
Palabras clave:OpenAI, Meta, IBM, Mistral AI, o3-pro, Laboratorio de Superinteligencia, Magistral, Computadora cuántica, Precio de o3-pro, Inversión de Scale AI, Magistral-Small-2506, Computadora cuántica Starling, Pruebas de aplicaciones militares de IA
🔥 Enfoque
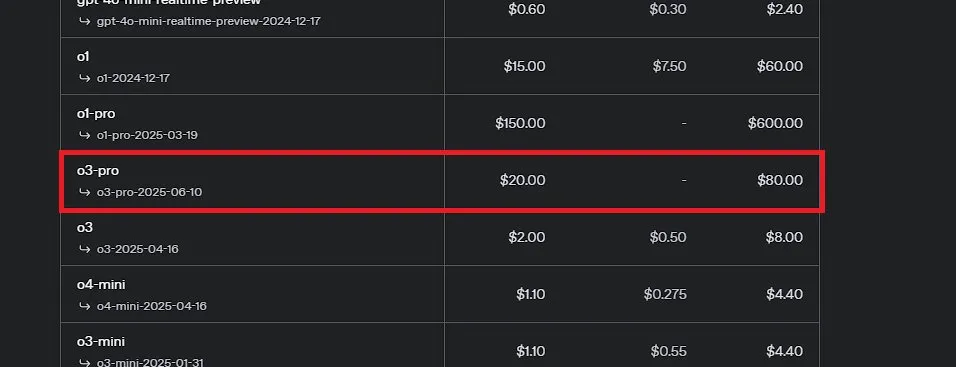
OpenAI lanza o3-pro, promocionado como el modelo más potente de la historia, y reduce drásticamente el precio de o3: OpenAI ha lanzado oficialmente o3-pro, su modelo de inferencia más potente hasta la fecha, ya disponible para usuarios de ChatGPT Pro y Team, con la API también lanzada simultáneamente. o3-pro supera a sus predecesores en campos como la ciencia, educación, programación, negocios y asistencia en escritura, y es compatible con múltiples herramientas como búsqueda web, análisis de archivos, entrada visual y programación en Python. Su precio es de 20 dólares por millón de tokens de entrada y 80 dólares por millón de tokens de salida. Al mismo tiempo, el precio del modelo o3 original se ha reducido drásticamente en un 80%, ajustándose a 2 dólares por millón de tokens de entrada y 8 dólares por millón de tokens de salida, igualando a GPT-4o. Esta medida podría desencadenar una guerra de precios en los modelos de IA e impulsar la aplicación profunda de la IA en campos profesionales, aunque o3-pro también tiene limitaciones como un tiempo de respuesta más largo y la falta de soporte temporal para conversaciones ad hoc. (Fuente: OpenAI, sama, OpenAIDevs, scaling01, dotey)
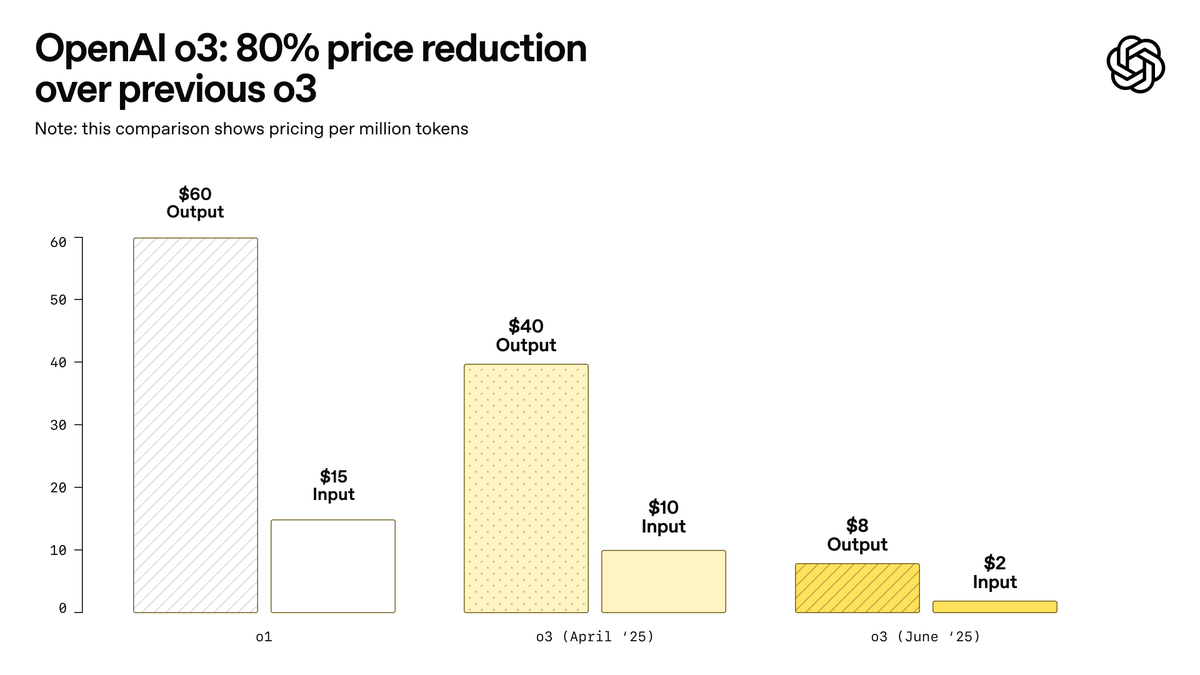
Meta establece el “Superintelligence Lab” e invierte fuertemente en Scale AI para revitalizar su competitividad en IA: Según The New York Times y otras fuentes, Meta Platforms está reorganizando su división de IA, estableciendo un nuevo “Superintelligence Lab”, y planea invertir más de 14.000 millones de dólares para adquirir el 49% de las acciones de la empresa de etiquetado de datos Scale AI. El cofundador y CEO de Scale AI, Alexandr Wang, se unirá a Meta y dirigirá este nuevo laboratorio. Esta medida tiene como objetivo acelerar la investigación y desarrollo de la inteligencia artificial general (AGI) y mejorar la competitividad general de Meta en el campo de la IA, especialmente en el procesamiento de datos de alta calidad y la contratación de talento de primer nivel. Esto marca un ajuste importante en la estrategia de IA de Meta y podría tener un profundo impacto en el panorama competitivo de la industria. (Fuente: natolambert, kylebrussell, Yuchenj_UW, steph_palazzolo)

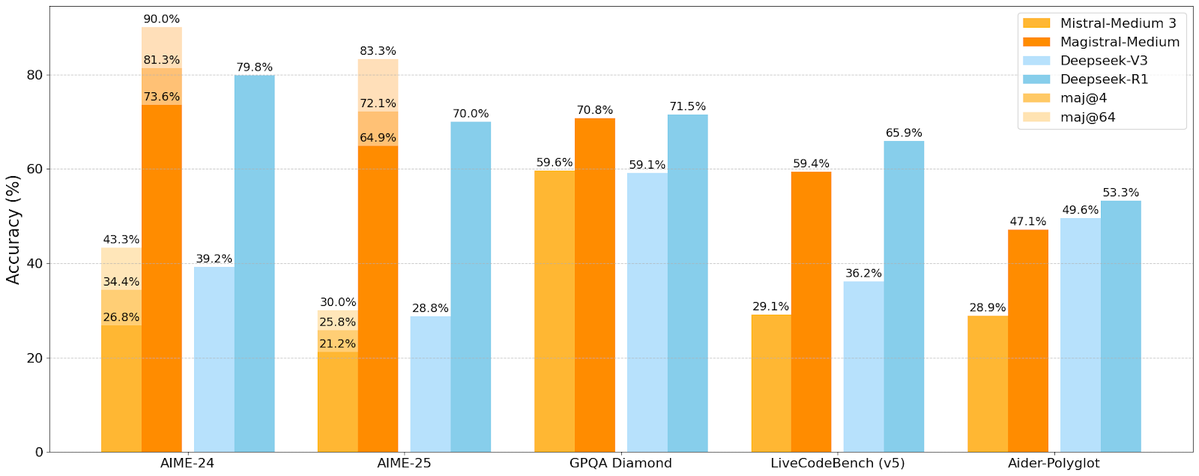
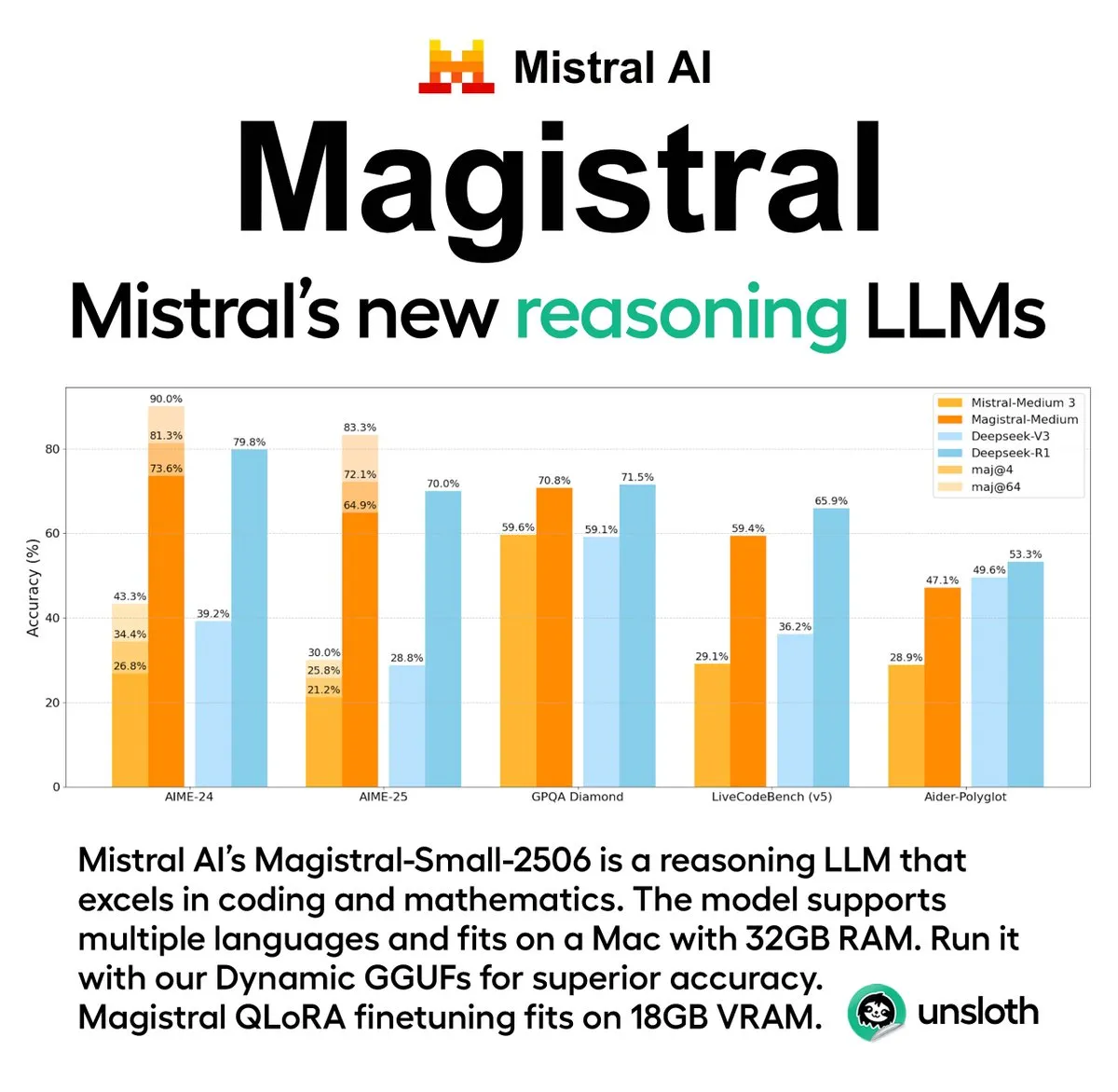
Mistral AI lanza su primera serie de modelos de inferencia Magistral, incluyendo una versión de código abierto: La startup francesa de IA, Mistral AI, ha lanzado Magistral, su primera serie de modelos diseñada específicamente para la inferencia. La serie incluye un modelo de código cerrado de nivel empresarial más potente, Magistral Medium, y un modelo de código abierto de 24 mil millones de parámetros, Magistral Small (Magistral-Small-2506), este último publicado bajo la licencia Apache 2.0. Estos modelos destacan en matemáticas, codificación e inferencia multilingüe, con el objetivo de proporcionar capacidades de inferencia más transparentes y específicas de dominio. Se informa que la velocidad de inferencia de Magistral Medium en la plataforma Le Chat es 10 veces más rápida que la de sus competidores, mientras que Magistral Small ofrece a la comunidad una potente opción para ejecución local. (Fuente: Mistral AI, jxmnop, karminski3)
IBM planea construir el ordenador cuántico tolerante a fallos a gran escala Starling para 2028: IBM ha anunciado su hoja de ruta para la computación cuántica, planeando construir un ordenador cuántico tolerante a fallos a gran escala llamado Starling para 2028, y espera abrirlo a los usuarios a través de servicios en la nube en 2029. Se espera que el sistema Starling contenga alrededor de 100 módulos y 200 cúbits lógicos, con el objetivo principal de lograr una corrección de errores efectiva, uno de los mayores desafíos técnicos actuales en el campo de la computación cuántica. La máquina utilizará los códigos de paridad de baja densidad (LDPC) de IBM para la corrección de errores y se centrará en lograr un diagnóstico de errores en tiempo real. Si tiene éxito, esto supondrá un gran avance en el campo de la computación cuántica, pudiendo acelerar su aplicación en problemas complejos como la ciencia de materiales y el desarrollo de fármacos. (Fuente: MIT Technology Review)

🎯 Tendencias
Los avances relacionados con la IA de Apple en la WWDC 2025 no logran impresionar a los desarrolladores: Apple anunció múltiples actualizaciones en la WWDC 2025, incluyendo el nuevo lenguaje de diseño “liquid glass” y la integración de ChatGPT en Xcode 26, entre otros. Sin embargo, la comunidad de desarrolladores expresó en general que sus avances en inteligencia artificial “no cumplieron con las expectativas”. Aunque Apple abrió por primera vez sus modelos de IA en dispositivo (on-device) a los desarrolladores e introdujo el framework Foundation Models para simplificar la integración de funciones de IA, la muy esperada actualización de Siri podría retrasarse hasta el próximo año. El analista Ming-Chi Kuo señaló que la estrategia de IA de Apple ocupa un lugar central, pero no se han visto avances tecnológicos significativos, siendo la gestión de las expectativas del mercado un factor clave. Apple parece centrarse más en mejorar la interfaz de usuario y las funciones del sistema operativo que en realizar innovaciones disruptivas en los propios modelos de IA. (Fuente: MIT Technology Review, jonst0kes, rowancheung)
El Pentágono reduce el tamaño de la oficina de pruebas y evaluación de sistemas de armas de IA: El Secretario de Defensa de EE. UU., Pete Hegseth, anunció que el tamaño de la Oficina del Director de Pruebas y Evaluaciones Operativas del Departamento de Defensa (DOT&E) se reducirá a la mitad, con una disminución de personal de 94 a aproximadamente 45 personas. Esta oficina es responsable de probar y evaluar la seguridad y eficacia de las armas y los sistemas de IA. Este ajuste tiene como objetivo “reducir la burocracia inflada y el gasto derrochador, y aumentar la letalidad”. Esta medida ha suscitado preocupaciones sobre el posible impacto en las pruebas de seguridad y eficacia de las aplicaciones militares de la IA, especialmente en el contexto de que el Pentágono está integrando activamente la tecnología de IA (incluidos los grandes modelos lingüísticos) en diversos sistemas militares. (Fuente: MIT Technology Review)

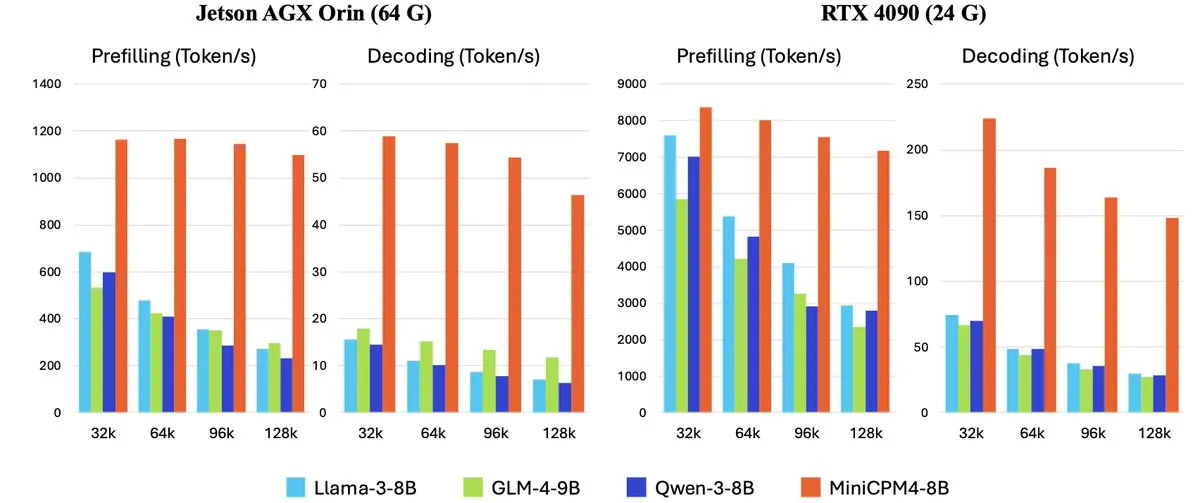
OpenBMB lanza la serie MiniCPM-4 de modelos de lenguaje grandes y eficientes para dispositivos edge: OpenBMB (Mianbi Intelligence) ha lanzado la serie de modelos MiniCPM-4, diseñados específicamente para dispositivos edge, con el objetivo de lograr una operación de ultra alta eficiencia. La serie incluye MiniCPM4-0.5B, MiniCPM4-8B (modelo insignia), BitCPM4 (modelo cuantizado de 1 bit), MiniCPM4-Survey (especializado para la generación de informes) y el modelo específico para MCP, MiniCPM4-MCP. El informe técnico detalla su arquitectura de modelo eficiente (como el mecanismo de atención dispersa entrenable InfLLM v2), algoritmos de aprendizaje eficientes (como Model Wind Tunnel 2.0) y métodos de procesamiento de datos de entrenamiento de alta calidad. Estos modelos ya están disponibles para su descarga en Hugging Face. (Fuente: _akhaliq, arankomatsuzaki, karminski3)
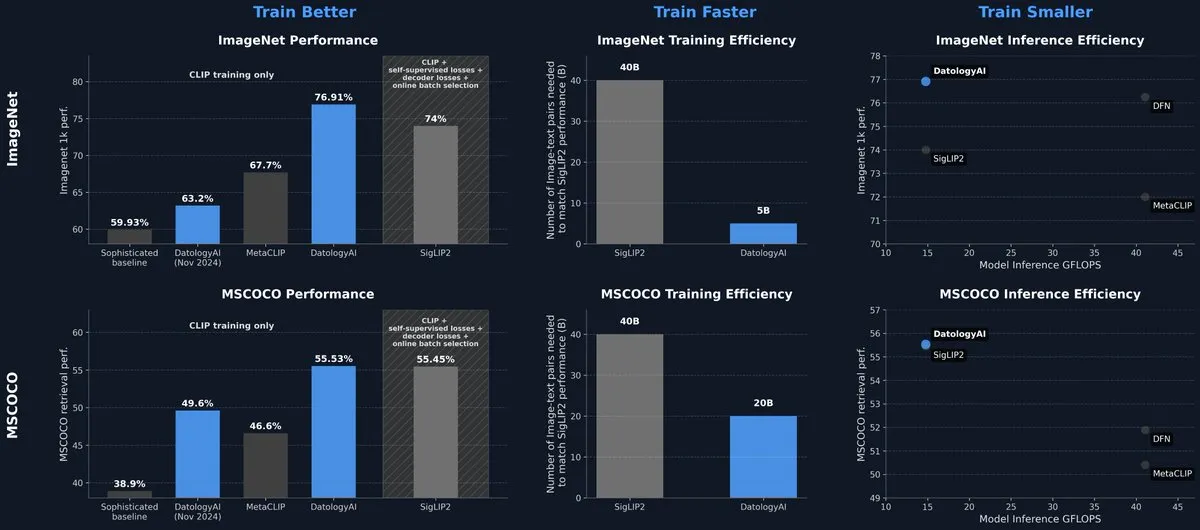
DatologyAI lanza un modelo CLIP que alcanza el nivel SOTA únicamente mediante la gestión de datos: DatologyAI ha presentado sus últimos resultados de investigación en el campo multimodal, logrando que su modelo CLIP ViT-B/32 alcance una precisión del 76.9% en ImageNet 1k, superando el 74% reportado por SigLIP2, mediante una meticulosa gestión de datos (data curation) en lugar de innovaciones en algoritmos o arquitectura. Este método también ha supuesto una mejora de 8 veces en la eficiencia del entrenamiento y de 2 veces en la eficiencia de la inferencia. El modelo ha sido publicado abiertamente, destacando el enorme potencial de los datos de alta calidad para mejorar el rendimiento del modelo. (Fuente: code_star, andersonbcdefg)
Krea AI lanza su primer modelo de imagen propio, Krea 1: Krea AI ha lanzado Krea 1, su primer modelo de imagen, que destaca en control estético y calidad de imagen, posee un amplio conocimiento artístico y admite referencias de estilo y entrenamiento personalizado. Krea 1 tiene como objetivo mejorar el realismo de la imagen, las texturas detalladas y una rica expresión de estilos. Actualmente, Krea 1 está disponible para pruebas beta gratuitas, permitiendo a los usuarios experimentar sus potentes capacidades de generación de imágenes. (Fuente: _akhaliq, op7418)
NVIDIA lanza el modelo de robot humanoide personalizable de código abierto GR00T N1: NVIDIA ha lanzado GR00T N1, un modelo de robot humanoide personalizable y de código abierto. Esta iniciativa tiene como objetivo impulsar la investigación y el desarrollo en el campo de los robots humanoides, proporcionando a los desarrolladores una plataforma flexible para construir y experimentar con diversas aplicaciones robóticas. Se espera que la naturaleza de código abierto de GR00T N1 atraiga una participación comunitaria más amplia, acelerando el progreso de la tecnología de robots humanoides. (Fuente: Ronald_vanLoon)
RoboBrain 2.0 lanza modelos robóticos multimodales de 7B y 32B: RoboBrain 2.0 ha lanzado sus modelos robóticos multimodales de 7B y 32B parámetros, con el objetivo de mejorar las capacidades de los robots en percepción, razonamiento y ejecución de tareas. Los nuevos modelos admiten razonamiento interactivo, planificación a largo plazo, retroalimentación de bucle cerrado, percepción espacial precisa (predicción de puntos y cuadros delimitadores), percepción temporal (estimación de trayectorias futuras) y razonamiento de escenas logrado mediante la construcción y actualización de memoria estructurada en tiempo real. Se espera que estas mejoras impulsen el nivel de operación autónoma y toma de decisiones de los robots en entornos complejos. (Fuente: Reddit r/LocalLLaMA)
Kling AI compartirá las últimas investigaciones sobre modelos de generación de video en CVPR 2025: Pengfei Wan, responsable del modelo de generación de video de Kling AI, pronunciará una conferencia magistral titulada “Introducción a Kling y nuestra investigación sobre modelos de generación de video más potentes” en la principal conferencia de visión por computadora, CVPR 2025. Junto con expertos de instituciones como Google DeepMind, discutirá los últimos avances y progresos de vanguardia en la tecnología de generación de video. Esta presentación profundizará en los logros de Kling en el avance de la tecnología de generación de video. (Fuente: Kling_ai)

La tecnología de IA asiste al Gaokao de China 2025, múltiples regiones implementan sistemas de inspección inteligente: El Gaokao de China 2025 adopta ampliamente sistemas de inspección inteligente por IA, con cobertura total de supervisión por IA en los centros de examen de múltiples lugares como Tianjin, Jiangxi, Hubei y Yangjiang en Guangdong. Estos sistemas utilizan cámaras 4K, seguimiento esquelético, reconocimiento facial, monitoreo de audio y otras tecnologías para detectar en tiempo real comportamientos irregulares de los examinados, como comenzar a responder antes de tiempo, pasar objetos, cuchichear, desviar la mirada de manera anormal, etc., y pueden emitir alertas. Esta medida tiene como objetivo mejorar la equidad de los exámenes y garantizar la disciplina en los centros de examen. La aplicación de sistemas de supervisión por IA marca la entrada de la gestión de exámenes en una era inteligente, trayendo cambios a los métodos tradicionales de supervisión. (Fuente: 36氪)
Lanzamiento del modelo de escritorio Gemma 3n, compatible con multiplataforma y dispositivos IoT: Google ha lanzado los modelos de escritorio Gemma 3n, incluyendo versiones de 2 mil millones y 4 mil millones de parámetros, optimizados para escritorio (Mac/Windows/Linux) y dispositivos de Internet de las Cosas (IoT). Este modelo está impulsado por la nueva biblioteca LiteRT-LM, diseñada para proporcionar capacidades eficientes de ejecución local. Los desarrolladores pueden acceder a vistas previas en Hugging Face y recursos relacionados en GitHub, impulsando aún más la aplicación de modelos de IA ligeros en dispositivos edge. (Fuente: ClementDelangue, demishassabis)
🧰 Herramientas
Yutori AI lanza Scouts: Agentes de IA para monitoreo web en tiempo real: Yutori AI, fundada por ex investigadores de Meta AI, ha lanzado un producto de agente de IA llamado Scouts. Scouts puede monitorear información de Internet en tiempo real basándose en temas o palabras clave establecidos por el usuario, y notificar al usuario cuando aparece contenido relevante. La herramienta tiene como objetivo ayudar a los usuarios a filtrar contenido valioso para ellos de la abrumadora información de la web, como el seguimiento de noticias en campos específicos, tendencias de mercado, ofertas de productos e incluso reservas escasas. El lanzamiento de Scouts marca un mayor desarrollo de las herramientas personalizadas de adquisición de información, convirtiendo a la IA en los “exploradores” digitales de los usuarios. (Fuente: DhruvBatraDB, krandiash, saranormous, JeffDean)
Replit lanza nueva función: Convierte diseños de Figma y otros en aplicaciones funcionales con un solo clic: Replit ha lanzado la función Replit Import, que permite a los usuarios importar directamente diseños de plataformas como Figma, Lovable, Bolt y convertirlos en aplicaciones ejecutables. Esta función tiene como objetivo reducir la barrera de entrada al desarrollo, permitiendo que incluso los no programadores conviertan rápidamente sus ideas de diseño en realidad. Replit Import mantiene la fidelidad del diseño e incluye escaneo de seguridad y gestión de claves integrados. Combinado con Replit Agent, bases de datos, autenticación y servicios de hosting, permite crear aplicaciones full-stack. (Fuente: amasad, pirroh)
Hugging Face lanza AISheets: Combina hojas de cálculo con miles de modelos de IA: El cofundador de Hugging Face, Thomas Wolf, anunció el lanzamiento del producto experimental AISheets, una herramienta que combina la facilidad de uso de las hojas de cálculo con la potente funcionalidad de miles de modelos de IA de código abierto (especialmente LLMs). Los usuarios pueden construir, analizar y automatizar tareas de procesamiento de datos en una interfaz de hoja de cálculo familiar, utilizando modelos de IA para obtener información de los datos y automatizar tareas, con el objetivo de proporcionar una nueva forma rápida, sencilla y potente de análisis de datos. (Fuente: _akhaliq, clefourrier, ClementDelangue, huggingface)
LlamaIndex permite convertir Agents en servidores MCP para interactuar con modelos como Claude: LlamaIndex ha anunciado soporte para convertir cualquiera de sus Agents en un servidor de Protocolo de Contexto de Modelo (MCP). Mediante código de ejemplo y videos, se demuestra cómo desplegar un flujo de trabajo personalizado de FidelityFundExtraction (utilizado para extraer datos estructurados de PDFs complejos) como un servidor MCP e invocarlo desde un modelo Claude. Esta funcionalidad tiene como objetivo mejorar el nivel de agentificación de las herramientas, facilitando la integración con clientes MCP como Claude Desktop y Cursor, y simplificando el proceso de conectar flujos de trabajo existentes a un ecosistema de IA más amplio. (Fuente: jerryjliu0)
GPT Researcher integra el Protocolo de Contexto de Modelo (MCP) de LangChain: GPT Researcher ahora utiliza el adaptador del Protocolo de Contexto de Modelo (MCP) de LangChain para la selección inteligente de herramientas e investigación. Esta integración combina sin problemas MCP con la funcionalidad de búsqueda web para lograr una recopilación de datos exhaustiva. Los usuarios pueden consultar la documentación de integración relevante para aprender a configurar y utilizar esta nueva función, mejorando así la eficiencia y profundidad de la investigación. (Fuente: hwchase17)
Tesslate lanza la serie UIGEN-T3 de modelos de generación de UI, compatible con múltiples tamaños: El equipo de Tesslate ha lanzado la serie UIGEN-T3 de modelos de generación de UI, incluyendo varias escalas de parámetros como 32B, 14B, 8B y 4B. Estos modelos están diseñados específicamente para generar componentes de UI (como breadcrumbs, botones, tarjetas) y código front-end completo (como páginas de inicio de sesión, dashboards, interfaces de chat), y son compatibles con Tailwind CSS. Los modelos están disponibles en Hugging Face y tienen como objetivo ayudar a los desarrolladores a construir rápidamente interfaces de usuario. Los desarrolladores informan que la cuantización estándar reduce significativamente la calidad del modelo, y recomiendan ejecutarlo en BF16 o FP8 para obtener resultados óptimos. (Fuente: Reddit r/LocalLLaMA)
Lanzamiento del modelo Doubao Podcast, genera podcasts de IA humanizados con un solo clic: Volcano Engine ha lanzado el modelo Doubao Podcast, capaz de generar rápidamente podcasts con un estilo de conversación altamente humanizado a partir de texto introducido por el usuario (como enlaces a artículos o prompts). El audio generado por el modelo se acerca al de una persona real en términos de tono, pausas y expresiones coloquiales, e incluso puede mantener discusiones con puntos de vista basados en el contenido. Esta tecnología se basa en el modelo de voz en tiempo real de extremo a extremo del equipo de tecnología de voz de ByteDance, logrando comprensión e inferencia directa en la modalidad de voz. Actualmente, esta función está disponible en la versión para PC de Doubao y en Kouzi Space, con el objetivo de reducir la barrera para la creación de contenido de audio y proporcionar una forma eficiente y personalizada de obtener información. (Fuente: 量子位)

Unsloth AI ofrece la versión cuantizada GGUF de Magistral-Small-2506: Para el modelo de inferencia Magistral-Small-2506 recientemente lanzado por Mistral AI, Unsloth AI ha proporcionado una versión cuantizada GGUF. Esto permite a los usuarios ejecutar este modelo de 24 mil millones de parámetros localmente, por ejemplo, en dispositivos con solo 32GB de RAM. Esta medida reduce la barrera de hardware para los modelos de inferencia de alto rendimiento, facilitando que un espectro más amplio de desarrolladores e investigadores experimenten y utilicen el modelo Magistral en entornos locales. (Fuente: ImazAngel)
📚 Aprendizaje
Análisis técnico profundo de la construcción del asistente visual LLaVA-1.5: LearnOpenCV ha publicado un artículo de análisis técnico profundo sobre la arquitectura de LLaVA-1.5. El artículo detalla cómo LLaVA-1.5 construye asistentes visuales de IA de vanguardia, incluyendo su innovadora tecnología de ajuste fino de instrucciones visuales (Visual Instruction Tuning) y los conjuntos de datos de código abierto que han transformado el campo de la IA multimodal. Esta guía tiene un valor de referencia importante para que los ingenieros e investigadores de IA/ML comprendan los principios de funcionamiento y los métodos de entrenamiento de los grandes modelos de lenguaje multimodales. (Fuente: LearnOpenCV)
Publicada guía de introducción al aprendizaje automático para proteínas: DL Weekly compartió una guía completa de aprendizaje automático para proteínas dirigida a principiantes. La guía cubre tipos de datos básicos relacionados con proteínas, modelos de aprendizaje profundo, métodos computacionales y conceptos biológicos fundamentales, con el objetivo de ayudar a investigadores y desarrolladores interesados en este campo interdisciplinario a iniciarse rápidamente. (Fuente: dl_weekly)
Qdrant y DataTalksClub lanzan un curso gratuito sobre RAG y búsqueda vectorial: Qdrant anunció una colaboración con DataTalksClub para ofrecer un curso online gratuito de 10 semanas. El contenido del curso incluye generación aumentada por recuperación (RAG), búsqueda vectorial, búsqueda híbrida, métodos de evaluación, etc., y contiene un proyecto práctico de extremo a extremo. Los expertos de Qdrant, Kacper Łukawski y Daniel Wanderung, impartirán personalmente el curso, con el objetivo de ayudar a los alumnos a dominar las habilidades prácticas para construir aplicaciones avanzadas de IA. (Fuente: qdrant_engine)
Podcast de Weaviate discute la salida estructurada de LLM y la decodificación restringida: El último episodio del podcast de Weaviate invitó a Will Kurt y Cameron Pfiffer de dottxt.ai, quienes junto con el presentador Connor Shorten, discutieron el problema de la salida estructurada de los grandes modelos de lenguaje (LLM). El programa profundizó en cómo asegurar que los LLM generen resultados fiables y predecibles (como JSON válido, correos electrónicos, tuits, etc.) mediante técnicas de decodificación restringida, y no solo una simple validación del formato JSON. También presentaron la herramienta de código abierto Outlines y su aplicación en casos de uso reales de IA, y展望aron el impacto de esta tecnología en los futuros sistemas de IA. (Fuente: bobvanluijt)
Artículo de ACL 2025 NLP SynthesizeMe!: Generación de prompts personalizados a partir de la interacción del usuario: Un artículo de la conferencia ACL 2025 NLP titulado “SynthesizeMe!” propone un nuevo método para crear modelos de usuario personalizados en lenguaje natural mediante el análisis de las interacciones del usuario con la IA (incluyendo retroalimentación implícita y explícita). El método primero genera y valida procesos de razonamiento que explican las preferencias del usuario, luego induce un perfil de usuario sintético a partir de ellos, filtra interacciones previas ricas en información del usuario y, finalmente, construye prompts personalizados para usuarios específicos, con el objetivo de mejorar el modelado de recompensas personalizadas y la capacidad de respuesta de los LLM. DSPy también retuiteó y mencionó que este es un excelente caso de aplicación de dspy.MIPROv2. (Fuente: lateinteraction, stanfordnlp)
Nuevo artículo explora el monitoreo y “overclocking” de LLMs con escalado en tiempo de prueba (Test-Time Scaling): Un nuevo artículo se centra en la técnica de escalado en tiempo de prueba utilizada por modelos como o3 y DeepSeek-R1, que permite a los LLM realizar más inferencias antes de responder, pero los usuarios a menudo no pueden conocer su progreso interno ni controlarlo. Los investigadores proponen exponer el “reloj” interno del LLM y demuestran cómo monitorear su proceso de inferencia y “hacerle overclocking” para acelerarlo. Esto proporciona nuevas ideas para comprender y optimizar la eficiencia de los grandes modelos de inferencia. (Fuente: arankomatsuzaki)

Artículo propone CARTRIDGES: Compresión de la caché KV de LLM de contexto largo mediante autoaprendizaje offline: Investigadores de HazyResearch de la Universidad de Stanford han propuesto un nuevo método llamado CARTRIDGES, destinado a resolver el problema del alto consumo de memoria de la caché KV en LLMs de contexto largo. Este método, mediante un mecanismo de entrenamiento en tiempo de prueba de “autoaprendizaje”, entrena offline una caché KV más pequeña (llamada cartridge) para almacenar información de documentos, logrando así reducir en promedio 39 veces la memoria de la caché y aumentar 26 veces el rendimiento máximo, manteniendo al mismo tiempo el rendimiento en la tarea. Este cartridge, una vez entrenado, puede ser reutilizado por diferentes solicitudes de usuarios, ofreciendo una nueva vía de optimización para el procesamiento de contextos largos. (Fuente: gallabytes, simran_s_arora, stanfordnlp)

Nuevo artículo Grafting: Edición de arquitecturas de Diffusion Transformers preentrenados a bajo costo: Investigadores de la Universidad de Stanford han propuesto un nuevo método llamado Grafting para editar arquitecturas de modelos Diffusion Transformer preentrenados. Esta técnica permite reemplazar mecanismos de atención y otros componentes del modelo con nuevas primitivas computacionales, utilizando solo el 2% del costo computacional del preentrenamiento, lo que posibilita el diseño personalizado de la arquitectura del modelo con un presupuesto computacional reducido. Esto es significativo para explorar nuevas arquitecturas de modelos y mejorar la eficiencia de los modelos existentes. (Fuente: realDanFu, togethercompute)
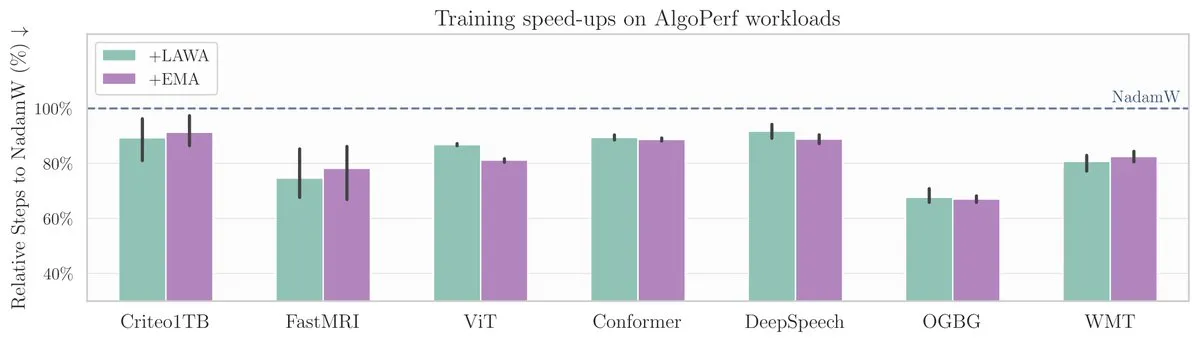
Nuevo artículo de ICML: El método de promediar checkpoints acelera el entrenamiento de modelos en el benchmark AlgoPerf: Un nuevo artículo de ICML investiga la aplicación del método clásico de promediar checkpoints (Averaging Checkpoints) para mejorar la velocidad de entrenamiento y el rendimiento de los modelos de aprendizaje automático. Los investigadores probaron este método en AlgoPerf, un benchmark estructurado y diversificado de algoritmos de optimización, para explorar sus beneficios prácticos en diferentes tareas, proporcionando una referencia práctica para acelerar el entrenamiento de modelos. (Fuente: aaron_defazio)
Herramienta de explicación visual de Transformers de código abierto: DL Weekly presentó una herramienta de visualización interactiva diseñada para ayudar a los usuarios a comprender el funcionamiento de los modelos basados en la arquitectura Transformer (como GPT). La herramienta desglosa los mecanismos internos del modelo de forma visual, facilitando la comprensión de conceptos complejos, y es adecuada para estudiantes e investigadores interesados en los modelos Transformer. El proyecto es de código abierto en GitHub. (Fuente: dl_weekly)
La Universidad de Zhejiang propone InftyThink: Razonamiento de profundidad infinita mediante segmentación y resumen: Un equipo de investigación de la Universidad de Zhejiang, en colaboración con la Universidad de Pekín, ha propuesto un nuevo paradigma de inferencia para modelos grandes llamado InftyThink. Este método divide el razonamiento largo en múltiples fragmentos cortos e introduce resúmenes entre los fragmentos para conectar el contexto, logrando así teóricamente un razonamiento de profundidad infinita mientras se mantiene un alto rendimiento de generación. Este método no depende de ajustes en la estructura del modelo y es compatible con los flujos de preentrenamiento y ajuste fino existentes al reestructurar los datos de entrenamiento en un formato de inferencia de múltiples turnos. Los experimentos demuestran que InftyThink puede mejorar significativamente el rendimiento del modelo en benchmarks como AIME24 y aumentar el rendimiento de generación. (Fuente: 量子位)

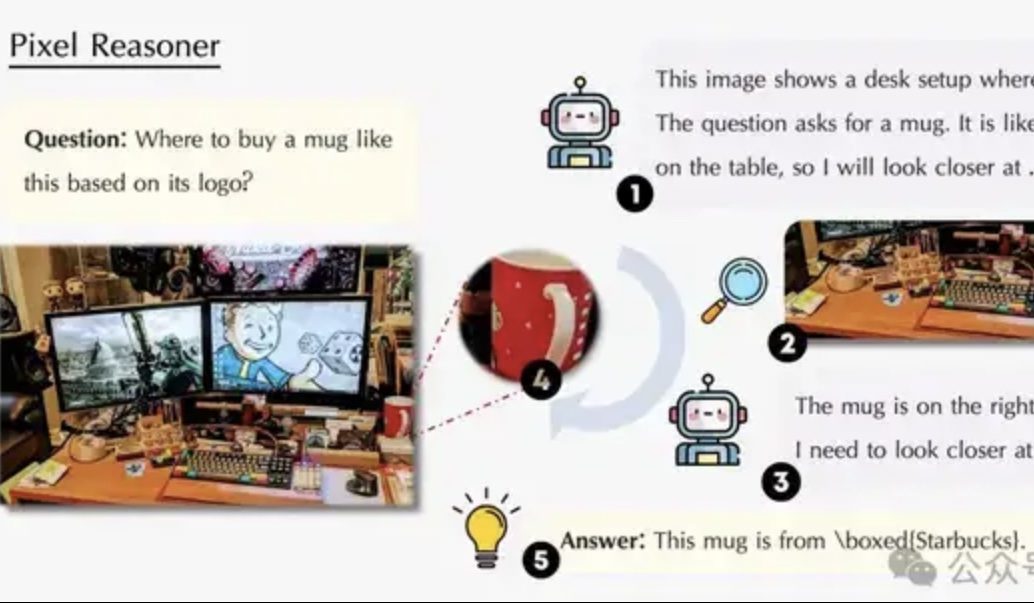
Artículo explora el razonamiento en el espacio de píxeles: Permitir que los VLM “usen ojos y cerebro” como los humanos: Un equipo de investigación de la Universidad de Waterloo, HKUST y USTC ha propuesto el paradigma de “razonamiento en el espacio de píxeles” (Pixel-Space Reasoning), que permite a los modelos de lenguaje visual (VLM) operar y razonar directamente a nivel de píxeles, como el zoom visual y el etiquetado espaciotemporal, en lugar de depender de tokens de texto como intermediarios. Mediante un esquema de aprendizaje por refuerzo con incentivos de curiosidad intrínseca y corrección extrínseca, se supera la “inercia cognitiva” del modelo. Pixel-Reasoner, construido sobre Qwen2.5-VL-7B, muestra un rendimiento excelente en múltiples benchmarks como V*Bench, con el modelo de 7B superando el rendimiento de GPT-4o. (Fuente: 量子位)
DeepLearning.AI lanza el quinto curso de su Certificado Profesional en Análisis de Datos: Narración de Datos (Data Storytelling): DeepLearning.AI ha lanzado el quinto curso de su Certificado Profesional en Análisis de Datos, con el tema “Narración de Datos” (Data Storytelling). El curso enseña cómo elegir el medio adecuado (dashboards, memorandos, presentaciones) para presentar insights, usar Tableau para diseñar dashboards interactivos, alinear los descubrimientos con los objetivos de negocio y comunicarlos eficazmente, además de ofrecer orientación para la búsqueda de empleo. Se enfatiza la importancia de la narración de datos para mejorar el rendimiento empresarial y comunicar eficazmente los insights. (Fuente: DeepLearningAI)

Artículo explora el impacto del conflicto de conocimiento en los grandes modelos de lenguaje: Un nuevo artículo evalúa sistemáticamente el comportamiento de los grandes modelos de lenguaje (LLM) cuando se enfrentan a conflictos entre la entrada contextual y el conocimiento parametrizado (es decir, la “memoria” interna del modelo). La investigación encontró que el conflicto de conocimiento tiene un impacto mínimo en las tareas que no dependen de la utilización del conocimiento; cuando el contexto es consistente con el conocimiento parametrizado, el modelo funciona mejor; incluso cuando se le indica, el modelo no puede suprimir completamente el conocimiento interno; proporcionar razones que expliquen el conflicto aumenta la dependencia del modelo del contexto. Estos hallazgos cuestionan la validez de las evaluaciones basadas en modelos y enfatizan la necesidad de considerar los problemas de conflicto de conocimiento al desplegar LLMs. (Fuente: HuggingFace Daily Papers)
Artículo CyberV: Un marco cibernético para el escalado en tiempo de prueba en la comprensión de video: Para abordar los problemas de demanda computacional, robustez y precisión que enfrentan los grandes modelos de lenguaje multimodales (MLLM) al procesar videos largos o complejos, los investigadores proponen el marco CyberV. Inspirado en los principios de la cibernética, este marco rediseña los MLLM de video como sistemas adaptativos, que incluyen un sistema de inferencia MLLM, sensores y un controlador. Los sensores monitorean el proceso de avance del modelo y recopilan interpretaciones intermedias (como la deriva de la atención), mientras que el controlador decide cuándo y cómo activar la autocorrección y generar retroalimentación. Este marco de expansión adaptativa en tiempo de prueba mejora los MLLM existentes sin necesidad de reentrenamiento, y los experimentos demuestran que mejora significativamente el rendimiento de modelos como Qwen2.5-VL-7B en benchmarks como VideoMMMU. (Fuente: HuggingFace Daily Papers)
Artículo propone LoRMA: Adaptación multiplicativa de bajo rango para el ajuste fino eficiente de parámetros de LLM: Para abordar los problemas de colapso de representación y desequilibrio de carga de expertos existentes en los métodos de ajuste fino eficiente de parámetros (PEFT) basados en LoRA y MoE, los investigadores proponen la Adaptación Multiplicativa de Bajo Rango (LoRMA). Este método cambia la forma en que se actualizan los expertos del adaptador PEFT, pasando de una transformación aditiva a una multiplicativa matricial más rica, abordando la complejidad computacional y los cuellos de botella de rango mediante operaciones de reordenamiento efectivas y la introducción de estrategias de expansión de rango. Los experimentos demuestran que el método heterogéneo MoA (Mezcla de Adaptadores) supera a los métodos homogéneos MoE-LoRA tanto en rendimiento como en eficiencia de parámetros. (Fuente: Reddit r/MachineLearning)
Artículo propone FlashDMoE: Implementación rápida de MoE distribuido en un solo núcleo: Los investigadores han lanzado FlashDMoE, el primer sistema que fusiona completamente la propagación hacia adelante de la Mezcla de Expertos (MoE) distribuida en un solo núcleo CUDA. Al escribir la capa de fusión desde cero en CUDA puro, FlashDMoE logra un aumento de hasta 9 veces en la utilización de la GPU, una reducción de latencia de 6 veces y una mejora de 4 veces en la eficiencia de escalado débil. Este trabajo proporciona nuevas ideas e implementaciones para optimizar la eficiencia de inferencia de los modelos MoE a gran escala. (Fuente: Reddit r/MachineLearning)
💼 Negocios
xAI colabora con Polymarket, fusionando predicciones de mercado con análisis de Grok: xAI, la empresa de inteligencia artificial de Elon Musk, ha anunciado una asociación con la plataforma de mercados de predicción descentralizados Polymarket. Esta colaboración tiene como objetivo combinar los datos de predicción de mercado de Polymarket con los datos de X (anteriormente Twitter) y las capacidades analíticas de Grok AI para crear un “motor de verdad hardcore” que revele los factores que moldean el mundo. xAI afirma que esto es solo el comienzo de la colaboración y que habrá más contenido colaborativo en el futuro. (Fuente: xai)
La empresa de chips de inferencia de IA Groq obtiene un compromiso de inversión de 1.500 millones de dólares de Arabia Saudita, centrándose en una estrategia de integración vertical: La empresa de chips de inferencia de IA Groq anunció un compromiso de inversión de 1.500 millones de dólares de Arabia Saudita para expandir la escala de entrega local de su infraestructura de inferencia de IA basada en LPU (Unidad de Procesamiento de Lenguaje). Groq, fundada por Jonathan Ross, uno de los inventores de la TPU, se especializa en computación de inferencia de IA. Sus chips LPU utilizan una arquitectura de pipeline programable con memoria y unidades de cómputo integradas en el mismo chip, lo que mejora drásticamente la velocidad de acceso a datos y la eficiencia energética. Groq no solo vende chips, sino que también ofrece clústeres GroqRack (nube privada/centro de cómputo de IA) y la plataforma en la nube GroqCloud (Tokens-as-a-Service), y es compatible con los principales modelos de código abierto como Llama, DeepSeek y Qwen. La compañía también ha desarrollado el sistema de IA compuesto Compound para mejorar el valor de la nube de inferencia de IA. (Fuente: 36氪)

La empresa de robots interactivos humanoides de Shenzhen “Digital Huaxia” completa una ronda de financiación Ángel+ de decenas de millones de yuanes: Digital Huaxia (Shenzhen) Technology Co., Ltd. completó recientemente una ronda de financiación Ángel+ de decenas de millones de yuanes, con inversión exclusiva de Co-Stone Capital (同创伟业). La empresa se centra en la comercialización a gran escala de robots AGI, y sus productos principales incluyen el robot humanoide “Xia Lan”, el robot humanoide de propósito general “Xia Qi” y la serie de robots IP “Xingxingxia”. El robot “Xia Lan”, con tecnología biónica de precisión como núcleo, puede imitar la mayoría de las expresiones humanas y posee capacidades de interacción multimodal. La compañía ya ha obtenido pedidos por valor de cientos de millones de yuanes de clientes que incluyen importantes fabricantes de TIC y redes eléctricas locales. (Fuente: 36氪)

🌟 Comunidad
Sam Altman publica una entrada de blog “La Singularidad Suave”, discutiendo la revolución gradual de la IA y el futuro: El CEO de OpenAI, Sam Altman, publicó una entrada de blog argumentando que la singularidad tecnológica está ocurriendo de una manera más suave y “gentil” de lo esperado, como un proceso gradual, continuo y de aceleración exponencial. Predice que para 2025, los agentes de IA capaces de realizar trabajos mentales complejos de forma independiente (como la programación) remodelarán la industria del software; para 2026, podrían surgir sistemas capaces de descubrir nuevos conocimientos científicos; y para 2027, podrían aparecer robots capaces de completar tareas en el mundo real. Altman enfatiza que resolver el problema de alineación de la IA y garantizar la accesibilidad universal de la tecnología son claves para un futuro próspero. También reveló que el primer modelo de pesos de código abierto de OpenAI se retrasará hasta finales del verano, ya que el equipo de investigación ha logrado “resultados sorprendentes e inesperados”. (Fuente: dotey, scaling01, sama)
Debate en la comunidad sobre o3-pro de OpenAI: Potente rendimiento pero alto costo, la reducción de precio de o3 desencadena reacciones en cadena: El lanzamiento de o3-pro de OpenAI y su elevado precio (80 $/M tokens de salida) se han convertido en el foco de discusión de la comunidad. Los usuarios generalmente reconocen sus potentes capacidades en tareas complejas de razonamiento, programación, etc., pero también expresan preocupación por su velocidad de respuesta y costo, con algunos usuarios bromeando que un simple saludo “Hi” podría costar 80 dólares. Al mismo tiempo, la drástica reducción del 80% en el precio del modelo o3 se considera un posible desencadenante de una guerra de precios en los modelos de IA, compitiendo con GPT-4o y otros productos. Existe controversia en la comunidad sobre si el rendimiento de o3 ha “disminuido en inteligencia” tras la reducción de precio. Posteriormente, OpenAI anunció que duplicaría la cuota de uso de o3 para los usuarios de ChatGPT Plus en respuesta a la demanda de los usuarios. (Fuente: Yuchenj_UW, scaling01, imjaredz, kevinweil, dotey)
La alta remuneración de Meta para atraer talento y la inversión en su organización de IA generan un acalorado debate: Los elevados paquetes de compensación ofrecidos por Meta a los investigadores de IA (que según se informa alcanzan cifras de nueve dígitos en dólares) han provocado discusiones en la comunidad. Nat Lambert comentó que tal remuneración podría financiar una institución de investigación completa del tamaño de AI2, lo que implica el altísimo costo del talento de primer nivel. Combinado con el establecimiento por parte de Meta del “Superintelligence Lab” y su masiva inversión en Scale AI, la comunidad en general cree que Meta está remodelando su competitividad en IA a cualquier costo, pero también presta atención a sus problemas internos de política organizacional y eficiencia. El contenido de ChinaTalk retuiteado por Helen Toner señaló que esta medida de Meta tiene como objetivo romper los problemas de política y arrogancia dentro de la organización. (Fuente: natolambert, natolambert)
El nuevo estilo de UI “Liquid Glass” de Apple en la WWDC genera debate sobre diseño y usabilidad: El nuevo estilo de diseño de UI “Liquid Glass” presentado por Apple en la WWDC 2025 ha generado una amplia discusión en las comunidades de desarrolladores y diseñadores. Algunas opiniones consideran que su efecto visual es novedoso y refleja la exploración de Apple hacia el diseño de interfaces 3D. Sin embargo, personalidades experimentadas como ID_AA_Carmack (John Carmack) señalaron que las interfaces de usuario semitransparentes suelen tener problemas de usabilidad, ya que pueden causar distracciones visuales y bajo contraste, afectando la lectura y la operación, y mencionaron que tanto Windows como Mac intentaron diseños similares en el pasado pero finalmente los ajustaron debido a problemas de usabilidad. Que la experiencia del usuario (UX) debe priorizarse sobre los efectos visuales de la interfaz de usuario (UI) se convirtió en el núcleo de la discusión. (Fuente: gfodor, ID_AA_Carmack, ReamBraden, dotey)
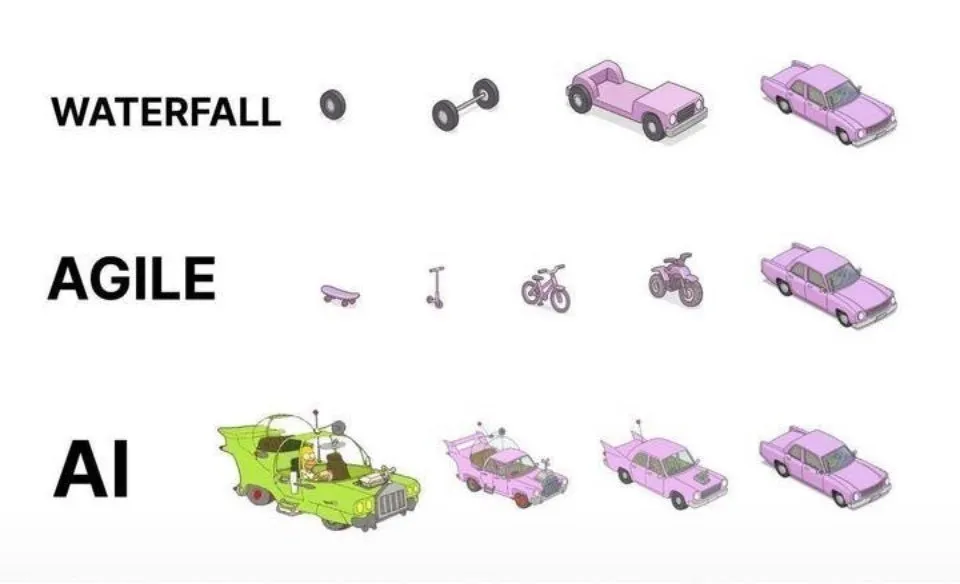
Prácticas de programación asistida por IA: La iteración ágil es superior a la generación única: En las redes sociales, dotey expresó su opinión sobre las mejores prácticas para programar usando IA (como Claude Code). Sostiene que no se debe adoptar el enfoque de proporcionar requisitos completos de una vez para que la IA genere un producto semiacabado masivo (modelo en cascada) o generar primero un producto imperfecto y luego optimizarlo (similar al tercer patrón en la imagen), ya que esto dificulta el control de calidad y el mantenimiento posterior. Aboga por adoptar un modelo de iteración ágil (similar al primer patrón en la imagen), dividiendo proyectos grandes (como sistemas ERP) en múltiples versiones pequeñas que puedan funcionar de manera estable e independiente, desarrollándolos iterativamente para garantizar la integridad funcional y la controlabilidad de cada versión, lo cual es consistente con las mejores prácticas de la ingeniería de software tradicional. (Fuente: dotey)
Mustafa Suleyman: La tecnología de IA está evolucionando de unificada y fija a dinámica y personalizada: Mustafa Suleyman, cofundador de Inflection AI y ex DeepMind, comentó que la tecnología tradicional suele ser fija, unificada y de “talla única”, mientras que la tecnología de inteligencia artificial actual presenta características dinámicas, personalizadas y emergentes. Considera que esto significa que la tecnología está pasando de ofrecer resultados únicos y repetitivos a explorar caminos de posibilidades infinitas, enfatizando el enorme potencial de la IA en servicios personalizados y aplicaciones creativas. (Fuente: mustafasuleyman)
Perplexity AI sufre problemas de infraestructura, el CEO sale a explicar: El CEO de Perplexity AI, Arav Srinivas, respondió en redes sociales a las preguntas de los usuarios sobre la inestabilidad del servicio, afirmando que debido a problemas de infraestructura, tuvieron que habilitar una experiencia de usuario degradada (degraded UX) para parte del tráfico. Enfatizó que los datos de los usuarios (como la biblioteca o los hilos) no se han perdido y que todas las funciones se restablecerán a la normalidad una vez que el sistema se estabilice. Esto refleja los desafíos que enfrentan los servicios de IA en su rápido desarrollo en términos de estabilidad y escalabilidad de la infraestructura. (Fuente: AravSrinivas)
Sergey Levine discute las diferencias de aprendizaje entre modelos de lenguaje y modelos de video: El profesor Sergey Levine de UC Berkeley, en su artículo “Modelos de Lenguaje en la Caverna de Platón”, plantea una pregunta profunda: ¿Por qué los modelos de lenguaje pueden aprender tanto prediciendo la siguiente palabra, mientras que los modelos de video aprenden relativamente poco prediciendo el siguiente fotograma? Sostiene que los LLM obtienen potentes capacidades de razonamiento al aprender las “sombras” del conocimiento humano (datos textuales), lo que se asemeja más a una “ingeniería inversa” de la cognición humana que a una exploración verdaderamente autónoma del mundo físico. Los modelos de video observan directamente el mundo físico, pero actualmente son inferiores a los LLM en razonamiento complejo. Propone que el objetivo a largo plazo de la IA debería ser superar la dependencia de las “sombras” del conocimiento humano e interactuar directamente con el mundo físico a través de sensores para lograr una exploración autónoma. (Fuente: 36氪)
💡 Otros
Debate sobre ética e IA: ¿Puede la IA tener verdadera conciencia?: MIT Technology Review se centra en el complejo tema de la conciencia de la IA. El artículo señala que la conciencia de la IA no es solo un rompecabezas intelectual, sino también un tema con peso moral. Juzgar erróneamente la conciencia de la IA podría llevar a la esclavización involuntaria de IA con capacidad de sentir, o al sacrificio del bienestar humano por máquinas sin percepción. La comunidad investigadora ha progresado en la comprensión de la naturaleza de la conciencia, y estos avances podrían guiar la exploración y el manejo de la conciencia artificial. Esto suscita profundas reflexiones sobre los derechos de la IA, la responsabilidad y las relaciones entre humanos y máquinas. (Fuente: MIT Technology Review)
Joseph Sifakis, ganador del Premio Turing: La IA actual no es verdadera inteligencia, hay que tener cuidado con la confusión entre conocimiento e información: Joseph Sifakis, ganador del Premio Turing, señala en sus obras y entrevistas que la comprensión actual de la IA por parte de la sociedad es errónea, confunde la acumulación de información con la creación de sabiduría y sobreestima la “inteligencia” de las máquinas. Considera que actualmente no existen sistemas verdaderamente inteligentes y que el impacto real de la IA en la industria es mínimo. La IA carece de comprensión de sentido común, su “inteligencia” es producto de modelos estadísticos y le resulta difícil sopesar valores y riesgos en contextos sociales complejos. Enfatiza que el núcleo de la educación es cultivar el pensamiento crítico y la creatividad, no la transmisión de conocimientos, y pide el establecimiento de estándares globales para las aplicaciones de IA, definiendo claramente los límites de responsabilidad, para que la IA se convierta en un socio que potencie a los humanos en lugar de reemplazarlos. (Fuente: 36氪)
La reestructuración de la industria publicitaria en la era de la IA: Una transformación desde la generación creativa hasta la entrega personalizada: La conferencia Google I/O 2025 demostró cómo la IA está reestructurando profundamente la industria publicitaria. Las tendencias incluyen: 1) Automatización creativa impulsada por IA, donde desde imágenes hasta guiones de video pueden ser generados por IA, con herramientas como Veo 3, Imagen 4 y Flow reduciendo la barrera para la creación de contenido de alta calidad. 2) El paradigma de personalización está cambiando de “mil caras para mil personas” a “mil caras para una persona”, donde los agentes inteligentes de IA pueden comprender proactivamente las necesidades del usuario y facilitar transacciones. 3) Los límites entre publicidad y contenido se difuminan, con la publicidad integrándose directamente en los resultados de búsqueda generados por IA, convirtiéndose en parte de la información. Las marcas necesitan construir sus propios agentes inteligentes, ofrecer servicios orientados a la IA y adherirse a una estrategia a largo plazo de “integración de marca y rendimiento” para adaptarse al cambio. (Fuente: 36氪)