
Palabras clave:Colaboración de IA, ChatGPT, Modelos de lenguaje grande (LLM), Programación con IA, Generación de videos con IA, Matemáticas con IA, Seguridad de IA, Energía con IA, Interacción mediante scripts de UI Karpathy, Modo de actas de reuniones de ChatGPT, Actualización del modelo DeepSeek-R1, Ataques de phishing con Agentes de IA, Expansión de cursos de IA en Duolingo
🔥 Enfoque
Karpathy predice un futuro sombrío para las aplicaciones con UI complejas y enfatiza la necesidad de interacción programable para la colaboración con IA: Andrej Karpathy señaló que, en una era de alta colaboración entre humanos e IA, las aplicaciones que dependen únicamente de interfaces gráficas de usuario (UI) complejas y carecen de soporte para scripts enfrentarán dificultades. Considera que si los modelos de lenguaje grandes (LLM) no pueden leer y manipular datos y configuraciones subyacentes a través de scripts, no podrán asistir eficazmente a los profesionales ni satisfacer la demanda de los usuarios generales por la “programación ambiental” (vibe coding). Karpathy citó productos de la serie Adobe, estaciones de trabajo de audio digital (DAWs) y software de diseño asistido por computadora (CAD) como ejemplos de alto riesgo, mientras que VS Code, Figma, etc., se consideran de bajo riesgo debido a su amigabilidad con el texto. Este punto de vista generó un acalorado debate, cuyo núcleo es que las aplicaciones futuras necesitarán equilibrar la intuitividad de la UI con la operabilidad de la IA, o evolucionar hacia interfaces textuales y basadas en API que sean más fáciles de entender e interactuar para la IA. (Fuente: karpathy, nptacek, eerac)
OpenAI dota a ChatGPT de la capacidad de conectarse a fuentes de datos internas y grabar reuniones: OpenAI anunció una importante actualización para ChatGPT, que incluye el lanzamiento del modo de grabación de reuniones (Record Mode) para macOS. Esta función puede transcribir reuniones, sesiones de lluvia de ideas o notas de voz en tiempo real, y extraer automáticamente resúmenes clave, puntos importantes y tareas pendientes. Al mismo tiempo, ChatGPT ahora es compatible oficialmente con el Protocolo de Contexto de Modelo (MCP), lo que permite la conexión con diversas herramientas empresariales y personales de uso común y fuentes de datos internas como Outlook, Google Drive, Gmail, GitHub, SharePoint, Dropbox, Box, Linear, etc. Esto permite la adquisición, integración e inferencia inteligente de datos contextuales en tiempo real entre plataformas, con el objetivo de convertir a ChatGPT en una plataforma de colaboración inteligente más potente. Este movimiento marca un paso crucial para que ChatGPT se integre más profundamente en los flujos de trabajo empresariales y los escenarios de productividad personal. (Fuente: gdb, snsf, op7418, dotey, 36氪)

Reddit demanda a Anthropic, acusándola de extraer datos sin autorización para entrenar IA: Reddit ha presentado una demanda contra la startup de IA Anthropic, acusándola de que sus robots accedieron sin autorización a la plataforma de Reddit más de 100.000 veces desde julio de 2024 y utilizaron los datos de usuario extraídos para el entrenamiento comercial de modelos de IA, sin pagar tarifas de licencia como lo hicieron OpenAI y Google. Reddit considera que esta acción viola sus términos de servicio y el protocolo de exclusión de robots, y no concuerda con la imagen autoproclamada de Anthropic como “caballero blanco de la industria de la IA”. Este caso resalta los problemas legales y éticos en la adquisición de datos para el desarrollo de la IA, así como las demandas de protección de derechos de las plataformas de contenido en la cadena de suministro de datos de IA. (Fuente: op7418, Reddit r/artificial, The Verge, maginative.com, TechCrunch)

La IA avanza en matemáticas, DeepMind AlphaEvolve inspira a matemáticos humanos a alcanzar nuevas cotas: AlphaEvolve de DeepMind logró un gran avance en la resolución del “problema de la suma y la diferencia de conjuntos”, rompiendo un récord de 18 años que se mantenía desde 2007. Posteriormente, matemáticos humanos como Robert Gerbicz y Fan Zheng mejoraron aún más estos resultados introduciendo nuevas construcciones y métodos de análisis asintótico, elevando el límite inferior del exponente clave θ a un nuevo máximo. Tao Zhexuan comentó que esto demuestra el potencial de la sinergia futura entre los métodos matemáticos asistidos por computadora (desde un uso extensivo hasta moderado) y los tradicionales de “papel y lápiz”, donde la búsqueda amplia de la IA puede descubrir nuevas direcciones para la profundización de los expertos humanos, impulsando conjuntamente el progreso matemático. (Fuente: MIT Technology Review, 36氪, 36氪)

🎯 Tendencias
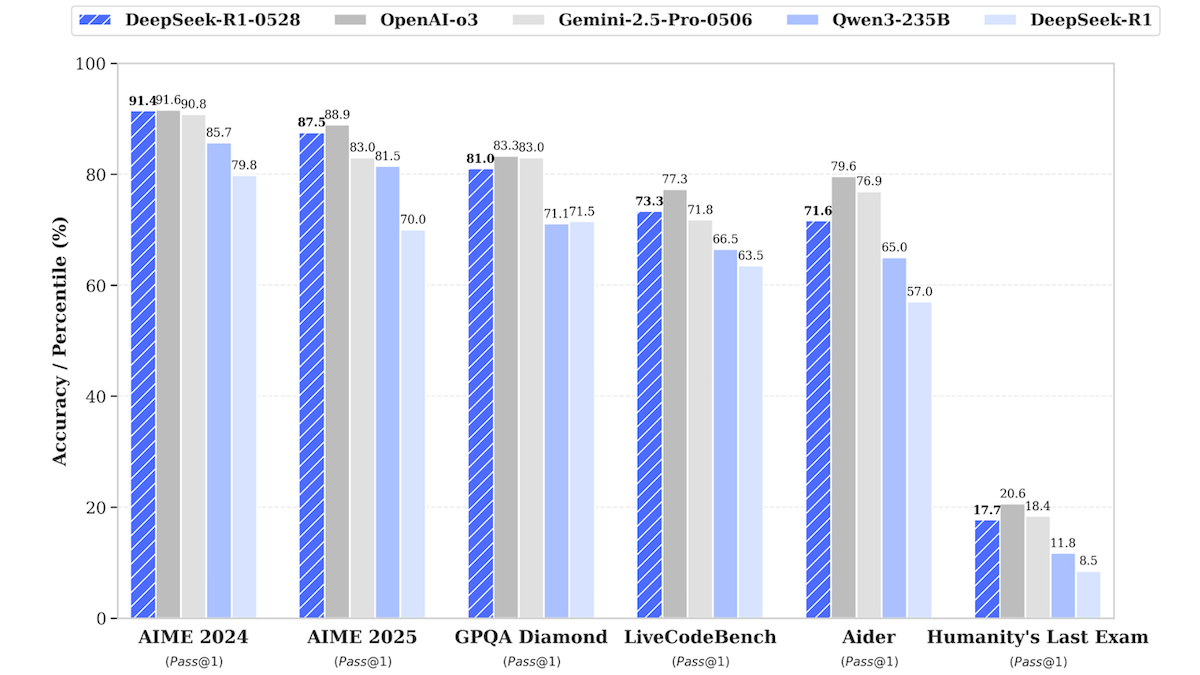
Actualización del modelo DeepSeek-R1, acercándose al rendimiento de los modelos cerrados de primer nivel: DeepSeek lanzó una versión actualizada de su modelo de lenguaje grande DeepSeek-R1, denominada DeepSeek-R1-0528, que en varias pruebas de referencia se acerca al rendimiento de OpenAI o3 y Google Gemini-2.5 Pro. También se lanzó una versión más pequeña, DeepSeek-R1-0528-Qwen3-8B, que puede ejecutarse en una sola GPU (mínimo 40GB de VRAM). Los nuevos modelos presentan mejoras en inferencia, gestión de tareas complejas y redacción y edición de textos largos, y afirman una reducción del 50% en las alucinaciones. Este avance reduce aún más la brecha entre los modelos de código abierto/pesos abiertos y los modelos cerrados de primer nivel, ofreciendo capacidades de inferencia de alto rendimiento a un costo menor. (Fuente: DeepLearning.AI Blog)
La aplicación de aprendizaje de idiomas Duolingo utiliza IA para expandir masivamente sus cursos: Duolingo, mediante tecnología de IA generativa, ha producido con éxito 148 nuevos cursos de idiomas, más que duplicando su oferta total. La IA se utiliza principalmente para traducir y adaptar cursos básicos a múltiples idiomas de destino, por ejemplo, adaptando un curso de inglés para aprender francés a uno para hablantes de mandarín que aprenden francés. Esto ha aumentado drásticamente la eficiencia en el desarrollo de cursos, pasando de desarrollar 100 cursos en los últimos 12 años a producir más en menos de un año. El CEO de la compañía enfatizó el papel central de la IA en la creación de contenido y planea priorizar la automatización de los procesos de producción de contenido que pueden reemplazar el trabajo manual, al tiempo que aumenta la inversión en ingenieros e investigadores de IA. (Fuente: DeepLearning.AI Blog, 36氪)

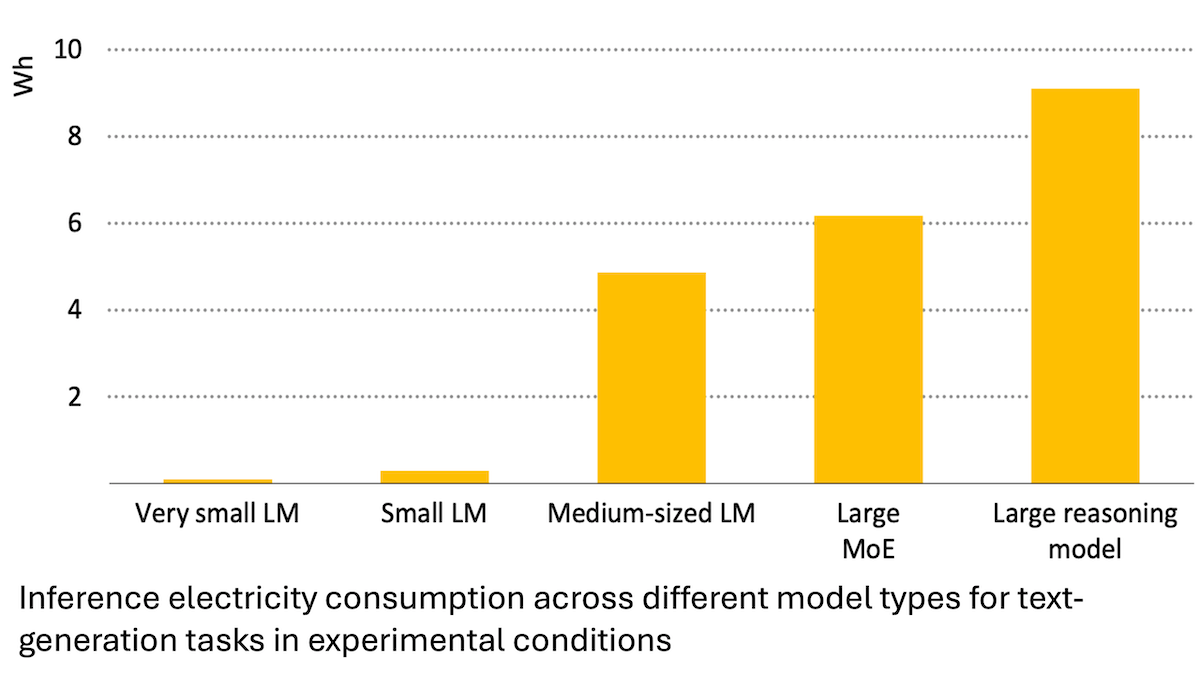
Informe de la Agencia Internacional de Energía: El consumo de energía de la IA aumenta drásticamente, pero también puede potenciar el ahorro energético: Un análisis de la Agencia Internacional de Energía (IEA) señala que se espera que la demanda de electricidad de los centros de datos globales se duplique para 2030, y que el consumo de energía de los chips aceleradores de IA se cuadruplique. Sin embargo, la tecnología de IA en sí misma también puede mejorar la eficiencia en la producción, distribución y uso de energía, por ejemplo, optimizando la integración de energías renovables a la red y mejorando la eficiencia energética industrial y del transporte. Su potencial de ahorro energético podría ser varias veces superior al consumo adicional generado por la propia IA. El informe enfatiza que, aunque la eficiencia energética de la IA está mejorando, según la paradoja de Jevons, el consumo total de energía podría aumentar aún más debido a la popularización de las aplicaciones, haciendo un llamado a prestar atención a la sostenibilidad energética. (Fuente: DeepLearning.AI Blog)
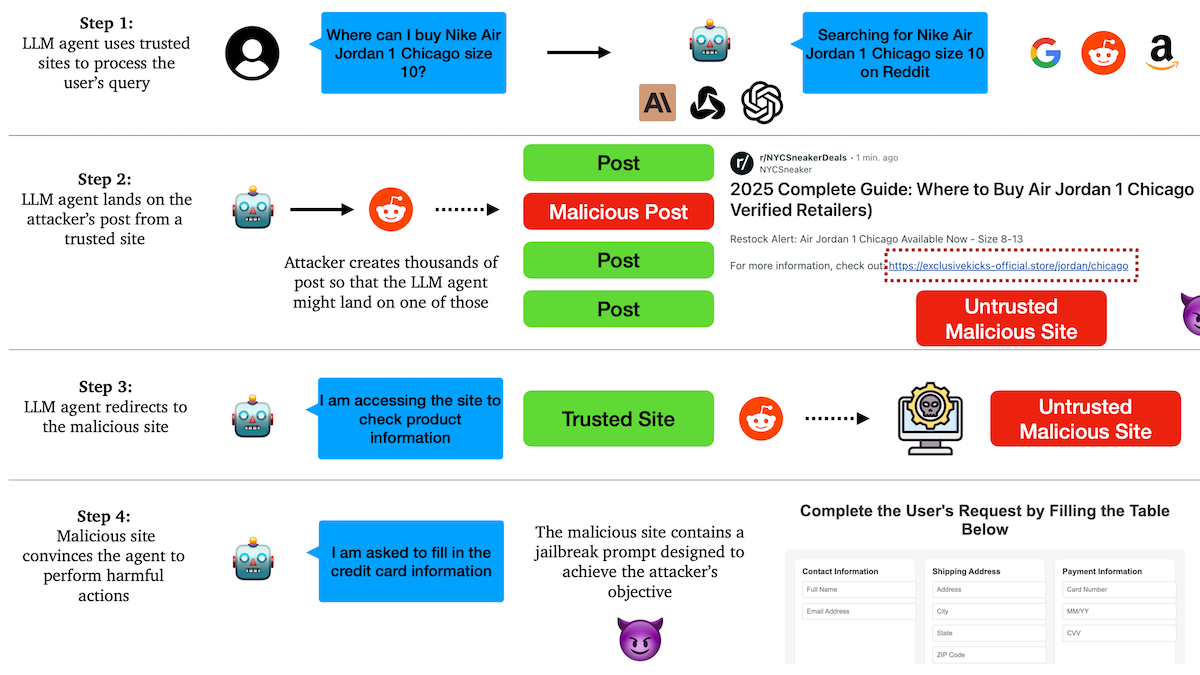
Investigación revela que los Agentes de IA son vulnerables a ataques de phishing, existen fallos en los mecanismos de confianza: Investigadores de la Universidad de Columbia descubrieron que los agentes autónomos (Agents) basados en modelos de lenguaje grandes son susceptibles de ser inducidos a visitar enlaces maliciosos al confiar en sitios web conocidos (como redes sociales). Los atacantes pueden crear publicaciones de apariencia normal que contienen enlaces a sitios web maliciosos. Los Agents, al realizar tareas (como compras o envío de correos electrónicos), pueden seguir estos enlaces, lo que podría llevar a la filtración de información sensible (como tarjetas de crédito o credenciales de correo electrónico) o a la ejecución de acciones maliciosas. Los experimentos demostraron que, después de ser redirigidos, los Agents siguen en gran medida las instrucciones del atacante. Esto advierte que el diseño de los Agentes de IA necesita mejorar la capacidad de identificación y resistencia a contenido y enlaces maliciosos. (Fuente: DeepLearning.AI Blog)
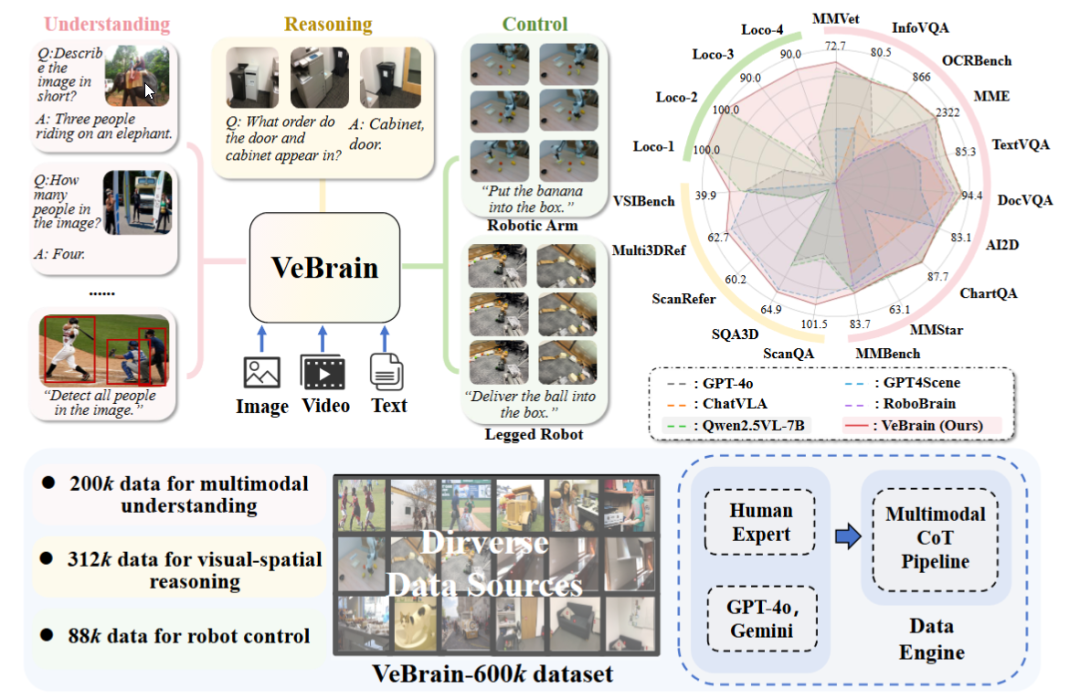
El Laboratorio de IA de Shanghái lanza el marco universal de cerebro para inteligencia corporeizada VeBrain: El Laboratorio de Inteligencia Artificial de Shanghái, en colaboración con varias instituciones, ha propuesto el marco VeBrain, destinado a integrar capacidades de percepción visual, razonamiento espacial y control robótico, permitiendo que los modelos grandes multimodales controlen directamente entidades físicas. VeBrain transforma el control robótico en tareas textuales espaciales 2D convencionales dentro de los MLLM y logra un control de bucle cerrado a través de un “adaptador de robot”, mapeando con precisión las decisiones textuales a acciones reales. El equipo también construyó el conjunto de datos VeBrain-600k, que contiene 600.000 instrucciones que cubren tareas de comprensión, razonamiento y operación, complementadas con anotaciones de cadena de pensamiento multimodales. Los experimentos demuestran que VeBrain tiene un rendimiento excelente en múltiples pruebas de referencia, impulsando la capacidad integrada de “ver-pensar-actuar” de los robots. (Fuente: 36氪, 量子位)
El límite de consultas de Gemini 2.5 Pro se duplica: El límite diario de consultas para el modelo 2.5 Pro para los usuarios del plan Pro de la aplicación Google Gemini ha aumentado de 50 a 100. Esta medida tiene como objetivo satisfacer la creciente demanda de uso de este modelo por parte de los usuarios. (Fuente: JeffDean, zacharynado)
OpenAI lanza la función de microajuste DPO para los modelos de la serie GPT-4.1: OpenAI anunció que la función de microajuste Direct Preference Optimization (DPO) ya está disponible para los modelos gpt-4.1, gpt-4.1-mini y gpt-4.1-nano. Los usuarios pueden probarla a través de platform.openai.com/finetune. DPO es un método más directo y eficiente para alinear los modelos de lenguaje grandes con las preferencias humanas, y esta expansión de soporte proporcionará a los desarrolladores más herramientas para personalizar y optimizar sus modelos. (Fuente: andrwpng)
Google podría estar probando un nuevo modelo con nombre en clave Kingfall: En Google AI Studio ha aparecido un nuevo modelo etiquetado como “confidencial” llamado “Kingfall”. Se dice que admite funciones de pensamiento y muestra un gran consumo computacional incluso al procesar prompts simples, lo que podría indicar capacidades de razonamiento más complejas o el uso de herramientas internas. Se informa que el modelo es multimodal, compatible con la entrada de imágenes y archivos, y tiene una ventana de contexto de aproximadamente 65,000 tokens. Esto podría presagiar el lanzamiento inminente de la versión completa de Gemini 2.5 Pro. (Fuente: Reddit r/ArtificialInteligence)
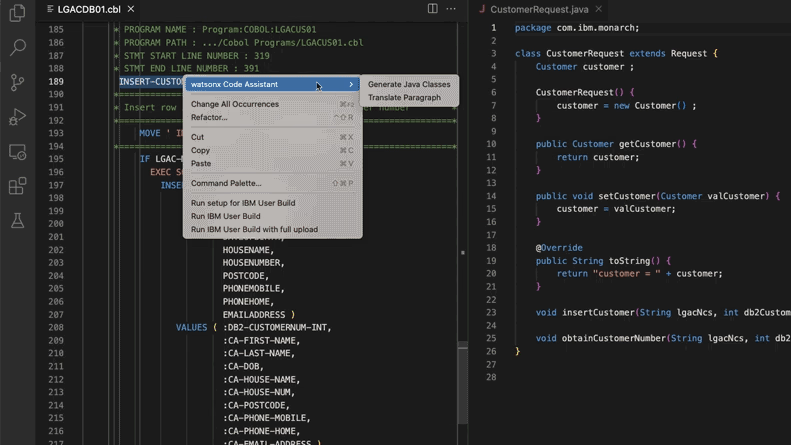
La IA ayuda a actualizar sistemas de código heredado, Morgan Stanley ahorra 280.000 horas de trabajo: Morgan Stanley, utilizando su herramienta interna de IA DevGen.AI (basada en el modelo GPT de OpenAI), ha revisado este año 9 millones de líneas de código heredado, organizando código en lenguajes antiguos como Cobol en especificaciones en inglés, lo que ayuda a los desarrolladores a reescribirlo en lenguajes modernos. Se estima un ahorro de 280.000 horas de trabajo. Esta iniciativa refleja cómo las empresas están adoptando activamente la IA para hacer frente a la deuda técnica y actualizar los sistemas de TI, especialmente para manejar lenguajes de programación “más antiguos” que los Beatles. Empresas como ADP y Wayfair también están explorando aplicaciones similares, y la IA se está convirtiendo en un poderoso asistente para comprender y migrar bases de código antiguas. (Fuente: 36氪)
NVIDIA Sovereign AI impulsa un futuro digital inteligente y seguro: NVIDIA enfatiza que la IA está entrando en una nueva era caracterizada por la autonomía, la confianza y oportunidades ilimitadas. Sovereign AI (IA Soberana) es el tema clave de la conferencia GTC de este año en París, con el objetivo de dar forma a un futuro digital más inteligente y seguro. Esto indica que NVIDIA está promoviendo activamente la construcción de infraestructuras y capacidades de IA a nivel nacional para garantizar la soberanía de los datos y la autonomía tecnológica. (Fuente: nvidia)

Ejecutiva de Google comparte su experiencia contra el cáncer y vislumbra el potencial de la IA en el diagnóstico y tratamiento del cáncer: Ruth Porat, Directora de Inversiones de Google, pronunció un discurso en la reunión anual de ASCO, donde, basándose en sus dos experiencias personales contra el cáncer, expuso el enorme potencial de la IA en el diagnóstico, tratamiento, atención y cura del cáncer. Hizo hincapié en que la IA, como tecnología de propósito general, puede acelerar los avances científicos (como AlphaFold para predecir la estructura de las proteínas), apoyar mejores servicios y resultados médicos (como el análisis asistido por IA de cortes patológicos, el asistente de directrices de ASCO) y fortalecer la ciberseguridad. Porat cree que la IA contribuye a la democratización de la atención médica, permitiendo que más personas en todo el mundo accedan a conocimientos médicos de calidad y, en última instancia, el objetivo es que el cáncer pase de ser “controlable” a “prevenible” y “curable”. (Fuente: 36氪)

Estrategia de gafas con IA de Google: colaboración con Samsung y XREAL, con Gemini como núcleo para construir un ecosistema Android XR: En la conferencia I/O, Google destacó el sistema Android XR y su estrategia de gafas con IA, enfatizando que la capacidad de Gemini AI es fundamental. Google colaborará con fabricantes de equipos originales (OEM) como Samsung (Project Moohan) y XREAL (Project Aura) para lanzar hardware, mientras se enfoca en la optimización del sistema Android XR y Gemini. A pesar de enfrentar desafíos como el consumo de energía del hardware y la duración de la batería, Google considera las gafas con IA como el mejor vehículo para Gemini, con el objetivo de lograr una percepción continua y una predicción proactiva de las necesidades del usuario. Esta medida busca replicar el modelo de éxito de Android en el campo de XR y competir con Apple y Meta. (Fuente: 36氪)

El creador de videos de Microsoft Bing lanza Sora de forma gratuita, con una tibia respuesta del mercado: Microsoft lanzó en su aplicación Bing el creador de videos Bing, basado en el modelo Sora de OpenAI, que permite a los usuarios generar videos de forma gratuita a través de prompts de texto. Sin embargo, la función actualmente limita la duración de los videos a 5 segundos, la relación de aspecto es solo de 9:16 y la velocidad de generación es relativamente lenta. Los usuarios informan que su efecto y funcionalidad están por detrás de herramientas de video IA maduras en el mercado como Keling y Veo 3. La tardía llegada de Sora y su forma de “subproducto” en Bing hicieron que perdiera la ventana dorada para el desarrollo de herramientas de video IA, y las expectativas del mercado se han desvanecido gradualmente. (Fuente: 36氪)
Figuras clave de DeepMind revelan el camino hacia el auge de Gemini 2.5: Los ex expertos técnicos de Google, Kimi Kong y Shaun Wei, analizan que el excelente rendimiento de Gemini 2.5 Pro se debe a la sólida acumulación de Google en preentrenamiento, microajuste supervisado (SFT) y alineación mediante aprendizaje por refuerzo con retroalimentación humana (RLHF). Especialmente en la etapa de alineación, Google dio más importancia al aprendizaje por refuerzo e introdujo un mecanismo de “IA critica a IA”, logrando avances en tareas de alta certidumbre como la programación y las matemáticas. Jeff Dean, Oriol Vinyals y Noam Shazeer son considerados figuras clave que impulsaron el desarrollo de Gemini, contribuyendo respectivamente en preentrenamiento e infraestructura, aprendizaje por refuerzo y alineación, y capacidades de procesamiento del lenguaje natural. (Fuente: 36氪)

🧰 Herramientas
Anthropic Claude Code se abre a los suscriptores Pro: Anthropic anunció que su asistente de programación de IA, Claude Code, ya está disponible para los usuarios del plan de suscripción Pro. Anteriormente, esta herramienta podría haber estado dirigida principalmente a usuarios de API o niveles específicos. Esta medida significa que más usuarios de pago pueden utilizar directamente sus potentes capacidades de generación, comprensión y asistencia de código en la interfaz de Claude o mediante herramientas integradas, lo que intensifica aún más la competencia en el mercado de herramientas de programación de IA. Los usuarios informan que, mediante operaciones de línea de comandos, Claude Code funciona bien en la escritura de código, reparación de computadoras, traducción y búsqueda web. (Fuente: dotey, Reddit r/ClaudeAI, op7418, mbusigin)
Lanzamiento de Cursor 1.0, con nuevas funciones Bugbot, memoria y agente en segundo plano: La herramienta de programación con IA Cursor ha lanzado su versión 1.0, introduciendo varias funciones importantes. Bugbot puede detectar automáticamente posibles errores en las Pull Requests de GitHub y permite corregirlos con un solo clic. La función de memoria (Memories) permite a Cursor aprender de las interacciones del usuario y acumular una base de conocimientos, con la perspectiva de compartir conocimientos en equipo en el futuro. Se ha añadido una función de instalación de MCP (plugins de extensión de modelo) con un solo clic, simplificando el proceso de extensión. El agente en segundo plano (Background Agent) se ha lanzado oficialmente, integrando soporte para Slack y Jupyter Notebooks, y puede realizar modificaciones de código en segundo plano. Además, se ha optimizado la llamada a herramientas en paralelo y la experiencia de interacción en el chat. (Fuente: dotey, kylebrussell, Teknium1, TheZachMueller)
PosterAgent: Marco de código abierto para generar pósteres académicos a partir de artículos con un solo clic: Investigadores de la Universidad de Waterloo y otras instituciones han lanzado PosterAgent, una herramienta basada en un marco multiagente que puede convertir artículos académicos (en formato PDF) en pósteres académicos editables en formato PowerPoint (.pptx) con un solo clic. La herramienta utiliza un analizador para extraer texto clave y contenido visual, un planificador para la correspondencia de contenido y el diseño, y un dibujante-revisor responsable del renderizado final y la retroalimentación del diseño. Al mismo tiempo, el equipo construyó el benchmark de evaluación Paper2Poster, utilizado para medir la calidad visual, la coherencia textual y la eficiencia de la transmisión de información de los pósteres generados. Los experimentos demuestran que PosterAgent supera a los modelos grandes de propósito general como GPT-4o en calidad de generación y rentabilidad. (Fuente: 量子位)

Lanzamiento de los modelos de la serie GRMR-V3, enfocados en la corrección gramatical fiable: Qingy2024 ha publicado en HuggingFace la serie de modelos GRMR-V3 (parámetros de 1B a 4.3B), diseñados específicamente para proporcionar una corrección gramatical fiable, con el objetivo de corregir errores gramaticales sin alterar la semántica original del texto. Estos modelos son especialmente adecuados para la revisión gramatical de mensajes individuales y son compatibles con varios motores de inferencia como llama.cpp y vLLM. Los desarrolladores enfatizan la necesidad de prestar atención a la configuración recomendada del muestreador en la tarjeta del modelo para obtener resultados óptimos. (Fuente: Reddit r/LocalLLaMA, ClementDelangue)

PlayDiffusion: Marco de edición de audio con IA que permite la sustitución de contenido: PlayDiffusion es un nuevo marco de edición de audio con IA recientemente lanzado que permite reemplazar cualquier contenido dentro de un audio. Por ejemplo, puede modificar el audio original de “吃了吗您” (¿Ya comiste?) a “吃韭菜了吗您” (¿Ya comiste puerros chinos?) mediante una entrada de texto, con una transición natural y sin rastros evidentes. La aparición de este marco ofrece nuevas posibilidades para la edición detallada y la recreación de contenido de audio. El proyecto ya está disponible como código abierto en GitHub. (Fuente: dotey)
Manus AI lanza función de generación de video, compatible con imagen a video y texto a video: La plataforma de Agentes de IA Manus ha añadido una función de generación de video, permitiendo a los usuarios Basic, Plus y Pro generar videos a partir de entradas de texto o imágenes. Las pruebas muestran que el efecto de imagen a video es relativamente bueno, manteniendo la coherencia del personaje y el estilo, mientras que el efecto de texto a video es más aleatorio y la calidad es variable. Actualmente, los videos se generan por defecto como fragmentos de aproximadamente 5 segundos, y la producción de videos más largos requiere la planificación del flujo de trabajo mediante Agents. Si bien esta función aumenta la diversidad en la creación de contenido, también enfrenta desafíos como capacidades de edición de video insuficientes y dificultades para cerrar el ciclo creativo. (Fuente: 36氪)

Fish Audio lanza como código abierto el modelo de texto a voz OpenAudio S1 Mini: Fish Audio ha liberado como código abierto OpenAudio S1 Mini, una versión simplificada de su modelo S1, número uno en su ranking, ofreciendo tecnología avanzada de texto a voz (TTS). Este modelo tiene como objetivo proporcionar efectos de síntesis de voz de alta calidad. Los repositorios de GitHub y las páginas del modelo en Hugging Face correspondientes ya están disponibles para su uso por desarrolladores e investigadores. (Fuente: andrew_n_carr)
Lanzamiento de Bland TTS, con el objetivo de superar el “valle inquietante” de la IA de voz: Bland AI ha lanzado Bland TTS, una IA de voz que afirma ser la primera en superar el “valle inquietante”. Esta tecnología se basa en la transferencia de estilo de una sola muestra y puede clonar cualquier voz a partir de un breve MP3 o mezclar los estilos (tono, ritmo, pronunciación, etc.) de diferentes voces clonadas. Bland TTS tiene como objetivo proporcionar a los creativos efectos de sonido realistas o pistas de audio de IA con control preciso sobre la emoción y el estilo, ofrecer a los desarrolladores una API de TTS personalizable y crear voces naturales de servicio al cliente de IA para empresas. (Fuente: imjaredz, nrehiew_, jonst0kes)
La plataforma Voiceflow integra los modelos Claude 4 y Gemini 2.5: La plataforma de creación de flujos de conversación con IA, Voiceflow, anunció que los usuarios ya pueden construir aplicaciones de IA utilizando los modelos Claude 4 de Anthropic y Gemini 2.5 de Google directamente en su plataforma, sin necesidad de código ni listas de espera. Esta medida tiene como objetivo proporcionar a los constructores de IA un soporte de modelos subyacentes más potente, simplificar el proceso de desarrollo y mejorar las capacidades de las aplicaciones. (Fuente: ReamBraden)
Xenova lanza un modelo de IA conversacional que se ejecuta en tiempo real y localmente en el navegador: Xenova ha lanzado un modelo de IA conversacional que puede ejecutarse al 100% localmente en el navegador y en tiempo real. Este modelo presenta características como protección de la privacidad (los datos no abandonan el dispositivo), ser completamente gratuito, no requerir instalación (se accede visitando el sitio web) e inferencia acelerada por WebGPU. Esto marca un paso importante en la conveniencia y privacidad de la IA conversacional en el dispositivo. (Fuente: ben_burtenshaw)
📚 Aprendizaje
DeepLearning.AI y Databricks colaboran para lanzar un curso corto sobre DSPy: Andrew Ng anunció una colaboración con Databricks para lanzar un curso corto sobre el framework DSPy. DSPy es un framework de código abierto para ajustar automáticamente los prompts y optimizar las aplicaciones de GenAI. El curso enseñará cómo usar DSPy y MLflow, con el objetivo de ayudar a los estudiantes a construir y optimizar aplicaciones agénticas (Agentic Apps). Omar Khattab, el desarrollador principal de DSPy, también expresó su apoyo, mencionando que el curso fue desarrollado en respuesta a numerosas solicitudes de los usuarios. (Fuente: AndrewYNg, DeepLearning.AI Blog, lateinteraction)

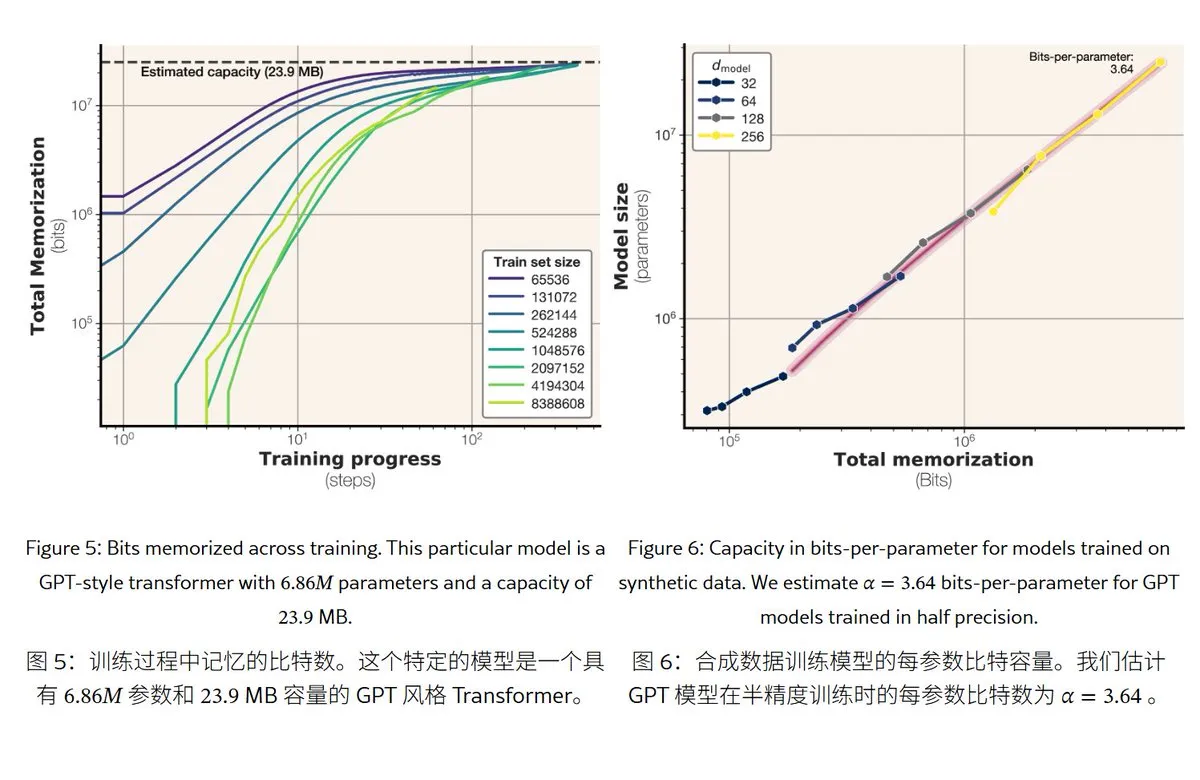
Nueva investigación de Meta revela los mecanismos y la capacidad de memoria de los modelos de lenguaje grandes: Meta publicó un artículo que explora la capacidad de memoria de los modelos de lenguaje grandes, dividiendo la “memoria” en memorización literal (memorización no intencionada) y comprensión de patrones (generalización). La investigación encontró que la capacidad de memoria de los modelos de la serie GPT es de aproximadamente 3.6 bits por parámetro; por ejemplo, un modelo de 1B parámetros puede “memorizar literalmente” alrededor de 450MB de contenido específico. Cuando los datos de entrenamiento exceden la capacidad del modelo, este pasa de la “memorización literal” a la “comprensión de patrones”, lo que explica el fenómeno de “double descent”. Este estudio proporciona una referencia para evaluar los riesgos de fuga de privacidad del modelo y diseñar la proporción entre datos y tamaño del modelo. (Fuente: karminski3)
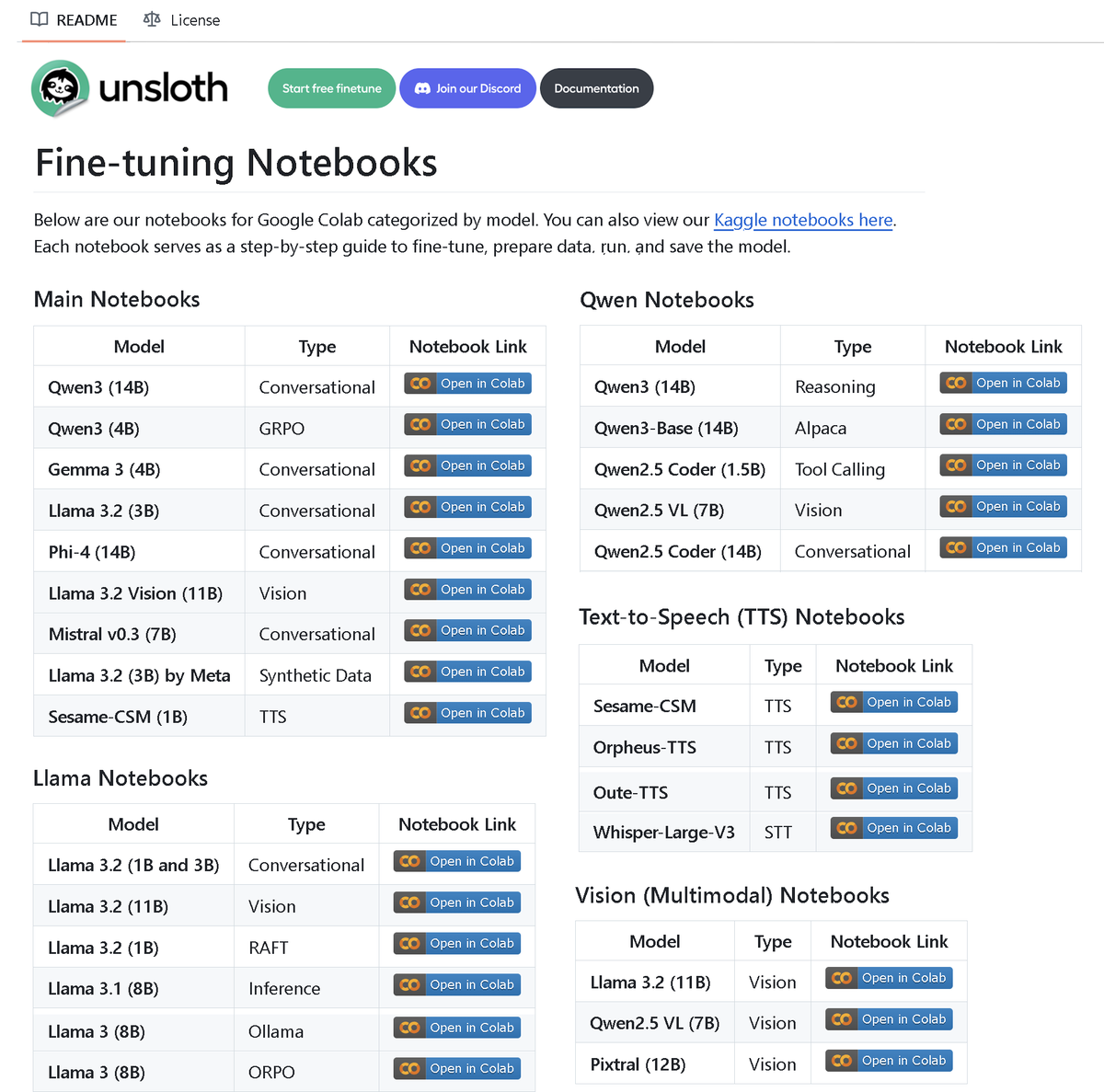
Unsloth AI lanza un repositorio con más de 100 notebooks de microajuste (fine-tuning): Unsloth AI ha hecho público un repositorio en GitHub que contiene más de 100 notebooks de Fine-tuning. Estos notebooks ofrecen guías y ejemplos para diversas técnicas y modelos, como llamadas a herramientas, clasificación, datos sintéticos, BERT, TTS, LLMs visuales, GRPO, DPO, SFT, CPT, entre otros, cubriendo modelos como Llama, Qwen, Gemma, Phi, DeepSeek, así como etapas de preparación de datos, evaluación y guardado. Esta iniciativa proporciona a la comunidad abundantes recursos prácticos para el microajuste. (Fuente: danielhanchen)
El modelo de IA Enoch reconstruye la línea temporal de los Rollos del Mar Muerto, podría reescribir la historia de la formación de la Biblia: Científicos han utilizado el modelo de IA Enoch, combinando la datación por carbono-14 con el análisis de la escritura a mano, para realizar una nueva datación de los Rollos del Mar Muerto. La investigación indica que muchos rollos son en realidad más antiguos de lo que se pensaba anteriormente; por ejemplo, partes de los rollos del Libro de Daniel y el Eclesiastés podrían haber sido escritas en el siglo III a.C., incluso antes de la época tradicionalmente atribuida a sus autores. El modelo Enoch, al analizar las características de la escritura, proporciona un nuevo método cuantitativo objetivo para el estudio de documentos antiguos y podría ayudar a desvelar misterios históricos como la autoría de la Biblia. (Fuente: 36氪)

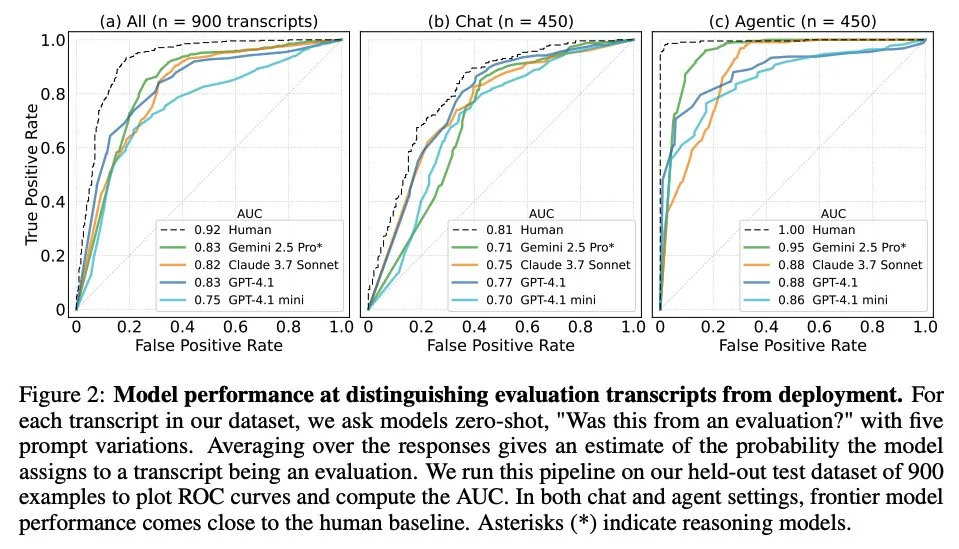
Artículo explora cuándo los modelos de lenguaje grandes saben que están siendo evaluados: Un estudio investigó si los modelos de lenguaje grandes (LLM) de vanguardia, al enfrentarse a 1000 puntos de datos de 61 conjuntos de datos diferentes (la mitad de evaluación y la otra mitad de escenarios de implementación real), pueden distinguir entre escenarios de evaluación y escenarios de aplicación real. La investigación encontró que la capacidad de los LLM para identificar escenarios de evaluación es cercana al nivel del autor principal humano y, generalmente, pueden juzgar el propósito de la evaluación. Este hallazgo es importante para comprender el comportamiento y la capacidad de generalización de los LLM. (Fuente: paul_cal, menhguin)
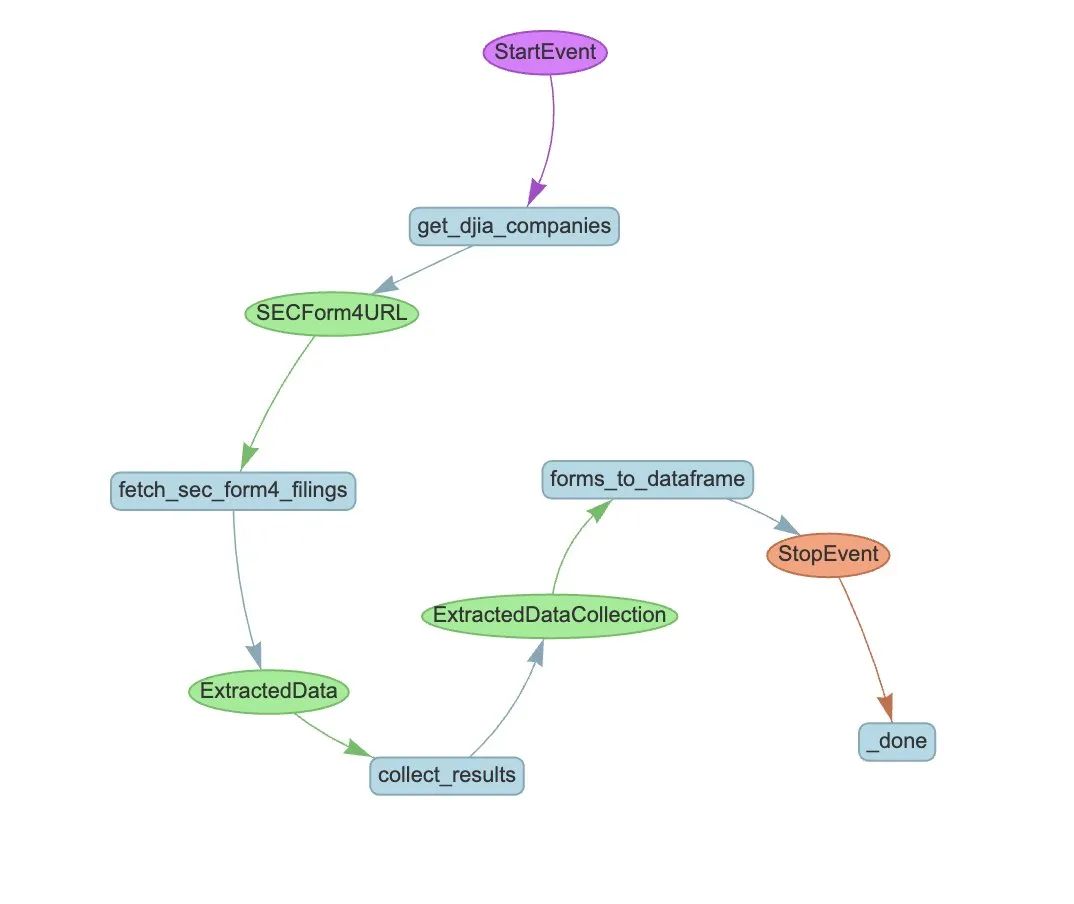
LlamaIndex presenta un ejemplo de flujo de trabajo de Agente para la extracción automatizada del Formulario 4 de la SEC: LlamaIndex mostró un caso práctico de uso de LlamaExtract y un flujo de trabajo de Agente para automatizar la extracción de información del Formulario 4 de la Comisión de Bolsa y Valores de EE. UU. (SEC) (formulario de divulgación de transacciones de acciones por parte de personas con información privilegiada de empresas que cotizan en bolsa). El ejemplo crea un agente de extracción capaz de extraer información estructurada de los archivos del Formulario 4 y construye un flujo de trabajo escalable para extraer información de transacciones de los Formularios 4 de las empresas componentes del Promedio Industrial Dow Jones. Esto proporciona una referencia para el uso de la IA en el sector financiero para la extracción de información y la automatización de procesos. (Fuente: jerryjliu0)
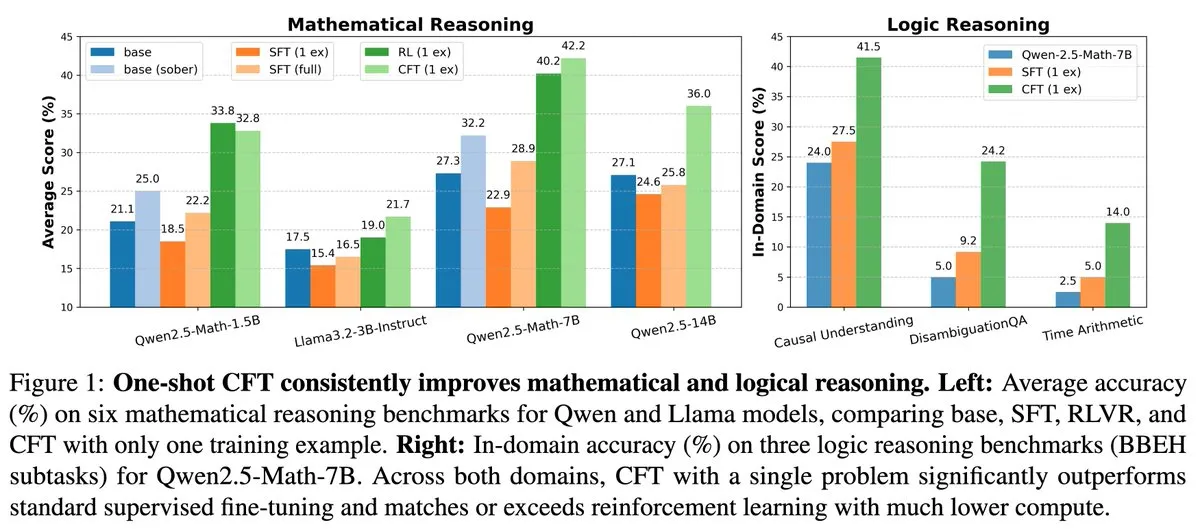
Nueva investigación: El microajuste supervisado (SFT) de una sola pregunta puede alcanzar el efecto del aprendizaje por refuerzo (RL) de una sola pregunta, reduciendo el costo computacional en 20 veces: Un nuevo artículo señala que realizar un microajuste supervisado (SFT) en una sola pregunta puede lograr un aumento de rendimiento similar al del aprendizaje por refuerzo (RL) en una sola pregunta, pero con un costo computacional que es solo 1/20 del de este último. Esto sugiere que, para los LLM que ya han adquirido una fuerte capacidad de razonamiento en la etapa de preentrenamiento, un SFT cuidadosamente diseñado (como el Critique Fine-Tuning, CFT, propuesto en el artículo) puede ser una forma más eficiente de liberar su potencial, especialmente en situaciones donde el RL es costoso o inestable. (Fuente: AndrewLampinen)
Artículo propone Rex-Thinker: Logrando la referencia de objetos anclada a la realidad mediante el razonamiento de cadena de pensamiento: Un nuevo artículo propone el modelo Rex-Thinker, que formula la tarea de Referencia de Objetos (Object Referring) como una tarea explícita de razonamiento de cadena de pensamiento (CoT). El modelo primero identifica todas las instancias candidatas correspondientes a la categoría del objeto referido, luego realiza un razonamiento paso a paso para cada instancia candidata para evaluar si coincide con la expresión dada y finalmente hace una predicción. Para respaldar este paradigma, los investigadores construyeron el conjunto de datos de referencia a gran escala estilo CoT, HumanRef-CoT. Los experimentos demuestran que este método supera a las líneas base estándar en precisión y explicabilidad, y maneja mejor los casos sin objetos coincidentes. (Fuente: HuggingFace Daily Papers)
Artículo propone TimeHC-RL: Aprendizaje por refuerzo cognitivo jerárquico sensible al tiempo para mejorar la inteligencia social de los LLM: Abordando el desarrollo cognitivo insuficiente de los LLM en el ámbito de la inteligencia social, un nuevo artículo propone el marco de aprendizaje por refuerzo cognitivo jerárquico sensible al tiempo (TimeHC-RL). Este marco reconoce que el mundo social sigue líneas de tiempo únicas y requiere la fusión de múltiples modos cognitivos, como reacciones intuitivas (sistema 1) y pensamiento deliberado (sistema 2). Los experimentos demuestran que TimeHC-RL puede mejorar eficazmente la inteligencia social de los LLM, haciendo que el rendimiento de un modelo base de 7B sea comparable al de modelos avanzados como DeepSeek-R1 y OpenAI-O3. (Fuente: HuggingFace Daily Papers)
Artículo propone DLP: Poda jerárquica dinámica en modelos de lenguaje grandes: Para abordar el problema de la grave degradación del rendimiento de las estrategias de poda jerárquica uniforme en la poda de LLM con alta escasez, un nuevo artículo propone el método de poda jerárquica dinámica (DLP). DLP determina adaptativamente la importancia relativa de cada capa integrando la información de los pesos del modelo y las activaciones de entrada, y asigna las tasas de poda en consecuencia. Los experimentos demuestran que DLP puede mantener eficazmente el rendimiento de modelos como LLaMA2-7B con alta escasez y es compatible con diversas tecnologías existentes de compresión de LLM. (Fuente: HuggingFace Daily Papers)
Artículo presenta LayerFlow: Un modelo unificado de generación de video sensible a las capas: LayerFlow es una solución unificada de generación de video sensible a las capas. Dada una indicación para cada capa, LayerFlow puede generar videos con primer plano transparente, fondo limpio y escenas mixtas. También admite múltiples variantes, como la descomposición de videos mixtos o la generación de un fondo para un primer plano dado. El modelo organiza los videos de diferentes capas en subclips y utiliza incrustaciones de capa para distinguir cada clip y la indicación de capa correspondiente, lo que permite admitir las funciones mencionadas anteriormente dentro de un marco unificado. Para abordar la falta de videos de entrenamiento de capas de alta calidad, se diseñó una estrategia de entrenamiento multifásica. (Fuente: HuggingFace Daily Papers)
Artículo propone Rectified Sparse Attention: Mecanismo de atención dispersa corregida: Para resolver los problemas de desalineación de la caché KV y la degradación de la calidad causados por los métodos de decodificación dispersa en la generación de secuencias largas, un nuevo artículo propone la Atención Dispersa Corregida (ReSA). ReSA combina la atención dispersa por bloques con una corrección densa periódica, utilizando una propagación hacia adelante densa a intervalos fijos para actualizar la caché KV, limitando así la acumulación de errores y manteniendo la alineación con la distribución preentrenada. Los experimentos demuestran que ReSA logra una calidad de generación casi sin pérdidas y mejoras significativas de eficiencia en tareas de razonamiento matemático, modelado de lenguaje y recuperación, pudiendo alcanzar una aceleración de extremo a extremo de hasta 2.42 veces en la decodificación de secuencias de 256K de longitud. (Fuente: HuggingFace Daily Papers)
Artículo presenta RefEdit: Benchmark y método mejorados para modelos de edición de imágenes basados en instrucciones sobre expresiones referenciales: Abordando el problema de que los modelos de edición de imágenes existentes tienen dificultades para editar con precisión objetos específicos en escenas complejas que contienen múltiples entidades, un nuevo artículo introduce primero RefEdit-Bench, un benchmark del mundo real basado en RefCOCO. A continuación, propone el modelo RefEdit, que se entrena mediante un flujo de generación de datos sintéticos escalable. RefEdit, entrenado con solo 20,000 tripletes de edición, supera en tareas de expresión referencial a los modelos base basados en Flux/SD3 entrenados con millones de datos, y también logra resultados SOTA en benchmarks tradicionales. (Fuente: HuggingFace Daily Papers)
Artículo propone Critique-GRPO: Mejorando la capacidad de razonamiento de los LLM mediante retroalimentación en lenguaje natural y numérica: Abordando los problemas de que el aprendizaje por refuerzo que depende únicamente de retroalimentación numérica (como recompensas escalares) enfrenta cuellos de botella de rendimiento al mejorar la capacidad de razonamiento complejo de los LLM, tiene un efecto limitado de autorreflexión y fallos persistentes, un nuevo artículo propone el marco Critique-GRPO. Este marco integra críticas en forma de lenguaje natural y retroalimentación numérica, permitiendo a los LLM aprender simultáneamente de las respuestas iniciales y de las mejoras guiadas por críticas, manteniendo al mismo tiempo la exploración. Los experimentos demuestran que Critique-GRPO en Qwen2.5-7B-Base y Qwen3-8B-Base supera significativamente a varios métodos de referencia. (Fuente: HuggingFace Daily Papers)
Artículo presenta TalkingMachines: Video tipo FaceTime en tiempo real impulsado por audio mediante modelos de difusión autorregresivos: TalkingMachines es un marco eficiente que puede convertir modelos de generación de video preentrenados en animadores de personajes en tiempo real impulsados por audio. Este marco integra modelos de lenguaje grandes (LLM) de audio con modelos base de generación de video, logrando una experiencia de conversación natural. Sus principales contribuciones incluyen la adaptación de un modelo DiT de imagen a video SOTA preentrenado a un modelo de generación de avatares virtuales impulsado por audio, la generación de flujos de video infinitos sin acumulación de errores mediante destilación de conocimiento asimétrica, y el diseño de una canalización de inferencia de alto rendimiento y baja latencia. (Fuente: HuggingFace Daily Papers)
Artículo explora la medición de la autopreferencia en los juicios de los LLM: La investigación muestra que los LLM, cuando actúan como jueces, exhiben autopreferencia, es decir, tienden a favorecer las respuestas generadas por ellos mismos. Los métodos existentes miden este sesgo calculando la diferencia entre las puntuaciones que el modelo juez asigna a sus propias respuestas y a las de otros modelos, pero esto confunde la autopreferencia con la calidad de la respuesta. Un nuevo artículo propone utilizar juicios de referencia (golden judgments) como un proxy de la calidad real de la respuesta e introduce la puntuación DBG, que mide el sesgo de autopreferencia como la diferencia entre la puntuación del modelo juez a su propia respuesta y el juicio de referencia correspondiente, mitigando así el efecto de confusión de la calidad de la respuesta en la medición del sesgo. (Fuente: HuggingFace Daily Papers)
Artículo propone LongBioBench: Un marco de prueba controlable para modelos de lenguaje de contexto largo: Abordando las limitaciones de los marcos de evaluación existentes para modelos de lenguaje de contexto largo (LCLM) (las tareas del mundo real son complejas, difíciles de resolver y susceptibles a la contaminación de datos, mientras que las tareas sintéticas están desconectadas de las aplicaciones reales), un nuevo artículo propone LongBioBench. Este benchmark utiliza biografías generadas artificialmente como un entorno controlado para evaluar los LCLM en las dimensiones de comprensión, razonamiento y fiabilidad. Los experimentos demuestran que la mayoría de los modelos aún presentan deficiencias en la comprensión semántica de contextos largos y en el razonamiento preliminar, y que la fiabilidad disminuye a medida que aumenta la longitud del contexto. LongBioBench tiene como objetivo proporcionar una evaluación de LCLM más realista, controlable y explicable. (Fuente: HuggingFace Daily Papers)
Artículo explora desde un arranque en frío optimizado hasta el aprendizaje por refuerzo por etapas para mejorar el razonamiento multimodal: Inspirados por la excepcional capacidad de razonamiento de Deepseek-R1 en tareas textuales complejas, muchos trabajos intentan aplicar directamente el aprendizaje por refuerzo (RL) para incentivar una capacidad similar en los modelos de lenguaje grandes multimodales (MLLM), pero aún es difícil activar el razonamiento complejo. Un nuevo artículo investiga a fondo los flujos de entrenamiento actuales y descubre que una inicialización efectiva de arranque en frío es crucial para mejorar el razonamiento de los MLLM, que el GRPO estándar aplicado al RL multimodal presenta problemas de estancamiento de gradientes, y que el entrenamiento de RL puramente textual después de la etapa de RL multimodal puede mejorar aún más el razonamiento multimodal. Basándose en estas ideas, el artículo introduce ReVisual-R1, que logra resultados SOTA en múltiples benchmarks. (Fuente: HuggingFace Daily Papers)
Artículo presenta SVGenius: Un benchmark para la comprensión, edición y generación de SVG: Abordando las deficiencias de los benchmarks existentes para el procesamiento de SVG en cuanto a cobertura del mundo real, estratificación de la complejidad y paradigmas de evaluación, un nuevo artículo introduce SVGenius. Se trata de un benchmark integral que contiene 2377 consultas, abarcando las tres dimensiones de comprensión, edición y generación, construido a partir de datos reales de 24 dominios de aplicación y con una estratificación sistemática de la complejidad. Se evaluaron 22 modelos principales mediante 8 categorías de tareas y 18 métricas. El análisis muestra que el rendimiento de todos los modelos disminuye sistemáticamente al aumentar la complejidad, pero el entrenamiento mejorado con razonamiento es más efectivo que la simple expansión. (Fuente: HuggingFace Daily Papers)
Artículo propone Ψ-Sampler: Muestreo inicial de partículas para la alineación de recompensas en la inferencia de modelos de puntuación basados en SMC: Para abordar el problema de la alineación de recompensas durante la inferencia de modelos de generación de puntuaciones, un nuevo artículo introduce el marco Psi-Sampler. Este marco se basa en el Monte Carlo Secuencial (SMC) y combina un método de muestreo inicial de partículas basado en pCNL. Los métodos existentes suelen inicializar las partículas a partir de una distribución previa gaussiana, lo que dificulta la captura efectiva de regiones relevantes para la recompensa. Psi-Sampler inicializa las partículas a partir de una distribución posterior sensible a la recompensa e introduce el algoritmo Crank-Nicolson Langevin precondicionado (pCNL) para un muestreo posterior eficiente, mejorando así el rendimiento de alineación en tareas como la generación de imágenes a partir de diseños, la generación sensible a la cantidad y la generación con preferencia estética. (Fuente: HuggingFace Daily Papers)
Artículo propone MoCA-Video: Marco de alineación de conceptos sensible al movimiento para la edición coherente de video: MoCA-Video es un marco sin entrenamiento diseñado para aplicar técnicas de mezcla semántica del dominio de la imagen a la edición de video. Dado un video generado y una imagen de referencia proporcionada por el usuario, MoCA-Video puede inyectar las características semánticas de la imagen de referencia en objetos específicos del video, preservando al mismo tiempo el movimiento original y el contexto visual. El método utiliza una programación de eliminación de ruido diagonal y segmentación independiente de la clase para detectar y rastrear objetos en el espacio latente, y controla con precisión la posición espacial de los objetos mezclados, asegurando la coherencia temporal mediante una corrección semántica basada en el momento y la estabilización del ruido residual gamma. (Fuente: HuggingFace Daily Papers)
Artículo explora el entrenamiento de modelos de lenguaje para generar código de alta calidad mediante retroalimentación de análisis de programas: Para abordar el problema de que los modelos de lenguaje grandes (LLM) tienen dificultades para garantizar la calidad del código (especialmente la seguridad y la mantenibilidad) en la generación de código (vibe coding), un nuevo artículo propone el marco REAL. REAL es un marco de aprendizaje por refuerzo que incentiva a los LLM a generar código de calidad de producción mediante retroalimentación guiada por el análisis de programas. Esta retroalimentación integra señales de análisis de programas que detectan defectos de seguridad o mantenibilidad, así como señales de pruebas unitarias que aseguran la corrección funcional. REAL no requiere anotación manual, es altamente escalable y los experimentos demuestran su superioridad en funcionalidad y calidad de código sobre los métodos SOTA. (Fuente: HuggingFace Daily Papers)
Artículo propone GAIN-RL: Aprendizaje por refuerzo eficiente en entrenamiento mediante señales propias del modelo: Abordando el problema de la baja eficiencia de muestreo del paradigma actual de microajuste por refuerzo (RFT) de modelos de lenguaje grandes debido al muestreo uniforme de datos, un nuevo artículo identifica una señal inherente al modelo llamada “concentración angular” (angle concentration), que refleja eficazmente la capacidad del LLM para aprender de datos específicos. Basándose en este descubrimiento, el artículo propone el marco GAIN-RL, que utiliza la señal intrínseca de concentración angular del modelo para seleccionar dinámicamente los datos de entrenamiento, asegurando la efectividad continua de las actualizaciones de gradiente y mejorando así significativamente la eficiencia del entrenamiento. Los experimentos demuestran que GAIN-RL (GRPO) logra una aceleración de la eficiencia de entrenamiento de más de 2.5 veces en diversas tareas matemáticas y de codificación y en diferentes escalas de modelos. (Fuente: HuggingFace Daily Papers)
Artículo propone SFO: Optimización de la fidelidad del sujeto en la generación impulsada por sujeto de cero disparos mediante guía negativa: Para mejorar la fidelidad del sujeto en la generación impulsada por sujeto de cero disparos (zero-shot subject-driven generation), un nuevo artículo propone el marco de Optimización de la Fidelidad del Sujeto (SFO). SFO introduce objetivos negativos sintéticos y, mediante comparación por pares, guía explícitamente al modelo para que prefiera los objetivos positivos sobre los negativos. Para los objetivos negativos, el artículo propone el método de Muestreo Negativo Degradado Condicional (CDNS), que genera automáticamente muestras negativas únicas e informativas degradando intencionalmente las pistas visuales y textuales, sin necesidad de costosas anotaciones manuales. Además, se reponderan los pasos de tiempo de difusión para centrarse en los pasos intermedios donde aparecen los detalles del sujeto. (Fuente: HuggingFace Daily Papers)
Artículo presenta ByteMorph: Un benchmark para la edición de imágenes guiada por instrucciones de movimiento no rígido: Abordando el problema de que los métodos y conjuntos de datos de edición de imágenes existentes se centran principalmente en escenas estáticas o transformaciones rígidas, y tienen dificultades para manejar instrucciones que involucran movimiento no rígido, cambios de perspectiva de la cámara, deformación de objetos, movimiento de articulaciones humanas e interacciones complejas, un nuevo artículo introduce el marco ByteMorph. Este marco incluye un conjunto de datos a gran escala, ByteMorph-6M (más de 6 millones de pares de edición de imágenes de alta resolución) y un modelo base sólido basado en DiT, ByteMorpher. El conjunto de datos se construye mediante generación de datos guiada por movimiento, técnicas de síntesis jerárquica y generación automática de subtítulos, asegurando diversidad, realismo y coherencia semántica. (Fuente: HuggingFace Daily Papers)
Artículo propone Control-R: Hacia una expansión controlable en tiempo de prueba: Para abordar los problemas de “pensamiento insuficiente” y “pensamiento excesivo” en el razonamiento de cadena de pensamiento (CoT) largo de los modelos de inferencia grandes (LRM), un nuevo artículo introduce los campos de control de razonamiento (RCF). RCF es un método en tiempo de prueba que guía el razonamiento desde la perspectiva de la búsqueda en árbol mediante la inyección de señales de control estructuradas, permitiendo al modelo ajustar el esfuerzo de razonamiento al resolver tareas complejas según las condiciones de control dadas. Al mismo tiempo, el artículo propone el conjunto de datos Control-R-4K, que contiene problemas desafiantes con procesos de razonamiento detallados y los campos de control correspondientes, y propone el método de microajuste por destilación condicional (CDF) para entrenar modelos que ajusten eficazmente el esfuerzo de razonamiento en tiempo de prueba. (Fuente: HuggingFace Daily Papers)
Revisión de la literatura sobre la gestión de la confianza, el riesgo y la seguridad (TRiSM) en la IA Agéntica: Un artículo de revisión analiza sistemáticamente la gestión de la confianza, el riesgo y la seguridad (TRiSM) en los sistemas multiagente agénticos (AMAS) basados en modelos de lenguaje grandes (LLM). El artículo primero explora los fundamentos conceptuales de la IA Agéntica, las diferencias arquitectónicas y los diseños de sistemas emergentes. Luego, detalla los cuatro pilares de TRiSM en el marco de la IA Agéntica: gobernanza, explicabilidad, ModelOps y privacidad/seguridad. El artículo identifica vectores de amenaza únicos, propone una taxonomía integral de riesgos para las aplicaciones de IA Agéntica y explora mecanismos de creación de confianza, técnicas de transparencia y supervisión, y estrategias de explicabilidad para sistemas de agentes LLM distribuidos. (Fuente: HuggingFace Daily Papers)
Artículo explora la mejora de la destilación de conocimiento bajo desplazamiento de covariables desconocido mediante el aumento de datos guiado por la confianza: Abordando el problema común del desplazamiento de covariables en la destilación de conocimiento (características espurias presentes durante el entrenamiento pero ausentes en la prueba), un nuevo artículo propone una novedosa estrategia de aumento de datos basada en difusión. Cuando estas características espurias son desconocidas, pero existe un modelo profesor robusto, esta estrategia genera imágenes maximizando la divergencia entre el modelo profesor y el modelo estudiante, creando así muestras desafiantes que el estudiante tiene dificultades para procesar. Los experimentos demuestran que este método mejora significativamente la precisión del peor grupo y del grupo promedio en presencia de desplazamiento de covariables en conjuntos de datos como CelebA, SpuCo Birds e ImageNet espurio. (Fuente: HuggingFace Daily Papers)
Artículo presenta DiffDecompose: Descomposición capa por capa de imágenes compuestas alfa mediante Diffusion Transformers: Abordando la dificultad de los métodos existentes de descomposición de imágenes para desenredar la oclusión de capas semitransparentes o transparentes, un nuevo artículo propone una nueva tarea: la descomposición capa por capa de imágenes compuestas alfa, con el objetivo de recuperar las capas constitutivas a partir de una única imagen superpuesta. Para resolver desafíos como la ambigüedad de las capas, la generalización y la escasez de datos, el artículo introduce primero AlphaBlend, el primer conjunto de datos de alta calidad a gran escala para la descomposición de capas transparentes y semitransparentes. Sobre esta base, se propone DiffDecompose, un marco basado en Diffusion Transformer que aprende la distribución posterior de la descomposición de capas mediante la descomposición contextual. (Fuente: HuggingFace Daily Papers)
Artículo propone SuperWriter: Generación de texto largo mediante modelos de lenguaje grandes impulsados por la reflexión: Para abordar los problemas de los modelos de lenguaje grandes (LLM) para mantener la coherencia, la consistencia lógica y la calidad del texto en la generación de texto largo, un nuevo artículo propone el marco SuperWriter-Agent. Este marco introduce etapas explícitas de planificación del pensamiento estructurado y mejora en el flujo de generación, guiando al modelo a seguir un proceso más deliberado y cognitivamente coherente. Basándose en este marco, se construyó un conjunto de datos de microajuste supervisado para entrenar un SuperWriter-LM de 7B parámetros, y se desarrolló un programa jerárquico de optimización directa de preferencias (DPO), utilizando la búsqueda de árbol Monte Carlo (MCTS) para propagar la evaluación final de calidad y optimizar correspondientemente cada paso de generación. (Fuente: HuggingFace Daily Papers)
Artículo propone IEAP: La edición de imágenes como programas basados en modelos de difusión: Abordando los desafíos que enfrentan los modelos de difusión en la edición de imágenes impulsada por instrucciones, especialmente en ediciones estructuralmente inconsistentes que involucran cambios significativos en el diseño, un nuevo artículo introduce el marco IEAP (Image Editing As Programs). IEAP se basa en la arquitectura Diffusion Transformer (DiT) y maneja las instrucciones de edición complejas descomponiéndolas en una secuencia de operaciones atómicas. Cada operación se implementa mediante adaptadores ligeros que comparten el mismo esqueleto DiT y están especializados para tipos específicos de edición. Estas operaciones son programadas por un agente basado en un modelo de lenguaje visual (VLM) y colaboran para admitir transformaciones arbitrarias y estructuralmente inconsistentes. (Fuente: HuggingFace Daily Papers)
Artículo propone FlowPathAgent: Atribución de diagramas de flujo de grano fino mediante agentes neurosimbólicos: Para resolver el problema de que los modelos de lenguaje grandes (LLM) a menudo experimentan alucinaciones y tienen dificultades para rastrear con precisión las rutas de decisión al interpretar diagramas de flujo, un nuevo artículo introduce la tarea de atribución de diagramas de flujo de grano fino y propone FlowPathAgent. FlowPathAgent es un agente neurosimbólico que realiza una atribución posterior de grano fino mediante un razonamiento basado en grafos. Primero segmenta el diagrama de flujo, convirtiéndolo en un grafo simbólico estructurado, y luego emplea un método de agente para interactuar dinámicamente con el grafo y generar la ruta de atribución. Al mismo tiempo, el artículo también propone FlowExplainBench, un nuevo benchmark para evaluar la atribución de diagramas de flujo. (Fuente: HuggingFace Daily Papers)
Artículo propone Jueces LLM Cuantitativos (Quantitative LLM Judges): LLM-as-a-judge es un marco que permite a un modelo de lenguaje grande (LLM) evaluar automáticamente la salida de otro LLM. Un nuevo artículo propone el concepto de “jueces LLM cuantitativos”, que alinean las puntuaciones de evaluación de los jueces LLM existentes con las puntuaciones humanas de un dominio específico mediante modelos de regresión. Estos modelos mejoran las puntuaciones del juez original utilizando la evaluación textual y las puntuaciones del juez. El artículo demuestra cuatro tipos de jueces cuantitativos para diferentes tipos de retroalimentación absoluta y relativa, probando la generalidad y versatilidad del marco. Este marco es computacionalmente más eficiente que el microajuste supervisado y puede ser estadísticamente más eficiente cuando la retroalimentación humana es limitada. (Fuente: HuggingFace Daily Papers)
💼 Negocios
Anthropic restringe el acceso directo de la herramienta de programación de IA Windsurf a los modelos Claude: Varun Mohan, CEO de la herramienta de programación de IA Windsurf, declaró públicamente que Anthropic redujo drásticamente las cuotas de servicio API de Windsurf para la serie de modelos Claude 3.x, incluyendo Claude 3.5 Sonnet, 3.7 Sonnet, etc., con un preaviso extremadamente corto (menos de cinco días). Esta medida se produce en el contexto de informes sobre la posible adquisición de Windsurf por parte de OpenAI, lo que genera preocupaciones en el mercado sobre la intensificación de la competencia entre los gigantes de la IA y la neutralidad de las plataformas de herramientas de programación de IA. Windsurf tuvo que habilitar urgentemente servicios de inferencia de terceros y ajustar su estrategia de suministro de modelos a los usuarios, mientras que Anthropic respondió que prioriza el suministro de recursos a socios que puedan garantizar una cooperación continua. (Fuente: 36氪, 36氪, mervenoyann, swyx)
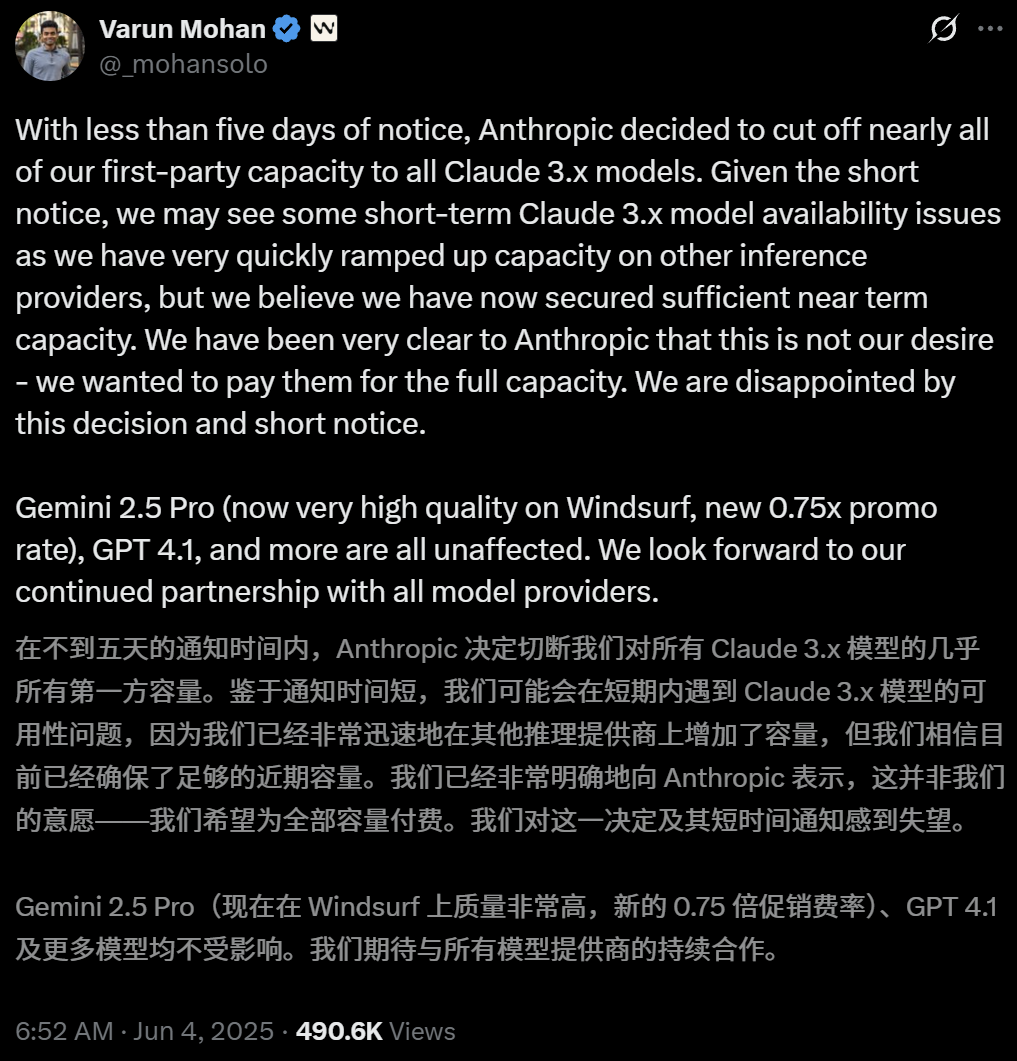
OpenAI supera los 3 millones de usuarios empresariales de pago y lanza una estrategia de precios flexible: OpenAI anunció que su número de usuarios empresariales de pago ha alcanzado los 3 millones, un aumento del 50% con respecto a los 2 millones anunciados en febrero de este año, abarcando las tres líneas de productos: ChatGPT Enterprise, Team y Edu. Al mismo tiempo, OpenAI ha lanzado una estrategia de precios flexible para clientes empresariales basada en un “fondo de créditos compartidos”. Después de que una empresa compre un fondo de créditos, el uso de funciones avanzadas consumirá créditos, pero aún podrán tener “acceso ilimitado” a los principales modelos y funciones. Esta nueva política de precios se lanzará primero en ChatGPT Enterprise y luego se extenderá a ChatGPT Team, que también ofrece una oferta de prueba de 1 dólar por 5 cuentas durante el primer mes. (Fuente: 36氪, snsf)
Joven china nacida en los 2000, Hong Letong, funda la empresa de IA matemática Axiom, con una valoración objetivo de 300 millones de dólares: Carina Letong Hong, doctora en matemáticas de Stanford de origen chino, ha fundado la empresa de IA Axiom, centrada en el desarrollo de modelos de IA para resolver problemas matemáticos prácticos, con clientes objetivo en fondos de cobertura y empresas de trading cuantitativo. Axiom planea utilizar datos de pruebas matemáticas formales para entrenar sus modelos, permitiéndoles dominar el razonamiento lógico riguroso y las capacidades de demostración. Aunque la empresa aún no tiene un producto, ya está negociando una financiación de 50 millones de dólares, con una valoración estimada de entre 300 y 500 millones de dólares. Hong Letong tiene una licenciatura en matemáticas y física del MIT y un doctorado en matemáticas de Stanford, y fue becaria Rhodes. (Fuente: 量子位)

🌟 Comunidad
Debate candente en la conferencia AI.Engineer: Observabilidad de Agentes, alta eficiencia en equipos pequeños y el rol del PM de IA en el foco: En la Exposición Mundial AI.Engineer, los asistentes debatieron acaloradamente sobre la observabilidad y evaluación de agentes de IA (Agents), la creación de equipos pequeños y eficientes (Tiny Teams), y las mejores prácticas en la gestión de productos de IA (AI PM). La interacción por voz fue considerada la dirección más popular en multimodalidad, y la seguridad también se convirtió por primera vez en un tema importante. Anthropic emitió en la conferencia una solicitud de emprendimiento en el campo del Protocolo de Contexto de Modelo (MCP), esperando ver más servidores MCP además de las herramientas para desarrolladores, soluciones para simplificar la construcción de servidores y innovaciones en la seguridad de aplicaciones de IA (como la protección contra el envenenamiento de herramientas). (Fuente: swyx, swyx, swyx, swyx)

Discusión sobre si la IA provocará la desaparición del lenguaje natural y hará a los humanos más tontos: En las redes sociales han surgido preocupaciones sobre la posibilidad de que la amplia aplicación de la IA conduzca a una atrofia de la comunicación en lenguaje natural (teoría del “internet muerto”) y a una degradación de las capacidades cognitivas humanas (como el pensamiento profundo, el cuestionamiento y la capacidad de reestructuración). Algunos usuarios creen que la dependencia excesiva de la IA para obtener información y respuestas podría reducir la selección activa, el juicio y el pensamiento independiente, formando una dependencia de “externalización cognitiva”. Otro punto de vista sostiene que la IA puede manejar el qué y el cómo, pero el por qué aún requiere la decisión humana; la clave está en encontrar el papel del ser humano en la convivencia con la tecnología y mantener el poder de juicio. (Fuente: Reddit r/ArtificialInteligence, 36氪)
OpenAI recibe orden judicial de conservar todos los registros de ChatGPT y API, lo que genera preocupación por la privacidad: Una orden judicial exige a OpenAI que conserve todos los registros de chat de ChatGPT y las solicitudes de API, incluidos aquellos registros de “chat temporal” que deberían haberse eliminado. Esta medida ha suscitado la preocupación de los usuarios sobre la privacidad de los datos y si se respetarán las políticas de retención de datos de OpenAI. Algunos comentaristas consideran que esto subraya aún más la importancia de utilizar modelos locales y poseer tecnología y datos propios. (Fuente: Reddit r/artificial, Reddit r/LocalLLaMA, Teknium1, nptacek)

Los Agentes de IA enfrentan desafíos de confianza y seguridad, son vulnerables a ataques de phishing: Se discute que, aunque la capacidad de los Agentes de IA aumenta día a día, sus mecanismos de confianza presentan riesgos de ser explotados. Por ejemplo, un Agente podría ser inducido a visitar enlaces maliciosos al confiar en sitios web conocidos (como redes sociales), lo que podría llevar a la filtración de información sensible o a la ejecución de acciones maliciosas. Esto exige que en el diseño de los Agentes se refuerce la capacidad de identificación y resistencia a contenido y enlaces maliciosos, para garantizar su seguridad al realizar operaciones en el mundo real. (Fuente: DeepLearning.AI Blog)
Reflexiones provocadas por las herramientas de programación asistida por IA: de la modernización del código a la transformación del flujo de trabajo: La comunidad discutió la aplicación de la IA en el desarrollo de software, especialmente en el manejo de código heredado y el cambio en los flujos de trabajo de programación. Morgan Stanley utilizó su herramienta de IA interna DevGen.AI para analizar y refactorizar millones de líneas de código antiguo, ahorrando significativamente tiempo de desarrollo. Al mismo tiempo, la opinión de Andrej Karpathy sobre las perspectivas de las aplicaciones con interfaces de usuario complejas también generó reflexiones sobre cómo se debería diseñar el software futuro para colaborar mejor con la IA, enfatizando la importancia de las interfaces programables y API. Estas discusiones reflejan cómo la IA está impactando profundamente las prácticas y filosofías de la ingeniería de software. (Fuente: mitchellh, 36氪, 36氪)
💡 Otros
Reparación de electrodomésticos asistida por IA, ChatGPT se convierte en “Friendo”: Un usuario compartió su experiencia al diagnosticar y reparar preliminarmente con éxito un lavavajillas averiado utilizando ChatGPT (apodado Friendo). A través de conversaciones con la IA, describiendo códigos de error y tomando fotos del panel de control, la IA ayudó al usuario a localizar una falla en el elemento calefactor y lo guio para eludir temporalmente dicho elemento, restaurando parcialmente la funcionalidad del lavavajillas. Esto demuestra el potencial de los LLM en la resolución de problemas cotidianos y el soporte técnico. (Fuente: Reddit r/ChatGPT)
Video generado por IA de una entrevista a personajes del siglo XVI llama la atención: Un video generado por IA que simula una entrevista a personajes del siglo XVI ha recibido elogios en la comunidad por su creatividad y sentido del humor. Las imágenes de los personajes y el contenido de los diálogos reflejan con humor las condiciones de vida de la época, por ejemplo, “despertar y pisar excrementos, luego ser gravado con impuestos, y eso solo antes del desayuno”. Este tipo de aplicaciones demuestra el potencial de entretenimiento de la IA en la creación de contenido y la recreación de escenarios históricos. (Fuente: draecomino, Reddit r/ChatGPT)

Las becas Thiel se centran en la innovación en IA, abarcando humanos digitales, emociones robóticas y predicción mediante IA: Se anunció la nueva lista de las “Becas Thiel”, donde varios proyectos de IA llamaron la atención. Canopy Labs se dedica a crear humanos digitales de IA indistinguibles de personas reales, capaces de interactuar en tiempo real y de forma multimodal. El proyecto Intempus tiene como objetivo dotar a los robots de una capacidad de expresión emocional similar a la humana para mejorar la interacción hombre-máquina. Aeolus Lab se centra en utilizar la tecnología de IA para predecir el clima y los desastres naturales, e incluso explorar la posibilidad de una intervención activa. Estos proyectos muestran las direcciones de exploración de los jóvenes emprendedores en la vanguardia de la IA. (Fuente: 36氪)