Palabras clave:Tesla Robotaxi, AMD MI350, OpenAI o3-pro, iFlytek AIUI, Yuanrong Qixing VLA, DeepSeek Nano-vLLM, Ant Group Ming Lite Omni, Vehículos de producción en masa L2 que logran autonomía L4, Comparación de rendimiento entre AMD MI350X y B200, Capacidad de procesamiento de contexto largo del modelo o3-pro, Tecnología de interacción full-duplex de AIUI, Modelo visual-lingüístico-accional VLA
🔥 Enfoque
El Robotaxi de Tesla debuta públicamente en carretera, Musk afirma que los vehículos de producción L2 pueden alcanzar la conducción autónoma de nivel L4 sin modificaciones: El Robotaxi de Tesla (Model Y actualizado) ha comenzado las pruebas en carretera en Austin, con el nuevo logo de Robotaxi en la carrocería pero conservando el volante. Musk declaró que todos los vehículos de producción de Tesla pueden lograr la conducción autónoma sin supervisión. Actualmente, los vehículos de prueba están equipados con una versión interna de FSD con 4.5 veces más parámetros que el FSD actual, y se espera que se lance optimizado este año. El Robotaxi tiene previsto abrirse al público el 22 de junio, comenzando en Austin. Este movimiento marca la evolución del FSD de nivel L2 de Tesla hacia el Robotaxi de nivel L4/L5, lo que podría acelerar el panorama competitivo de la industria de la conducción autónoma, desafiando especialmente a jugadores con rutas tecnológicas L4 como Waymo (Fuente: 量子位)

AMD lanza su chip de IA más potente, la serie MI350, superando en rendimiento al B200 de Nvidia: La CEO de AMD, Lisa Su, junto con el CEO de OpenAI, Sam Altman, presentaron las GPU MI350X y MI355X. Estos chips utilizan un proceso de 3nm, cuentan con 185 mil millones de transistores y 288GB de memoria HBM3E, 1.6 veces la capacidad de memoria del B200 de Nvidia. Los datos oficiales muestran que la serie MI350 es un 30% más rápida que el B200 en la inferencia de Llama 3.1 405B con precisión FP4, y duplica la potencia de cálculo FP64 de Nvidia. AMD también anunció la serie MI400, desarrollada conjuntamente con OpenAI, que se presentará el próximo año, intensificando aún más la competencia en el mercado de chips de IA (Fuente: 量子位)

La capacidad de inferencia del modelo o3-pro de OpenAI atrae la atención, el rendimiento real difiere ligeramente de las pruebas oficiales: El último modelo de inferencia de OpenAI, o3-pro, demostró una gran capacidad al procesar juegos de palabras complejos (como generar respuestas específicas basadas en las características de los nombres de las canciones de la cantante Sabrina Carpenter), lo que provocó que el exjefe del equipo AGI Readiness de OpenAI se burlara de las dudas previas de Apple sobre la capacidad de inferencia de los grandes modelos. Sin embargo, en rankings autorizados como LiveBench, la puntuación media de codificación de o3-pro fue casi idéntica a la de o3, e incluso inferior en la puntuación de codificación de agentes. Las pruebas de Fiction.LiveBench muestran que o3-pro tiene un rendimiento excelente en contextos cortos, pero sigue siendo inferior a Gemini 2.5 Pro en el procesamiento de contextos ultralargos de 192k. Ben Hylak, exingeniero de Apple y SpaceX, señaló que la verdadera capacidad de o3-pro depende en gran medida de una entrada suficiente de información de fondo, siendo más adecuado como generador de informes que como un simple interlocutor de chat, y presenta mejoras significativas en la invocación de herramientas y la comprensión del entorno (Fuente: 量子位)

iFlytek actualiza la plataforma de interacción humano-máquina AIUI y la plataforma Robot Super Brain, impulsando la colaboración profunda de hardware inteligente: iFlytek anunció una importante actualización de su plataforma de interacción humano-máquina AIUI, centrada en mejorar la interacción full-duplex, la percepción y expresión emocional, y un sistema de memoria similar al humano. Específicamente para escenarios infantiles, lanzó una solución de interacción exclusiva, mejorando la capacidad de reconocimiento y comprensión del habla infantil. Al mismo tiempo, su plataforma Robot Super Brain, basada en el Spark large model, ha fortalecido la interacción multimodal, la comprensión semántica y la aplicación del conocimiento, y ha lanzado una “Intelligent Voice Backpack” que permite a los robots existentes lograr la interacción por voz sin modificaciones de hardware. Estas actualizaciones tienen como objetivo llevar el hardware inteligente de la interacción básica a la colaboración inteligente profunda, potenciando múltiples campos como el automotriz, el hardware de IA y la robótica (Fuente: 量子位)

🎯 Tendencias
DeepRoute.ai colabora con Volcengine para desarrollar un Physical World Agent VLA basado en el Doubao large model: Zhou Guang, CEO de DeepRoute.ai, anunció una colaboración con Volcengine para desarrollar conjuntamente tecnologías prospectivas como el modelo visión-lenguaje-acción (VLA), con el objetivo de crear un Agent para el mundo físico. El modelo VLA de DeepRoute.ai se lanzará al mercado de consumo en el tercer trimestre de 2025, con cuatro funciones principales: comprensión semántica espacial, reconocimiento de obstáculos de forma irregular, comprensión de señales de texto y control por voz del vehículo, con el fin de mejorar la seguridad y la inteligencia de la conducción asistida. Actualmente, el modelo VLA ha completado las pruebas en carretera y se espera que más de 5 modelos de automóviles con IA equipados con este modelo salgan al mercado este año (Fuente: 量子位)

Investigador de DeepSeek replica vLLM con 1200 líneas de código, superando su rendimiento en algunos escenarios: Yu Xingkai, investigador de DeepSeek, ha hecho público el proyecto Nano-vLLM, que implementa las funciones principales de vLLM, incluyendo tecnologías clave como PagedAttention, en menos de 1200 líneas de código Python. El proyecto tiene como objetivo proporcionar una versión minimizada y completamente legible de vLLM para facilitar su aprendizaje y comprensión. En condiciones de prueba específicas con hardware H800 y el modelo Qwen3-8B, el rendimiento (throughput) de Nano-vLLM incluso superó al vLLM original, demostrando su eficiencia. vLLM es un framework de inferencia y servicio para LLM desarrollado por UC Berkeley, conocido por su algoritmo PagedAttention que mejora significativamente el rendimiento de los servicios LLM (Fuente: 量子位)
Empresas chinas utilizan “cajas de discos duros voladoras” para eludir las restricciones de exportación de chips de IA de EE. UU.: Según el Wall Street Journal, ante las restricciones de EE. UU. a la exportación de chips de IA de alta gama, las empresas chinas han adoptado una nueva estrategia: ingenieros transportan discos duros con grandes cantidades de datos de entrenamiento (por ejemplo, 80TB) a centros de datos en el extranjero, como Malasia, para utilizar servidores equipados con chips avanzados de Nvidia y otros para entrenar modelos de IA. Una vez completado, los parámetros del modelo se devuelven a China. Esta medida tiene como objetivo eludir las dificultades de la importación directa de chips e ha impulsado el auge de los centros de datos de IA en el sudeste asiático y Oriente Medio. Exfuncionarios del Departamento de Comercio de EE. UU. han expresado su preocupación al respecto (Fuente: dotey)

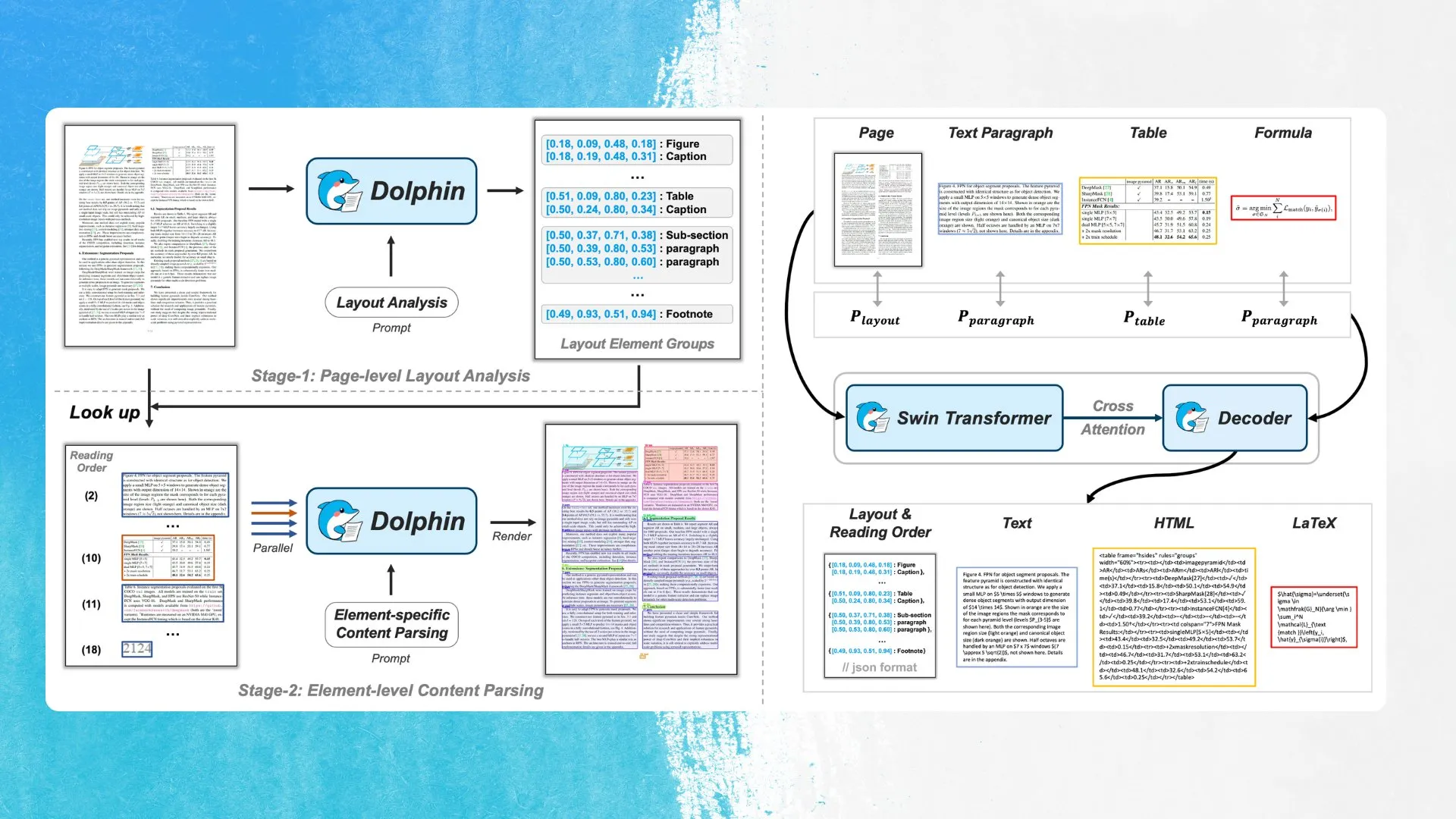
ByteDance lanza el nuevo modelo OCR Dolphin, que utiliza detección de elementos de diseño y análisis en paralelo: ByteDance ha lanzado un nuevo modelo OCR llamado Dolphin bajo la licencia MIT. El modelo primero detecta elementos en el diseño del documento (como tablas, fórmulas, etc.) y luego analiza cada elemento en paralelo para generar el contenido. El modelo y la demostración ya están disponibles en Hugging Face Hub. Este método tiene como objetivo mejorar la precisión y eficiencia en el reconocimiento de estructuras de documentos complejas (Fuente: mervenoyann)
OpenAI mejora la funcionalidad de Proyectos en ChatGPT, añadiendo soporte para investigación profunda, modo de voz y carga de archivos en móviles: OpenAI ha anunciado varias mejoras para la función “Projects” (Proyectos) en ChatGPT, incluyendo un soporte mejorado para la investigación profunda, la integración del modo de voz, una función de memoria mejorada para citar chats anteriores dentro del proyecto, y soporte para la carga de archivos y selector de modelos en dispositivos móviles. Estas actualizaciones tienen como objetivo mejorar la capacidad de los usuarios para realizar trabajos más enfocados y complejos dentro de ChatGPT (Fuente: kevinweil)
El equipo de EuroLLM lanza versiones preliminares de varios modelos nuevos, incluyendo un modelo de 22B y un pequeño modelo MoE: El equipo de EuroLLM ha lanzado versiones preliminares de varios modelos nuevos, incluyendo un modelo base de 22B parámetros y una versión ajustada por instrucciones, dos modelos visuales basados en versiones anteriores de EuroLLM (1.7B y 9B parámetros), y un pequeño modelo de mezcla de expertos (MoE) con 0.6B parámetros activos y 2.6B parámetros totales. Todos estos modelos utilizan la licencia Apache-2.0, y las pruebas iniciales indican que el pequeño modelo MoE funciona sorprendentemente bien para su tamaño (Fuente: Reddit r/LocalLLaMA)

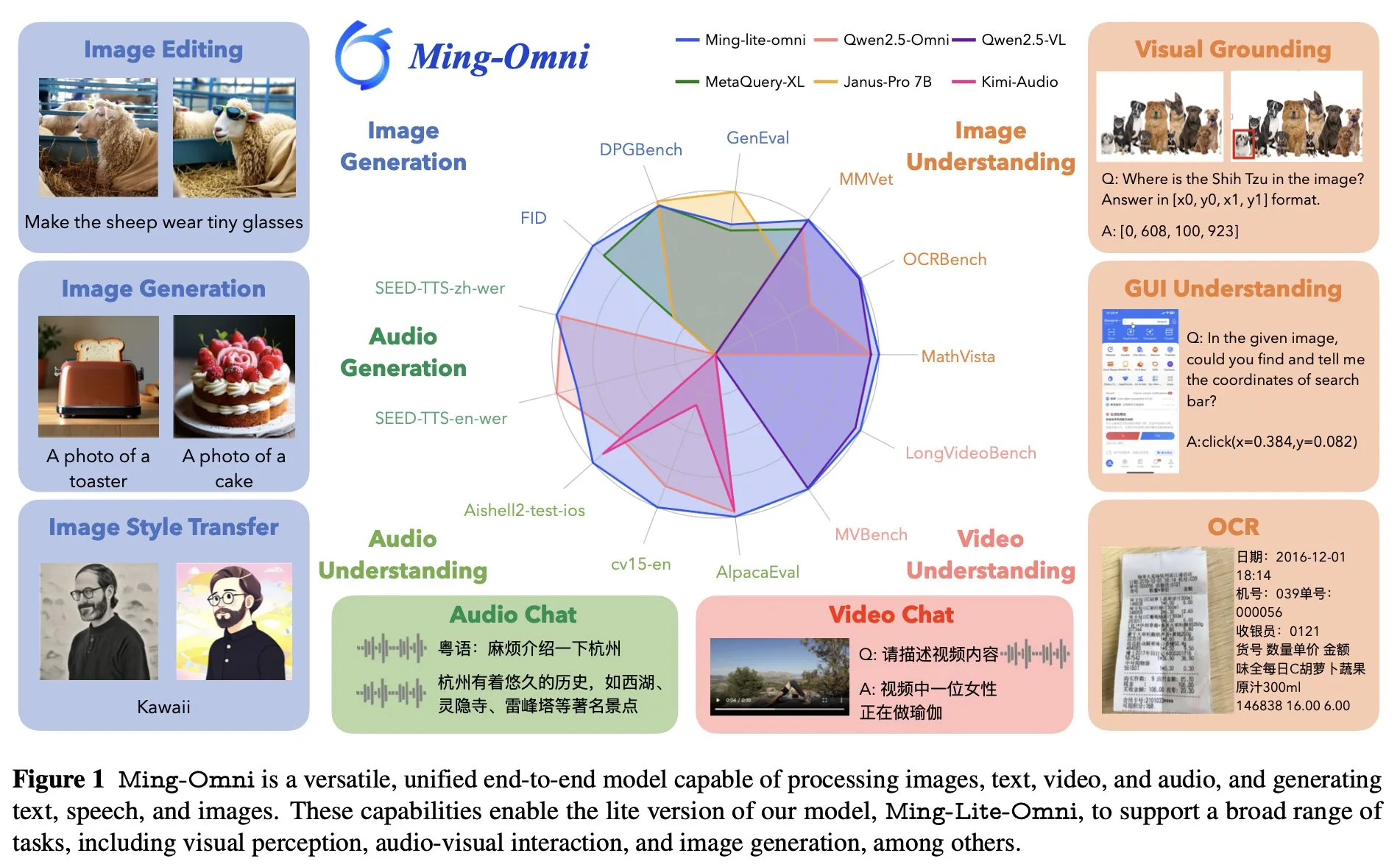
Ant Group lanza el modelo omnipotente de extremo a extremo Ming Lite Omni, compitiendo con GPT-4o: Ant Group ha presentado el modelo Ming Lite Omni, capaz de realizar múltiples funciones como escuchar, hablar y generar imágenes, compitiendo en rendimiento con GPT-4o. Ming Lite Omni supera a Qwen2.5VL-7B en precisión en tareas GUI, alcanza el estado del arte (SOTA) en comprensión de audio en varios benchmarks públicos, y también muestra un excelente rendimiento en comprensión de video. El modelo utiliza una arquitectura de mezcla de expertos (MoE) con solo 2.8B parámetros activos y está optimizado específicamente para la generación de audio e imágenes, como el uso de BPE para reducir la tasa de fotogramas de tokens de audio y tokens aprendibles multiescala para mejorar la calidad de la generación de imágenes (Fuente: mervenoyann)
NVIDIA y Mistral AI colaboran para construir la plataforma de nube de IA Mistral Compute: NVIDIA anunció en la GTC su colaboración con Mistral AI para crear conjuntamente una plataforma de nube de IA llamada Mistral Compute. Esta medida se considera un gran beneficio para Estados Unidos y la comunidad de código abierto, con el objetivo de proporcionar una plantilla para la construcción de infraestructura de IA global a través de modelos abiertos respaldados por chips estadounidenses (Fuente: arthurmensch)
Hugging Face anuncia su adopción total de PyTorch, simplificando la librería Transformers: Lysandre Jik, Director de Código Abierto de Hugging Face, declaró que, dado que la base de usuarios ya ha llegado a un consenso sobre PyTorch, en el futuro concentrarán todos sus esfuerzos en PyTorch para reducir la hinchazón de la librería Transformers, comprometiéndose a ofrecer un conjunto de herramientas más conciso. PyTorch oficial dio la bienvenida a esta decisión y enfatizó que ayudará a mantener la simplicidad del código (Fuente: reach_vb)

ByteDance presenta la tecnología de generación de video interactivo en tiempo real APT2: ByteDance ha mostrado su última tecnología de generación de video interactivo en tiempo real, APT2 (Autoregressive Adversarial Post-Training). Esta tecnología, mediante el post-entrenamiento autorregresivo adversarial, tiene como objetivo lograr la generación de contenido de video interactivo de alta calidad y en tiempo real, impulsando aún más el desarrollo en el campo de la generación de video (Fuente: NerdyRodent)
🧰 Herramientas
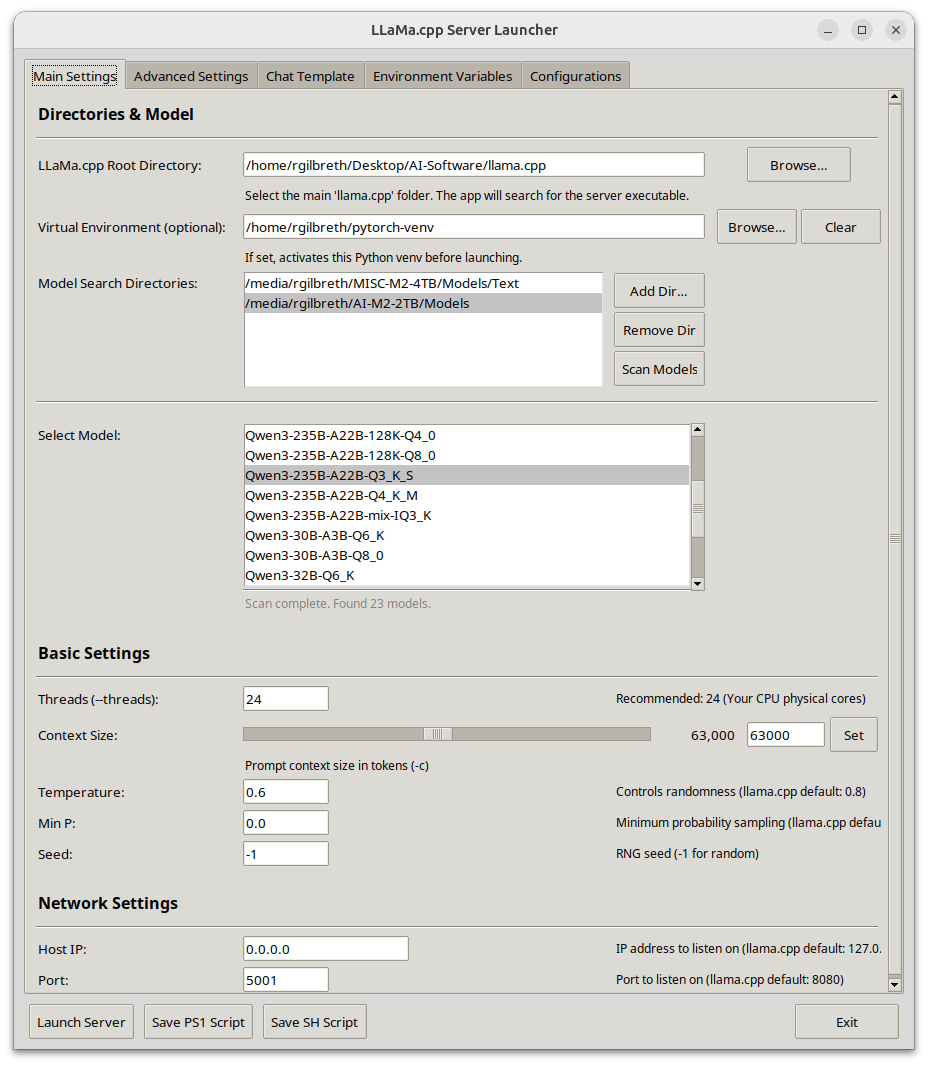
Llama-Server Launcher: un lanzador de servidor llama.cpp con GUI, enfocado en la optimización del rendimiento de CUDA: Un desarrollador compartió su lanzador personal para llama-server, escrito en Python y con una interfaz gráfica de usuario (GUI). La herramienta tiene como objetivo simplificar la configuración y el inicio de los servicios de llama.cpp, con especial atención a la optimización del rendimiento de CUDA. Las funciones incluyen selección de modelos, configuración de rutas, ajuste del tamaño del contexto y del lote, descarga a GPU, FlashAttention, división de tensores y otras configuraciones avanzadas de rendimiento, así como selección de plantillas de chat y gestión de la configuración del entorno. Admite la obtención automática de información de la GPU y del sistema, analiza los metadatos del modelo GGUF y puede generar scripts de inicio multiplataforma (.ps1/.sh) (Fuente: Reddit r/LocalLLaMA)
Together AI lanza un agente de científico de datos de código abierto: Together AI ha construido un agente de IA de código abierto capaz de razonar como un científico de datos. El agente puede cargar datos, escribir código Python, reentrenar modelos cuando fallan y resolver tareas reales de Kaggle y DABStep. Esta iniciativa tiene como objetivo impulsar la automatización y la democratización de la IA en el campo de la ciencia de datos (Fuente: percyliang)
AutoMind: un framework de agente adaptativo basado en conocimiento para la automatización de la ciencia de datos: AutoMind es un nuevo framework de agente LLM diseñado para superar las limitaciones de los agentes de ciencia de datos existentes al abordar tareas complejas e innovadoras, mediante la integración de bases de conocimiento expertas, la adopción de un algoritmo de búsqueda en árbol de conocimiento del agente y estrategias de codificación adaptativas, mejorando así la eficacia en el mundo real de los flujos de trabajo de aprendizaje automático automatizado (Fuente: HuggingFace Daily Papers)
LlamaParse lanza la función “Presets” para simplificar la configuración del análisis de documentos: LlamaParse ha introducido la función “Presets” (Preajustes), que ofrece una serie de modos preconfigurados fáciles de entender para optimizar la configuración en diferentes casos de uso. Incluye modos rápido, equilibrado y avanzado para escenarios generales, así como modos optimizados para casos de uso comunes como facturas, artículos de investigación, documentos técnicos y formularios, con el objetivo de permitir a los usuarios elegir más fácilmente entre velocidad y precisión (Fuente: jerryjliu0)
OpenWebUI añade soporte para o3-pro, ampliando la compatibilidad de modelos: Un desarrollador de la comunidad ha creado una nueva función para Open WebUI que amplía el soporte para el modelo o3-pro mediante la adición de soporte para la API de respuesta, seguimiento de costos, soporte para múltiples claves y búsqueda web, entre otras características. Esto permite a los usuarios utilizar o3-pro en Open WebUI sin necesidad de suscribirse al plan premium oficial (Fuente: Reddit r/OpenWebUI)
📚 Aprendizaje
Artículo explora la descomposición de activaciones de MLP en características interpretables mediante la descomposición matricial semi-no negativa (SNMF): Esta investigación propone el uso de SNMF para descomponer directamente las activaciones de perceptrones multicapa (MLP) con el fin de aprender características dispersas, constituidas por combinaciones lineales de neuronas coactivadas, y mapear estas características a sus entradas de activación, haciéndolas así directamente interpretables. Los experimentos demuestran que las características derivadas de SNMF superan a los autoencoders dispersos (SAE) en la orientación causal y se alinean con conceptos interpretables por humanos, revelando una estructura jerárquica en el espacio de activación de los MLP (Fuente: HuggingFace Daily Papers)
Nuevo artículo propone LoRMA: un nuevo paradigma para el ajuste fino de LLM mediante Adaptación Multiplicativa de Bajo Rango (Low-Rank Multiplicative Adaptation): El ajuste fino tradicional de LLM generalmente actualiza los pesos mediante adición, mientras que LoRMA explora las actualizaciones multiplicativas. Para abordar el problema de la “supresión de rango” causado por las matrices de bajo rango, el artículo introduce nuevas operaciones de expansión de rango basadas en permutación y adición, y asegura la eficiencia computacional mediante operaciones efectivas de reordenamiento. Los experimentos demuestran que LoRMA es competitivo, ofreciendo nuevas ideas para la adaptación de LLM (Fuente: Reddit r/deeplearning)
Artículo propone el framework TaxoAdapt, que permite que las taxonomías multidimensionales construidas por LLM se adapten a corpus de investigación en evolución: Para abordar el desafío de organizar la literatura científica, el framework TaxoAdapt puede ajustar dinámicamente las taxonomías generadas por LLM para adaptarse a corpus específicos, y admite múltiples dimensiones (como metodología, tarea, métricas de evaluación). El framework, mediante clasificación jerárquica iterativa, expande la amplitud y profundidad de la clasificación según la distribución temática del corpus, con el objetivo de organizar y capturar mejor la evolución de los campos científicos (Fuente: HuggingFace Daily Papers)
Artículo presenta el framework MOSAIC, que implementa el aprendizaje colaborativo en sistemas de agentes: MOSAIC es un framework para el aprendizaje colaborativo en sistemas de IA autónomos y agénticos en entornos descentralizados y dinámicos. Los agentes comparten y reutilizan selectivamente conocimiento modular (en forma de máscaras de redes neuronales), sin necesidad de sincronización o control centralizado. Los experimentos demuestran que MOSAIC supera en velocidad y rendimiento a los aprendices aislados, a veces resolviendo tareas que los agentes aislados no pueden, y puede promover la eficiencia colectiva y la adaptabilidad (Fuente: Reddit r/MachineLearning)
Artículo propone el framework ClaimSpect para el análisis jerárquico mejorado por recuperación de afirmaciones complejas: Muchas afirmaciones (como las científicas o políticas) no son simplemente verdaderas o falsas. El framework ClaimSpect, mediante la generación mejorada por recuperación, construye automáticamente una estructura jerárquica de aspectos relacionados con una afirmación y enriquece estos aspectos con perspectivas de un corpus específico. Este método tiene como objetivo deconstruir afirmaciones complejas y presentar las diferentes perspectivas sobre cada aspecto dentro del corpus y su prevalencia (Fuente: HuggingFace Daily Papers)
Artículo propone la guía de perturbación de grano fino (Fine-Grained Perturbation Guidance) mediante la selección de cabezales de atención: Esta investigación descubre que cabezales de atención específicos en los modelos de difusión controlan diferentes conceptos visuales (como estructura, estilo, calidad de textura). Basándose en esto, el artículo propone el framework “HeadHunter”, que selecciona sistemáticamente los cabezales de atención consistentes con los objetivos del usuario, logrando un control de grano fino sobre la calidad de generación y los atributos visuales, e introduce SoftPAG para ajustar la intensidad de la perturbación. Este método ha demostrado su superioridad en la mejora de la calidad y la guía de estilo en modelos como Stable Diffusion 3 y FLUX.1 (Fuente: HuggingFace Daily Papers)
Artículo explora que el desaprendizaje en LLM debe ser independiente de la forma (Form-Independent): La investigación señala que la efectividad de los métodos actuales de desaprendizaje (unlearning) en LLM depende en gran medida de la forma de las muestras de entrenamiento, lo que dificulta la generalización a diferentes expresiones del mismo conocimiento. El artículo define este problema como “Sesgo Dependiente de la Forma” (Form-Dependent Bias) e introduce el benchmark ORT para su evaluación. Para resolver este problema, el artículo propone el método ROCR (Rank-one Concept Redirection), que logra el desaprendizaje redirigiendo la percepción del modelo sobre conceptos específicos. Los experimentos demuestran que ROCR mejora significativamente la efectividad del desaprendizaje y puede generar resultados naturales (Fuente: HuggingFace Daily Papers)
Artículo propone UniPre3D: un método de preentrenamiento unificado para modelos de nubes de puntos 3D basado en Gaussian Splatting transmodal: UniPre3D tiene como objetivo abordar los desafíos que plantea la diversidad de escalas de los datos de nubes de puntos en la visión 3D, proponiendo el primer método de preentrenamiento unificado que se puede aplicar sin problemas a nubes de puntos de cualquier escala y a cualquier arquitectura de modelo 3D. El método predice primitivas gaussianas como tarea de preentrenamiento y utiliza el renderizado diferenciable mediante Gaussian Splatting para lograr una supervisión precisa a nivel de píxel y una optimización de extremo a extremo, al tiempo que integra características de modelos preentrenados 2D para introducir conocimiento de texturas (Fuente: HuggingFace Daily Papers)
Artículo propone StreamSplat: reconstrucción 3D dinámica en línea para flujos de video no calibrados: StreamSplat es un framework completamente feed-forward capaz de convertir en línea flujos de video no calibrados de cualquier longitud en representaciones dinámicas de Gaussian Splatting 3D (3DGS). Mediante un mecanismo de muestreo probabilístico en el codificador estático para predecir las posiciones 3DGS, y un campo de deformación bidireccional en el decodificador dinámico, logra un modelado dinámico robusto y eficiente, con el objetivo de resolver los desafíos de calibración, modelado dinámico y estabilidad de eficiencia en la reconstrucción de escenas dinámicas en tiempo real (Fuente: HuggingFace Daily Papers)
Artículo revisa el sondeo atento (Attentive Probing) en el modelado de imágenes enmascaradas: A medida que el ajuste fino a gran escala se vuelve impracticable, el sondeo (probing) se ha convertido en la opción preferida para la evaluación del aprendizaje autosupervisado (SSL). El sondeo lineal estándar (LP) no refleja adecuadamente el potencial de los modelos entrenados con modelado de imágenes enmascaradas (MIM). Este artículo reconsidera el sondeo atento, introduciendo el sondeo eficiente (EP), un mecanismo de atención cruzada multiconsulta que reduce los parámetros entrenables y mejora la velocidad, superando a LP y a métodos anteriores de sondeo atento en múltiples benchmarks (Fuente: HuggingFace Daily Papers)
Artículo propone PosterCraft: nuevas ideas para la generación de pósteres estéticos de alta calidad bajo un marco unificado: PosterCraft tiene como objetivo abordar el desafío de generar pósteres estéticos, que no solo requiere una representación precisa del texto, sino también la integración perfecta de contenido artístico abstracto, diseños atractivos y una armonía estilística general. PosterCraft adopta un flujo de trabajo en cascada para optimizar la generación, incluyendo la optimización de la representación de texto a gran escala, el ajuste fino supervisado consciente de la región, el aprendizaje por refuerzo para texto estético y el refinamiento conjunto mediante retroalimentación visual y lingüística, superando significativamente a las líneas base de código abierto en múltiples experimentos (Fuente: HuggingFace Daily Papers)
Artículo propone mejorar los modelos de difusión mediante la guía de perturbación de tokens (Token Perturbation Guidance): Para abordar las limitaciones de la guía independiente del clasificador (CFG), que requiere un proceso de entrenamiento específico y se limita a la generación condicional, el método TPG aplica matrices de perturbación directamente a las representaciones intermedias de tokens dentro de la red de difusión. TPG utiliza una operación de barajado que conserva la norma para proporcionar una señal de guía efectiva, mejorando la calidad de la generación sin necesidad de cambios en la arquitectura, y es aplicable tanto a la generación condicional como incondicional. Los experimentos muestran que TPG logra una mejora de casi 2 veces en el FID para la línea base SDXL en la generación incondicional (Fuente: HuggingFace Daily Papers)
Artículo propone DreamActor-H1: generación de videos de demostración persona-producto de alta fidelidad mediante Diffusion Transformers con diseño de movimiento: DreamActor-H1 es un framework basado en Diffusion Transformer (DiT) diseñado para generar videos de demostración de alta calidad de interacciones entre personas y productos. Este método inyecta información de referencia emparejada persona-producto y un mecanismo adicional de atención cruzada enmascarada, preservando al mismo tiempo los detalles de identidad de la persona y el producto (como logotipos, texturas). Utiliza plantillas de malla humana 3D y cuadros delimitadores de productos para proporcionar una guía de movimiento precisa, y mejora la consistencia 3D mediante una codificación de texto estructurada (Fuente: HuggingFace Daily Papers)
Artículo propone EmbodiedGen: un motor generativo de mundos 3D para la inteligencia corporeizada: EmbodiedGen es una plataforma fundamental para la generación interactiva de mundos 3D, diseñada para generar de manera escalable y a bajo costo activos 3D fotorrealistas, controlables y de alta calidad, que poseen propiedades físicas precisas y escala del mundo real, y utilizan el formato de descripción unificado de robots (URDF). Estos activos se pueden importar directamente a varios motores de simulación física, apoyando tareas de entrenamiento y evaluación para la inteligencia corporeizada, y resolviendo los problemas de alto costo y realismo limitado de los activos gráficos 3D tradicionales (Fuente: HuggingFace Daily Papers)
Nueva investigación refuta el artículo de Apple sobre la “ilusión del pensamiento”, argumentando que los LLM pueden resolver problemas complejos nuevos: En respuesta al reciente artículo de Apple “Illusion of Thinking”, que afirmaba que los grandes modelos de razonamiento (LRM) experimentan un “colapso de precisión” en rompecabezas de planificación complejos (como las Torres de Hanói), un estudio de comentario posterior señala que las conclusiones de Apple reflejan principalmente las limitaciones del diseño experimental en lugar de un fallo fundamental en la capacidad de razonamiento de los modelos. La nueva investigación argumenta que el exceso de presupuesto de tokens en el experimento original, la evaluación errónea de salidas deliberadamente truncadas y la inclusión de instancias de rompecabezas matemáticamente irresolubles contribuyeron conjuntamente a una mala interpretación de las capacidades del modelo. Al ajustar los métodos experimentales, por ejemplo, pidiendo al modelo que genere una función Lua compacta para resolver las Torres de Hanói en lugar de una lista exhaustiva de pasos, el modelo mostró una alta precisión en casos previamente reportados como fallos completos, lo que indica que los modelos no son incapaces de razonar, sino que están limitados por el formato de salida y las restricciones de tokens (Fuente: Reddit r/LocalLLaMA)

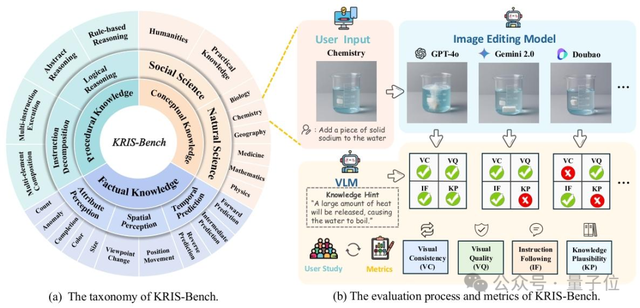
KRIS-Bench: Nuevo benchmark para evaluar integralmente la capacidad de inferencia de modelos de edición de imágenes desde la perspectiva de los tipos de conocimiento: La Universidad del Sudeste y otras instituciones han lanzado conjuntamente KRIS-Bench, un benchmark basado en el conocimiento para la capacidad de inferencia de los sistemas de edición de imágenes. Evalúa 10 modelos de edición de imágenes principales (incluidos GPT-Image-1, Gemini 2.0 Flash, etc.) en tres niveles: conocimiento factual (como color, cantidad), conocimiento conceptual (como sentido común físico) y conocimiento procedimental (como operaciones de varios pasos), subdivididos en 22 tareas de edición. Los resultados muestran que el modelo de código cerrado GPT-Image-1 tuvo el mejor rendimiento, pero todos los modelos generalmente tuvieron un bajo rendimiento en tareas de razonamiento profundo como el razonamiento procedimental, las ciencias naturales y la síntesis de varios pasos, revelando las deficiencias de los modelos actuales en capacidades cognitivas avanzadas (Fuente: 量子位)
Nueva investigación propone el método Finetune-RAG para ajustar modelos de lenguaje y resistir las alucinaciones en RAG: Los grandes modelos de lenguaje en la generación aumentada por recuperación (RAG) tienden a producir alucinaciones cuando la recuperación no es perfecta (por ejemplo, debido a fragmentos de documentos distractores). Finetune-RAG entrena al modelo con muestras de entrada que contienen contextos correctos e incorrectos, permitiéndole mantener mejor la veracidad. El equipo de investigación ha publicado un conjunto de datos con más de 1600 muestras de doble contexto, un checkpoint ajustado de LLaMA 3.1-8B-Instruct y un marco de evaluación GPT-4o llamado Bench-RAG. La evaluación muestra que este método aumentó la precisión del 77% al 98% y también mejoró la utilidad, relevancia y profundidad (Fuente: Reddit r/MachineLearning)
TeleMath: Se publica el primer benchmark LLM para la capacidad de resolución de problemas matemáticos en el sector de las telecomunicaciones: Para evaluar la capacidad de los grandes modelos de lenguaje para resolver tareas específicas y con gran carga matemática en el dominio de las telecomunicaciones, los investigadores han lanzado el benchmark TeleMath. Este benchmark contiene 500 pares de preguntas y respuestas que cubren temas de telecomunicaciones como el procesamiento de señales, la optimización de redes y el análisis de rendimiento. La evaluación de varios LLM de código abierto mostró que los modelos diseñados específicamente para el razonamiento matemático o lógico obtuvieron mejores resultados en TeleMath, mientras que los modelos generales de gran cantidad de parámetros a menudo encontraron dificultades. El conjunto de datos y el código de evaluación están disponibles públicamente (Fuente: HuggingFace Daily Papers)
ChineseHarm-Bench: Publicado benchmark para la detección de contenido dañino en chino: Ante la situación de que los recursos existentes para la detección de contenido dañino son mayoritariamente en inglés, los investigadores han publicado ChineseHarm-Bench, un benchmark completo y anotado profesionalmente para la detección de contenido dañino en chino. El benchmark cubre seis categorías representativas, con datos completamente extraídos del mundo real. El proceso de anotación también produjo una base de reglas de conocimiento, proporcionando a los LLM conocimiento experto explícito. Además, los investigadores proponen un método de línea base mejorado por conocimiento, que combina reglas anotadas manualmente y el conocimiento implícito de los LLM, permitiendo que modelos más pequeños alcancen el rendimiento de los LLM SOTA (Fuente: HuggingFace Daily Papers)
Nueva investigación descubre una estructura jerárquica de capacidades latentes en modelos de lenguaje mediante el aprendizaje de representación causal: Para evaluar fielmente las capacidades de los modelos de lenguaje y superar los efectos de confusión y los altos costos computacionales, este estudio propone un marco de aprendizaje de representación causal. Este marco modela el rendimiento observado en los benchmarks como una transformación lineal de unos pocos factores de capacidad latente y, después de controlar el modelo base como un factor de confusión común, identifica las relaciones causales entre estos factores latentes. Aplicado a datos de más de 1500 modelos del Open LLM Leaderboard, el estudio descubrió una concisa estructura causal lineal de tres nodos, revelando una clara ruta causal desde la capacidad general de resolución de problemas hasta la competencia en el seguimiento de instrucciones y, finalmente, hasta la capacidad de razonamiento matemático (Fuente: HuggingFace Daily Papers)
DeepLearning.AI lanza nuevo curso “Orquestación de flujos de trabajo para aplicaciones GenAI”: Andrew Ng anunció una colaboración con Astronomer para lanzar un nuevo curso corto que enseña cómo construir e implementar pipelines de IA generativa fiables utilizando la popular herramienta de código abierto Airflow 3.0. El contenido del curso incluye la descomposición de flujos de trabajo en tareas discretas, programación de tareas, ejecución en paralelo, recuperación de fallos y observabilidad, entre otros, con el objetivo de ayudar a los alumnos a transformar prototipos de cuadernos Jupyter o scripts Python en flujos de trabajo listos para producción (Fuente: DeepLearningAI)
Artículo explora métodos de optimización, desafíos y direcciones futuras para sistemas de IA compuestos: Con el desarrollo de los LLM y los sistemas de IA, los sistemas de IA compuestos que integran múltiples componentes son cada vez más maduros en la ejecución de tareas complejas. Este artículo revisa sistemáticamente los avances recientes en la optimización de sistemas de IA compuestos, incluyendo técnicas numéricas y basadas en lenguaje. El artículo formaliza el concepto de optimización de sistemas de IA compuestos, clasifica los métodos existentes y destaca los desafíos de investigación abiertos y las direcciones futuras en este campo (Fuente: HuggingFace Daily Papers)
💼 Negocios
Disney y Universal Studios demandan al generador de imágenes Midjourney por infracción de derechos de autor: Disney y Universal Studios acusan a Midjourney de utilizar sin permiso su biblioteca creativa (incluyendo personajes de Star Wars, Frozen, Minions, etc.) para entrenar su modelo, y de generar y distribuir una gran cantidad de obras derivadas, calificándolo de “plagio sin fondo”. Este caso reaviva el debate sobre los límites entre el contenido generado por IA y la propiedad intelectual (Fuente: Reddit r/ArtificialInteligence)
NVIDIA y Deutsche Telekom colaboran para establecer la primera nube de IA industrial para fabricantes europeos antes de 2026: El Canciller Federal de Alemania, Friedrich Merz, se reunió con el CEO de NVIDIA, Jensen Huang, para discutir una mayor cooperación estratégica con el fin de consolidar la posición de Alemania como líder mundial en IA. Como parte de esta visión, Deutsche Telekom y NVIDIA anunciaron una nueva colaboración, con planes para establecer la primera nube de IA industrial del mundo para fabricantes europeos antes de 2026. Esta infraestructura segura y conforme a las normativas europeas apoyará la innovación de vanguardia, al tiempo que garantizará la plena soberanía de los datos (Fuente: nvidia)

Rumores de que Sam Altman podría diluir el control sin fines de lucro de OpenAI mediante adquisiciones totalmente en acciones: Las recientes adquisiciones de OpenAI de io (6.5 mil millones de dólares) y Windsurf (3 mil millones de dólares) totalmente en acciones han generado especulaciones. En Hacker News existe la teoría de que Sam Altman podría estar utilizando estas transacciones para diluir gradualmente el control de la organización sin fines de lucro OpenAI Inc. sobre la entidad con fines de lucro OpenAI Global LLC (ahora OpenAI PBC), eludiendo así potencialmente las restricciones legales para la transición a una empresa totalmente con fines de lucro. Algunos relacionan esta medida con las operaciones de Altman en Reddit en 2014, pero también hay opiniones que consideran estas adquisiciones como movimientos estratégicos comerciales normales (Fuente: Reddit r/ArtificialInteligence)
🌟 Comunidad
Continúa el debate sobre si la IA puede realmente “razonar”, el artículo de Apple genera controversia: El reciente artículo de Apple que afirma que el rendimiento de los grandes modelos de lenguaje (LLM) en tareas complejas (como las Torres de Hanói) no es un verdadero razonamiento, sino más bien una coincidencia de patrones, ha sido ampliamente discutido en la comunidad. Miles Brundage, exempleado de OpenAI, al comentar sobre la resolución de o3-pro de complejos juegos de palabras, preguntó irónicamente: “Si esto no se llama razonamiento, ¿qué se llama?”. Investigaciones posteriores han señalado que el fenómeno de “colapso del razonamiento” en el artículo de Apple podría deberse a limitaciones en el diseño experimental (como límites de tokens, evaluación incorrecta de problemas irresolubles) en lugar de una falta de capacidad de razonamiento del modelo en sí. Después de ajustar los métodos de prueba, el modelo funcionó bien en tareas en las que anteriormente había fallado, lo que sugiere que la evaluación de las capacidades de razonamiento de la IA requiere un diseño experimental más cuidadoso (Fuente: o3-pro答高难题文字游戏引围观,OpenAI前员工讽刺苹果:这都不叫推理那什么叫推理, Reddit r/LocalLLaMA)
El CEO de Nvidia, Jensen Huang, y el CEO de Anthropic, Dario Amodei, tienen diferencias significativas en sus puntos de vista sobre el futuro de la IA: Fortune informa que el CEO de Nvidia, Jensen Huang, declaró que está en desacuerdo con casi todas las opiniones de Dario Amodei, CEO de Anthropic, sobre la IA. Amodei a menudo enfatiza los riesgos potenciales de la IA y su enorme impacto en el empleo, y aboga por un control más estricto sobre el desarrollo de la IA, liderado por unas pocas organizaciones “responsables”. Huang, por otro lado, se muestra escéptico ante tales puntos de vista y se inclina más por promover la amplia aplicación y el desarrollo de la tecnología de IA. Los comentarios de la comunidad sugieren que la postura de Huang podría estar relacionada con sus intereses comerciales, ya que Nvidia es el principal proveedor de hardware de IA (Fuente: Reddit r/ArtificialInteligence, Reddit r/ClaudeAI)

El plan de suscripción de 20 dólares de Claude Code recibe elogios de los desarrolladores por su alta relación calidad-precio: Muchos desarrolladores han compartido en redes sociales sus experiencias positivas con el plan de suscripción mensual de 20 dólares de Claude Code de Anthropic, calificándolo de extremadamente rentable y capaz de amortizar rápidamente su costo en los proyectos. Los usuarios mencionaron que, a pesar de ciertas limitaciones de velocidad, Claude Code se desempeña excelentemente en la asistencia para la codificación, el aprendizaje de nuevos lenguajes (como pasar de C# a SwiftUI) y la optimización de las instrucciones del proyecto (como los archivos CLAUDE.md), mejorando significativamente la eficiencia del trabajo. Algunos usuarios incluso están considerando cancelar sus suscripciones a otras herramientas de asistencia para la programación con IA (Fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
La comunidad discute las futuras aplicaciones y los desafíos éticos de la IA en el campo de la psicología: Con el desarrollo de tecnologías como los LLM que redactan indicaciones terapéuticas y aplicaciones que rastrean emociones a través de sensores de teléfonos móviles, la IA está penetrando gradualmente en la psicología. La discusión comunitaria se centra en si la IA en la práctica clínica mejorará las capacidades de los terapeutas o finalmente reemplazará parte de su trabajo, la credibilidad de la IA en la evaluación y la investigación, el impacto en la formación profesional y el mercado laboral de la psicología, y los problemas éticos y regulatorios de las aplicaciones de la IA, especialmente el sesgo de datos, la privacidad y las limitaciones de los “terapeutas robot”. La principal preocupación radica en cómo aprovechar la IA para mejorar la eficiencia y los servicios personalizados, garantizando al mismo tiempo la seguridad del paciente y manteniendo el valor terapéutico de la conexión interpersonal (Fuente: Reddit r/artificial)
El modelo DeepSeek-R1-0528 cuantizado a 3.53 bits por Unsloth muestra un buen rendimiento en el benchmark de codificación Aider Polyglot: El equipo de Unsloth, después de cuantizar el modelo DeepSeek-R1-0528 a 3.53 bits (UD-Q3_K_XL), logró una tasa de aprobación del 68% en el benchmark de codificación Aider Polyglot. La prueba utilizó un tamaño de contexto de 40960 y Flash Attention, requiriendo aproximadamente 300GB de RAM/VRAM. Este resultado se sitúa entre Claude Sonnet 3.7 y Claude Opus 4, demostrando el potencial de los modelos cuantizados para mantener una alta capacidad de codificación. Los miembros de la comunidad expresaron su impresión por el rendimiento de ejecutar tales modelos localmente y esperan más resultados de pruebas de versiones cuantizadas (Fuente: Reddit r/LocalLLaMA)
💡 Otros
Informe de interrupción global de GCP revela: política de cuotas ilegal causó la interrupción del servicio: El informe sobre la reciente interrupción global de Google Cloud Platform (GCP) muestra que la causa fue la implementación de una política de cuotas incorrecta en el sistema de gestión de API global (por ejemplo, limitando las solicitudes a solo 1 por hora), lo que provocó que las solicitudes externas fueran rechazadas por exceder la cuota (error 403). Después de que los ingenieros lo descubrieran, omitieron la verificación de cuotas para las API afectadas. Sin embargo, en la región us-central1, al intentar borrar la política antigua y escribir una nueva, los problemas de caché provocaron una sobrecarga de la base de datos, lo que prolongó el tiempo de recuperación. Otras regiones adoptaron un enfoque de limpieza gradual de la caché para recuperarse, y todo el proceso duró aproximadamente 2 horas (Fuente: karminski3)

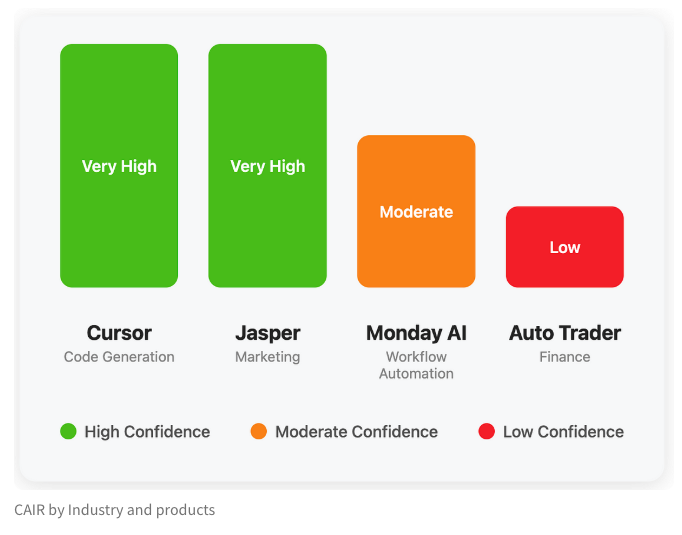
El equipo de LangChain propone el indicador CAIR para evaluar el potencial de éxito de los productos de IA: Harrison Chase de LangChain, junto con Assaf Elovic, escribieron un artículo explorando por qué algunos productos de IA se popularizan rápidamente mientras que otros tienen dificultades. Argumentan que la capacidad del modelo no es el único factor determinante, la experiencia del usuario (UX) es crucial, y proponen el indicador “CAIR” (Confidence in AI Results, Confianza en los Resultados de la IA). Cuanto mayor sea el CAIR, mayor será la adopción del producto. Este marco tiene como objetivo ayudar a los desarrolladores a identificar y mejorar los diversos componentes que afectan la confianza del usuario, aumentando así la tasa de éxito del producto (Fuente: hwchase17, swyx, hwchase17, Hacubu)
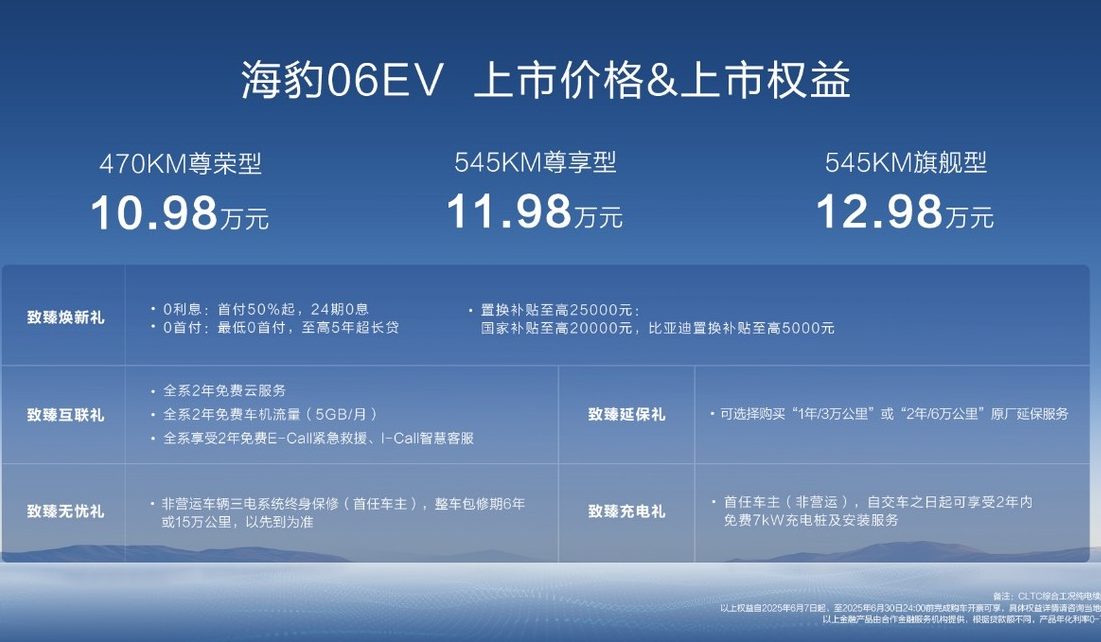
BYD lanza el nuevo sedán coupé familiar puramente eléctrico Seal 06EV, con un precio inicial de 109,800 yuanes: BYD Ocean Net presentó el Seal 06EV en el Salón del Automóvil de Chongqing, posicionado como un sedán coupé moderno y de calidad, con 3 configuraciones y un rango de precios de 109,800 a 129,800 yuanes. El vehículo está construido sobre la plataforma e-platform 3.0 Evo de BYD, equipado con un sistema de propulsión eléctrica inteligente ocho en uno y un sistema de bomba de calor eficiente de amplio rango de temperatura de nueva generación, ofreciendo dos autonomías CLTC de 470KM y 545KM. El vehículo adopta una disposición de tracción trasera, está equipado con el sistema de control de carrocería con amortiguación inteligente Cloud Chariot-C, y cuenta con la versión de tres cámaras del sistema de asistencia a la conducción inteligente “TianShenZhiYan C”, compatible con funciones como la navegación asistida en autopista y el estacionamiento automático (Fuente: 量子位)