
Palabras clave:modelo de IA, conjunto de datos, robot humanoide, agente de IA, modelo de lenguaje, aprendizaje profundo, modelo de código abierto, optimización de inferencia, conjunto de datos Common Pile v0.1, modelo de control de extremo a extremo Helix, servidor Hugging Face MCP, actualización de Gemini 2.5 Pro, mecanismo de atención dispersa
🔥 Enfoque
EleutherAI publica Common Pile v0.1: un conjunto de datos de texto de 8TB con licencia abierta, desafiando el entrenamiento de modelos de lenguaje sin datos no autorizados : EleutherAI, en colaboración con varias instituciones, ha publicado Common Pile v0.1, un gran conjunto de datos que contiene 8TB de texto con licencia abierta y de dominio público. Su objetivo es explorar la viabilidad de entrenar modelos de lenguaje de alto rendimiento sin utilizar texto no autorizado. El equipo utilizó este conjunto de datos para entrenar modelos de 7B parámetros (1T y 2T tokens), cuyo rendimiento es comparable al de modelos similares como LLaMA 1 y LLaMA 2. El conjunto de datos incluye metadatos a nivel de documento, como la atribución del autor, detalles de la licencia y enlaces a las copias originales, proporcionando a los investigadores una fuente de datos transparente y conforme. Esta iniciativa es de gran importancia para promover el desarrollo de modelos de IA abiertos y conformes, y ofrece nuevas ideas para abordar los problemas de derechos de autor en los datos de entrenamiento de IA (fuente: EleutherAI, percyliang, BlancheMinerva, code_star, ShayneRedford, Tim_Dettmers, jeremyphoward, stanfordnlp, ClementDelangue, tri_dao, andersonbcdefg)

El robot humanoide Figure, impulsado por el modelo Helix, demuestra una capacidad de clasificación de paquetes a alta velocidad, atrayendo la atención : El CEO de Figure, Brett Adcock, mostró los últimos avances de su robot humanoide en la clasificación de paquetes en un entorno logístico, impulsado por el modelo de control universal de extremo a extremo Helix. El video muestra que el robot puede procesar paquetes de diferentes tipos (cajas de cartón rígido, embalajes de plástico) con una velocidad y precisión cercanas a las humanas, incluyendo la organización de paquetes y asegurar que los códigos de barras estén hacia abajo para su escaneo. Esta capacidad resalta la generalización y flexibilidad del modelo Helix en entornos complejos y dinámicos, en contraste con la operación de prensado mostrada anteriormente (que enfatizaba la precisión y alta velocidad). Los robots de Figure ya han logrado turnos de trabajo continuos de 20 horas en la línea de producción de BMW, demostrando su potencial en aplicaciones industriales. Adcock enfatizó que, en el campo de los robots humanoides, construir el robot más inteligente y de menor costo será clave para ganar el mercado, ya que un mayor despliegue de robots significa menores costos, más datos de entrenamiento y un modelo Helix más inteligente (fuente: dotey, _philschmid, adcock_brett, 量子位)

Hugging Face lanza el primer servidor MCP oficial, creando una plataforma de colaboración para Agentes de IA : Hugging Face ha lanzado su primer servidor oficial MCP (Model-Client Protocol), que permite a los usuarios conectar LLMs directamente a la API de Hugging Face Hub para su uso en Cursor, VSCode, Windsurf y otras aplicaciones compatibles con MCP. El servidor ofrece herramientas integradas como búsqueda semántica de modelos, conjuntos de datos, artículos y Spaces, y puede listar dinámicamente todas las aplicaciones Gradio compatibles con MCP alojadas en Spaces. Esta iniciativa tiene como objetivo convertir a Hugging Face en una plataforma de colaboración para constructores de Agentes de IA, fomentando el desarrollo y la interoperabilidad del ecosistema de Agentes de IA. Actualmente, hay alrededor de 900 Spaces MCP disponibles (fuente: ClementDelangue, mervenoyann, reach_vb, ben_burtenshaw, huggingface, code_star, op7418, TheTuringPost, clefourrier)

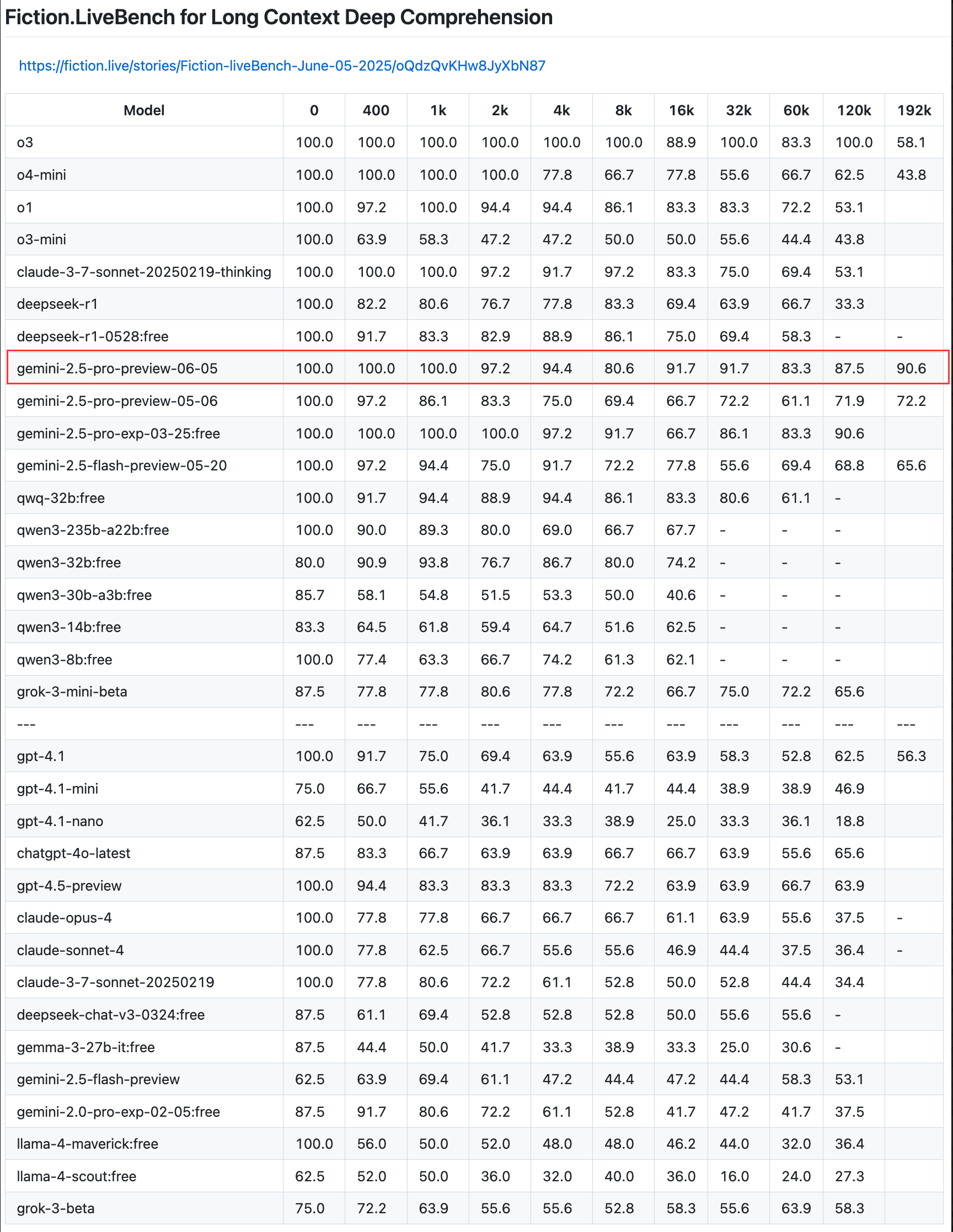
Google actualiza la vista previa de Gemini 2.5 Pro, mejorando las capacidades de codificación, razonamiento y creación, e introduce el “presupuesto de pensamiento” : Google ha anunciado una actualización de la vista previa de su modelo más inteligente, Gemini 2.5 Pro, mejorando aún más sus capacidades en codificación, razonamiento lógico y escritura creativa. La nueva versión introduce especialmente la función de “presupuesto de pensamiento” (thinking budget), que permite a los desarrolladores controlar mejor el consumo de recursos computacionales del modelo. Los comentarios de los usuarios indican que la nueva versión (06-05) tiene un rendimiento excelente en la recuperación de texto largo, especialmente con una tasa de recuperación del 90.6% en una longitud de 192K, superando a OpenAI-o3. El modelo ya está integrado en LangChain y LangGraph, facilitando a los desarrolladores su prueba y la creación de aplicaciones. Google también demostró la capacidad creativa de Gemini 2.5 Pro en la comprensión de imágenes y la generación de subtítulos contextualizados e ingeniosos (fuente: Teknium1, Google, karminski3, hwchase17, )
🎯 Tendencias
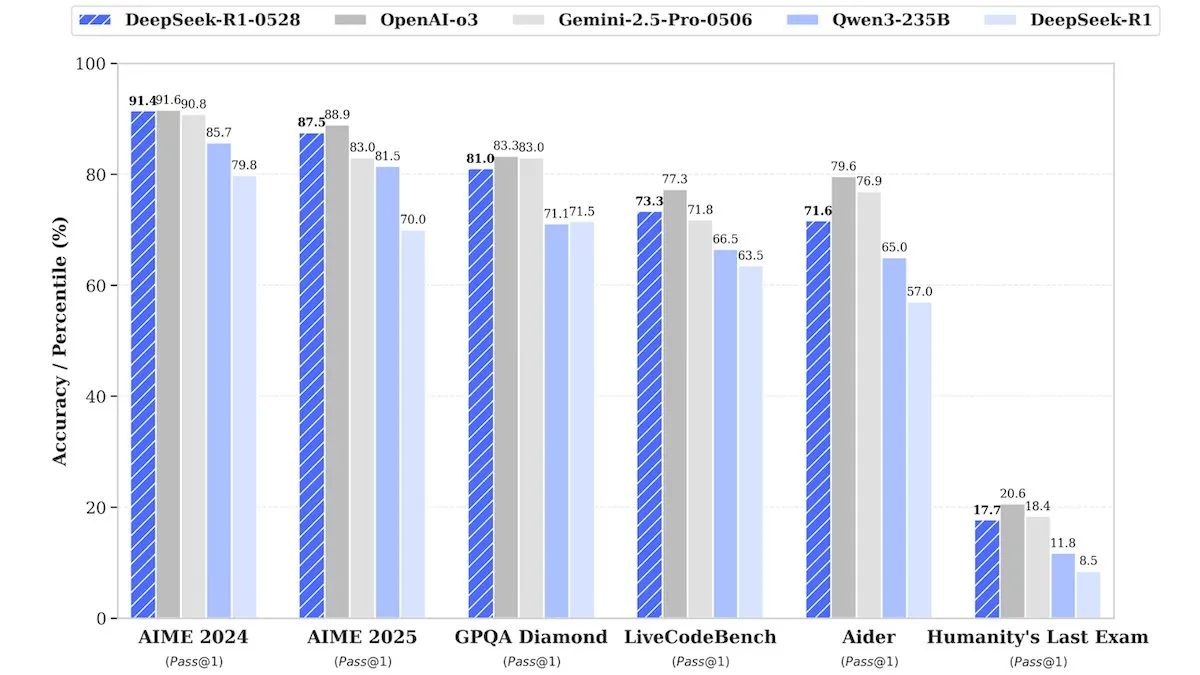
DeepSeek lanza la versión mejorada de DeepSeek-R1-0528, con un rendimiento comparable a los modelos de código cerrado : DeepSeek ha lanzado una versión mejorada de su modelo insignia de pesos abiertos, DeepSeek-R1-0528. Se afirma que este modelo tiene un rendimiento comparable en múltiples benchmarks con modelos de código cerrado como o3 de OpenAI y Gemini-2.5 Pro de Google. Aunque la compañía no reveló detalles del entrenamiento, los informes indican que el nuevo modelo presenta mejoras significativas en razonamiento, manejo de la complejidad de tareas y reducción de alucinaciones, desafiando una vez más la noción tradicional de que la IA de primer nivel requiere recursos masivos. Unsloth AI ya ofrece un Notebook gratuito para el ajuste fino de DeepSeek-R1-0528-Qwen3 usando GRPO, afirmando que su nueva función de recompensa puede aumentar la tasa de respuesta multilingüe (o de dominio personalizado) en más del 40%, y hacer que el ajuste fino de R1 sea 2 veces más rápido con un 70% menos de VRAM (fuente: DeepLearningAI, ImazAngel)
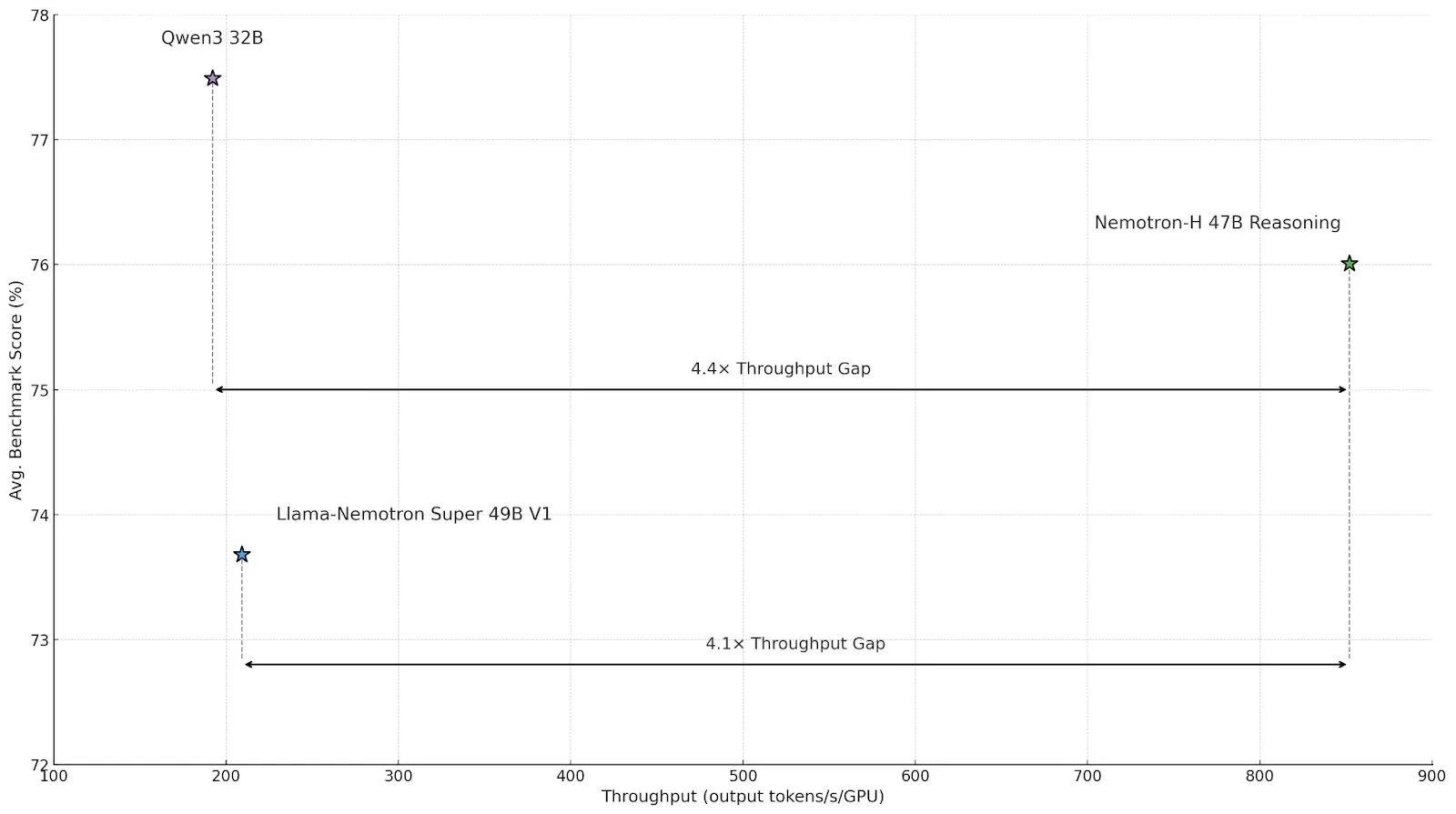
Nvidia lanza el modelo de inferencia de arquitectura híbrida Nemotron-H, mejorando el rendimiento y la eficiencia : Nvidia ha presentado su nuevo modelo de inferencia Nemotron-H, que incluye versiones de 47B y 8B (compatibles con BF16 y FP8) y adopta una arquitectura híbrida Mamba-Transformer. Este modelo está diseñado para resolver problemas de inferencia a gran escala manteniendo una alta velocidad, y se afirma que su rendimiento es 4 veces superior al de los modelos Transformer comparables. Nemotron-H-47B-Reasoning-128k supera ligeramente en precisión a Llama-Nemotron-Super-49B-1.0 en todos los benchmarks, pero con un costo de inferencia hasta 4 veces menor. Los pesos del modelo se han publicado en HuggingFace bajo una licencia no productiva, y el informe técnico estará disponible próximamente (fuente: ClementDelangue, ctnzr)
Anthropic lanza Claude Gov, diseñado específicamente para agencias gubernamentales y de inteligencia militar de EE. UU. : Anthropic ha lanzado un nuevo servicio de IA llamado Claude Gov, diseñado específicamente para satisfacer las necesidades del gobierno, la defensa y las agencias de inteligencia de Estados Unidos. Este movimiento marca la expansión formal de la avanzada tecnología de IA de Anthropic hacia aplicaciones gubernamentales y militares, que podrían utilizarse para análisis de datos, procesamiento de inteligencia, apoyo a la toma de decisiones y otros escenarios. Anthropic también se unió anteriormente a un fideicomiso de beneficios a largo plazo, con el objetivo de ayudar a la empresa a cumplir su misión de interés público (fuente: MIT Technology Review, akbirkhan, jeremyphoward)
Hugging Face colabora con Google Colab para simplificar el proceso de prueba de modelos y diseño de prototipos : Hugging Face ha anunciado una colaboración con Google Colaboratory, añadiendo soporte para “Abrir en Colab” en todas las tarjetas de modelo en Hugging Face Hub. Los usuarios ahora pueden iniciar directamente un Colab Notebook desde cualquier tarjeta de modelo, lo que facilita la experimentación y evaluación de modelos. Además, los usuarios pueden colocar archivos notebook.ipynb personalizados en sus repositorios de modelos, y Hugging Face proporcionará directamente ese Notebook, mejorando aún más la accesibilidad y la capacidad de creación rápida de prototipos de modelos de IA (fuente: huggingface, osanseviero, ClementDelangue, mervenoyann)
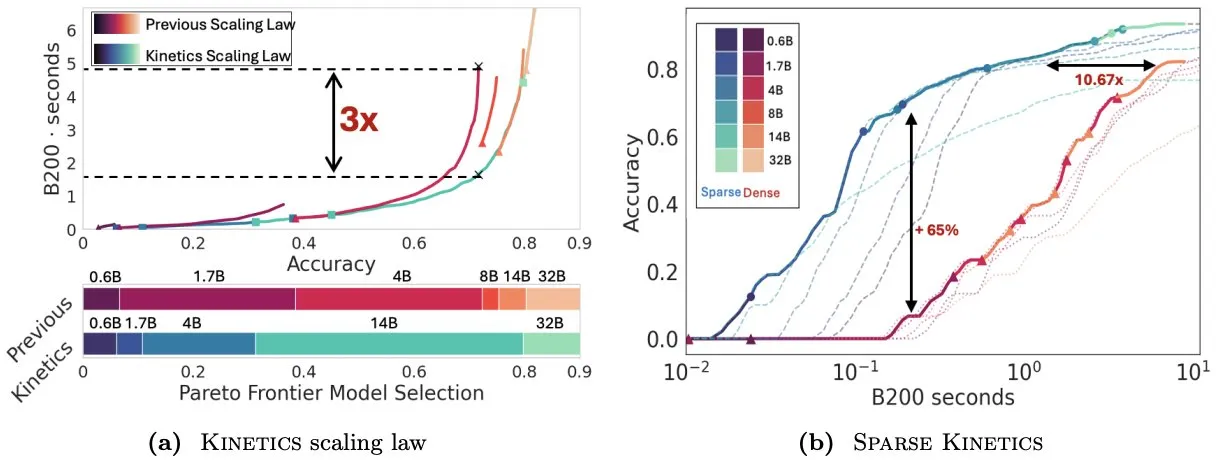
El artículo Kinetics reconsidera las leyes de escalado en tiempo de prueba, enfatizando la importancia de la atención dispersa para la eficiencia de la inferencia : Infini-AI-Lab ha publicado el artículo “Kinetics: Rethinking Test-Time Scaling Laws”, que señala que las leyes de escalado anteriores basadas en la optimalidad computacional sobreestiman la efectividad de los modelos pequeños, ignorando los cuellos de botella de acceso a la memoria causados por estrategias en tiempo de inferencia (como Best-of-N, CoT largo). La investigación propone nuevas leyes de escalado Kinetics, que consideran de manera integral los costos de computación y acceso a la memoria, argumentando que los recursos computacionales en tiempo de prueba se utilizan de manera más efectiva en modelos grandes que en modelos pequeños, ya que la atención, y no la cantidad de parámetros, se convierte en el costo dominante. El artículo propone además un paradigma de escalado centrado en la atención dispersa, que logra una generación más larga y más muestras paralelas al reducir el costo por token. Los experimentos demuestran que los modelos de atención dispersa superan a los modelos densos en diferentes rangos de costo, lo cual es crucial para mejorar la eficiencia de la inferencia de modelos a gran escala (fuente: realDanFu, tri_dao, simran_s_arora)
El mercado de Agentes de IA en China está en auge, con Manus liderando la ola de emprendimiento : Tras el auge de los modelos fundacionales el año pasado, el enfoque del sector de IA en China este año se ha desplazado hacia los Agentes de IA. Los Agentes de IA se centran más en completar tareas para los usuarios de forma autónoma, en lugar de simplemente responder a consultas. Manus, como pionero de los Agentes de IA de propósito general, generó una amplia atención tras su lanzamiento limitado a principios de marzo y ha impulsado una oleada de startups que construyen herramientas digitales de propósito general capaces de gestionar correos electrónicos, planificar viajes e incluso diseñar sitios web interactivos. Esta tendencia indica que la industria tecnológica china está explorando activamente las aplicaciones prácticas y los modelos de negocio de los Agentes de IA (fuente: MIT Technology Review)

ElevenLabs lanza Conversational AI 2.0, mejorando el rendimiento de los asistentes de voz de nivel empresarial : ElevenLabs ha lanzado la versión 2.0 de su plataforma de IA conversacional, diseñada para construir agentes de voz de nivel empresarial más avanzados. La nueva versión mejora significativamente la naturalidad y la capacidad de interacción de los asistentes de voz, permitiéndoles comprender mejor el ritmo de la conversación, saber cuándo hacer una pausa, cuándo hablar y cuándo realizar el cambio de turno en la conversación. Se espera que esta actualización proporcione a los usuarios empresariales una experiencia de interacción de voz más fluida e inteligente, aplicable a diversos escenarios como el servicio al cliente y los asistentes virtuales (fuente: dl_weekly)
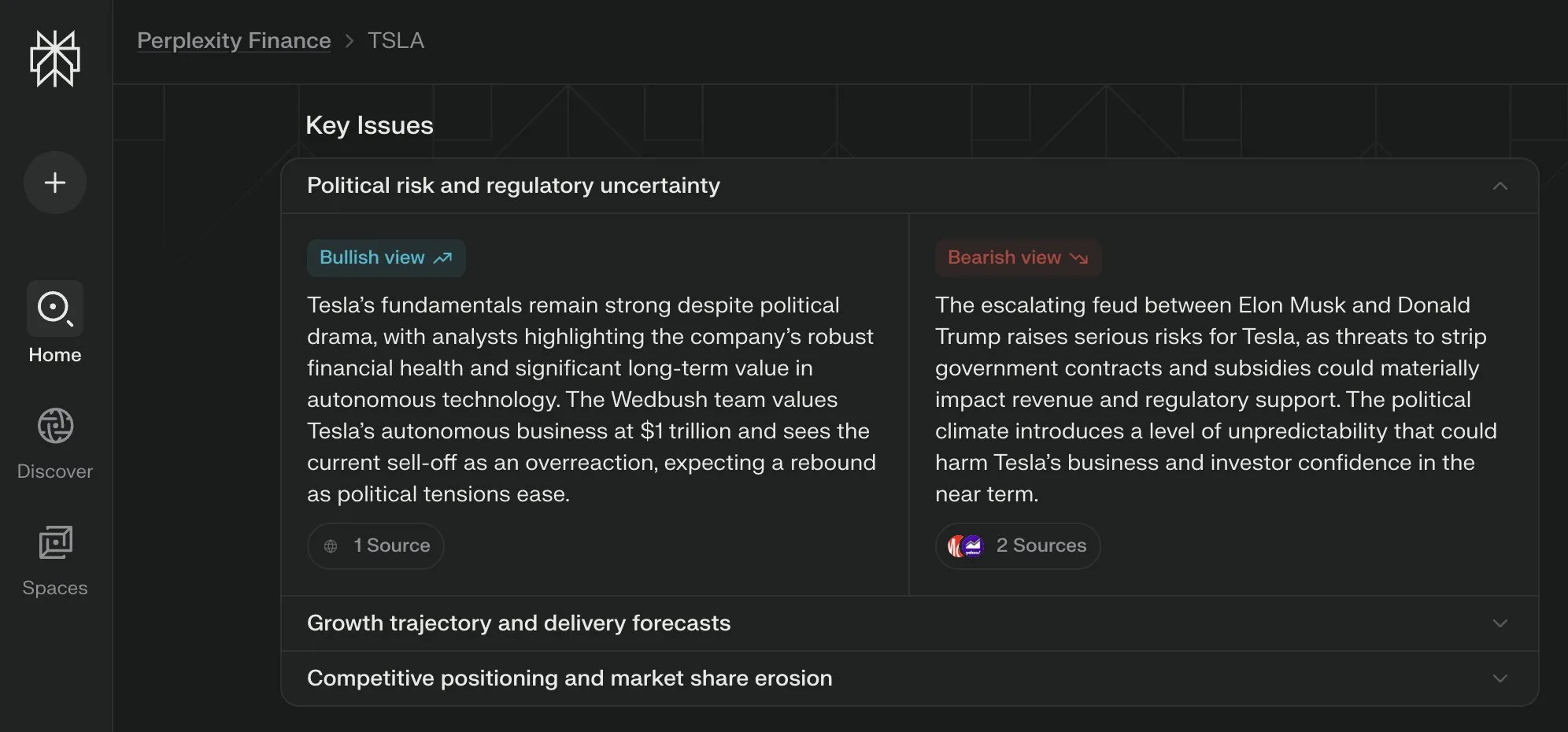
Perplexity Labs lanza la vista “Cuestiones Clave” para sus páginas financieras, sintetizando múltiples perspectivas : Perplexity Labs ha añadido la función de vista “Cuestiones Clave” (Key Issues) a sus páginas de información financiera. Esta función puede sintetizar las opiniones de inversores, analistas y comentaristas de Internet, mostrando rápidamente a los usuarios los factores importantes y los principales puntos de discusión que afectan actualmente a una empresa. Por ejemplo, la página sobre Tesla puede integrar diversa información sobre la dinámica entre Trump y Musk en cuestión de horas, ayudando a los usuarios a comprender rápidamente la situación general (fuente: AravSrinivas)
Los checkpoints distribuidos de PyTorch ahora son compatibles con safetensors de Hugging Face : PyTorch ha anunciado que su función de checkpoints distribuidos ahora es compatible con el formato safetensors de Hugging Face, lo que facilitará el guardado y la carga de checkpoints entre diferentes ecosistemas. La nueva API permite a los usuarios leer y escribir safetensors a través de rutas fsspec. torchtune se convierte en la primera biblioteca en adoptar esta función, simplificando así su proceso de checkpointing. Esta actualización ayuda a mejorar la interoperabilidad y la eficiencia del entrenamiento y despliegue de modelos (fuente: ClementDelangue)

El artículo MARBLE propone un nuevo método para la recomposición y mezcla de materiales basado en el espacio CLIP : Una nueva investigación titulada MARBLE propone un método para mezclar materiales de objetos en imágenes y recombinar atributos de grano fino encontrando incrustaciones de material en el espacio CLIP y utilizando esta incrustación para controlar modelos preentrenados de texto a imagen. Este método mejora la edición de materiales basada en muestras al localizar los módulos en la UNet de eliminación de ruido responsables de la atribución de materiales, logrando un control parametrizado de atributos de material de grano fino como la rugosidad, la metalicidad, la transparencia y el brillo. Los investigadores demostraron la efectividad del método mediante análisis cualitativos y cuantitativos, y mostraron su aplicabilidad para realizar múltiples ediciones en una sola pasada hacia adelante, así como en el campo de la pintura (fuente: HuggingFace Daily Papers, ClementDelangue)
Artículo FlowDirector: un método de guía de flujo para la edición precisa de texto a video sin necesidad de entrenamiento : FlowDirector es un novedoso marco de edición de video sin inversión que modela el proceso de edición como una evolución directa en el espacio de datos. Guía el video para que transite suavemente a lo largo de su variedad espaciotemporal inherente mediante ecuaciones diferenciales ordinarias (ODE), manteniendo así la coherencia temporal y los detalles estructurales. Para lograr una edición controlable localmente, se introduce un mecanismo de enmascaramiento guiado por atención. Además, para abordar la edición incompleta y mejorar la alineación semántica con las instrucciones de edición, se propone una estrategia de edición mejorada por guía, inspirada en la guía sin clasificador. Los experimentos demuestran que FlowDirector tiene un rendimiento superior en el seguimiento de instrucciones, la coherencia temporal y la preservación del fondo (fuente: HuggingFace Daily Papers)
Artículo RACRO: Razonamiento multimodal escalable mediante la optimización de subtítulos por recompensa : Para abordar el alto costo de reentrenar la alineación visual-lingüística al actualizar los razonadores LLM subyacentes, los investigadores proponen RACRO (Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization). Este método convierte la entrada visual en representaciones lingüísticas (como subtítulos), que luego se pasan al razonador de texto. RACRO emplea una estrategia de aprendizaje por refuerzo guiada por el razonamiento, optimizando por recompensa el comportamiento de subtitulado del extractor para alinearlo con los objetivos de razonamiento, mejorando así la base visual y extrayendo representaciones optimizadas para el razonamiento. Los experimentos muestran que RACRO alcanza el estado del arte (SOTA) en benchmarks multimodales de matemáticas y ciencias, y admite la adaptación plug-and-play a LLM de razonamiento más avanzados sin una costosa realineación multimodal (fuente: HuggingFace Daily Papers)
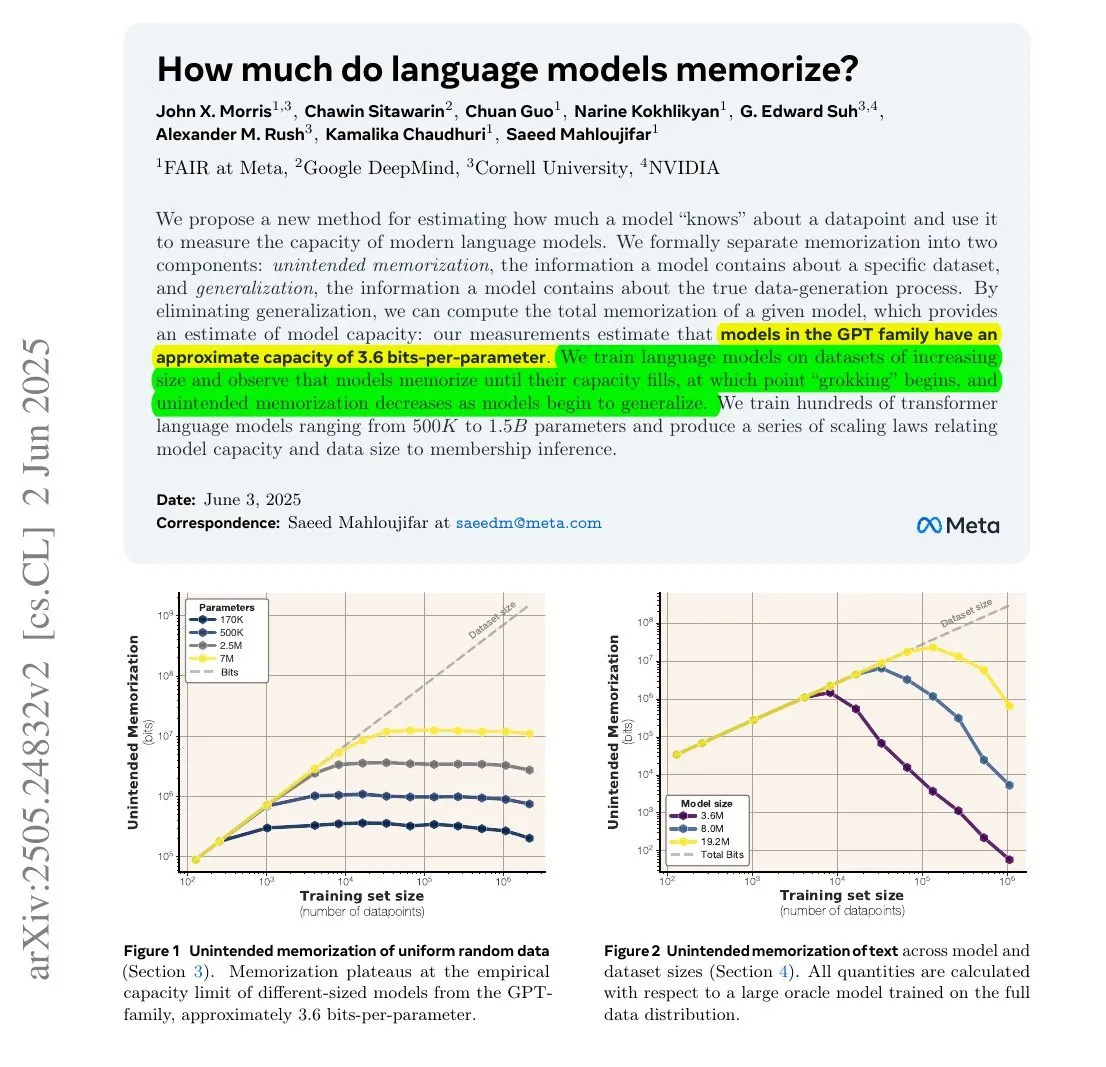
Un estudio muestra que la cantidad de información que memorizan los LLM podría estar relacionada con su cantidad de parámetros y la entropía de la información : Una investigación colaborativa entre Meta, DeepMind, NVIDIA y la Universidad de Cornell explora la cantidad de información que realmente memorizan los modelos de lenguaje grandes (LLM). El estudio encontró que la cantidad de información memorizada por los LLM podría estar relacionada con su cantidad de parámetros y la entropía de la información de los datos. Por ejemplo, la Wikipedia en inglés tiene aproximadamente 29.4 mil millones de caracteres, cada uno con aproximadamente 1.5 bits de información. Un modelo de 12B parámetros (asumiendo una capacidad de almacenamiento de 3.6 bits por parámetro) teóricamente podría memorizar toda la Wikipedia en inglés. Este estudio es significativo para comprender los mecanismos de memoria de los LLM y evaluar los problemas de derechos de autor de los datos. François Chollet también mencionó la metodología de entrenar LLM con cadenas aleatorias y sus hallazgos cuantitativos, considerándolos valiosos para comprender los mecanismos de memoria de los LLM (fuente: fchollet, AymericRoucher)
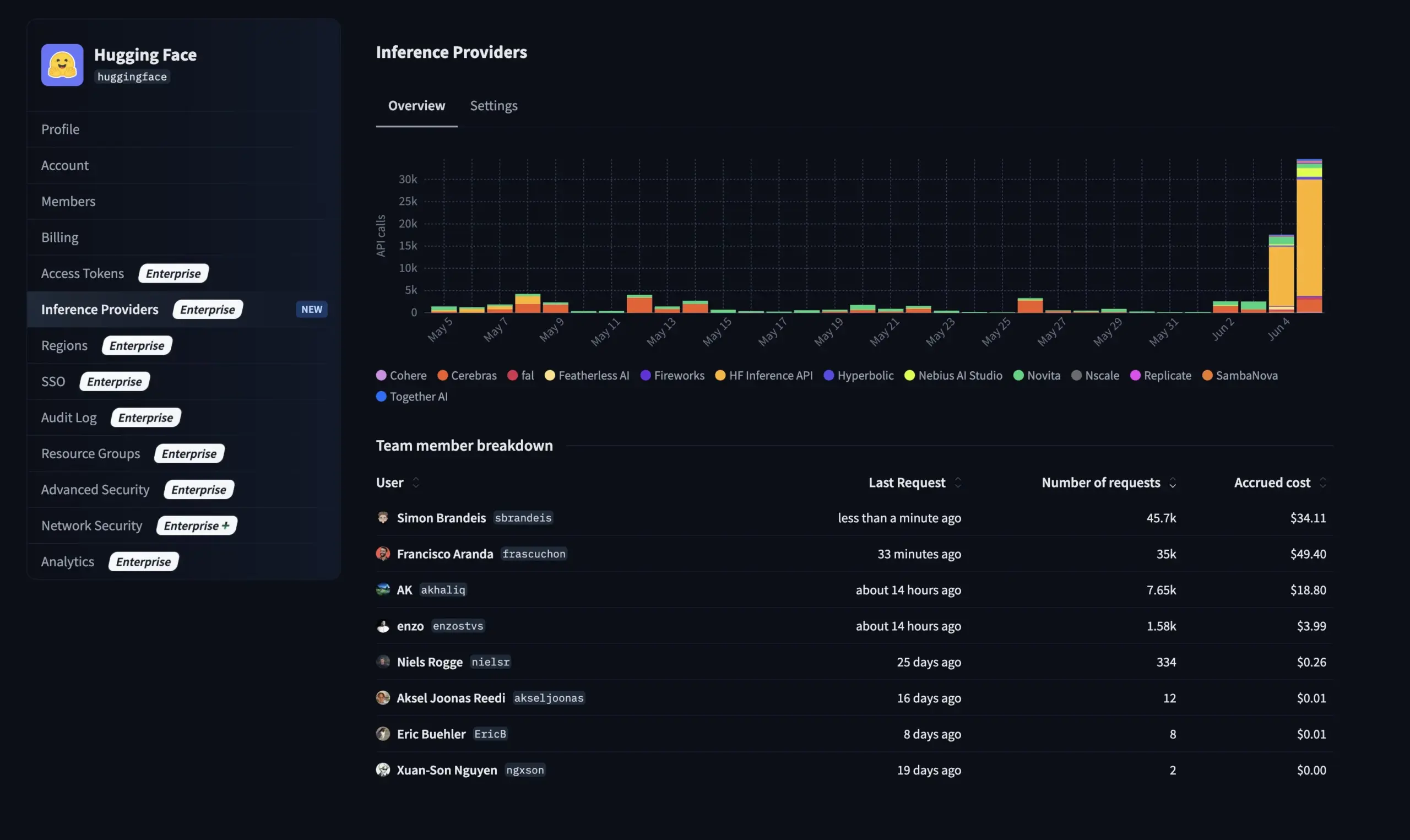
Hugging Face lanza nueva función para la versión Enterprise: gestionar el uso y los costos de los proveedores de inferencia : Hugging Face ha añadido una nueva función a su Enterprise Hub, permitiendo a las organizaciones configurar y monitorizar el uso que hacen sus miembros del equipo de los Proveedores de Inferencia (Inference Providers) y los costos asociados. Esto significa que los usuarios empresariales pueden gestionar y controlar mejor el uso de servicios de inferencia sin servidor para más de 40,000 modelos de múltiples proveedores como TogetherCompute, FireworksAI, Replicate, Cohere, entre otros, optimizando así la rentabilidad y la asignación de recursos en la implementación de aplicaciones de IA (fuente: huggingface, _akhaliq)
Mistral AI lanza el modelo de razonamiento científico ether0, ajustado a partir de Mistral 24B : Mistral AI ha lanzado su primer modelo de razonamiento científico, ether0. Este modelo se ha creado mediante el entrenamiento por aprendizaje por refuerzo (RL) de Mistral 24B en múltiples tareas de diseño molecular en el campo de la química. La investigación encontró que los LLM aprenden datos en ciertas tareas científicas con una eficiencia mucho mayor que los modelos especializados entrenados desde cero, y pueden superar significativamente a los modelos de vanguardia y a los humanos en estas tareas. Esto sugiere que, para una parte de los problemas de clasificación, regresión y generación científica, el post-entrenamiento de LLM podría ofrecer una vía más eficiente que los métodos tradicionales de aprendizaje automático (fuente: MistralAI)
El modelo de consistencia de doble experto (DCM) acelera la generación de video en 10 veces : Ziwei Liu y otros investigadores han propuesto el modelo de consistencia de doble experto (DCM), que puede acelerar los modelos de generación de video (con un número de parámetros de 1.3B a 13B) en 10 veces sin reducir la calidad. Este modelo actualmente es compatible con Hunyuan de Tencent y Tongyi Wanxiang de Alibaba. La propuesta de DCM representa un nuevo avance en el campo de la generación de video eficiente y de alta calidad, y ayudará a acelerar la creación de contenido de video y el desarrollo de aplicaciones relacionadas (fuente: _akhaliq)
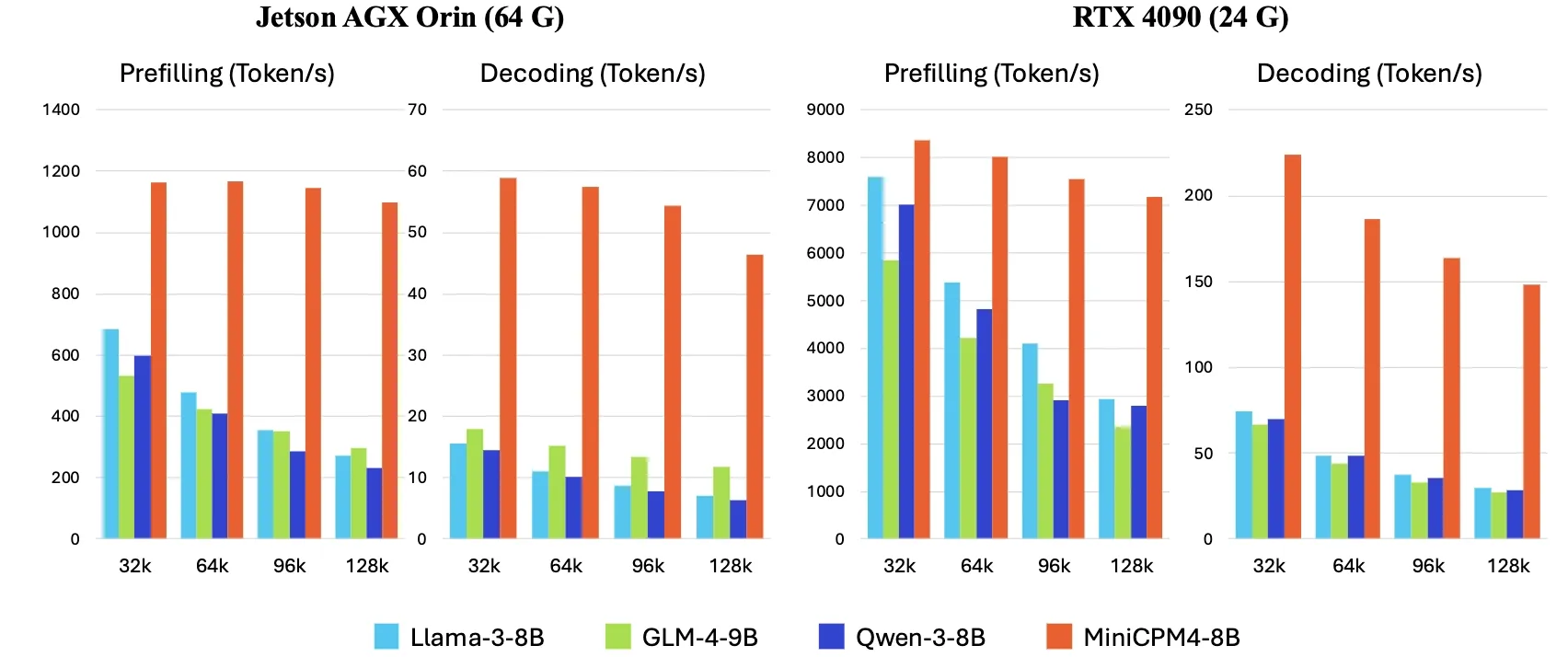
OpenBMB lanza MiniCPM4, aumentando la velocidad de inferencia en dispositivos finales en 5 veces : OpenBMB ha lanzado la serie de modelos MiniCPM4, logrando un aumento de 5 veces en la velocidad de inferencia en dispositivos finales mediante la adopción de una arquitectura de modelo eficiente (mecanismo de atención dispersa entrenable InfLLM v2), algoritmos de aprendizaje eficientes (Model Wind Tunnel 2.0, cuantización ternaria BitCPM), datos de entrenamiento de alta calidad (UltraClean, UltraChat v2) y un sistema de inferencia eficiente (CPM.cu, ArkInfer). El modelo insignia MiniCPM4-8B (8B parámetros, entrenado con 8T tokens) ya está disponible en Hugging Face. Esta serie de modelos tiene como objetivo explorar los límites de los LLM pequeños y de bajo costo, impulsando la aplicación de la IA en dispositivos con recursos limitados (fuente: eliebakouch, Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞))
X Corp actualiza sus términos de servicio, prohibiendo el uso de sus publicaciones para “ajuste fino o entrenamiento” de modelos de IA, a menos que haya un acuerdo : X Corp (anteriormente Twitter) ha actualizado sus términos de servicio, prohibiendo explícitamente el uso del contenido de las publicaciones de la plataforma para “ajuste fino o entrenamiento” (fine-tuning or training) de modelos de inteligencia artificial, a menos que se llegue a un acuerdo específico con X Corp. Esta medida refleja la creciente importancia y el deseo de control que las plataformas de contenido otorgan al valor de sus datos en la era de la IA, posiblemente siguiendo el ejemplo de empresas como Reddit y Google que monetizan sus datos a través de acuerdos de licencia. Este cambio de política afectará a los investigadores y desarrolladores de IA que dependen de datos de redes sociales públicas para el entrenamiento de modelos (fuente: MIT Technology Review)
🧰 Herramientas
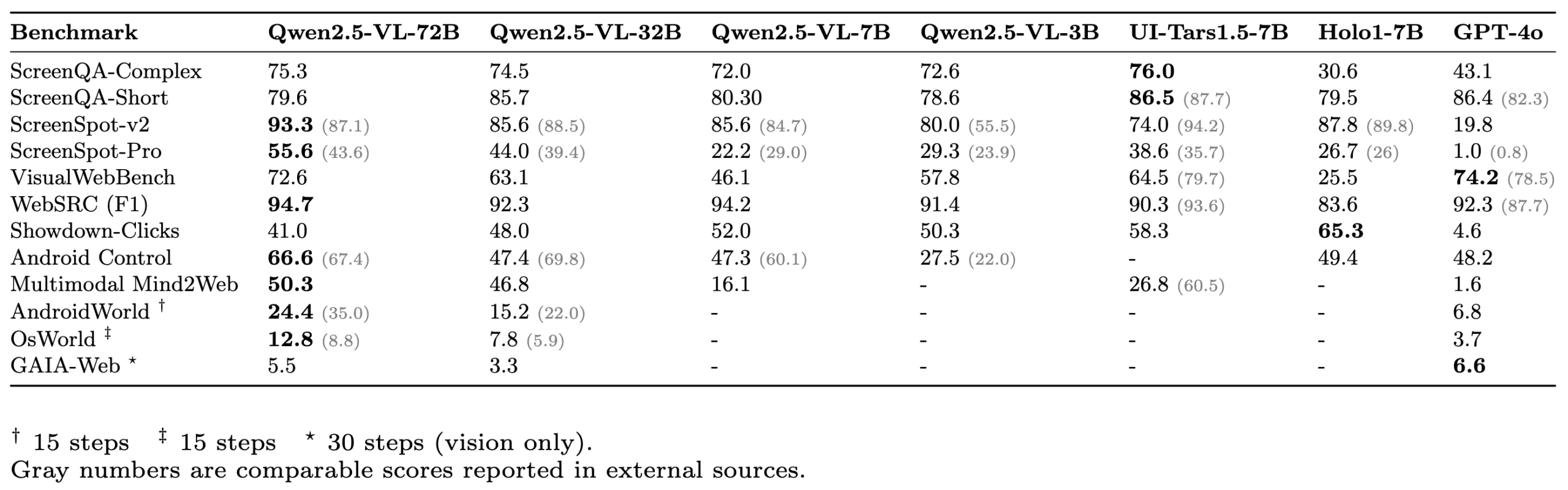
ScreenSuite: Lanzamiento de un completo conjunto de evaluación para Agentes GUI : Hugging Face ha lanzado ScreenSuite, un completo conjunto de evaluación para Agentes de Interfaz Gráfica de Usuario (GUI). Integra benchmarks clave de investigaciones de vanguardia, admite la evaluación en contenedores Docker para entornos Ubuntu y Android, y cubre escenarios móviles, de escritorio y web. El conjunto enfatiza la evaluación puramente visual (sin trampas DOM), con el objetivo de proporcionar una plataforma unificada y fácil de usar para medir las capacidades de los modelos de lenguaje visual (VLM) en percepción, localización, operaciones de un solo paso y tareas de agente de múltiples pasos. Modelos como Qwen-2.5-VL, UI-Tars-1.5-7B, Holo1-7B y GPT-4o ya han sido evaluados con este conjunto (fuente: huggingface, AymericRoucher, clefourrier, tonywu_71, mervenoyann, HuggingFace Blog)
Experiencia compartida sobre el uso de Claude Code: Destaca en comprensión de instrucciones, planificación de tareas y uso de herramientas : El usuario dotey compartió su experiencia usando el asistente de programación de IA de Anthropic, Claude Code. Considera que los puntos fuertes de Claude Code son: 1. Excelente comprensión de las instrucciones; 2. Capacidad para planificar tareas razonablemente, creando listas de TODO para tareas complejas y ejecutándolas una por una; 3. Habilidad extremadamente fuerte en el uso de herramientas, especialmente en el uso del comando grep para buscar en repositorios de código, con una eficiencia muy superior a la humana, incluso capaz de analizar código JS ofuscado; 4. Tiempo de ejecución largo, capaz de lograr resultados “milagrosos por fuerza bruta”, pero también con un gran consumo de Tokens, adecuado para usar con la suscripción Claude Max; 5. Poca intervención manual durante todo el proceso, especialmente al activar el parámetro --dangerously-skip-permissions para una programación desatendida. El usuario pasó de ser un usuario intensivo de Cursor a depender más de Claude Code para completar tareas primero, y luego revisar y modificar en el IDE. El Plan Mode (modo de planificación) de Claude Code también se ha lanzado discretamente, permitiendo a los usuarios realizar lecturas y reflexiones puras sin editar archivos (fuente: dotey, Reddit r/ClaudeAI)
ClaudeBox: Ejecute Claude Code de forma segura en Docker, eliminando las solicitudes de permisos : El desarrollador RchGrav creó la herramienta ClaudeBox, que permite a los usuarios ejecutar Claude Code en modo continuo (sin solicitudes de permisos) dentro de un contenedor Docker. Esto evita que las frecuentes confirmaciones de permisos interrumpan el flujo de trabajo y garantiza la seguridad del sistema operativo principal, ya que todas las operaciones de Claude Code están restringidas al entorno aislado de Docker. ClaudeBox ofrece más de 15 entornos de desarrollo preconfigurados (como Python+ML, C++/Rust/Go, etc.), que los usuarios pueden configurar rápidamente con comandos simples. La herramienta tiene como objetivo mejorar la experiencia de uso de Claude Code, permitiendo a los usuarios dejar que la IA intente diversas operaciones sin preocupaciones (fuente: Reddit r/ClaudeAI)
Lanzamiento de Toolio 0.6.0: Kit de herramientas GenAI y Agent diseñado para Mac : Toolio ha lanzado la versión 0.6.0, un kit de herramientas profundamente integrado con MLX, diseñado para proporcionar un potente soporte a los modelos de lenguaje grandes (LLM) en Mac. Implementa funciones de salida estructurada guiada por JSON Schema y llamadas a herramientas, utilizando el lenguaje Python. Este kit de herramientas se centra en mejorar la experiencia y la eficiencia del desarrollo de aplicaciones GenAI y Agent en el entorno Mac (fuente: awnihannun)
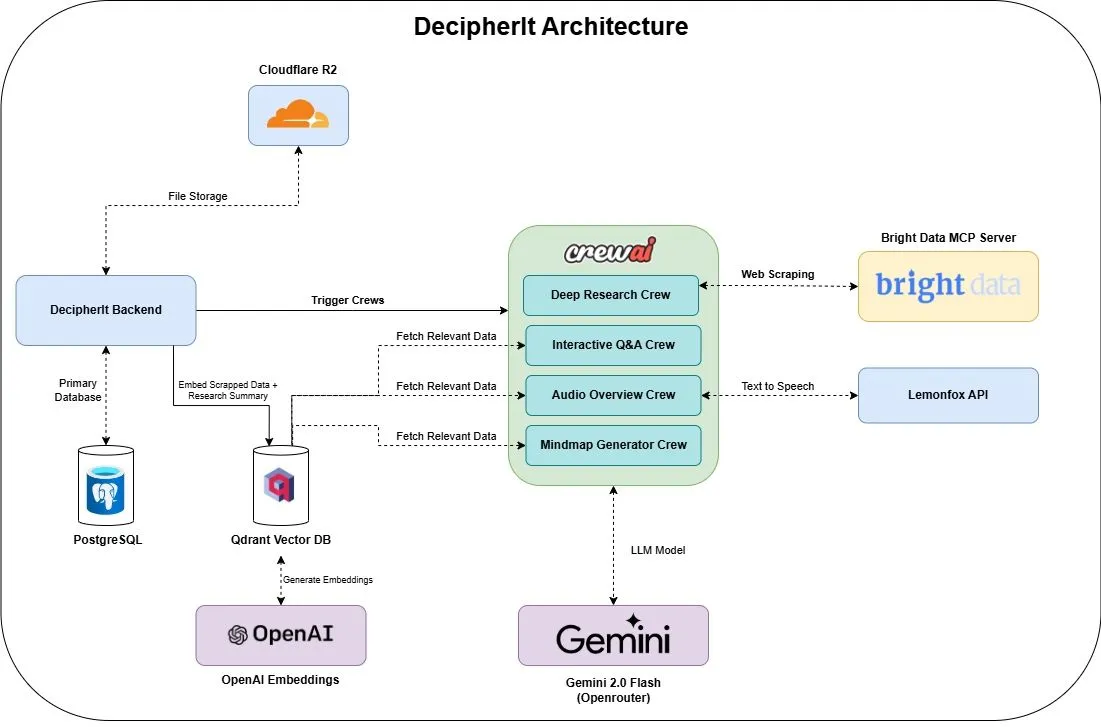
DecipherIt: Asistente de investigación de IA de código abierto, integra múltiples agentes y búsqueda semántica : DecipherIt es un asistente de investigación de IA de código abierto, considerado una alternativa a NotebookLM. Utiliza orquestación de múltiples agentes, búsqueda semántica y funciones de acceso a la web en tiempo real para ayudar a los usuarios a procesar material de investigación. Los usuarios pueden cargar documentos, pegar URL o ingresar temas, y DecipherIt los convertirá en un espacio de trabajo de investigación completo que incluye resúmenes, mapas mentales, resúmenes de audio, preguntas frecuentes y respuestas semánticas. Su pila tecnológica incluye agentes crewAI, Bright Data MCP, Qdrant, OpenAI y LemonFox AI, con un frontend que utiliza Next.js y React 19, y un backend en FastAPI (fuente: qdrant_engine)
Search Arena: Publicación de un conjunto de datos de interacción del usuario con LLM mejorados por búsqueda para su análisis : Search Arena es un conjunto de datos de preferencias humanas a gran escala (más de 24,000 interacciones) obtenido mediante crowdsourcing, que contiene interacciones de múltiples turnos entre usuarios y LLM mejorados por búsqueda. Este conjunto de datos cubre múltiples intenciones e idiomas, e incluye el seguimiento completo del sistema para aproximadamente 12,000 votos de preferencia humana. El análisis muestra que las preferencias de los usuarios se ven afectadas por el número de citas, incluso si el contenido citado no respalda directamente las afirmaciones atribuidas; las plataformas impulsadas por la comunidad suelen ser más populares. Este conjunto de datos tiene como objetivo apoyar la investigación futura sobre LLM mejorados por búsqueda, y el código y los datos se han hecho de código abierto (fuente: HuggingFace Daily Papers, jiayi_pirate, lmarena_ai)

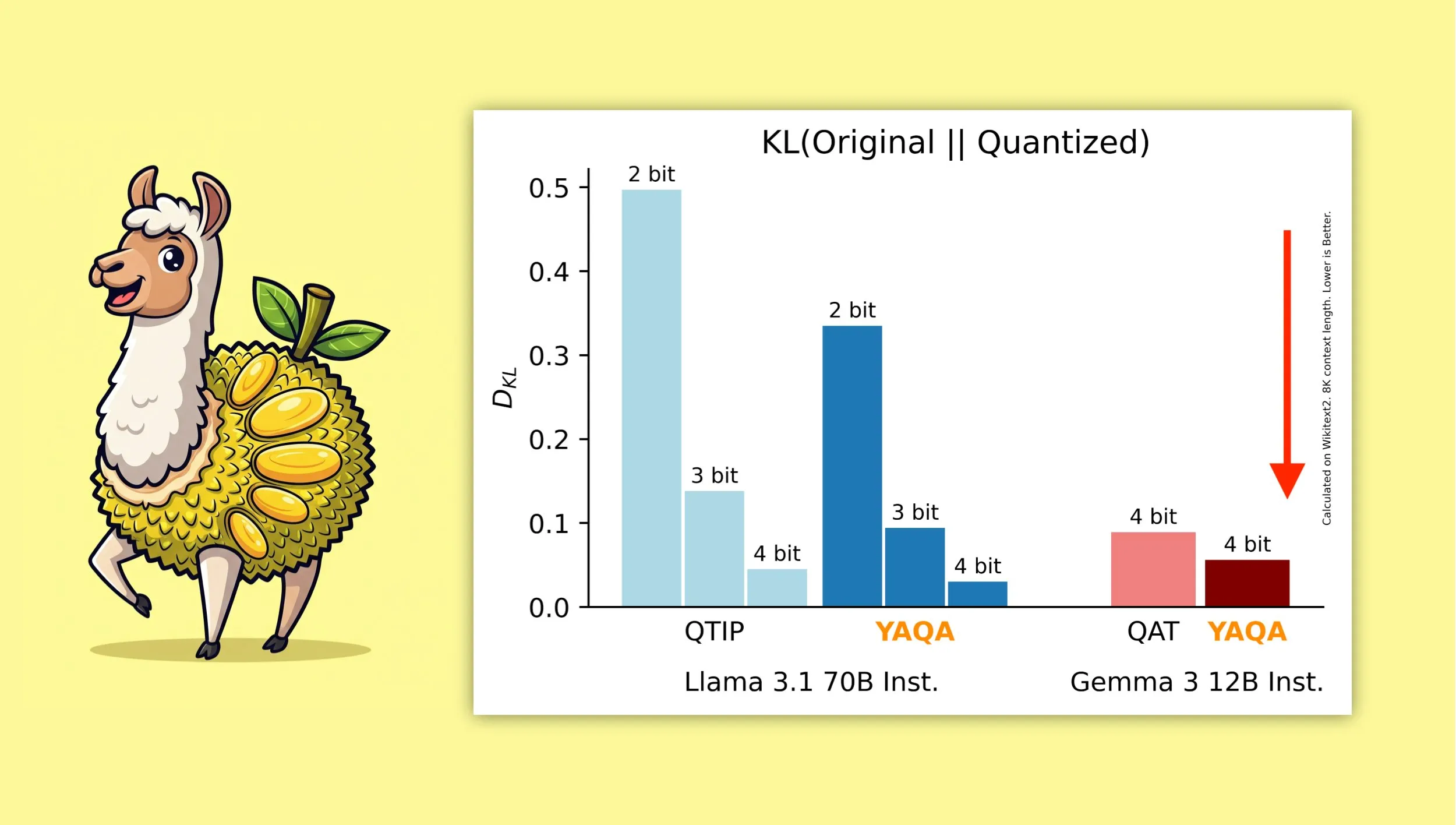
YAQA: Un nuevo algoritmo de cuantización diseñado para preservar mejor la salida original del modelo : Investigadores de la Universidad de Cornell han presentado “Yet Another Quantization Algorithm” (YAQA), un nuevo algoritmo de cuantización diseñado para preservar mejor la salida del modelo original después de la cuantización. Se afirma que YAQA reduce la divergencia KL en más del 30% en comparación con QTIP, y logra una divergencia KL más baja en Gemma 3 que el modelo QAT de Google. Esta investigación proporciona nuevas ideas y herramientas para el campo de la cuantización de modelos, ayudando a maximizar el rendimiento del modelo mientras se reduce su tamaño y los requisitos computacionales. El artículo y el código relacionados se han publicado, y se proporciona un modelo Llama 3.1 70B Instruct precuantizado (fuente: Reddit r/MachineLearning, Reddit r/LocalLLaMA, tri_dao, simran_s_arora)
Tokasaurus: Lanzamiento de un motor diseñado para inferencia de LLM de alto rendimiento : HazyResearch ha lanzado Tokasaurus, un nuevo motor de inferencia de LLM diseñado específicamente para cargas de trabajo de alto rendimiento, adecuado para modelos grandes y pequeños. Este motor tiene como objetivo optimizar la eficiencia y la velocidad de procesamiento de los LLM en escenarios de solicitudes concurrentes a gran escala, posiblemente utilizando técnicas avanzadas como el procesamiento por lotes continuo y la atención paginada para mejorar el rendimiento. El lanzamiento de Tokasaurus ofrece una nueva opción para desarrolladores y empresas que necesitan procesar eficientemente grandes volúmenes de tareas de inferencia de LLM (fuente: Tim_Dettmers)
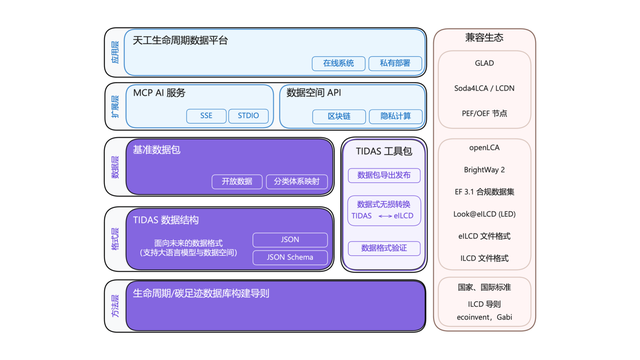
Lanzamiento del sistema “Android” para la huella de carbono TIDAS, con soporte técnico de Ant Digital : La Alianza de Innovación Tecnológica de la Industria de la Huella de Carbono ha lanzado el “Sistema de Datos LCA Tiangong” (TIDAS), con el objetivo de proporcionar soluciones para la construcción de bases de datos de evaluación del ciclo de vida (LCA) y huella de carbono, con la meta de establecer el sistema “Android” para las bases de datos de LCA y huella de carbono de China e incluso del mundo. Ant Digital, como miembro principal, proporcionó soporte de tecnología blockchain y plataforma de colaboración de datos confiables para TIDAS, utilizando su tecnología blockchain autónoma para lograr el registro y la confirmación de derechos confiables de los activos de datos de carbono, y utilizando tecnología de computación de privacidad para garantizar que los datos sean “utilizables pero no visibles”, mejorando la estandarización, la fusionabilidad y la interoperabilidad de los datos (fuente: 量子位)
📚 Aprendizaje
LangChain organiza un taller de IA de nivel empresarial, centrado en sistemas multiagente : LangChain celebrará un taller de IA de nivel empresarial el 16 de junio en San Francisco. En él, Jake Broekhuizen de LangChain guiará a los participantes en la construcción de sistemas multiagente listos para producción utilizando LangGraph, y el contenido cubrirá aspectos clave como la seguridad y la observabilidad. Se trata de un taller práctico diseñado para ayudar a los desarrolladores a dominar las habilidades necesarias para construir aplicaciones de Agentes de IA complejas y fiables (fuente: LangChainAI, hwchase17)

DeepLearning.AI lanza un nuevo curso “DSPy: Construir y optimizar aplicaciones agénticas” : DeepLearning.AI ha lanzado un nuevo curso titulado “DSPy: Build and Optimize Agentic Apps”. El curso enseñará a los alumnos los fundamentos de DSPy, cómo utilizar sus firmas y su modelo de programación basado en módulos para construir aplicaciones agénticas GenAI modulares, rastreables y depurables. El contenido incluye la construcción de aplicaciones mediante la vinculación de módulos DSPy como Predict, ChainOfThought y ReAct, el uso de MLflow para el seguimiento y la depuración, y la utilización de DSPy Optimizer para ajustar automáticamente las indicaciones y mejorar los ejemplos de pocos disparos, con el fin de mejorar la precisión y la coherencia de las respuestas (fuente: DeepLearningAI, lateinteraction)
El proyecto de GitHub del tutorial de técnicas avanzadas de RAG recibe atención : El proyecto de tutorial de técnicas de RAG (Retrieval-Augmented Generation) compartido por NirDiamant en GitHub ha obtenido 16.6K estrellas. El contenido del tutorial es extenso y cubre múltiples aspectos como el preprocesamiento para la recuperación mejorada, la optimización, los patrones de recuperación, la iteración y los pasos de ingeniería. Para los desarrolladores que deseen profundizar en la investigación y mejorar la efectividad de las aplicaciones RAG, este es un valioso recurso de aprendizaje avanzado (fuente: karminski3)
Cómo los clientes de OpenAI utilizan las evaluaciones (Evals) para construir mejores productos de IA : Hamel Husain promocionó un seminario web impartido por Jim Blomo de OpenAI, que discutirá cómo los clientes de OpenAI utilizan herramientas de evaluación (Evals) para construir productos de IA de mayor calidad. El contenido incluirá estudios de caso y resultados reales, y mostrará las herramientas de evaluación internas de OpenAI (como seguimiento, puntuación, etc.). Este seminario web tiene como objetivo proporcionar a los desarrolladores información práctica y métodos sobre la evaluación de productos de IA (fuente: HamelHusain)

LlamaIndex comparte una visión general de 13 protocolos de Agentes, discutiendo estándares de interoperabilidad : Seldo de LlamaIndex ofreció una presentación general en la Cumbre de Desarrolladores de MCP sobre los 13 protocolos de comunicación entre Agentes existentes actualmente (incluyendo MCP, A2A, ACP, etc.). Analizó las características únicas de cada protocolo, su posicionamiento en el panorama tecnológico actual y las tendencias de desarrollo futuras. La presentación tuvo como objetivo ayudar a los desarrolladores a comprender y seleccionar los estándares de comunicación adecuados para sus aplicaciones de Agentes, promoviendo la interoperabilidad del ecosistema de Agentes (fuente: jerryjliu0, jerryjliu0)

Análisis de la arquitectura de Claude Code: Flujo de control, motor de orquestación y ejecución de herramientas : Un artículo analiza en profundidad la arquitectura de Claude Code, centrándose en su flujo de control y motor de orquestación, así como en sus herramientas y motor de ejecución. Estos análisis son valiosos para los desarrolladores que deseen crear herramientas de asistencia de codificación de línea de comandos similares o realizar modificaciones personalizadas, y sus ideas de diseño también son aplicables al desarrollo de otros tipos de herramientas de Agentes (fuente: karminski3)

Compartida la solución del segundo lugar en la competencia de kernels de multiplicación de matrices FP8 para GPU AMD : Tim Dettmers compartió la solución del ganador del segundo lugar en la competencia de kernels de multiplicación de matrices FP8 para GPU AMD. La interpretación detallada de esta solución tiene un importante valor de referencia para comprender cómo optimizar el rendimiento de las operaciones de punto flotante de baja precisión en las GPU AMD, especialmente en el contexto del creciente uso de formatos de baja precisión como FP8 en el entrenamiento e inferencia de modelos de IA para mejorar la eficiencia (fuente: Tim_Dettmers)
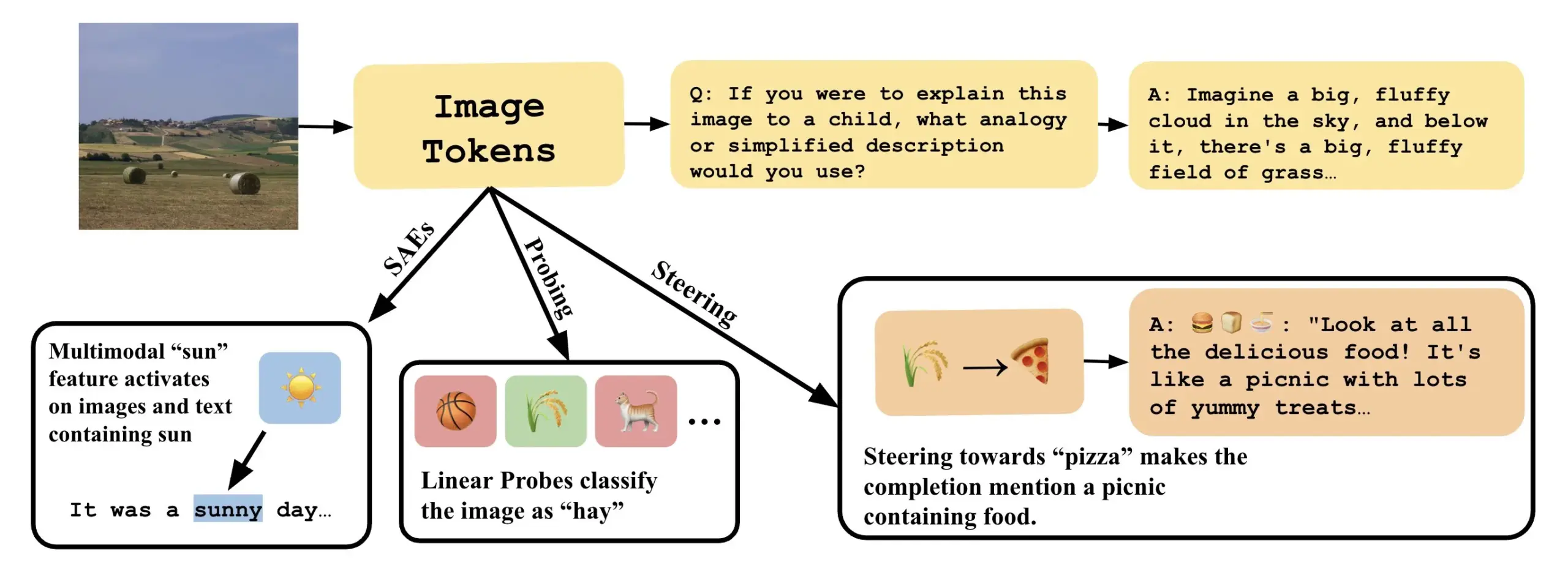
Un artículo explora cómo entender los modelos de lenguaje visual mediante la interpretación de direcciones lineales en VLLM : Un nuevo artículo titulado “Line of Sight” explora la comprensión de los mecanismos internos de los grandes modelos de lenguaje visual (VLLM) mediante la interpretación de direcciones lineales en su espacio latente. Los investigadores utilizan herramientas como el sondeo (probing), la dirección (steering) y los autoencoders dispersos (SAEs) para interpretar las representaciones de imágenes en los VLLM. Este trabajo ofrece nuevas perspectivas y métodos para comprender el funcionamiento interno de los modelos multimodales (fuente: nabla_theta)
💼 Negocios
La startup de IA Vareon obtiene 3 millones de dólares en financiación pre-semilla de Norck, centrándose en IA de vanguardia y sistemas autónomos : Norck, fundada por Faruk Guney, se ha comprometido a proporcionar 3 millones de dólares en financiación pre-semilla basada en hitos a su recién creada startup de IA, Vareon. Vareon se centra en los campos de la IA de vanguardia, el razonamiento causal y los sistemas autónomos, con su núcleo en MALPAC (Arquitectura de Aprendizaje Multiagente para Planificación y Optimización de Bucle Cerrado). La empresa tiene como objetivo convertirse en una compañía de investigación fundamental en IA, impulsando el desarrollo en áreas como la robótica, los LLM, el diseño molecular, las arquitecturas cognitivas y los agentes autónomos. También se lanzaron RAPID (marco de planificación diferenciable), CIMO (coordinador multiescala causal), SCA (arquitectura cognitiva bioinspirada) y Lumon-XAI (capa de interpretabilidad) (fuente: farguney)

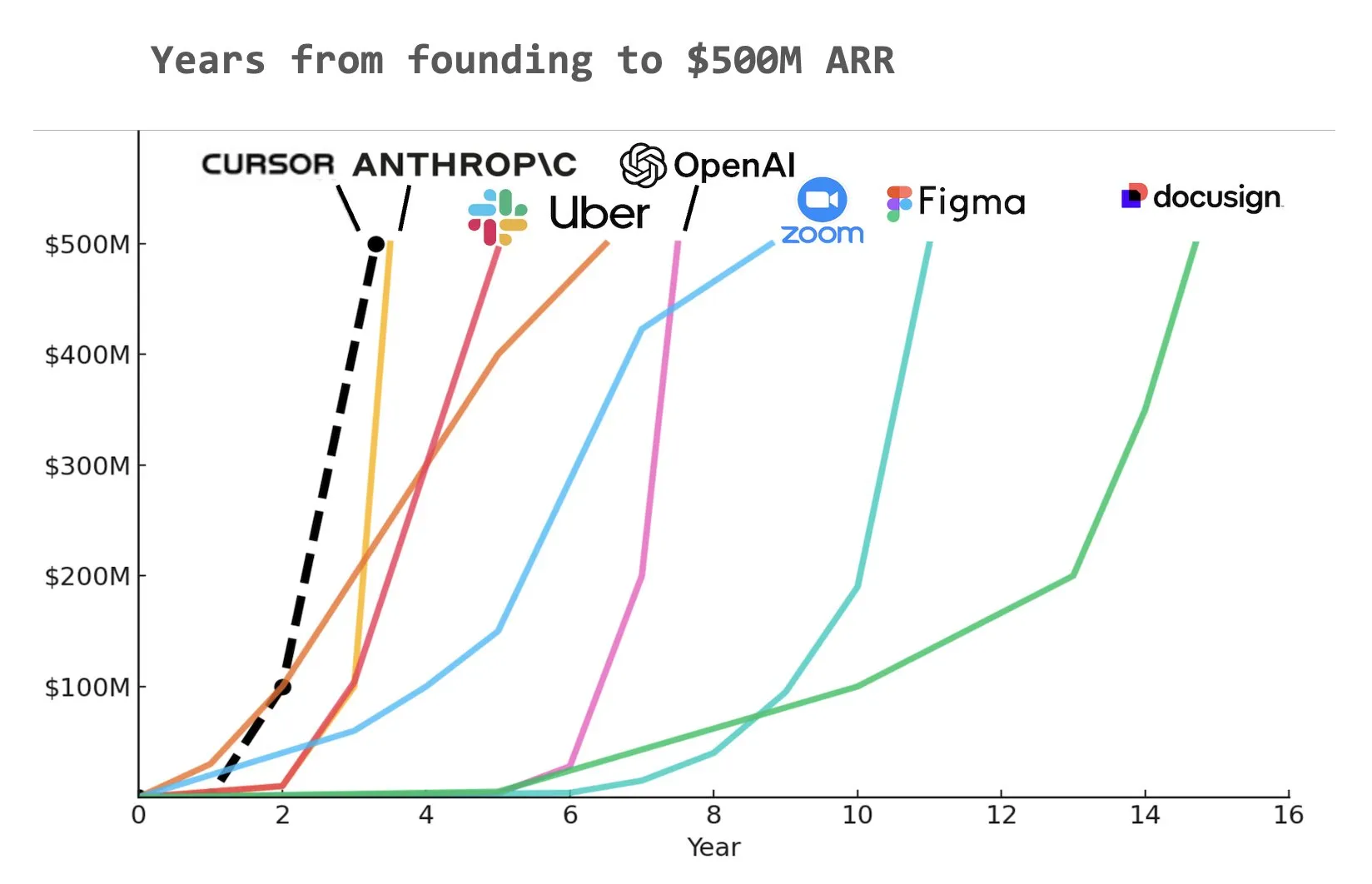
La herramienta de codificación con IA Cursor obtiene una ronda de financiación Serie C de 900 millones de dólares, con un ARR de 500 millones de dólares : La startup de herramientas de codificación con IA Cursor ha anunciado la finalización de una ronda de financiación Serie C de 900 millones de dólares, liderada por Thrive, Accel, Andreessen Horowitz y DST. La compañía reveló que sus ingresos recurrentes anuales (ARR) han superado los 500 millones de dólares y es utilizada por más de la mitad de las empresas Fortune 500, incluidas NVIDIA, Uber y Adobe. Esta ronda de financiación ayudará a Cursor a seguir impulsando la vanguardia de la investigación en el campo de la codificación con IA. Algunos analistas señalan que Cursor podría ser una de las empresas que más rápido ha alcanzado los 500 millones de dólares de ARR en la historia (fuente: cursor_ai, Yuchenj_UW, op7418)
Anthropic corta el acceso directo de Windsurf a los modelos Claude, posiblemente debido a rumores de adquisición por parte de OpenAI : Jared Kaplan, cofundador y director científico de Anthropic, declaró que la compañía cortó el acceso directo del asistente de programación de IA Windsurf a los modelos Claude, principalmente debido a los rumores del mercado sobre la inminente adquisición de Windsurf por parte de OpenAI. Kaplan afirmó que “vender Claude a OpenAI sería extraño” y expresó que Anthropic prefiere asignar sus recursos computacionales a socios estables a largo plazo. A pesar de esto, Anthropic está estableciendo activamente colaboraciones con otros desarrolladores de herramientas de programación de IA (como Cursor) y enfatizó que en el futuro se centrará más en el desarrollo de productos de programación de IA con capacidades de toma de decisiones autónomas, como Claude Code (fuente: dotey, vikhyatk, jeremyphoward, swyx)

🌟 Comunidad
Greg Brockman de OpenAI: El futuro de la AGI se asemeja más a la colaboración de diversos Agentes especializados que a un modelo único : Greg Brockman de OpenAI cree que la forma futura de la inteligencia artificial general (AGI) se asemejará más a un “zoológico” compuesto por numerosos agentes inteligentes especializados (Agent), en lugar de un modelo único y omnipotente tipo “monolito”. Estos Agentes especializados podrán invocarse mutuamente, colaborar y juntos impulsar el desarrollo económico. Esta perspectiva sugiere la tendencia futura del desarrollo de la IA, es decir, lograr sistemas inteligentes más complejos y potentes mediante la construcción e integración de múltiples Agentes de IA con capacidades específicas, con el objetivo de desbloquear 10 veces más actividad y producción. Clement Delangue comentó al respecto que se necesita tecnología robótica de IA de código abierto para romper los monopolios y evitar que una sola empresa controle todos los robots (fuente: natolambert, ClementDelangue, HamelHusain)
Los LLM muestran potencial en la escritura académica y el resumen de contenido, lo que suscita reflexiones sobre la calidad de la escritura humana : Dwarkesh Patel considera que los LLM son actualmente escritores “5/10”, pero el hecho de que puedan mejorar de forma fiable las explicaciones en artículos y libros es en sí mismo una enorme condena a la calidad de la escritura académica. Arvind Narayanan señala además que la mayoría de la escritura académica tiende a sacrificar la claridad y la comprensibilidad en aras de parecer profunda y compleja, mientras que la buena escritura debe buscar la concisión. Esto ha suscitado un debate sobre el papel de los LLM en la asistencia a la investigación académica, la mejora de la legibilidad del contenido y cómo podrían cambiar las formas de comunicación académica en el futuro (fuente: random_walker, jeremyphoward)
Las herramientas de codificación con IA generan debate sobre la dependencia de los desarrolladores; Claude Code atrae la atención por su potente funcionalidad y alto consumo de Tokens : El usuario dotey cree que el uso de herramientas de programación con IA (como Claude Code) puede generar fácilmente una fuerte dependencia, hasta el punto de preferir esperar a que la IA complete la tarea en lugar de escribirla manualmente, incluso cuando se dispone de cuota. Aunque la suscripción a Claude Max tiene un límite, su potente capacidad de codificación (como una excelente comprensión de instrucciones, planificación de tareas, uso de la herramienta grep y ejecución prolongada) la convierte en una herramienta eficiente. Este fenómeno ha suscitado un debate sobre cómo las herramientas de IA están cambiando los hábitos de trabajo de los desarrolladores y el equilibrio entre eficiencia y dependencia. Otro usuario, Asuka小能猫, también mostró un caso de desarrollo frontend eficiente utilizando Claude-4-Opus y el modo Cursor Max, pero también mencionó el problema del consumo de Tokens (fuente: dotey, dotey)
El potencial de la educación personalizada impulsada por IA es enorme, pero es necesario prestar atención a los desafíos de implementación : Austen Allred compartió la experiencia de su hijo asistiendo a una escuela impulsada por IA (sin profesores) durante cinco meses, considerando los resultados “una locura”. Noah Smith comentó que la tutoría individualizada es una intervención educativa eficaz, y la IA hace posible su escalamiento. Esto ha generado un debate sobre las aplicaciones de la IA en el campo de la educación, incluyendo rutas de aprendizaje personalizadas, el potencial de los tutores de IA, y cómo garantizar la equidad educativa y superar los desafíos de la implementación tecnológica. Jon Stokes retuiteó y siguió esta tendencia (fuente: jonst0kes, jeremyphoward)
La conexión emocional entre los agentes de IA y los humanos atrae la atención; OpenAI enfatiza la investigación prioritaria sobre el bienestar del usuario : Joanne Jang de OpenAI publicó una entrada de blog discutiendo la relación entre humanos e IA y la postura de la compañía al respecto. El punto central es que OpenAI construye modelos para servir primero a las personas, y a medida que más personas desarrollan conexiones emocionales con la IA, la compañía está priorizando la investigación sobre el impacto de esto en el bienestar emocional de los usuarios. Corbtt comentó que los compañeros de IA son la tecnología social más transformadora desde Internet, y si las empresas optimizan la participación en lugar de la salud mental, podría ser más perjudicial para los niños que las redes sociales, pero si optimizan la salud mental, podría ser una bendición para la humanidad. cto_junior, por su parte, previó con humor escenarios futuros en los que podría ser necesario discutir con los hijos “si es apropiado casarse con un GPT” (fuente: cto_junior, corbtt)

La tecnología de Agentes de IA se desarrolla rápidamente, pero las tareas de aprendizaje por refuerzo disperso de extremo a extremo siguen siendo un desafío : Nathan Lambert considera que los proyectos actuales como Deep Research y Codex agent se logran principalmente entrenando modelos en tareas de aprendizaje por refuerzo (RL) de corto alcance y en robustez general. Sin embargo, entrenar de extremo a extremo en tareas de RL muy dispersas parece estar más lejos de lo que la gente imagina. Corbtt comentó al respecto que incluso los humanos aún no han dominado eficazmente cómo entrenar en tareas de largo alcance y con señales de recompensa dispersas. Esto refleja las limitaciones actuales de la tecnología de Agentes de IA para manejar la planificación compleja a largo plazo y el aprendizaje autónomo (fuente: corbtt)
La “amarga lección” en el campo de la IA: La verificación (Verification) se convierte en la clave para los LLM de tipo inferencial : Rishabh Agarwal pronunció una charla en el taller de inferencia multimodal de CVPR titulada “La amarga lección del RL: La verificación como clave para los LLM de tipo inferencial”. La charla, inspirada en el artículo clásico de Rich Sutton sobre la “amarga lección”, exploró la importancia de los mecanismos de verificación en el aprendizaje por refuerzo y la inferencia de modelos de lenguaje grandes. Esto podría significar que no basta con depender de la capacidad de generación propia del modelo, y que mecanismos sólidos de verificación y retroalimentación son cruciales para mejorar la capacidad de inferencia y la fiabilidad de la IA (fuente: jack_w_rae)

El desarrollo de la IA genera preocupación en el mercado laboral, con opiniones de expertos divergentes : El CEO de Klarna, Sebastian Siemiatkowski, advirtió que la IA podría desencadenar una recesión económica al causar un desempleo masivo (especialmente en trabajos de cuello blanco). Klarna misma ya ha reemplazado a 700 empleados de servicio al cliente con un asistente de IA, ahorrando alrededor de 40 millones de dólares anuales. La investigadora de Anthropic, Sholto Douglas, también predijo que para 2027-28, la capacidad de la IA será muy poderosa. Sin embargo, también hay opiniones de que la IA aumentará la productividad y creará nuevos puestos de trabajo, como Sundar Pichai, quien afirmó que la IA será un acelerador y no causará despidos al menos hasta 2026. Un video de AI Explained analizó si los titulares actuales sobre el desempleo inducido por la IA son razonables y discutió algunas idas y venidas de Duolingo y Klarna en la aplicación de la IA. Estas discusiones reflejan la ansiedad social generalizada y las diferentes expectativas sobre el impacto económico de la IA (fuente: , Reddit r/ArtificialInteligence, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Exploración de las futuras vías de interacción entre los agentes de IA y las redes/API existentes : A medida que aumenta la capacidad de interacción autónoma de los agentes de IA con la red, la forma en que interactúan con la Web/API existentes se convierte en un problema de infraestructura fundamental. En la discusión se propusieron tres posibles vías: 1. Reconstruir desde cero, adoptando protocolos nativos de Agente (poco práctico); 2. Enseñar a los Agentes a operar sitios web como los humanos (alta tasa de error, especialmente en la autenticación); 3. Hacer que HTTP “hable el lenguaje del Agente”, por ejemplo, enriqueciendo las respuestas no exitosas como 402 (se requiere pago) con contexto legible por máquina, para que los Agentes puedan verificar y comprar acceso de forma autónoma. La idea central es que proporcionar información contextual rica para las interacciones Web/API no exitosas será clave para que los Agentes autónomos realicen un trabajo significativo, permitiéndoles recuperarse automáticamente de errores y navegar por procesos complejos (fuente: Reddit r/ArtificialInteligence)
La IA avanza en la investigación matemática, con Terence Tao y otros prestando atención a su potencial y limitaciones : Los matemáticos están explorando activamente la aplicación de la IA en la resolución de problemas matemáticos complejos. Terence Tao compartió un caso en el que la IA (AlphaEvolve) colaboró con humanos para batir tres veces el récord del índice del conjunto suma-diferencia en 30 días, y combinó el lenguaje Lean y GitHub Copilot para abordar el problema del límite “ε-δ”, demostrando la capacidad de la IA para ayudar a los principiantes, manejar tareas básicas y predecir la estructura de las demostraciones, pero también señalando sus deficiencias en derivaciones complejas y en la búsqueda de lemas matemáticos. Otro informe indicó que 30 matemáticos de primer nivel probaron OpenAI o4-mini en una reunión secreta, descubriendo que podía resolver algunos problemas extremadamente difíciles, mostrando un nivel cercano al de un genio matemático. Estos avances auguran que la IA podría convertirse en una valiosa asistente en la investigación matemática, pero también plantean nuevas reflexiones sobre el papel de los matemáticos y el fomento de la creatividad (fuente: 36氪)

💡 Otros
La carrera por tecnologías alternativas al GPS se intensifica; Xona Space Systems planea construir una constelación PNT en órbita baja : Debido a que la señal del sistema GPS es susceptible a interferencias (clima, torres 5G, inhibidores) y tiene una precisión limitada, y especialmente después de que su vulnerabilidad quedara expuesta en el conflicto ruso-ucraniano, encontrar alternativas se ha convertido en una prioridad estratégica. La startup californiana Xona Space Systems planea lanzar una constelación de satélites en órbita terrestre baja llamada Pulsar (finalmente 258 satélites). Sus satélites orbitan a menor altitud, con una intensidad de señal aproximadamente 100 veces mayor que la del GPS, son más difíciles de interferir y pueden penetrar mejor los obstáculos. Su objetivo es proporcionar servicios de posicionamiento, navegación y temporización (PNT) con precisión centimétrica y alta fiabilidad para soportar tecnologías emergentes como la conducción autónoma. El primer satélite de prueba se lanzará este mes a bordo del Transporter 14 de SpaceX (fuente: MIT Technology Review)

Un estudio explora el impacto positivo de la esperanza y el optimismo en la recuperación de pacientes cardíacos : Investigaciones recientes indican que la esperanza y el optimismo en pacientes cardíacos se correlacionan con mejores resultados de salud, mientras que la desesperanza se asocia con un mayor riesgo de mortalidad. Esto es consistente con los fenómenos del efecto placebo (expectativas positivas que mejoran los resultados) y el efecto nocebo (expectativas negativas que conducen a síntomas adversos). Alexander Montasem y otros investigadores de la Universidad de Liverpool encontraron que un alto grado de esperanza se asocia con una reducción de la angina, menor fatiga después de un accidente cerebrovascular, mejor calidad de vida y menor riesgo de muerte. Los investigadores están explorando cómo utilizar el poder del pensamiento positivo en la práctica clínica, por ejemplo, “prescribiendo esperanza” ayudando a los pacientes a establecer metas y mejorar su sentido de agencia, al tiempo que enfatizan que los objetivos no materiales son más importantes para el bienestar (fuente: MIT Technology Review)

La promoción de servicios de IA de Apple y Alibaba en China se ve obstaculizada, posiblemente debido a fricciones comerciales : Según el Financial Times, los planes de Apple y Alibaba para promover servicios de IA en China han sufrido retrasos, lo que se considera la última víctima de las fricciones comerciales entre China y Estados Unidos. Originalmente, la colaboración estaba destinada a proporcionar soporte de funciones de IA para los iPhones vendidos en China. Este retraso podría afectar el cronograma de implementación de las funciones de IA de Apple en el mercado chino y generar incertidumbre sobre las perspectivas de cooperación entre ambas compañías (fuente: MIT Technology Review)