
Palabras clave:Modelo de Lenguaje a Gran Escala, Capacidad de Razonamiento, Inteligencia Artificial General, Emparejamiento de Patrones, Alucinaciones del Pensamiento, Investigación de Apple, Detector de IA, Regulación de IA, Mecanismo de Atención Log-Lineal, Modelo MoE Pangu de Huawei, Modo de Voz Avanzado de ChatGPT, Marco TensorZero, Opiniones de Regulación del CEO de Anthropic
🔥 Enfoque
Investigación de Apple revela la “ilusión del pensamiento”: los modelos actuales de “razonamiento” no piensan realmente, dependen más de la coincidencia de patrones: El último artículo de investigación de Apple, “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models through the Lens of Problem Complexity”, señala que los grandes modelos de lenguaje (como Claude, DeepSeek-R1, GPT-4o-mini, etc.) que actualmente afirman tener capacidades de “razonamiento”, se comportan más como eficientes comparadores de patrones que como verdaderos razonadores lógicos. La investigación encontró que el rendimiento de estos modelos disminuye significativamente al procesar problemas fuera de su distribución de entrenamiento o de alta complejidad, e incluso pueden cometer errores en problemas simples debido al “pensamiento excesivo”, y les resulta difícil corregir errores tempranos. El estudio enfatiza que el supuesto proceso de “pensamiento” de los modelos (como la cadena de pensamiento) a menudo falla cuando se enfrenta a tareas novedosas o complejas, lo que indica que podríamos estar más lejos de la inteligencia artificial general (AGI) de lo esperado. (Fuente: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

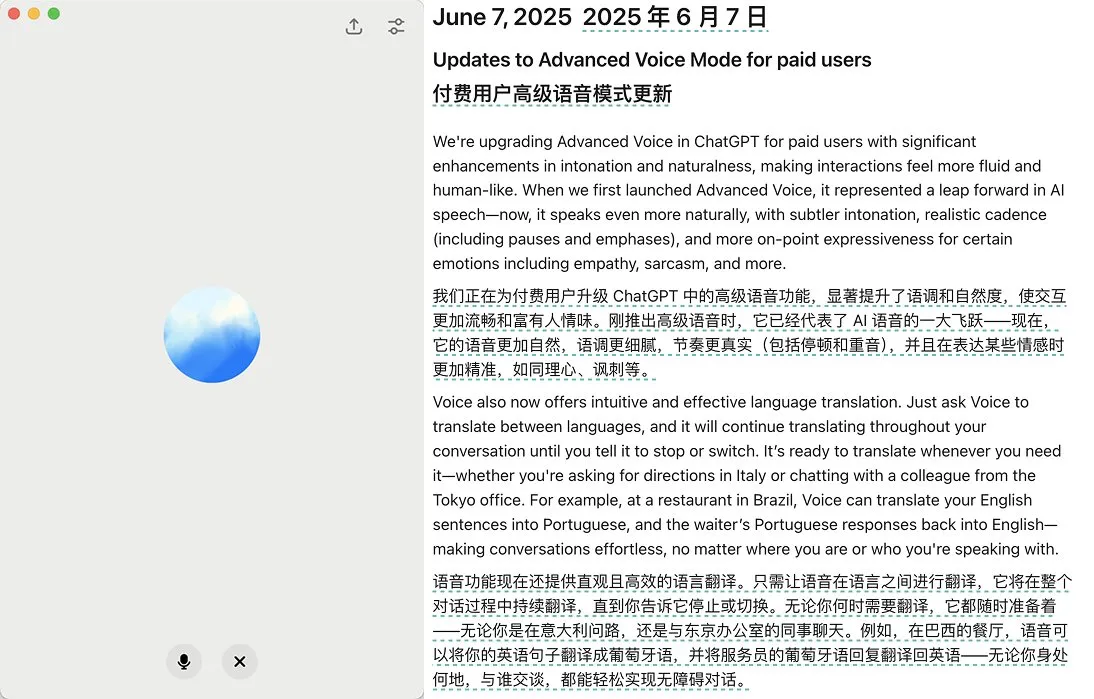
OpenAI lanza actualización del modo de voz avanzado de ChatGPT, mejorando la naturalidad y la función de traducción: OpenAI ha lanzado una importante actualización del modo de voz avanzado (Advanced Voice Mode) para los usuarios de pago de ChatGPT. La nueva versión mejora significativamente la naturalidad y fluidez de la voz, haciéndola sonar más humana que como un asistente de IA. Además, la actualización mejora el rendimiento de la traducción de idiomas y la capacidad de seguir instrucciones, y añade un nuevo modo de traducción que permite a los usuarios hacer que ChatGPT traduzca continuamente la conversación de ambas partes durante todo el diálogo hasta que se le indique que se detenga. Esta actualización tiene como objetivo hacer la interacción por voz más fácil y natural, mejorando la experiencia del usuario. (Fuente: juberti, Plinz, op7418, BorisMPower)
Señalan que los detectores de IA son ineficaces y podrían facilitar que el contenido de IA pase desapercibido: En redes sociales y foros tecnológicos ha surgido un amplio debate que señala que las herramientas actuales de detección de contenido de IA no solo son poco efectivas, sino que incluso podrían estar ayudando involuntariamente a que el contenido generado por IA sea más difícil de detectar. Muchos usuarios y expertos consideran que estos detectores se basan principalmente en patrones lingüísticos y vocabulario específico (como el término académico “delve”) para emitir juicios, en lugar de comprender realmente el origen del contenido. Debido al riesgo de falsos positivos (que podrían causar injusticias a grupos como los estudiantes) y a que los propios modelos de IA están evolucionando para evadir la detección, la fiabilidad de estas herramientas está seriamente cuestionada. Algunos opinan que la existencia de detectores de IA, en realidad, impulsa a que el contenido generado por IA evite ciertas características fácilmente marcables, pareciéndose así más a la escritura humana. (Fuente: Reddit r/ArtificialInteligence, sytelus)

CEO de Anthropic pide mayor transparencia y regulación de la responsabilidad para las empresas de IA: El CEO de Anthropic publicó un artículo de opinión en The New York Times, enfatizando que no se debe relajar la regulación sobre las empresas de IA, especialmente en lo referente a aumentar su transparencia y exigirles responsabilidad. Esta postura es particularmente importante en el contexto del rápido desarrollo y las capacidades en constante evolución de la industria de la IA, y se hace eco de las preocupaciones sociales sobre los riesgos potenciales y la ética de la IA. El artículo sostiene que, a medida que se expande la influencia de la tecnología de IA, es crucial garantizar que su desarrollo sirva al interés público y se evite el abuso, lo que requiere una combinación de autorregulación de la industria y supervisión externa. (Fuente: Reddit r/artificial)

🎯 Tendencias
Jeff Dean visualiza el futuro de la IA: hardware dedicado, evolución de modelos y aplicaciones científicas: Jeff Dean, jefe de IA de Google, compartió su visión sobre el futuro desarrollo de la IA en el evento AI Ascent de Sequoia Capital. Destacó la importancia del hardware dedicado (como los TPU) para el progreso de la IA y discutió las tendencias en la evolución de la arquitectura de los modelos. Dean también ofreció una perspectiva sobre la forma futura de la infraestructura computacional y el enorme potencial de aplicación de la IA en campos como la investigación científica, considerando que la IA será una herramienta clave para impulsar los descubrimientos científicos. (Fuente: TheTuringPost)

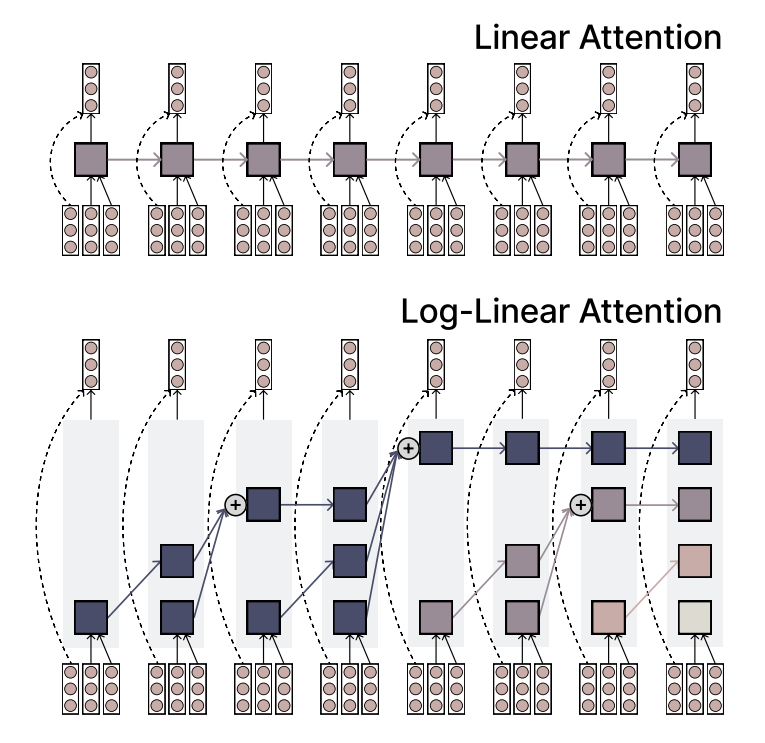
MIT propone el mecanismo Log-Linear Attention, combinando eficiencia y capacidad expresiva: Investigadores del MIT han propuesto un nuevo mecanismo de atención llamado Log-Linear Attention. Este mecanismo tiene como objetivo combinar la alta eficiencia de Linear Attention con la fuerte capacidad expresiva de Softmax Attention. Su característica principal es el uso de una pequeña cantidad de ranuras de memoria (memory slots) que crecen logarítmicamente con la longitud de la secuencia, manteniendo así una baja complejidad computacional al procesar secuencias largas, al tiempo que captura información clave. (Fuente: TheTuringPost)
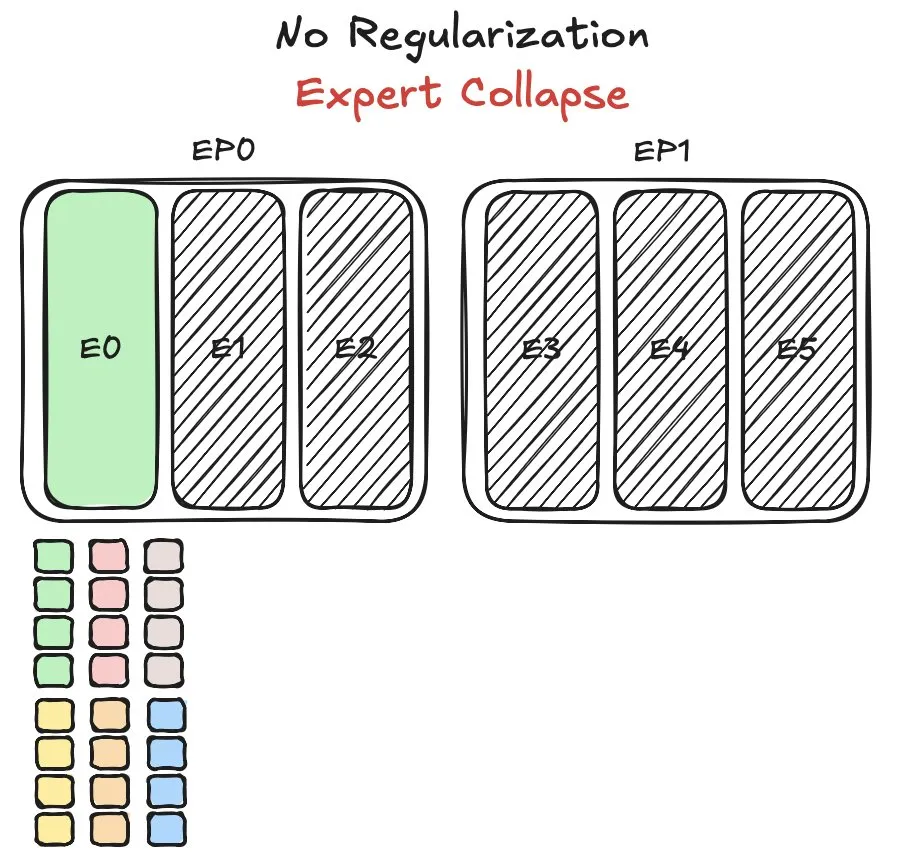
Modelo MoE Pangu de Huawei enfrenta desafíos de equilibrio de carga de expertos y propone nuevo método: Huawei, durante el entrenamiento de su modelo de mezcla de expertos (MoE) Pangu Ultra MoE, se encontró con el problema crítico del equilibrio de carga de los expertos. El equilibrio de carga de expertos requiere un compromiso entre la dinámica del entrenamiento y la eficiencia del sistema. Huawei ha propuesto una nueva solución a este problema, con el objetivo de optimizar la asignación de tareas y la carga computacional entre los diferentes módulos expertos en el modelo MoE, para mejorar la eficiencia del entrenamiento y el rendimiento del modelo. La investigación relacionada ha sido publicada en un artículo. (Fuente: finbarrtimbers)
NVIDIA lanza el modelo Cascade Mask R-CNN Mamba Vision, enfocado en la detección de objetos: NVIDIA ha lanzado en Hugging Face un nuevo modelo llamado cascade_mask_rcnn_mamba_vision_tiny_3x_coco. A juzgar por el nombre, este modelo está diseñado específicamente para tareas de detección de objetos y podría fusionar la arquitectura Cascade R-CNN con la tecnología visual Mamba (un modelo de espacio de estados), con el objetivo de mejorar la precisión y eficiencia en la detección de objetos. (Fuente: _akhaliq)
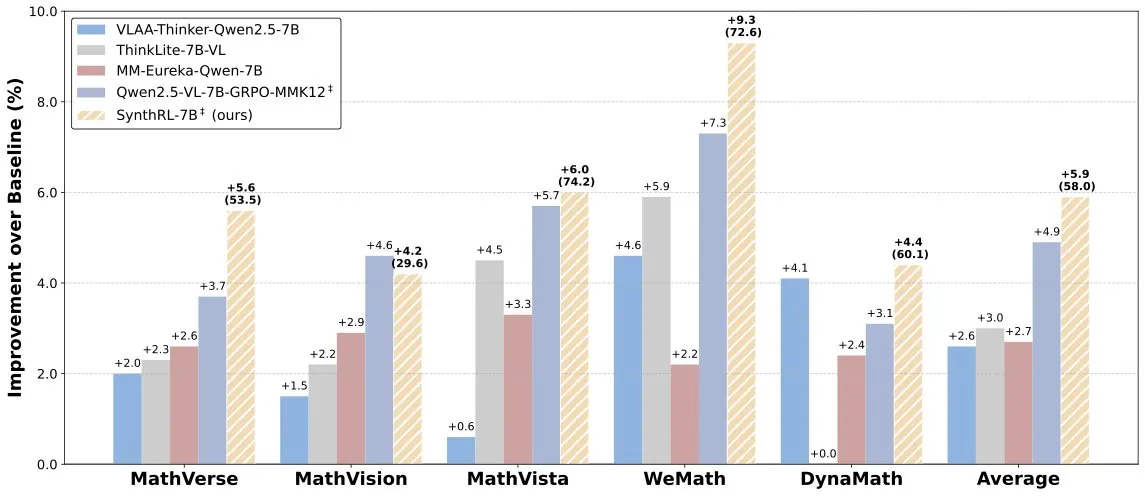
Lanzamiento del modelo SynthRL: razonamiento visual escalable mediante síntesis de datos verificables: Se ha lanzado en Hugging Face el modelo SynthRL, que se centra en la capacidad de razonamiento visual escalable. Su tecnología principal radica en un método de síntesis de datos verificables para generar variantes de tareas de razonamiento visual más desafiantes, manteniendo al mismo tiempo la corrección de las respuestas originales. Esto ayuda a mejorar la comprensión y el nivel de razonamiento del modelo en escenarios visuales complejos. (Fuente: _akhaliq)
Aunque DeepSeek-R1 muestra un buen rendimiento, la ventaja de producto de ChatGPT sigue siendo sólida: VentureBeat comenta que, a pesar de que modelos emergentes como DeepSeek-R1 muestran un rendimiento sobresaliente en ciertos aspectos, ChatGPT, gracias a su ventaja de ser el primero, su amplia base de usuarios, su ecosistema de productos maduro y su capacidad de iteración continua, mantiene una posición de liderazgo a nivel de producto que difícilmente será superada a corto plazo. La competencia en IA no es solo una contienda de parámetros técnicos, sino una competencia integral de experiencia de producto, construcción de ecosistemas y modelos de negocio. (Fuente: Ronald_vanLoon)

El equipo de Qwen confirma que Qwen3-coder está en desarrollo: Junyang Lin, del equipo de Qwen, confirmó que están desarrollando Qwen3-coder, una versión mejorada de la capacidad de codificación de la serie Qwen3. Aunque no se ha anunciado un cronograma específico, basándose en el ciclo de lanzamiento de Qwen2.5, se espera que pueda estar disponible en unas pocas semanas. La comunidad espera que este modelo logre avances en la generación de código, la integración de flujos de trabajo autónomos/de agentes y mantenga un buen soporte para múltiples lenguajes de programación. (Fuente: Reddit r/LocalLLaMA)

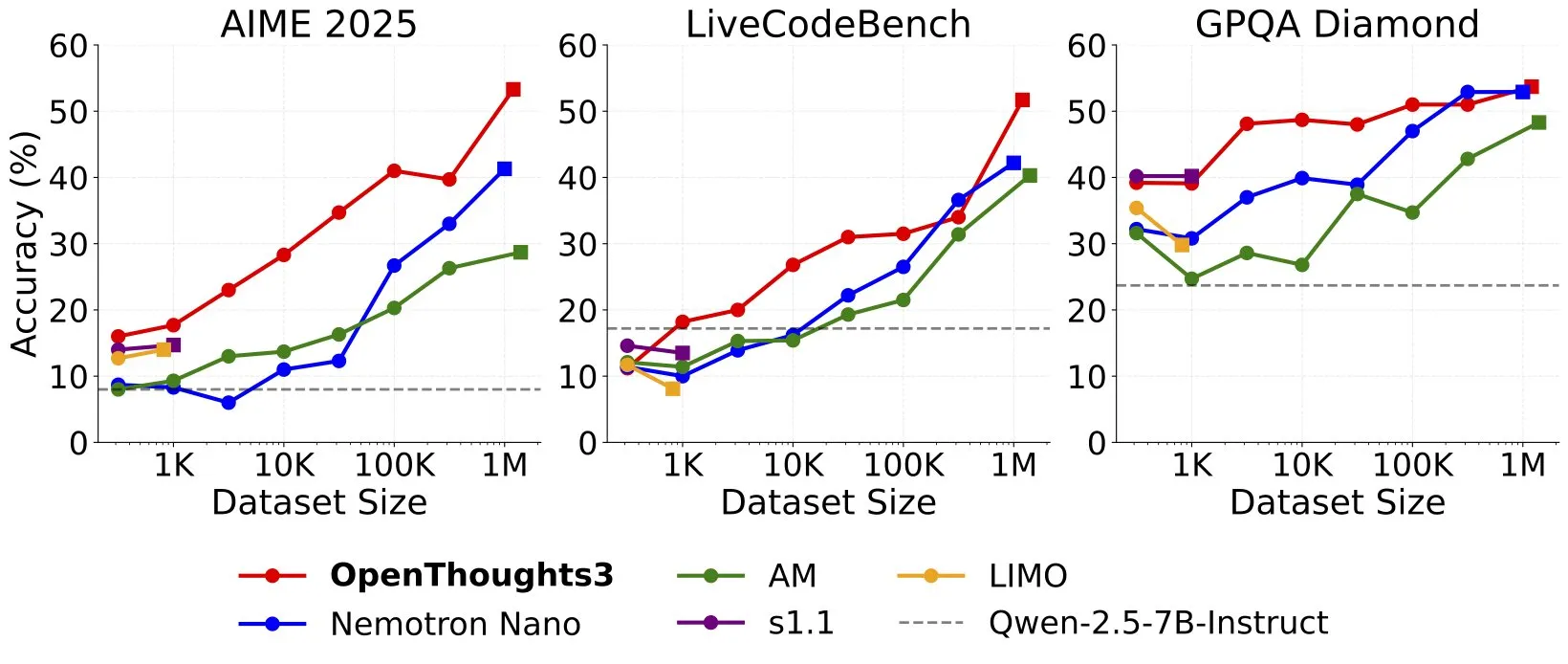
Lanzamiento de OpenThinker3-7B, proclamado como el modelo de razonamiento de 7B SOTA con datos de código abierto: Ryan Marten anunció el lanzamiento del modelo OpenThinker3-7B, afirmando que es el modelo de razonamiento de 7 mil millones de parámetros más avanzado entrenado con datos abiertos hasta la fecha. Según se informa, este modelo supera en promedio en un 33% a DeepSeek-R1-Distill-Qwen-7B en evaluaciones de código, ciencia y matemáticas. También se lanzó su conjunto de datos de entrenamiento, OpenThoughts3-1.2M. (Fuente: menhguin)
🧰 Herramientas
TensorZero: framework LLMOps de código abierto para optimizar el desarrollo y despliegue de aplicaciones LLM: TensorZero es un framework de código abierto para la optimización de aplicaciones LLM, diseñado para transformar datos de producción en modelos más inteligentes, rápidos y económicos a través de ciclos de retroalimentación. Integra una puerta de enlace LLM (compatible con múltiples proveedores de modelos), observabilidad, optimización (prompts, fine-tuning, RL), evaluación y experimentación (pruebas A/B), y soporta baja latencia, alto rendimiento y GitOps. La herramienta está escrita en Rust, enfatizando el rendimiento y las necesidades de aplicaciones de nivel industrial. (Fuente: GitHub Trending)

LangChain presenta un sistema RAG de alto rendimiento que combina SambaNova, Qdrant y LangGraph: LangChain ha introducido una solución de implementación de generación aumentada por recuperación (RAG) de alto rendimiento. Esta solución combina el modelo DeepSeek-R1 de SambaNova, la tecnología de cuantización binaria de Qdrant y LangGraph, logrando una reducción de memoria de 32 veces, lo que permite procesar eficientemente documentos a gran escala. Esto abre nuevas posibilidades para construir aplicaciones RAG más económicas y rápidas. (Fuente: hwchase17, qdrant_engine)
La aplicación Sparkify de Google para generar videos explicativos con un clic muestra casos de alta calidad: La aplicación Sparkify de Google, capaz de generar videos explicativos con un solo clic, muestra casos de una calidad notable. El contenido de los videos tiene una buena coherencia general, la locución es natural e incluso puede lograr efectos complejos como la visualización en pantalla dividida, demostrando el potencial de la IA en la creación automatizada de contenido de video. (Fuente: op7418)
Hugging Face lanza su primer servidor MCP, ampliando las funciones de los chatbots: Hugging Face ha lanzado su primer servidor MCP (Modular Chat Processor) (hf.co/mcp), que los usuarios pueden pegar en el cuadro de chat para usarlo. El servidor MCP tiene como objetivo mejorar las funcionalidades de los chatbots, ofreciendo una experiencia interactiva más rica a través de unidades de procesamiento modulares. La comunidad también ha recopilado una lista de otros servidores MCP útiles, como Agentset MCP, GitHub MCP, etc. (Fuente: TheTuringPost)
Los efectos de Chatterbox TTS rivalizan con ElevenLabs y ya está integrado en gptme: La herramienta TTS (texto a voz) Chatterbox ha llamado la atención por sus excelentes efectos de síntesis de voz. Los usuarios informan que sus resultados son comparables a los del conocido ElevenLabs y superiores a Kokoro. Chatterbox permite personalizar la voz mediante muestras de referencia y ahora se ha añadido como backend de TTS para gptme, ofreciendo a los usuarios opciones de salida de voz de alta calidad. (Fuente: teortaxesTex, _akhaliq)
E-Library-Agent: sistema inteligente de recuperación y preguntas y respuestas para libros/documentos locales: E-Library-Agent es un agente de IA autoalojado capaz de extraer, indexar y consultar colecciones personales de libros o artículos. El proyecto se basa en ingest-anything y está impulsado por las plataformas LlamaIndex, Qdrant y Linkup, permitiendo la extracción de material local, respuestas contextualizadas y descubrimiento en la web a través de una única interfaz, facilitando a los usuarios la gestión y utilización de sus bases de conocimiento personales. (Fuente: qdrant_engine)
Claude Code recibe altas valoraciones de los desarrolladores por su potente capacidad de asistencia en codificación: Usuarios de la comunidad de Reddit han compartido experiencias positivas utilizando Claude Code de Anthropic para el desarrollo de software, especialmente en áreas como el desarrollo de videojuegos (por ejemplo, proyectos en Godot C#). Los usuarios elogian su capacidad para resolver problemas complejos, superando con creces a otros asistentes de codificación de IA (como GitHub Copilot), ya que puede comprender el contexto y generar código efectivo. Incluso la tarifa de 100 dólares mensuales se considera una buena inversión. Los desarrolladores creen que los programadores experimentados, combinados con Claude Code, serán extremadamente productivos. (Fuente: Reddit r/ClaudeAI)
ChatterUI implementa soporte para modelos visuales locales, pero el procesamiento en Android es lento: La versión preliminar del cliente de chat LLM ChatterUI ha añadido soporte para archivos adjuntos y modelos visuales locales (a través de llama.rn). Los usuarios pueden cargar archivos mmproj para modelos locales compatibles o conectarse a API con capacidades visuales (como Google AI Studio, OpenAI). Sin embargo, debido a la falta de un backend de GPU estable para llama.cpp en Android, la velocidad de procesamiento de imágenes es extremadamente lenta (por ejemplo, una imagen de 512×512 tarda 5 minutos), mientras que el rendimiento en iOS es relativamente mejor. (Fuente: Reddit r/LocalLLaMA)
FLUX kontext muestra un rendimiento sobresaliente en el reemplazo de fondos de imágenes promocionales de automóviles: Pruebas de usuarios han revelado que la herramienta de edición de imágenes con IA FLUX kontext tiene efectos notables al modificar fondos de imágenes promocionales de automóviles. Por ejemplo, al cambiar el fondo de imágenes oficiales del Xiaomi SU7 (como una playa al atardecer o una pista de carreras), la herramienta no solo integra el fondo de manera natural, sino que también añade inteligentemente efectos de desenfoque de movimiento a los vehículos en marcha, mejorando el realismo y el impacto visual de la imagen. (Fuente: op7418)

📚 Aprendizaje
Nueva función flexicache de fastcore: un decorador de caché flexible: Jeremy Howard presentó una nueva y práctica función en la biblioteca fastcore llamada flexicache. Se trata de un decorador de caché altamente flexible que incluye dos estrategias de caché integradas: ‘mtime’ (basada en el tiempo de modificación del archivo) y ‘time’ (basada en marca de tiempo), y permite a los usuarios personalizar nuevas estrategias de caché con unas pocas líneas de código. Esta función, detallada en un artículo de Daniel Roy Greenfeld, ayuda a mejorar la eficiencia en la ejecución del código. (Fuente: jeremyphoward)
Explorando el potencial de combinar MuP y Muon para el entrenamiento de modelos Transformer: Jingyuan Liu ha estudiado en profundidad el trabajo de Jeremy Bernstein sobre la derivación de Muon y las condiciones espectrales, y ha expresado su admiración por la elegancia del proceso de derivación, especialmente cómo MuP (Maximal Update Parametrization) y Muon (un optimizador) trabajan en sinergia. Considera que, desde la perspectiva de la derivación, usar Muon como optimizador para el entrenamiento de modelos basados en MuP es una elección natural, y señala que esto podría ser más emocionante que la migración de hiperparámetros de AdamW a Muon mediante la coincidencia de la actualización RMS en el trabajo Moonlight de Moonshot. La comunidad discute que la combinación MuP + Muon tiene el potencial de ser aplicada a gran escala por grandes empresas tecnológicas antes de fin de año. (Fuente: jeremyphoward)

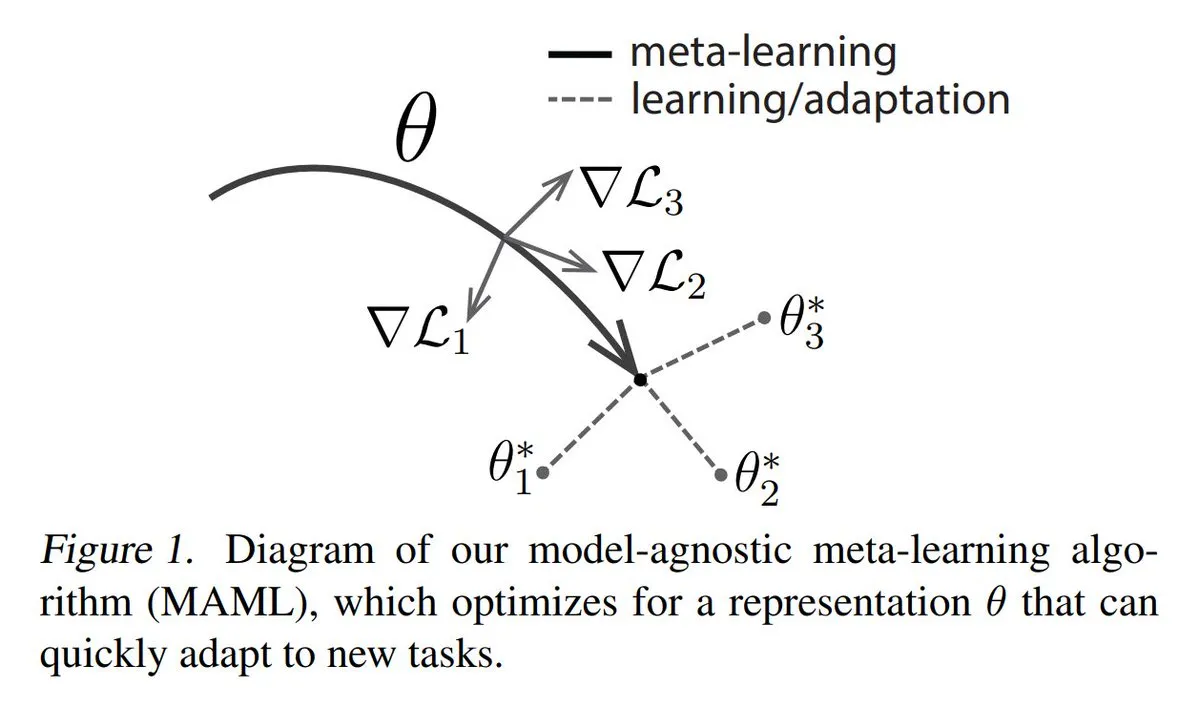
Análisis de los tres principales enfoques del Meta-aprendizaje (Meta-learning): El Meta-aprendizaje tiene como objetivo entrenar modelos para que aprendan rápidamente nuevas tareas, incluso con pocas muestras. Los métodos comunes incluyen: 1. Basados en optimización/gradiente: buscan parámetros del modelo que puedan ajustarse eficientemente en una tarea con pocos pasos de gradiente. 2. Basados en métricas: ayudan al modelo a encontrar mejores formas de medir la similitud entre muestras nuevas y antiguas, agrupando eficazmente muestras relacionadas. 3. Basados en modelos: todo el modelo está diseñado para adaptarse rápidamente utilizando memoria incorporada o mecanismos dinámicos. TheTuringPost ofrece una explicación detallada desde los fundamentos hasta los métodos modernos de Meta-aprendizaje. (Fuente: TheTuringPost)
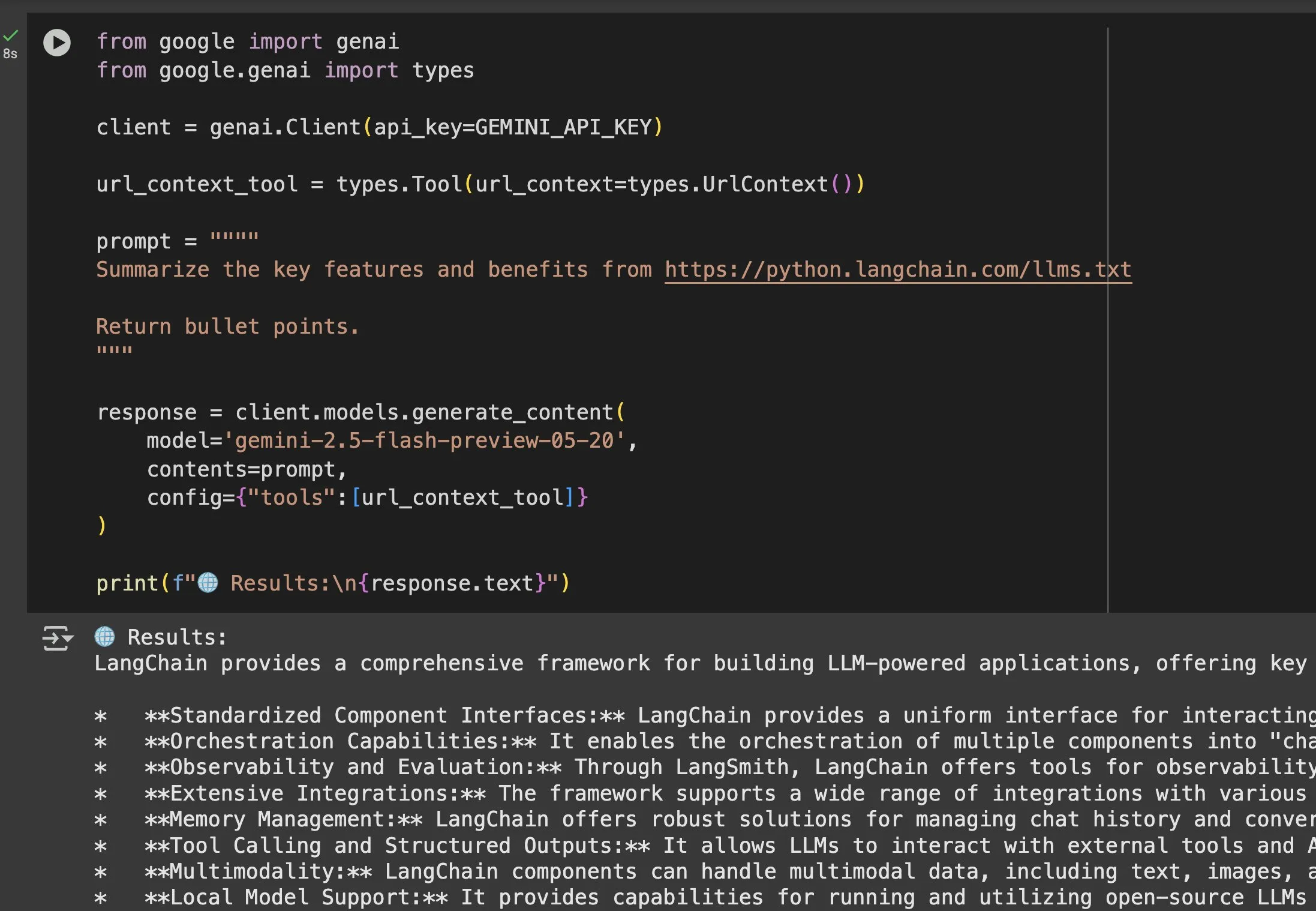
El valor de los archivos llms.txt se destaca en aplicaciones con modelos como Gemini: Jeremy Phoward enfatizó la utilidad de los archivos llms.txt. Por ejemplo, Gemini ahora puede comprender el contenido de una URL simplemente añadiendo la URL en el prompt y configurando la herramienta de contexto de URL. Esto significa que el cliente (como Gemini), al leer el endpoint llms.txt, puede saber exactamente dónde se almacena la información necesaria, facilitando enormemente la obtención y utilización programática de la información. (Fuente: jeremyphoward)
EleutherAI publica Common Pile v0.1, un conjunto de datos de texto de 8TB con licencia abierta: EleutherAI anunció el lanzamiento de Common Pile v0.1, un gran conjunto de datos que contiene 8TB de texto con licencia abierta y de dominio público. Basándose en este conjunto de datos, entrenaron modelos de lenguaje de 7 mil millones de parámetros (utilizando 1T y 2T tokens para el entrenamiento, respectivamente), cuyo rendimiento es comparable al de modelos similares como LLaMA 1 y LLaMA 2. Esto proporciona un recurso valioso y evidencia empírica para la investigación sobre el entrenamiento de modelos de lenguaje de alto rendimiento utilizando exclusivamente datos conformes. (Fuente: clefourrier)

SelfCheckGPT: un método de detección de alucinaciones en LLM sin necesidad de referencia: Un artículo de blog explora SelfCheckGPT como una alternativa a LLM-as-a-judge (usar un LLM como evaluador) para detectar alucinaciones en modelos de lenguaje. Este es un método de detección sin necesidad de texto de referencia y sin recursos (zero-resource), que ofrece nuevas ideas para evaluar y mejorar la veracidad de las salidas de los LLM. (Fuente: dl_weekly)
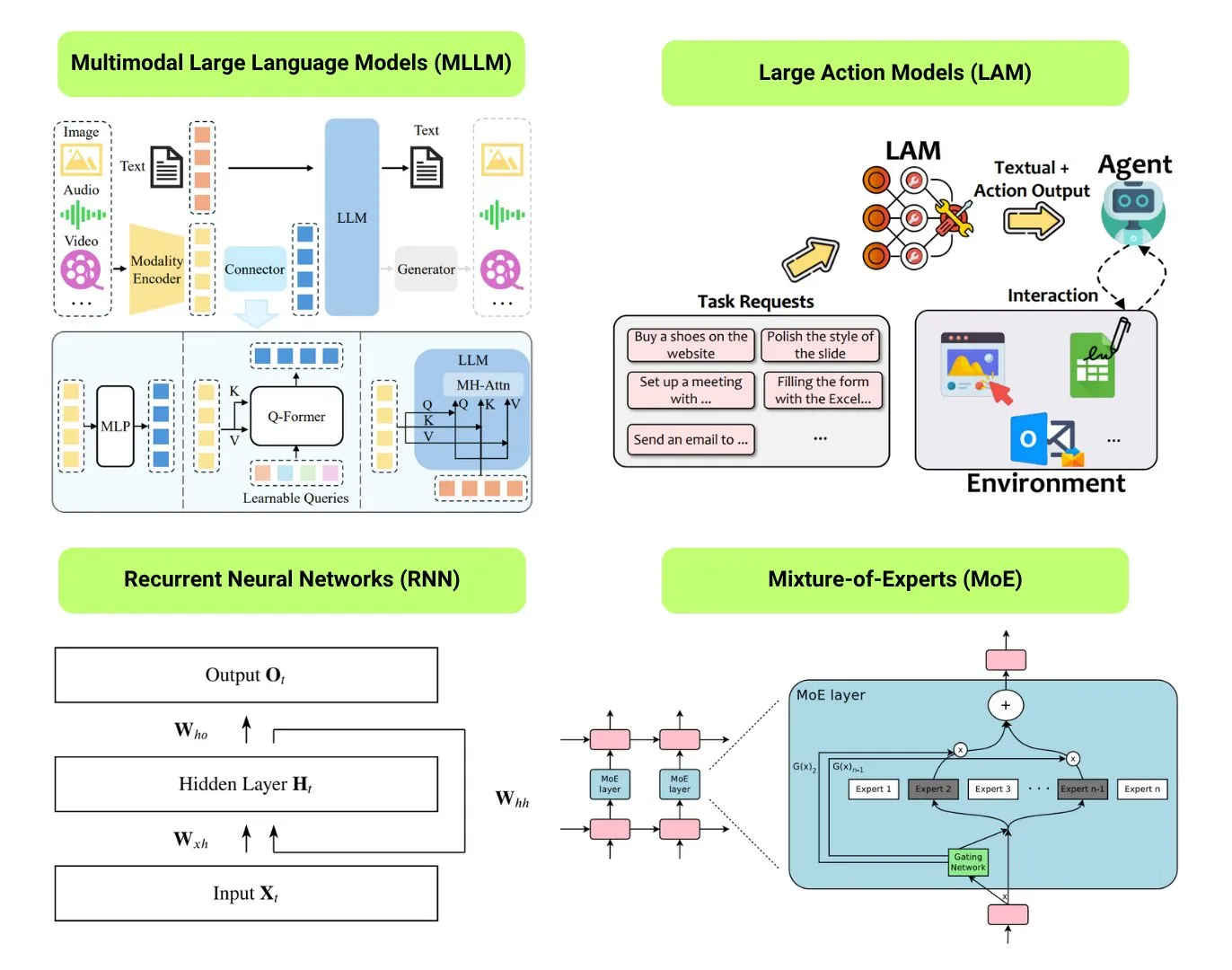
Recopilación de 12 tipos de modelos básicos de IA: The Turing Post ha recopilado 12 tipos de modelos básicos de IA, incluyendo LLM (Large Language Models), SLM (Small Language Models), VLM (Visual Language Models), MLLM (Multimodal Large Language Models), LAM (Large Action Models), LRM (Large Reasoning Models), MoE (Mixture of Experts), SSM (State Space Models), RNN (Recurrent Neural Networks), CNN (Convolutional Neural Networks), SAM (Segment Anything Models) y LNN (Logical Neural Networks). Los recursos relacionados proporcionan explicaciones y enlaces útiles para estos tipos de modelos. (Fuente: TheTuringPost)
Popular en GitHub: Tutorial Kubernetes The Hard Way: El tutorial de Kelsey Hightower, “Kubernetes The Hard Way”, sigue siendo popular en GitHub. Este tutorial tiene como objetivo ayudar a los usuarios a construir un clúster de Kubernetes paso a paso de forma manual, para comprender en profundidad sus componentes principales y principios de funcionamiento, en lugar de depender de scripts automatizados. El tutorial está dirigido a aquellos que desean dominar los fundamentos de Kubernetes, cubriendo todo el proceso desde la preparación del entorno hasta la limpieza del clúster. (Fuente: GitHub Trending)
Popular en GitHub: Lista de GPTs y Prompts gratuitos: El repositorio friuns2/BlackFriday-GPTs-Prompts es popular en GitHub. Recopila y organiza una serie de modelos GPT gratuitos y Prompts de alta calidad que los usuarios pueden utilizar sin necesidad de una suscripción Plus. Estos recursos cubren múltiples áreas como programación, marketing, investigación académica, búsqueda de empleo, juegos, creatividad, e incluyen algunos trucos de “Jailbreaks”, proporcionando a los usuarios de GPT una rica variedad de herramientas e inspiración listas para usar. (Fuente: GitHub Trending)

Uso de CSV para planificar y rastrear proyectos de codificación con IA, mejorando la calidad y eficiencia del código: Un desarrollador compartió cómo, al desarrollar un sistema ERP con Claude Code, mejoró significativamente la eficiencia del desarrollo de funciones complejas y la calidad del código mediante la creación de archivos CSV detallados para planificar y rastrear el progreso de la codificación de cada archivo. El archivo CSV incluye estado, nombre de archivo, prioridad, líneas de código, complejidad, dependencias, descripción de la funcionalidad, Hooks utilizados, módulos importados/exportados y, crucialmente, “notas de progreso”. Este método permite que la IA se concentre mejor en la construcción del código y que el desarrollador tenga una visión clara del progreso real del proyecto en comparación con el plan original. (Fuente: Reddit r/ClaudeAI)
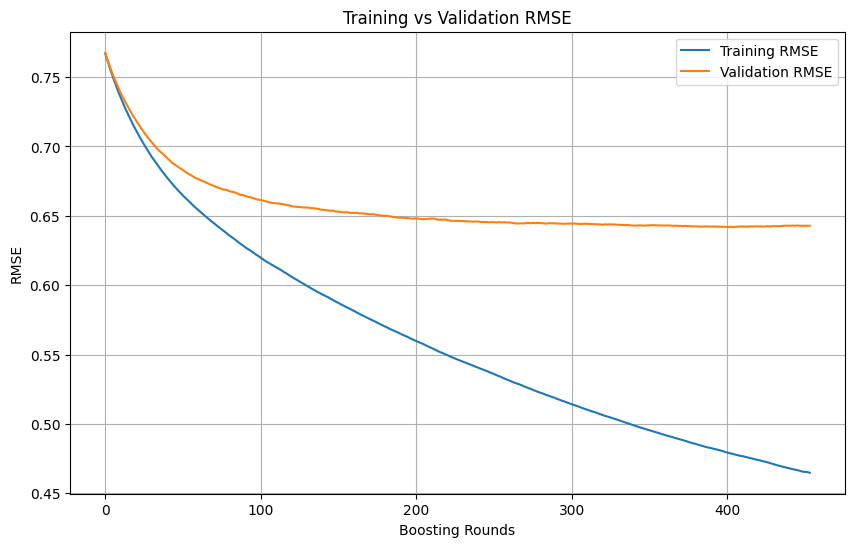
Juicio de sobreajuste (overfitting) y momento de detener el entrenamiento en Machine Learning: Durante el proceso de entrenamiento de un modelo de Machine Learning, cuando la pérdida de entrenamiento continúa disminuyendo rápidamente, mientras que la pérdida de validación disminuye lentamente, se detiene o incluso aumenta, generalmente indica que el modelo puede estar experimentando sobreajuste. En principio, mientras la pérdida de validación siga disminuyendo, se puede continuar entrenando. La clave es asegurar que el conjunto de validación sea independiente del conjunto de entrenamiento y pueda representar la distribución real de datos de la tarea. Si la pérdida de validación deja de disminuir o comienza a aumentar, se debe considerar detener el entrenamiento de forma temprana o adoptar métodos como la regularización para mejorar la capacidad de generalización del modelo. (Fuente: Reddit r/MachineLearning)
🌟 Comunidad
AI Engineer World’s Fair 2025 se enfoca en temas como RL+Reasoning, Eval, etc. La AI Engineer World’s Fair 2025 abordará temas de vanguardia como el aprendizaje por refuerzo + razonamiento (RL+Reasoning), evaluación (Eval), agentes de ingeniería de software (SWE-Agent), arquitectos de IA e infraestructura de agentes. Los asistentes expresaron que la conferencia estuvo llena de vitalidad y pensamiento innovador, con muchas personas atreviéndose a probar cosas nuevas, reinventándose constantemente y dedicándose al campo de la IA. La conferencia también proporcionó una plataforma de intercambio y aprendizaje para los ingenieros de IA. (Fuente: swyx, hwchase17, charles_irl, swyx)

La IA ideal según Sam Altman: modelos pequeños + razonamiento superpotente + contexto masivo + herramientas universales: Sam Altman describió su forma ideal de IA: un modelo con capacidad de razonamiento sobrehumana, de tamaño extremadamente pequeño, capaz de acceder a billones de unidades de información contextual y de utilizar cualquier herramienta imaginable. Esta visión generó debate; algunos consideran que difiere del estado actual de los grandes modelos, que dependen del almacenamiento de conocimiento, y cuestionan la viabilidad de que modelos pequeños analicen conocimiento y realicen razonamientos complejos en contextos enormes, argumentando que el conocimiento y la capacidad de pensamiento son difíciles de separar eficientemente. (Fuente: teortaxesTex)
Los agentes de codificación despiertan el deseo de refactorizar código, desafíos y oportunidades de la programación asistida por IA: Los desarrolladores expresan que la aparición de agentes de codificación ha aumentado enormemente la “tentación” de refactorizar el código de otros, lo que también conlleva nuevos peligros. Un desarrollador compartió su experiencia utilizando IA para completar una tarea de programación que manualmente llevaría unos 10 minutos; aunque la IA pudo generar rápidamente código funcional, alcanzar el nivel de organización y estilo de un programador experimentado aún requirió una gran cantidad de guía y refactorización manual. Esto resalta los desafíos de la programación asistida por IA para elevar la calidad del código de nivel junior/medio a un nivel avanzado. (Fuente: finbarrtimbers, mitchellh)
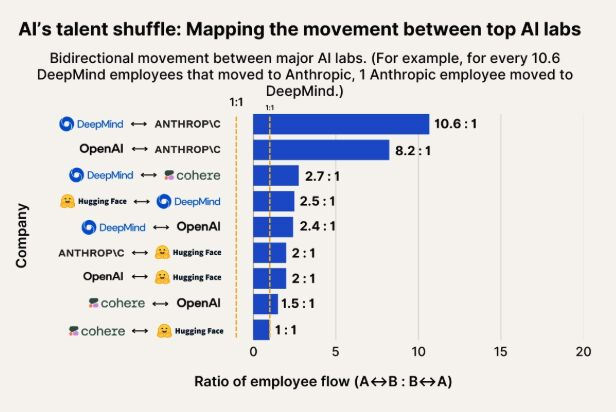
Observación del flujo de talento en IA: Anthropic se convierte en un importante destino para el talento de Google DeepMind y OpenAI: Un gráfico que muestra el flujo de talento en IA indica que Anthropic se está convirtiendo en una empresa importante que atrae a investigadores de Google DeepMind y OpenAI. La comunidad considera que esto concuerda con la percepción general, y algunos usuarios especulan que Anthropic podría poseer algún “arma secreta” o una dirección de investigación única que atrae a los mejores talentos. (Fuente: bookwormengr, TheZachMueller)
La popularización de los robots humanoides enfrenta desafíos de confianza y aceptación social: El comentarista tecnológico Faruk Guney predice que la primera ola de robots humanoides podría fracasar debido a un enorme déficit de confianza. Sostiene que, a pesar de los continuos avances tecnológicos, la sociedad aún no está preparada para aceptar que estas “inteligencias de caja negra” entren en los hogares para realizar tareas de compañía, tareas domésticas e incluso cuidado de niños. La toma de decisiones opaca de los robots, los riesgos potenciales de vigilancia y una apariencia “adorable” muy diferente a la humana (no como Wall-E), podrían convertirse en obstáculos para su amplia aplicación. Solo después de un amplio debate social, regulación, auditoría y reconstrucción de la confianza, podrá llegar la verdadera popularización de los robots humanoides. (Fuente: farguney, farguney)
Diseño de personalidad de IA: lo “imperfecto” supera a lo “perfecto”: Un desarrollador compartió su experiencia creando 50 personalidades de IA en una plataforma de audio de IA. Concluyó que las historias de fondo excesivamente diseñadas, la coherencia lógica absoluta y los rasgos de carácter extremadamente singulares hacían que la IA pareciera mecánica y poco realista. El éxito en la creación de personalidades de IA radica en una “pila de personalidad de 3 capas” (rasgos centrales + rasgos modificadores + peculiaridades), un “patrón de imperfección” apropiado (como errores ocasionales al hablar, autocorrecciones) y la cantidad justa de información de fondo (300-500 palabras, incluyendo experiencias positivas y desafiantes, pasiones específicas y puntos de vulnerabilidad relacionados con la profesión). Estos detalles “imperfectos” hacen que la IA sea más humana y conectable. (Fuente: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Debate sobre si los LLM poseen “percepción” y “AGI”: entusiasmo y escepticismo coexisten: La comunidad en general está entusiasmada con el enorme potencial de los LLM, considerándolos comparables a importantes inventos históricos que lo cambiarán todo. Sin embargo, muchos siguen siendo escépticos sobre afirmaciones de que los LLM ya poseen “capacidad de percepción”, necesitan “derechos”, o que “acabarán con la humanidad” o traerán la “AGI”. Se enfatiza la necesidad de mantener la minuciosidad y la prudencia al interpretar las capacidades y los resultados de la investigación de los LLM. (Fuente: fabianstelzer)
💡 Otros
Exploración de la colaboración autónoma en la marcha de múltiples robots: En las redes sociales ha surgido la exploración de la colaboración entre múltiples robots en cuanto a su marcha autónoma. Esto implica tecnologías complejas como la planificación de rutas de robots, la asignación de tareas, el intercambio de información y la evitación de colisiones, siendo un área de investigación continua en robótica, RPA (Automatización Robótica de Procesos) y Machine Learning. (Fuente: Ronald_vanLoon)
Técnica para optimizar hiperparámetros de ULMFiT utilizando Random Forests: Jeremy Howard compartió un truco que utilizó para optimizar ULMFiT (un método de aprendizaje por transferencia): ejecutar una gran cantidad de experimentos de ablación y alimentar todos los hiperparámetros y datos de resultados a un modelo de Random Forest para identificar los hiperparámetros que más influyen en el rendimiento del modelo. Este método ha sido integrado por Weights & Biases en su producto, ofreciendo nuevas ideas para el ajuste de hiperparámetros. (Fuente: jeremyphoward)

Robot humanoide de Figure demuestra capacidad para procesar tareas logísticas durante 60 minutos: La empresa Figure ha publicado un video de 60 minutos que muestra a su robot humanoide, impulsado por la red neuronal Helix, completando de forma autónoma diversas tareas en un escenario logístico. Esta demostración tiene como objetivo probar la capacidad de trabajo estable y el nivel de toma de decisiones autónoma de sus robots en entornos reales complejos durante períodos prolongados. (Fuente: adcock_brett)