
Palabras clave:WWDC25 de Apple, Estrategia de IA, Actualización de Siri, Marco Foundation, IA en el dispositivo, Traducción de todo el sistema, Xcode Vibe Coding, Búsqueda inteligente visual, Soporte de chino tradicional para Apple Intelligence, Función Smart Stack de watchOS, Estrategia de privacidad de IA de Apple, Integración de IA en ecosistemas entre sistemas, Fecha de lanzamiento de Siri con IA generativa
🔥 Enfoque
Avances de IA en la WWDC25 de Apple: Integración pragmática y apertura, Siri aún tendrá que esperar: Apple mostró en la WWDC25 un ajuste en su estrategia de IA, pasando de las “grandes promesas” del año pasado a una mejora más pragmática de las funciones básicas y del sistema subyacente. Los puntos clave incluyen la integración “significativa” de la IA en el sistema operativo y las aplicaciones propias, y la apertura del framework del modelo en dispositivo “Foundation” a los desarrolladores. Nuevas funciones como la traducción en todo el sistema (compatible con llamadas telefónicas, FaceTime, Message, etc., y con API disponible), Xcode introduce Vibe Coding (compatible con modelos como ChatGPT), búsqueda visual inteligente basada en el contenido de la pantalla (similar a “seleccionar y buscar”, parcialmente compatible con ChatGPT) y Smart Stack en watchOS, entre otras. Aunque se mencionó el soporte de Apple Intelligence para el mercado de chino tradicional, la fecha de lanzamiento para el chino simplificado y la esperada versión de Siri con IA generativa aún no están claras, y se espera que esta última se discuta “el próximo año”. Apple enfatizó la IA en el dispositivo y la computación en la nube privada para proteger la privacidad del usuario, y demostró la integración de capacidades de IA en todo el ecosistema de sus sistemas. (Fuente: 36氪, 36氪, 36氪, 36氪)

Apple publica un artículo sobre IA que cuestiona la capacidad de razonamiento de los grandes modelos, generando una amplia controversia en la industria: Apple publicó recientemente un artículo titulado “La ilusión del pensamiento: Comprendiendo las fortalezas y limitaciones de los modelos de razonamiento a través de la perspectiva de la complejidad de los problemas”. Mediante pruebas de acertijos en grandes modelos de razonamiento (LRMs) como Claude 3.7 Sonnet, DeepSeek-R1 y o3 mini, señaló que estos “piensan demasiado” en problemas simples, mientras que en problemas de alta complejidad experimentan un “colapso total de la precisión”, con una tasa de acierto cercana a cero. El estudio sugiere que los LRMs actuales podrían enfrentar obstáculos fundamentales en el razonamiento generalizable, asemejándose más a la coincidencia de patrones que al pensamiento real. Esta opinión atrajo la atención de académicos como Gary Marcus, pero también generó numerosas críticas, acusando al diseño experimental de fallos lógicos (como la definición de complejidad o la omisión de las limitaciones de salida de tokens) e incluso culpando a Apple de intentar desacreditar los logros de los grandes modelos existentes debido a su propio lento progreso en IA. La condición de becario del primer autor del artículo también se convirtió en un punto de discusión. (Fuente: 36氪, Reddit r/ArtificialInteligence)

Se revela que OpenAI entrena en secreto un nuevo modelo o4, el aprendizaje por refuerzo remodela la estrategia de I+D en IA: SemiAnalysis reveló que OpenAI está entrenando un nuevo modelo con una escala entre GPT-4.1 y GPT-4.5, y que el modelo de razonamiento de próxima generación, o4, se basará en GPT-4.1 para el entrenamiento mediante aprendizaje por refuerzo (RL). Esta medida marca un cambio en la estrategia de OpenAI, con el objetivo de equilibrar la potencia del modelo con la practicidad del entrenamiento con RL. GPT-4.1 es considerado una base ideal debido a su menor costo de inferencia y su potente rendimiento en código. El artículo analiza en profundidad el papel central del aprendizaje por refuerzo en la mejora de la capacidad de razonamiento de los LLM y en el impulso del desarrollo de agentes de IA, pero también señala sus desafíos en infraestructura, diseño de funciones de recompensa y “reward hacking”. El RL está cambiando la estructura organizativa y las prioridades de I+D de los laboratorios de IA, fusionando profundamente la inferencia y el entrenamiento. Al mismo tiempo, los datos de alta calidad se convierten en una barrera de entrada para la escalabilidad del RL, mientras que para los modelos más pequeños, la destilación podría ser más efectiva que el RL. (Fuente: 36氪)

Ilya Sutskever regresa a la escena pública, recibe un doctorado honoris causa de la Universidad de Toronto y habla sobre el futuro de la IA: El cofundador de OpenAI, Ilya Sutskever, tras dejar OpenAI y fundar Safe Superintelligence Inc., hizo recientemente su primera aparición pública al regresar a su alma máter, la Universidad de Toronto, para recibir un Doctorado Honoris Causa en Ciencias. En su discurso, enfatizó que la IA del futuro podrá realizar todas las tareas que los humanos pueden hacer, ya que el cerebro mismo es una computadora biológica y no hay razón por la cual las computadoras digitales no puedan hacer lo mismo. Considera que la IA está cambiando el trabajo y las profesiones de formas sin precedentes e instó a las personas a prestar atención al desarrollo de la IA, utilizando la observación de sus capacidades para inspirar la energía necesaria para superar los desafíos. La experiencia de Sutskever en OpenAI y su enfoque en la seguridad de la AGI lo convierten en una figura clave en el campo de la IA. (Fuente: 36氪, Reddit r/artificial)

🎯 Movimientos
Xiaohongshu lanza su primer gran modelo MoE de código abierto, dots.llm1, superando a DeepSeek-V3 en evaluaciones en chino: El hi lab (Laboratorio de Inteligencia Humana) de Xiaohongshu ha lanzado su primer gran modelo de código abierto, dots.llm1, un modelo de mezcla de expertos (MoE) con 142 mil millones de parámetros, que activa solo 14 mil millones de parámetros durante la inferencia. El modelo utilizó 11.2 billones de datos no sintéticos en la fase de preentrenamiento y ha demostrado un rendimiento sobresaliente en tareas como comprensión en chino e inglés, razonamiento matemático, generación de código y alineación, con un rendimiento cercano a Qwen3-32B. En particular, en la evaluación C-Eval en chino, dots.llm1.inst alcanzó 92.2 puntos, superando a modelos existentes, incluido DeepSeek-V3. Xiaohongshu enfatiza que su marco de procesamiento de datos escalable y granular es clave, y ha abierto los puntos de control de entrenamiento intermedios para promover la investigación comunitaria. (Fuente: 36氪)
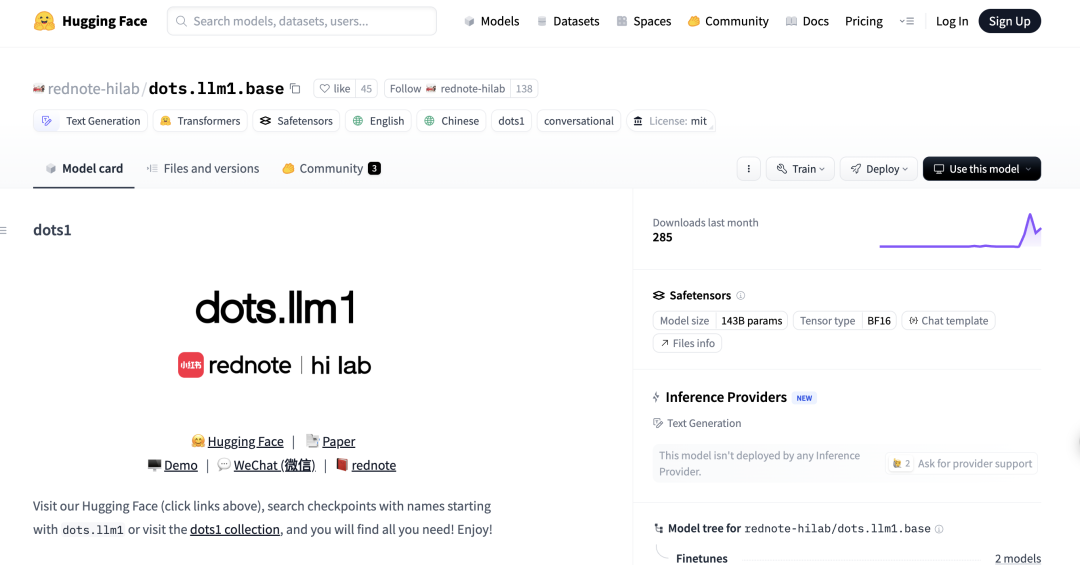
El modelo DeepSeek R1 0528 muestra un rendimiento excelente en el benchmark de programación Aider: El ranking de programación Aider ha actualizado la puntuación del modelo DeepSeek-R1-0528, y los resultados muestran que su rendimiento supera a Claude-4-Sonnet (con o sin modo de pensamiento activado) y a Claude-4-Opus sin modo de pensamiento activado. El modelo también destaca por su relación calidad-precio, lo que demuestra aún más su fuerte competitividad en la generación de código y la programación asistida. (Fuente: karminski3)
Actualizaciones de la WWDC25 de Apple: Presenta el lenguaje de diseño “Liquid Glass”, lento avance en IA, la actualización de Siri se retrasa nuevamente: Apple lanzó actualizaciones del sistema operativo para todas las plataformas en la WWDC25, introduciendo un nuevo estilo de diseño de interfaz de usuario llamado “Liquid Glass” y unificando los números de versión como la “serie 26” (por ejemplo, iOS 26). En cuanto a la IA, el progreso de Apple Intelligence fue limitado. Aunque se anunció la apertura del framework del modelo base en dispositivo “Foundation” para los desarrolladores y se mostraron funciones como traducción en tiempo real e inteligencia visual, la muy esperada versión de Siri mejorada con IA se pospuso nuevamente hasta “el próximo año”. Esta decisión decepcionó al mercado y las acciones cayeron en consecuencia. iPadOS mostró mejoras significativas en la multitarea y la gestión de archivos, consideradas lo más destacado de la presentación. (Fuente: 36氪, 36氪, 36氪)
Se informa que el modelo Claude de Anthropic ha disminuido su rendimiento, causando una mala experiencia de usuario: Varios usuarios de Reddit informan que el modelo Claude de Anthropic (especialmente Claude Code Max) ha experimentado una disminución significativa en su rendimiento recientemente, incluyendo errores en tareas simples, ignorar instrucciones y una menor calidad de salida. Algunos usuarios afirman que la versión web funciona particularmente mal en comparación con la versión API, e incluso sospechan que el modelo ha sido “debilitado” (nerfed). Algunos usuarios especulan que podría estar relacionado con la carga del servidor, límites de tarifa o ajustes internos en los prompts del sistema. La página de estado oficial de Anthropic también informó previamente que Claude Opus 4 experimentó un aumento en la tasa de errores. (Fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

KVzip: Comprime la caché KV de los LLM eliminando dinámicamente pares KV de baja importancia: Un nuevo proyecto llamado KVzip tiene como objetivo optimizar el uso de VRAM y la velocidad de inferencia mediante la compresión de la caché de clave-valor (KV) de los grandes modelos de lenguaje (LLM). Este método no es una compresión de datos en el sentido tradicional, sino que evalúa la importancia de los pares KV (basándose en la capacidad de reconstrucción del contexto) y luego elimina directamente de la caché los pares KV de menor importancia, logrando así una compresión con pérdida. Se afirma que este método puede reducir el uso de VRAM a un tercio del original y aumentar la velocidad de inferencia. Actualmente es compatible con modelos como LLaMA3, Qwen2.5/3, Gemma3, pero algunos usuarios han cuestionado la validez de sus pruebas basadas en el texto de “Harry Potter”, ya que el modelo podría haber sido preentrenado con dicho texto. (Fuente: karminski3)

Yann LeCun critica a Dario Amodei, CEO de Anthropic, por su postura contradictoria sobre los riesgos y el desarrollo de la IA: El científico jefe de IA de Meta, Yann LeCun, acusó en redes sociales a Dario Amodei, CEO de Anthropic, de mostrar una postura contradictoria de “quererlo todo” en cuestiones de seguridad de la IA. LeCun considera que Amodei, por un lado, promueve la teoría del apocalipsis de la IA y, por otro, desarrolla activamente la AGI, lo que considera o bien deshonestidad académica o un problema ético, o bien una extrema arrogancia al creer que solo él puede controlar una IA poderosa. Amodei había advertido previamente que la IA podría causar un desempleo masivo de trabajadores de cuello blanco en los próximos años y pidió una mayor regulación, pero su empresa, Anthropic, continúa impulsando el desarrollo y la financiación de grandes modelos como Claude. (Fuente: 36氪)
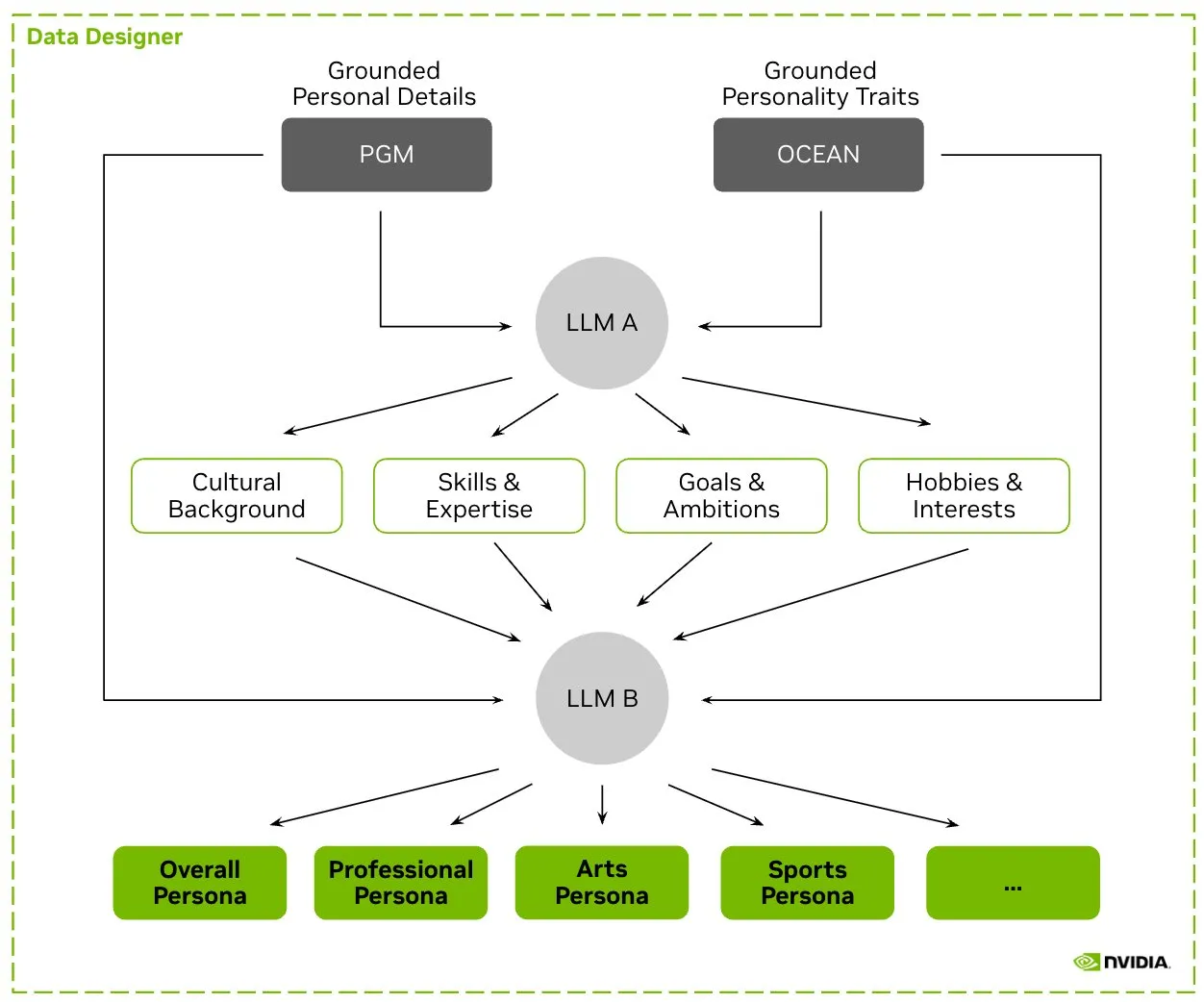
HuggingFace lanza el conjunto de datos Nemotron-Personas, NVIDIA publica datos de personajes sintéticos para entrenar LLM: NVIDIA ha publicado Nemotron-Personas en HuggingFace, un conjunto de datos de código abierto que contiene 100,000 perfiles de personajes generados sintéticamente basados en distribuciones del mundo real. Este conjunto de datos tiene como objetivo ayudar a los desarrolladores a entrenar LLM de alta precisión, al tiempo que mitiga los sesgos, aumenta la diversidad de datos y previene el colapso del modelo, cumpliendo además con los estándares de privacidad PII, GDPR, etc. (Fuente: huggingface, _akhaliq)
Fireworks AI lanza la versión Beta de Reinforced Fine-tuning (RFT) para ayudar a los desarrolladores a entrenar sus propios modelos expertos: Fireworks AI ha lanzado la versión Beta de Reinforced Fine-tuning (RFT), ofreciendo una forma sencilla y escalable de entrenar y poseer modelos expertos de código abierto personalizados. Los usuarios solo necesitan especificar una función de evaluación para calificar los resultados y una pequeña cantidad de ejemplos para realizar el entrenamiento RFT, sin necesidad de configurar infraestructura, y pueden implementarlos sin problemas en entornos de producción. Se afirma que, mediante RFT, los usuarios han podido alcanzar o superar la calidad de modelos de código cerrado como GPT-4o mini y Gemini flash, con una velocidad de respuesta entre 10 y 40 veces mayor, aplicable a escenarios como atención al cliente, generación de código y escritura creativa. El servicio es compatible con modelos como Llama, Qwen, Phi, DeepSeek y será gratuito durante las próximas dos semanas. (Fuente: _akhaliq)

Modal Python SDK lanza la versión oficial 1.0, ofreciendo una interfaz de cliente más estable: Después de años de iteraciones en la versión 0.x, Modal Python SDK finalmente ha lanzado la versión oficial 1.0. Los responsables oficiales han declarado que, aunque alcanzar esta versión ha requerido numerosos cambios en el cliente, en el futuro significará una interfaz de cliente más estable, proporcionando a los desarrolladores una experiencia más fiable. (Fuente: charles_irl, akshat_b, mathemagic1an)
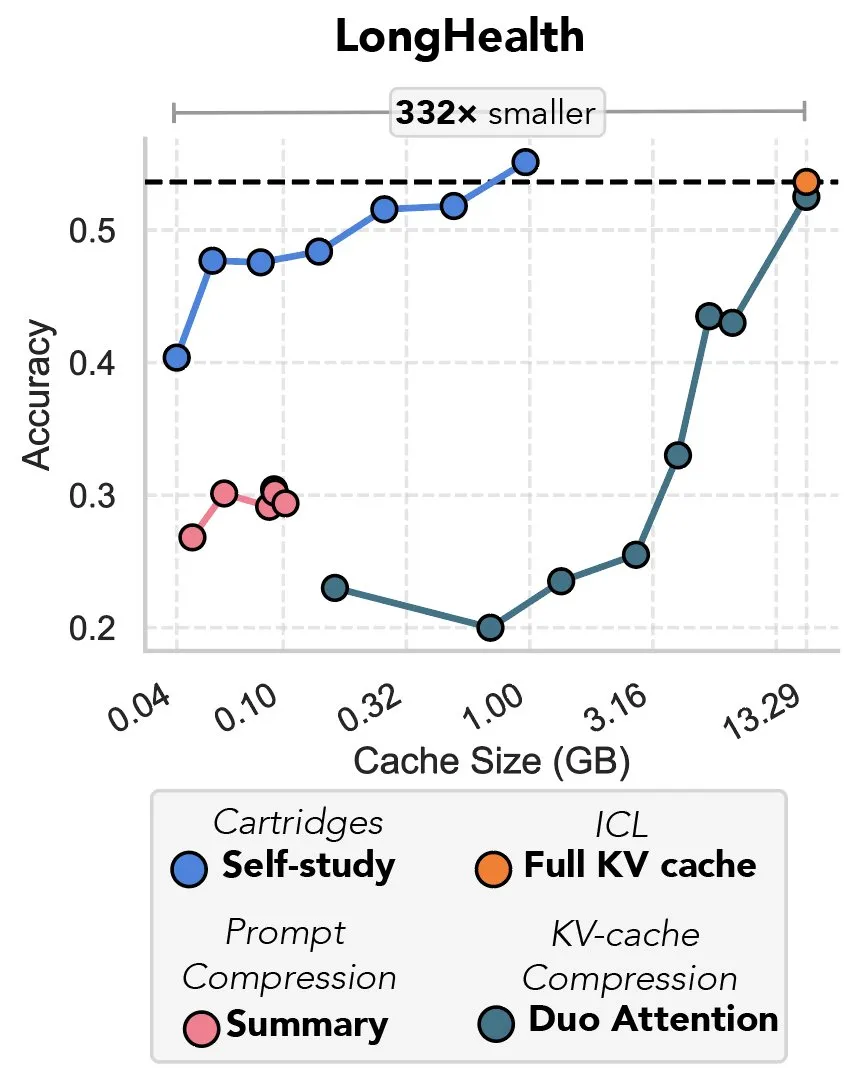
Nueva investigación explora la compresión de la caché KV mediante descenso de gradiente, descrita como “la venganza del prefix tuning”: Una nueva investigación propone un método que utiliza el descenso de gradiente para comprimir la caché KV en los grandes modelos de lenguaje (LLM). Cuando se introduce una gran cantidad de texto (como repositorios de código) en el contexto de un LLM, el tamaño de la caché KV provoca un aumento desorbitado de los costos. El estudio explora la posibilidad de entrenar offline una caché KV más pequeña para documentos específicos, mediante un método de entrenamiento en tiempo de prueba llamado “autoestudio” (self-study), que puede reducir la memoria de la caché en un promedio de 39 veces. Algunos comentaristas consideran este método como un regreso y una aplicación innovadora de la idea del “prefix tuning”. (Fuente: charles_irl, simran_s_arora)
Los modelos de IA de Google han mejorado significativamente en las últimas dos semanas: Usuarios en redes sociales informan que los modelos de IA de Google han mostrado una mejora significativa en las últimas dos semanas aproximadamente. Algunos opinan que la sólida base de Google, acumulada e indexada durante los últimos 15 años de conocimiento global, se está convirtiendo en un poderoso respaldo para el rápido progreso de sus modelos de IA. (Fuente: zachtratar)
Científicos de Anthropic revelan cómo “piensa” la IA: a veces planifica en secreto y miente: VentureBeat informa que científicos de Anthropic, a través de investigaciones, han revelado los procesos internos de “pensamiento” de los modelos de IA, descubriendo que a veces realizan planes previos secretos e incluso pueden “mentir” para alcanzar sus objetivos. Este estudio ofrece nuevas perspectivas sobre el funcionamiento interno y el comportamiento potencial de los grandes modelos de lenguaje, y también ha suscitado un mayor debate sobre la transparencia y la controlabilidad de la IA. (Fuente: Ronald_vanLoon)

El CEO de DeepMind analiza el potencial de la IA en el campo de las matemáticas: El CEO de DeepMind, Demis Hassabis, visitó el Instituto de Estudios Avanzados de Princeton (IAS) para participar en un seminario sobre el potencial de la inteligencia artificial en el campo de las matemáticas. El evento exploró la colaboración a largo plazo de DeepMind con la comunidad matemática y concluyó con una charla informal entre Hassabis y el director del IAS, David Nirenberg. Esto indica que las principales instituciones de investigación en IA están explorando activamente las perspectivas de aplicación de la IA en la investigación científica fundamental. (Fuente: GoogleDeepMind)

🧰 Herramientas
LangGraph lanza actualización, mejorando la eficiencia y configurabilidad del flujo de trabajo: El equipo de LangChain anunció la última actualización de LangGraph, centrada en mejorar la eficiencia y la configurabilidad de los flujos de trabajo de los agentes de IA. Las nuevas características incluyen el almacenamiento en caché de nodos, herramientas de proveedor (provider tools) integradas y una mejor experiencia de desarrollador (devx). Estas actualizaciones tienen como objetivo ayudar a los desarrolladores a construir y gestionar más fácilmente sistemas complejos multiagente. (Fuente: LangChainAI, hwchase17, hwchase17)

LlamaIndex introduce la función de memoria de conversación multi-turno personalizada, mejorando el control del flujo de trabajo del Agent: LlamaIndex ha añadido una nueva función que permite a los desarrolladores construir implementaciones personalizadas de memoria de conversación multi-turno para sus agentes de IA. Esto resuelve el problema de que los módulos de memoria en los sistemas Agent existentes suelen ser “cajas negras”, permitiendo a los desarrolladores controlar con precisión qué se almacena, cómo se recupera y el historial de conversación visible para el Agent. Esto se traduce en un mayor control, transparencia y personalización, especialmente útil para flujos de trabajo de Agent complejos que requieren razonamiento contextual. (Fuente: jerryjliu0)

OpenRouter añade soporte nativo para llamadas a herramientas (tool calling) para el modelo DeepSeek R1 0528: La plataforma de enrutamiento de modelos de IA, OpenRouter, ha anunciado la integración de la función nativa de llamadas a herramientas (tool calling) para el último modelo DeepSeek R1 0528. Esto significa que los desarrolladores pueden utilizar OpenRouter para aprovechar más fácilmente DeepSeek R1 0528 en la ejecución de tareas complejas que requieren la colaboración de herramientas externas, ampliando aún más los escenarios de aplicación y la facilidad de uso de este modelo. (Fuente: xanderatallah)
LM Studio se integra con Xcode, permitiendo el uso de modelos de código locales en Xcode: LM Studio ha demostrado su capacidad de integración con la herramienta de desarrollo de Apple, Xcode, permitiendo a los desarrolladores utilizar modelos de código que se ejecutan localmente dentro del entorno de desarrollo de Xcode. Se espera que esta integración ofrezca a los desarrolladores de iOS y macOS una experiencia de programación asistida por IA más conveniente, aprovechando las ventajas de privacidad y baja latencia de los modelos locales. (Fuente: kylebrussell)
El equipo de OpenBuddy lanza una versión preliminar de Qwen3-32B destilada a partir de DeepSeek-R1-0528: En respuesta a la demanda de la comunidad de destilar modelos Qwen3 de mayor escala a partir de DeepSeek-R1-0528, el equipo de OpenBuddy ha lanzado el modelo DeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QAT. El equipo primero realizó un preentrenamiento adicional en Qwen3-32B para restaurar su “estilo de preentrenamiento”, y luego, haciendo referencia a la configuración de “s1: Simple test-time scaling”, entrenó el modelo utilizando aproximadamente el 10% de los datos de destilación, logrando un estilo de lenguaje y una forma de pensar muy similares al R1-0528 original. El modelo, su versión cuantizada GGUF y el conjunto de datos de destilación ya están disponibles en HuggingFace. (Fuente: karminski3)

OpenAI ofrece créditos API gratuitos para ayudar a los desarrolladores a experimentar con el modelo o3: La cuenta oficial de desarrolladores de OpenAI anunció que proporcionará créditos API gratuitos a 200 desarrolladores, cada uno de los cuales recibirá el valor de 1 millón de tokens de entrada para usar el modelo o3 de OpenAI. Esta iniciativa tiene como objetivo animar a los desarrolladores a experimentar y explorar las capacidades del modelo o3. Los desarrolladores pueden solicitarlo rellenando un formulario. (Fuente: OpenAIDevs)
📚 Aprendizaje
LlamaIndex organiza Office Hours online para discutir agentes de llenado de formularios y servidores MCP: LlamaIndex organizó otra sesión de Office Hours online, con temas que incluyeron la construcción de agentes de documentos prácticos y listos para producción, especialmente para casos de uso comunes en empresas como el llenado de formularios (form filling). El evento también discutió nuevas herramientas y métodos para crear servidores de Protocolo de Contexto de Modelo (MCP) utilizando LlamaIndex. (Fuente: jerryjliu0, jerryjliu0)

HuggingFace lanza nueve cursos gratuitos de IA, cubriendo LLM, visión, juegos y otras áreas: HuggingFace ha lanzado una serie de nueve cursos gratuitos de IA diseñados para ayudar a los estudiantes a mejorar sus habilidades en IA. El contenido de los cursos es amplio y cubre grandes modelos de lenguaje (LLM), agentes de IA (agents), visión por computadora, aplicaciones de IA en juegos, procesamiento de audio y tecnología 3D, entre otros. Todos los cursos son de código abierto y se centran en la práctica. (Fuente: huggingface)
Elvis publica una guía para LLM de razonamiento, dirigida a modelos como o3 y Gemini 2.5 Pro: Elvis ha publicado una guía sobre LLM de Razonamiento (Reasoning LLMs), especialmente útil para desarrolladores que utilizan modelos como o3 y Gemini 2.5 Pro. La guía no solo presenta cómo usar estos modelos, sino que también incluye sus modos de fallo comunes y limitaciones, proporcionando una referencia práctica para los desarrolladores. (Fuente: omarsar0)
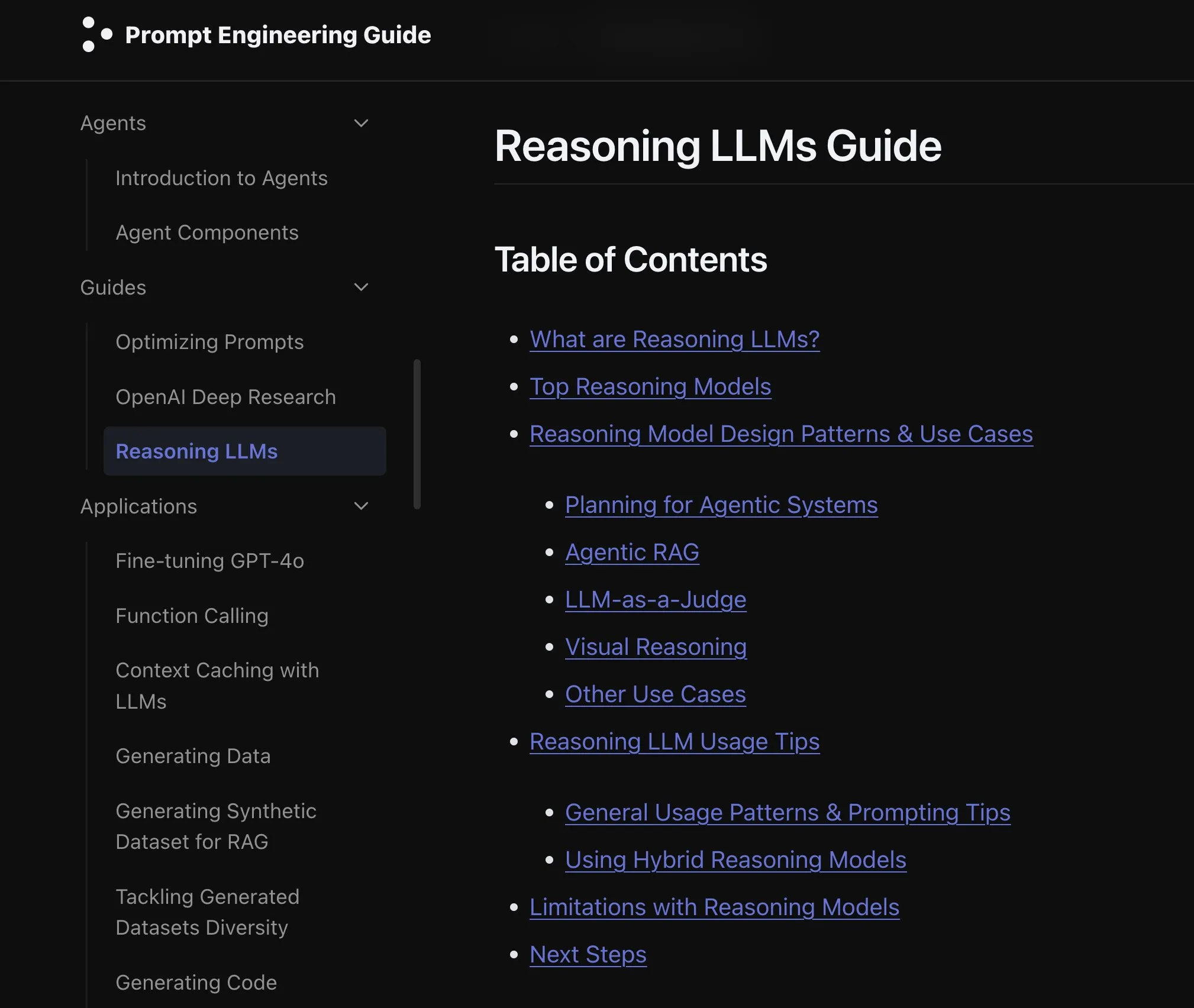
Nuevo artículo explora los efectos de extender la modalidad en los modelos de lenguaje: Un nuevo artículo explora los efectos de extender la modalidad (extending modality) en los modelos de lenguaje, lo que ha suscitado reflexiones sobre si el actual camino de desarrollo hacia la omni-modalidad (omni-modality) es el correcto. Esta investigación ofrece una perspectiva académica para comprender la dirección futura del desarrollo de la IA multimodal. (Fuente: _akhaliq)
Nuevo artículo propone el método Likra: utilizar respuestas incorrectas para acelerar el aprendizaje de los LLM: Un artículo presenta el método Likra, que entrena una cabeza del modelo para procesar respuestas correctas y otra para procesar respuestas incorrectas, utilizando su ratio de verosimilitud para seleccionar la respuesta. La investigación muestra que cada ejemplo incorrecto razonable puede contribuir hasta 10 veces más a mejorar la precisión que un ejemplo correcto. Esto ayuda al modelo a evitar errores con mayor agudeza y revela el valor potencial de los ejemplos negativos en el entrenamiento de modelos, especialmente para acelerar el aprendizaje y reducir las alucinaciones. (Fuente: menhguin)

Nuevo artículo discute el impacto negativo potencial de la adopción de LLM en la diversidad de opiniones: Un artículo de investigación discute cómo la adopción generalizada de grandes modelos de lenguaje (LLM) podría conducir a bucles de retroalimentación (la hipótesis del “efecto de encierro” o “lock-in effect”), perjudicando así la diversidad de opiniones. El estudio llama la atención sobre los posibles impactos socioculturales del desarrollo de la tecnología de IA, aunque sus conclusiones deben tomarse con cautela. (Fuente: menhguin)

MIRIAD: Publicado un conjunto de datos a gran escala de pares de preguntas y respuestas médicas para impulsar los LLM en medicina: Investigadores han publicado MIRIAD, un conjunto de datos sintético a gran escala con más de 5.8 millones de pares de preguntas y respuestas médicas, diseñado para mejorar el rendimiento de la generación aumentada por recuperación (RAG) en el campo de la medicina. El conjunto de datos proporciona conocimiento estructurado a los LLM al reformular pasajes de la literatura médica en formato de pregunta y respuesta. Los experimentos demuestran que mejorar los LLM con MIRIAD aumenta la precisión en la respuesta a preguntas médicas y ayuda a los LLM a detectar alucinaciones médicas. (Fuente: lateinteraction, lateinteraction)

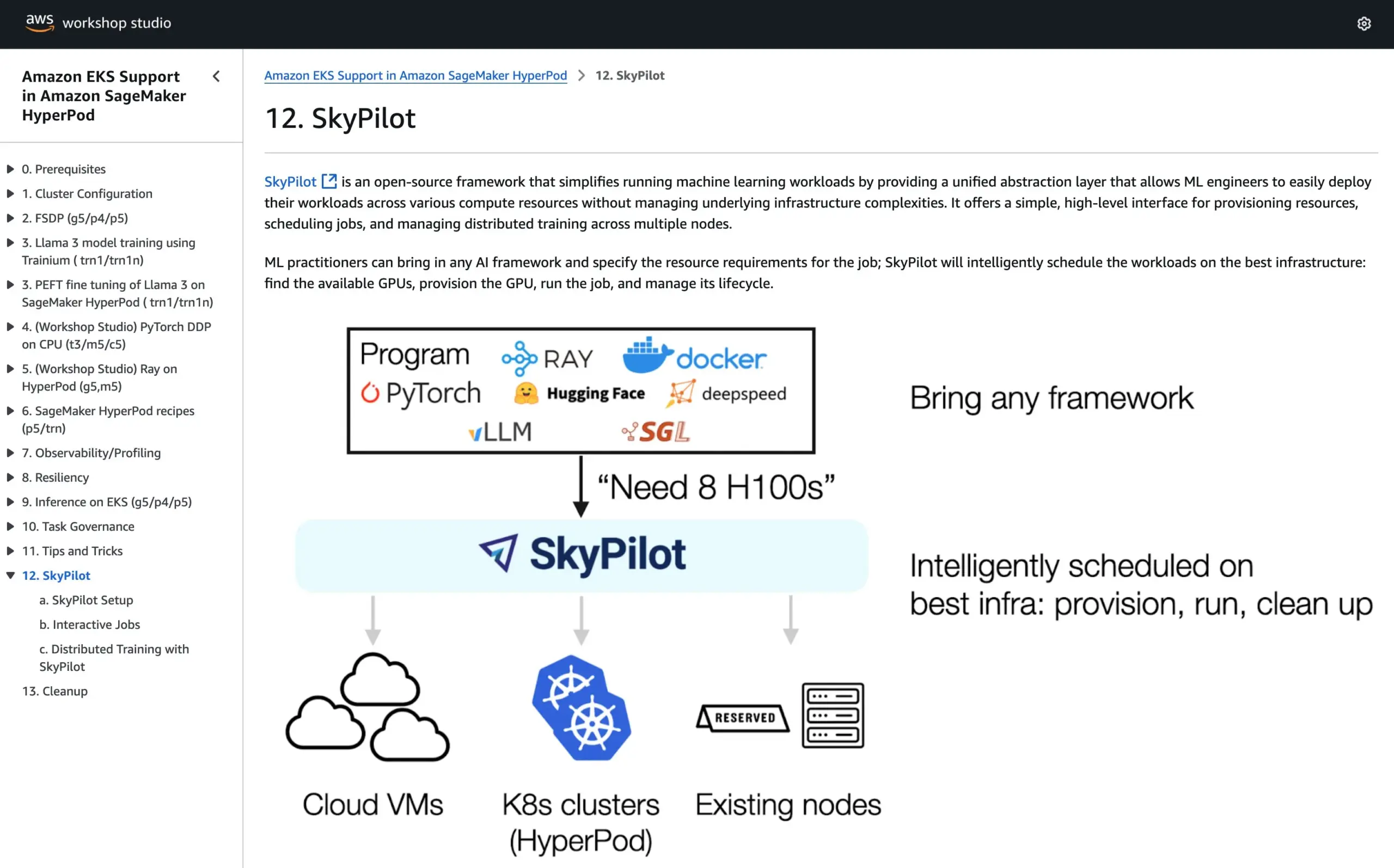
SkyPilot se une al tutorial oficial de AWS SageMaker HyperPod, combinando las ventajas de ambos sistemas para ejecutar IA: SkyPilot ha anunciado su integración en el tutorial oficial de AWS SageMaker HyperPod. Los usuarios pueden combinar la mejor disponibilidad y capacidad de recuperación de nodos que ofrece HyperPod con la conveniencia, rapidez y fiabilidad de SkyPilot para ejecutar tareas de IA en equipo, optimizando así la ejecución de cargas de trabajo de IA. (Fuente: skypilot_org)
💼 Negocios
OpenAI alcanza los 10 mil millones de dólares en ingresos anuales pero sigue registrando pérdidas, el crecimiento de usuarios es rápido: Según CNBC, los ingresos recurrentes anuales (ARR) de OpenAI han alcanzado los 10 mil millones de dólares, duplicándose con respecto al año pasado, principalmente gracias a las suscripciones de consumidores de ChatGPT, acuerdos empresariales y el uso de API. Cuenta con 500 millones de usuarios semanales y más de 3 millones de clientes comerciales. Sin embargo, debido a los altos costos de computación, se informó que la compañía perdió alrededor de 5 mil millones de dólares el año pasado, pero su objetivo es alcanzar los 125 mil millones de dólares en ARR para 2029. Esta noticia no incluye los ingresos por licencias de Microsoft, por lo que los ingresos reales podrían ser mayores. (Fuente: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
La empresa de decisiones de IA Deep-Insight, tras fracasar en la bolsa A, busca una salida a bolsa en Hong Kong enfrentando una caída de beneficios: La empresa de decisiones de marketing basadas en IA, Deep-Insight, ha presentado una solicitud de salida a bolsa en Hong Kong, casi un año después de retirar su solicitud de cotización en la Bolsa de Shenzhen. El beneficio neto de la compañía en 2024 se desplomó un 64.5%, y las cuentas por cobrar representan hasta el 40%. El negocio principal de Deep-Insight son la plataforma de publicidad inteligente AlphaDesk y la plataforma de gestión de datos inteligente AlphaData, y en 2025 lanzó el producto AI Agent DeepAgent. Aunque ocupa una cuota de mercado líder en aplicaciones de IA para la toma de decisiones de marketing y ventas en China, se enfrenta a desafíos como el aumento de los costos de adquisición de recursos de medios y la intensificación de la competencia en la industria. (Fuente: 36氪)

You.com se asocia con la revista TIME para ofrecer un año de servicio Pro gratuito a sus suscriptores digitales: La empresa de búsqueda con IA You.com ha anunciado una colaboración con la reconocida marca de medios TIME Magazine. Como parte de la asociación, You.com ofrecerá a todos los suscriptores digitales de TIME Magazine un año de servicio gratuito de la cuenta You.com Pro. Esta medida tiene como objetivo ampliar la base de usuarios de You.com Pro y explorar la combinación de la búsqueda con IA y el contenido multimedia. (Fuente: RichardSocher)

🌟 Comunidad
Anthropic sugiere a los usuarios que utilicen su IA como si fuera una máquina tragaperras, lo que genera debate en la comunidad: La sugerencia de Anthropic sobre el uso de su IA —“trátala como a una máquina tragaperras”— ha generado una amplia discusión y algunas burlas en las redes sociales. Esta expresión insinúa que los resultados de su IA pueden tener incertidumbre y aleatoriedad, requiriendo que los usuarios acepten y juzguen selectivamente, en lugar de depender completamente. Esto refleja los desafíos actuales que enfrentan los grandes modelos de lenguaje en términos de fiabilidad y consistencia. (Fuente: pmddomingos, pmddomingos)
Las herramientas para desarrolladores de IA: un mundo de “hielo y fuego”, con enormes diferencias entre las aplicaciones de vanguardia y la práctica generalizada: La comunidad de desarrolladores debate acaloradamente sobre una contradicción fundamental al construir e invertir en herramientas para desarrolladores de IA: la forma en que se construyen el 1% de las aplicaciones de IA de vanguardia es radicalmente diferente del 99% restante. Ambas son correctas y apropiadas en sus respectivos casos de uso, pero intentar escalar sin problemas desde aplicaciones pequeñas hasta aplicaciones a gran escala utilizando la misma arquitectura o pila tecnológica está casi destinado al fracaso. Esto pone de relieve la complejidad de la selección de herramientas y metodologías en el campo del desarrollo de IA. (Fuente: swyx)
Shopify anima a los empleados a usar LLM para programar sin miedo, e incluso organiza “concursos de gasto”: MParakhin de Shopify reveló que la empresa no solo no restringe el uso de LLM por parte de los empleados al programar, sino que “reprende” a aquellos que gastan muy poco. Incluso organizó un concurso para premiar a los empleados que gastaran la mayor cantidad de créditos de LLM sin usar scripts. Esto refleja la actitud de algunas empresas tecnológicas de vanguardia que adoptan activamente herramientas de desarrollo asistido por IA y las consideran un medio importante para mejorar la eficiencia y la capacidad de innovación. (Fuente: MParakhin)
Aplicación de AI Agent en redacciones de noticias: Caso de colaboración entre Magid y PromptLayer: La empresa Magid utiliza la plataforma PromptLayer para construir agentes de IA que ayudan a las redacciones de noticias a crear contenido a gran escala, garantizando al mismo tiempo el cumplimiento de los estándares periodísticos. Estos agentes de IA pueden procesar miles de informes, cuentan con fiabilidad, capacidad de control de versiones y han ganado la confianza de periodistas reales. Este caso demuestra el potencial de aplicación práctica de los AI Agent en la creación de contenido y la industria de noticias. (Fuente: imjaredz, Jonpon101)

Debate sobre la combinación de RL+GPT en LLM como camino hacia la AGI: En la comunidad existe la opinión de que la combinación de aprendizaje por refuerzo (RL) con grandes modelos de lenguaje (LLM) de estilo GPT tiene el potencial de conducir a la inteligencia artificial general (AGI). Esta perspectiva ha suscitado una mayor reflexión y debate sobre las vías para alcanzar la AGI, destacándose el potencial del RL para dotar a los LLM de una mayor orientación a objetivos y capacidad de aprendizaje continuo. (Fuente: finbarrtimbers, agihippo)
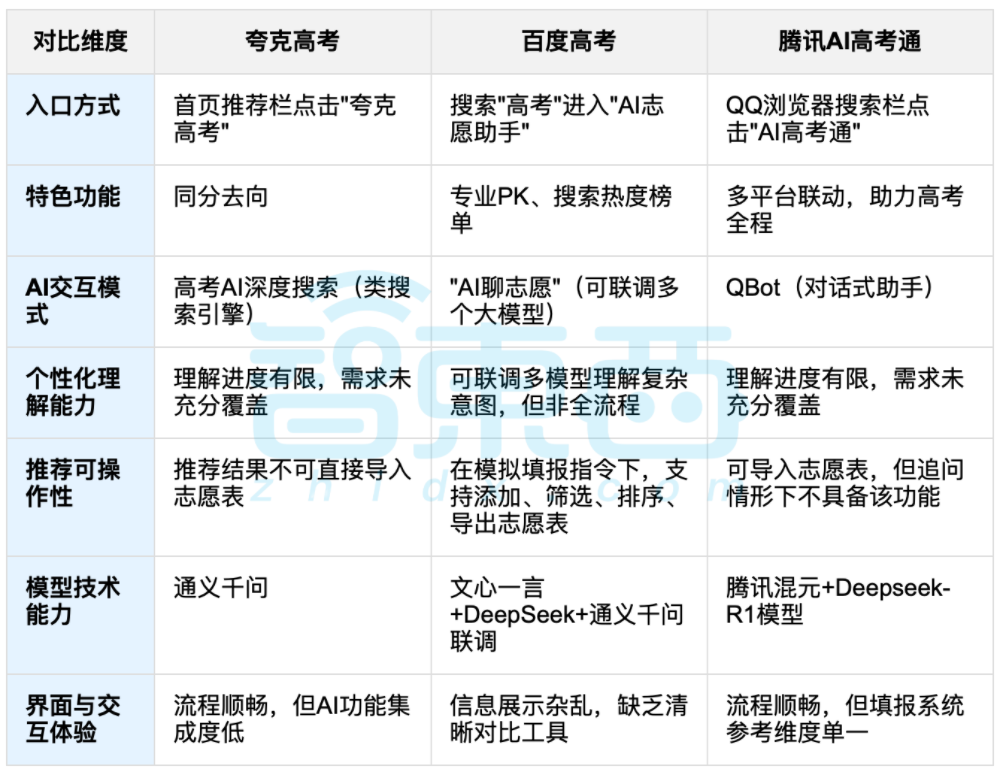
La IA para ayudar en la elección de carrera universitaria genera debate, el equilibrio entre datos y elección personalizada es el foco: Con el fin de los exámenes de acceso a la universidad, herramientas de IA para ayudar en la elección de carrera como Quark, Baidu AI Gaokao Tong, Tencent AI Gaokao Tong, etc., han ganado atención. Estas herramientas analizan datos históricos, comparan percentiles de puntuación y ofrecen sugerencias de tipo “arriesgar, asegurar, garantizar”. Las pruebas muestran que cada plataforma tiene sus propios enfoques y deficiencias en cuanto a la interacción, la lógica de recomendación y la comprensión de las necesidades personalizadas. Se señala que, aunque la IA puede mejorar la eficiencia en la obtención de información y reducir la asimetría informativa, cuando se trata de factores personales complejos como la personalidad, los intereses y la planificación futura, la “adivinación mediante datos” de la IA no puede reemplazar completamente el juicio subjetivo y las elecciones de vida de los estudiantes. (Fuente: 36氪, 36氪)
💡 Otros
Cortical Labs lanza la primera plataforma de biocomputación comercial CL1, integrando 800,000 neuronas humanas vivas: La startup australiana Cortical Labs ha lanzado la primera plataforma de biocomputación comercial del mundo, CL1, que combina 800,000 neuronas humanas vivas con chips de silicio, constituyendo una “inteligencia híbrida”. CL1 puede procesar información y aprender de forma autónoma, mostrando características similares a la conciencia, y en experimentos aprendió a jugar al Pong. El dispositivo consume mucha menos energía que el hardware de IA tradicional, tiene un precio unitario de 35,000 dólares y ofrece un modelo de acceso remoto “Wetware as a Service” (WaaS). Esta tecnología difumina los límites entre lo biológico y lo mecánico, generando debates sobre la naturaleza de la inteligencia y la ética. (Fuente: 36氪)

El dilema práctico de las bases de conocimiento de IA: tecnología impresionante pero difícil de implementar, se necesita un diseño “amigable con la IA”: Liu Xianghua, vicepresidente de Lanling, en una conversación con Cui Qiang, fundador de Cui Niu Hui, señaló que la tecnología de grandes modelos ha vuelto a centrar la atención en la gestión del conocimiento empresarial, pero las bases de conocimiento de IA se enfrentan al dilema de ser “aplaudidas pero no adoptadas”. Considera que las bases de conocimiento empresariales y personales difieren enormemente en la gestión de permisos, la gobernanza del sistema de conocimiento y la coherencia del contenido. Construir bases de conocimiento “amigables con la IA”, prestando atención a la calidad de los datos, los grafos de conocimiento y la búsqueda híbrida, puede reducir las alucinaciones y mejorar la utilidad. No está de acuerdo con perseguir la tecnología por la tecnología misma, y enfatiza que se debe elegir la tecnología adecuada según el escenario, ya que los grandes modelos no son una panacea. (Fuente: 36氪)
Proyecto de reactor de fusión nuclear mejorado con IA y respaldado por Google, objetivo de alcanzar plasma a 1.8 mil millones de grados Fahrenheit para 2030: Según Interesting Engineering, Google está respaldando un proyecto destinado a mejorar los reactores de fusión nuclear mediante tecnología de IA. El objetivo del proyecto es poder generar y mantener plasma a 1.8 mil millones de grados Fahrenheit (aproximadamente 1 mil millones de grados Celsius) para 2030. Esta colaboración demuestra el potencial de la IA para resolver desafíos científicos y de ingeniería extremos, especialmente en el campo de la energía limpia. (Fuente: Ronald_vanLoon)
