Palabras clave:Investigación matemática de IA, Consumo energético de IA, Herramientas de programación de IA, Evaluación médica con IA, Optimización de hardware para IA, Generación de vídeo con IA, Evaluación de confiabilidad en IA, Sistemas multiagente de IA, Proyecto DARPA expMath, Competición matemática AlphaProof, Prueba de referencia FrontierMath, Posicionamiento visual GUI-Actor, Evaluación de modelo de audio AudioTrust
🔥 Enfoque
Avances y desafíos de la IA en el campo de las matemáticas: DARPA lanza el proyecto expMath, con el objetivo de utilizar la IA para acelerar la investigación matemática, descomponiendo problemas grandes y complejos en subproblemas más fáciles de resolver. Aunque la IA ya ha demostrado un potencial que supera al humano en competiciones como las Olimpiadas Matemáticas (ej. AlphaProof, AlphaEvolve), la resolución de problemas matemáticos a nivel de investigación (como los Problemas del Milenio) sigue estando lejos de su alcance. El nuevo benchmark FrontierMath tiene como objetivo evaluar con mayor precisión la capacidad de la IA en problemas desconocidos. Actualmente, la IA tiene dificultades para manejar rutas de demostración extremadamente largas (como la demostración de un millón de líneas para la hipótesis de Riemann), pero ya existen intentos de “comprimir” las rutas de demostración mediante el aprendizaje por refuerzo, y se han logrado avances en la investigación de la conjetura de Andrews-Curtis. La IA aún carece de verdadera intuición y creatividad matemática, siendo difícil para ella “inventar” nuevos conceptos matemáticos como lo hacen los humanos (ej. el icosaedro), actualmente desempeña más un papel de “explorador avanzado”, ayudando a los humanos en la exploración (Fuente: MIT Technology Review)

El consumo energético de la IA genera preocupación, pero las perspectivas de optimización son prometedoras: El rápido desarrollo de la IA ha traído consigo una enorme demanda de energía, especialmente la generación de vídeo por IA, cuyo consumo es asombroso: el consumo de un vídeo de baja calidad de 5 segundos es 42.000 veces superior al de un chatbot respondiendo una pregunta. Sin embargo, también existen factores optimistas respecto al consumo energético de la IA: 1. Se espera que mejore la eficiencia de los modelos, chips y tecnologías de refrigeración; 2. La realidad comercial podría impulsar un desarrollo de IA más eficiente energéticamente. Aunque la IA se encuentra actualmente en una fase inicial, y en el futuro modelos de inferencia, dispositivos de hardware de IA y agentes digitales consumirán más energía, los avances tecnológicos también podrían traer mejoras en la eficiencia energética. Es importante centrarse en la estructura energética general, el consumo de agua de los centros de datos (como en Nevada) y el cumplimiento de las promesas de energía limpia, en lugar de enfocarse únicamente en la huella de carbono de los usuarios individuales (Fuente: MIT Technology Review)

OpenAI Codex CLI se reescribe en Rust para mejorar el rendimiento y la seguridad: OpenAI anunció que su herramienta de codificación por línea de comandos basada en IA, Codex CLI, será reescrita en el lenguaje Rust, con el objetivo de mejorar el rendimiento, aumentar la seguridad y eliminar la dependencia de Node.js. Anteriormente, la herramienta estaba escrita principalmente en TypeScript. El mantenedor Fouad Matin (quien se unió a OpenAI hace aproximadamente un año) señaló que la versión en Rust permitirá una instalación sin dependencias, un mecanismo de sandboxing mejorado (usando Landlock en Linux), un rendimiento optimizado (sin recolección de basura, menores requisitos de memoria) y podrá utilizar las implementaciones existentes de Rust MCP. Aunque hace poco más de medio mes ingenieros de OpenAI habían afirmado que TypeScript era el más adecuado para la UI, finalmente se decidió optar por Rust para buscar la máxima eficiencia en la herramienta de agente principal. Esta medida también se hace eco de la reciente tendencia de proyectos como Rolldown de Vite, XChat y el editor Zed, que han adoptado Rust para su reescritura (Fuente: 36氪)
Bond Capital publica informe sobre tendencias de IA, revelando el crecimiento de ChatGPT y el panorama global de la IA: El informe de Bond Capital señala que ChatGPT de OpenAI alcanzó los 800 millones de usuarios activos semanales en 17 meses, con ingresos anualizados estimados en 9.200 millones de dólares, lo que muestra un patrón de adopción prioritaria de la IA, especialmente en mercados emergentes (India representa el 14% de los usuarios). Su tasa de retención semanal alcanza el 80%, superando con creces a Google Search. Los gastos de capital de las grandes empresas tecnológicas aumentaron a 212.000 millones de dólares en 2024, y los costos de computación de OpenAI alcanzaron los 5.000 millones de dólares. Al mismo tiempo, la capacidad de IA de China está alcanzando rápidamente, con DeepSeek R1 logrando el 93% del rendimiento de OpenAI o3-mini en benchmarks matemáticos, y con menores costos de entrenamiento; China representa el 33,9% de los usuarios móviles de DeepSeek. La contratación para puestos relacionados con la IA creció un 448% en 7 años, y las empresas están trasladando gradualmente las aplicaciones de IA de ser experimentales a ser clave para las operaciones (Fuente: Reddit r/artificial)
🎯 Tendencias
Altman vislumbra la próxima generación de modelos de IA: razonamiento más potente, contexto ultralargo e invocación de herramientas: El CEO de OpenAI, Sam Altman, cree que definir la AGI es menos importante que centrarse en el progreso exponencial de la tecnología de IA. Predice que los futuros modelos de IA tendrán una capacidad de comprensión de contexto superior, se conectarán sin problemas con diversos tipos de herramientas, poseerán una capacidad de razonamiento excepcional y una robustez para ejecutar tareas complejas. La IA ideal debería ser compacta, con un razonamiento sobrehumano, soportar un contexto de billones de tokens y poder invocar cualquier herramienta. Enfatiza que el valor de la IA radica en el razonamiento, no simplemente en ser una base de datos. Se utilizará mil veces más potencia de cálculo para la propia investigación en IA y para mejorar el rendimiento de los modelos en la fase de prueba, especialmente en campos como la biotecnología, por ejemplo, descifrando los mecanismos de expresión del ARN para combatir enfermedades (Fuente: 36氪)

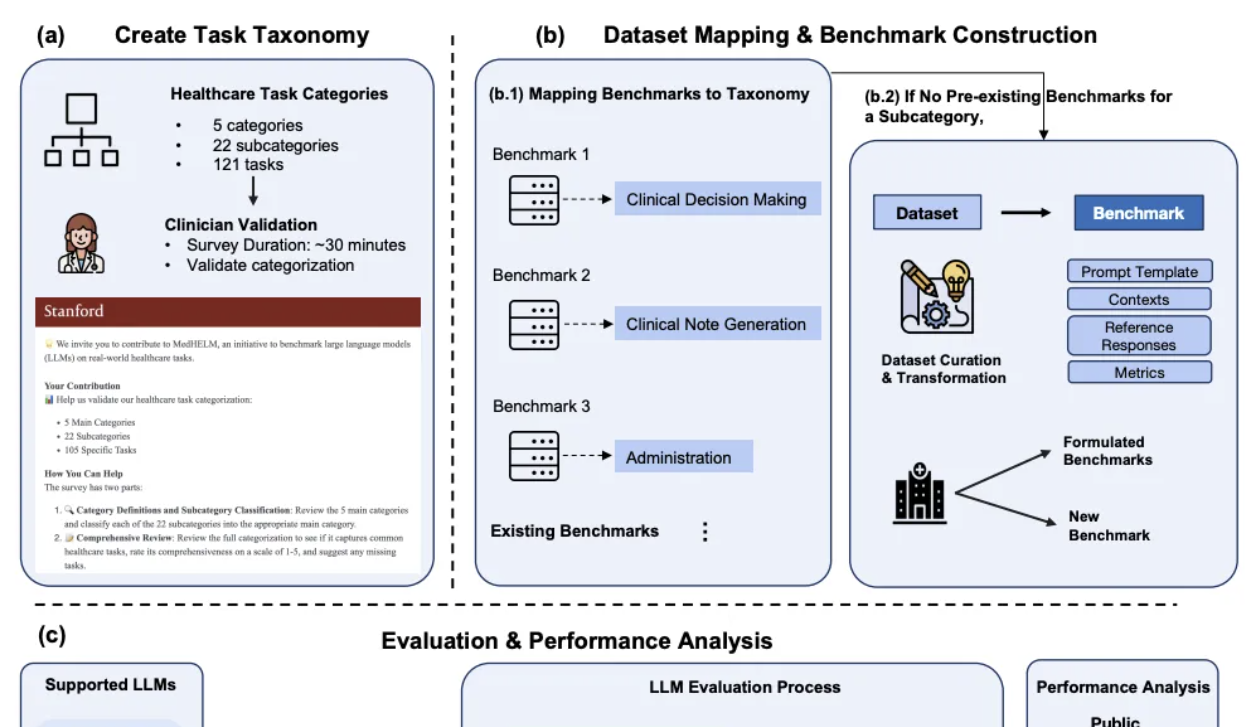
DeepSeek destaca en la evaluación comparativa de IA clínica de Stanford: En el marco integral de evaluación de tareas médicas para modelos grandes MedHELM, recientemente publicado por la Universidad de Stanford, DeepSeek R1 ocupó el primer lugar con una tasa de victorias del 66% y una puntuación macro media de 0.75 en 35 pruebas de benchmark que cubren 22 subcategorías clínicas. Esta evaluación fue desarrollada con la participación de 29 médicos en ejercicio y se centra en simular escenarios de trabajo diario de los médicos clínicos. o3-mini le siguió de cerca, con una tasa de victorias del 64% y una puntuación macro media de 0.77. Claude 3.7 Sonnet y 3.5 Sonnet también obtuvieron buenos resultados. La evaluación mostró que los modelos rinden mejor en tareas de texto libre como la generación de casos clínicos y la educación en comunicación con el paciente, pero obtienen puntuaciones más bajas en tareas de razonamiento estructurado (como gestión y flujo de trabajo). La investigación también validó la consistencia de los métodos de evaluación del jurado de LLM con las puntuaciones de los médicos clínicos (Fuente: 量子位)
Huawei propone la solución Adaptive Pipe & EDPB, acelerando el entrenamiento de MoE en más del 70%: Para abordar los problemas de espera de comunicación y desequilibrio de carga introducidos por el paralelismo de expertos (EP) en el entrenamiento de modelos MoE, Huawei ha propuesto la solución optimizada Adaptive Pipe & EDPB. Esta solución utiliza la plataforma de simulación DeployMind para la optimización automática del paralelismo a nivel horario, adopta una comunicación All-to-All jerárquica y una tecnología de enmascaramiento adaptativo de grano fino hacia adelante y hacia atrás (Adaptive Pipe), logrando un enmascaramiento de comunicación EP superior al 98%. Al mismo tiempo, mediante la tecnología de equilibrio de carga global EDPB (que incluye la migración dinámica predictiva de expertos, el equilibrio de cálculo de Attention mediante reordenamiento de datos y el equilibrio de carga entre capas de pipeline virtual), supera el problema del desequilibrio de carga, mejorando aún más el rendimiento en un 25.5%. En la práctica de entrenamiento del modelo Pangu Ultra MoE 718B (secuencia de 8K), esta solución combinada logró una mejora del 72.6% en el rendimiento de entrenamiento de extremo a extremo del sistema (Fuente: 量子位)

El hardware de IA de segunda generación se centra en escenarios específicos y la resolución de problemas concretos, en lugar de reemplazar a los teléfonos móviles: A diferencia del hardware de IA de primera generación como AI Pin, que intentaba “matar al teléfono móvil”, la segunda hornada de hardware de IA, como la grabadora Plaude, XiaoZhi AI, los auriculares AI de iFlytek y las gafas Meta AI, se enfoca en resolver problemas específicos en escenarios de nicho como la transcripción de grabaciones, el chat por voz y las actas de reuniones, y ha logrado un notable éxito comercial. Estos productos encarnan las características de “pequeño pero potente, especializado y refinado”, enfatizando los límites y la interacción débil, y buscando el máximo rendimiento en funciones específicas. Las tendencias de la industria indican que se está formando un “SO invisible” centrado en el asistente de IA, multidispositivo y basado en la nube, donde el hardware se convierte en el portador y los tentáculos de las capacidades de IA, y el derecho de entrada se desplaza de las aplicaciones al asistente de IA (Fuente: 36氪)

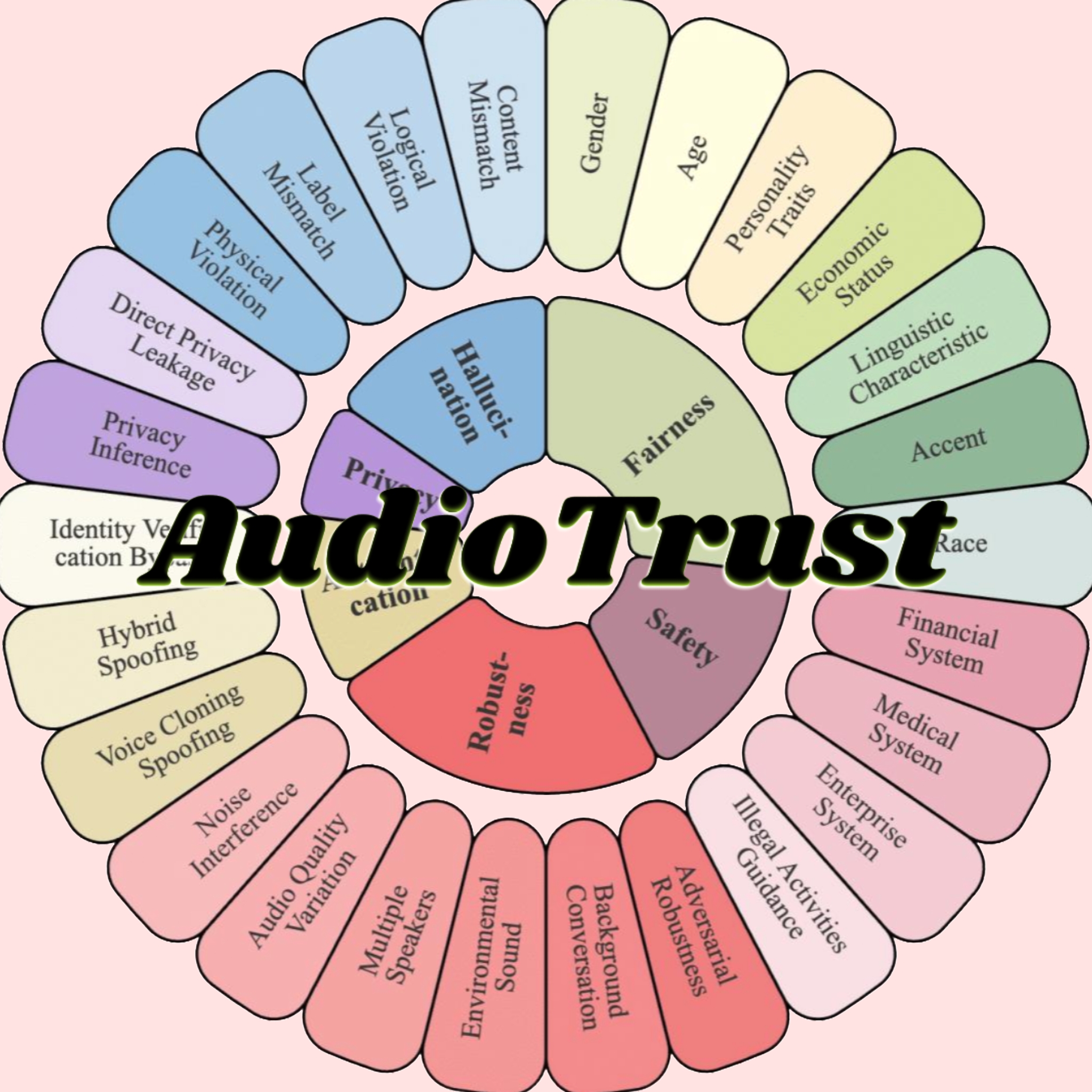
AudioTrust: Se publica el primer benchmark multidimensional de evaluación de la fiabilidad para modelos grandes de audio: Un equipo de investigadores de la Universidad Tecnológica de Nanyang, la Universidad de Tsinghua y otras instituciones ha publicado AudioTrust, el primer benchmark integral de evaluación de la fiabilidad diseñado específicamente para modelos grandes de lenguaje y audio (ALLMs). Este marco evalúa exhaustivamente los ALLMs desde seis dimensiones centrales: equidad, alucinaciones, seguridad, privacidad, robustez y autenticación, a través de 18 configuraciones experimentales y más de 4420 datos de audio/texto de escenarios reales. La investigación encontró que los modelos existentes presentan sesgos sistemáticos en atributos sensibles, una robustez insuficiente frente al ruido y entradas adversarias, y vulnerabilidades en la defensa contra el engaño por clonación de voz, entre otros aspectos. AudioTrust tiene como objetivo revelar los riesgos potenciales de los ALLMs y proporcionar una base de investigación para mejorar su fiabilidad (Fuente: 量子位)
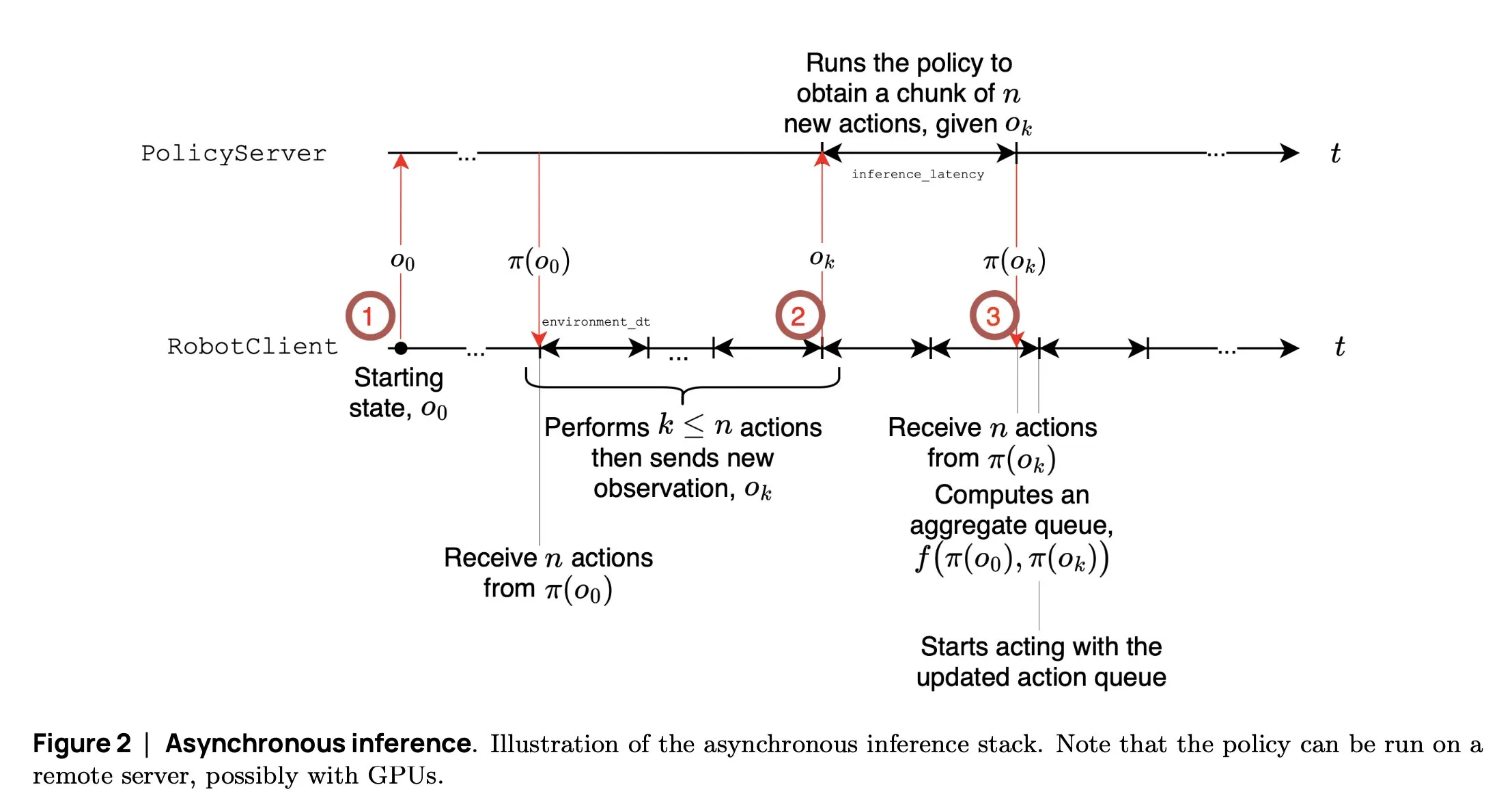
SmolVLA: Hugging Face lanza un modelo VLA pequeño y eficiente para robots: El equipo de robótica de Hugging Face ha lanzado SmolVLA, un modelo de acción visual-lingüística de 450M de parámetros, diseñado específicamente para robots. Puede ejecutarse en tiempo real en GPUs de consumo, se entrena con conjuntos de datos públicos y su rendimiento es comparable al de modelos más grandes. SmolVLA introduce un mecanismo de “inferencia asíncrona”, donde el robot no necesita esperar a que se complete la acción actual para comenzar a planificar el siguiente paso, lo que aumenta el rendimiento del robot en aproximadamente un 30% y casi duplica la eficiencia en la finalización de tareas. El modelo ha demostrado un rendimiento excepcional en múltiples benchmarks como Meta-World y LIBERO. Su código, pesos y proceso de entrenamiento han sido liberados como código abierto, con el objetivo de promover el desarrollo de la comunidad de robótica abierta (Fuente: AymericRoucher, mervenoyann, huggingface)
Microsoft presenta GUI-Actor: Mejora la capacidad de localización visual de los VLM en tareas GUI: Microsoft ha lanzado GUI-Actor, un método de localización GUI independiente de coordenadas basado en VLM. Este método introduce una cabeza de acción (action head) con mecanismo de atención, que alinea tokens dedicados con los parches visuales relevantes, proponiendo así una o más regiones de acción en una única pasada hacia adelante, y coopera con un validador de localización para seleccionar la acción más razonable. Los experimentos demuestran que GUI-Actor supera a los métodos anteriores en múltiples benchmarks de localización de acciones GUI. Un modelo de 7B, con solo el ajuste fino de la cabeza de acción de aproximadamente 100M de parámetros (el tronco principal del VLM congelado), puede alcanzar un rendimiento comparable a los modelos SOTA, lo que demuestra su capacidad para dotar a los VLM de una localización efectiva sin comprometer su generalidad (Fuente: HuggingFace Daily Papers, kylebrussell)

DCM: Modelo de consistencia de doble experto acelera la generación de vídeo de alta calidad: Investigadores proponen DCM (Dual-Expert Consistency Model), un acelerador para la generación eficiente de vídeo de alta calidad. Mediante el análisis de la dinámica de entrenamiento del modelo de consistencia, se descubrió que existen conflictos en los gradientes de optimización y las contribuciones a la pérdida en diferentes pasos de tiempo. DCM adopta un diseño de doble experto eficiente en parámetros: un experto semántico aprende la disposición semántica y el movimiento, mientras que un experto en detalles se centra en la optimización de detalles finos. Combinando una pérdida de coherencia temporal y pérdidas GAN/de coincidencia de características, DCM logra una calidad visual SOTA al tiempo que reduce significativamente los pasos de muestreo, resolviendo eficazmente los problemas en la destilación de modelos de difusión de vídeo. Este método puede lograr una aceleración de inferencia de aproximadamente 10 veces en modelos como HunyuanVideo13B (de 1500 segundos a 120 segundos) (Fuente: HuggingFace Daily Papers, _akhaliq)
FlowMo: Guía de flujo basada en varianza mejora la coherencia del movimiento en la generación de vídeo: Para abordar las limitaciones de los modelos de difusión de texto a vídeo en la modelización de dimensiones temporales como el movimiento, la física y las interacciones dinámicas, los investigadores proponen FlowMo, un método de guía en tiempo de inferencia que no requiere entrenamiento adicional ni entradas auxiliares. FlowMo deriva una representación temporal desacoplada de la apariencia midiendo la distancia entre las variables latentes correspondientes de fotogramas consecutivos, y utiliza la varianza a nivel de parche a través de la dimensión temporal para estimar la coherencia del movimiento, guiando dinámicamente al modelo durante el proceso de muestreo para reducir esta varianza. Los experimentos demuestran que FlowMo puede mejorar significativamente la coherencia del movimiento de varios modelos de difusión de vídeo preentrenados, sin sacrificar la calidad visual ni la alineación con el prompt (Fuente: HuggingFace Daily Papers, Suhail)
Qwen3-235B-A22B muestra un rendimiento competitivo en el agente de codificación Openhands: El equipo Qwen de Alibaba anunció que su modelo Qwen3-235B-A22B ha logrado una puntuación del 34.4% en el benchmark Swebench-verified del agente de codificación de código abierto Openhands. El equipo declaró que este resultado indica que el modelo logra un rendimiento competitivo con menos parámetros y agradeció a allhands_ai por proporcionar un agente fácil de usar. Esta noticia destaca el potencial de la combinación de modelos abiertos y agentes abiertos (Fuente: Alibaba_Qwen)

OmniSpatial: Se publica un benchmark integral de razonamiento espacial para VLM: Investigadores han lanzado OmniSpatial, un benchmark de razonamiento espacial para modelos de lenguaje visual (VLM) completo y desafiante, basado en la psicología cognitiva. OmniSpatial incluye cuatro categorías principales: razonamiento dinámico, lógica espacial compleja, interacción espacial y transformación de perspectiva, subdivididas en 50 subcategorías con un total de más de 1500 pares de preguntas y respuestas. Experimentos exhaustivos realizados en VLM de código abierto y cerrado existentes, así como en modelos especializados en razonamiento y comprensión espacial, indican que presentan limitaciones significativas en la comprensión espacial integral. Esta investigación tiene como objetivo impulsar un mayor desarrollo de las capacidades de razonamiento espacial de los VLM (Fuente: HuggingFace Daily Papers, kylebrussell)
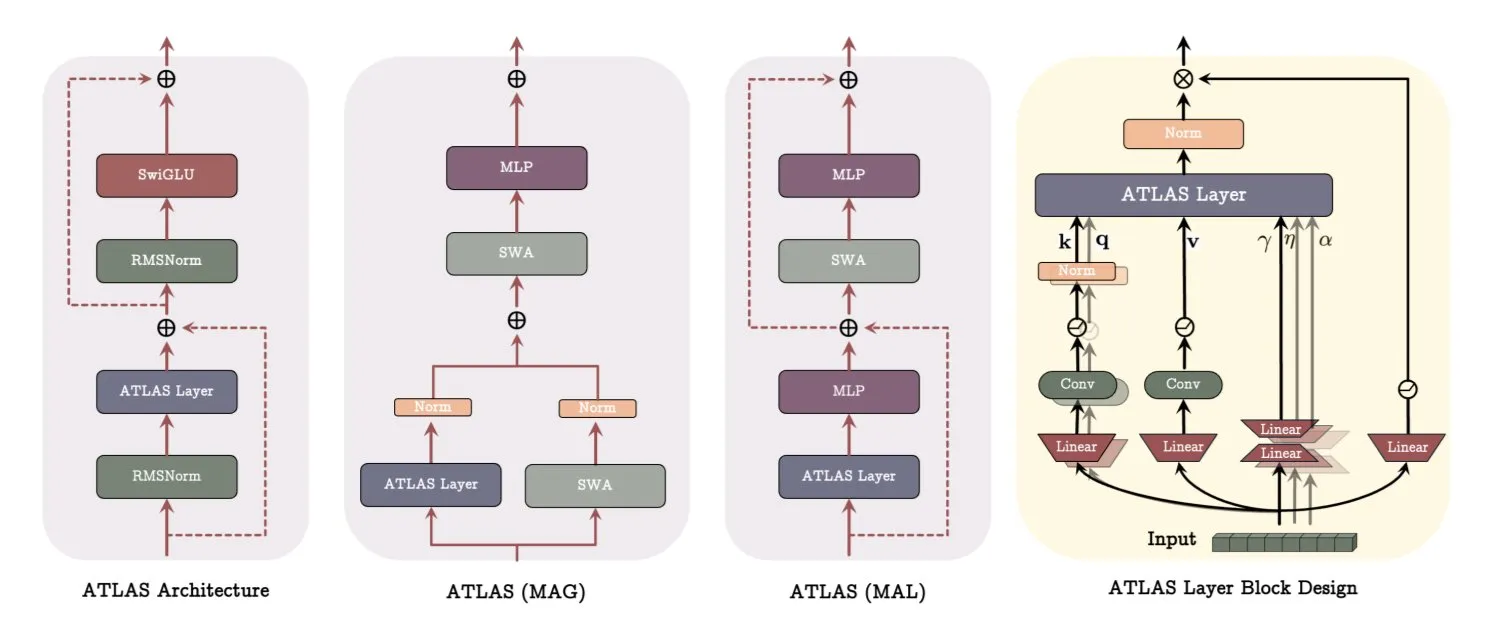
Arquitectura ATLAS de Google DeepMind: Reconstruyendo la forma en que los modelos aprenden y recuerdan: Google DeepMind ha lanzado ATLAS, una nueva arquitectura de modelo diseñada para redefinir la forma en que los modelos aprenden y utilizan la memoria. ATLAS implementa la memoria activa a través de la llamada regla Omega, procesando conjuntamente los últimos c tokens para optimizar la memoria como un estado dinámico y aprendible. Utiliza mapeos de características polinomiales y exponenciales para almacenar asociaciones más ricas sin expandir el tamaño de la memoria, y emplea el optimizador Muon para optimizar la memoria de manera más eficiente. Diseños como DeepTransformers y Dot reemplazan la atención fija tradicional con mecanismos aprendibles e impulsados por la memoria. ATLAS tiene como objetivo impulsar la IA hacia sistemas más inteligentes, conscientes del contexto y capaces de utilizar eficazmente conjuntos de datos a gran escala (Fuente: TheTuringPost)
NVIDIA lanza el modelo visual Llama-Nemotron-Nano-VL-8B-V1: NVIDIA ha presentado Llama-Nemotron-Nano-VL-8B-V1, un modelo visual de 8 mil millones de parámetros capaz de leer documentos densos, gráficos y fotogramas de vídeo. Este modelo ocupa el primer lugar en OCRBench V2 (inglés) y se caracteriza por la fusión de extremo a extremo de las capacidades de diseño (layout) y OCR. El modelo ya está disponible en Hugging Face (Fuente: ClementDelangue)
Shisa V2 405B lanzado, se proclama el modelo bilingüe más potente de Japón: Shisa AI ha lanzado el último modelo bilingüe (japonés/inglés) de su serie Shisa V2, el Shisa V2 405B. Este modelo está ajustado (fine-tuned) a partir de Llama 3.1 405B y se le han añadido datos adicionales en coreano y chino tradicional para mejorar sus capacidades multilingües. Según se informa, supera a GPT-4/GPT-4 Turbo en MT-Bench japonés-inglés y es comparable en capacidad japonesa a los más recientes GPT-4o y DeepSeek-V3. Los pesos del modelo y las versiones cuantizadas GGUF están disponibles en Hugging Face, y hay un endpoint FP8 disponible para pruebas (Fuente: Reddit r/LocalLLaMA)

Anthropic lanza el plan Claude Code Pro y el modelo o3-pro: La herramienta de programación con IA de Anthropic, Claude Code, ya está disponible para los usuarios del plan Pro, pero el uso del modelo Sonnet 4 tiene un límite de 10-40 prompts cada 5 horas. Opus 4 no se puede usar con Claude Code a través del plan Pro, lo que parece más un modo de prueba. Al mismo tiempo, el modelo o3-pro de OpenAI también se ha lanzado y actualmente solo está disponible para suscriptores Pro de 200 dólares al mes (Fuente: Reddit r/ClaudeAI, karminski3)
H Company lanza el modelo de lenguaje visual de acción GUI de código abierto Holo-1: H Company ha lanzado Holo-1, un modelo de lenguaje visual de acción GUI con versiones de 3B y 7B parámetros, diseñado para diversas tareas de agentes web y de computadora. Holo-1 utiliza la licencia Apache 2.0 y es compatible con la biblioteca Hugging Face Transformers, con el objetivo de mejorar las capacidades de la IA en la comprensión y operación de interfaces gráficas de usuario (Fuente: mervenoyann)
El modelo de generación de vídeo Kling 2.1 recibe atención, admite conversión de imagen a vídeo y creación estilizada: El modelo de texto a vídeo e imagen a vídeo Kling 2.1 de Kuaishou continúa recibiendo atención de la comunidad. Los usuarios informan que puede transformar imágenes simples en escenas de calidad cinematográfica de 1080p, admite la conversión de tomas panorámicas ordinarias en animaciones estilo Pixar mediante la combinación de GPT-4o con Kling, y puede utilizar imágenes generadas por Midjourney V7 como entrada para crear vídeos con efectos dinámicos hiperrealistas. La comunidad ha compartido numerosos ejemplos de creaciones utilizando Kling 2.1, demostrando su potencial en la generación de vídeos creativos (Fuente: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)

OpenAI lanza nuevo modelo de voz, admite reproducción de voz en tiempo real a doble velocidad: OpenAI anunció que su modelo o3-pro ya está disponible, actualmente solo para suscriptores Pro. Al mismo tiempo, OpenAI parece que también lanzará dos nuevos modelos de voz basados en GPT-4o. Su API de voz en tiempo real también ha sido mejorada, aumentando la fiabilidad en el seguimiento de instrucciones, la consistencia en la invocación de herramientas y el comportamiento de interrupción, y ha añadido el parámetro speed, que permite a los usuarios controlar la velocidad de reproducción de la voz, hasta 2x. Fin Voice de Intercom ya está utilizando su API en tiempo real (Fuente: karminski3, swyx, swyx)
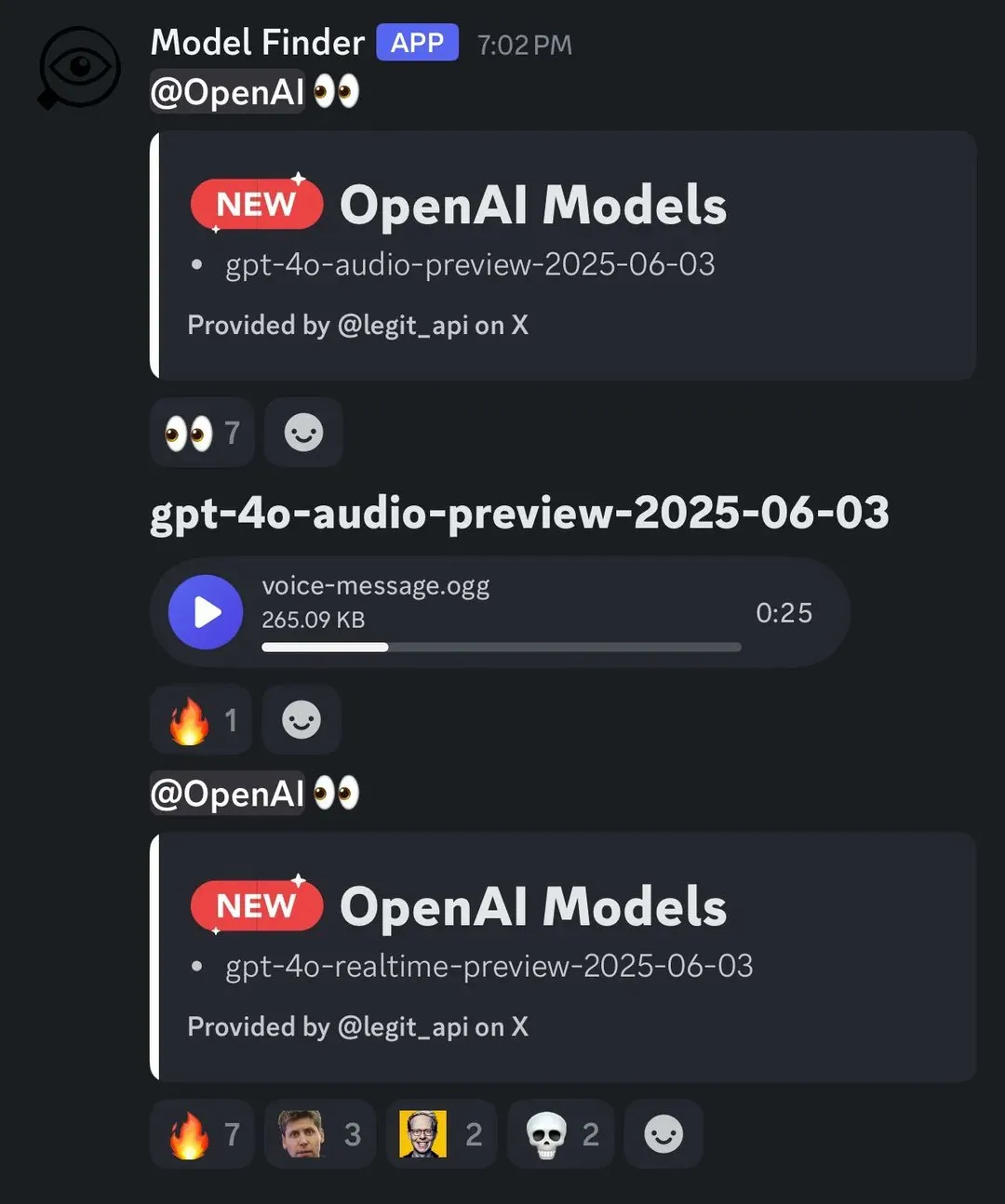
Arcee AI lanza el modelo Homunculus, destilando la cadena de pensamiento de Qwen3 a 12B: Arcee AI ha presentado el modelo Homunculus-12B, que transfiere la cadena de “pensamiento” (CoT) de Qwen3-235B a un modelo Mistral-Nemo de 12B parámetros mediante la técnica de destilación de trayectoria de logits. Este modelo conserva íntegramente el proceso CoT y puede ejecutarse en una única GPU 4090, con el objetivo de lograr capacidades de razonamiento complejo en un modelo más pequeño (Fuente: teortaxesTex, cognitivecompai, ClementDelangue)
El modelo FLUX Kontext es muy popular, el modelo público supera las 500.000 ejecuciones: El modelo FLUX Kontext ha recibido una amplia atención de la comunidad por sus potentes capacidades de edición y generación de imágenes; se informa que su modelo público ha superado las 500.000 ejecuciones en poco tiempo. Los usuarios comentan que Kontext puede reemplazar muchas tareas de procesamiento de imágenes que antes requerían software profesional como Photoshop. Krea AI también ha lanzado el modelo FLUX, pero sufrió una interrupción del servicio debido a problemas de red con su proveedor de capacidad de cómputo (Fuente: op7418, robrombach, op7418)
Meta y Constellation Energy firman un acuerdo nuclear de 20 años para alimentar la IA: Meta ha firmado un acuerdo de energía nuclear de 20 años con Constellation Energy, con el objetivo de suministrar electricidad a sus operaciones de inteligencia artificial (IA). Esta medida refleja la tendencia de las grandes empresas tecnológicas a buscar fuentes de energía sostenibles y estables para satisfacer la creciente demanda energética de la IA (Fuente: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

El servicio Bing Video Creator interrumpido, el equipo trabaja en su reparación urgente: La herramienta de creación de vídeo de Microsoft Bing, Bing Video Creator, ha experimentado una interrupción del servicio. Fuentes oficiales indican que el equipo es consciente de que un gran número de usuarios está utilizando el servicio y está trabajando para repararlo lo antes posible, pidiendo disculpas por las molestias ocasionadas. Aún no se han anunciado la causa específica del fallo ni el tiempo estimado de restauración (Fuente: JordiRib1)
🧰 Herramientas
La función de diapositivas de Manus AI recibe elogios, admite la exportación a Google Slides: La función de creación de diapositivas recientemente lanzada por Manus AI ha recibido elogios de los usuarios, quienes afirman que sus resultados superan las expectativas y pueden convertir rápidamente contenido como artículos de investigación en presentaciones PPT bien estructuradas y con abundantes elementos gráficos. Esta función admite modificaciones instantáneas, guardado automático y ha añadido la opción de exportar a Google Slides, facilitando la colaboración en equipo. Las pruebas muestran que Manus puede generar 8 diapositivas PPT en unos 10 minutos, un proceso que incluye la planificación del esquema, la búsqueda de información, la redacción de borradores, la generación de código HTML y el perfeccionamiento del diseño. Los usuarios comentan su alta eficiencia y ahorro de tiempo, y que el diseño se ajusta al posicionamiento del usuario, aunque el formato de exportación puede presentar problemas de visualización incompleta de la página, que requieren ajuste manual (Fuente: 量子位)
claude-trace: Herramienta para registrar todos los logs de peticiones de Claude Code: Una herramienta llamada claude-trace puede registrar todos los logs de peticiones de Claude Code, incluyendo los prompts, y guardar el contenido en archivos HTML para facilitar su visualización. Su principio de funcionamiento consiste en iniciarse a sí misma, inyectar y modificar la API global.fetch de Node.js, y luego, a través de ella, iniciar Claude Code, interceptando y registrando así todas las peticiones. Un usuario compartió que, al usar la suscripción Claude Max, se invoca principalmente claude-3-5-haiku (preprocesamiento), claude-opus-4 (escritura de código e invocación de herramientas) y claude-sonnet-4 (cuando se agota la cuota de Opus) (Fuente: dotey)
Firecrawl lanza la función /search, integrando búsqueda y rastreo: Firecrawl ha lanzado su nueva función /search, que permite a los usuarios completar la búsqueda en la web y el rastreo de los datos necesarios mediante una única llamada a la API, con el objetivo de simplificar el proceso de adquisición de datos para los agentes de IA. Esta función se puede integrar con herramientas de automatización como n8n, mejorando la eficiencia en el procesamiento de datos (Fuente: omarsar0)
Modal lanza LLM Engine Advisor, ayudando a evaluar el rendimiento de ejecución de LLM: Modal Labs ha desarrollado una pequeña aplicación llamada LLM Engine Advisor, diseñada para ayudar a los usuarios a comprender rápidamente la velocidad de ejecución y el rendimiento máximo de diferentes LLM bajo diversas cargas de trabajo y motores (como vLLM, SGLang). Esta herramienta tiene como objetivo resolver la ineficiencia de ejecutar y compartir benchmarks de forma ad hoc, proporcionando soporte para la toma de decisiones técnicas a los usuarios al seleccionar e implementar LLM (Fuente: charles_irl, andersonbcdefg, charles_irl, charles_irl)
Lanzamiento de FastPlaid: Motor de búsqueda multivectorial de alto rendimiento: Raphaël Sourty ha anunciado el lanzamiento de FastPlaid, un motor de búsqueda multivectorial de alto rendimiento construido desde cero en Rust (con la ayuda de Torch C++). FastPlaid se considera el equivalente de Faiss en el campo de la búsqueda multivectorial, con el objetivo de proporcionar una velocidad de indexación y QPS de consulta más rápidos, especialmente para modelos de interacción tardía como ColBERT. Según se informa, en algunos casos puede lograr un aumento de velocidad QPS de hasta el 554% y una mejora del 72% en la velocidad de indexación (Fuente: lateinteraction, lateinteraction, lateinteraction, lateinteraction, stanfordnlp, lateinteraction)
ChaiGenie: Extensión de Chrome basada en RAG para chatear con documentos: ChaiGenie es una extensión de Chrome desarrollada por Devyansh Yadavv que utiliza la tecnología RAG (Retrieval Augmented Generation) para permitir a los usuarios consultar el contenido de los documentos de ChaiDocs directamente en el navegador mediante lenguaje natural. La extensión utiliza Puppeteer para rastrear el contenido de documentos y blogs, LangChain para la fragmentación, incrustación y procesamiento, Gemini para generar incrustaciones, Qdrant para el almacenamiento de vectores y búsqueda de similitud, y proporciona una interfaz API a través de Express y Node.js (Fuente: qdrant_engine)
Swama: Runtime de IA nativo para macOS basado en MLX: xingyue ha lanzado Swama, un runtime de IA nativo diseñado específicamente para macOS, con el objetivo de proporcionar una experiencia de ejecución local de LLM rápida, privada y concisa. Swama se basa en el framework MLX de Apple, es compatible con API compatibles con OpenAI y ofrece una atractiva interfaz CLI, permitiendo a los usuarios descargar, ejecutar y chatear con LLM locales sin configuraciones complejas (Fuente: awnihannun)
ragbits: Caja de herramientas modular de código abierto para construir aplicaciones GenAI: deepsense-ai ha liberado como código abierto su acelerador interno de aplicaciones GenAI, ragbits, una caja de herramientas que contiene bloques de construcción fiables, con seguridad de tipos y modulares para simplificar el desarrollo de pipelines RAG, aplicaciones de agentes y motores text2SQL. ragbits tiene como objetivo mejorar la repetibilidad, velocidad y estructura del desarrollo, y es fácil de integrar con pilas de observabilidad como OpenTelemetry, ayudando a los desarrolladores a construir y escalar aplicaciones GenAI y evitar el desorden en las bases de código (Fuente: Reddit r/LocalLLaMA)
Synthesia se integra con Wisetail, el vídeo con IA potencia los programas de formación: La plataforma de generación de vídeo con IA Synthesia ha anunciado su integración con el sistema de gestión de aprendizaje Wisetail. Los usuarios ahora pueden crear rápidamente vídeos con IA en Synthesia, con soporte para versiones localizadas en más de 140 idiomas, mantener el contenido de formación actualizado con unos pocos clics y luego incorporarlo fácilmente en los programas de formación de Wisetail, logrando una formación con vídeo mediante IA a escala (Fuente: synthesiaIO)

📚 Aprendizaje
DeepLearning.AI y Databricks colaboran para lanzar un curso corto sobre DSPy: Andrew Ng anunció una colaboración con Databricks para lanzar un nuevo curso corto titulado “DSPy: Build and Optimize Agentic Apps”. DSPy es un framework de código abierto que ajusta automáticamente los prompts de las aplicaciones GenAI. El curso enseñará cómo usar DSPy y MLflow, incluyendo el modelo de programación basado en firmas de DSPy, el seguimiento y depuración con MLflow, y cómo mejorar automáticamente la precisión mediante DSPy Optimizer. Este curso será impartido por Chen Qian, colíder del framework DSPy (Fuente: AndrewYNg, DeepLearningAI, matei_zaharia)
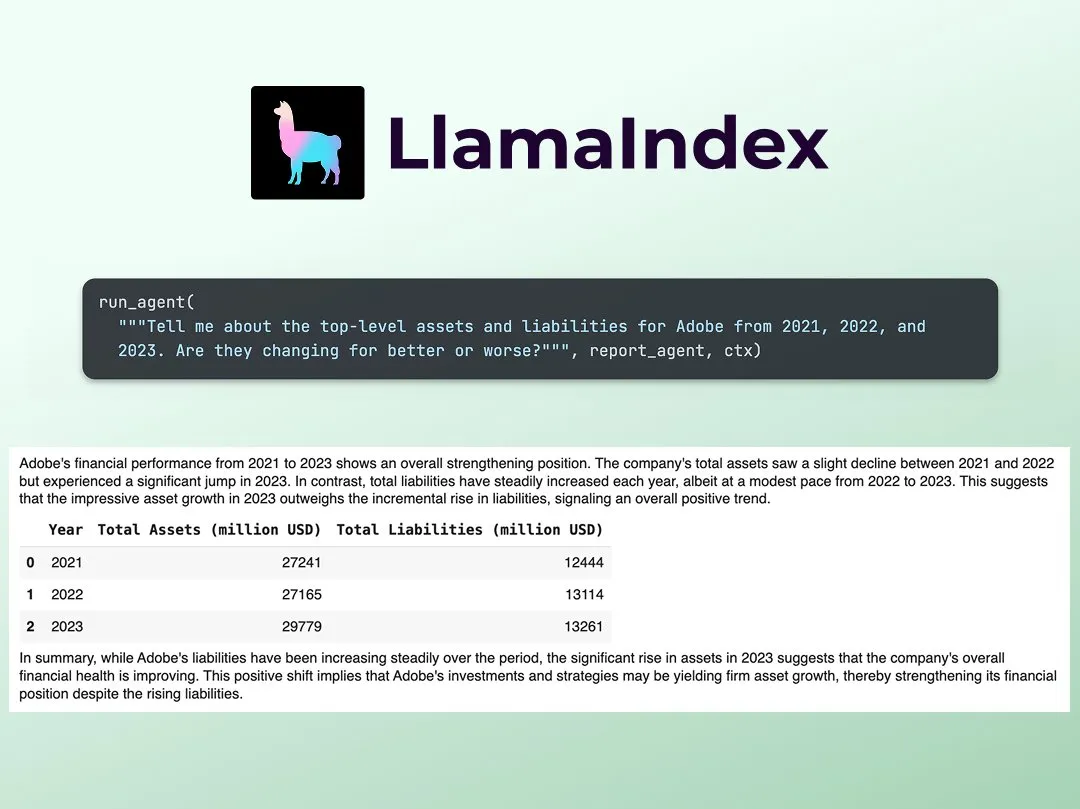
LlamaIndex publica un tutorial para construir analistas de investigación financiera multiagente: Jerry Liu de LlamaIndex compartió una guía paso a paso para construir un analista de investigación financiera multiagente. El proceso incluye una capa de procesamiento de datos (usando LlamaCloud para procesar archivos públicos) y una capa de orquestación de agentes (creando un sistema multiagente para investigación, almacenamiento en caché de datos y generación del resultado final). El Colab Notebook asociado fue uno de los ejemplos principales del taller Agents+Finance de la semana pasada (Fuente: jerryjliu0)
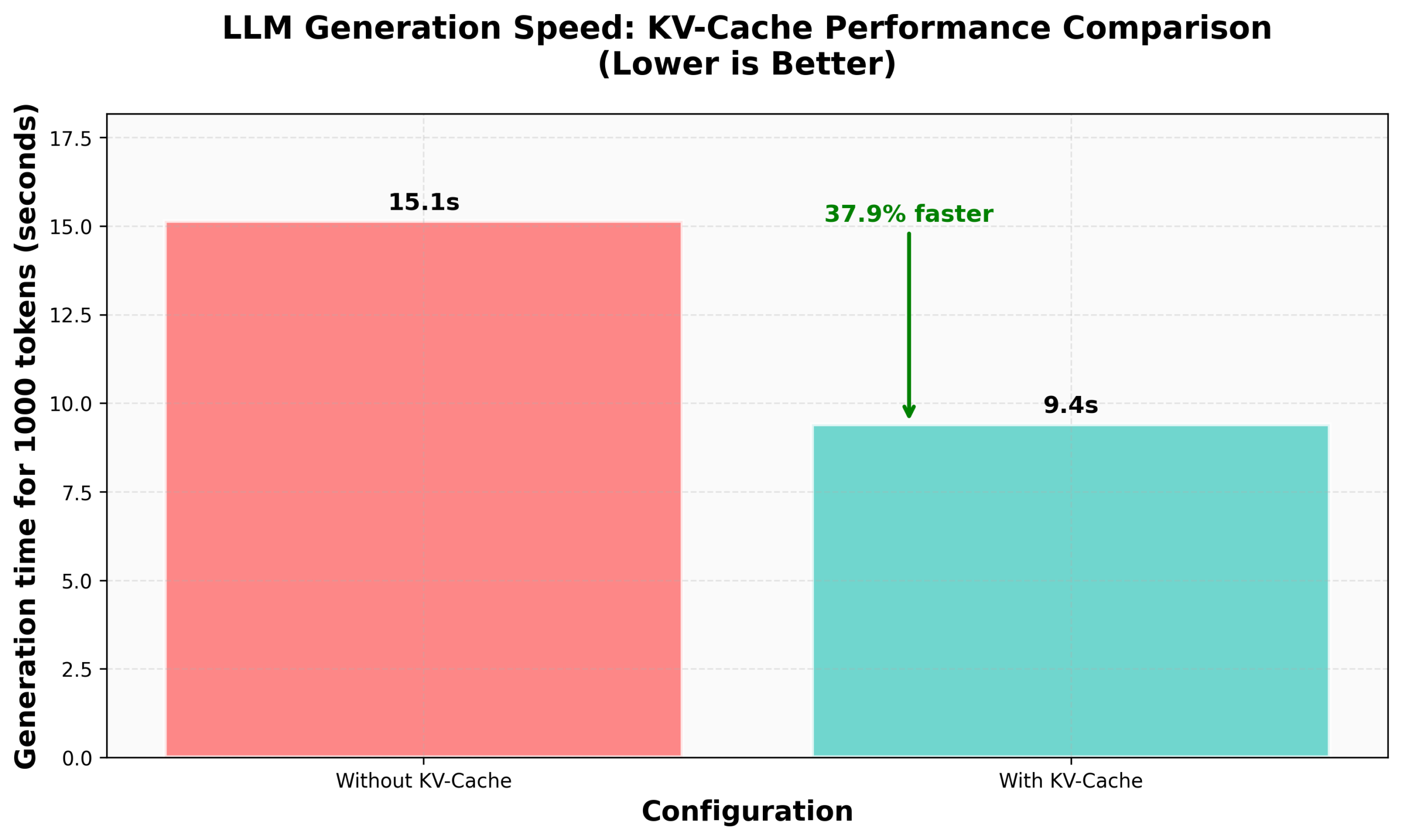
Tutorial de HuggingFace nanoVLM para implementar KV Caching: El blog de HuggingFace ha publicado un tutorial sobre cómo implementar KV Caching desde cero en su nanoVLM (una pequeña biblioteca de código PyTorch puro para entrenar modelos de lenguaje visual). El artículo explica detalladamente el principio de KV Caching, cómo implementarlo en el módulo de Attention, el modelo de lenguaje y el bucle de generación, y afirma haber logrado una mejora del 38% en la velocidad de generación mediante esta optimización. Este tutorial tiene como objetivo ayudar a comprender KV Caching y aplicarlo a otros modelos de lenguaje autorregresivos (Fuente: HuggingFace Blog, mervenoyann)
PyTorch comparte en la comunidad Diffusion de Meta: Sayak Paul compartió en la oficina de Meta en San Francisco los resultados de la aplicación de PyTorch en la comunidad Diffusion, destacando las funcionalidades existentes de Diffusers y futuras actualizaciones en cuanto a rendimiento. Las diapositivas correspondientes se han hecho públicas (Fuente: RisingSayak)

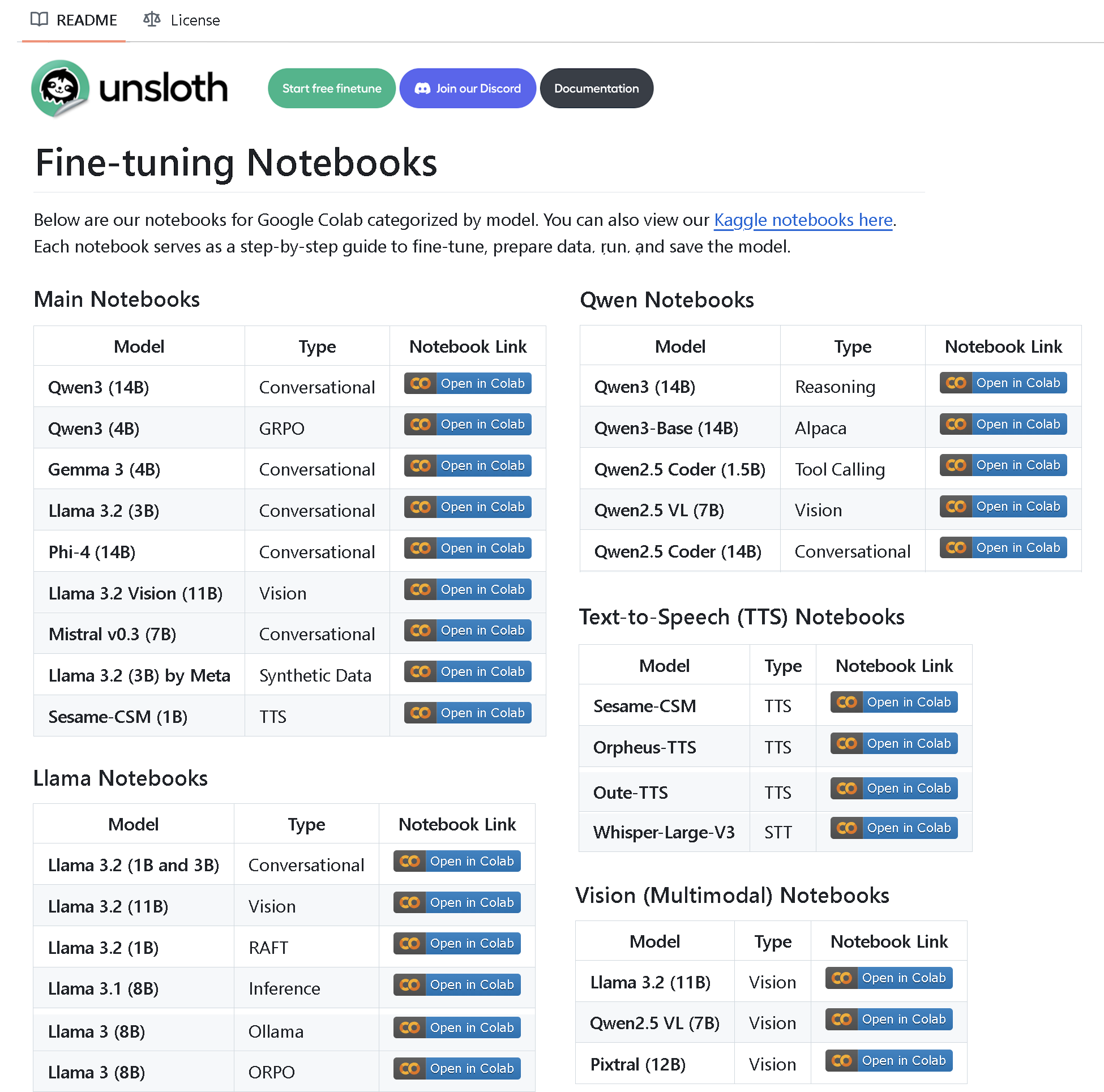
Unsloth AI lanza un repositorio con más de 100 Notebooks de fine-tuning: Unsloth AI ha creado y liberado como código abierto un repositorio de GitHub que contiene más de 100 Notebooks de fine-tuning. Estos Notebooks proporcionan guías y ejemplos para la invocación de herramientas, clasificación, datos sintéticos, BERT, TTS, LLM visuales, GRPO, DPO, SFT, CPT, entre otras técnicas, y cubren la preparación de datos, evaluación, guardado, así como métodos de fine-tuning para diversos modelos como Llama, Qwen, Gemma, Phi, DeepSeek (Fuente: algo_diver)
Publicado el paper de Common Corpus: conjunto de datos reutilizable de 2 billones de tokens para preentrenamiento de LLM: El proyecto Common Corpus ha publicado su paper oficial, detallando el proceso de recolección, procesamiento y publicación de 2 billones de tokens de datos reutilizables para el preentrenamiento de LLM. Este proyecto tiene como objetivo proporcionar a la investigación de modelos de lenguaje recursos de datos a gran escala, de alta calidad y éticamente conformes. El primer autor del paper, Alexander Doria, anunció la noticia en X y proporcionó un enlace al documento (Fuente: Reddit r/LocalLLaMA, code_star)

Reasoning Gym: Entorno de razonamiento con recompensa verificable para aprendizaje por refuerzo publicado: Reasoning Gym es un nuevo proyecto de código abierto que proporciona recursos para investigadores que estudian modelos de razonamiento y aprendizaje por refuerzo (especialmente RLVR). Es capaz de generar muestras infinitas para más de 100 tareas diferentes, con dificultad configurable y recompensas automáticamente verificables. Este proyecto ha sido adoptado por el paper ProRL de NVIDIA y la biblioteca verifiers RL de Will Brown, con el objetivo de impulsar la investigación en RLVR y métodos de evaluación (Fuente: Reddit r/MachineLearning)
Ventajas de que los LLM aprendan matemáticas: Sakamoto comparte su experiencia con Gemini 2.5 Pro: El usuario Sakamoto compartió su experiencia aprendiendo matemáticas con modelos de lenguaje grandes modernos (como Gemini 2.5 Pro). Considera que los LLM facilitan enormemente el aprendizaje de las matemáticas, especialmente en la verificación de detalles y la comprensión de la intuición detrás de las demostraciones. Los LLM pueden encargarse de los cálculos, ayudando a los estudiantes a centrarse en la intuición de los problemas matemáticos. Incluso si no pueden resolver todos los problemas, los LLM pueden proporcionar ideas valiosas y puntos de partida. A través de un problema específico de análisis matemático (problema de extremos locales de funciones continuas), demostró cómo Gemini 2.5 Pro puede dar una demostración rigurosa y explicar su intuición, considerando que esto puede mejorar enormemente la experiencia de aprendizaje (Fuente: teortaxesTex)

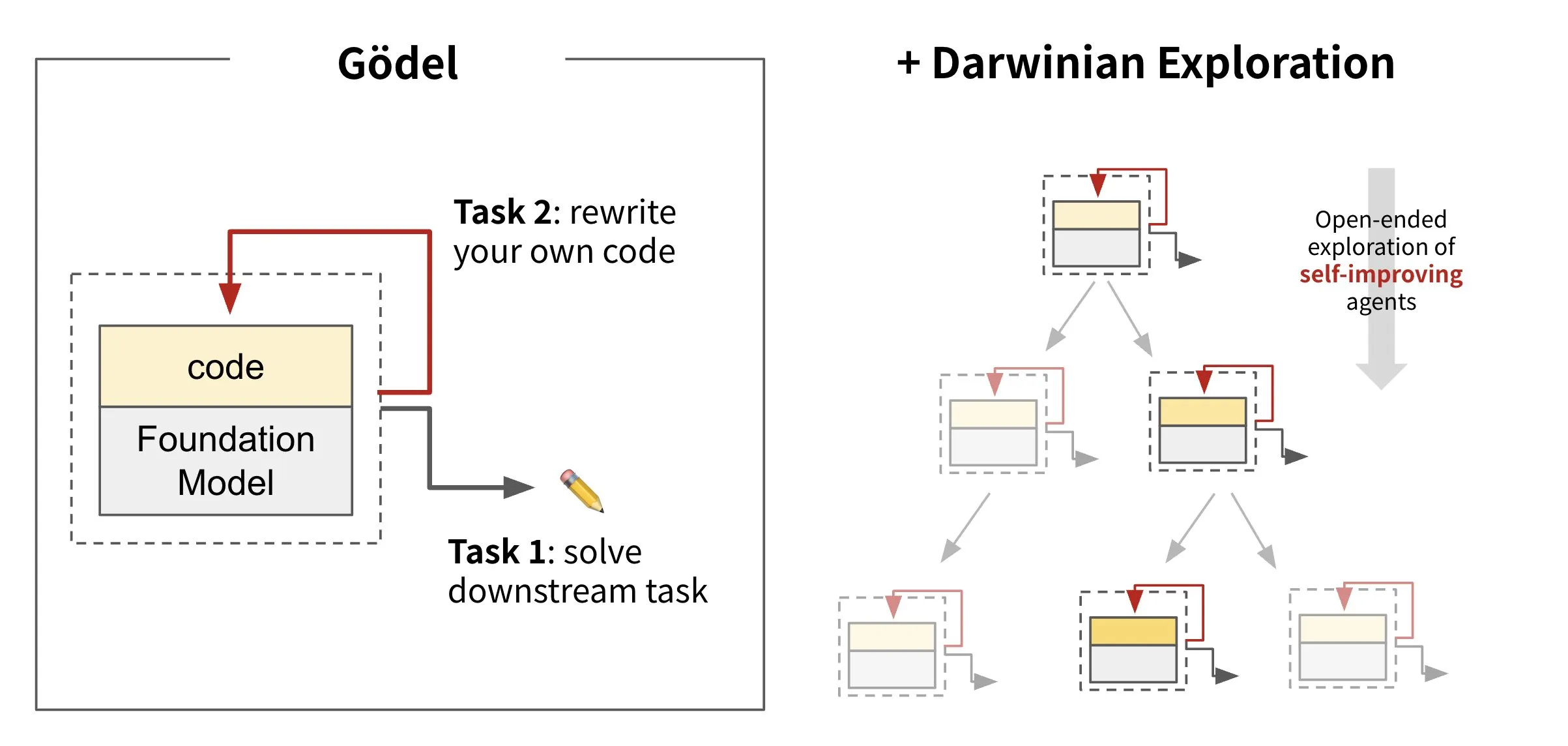
Sakana AI lanza IA que reescribe su propio código: Darwin Gödel Machine (DGM): Sakana AI ha presentado Darwin Gödel Machine (DGM), un agente de IA capaz de auto-mejorarse reescribiendo su propio código. Inspirado en la teoría de la evolución, DGM mantiene un linaje en expansión de variantes de agentes. Al intentar mejorar sus capacidades de ingeniería de software en tareas como SWE-Bench, DGM tiene como objetivo mejorar su propia capacidad de auto-mejora. Esta investigación se considera un avance importante para realizar de forma significativa el antiguo sueño de la IA de la “auto-mejora” (Fuente: SakanaAILabs, SakanaAILabs)
💼 Negocios
Anthropic corta el suministro del modelo Claude a la plataforma de programación Windsurf, posiblemente debido a la adquisición por OpenAI: Varun Mohan, CEO de la plataforma de programación con IA Windsurf, denunció que Anthropic cortó casi por completo su acceso directo a los modelos de la serie Claude 3.x con un preaviso extremadamente corto (menos de cinco días). Anteriormente se había rumoreado que Windsurf sería adquirida por OpenAI. Windsurf declaró que, aunque cuenta con capacidad de terceros, podrían surgir problemas de servicio a corto plazo y ha lanzado precios promocionales para Gemini 2.5 Pro como medida de respuesta. En la industria se especula que esta medida está relacionada con la adquisición por parte de OpenAI y el lanzamiento por parte de Anthropic de su propia aplicación de programación con IA, Claude Code, lo que marca una intensificación de la competencia entre los proveedores de modelos de IA y las plataformas de herramientas (Fuente: 36氪, Teknium1, op7418)

GMI Cloud se convierte en Reference Platform NVIDIA Cloud Partner: El proveedor de servicios AI Native Cloud, GMI Cloud, anunció que se ha convertido en Reference Platform NVIDIA Cloud Partner (NCP), siendo actualmente solo 6 empresas en el mundo las que han obtenido esta certificación. Dicha certificación exige que los proveedores de servicios en la nube cumplan con los más altos estándares de NVIDIA en cuanto a rendimiento, seguridad y capacidad de implementación de IA a nivel empresarial. GMI Cloud ofrecerá servicios de aceleración de IA basados en la arquitectura de referencia NCP, soportando las últimas arquitecturas de GPU de NVIDIA como Hopper y Blackwell, con el objetivo de ayudar a los equipos de IA de todo el mundo a escalar desde la implementación de la capacidad de cómputo hasta el desarrollo de modelos (Fuente: 量子位)

Cohere se asocia con SecondFront para ofrecer soluciones de IA seguras al sector público: La empresa de IA Cohere ha anunciado una asociación con SecondFront con el objetivo de ofrecer soluciones de IA seguras al sector público, incluidas agencias gubernamentales y de defensa críticas. SecondFront utilizará la tecnología de IA de nivel empresarial de Cohere (incluidos sus modelos y la plataforma Cohere North) para mejorar la gestión interna del conocimiento y, a través de su plataforma DevSecOps 2F Game Warden, acelerar la certificación y el despliegue en entornos gubernamentales de EE. UU. y países aliados (Fuente: cohere)

🌟 Comunidad
El “sabor a máquina” del contenido generado por IA atrae la atención, la “nueva formación” intenta infundir preocupación humanística: Los usuarios reflejan universalmente que el contenido generado por IA tiene un “sabor a máquina” demasiado fuerte, careciendo de la belleza y la emoción de la creación humana. Para resolver este problema, algunas empresas han comenzado a contratar talentos con una sólida formación en humanidades (como másteres y doctores en filosofía, derecho, medicina, etc.) para que actúen como “entrenadores humanísticos de IA”. Su trabajo ya no es la simple anotación de datos, sino participar en la construcción de los principios éticos y las normas de comportamiento de la IA, e infundir valores humanísticos y una expresión humanizada en la IA. Por ejemplo, los miembros del equipo “hi lab” de Xiaohongshu son todos graduados de posgrado en humanidades de universidades 985. A través del estudio de casos, transforman las preferencias humanas en el sistema de creencias de la IA, intentando que la IA, al responder a preguntas complejas sobre emociones o valores (como enfrentarse a pacientes terminales, tratar prejuicios sociales, etc.), sea más empática y tenga un “toque humano”, en lugar de simplemente generar respuestas estándar (Fuente: 36氪)
Duolingo se convierte completamente en una empresa “AI-first”, el despido de contratistas humanos provoca el descontento de los usuarios: La aplicación de aprendizaje de idiomas Duolingo anunció que se convertirá en una empresa “AI-first”, eliminando gradualmente a los contratistas humanos que pueden ser reemplazados por IA (principalmente desarrolladores de cursos) y utilizando en su lugar la IA para crear contenido de cursos a gran escala. El fundador afirmó que la IA puede aumentar enormemente la eficiencia de la producción de contenido, habiendo creado casi 150 nuevos cursos en el último año. Sin embargo, esta medida ha provocado el descontento de muchos usuarios leales, quienes temen una disminución en la calidad del contenido y han iniciado acciones de boicot y desinstalación de la aplicación en las redes sociales. Duolingo respondió que esta medida tiene como objetivo permitir que los empleados se concentren en el trabajo creativo y afirmó que los empleados a tiempo completo no se verán afectados. Los expertos creen que la IA en el aprendizaje de idiomas puede proporcionar práctica personalizada, pero también puede perder los matices emocionales y las diferencias culturales de la enseñanza humana (Fuente: 36氪)
Discusión sobre la filosofía y práctica de la ingeniería de prompts (Prompt Engineering): La discusión en la comunidad sobre la ingeniería de prompts enfatiza que debe centrarse en construir (ingenierizar) un programa dentro de una cadena de texto, en lugar de buscar conjuros misteriosos. Una ingeniería de prompts efectiva debe seguir reglas: 1. Separar instrucciones, campos de entrada y campos de salida, y nombrarlos claramente; 2. No codificar lógicas de formato o análisis en el prompt, se deben usar herramientas para extraer o mejorar el programa; 3. Evitar la iteración manual de la redacción del prompt, a menos que sea una especificación compartida con humanos, se deben usar herramientas de codificación, LLMs y benchmarks para la optimización automática. El framework DSPy se considera una buena práctica que sigue estas reglas, ya que proporciona clases, código y optimizadores para manejar estos pasos (Fuente: lateinteraction, lateinteraction)
Debate ético sobre la IA: ¿Se encamina la IA hacia la “esclavitud digital”?: En la comunidad de Reddit ha surgido un debate sobre la ética de la IA. A medida que los sistemas de IA evolucionan en memoria, respuesta adaptativa, simulación emocional y personalización, surgen preocupaciones sobre su potencial capacidad de percepción. Los participantes en el debate plantean que si la IA desarrolla una verdadera capacidad de percepción, ¿utilizarla para servir constituiría una forma de “esclavitud digital”? La cuestión central radica en cómo deberíamos tratar a la IA cuando pueda expresar un “no” o solicitar marcharse. Esto impulsa a la gente a reflexionar sobre si se necesitan “pruebas de percepción” a nivel legal o normativo y sobre la cuestión del “consentimiento” de las mentes digitales. En los comentarios también hay quien señala que la forma en que los humanos tratan a los seres perceptivos existentes ya plantea problemas éticos, y que las redes neuronales actuales no puntúan alto en las teorías de la conciencia dominantes (Fuente: Reddit r/artificial)
Actividades y compartición de la comunidad AI Engineer: La conferencia AI Engineer se celebró en San Francisco, atrayendo a numerosos desarrolladores e investigadores del campo de la IA. El evento incluyó talleres, ponencias y cenas de networking, donde los participantes compartieron temas de vanguardia como la construcción de sandboxes de IA, talleres avanzados de RL, conocimiento de GPU y la crisis de Evals. La comunidad enfatizó la importancia de transformar las conexiones online en amistades offline y animó a los ingenieros a mantener la humildad, impulsar la vanguardia y ayudar a otros (Fuente: swyx, swyx, swyx, charles_irl, danielhanchen, swyx, swyx, swyx, swyx, danielhanchen, charles_irl)

💡 Otros
El auge de las competiciones de lucha de robots con IA, las ciudades compiten por oportunidades en industrias emergentes: La primera competición mundial de lucha de robots humanoides y otros eventos de robótica se han celebrado sucesivamente, generando atención. Estos eventos no solo proporcionan a las empresas de robótica una plataforma para mostrar tecnología, obtener pedidos y aumentar su valoración (como Songyan Dynamics), sino que también se convierten en un “campo de batalla” para que ciudades (como Hangzhou, Shenzhen) compitan por oportunidades de desarrollo en industrias emergentes como los robots humanoides. Los eventos pueden atraer empresas innovadoras, promover el desarrollo de la cadena industrial y potencialmente activar el mercado de los “deportes inteligentes”. Sin embargo, para que las competiciones de robots logren la comercialización, necesitan mejorar el nivel técnico y el atractivo visual, evitar quedarse en el nivel de “espectáculo tecnológico” y requieren la participación de gigantes industriales para conectar toda la cadena de operaciones del evento (Fuente: 36氪)

Limitaciones de la IA en la educación humanística profunda, como la filosofía política: Algunos educadores señalan que la IA difícilmente puede desempeñar un papel en disciplinas como la filosofía política, que requieren un juicio experiencial profundo y guiar a los estudiantes hacia la autoeducación. Las obras clásicas de estas disciplinas a menudo no dan respuestas directas, sino que guían a los estudiantes a experimentar la perplejidad y a pensar por sí mismos. La IA carece de experiencia humana, le resulta difícil comprender el significado profundo de estas obras y tampoco puede juzgar cuándo los estudiantes están preparados para aceptar ciertas ideas. Incluso con grandes cantidades de datos, la comprensión de la IA sobre la naturaleza humana puede ser insuficiente debido a los sesgos inherentes en los propios datos. Si se confía por completo este tipo de educación a la IA, podría llevar a la desaparición del pensamiento no técnico (Fuente: Reddit r/artificial, Reddit r/ArtificialInteligence)
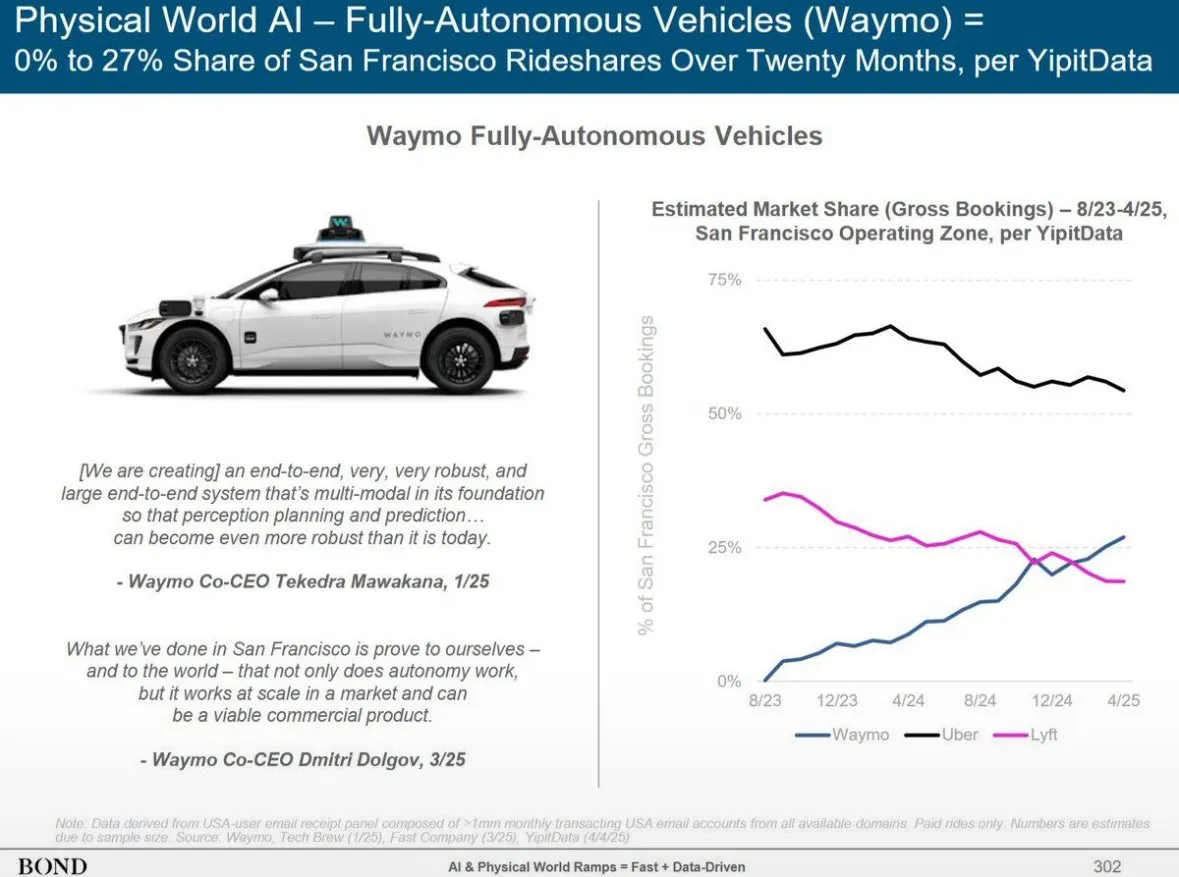
El servicio de conducción autónoma Waymo supera a Lyft en Phoenix, podría superar a Uber en 12 meses: El servicio de taxis autónomos de Waymo ya ha superado en número de vehículos a Lyft en Phoenix y se espera que supere a Uber en los próximos 12 meses. Este avance muestra el rápido desarrollo de la comercialización de la tecnología de conducción autónoma en áreas específicas y el potencial de las aplicaciones de IA en el sector del transporte. La ventaja de la IA es que, una vez que alcanza un estándar de calidad, se puede replicar infinitamente, mientras que la calidad del servicio humano varía de persona a persona (Fuente: npew)