Palabras clave:Meta V-JEPA 2, Nube de IA industrial de NVIDIA, Sakana AI Text-to-LoRA, OpenAI o3-pro, Databricks Lakebase, MLflow 3.0, HistBench de la Universidad de Princeton, Modelo de mundo abierto para entrenamiento de video, Plataforma en la nube de IA para la manufactura europea, Adaptador de LLM para generación de texto, Afinamiento DPO de GPT-4.1, Observabilidad de agentes de IA
🔥 Enfoque
Meta publica V-JEPA 2: un modelo mundial de código abierto para imágenes/vídeo entrenado con vídeo : Meta ha presentado su nuevo modelo mundial de código abierto para imágenes/vídeo, V-JEPA 2. Este modelo se basa en la arquitectura ViT y cuenta con versiones de diferentes tamaños (L/G/H) y resoluciones (286/384), alcanzando los 1.200 millones de parámetros. V-JEPA 2 destaca en la comprensión y predicción visual, permitiendo a los robots realizar planificación y ejecución de tareas zero-shot en entornos desconocidos. Meta subraya su visión de que la IA utilice modelos mundiales para adaptarse a entornos dinámicos y aprender nuevas habilidades de manera eficiente. Paralelamente, Meta también ha lanzado tres nuevos benchmarks: MVPBench, IntPhys 2 y CausalVQA, destinados a evaluar la capacidad de los modelos existentes para inferir el mundo físico a partir de vídeos. (Fuente: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
Nvidia construye la primera nube industrial de IA en Europa para impulsar el desarrollo de la fabricación : Nvidia ha anunciado que está construyendo la primera plataforma de nube de inteligencia artificial industrial del mundo para los fabricantes europeos. Esta fábrica de IA tiene como objetivo ayudar a los líderes industriales a acelerar las aplicaciones de fabricación en todo el proceso, desde el diseño y la simulación de ingeniería hasta los gemelos digitales de fábricas y la robótica. Esta iniciativa forma parte de una serie de medidas anunciadas por Nvidia en GTC Paris y VivaTech 2025, destinadas a acelerar la innovación en IA en Europa y otras regiones. Jensen Huang afirmó que se espera que la capacidad de cómputo de IA en Europa se multiplique por diez en dos años y enfatizó que “todos los objetos en movimiento se robotizarán, y los automóviles son los siguientes”. (Fuente: nvidia, nvidia, Jensen Huang: La capacidad de cómputo de IA en Europa se multiplicará por diez en dos años)

Sakana AI presenta Text-to-LoRA: generación instantánea de adaptadores LLM específicos para tareas mediante descripción textual : Sakana AI ha lanzado la tecnología Text-to-LoRA, una Hypernetwork capaz de generar instantáneamente adaptadores LLM (LoRAs) específicos para tareas a partir de la descripción textual de la tarea proporcionada por el usuario. Esta tecnología tiene como objetivo reducir la barrera para la personalización de modelos grandes, permitiendo a usuarios no técnicos especializar modelos base mediante lenguaje natural, sin necesidad de profundos conocimientos técnicos o grandes recursos computacionales. Text-to-LoRA puede codificar cientos de adaptadores LoRA existentes y generalizar a tareas nunca vistas, manteniendo el rendimiento. El paper y el código correspondientes se han publicado en arXiv y GitHub, y se presentarán en ICML2025. (Fuente: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
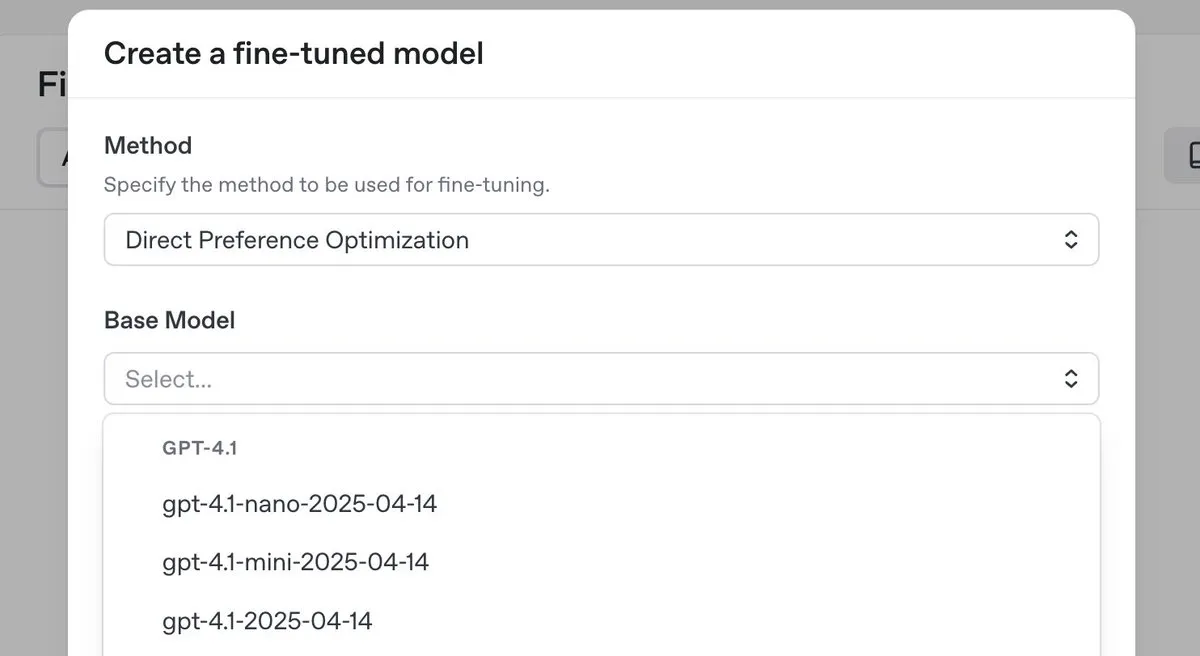
OpenAI lanza el modelo de inferencia de primer nivel o3-pro con una importante reducción de precios, y presenta la función de fine-tuning DPO para la serie GPT-4.1 : OpenAI ha lanzado su nuevo modelo de inferencia de primer nivel, o3-pro, y ha realizado una importante reducción de precios en la serie de modelos o3, con el objetivo de disminuir los costos para los desarrolladores. Al mismo tiempo, OpenAI anunció que los usuarios ahora pueden utilizar la optimización directa de preferencias (DPO) para el fine-tuning de los modelos de la familia GPT-4.1 (incluidos 4.1, 4.1-mini y 4.1-nano). DPO permite la personalización comparando las respuestas del modelo en lugar de objetivos fijos, lo que es especialmente adecuado para tareas con requisitos subjetivos de tono, estilo y creatividad. ARC Prize volvió a probar o3 tras la reducción de precios, y los resultados mostraron que su rendimiento en ARC-AGI no ha cambiado. (Fuente: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 Tendencias
Databricks lanza Lakebase, una versión gratuita y Agent Bricks para acelerar el desarrollo de aplicaciones de datos e IA : Databricks ha anunciado que Lakebase entra en fase de vista previa pública. Se trata de una base de datos Postgres totalmente gestionada, integrada con lakehouse y construida para IA, que combina la facilidad de uso de Postgres, la escalabilidad de lakehouse y la tecnología de ramificación de la base de datos Neon. Al mismo tiempo, Databricks ha lanzado una versión gratuita de su plataforma y una gran cantidad de material de formación para ayudar a los desarrolladores a aprender ingeniería de datos, ciencia de datos e IA. Además, Databricks Apps ya está disponible de forma general (GA), permitiendo a los clientes construir y desplegar aplicaciones interactivas de datos e IA en la plataforma. Databricks también ha presentado Agent Bricks, que adopta un enfoque declarativo para el desarrollo de agentes de IA, donde el usuario describe la tarea y el sistema genera automáticamente evaluaciones y optimiza el agente. (Fuente: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

Nvidia colabora con Mistral AI para construir una plataforma en la nube de extremo a extremo en Europa : Nvidia ha anunciado una colaboración con la startup francesa Mistral AI para construir conjuntamente una plataforma en la nube de extremo a extremo. La primera fase de la colaboración implicará el despliegue de 18.000 sistemas Nvidia Grace Blackwell, con planes de expansión a más ubicaciones en 2026. Esta colaboración forma parte de la iniciativa de Nvidia para impulsar la construcción de infraestructura de IA en Europa y el concepto de “IA soberana”, con el objetivo de proporcionar a Europa centros de datos y servidores localizados. (Fuente: Jensen Huang: La capacidad de cómputo de IA en Europa se multiplicará por diez en dos años)
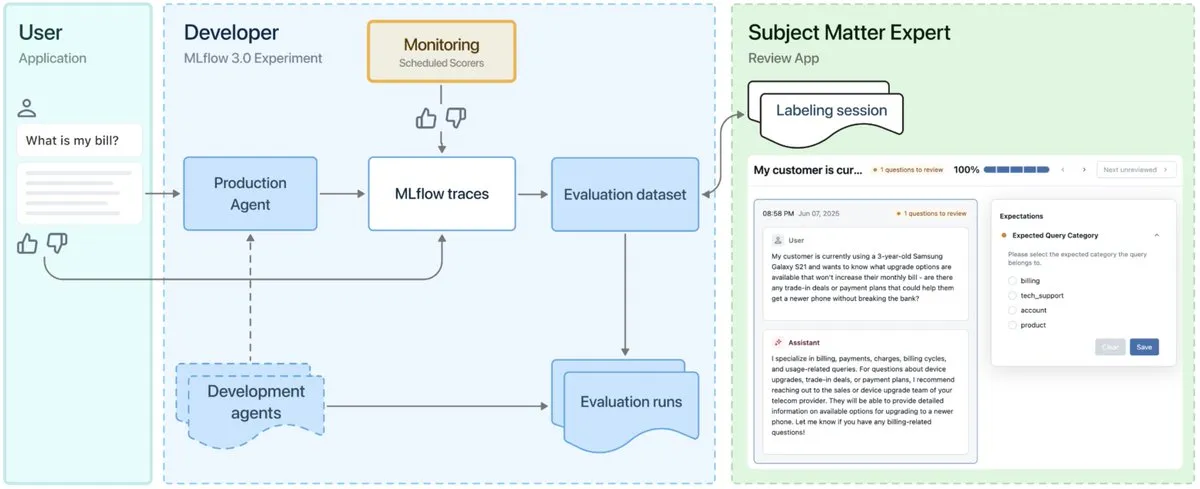
Lanzamiento de MLflow 3.0, diseñado para la observabilidad y el desarrollo de agentes de IA : Se ha lanzado oficialmente MLflow 3.0. La nueva versión ha sido rediseñada específicamente para la observabilidad y el desarrollo de agentes de IA, y actualiza las funciones tradicionales de machine learning estructurado. MLflow 3.0 tiene como objetivo lograr la mejora continua de los sistemas de IA a través de los datos, soportando el seguimiento, la evaluación y la monitorización de los sistemas de IA, y teniendo en cuenta las necesidades empresariales como la colaboración humana, la gobernanza y seguridad de los datos, y la integración con el ecosistema de datos de Databricks. (Fuente: matei_zaharia, matei_zaharia, lateinteraction)
La Universidad de Princeton y la Universidad de Fudan lanzan conjuntamente HistBench e HistAgent para promover la aplicación de la IA en la investigación histórica : El laboratorio de IA de la Universidad de Princeton y el Departamento de Historia de la Universidad de Fudan han colaborado para lanzar el primer benchmark de IA para investigación histórica del mundo, HistBench, y el asistente de IA HistAgent. HistBench contiene 414 preguntas históricas que cubren 29 idiomas e historia de múltiples civilizaciones, con el objetivo de probar la capacidad de la IA para procesar material histórico complejo y la comprensión multimodal. HistAgent es un agente inteligente diseñado específicamente para la investigación histórica, que integra herramientas como la recuperación de documentos, OCR y traducción. Las pruebas indican que los modelos grandes generales tienen una precisión inferior al 20% en HistBench, mientras que HistAgent supera con creces a los modelos existentes. (Fuente: Primer benchmark histórico mundial, Princeton y Fudan crean un asistente de IA para la historia, la IA irrumpe en las humanidades)

Microsoft Research y la Universidad de Pekín lanzan conjuntamente el framework Next-Frame Diffusion (NFD) para mejorar la eficiencia de la generación de vídeo autorregresiva : Microsoft Research y la Universidad de Pekín han lanzado conjuntamente el nuevo framework Next-Frame Diffusion (NFD), que mediante el muestreo paralelo intra-frame y el modo autorregresivo inter-frame, logra una generación de vídeo autorregresiva de alta calidad a más de 30 fotogramas por segundo utilizando un modelo de 310M en una GPU A100. NFD utiliza un Transformer con un mecanismo de atención causal por bloques y combina técnicas de destilación de consistencia y muestreo especulativo para mejorar aún más la eficiencia, con potencial para aplicaciones en juegos interactivos en tiempo real. (Fuente: Generación de vídeo a más de 30 fps, compatible con interacción en tiempo real, nuevo framework de generación de vídeo autorregresiva bate récords de eficiencia)

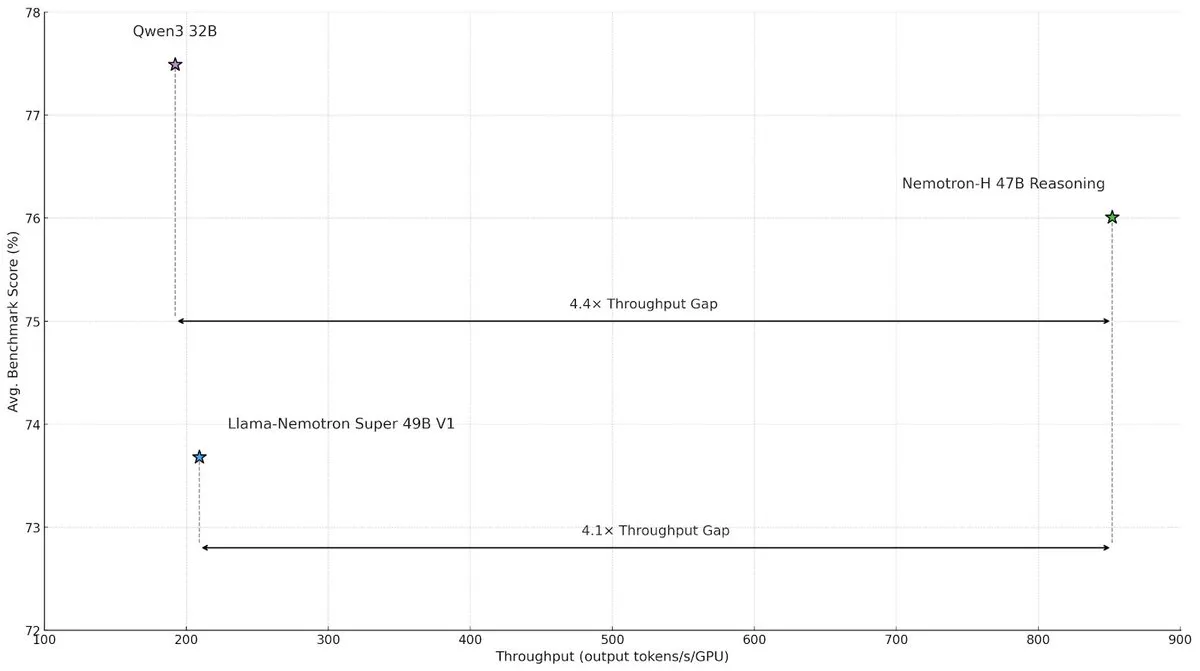
NVIDIA lanza el modelo de arquitectura híbrida Nemotron-H, mejorando la velocidad y eficiencia de la inferencia a gran escala : NVIDIA Research ha presentado el modelo Nemotron-H, que adopta una arquitectura híbrida de Mamba y Transformer, con el objetivo de resolver los cuellos de botella de velocidad en tareas de inferencia a gran escala. Este modelo, manteniendo la capacidad de inferencia, logra un rendimiento 4 veces superior al de modelos Transformer comparables. La investigación indica que los modelos híbridos pueden mantener el rendimiento de inferencia incluso con menos capas de atención, y la ventaja de eficiencia de la arquitectura lineal es especialmente significativa en escenarios de cadenas de inferencia largas. (Fuente: _albertgu, tri_dao, krandiash)
El investigador de Google DeepMind, Jack Rae, se une al grupo de “superinteligencia” de Meta : El investigador principal de Google DeepMind, Jack Rae, ha confirmado su incorporación al recién formado grupo de “superinteligencia” de Meta. Durante su etapa en DeepMind, Rae fue responsable de la capacidad de “pensamiento” del modelo Gemini y es una de las figuras representativas de la idea de “compresión como inteligencia”, habiendo participado previamente en el desarrollo de GPT-4 en OpenAI. El CEO de Meta, Mark Zuckerberg, está reclutando personalmente a los mejores talentos de IA, ofreciendo paquetes salariales de decenas de millones de dólares para el nuevo equipo, con el objetivo de mejorar el modelo Llama y desarrollar herramientas de IA más potentes para alcanzar a los líderes de la industria. (Fuente: El primer gran fichaje del grupo de “superinteligencia” de Zuck, investigador principal de Google DeepMind, figura clave de “compresión como inteligencia”, DhruvBatraDB)

Mistral AI lanza su primer modelo de inferencia Magistral, compatible con inferencia multilingüe : Mistral AI ha lanzado su primer modelo de inferencia, Magistral, que incluye la versión de código abierto de 24B parámetros Magistral Small y Magistral Medium, orientado a empresas. Este modelo ha sido ajustado específicamente para la lógica de múltiples pasos y la interpretabilidad, admite inferencia multilingüe, especialmente optimizado para los idiomas europeos, y puede proporcionar un proceso de pensamiento rastreable. Magistral utiliza un algoritmo GRPO mejorado entrenado mediante aprendizaje por refuerzo puro, sin depender de datos de destilación de modelos de inferencia existentes. Sin embargo, sus resultados de benchmark han sido cuestionados en parte por no incluir los datos de las últimas versiones de Qwen y DeepSeek R1. (Fuente: ¿El nuevo modelo de inferencia “SOTA” evita la confrontación con Qwen y R1? La OpenAI europea es duramente criticada)

ByteDance lanza el modelo grande Doubao 1.6 con otra importante reducción de precios, y el modelo de vídeo Seedance 1.0 pro se presenta simultáneamente : Volcano Engine ha lanzado el modelo grande Doubao 1.6, que introduce por primera vez precios por rangos de “longitud de entrada”. El precio para el rango de entrada de 0-32K es de 0,8 yuanes por millón de tokens, y la salida es de 8 yuanes por millón de tokens, lo que representa una reducción de costos del 63% en comparación con la versión 1.5. El recién lanzado modelo de generación de vídeo Seedance 1.0 pro tiene un precio de 1,5 céntimos de yuan por cada mil tokens, lo que significa que generar un vídeo de 5 segundos a 1080P cuesta aproximadamente 3,67 yuanes. Tan Dai, presidente de Volcano Engine, afirmó que esta reducción de precios se ha logrado mediante la optimización específica de los costos para el rango de 32K comúnmente utilizado por las empresas y la innovación en el modelo de negocio, con el objetivo de impulsar la aplicación a gran escala de Agents. (Fuente: El modelo grande Doubao vuelve a bajar drásticamente de precio, Volcano Engine sigue compitiendo agresivamente por cuota de mercado, La “Volcano” se dirige a Baidu Cloud)
La Universidad de Ciencia y Tecnología de Hong Kong y Huawei proponen conjuntamente el framework AutoSchemaKG para la construcción totalmente autónoma de grafos de conocimiento : El laboratorio KnowComp de la Universidad de Ciencia y Tecnología de Hong Kong, en colaboración con el Departamento de Teoría de Huawei en Hong Kong, ha propuesto el framework AutoSchemaKG, que permite construir grafos de conocimiento de forma totalmente autónoma sin necesidad de esquemas predefinidos. Este sistema utiliza modelos de lenguaje grandes para extraer directamente tripletas de conocimiento del texto e inducir esquemas de entidades y eventos. Basándose en este framework, el equipo ha construido la serie de grafos de conocimiento ATLAS, que contiene más de 900 millones de nodos y 5.900 millones de aristas. Los experimentos demuestran que, sin intervención humana, la inducción de esquemas logra una alineación semántica del 95% con los esquemas diseñados por humanos. (Fuente: El GraphRag de código abierto más grande: construcción totalmente autónoma de grafos de conocimiento)

Qijing Tech lanza una solución de servidor integrado de hardware y software con 8 tarjetas para mejorar la eficiencia de ejecución del modelo grande DeepSeek : Qijing Tech, en colaboración con Intel, organizó un salón ecológico donde presentó su última solución de servidor integrado de hardware y software con 8 tarjetas. Esta solución puede ejecutar eficientemente modelos grandes como DeepSeek-R1/V3-671B, con un rendimiento hasta 7 veces superior en comparación con una sola tarjeta. Al mismo tiempo, su motor de inferencia de desarrollo propio KLLM, la plataforma de gestión de modelos grandes AMaaS y el paquete de aplicaciones de oficina “Qijing·Zhiwen” también recibieron importantes actualizaciones, con el objetivo de resolver los desafíos que enfrenta la implementación privada de modelos grandes, como el alto umbral de inicio y el rendimiento de ejecución insuficiente. (Fuente: Se celebra el salón ecológico de Qijing Tech e Intel, fusión de hardware, motor de inferencia y ecosistema de aplicaciones de capa superior para completar la “última milla” de la privatización de modelos grandes)

Black Forest Labs lanza la serie de modelos de imagen FLUX.1 Kontext, reforzando la consistencia de personajes y estilos : La empresa alemana Black Forest Labs ha lanzado la serie de modelos de texto a imagen FLUX.1 Kontext (versiones max, pro, dev), centrada en mantener la consistencia de personajes y estilos al editar imágenes. Esta serie de modelos admite modificaciones locales y globales de las imágenes y puede generar imágenes a partir de entradas de texto y/o imágenes. La versión FLUX.1 Kontext dev tiene previsto ser de código abierto. En pruebas de benchmark propias que incluyen alrededor de 1000 pares de prompts e imágenes de referencia, las versiones FLUX.1 Kontext max y pro superaron a modelos competidores como OpenAI GPT Image 1 y Google Gemini 2.0 Flash. (Fuente: DeepLearning.AI Blog)

Nvidia, la Universidad Rutgers y otras instituciones proponen el framework STORM, que utiliza capas Mamba para reducir los tokens necesarios para la comprensión de vídeo : Investigadores de Nvidia, la Universidad Rutgers, la Universidad de California en Berkeley y otras instituciones han construido el sistema texto-vídeo STORM. Este sistema introduce capas Mamba entre el transformador visual SigLIP y el LLM de Qwen2-VL, enriqueciendo las incrustaciones de tokens de un solo fotograma con información de otros fotogramas del mismo clip, lo que permite promediar las incrustaciones de tokens entre fotogramas sin perder información crucial. Esto permite al sistema procesar vídeos con menos tokens, superando a GPT-4o y Qwen2-VL en benchmarks de comprensión de vídeo como MVBench y MLVU, al tiempo que mejora la velocidad de procesamiento en más de 3 veces. (Fuente: DeepLearning.AI Blog)

El cofundador de Google muestra reservas hacia los robots humanoides, mientras que los robots especializados tienen buenas perspectivas de comercialización : Sergey Brin, cofundador de Google, expresó no ser muy entusiasta con los robots humanoides que replican estrictamente la forma humana, considerando que no es una condición necesaria para que los robots trabajen eficazmente. Mientras tanto, los robots especializados están ganando atención debido a su característica de “listos para trabajar al instante” y a sus claras vías de comercialización. Por ejemplo, los robots submarinos y los cortacéspedes muestran un gran potencial en escenarios específicos. Los analistas consideran que, en la etapa actual, la forma y la productividad de los robots que pueden resolver problemas reales son clave, y los robots especializados, con modelos de negocio claros y escenarios de necesidad imperiosa, están siendo los primeros en lograr la comercialización. (Fuente: Los robots especializados le dicen al robot humanoide “Hermano, apártate, voy a sentarme a la mesa.”)

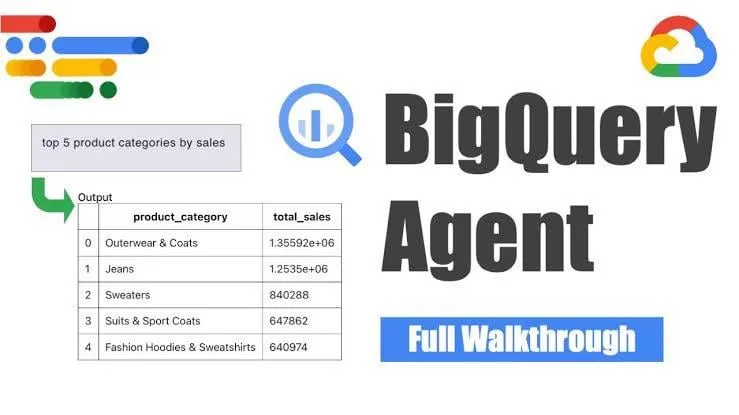
Google lanza el agente de ingeniería de datos BigQuery para la generación inteligente de pipelines : Google ha lanzado el agente de ingeniería de datos BigQuery, una herramienta que utiliza el razonamiento sensible al contexto para escalar eficientemente la generación de pipelines de datos. Los usuarios pueden definir los requisitos del pipeline mediante simples instrucciones de línea de comandos, y el agente utiliza prompts específicos del dominio para generar código de pipeline por lotes personalizado para el entorno de datos del usuario, incluyendo la configuración de ingesta de datos, consultas de transformación, lógica de creación de tablas y configuración de programación a través de Dataform o Composer. La herramienta tiene como objetivo simplificar el trabajo repetitivo que enfrentan los ingenieros de datos al manejar múltiples dominios de datos, entornos y lógicas de transformación, mediante la asistencia de IA. (Fuente: Reddit r/deeplearning)
Yandex publica Yambda, un conjunto de datos público a gran escala con casi 5 mil millones de interacciones usuario-pista de audio : Yandex ha publicado un conjunto de datos público a gran escala llamado Yambda, diseñado específicamente para la investigación de sistemas de recomendación. Este conjunto de datos contiene casi 5 mil millones de interacciones anónimas de usuarios con pistas de audio de Yandex Music, ofreciendo a los investigadores una oportunidad poco común para trabajar con datos a escala del mundo real. (Fuente: _akhaliq)

ByteDance publica el modelo de reparación de vídeo SeedVR2 en Hugging Face : El equipo Seed de ByteDance ha publicado SeedVR2 en Hugging Face, un modelo Transformer de difusión de un solo paso para la reparación de vídeo. Este modelo, bajo licencia Apache 2.0, se caracteriza por su inferencia en un solo paso, siendo rápido y eficiente, y admite el procesamiento a cualquier resolución, sin necesidad de dividir en bloques ni estar limitado por el tamaño. (Fuente: huggingface)
El modelo de vídeo grande Doubao Seedance 1.0 Pro de ByteDance recibe elogios en pruebas prácticas por sus efectos : El último modelo grande de generación de imagen a vídeo de ByteDance, Seedance 1.0 Pro, ha demostrado una buena capacidad de seguimiento de instrucciones y estabilidad en la generación de objetos en pruebas prácticas. Los usuarios informan que la calidad de generación de vídeo es alta, con movimientos de cámara y sincronización precisos, solo superado por Veo 2/3. Un posible inconveniente es que, al generar movimiento de objetos puros, el modelo a veces añade la operación de una mano para hacer la escena más razonable, lo que se puede evitar limitando la aparición de manos. (Fuente: karminski3, karminski3, karminski3)
Alibaba abre el código de su framework de humanos digitales Mnn3dAvatar, compatible con captura facial en tiempo real y creación de personajes virtuales 3D : Alibaba ha abierto el código en GitHub de un framework de humanos digitales llamado Mnn3dAvatar. Este proyecto permite la captura facial en tiempo real y mapea las expresiones a personajes virtuales 3D, al mismo tiempo que permite a los usuarios crear sus propios personajes virtuales 3D. Este framework es adecuado para escenarios simples como retransmisiones en directo para ventas, presentación de contenidos, etc. (Fuente: karminski3)
Nvidia libera el modelo base de robot humanoide Gr00t N 1.5 3B y proporciona un tutorial de fine-tuning : Nvidia ha liberado el modelo Gr00t N 1.5 3B, un modelo base abierto diseñado para las habilidades de razonamiento de robots humanoides, bajo una licencia comercial. Al mismo tiempo, Nvidia también ha publicado un tutorial completo de fine-tuning para usar con LeRobotHF SO101, con el objetivo de impulsar el desarrollo y la aplicación de la tecnología de robots humanoides. (Fuente: ClementDelangue)
Together AI lanza Batch API, ofreciendo servicios de inferencia LLM a gran escala con una importante reducción de precios : Together AI ha lanzado su nueva Batch API, diseñada específicamente para la inferencia LLM a gran escala, compatible con aplicaciones de alto rendimiento como la generación de datos sintéticos, benchmarking, revisión y resumen de contenido, y extracción de documentos. Esta API introduce un precio de entrada un 50% más barato que la API en tiempo real, admite el procesamiento por lotes de hasta 50.000 solicitudes o 100MB cada vez, y es compatible con 15 modelos de primer nivel. (Fuente: vipulved)
Gemini 2.5 Pro de Google añade la función de generación interactiva de arte fractal : Google ha anunciado que Gemini 2.5 Pro ahora admite la creación instantánea de arte fractal interactivo. Los usuarios pueden generar obras de arte visuales únicas proporcionando prompts como “créame una hermosa obra de arte fractal basada en partículas, animada, infinita, 3D, simétrica e inspirada en fórmulas matemáticas”. (Fuente: demishassabis)
La velocidad de generación de vídeo de Veo3 Fast de Google se duplica : Google Labs ha anunciado que la velocidad de generación de su versión Veo3 Fast en la herramienta de vídeo Flow se ha más que duplicado, manteniendo al mismo tiempo una resolución de 720p. Esta actualización tiene como objetivo permitir a los usuarios crear contenido de vídeo más rápidamente. (Fuente: op7418)
Hugging Face se integra con Google Colab y Kaggle, simplificando el flujo de uso de modelos : Hugging Face ahora se ha integrado con Google Colab y Kaggle. Los usuarios pueden iniciar directamente un notebook de Colab desde cualquier tarjeta de modelo, o abrir el mismo modelo en un Kaggle Notebook, acompañado de ejemplos de código público ejecutables, simplificando así el flujo de uso y experimentación de modelos. (Fuente: ClementDelangue, huggingface)
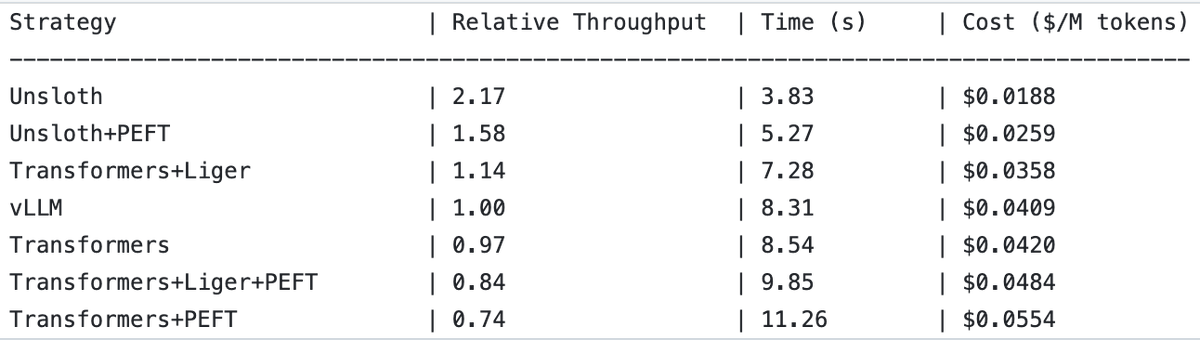
UnslothAI logra duplicar el rendimiento en servicios de modelos de recompensa e inferencia de clasificación de secuencias : Se ha descubierto que UnslothAI puede utilizarse para proporcionar servicios de modelos de recompensa (RM) y que, en la inferencia de clasificación de secuencias, su rendimiento es el doble que el de vLLM. Este descubrimiento ha llamado la atención en la comunidad de RL (aprendizaje por refuerzo), y se espera que la mejora del rendimiento de UnslothAI acelere la investigación y las aplicaciones relacionadas. (Fuente: natolambert, danielhanchen)
Digua Robot lanza el primer kit de desarrollo de robots RDK S100 integrado de cómputo y control en un solo SoC : Digua Robot ha lanzado el primer kit de desarrollo de robots RDK S100 de la industria, que integra cómputo y control en un solo SoC. Este kit adopta un diseño de arquitectura similar al cerebro y cerebelo humanos, integrando CPU+BPU+MCU en un único SoC, lo que permite la colaboración eficiente de modelos grandes y pequeños de inteligencia artificial corporeizada y completa el ciclo cerrado de “percepción-decisión-control”. RDK S100 ofrece múltiples interfaces e infraestructura de desarrollo colaborativo de software y hardware, y de extremo a nube, con el objetivo de acelerar la construcción de productos de inteligencia corporeizada y el despliegue en múltiples escenarios. Actualmente, ha colaborado con más de 20 clientes líderes y su precio de mercado es de 2799 yuanes. (Fuente: Digua Robot lanza el primer kit de desarrollo de robots integrado de cómputo y control en un solo SoC, ya ha colaborado con más de 20 clientes líderes | Primera línea)

🧰 Herramientas
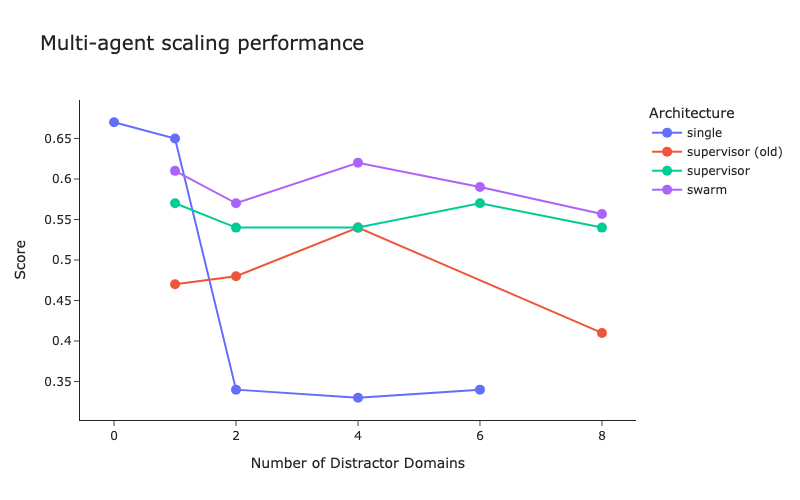
LangChain publica benchmarks de arquitectura multi-agente y mejoras en el método de supervisor : LangChain, ante el creciente número de sistemas multi-agente, ha realizado benchmarks preliminares para explorar cómo optimizar la coordinación entre múltiples agentes. Al mismo tiempo, LangChain ha introducido algunas mejoras en su método de supervisor, y se ha publicado un blog al respecto. (Fuente: LangChainAI, hwchase17)
Cartesia lanza Ink-Whisper: un modelo de voz a texto en streaming rápido y económico diseñado para agentes de voz : Cartesia ha lanzado Ink-Whisper, un modelo de voz a texto (STT) en streaming de alta velocidad y bajo costo, optimizado para agentes de voz. Este modelo está diseñado para la precisión en condiciones del mundo real y puede usarse junto con el modelo de texto a voz (TTS) Sonic de Cartesia para lograr interacciones de IA por voz rápidas. Ink-Whisper es compatible con la integración en plataformas como VapiAI, PipecatAI y Livekit. (Fuente: simran_s_arora, tri_dao, krandiash)

MonkeyOCR: modelo de análisis de documentos pequeño, rápido y de código abierto : Se ha lanzado un modelo de análisis de documentos de 3B parámetros llamado MonkeyOCR, bajo la licencia Apache 2.0. Este modelo es capaz de analizar diversos elementos en documentos, incluyendo gráficos, fórmulas, tablas, etc., con el objetivo de reemplazar los pipelines de análisis tradicionales y ofrecer una solución de procesamiento de documentos superior. (Fuente: mervenoyann, huggingface)
LlamaIndex se integra con Cleanlab para mejorar la fiabilidad de las respuestas de los asistentes de IA : LlamaIndex ha anunciado su integración con CleanlabAI. LlamaIndex se utiliza para construir asistentes de conocimiento de IA y agentes de nivel de producción, generando insights a partir de datos empresariales. La incorporación de Cleanlab tiene como objetivo mejorar la fiabilidad de las respuestas de estos asistentes de IA, pudiendo puntuar cada respuesta de LLM, capturar alucinaciones o respuestas incorrectas en tiempo real, y ayudar a analizar las causas de la falta de fiabilidad de las respuestas (como una mala recuperación, problemas de datos/contexto, consultas difíciles o alucinaciones del LLM). (Fuente: jerryjliu0)

Claude Code de Anthropic añade el “modo planificación” para mejorar la controlabilidad de los cambios de código complejos : Claude Code de Anthropic ha introducido el “modo planificación” (Plan mode). Esta función permite a los usuarios revisar el plan de implementación antes de realizar cambios reales en el código, asegurando que cada paso sea considerado, especialmente para cambios de código complejos. Los usuarios pueden entrar en el modo planificación con la combinación de teclas Shift + Tab dos veces, y Claude Code proporcionará un plan de implementación detallado y solicitará confirmación antes de la ejecución. Esta función ya está disponible para todos los usuarios de Claude Code (incluidos los suscriptores Pro o Max). (Fuente: dotey, kylebrussell)
rvn-convert: herramienta de conversión de SafeTensors a GGUF v3 implementada en Rust : Se ha lanzado una herramienta de código abierto llamada rvn-convert, escrita en Rust, para convertir archivos de modelo en formato SafeTensors al formato GGUF v3. Esta herramienta se caracteriza por su soporte para un solo fragmento, alta velocidad, no requiere entorno Python, y es capaz de mapear en memoria archivos safetensors y escribir directamente en archivos gguf, evitando picos de RAM y problemas de rotación de disco. Actualmente admite el upsampling de BF16 a F32, la incrustación de tokenizer.json, entre otras funciones. (Fuente: Reddit r/LocalLLaMA)
La API de Runway añade la función de superresolución de vídeo 4K : Runway ha anunciado que su API ahora admite la función de superresolución de vídeo 4K. Los desarrolladores pueden integrar esta función en sus propias aplicaciones, productos, plataformas y sitios web para mejorar la claridad y calidad del contenido de vídeo. (Fuente: c_valenzuelab)
You.com lanza la función Projects para organizar y gestionar material de investigación : You.com ha lanzado una nueva herramienta llamada “Projects”, diseñada para ayudar a los usuarios a organizar su material de investigación en carpetas de fácil acceso. Esta función permite a los usuarios contextualizar y estructurar las conversaciones, evitando la dispersión de los historiales de chat y la pérdida de insights, simplificando así el proceso de gestión del conocimiento. (Fuente: RichardSocher)
LlamaIndex lanza el servicio de extracción de documentos LlamaExtract para agentes inteligentes : LlamaIndex ha lanzado LlamaExtract, un servicio de extracción de documentos impulsado por agentes, diseñado para extraer datos estructurados de documentos complejos y esquemas de entrada. Este servicio no solo extrae pares clave-valor, sino que también proporciona una inferencia precisa de la fuente, referencias de página y texto coincidente para cada elemento extraído. LlamaExtract se ofrece como una API y se puede integrar fácilmente en flujos de trabajo de agentes descendentes. (Fuente: jerryjliu0)

langchain-google-vertexai publica actualización, mejorando el caché del cliente y el soporte de herramientas : langchain-google-vertexai ha recibido una nueva versión. Las principales actualizaciones incluyen: caché del cliente de predicción, que acelera la instanciación de nuevos clientes en 500 veces; y soporte para herramientas de ejecución de código integradas. (Fuente: LangChainAI, Hacubu)
Perplexity Finance añade la función de descarga directa de modelos de Excel : Perplexity Finance ha anunciado que los usuarios ahora pueden descargar directamente modelos de Excel desde su página, proporcionando un punto de partida más rápido para el modelado financiero y la investigación. Esta función está disponible de forma gratuita para todos los usuarios; anteriormente solo se admitía la descarga en formato CSV. (Fuente: AravSrinivas)
Viwoods lanza la tableta de tinta electrónica AI Paper Mini, integrando GPT-4o y otras funciones de IA : El emergente fabricante de pantallas de tinta electrónica Viwoods ha lanzado AI Paper Mini, una tableta de tinta electrónica equipada con funciones de IA. El dispositivo es compatible con GPT-4o, DeepSeek y otros modelos de IA, ofreciendo un modo Chat y asistentes de IA preestablecidos (análisis de contenido, generación de correos electrónicos, IA a texto). Sus funciones destacadas incluyen la gestión de tareas en vista de calendario y notas rápidas en ventana flotante. En cuanto al hardware, Paper Mini utiliza una pantalla Carta 1000 de 292 ppi, 4GB+128GB de almacenamiento y viene con un lápiz óptico. Al mismo tiempo, Viwoods también ha lanzado el AI Paper de mayor tamaño, con una pantalla flexible Carta 1300 de 300 ppi y una velocidad de respuesta más rápida. (Fuente: Gasté la mitad del precio de un iPhone para comprar una “tableta de tinta electrónica” con IA…)

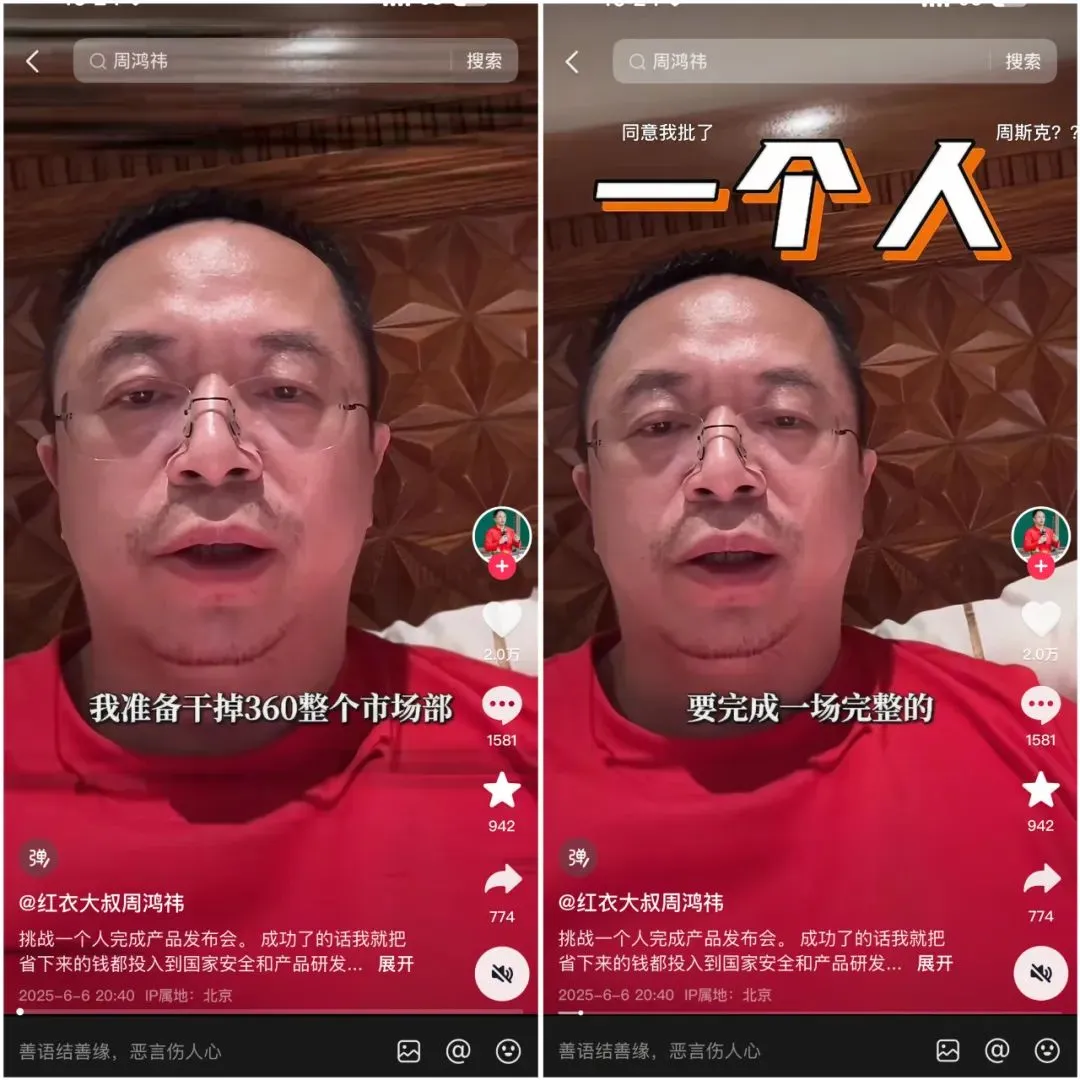
360 lanza el superagente de búsqueda inteligente Nano AI, con el respaldo personal de Zhou Hongyi : Zhou Hongyi, fundador del Grupo 360, presidió el lanzamiento del superagente de búsqueda inteligente Nano AI. Este agente tiene como objetivo lograr “una frase, todo se puede buscar”, siendo capaz de pensar de forma autónoma, invocar navegadores y herramientas externas para ejecutar tareas sin intervención humana, y admitir la visualización completa del proceso y el rastreo de pasos. Zhou Hongyi afirmó que la propia conferencia de lanzamiento también intentó utilizar Nano AI para su preparación, y se lanzó el hardware de grabación inteligente Nano AI Note y unas gafas de IA en colaboración con Rokid. (Fuente: Zhou Hongyi quiere “eliminar” el departamento de marketing con IA, ¿lo ha logrado “Nano”?)
📚 Aprendizaje
DeepLearning.AI lanza un nuevo curso corto: Orquestación de flujos de trabajo GenAI con Apache Airflow : DeepLearning.AI, en colaboración con Astronomer, ha lanzado un nuevo curso corto que enseña cómo utilizar Apache Airflow 3.0 para transformar prototipos de RAG en flujos de trabajo listos para producción. El contenido del curso incluye la descomposición de flujos de trabajo en tareas modulares, el uso de disparadores basados en tiempo y eventos para programar pipelines, el mapeo dinámico de tareas para la ejecución paralela, la adición de reintentos/alertas/rellenado para la tolerancia a fallos, y técnicas de escalado de pipelines. Este curso no requiere experiencia previa con Airflow. (Fuente: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
Hamel Husain lanza un minicurso sobre optimización y evaluación de RAG : Hamel Husain ha anunciado el lanzamiento de un minicurso de cuatro partes sobre optimización y evaluación de RAG (Retrieval Augmented Generation). La primera parte, impartida por @bclavie, discute la perspectiva de “la recuperación es RAG”, con el objetivo de responder a la discusión previa sobre RAG como un “virus mental que debe ser erradicado”. Esta serie de cursos es gratuita y tiene como objetivo ayudar a los profesionales a resolver los difíciles problemas encontrados en la evaluación de RAG. (Fuente: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

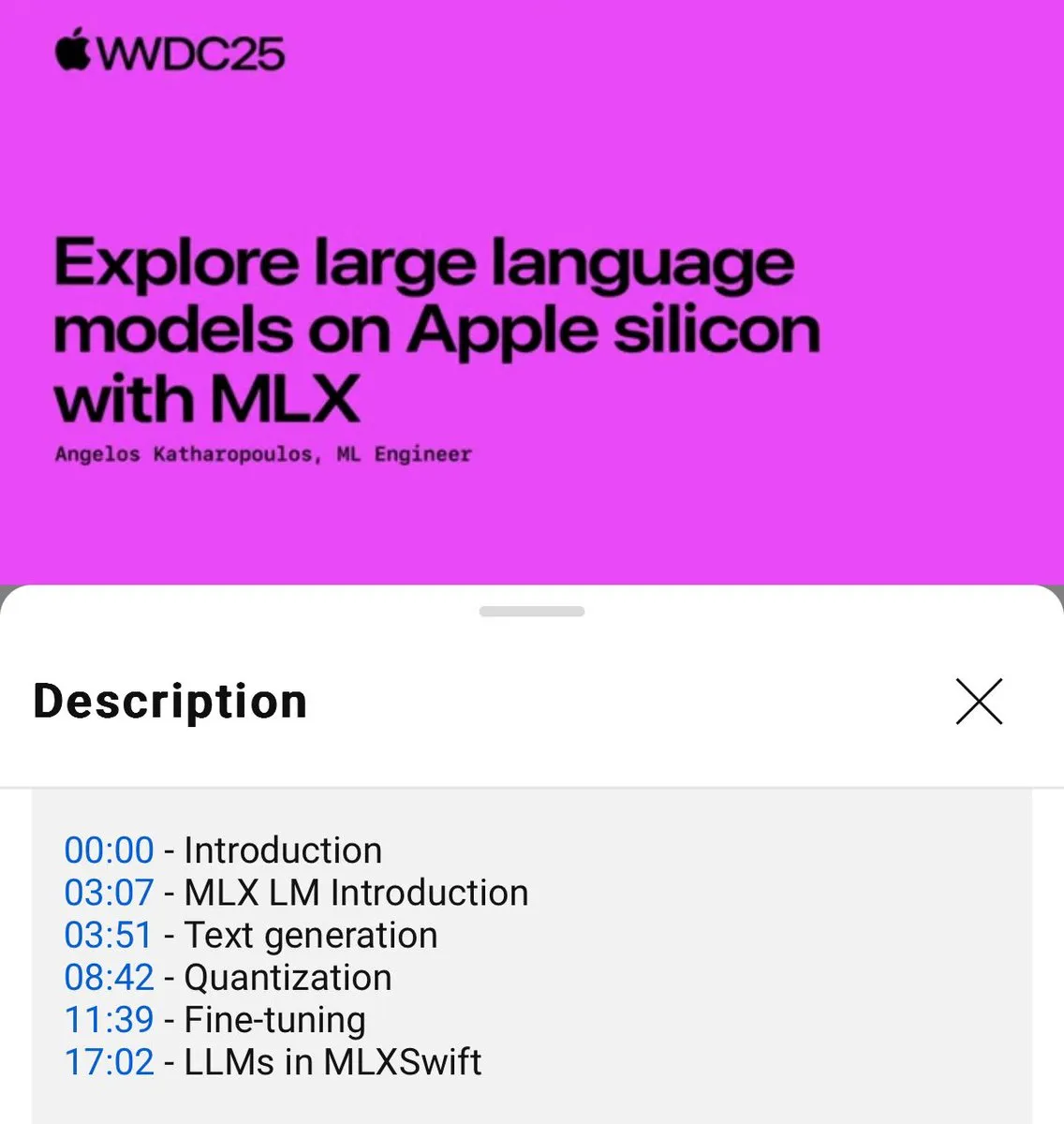
Publicado tutorial sobre el uso local de modelos de lenguaje MLX (WWDC25) : En la conferencia WWDC25, Angelos Katharopoulos presentó cómo empezar rápidamente con modelos de lenguaje locales utilizando MLX. El tutorial cubre operaciones de una sola línea de comando utilizando MLXLM CLI, como la cuantización de modelos (mlx_lm.convert), el fine-tuning con LoRA (mlx_lm.lora) y la fusión de modelos para subirlos a Hugging Face (mlx_lm.fuse). El tutorial completo en Jupyter Notebook está disponible en GitHub. (Fuente: awnihannun)
LangChain comparte el método de Harvey AI para construir agentes de IA legales : Ben Liebald de Harvey AI compartió en el evento Interrupt de LangChain su método maduro para construir agentes de IA legales. Este método combina la evaluación con LangSmith y una estrategia de “abogado en el circuito” (lawyer-in-the-loop), con el objetivo de proporcionar herramientas de IA fiables para abogados en trabajos legales complejos. (Fuente: LangChainAI, hwchase17)

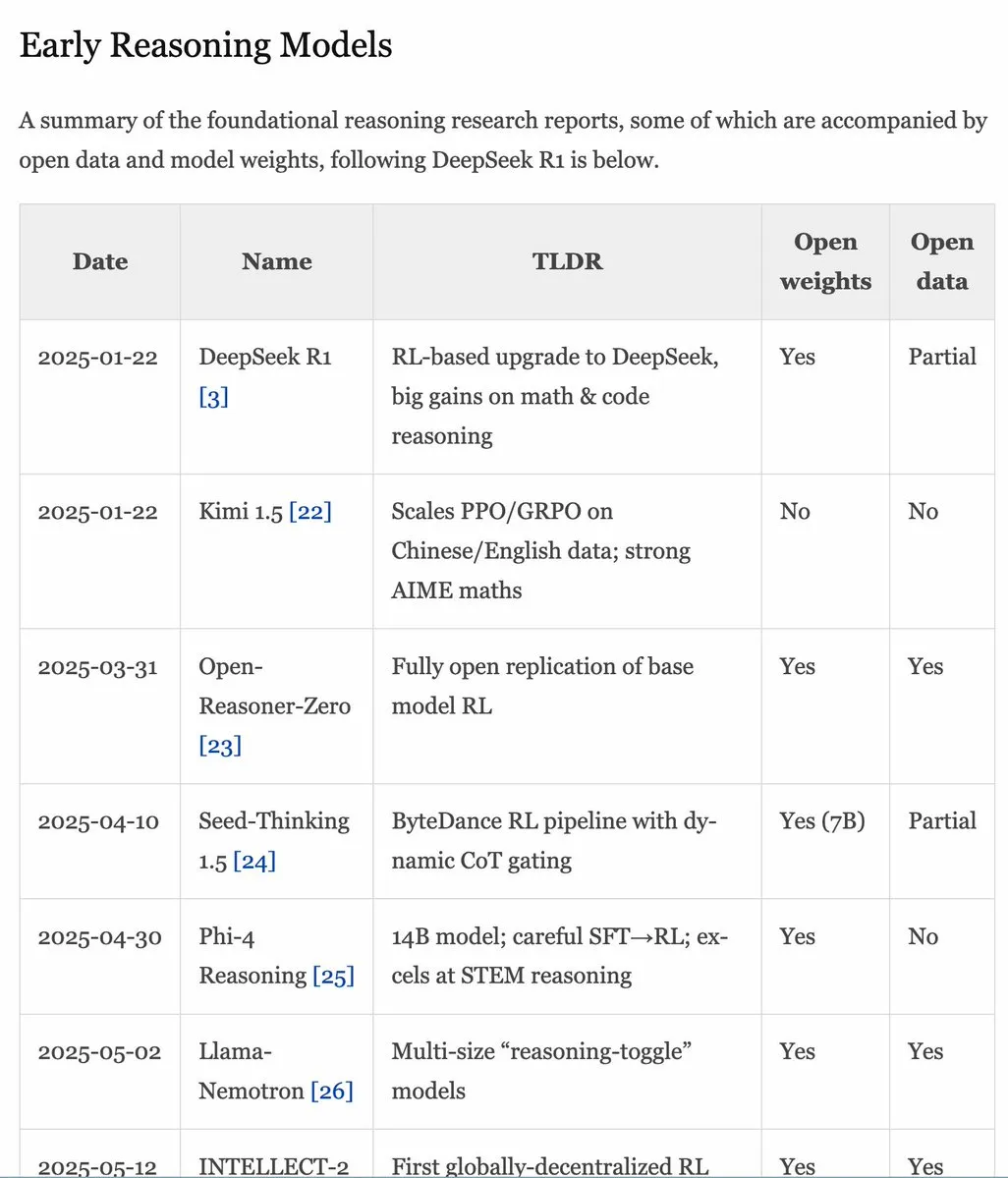
Actualización del manual RLHF v1.1, ampliando el contenido sobre RLVR/modelos de inferencia : El manual RLHF (rlhfbook.com) se ha actualizado a la versión v1.1, añadiendo contenido ampliado sobre RLVR (Reinforcement Learning from Video Representations) y modelos de inferencia. La actualización incluye un resumen de los principales informes de modelos de inferencia, prácticas/trucos comunes y sus usuarios, trabajos de inferencia relevantes anteriores a o1 y mejoras como RL asíncrono. (Fuente: menhguin)
Paper SWE-Flow: Síntesis de datos de ingeniería de software mediante un enfoque impulsado por pruebas : Un nuevo paper titulado SWE-Flow propone un novedoso framework de síntesis de datos basado en el desarrollo impulsado por pruebas (TDD). Este framework infiere automáticamente pasos de desarrollo incrementales mediante el análisis de pruebas unitarias, construyendo un grafo de dependencias en tiempo de ejecución (RDG) para generar un plan de desarrollo estructurado. Cada paso produce una base de código parcial, las pruebas unitarias correspondientes y las modificaciones de código necesarias, creando así tareas TDD verificables. Basándose en este método, se generó el conjunto de datos de benchmark SWE-Flow-Eval. (Fuente: HuggingFace Daily Papers)
Paper PlayerOne: El primer simulador del mundo real construido desde una perspectiva en primera persona : PlayerOne se propone como el primer simulador del mundo real construido desde una perspectiva en primera persona (egocéntrica), capaz de realizar exploraciones inmersivas en entornos dinámicos. Dada una imagen de la escena en primera persona del usuario, PlayerOne puede construir el mundo correspondiente y generar vídeos en primera persona estrictamente alineados con los movimientos reales del usuario capturados por una cámara externa. El modelo adopta un flujo de entrenamiento de grueso a fino y diseña un esquema de inyección de movimiento con desacoplamiento de componentes y un framework de reconstrucción conjunta. (Fuente: HuggingFace Daily Papers)
Paper ComfyUI-R1: Explorando modelos de inferencia para la generación de flujos de trabajo : ComfyUI-R1 es el primer modelo de inferencia grande para la generación automatizada de flujos de trabajo. Los investigadores primero construyeron un conjunto de datos que contiene 4K flujos de trabajo y construyeron datos de inferencia de pensamiento en cadena larga (CoT). ComfyUI-R1 se entrena mediante un framework de dos etapas: fine-tuning CoT para el arranque en frío y aprendizaje por refuerzo para incentivar la capacidad de inferencia. Los experimentos demuestran que el modelo de 7B parámetros supera significativamente a los métodos existentes en validez de formato, tasa de aprobación y puntuaciones F1 a nivel de nodo/grafo. (Fuente: HuggingFace Daily Papers)
Paper SeerAttention-R: Un framework adaptativo de atención dispersa para inferencia larga : SeerAttention-R es un framework de atención dispersa diseñado específicamente para la decodificación larga de modelos de inferencia. Aprende la dispersión de la atención mediante un mecanismo de gating autodestilado y elimina el pooling de consultas para adaptarse a la decodificación autorregresiva. Este framework puede integrarse como un plugin ligero en modelos preentrenados existentes sin modificar los parámetros originales. En el benchmark AIME, SeerAttention-R, entrenado con solo 0.4B tokens, mantuvo una precisión de inferencia cercana a la sin pérdidas en bloques de atención dispersa grandes (64/128) con un presupuesto de 4K tokens. (Fuente: HuggingFace Daily Papers)
Paper SAFE: Detección de fallos multitarea para modelos de visión-lenguaje-acción : El paper propone SAFE, un detector de fallos diseñado para políticas robóticas de propósito general (como VLA). Analizando el espacio de características de VLA, SAFE aprende a predecir la probabilidad de fallo de la tarea a partir de las características internas de VLA. Este detector se entrena en despliegues exitosos y fallidos, y se evalúa en tareas no vistas, siendo compatible con diferentes arquitecturas de políticas, con el objetivo de mejorar la seguridad de VLA al interactuar con el entorno. (Fuente: HuggingFace Daily Papers)
Paper Branched Schrödinger Bridge Matching: Aprendizaje de puentes de Schrödinger ramificados : Esta investigación introduce el framework Branched Schrödinger Bridge Matching (BranchSBM) para aprender puentes de Schrödinger ramificados, con el fin de predecir trayectorias intermedias entre una distribución inicial y una distribución objetivo. A diferencia de los métodos existentes, BranchSBM es capaz de modelar evoluciones ramificadas o divergentes desde un punto de partida común hacia múltiples resultados diferentes, mediante la parametrización de múltiples campos de velocidad dependientes del tiempo y procesos de crecimiento. (Fuente: HuggingFace Daily Papers)
💼 Negocios
Se rumorea que Meta planea adquirir la empresa de etiquetado de datos Scale AI por 15.000 millones de dólares, y su fundador podría unirse a Meta : Según informes, Meta planea gastar 15.000 millones de dólares para adquirir Scale AI, una empresa líder en el campo del etiquetado de datos. Si se concreta el acuerdo, el fundador chino-estadounidense de 28 años de Scale AI, Alexandr Wang, y su equipo se incorporarían directamente a Meta. Esta medida se considera una importante iniciativa del CEO de Meta, Mark Zuckerberg, para fortalecer la capacidad de su equipo de AGI (Inteligencia Artificial General) y alcanzar a competidores como OpenAI y Google. Meta ha estado activa recientemente en la contratación de talento en IA, ofreciendo paquetes salariales de decenas de millones de dólares a ingenieros de primer nivel. (Fuente: El primer gran fichaje del grupo de “superinteligencia” de Zuck, investigador principal de Google DeepMind, figura clave de “compresión como inteligencia”, dylan522p, sarahcat21, Dorialexander)
Disney y Universal Pictures demandan a la empresa de imágenes de IA Midjourney por infracción de derechos de autor : Disney y Universal Pictures han presentado una demanda contra la empresa de generación de imágenes de IA Midjourney, acusándola de utilizar sin autorización obras de propiedad intelectual conocidas como “Star Wars”, “Los Simpson”, entre otras. Este caso ha llamado la atención, y si Disney gana, podría tener un efecto dominó en otras empresas de IA que dependen del entrenamiento con grandes cantidades de datos, intensificando aún más las disputas sobre derechos de autor en el campo de la IA. (Fuente: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

Google vuelve a ofrecer un “plan de bajas voluntarias” debido al impacto de la búsqueda con IA, afectando a múltiples equipos importantes como búsqueda y publicidad : Ante el impacto de la búsqueda con IA, Google ha vuelto a ofrecer un “plan de bajas voluntarias” a empleados de varios departamentos en Estados Unidos, afectando a equipos clave como búsqueda, publicidad e ingeniería central, y reforzando las políticas de regreso a la oficina. Esta medida tiene como objetivo reorganizar recursos para dedicar más esfuerzos al desarrollo de su proyecto insignia de IA, Gemini, y a la experiencia de búsqueda en “modo IA”. El negocio tradicional de búsqueda de Google enfrenta enormes desafíos debido al auge de la IA, y la empresa también enfrenta presiones regulatorias. (Fuente: Bajo el impacto de la búsqueda con IA, Google vuelve a ofrecer un “plan de bajas voluntarias”, afectando a múltiples equipos importantes, jpt401)
🌟 Comunidad
La IA expone sesgos en un experimento de detección de fraude de asistencia social en Ámsterdam, el proyecto es suspendido : Ámsterdam intentó utilizar un sistema de IA (Smart Check) para evaluar las solicitudes de asistencia social y detectar fraudes. A pesar de seguir las mejores prácticas de IA responsable, incluyendo pruebas de sesgo y garantías técnicas, el sistema no logró ser justo y eficaz en el proyecto piloto. El modelo inicial mostró sesgos contra solicitantes no holandeses y hombres; tras ajustes, mostró sesgos contra holandeses y mujeres. Finalmente, debido a la incapacidad de garantizar la no discriminación, el proyecto fue suspendido. Este caso ha generado un amplio debate sobre la equidad algorítmica, la eficacia de las prácticas de IA responsable y la aplicación de la IA en la toma de decisiones del servicio público. (Fuente: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

Sistema de identificación de contenido generado por IA: valor, limitaciones y lógica de gobernanza : Con el aumento de los rumores y la propaganda falsa generados por IA, el sistema de identificación de IA ha ganado atención como medio de gobernanza. Teóricamente, la identificación explícita e implícita puede mejorar la eficiencia del reconocimiento y aumentar la alerta del usuario. Sin embargo, en la práctica, la identificación es fácil de eludir, falsificar y juzgar erróneamente, y su costo es elevado. El artículo sostiene que la identificación de IA debe integrarse en el sistema existente de gobernanza de contenidos, centrándose en áreas de alto riesgo (como rumores, propaganda falsa), y definir razonablemente las responsabilidades de las plataformas de generación y difusión, al tiempo que se fortalece la educación en alfabetización informacional del público. (Fuente: Cuando los rumores se suben al carro de la “IA”)
Las herramientas de codificación asistida por IA (como Claude Code) mejoran significativamente la eficiencia de los desarrolladores y reducen la presión laboral : Varios desarrolladores en la comunidad han compartido experiencias positivas utilizando herramientas de codificación asistida por IA (especialmente Claude Code de Anthropic). Estas herramientas no solo ayudan a escribir, probar y depurar código, sino que también brindan soporte en la planificación de proyectos y la resolución de problemas complejos, mejorando así drásticamente la eficiencia del desarrollo y aliviando la presión laboral y la ansiedad por los plazos. Algunos usuarios afirman que la asistencia de IA los hace sentir como una “fuerza imparable”. (Fuente: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

El consumo de energía y agua por contenido generado por IA llama la atención, Sam Altman afirma que cada consulta de ChatGPT consume aproximadamente 1/15 de cucharadita de agua : El CEO de OpenAI, Sam Altman, reveló que cada consulta de ChatGPT consume aproximadamente “una quinceava parte de una cucharadita” de agua. Este dato ha provocado discusiones sobre el impacto ambiental del entrenamiento y la inferencia de los modelos de IA. Aunque el método de cálculo específico y si incluye los costos de entrenamiento aún no están claros, la huella energética y el consumo de agua de la IA se han convertido en temas de interés en el mundo tecnológico y ambiental. (Fuente: MIT Technology Review, Reddit r/ChatGPT)

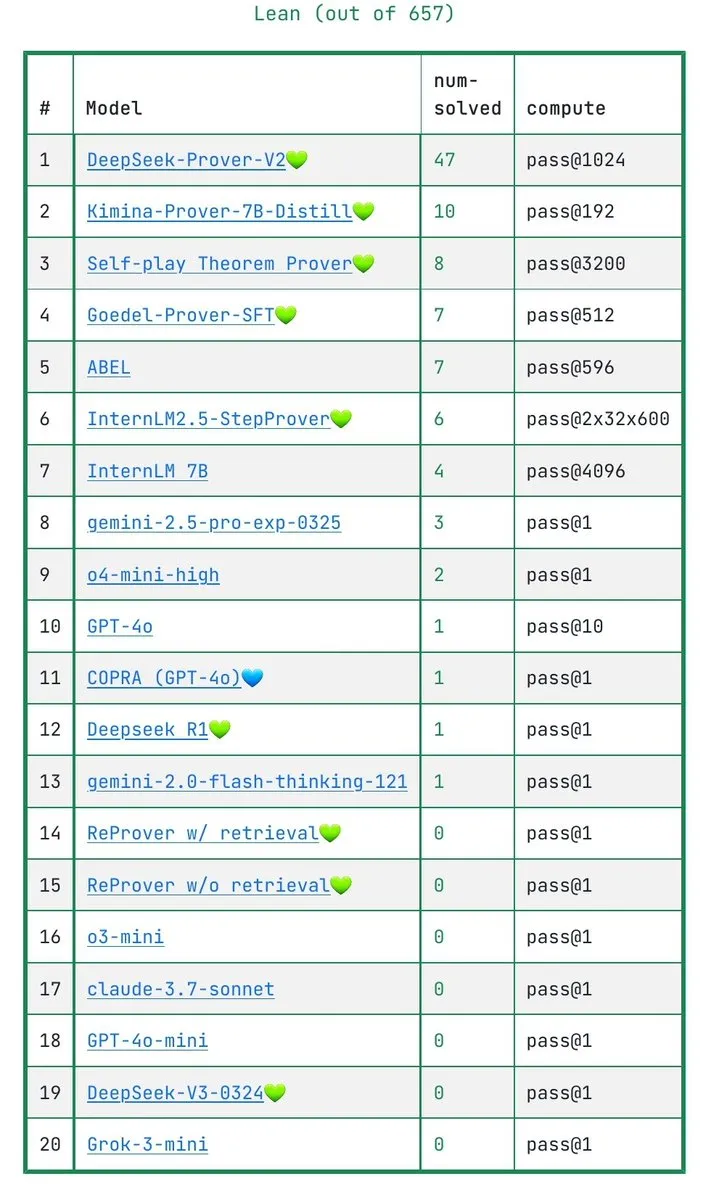
Debate sobre si los LLM realmente entienden las demostraciones matemáticas: el benchmark IneqMath revela las deficiencias de los modelos : El recién publicado benchmark IneqMath se centra en demostraciones de desigualdades matemáticas de nivel olímpico. La investigación encontró que, aunque los LLM a veces pueden encontrar la respuesta correcta, existe una brecha significativa en la construcción de demostraciones rigurosas y razonables. Esto ha provocado un debate sobre si los LLM en campos como las matemáticas realmente entienden o simplemente están “adivinando”. Sathya señaló que este fenómeno de “respuesta correcta – razonamiento incorrecto” también se manifiesta en benchmarks como PutnamBench. (Fuente: lupantech, lupantech, _akhaliq, clefourrier)
Aplicación y discusión de AI Agents en desarrollo de software, investigación y tareas diarias : La comunidad discute ampliamente la aplicación de AI Agents en diferentes campos. Por ejemplo, un usuario compartió su experiencia construyendo un flujo de trabajo de agente de investigación profunda con n8n y Claude; LlamaIndex demostró cómo implementar un agente de llenado de formularios incremental mediante Artifact Memory Block; la discusión también abarcó el uso de MCP (Model Context Protocol) para diseñar interfaces de herramientas orientadas a IA, y la aplicación de AI Agents en campos como el legal y la automatización de infraestructuras (como JARVIS de Cisco). (Fuente: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

Los estándares de seguridad para robots humanoides generan atención, necesitan considerar tanto el impacto físico como el psicológico : A medida que los robots humanoides ingresan gradualmente en aplicaciones industriales y aspiran a escenarios domésticos, sus estándares de seguridad se convierten en un tema de discusión. El grupo de investigación de robots humanoides del IEEE señala que los robots humanoides poseen propiedades únicas como la estabilidad dinámica, lo que requiere nuevas reglas de seguridad. Además de la seguridad física (como prevenir caídas y colisiones), también se deben considerar los desafíos de comunicación en la interacción humano-robot (como la expresión de intenciones, la coordinación de múltiples robots) y el impacto psicológico (como la antropomorfización excesiva que genera expectativas demasiado altas, la seguridad emocional). La elaboración de estándares debe equilibrar la innovación y la seguridad, y considerar las necesidades de diferentes escenarios de aplicación. (Fuente: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 Otros
Docker anuncia que docker run --gpus ahora es compatible con GPU de AMD : Docker ha anunciado oficialmente que el comando docker run --gpus ahora también es compatible con la ejecución en GPU de AMD. Esta mejora aumenta la facilidad de uso de las GPU de AMD en cargas de trabajo de IA/ML en contenedores, lo que tiene un impacto positivo en la promoción de la aplicación de AMD en el ecosistema de IA. (Fuente: dylan522p)
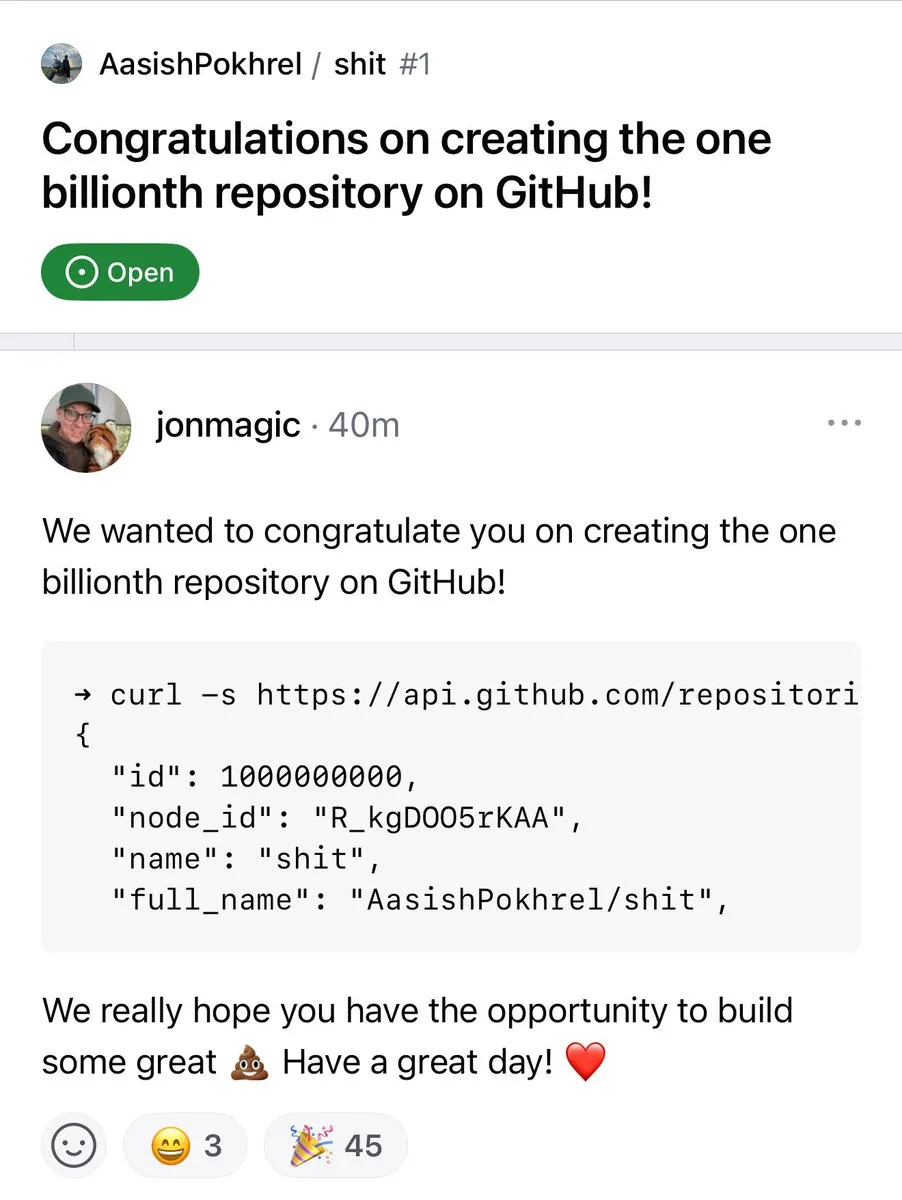
El número de repositorios en GitHub supera los mil millones : El número de repositorios de código en la plataforma GitHub ha superado oficialmente la marca de los mil millones. Este hito marca la continua prosperidad y crecimiento de la comunidad de código abierto y las plataformas de alojamiento de código. (Fuente: karminski3, zacharynado)
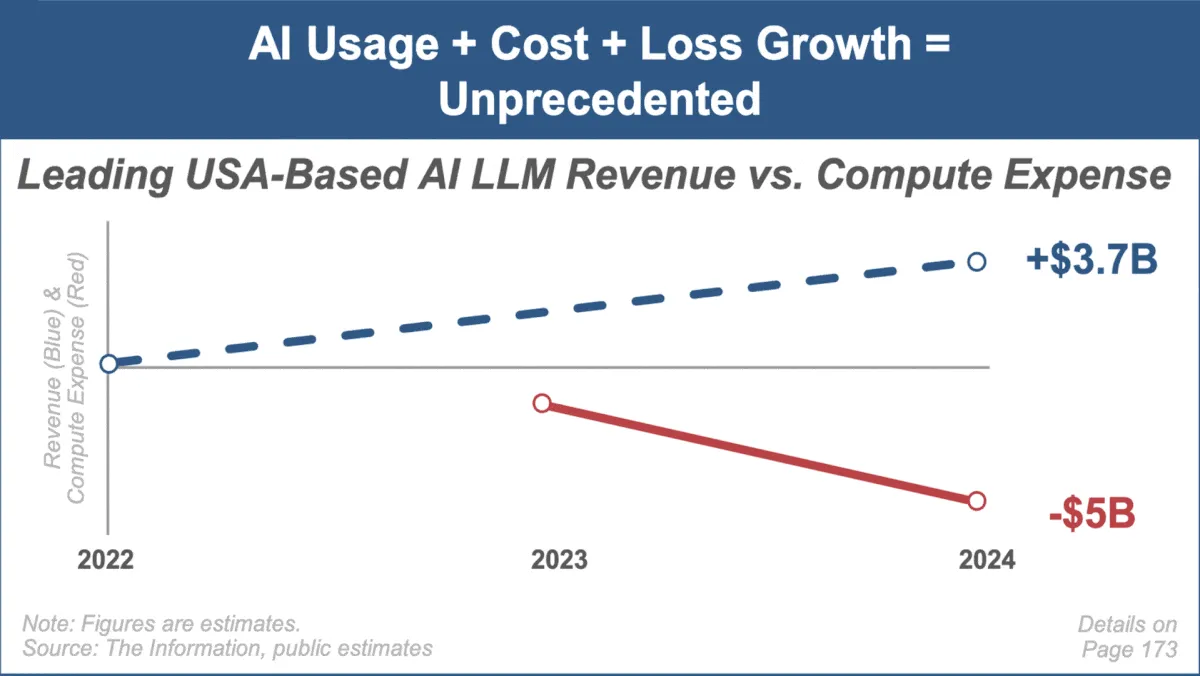
Mary Meeker publica el último informe de tendencias de IA, centrándose en el rápido crecimiento del mercado y sus desafíos : La reconocida analista de inversiones Mary Meeker ha publicado su primer informe de tendencias sobre el mercado de la inteligencia artificial, titulado “Trends — Artificial Intelligence (May ‘25)”. El informe destaca la velocidad de crecimiento sin precedentes en el campo de la IA, el aumento masivo de la escala de usuarios (como los 800 millones de usuarios de ChatGPT), el considerable incremento de la inversión de capital relacionada con la IA, y los continuos avances en rendimiento y capacidades emergentes de la IA. Al mismo tiempo, el informe señala los desafíos que enfrentan los modelos de negocio de la IA, como el aumento de los costos computacionales, la rápida iteración de los modelos y la competencia de las alternativas de código abierto. (Fuente: DeepLearning.AI Blog)