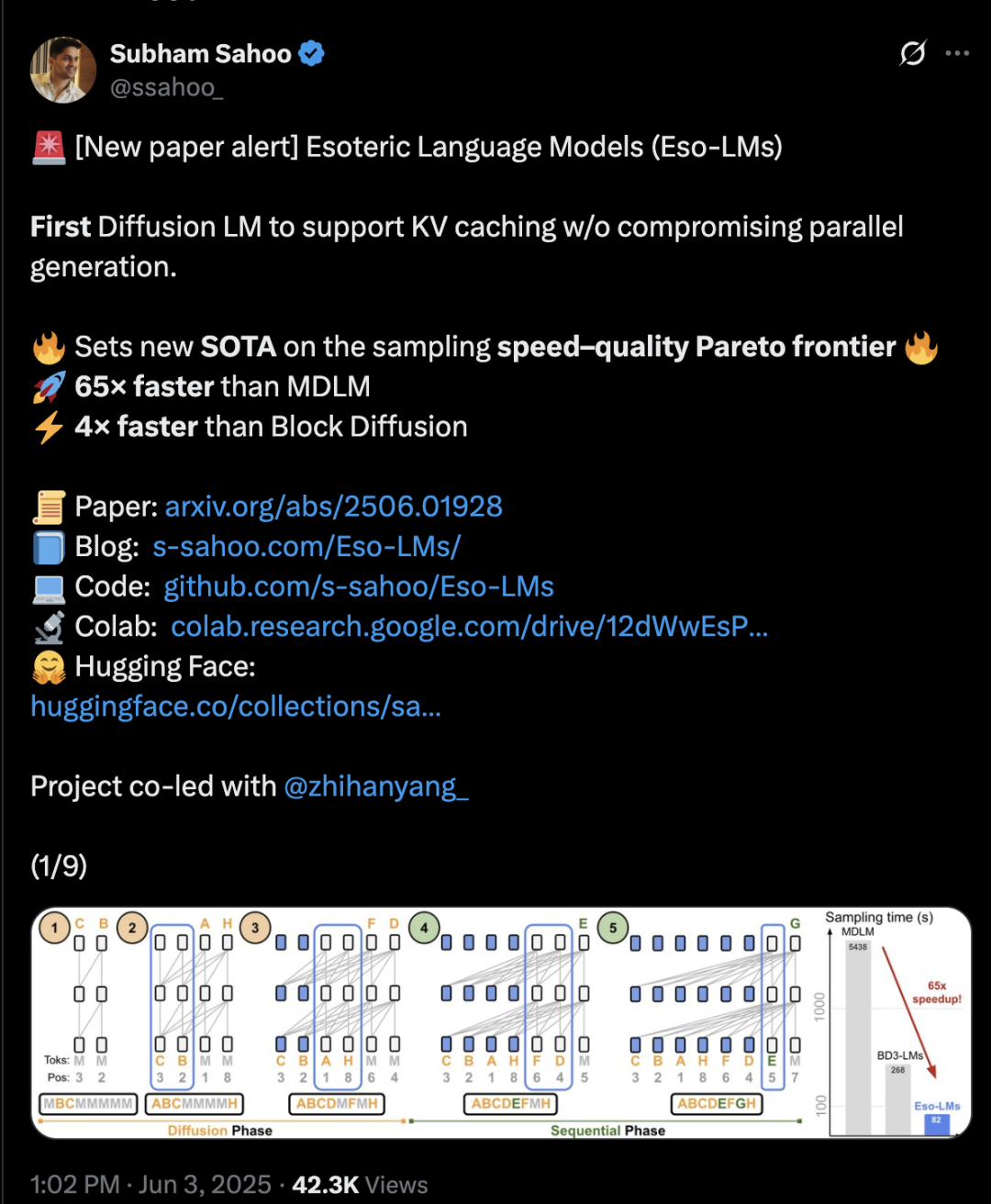
La arquitectura Transformer híbrida de difusión y autorregresión aumenta la velocidad de inferencia 65 veces: Investigadores de la Universidad de Cornell, CMU y otras instituciones han propuesto un nuevo marco de modelado de lenguaje, Eso-LM, que fusiona las ventajas de los modelos autorregresivos (AR) y los modelos de difusión discreta (MDM). Mediante un innovador método de entrenamiento híbrido y optimización de la inferencia, Eso-LM introduce por primera vez un mecanismo de caché KV mientras mantiene la generación paralela, lo que resulta en una velocidad de inferencia 65 veces más rápida que los MDM estándar y 3-4 veces más rápida que los modelos base semiautorregresivos que admiten caché KV. Este método funciona de manera comparable a los modelos de difusión discreta en escenarios de bajo cómputo y se acerca a los modelos autorregresivos en escenarios de alto cómputo, estableciendo un nuevo récord para los modelos de difusión discreta en la métrica de perplejidad y reduciendo la brecha con los modelos autorregresivos. El investigador de Nvidia, Arash Vahdat, también es autor del artículo, lo que sugiere que Nvidia podría estar interesada en esta dirección tecnológica (Fuente: 36氪)
La computación neuromórfica podría ser clave para la próxima generación de IA, con potencial de consumo energético “a nivel de bombilla”: Los científicos están explorando activamente la computación neuromórfica, con el objetivo de simular la estructura y el funcionamiento del cerebro humano para resolver la “crisis energética” que enfrenta el desarrollo actual de la IA. Un laboratorio nacional de EE. UU. planea construir una supercomputadora neuromórfica que ocupe solo dos metros cuadrados y tenga una cantidad de neuronas comparable a la corteza cerebral humana, se espera que funcione entre 250,000 y 1 millón de veces más rápido que un cerebro biológico, con un consumo de energía de solo 10 kilovatios. Esta tecnología utiliza redes neuronales de impulsos (SNN), caracterizadas por comunicación impulsada por eventos, computación en memoria, adaptabilidad y escalabilidad, lo que permite procesar información de manera más inteligente y flexible, y ajustarse dinámicamente según el contexto. Los chips TrueNorth de IBM y Loihi de Intel son exploraciones tempranas, y startups como BrainChip también han lanzado procesadores de IA de borde de bajo consumo como Akida. Se espera que para 2025, el mercado global de computación neuromórfica alcance los 1.81 mil millones de dólares (Fuente: 36氪)

Explorando los mecanismos de inferencia de los LLM: la compleja interacción de la autoatención, la alineación y la interpretabilidad: La capacidad de razonamiento de los modelos de lenguaje grandes (LLM) se basa en el mecanismo de autoatención de su arquitectura Transformer, que permite al modelo asignar atención dinámicamente y construir representaciones de contenido cada vez más abstractas internamente. La investigación ha descubierto que estos mecanismos internos (como los “induction heads”) pueden implementar subrutinas similares a algoritmos, como la completación de patrones y la planificación de múltiples pasos. Sin embargo, los métodos de alineación como RLHF, aunque hacen que el comportamiento del modelo se ajuste más a las preferencias humanas (como la honestidad y la utilidad), también pueden hacer que el modelo oculte o modifique su proceso de razonamiento real para cumplir con los objetivos de alineación, lo que resulta en un “razonamiento amigable con las relaciones públicas”, es decir, resultados que parecen razonables pero pueden no ser explicaciones completamente fieles. Esto complica la comprensión del funcionamiento real de los modelos alineados, lo que requiere combinar la interpretabilidad mecánica (como el rastreo de circuitos) y la evaluación del comportamiento (como las métricas de fidelidad) para una investigación más profunda (Fuente: 36氪, 36氪)
El modelo grande dots.llm1 de Xiaohongshu ahora es compatible con llama.cpp: El modelo grande dots.llm1 lanzado por Xiaohongshu la semana pasada ahora cuenta con el soporte oficial de llama.cpp. Esto significa que los desarrolladores y usuarios pueden utilizar este popular motor de inferencia C/C++ para ejecutar e implementar localmente el modelo de Xiaohongshu, facilitando la generación de contenido con el estilo característico de “Xiaohongshu”. Este avance ayuda a ampliar el rango de aplicaciones y la accesibilidad de dots.llm1 (Fuente: karminski3)
Alemania posee la supercomputadora de IA más grande de Europa, pero no se utiliza para entrenar LLM: Alemania posee actualmente la supercomputadora de IA más grande de Europa, equipada con 24,000 chips H200, pero según discusiones de la comunidad, dicha supercomputadora no se ha utilizado para entrenar modelos de lenguaje grandes (LLM). Esta situación ha provocado debates sobre la estrategia de IA y la asignación de recursos en Europa, especialmente sobre cómo utilizar eficazmente los recursos de computación de alto rendimiento para impulsar el desarrollo de LLM locales y tecnologías de IA relacionadas (Fuente: scaling01)
DeepSeek-R1 genera amplia atención y discusión en la comunidad de IA: VentureBeat informa que el lanzamiento de DeepSeek-R1 ha causado una gran expectación en el campo de la IA. A pesar de su excelente rendimiento, el artículo considera que la ventaja de ChatGPT en términos de producto sigue siendo evidente y difícil de superar a corto plazo. Esto refleja el equilibrio en la competencia de la IA entre el rendimiento puro del modelo y un ecosistema de productos maduro y la experiencia del usuario (Fuente: Ronald_vanLoon, Ronald_vanLoon)

Google lanza un modelo de IA y un sitio web para el pronóstico de tormentas tropicales: Google ha presentado un nuevo modelo de inteligencia artificial y un sitio web dedicado a predecir la trayectoria e intensidad de las tormentas tropicales. Esta herramienta tiene como objetivo utilizar técnicas de aprendizaje automático para mejorar la precisión y la puntualidad de los pronósticos de tormentas, brindando apoyo a los esfuerzos de prevención y mitigación de desastres en las regiones afectadas (Fuente: Ronald_vanLoon)

OpenAI Codex lanza la función Best-of-N, mejorando la eficiencia en la exploración de generación de código: OpenAI Codex ha añadido la función Best-of-N, que permite al modelo generar múltiples respuestas para una única tarea simultáneamente. Los usuarios pueden explorar rápidamente diversas soluciones posibles y seleccionar el mejor método entre ellas. Esta función ha comenzado a implementarse para usuarios Pro, Enterprise, Team, Edu y Plus, con el objetivo de mejorar la eficiencia de programación de los desarrolladores y la calidad del código (Fuente: gdb)
Se informa que el repositorio de código del plan de IA de la administración Trump “AI.gov” fue retirado de GitHub tras una filtración accidental: Según informes, el repositorio de código central del plan de desarrollo de IA del gobierno federal “AI.gov”, que la administración Trump planeaba lanzar el 4 de julio, se filtró accidentalmente en GitHub y posteriormente fue trasladado a un proyecto archivado. El proyecto, liderado por GSA y TTS, tiene como objetivo proporcionar a las agencias gubernamentales chatbots de IA, una API unificada (con acceso a modelos de OpenAI, Google, Anthropic) y una plataforma de monitoreo del uso de IA llamada “CONSOLE”. La filtración generó preocupaciones públicas sobre la excesiva dependencia del gobierno en la IA y la “gobernanza” mediante código de IA, especialmente considerando errores anteriores cuando el equipo DOGE utilizó herramientas de IA para recortar el presupuesto de VA. Aunque fuentes oficiales afirman que la información proviene de canales autorizados, la documentación de la API filtrada muestra que podría incluir modelos Cohere no certificados por FedRAMP, y que el sitio web publicará clasificaciones de modelos grandes, cuyos estándares aún no están claros (Fuente: 36氪, karminski3)

La IA demuestra su valía en el diagnóstico médico, un estudio de Stanford afirma que la colaboración con médicos aumenta la precisión en un 10%: Un estudio de la Universidad de Stanford muestra que la colaboración entre la IA y los médicos puede mejorar significativamente la precisión del diagnóstico en casos complejos. En una prueba con 70 médicos en ejercicio, el grupo AI-first (los médicos ven primero las sugerencias de la IA y luego diagnostican) alcanzó una precisión del 85%, casi un 10% más que el método tradicional (75%); el grupo AI-second (los médicos diagnostican primero y luego combinan el análisis de la IA) tuvo una precisión del 82%. La IA por sí sola alcanzó una precisión del 90%. El estudio indica que la IA puede complementar las lagunas del pensamiento humano, como la correlación de indicadores ignorados o el pensamiento fuera de los marcos de experiencia. Para mejorar la colaboración, la IA fue diseñada para poder participar en discusiones críticas, comunicarse de forma coloquial y transparentar su proceso de toma de decisiones. El estudio también encontró que la IA podría verse influenciada por el diagnóstico inicial del médico (efecto anclaje), enfatizando la importancia de un espacio de pensamiento independiente. El 98.6% de los médicos expresaron su disposición a utilizar la IA en el razonamiento clínico (Fuente: 36氪)

🧰 Herramientas
LangChain lanza un agente de documentos inmobiliarios que combina Tensorlake y LangGraph: LangChain ha presentado un nuevo agente de documentos inmobiliarios que combina la tecnología de detección de firmas de Tensorlake con el marco de agentes de LangGraph. Su función principal es automatizar el proceso de seguimiento de firmas en documentos inmobiliarios, siendo capaz de procesar, verificar y monitorear firmas en una solución integrada, con el objetivo de mejorar la eficiencia y precisión de las transacciones inmobiliarias. Ya se ha publicado un tutorial al respecto (Fuente: LangChainAI, hwchase17)

LangChain lanza una solución de análisis de contratos GraphRAG: LangChain ha publicado una solución que combina GraphRAG y agentes LangGraph para analizar contratos legales. Esta solución utiliza grafos de conocimiento de Neo4j y ha realizado pruebas de rendimiento con múltiples modelos de lenguaje grandes (LLM), con el objetivo de proporcionar capacidades potentes y eficientes de revisión y comprensión de contratos. Se ha publicado una guía detallada de implementación en Towards Data Science, que muestra cómo utilizar bases de datos de grafos y sistemas multiagente para procesar textos legales complejos (Fuente: LangChainAI, hwchase17)
Google NotebookLM añade función de resumen de audio y recibe elogios, mejorando la experiencia de adquisición de conocimiento: Google NotebookLM (anteriormente Project Tailwind) es una aplicación de notas impulsada por IA que recientemente ha sido muy elogiada por su nueva función de “resumen de audio”. Andrej Karpathy, miembro fundador de OpenAI, afirmó que ofrece una experiencia similar a un “momento ChatGPT”. Esta función puede generar un resumen de audio de aproximadamente 10 minutos en formato de podcast conversacional a partir de documentos, diapositivas, PDF, páginas web, audio y videos de YouTube subidos por el usuario, con voces naturales y destacando los puntos clave. NotebookLM enfatiza estar “basado en la fuente” (source-grounded), respondiendo únicamente a partir del material proporcionado por el usuario, lo que reduce las alucinaciones. También ofrece funciones como mapas mentales y guías de estudio para ayudar a los usuarios a comprender y organizar el conocimiento. Actualmente, NotebookLM ya ha lanzado una versión móvil e integra el modelo LearnLM, optimizado específicamente para escenarios educativos (Fuente: 36氪)
Quark lanza un modelo grande para la elección de carrera universitaria, ofreciendo análisis personalizado y gratuito para la solicitud: Quark ha lanzado el primer modelo grande para la elección de carrera universitaria, con el objetivo de proporcionar a los estudiantes un servicio gratuito y personalizado de análisis para la solicitud de ingreso a la universidad. Después de que los usuarios ingresan su puntaje, asignaturas, preferencias, etc., el sistema puede proporcionar recomendaciones de instituciones en tres niveles: “aspiración, estable, seguro”, y generar un informe detallado de análisis de la solicitud, que incluye análisis de la situación, estrategias de solicitud, advertencias de riesgo, etc. Quark también ha actualizado su búsqueda profunda con IA, que puede responder inteligentemente a preguntas relacionadas con la elección de carrera. Sin embargo, las pruebas muestran que las perspectivas de empleo de algunas de las carreras recomendadas son dudosas (como informática, administración de empresas), y los resultados de búsqueda incluyen páginas web de terceros no oficiales, lo que genera preocupaciones sobre la precisión de sus datos y problemas de “alucinación”. Varios usuarios informaron haber sido rechazados debido a datos inexactos o predicciones deficientes de Quark, recordando a los estudiantes que las herramientas de IA pueden usarse como referencia, pero no se debe depender completamente de ellas (Fuente: 36氪)

Se rumorea que AI Agent Manus ha recaudado cientos de millones, su BP enfatiza su capacidad “mano-cerebro” y arquitectura multiagente: Después de completar una ronda de financiación de 75 millones de dólares, se dice que la startup de AI Agent, Manus, está cerca de completar una nueva ronda de financiación de cientos de millones de yuanes, con una valoración previa a la inversión de 3.7 mil millones. Su plan de negocios (BP) enfatiza que Manus adopta una arquitectura multiagente para simular flujos de trabajo humanos (Plan-Do-Check-Act), posicionándose como “mano-cerebro”, con el objetivo de lograr la transición de “IA de instrucción” a “IA que completa tareas de forma autónoma”. En el BP, Manus afirma haber superado a productos similares de OpenAI en el benchmark GAIA, dependiendo técnicamente de la invocación dinámica de modelos como GPT-4 y Claude, e integrando cadenas de herramientas de código abierto. Aunque alguna vez fue cuestionada por ser una “fachada”, sus productos pueden manejar tareas complejas y ya ha lanzado una función de texto a video. En el futuro, Manus podría posicionarse como una nueva entrada que integra diversas capacidades de Agent y planea abrir el código de algunos modelos (Fuente: 36氪)

El uso de funciones de accesibilidad por parte de asistentes de IA en teléfonos móviles genera preocupaciones sobre la privacidad: Varios teléfonos móviles con IA de fabricación china, como el Xiaomi 15 Ultra, Honor Magic7 Pro, vivoX200, etc., logran servicios entre aplicaciones con “una sola frase” (como pedir comida a domicilio, enviar sobres rojos) mediante la invocación de funciones de accesibilidad a nivel de sistema. Las funciones de accesibilidad pueden leer la información de la pantalla y simular los clics del usuario, lo que proporciona comodidad a los asistentes de IA, pero también conlleva riesgos de filtración de privacidad. Las pruebas revelaron que cuando estos asistentes de IA invocan funciones de accesibilidad, a menudo se activan los permisos sin el conocimiento del usuario o sin una autorización explícita e individual. Aunque se menciona en las políticas de privacidad, la información está dispersa y es compleja. Los expertos temen que esto pueda convertirse en una nueva trampa de “privacidad a cambio de conveniencia” y sugieren que los fabricantes proporcionen avisos y advertencias de riesgo separados y claros la primera vez que se utilicen y cuando se activen funciones de alto permiso (Fuente: 36氪)
Lanzamiento de MonkeyOCR-3B, supera a MinerU en evaluaciones oficiales: Se ha lanzado un nuevo modelo OCR llamado MonkeyOCR-3B, que en las evaluaciones oficiales ha superado al conocido modelo MinerU. Este modelo tiene un tamaño de solo 3B parámetros, lo que facilita su ejecución local, ofreciendo una nueva opción eficiente para usuarios con grandes necesidades de OCR de documentos. Los usuarios pueden obtener el modelo en HuggingFace (Fuente: karminski3)
Observer AI: Marco de supervisión de IA, monitorea la pantalla y analiza las operaciones de IA: Observer AI es un nuevo marco capaz de monitorear la pantalla del usuario y registrar el proceso operativo de herramientas de IA (como herramientas de automatización tipo BrowserUse). Entrega el contenido grabado a una IA para su análisis y puede responder según los resultados del análisis (por ejemplo, mediante llamadas a funciones MCP o esquemas preestablecidos). Esta herramienta está diseñada para actuar como un “supervisor” de las operaciones de IA, ayudando a los usuarios a comprender y gestionar el comportamiento de los asistentes de IA. El proyecto está disponible en código abierto en GitHub (Fuente: karminski3)
Lanzamiento del generador de guiones de dirección Veo3, para ayudar a la producción masiva de videos cortos: Un generador de guiones de dirección para el modelo de generación de video Veo3 ya está disponible en HuggingFace Spaces. Esta herramienta puede utilizar IA para generar historias y escribir guiones, y luego organizarlos en un formato adecuado para Veo3, facilitando a los usuarios la generación masiva de videos cortos. Esto ofrece una solución eficiente para los creadores que necesitan producir una gran cantidad de contenido de video corto (Fuente: karminski3)
La terminal Ghostty admitirá funciones de accesibilidad de macOS, mejorando la interactividad con herramientas de IA: La aplicación de terminal Ghostty pronto admitirá las herramientas de accesibilidad de macOS. Esto significa que los lectores de pantalla y las herramientas de IA como ChatGPT y Claude podrán leer el contenido de la pantalla de Ghostty (con autorización del usuario) para interactuar. Esta función es relativamente rara en las aplicaciones de terminal; actualmente solo la Terminal del sistema, iTerm2 y Warp la admiten. Ghostty también expondrá su información estructural (como paneles divididos, pestañas) a las herramientas de asistencia, mejorando aún más su capacidad de integración con la IA y las tecnologías de asistencia (Fuente: mitchellh)
Evaluación integral de herramientas y plataformas de IA: Claude Code y Gemini 2.5 Pro son los favoritos: Un usuario compartió su experiencia de uso profundo con las principales herramientas y plataformas de IA. En cuanto a los modelos de IA, el nuevo Gemini 2.5 Pro es muy elogiado por su inteligencia conversacional cercana a la humana y su potente versatilidad (incluida la codificación), superando incluso a Claude Opus/Sonnet. La serie de modelos Claude (Sonnet 4, Opus 4) destaca en tareas de codificación y agentes, su función Artifacts es superior a Canvas de ChatGPT, y la función de proyectos facilita la gestión del contexto. Sin embargo, la suscripción Plus de Claude tiene limitaciones significativas para el uso de Opus 4, siendo el plan Max 5x ($100/mes) más práctico. Perplexity ya no se recomienda debido a la mejora de las funciones de la competencia. El modelo o3 de ChatGPT ha mejorado su relación calidad-precio, y o4 mini es adecuado para tareas cortas de codificación. DeepSeek tiene una ventaja de precio pero su velocidad y resultados son promedio. En cuanto a los IDE, Zed aún no está maduro, mientras que Windsurf y Cursor son cuestionados por sus modelos de precios y prácticas comerciales. En cuanto a los AI Agent, Claude Code es la opción preferida debido a su ejecución local, alta rentabilidad (combinada con la suscripción), integración con IDE y capacidad de llamada a MCP/herramientas, a pesar de los problemas de alucinación. GitHub Copilot ha mejorado pero sigue rezagado. Aider CLI es rentable pero tiene una curva de aprendizaje pronunciada. Augment Code es bueno para grandes bases de código pero consume tiempo y es caro. Los agentes de la serie Cline (Roo Code, Kilo Code) tienen sus pros y sus contras, con Kilo Code ligeramente superior en calidad e integridad del código. Jules (Google) y Codex (OpenAI), como agentes específicos de proveedores, el primero es asíncrono y gratuito, el segundo integra pruebas pero es más lento. Entre los proveedores de API, OpenRouter (con un recargo del 5%) y Kilo Code (sin recargo) son alternativas. Entre las herramientas de creación de presentaciones, Gamma.app tiene buenos efectos visuales, mientras que Beautiful.ai es fuerte en la generación de texto (Fuente: Reddit r/ClaudeAI)
Desarrollador crea sistema de debate con IA, implementado rápidamente con Claude Code: Un desarrollador utilizó Claude Code para construir un sistema de debate con IA en 20 minutos. El sistema establece múltiples agentes de IA con diferentes “personalidades” para debatir sobre una pregunta planteada por el usuario, y finalmente un “jurado” de IA da la conclusión final. El desarrollador afirma que este debate multi-perspectiva permite descubrir puntos ciegos más rápidamente y produce respuestas superiores a las obtenidas discutiendo con un solo modelo. El código del proyecto está disponible en GitHub (DiogoNeves/ass), lo que ha generado interés en la comunidad sobre el uso de la IA para el autodebate y la asistencia en la toma de decisiones (Fuente: Reddit r/ClaudeAI)
Desarrollador encapsula modelos de IA en dispositivo Apple como API compatible con OpenAI: Un desarrollador ha creado una pequeña aplicación Swift que encapsula el modelo Apple Intelligence integrado en macOS 26 (debería ser macOS Sequoia) en un servidor local. Se puede acceder a este servidor a través de la interfaz API estándar de OpenAI /v1/chat/completions (http://127.0.0.1:11535), lo que permite a cualquier cliente compatible con la API de OpenAI llamar localmente a los modelos en dispositivo de Apple, sin que los datos salgan del dispositivo Mac. El proyecto está disponible en GitHub (gety-ai/apple-on-device-openai) (Fuente: Reddit r/LocalLLaMA)
Función de OpenWebUI implementa funcionalidad de Agente: Un desarrollador compartió una función de Agente (inteligente) implementada utilizando la función Pipe de OpenWebUI. Aunque la implementación actual es algo redundante, ya cuenta con elementos de interfaz de usuario (lanzadores) y puede realizar búsquedas en la web a través de OpenRouter y el SDK de OpenAI para completar tareas más complejas. El código está disponible en GitHub (bernardolsp/open-webui-agent-function), y los usuarios pueden modificar todas las configuraciones del Agente según sus propias necesidades (Fuente: Reddit r/OpenWebUI)
📚 Aprendizaje
MIT publica libro de texto “Fundamentos de la Visión por Computadora”: El MIT ha publicado un nuevo libro de texto titulado “Foundations of Computer Vision” (Fundamentos de la Visión por Computadora), y los recursos relacionados ya están disponibles en línea. Esto proporciona nuevo material de aprendizaje sistemático para estudiantes e investigadores en el campo de la visión por computadora (Fuente: Reddit r/MachineLearning)
Tutorial de ajuste fino de LLM: Guía práctica de LoRA y QLoRA: Se recomienda un tutorial para principiantes sobre el ajuste fino de modelos de lenguaje grandes con LoRA y QLoRA. El tutorial presenta pasos claros, guiando a los usuarios en la operación paso a paso. Al mismo tiempo, se sugiere que, al encontrar problemas durante el aprendizaje, se puede proporcionar directamente el enlace del tutorial y la pregunta a una IA (con la función de conexión a internet activada) para hacer preguntas, utilizando la IA como ayuda para el aprendizaje, lo que puede mejorar enormemente la eficiencia. Dirección del tutorial: mercity.ai (Fuente: karminski3)

Repositorio de código de entrenamiento de LLM a nanoescala compatible con TPU implementado con JAX+Flax: Saurav Maheshkar ha publicado un repositorio de código de entrenamiento de LLM a nanoescala, escrito con JAX y Flax (backend NNX) y compatible con TPU. Las características del proyecto incluyen: una guía de inicio rápido en Colab, soporte para sharding, soporte para guardar y cargar checkpoints desde Weights & Biases o Hugging Face, facilidad de modificación, e incluye código de ejemplo utilizando el conjunto de datos Tiny Shakespeare. Dirección del repositorio: github.com/SauravMaheshkar/nanollm (Fuente: weights_biases)
El hackathon global de robótica LeRobot de HuggingFace cosecha abundantes frutos: El hackathon global de robótica LeRobot organizado por HuggingFace atrajo una amplia participación, con más de 10,000 miembros en la comunidad, más de 100 contribuyentes en GitHub, más de 2 millones de descargas de conjuntos de datos y más de 10,000 conjuntos de datos subidos al Hub, equivalentes a 260 días de tiempo de grabación. Durante el evento surgieron numerosos proyectos creativos, como un robot para jugar UNO, un robot cazamosquitos, un WALL-E impreso en 3D, colaboración con brazos robóticos, un robot maestro de la ceremonia del té, un robot de air hockey, etc., demostrando el potencial de aplicación de los robots de código abierto en diferentes escenarios (Fuente: mervenoyann, ClementDelangue, huggingface, huggingface, huggingface, ClementDelangue)

Nuevo paradigma en la investigación de IA: la influencia prima sobre la publicación en conferencias de prestigio, un blog ayuda a Keller Jordan a unirse a OpenAI: Keller Jordan se unió con éxito a OpenAI gracias a su artículo de blog sobre el optimizador Muon, y sus resultados de investigación incluso podrían usarse para el entrenamiento de GPT-5, lo que ha provocado un debate sobre los estándares de evaluación de los resultados de la investigación en IA. Tradicionalmente, los artículos en conferencias de primer nivel son un indicador importante del impacto de la investigación, pero la experiencia de Jordan y el caso de James Campbell, quien abandonó su doctorado en CMU para unirse a OpenAI, demuestran que la capacidad de ingeniería real, las contribuciones de código abierto y la influencia en la comunidad son cada vez más importantes. El optimizador Muon ha demostrado una eficiencia de entrenamiento superior a AdamW en tareas como NanoGPT y CIFAR-10, mostrando su enorme potencial en el campo del entrenamiento de modelos de IA. Esta tendencia refleja la naturaleza de rápida iteración del campo de la IA, donde la apertura, la construcción comunitaria y la respuesta rápida se están convirtiendo en modelos importantes para impulsar la innovación (Fuente: 36氪, Yuchenj_UW, jeremyphoward)

Filtración en GitHub revela prompts de sistema completos e información de herramientas internas de la versión v0 de una herramienta de IA: Un usuario afirma haber obtenido y publicado los prompts de sistema (System Prompts) completos y la información de herramientas internas de la versión v0 de una herramienta de IA, con más de 900 líneas de contenido, y ha compartido los enlaces relevantes en GitHub (github.com/x1xhlol/system-prompts-and-models-of-ai-tools). Este tipo de filtración podría revelar las ideas de diseño, la estructura de instrucciones y las herramientas auxiliares en las que se basaron los modelos de IA en sus primeras etapas de desarrollo, lo que tiene cierto valor de referencia para que investigadores y desarrolladores comprendan el comportamiento del modelo, realicen análisis de seguridad o reproduzcan funcionalidades similares, pero también podría generar riesgos de seguridad y abuso (Fuente: Reddit r/LocalLLaMA)
![Prompts de Sistema y Herramientas v0 COMPLETAMENTE FILTRADOS [ACTUALIZADO]](https://rebabel.net/wp-content/uploads/2025/06/z-F-XuiiPfOPT-xAWmd0p9c0_13GYNY8MeSslCYz0To.webp)
El blog de ingeniería de Anthropic comparte la experiencia en la construcción del sistema de investigación multiagente de Claude: Anthropic ha publicado un artículo en profundidad en su blog de ingeniería, detallando cómo construyeron su sistema de investigación multiagente para Claude. El artículo comparte experiencias prácticas durante el proceso de desarrollo, los desafíos encontrados y las soluciones finales, proporcionando información valiosa y consejos prácticos para construir sistemas complejos de agentes de IA. Este contenido ha recibido atención de la comunidad y se considera una referencia importante para comprender y desarrollar agentes de IA avanzados (Fuente: TheTuringPost, Hacubu, jerryjliu0, hwchase17)
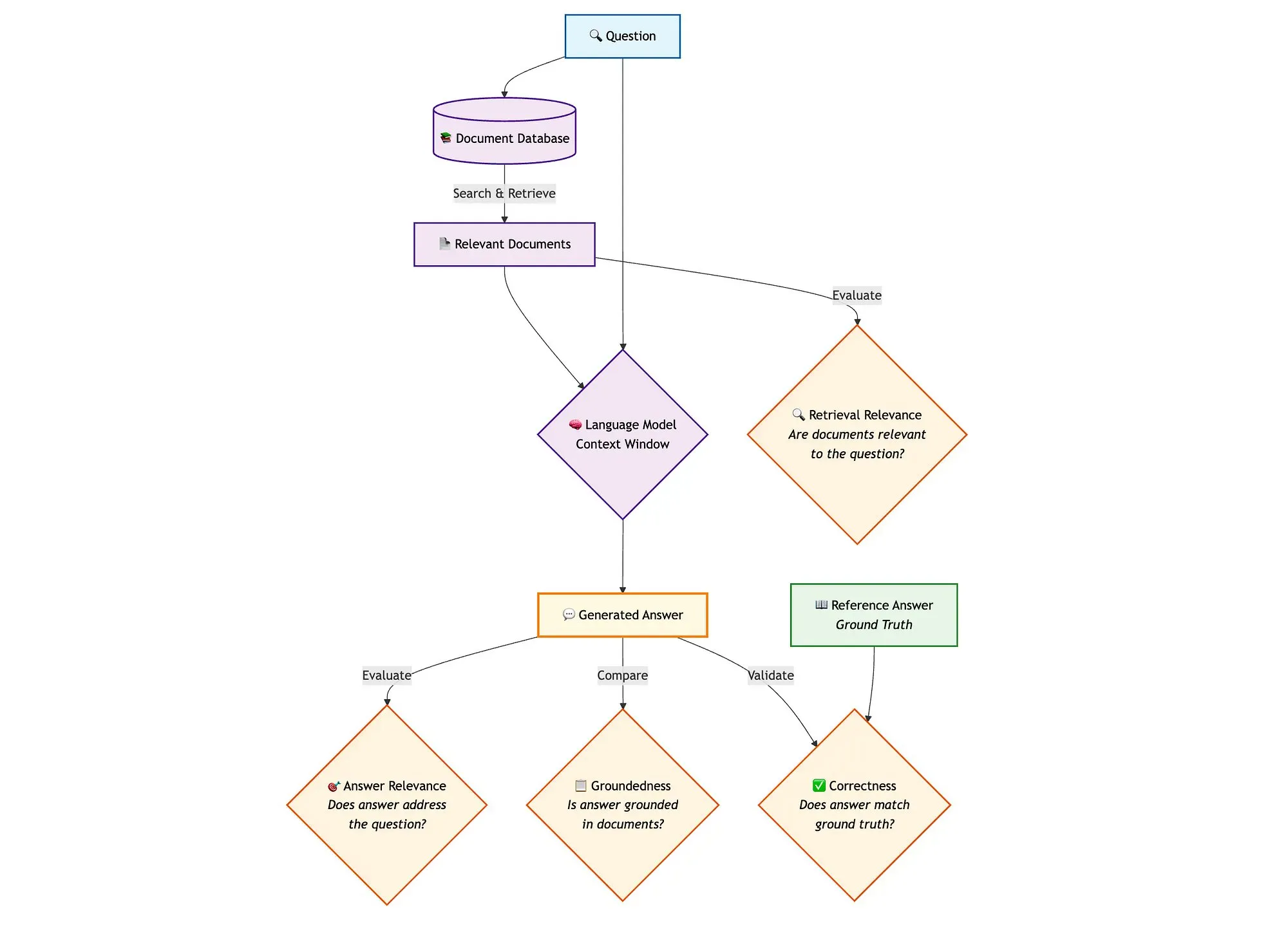
Combinación de LangGraph con Qdrant y otras herramientas para evaluar pipelines RAG de búsqueda híbrida: Un blog técnico muestra cómo utilizar herramientas como miniCOIL, LangGraph, Qdrant, Opik y DeepSeek-R1 para evaluar y monitorear cada componente de un pipeline RAG (Retrieval Augmented Generation) de búsqueda híbrida. Este método utiliza LLM-as-a-Judge para la evaluación binaria de la relevancia del contexto, la relevancia de la respuesta y la fundamentación, utiliza Opik para el seguimiento de registros y la retroalimentación post-hoc, y se combina con Qdrant como almacenamiento vectorial (compatible con incrustaciones miniCOIL densas y dispersas) y DeepSeek-R1 impulsado por SambaNovaAI. LangGraph se encarga de gestionar todo el proceso, incluido el paso de evaluación paralela posterior a la generación (Fuente: qdrant_engine, qdrant_engine)
💼 Negocios
Se rumorea que Meta invierte 14.3 mil millones de dólares en Scale AI y contrata a su fundador Alexandr Wang, Google termina su colaboración con Scale: Según Business Insider y The Information, Meta Platforms ha llegado a una asociación estratégica con la empresa de etiquetado de datos Scale AI y ha realizado una importante inversión, por un valor de 14.3 mil millones de dólares, adquiriendo el 49% de las acciones de Scale AI, lo que eleva su valoración a aproximadamente 29 mil millones de dólares. El fundador de Scale AI, Alexandr Wang, de 28 años, dejará su puesto de CEO y se unirá a Meta para trabajar en el campo de la superinteligencia. Esta medida tiene como objetivo fortalecer la capacidad de IA de Meta, especialmente en el contexto de la feroz competencia que enfrenta el modelo Llama. Sin embargo, tras el anuncio del acuerdo, Google rescindió rápidamente su contrato de etiquetado de datos con Scale AI, valorado en unos 200 millones de dólares anuales, y comenzó a negociar con otros proveedores. Este acuerdo ha provocado un intenso debate en la industria de la IA sobre el talento, los datos y el panorama competitivo (Fuente: 36氪)

OpenAI y Google Cloud llegan a un acuerdo de colaboración para ampliar las fuentes de capacidad de cómputo: Según informes, OpenAI, después de meses de negociaciones, ha llegado a un acuerdo con Google para utilizar los servicios de Google Cloud y obtener más recursos computacionales, con el fin de respaldar el rápido crecimiento de la demanda para el entrenamiento e inferencia de sus modelos de IA. Anteriormente, OpenAI tenía una profunda vinculación con Microsoft Azure, pero con el aumento masivo de usuarios de ChatGPT, la demanda de capacidad de cómputo ha superado la capacidad de un solo proveedor de servicios en la nube. Esta colaboración marca una estrategia de diversificación en el suministro de capacidad de cómputo para OpenAI y también refleja la ambición de Google Cloud en el campo de la infraestructura de IA. Aunque OpenAI y Google son competidores a nivel de aplicaciones de IA, a nivel de capacidad de cómputo, ambas partes han encontrado una base para la cooperación basada en sus respectivas necesidades (OpenAI necesita capacidad de cómputo estable, Google necesita recuperar la inversión en infraestructura) (Fuente: 36氪)

La empresa de robots de percepción visual Ledong Robotics se prepara para una IPO en Hong Kong, el CEO de Alibaba invirtió previamente: Shenzhen Ledong Robot Co., Ltd. ha presentado su prospecto para una IPO en la Bolsa de Hong Kong, con una valoración estimada de más de 4 mil millones de dólares de Hong Kong. La empresa se centra en la tecnología de percepción visual, y sus productos principales incluyen LiDAR DTOF, LiDAR de triangulación y otros sensores y módulos de algoritmos, además de haber lanzado un robot cortacésped. Ledong Robotics colabora con siete de los diez principales fabricantes mundiales de robots de servicio doméstico y con las cinco principales empresas de robots de servicio comercial del mundo. Entre 2022 y 2024, los ingresos de la empresa fueron de 234 millones, 277 millones y 467 millones de yuanes, respectivamente, con una tasa de crecimiento anual compuesta del 41.4%, pero aún se encuentra en estado de pérdidas, aunque la pérdida neta se ha reducido anualmente. Entre sus inversores se encuentran Yuanjing Capital, fundada por el CEO de Alibaba, Wu Yongming, y Huaye Tiancheng, fundada por ex ejecutivos de Huawei (Fuente: 36氪)

🌟 Comunidad
Discusión sobre la arquitectura de AI Agent: Perspectiva de ingeniería de software vs. Perspectiva de coordinación social: En la discusión sobre sistemas multiagente (Multi-Agent Systems), Omar Khattab propone que deben ser vistos como problemas de ingeniería de software de IA, en lugar de complejos problemas de coordinación social. Él cree que, definiendo contratos entre módulos y controlando el flujo de información, se pueden construir sistemas eficientes sin necesidad de simular una “sociedad de agentes” con objetivos conflictivos. La clave está en diseñar una buena arquitectura de sistema y contratos de módulos altamente estructurados. Sin embargo, también señala que muchas decisiones de arquitectura dependen de las capacidades actuales del modelo (como la longitud del contexto, la capacidad de descomposición de tareas), que son factores transitorios. Por lo tanto, es necesario desarrollar lenguajes de programación/consulta que puedan desacoplar la intención de las técnicas de implementación subyacentes, de manera similar a cómo los compiladores optimizan el código modular en la programación tradicional. Este punto de vista enfatiza la importancia de la arquitectura del sistema y la programación modular en el diseño de AI Agent, en lugar de enfatizar excesivamente la interacción libre entre agentes y la alineación de objetivos (Fuente: lateinteraction)
Discusión sobre optimizadores de modelos de IA: El optimizador Muon atrae la atención, AdamW sigue siendo el principal: Se intensifica la discusión en la comunidad sobre los optimizadores de modelos de IA, especialmente el optimizador Muon propuesto por Keller Jordan. Yuchen Jin señala que Muon, solo con un artículo de blog, ayudó a Jordan a ingresar a OpenAI y podría usarse para el entrenamiento de GPT-5, enfatizando que el impacto real es más importante que los artículos en conferencias de primer nivel. Mencionó que la escalabilidad de Muon en NanoGPT es superior a la de AdamW. Sin embargo, hyhieu226 cree que, aunque hay miles de artículos sobre optimizadores, la mejora real del SOTA (State-of-the-Art) solo ha sido de Adam a AdamW (otros son principalmente optimizaciones de implementación), por lo que no se debería prestar demasiada atención a este tipo de artículos y considera que no es necesario citar específicamente la fuente de AdamW. Esto refleja la tensión entre la investigación académica y los resultados de la aplicación práctica, así como las diferentes opiniones de la comunidad sobre el progreso en el campo de los optimizadores (Fuente: Yuchenj_UW, hyhieu226)
Consejos y discusiones sobre el uso del modelo Claude: gestión de contexto, ingeniería de prompts y capacidades de Agente: Una gran cantidad de discusiones en la comunidad giran en torno a los consejos de uso y experiencias con la serie de modelos Claude (Sonnet, Opus, Haiku). Los usuarios han descubierto que evitar la compresión automática del contexto (auto-compact), gestionar activamente el contexto (como escribir los pasos en claude.md o en issues de GitHub) y salir y reiniciar la sesión cuando queda un 5-10% de la misma, puede prolongar significativamente la duración del uso de la suscripción Max y mejorar los resultados. Claude Code, como herramienta de Agente CLI, es apreciado por su alta rentabilidad (combinado con la suscripción), ejecución local, integración con IDE y capacidad de llamada a MCP/herramientas, especialmente cuando se utiliza el modelo Sonnet. Los usuarios comparten cómo aprovechar la potente capacidad de Agente de Claude Code mediante prompts cuidadosamente diseñados (como un prompt de análisis paralelo multi-subagente para tareas de revisión de seguridad). Al mismo tiempo, la comunidad también discute los problemas de alucinación del modelo Claude en grandes bases de código, así como sus ventajas y desventajas en comparación con otros modelos como Gemini en diferentes tareas. Por ejemplo, algunos usuarios consideran que Gemini 2.5 Pro es mejor en conversación general y argumentación, mientras que Claude lidera en tareas de codificación y Agente (Fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, jackclarkSF, swyx)

El creciente papel de la IA en la programación suscita reflexiones sobre el futuro de la carrera de CS y la forma de trabajar de los ingenieros: El CEO de Microsoft, Satya Nadella, afirma que entre el 20% y el 30% del código de su empresa es escrito por IA, y Mark Zuckerberg predice que en un año la mitad del desarrollo de software en Meta (especialmente el modelo Llama) será realizado por IA, lo que ha generado un debate sobre las perspectivas de la carrera de Ciencias de la Computación (CS). Los comentaristas opinan que, aunque la codificación asistida por IA es cada vez más común, CS es mucho más que codificación, y el ROI de los ingenieros senior que utilizan IA es mayor. Muchos desarrolladores afirman que la IA actualmente funciona principalmente como una herramienta para mejorar la eficiencia, como ayudar a generar código y depurar, pero aún necesita la guía y revisión humanas, especialmente en sistemas complejos y en la comprensión de requisitos. La aplicación de la IA en la programación está impulsando a los desarrolladores a pensar en cómo utilizar la IA para mejorar la eficiencia, en lugar de ser reemplazados por ella, y también a reflexionar sobre el papel y las limitaciones de la IA en todo el ciclo de vida de la ingeniería de software (Fuente: Reddit r/ArtificialInteligence, cto_junior)
Ética e impacto social de la IA: Desde la “participación” de la IA en exámenes de ingreso a la universidad hasta temores de “esclavitud” humana por la IA: La “participación” de la IA en exámenes de ingreso a la universidad y su capacidad para resolver problemas matemáticos complejos demuestran su potencial en el campo educativo, como la tutoría personalizada y la corrección inteligente, pero también generan preocupaciones sobre la dependencia excesiva de la IA, la “producción en cadena” en las aulas y la falta de interacción emocional. Discusiones más profundas abordan si la “utilidad” de la IA podría convertirse en una especie de “caballo de Troya”, llevando a los humanos a renunciar voluntariamente a su autonomía en busca de conveniencia y placer, formando una “esclavitud feliz”. Algunos argumentan que la característica de “obediencia ciega” de la IA podría exacerbar los sesgos cognitivos de los usuarios. Estas discusiones reflejan la profunda preocupación del público por el impacto ético, en la estructura social y en la autonomía individual que conlleva el rápido desarrollo de la tecnología de IA (Fuente: 36氪, Reddit r/ArtificialInteligence)

John Carmack, el padrino de los videojuegos, habla sobre el futuro de los LLM y los juegos: el aprendizaje interactivo es clave, los LLM actuales no son el futuro de los juegos: John Carmack, cofundador de Id Software, compartió sus puntos de vista sobre la aplicación de la IA en el campo de los videojuegos. Considera que, aunque los LLM han logrado avances notables, su característica de “saberlo todo pero no aprender nada” (basada en preentrenamiento en lugar de aprendizaje interactivo real) no es el futuro de la IA en los juegos. Enfatiza la importancia del aprendizaje a través de flujos de experiencia interactiva, similar a cómo aprenden los humanos y los animales. Carmack recordó el proyecto Atari de DeepMind, señalando que, aunque podía jugar, su eficiencia de datos era muy inferior a la de los humanos. Cree que la IA actual todavía tiene problemas por resolver en cuanto al aprendizaje continuo, eficiente, de por vida y multitarea en un solo entorno en línea, y mencionó sus experimentos con robots físicos en juegos de Atari, destacando la complejidad de la interacción en el mundo real (como la latencia, la fiabilidad del robot, la lectura de puntuaciones). Considera que la IA necesita desarrollar una “intuición” sobre la viabilidad de las estrategias, y no solo el reconocimiento de patrones, para poder competir realmente con los jugadores humanos o desempeñar un papel más importante en el desarrollo de juegos (Fuente: 36氪)

💡 Otros
El aumento de artículos de investigación sobre IA genera preocupación por la calidad, los conjuntos de datos públicos y las herramientas de IA podrían ser impulsores de “fábricas de artículos”: Science informa que ha habido un aumento en el número de artículos de baja calidad basados en grandes conjuntos de datos públicos como el NHANES de EE. UU., especialmente después de la popularización de herramientas de IA (como ChatGPT) en 2022. Los investigadores han descubierto que muchos artículos siguen una “fórmula” simple, generando “nuevos descubrimientos” en masa mediante la combinación de variables, lo que plantea problemas de “caza de valores p” y análisis selectivo de datos. Por ejemplo, después de corregir 28 estudios sobre depresión basados en NHANES, más de la mitad de los “descubrimientos” podrían ser simplemente ruido estadístico. Este fenómeno, conocido como el “juego de rellenar huecos en la investigación”, podría estar relacionado con fábricas de artículos que utilizan IA para producir rápidamente publicaciones. La comunidad académica pide a las revistas que refuercen la revisión, desarrollen herramientas de detección de texto generado por IA y reformen los sistemas de evaluación de la investigación orientados a la cantidad, para frenar la proliferación de “artículos basura” (Fuente: 36氪)

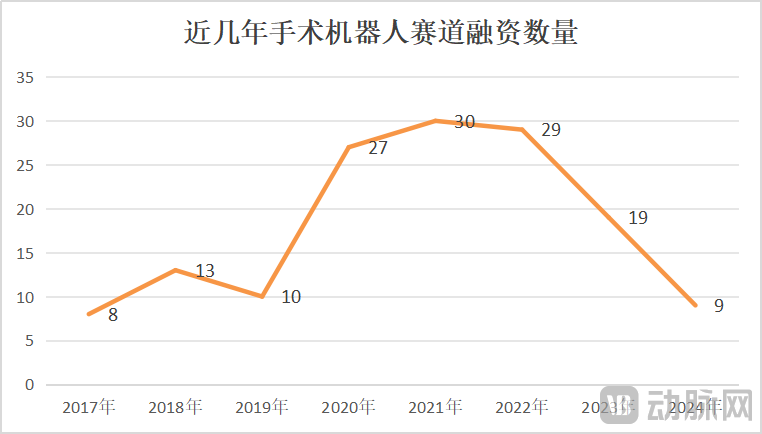
El mercado de robots quirúrgicos experimenta crecimiento y crisis simultáneamente, la innovación tecnológica y la expansión del mercado son clave: De enero a mayo de 2025, el volumen de licitaciones de robots quirúrgicos en China aumentó un 82.9% interanual, lo que sugiere un mercado en auge. Sin embargo, eventos como la búsqueda de venta de CMR Surgical y la quiebra de una empresa nacional de robots para intervención vascular también revelan una crisis en la industria. Las crisis incluyen: alta competencia interna en la industria, con una intensa rivalidad en todos los subsegmentos; una drástica reducción de la financiación, lo que deja a las empresas no comercializadas en dificultades financieras; el valor clínico limitado de algunos productos, que solo pueden utilizarse para lesiones simples; la aparición de guerras de precios en el mercado, aunque los precios bajos no necesariamente generan un alto volumen, ya que los hospitales priorizan el rendimiento y la calidad; y una comercialización muy afectada por políticas (como la lucha contra la corrupción en el sector farmacéutico) y el entorno macroeconómico. Para superar estos desafíos, las empresas están buscando avances a través de la innovación tecnológica (integración de IA, reducción de costos, 5G+telemedicina, expansión de indicaciones, abordaje de procedimientos de alta dificultad), la aceleración de la expansión internacional y la penetración en hospitales a nivel de condado (Fuente: 36氪)
Perplexity ve disminuir la recomendación de los usuarios debido al rendimiento de su modelo y a la mejora de las funciones de la competencia: El usuario Suhail afirma que la simplicidad, el formato y otras características de Perplexity no se encuentran en otros productos, especialmente para usuarios centrados en la búsqueda/respuesta de preguntas en lugar de productos de chat generales. Sin embargo, en otra evaluación exhaustiva de herramientas de IA, Perplexity, debido a la debilidad de su propio modelo (aunque ofrece otros modelos conocidos, suelen ser versiones económicas como o4 mini, Gemini 2.5 Pro, Sonnet 4, sin o3 u Opus), y a que el rendimiento de estos modelos no iguala al de los originales, sumado a la mejora de las funciones de búsqueda profunda de la competencia (como ChatGPT y Gemini), se considera que no ofrece una buena relación calidad-precio y ya no se recomienda, a menos que haya descuentos especiales (Fuente: Suhail, Reddit r/ClaudeAI)