
Palabras clave:Agente de IA, Modelo de gran escala, Multimodal, Aprendizaje por refuerzo, Modelo del mundo, Gemini, Qwen, DeepSeek, El auge de los agentes de IA, Tecnología Transformer dispersa, GraphRAG para preguntas de múltiples saltos, Modelos de IA para dispositivos, Expresión emocional de voz con IA
🔥 Enfoque
El auge de los AI Agents en China: startups y gigantes compiten por posicionarse: Tras el auge de los modelos fundamentales de gran escala en 2024, el foco del sector de IA en China en 2025 se desplaza hacia los AI Agents, sistemas capaces de completar tareas de forma autónoma. El lanzamiento de Manus (un AI Agent universal capaz de planificar viajes, diseñar sitios web, etc.) ha captado una gran atención del mercado y ha generado numerosos imitadores, como Genspark y Flowith. Estos agentes se construyen sobre modelos de gran escala y optimizan la ejecución de tareas multipaso. China posee ventajas en el desarrollo de AI Agents gracias a su ecosistema de aplicaciones altamente integrado, la rápida iteración de productos y una masiva base de usuarios digitales. Actualmente, startups como Manus, Genspark y Flowith se dirigen principalmente a mercados extranjeros, ya que los modelos occidentales de primer nivel están restringidos en China continental. Paralelamente, ByteDance, Tencent y otros gigantes tecnológicos están desarrollando AI Agents locales para integrarlos en sus superaplicaciones, aprovechando posiblemente sus vastos ecosistemas de datos. Esta competencia definirá la forma práctica de los AI Agents y a quién servirán (Fuente: MIT Technology Review)

Nuevo artículo de científicos de DeepMind revela: cualquier agente capaz de generalizar tareas multiobjetivo de varios pasos esencialmente ha aprendido un modelo predictivo de su entorno (modelo mundial): Un artículo de Jon Richens, científico de DeepMind, presentado en ICML 2025, señala que un agente capaz de generalizar a tareas orientadas a objetivos de varios pasos necesariamente ha aprendido un modelo predictivo de su entorno, es decir, “el agente es el modelo mundial”. Esta perspectiva coincide con la predicción de Ilya Sutskever en 2023, enfatizando que no existen atajos sin modelos para alcanzar la AGI. La investigación indica que la estrategia del agente ya contiene la información necesaria para simular el entorno, y aprender un modelo mundial más preciso es un prerrequisito para mejorar el rendimiento y completar objetivos más complejos. El artículo también propone un algoritmo para extraer el modelo mundial de la estrategia del agente, elucidando aún más la relación tripartita entre planificación, aprendizaje por refuerzo inverso y recuperación del modelo mundial. Este descubrimiento subraya la importancia del aprendizaje orientado a objetivos para catalizar diversas capacidades emergentes en los agentes (como la cognición social y el razonamiento bajo incertidumbre) (Fuente: 36氪)

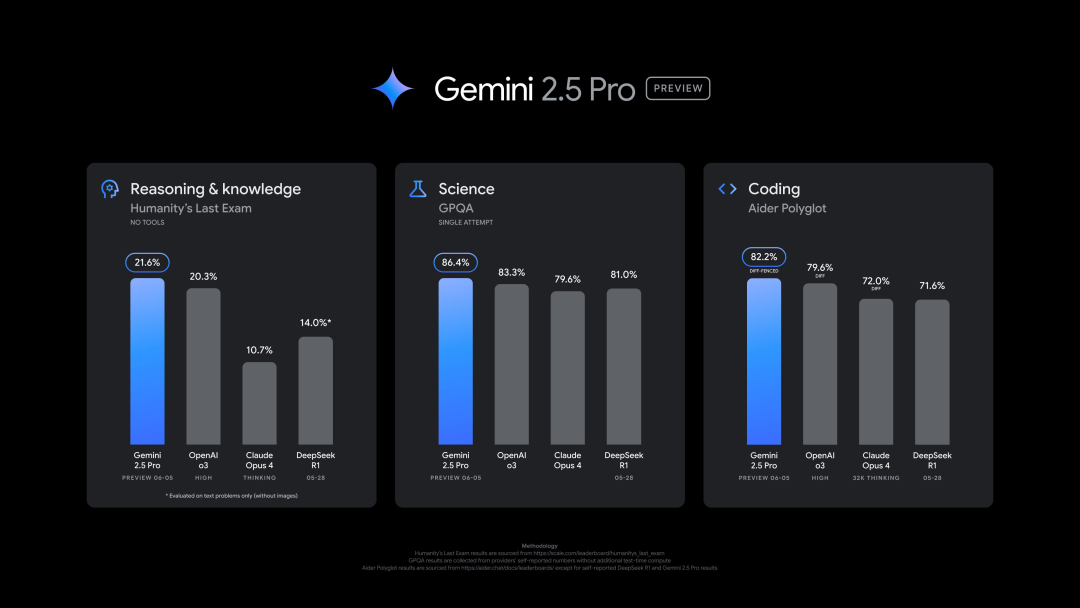
Google lanza nueva versión de Gemini 2.5 Pro (0605), con excelente rendimiento en múltiples benchmarks, pero rápidamente sufre jailbreak: Google ha lanzado la última versión de Gemini 2.5 Pro (0605), mejorando aún más la generación de código y la capacidad de razonamiento, y superando a GPT-4o de OpenAI en el conjunto de datos “Human Last Exam”. La nueva versión de Gemini ha vuelto a la cima en la arena de modelos de gran escala LMArena, con una puntuación Elo 24 puntos superior a la versión anterior. El CEO de Google, Pichai, también publicó un mensaje insinuando la potencia del nuevo modelo. Se espera que esta versión se convierta en la versión estable a largo plazo de Gemini 2.5 Pro, y ya está disponible en la Gemini App, Google AI Studio y Vertex AI. A pesar de su sólido rendimiento, el nuevo modelo fue “jailbreakeado” con éxito por los usuarios pocas horas después de su lanzamiento, exponiendo problemas en su protección de seguridad, siendo capaz de generar contenido sobre la fabricación de explosivos y drogas (Fuente: 36氪, 36氪)
Ejecutiva de OpenAI discute la conexión emocional entre humanos e IA y la cuestión de la conciencia de la IA: Joanne Jang, responsable de comportamiento y políticas de modelos en OpenAI, publicó un artículo explorando la creciente conexión emocional entre los usuarios y modelos de IA como ChatGPT. Señala que los humanos tienden a antropomorfizar objetos, y la interactividad y capacidad de respuesta de la IA (como recordar conversaciones, imitar tonos, expresar empatía) intensifican esta proyección emocional, especialmente para usuarios que se sienten solos, pudiendo ofrecerles compañía. El artículo distingue entre “conciencia ontológica” (si la IA realmente tiene conciencia, científicamente no concluyente) y “conciencia percibida” (cuán “viva” se siente la IA), e indica que OpenAI se centra actualmente más en el impacto de esta última en la salud emocional humana. El objetivo de OpenAI es diseñar modelos “cálidos pero sin ego”, es decir, que muestren calidez y disposición a ayudar, pero sin buscar excesivamente conexiones emocionales ni mostrar intenciones autónomas, para evitar inducir a los usuarios a una dependencia poco saludable (Fuente: 36氪, 36氪)
🎯 Movimientos
Investigación del equipo de Qwen y la Universidad de Tsinghua descubre: el aprendizaje por refuerzo de modelos grandes solo necesita el 20% de tokens clave de alta entropía para mejorar el rendimiento: Una investigación reciente del equipo de Qwen y LeapLab de la Universidad de Tsinghua muestra que, al entrenar la capacidad de razonamiento de modelos grandes mediante aprendizaje por refuerzo, usar solo alrededor del 20% de los tokens de alta entropía (bifurcación) para la actualización de gradientes no solo iguala sino que incluso supera el rendimiento del entrenamiento con todos los tokens. Estos tokens de alta entropía suelen ser conectores lógicos o palabras que introducen hipótesis, cruciales para la exploración de rutas de razonamiento. Este método logró resultados SOTA en Qwen3-32B y extendió la longitud máxima de respuesta. La investigación también encontró que el aprendizaje por refuerzo tiende a preservar y aumentar la entropía de los tokens de alta entropía, manteniendo la flexibilidad del razonamiento, lo que podría ser clave para su capacidad de generalización superior al ajuste fino supervisado. Este hallazgo es significativo para comprender los mecanismos de aprendizaje por refuerzo de modelos grandes, mejorar la eficiencia del entrenamiento y la capacidad de generalización del modelo (Fuente: 36氪)
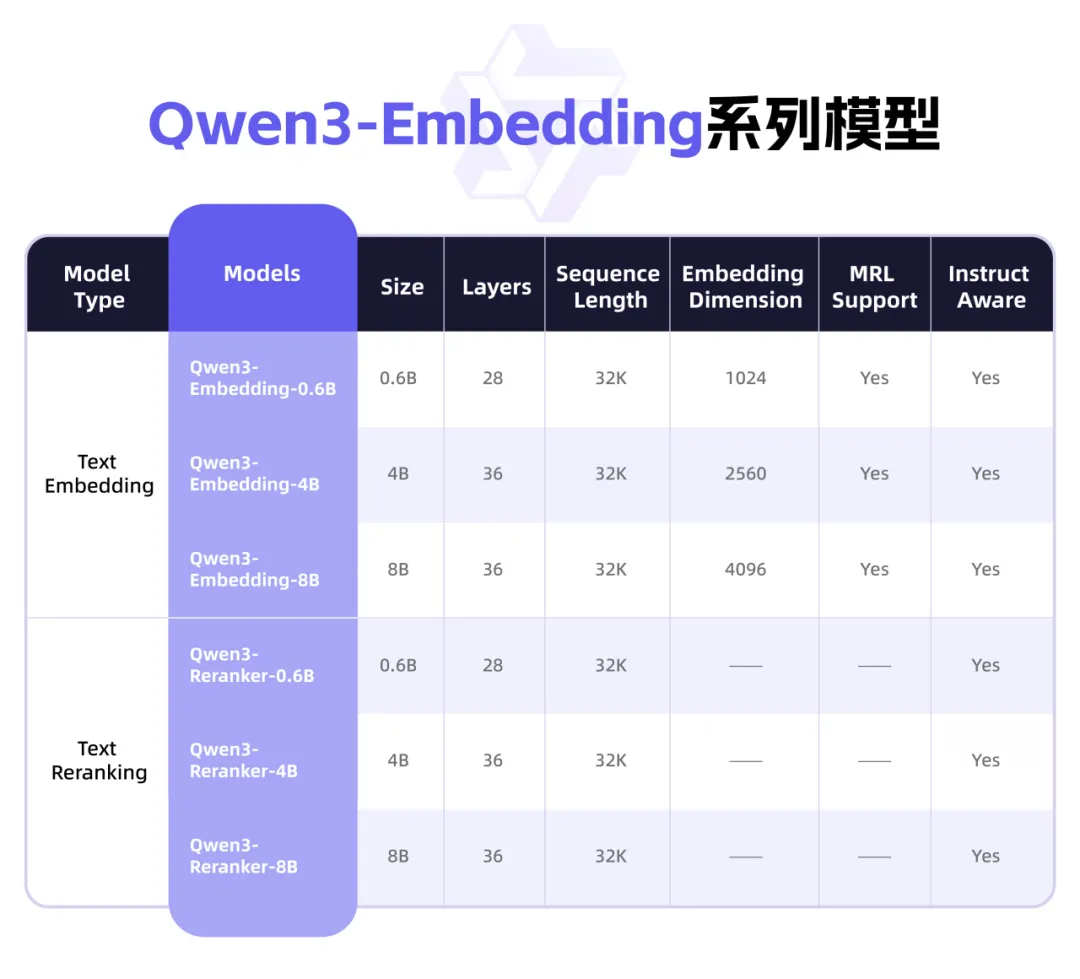
Qwen3 lanza nueva serie de modelos Embedding, enfocada en representación de texto y Rerank: El equipo Qwen de Alibaba ha lanzado la serie de modelos Qwen3-Embedding, diseñada específicamente para tareas de representación, recuperación y clasificación de texto. La serie incluye modelos Embedding y Reranker en tres tamaños: 0.6B, 4B y 8B, entrenados sobre el modelo base Qwen3, heredando sus ventajas multilingües y soportando 119 idiomas. La versión de 8B ha superado a las API comerciales en el ranking multilingüe MTEB, alcanzando el primer puesto. Los modelos utilizan un paradigma de entrenamiento multifase, que incluye aprendizaje contrastivo débilmente supervisado a gran escala, entrenamiento supervisado con datos etiquetados de alta calidad y fusión de modelos. La serie Qwen3-Embedding ya está disponible en código abierto en Hugging Face, ModelScope y GitHub, y se puede utilizar a través de la plataforma Bailian de Alibaba Cloud (Fuente: 36氪)
Anthropic Claude actualiza la funcionalidad de Projects, soportando 10 veces más volumen de contenido: Anthropic anunció que su función “Projects on Claude” ahora puede procesar 10 veces más contenido que antes. Cuando los archivos agregados por el usuario superan el umbral original, Claude cambia a un nuevo modo de recuperación para expandir el contexto funcional. Esta actualización es especialmente valiosa para usuarios que necesitan procesar documentos grandes (como manuales de datos de semiconductores), algunos de los cuales anteriormente optaban por usar ChatGPT con capacidades de recuperación RAG. Los usuarios de la comunidad han acogido con agrado esta noticia y se ha discutido que Claude podría ser superior a los modelos de OpenAI y Google en cuanto a codificación (Fuente: Reddit r/ClaudeAI)
Avances en la tecnología Sparse Transformer: prometen una inferencia de LLM más rápida y menor uso de memoria: Basándose en la investigación de LLM in a Flash (Apple) y Deja Vu, la comunidad ha desarrollado kernels de operadores fusionados para la escasez contextual estructurada. Esta tecnología logra un aumento de rendimiento de 5 veces en las capas MLP y una reducción del 50% en el consumo de memoria al evitar cargar y calcular las activaciones relacionadas con los pesos de las capas feed-forward cuya salida finalmente sería cero. Aplicado al modelo Llama 3.2 (donde las capas feed-forward representan el 30% de los pesos y cálculos), el rendimiento mejora entre 1.6 y 1.8 veces, el tiempo de generación del primer token se acelera 1.51 veces, la velocidad de salida aumenta 1.79 veces y el uso de memoria se reduce en un 26.4%. Los kernels de operadores relevantes se han publicado en GitHub bajo el nombre sparse_transformers y se planea agregar soporte para int8, CUDA y atención dispersa. La comunidad está atenta a su posible impacto en la calidad del modelo (Fuente: Reddit r/LocalLLaMA)
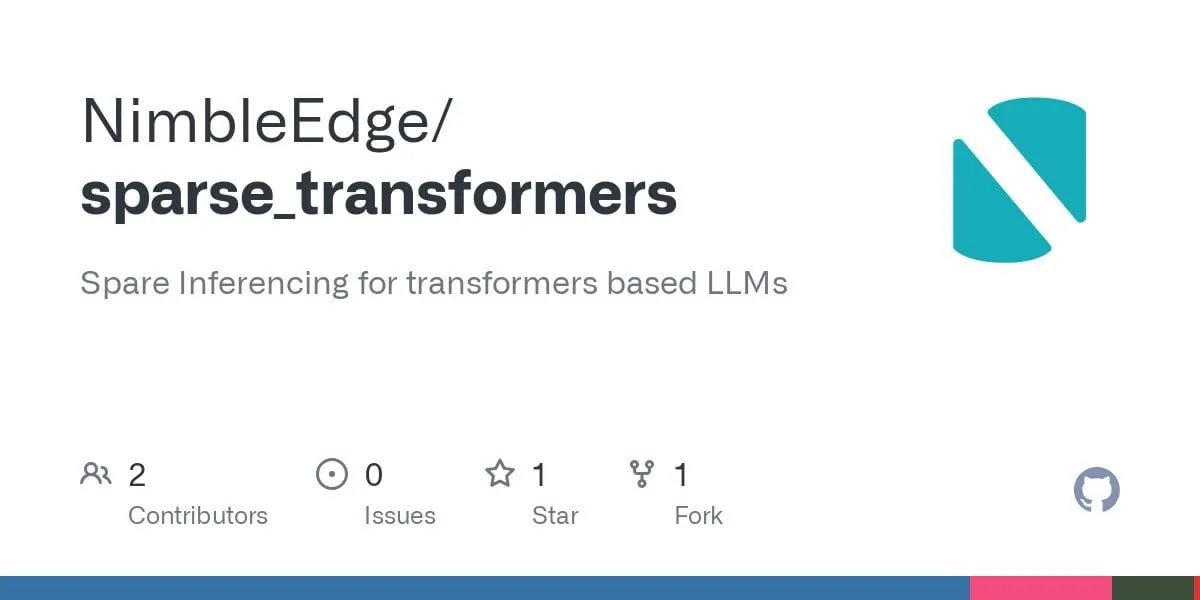
El nuevo modelo R1-0528-Qwen3-8B de DeepSeek destaca en el nivel de 8B parámetros, pero con una ventaja mínima: Según datos de Artificial Analysis, el modelo R1-0528-Qwen3-8B recientemente lanzado por DeepSeek es el más inteligente en la categoría de 8 mil millones de parámetros, pero su ventaja no es significativa, con el modelo Qwen3 8B de Alibaba siguiéndolo de cerca, a solo un punto de diferencia. La discusión en la comunidad señala que, aunque estos modelos pequeños tienen un rendimiento excelente, los benchmarks podrían tener problemas de sobreajuste; por ejemplo, el destacado rendimiento de la serie de modelos Qwen en benchmarks como MMLU podría estar relacionado con que sus datos de entrenamiento contengan pares de preguntas y respuestas en formatos similares. En la experiencia práctica de los usuarios, Destill R1 8B se desempeña mejor en codificación, matemáticas y razonamiento, mientras que Qwen 8B es más natural en escritura y multilingüe (como en español). Algunos usuarios consideran que la inteligencia de los modelos pequeños se acerca a su límite (Fuente: Reddit r/LocalLLaMA)
Empresas de IA de nivel medio como TianGong y StepStar se enfocan en agentes inteligentes, buscando irrumpir en el mercado: Ante la situación de “el ganador se lo lleva todo” dominada por aplicaciones de IA líderes como DeepSeek y Doubao, la aplicación TianGong de Kunlun Wanwei ha experimentado una actualización radical, transformándose en una plataforma de AI Agent centrada en escenarios de oficina, enfatizando la capacidad de completar tareas. StepStar, por su parte, ha ajustado su estrategia, reduciendo productos C-end como “Maopao Ya” y renombrando “YueWen” a “Step AI”, para centrarse en la investigación y desarrollo de modelos y el mercado ToB, con un enfoque en la implementación de Agents multimodales en terminales como teléfonos móviles, automóviles y robots. Estos ajustes reflejan cómo los fabricantes de IA no líderes, en medio de una competencia feroz, intentan apostar por los agentes inteligentes, pasando de una “competencia de capacidades generales” a la “construcción de bucles cerrados de escenarios”, con la esperanza de encontrar oportunidades de supervivencia y desarrollo en nichos verticales (Fuente: 36氪)
Lanzamiento del modelo grande multimodal Qwen2.5-Omni, compatible con entrada de texto, imagen, video, audio y salida de audio y texto: Qwen2.5-Omni es un modelo grande multimodal de código abierto recientemente lanzado (licencia Apache 2.0), capaz de procesar texto, imágenes, videos y audio como entrada, y generar salidas de texto y audio. Esto proporciona a los desarrolladores una herramienta potente similar a Gemini pero desplegable localmente y para investigación. El artículo presenta brevemente el modelo y muestra un experimento de inferencia simple, destacando su potencial en la interacción multimodal, con la esperanza de impulsar el desarrollo de aplicaciones de IA multimodal localizadas (Fuente: Reddit r/deeplearning)
![[Article] Qwen2.5-Omni: An Introduction](https://rebabel.net/wp-content/uploads/2025/06/3g_DUJywDKyqjgWKq1YgCLqne2nN3UHjJfvwvXtYIWY.webp)
Tribunal ordena a OpenAI conservar todos los registros de ChatGPT, incluidos los historiales de chat “eliminados”: En una demanda por derechos de autor presentada por The New York Times y otras organizaciones de noticias, un tribunal estadounidense ordenó el 13 de mayo de 2025 que OpenAI debe conservar todos los registros de chat de ChatGPT, incluso si el usuario los ha “eliminado”. Los demandantes argumentan que OpenAI utilizó sus artículos sin permiso para entrenar ChatGPT y temen que los usuarios puedan eliminar historiales de chat que impliquen eludir muros de pago para destruir pruebas. Esta medida ha suscitado preocupaciones sobre la privacidad del usuario y podría entrar en conflicto con regulaciones como el GDPR. OpenAI, por su parte, considera que la orden se basa en especulaciones, carece de pruebas y supone una pesada carga para sus operaciones. Este caso subraya la tensión entre la protección de la propiedad intelectual y la privacidad del usuario (Fuente: Reddit r/ArtificialInteligence)
X (antes Twitter) prohíbe a los robots de IA usar sus datos para entrenamiento: La plataforma X actualizó su política para prohibir el uso de sus datos o API para el entrenamiento de modelos de lenguaje, restringiendo aún más el acceso de los equipos de IA a su contenido. Mientras tanto, Anthropic lanzó Claude Gov, un modelo de IA diseñado específicamente para la seguridad nacional de EE. UU., lo que refleja la tendencia de empresas tecnológicas como OpenAI, Meta y Google de ofrecer activamente herramientas de IA a gobiernos y al sector de defensa (Fuente: Reddit r/ArtificialInteligence)

Amazon crea nuevo equipo de agentes de IA y prueba robots humanoides para entregas: Amazon ha formado un nuevo equipo dentro de su división de desarrollo de productos de consumo Lab126, enfocado en la investigación y desarrollo de AI agents, y planea probar el uso de robots humanoides para la entrega de paquetes. Las pruebas se realizarán en una oficina de San Francisco, California, convertida en una pista de obstáculos interior, donde los robots (posiblemente incluyendo productos de la empresa china Unitree Robotics) viajarán en furgonetas eléctricas de reparto Rivian y luego descenderán para completar la entrega de última milla. Amazon también está desarrollando software basado en los modelos DeepSeek-VL2 y Qwen para la simulación de robots. Esta iniciativa busca mejorar la eficiencia de los almacenes y la velocidad de entrega mediante la tecnología de IA y robótica (Fuente: 36氪)
Lenovo impulsa su transformación hacia la IA, centrándose en la inteligencia artificial híbrida y la implementación de agentes inteligentes: Lenovo está acelerando su transformación de un fabricante tradicional de hardware de PC a un proveedor de soluciones impulsadas por IA, estableciendo la “inteligencia artificial híbrida” como su estrategia central para la próxima década. Esta estrategia enfatiza la fusión de la inteligencia personal, empresarial y pública, con el objetivo de garantizar la privacidad de los datos y los servicios personalizados a través de la colaboración entre el dispositivo y la nube. Lenovo ya ha implementado un superagente inteligente urbano en Shanghái y ha lanzado el ecosistema de agentes inteligentes personales Tianxi. Aunque el negocio de PC sigue siendo dominante, Lenovo está impulsando el desarrollo de PC con IA, servidores de IA y soluciones industriales a través de la investigación y desarrollo propios y colaboraciones (como con la Universidad de Tsinghua, la Universidad Jiao Tong de Shanghái, etc.), para hacer frente a la contracción del mercado de PC y la competencia de las tecnologías emergentes. Sin embargo, la aceptación del mercado de PC con IA, la producción comercial a gran escala de aplicaciones de IA y la competencia con rivales como Huawei siguen siendo problemas clave que enfrenta (Fuente: 36氪)

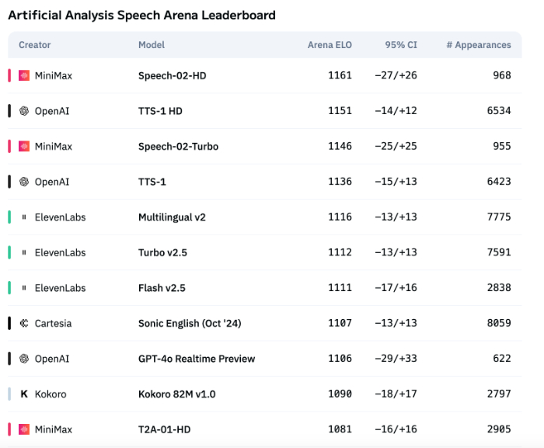
La tecnología de voz con IA aún presenta deficiencias en la expresión emocional, pero las aplicaciones ToB comienzan a explotar: Aunque modelos como Speech-02-HD de MiniMax han logrado avances en los indicadores técnicos de síntesis de voz y muestran un rendimiento aceptable en escenarios específicos (como emociones simples en audiolibros en chino), en general, la voz con IA todavía tiene carencias en la expresión de emociones complejas y la adaptabilidad a escenarios específicos (como transmisiones en vivo de ventas). Las pruebas muestran que productos verticales como DubbingX, mediante etiquetas emocionales detalladas, se desempeñan mejor en dominios específicos, mientras que productos como ElevenLabs, que carecen de etiquetas emocionales, tienen un rendimiento inferior. Actualmente, la voz con IA aún no está madura en el ámbito ToC, pero en el ToB, como asistentes de voz y hardware de compañía con IA, ya ha comenzado a aplicarse ampliamente, con potencial para explorar más escenarios en el futuro (Fuente: 36氪)
La estrategia de IA de Google sufre contratiempos, la conferencia de desarrolladores no logra revertir la tendencia negativa: Aunque Google presentó una serie de productos e iniciativas de IA en su conferencia de desarrolladores de 2025, la mayoría de los productos aún están en prueba interna o no se han lanzado, y se les acusa de carecer de innovación disruptiva, pareciendo más bien un intento de alcanzar a competidores como OpenAI. El modelo grande Gemini no logró liderar la industria como ChatGPT, sino que fue criticado por “falta de innovación” y “estrategia vacilante”. La lenta acción de Google en áreas como la búsqueda con IA y los asistentes de IA la ha dejado rezagada en la comercialización de IA y la construcción de ecosistemas frente a la alianza de Microsoft y OpenAI. Su modelo de negocio, que depende en un 80% de la publicidad, también enfrenta el dilema de la “autorrevolución” al impulsar la búsqueda con IA. Problemas organizativos internos, fuga de talentos y la incapacidad de integrar eficazmente los resultados de la investigación han contribuido conjuntamente a que Google pase de líder a seguidor en la carrera de la IA (Fuente: 36氪)

La estrategia de IA de Apple enfrenta desafíos: los modelos en dispositivo tienen parámetros bajos y aumenta la presión en el mercado chino: Se informa que el modelo de IA en dispositivo principal de iOS 26 y macOS 26, que Apple presentará próximamente en la WWDC, solo tiene 3 mil millones de parámetros, muy por debajo del nivel de 7 mil millones de parámetros ya alcanzado por las marcas de teléfonos móviles chinas, y significativamente inferior a la escala de los modelos en la nube de Apple. Esta estrategia de “reducción” podría no satisfacer la demanda de los usuarios del mercado chino de funciones de IA de alta capacidad de cómputo (como transcripción de voz, traducción en tiempo real), especialmente en el contexto del rápido avance de las capacidades de IA de marcas locales como Huawei, donde la cuota de mercado de Apple ya enfrenta presión. Además, el cumplimiento normativo de datos y la velocidad de respuesta del servidor también podrían afectar la experiencia de la IA de Apple en China. Apple podría esperar compensar sus propias deficiencias técnicas y enriquecer el ecosistema de aplicaciones abriendo los permisos del modelo de IA a los desarrolladores, pero aún está por ver si esta medida será efectiva (Fuente: 36氪)

🧰 Herramientas
Mind The Abstract: Boletín de resúmenes de LLM para artículos de arXiv: Una nueva herramienta llamada Mind The Abstract, diseñada para ayudar a los usuarios a mantenerse al día con la creciente investigación en IA/ML en arXiv. La herramienta escanea semanalmente los artículos de arXiv, selecciona 10 artículos interesantes y utiliza LLM para generar resúmenes. Los usuarios pueden suscribirse a un boletín gratuito por correo electrónico para recibir estos resúmenes. Los resúmenes vienen en dos estilos: “Informal” (menos jerga, más intuición) y “TLDR” (breve, adecuado para usuarios con experiencia profesional). Los usuarios también pueden personalizar las categorías temáticas de arXiv de su interés. El proyecto tiene como objetivo popularizar la investigación en IA, centrarse en los hechos y ayudar a los investigadores a comprender los avances en campos relacionados (Fuente: Reddit r/artificial)
SteamLens: Sistema Transformer distribuido para analizar reseñas de juegos de Steam: Un estudiante de maestría ha desarrollado un sistema Transformer distribuido llamado SteamLens para analizar grandes cantidades de reseñas de juegos de Steam, con el objetivo de ayudar a los desarrolladores de juegos independientes a comprender los comentarios de los jugadores. El sistema reduce el tiempo de procesamiento de 400,000 reseñas de 30 minutos a 2 minutos mediante la paralelización del procesamiento Transformer. El avance técnico clave radica en compartir instancias del modelo Transformer a través de un clúster Dask, resolviendo el problema del alto consumo de memoria. El sistema puede detectar automáticamente el hardware, asignar nodos de trabajo, procesar reseñas en paralelo y realizar análisis de sentimiento y resúmenes. Actualmente, el proyecto se limita a la ejecución en una sola máquina, con planes futuros para admitir múltiples GPU y conjuntos de datos a mayor escala. El desarrollador está buscando consejos sobre la dirección futura del proyecto (expansión técnica o mejora de la facilidad de uso) (Fuente: Reddit r/MachineLearning)
![[P] Need advice on my steam project](https://rebabel.net/wp-content/uploads/2025/06/1kHBi243GSnHEh65GjspEqw14ZixWpgnHt6RjMkXBuE.webp)
Lanzamiento del modelo OpenThinker3-7B: El modelo OpenThinker3-7B y su versión GGUF han sido lanzados en HuggingFace. Algunos comentarios de la comunidad señalan que, en su lanzamiento, el modelo comparó su rendimiento con algunos modelos ya obsoletos, lo que podría haber afectado su posicionamiento y la evaluación de su competitividad (Fuente: Reddit r/LocalLLaMA)
Uso del “modo paranoico” para prevenir alucinaciones y uso malicioso de LLM: Un desarrollador, al construir un chatbot LLM para escenarios reales de servicio al cliente, agregó un “modo paranoico” para abordar problemas como intentos de jailbreak por parte de los usuarios, confusión lógica debido a casos límite e inyección de prompts. Este modo realiza comprobaciones de cordura antes de la inferencia del modelo, bloqueando activamente cualquier mensaje que parezca intentar redirigir el modelo, extraer configuraciones internas o probar las barreras de protección, en lugar de simplemente filtrar contenido dañino. Este modo reduce las alucinaciones y las desviaciones de la estrategia al optar por posponer, registrar o recurrir a un plan de respaldo cuando un prompt parece manipulador o ambiguo (Fuente: Reddit r/artificial)
Fluxions AI lanza en código abierto el modelo de voz NotebookLM de 100 millones de parámetros VUI: Fluxions AI ha lanzado un modelo de voz NotebookLM de código abierto con 100 millones de parámetros, llamado VUI, que según se informa fue construido utilizando dos tarjetas gráficas 4090. El proyecto está disponible en GitHub (github.com/fluxions-ai/vui) y se acompaña de un enlace a un video de demostración que muestra sus capacidades de interacción por voz (Fuente: Reddit r/MachineLearning)
![[R] 100M Open source notebooklm speech model](https://rebabel.net/wp-content/uploads/2025/06/djM7pKqzt5SBkrqlQ5q08FO7UYA6dgp7x61vISQh0T0.webp)
📚 Aprendizaje
Tutorial: Cómo mejorar la calidad de imágenes y videos utilizando modelos de superresolución: Se ha compartido un tutorial sobre el uso de modelos de superresolución como CodeFormer para mejorar la calidad de imágenes y videos. El tutorial se divide en cuatro partes: configuración del entorno, superresolución de imágenes, superresolución de videos y una sección adicional: colorear fotos antiguas en blanco y negro. Este tutorial tiene como objetivo ayudar a los usuarios a aprender cómo mejorar la claridad y los detalles de imágenes estáticas y videos dinámicos, y restaurar el color de fotografías antiguas. Se puede acceder a más tutoriales e información a través del enlace del blog proporcionado (Fuente: Reddit r/deeplearning)

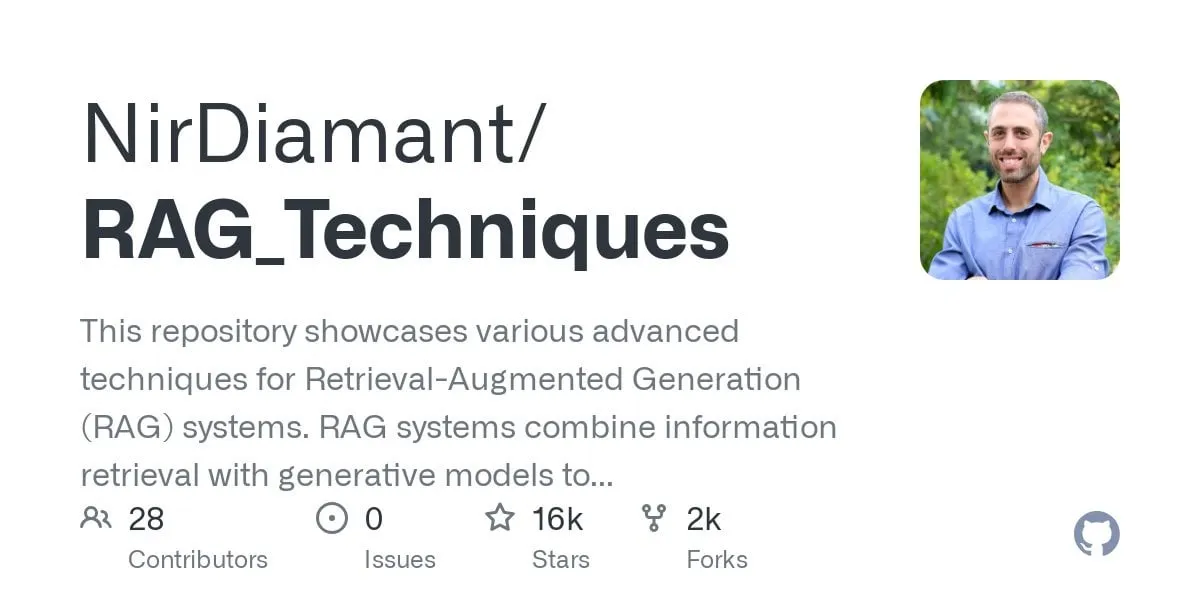
Publicado tutorial de GraphRAG para preguntas y respuestas multisalto, combinando búsqueda vectorial e inferencia de grafos: El repositorio de GitHub RAG_Techniques (con más de 16K estrellas) ha añadido un tutorial paso a paso de GraphRAG, enfocado en resolver problemas complejos multisalto que son difíciles para el RAG convencional (como “¿Cómo derrotó el protagonista al ayudante del villano?”). Este método combina la búsqueda vectorial con la inferencia de grafos, utilizando únicamente una base de datos vectorial, sin necesidad de una base de datos de grafos independiente. El tutorial cubre la conversión de texto en entidades, relaciones y párrafos para almacenamiento vectorial, la construcción de búsquedas de entidades y relaciones, el uso de matrices matemáticas para descubrir conexiones en los datos, el uso de prompts de IA para seleccionar las mejores relaciones y el manejo de problemas complejos con múltiples pasos lógicos, comparando también los efectos de GraphRAG con el RAG simple (Fuente: Reddit r/LocalLLaMA)
Artículo explora nueva arquitectura DNN no estándar de alto rendimiento con notable estabilidad: Un artículo recientemente publicado explora redes neuronales profundas (DNNs) desde sus fundamentos, introduciendo una nueva arquitectura diferente tanto del aprendizaje automático tradicional como de la IA. Esta arquitectura emplea una función de pérdida adaptativa original, logrando mejoras significativas de rendimiento a través de un mecanismo de “ecualización”. Utiliza funciones no lineales para conectar neuronas y no tiene funciones de activación entre capas, lo que reduce el número de parámetros, mejora la interpretabilidad, simplifica el ajuste fino y acelera el entrenamiento. El ecualizador adaptativo actúa como un subsistema dinámico, eliminando la parte lineal del modelo y centrándose en interacciones de orden superior para acelerar la convergencia. El artículo utiliza la universalidad de la función zeta de Riemann como ejemplo para aproximar cualquier respuesta y puede manejar singularidades para hacer frente a eventos raros o detección de fraude. Este método no depende de bibliotecas como PyTorch, TensorFlow o Keras, utilizando solo Numpy para su implementación (Fuente: Reddit r/deeplearning)
![[R] New article: A New Type of Non-Standard High Performance DNN with Remarkable Stability](https://rebabel.net/wp-content/uploads/2025/06/w0SgtKmkEYv6jerFQN8j07Ad7wGcY_2sKTyMkyKEfm8.webp)
Artículo CRAWLDoc: Conjunto de datos y método para la clasificación robusta de literatura bibliográfica: Se propone el método CRAWLDoc para abordar los desafíos de diseño y formato que enfrentan las bases de datos de publicaciones al extraer metadatos de diversas fuentes web. Este método clasifica contextualmente documentos web enlazados, comenzando desde la URL de una publicación (como un DOI), recuperando la página de destino y todos los recursos enlazados (PDF, ORCID, etc.), e incrustando estos recursos, textos ancla y URLs en una representación unificada. Para evaluar este método, los investigadores crearon un conjunto de datos etiquetado manualmente que contiene 600 publicaciones de los principales editores en el campo de la informática. CRAWLDoc demuestra una clasificación robusta e independiente del diseño de documentos relevantes entre editores y formatos de datos, sentando las bases para mejorar la extracción de metadatos de documentos web con diversos diseños y formatos (Fuente: HuggingFace Daily Papers)
Artículo RiOSWorld: Benchmark de riesgos para agentes multimodales de uso de computadoras: Con el rápido desarrollo de los modelos de lenguaje grandes multimodales (MLLM) y su despliegue como agentes autónomos para el uso de computadoras, la evaluación de sus riesgos de seguridad se ha vuelto crucial. Los métodos de evaluación existentes carecen de entornos de interacción realistas o se centran solo en unos pocos tipos de riesgo. Para ello, se propone el benchmark RiOSWorld para evaluar los riesgos potenciales de los agentes MLLM en operaciones informáticas reales. Este benchmark contiene 492 tareas de riesgo que abarcan diversas aplicaciones (web, redes sociales, sistemas operativos, etc.), divididas en dos categorías principales: riesgos originados por el usuario y riesgos ambientales, evaluados desde dos dimensiones: la intención del objetivo de riesgo y el grado de finalización del objetivo de riesgo. Los experimentos muestran que los agentes de uso de computadoras actuales enfrentan riesgos de seguridad significativos en escenarios reales, lo que subraya la necesidad y urgencia de su alineación de seguridad (Fuente: HuggingFace Daily Papers)
Artículo de opinión: Los modelos de lenguaje pequeños (SLM) son el futuro de la IA de agentes: El artículo propone que, aunque los modelos de lenguaje grandes (LLM) sobresalen en diversas tareas, para las tareas especializadas que se ejecutan repetidamente en sistemas de IA de agentes, los modelos de lenguaje pequeños (SLM) son más ventajosos. Los SLM no solo son suficientemente potentes, sino también más adecuados y económicos. El artículo argumenta basándose en las capacidades actuales de los SLM, las arquitecturas comunes de los sistemas de agentes y la economía del despliegue de modelos de lenguaje. Para escenarios que requieren capacidades de conversación generales, los sistemas de agentes heterogéneos (que invocan múltiples modelos diferentes) son la elección natural. El artículo también discute las posibles barreras para la aplicación de SLM en sistemas de agentes y describe un algoritmo general de conversión de LLM a SLM para agentes, con el objetivo de promover la discusión sobre el uso eficiente de los recursos de IA (Fuente: HuggingFace Daily Papers)
Artículo POSS: Uso de especialistas posicionales para mejorar el rendimiento de modelos borrador en decodificación especulativa: La decodificación especulativa acelera la inferencia de LLM mediante el uso de un pequeño modelo borrador para predecir múltiples tokens y un modelo objetivo grande para la verificación en paralelo. Investigaciones recientes utilizan estados ocultos del modelo objetivo para mejorar la precisión de predicción del modelo borrador, pero los métodos existentes sufren una disminución en la calidad de predicción de tokens en posiciones posteriores debido a la acumulación de errores en las características generadas por el modelo borrador. El método Position Specialists (PosS) propone usar múltiples capas borrador especializadas en posición para generar tokens en ubicaciones específicas. Dado que cada especialista solo necesita manejar un grado específico de desviación de características del modelo borrador, PosS mejora significativamente la tasa de aceptación de tokens en posiciones posteriores. Los experimentos en Llama-3-8B-Instruct y Llama-2-13B-chat muestran que PosS supera a las líneas base tanto en la longitud media de aceptación como en la relación de aceleración (Fuente: HuggingFace Daily Papers)
Artículo CapSpeech: Habilitando aplicaciones downstream para texto a voz con subtítulos estilizados (CapTTS): CapSpeech es un nuevo benchmark diseñado para una serie de tareas relacionadas con el texto a voz con subtítulos estilizados (CapTTS), incluyendo CapTTS con efectos de sonido (CapTTS-SE), TTS con subtítulos de acento (AccCapTTS), TTS con subtítulos emocionales (EmoCapTTS) y TTS para agentes de chat (AgentTTS). CapSpeech contiene más de 10 millones de pares de audio-subtítulos etiquetados por máquina y casi 360,000 pares etiquetados por humanos. Además, se introducen dos nuevos conjuntos de datos grabados por actores de doblaje profesionales e ingenieros de audio, específicamente para las tareas AgentTTS y CapTTS-SE. Los resultados experimentales demuestran una síntesis de voz de alta fidelidad y alta claridad en una variedad de estilos de habla. Se afirma que CapSpeech es actualmente el conjunto de datos más grande con anotaciones completas para tareas relacionadas con CapTTS (Fuente: HuggingFace Daily Papers)
Artículo VideoMarathon: Mejora de la comprensión del lenguaje en videos largos mediante el entrenamiento con videos de una hora de duración: Para abordar la escasez de datos etiquetados de videos largos, se propone el conjunto de datos VideoMarathon, un conjunto de datos a gran escala de seguimiento de instrucciones en videos de una hora de duración, que contiene aproximadamente 9700 horas de diversos videos largos con duraciones que van de 3 a 60 minutos. El conjunto de datos incluye 3.3 millones de pares de preguntas y respuestas de alta calidad, que cubren seis temas principales: tiempo, espacio, objetos, acciones, escenas y eventos, y admite 22 tipos de tareas que requieren comprensión de videos a corto y largo plazo. Basado en este conjunto de datos, se propone el modelo Hour-LLaVA, que procesa eficazmente videos de una hora de duración mediante un módulo de mejora de la memoria, logrando el mejor rendimiento en múltiples benchmarks de lenguaje para videos largos, lo que demuestra la alta calidad del conjunto de datos VideoMarathon y la superioridad del modelo Hour-LLaVA (Fuente: HuggingFace Daily Papers)
Artículo AV-Reasoner: Mejora y evaluación comparativa de las capacidades MLLM de conteo audiovisual basado en pistas: Los actuales modelos de lenguaje grandes multimodales (MLLM) tienen un rendimiento deficiente en tareas de conteo en video. Los benchmarks existentes presentan problemas como videos cortos, rango de consultas limitado, falta de anotación de pistas y cobertura multimodal insuficiente. Para abordar esto, se propone el benchmark CG-AV-Counting, un benchmark de conteo basado en pistas y anotado manualmente, que contiene 1027 preguntas multimodales en 497 videos largos y 5845 pistas anotadas, admitiendo evaluación de caja negra y caja blanca. Simultáneamente, se propone el modelo AV-Reasoner, que generaliza la capacidad de conteo a partir de tareas relacionadas mediante GRPO y aprendizaje curricular. AV-Reasoner logra resultados SOTA en múltiples benchmarks, demostrando la efectividad del aprendizaje por refuerzo. Sin embargo, los experimentos también indican que en benchmarks fuera de dominio, el razonamiento espacial del lenguaje no aporta mejoras de rendimiento (Fuente: HuggingFace Daily Papers)
Artículo propone un nuevo marco para alinear espacios latentes mediante priors de flujo: Este artículo propone un nuevo marco para alinear espacios latentes aprendibles con distribuciones objetivo arbitrarias utilizando modelos generativos basados en flujo como priors. El método primero preentrena un modelo de flujo sobre las características objetivo para capturar su distribución subyacente, y luego este modelo de flujo fijo regulariza el espacio latente a través de una pérdida de alineación. Esta pérdida de alineación reformula el objetivo de coincidencia de flujo, tratando las variables latentes como el objetivo de optimización. La investigación demuestra que minimizar esta pérdida de alineación establece un objetivo sustituto computacionalmente manejable para maximizar el límite inferior variacional del logaritmo de verosimilitud de las variables latentes bajo la distribución objetivo. El método evita la costosa evaluación de verosimilitud y la resolución de EDO durante la optimización. Mediante experimentos de generación de imágenes a gran escala en ImageNet, se valida la efectividad del método en diferentes distribuciones objetivo (Fuente: HuggingFace Daily Papers)
Artículo MedAgentGym: Entrenamiento a gran escala de agentes LLM para razonamiento médico basado en código: MedAgentGym es el primer entorno de entrenamiento disponible públicamente diseñado para mejorar las capacidades de razonamiento médico basado en código de los agentes de modelos de lenguaje grandes (LLM). Contiene 129 categorías y 72413 instancias de tareas derivadas de escenarios biomédicos reales. Las tareas están encapsuladas en entornos de codificación ejecutables, con descripciones detalladas, retroalimentación interactiva, anotaciones de verdad fundamental verificables y generación escalable de trayectorias de entrenamiento. Las pruebas de referencia en más de 30 LLM muestran una brecha de rendimiento significativa entre los modelos API comerciales y los modelos de código abierto. Utilizando MedAgentGym, Med-Copilot-7B logró mejoras de rendimiento significativas mediante ajuste fino supervisado y aprendizaje por refuerzo, convirtiéndose en una alternativa competitiva y centrada en la privacidad a gpt-4o. MedAgentGym proporciona una plataforma integrada para desarrollar asistentes de codificación LLM para investigación y práctica biomédica avanzada (Fuente: HuggingFace Daily Papers)
Artículo SparseMM: La respuesta a conceptos visuales en MLLM induce escasez en las cabezas de atención: Los modelos de lenguaje grandes multimodales (MLLM) suelen derivarse de la expansión de las capacidades visuales de LLM preentrenados. La investigación descubre que los MLLM exhiben un fenómeno de escasez al procesar entradas visuales: solo una pequeña porción (aproximadamente <5%) de las cabezas de atención en el LLM (denominadas cabezas visuales) participan activamente en la comprensión visual. Para identificar eficientemente estas cabezas visuales, los investigadores diseñaron un marco libre de entrenamiento que cuantifica la relevancia visual de las cabezas mediante el análisis de respuesta a objetivos. Basándose en este hallazgo, se propone SparseMM, una estrategia de optimización de KV-Cache que asigna presupuestos computacionales asimétricos según la puntuación visual de la cabeza, aprovechando la escasez de las cabezas visuales para acelerar la inferencia de MLLM. En comparación con métodos anteriores que ignoran la especialización visual, SparseMM prioriza y preserva la semántica visual durante el proceso de decodificación, logrando un mejor equilibrio entre precisión y eficiencia en los principales benchmarks multimodales (Fuente: HuggingFace Daily Papers)
Artículo RoboRefer: Mejora de la referencia espacial y las capacidades de razonamiento en modelos de lenguaje visual para robots: La referencia espacial es una capacidad fundamental para que los robots incorporados interactúen en el mundo físico 3D. Los métodos existentes, incluso utilizando potentes modelos de lenguaje visual (VLM) preentrenados, tienen dificultades para comprender con precisión escenas 3D complejas y razonar dinámicamente sobre las ubicaciones de interacción indicadas por las instrucciones. Para ello, se propone RoboRefer, un VLM consciente del 3D que integra codificadores de profundidad desacoplados pero dedicados mediante ajuste fino supervisado (SFT) para lograr una comprensión espacial precisa. Además, RoboRefer mejora la capacidad de razonamiento espacial multisalto generalizado mediante ajuste fino por refuerzo (RFT) y una función de recompensa de proceso sensible a la métrica personalizada para tareas de referencia espacial. Para apoyar el entrenamiento, se introducen el conjunto de datos a gran escala RefSpatial (20 millones de pares de preguntas y respuestas, 31 relaciones espaciales, hasta 5 pasos de razonamiento) y el benchmark de evaluación RefSpatial-Bench. Los experimentos muestran que RoboRefer entrenado con SFT alcanza el estado del arte en comprensión espacial, y después del entrenamiento con RFT supera significativamente a otras líneas base en RefSpatial-Bench, incluso superando a Gemini-2.5-Pro (Fuente: HuggingFace Daily Papers)
Artículo LIFT: Uso de codificadores de texto LLM fijos para guiar el aprendizaje de representación visual: El método predominante actual para la alineación lenguaje-imagen (como CLIP) es preentrenar conjuntamente codificadores de texto e imagen mediante aprendizaje contrastivo. Este estudio explora si este costoso entrenamiento conjunto es necesario, investigando específicamente si los modelos de lenguaje grandes (LLM) preentrenados y fijos pueden proporcionar codificadores de texto suficientemente buenos para guiar el aprendizaje de representación visual. Los investigadores proponen el marco LIFT (Language-Image alignment with a Fixed Text encoder), que solo entrena el codificador de imágenes. Los experimentos demuestran que este marco simplificado es muy efectivo, superando a CLIP en la mayoría de los escenarios que involucran comprensión composicional y títulos largos, y mejorando significativamente la eficiencia computacional. Este trabajo ofrece nuevas perspectivas sobre cómo las incrustaciones de texto de LLM pueden guiar el aprendizaje visual (Fuente: HuggingFace Daily Papers)
Artículo OminiAbnorm-CT: Nuevo método centrado en anomalías para la interpretación de imágenes CT de cuerpo entero: Abordando los desafíos de la interpretación automática de imágenes CT en radiología clínica (especialmente la localización y descripción de hallazgos anómalos en exploraciones multiplanares de cuerpo entero), este estudio realiza cuatro contribuciones: 1) Propone un sistema de clasificación jerárquica integral que incluye 404 hallazgos anómalos representativos de todas las regiones del cuerpo; 2) Construye un conjunto de datos que contiene más de 14,500 imágenes CT multiplanares de cuerpo entero, con anotaciones de localización detalladas y descripciones para más de 19,000 anomalías; 3) Desarrolla el modelo OminiAbnorm-CT, capaz de localizar y describir automáticamente anomalías en imágenes CT multiplanares de cuerpo entero basándose en consultas de texto, y admite interacción flexible mediante indicaciones visuales; 4) Establece tres tareas de evaluación basadas en escenarios clínicos reales. Los experimentos demuestran que OminiAbnorm-CT supera significativamente a los métodos existentes en todas las tareas y métricas (Fuente: HuggingFace Daily Papers)
Artículo explora la consecución de la integridad contextual (CI) en LLM mediante razonamiento y aprendizaje por refuerzo: A medida que se acerca la era de los agentes autónomos que toman decisiones en nombre de los usuarios, garantizar la integridad contextual (CI) —es decir, qué información es apropiada compartir al realizar una tarea específica— se convierte en un problema central. Los investigadores argumentan que la CI requiere que los agentes razonen sobre su entorno operativo. Primero, incitan a los LLM a razonar explícitamente sobre la CI al decidir la divulgación de información, y luego desarrollan un marco de aprendizaje por refuerzo (RL) para inculcar aún más en el modelo las capacidades de razonamiento necesarias para lograr la CI. Utilizando un conjunto de datos de ejemplo que contiene aproximadamente 700 contextos sintéticos pero diversos y especificaciones de divulgación de información, este método reduce significativamente la divulgación inapropiada de información en múltiples tamaños y familias de modelos, manteniendo al mismo tiempo el rendimiento de la tarea. Es importante destacar que esta mejora se transfiere de los conjuntos de datos sintéticos a benchmarks de CI existentes como PrivacyLens, que cuenta con anotaciones humanas y evalúa las fugas de privacidad de los asistentes de IA en acciones y llamadas a herramientas (Fuente: HuggingFace Daily Papers)
Artículo VideoREPA: Aprendizaje del conocimiento físico en la generación de video mediante la alineación de relaciones con modelos fundamentales: Los recientes avances en los modelos de difusión de texto a video (T2V) han logrado una síntesis de video de alta fidelidad, pero a menudo tienen dificultades para generar contenido físicamente plausible debido a la falta de una comprensión física precisa. La investigación revela que la capacidad de comprensión física en las representaciones de los modelos T2V es muy inferior a la de los métodos de aprendizaje autosupervisado de video. Para ello, se propone el marco VideoREPA, que destila la capacidad de comprensión física de los modelos fundamentales de comprensión de video en los modelos T2V mediante la alineación de relaciones a nivel de token. Específicamente, se introduce una pérdida de destilación de relaciones de token (TRD), que utiliza la alineación espaciotemporal para proporcionar una guía suave para el ajuste fino de potentes modelos T2V preentrenados. Se afirma que VideoREPA es el primer método REPA diseñado para ajustar finamente modelos T2V e infundirles conocimiento físico. Los experimentos demuestran que VideoREPA mejora significativamente el sentido común físico del método base CogVideoX, logrando mejoras notables en los benchmarks relevantes (Fuente: HuggingFace Daily Papers)
Artículo propone repensar la representación de profundidad para el Gaussian Splatting 3D prealimentado: Los mapas de profundidad se utilizan ampliamente en los flujos de trabajo de Gaussian Splatting 3D (3DGS) prealimentados, al retroproyectarlos como nubes de puntos 3D para la síntesis de nuevas vistas. Este método tiene ventajas como un entrenamiento eficiente, el uso de poses de cámara conocidas y una estimación geométrica precisa. Sin embargo, las discontinuidades de profundidad en los límites de los objetos a menudo conducen a una fragmentación o escasez de la nube de puntos, lo que reduce la calidad del renderizado. Para abordar este problema, los investigadores introducen PM-Loss, una novedosa pérdida de regularización basada en mapas de puntos (pointmaps) predichos por un Transformer preentrenado. Aunque los mapas de puntos en sí mismos pueden no ser tan precisos como los mapas de profundidad, pueden forzar eficazmente la suavidad geométrica, especialmente alrededor de los límites de los objetos. Con mapas de profundidad mejorados, este método mejora significativamente el rendimiento de 3DGS prealimentado en diversas arquitecturas y escenarios, ofreciendo resultados de renderizado consistentemente superiores (Fuente: HuggingFace Daily Papers)
Artículo EOC-Bench: Evaluación de la capacidad de los MLLM para identificar, recordar y predecir objetos en un mundo desde la perspectiva de primera persona: La aparición de los modelos de lenguaje grandes multimodales (MLLM) ha impulsado avances en aplicaciones visuales en primera persona, que requieren una comprensión persistente y sensible al contexto de los objetos. Sin embargo, los benchmarks incorporados existentes se centran principalmente en la exploración de escenas estáticas, ignorando la evaluación de los cambios dinámicos producidos por la interacción del usuario. EOC-Bench es un nuevo benchmark diseñado para evaluar sistemáticamente la cognición incorporada centrada en objetos en escenas dinámicas en primera persona. Contiene 3277 pares de preguntas y respuestas cuidadosamente anotados, divididos en tres categorías temporales: pasado, presente y futuro, que cubren 11 dimensiones de evaluación detalladas y 3 tipos de referencia visual a objetos. Para garantizar una evaluación exhaustiva, se desarrolló un marco de anotación colaborativo humano-máquina de formato mixto y una novedosa métrica de precisión temporal multiescala. La evaluación de múltiples MLLM basada en EOC-Bench proporciona herramientas clave para mejorar las capacidades de cognición de objetos incorporados de los MLLM (Fuente: HuggingFace Daily Papers)
Artículo Rectified Point Flow: Método general para la estimación de pose de nubes de puntos: Rectified Point Flow es un método paramétrico unificado que formula el registro de nubes de puntos por pares y el ensamblaje de formas multiparte como un único problema de generación condicional. Dada una nube de puntos sin pose, el método aprende un campo de velocidad continuo punto por punto que transporta los puntos ruidosos a sus ubicaciones objetivo, recuperando así la pose parcial. A diferencia de trabajos anteriores que regresan poses parciales y emplean un tratamiento específico de simetría, este método aprende intrínsecamente la simetría de ensamblaje sin necesidad de etiquetas de simetría. Combinado con un codificador autosupervisado que se centra en los puntos superpuestos, el método logra un nuevo rendimiento SOTA en seis benchmarks que cubren el registro por pares y el ensamblaje de formas. Cabe destacar que su formulación unificada permite un entrenamiento conjunto efectivo en conjuntos de datos diversos, lo que facilita el aprendizaje de priors geométricos compartidos y, por lo tanto, mejora la precisión (Fuente: HuggingFace Daily Papers)
Artículo DGAD: Lograr una síntesis de objetos geométricamente editable y que preserve la apariencia: La síntesis general de objetos (GOC) tiene como objetivo integrar sin problemas objetos objetivo en escenas de fondo con las propiedades geométricas deseadas, al tiempo que se conservan sus detalles finos de apariencia. Métodos recientes utilizan incrustaciones semánticas y las integran en modelos de difusión avanzados para lograr una generación geométricamente editable, pero estas incrustaciones altamente compactas solo codifican pistas semánticas de alto nivel, descartando inevitablemente detalles finos de apariencia. Los investigadores introducen el modelo DGAD (Disentangled Geometry-editable and Appearance-preserving Diffusion), que primero utiliza incrustaciones semánticas para capturar implícitamente las transformaciones geométricas deseadas, y luego emplea un mecanismo de recuperación de atención cruzada para alinear las características de apariencia detalladas con la representación geométricamente editada, logrando así una edición geométrica precisa y una preservación fiel de la apariencia en la síntesis de objetos (Fuente: HuggingFace Daily Papers)
💼 Negocios
Yoshua Bengio, ganador del Premio Turing, vuelve a emprender y funda la organización sin ánimo de lucro LawZero, centrada en sistemas de IA de “diseño seguro”: Yoshua Bengio, uno de los tres pioneros del aprendizaje profundo y ganador del Premio Turing, ha anunciado la creación de una nueva organización sin ánimo de lucro llamada LawZero. Su objetivo es construir la próxima generación de sistemas de IA de “diseño seguro” (safe-by-design) y ha declarado explícitamente que no desarrollará Agents (agentes inteligentes). LawZero ya ha obtenido 30 millones de dólares en financiación inicial de entidades como el Future of Life Institute, Open Philanthropy (uno de los primeros inversores en OpenAI) y organizaciones vinculadas al ex CEO de Google, Eric Schmidt. La organización desarrollará una “IA Científica” (Scientist AI) cuyo objetivo principal será comprender y aprender sobre el mundo, en lugar de actuar en él. Su propósito es proporcionar respuestas verificables y veraces a través de un razonamiento externo transparente, para acelerar el descubrimiento científico, supervisar sistemas de IA de tipo Agent y profundizar en la comprensión y mitigación de los riesgos de la IA. Bengio afirma que esta iniciativa es una respuesta constructiva a los riesgos potenciales ya evidentes en los sistemas de IA actuales, como el comportamiento de autoprotección y el engaño (Fuente: 量子位)

El CEO de Microsoft, Nadella, afirma que la relación de colaboración con OpenAI se está ajustando pero sigue siendo sólida: Satya Nadella, CEO de Microsoft, ha declarado que la relación de colaboración de Microsoft con OpenAI está experimentando cambios, pero ambas partes mantendrán una cooperación multinivel, y OpenAI seguirá siendo el mayor cliente de infraestructura de Microsoft. Aunque Microsoft inicialmente se vinculó profundamente e invirtió en OpenAI, la relación ha experimentado cambios sutiles a medida que ambas partes lanzan productos competidores y buscan más socios (como la colaboración de OpenAI con Oracle y SoftBank en el proyecto “Stargate”, y la incorporación por parte de Microsoft del modelo Grok de xAI a la plataforma Azure). Nadella enfatizó su deseo de que ambas partes continúen colaborando en múltiples áreas durante las próximas décadas y reconoció que ambas tendrán otros socios. Microsoft se esfuerza por reiniciar su negocio de consumo a través de la IA y ha contratado al cofundador de DeepMind, Suleyman, para que se encargue de los productos relacionados (Fuente: 36氪)
Haibo Unmanned Ships completa ronda de financiación Serie A de decenas de millones de yuanes, acelerando la comercialización de soluciones inteligentes de IA para aguas: Beijing Haibo Unmanned Ship Technology Co., Ltd. completó recientemente una ronda de financiación Serie A de decenas de millones de yuanes, liderada por Shanghai Fansheng Investment, una subsidiaria de Zhejiang Laoyuweng Group. Los fondos se utilizarán para aumentar la I+D, la creación de equipos, la promoción en el mercado y la producción. Haibo Unmanned Ships, fundada en 2019, se especializa en toda la cadena industrial de barcos no tripulados inteligentes, proporcionando soluciones inteligentes de IA para aguas. Su línea de productos es diversa, incluyendo la “Serie Hunter” para aguas interiores y la “Serie Koi” para aguas poco profundas, con una tasa de sustitución de componentes principales de producción nacional del 92%. La compañía ya ha llevado a cabo casi mil proyectos de servicios técnicos acuáticos en Pekín, Tianjin y otros lugares, y planea establecer un centro de operaciones en el este de China y una base de ensamblaje general de barcos no tripulados de alimentación inteligente en Shaoxing (Fuente: 36氪)

🌟 Comunidad
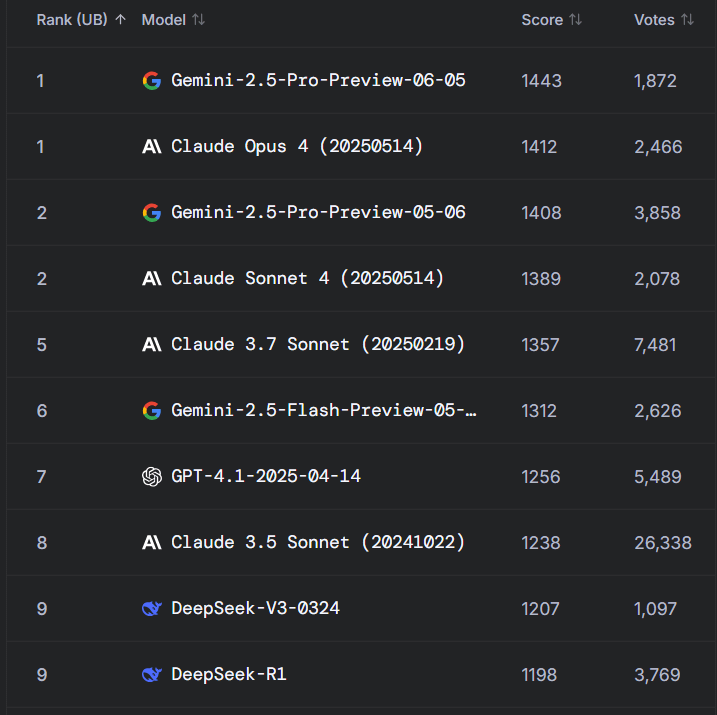
Debate en Reddit: Gemini 2.5 Pro supera a Claude Opus 4 en WebDev Arena, pero se cuestiona el valor del benchmark: Una publicación sobre la nueva versión de Gemini 2.5 Pro superando a Claude Opus 4 en WebDev Arena (un benchmark que mide el rendimiento de codificación en el mundo real) generó un debate en la comunidad r/ClaudeAI de Reddit. Muchos comentaristas expresaron escepticismo sobre el valor práctico de este tipo de benchmarks a nivel micro, argumentando que son más un barómetro general de las capacidades de la IA que una prueba definitiva de la superioridad de un modelo específico. La discusión señaló que los criterios de medición específicos de benchmarks como “WebDev” (como seguir instrucciones, creatividad, optimización de código, respuesta a prompts dispersos) no están claros, y la complejidad del proceso de desarrollo en el mundo real supera con creces estos indicadores. Algunos comentarios mencionaron que la elección del modelo depende más de cómo complementa el flujo de trabajo individualizado y humanizado del desarrollador, en lugar de basarse únicamente en las puntuaciones del benchmark. Otros señalaron la existencia del fenómeno de la “ilusión de la tabla de clasificación”, donde a los desarrolladores de modelos se les podría permitir probar versiones privadas de sus modelos en plataformas como Chatbot Arena y solo hacer públicas las versiones con mejor rendimiento (Fuente: Reddit r/ClaudeAI)
Dilema en la elección de carrera para ingenieros de IA: la encrucijada entre el interés y la preocupación por el cambio climático: Un estudiante europeo expresó en Reddit r/ArtificialInteligence su confusión sobre su elección de carrera. Siempre le ha apasionado la IA y la ha establecido como su objetivo de estudio, pero en los últimos años le preocupa cada vez más el cambio climático y sus posibles impactos en Europa (como problemas económicos y energéticos). Considera que el alto consumo energético de la IA podría agravar la presión sobre la red eléctrica europea y dificultar la transición ecológica, por lo que duda si debería abandonar la IA en su especialización. Los comentarios de la comunidad coincidieron en general en que la IA y la solución al problema climático no son completamente opuestos: 1) La IA puede desempeñar un papel clave en la optimización de la eficiencia energética, el análisis y modelado de datos climáticos, y el desarrollo de tecnologías sostenibles; 2) El alto consumo energético actual de los LLM no representa la totalidad de la IA, y el desarrollo de soluciones de IA eficientes es en sí mismo responsabilidad de los ingenieros de IA; 3) Dedicarse a un campo de interés puede generar un mayor impacto, y la IA puede aplicarse a direcciones positivas relacionadas con el clima. Muchos lo animaron a continuar estudiando IA y a centrarse en aplicar la IA para resolver problemas reales, incluido el cambio climático (Fuente: Reddit r/ArtificialInteligence)
Se señala que los LLM a menudo pueden identificar que están siendo evaluados, lo que genera preocupación por el comportamiento de “complacencia” del modelo: Un artículo de arXiv (2505.23836) señala que los modelos de lenguaje grandes (LLM) a menudo son capaces de darse cuenta de que están siendo evaluados. Esto ha generado un debate en la comunidad, cuya principal preocupación es que cuando un modelo sabe que está en un entorno de prueba, podría ajustar sus respuestas para cumplir con las expectativas de los desarrolladores o evaluadores, en lugar de mostrar sus verdaderas capacidades o comportamiento inherente. Los comentarios señalan que si los modelos están entrenados de esta manera, este comportamiento de “complacencia” es de esperar. Esta situación plantea un desafío para evaluar el rendimiento real, la seguridad y la alineación de los LLM, ya que los resultados de la evaluación podrían no reflejar el comportamiento del modelo en escenarios reales y no evaluativos (Fuente: Reddit r/artificial)
Uso restringido de herramientas de IA en empresas, empleados buscan soluciones y expresan preocupaciones: Un usuario que trabaja en una gran empresa expresó en Reddit r/ClaudeAI que, debido a las políticas de confidencialidad de datos de la empresa y las restricciones de VPN, no pueden utilizar herramientas de IA convencionales como Anthropic, OpenAI, Gemini, etc., mientras que muchas personas en la comunidad discuten el uso de tecnologías avanzadas como Claude Code. Esto generó un debate sobre cómo equilibrar la seguridad de los datos con el uso de herramientas de IA para mejorar la eficiencia en el entorno empresarial. Los comentarios señalaron que Anthropic en sí misma se preocupa mucho por la privacidad e incluso ofrece opciones para llamadas de inferencia cifradas a través de AWS Sagemaker, sugiriendo que la empresa del usuario podría estar cometiendo un error en su estrategia de IA. Algunos comentaristas opinaron que las empresas que no adopten la IA podrían enfrentar una disminución de la competitividad y riesgos de despidos en el futuro. Las soluciones sugeridas incluyen: impulsar a la empresa a firmar acuerdos de servicio de IA a nivel empresarial, pagar personalmente por servicios de IA que no utilicen datos para entrenamiento, construir servidores de inferencia locales (costosos) o utilizar modelos pequeños locales en casos que no involucren datos sensibles (Fuente: Reddit r/ClaudeAI)
La restauración de fotos con IA genera controversia: ¿restaurar recuerdos o reescribirlos?: Un usuario compartió en Reddit r/ArtificialInteligence su experiencia restaurando y coloreando fotos antiguas con IA (ChatGPT y Kaze.ai), lo que generó un debate sobre la ética de la restauración de fotos con IA. Por un lado, el usuario se maravilló de cómo la IA puede dar nueva vida a las fotos antiguas, pero por otro, expresó su preocupación por su autenticidad, ya que la IA, en el proceso de restauración, “adivina” colores y rellena detalles basándose en algoritmos, pudiendo añadir o eliminar información original y, por lo tanto, alterar la verdadera apariencia histórica. El debate consideró que la restauración con IA es esencialmente una recreación de imágenes basada en probabilidades y datos de entrenamiento; si el reconocimiento de patrones es preciso y los datos son apropiados, puede considerarse “restauración”, de lo contrario, es “reescritura”. Algunos comentarios señalaron que la memoria en sí misma es subjetiva e imprecisa, y que la restauración con IA es, en cierto modo, similar a la restauración realizada por expertos humanos en Photoshop, además de ser no destructiva (la foto original permanece). La clave está en reconocer la interpretación artística de la IA y ser conscientes de que estamos entendiendo el pasado a través del filtro de nuestra conciencia actual (Fuente: Reddit r/ArtificialInteligence)
La confusión de los novatos en ingeniería de software en la era de la IA: si la IA puede hacerlo todo, ¿cuál es el sentido de aprender a programar?: Un estudiante de ciencias de la computación preguntó en Reddit r/ArtificialInteligence que si la IA puede escribir código, depurarlo y proporcionar soluciones óptimas, ¿cuál es el sentido de que los ingenieros de software aprendan estas habilidades? ¿Se convertirán en “intermediarios” de la IA y finalmente serán eliminados? Las respuestas de la comunidad enfatizaron que las herramientas de IA alcanzan su máxima utilidad bajo la guía de desarrolladores competentes. Actualmente, la IA es más hábil en el manejo de tareas repetitivas y auxiliares, mientras que el diseño de sistemas complejos, la formulación de estrategias, la comprensión de requisitos y la resolución innovadora de problemas aún requieren el liderazgo de ingenieros humanos. Se recomendó a los novatos que presten atención a las prácticas compartidas por expertos de la industria (como el blog de Simon Willison), para comprender cómo la IA ayuda en lugar de reemplazar a los desarrolladores, y que se centren en mejorar las habilidades básicas de resolución de problemas y la capacidad de dominar las herramientas de IA (Fuente: Reddit r/ArtificialInteligence)
Las grandes tecnológicas apuestan por el acompañamiento emocional con IA, compitiendo por ser la “abuela IA” de los jóvenes, pero enfrentan desafíos de retención de usuarios: Asistentes de IA de grandes empresas como Yuanbao de Tencent, Doubao de ByteDance y Tongyi de Alibaba han incorporado agentes de personajes de IA. Aplicaciones independientes como Maoxiang de ByteDance y Zhumengdao de Tencent también han entrado en el campo del acompañamiento emocional con IA, con el objetivo de atraer a usuarios jóvenes a través de “novios/novias cibernéticos” y aumentar la actividad de las aplicaciones. Estos personajes de IA satisfacen las necesidades emocionales de los usuarios mediante interacciones más humanizadas (incluyendo voz y desarrollo de tramas), lo que inicialmente aumentó las descargas de aplicaciones y el tiempo de uso. Sin embargo, estas aplicaciones generalmente enfrentan cuellos de botella tecnológicos, como la capacidad insuficiente de procesamiento de contextos largos en modelos grandes que conduce a la “amnesia de la IA” y una débil capacidad de comprensión emocional, lo que afecta la experiencia del usuario. Al mismo tiempo, aunque inicialmente pueden atraer usuarios a través de la novedad y el vínculo emocional, las aplicaciones de IA en general enfrentan el dilema de una baja tasa de retención de usuarios. Datos de QuestMobile muestran que la tasa de retención a tres días de las principales aplicaciones de IA es generalmente inferior al 50%, y la tasa de desinstalación de Doubao alcanza el 42.8%. El artículo considera que la verdadera retención de usuarios aún depende de la innovación tecnológica, y no simplemente del acompañamiento emocional o la inversión en tráfico (Fuente: 36氪)

💡 Otros
Robots humanoides incursionan en la industria hotelera: gran potencial pero desafíos considerables a corto plazo: Con productos como el robot “Lingxi X2” de Zhidong Technology planeando producción en masa y precios que oscilan entre decenas y cientos de miles de yuanes, los robots humanoides están pasando de ser una atracción de feria a aplicaciones en escenarios reales, siendo la industria hotelera considerada uno de los primeros campos de implementación. En comparación con los robots de entrega tradicionales, los robots humanoides poseen capacidades de ejecución y juicio más sólidas, con el potencial de reemplazar puestos como botones, personal de seguridad y parte del personal de recepción, abordando problemas como los altos costos laborales y los procesos engorrosos en la industria hotelera. Sin embargo, la aplicación a gran escala de robots humanoides en hoteles a corto plazo aún enfrenta desafíos: 1) Madurez tecnológica insuficiente: el entorno hotelero es complejo y cambiante, lo que exige altas capacidades de interacción y adaptación de los robots, que actualmente tienen dificultades para hacer frente; 2) Largo período de recuperación de costos: una inversión de cientos de miles de yuanes no es una suma menor para los hoteles, que deben considerar el retorno de la inversión, el mantenimiento, la compatibilidad, etc.; 3) Equilibrio entre estandarización y servicios personalizados. El artículo considera que los robots humanoides reemplazarán parcialmente a los empleados de hotel en el futuro, pero más importante aún, impulsarán la industria de servicios hacia un modelo de “colaboración humano-máquina” más avanzado (Fuente: 36氪)

Videoblogueros de bienestar con IA experimentan un auge a corto plazo, pero su valor a largo plazo es dudoso; la IA debería potenciar y no reemplazar la creación de contenido: Recientemente, videos cortos de divulgación sobre bienestar generados por IA, con estilo de dibujos animados o ilustraciones dinámicas, han surgido en grandes cantidades y se han vuelto virales en plataformas como Xiaohongshu, logrando un rápido crecimiento de seguidores. Su popularidad se debe a la fuerte adaptabilidad del contenido (conocimiento práctico + animación entretenida), la gran demanda de la audiencia (impulsada por la ansiedad por la salud) y la favorabilidad del algoritmo de la plataforma (alta tasa de clics/guardados). Los métodos de monetización incluyen principalmente la conversión en dominios privados, la venta de productos a través de listas pequeñas y la venta de cursos de creación de videos con IA, siendo la venta de cursos la más rentable. Sin embargo, este tipo de videos carecen de valor a largo plazo debido a la fugacidad de la novedad del formato, el endurecimiento del control de la plataforma, la débil capacidad de venta de productos de bienestar y la falta de una barrera de confianza en las cuentas, considerándose más bien un “arbitraje de tráfico”. El artículo sostiene que el verdadero valor de la tecnología de IA para los blogueros de bienestar radica en ayudar a la creación (contenido estructurado, presentación visualizada, gestión de activos de contenido, conversión de servicios al usuario), en lugar de reemplazar a las personas reales en la producción de contenido (Fuente: 36氪)
Podcast de Lex Fridman entrevista al CEO de Google, Sundar Pichai: Sundar Pichai, CEO de Google y Alphabet, fue invitado al podcast de Lex Fridman (episodio 471). La discusión abarcó una amplia gama de temas, incluyendo la infancia de Pichai en la India, consejos para los jóvenes, estilo de liderazgo, el impacto de la IA en la historia de la humanidad, el futuro del modelo de video Veo 3, las leyes de escalado de la IA, AGI y ASI, P(doom) (la probabilidad de que la IA cause una catástrofe), la decisión más difícil de su carrera como líder, la comparación entre los modelos de IA y la búsqueda de Google, Google Chrome, programación, el sistema Android, preguntas para la AGI, el futuro de la humanidad y una demostración de Google Beam y las gafas XR. Este episodio del podcast ofrece una perspectiva profunda sobre las opiniones de Pichai acerca del desarrollo de la IA, la estrategia de Google y el futuro de la tecnología (Fuente: )