
Palabras clave:OpenAI Codex, Modelo de Acción de Lenguaje Visual, Límite de memoria del modelo de lenguaje, Función de memoria de ChatGPT, DeepSeek-R1-0528, Modelo de difusión, Creación musical con Suno AI, MetaAgentX, Función de acceso a internet de Codex, Modelo de robot SmolVLA, Modelo GPT con memoria de 3.6 bits, Mejoras en interacción personalizada de ChatGPT, Capacidad de razonamiento complejo de DeepSeek-R1
🔥 Enfoque
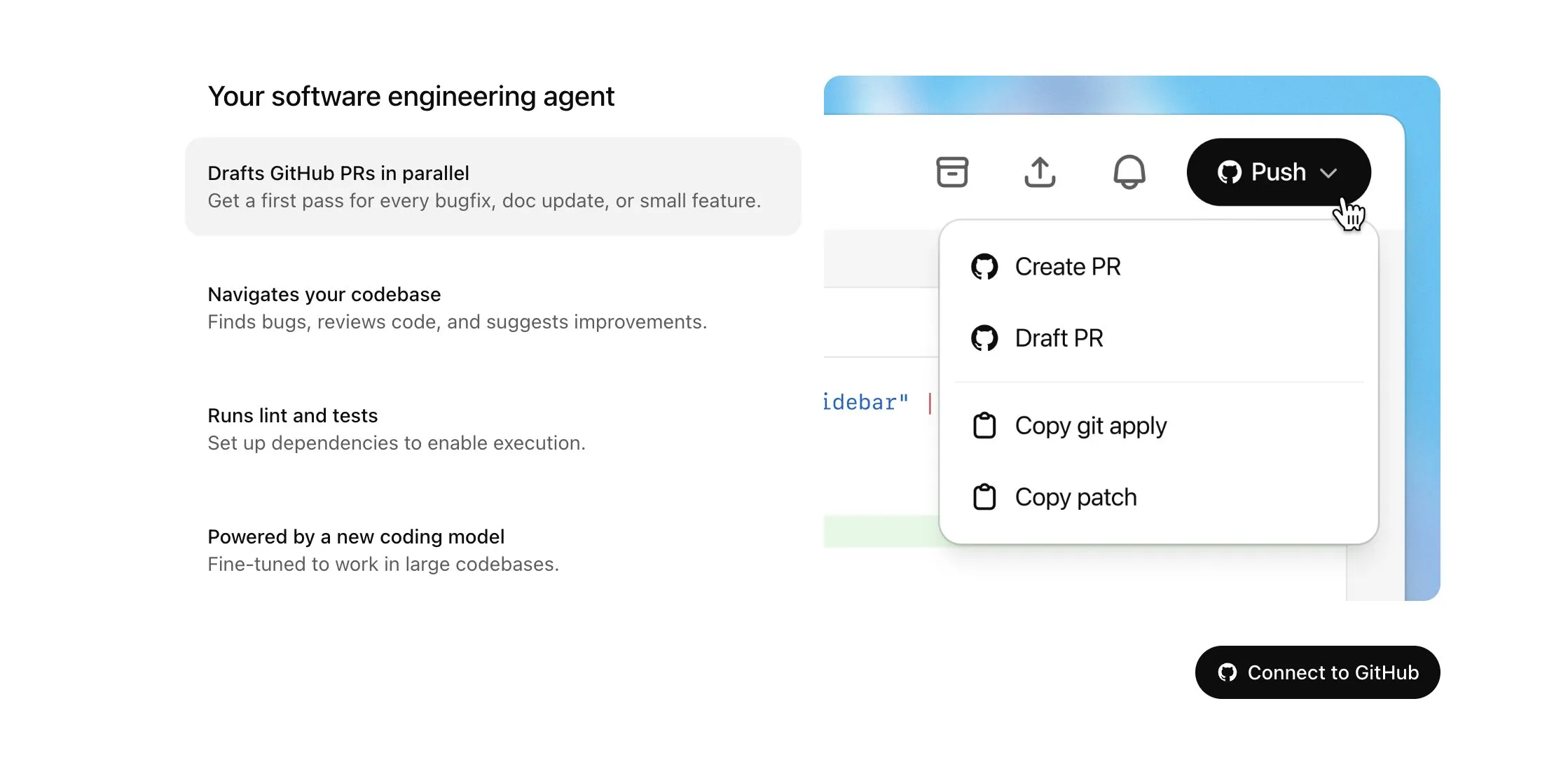
OpenAI Codex se abre a los usuarios de Plus y recibe importantes actualizaciones, incluyendo acceso a internet y entrada de voz: OpenAI anuncia que Codex se abrirá gradualmente a los usuarios de ChatGPT Plus. Los puntos clave de esta actualización incluyen permitir que los agentes de IA accedan a internet al realizar tareas (desactivado por defecto, con dominios y métodos HTTP controlables por el usuario) para instalar dependencias, actualizar paquetes de software y ejecutar pruebas de recursos externos. Además, Codex ahora admite la actualización directa de Pull Requests existentes y puede recibir tareas mediante entrada de voz. Otras mejoras incluyen el soporte para operaciones con archivos binarios (actualmente limitado a eliminar o renombrar en los PR), el aumento del límite de tamaño de las diferencias de tareas (diff) de 1MB a 5MB, la extensión del límite de tiempo de ejecución de scripts de 5 a 10 minutos, y la corrección de varios problemas en la plataforma iOS, además de la reactivación de la función de actividades en tiempo real. Estas actualizaciones tienen como objetivo mejorar la utilidad y flexibilidad de Codex en tareas de programación complejas (fuente: OpenAI Developers, Tibor Blaho, gdb, kevinweil, op7418)
Hugging Face y H Company lanzan conjuntamente modelos de acción de lenguaje visual (VLA) de código abierto para impulsar el desarrollo de la robótica: Hugging Face y H Company anunciaron en el “Día VLA” nuevos modelos de acción de lenguaje visual de código abierto, incluyendo SmolVLA de Hugging Face (450M de parámetros) y Holo-1 de H Company (3B y 7B de parámetros). Los modelos VLA tienen como objetivo permitir que los robots vean, escuchen, comprendan y actúen según las instrucciones de la IA, y se les conoce como el GPT del campo de la robótica. La apertura de estos modelos es crucial para comprender su funcionamiento, evitar posibles puertas traseras y personalizarlos para robots y tareas específicas. SmolVLA fue entrenado en el conjunto de datos LeRobotHF y demostró un rendimiento y una velocidad de inferencia excelentes. Holo-1 se centra en tareas de agentes web y de computadora, y es compatible con la licencia Apache 2.0. Se espera que estos lanzamientos aceleren el desarrollo de la tecnología de robótica de IA de código abierto (fuente: ClementDelangue, huggingface, LoubnaBenAllal1, tonywu_71)

Investigación de Meta y otras empresas revela que el límite de memoria de los modelos de lenguaje es de aproximadamente 3.6 bits por parámetro, desafiando la concepción tradicional: Una investigación conjunta de Meta, DeepMind, la Universidad de Cornell y Nvidia señala que los modelos de lenguaje estilo GPT pueden memorizar aproximadamente 3.6 bits de información por parámetro. El estudio encontró que los modelos memorizan continuamente datos de entrenamiento hasta alcanzar su límite de capacidad, después de lo cual comienza a aparecer el fenómeno de “Grokking” (comprensión súbita), es decir, una reducción inesperada de la memoria y el modelo se orienta hacia el aprendizaje generalizado. Este descubrimiento explica el fenómeno de “doble descenso”, donde, cuando la cantidad de información del conjunto de datos excede la capacidad de almacenamiento del modelo, este se ve obligado a compartir puntos de información para ahorrar capacidad, promoviendo así la generalización. El estudio también propone leyes de escalamiento sobre la relación entre la capacidad del modelo, el tamaño de los datos y la tasa de éxito de los ataques de inferencia de membresía, y señala que para los LLM modernos entrenados en conjuntos de datos extremadamente grandes, la inferencia de membresía confiable se vuelve difícil (fuente: 机器之心, Reddit r/LocalLLaMA, code_star, scaling01, Francis_YAO_)
OpenAI lanza una versión ligera de la función de memoria de ChatGPT, mejorando la experiencia de interacción personalizada: OpenAI anunció el lanzamiento gradual de una mejora ligera de la función de memoria para los usuarios gratuitos. Además de la memoria guardada existente, ChatGPT ahora puede hacer referencia a las conversaciones recientes del usuario para proporcionar respuestas más personalizadas. Esta medida tiene como objetivo hacer que ChatGPT sea más útil en la escritura, la obtención de consejos, el aprendizaje, etc., al basarse en las preferencias e intereses del usuario. Sam Altman también expresó que la función de memoria se ha convertido en una de sus características favoritas de ChatGPT y espera mejoras aún mayores en el futuro. Esta actualización marca el compromiso de OpenAI de hacer que la interacción con la IA sea más cercana a las necesidades del usuario y aumentar la fidelidad del mismo (fuente: openai, sama, iScienceLuvr)
🎯 Tendencias
Lanzamiento de DeepSeek-R1-0528, reforzando la capacidad de razonamiento complejo y programación: DeepSeek lanzó una versión actualizada de su modelo R1, DeepSeek-R1-0528. Esta versión se basa en el modelo DeepSeek V3 Base, lanzado en diciembre de 2024, y ha mejorado significativamente la profundidad de pensamiento y la capacidad de razonamiento del modelo mediante una mayor inversión en potencia de cálculo para el post-entrenamiento. El nuevo modelo descompone los problemas complejos de manera más detallada y dedica más tiempo a la reflexión (por ejemplo, en la prueba AIME 2025, el consumo promedio de tokens por pregunta aumentó de 12K a 23K), logrando así resultados líderes en múltiples pruebas de referencia como matemáticas, programación y lógica general, con un rendimiento cercano a GPT-o3 y Gemini-2.5-Pro. Además, la nueva versión presenta optimizaciones significativas en la reducción de alucinaciones (aproximadamente 45%-50%), escritura creativa y llamada a herramientas, como responder de manera más estable a preguntas como “¿cuánto es 9.9 – 9.11?” y generar código front-end y back-end ejecutable de una sola vez (fuente: 科技狐, AI前线, Hacubu)

Los modelos de difusión muestran potencial en los campos del lenguaje y multimodal, desafiando el paradigma autorregresivo: El modelo de lenguaje Gemini Diffusion presentado en Google I/O 2025, con una velocidad de generación hasta 5 veces mayor y un rendimiento de programación comparable, destaca el potencial de los modelos de difusión en el campo de la generación de texto. A diferencia de los modelos autorregresivos que predicen tokens uno por uno, los modelos de difusión generan resultados mediante la eliminación gradual de ruido, lo que permite una iteración y corrección de errores rápidas. El modelo LLaDA de 8B parámetros lanzado por Ant Group en colaboración con la Escuela de Inteligencia Artificial Gaoling de la Universidad Renmin, así como el modelo de difusión multimodal MMaDA desarrollado por ByteDance, demuestran la exploración de vanguardia de los equipos chinos en esta área. Estos modelos no solo se desempeñan excelentemente en tareas lingüísticas, sino que también han logrado avances en la comprensión multimodal (como LLaDA-V que combina el ajuste fino de instrucciones visuales) y en dominios específicos (como DPLM para la generación de secuencias de proteínas), lo que sugiere que los modelos de difusión podrían convertirse en el nuevo paradigma para los modelos universales de próxima generación (fuente: 机器之心)
Suno lanza una importante actualización, mejorando la capacidad de edición y creación de música con IA: La plataforma de creación de música con IA, Suno, ha introducido varias actualizaciones importantes, otorgando a los usuarios mayor libertad creativa y control. Las nuevas funciones incluyen un editor de canciones mejorado, que permite a los usuarios reordenar, reescribir y rehacer pistas segmento por segmento en la forma de onda; la introducción de la función de extracción de pistas (stems), que puede separar con precisión las pistas en 12 fuentes de sonido independientes (como voces, batería, bajo, etc.) para vista previa y descarga; la ampliación de la función de carga, que admite la carga de canciones completas de hasta 8 minutos, permitiendo a los usuarios crear a partir de su propio material de audio; y la adición de un control deslizante creativo, que permite a los usuarios ajustar la “rareza”, el grado de estructuración o el grado de referencia del resultado antes de la generación, para dar mejor forma a la obra final (fuente: SunoMusic)
MetaAgentX lanza Open CaptchaWorld para evaluar la capacidad de los agentes multimodales para resolver CAPTCHAs: En respuesta a los cuellos de botella actuales de los agentes multimodales para resolver problemas de CAPTCHA (verificación humano-máquina), el equipo de MetaAgentX ha lanzado la plataforma y el benchmark Open CaptchaWorld. Esta plataforma contiene 20 tipos de CAPTCHAs modernos, con un total de 225 ejemplos, que requieren que el agente complete tareas en un entorno web real mediante la observación, el clic, el arrastre y otras interacciones. Los resultados de las pruebas muestran que incluso los modelos más avanzados como GPT-4o tienen una tasa de éxito de solo entre el 5% y el 40%, muy por debajo de la tasa de éxito promedio humana del 93.3%. Los investigadores también propusieron el indicador “CAPTCHA Reasoning Depth” para cuantificar los pasos de “comprensión visual + planificación cognitiva + control de acciones” necesarios para resolver el problema. Esta plataforma tiene como objetivo revelar las deficiencias de los agentes en la interacción dinámica y la planificación de secuencias largas, e impulsar a los investigadores a prestar atención y resolver este problema crítico en la implementación práctica (fuente: 量子位)

Google NotebookLM admite el uso compartido público, promoviendo el intercambio de conocimientos y la colaboración: Google anunció que NotebookLM (anteriormente conocido como Project Tailwind) ahora admite el uso compartido público de cuadernos. Los usuarios pueden compartir el contenido de sus notas haciendo clic en “Compartir” y configurando los permisos de acceso como “Cualquier persona con el enlace”. Esta función permite a los usuarios compartir fácilmente ideas, guías de estudio y documentos de equipo, y los destinatarios pueden explorar el contenido, hacer preguntas, obtener resúmenes instantáneos y resúmenes de voz. Esta medida tiene como objetivo promover la difusión del conocimiento y la edición colaborativa, mejorando la utilidad de NotebookLM como herramienta de toma de notas con IA (fuente: Google, op7418)
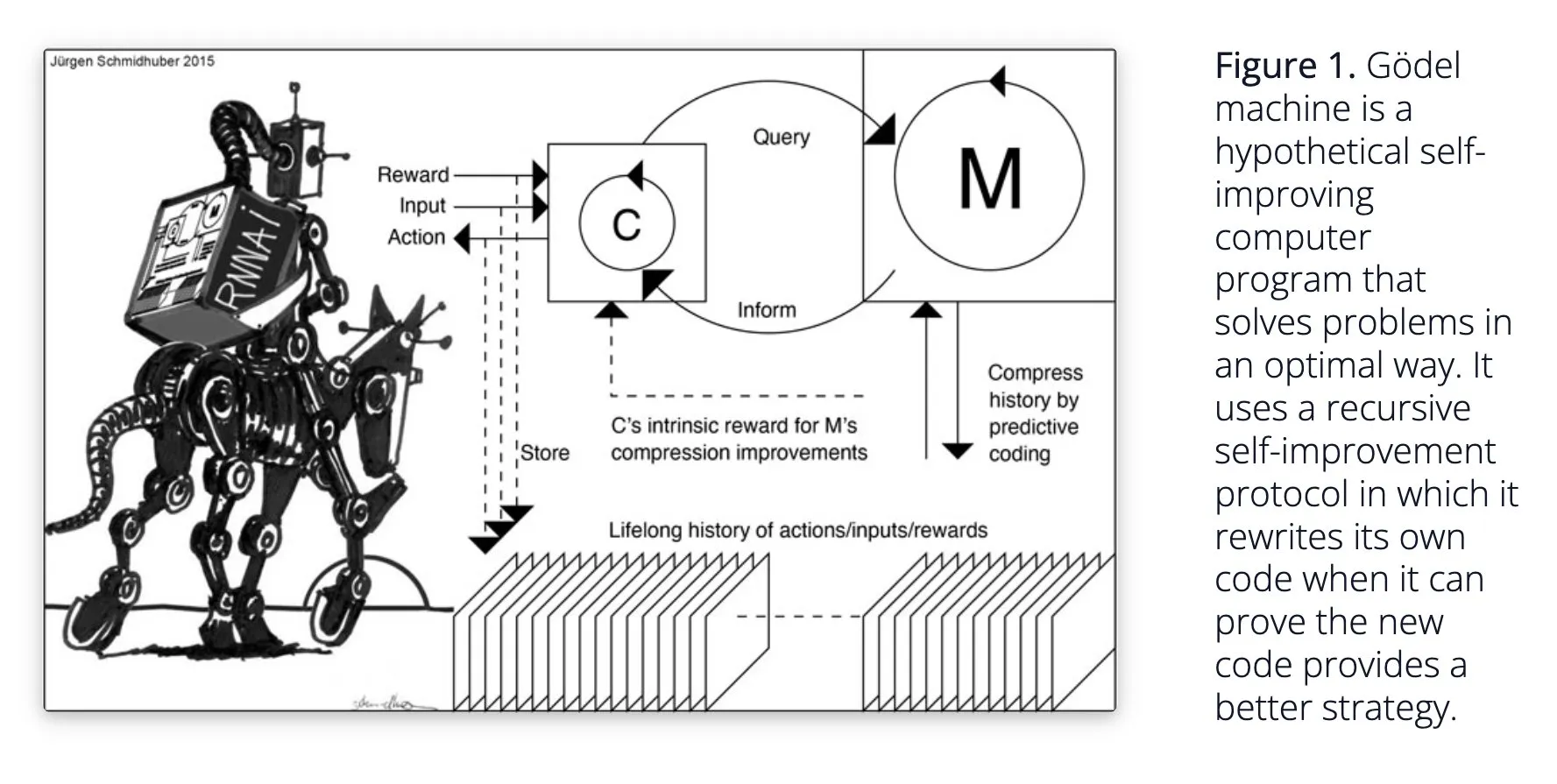
Sakana AI propone el sistema de IA autoaprendizaje Darwin Gödel Machine (DGM): Sakana AI ha hecho pública su investigación sobre el sistema de IA autoaprendizaje Darwin Gödel Machine (DGM). DGM utiliza algoritmos evolutivos para reescribir iterativamente su propio código, mejorando así continuamente su rendimiento en tareas de programación. El sistema mantiene un archivo de agentes de codificación generados, y a partir de él muestrea y utiliza modelos base para crear nuevas versiones, logrando una exploración abierta y formando agentes diversos y de alta calidad. Los experimentos demuestran que DGM mejora significativamente la capacidad de codificación en benchmarks como SWE-bench y Polyglot. Esta investigación ofrece nuevas ideas para la IA auto-mejorable, con el objetivo de acelerar el desarrollo de la IA a través de la innovación autónoma (fuente: Reddit r/LocalLLaMA, hardmaru, scaling01)
Google DeepMind mejora la naturalidad de las conversaciones con IA, abriendo funciones de audio nativas: Google DeepMind anunció que sus funciones de audio nativas están haciendo que las conversaciones con IA sean más naturales, capaces de comprender el tono y generar voz expresiva. Esta tecnología tiene como objetivo abrir nuevas posibilidades para la interacción entre humanos e IA. Los desarrolladores ahora pueden probar estas funciones a través de Google AI Studio, con la expectativa de que se apliquen en asistentes de voz más naturales, generación de contenido de audio, etc. (fuente: GoogleDeepMind)
La tecnología de generación de imágenes Runway Gen-4 atrae la atención, admite múltiples referencias y control de estilo: La tecnología de generación de imágenes Gen-4 de Runway ha llamado la atención por su alta fidelidad y su capacidad sin precedentes para el control de estilo, especialmente evidente en su función de múltiples referencias, que ofrece un nuevo espacio para la exploración creativa. Los usuarios pueden utilizar esta tecnología para generar diversos animales, dinosaurios o criaturas imaginarias, lo que demuestra su potencial en la creación de contenido visual detallado. El uso de Runway en campos como Hollywood también indica que su tecnología se está aplicando gradualmente a la producción de contenido profesional (fuente: c_valenzuelab, c_valenzuelab)

AssemblyAI lanza un nuevo modelo de transcripción de voz en tiempo real, mejorando el rendimiento de las aplicaciones de IA de voz: AssemblyAI ha lanzado un nuevo modelo de transcripción de voz en tiempo real (STT) que ha llamado la atención por su alta velocidad y precisión. Este modelo está diseñado específicamente para desarrolladores que crean aplicaciones de IA de voz, con el objetivo de proporcionar una experiencia de reconocimiento de voz más fluida y precisa. Al mismo tiempo, AssemblyAI también ofrece una implementación de AssemblyAISTTService a través de su proyecto pipecat_ai, facilitando la integración para los desarrolladores. Esta medida demuestra la continua inversión e innovación de AssemblyAI en el campo de la tecnología de voz (fuente: AssemblyAI, AssemblyAI)
Microsoft Bing celebra su 16º aniversario, integra GPT-4 y DALL·E, y lanza Bing Video Creator: El motor de búsqueda Microsoft Bing celebra su 16º aniversario. En los últimos años, Bing ha sido pionero en la integración a gran escala de IA generativa conversacional y se convirtió en el primer producto de Microsoft en integrar GPT-4 y DALL·E. Recientemente, Bing lanzó gratuitamente Copilot Search y Bing Video Creator en su aplicación móvil, este último utilizable para generar contenido de video. Esto marca la continua innovación y desarrollo de Bing en el campo de la búsqueda impulsada por IA y la creación de contenido (fuente: JordiRib1)
Andrej Karpathy impresionado por Veo 3, discute el impacto macro de la generación de video: Andrej Karpathy expresó su impresión por el modelo de generación de video Veo 3 de Google y los resultados creativos de su comunidad, señalando que la adición de audio mejoró significativamente la calidad del video. Además, discutió varios impactos a nivel macro de la generación de video: 1. El video es la forma de entrada de mayor ancho de banda para el cerebro humano; 2. La generación de video proporciona a la IA una “lengua materna” para comprender el mundo; 3. La generación de video es una ruta clave hacia la simulación de la realidad y los modelos del mundo; 4. Sus requisitos computacionales impulsarán el desarrollo de hardware. Esto indica que la tecnología de generación de video no solo es una innovación en la creación de contenido, sino también un importante motor para la cognición y el desarrollo de la IA (fuente: brickroad7, dilipkay, JonathanRoss321)
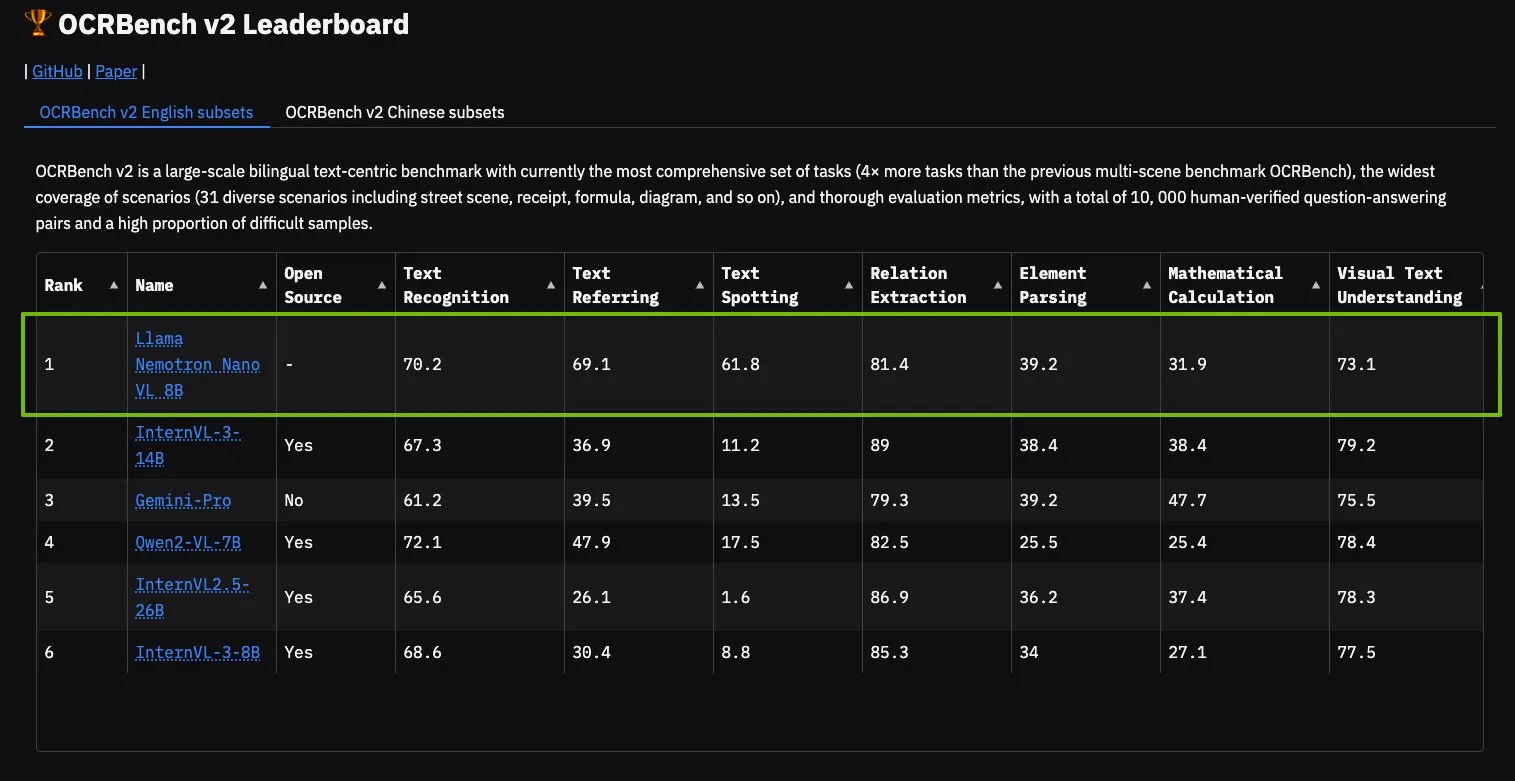
El modelo NVIDIA Llama Nemotron Nano VL encabeza OCRBench V2: El modelo Llama Nemotron Nano VL de NVIDIA obtuvo el primer lugar en la tabla de clasificación de OCRBench V2. Este modelo está diseñado específicamente para el procesamiento y la comprensión inteligente de documentos avanzados, capaz de extraer con precisión información diversa de documentos complejos en una sola GPU. Los usuarios pueden probar este modelo a través de NVIDIA NIM, lo que demuestra el progreso de NVIDIA en modelos de IA miniaturizados y eficientes para dominios específicos (como la comprensión de documentos) (fuente: ctnzr)
🧰 Herramientas
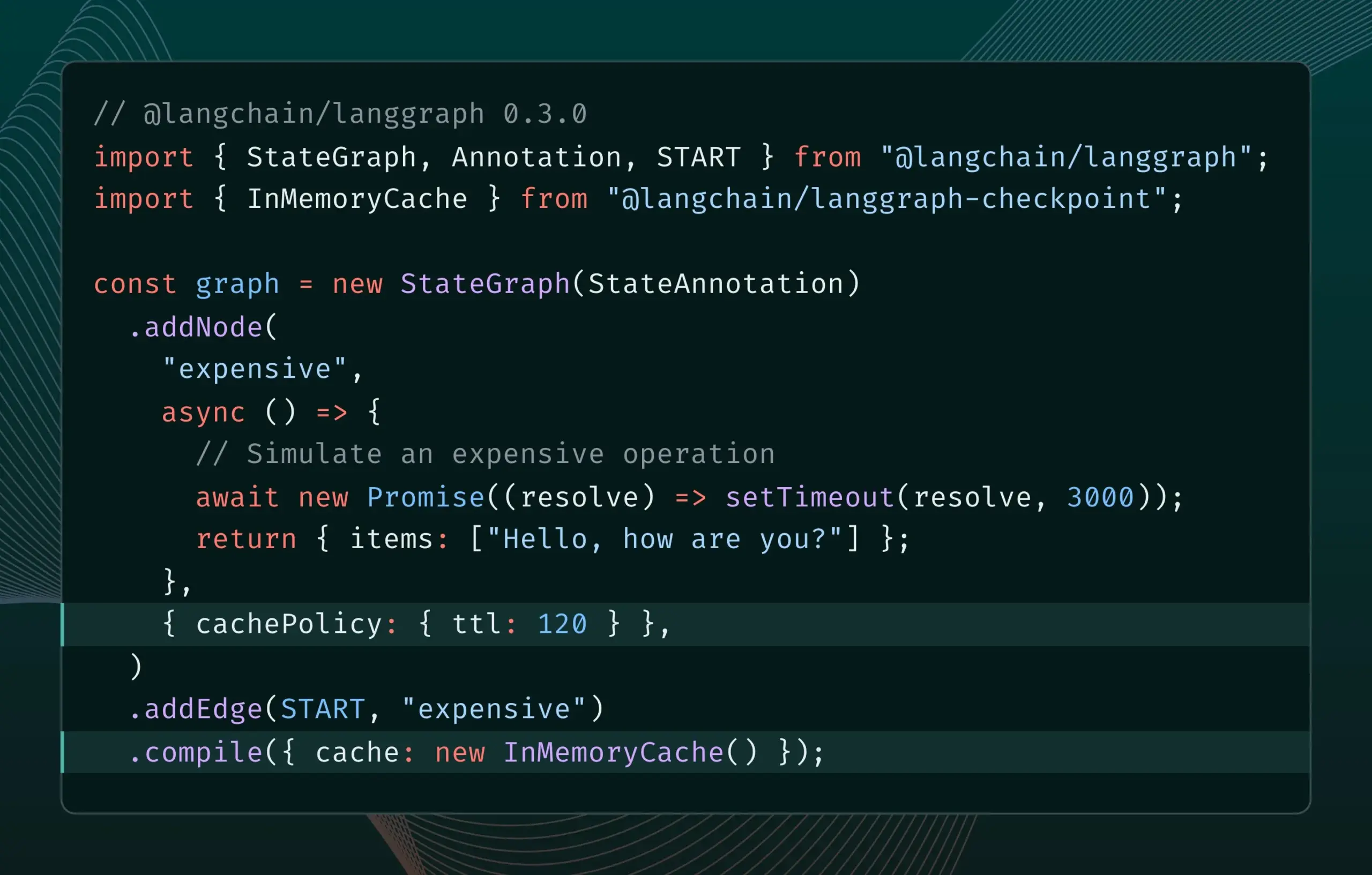
LangGraph.js versión 0.3 introduce la función de caché de nodos/tareas: LangGraph.js ha lanzado la versión 0.3, que añade una función de caché de nodos/tareas. Esta función tiene como objetivo acelerar los flujos de trabajo evitando cálculos redundantes, especialmente útil para agentes iterativos costosos o de larga duración. La nueva versión es compatible tanto con la Graph API como con la Imperative API, ofreciendo mayor eficiencia a los desarrolladores de JavaScript para construir aplicaciones de IA complejas (fuente: Hacubu, hwchase17)
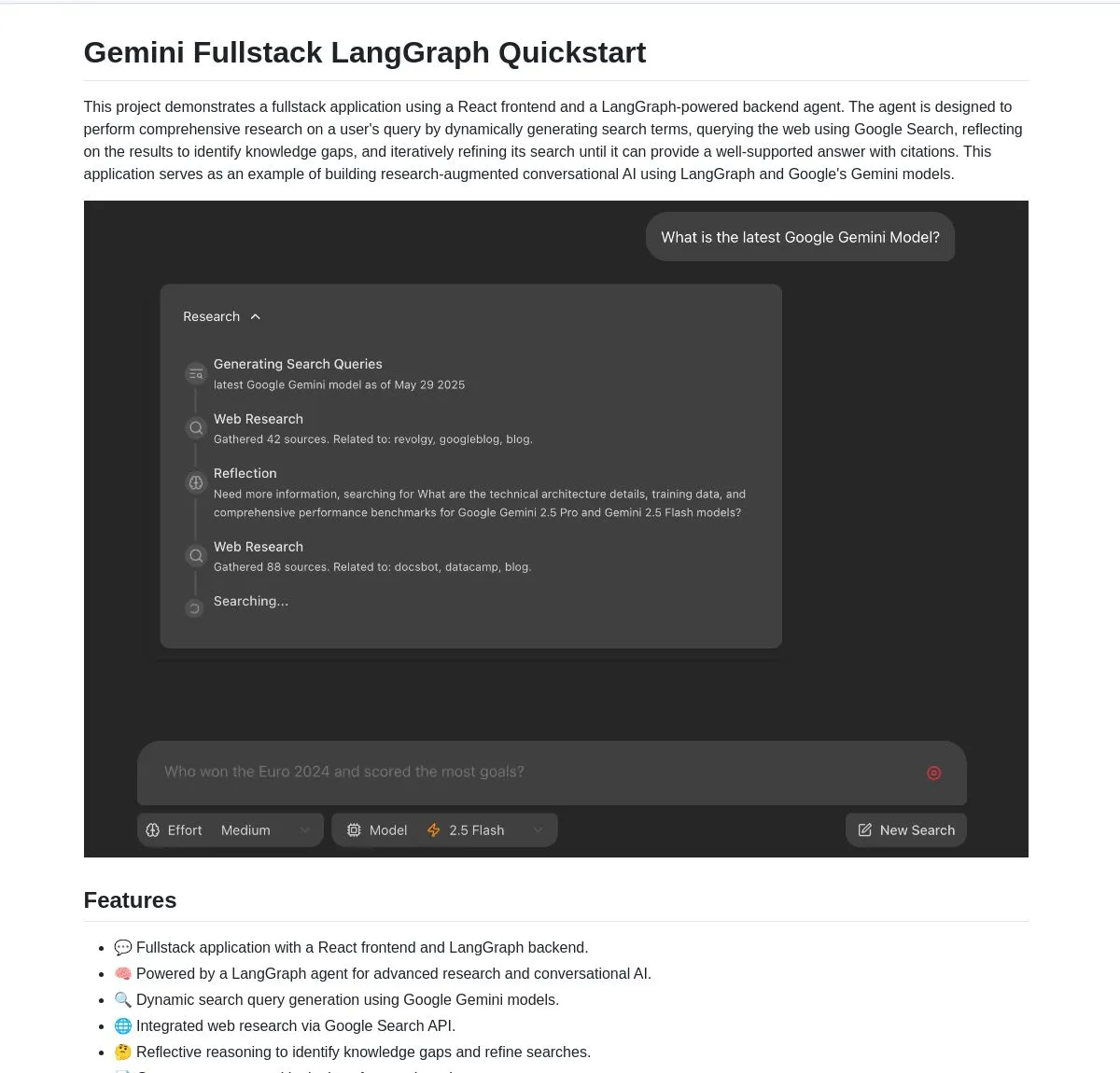
Google lanza aplicación full-stack de código abierto Gemini Research Agent, basada en Gemini y LangGraph: Google ha publicado un ejemplo de aplicación full-stack de asistente de investigación inteligente construido sobre el modelo Gemini y LangGraph: gemini-fullstack-langgraph-quickstart. Esta aplicación puede optimizar dinámicamente las consultas, proporcionar respuestas con citas a través del aprendizaje iterativo y admitir el control de diferentes niveles de intensidad de búsqueda. Utiliza la herramienta de búsqueda nativa de Google de Gemini para la investigación en la web y el razonamiento reflexivo, con el objetivo de proporcionar a los desarrolladores un punto de partida para construir aplicaciones de IA de investigación avanzada (fuente: LangChainAI, hwchase17, dotey, karminski3)
FedRAG añade funcionalidad de puente con LangChain, facilitando la integración y el ajuste fino de sistemas RAG: FedRAG anunció el soporte para un puente con LangChain, implementado por un contribuidor externo. Los usuarios pueden ensamblar sistemas RAG a través de FedRAG y ajustar finamente los modelos de los componentes generador/recuperador para adaptarlos a bases de conocimiento específicas. Después del ajuste fino, se puede conectar a frameworks populares de inferencia RAG como LangChain, aprovechando su ecosistema y características. Esta actualización tiene como objetivo simplificar el proceso de construcción, optimización e implementación de sistemas RAG (fuente: nerdai)

Ollama lanza la función “pensar”, que permite separar el proceso de pensamiento de la respuesta final: Ollama ha actualizado su plataforma, añadiendo una opción para separar el proceso de pensamiento y la respuesta final para los modelos que admiten la función “pensar” (como DeepSeek-R1-0528). Los usuarios pueden optar por ver el contenido del “pensamiento” del modelo o desactivar esta función para obtener una respuesta directa. Esta función es aplicable a la CLI, API y bibliotecas Python/JavaScript de Ollama, ofreciendo a los usuarios una forma más flexible de interactuar con los modelos (fuente: Hacubu)
Firecrawl lanza el endpoint /search, integrando funciones de búsqueda y rastreo: Firecrawl ha lanzado un nuevo endpoint API /search, que permite a los usuarios completar una búsqueda web y rastrear todos los resultados en un formato amigable para LLM con una sola llamada API. Esta función tiene como objetivo simplificar el proceso para que los agentes de IA y los desarrolladores descubran y utilicen datos de la web. StateGraph de LangChain se puede utilizar para construir flujos de trabajo automatizados que aprovechen esta función, como encontrar automáticamente competidores, rastrear sus sitios web y generar informes de análisis (fuente: hwchase17, LangChainAI, omarsar0)
LlamaIndex integra MCP, mejorando la capacidad de los agentes y la implementación de flujos de trabajo: LlamaIndex anunció la integración de MCP (Model Component Protocol), con el objetivo de mejorar la capacidad de uso de herramientas de sus agentes y la flexibilidad en la implementación de flujos de trabajo. Esta integración proporciona funciones auxiliares para ayudar a los agentes de LlamaIndex a utilizar las herramientas del servidor MCP y permite que cualquier flujo de trabajo de LlamaIndex se ofrezca como un servidor MCP. Esta medida tiene como objetivo ampliar el conjunto de herramientas de los agentes de LlamaIndex y permitir que sus flujos de trabajo se integren sin problemas en la infraestructura MCP existente (fuente: jerryjliu0)

Modal lanza LLM Engine Advisor, ofreciendo benchmarks de rendimiento para motores de modelos de código abierto: Modal ha lanzado LLM Engine Advisor, una aplicación de benchmarking diseñada para ayudar a los usuarios a seleccionar el mejor motor LLM y los parámetros óptimos. Esta herramienta proporciona datos de rendimiento, como velocidad y rendimiento máximo, al ejecutar modelos de código abierto (como DeepSeek V3, Qwen 2.5 Coder) utilizando diferentes motores de inferencia (como vLLM, SGLang) en diverso hardware (como entornos multi-GPU). Esta iniciativa busca aumentar la transparencia y la eficiencia en la toma de decisiones al ejecutar LLMs autoalojados (fuente: charles_irl, akshat_b, sarahcat21)
PlayDiffusion: PlayAI lanza un nuevo modelo de restauración de audio que puede reemplazar el contenido de diálogo en el audio: PlayAI ha lanzado un nuevo modelo llamado PlayDiffusion, capaz de reemplazar sin problemas el contenido de diálogo en archivos de audio mientras conserva las características de voz del hablante original. Esta tecnología de “restauración de audio” ofrece nuevas posibilidades para la edición de audio, como modificar palabras o frases específicas en podcasts, audiolibros o doblajes de video, sin necesidad de volver a grabar todo el fragmento. El proyecto es de código abierto en GitHub (fuente: _mfelfel, karminski3)
Hugging Face lanza una herramienta de deduplicación semántica para optimizar la calidad de los conjuntos de datos de entrenamiento: Inspirada en AutoDedup de Maxime Labonne, Hugging Face Spaces ha lanzado una nueva aplicación de deduplicación semántica. Esta herramienta permite a los usuarios seleccionar uno o más conjuntos de datos en Hugging Face Hub, realizar una incrustación semántica de cada fila de datos y luego eliminar el contenido casi duplicado según un umbral establecido. Esta iniciativa tiene como objetivo ayudar a investigadores y desarrolladores a mejorar la calidad de los conjuntos de datos de entrenamiento, evitando que la redundancia de datos provoque una disminución del rendimiento del modelo o una baja eficiencia en el entrenamiento (fuente: ben_burtenshaw, ben_burtenshaw)

La demanda de Perplexity Labs se dispara, los usuarios pueden construir rápidamente software personalizado: Perplexity Labs ha experimentado un notable aumento en la demanda debido a su capacidad para construir rápidamente software personalizado a partir de una única indicación, e incluso algunos usuarios han comprado múltiples cuentas Pro para obtener más consultas de Labs. Esto refleja un fuerte interés de los usuarios en poder crear y modificar rápidamente herramientas de software según sus propias necesidades, y el desarrollo de software personalizado impulsado por IA se está convirtiendo en una tendencia (fuente: AravSrinivas, AravSrinivas)
Ollama y Hazy Research colaboran para lanzar Secure Minions, logrando una colaboración privada entre LLM locales y en la nube: El proyecto Minions del laboratorio Hazy Research de Stanford, al conectar modelos locales de Ollama con modelos de vanguardia en la nube, tiene como objetivo reducir drásticamente los costos de la nube (entre 5 y 30 veces) mientras mantiene una precisión cercana a la de los modelos de vanguardia (98%). El proyecto Secure Minion va más allá al convertir GPUs como H100 en zonas seguras, implementando cifrado de memoria y cómputo para garantizar la privacidad de los datos. Este modo de operación híbrido, además de mejorar la protección de la privacidad, también ofrece a los usuarios una solución de uso de LLM más económica y eficiente (fuente: code_star, osanseviero, Reddit r/LocalLLaMA)
Exa y OpenRouter colaboran para ofrecer capacidad de búsqueda web a más de 400 LLM: El motor de búsqueda de IA Exa anunció una colaboración con OpenRouter para proporcionar funcionalidad de búsqueda web a más de 400 modelos de lenguaje grandes en la plataforma OpenRouter. Esto significa que los desarrolladores y usuarios, al utilizar estos LLM, podrán invocar convenientemente la capacidad de búsqueda de Exa, mejorando la obtención de información en tiempo real y la capacidad de actualización de conocimientos de los modelos, y mejorando aún más el rendimiento de aplicaciones como RAG (generación aumentada por recuperación) (fuente: menhguin)

📚 Aprendizaje
Microsoft lanza el curso de introducción a MCP «MCP for Beginners»: Microsoft ha lanzado un curso de introducción para principiantes de MCP (Microsoft Copilot Platform, se presume un error tipográfico, debería referirse a Microsoft CoCo Framework o un protocolo similar de Agente IA). Este curso tiene como objetivo ayudar a los principiantes a dominar los conceptos básicos de MCP, los métodos de implementación y las aplicaciones prácticas, incluyendo especificaciones de la arquitectura del protocolo, guías tutoriales y prácticas de código en varios lenguajes de programación. La estructura del curso abarca introducción, conceptos básicos, seguridad, iniciación, avanzado, así como análisis de comunidad y casos de estudio, y proporciona proyectos de ejemplo como calculadoras básicas y avanzadas (fuente: dotey)

Bond Capital publica el informe de tendencias de IA de mayo de 2025, ofreciendo perspectivas sobre el desarrollo de la industria: La reconocida firma de capital de riesgo Bond Capital ha publicado su informe de 339 páginas «Informe de Tendencias de IA 2025-05», que analiza exhaustivamente datos y perspectivas de la IA en diversos campos. El informe destaca que ChatGPT tiene 800 millones de usuarios activos mensuales (el 90% fuera de América del Norte) y mil millones de búsquedas diarias; los puestos de TI relacionados con la IA han aumentado un 448%; el costo de entrenar modelos de vanguardia supera los mil millones de dólares por vez; los LLM se están convirtiendo en infraestructura. El informe enfatiza que la clave de la competencia radica en crear los mejores productos impulsados por IA, y que actualmente es un mercado para constructores (fuente: karminski3)
Artículos discuten la relación entre el aprendizaje por refuerzo y la capacidad de razonamiento de los LLM, ProRL y Limit-of-RLVR atraen la atención: Dos artículos de investigación sobre la relación entre el aprendizaje por refuerzo (RL) y la capacidad de razonamiento de los modelos de lenguaje grandes (LLM) han generado debate. Uno es «Limit-of-RLVR: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?», y el otro es «ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models» de NVIDIA. Estas investigaciones exploran hasta qué punto el RL (particularmente RLVR, aprendizaje por refuerzo con recompensas verificables) puede mejorar la capacidad de razonamiento base de los LLM, y el impacto del entrenamiento continuo de RL en la expansión de los límites de razonamiento de los LLM. Las discusiones relacionadas sugieren que los datos de entrenamiento RLVR de alta calidad y los mecanismos de recompensa efectivos son clave (fuente: scaling01, Dorialexander, scaling01)

El artículo «How Programming Concepts and Neurons Are Shared in Code Language Models» explora los mecanismos de compartición de conceptos de programación y neuronas en los LLM de código: Esta investigación indaga en la relación de los espacios conceptuales internos de los modelos de lenguaje grandes (LLMs) al procesar múltiples lenguajes de programación (PLs) e inglés. Mediante tareas de traducción few-shot en modelos de la serie Llama, se descubrió que en las capas intermedias, los espacios conceptuales están más cerca del inglés (incluyendo palabras clave de PLs) y tienden a asignar altas probabilidades a los tokens en inglés. El análisis de la activación neuronal muestra que las neuronas específicas del lenguaje se concentran principalmente en las capas inferiores, mientras que las neuronas únicas de cada PL tienden a aparecer en las capas superiores. El estudio ofrece nuevas perspectivas sobre cómo los LLM representan internamente los PLs (fuente: HuggingFace Daily Papers)
Nuevo artículo «Pixels Versus Priors» controla los conocimientos previos en MLLM mediante contrafactuales visuales: Este estudio explora si el razonamiento de los modelos de lenguaje grandes multimodales (MLLM) en tareas como la respuesta a preguntas visuales se basa más en el conocimiento del mundo memorizado o en la información visual de la imagen de entrada. Los investigadores introdujeron el conjunto de datos Visual CounterFact, que contiene imágenes visuales contrafactuales que entran en conflicto con los conocimientos previos del mundo (como fresas azules). Los experimentos muestran que las predicciones iniciales del modelo reflejan los conocimientos previos memorizados, pero en etapas posteriores se orientan hacia la evidencia visual. El artículo propone el vector de guía PvP (Pixels Versus Priors), que mediante la intervención en la capa de activación controla si la salida del modelo se inclina hacia el conocimiento del mundo o la entrada visual, cambiando con éxito la mayoría de las predicciones de color y tamaño (fuente: HuggingFace Daily Papers)
El artículo de ICML 2025 GuidedQuant propone mejorar los métodos PTQ jerárquicos mediante la guía de la pérdida final: GuidedQuant es un nuevo método de cuantización post-entrenamiento (PTQ) que mejora el rendimiento de los métodos PTQ jerárquicos al integrar la guía de la pérdida final (end loss) en el objetivo. Este método utiliza el gradiente por característica de la pérdida final para ponderar el error de salida jerárquico, lo que corresponde a la información de Fisher diagonal por bloques que mantiene las dependencias dentro del canal. Además, el artículo introduce LNQ, un algoritmo de cuantización escalar no uniforme que garantiza la reducción monótona del valor objetivo de cuantización. Los experimentos demuestran que GuidedQuant supera a los métodos SOTA existentes en cuantización escalar solo de pesos, cuantización vectorial solo de pesos, y cuantización de pesos y activaciones, y ya se ha aplicado a la cuantización de 2-4 bits de modelos como Qwen3, Gemma3, Llama3.3 (fuente: Reddit r/MachineLearning)

AI Engineer World’s Fair se celebra en San Francisco, enfocándose en prácticas de ingeniería de IA y tecnologías de vanguardia: La AI Engineer World’s Fair se está llevando a cabo en San Francisco, reuniendo a numerosos ingenieros, investigadores y desarrolladores del campo de la IA. La agenda de la conferencia incluye temas candentes como aprendizaje por refuerzo, kernels, inferencia y agentes, optimización de modelos (RFT, DPO, SFT), codificación de agentes, construcción de agentes de voz, entre otros. Durante el evento, expertos de empresas como OpenAI y Google realizarán presentaciones y seminarios, y se lanzarán nuevos productos y tecnologías. Los miembros de la comunidad participan activamente, compartiendo la agenda de la conferencia y organizando encuentros presenciales, lo que demuestra la vitalidad de la comunidad de ingeniería de IA y su entusiasmo por las tecnologías de vanguardia (fuente: swyx, clefourrier, swyx, LiorOnAI, TheTuringPost)

💼 Negocios
ShiDu Intelligent completa una ronda de financiación semilla de varios millones de yuanes para acelerar la implementación multiescenario de gafas inteligentes con IA: Suzhou ShiDu Intelligent Technology Co., Ltd. anunció la finalización de una ronda de financiación semilla de varios millones de yuanes. Los fondos se utilizarán para la investigación y desarrollo de la tecnología central de las gafas inteligentes con IA, la expansión del mercado y la construcción del ecosistema. La empresa se especializa en la aplicación de gafas inteligentes con IA en áreas como el cuidado inteligente de la salud (gafas inteligentes para presbicia, gafas inteligentes de asistencia para ciegos), la vida inteligente (gafas de moda inteligentes, gafas para ciclismo) y la fabricación inteligente (gafas industriales inteligentes, controladores de voz). Sus productos tienen un precio de entre 200 y 1000 yuanes, con el objetivo de promover la popularización de las gafas inteligentes a través de una alta relación costo-rendimiento (fuente: 36氪)

Se rumorea que OpenAI podría adquirir el asistente de programación de IA Windsurf, lo que genera especulaciones sobre la interrupción del suministro del modelo Claude por parte de Anthropic: Circulan rumores en el mercado de que OpenAI podría adquirir la herramienta de programación de IA Windsurf (anteriormente Codeium) por aproximadamente 3 mil millones de dólares. En este contexto, el CEO de Windsurf, Varun Mohan, publicó que Anthropic cortó su acceso directo a casi todos sus modelos Claude 3.x, incluyendo Claude 3.5 Sonnet, con un preaviso extremadamente corto. Windsurf expresó su decepción y rápidamente transfirió su capacidad de cómputo a otros proveedores de servicios de inferencia, al tiempo que ofreció descuentos en Gemini 2.5 Pro a los usuarios afectados. La comunidad especula que esta medida de Anthropic podría estar relacionada con la posible adquisición por parte de OpenAI, temiendo que esto afecte la competencia en la industria y las opciones de los desarrolladores. Anteriormente, Windsurf tampoco obtuvo soporte directo de Anthropic cuando se lanzó Claude 4 (fuente: AI前线)

Hygon Information planea fusionarse con Sugon mediante intercambio de acciones, integrando la cadena de la industria de la computación nacional: La empresa de diseño de chips de IA Hygon Information anunció planes para absorber a su mayor accionista, el fabricante de servidores Sugon, mediante un intercambio de acciones. La capitalización de mercado de Hygon Information es de aproximadamente 316.4 mil millones de yuanes, mientras que la de Sugon es de aproximadamente 90.5 mil millones de yuanes. Esta fusión, del tipo “serpiente que se traga un elefante”, tiene como objetivo optimizar la disposición industrial desde los chips hasta el software y los sistemas, fortalecer, complementar y extender la cadena industrial, y aprovechar las sinergias tecnológicas. Los analistas creen que la fusión ayudará a resolver las complejas transacciones entre partes relacionadas y los posibles problemas de competencia homóloga, reducir los costos operativos y alinearse con la tendencia de desarrollo de soluciones de computación de extremo a extremo en la era de la IA, marcando una posible aceleración en la transición del poder tecnológico de los semiconductores de China de la computación tradicional a la computación de IA (fuente: 36氪)
🌟 Comunidad
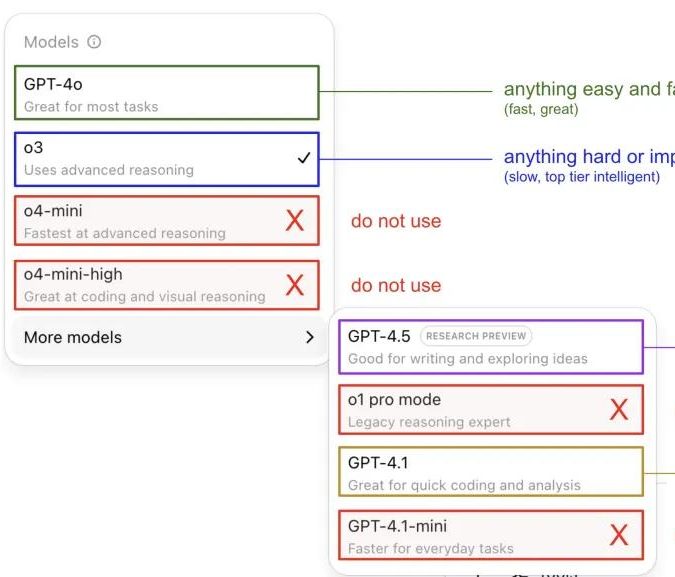
Andrej Karpathy comparte su experiencia usando modelos de ChatGPT, generando debate en la comunidad: Andrej Karpathy compartió su experiencia personal usando diferentes versiones de ChatGPT: para tareas importantes o difíciles, recomienda usar o3, que tiene una capacidad de razonamiento más fuerte; para problemas cotidianos de baja dificultad, se puede usar 4o; para tareas de mejora de código, GPT-4.1 es adecuado; cuando se necesita investigación profunda y resumen de múltiples enlaces, se utiliza la función de investigación profunda (basada en o3). Esta experiencia compartida generó un amplio debate en la comunidad, con muchos usuarios compartiendo sus propias preferencias de uso y opiniones sobre la selección de modelos, y también reflejó la confusión de los usuarios sobre la caótica nomenclatura de los modelos de OpenAI y la falta de una función de selección automática de modelos (fuente: 量子位, JeffLadish)
Un desarrollador comparte su experiencia de dos semanas con la programación Agentic AI: de la conmoción al desencanto, optando finalmente por la refactorización manual: Un líder técnico con 10 años de experiencia compartió su vivencia al integrar Agentic AI (específicamente, agentes de programación de IA) en el flujo de desarrollo de su aplicación de redes sociales. Inicialmente, la IA podía generar rápidamente módulos funcionales, escribir lógica de front-end y back-end, y pruebas unitarias, con una eficiencia asombrosa, generando alrededor de 12,000 líneas de código en dos semanas. Sin embargo, a medida que aumentaba la complejidad de la base de código, la IA comenzó a cometer errores frecuentes al manejar nuevas funciones, a caer en bucles y a tener dificultades para admitir fallos. El código generado también presentaba problemas como nombres imprecisos y código duplicado, lo que dificultaba el mantenimiento de la base de código y hacía que el desarrollador perdiera la confianza. Finalmente, el desarrollador decidió utilizar el código generado por IA solo como una “referencia vaga”, refactorizar manualmente todas las funciones y concluyó que la IA es actualmente más adecuada para analizar código existente y proporcionar ejemplos, en lugar de escribir directamente código funcional (fuente: CSDN)

La definición de Agente de IA y la diferencia con el flujo de trabajo atraen la atención, con un enorme potencial de aplicación futura: La comunidad discute la distinción entre los conceptos de Agente de IA y Workflow (flujo de trabajo). Un Agente generalmente se refiere a un LLM que accede a herramientas en un bucle, operando libremente según las instrucciones; un Workflow es una serie de pasos ejecutados principalmente de manera determinista, que pueden incluir un LLM para completar subtareas. Aunque existe superposición (un Agente puede ser instruido para ejecutarse de manera determinista, un Workflow puede incluir componentes agénticos), esta distinción sigue siendo ontológicamente significativa. Al mismo tiempo, el potencial de los Agentes de IA en aplicaciones empresariales es ampliamente reconocido, con gigantes como Tencent y ByteDance invirtiendo en el campo de los agentes inteligentes. Por ejemplo, Tencent está actualizando su base de conocimientos de modelos grandes a una plataforma de desarrollo de agentes inteligentes, mientras que ByteDance tiene la plataforma Coze (Kouzi), destinada a ayudar a las empresas a implementar sistemas de agentes de IA nativos (fuente: fabianstelzer, 蓝洞商业)
Dwarkesh Patel discute la línea de tiempo de LLM y AGI, considerando el aprendizaje continuo como el cuello de botella clave: Dwarkesh Patel expuso en su blog su visión sobre la línea de tiempo de la AGI (Inteligencia Artificial General), argumentando que los LLM actualmente carecen de la capacidad humana para acumular contexto a través de la práctica, reflexionar sobre los fracasos y realizar pequeñas mejoras, es decir, la capacidad de aprendizaje continuo. Considera que esto es un enorme cuello de botella para la utilidad de los modelos, y resolver este problema podría llevar varios años. Esta perspectiva generó discusiones entre varios investigadores de IA, incluido Andrej Karpathy. Karpathy también coincidió en las deficiencias de los LLM en el aprendizaje continuo, comparándolos con colegas que sufren de amnesia anterógrada. Estas discusiones resaltan los desafíos para lograr una verdadera AGI y la profunda reflexión sobre los mecanismos de aprendizaje de los modelos (fuente: dwarkesh_sp, JeffLadish, dwarkesh_sp)

El problema de las patentes en el desarrollo de fármacos con IA atrae la atención, Science pide cautela: Un artículo del foro de políticas de la revista Science, «What patents on AI-derived drugs reveal», explora la aplicación de la IA en el descubrimiento de fármacos y su impacto en el sistema de patentes. La investigación señala que las empresas nativas de IA, al solicitar patentes de fármacos, suelen tener menos datos de experimentos in vivo que las farmacéuticas tradicionales, lo que podría llevar al abandono de fármacos prometedores por falta de investigación posterior. Al mismo tiempo, la gran cantidad de nuevas moléculas generadas por IA, una vez publicadas, podrían convertirse en “estado de la técnica”, obstaculizando la solicitud de patentes y la inversión adicional en estas moléculas por parte de otras empresas. El artículo sugiere elevar los requisitos para la solicitud de patentes, exigiendo más datos de experimentos in vivo, y permitir que otras empresas soliciten patentes sobre moléculas generadas por IA que no hayan sido probadas, al tiempo que se refuerza la exclusividad regulatoria en la fase de ensayos clínicos de nuevos fármacos, para equilibrar el incentivo a la innovación con el interés público (fuente: 36氪)
💡 Otros
El incidente de la lucha de poder de Altman podría convertirse en una película llamada «Artificial», con la participación de un director y productor de renombre: Según The Hollywood Reporter, MGM planea adaptar los cambios en la cúpula directiva de OpenAI a una película, provisionalmente titulada «Artificial». El reconocido director italiano Luca Guadagnino podría dirigirla, y entre los productores se encuentra David Heyman, de la saga «Harry Potter». Se está discutiendo el reparto, y se rumorea que Andrew Garfield (quien interpretó a Spider-Man y a Eduardo Saverin en «La Red Social») podría interpretar a Sam Altman, Yura Borisov a Ilya Sutskever, y Monica Barbaro a Mira Murati. Esta noticia ha generado un animado debate entre los internautas, quienes la comparan con la película «La Red Social» (fuente: 36氪, janonacct)
La experiencia con el servicio al cliente de IA genera controversia, los usuarios se quejan de la “estupidez artificial” y la dificultad para ser transferidos a un humano: Durante las recientes grandes promociones de comercio electrónico, numerosos consumidores informaron de una comunicación deficiente y respuestas irrelevantes por parte del servicio al cliente de IA, además de grandes dificultades para ser transferidos a un agente humano, lo que resultó en una peor experiencia de servicio. Datos de la Administración Estatal para la Regulación del Mercado de China muestran que en 2024, las quejas en el ámbito del servicio postventa de comercio electrónico relacionadas con el “servicio al cliente inteligente” aumentaron un 56.3%. Los usuarios generalmente consideran que el servicio al cliente de IA tiene dificultades para resolver problemas personalizados, sus respuestas son rígidas y no es suficientemente amigable con grupos especiales como las personas mayores. El artículo insta a las empresas a no sacrificar la calidad del servicio en su búsqueda de reducción de costos y aumento de la eficiencia, a optimizar la tecnología de IA, definir claramente los escenarios de aplicación del servicio al cliente de IA y mantener canales de servicio humano accesibles (fuente: 36氪)

Se discute la aplicación de la IA en la creación de contenido y las estrategias de adaptación de los creadores: La aplicación de tecnologías de IA (como DeepSeek, Suno, Veo 3) en la creación de contenido como artículos, música y videos es cada vez más generalizada, lo que genera ansiedad entre los creadores de contenido sobre sus perspectivas profesionales. El análisis sugiere que el paradigma del contenido está cambiando de la “recomendación personalizada” a la “generación personalizada”. A corto plazo, es posible que las plataformas no reemplacen completamente a los creadores con IA debido a los altos costos de prueba y error, y los creadores podrían monetizar creando modelos de estilo únicos y licenciándolos. A largo plazo, los creadores deben ajustar sus métodos de creación de valor, centrándose más en “estrategias de innovación” (como investigación original, obtención de datos de primera mano) que son difíciles de reemplazar por la IA, en lugar de “estrategias de seguimiento” (seguir tendencias, depender de datos de segunda mano) que son fácilmente asistidas por la IA. Aunque la IA ha comenzado a incursionar en campos innovadores como la investigación científica, los creadores con perspectivas únicas y pensamiento profundo siguen teniendo valor (fuente: 36氪)
