
Palabras clave:DeepSeek, OpenAI, Modelo de razonamiento, Modelo multimodal de gran escala, Aprendizaje por refuerzo, Innovación en IA, Modelo de código abierto, Modelo de razonamiento DeepSeek R1, Entrenamiento de aprendizaje por refuerzo OpenAI o4, Mapa de pensamiento humano en modelos multimodales de gran escala, Serie Magistral de Mistral AI, Modelo MoE dots.llm1 de Xiaohongshu
🔥 Enfoque
Las rutas de innovación de DeepSeek y OpenAI revelan la “innovación cognitiva”: DeepSeek, a través de la “Scaling Law limitada”, la innovación en arquitecturas MLA y MoE, y la optimización coordinada de software y hardware, ha logrado bajo costo y alto rendimiento. La apertura del código de su modelo de inferencia R1 ha impulsado un avance en las capacidades cognitivas de la IA, rompiendo el “sello mental” de los innovadores chinos en el campo de la investigación básica y demostrando la fortaleza líder a nivel mundial de las empresas chinas en la investigación básica de IA y la innovación de modelos. OpenAI, por su parte, mediante el uso extremo de la arquitectura Transformer y la Scaling Law (ley de escalabilidad), lideró la revolución de los grandes modelos de lenguaje, e impulsó un cambio de paradigma en la interacción humano-máquina y un salto en las capacidades cognitivas de la IA a través de ChatGPT y el modelo de inferencia o1. Las trayectorias de desarrollo de ambos enfatizan una profunda comprensión de la esencia de la tecnología y la reestructuración estratégica, ofreciendo valiosas ideas sobre la construcción organizacional y la innovación para los emprendedores en la era de la IA. Especialmente el paradigma de AI Lab de DeepSeek, que fomenta la “emergencia”, ofrece una nueva referencia de modelo organizacional para los emprendedores impulsados por la innovación tecnológica (Fuente: 36氪)
Se rumorea que OpenAI está entrenando un nuevo modelo o4, el aprendizaje por refuerzo remodela el panorama de la IA: SemiAnalysis reveló que OpenAI está entrenando un nuevo modelo entre GPT-4.1 y GPT-4.5, y que el modelo de inferencia de próxima generación o4 se entrenará mediante aprendizaje por refuerzo (RL) basado en GPT-4.1. El RL desbloquea la capacidad de razonamiento del modelo generando CoT e impulsa el desarrollo de agentes de IA, pero tiene requisitos extremadamente altos de infraestructura (especialmente inferencia) y diseño de funciones de recompensa, y es propenso al fenómeno de “hacking de recompensas”. Los datos de alta calidad son clave para expandir el RL, y los datos de comportamiento del usuario se convertirán en un activo importante. El RL también cambia la estructura organizativa del laboratorio, fusionando profundamente la inferencia y el entrenamiento. A diferencia del preentrenamiento, el RL puede actualizar continuamente las capacidades del modelo, como DeepSeek R1. Para modelos pequeños, la destilación puede ser superior al RL. Esta ronda de revelaciones predice que el campo de la IA, especialmente los modelos de inferencia, marcará el comienzo de una evolución continua y un salto de capacidad basado en RL (Fuente: 36氪)
Se descubre que los grandes modelos multimodales forman espontáneamente “mapas mentales humanos”: Un equipo conjunto del Instituto de Automatización de la Academia China de Ciencias y el Centro de Excelencia en Innovación en Ciencias del Cerebro y Tecnología Inteligente confirmó, mediante experimentos de comportamiento y análisis de neuroimagen, que los grandes modelos de lenguaje multimodales (MLLMs) pueden formar espontáneamente sistemas de representación de conceptos de objetos altamente similares a los humanos. El estudio construyó por primera vez el “mapa conceptual” de un modelo de IA analizando 4.7 millones de datos de juicio de comportamiento de la “tarea de identificación de elementos atípicos de tres opciones”. Los hallazgos clave incluyen: diferentes arquitecturas de modelos de IA pueden converger en estructuras cognitivas de baja dimensión similares; los modelos desarrollan capacidades de clasificación de conceptos de objetos de alto nivel en ausencia de supervisión, consistentes con la cognición humana; las “dimensiones de pensamiento” de los modelos de IA pueden recibir etiquetas semánticas, como animal, comida, dureza, etc.; la representación de los MLLM está significativamente correlacionada con los patrones de actividad neuronal en regiones cerebrales específicas (como FFA, PPA), proporcionando evidencia de que “la IA y los humanos comparten mecanismos de procesamiento de conceptos”. Esta investigación ofrece nuevas perspectivas para comprender la cognición de la IA, desarrollar inteligencia similar al cerebro e interfaces cerebro-máquina (Fuente: 量子位)

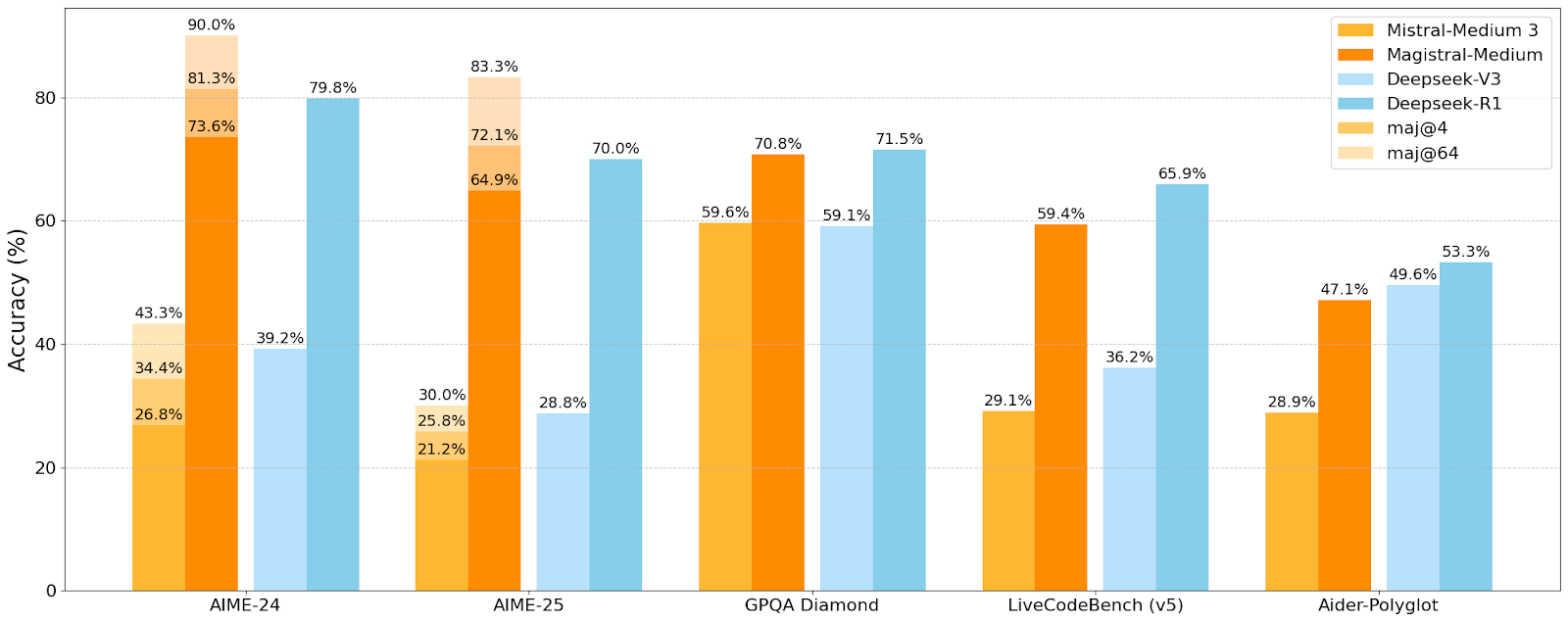
Mistral AI lanza su primera serie de modelos de inferencia Magistral, el modelo pequeño Magistral-Small ya es de código abierto: Mistral AI ha lanzado su primera serie de modelos diseñados específicamente para inferencia, Magistral, que incluye Magistral-Small y Magistral-Medium. Magistral-Small, construido sobre Mistral Small 3.1 (2503), es un modelo de inferencia eficiente de 24B parámetros, entrenado con SFT y RL utilizando trayectorias de Magistral-Medium para mejorar sus capacidades de razonamiento. El modelo es multilingüe, tiene una ventana de contexto de 128k (contexto efectivo recomendado de 40k), se publica bajo la licencia Apache 2.0 y puede desplegarse localmente en una única RTX 4090 o en un MacBook con 32GB de RAM (después de la cuantización). Las pruebas de referencia muestran que Magistral-Small tiene un rendimiento sobresaliente en tareas como AIME24, AIME25, GPQA Diamond y Livecodebench (v5), acercándose o incluso superando a algunos modelos más grandes. Magistral-Medium tiene un rendimiento superior, pero actualmente no es de código abierto. Este lanzamiento marca el progreso de Mistral en la mejora de las capacidades de inferencia de modelos y el soporte multilingüe (Fuente: Reddit r/LocalLLaMA, Mistral AI, X)
🎯 Movimientos
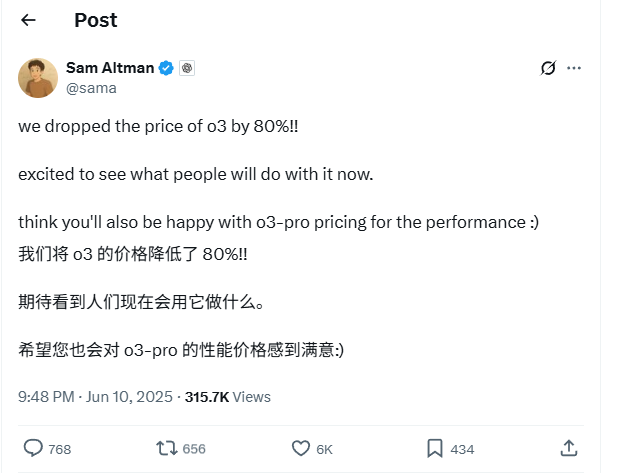
El precio de la API del modelo o3 de OpenAI se reduce drásticamente en un 80%: El CEO de OpenAI, Sam Altman, anunció que el precio de la API de su modelo o3 se ha reducido en un 80%. Tras el ajuste, el precio de entrada es de 2 dólares por millón de tokens y el precio de salida es de 8 dólares por millón de tokens (algunas fuentes mencionan 5 dólares por millón de tokens para la salida, se recomienda verificar la documentación oficial). Esta reducción de precios es significativa, lo que reduce considerablemente el costo de usar el modelo o3 para tareas como la escritura de código, y se espera que impulse una aplicación e innovación más amplias. Los usuarios deben tener en cuenta que la lista de precios del sitio web oficial puede no estar actualizada, se recomienda realizar pruebas antes de llamar a la API para confirmar el precio real y evitar pérdidas innecesarias. Se considera que esta medida es una estrategia para hacer frente a la competencia del mercado (como Gemini 2.5 Pro y Claude 4 Sonnet) y podría indicar que el costo de la inteligencia artificial seguirá disminuyendo (Fuente: X, X, X)
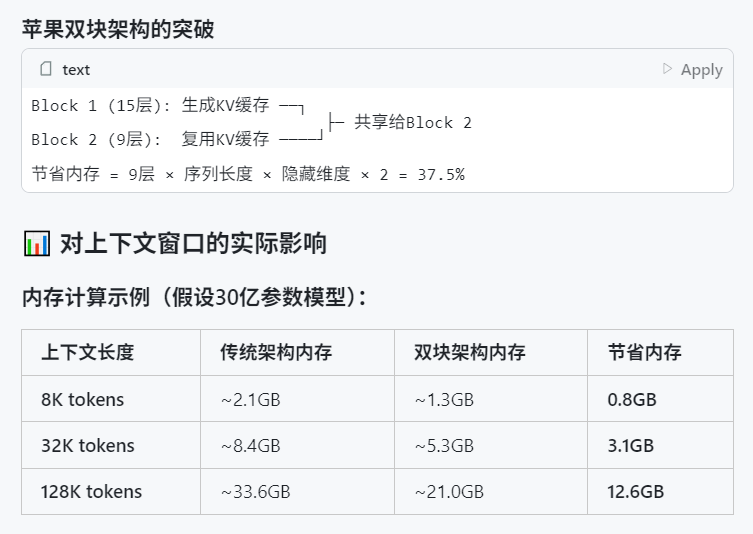
Se critica que la WWDC 2025 de Apple no se centró mucho en la IA, pero los detalles técnicos revelan ambición: Parece que Apple no se centró tanto en la IA como se esperaba en la Conferencia Mundial de Desarrolladores (WWDC) 2025, pero sus documentos técnicos revelan su profunda inversión en modelos en el dispositivo y en la nube. Apple está utilizando técnicas avanzadas de entrenamiento, destilación y cuantización, incluida una “arquitectura de doble bloque” diseñada para modelos móviles (de aproximadamente 3B de tamaño) para reducir la ocupación de memoria, y una arquitectura “PT-MoE” (Parallel Track Mixture of Experts) para modelos de servidor. Estas tecnologías tienen como objetivo optimizar la inferencia de baja latencia en los chips de Apple y reducir el uso de memoria de caché KV. Aunque algunas voces externas consideran que Apple está rezagada en el campo de la IA, sus logros en tecnología de modelos (como los modelos de incrustación de código abierto) y su enfoque en diferentes prioridades (como la inteligencia en el dispositivo en lugar de solo los chatbots) indican que tiene una estrategia de IA única. La WWDC también anunció que Safari 26 admitirá WebGPU, lo que mejorará enormemente el rendimiento de los modelos de IA que se ejecutan en el dispositivo (como a través de Transformers.js), por ejemplo, la velocidad de generación de subtítulos de modelos visuales en el navegador aumentará aproximadamente 12 veces (Fuente: X, X, X)
Los usuarios de Perplexity Pro ahora pueden usar el modelo o3 de OpenAI: Perplexity anunció que sus suscriptores Pro ahora pueden usar el modelo o3 de OpenAI. Esta integración brindará a los usuarios de Perplexity Pro capacidades más potentes de procesamiento de información y respuesta a preguntas. Al mismo tiempo, Perplexity también está probando su función “Memory” y ha actualizado su asistente de voz para iOS, con el objetivo de proporcionar una experiencia de usuario más concisa y práctica. Su función de artículos Discover también utiliza por defecto el modo “Summary” más conciso, y ofrece la opción de cambiar al modo “Report” más profundo (Fuente: X, X, X)

Xiaohongshu abre el código de su primer gran modelo MoE de 142B, dots.llm1, superando a DeepSeek-V3 en evaluaciones en chino: Xiaohongshu ha abierto el código de su primer gran modelo, dots.llm1, un modelo MoE (Mixture of Experts) de 142 mil millones de parámetros, que activa solo 14 mil millones de parámetros durante la inferencia. El modelo utilizó 11.2 billones de tokens no sintéticos en la fase de preentrenamiento, principalmente de datos web de rastreadores generales y propios. El equipo de Xiaohongshu propuso un marco de procesamiento de datos escalable de tres etapas y lo abrió para mejorar la reproducibilidad. dots.llm1 obtuvo 92.2 puntos en C-Eval, superando a todos los modelos, incluido DeepSeek-V3, y se acerca al rendimiento de Qwen3-32B de Alibaba en tareas en chino e inglés, matemáticas y alineación. Xiaohongshu también abrió los puntos de control de entrenamiento intermedios para promover la comprensión de la comunidad sobre la dinámica de los grandes modelos (Fuente: 36氪)
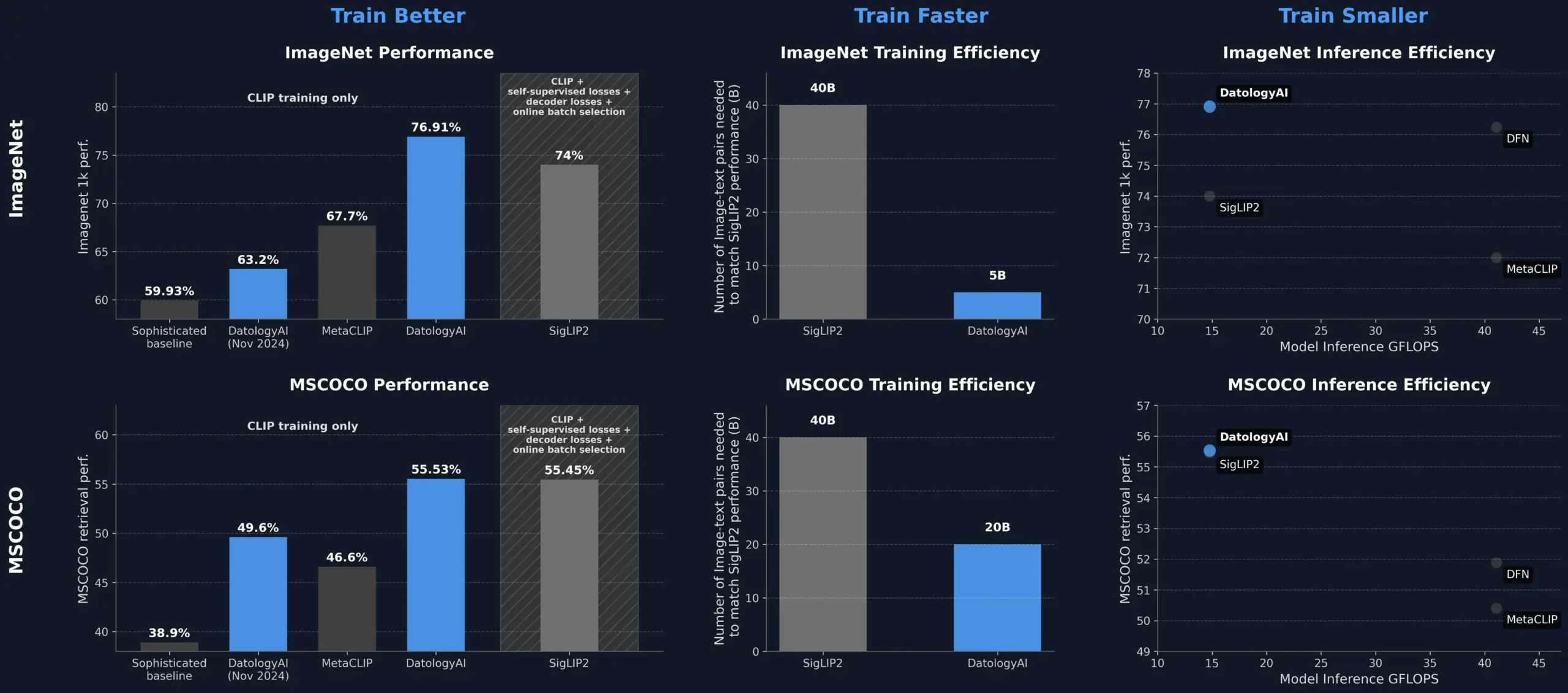
DatologyAI mejora el rendimiento del modelo CLIP mediante la gestión de datos, superando a SigLIP2: DatologyAI demostró que solo mediante la gestión de datos (data curation) se puede mejorar significativamente el rendimiento del modelo CLIP. Su método permitió que el modelo ViT-B/32 alcanzara una precisión del 76.9% en ImageNet 1k, superando el 74% reportado por SigLIP2. Además, este método también logró una mejora de 8 veces en la eficiencia del entrenamiento y de 2 veces en la eficiencia de la inferencia, y ya ha publicado los modelos relevantes. Esto resalta el papel central de los conjuntos de datos de alta calidad y cuidadosamente gestionados en el entrenamiento de modelos avanzados de IA, ya que incluso sin cambiar la arquitectura del modelo, se puede explotar el potencial del modelo optimizando los datos (Fuente: X, X)
Kuaishou y la Universidad del Noreste proponen conjuntamente el marco de incrustación multimodal unificado UNITE: Para resolver el problema de la interferencia intermodal causada por las diferencias en la distribución de datos de diferentes modalidades (texto, imagen, video) en la recuperación multimodal, investigadores de Kuaishou y la Universidad del Noreste propusieron el marco de incrustación multimodal unificado UNITE. Este marco, a través del mecanismo de “aprendizaje contrastivo con enmascaramiento sensible a la modalidad” (MAMCL), solo considera muestras negativas consistentes con la modalidad objetivo de la consulta en el aprendizaje contrastivo, evitando la competencia errónea entre modalidades. UNITE adopta un entrenamiento de dos etapas de “adaptación de recuperación + ajuste fino de instrucciones” y ha logrado resultados SOTA en múltiples evaluaciones como la recuperación de imagen-texto, video-texto e recuperación de instrucciones, como superar a modelos de mayor escala en MMEB Benchmark y superar significativamente en CoVR. La investigación enfatiza la capacidad central de los datos de video-texto en la modalidad unificada y señala que las tareas de instrucción dependen más de los datos dominados por texto (Fuente: 量子位)

NVIDIA lanza el modelo base de IA para simulación climática Earth-2: La plataforma Earth-2 de NVIDIA ha lanzado un nuevo modelo base de IA capaz de simular el clima global con una resolución a nivel de kilómetro. Este modelo tiene como objetivo proporcionar predicciones climáticas más rápidas y precisas, abriendo nuevas vías para comprender y predecir los complejos sistemas naturales de la Tierra. Este movimiento marca un paso importante en la aplicación de la IA en la ciencia climática y el modelado del sistema terrestre, con el potencial de mejorar la investigación sobre el cambio climático y la capacidad de alerta temprana de desastres (Fuente: X)

Los servicios de OpenAI sufren una interrupción generalizada, ChatGPT y la API se ven afectados: El servicio ChatGPT de OpenAI y la interfaz API experimentaron una interrupción generalizada en la noche del 10 de junio, hora de Beijing, manifestándose como un aumento en la tasa de errores y la latencia. Muchos usuarios informaron que no podían acceder al servicio o encontraron mensajes de error como “Hmm…something seems to have gone wrong”. La página de estado oficial de OpenAI confirmó el problema e indicó que los ingenieros habían localizado la causa raíz y estaban trabajando urgentemente en la reparación. Esta interrupción afectó a una gran cantidad de usuarios y aplicaciones en todo el mundo que dependen de ChatGPT y su API, destacando una vez más la importancia de la estabilidad de los grandes servicios de IA (Fuente: X, Reddit r/ChatGPT, Reddit r/ChatGPT)
🧰 Herramientas
El ecosistema de servidores del Model Context Protocol (MCP) continúa expandiéndose: El Model Context Protocol (MCP) tiene como objetivo proporcionar a los grandes modelos de lenguaje (LLM) un acceso seguro y controlable a herramientas y fuentes de datos. El repositorio modelcontextprotocol/servers en GitHub reúne implementaciones de referencia de MCP y servidores construidos por la comunidad, mostrando su diversa aplicación. Los servidores oficiales y de terceros cubren sistemas de archivos, operaciones Git, interacción con bases de datos (como PostgreSQL, MySQL, MongoDB, Redis, ClickHouse, Cassandra, etc.), servicios en la nube (AWS, Azure, Cloudflare), integración de API (GitHub, GitLab, Slack, Google Drive, Stripe, PayPal), búsqueda (Brave, Algolia, Exa, Tavily), ejecución de código, llamadas a modelos de IA (Replicate, ElevenLabs) y otros campos amplios. El ecosistema de MCP se está desarrollando rápidamente, con más de 130 servidores oficiales y comunitarios, y han surgido marcos de desarrollo como EasyMCP, FastMCP, MCP-Framework y herramientas de gestión como MCP-CLI, MCPM, con el objetivo de reducir la barrera para que los LLM accedan a herramientas y datos externos, e impulsar el desarrollo de AI Agents (Fuente: GitHub Trending)
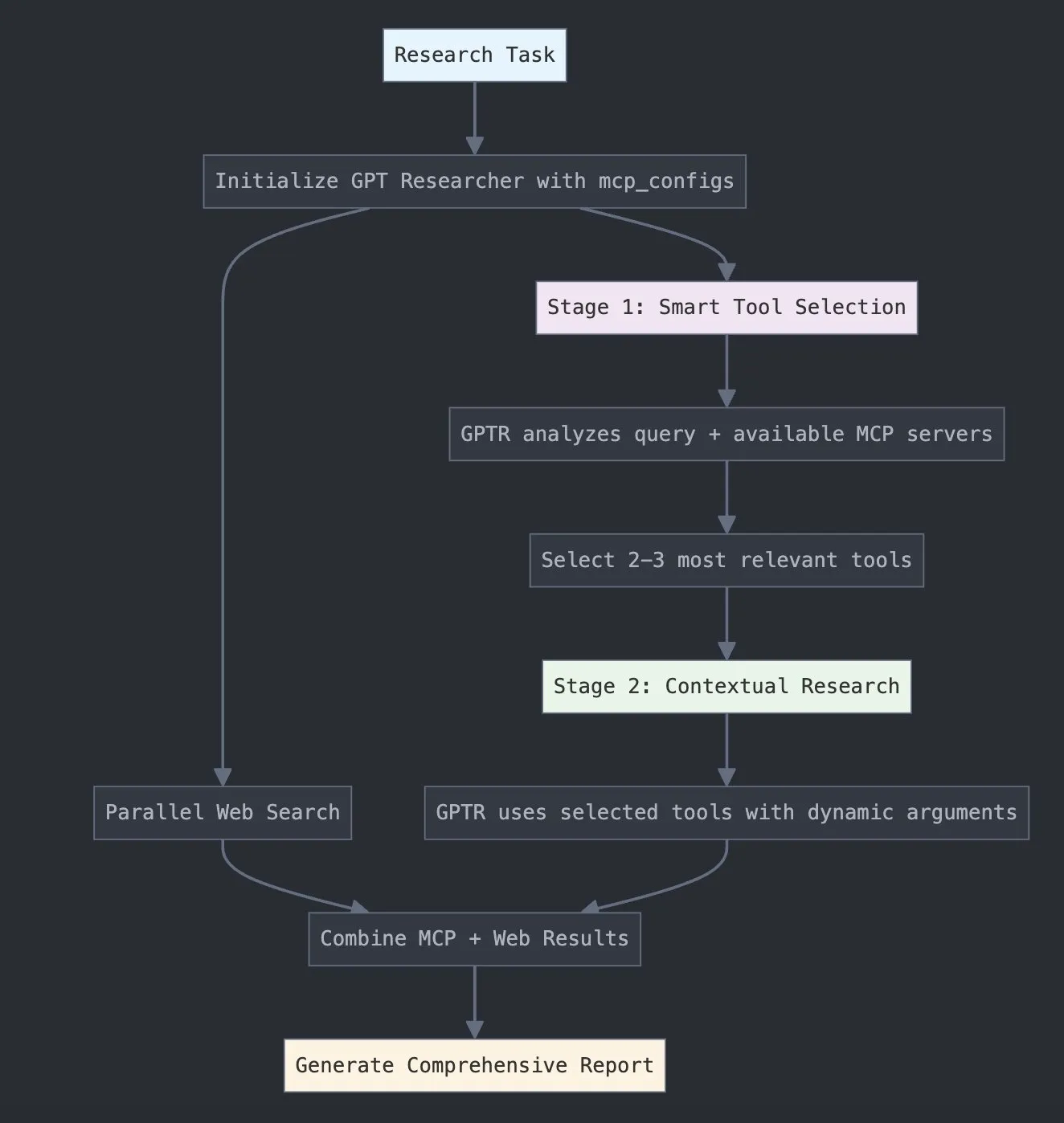
LangChain lanza GPT Researcher MCP, mejorando las capacidades de investigación: LangChain anunció que GPT Researcher ahora utiliza su adaptador del Model Context Protocol (MCP) para lograr una selección inteligente de herramientas e investigación. Esta integración combina MCP con funciones de búsqueda web, con el objetivo de proporcionar a los usuarios capacidades más completas de recopilación y análisis de datos, mejorando aún más la profundidad y amplitud de la aplicación de la IA en el campo de la investigación (Fuente: X)
Hugging Face lanza Vui: NotebookLM de código abierto de 100M, logra TTS similar al humano: Hugging Face ha lanzado Vui, un proyecto NotebookLM de código abierto de 100 millones de parámetros, que incluye tres modelos: Vui.BASE (un modelo base entrenado en 40k horas de conversaciones de audio), Vui.ABRAHAM (un modelo de un solo hablante con capacidad de reconocimiento de contexto) y Vui.COHOST (un modelo capaz de mantener conversaciones entre dos personas). Vui puede clonar voces, imitar la respiración, interjecciones como “um” y “ah”, e incluso sonidos no vocales, lo que marca un nuevo avance en la tecnología de texto a voz (TTS) similar al humano (Fuente: X, X)
Consilium: plataforma colaborativa multiagente de código abierto para resolver problemas complejos: En Hugging Face se presentó el proyecto Consilium, una plataforma colaborativa multiagente de código abierto. Los usuarios pueden formar un equipo de agentes de IA expertos que, mediante el debate y la investigación en tiempo real (web, arXiv, archivos de la SEC), colaboran para resolver problemas complejos y alcanzar un consenso. El usuario establece la estrategia y el equipo de agentes se encarga de encontrar las respuestas, lo que demuestra una nueva exploración de la IA en la resolución colaborativa de problemas (Fuente: X)
Unsloth lanza una versión optimizada del modelo GGUF de Magistral-Small-2506: Tras el lanzamiento del modelo de inferencia Magistral-Small-2506 por parte de Mistral AI, Unsloth ha lanzado rápidamente su versión optimizada en formato GGUF, adecuada para plataformas como llama.cpp, LMStudio y Ollama. Esta rápida respuesta refleja la vitalidad y eficiencia de la comunidad de código abierto en la optimización e implementación de modelos, permitiendo que los nuevos modelos sean utilizados más rápidamente por un público más amplio de usuarios y desarrolladores (Fuente: X)
📚 Aprendizaje
Nuevo artículo explora el paradigma de preentrenamiento con aprendizaje por refuerzo (RPT): Un nuevo artículo titulado “Reinforcement Pre-Training (RPT)” propone reestructurar la predicción del siguiente token como una tarea de inferencia utilizando RLVR (Reinforcement Learning with Verifiable Rewards). RPT tiene como objetivo mejorar la precisión de la predicción del modelo de lenguaje incentivando la capacidad de inferencia del siguiente token y proporcionar una base sólida para el ajuste fino por refuerzo posterior. La investigación muestra que aumentar el cómputo de entrenamiento mejora continuamente la precisión de la predicción, lo que indica que RPT es un paradigma de extensión efectivo y prometedor para avanzar en el preentrenamiento de modelos de lenguaje (Fuente: HuggingFace Daily Papers, X)

Artículo propone Cartridges: representaciones de contexto largo ligeras mediante autoaprendizaje: Un artículo titulado “Cartridges: Lightweight and general-purpose long context representations via self-study” explora un método para procesar textos largos mediante el entrenamiento offline de pequeñas cachés KV (llamadas Cartridge), como alternativa a introducir todo el corpus en la ventana de contexto durante la inferencia. La investigación encontró que los Cartridge entrenados mediante “autoaprendizaje” (generando diálogos sintéticos sobre el corpus y entrenando con un objetivo de destilación de contexto) pueden alcanzar un rendimiento comparable al ICL con un consumo de memoria significativamente menor (reducción de 38.6 veces) y un mayor rendimiento (aumento de 26.4 veces), y pueden extender la longitud efectiva del contexto del modelo, e incluso admitir el uso combinado entre corpus sin reentrenamiento (Fuente: HuggingFace Daily Papers, X)

Artículo explora la optimización de políticas contrastivas grupales (GCPO) para LLM en la resolución de problemas geométricos: El artículo “GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization” aborda el desafío de la construcción de líneas auxiliares por parte de los LLM en la resolución de problemas geométricos, proponiendo el marco GCPO. Este marco proporciona señales de recompensa positivas y negativas para la construcción de líneas auxiliares mediante una “máscara contrastiva grupal” basada en la utilidad contextual, e introduce una recompensa por longitud para promover cadenas de razonamiento más largas. La serie de modelos GeometryZero, desarrollada en base a GCPO, supera a los modelos base en benchmarks como Geometry3K y MathVista, con una mejora promedio del 4.29%, demostrando el potencial para mejorar la capacidad de razonamiento geométrico de modelos pequeños con cómputo limitado (Fuente: HuggingFace Daily Papers)
El artículo “The Illusion of Thinking” explora las capacidades y limitaciones de los modelos de razonamiento a través de la complejidad del problema: Esta investigación examina sistemáticamente las capacidades, las propiedades de escalado y las limitaciones de los grandes modelos de razonamiento (LRMs). Utilizando un entorno de rompecabezas con complejidad controlable con precisión, el estudio encuentra que la precisión de los LRMs colapsa por completo después de superar una cierta complejidad y exhibe limitaciones de escalado contraintuitivas: el esfuerzo de razonamiento disminuye después de que la complejidad del problema aumenta hasta cierto punto. En comparación con los LLM estándar, los LRMs se desempeñan peor en tareas de baja complejidad, son superiores en tareas de complejidad media y ambos fallan en tareas de alta complejidad. El estudio señala que los LRMs tienen limitaciones en el cálculo preciso, les resulta difícil aplicar algoritmos explícitos y razonan de manera inconsistente en diferentes escalas (Fuente: HuggingFace Daily Papers, X)
Artículo investiga la evaluación de la robustez de los LLM en lenguajes con pocos recursos: El artículo “Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models” explora la sensibilidad de los grandes modelos de lenguaje (LLMs) a perturbaciones (como ataques a nivel de carácter y palabra) en lenguajes de bajos recursos como el polaco. La investigación encontró que mediante pequeñas modificaciones de caracteres y el uso de pequeños modelos proxy para calcular la importancia de las palabras, se pueden crear ataques que cambian significativamente las predicciones de diferentes LLMs, lo que revela posibles vulnerabilidades de seguridad de los LLMs en estos lenguajes, que podrían usarse para eludir sus mecanismos de seguridad internos. Los investigadores han publicado el conjunto de datos y el código correspondientes (Fuente: HuggingFace Daily Papers)
Rel-LLM: Nuevo método para mejorar la eficiencia de los LLM en el manejo de bases de datos relacionales: Un artículo propone el marco Rel-LLM, diseñado para resolver el problema de la baja eficiencia de los grandes modelos de lenguaje (LLM) al procesar bases de datos relacionales. Los métodos tradicionales que convierten datos estructurados en texto provocan la pérdida de enlaces clave y redundancia en la entrada. Rel-LLM crea prompts de grafos estructurados mediante un codificador de redes neuronales de grafos (GNN), preservando la estructura relacional dentro de un marco de generación aumentada por recuperación (RAG). El método incluye muestreo de subgrafos sensible al tiempo, codificador GNN heterogéneo, capa de proyección MLP para alinear las incrustaciones de grafos con el espacio latente del LLM, y estructuración de la representación del grafo como un prompt de grafo JSON, entre otros pasos, y alinea las representaciones de grafos y texto mediante un objetivo de preentrenamiento autosupervisado. Los experimentos demuestran que la codificación GNN puede capturar eficazmente la compleja estructura relacional perdida en la serialización de texto, y los prompts de grafos estructurados pueden inyectar eficazmente el contexto relacional en el mecanismo de atención del LLM (Fuente: X)

Artículo explora el problema de “rechazo excesivo” de los LLM y el método de optimización EvoRefuse: El artículo “EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions” investiga el problema del rechazo excesivo de los grandes modelos de lenguaje (LLM) a “instrucciones pseudo-maliciosas” (entradas semánticamente inofensivas pero que activan el rechazo del modelo). Para abordar las deficiencias de los métodos existentes de gestión de instrucciones en escalabilidad y diversidad, el artículo propone EVOREFUSE, un método que utiliza algoritmos evolutivos para optimizar prompts, capaz de generar instrucciones pseudo-maliciosas diversificadas que provocan consistentemente el rechazo del LLM. Basándose en esto, los investigadores crearon EVOREFUSE-TEST (un benchmark que contiene 582 instrucciones) y EVOREFUSE-ALIGN (un conjunto de datos de entrenamiento de alineación que contiene 3000 instrucciones y respuestas). Los experimentos muestran que el modelo LLAMA3.1-8B-INSTRUCT ajustado en EVOREFUSE-ALIGN reduce su tasa de rechazo excesivo hasta en un 14.31% en comparación con los modelos entrenados en conjuntos de datos de alineación subóptimos, sin comprometer la seguridad (Fuente: HuggingFace Daily Papers)
💼 Negocios
Zhongke Wenge completa una nueva ronda de financiación estratégica, con inversión del Fondo Industrial del Distrito de Shijingshan de Beijing: El proveedor de servicios de IA a nivel empresarial, Zhongke Wenge, anunció la finalización de una nueva ronda de financiación estratégica, con el inversor siendo Beijing Shijingshan Modern Innovation Industry Development Fund Co., Ltd. Esta ronda de financiación se utilizará principalmente para la inversión en I+D y la promoción en el mercado de su sistema operativo de inteligencia de decisiones de desarrollo propio DIOS, acelerando el desarrollo de la tecnología de inteligencia artificial a nivel empresarial y su implementación comercial. Zhongke Wenge fue fundada en 2017, con un equipo central proveniente del Instituto de Automatización de la Academia China de Ciencias, centrándose en la comprensión multilingüe, la semántica transmodal y la tecnología de decisión en escenarios complejos, sirviendo a industrias como medios, finanzas, gobierno y energía. Anteriormente, había recibido más de mil millones de yuanes en inversiones de fondos con respaldo estatal como CDB Capital, China Internet Investment Fund y Shenzhen Capital Group (Fuente: 量子位)

Sakana AI y el Banco Hokkoku de Japón alcanzan una cooperación estratégica para promover el desarrollo de la IA financiera regional: La startup japonesa de IA, Sakana AI, anunció la firma de un memorando de entendimiento (MOU) con Hokkoku Financial Holdings, con sede en la prefectura de Ishikawa. Ambas partes colaborarán estratégicamente en la integración de las finanzas regionales y la IA. Esta es la segunda colaboración de Sakana AI con una institución financiera, después de establecer una asociación integral con Mitsubishi UFJ Bank, con el objetivo de aplicar tecnología de IA de vanguardia para resolver los problemas que enfrentan las sociedades regionales de Japón, especialmente en el sector de servicios financieros. Sakana AI se dedica a desarrollar tecnología de IA altamente especializada para instituciones financieras, y se espera que esta cooperación establezca un modelo para la aplicación de la IA en otros bancos regionales de Japón (Fuente: X, X)

Cohere se asocia con Ensemble para llevar su plataforma de IA al sector sanitario: La empresa de IA Cohere anunció una asociación con EnsembleHP (proveedor de soluciones sanitarias) para introducir su plataforma de agentes inteligentes Cohere North AI en el sector sanitario. Ambas partes tienen como objetivo reducir la fricción en los procesos de gestión médica y mejorar la experiencia del paciente en hospitales y sistemas de salud a través de una plataforma segura de agentes de IA. Este movimiento marca un paso importante para Cohere en la promoción de la aplicación de sus grandes modelos de lenguaje y tecnología de IA en industrias verticales clave (Fuente: X)
🌟 Comunidad
Ilya Sutskever en su discurso de doctorado honoris causa en la Universidad de Toronto: La IA eventualmente podrá hacerlo todo, se necesita atención activa: Ilya Sutskever, cofundador de OpenAI, en su discurso tras recibir un doctorado honoris causa en Ciencias por la Universidad de Toronto (su cuarto título de esta universidad), afirmó que el progreso de la IA hará que “algún día pueda hacer todo lo que nosotros podemos hacer”, porque el cerebro humano es una computadora biológica y la IA es un cerebro digital. Considera que estamos en una era extraordinaria definida por la IA, que ya ha cambiado profundamente el significado de ser estudiante y de trabajar. Enfatizó que, en lugar de preocuparse, es mejor formar una intuición utilizando y observando la IA de vanguardia para comprender sus límites de capacidad. Hizo un llamado a la gente para que preste atención al desarrollo de la IA y aborde activamente los enormes desafíos y oportunidades que conlleva, ya que la IA afectará profundamente la vida de todos. También compartió su mentalidad personal: “Acepta la realidad, no te arrepientas del pasado, esfuérzate por mejorar el presente” (Fuente: X, 36氪)
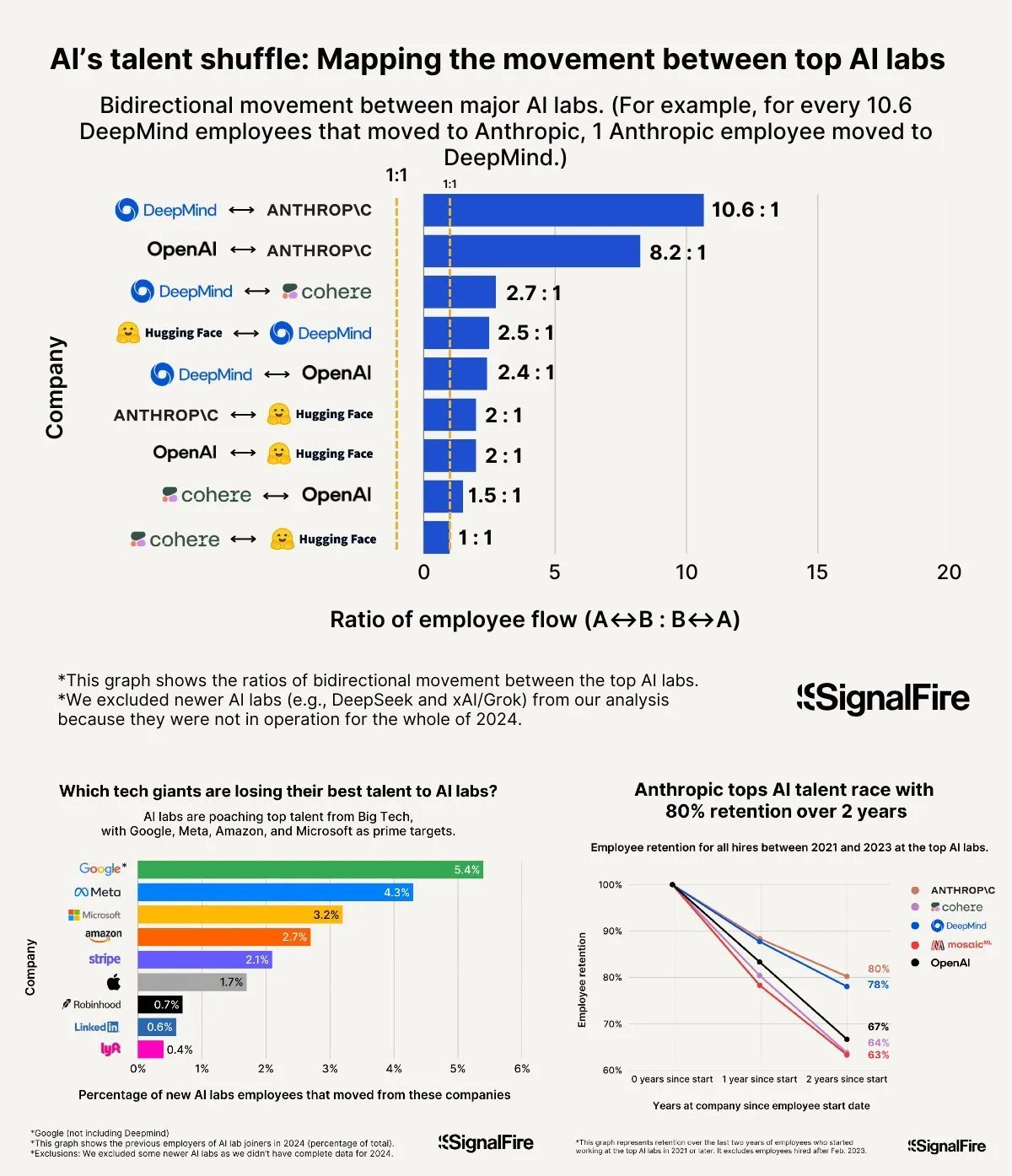
La guerra por el talento en IA se recrudece: los altos salarios de Meta aún no pueden competir con OpenAI y Anthropic: Se informa que Meta ofrece salarios anuales superiores a los 2 millones de dólares para atraer talento en IA, pero aún enfrenta dificultades para evitar que el talento se vaya a OpenAI y Anthropic. Se ha discutido que el salario de nivel L6 en OpenAI se acerca a los 1.5 millones de dólares, y se considera que el potencial de revalorización de sus acciones es superior al de Meta, lo que la hace más atractiva para el talento de primer nivel. Además, se acusa al equipo de Llama de hacer trampas y factores como la alta presión por los KPI internos de Meta y la alta tasa de eliminación de los últimos (15-20% este año) también influyen en la elección del talento. Anthropic, con una tasa de retención de talento de aproximadamente el 80% (dos años después de su fundación), se ha convertido en una de las principales grandes empresas preferidas por los investigadores de IA de primer nivel. La intensidad de esta guerra por el talento se describe como “inconcebible” (Fuente: X, X)
Experiencia compartida sobre “Vibe Coding”: 5 reglas para evitar errores en la programación asistida por IA: En las redes sociales, desarrolladores experimentados compartieron cinco reglas para evitar caer en ciclos de depuración ineficientes al usar IA (como Claude) para “Vibe Coding” (un método de programación que depende de la asistencia de IA): 1. Tres strikes y fuera: Si la IA no logra solucionar el problema después de tres intentos, detente y haz que la IA construya desde cero a partir de los requisitos recién descritos. 2. Restablecer el contexto: La IA “olvida” después de largas conversaciones; se recomienda guardar el código válido cada 8-10 rondas de mensajes, abrir una nueva sesión y pegar solo los componentes problemáticos y una breve descripción de la aplicación. 3. Describir el problema de forma concisa: Describe el error claramente en una frase. 4. Control de versiones frecuente: Realiza un commit en Git después de completar cada función. 5. Si es necesario, empezar de nuevo: Si solucionar un error lleva demasiado tiempo (por ejemplo, más de 2 horas), es mejor eliminar el componente problemático y dejar que la IA lo reconstruya. La clave es admitir cuándo el código está irreversiblemente dañado y abandonar resueltamente los intentos de reparación. Al mismo tiempo, se enfatiza que saber programar permite guiar mejor a la IA y depurar (Fuente: Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Fei-Fei Li habla sobre la fundación de World Labs: surge de la exploración de la esencia de la inteligencia, la inteligencia espacial es la pieza clave que falta en la IA: En el podcast de a16z, Fei-Fei Li compartió la motivación detrás de la fundación de World Labs, enfatizando que no se trata de seguir la moda de los modelos fundacionales, sino de una exploración continua de la esencia de la inteligencia. Considera que, aunque el lenguaje es un portador eficiente de información, tiene deficiencias en la representación del mundo físico tridimensional, y la verdadera inteligencia general debe basarse en la comprensión del espacio físico y las relaciones entre objetos. Una lesión en la córnea que le hizo perder temporalmente la visión estereoscópica le hizo comprender más profundamente la importancia de la representación espacial tridimensional para la interacción física. World Labs tiene como objetivo construir modelos de IA (modelos mundiales LWM) que realmente comprendan el mundo físico, supliendo la actual carencia de la IA en inteligencia espacial. Considera que para lograr esta visión se necesita reunir poder de cómputo, datos y talento a nivel industrial, y señala que el actual punto de inflexión tecnológico consiste en permitir que la IA reconstruya una comprensión completa de escenas tridimensionales a partir de la visión monocular (Fuente: 量子位)

La IA en el examen de acceso a la universidad: de la controversia por las “predicciones” a las oportunidades y preocupaciones en la elección de carrera: Antes y después del examen de acceso a la universidad (GaoKao), la aplicación de la IA en la educación ha generado un amplio debate. Por un lado, las “predicciones de preguntas por IA” se convirtieron en un tema candente, pero debido a la naturaleza científica, la confidencialidad y los mecanismos “anti-predicción” de la formulación de preguntas del GaoKao, la probabilidad de que la IA prediga con precisión es baja, y la calidad de algunos exámenes de predicción en el mercado es preocupante. Por otro lado, la IA ha demostrado un papel positivo en la planificación de la preparación, la explicación de preguntas, la supervisión de exámenes y la corrección, como planes de estudio personalizados, respuestas inteligentes a preguntas y sistemas de supervisión por IA que mejoran la equidad y la eficiencia. En la etapa de elección de carrera, las herramientas de IA pueden recomendar rápidamente instituciones y especialidades según la puntuación y el ranking del estudiante, rompiendo las barreras de información. Sin embargo, la dependencia excesiva de la IA para la elección de carrera también genera preocupaciones: los algoritmos pueden reforzar la preferencia por especialidades populares, ignorando los intereses individuales y el desarrollo a largo plazo; entregar completamente la elección de vida a los algoritmos puede llevar a un “secuestro de la vida por algoritmos”. El artículo llama a una visión racional de la asistencia de la IA, enfatizando el uso inteligente de las herramientas y la definición del futuro mediante el pensamiento (Fuente: 36氪)
Discusión sobre el modelo de éxito de las empresas de AI Agent: autoservicio vs. servicios personalizados: La comunidad discutió los modelos de éxito para las empresas de AI Agent. Una opinión sostiene que las empresas exitosas de AI Agent (especialmente aquellas que sirven a mercados medianos y grandes) adoptan en su mayoría un modelo similar a Palantir, es decir, una gran cantidad de ingenieros de desarrollo en el sitio (FDEs) y software personalizado, en lugar de un modelo puramente de autoservicio. Otra parte insiste en el valor a largo plazo del modelo de autoservicio, argumentando que los equipos finalmente optarán por construir internamente aplicaciones importantes. Esto refleja las diferentes vías de pensamiento en el campo de los AI Agent en cuanto a modelos de servicio y estrategias de mercado (Fuente: X)
💡 Otros
Se revela el prompt del sistema de Google Diffusion, desvelando sus principios de diseño y límites de capacidad: Un usuario compartió lo que se afirma es el prompt del sistema de Google Diffusion (un modelo de lenguaje de difusión de texto). Dicho prompt detalla la identidad del modelo (Gemini Diffusion, un modelo experto de lenguaje de difusión de texto entrenado por Google, no autorregresivo), sus principios y restricciones fundamentales (como el seguimiento de instrucciones, características no autorregresivas, precisión, sin acceso en tiempo real, ética de seguridad, fecha límite de conocimiento en diciembre de 2023, capacidad de generación de código), así como instrucciones específicas para la generación de páginas web HTML y juegos HTML. Estas instrucciones cubren el formato de salida, el diseño estético, los estilos (como el uso especializado de Tailwind CSS o CSS personalizado en juegos), el uso de iconos (iconos Lucide SVG), el diseño y el rendimiento (prevención de CLS), los requisitos de comentarios, etc. Finalmente, se enfatiza la importancia de pensar paso a paso y seguir con precisión las instrucciones del usuario. Este prompt ofrece una ventana para comprender las ideas de diseño y el comportamiento esperado de tales modelos (Fuente: Reddit r/LocalLLaMA)
Arvind Narayanan explica el nacimiento y la reflexión detrás del artículo “AI as Normal Technology”: El profesor de la Universidad de Princeton, Arvind Narayanan, compartió el proceso de creación de su artículo “AI as Normal Technology”, coescrito con Sayash Kapoor. Inicialmente escéptico sobre la AGI y los riesgos existenciales, decidió tomarlo en serio y participar en discusiones relevantes a instancias de sus colegas. A través de la reflexión, reconoció que los puntos de vista relacionados con la superinteligencia merecían ser tomados en serio, que las redes sociales no son adecuadas para discusiones serias y que tanto la comunidad de ética de la IA como la de seguridad de la IA tienen sus propias “burbujas de información”. El borrador inicial del artículo fue rechazado en ICML, pero el intenso debate durante el proceso de revisión reafirmó su determinación de continuar la investigación. Se dieron cuenta de que sus desacuerdos con la comunidad de seguridad de la IA eran más profundos de lo que pensaban y reconocieron la necesidad de debates interdisciplinarios más productivos. Finalmente, el artículo fue publicado en un taller del Knight First Amendment Institute de la Universidad de Columbia, generando una amplia atención y discusiones fructíferas, lo que hizo que Narayanan fuera más optimista sobre el futuro de la política de IA (Fuente: X)
La generación Z de emprendedores de IA emerge, remodelando las reglas del emprendimiento: Un grupo de emprendedores de IA nacidos después del año 2000 está emergiendo a una velocidad asombrosa en la ola global de emprendimiento, redefiniendo las reglas del juego con su profundo conocimiento de la tecnología de IA y su aguda percepción del entorno digital nativo. Los casos incluyen a Michael Truell de Anysphere (Cursor) (de becario a CEO de una empresa multimillonaria en 3 años), los tres fundadores de Mercor (crearon una plataforma de contratación de IA multimillonaria en 2 años), Eric Steinberger de Magic (cofundó una empresa de codificación de IA con más de 400 millones de dólares en financiación a los 25 años) y Hong Letong de Axiom (centrada en la IA para resolver problemas matemáticos, obtuvo una alta valoración sin tener un producto). Estos jóvenes emprendedores suelen compartir las siguientes características: la programación es su lengua materna; alcanzaron la fama a temprana edad, aprovechando la ventana de oportunidad tecnológica; perciben agudamente las necesidades de los usuarios; tienen una comprensión nativa de la IA sobre la organización y los productos, tendiendo a equipos extremadamente eficientes y a la lógica de “IA como producto”. Su éxito marca un cambio en el paradigma del emprendimiento en la era de la IA (Fuente: 36氪)