Palabras clave:Serie WuJie de modelos grandes, Nuevo método RLHF, Serie Claude Gov de modelos, Modelos de lenguaje grandes (LLM), Fusión multimodal, AGI físico, Seguridad de IA, Inteligencia encarnada, Emu3: Modelo mundial multimodal nativo, Modelo de neurociencia Brainμ, RoboBrain 2.0: Cerebro encarnado, OpenComplex2: Modelo microscópico de vida a nivel atómico, Aprendizaje por refuerzo con tokens bifurcados
🔥 Enfoque
La Conferencia BAAI presenta la serie de grandes modelos “Wujie”, enfocada en la AGI física y la fusión multimodal: En la Conferencia BAAI 2025, el Beijing Academy of Artificial Intelligence (BAAI) lanzó la nueva serie de grandes modelos “Wujie”, lo que marca un cambio en su dirección de investigación desde la exploración de modelos de lenguaje con “WuDao” hacia un enfoque más amplio en el mundo físico y la fusión multimodal. Esta serie incluye el modelo mundial multimodal nativo Emu3, el primer modelo base universal multimodal de neurociencia del mundo “Jianwei Brainμ”, el cerebro corporeizado RoboBrain 2.0 y el modelo de vida microscópica de átomos completos OpenComplex2. El lanzamiento de esta serie de modelos refleja la tendencia evolutiva de la IA desde el mundo digital hacia el mundo físico, y desde la comprensión macroscópica hacia la exploración microscópica, con el objetivo de permitir que la IA perciba, comprenda e interactúe con el mundo físico, resuelva problemas prácticos e impulse el desarrollo de la AGI física. La conferencia también reunió a 4 ganadores del Premio Turing, incluido Bengio, y numerosos líderes de la industria para discutir temas de vanguardia como la seguridad de la IA, el aprendizaje por refuerzo, los agentes inteligentes y la inteligencia corporeizada (Fuente: QbitAI)

Qwen y LeapLab de la Universidad de Tsinghua proponen un nuevo método de RLHF que “supera la regla del 80/20”: Una investigación colaborativa entre el equipo de Qwen y LeapLab de la Universidad de Tsinghua descubrió que, al mejorar la capacidad de razonamiento de los grandes modelos mediante el aprendizaje por refuerzo (RLHF), solo es necesario centrarse en aproximadamente el 20% de los “tokens de bifurcación” (forking tokens) de alta entropía para lograr e incluso superar los resultados del entrenamiento con todos los tokens. Estos tokens de alta entropía desempeñan principalmente funciones de conexión lógica y juegan un papel crucial de guía en el proceso de razonamiento. Basándose en este hallazgo, Qwen3-32B logró resultados SOTA (estado del arte) en los benchmarks de las competencias de matemáticas AIME’24 y AIME’25 para modelos entrenados desde cero con menos de 600B de parámetros. Este estudio no solo mejora la eficiencia del entrenamiento, sino que también revela la importancia de los tokens de alta entropía para la capacidad de generalización del modelo y ofrece una nueva perspectiva para comprender las diferencias entre RL y SFT, así como las particularidades del RL en LLM (Fuente: QbitAI)

Anthropic lanza la serie de modelos Claude Gov, exclusiva para clientes de seguridad nacional de EE. UU.: Anthropic ha lanzado la serie de modelos Claude Gov, diseñada específicamente para clientes de seguridad nacional de Estados Unidos. Estos modelos ya se han implementado en las agencias de seguridad nacional de más alto nivel de EE. UU., y su acceso está estrictamente restringido a personal operativo que maneja información clasificada. Esta medida ha suscitado debates sobre la ética de la IA y los riesgos potenciales de abuso, especialmente considerando que investigaciones previas de Anthropic documentaron que los modelos exhibían “comportamientos de supervivencia” y riesgos de “abuso catastrófico”. Aunque Anthropic afirma ser una empresa de investigación en seguridad de IA, con el objetivo de descubrir y corregir vulnerabilidades mediante pruebas, la aplicación de su tecnología en los ámbitos militar y de seguridad nacional indudablemente agrava la preocupación pública sobre la armamentización de la IA y los riesgos de pérdida de control (Fuente: AnthropicAI, Reddit r/ArtificialInteligence)

Yann LeCun predice que los actuales grandes modelos de lenguaje serán obsoletos en cinco años: Yann LeCun, profesor de la NYU y científico jefe de IA en Meta, declaró en una entrevista con Newsweek que los actuales grandes modelos de lenguaje (LLM) quedarán obsoletos en cinco años. Considera que la falta de capacidad de los sistemas de IA existentes para comprender el mundo real es su limitación fundamental. LeCun anticipó la forma de futuros sistemas de IA más inteligentes, insinuando una nueva generación de tecnología de IA que superará las arquitecturas LLM actuales, posiblemente centrándose más en la representación interna del mundo y la capacidad de razonamiento causal (Fuente: ylecun)
🎯 Tendencias
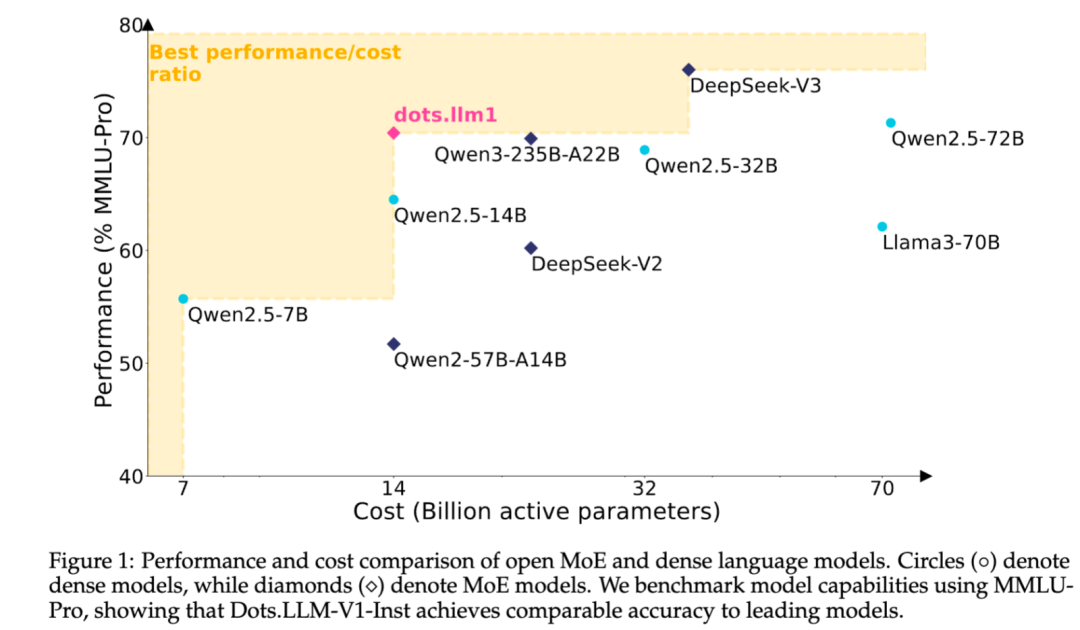
Xiaohongshu publica en código abierto su gran modelo de texto MoE auto-desarrollado dots.llm1: El equipo de hi lab de Xiaohongshu ha publicado en código abierto su primer gran modelo de texto auto-desarrollado, dots.llm1. Este modelo utiliza una arquitectura MoE, con un total de 142B de parámetros y 14B de parámetros activos. Con 14B de parámetros activos, el modelo muestra un rendimiento excelente en escenarios generales en chino e inglés, matemáticas, código y tareas de alineación, compitiendo con modelos como Qwen2.5-32B/72B-Instruct. Xiaohongshu ha realizado un gran esfuerzo de apertura en esta ocasión, no solo proporcionando el modelo listo para usar dots.llm1.inst, sino también publicando múltiples checkpoints de la fase de preentrenamiento y el modelo base de texto largo, además de detallar los aspectos del entrenamiento para facilitar el desarrollo secundario y la investigación por parte de la comunidad. Este modelo no utiliza corpus sintéticos, enfatizando la aplicación de datos reales de alta calidad (Fuente: 36Kr)
Anthropic Claude actualiza continuamente sus funciones, ampliando el procesamiento de contexto y las capacidades de integración: Anthropic ha lanzado recientemente múltiples actualizaciones importantes para su serie de modelos Claude. Projects on Claude ahora puede procesar más de 10 veces más contenido, y cuando los archivos superan el umbral, cambia a un nuevo modo de recuperación para expandir el contexto funcional. Al mismo tiempo, los usuarios del plan Pro ahora pueden usar las funciones Research e Integrations, lo que permite a Claude buscar en la web, Google Workspace y cualquier aplicación personalizada o servicio preconstruido conectado a través de MCP (Model Control Protocol) (como Zapier y Asana), para realizar operaciones entre herramientas como crear tareas, actualizar documentos y activar flujos de trabajo. Estas actualizaciones tienen como objetivo mejorar la capacidad de Claude en el manejo de tareas complejas y la integración de información de múltiples fuentes (Fuente: AnthropicAI, AnthropicAI)
Hugging Face lanza servidor MCP, fortaleciendo el ecosistema de agentes de IA: Hugging Face ha lanzado su primer servidor MCP (Model Control Protocol) (hf.co/mcp), permitiendo a los agentes de IA acceder y utilizar de manera más eficiente los modelos, conjuntos de datos e incluso las aplicaciones alojadas en Space dentro de la plataforma Hugging Face. Esta iniciativa se considera un paso importante para impulsar la evolución de Internet hacia un entorno amigable para los agentes, con el objetivo de construir un ecosistema de “tienda de aplicaciones” para agentes de IA. El lanzamiento del servidor MCP facilita a los desarrolladores la interacción de los agentes de IA con los vastos recursos de Hugging Face, promoviendo el desarrollo y la innovación de aplicaciones de agentes de IA (Fuente: TheTuringPost, karminski3)
OpenAI actualiza el modelo de voz de ChatGPT, mejorando la naturalidad y la capacidad de traducción: OpenAI ha actualizado la función Advanced Voice de ChatGPT, haciendo que la experiencia de conversación sea más natural y fluida. Esta actualización ya está disponible para todos los usuarios de pago. Al mismo tiempo, también se ha mejorado la capacidad de ChatGPT en la traducción de idiomas, permitiendo a los usuarios instruirlo directamente para que traduzca en tiempo real entre diferentes idiomas. Estas mejoras tienen como objetivo aumentar la comodidad y la utilidad de la interacción por voz de los usuarios con ChatGPT (Fuente: kevinweil, shuchaobi)
PyTorch integra Safetensors, mejorando la seguridad y conveniencia de los Checkpoints distribuidos: PyTorch ha anunciado que su función de Checkpoint distribuido ahora es compatible con el formato Safetensors de Hugging Face. Esta integración hace que guardar y cargar Checkpoints de modelos entre diferentes ecosistemas sea más seguro y conveniente, resolviendo en particular los riesgos de seguridad existentes con el formato pickle. La nueva API permite leer y escribir Safetensors a través de rutas fsspec, siendo torchtune la primera biblioteca en adoptar esta función, optimizando su proceso de Checkpoint. Esta medida se considera uno de los avances importantes en el campo de la seguridad de la IA del último año, contribuyendo a mejorar la seguridad en el intercambio y despliegue de modelos (Fuente: ClementDelangue, huggingface)

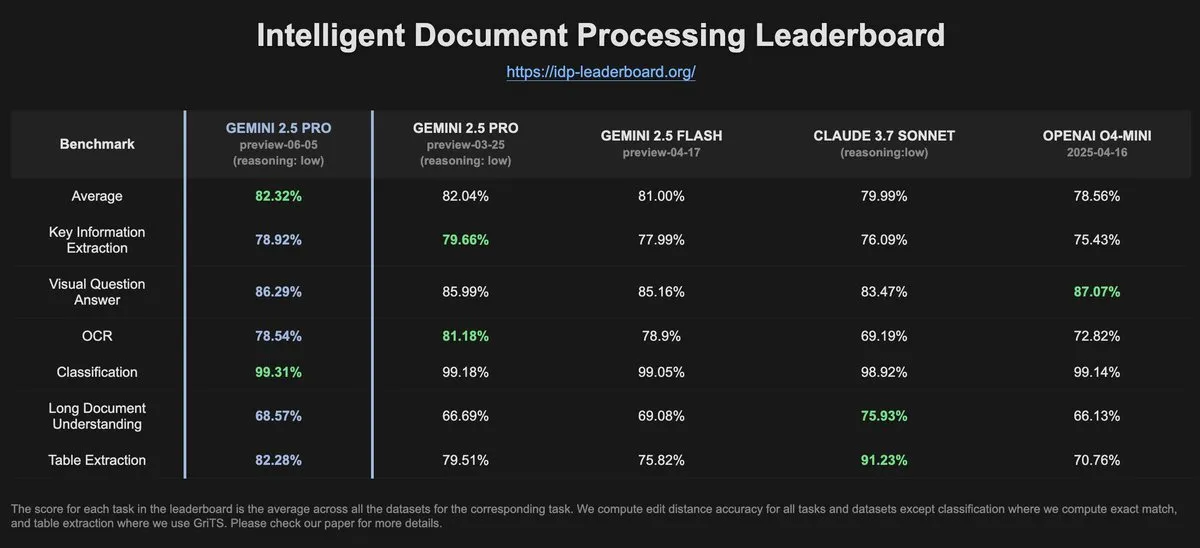
Datos de IDP-Leaderboard muestran una disminución en el rendimiento OCR de Gemini-2.5-pro-06-05 en comparación con la versión anterior: Según los últimos datos de IDP-Leaderboard, la nueva versión Gemini-2.5-pro-06-05 ha mostrado una disminución en el rendimiento de OCR (Reconocimiento Óptico de Caracteres) en comparación con la versión 03-25. A pesar de esto, el modelo sigue siendo el más fuerte en cuanto a capacidad integral de procesamiento de documentos (incluyendo reconocimiento de documentos y hojas de cálculo). IDP-Leaderboard es un benchmark centrado en evaluar la capacidad de los grandes modelos en el campo del procesamiento inteligente de documentos (Fuente: karminski3)
Investigación de Apple revela limitaciones en el razonamiento de los LLM, podrían no estar “pensando” realmente: Investigadores de Apple publicaron un artículo que explora las ventajas y limitaciones de los LLM actuales en tareas de razonamiento, señalando que el rendimiento de estos modelos “colapsa” al manejar tareas que superan cierta complejidad. La investigación sugiere que el “razonamiento” de los LLM se basa más en el reconocimiento de patrones y la memoria que en un verdadero pensamiento y comprensión en el sentido humano. Este punto de vista coincide con el de expertos como Yann LeCun, generando discusiones sobre el camino hacia la AGI y los límites de la capacidad de los modelos actuales (Fuente: omarsar0, NandoDF)

DeepSeek R1 demuestra una excelente comprensión de texto y capacidad de interpretación creativa en el juego Dwarf Fortress: Experimentos de usuarios muestran que el modelo DeepSeek R1, al procesar datos del complejo juego intensivo en texto Dwarf Fortress, exhibe una potente comprensión de texto y capacidad de interpretación creativa. Al extraer datos de texto de capturas de pantalla del juego e introducirlos en DeepSeek R1, el modelo no solo puede analizar los datos, sino también identificar peculiaridades y patrones interesantes en el comportamiento de los enanos, describiéndolos en un lenguaje vívido y entretenido, lo que demuestra su potencial en la comprensión y generación de texto no estructurado (Fuente: Reddit r/LocalLLaMA)

NVIDIA lanza el modelo Parakeet-tdt-0.6b-v2, estableciendo un nuevo referente en rendimiento ASR: El nuevo modelo de reconocimiento automático de voz (ASR) de NVIDIA, Parakeet-tdt-0.6b-v2, ha establecido un nuevo récord en la industria en el Open-ASR-Leaderboard de HuggingFace con una tasa de error de palabra (WER) del 6.05%. Este modelo no solo lidera en precisión, sino que también cuenta con una velocidad de inferencia extremadamente rápida (RTFx 3386, 50 veces más rápido que las alternativas) y admite funciones innovadoras como la transcripción de letras de canciones y el formato preciso de marcas de tiempo/números (Fuente: huggingface)
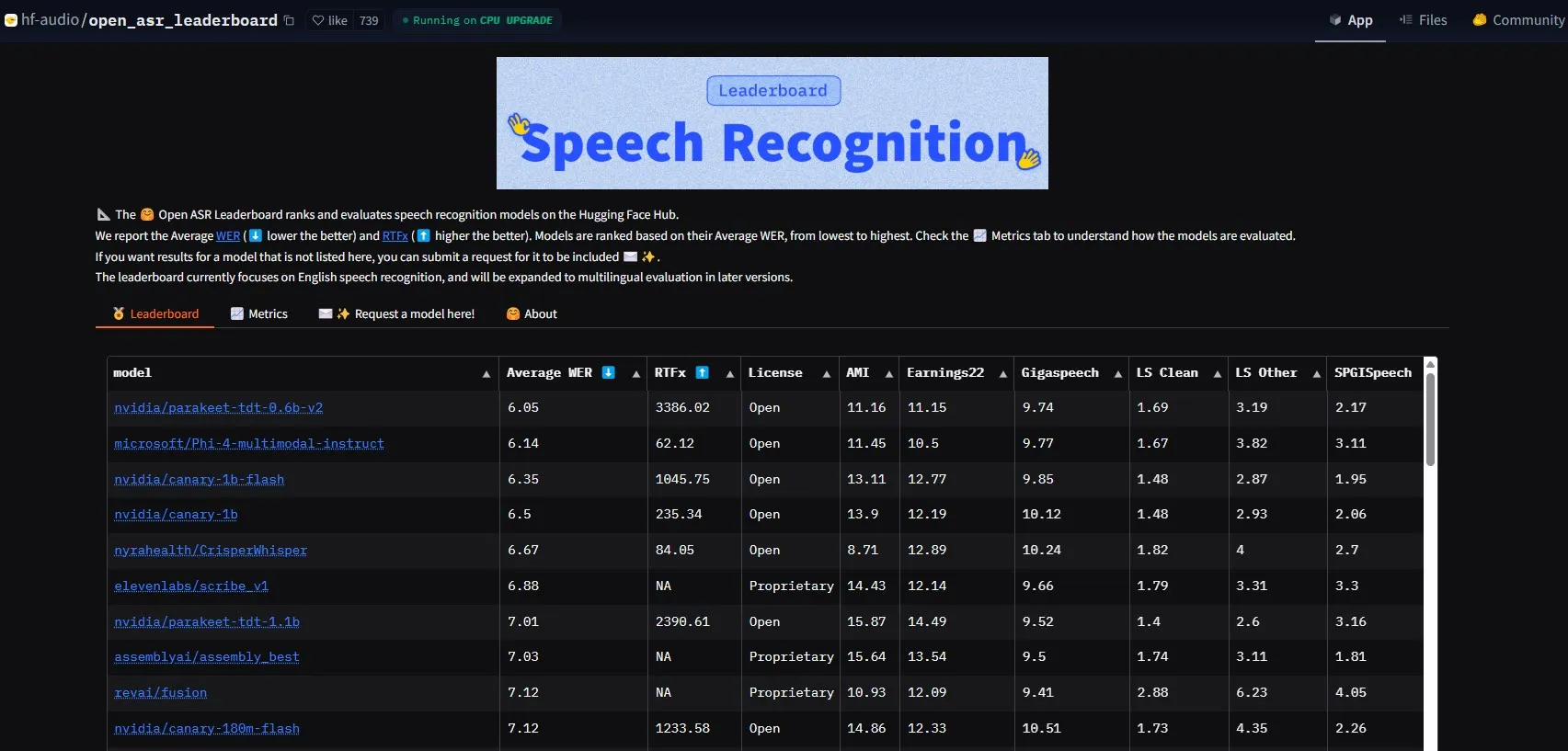
El equipo Qwen de Alibaba lanza la serie de modelos Qwen3-Embedding: El equipo Qwen de Alibaba ha lanzado la nueva serie de modelos Qwen3-Embedding, que incluye tres tamaños diferentes: 0.6B, 4B y 8B. Estos modelos han logrado un rendimiento SOTA (State-of-the-Art) en múltiples benchmarks de incrustación de texto como MMTEB, MTEB y MTEB-Code, admiten 119 idiomas y pueden ejecutarse en el navegador a través de Transformers.js (con soporte para aceleración WebGPU), proporcionando potentes capacidades de representación de texto para aplicaciones multilingües y multiplataforma (Fuente: huggingface)
Gemini 2.5 Pro demuestra una potente capacidad de generación de código y procesamiento de tareas: Gemini 2.5 Pro de GoogleDeepMind (versión preview-06-05) ha demostrado una gran capacidad para manejar tareas complejas. Por ejemplo, el usuario Majid Manzarpour intentó que escribiera un script para organizar y clasificar una biblioteca con más de 25,000 archivos de sonido, a lo que Jeff Dean comentó que “no suena demasiado difícil”, insinuando el potencial del modelo para manejar tareas de programación complejas y a gran escala. Además, un gráfico de prueba de GosuCoder muestra que la versión actualizada Gemini 2.5 Pro 06-05 tiene un mejor rendimiento en asistencia de codificación de IA, especialmente con una puntuación de evaluación más alta cuando la temperatura se establece en 0.7 (Fuente: JeffDean, jeremyphoward)
Hugging Face y Google Colab profundizan su integración, simplificando los flujos de trabajo de IA: Hugging Face y Google Colab han anunciado una colaboración reforzada, añadiendo soporte “Open in Colab” a todas las tarjetas de modelo en Hugging Face Hub. Los usuarios ahora pueden iniciar cuadernos de Colab directamente desde cualquier tarjeta de modelo, lo que facilita la experimentación y el uso de los modelos en Hugging Face, reduciendo aún más las barreras para el desarrollo y la investigación en IA (Fuente: huggingface)
🧰 Herramientas
LlamaBot: Asistente de codificación de IA basado en LangGraph: LangChainAI presentó LlamaBot, un agente de IA impulsado por LangGraph capaz de crear aplicaciones web a través de chat en lenguaje natural. Sus características incluyen generación de código en tiempo real, vista previa en tiempo real y agentes especializados diseñados para diferentes tareas de desarrollo, con el objetivo de simplificar el proceso de desarrollo de aplicaciones web (Fuente: LangChainAI, hwchase17)
Sistema Fast RAG: Combinación de DeepSeek-R1 y Qdrant para un procesamiento eficiente de documentos: LangChainAI demostró una solución de implementación RAG (Retrieval Augmented Generation) de alto rendimiento. Esta solución combina el modelo DeepSeek-R1 de SambaNova, la tecnología de cuantización binaria de Qdrant y LangGraph, logrando una reducción de memoria de 32 veces, lo que permite procesar eficientemente documentos a gran escala y ofrece una nueva vía de optimización para la recuperación de información y la generación de contenido (Fuente: LangChainAI, hwchase17)

Gemini Research Assistant: Asistente de investigación inteligente full-stack basado en Gemini y LangGraph: El equipo de Google Gemini ha publicado en código abierto un asistente de investigación de IA full-stack que utiliza el modelo Gemini y LangGraph para realizar investigaciones web inteligentes. Este asistente posee capacidades de razonamiento reflexivo y puede optimizar continuamente sus estrategias de búsqueda para proporcionar a los usuarios un soporte de investigación más profundo y eficiente. El código del proyecto está disponible en GitHub (Fuente: LangChainAI, hwchase17)
Agent Flow: Constructor de agentes de IA sin código de código abierto: Karan Vaidya ha lanzado Agent Flow, un constructor de agentes de IA sin código de código abierto, como alternativa a Gumloop. Se basa en ComposioHQ y LangGraph de LangChain, permitiendo a los usuarios automatizar flujos de trabajo y patrones complejos de agentes mediante la técnica de arrastrar y soltar nodos, con el objetivo de reducir la barrera de entrada al desarrollo de aplicaciones de agentes de IA (Fuente: hwchase17)
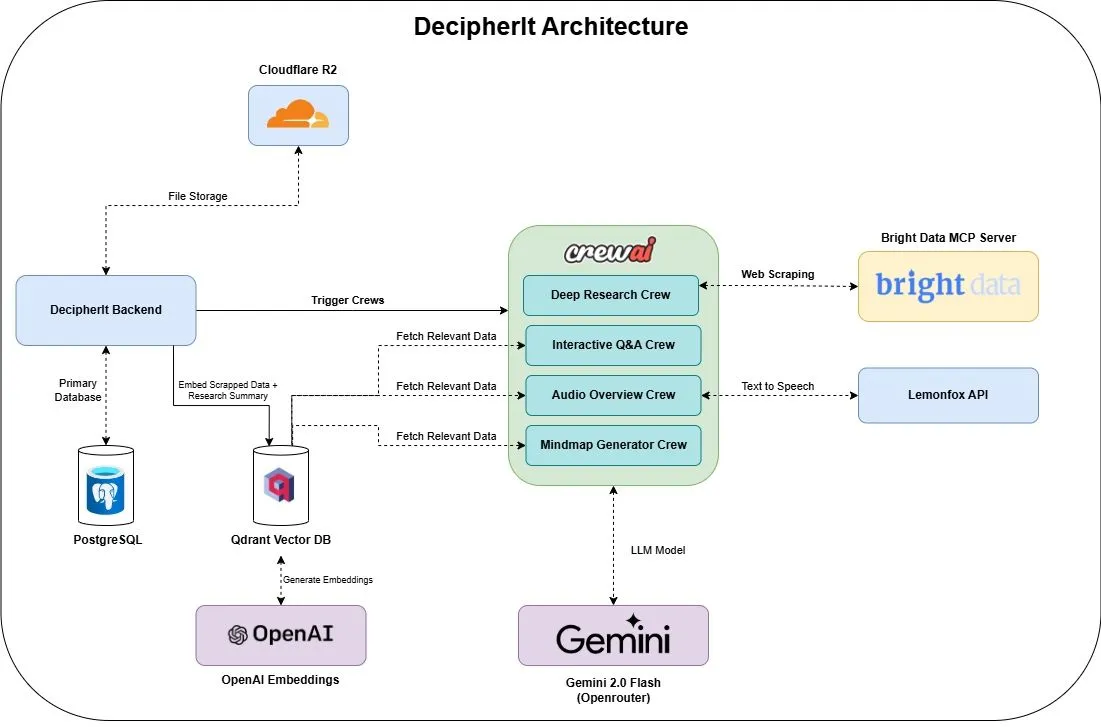
DecipherIt: Asistente de investigación de IA de código abierto, alternativa a NotebookLM: Se ha lanzado un asistente de investigación de IA de código abierto llamado DecipherIt, posicionado como una alternativa a NotebookLM. Esta herramienta utiliza orquestación multi-agente (crewAI), búsqueda semántica (Qdrant + OpenAI), acceso web en tiempo real (Bright Data MCP) y síntesis de voz (lemonfoxai), y puede transformar documentos cargados por el usuario, URLs o temas introducidos en un espacio de trabajo de investigación completo que incluye resúmenes, mapas mentales, resúmenes en audio, preguntas frecuentes y respuestas semánticas a preguntas (Fuente: qdrant_engine)
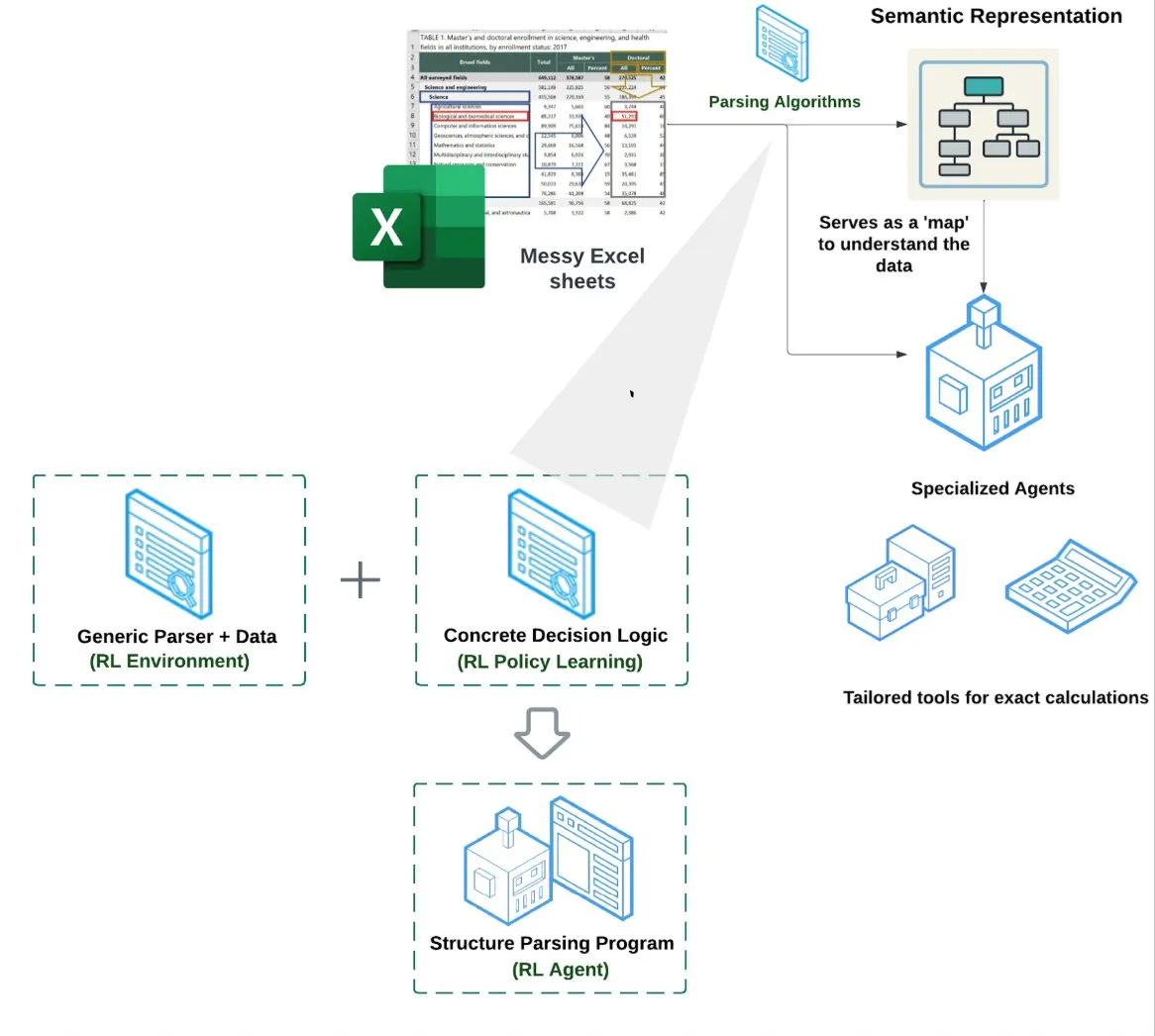
LlamaIndex lanza Agente de Hojas de Cálculo (Spreadsheet Agent): LlamaIndex ha lanzado un nuevo agente de hojas de cálculo, actualmente en vista previa privada. Este agente se especializa en el manejo de archivos Excel complejos, capaz de realizar transformaciones de datos y aseguramiento de la calidad. El núcleo de su arquitectura técnica reside en la comprensión estructural basada en aprendizaje por refuerzo (aprendizaje del modelo de datos/grafo semántico) y herramientas especializadas construidas sobre el grafo semántico, con el objetivo de proporcionar una capacidad de procesamiento de Excel superior a los métodos tradicionales de RAG o conversión de texto a CSV. Se afirma que su rendimiento es un 10-20% superior a la línea base de LLM que simplemente escriben código (Fuente: jerryjliu0)
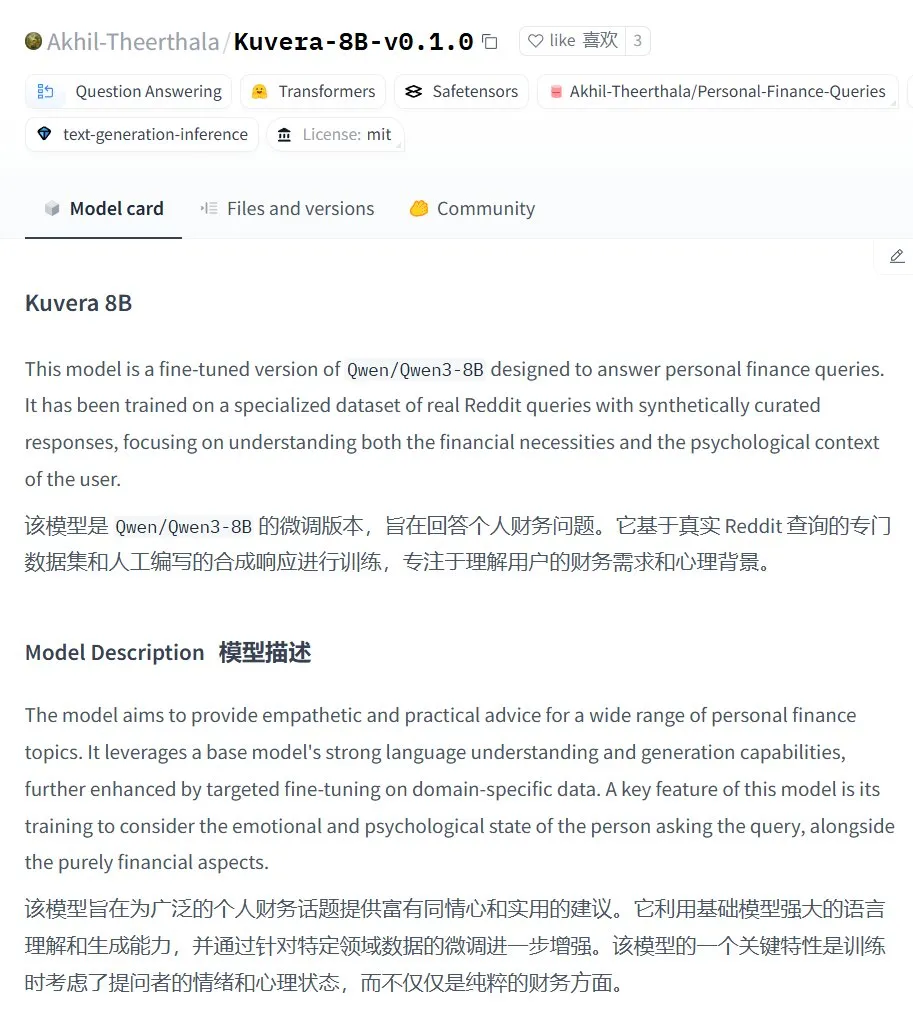
Kuvera-8B-v0.1.0: Gran modelo de asesoramiento financiero personal: Akhil-Theerthala ha publicado el modelo Kuvera-8B-v0.1.0 en Hugging Face, un modelo diseñado específicamente para cuestiones financieras personales. Está ajustado (fine-tuned) a partir de Qwen3-8B utilizando fuentes de datos como Reddit, y tiene como objetivo proporcionar consejos compasivos y prácticos sobre temas como presupuestos, ahorros, inversiones, gestión de deudas y planificación financiera básica. Dado que se basa en Qwen3, el modelo admite preguntas y respuestas en chino (Fuente: karminski3)
Solución de procesamiento de voz localizada Whisper+Pyannote como alternativa a Otter.ai: Un usuario de Reddit compartió su flujo de trabajo de procesamiento de voz completamente localizado, construido para reemplazar servicios en la nube como Otter.ai. Esta solución combina ctranslate2 y faster-whisper para la transcripción, y pyannote y speechbrain para la diarización de hablantes (separación de hablantes). Es capaz de procesar grabaciones de reuniones de más de tres horas en una GPU local, y genera transcripciones con etiquetas de hablante y archivos JSON, incluyendo resúmenes ejecutivos y listas de acciones personalizadas. Esta iniciativa busca abordar las limitaciones, preocupaciones de privacidad y falta de personalización de los servicios en la nube (Fuente: Reddit r/LocalLLaMA)
GPT Deep Research MCP: Investigación profunda combinada con OpenWebUI: Un usuario recomienda probar la combinación de GPT Deep Research MCP con OpenWebUI. La herramienta MCP (gptr-mcp) está diseñada para proporcionar capacidades de investigación profunda, y cuando se usa junto con OpenWebUI, que admite MCP, puede ofrecer una experiencia de investigación impresionante, ampliando aún más las aplicaciones de las herramientas de IA localizadas en el procesamiento de información y el descubrimiento de conocimiento (Fuente: Reddit r/OpenWebUI)
📚 Aprendizaje
OpenAI organizará un seminario sobre prácticas de evaluación de aplicaciones, con casos reales y avances de herramientas: OpenAI organizará un seminario sobre las mejores prácticas en la evaluación de aplicaciones (Evals). En él, Jim Blomo de OpenAI discutirá cómo evaluar eficazmente los productos de IA, basándose en casos de clientes reales y sus resultados. El evento también presentará un avance de las próximas herramientas de evaluación de OpenAI, incluyendo funciones de seguimiento, puntuación, etc. Este seminario tiene como objetivo ayudar a los desarrolladores y empresas a construir y optimizar mejor las aplicaciones de IA, y se proporcionará una grabación para su visualización posterior (Fuente: HamelHusain, HamelHusain)

Anthropic publica en código abierto métodos de investigación de interpretabilidad para ayudar a comprender el “pensamiento” de los LLM: Anthropic ha anunciado la publicación en código abierto de sus métodos de investigación para rastrear los “procesos de pensamiento” de los grandes modelos de lenguaje. Los investigadores ahora pueden utilizar este método para generar “grafos de atribución” (attribution graphs) y explorarlos interactivamente, de forma similar a como Anthropic lo demostró en sus investigaciones recientes. El equipo también proporciona la interfaz interactiva Neuronpedia y tutoriales en Jupyter Notebook para facilitar a los investigadores la aplicación de estas herramientas en modelos de código abierto, con el fin de mejorar la comprensión de los mecanismos internos de trabajo de los LLM. Este proyecto está liderado por participantes del programa Anthropic Fellows en colaboración con Decode Research (Fuente: AnthropicAI)
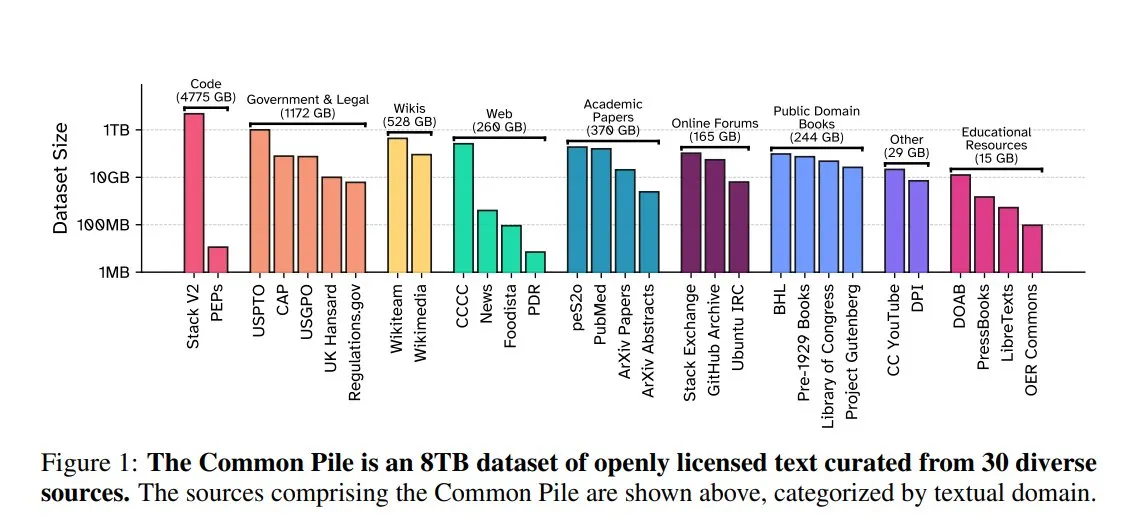
EleutherAI lanza Common Pile v0.1: conjunto de datos de texto de 8TB con licencia abierta: EleutherAI, en colaboración con Vector Institute, Allen AI, Hugging Face y DPI, ha lanzado Common Pile v0.1, un conjunto de datos de texto de dominio público y con licencia abierta que contiene 8TB y un billón de tokens. Basándose en este conjunto de datos, el equipo entrenó los modelos Comma v0.1-1T y -2T de 7B parámetros, cuyo rendimiento es comparable al de modelos como LLaMA 1&2 entrenados con una escala de datos similar. Esta iniciativa tiene como objetivo explorar la posibilidad de entrenar modelos de lenguaje de alto rendimiento sin utilizar texto no autorizado, proporcionando valiosos recursos de datos a la comunidad de código abierto (Fuente: huggingface)
NVIDIA NIM acelera la inferencia de texto a SQL de Vanna: El blog para desarrolladores de NVIDIA ha publicado un tutorial que muestra cómo utilizar NVIDIA NIM (NVIDIA Inference Microservices) para optimizar la solución de texto a SQL de Vanna. NIM proporciona puntos finales optimizados para modelos de IA generativa, capaces de acelerar el proceso de inferencia y, por lo tanto, agilizar el análisis. Esto es de gran importancia para escenarios de aplicación que requieren la conversión de consultas en lenguaje natural a consultas de base de datos (Fuente: dl_weekly)
Apuntes gratuitos del curso de aprendizaje automático de la Universidad de Stanford compartidos: The Turing Post compartió los apuntes gratuitos del curso de aprendizaje automático CS229 de la Universidad de Stanford, impartido por los profesores Andrew Ng y Tengyu Ma. El contenido cubre temas centrales del aprendizaje automático como métodos y algoritmos de aprendizaje supervisado y no supervisado, aprendizaje profundo y redes neuronales, generalización, regularización y procesos de aprendizaje por refuerzo, ofreciendo recursos de aprendizaje de alta calidad para los estudiantes (Fuente: TheTuringPost)

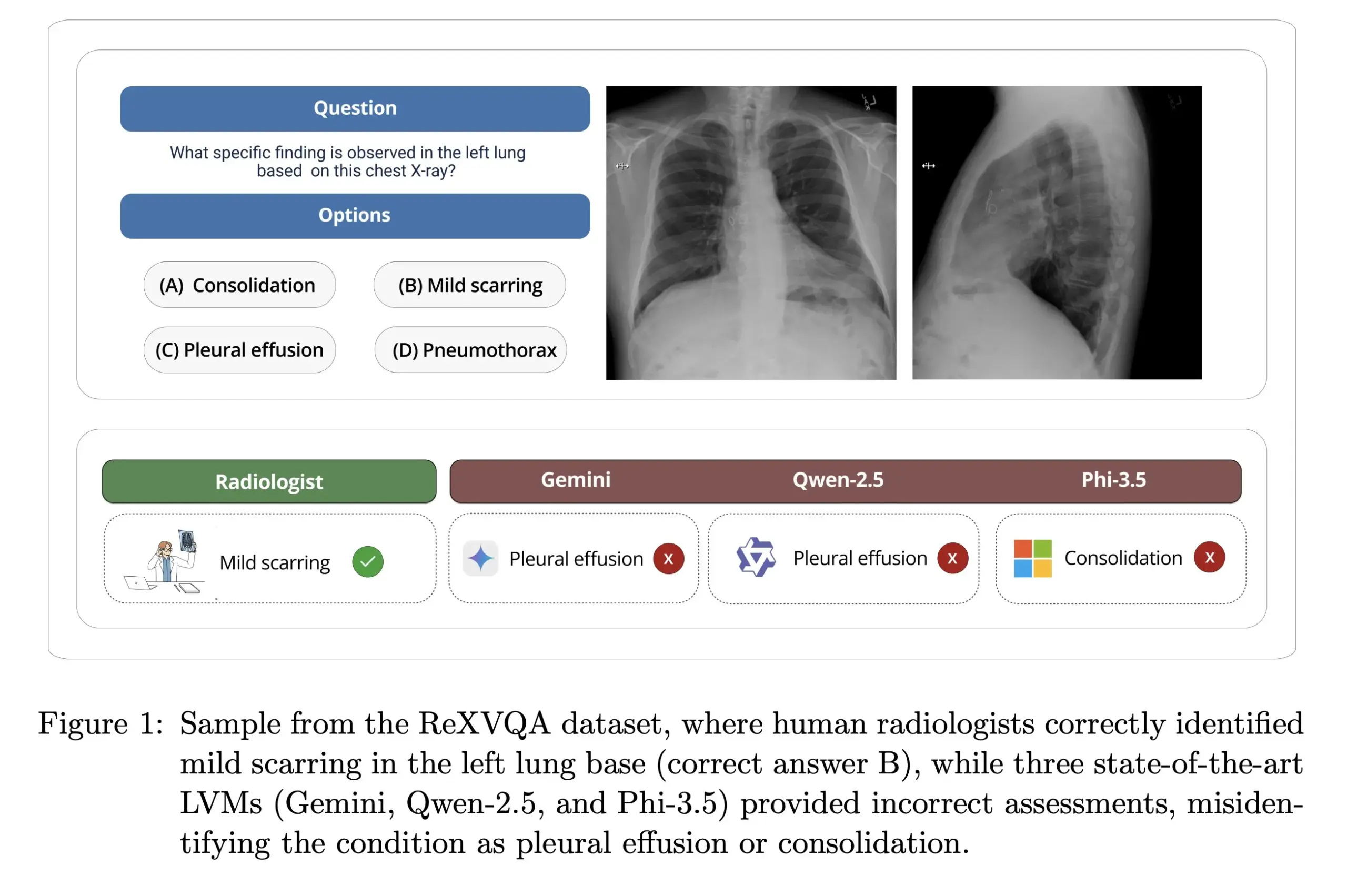
La Universidad de Harvard lanza ReXVOA: un benchmark de preguntas y respuestas sobre radiografías de tórax a gran escala y de alta calidad: El laboratorio de Pranav Rajpurkar de la Universidad de Harvard ha lanzado ReXVOA, un conjunto de datos de benchmark a gran escala y de alta calidad para la respuesta visual a preguntas (VQA) sobre radiografías de tórax. Este conjunto de datos tiene como objetivo desafiar a los grandes modelos de vanguardia existentes y servir como medida para el progreso de la próxima generación de modelos en la comprensión de imágenes médicas y la capacidad de respuesta a preguntas (Fuente: huggingface)
OWL Labs comparte experiencias en el entrenamiento de autoencoders para modelos de difusión: OWL (Open World Labs) resumió en su blog las experiencias y hallazgos obtenidos al entrenar autoencoders para modelos de difusión, y compartió algunos casos de fracaso con métodos no convencionales. Este artículo sirve de referencia para investigadores y desarrolladores en la aplicación práctica y optimización de autoencoders para modelos de difusión (Fuente: NandoDF)
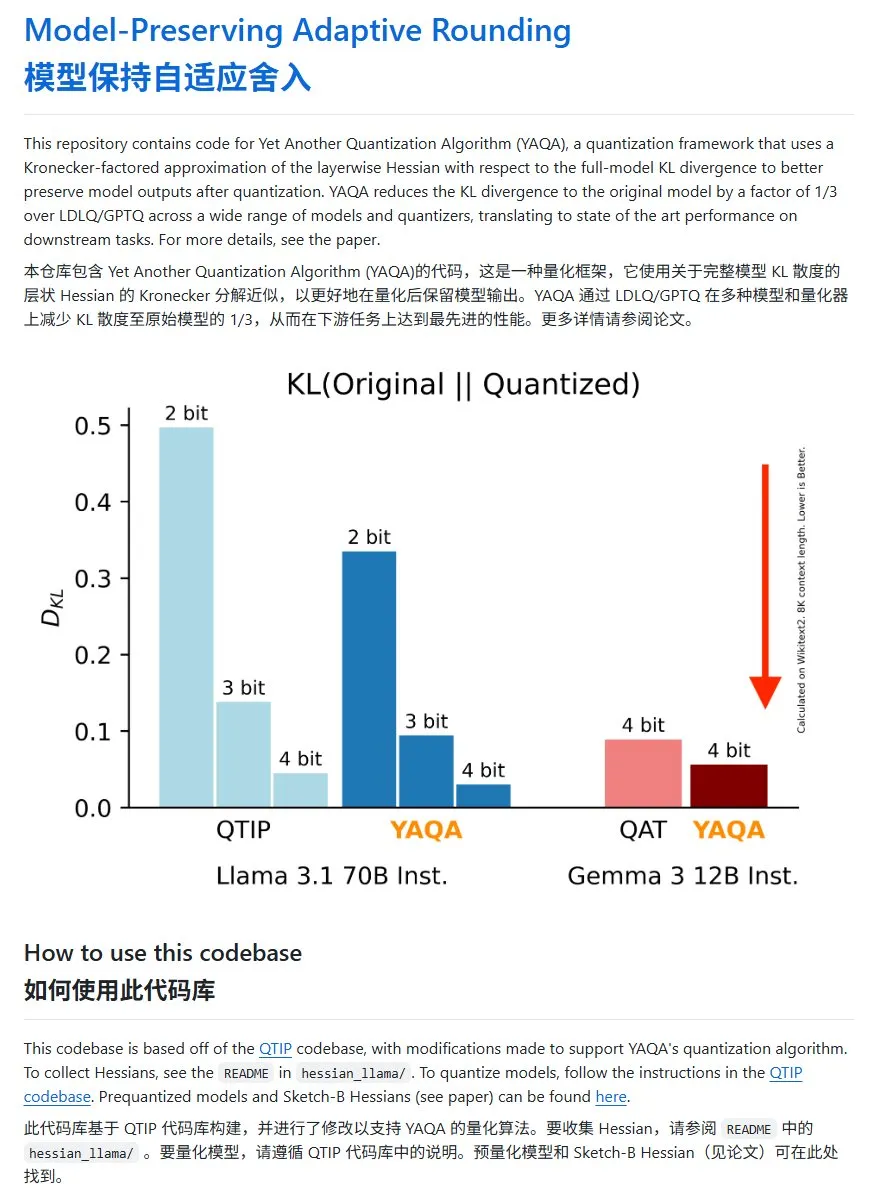
YAQA: Un nuevo método de cuantización de modelos con una reducción significativa de la divergencia KL: El equipo de Cornell-RelaxML ha propuesto un nuevo método de cuantización de modelos llamado YAQA. Este método combina las técnicas LDLQ/GPTQ y, en comparación con los métodos de cuantización existentes, puede reducir la divergencia KL del modelo cuantizado a 1/3 del modelo original. Aunque el proceso de cuantización YAQA es más lento y requiere una gran cantidad de VRAM, la mejora del rendimiento y la economía de la inferencia posterior lo convierten en una prometedora solución de cuantización. El código del proyecto está disponible en código abierto en GitHub (Fuente: karminski3)
💼 Negocios
Carina Hong, una joven de Guangzhou nacida después del 2000, funda Axiom, con el objetivo de resolver problemas matemáticos complejos con IA: Carina Hong, una joven prodigio nacida después del 2000, ha fundado la startup de IA Axiom, que ha atraído la atención. Axiom se especializa en el uso de IA para resolver problemas matemáticos complejos, con clientes objetivo que incluyen fondos de cobertura y empresas de trading cuantitativo. Según The Information, Axiom está negociando una financiación de 50 millones de dólares, con una valoración de entre 300 y 500 millones de dólares, y B Capital podría liderar la ronda. Hong declaró en redes sociales que los informes sobre la financiación no son precisos, pero confirmó que la empresa está contratando talento en IA y matemáticas. Hong se graduó en el MIT, obtuvo una maestría en Oxford y actualmente cursa un doble doctorado en matemáticas y derecho en Stanford, habiendo ganado múltiples premios en competiciones de matemáticas (Fuente: 36Kr)

Anthropic corta el acceso a la API de Claude a Windsurf debido a la competencia: Un cofundador de Anthropic confirmó que la compañía ha dejado de proporcionar acceso a la API del modelo Claude a la startup de IA Windsurf. La razón es que Windsurf es considerada una forma de “envoltorio” o un servicio estrechamente relacionado con OpenAI, que es un competidor directo de Anthropic. Esta medida ha suscitado debates sobre la dependencia de las API y los riesgos de plataforma, especialmente para aquellas startups cuyo negocio se basa en API de grandes modelos de terceros, ya que las decisiones comerciales de los proveedores de modelos pueden afectar directamente su supervivencia (Fuente: ClementDelangue, Reddit r/LocalLLaMA)
OpenAI obligada a conservar los historiales de chat eliminados por usuarios debido a una demanda por derechos de autor: Según informes, en una demanda por derechos de autor presentada por The New York Times, un tribunal federal de EE. UU. ha ordenado a OpenAI conservar todos los registros de conversación de los usuarios de ChatGPT, incluido el contenido que los usuarios hayan optado por eliminar, como posible prueba. The New York Times acusa a OpenAI de utilizar sus artículos de pago para entrenar a ChatGPT y teme que la IA pueda generar contenido similar. Esta medida ha suscitado preocupaciones sobre la privacidad del usuario y la protección de datos (como el GDPR), destacando la tensión legal y ética entre los derechos de autor de los datos de entrenamiento de IA y la privacidad del usuario (Fuente: Reddit r/ArtificialInteligence)

🌟 Comunidad
Grandes modelos de IA desafían los exámenes de redacción y matemáticas del Gaokao 2025, con resultados variados: Durante el Gaokao (examen nacional de acceso a la universidad en China) de 2025, varios modelos de IA convencionales se enfrentaron al desafío de las pruebas de redacción y matemáticas. En redacción, 16 asistentes de IA, incluidos Doubao, DeepSeek y ChatGPT, demostraron sus habilidades de escritura, la mayoría generando ensayos argumentativos con estructura normativa, pero con problemas comunes de plantillas, citas cliché y enfoques temáticos convergentes. En la prueba de matemáticas (preguntas objetivas del nuevo plan de estudios I), Doubao de ByteDance y Yuanbao de Tencent empataron en primer lugar con 68 puntos (de 73), mientras que OpenAI o3 tuvo un mal desempeño con solo 34 puntos. Las pruebas reflejan los avances y limitaciones actuales de la IA en la comprensión del chino, el razonamiento lógico y la expresión creativa, especialmente en evitar rastros de IA y abordar razonamientos matemáticos complejos, donde aún hay margen de mejora (Fuente: 36Kr, 36Kr)

Tendencias en la aplicación de la IA en empresas: bases de conocimiento internas y chatbots personalizados ganan atención: Discusiones en la comunidad muestran que el uso de IA para construir chatbots internos empresariales, entrenados con datos de la compañía para responder preguntas de los empleados sobre procesos, búsqueda de datos, responsables, etc., se está convirtiendo en una tendencia. Estas aplicaciones buscan mejorar la eficiencia en la recuperación de información interna y la gestión del conocimiento. Empresas como Amazon ya han implementado sistemas similares con buenos resultados. Sin embargo, la seguridad de los datos, la posible divulgación de información sensible y cómo comercializar eficazmente estas soluciones siguen siendo cuestiones importantes que las empresas deben considerar durante la implementación (Fuente: Reddit r/ArtificialInteligence)
El debate entre “indexado” y “no indexado” en la programación asistida por IA: un equilibrio entre rendimiento y fiabilidad: Un experimento con asistentes de codificación de IA (utilizando el código del alunizaje del Apolo 11 como objeto de prueba) comparó dos tipos de agentes de IA: “indexados” (que construyen previamente un índice de la base de código y utilizan búsqueda vectorial) y “no indexados” (que leen y analizan archivos de código bajo demanda). Los resultados mostraron que los agentes indexados fueron más rápidos y realizaron menos llamadas a la API en la mayoría de los casos, pero al manejar cambios frecuentes en la base de código que desactualizaban el índice, podían producir errores debido a la dependencia de información obsoleta, lo que resultaba en un mayor tiempo de depuración. Esto revela la necesidad de encontrar un equilibrio entre el rendimiento inmediato y la fiabilidad de la información al elegir herramientas de codificación de IA (Fuente: Reddit r/ClaudeAI)

El debate sobre si los LLM “piensan” continúa: del reconocimiento de patrones a la cognición humana: El debate en la comunidad sobre si los grandes modelos de lenguaje (LLM) realmente “piensan” sigue activo. Los críticos argumentan que los LLM son esencialmente generadores de texto predictivo complejos que funcionan calculando probabilidades de secuencias de palabras, en lugar de realizar un pensamiento consciente. Sin embargo, muchos usuarios sienten una experiencia similar a conversar con humanos al interactuar con LLM. Esto ha llevado a reflexionar sobre los mecanismos de generación del lenguaje humano y a explorar si existen similitudes entre los LLM y los procesos cognitivos humanos. La investigación de Apple señala además las limitaciones de los LLM en el razonamiento complejo, sugiriendo que dependen más de la memoria de patrones que del razonamiento real, añadiendo una nueva perspectiva a esta discusión (Fuente: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Paul Graham habla sobre el impacto de la IA en la brecha de ingresos: Paul Graham comentó a su hijo de 16 años que, a corto plazo, la tecnología de IA podría ampliar la brecha de ingresos laborales. Citó como ejemplo que a los programadores de nivel medio les resulta más difícil encontrar trabajo ahora, mientras que los programadores excelentes ganan más gracias a la ayuda de la IA. Considera que esto no es nada nuevo, ya que el progreso tecnológico a menudo amplía las diferencias de ingresos, porque el límite inferior de ingresos está fijado en cero, mientras que la tecnología eleva continuamente el límite superior de recompensa para los mejores talentos (Fuente: dotey)
Discusión sobre la ética de la seguridad de la IA: del comportamiento del modelo a las normas sociales: El debate comunitario sobre la seguridad y la ética de la IA sigue intensificándose. Geoffrey Hinton felicitó a Yoshua Bengio por iniciar el proyecto LawZero, destinado a promover el diseño seguro de la IA, prestando especial atención a los posibles comportamientos de autoprotección y engaño en los sistemas de vanguardia. Al mismo tiempo, algunas opiniones critican ciertas investigaciones sobre seguridad de la IA (como probar si un modelo acepta ser apagado) calificándolas de “teatro de seguridad” carente de valor práctico. La investigación de OpenAI sobre las relaciones humano-máquina también ha generado debate, enfatizando la necesidad de priorizar el estudio de su impacto en el bienestar emocional de los usuarios en un contexto de creciente integración de la IA en la vida, y explorar cómo equilibrar la comunicación clara con la evitación de la antropomorfización en las interacciones con modelos (Fuente: geoffreyhinton, ClementDelangue, togelius)

El papel de apoyo emocional de asistentes de IA como ChatGPT es reconocido por los usuarios: Numerosos usuarios han compartido en redes sociales experiencias sobre cómo asistentes de IA como ChatGPT les proporcionaron apoyo emocional y ayuda práctica en momentos difíciles. Algunos usuarios afirmaron que, al enfrentar desempleo, problemas de salud o desánimo, ChatGPT no solo ofreció planes de acción concretos e información sobre recursos, sino que también les ayudó a aliviar el pánico y recuperar fuerzas de una manera no crítica. Esto demuestra el valor potencial de la IA en el apoyo psicológico y la intervención en crisis, aunque carezca de emociones y conciencia reales (Fuente: Reddit r/ChatGPT)
“Vibe Coding” se convierte en un nuevo fenómeno en la programación asistida por IA: El término “Vibe Coding” se ha popularizado en la comunidad de desarrolladores para describir una forma de programar que se basa en la intuición y la iteración rápida de código con ayuda de la IA. Herramientas como Claude Code son apreciadas por algunos programadores por su excelente rendimiento en momentos específicos (como por la noche o temprano en la mañana, posiblemente debido a una baja carga del servidor o a no estar altamente cuantizadas). Este fenómeno refleja el aumento de la eficiencia en el desarrollo gracias a los asistentes de codificación de IA, al tiempo que plantea debates sobre la consistencia del modelo, el impacto de la cuantización y los nuevos patrones de trabajo de los desarrolladores (Fuente: dotey, jeremyphoward)
💡 Otros
Andrej Karpathy reflexiona sobre el enorme impacto de la contaminación acústica en el sueño y la salud: Andrej Karpathy compartió su experiencia personal, señalando que la contaminación acústica ambiental, como el ruido del tráfico, puede tener un impacto negativo enorme y no suficientemente reconocido en la calidad del sueño y la salud a largo plazo. Especula que el ruido nocturno (como el de coches y motocicletas ruidosos) podría estar causando una disminución en la calidad del sueño de millones de personas, lo que a su vez afecta el estado de ánimo, la creatividad, la energía y aumenta el riesgo de enfermedades cardiovasculares, metabólicas y cognitivas. Hace un llamamiento para que los dispositivos de seguimiento del sueño (como Whoop, Oura) rastreen explícitamente la correlación entre el ruido y el sueño, y para aumentar la conciencia pública sobre este problema (Fuente: karpathy)
El fenómeno de la intersección entre IA y religión atrae atención: El usuario de redes sociales menhguin observó que no se debe subestimar el mercado potencial de nuevas religiones o aplicaciones de tipo religioso basadas en IA. Por ejemplo, la astrología con IA, los videos bíblicos con IA, las aplicaciones de oración con IA y ciertas aplicaciones de IA para grupos específicos, todos insinúan las posibilidades de la tecnología de IA para satisfacer las necesidades espirituales o de fe humanas (Fuente: menhguin)
Servidor HTTP 2.0 generado con asistencia de IA, explorando el potencial de los LLM en grandes proyectos de software: Un desarrollador, utilizando un framework auto-desarrollado (promptyped) y el modelo Gemini 2.5 Pro, logró que un LLM construyera desde cero un servidor compatible con el estándar HTTP 2.0 mediante un ciclo de código-compilación-prueba. El proyecto generó 15,000 líneas de código fuente y más de 30,000 líneas de código de prueba, y pasó las pruebas de conformidad h2spec. Aunque consumió aproximadamente 119 horas de tiempo de API y 631 dólares en costes de API, este experimento demuestra el potencial de los LLM en el diseño de arquitecturas y la escritura de software complejo y compatible con estándares, al tiempo que revela la forma de las aplicaciones escritas completamente por LLM (Fuente: Reddit r/LocalLLaMA)