
Palabras clave:Gemini 2.5 Pro, VeBrain, Segment Anything Model 2, Qwen3-Embedding, Agente de IA, Modo Deep Think de Gemini 2.5 Pro, Marco de Cerebro Embebido Universal VeBrain, Segmentación de imágenes y videos SAM 2, Qwen3-Embedding con contexto de 32k, Comprensión multimodal de Agentes de IA
🔥 Enfoque
Google anuncia múltiples avances en AI: el modo Deep Think de Gemini 2.5 Pro mejora la capacidad de razonamiento complejo: En la conferencia Google I/O, Google anunció el modo Deep Think para Gemini 2.5 Pro, diseñado para mejorar significativamente la capacidad de razonamiento de la AI al abordar problemas complejos (como problemas matemáticos de nivel USAMO). Al mismo tiempo, Google también presentó AlphaEvolve, un agente de codificación impulsado por Gemini para el descubrimiento de algoritmos, que ya ha logrado resultados en el diseño de algoritmos de multiplicación de matrices y en la resolución de problemas matemáticos abiertos, y se aplica para optimizar los centros de datos internos de Google, el diseño de chips y la eficiencia del entrenamiento de AI. Además, también se lanzaron el modelo de vídeo Veo 3, el modelo de imagen Imagen 4 y la herramienta de edición de AI FLOW, demostrando el diseño integral y el rápido progreso de Google en el campo de la AI multimodal. (Fuente: OriolVinyalsML, demishassabis, demishassabis, op7418)
El Laboratorio de IA de Shanghái lanza conjuntamente el framework universal de cerebro para inteligencia corpórea VeBrain: El Laboratorio de Inteligencia Artificial de Shanghái, en colaboración con varias instituciones, ha lanzado VeBrain (Visual Embodied Brain), un framework universal de cerebro para inteligencia corpórea destinado a unificar las capacidades de percepción visual, razonamiento espacial y control robótico. Este framework transforma las tareas de control robótico en tareas de texto espacial 2D dentro de MLLM (como la detección de puntos clave y el reconocimiento de habilidades corpóreas) e introduce un “adaptador de robot” para lograr un mapeo preciso y un control de bucle cerrado desde la decisión textual hasta la acción real. Para apoyar el entrenamiento del modelo, el equipo construyó el conjunto de datos VeBrain-600k, que contiene 600.000 entradas de datos de instrucciones, cubriendo tareas de comprensión multimodal, razonamiento visoespacial y operación robótica. Las pruebas indican que VeBrain alcanza el nivel SOTA en comprensión multimodal, razonamiento espacial y control de robots reales (brazos robóticos y perros robot). (Fuente: 量子位)

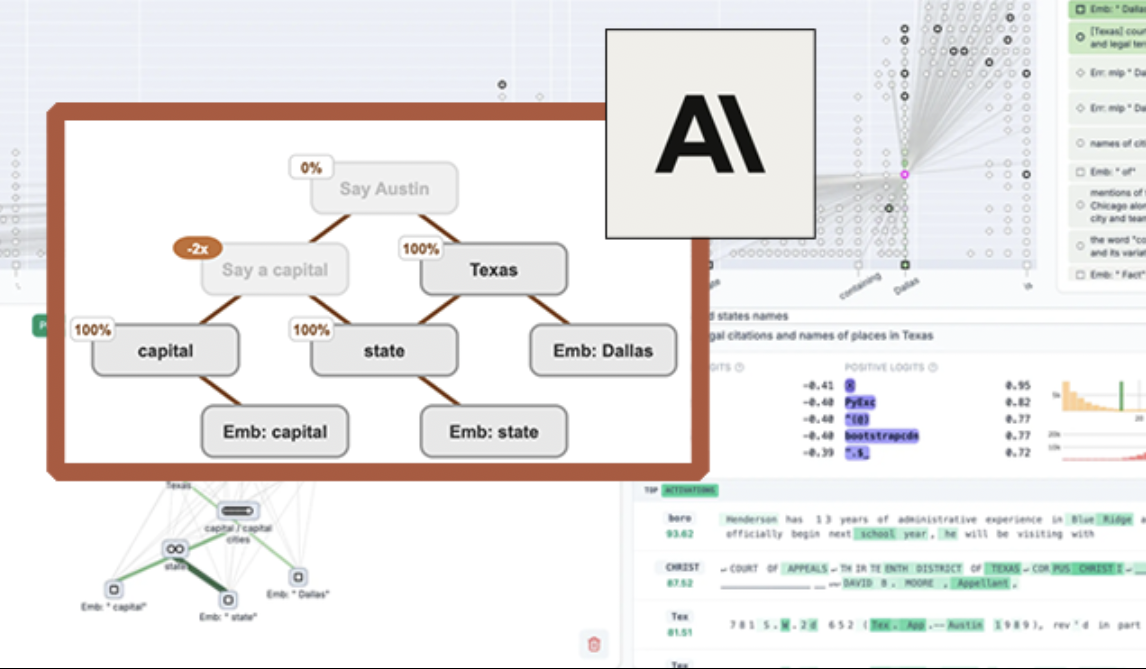
Anthropic lanza la herramienta de visualización de LLM de código abierto “circuit tracing”, mejorando la interpretabilidad del modelo: Anthropic ha lanzado la herramienta de código abierto “circuit tracing”, diseñada para ayudar a los investigadores a comprender los mecanismos internos de los large language models (LLM). La herramienta genera “attribution graphs” (gráficos de atribución), visualizando los supernodos internos y sus interconexiones mientras el modelo procesa información, de forma similar a los diagramas de redes neuronales. Los investigadores pueden verificar la función de cada nodo interviniendo en sus valores de activación y observando los cambios en el comportamiento del modelo, para decodificar la lógica de decisión del LLM. La herramienta permite generar gráficos de atribución en los principales modelos de código abierto y proporciona una interfaz frontend interactiva, Neuronpedia, para visualización, anotación y compartición. Esta iniciativa tiene como objetivo impulsar la investigación en interpretabilidad de la AI, permitiendo a una comunidad más amplia explorar y comprender el comportamiento de los modelos. (Fuente: 量子位, swyx)
Meta lanza Segment Anything Model 2 (SAM 2), mejorando la capacidad de segmentación de imágenes y vídeos: Meta AI Research (FAIR) ha lanzado SAM 2, una versión mejorada de su popular Segment Anything Model. SAM 2 es un modelo fundacional centrado en tareas de segmentación visual sugestionable en imágenes y vídeos, capaz de identificar y segmentar con precisión objetos o regiones específicas en una imagen o vídeo basándose en indicaciones (como puntos, cuadros, texto). El modelo ya es de código abierto, bajo la licencia Apache, para que investigadores y desarrolladores lo utilicen y construyan aplicaciones de forma gratuita, impulsando aún más el desarrollo en el campo de la visión por computadora. (Fuente: AIatMeta)
🎯 Tendencias
El Instituto de IA de Beijing (BAAI) lanza Video-XL-2 de código abierto, logrando la comprensión de vídeos de 10.000 fotogramas con una sola tarjeta: El Instituto de IA de Beijing, en colaboración con la Universidad Jiao Tong de Shanghái y otras instituciones, ha lanzado el modelo de comprensión de vídeo ultralargo de nueva generación, Video-XL-2. Este modelo presenta mejoras significativas en efectividad, longitud de procesamiento y velocidad, pudiendo procesar entradas de vídeo de hasta 10.000 fotogramas con una sola tarjeta y codificar 2048 fotogramas de vídeo en solo 12 segundos. Video-XL-2 utiliza el codificador visual SigLIP-SO400M, un módulo de síntesis dinámica de tokens (DTS) y el large language model Qwen2.5-Instruct. Logra un alto rendimiento mediante un entrenamiento progresivo de cuatro etapas y estrategias de optimización de la eficiencia (como el precargado segmentado y la decodificación KV de doble granularidad). El modelo ha demostrado un rendimiento excelente en benchmarks como MLVU y Video-MME, y sus pesos se han hecho de código abierto. (Fuente: 量子位)

Character.ai lanza la función de generación de vídeo AvatarFX, permitiendo que personajes de imágenes se muevan e interactúen: Character.ai (c.ai), la aplicación líder de compañía de AI, ha lanzado la función AvatarFX, que permite a los usuarios animar personajes de imágenes estáticas (incluidas figuras no humanas como mascotas), haciéndolos capaces de hablar, cantar e interactuar con los usuarios. La función se basa en la arquitectura DiT, enfatizando la alta fidelidad y la coherencia temporal, manteniendo la estabilidad incluso en escenarios complejos como conversaciones con múltiples personajes y secuencias largas. Actualmente, AvatarFX está disponible para todos los usuarios en la versión web, y pronto se lanzará en la aplicación. Al mismo tiempo, c.ai también anunció nuevas funciones como Scenes (escenarios de historias interactivas), Imagine Animated Chat (registros de chat animados) y Stream (generación de historias entre personajes), enriqueciendo aún más la experiencia de creación con AI. (Fuente: 量子位)

Nvidia lanza el modelo de lenguaje visual Llama-3.1 Nemotron-Nano-VL-8B-V1: Nvidia ha lanzado un nuevo modelo de visión a texto, Llama-3.1-Nemotron-Nano-VL-8B-V1. Este modelo puede procesar entradas de imágenes, vídeos y texto, y generar salidas de texto, poseyendo un cierto grado de capacidad de razonamiento y reconocimiento de imágenes. El lanzamiento de este modelo es una manifestación de la continua inversión de Nvidia en el campo de la AI multimodal. Al mismo tiempo, la discusión en la comunidad señala que la decisión de Llama-4 de abandonar los modelos por debajo de 70B podría crear oportunidades para modelos como Gemma3 y Qwen3 en el mercado del fine-tuning. (Fuente: karminski3)
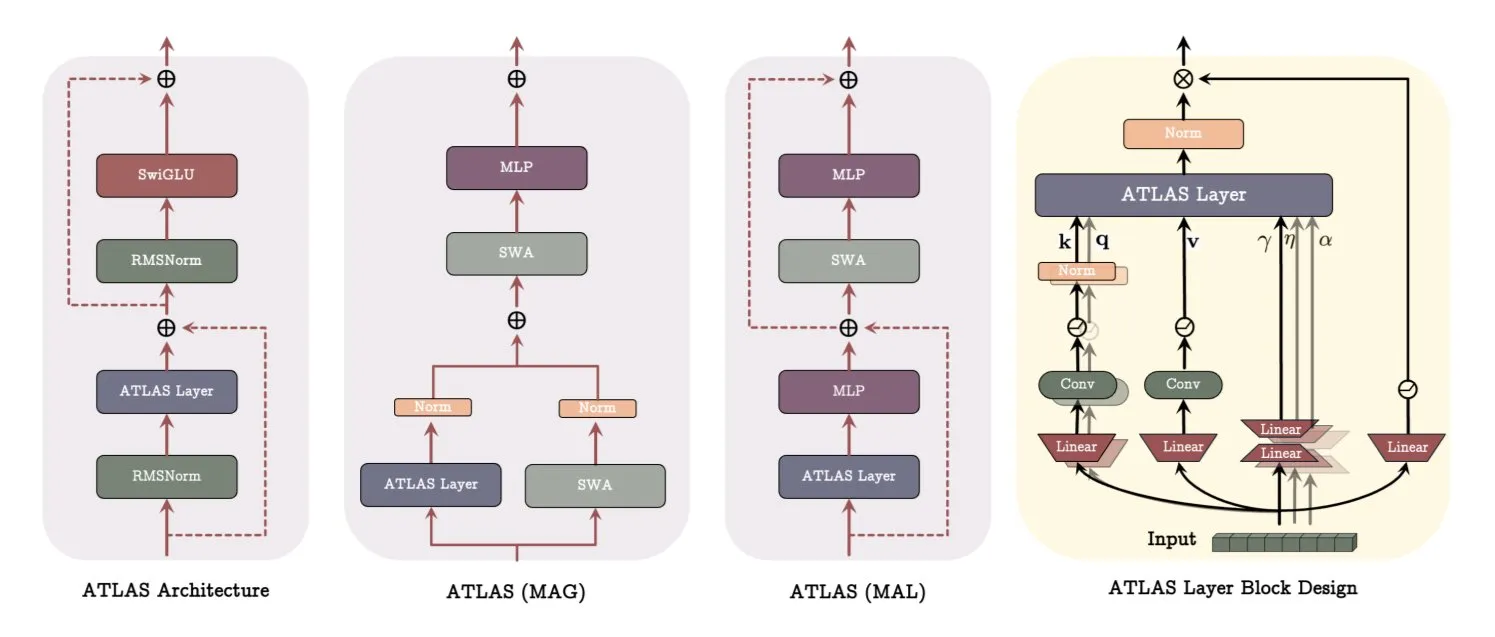
Google publica un artículo sobre la arquitectura ATLAS, revolucionando la forma en que los modelos aprenden y memorizan: Un reciente artículo de Google presenta una nueva arquitectura de modelo llamada ATLAS, diseñada para optimizar las capacidades de aprendizaje y memoria del modelo mediante memoria activa (regla Omega para procesar los últimos c tokens) y una gestión más inteligente de la capacidad de memoria (mapeo de características polinómicas y exponenciales). ATLAS utiliza el optimizador Muon para actualizaciones de memoria más eficientes e introduce diseños como DeepTransformers y Dot (Deep Omega Transformers), reemplazando la atención fija tradicional con mecanismos aprendibles impulsados por la memoria. Esta investigación marca un avance de la AI hacia sistemas más inteligentes y conscientes del contexto, con el potencial de mejorar la capacidad de la AI para procesar y utilizar conjuntos de datos a gran escala. (Fuente: TheTuringPost)
Qwen lanza la serie de modelos Qwen3-Embedding, mejorando significativamente el rendimiento de embedding: El equipo de Qwen ha lanzado la nueva serie de modelos Qwen3-Embedding, que incluye tres versiones: 0.6B, 4B y 8B. Estos modelos admiten longitudes de contexto de hasta 32k y 100 idiomas, logrando resultados SOTA en MTEB (Massive Text Embedding Benchmark), con algunos indicadores superando al segundo lugar en 10 puntos. Este avance marca otro hito importante en la tecnología de text embedding, proporcionando una base más sólida para aplicaciones como la búsqueda semántica y RAG. (Fuente: AymericRoucher, ClementDelangue)

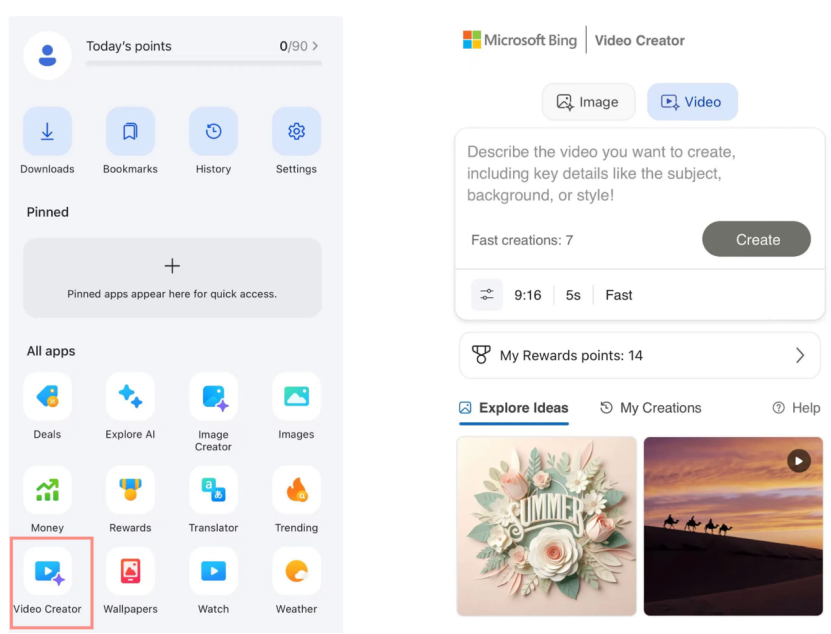
Microsoft Bing Video Creator se lanza, basado en el modelo Sora de OpenAI y disponible gratuitamente: Microsoft ha lanzado Bing Video Creator en su aplicación Bing. Esta función se basa en el modelo Sora de OpenAI y permite a los usuarios generar vídeos de forma gratuita mediante prompts de texto. Esta es la primera vez que el modelo Sora se abre al público a gran escala de forma gratuita. Aunque es gratuito, actualmente existen limitaciones funcionales, como una duración de vídeo de solo 5 segundos, una relación de aspecto de 9:16 y una velocidad de generación relativamente lenta. Los comentarios de los usuarios indican que sus resultados presentan una brecha en comparación con los modelos de vídeo SOTA actuales (como Kling, Veo3), lo que ha generado discusiones sobre la velocidad de iteración de la tecnología Sora y la estrategia de producto de Microsoft. (Fuente: 36氪)
OpenAI lanza múltiples funciones de nivel empresarial, mejorando la integración en el lugar de trabajo: OpenAI ha lanzado una serie de nuevas funciones dirigidas a usuarios empresariales, incluyendo conectores dedicados para aplicaciones como Google Drive, así como la implementación de funciones de grabación, transcripción y resumen de reuniones en ChatGPT, además de soporte para SSO (Single Sign-On) y precios de edición empresarial basados en créditos. Estas actualizaciones tienen como objetivo integrar ChatGPT más profundamente en los flujos de trabajo empresariales, mejorando la eficiencia en la oficina. (Fuente: TheRundownAI, EdwardSun0909)
Hugging Face lanza el eficiente modelo robótico SmolVLA, ejecutable en MacBook: Hugging Face ha lanzado un modelo robótico llamado SmolVLA, caracterizado por su altísima eficiencia, pudiendo incluso ejecutarse en un MacBook. Después de un fine-tuning con una pequeña cantidad de datos de demostración (como 31), el modelo puede alcanzar o superar el rendimiento de las líneas base de tarea única en tareas específicas (como la operación del Koch Arm), demostrando su potencial para desplegar AI robótica en entornos con recursos limitados. (Fuente: mervenoyann, sytelus)
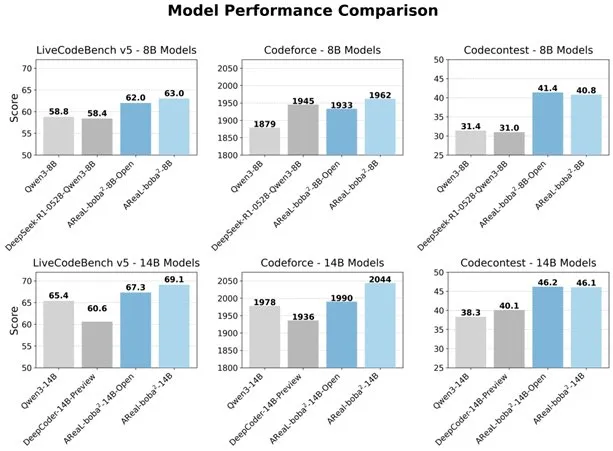
Alibaba lanza el sistema RL totalmente asíncrono AReaL-boba² de código abierto, mejorando la capacidad de codificación de LLM: El equipo Qwen de Alibaba ha lanzado el sistema de aprendizaje por refuerzo totalmente asíncrono AReaL-boba² de código abierto, diseñado específicamente para large language models (LLM), y ha logrado efectos de aprendizaje por refuerzo de código SOTA en Qwen3-14B. A través del diseño colaborativo del sistema y el algoritmo, el sistema logra una aceleración del entrenamiento de 2.77 veces, alcanza 69.1 puntos en LiveCodeBench y admite aprendizaje por refuerzo de múltiples rondas. (Fuente: _akhaliq)
DuckDB lanza la extensión DuckLake, integrando data lakes con formatos de catálogo: DuckDB ha lanzado la extensión DuckLake, un formato abierto de lakehouse basado en SQL y Parquet. DuckLake almacena metadatos en una base de datos de catálogo y datos en archivos Parquet. A través de esta extensión, DuckDB puede leer y escribir directamente datos en DuckLake, admitiendo la creación, modificación, consulta de tablas, time travel y evolución de esquemas, con el objetivo de simplificar la construcción y gestión de data lakes. (Fuente: GitHub Trending)
Lanzamiento del SDK de Ruby para Model Context Protocol (MCP): Model Context Protocol (MCP) ha lanzado su SDK oficial de Ruby, mantenido en colaboración con Shopify, para implementar servidores MCP. MCP tiene como objetivo proporcionar una forma estandarizada para que los modelos de AI (especialmente los Agents) descubran e invoquen herramientas, accedan a recursos y ejecuten prompts predefinidos. Este SDK es compatible con JSON-RPC 2.0 y proporciona funciones básicas como el registro de herramientas, la gestión de prompts y el acceso a recursos, facilitando a los desarrolladores la creación de aplicaciones de AI que cumplan con la especificación MCP. (Fuente: GitHub Trending)
La tecnología de AI ayuda a las baterías de zinc a alcanzar una eficiencia del 99.8% y 4300 horas de funcionamiento: Mediante la optimización con inteligencia artificial, una nueva generación de baterías de zinc ha alcanzado una eficiencia coulómbica del 99.8% y un tiempo de funcionamiento de hasta 4300 horas. La aplicación de la AI en el campo de la ciencia de los materiales, especialmente en el diseño y la predicción del rendimiento de las baterías, está impulsando avances en la tecnología de almacenamiento de energía, con el potencial de ofrecer soluciones energéticas más eficientes y duraderas para vehículos eléctricos, dispositivos electrónicos portátiles y otros campos. (Fuente: Ronald_vanLoon)

🧰 Herramientas
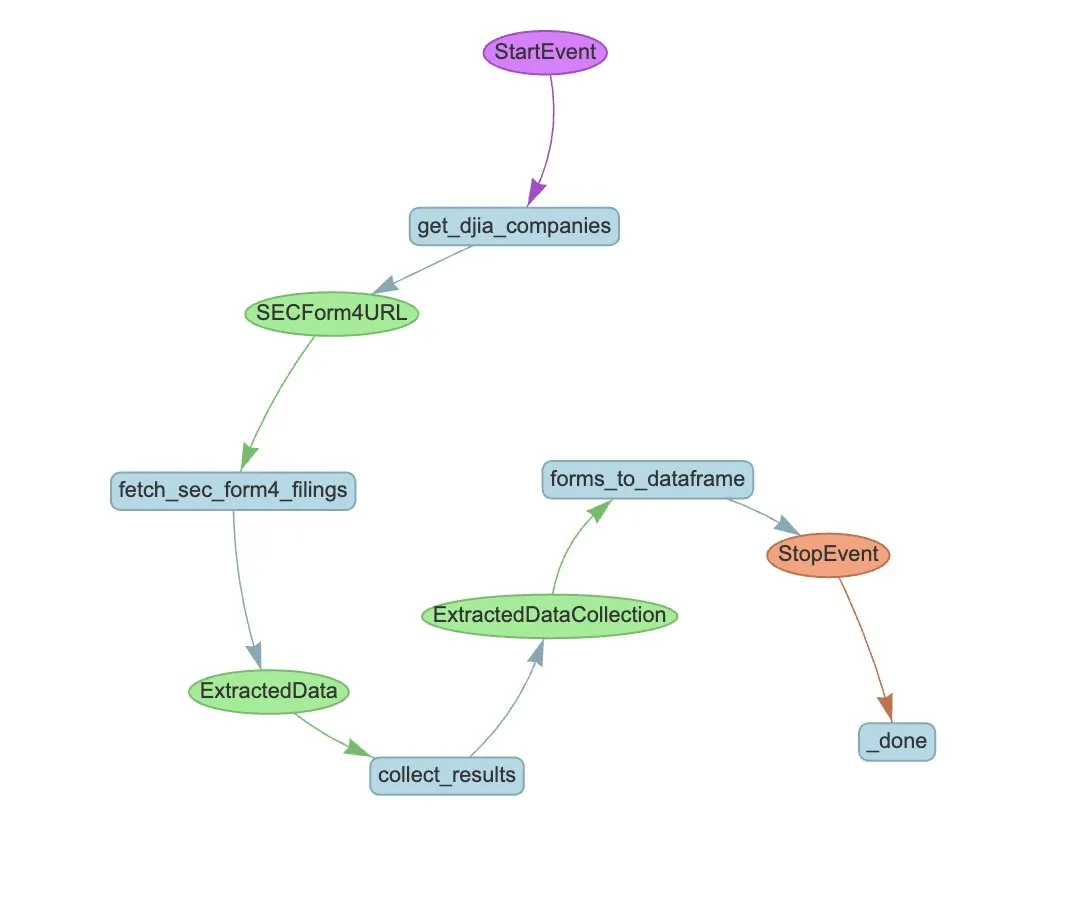
LlamaIndex lanza LlamaExtract y flujos de trabajo de Agent para automatizar la extracción de SEC Form 4: LlamaIndex ha demostrado cómo utilizar LlamaExtract y flujos de trabajo de Agent para extraer automáticamente información estructurada de los archivos SEC Form 4. El SEC Form 4 es un documento importante para que los ejecutivos, directores y principales accionistas de empresas que cotizan en bolsa revelen sus transacciones de acciones. Mediante la construcción de agentes de extracción y flujos de trabajo escalables, se pueden procesar eficientemente las declaraciones del Form 4 de todas las empresas del Promedio Industrial Dow Jones, mejorando la transparencia del mercado y la eficiencia del análisis de datos. (Fuente: jerryjliu0)
Cognee: Herramienta de código abierto que proporciona memoria dinámica a los AI Agents: Cognee es un proyecto de código abierto diseñado para dotar de capacidad de memoria dinámica a los AI Agents, afirmando que se puede integrar con solo 5 líneas de código. Construye pipelines ECL (Extract, Cognify, Load) escalables y modulares, ayudando a los Agents a interconectar y recuperar conversaciones pasadas, documentos, imágenes y transcripciones de audio, con el fin de reemplazar los sistemas RAG tradicionales, reducir la dificultad y los costes de desarrollo, y admitir el procesamiento y la carga de datos desde más de 30 fuentes de datos. (Fuente: GitHub Trending)
Claude Code ya está disponible para usuarios Pro y se lanza una GitHub Action comunitaria: Claude Code, el asistente de programación de AI de Anthropic, ya está disponible para los suscriptores Pro, quienes pueden usarlo a través de plugins para IDEs de JetBrains, entre otros. Desarrolladores de la comunidad también han lanzado una versión fork de una GitHub Action para Claude Code, que permite a los usuarios de pago invocar directamente Claude Code en Issues o PRs de GitHub, utilizando su cuota de suscripción para completar tareas como revisión de código y respuesta a preguntas, sin incurrir en costes adicionales de API. (Fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
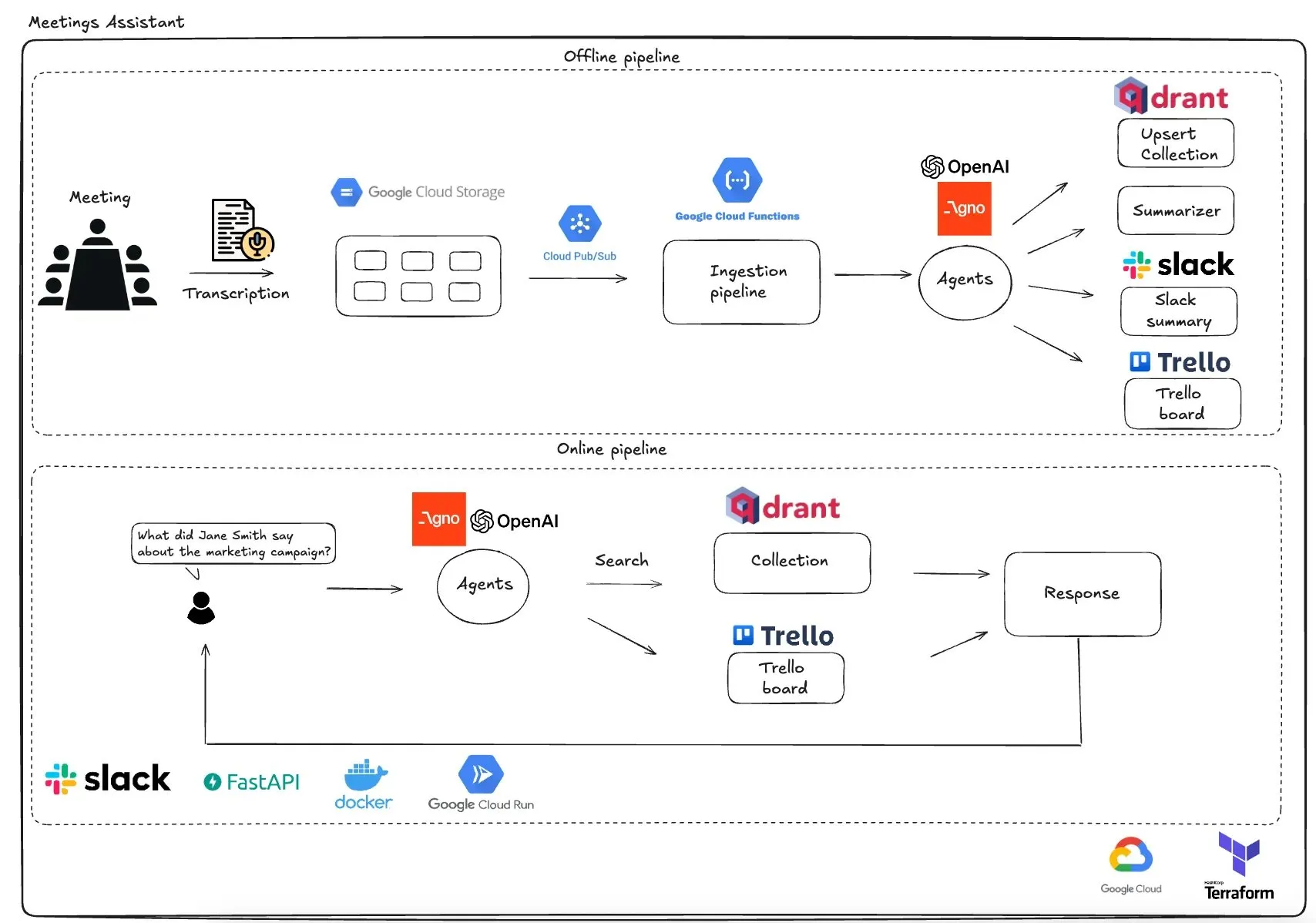
Qdrant lanza un asistente de reuniones multiagente basado en GCP: Qdrant ha presentado un sistema de asistente de reuniones multiagente completamente serverless. Este sistema puede transcribir el contenido de las reuniones, utilizar agentes LLM para resumirlo, almacenar la información contextual en la base de datos vectorial Qdrant y sincronizar las tareas con Trello, entregando los resultados finales directamente en Slack. El sistema utiliza AgnoAgi para la orquestación de agentes, FastAPI ejecutándose en Cloud Run y OpenAI para embeddings e inferencia. (Fuente: qdrant_engine)
Microsoft lanza GUI-Actor, logrando la localización de elementos GUI sin coordenadas: Microsoft ha lanzado GUI-Actor en Hugging Face, un método para localizar elementos de la GUI (interfaz gráfica de usuario) sin necesidad de coordenadas. Este método permite a los agentes de AI apuntar directamente a bloques visuales nativos (visual patches) mediante un token especial <actor>, en lugar de depender de la predicción de coordenadas basada en texto, con el objetivo de mejorar la precisión y robustez de la operación de los agentes GUI. (Fuente: _akhaliq)

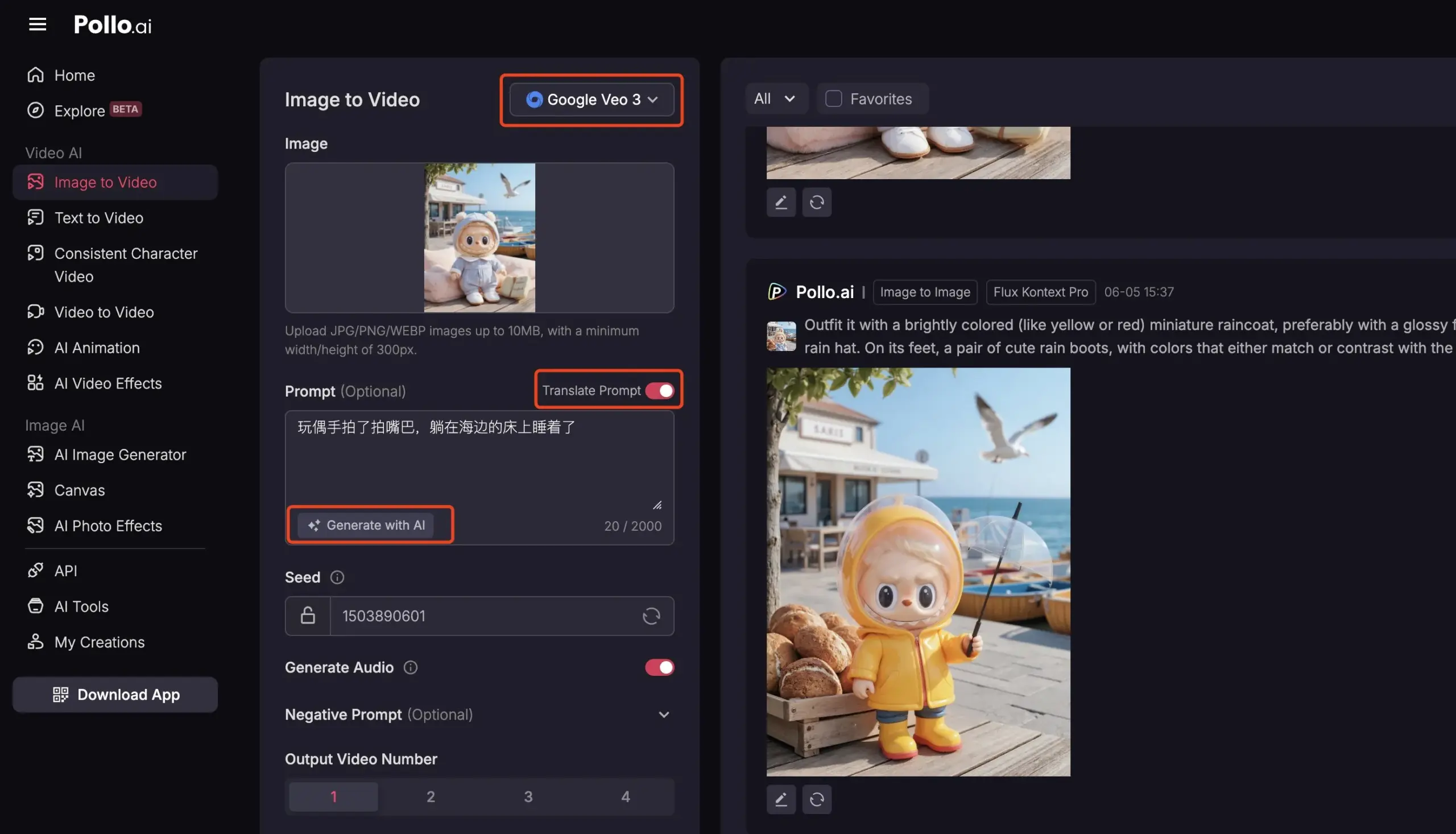
Pollo AI integra Veo3 y FLUX Kontext, ofreciendo servicios integrales de vídeo con AI: La plataforma de herramientas de AI, Pollo AI, se ha actualizado frecuentemente en los últimos tiempos, integrando el modelo de generación de vídeo Veo3 de Google y la función de edición de imágenes FLUX Kontext. Los usuarios pueden modificar imágenes en la plataforma usando FLUX Kontext y luego enviarlas directamente a Veo3 para generar vídeos. La plataforma también ofrece una interfaz API, que permite el acceso único a múltiples modelos grandes de vídeo convencionales del mercado, e incorpora funciones auxiliares como la generación de prompts de AI y la traducción multilingüe, con el objetivo de mejorar la comodidad y eficiencia de la creación de vídeos con AI. (Fuente: op7418)
📚 Aprendizaje
Análisis profundo de Meta-Learning: Enseñando a la AI cómo aprender: Meta-Learning, también conocido como “aprender a aprender”, tiene como idea central entrenar modelos para que puedan adaptarse rápidamente a nuevas tareas, incluso con pocas muestras. Este proceso generalmente involucra dos modelos: un base-learner que aprende rápidamente a adaptarse a tareas específicas (como la clasificación de imágenes con pocas muestras) en un bucle de aprendizaje interno, y un meta-learner que gestiona y actualiza los parámetros o estrategias del base-learner en un bucle de aprendizaje externo, para mejorar su capacidad de resolver nuevas tareas. Una vez completado el entrenamiento, el base-learner se inicializará utilizando el conocimiento aprendido por el meta-learner. (Fuente: TheTuringPost, TheTuringPost)

Análisis del artículo 《A Controllable Examination for Long-Context Language Models》: Este artículo aborda las limitaciones de los marcos de evaluación existentes para los long-context language models (LCLM) (la complejidad y dificultad de resolución de las tareas del mundo real, la susceptibilidad a la contaminación de datos; la falta de coherencia contextual en tareas sintéticas como NIAH), y propone tres características que un marco de evaluación ideal debería poseer: contexto sin fisuras, configuración controlable y evaluación sólida. Presenta LongBioBench, un nuevo benchmark que utiliza biografías generadas artificialmente como entorno controlado para evaluar los LCLM desde las dimensiones de comprensión, razonamiento y fiabilidad. Los experimentos demuestran que la mayoría de los modelos todavía tienen deficiencias en la comprensión semántica, el razonamiento preliminar y la fiabilidad en contextos largos. (Fuente: HuggingFace Daily Papers)
Análisis del artículo 《Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning》: Inspirado por la excepcional capacidad de razonamiento de Deepseek-R1 en tareas textuales complejas, este estudio explora cómo mejorar la capacidad de razonamiento complejo de los multimodal large language models (MLLM) mediante la optimización del arranque en frío (cold start) y el aprendizaje por refuerzo (RL) por etapas. La investigación descubre que una inicialización eficaz del arranque en frío es crucial para mejorar el razonamiento de los MLLM; la simple inicialización con datos textuales cuidadosamente seleccionados puede superar a muchos modelos existentes. La aplicación estándar de GRPO al RL multimodal presenta problemas de estancamiento de gradientes, mientras que el entrenamiento posterior con RL puramente textual puede mejorar aún más el razonamiento multimodal. Basándose en estos hallazgos, los investigadores presentan ReVisual-R1, que logra resultados SOTA en múltiples benchmarks desafiantes. (Fuente: HuggingFace Daily Papers)
Análisis del artículo 《Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem》: Esta investigación propone un método eficiente para liberar el potencial de razonamiento de los LLM preentrenados: el Critique Fine-Tuning (CFT) sobre un solo problema. Mediante la recopilación de múltiples soluciones generadas por el modelo para un único problema y utilizando un LLM profesor para proporcionar críticas detalladas, se construyen datos de crítica para el fine-tuning. Los experimentos demuestran que, tras aplicar CFT sobre un solo problema a los modelos de las series Qwen y Llama, se obtienen mejoras significativas de rendimiento en diversas tareas de razonamiento. Por ejemplo, Qwen-Math-7B-CFT mejora en promedio un 15-16% en benchmarks de razonamiento matemático y lógico, con un coste computacional muy inferior al del aprendizaje por refuerzo. (Fuente: HuggingFace Daily Papers)
Análisis del artículo 《SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation》: Para abordar los problemas de cobertura limitada, falta de estratificación de complejidad y paradigmas de evaluación fragmentados en los benchmarks existentes para el procesamiento de SVG (Scalable Vector Graphics), nace SVGenius. Es un benchmark integral que contiene 2377 consultas, cubriendo las dimensiones de comprensión, edición y generación, construido a partir de datos reales de 24 áreas de aplicación y con una estratificación sistemática de la complejidad. Se evaluaron 22 modelos principales a través de 8 categorías de tareas y 18 métricas, revelando las limitaciones de los modelos actuales al procesar SVG complejos e indicando que el entrenamiento mejorado por razonamiento es más efectivo que la simple expansión de escala. (Fuente: HuggingFace Daily Papers)
Publicado el registro de cambios de Hugging Face Hub: Hugging Face Hub ha publicado su último registro de cambios, donde los usuarios pueden consultar para conocer las nuevas funciones de la plataforma, actualizaciones de la biblioteca de modelos, ampliación de conjuntos de datos y mejoras en la cadena de herramientas, entre otras novedades. Esto ayuda a los usuarios de la comunidad a conocer y utilizar oportunamente los últimos recursos y capacidades del ecosistema de Hugging Face. (Fuente: huggingface, _akhaliq)
Maxime Labonne y otros autores publican una gran cantidad de LLM Notebooks de código abierto: Maxime Labonne, autor del LLM Engineer Handbook, e Iustin Paul han publicado una serie de Jupyter Notebooks relacionados con LLM de código abierto. Estos Notebooks son ricos en contenido, incluyendo no solo técnicas básicas de fine-tuning, sino también temas avanzados como la evaluación automática, lazy merges, la construcción de modelos de mezcla de expertos (frankenMoEs) y técnicas para eludir la censura, proporcionando valiosos recursos prácticos para desarrolladores e investigadores de LLM. (Fuente: maximelabonne)
DeepLearningAI publica el boletín semanal The Batch, discutiendo cómo AI Fund cultiva constructores de AI: Andrew Ng, en su última edición del boletín semanal The Batch, comparte la experiencia y estrategias de AI Fund en la formación de talento y constructores de AI. Esta edición del boletín también cubre temas candentes como el rendimiento del nuevo modelo de código abierto de DeepSeek que rivaliza con los LLM de primer nivel, cómo Duolingo utiliza la AI para expandir sus cursos de idiomas, el equilibrio del consumo de energía de la AI y el potencial engaño de los AI Agents por enlaces maliciosos. (Fuente: DeepLearningAI)

💼 Negocios
Reddit demanda a Anthropic, acusándola de usar datos de usuarios sin autorización para entrenar AI: Reddit ha presentado una demanda contra la empresa de AI Anthropic, acusándola de utilizar robots automatizados para extraer contenido de Reddit sin permiso para entrenar sus modelos de AI (como Claude), lo que constituye un incumplimiento de contrato y competencia desleal. Este caso subraya la controversia actual sobre la legalidad de la extracción de datos y el entrenamiento de modelos en el desarrollo de la AI, y también refleja la creciente importancia que las plataformas de contenido otorgan a la protección del valor de sus datos. (Fuente: Reddit r/artificial, Reddit r/ArtificialInteligence, TheRundownAI)

Amazon planea invertir 10.000 millones de dólares en la construcción de centros de datos de AI en Carolina del Norte: Amazon ha anunciado que invertirá 10.000 millones de dólares en la construcción de nuevos centros de datos en Carolina del Norte para satisfacer la creciente demanda de su negocio de AI. Esta medida refleja la continua inversión de las grandes empresas tecnológicas en infraestructura de AI, con el objetivo de satisfacer los recursos masivos de computación y almacenamiento necesarios para el entrenamiento y la inferencia de modelos de AI. (Fuente: Reddit r/artificial)

Anthropic recorta el acceso a la API del modelo Claude para Windsurf.ai, generando preocupaciones sobre el riesgo de plataforma: La plataforma de desarrollo de aplicaciones de AI Windsurf.ai reveló que Anthropic, con un preaviso de menos de 5 días, redujo drásticamente su capacidad de acceso a la API para los modelos Claude 3.x y Claude 4. Esta medida obligó a Windsurf.ai a buscar urgentemente proveedores externos para garantizar el servicio a los usuarios de pago y a ofrecer una opción BYOK (Bring Your Own Key) para los usuarios gratuitos y Pro. Este incidente ha aumentado las preocupaciones de los desarrolladores sobre el riesgo de plataforma de los proveedores de modelos de AI, es decir, que los proveedores de modelos pueden ajustar sus políticas de servicio en cualquier momento, e incluso competir con las aplicaciones downstream. (Fuente: swyx, scaling01, mervenoyann)
🌟 Comunidad
La Conferencia de Ingenieros de AI (@aiDotEngineer) genera debate, centrándose en el diseño de Agents y el emprendimiento en AI: La Conferencia de Ingenieros de AI (@aiDotEngineer) celebrada en San Francisco se convirtió en un tema candente en la comunidad. LlamaIndex compartió patrones de diseño de Agents efectivos en entornos de producción; Anthropic emitió en la conferencia una “lista de necesidades” para startups, centrándose en la aplicación de servidores MCP en nuevos campos, la simplificación de la construcción de servidores y la seguridad de las aplicaciones de AI (como el envenenamiento de herramientas); Graphite presentó una herramienta de revisión de código impulsada por AI. La conferencia también discutió los desafíos de investigación fundamental para escalar la próxima generación de modelos GPT, entre otros temas. (Fuente: swyx, swyx, swyx, iScienceLuvr)

El investigador Rohan Anil se une a Anthropic, generando atención: El investigador Rohan Anil anunció que se unirá al equipo de Anthropic, una noticia que ha generado amplia atención y discusión en la comunidad de AI. Muchos profesionales de la industria y seguidores le han felicitado y esperan sus nuevas contribuciones al trabajo de investigación de Anthropic. Esto también refleja el impacto potencial que la movilidad del talento de primer nivel en AI tiene en el panorama de la industria. (Fuente: arohan, gallabytes, andersonbcdefg, scaling01, zacharynado)
Un tribunal exige a OpenAI conservar todos los registros de ChatGPT, lo que suscita un debate sobre las políticas de retención de datos: Según se informa, un tribunal ha exigido a OpenAI que conserve todos los registros de ChatGPT, incluidos los “chats temporales” y las solicitudes de API que deberían haberse eliminado. Esta noticia ha provocado un debate en la comunidad sobre las políticas de retención de datos, especialmente para las aplicaciones que utilizan la API de OpenAI. Esto podría significar que sus propias políticas de retención de datos no podrán cumplirse por completo, lo que plantea nuevos desafíos para la privacidad del usuario y la gestión de datos. Se recomienda a los usuarios que, siempre que sea posible, den prioridad al uso de modelos locales para proteger sus datos. (Fuente: code_star, TomLikesRobots)

La proliferación de contenido generado por AI y el fenómeno “AI Slop” generan preocupación: El contenido generado por AI de baja calidad y que busca llamar la atención (conocido como “AI Slop”) prolifera cada vez más en las redes sociales, desde publicaciones generadas por AI en Reddit hasta imágenes de AI como el “Jesús camarón” en Facebook, lo que genera preocupación entre los usuarios por la calidad de la información y el deterioro del entorno online. Este contenido suele ser generado de forma barata por robots o por quienes buscan tráfico, con el objetivo de obtener “me gusta” y compartidos mediante “cebos de participación”. Las investigaciones señalan que una gran cantidad del tráfico de Internet ya está compuesto por “robots malos” que difunden información falsa y roban datos. Este fenómeno no solo afecta la experiencia del usuario, sino que también representa una amenaza para la democracia y la comunicación política, y al mismo tiempo podría contaminar los datos de entrenamiento de futuros modelos de AI. (Fuente: aihub.org)

Discusión sobre el coste de los LLM: Gemini es rentable, el coste de codificación de Claude 4 genera atención: La comunidad discute las notables diferencias de coste en el uso actual de los LLM. Por ejemplo, el coste de procesar un documento de seguro completo y realizar numerosas preguntas con Gemini es de solo unos 0,01 dólares, lo que demuestra una alta rentabilidad. En comparación, aunque el modelo Claude 4 funciona excelentemente en tareas como la codificación, su uso en el modo máximo (max mode) en plataformas como Cursor.ai tiene un coste elevado, lo que lleva a los usuarios a optar por alternativas más rentables como Google Gemini 2.5 Pro. (Fuente: finbarrtimbers, Teknium1)
Los AI Agents enfrentan desafíos al resolver CAPTCHA en escenarios web reales: El equipo de MetaAgentX ha lanzado la plataforma Open CaptchaWorld, centrada en evaluar la capacidad de los agentes interactivos multimodales para resolver CAPTCHA. Las pruebas muestran que incluso los modelos SOTA como GPT-4o, al enfrentarse a 20 tipos de CAPTCHAs interactivos en entornos web reales, tienen una tasa de éxito de solo el 5%-40%, muy por debajo de la tasa de éxito promedio humana del 93.3%. Esto indica que los AI Agents actuales todavía tienen cuellos de botella en la comprensión visual, la planificación de múltiples pasos, el seguimiento del estado y la interacción precisa, convirtiendo los CAPTCHAs en un obstáculo importante para su despliegue práctico. (Fuente: 量子位)

El mercado de formación de AI Agents está en auge, la calidad de los cursos y las perspectivas de empleo generan atención: Con el auge del concepto de AI Agent, también han surgido numerosos cursos de formación relacionados. Algunas instituciones de formación afirman ofrecer orientación integral desde el nivel básico hasta el empleo, e incluso prometen “empleo garantizado”, con matrículas que van desde unos cientos hasta decenas de miles de yuanes. Sin embargo, la calidad de los cursos en el mercado es desigual, y algunos cursos son criticados por su contenido superficial, marketing excesivo e incluso por ser similares a las clases de “enriquecimiento rápido” con AI que buscan “esquilmar” a los alumnos. Los estudiantes y observadores se muestran cautelosos sobre la efectividad real de esta formación, las cualificaciones de los instructores y la veracidad de las promesas de “empleo garantizado”, temiendo que pueda convertirse en otra “falsa demanda” en el período de transición del desarrollo de la AI. (Fuente: 36氪)

💡 Otros
Avances en la aplicación de la AI en robótica: mano con percepción táctil, robot anfibio y perro robot bombero: La tecnología de AI está ampliando las fronteras de las capacidades robóticas. Investigadores han desarrollado una mano mecánica con capacidad de percepción táctil, permitiéndole interactuar mejor con el entorno. Copperstone HELIX Neptune ha presentado un robot anfibio impulsado por AI, capaz de operar en diferentes terrenos. China, por su parte, ha lanzado un perro robot bombero capaz de lanzar chorros de agua a 60 metros, subir escaleras y transmitir rescates en directo. Estos avances demuestran el potencial de la AI para mejorar la percepción, la toma de decisiones y la ejecución de tareas complejas por parte de los robots. (Fuente: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Discusión comparativa entre AI Agents e IA Generativa: En la comunidad ha surgido una discusión sobre las diferencias y conexiones entre los AI Agents (IA de agentes inteligentes) y la IA Generativa (Generative AI). La IA Generativa se centra principalmente en la creación de contenido, mientras que los AI Agents se enfocan más en la toma de decisiones autónoma y la ejecución de tareas basadas en la percepción, planificación y acción. Comprender las diferencias entre ambos ayuda a captar mejor la dirección del desarrollo de la tecnología de AI y sus escenarios de aplicación. (Fuente: Ronald_vanLoon, Ronald_vanLoon)
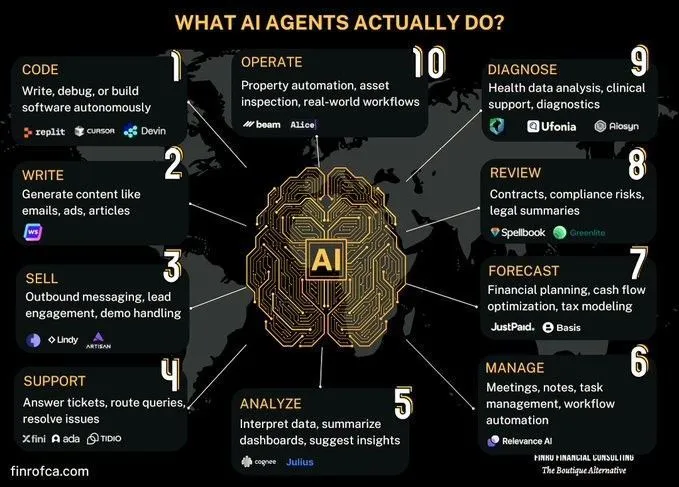
Explorando los desafíos de la AI en la automatización de procesos organizacionales complejos: La AI ha logrado avances en la automatización o asistencia de tareas específicas, pero reemplazar al personal o equipos para lograr una transformación económica más amplia enfrenta una enorme complejidad. Muchas organizaciones tienen procesos cruciales no documentados explícitamente, que son de alto riesgo pero ocurren con poca frecuencia, y pueden haberse convertido en rutina hasta el punto de olvidar su razón de ser. Los AI agents difícilmente pueden aprender este conocimiento tácito mediante prueba y error, debido a su alto coste y limitadas oportunidades de aprendizaje. Esto requiere un nuevo paradigma tecnológico, no simplemente machine learning. (Fuente: random_walker)