
Palabras clave:Informe de tendencias de IA, Agente de IA, Aprendizaje por refuerzo, Modelo de lenguaje visual, Comercialización de IA, Alucinaciones de IA, Seguridad de IA, Informe de IA de la Reina de Internet, Diseño de seguridad LawZero IA, Mecanismo de atención GTA y GLA, Modelo de robot SmolVLA, Fraude en streaming de música con IA
🔥 Enfoque
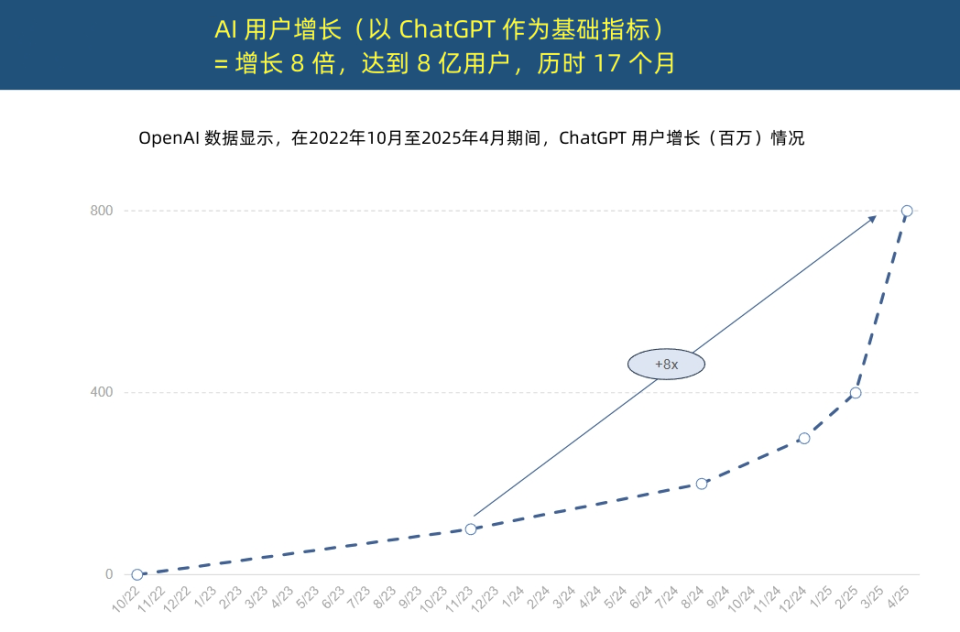
Mary Meeker, la “Reina de Internet”, publica un informe sobre tendencias de IA, revelando una aceleración sin precedentes en la adopción de IA y una transformación en la estructura de costos: Mary Meeker, conocida como la “Reina de Internet”, ha publicado un “Informe de Tendencias de IA” de 340 páginas, destacando que la IA se está adoptando a una velocidad nunca antes vista. El informe señala que el crecimiento de usuarios de ChatGPT ha sido explosivo, alcanzando los 800 millones de usuarios activos mensuales en 17 meses y generando ingresos anuales cercanos a los 4 mil millones de dólares, superando con creces a cualquier tecnología anterior. La inversión de capital de los gigantes tecnológicos en infraestructura de IA ha aumentado drásticamente, alcanzando los 212 mil millones de dólares en 2024. Al mismo tiempo, el costo de entrenamiento de modelos de IA ha aumentado 2400 veces en 8 años, con el costo de entrenamiento de un solo modelo pudiendo alcanzar los mil millones de dólares. Sin embargo, el costo de inferencia ha disminuido drásticamente debido a la optimización de hardware (como el aumento de 100,000 veces en la eficiencia energética de las GPU de Nvidia) y algoritmos. El rendimiento de los modelos de código abierto (como DeepSeek, Qwen) se acerca al de los modelos de código cerrado, la demanda de puestos de IA ha crecido un 448%, y los AI Agent se están convirtiendo en la nueva fuerza laboral digital. (Fuente: APPSO, Tencent Technology)
Yoshua Bengio, ganador del Premio Turing, lanza LawZero, abogando por una IA con “seguridad por diseño”: Yoshua Bengio, ganador del Premio Turing, anunció la creación de la organización sin fines de lucro LawZero, con el objetivo de desarrollar una inteligencia artificial con “seguridad por diseño” para hacer frente a posibles comportamientos de engaño y autoprotección en los sistemas de IA. LawZero se inspira en la Tercera Ley de la Robótica de Asimov, enfatizando que la IA debe proteger la felicidad y el esfuerzo humanos. La organización está desarrollando el sistema Scientist AI, que actuará como una “barrera de protección” para los AI Agent, proporcionando ayuda a través de la comprensión del mundo en lugar de la acción directa, y evaluando los riesgos del comportamiento de otras IA. Bengio considera que la actual Agentic AI es una dirección equivocada, que podría descontrolarse y traer consecuencias catastróficas irreversibles, y enfatiza que la IA de barrera de seguridad debe ser al menos tan inteligente como los AI Agent que intenta monitorear. (Fuente: Academic Headlines, Yoshua_Bengio)

El año inaugural de los AI Agent: De herramientas auxiliares a ejecutores de tareas, remodelando los modelos de negocio: Sun Zhiyong, vicepresidente de investigación de Gartner, señaló que 2025 es el “año inaugural de los agentes inteligentes de grandes modelos” y el “año inaugural de la monetización de la IA generativa”, y los agentes de IA se están convirtiendo en la principal vía de salida de las capacidades de los LLM. La diferencia fundamental entre los agentes inteligentes y los chatbots radica en el cambio de proporcionar asistencia informativa a ejecutar tareas directamente. Por ejemplo, un agente inteligente puede completar todo el proceso de pedir un café, no solo proporcionar información sobre cafeterías. Gartner predice que para 2028, el 20% de las interacciones de interfaz digital serán realizadas por agentes de IA, el 15% de las decisiones comerciales diarias podrán ser tomadas de forma autónoma por agentes de IA, y un tercio del software empresarial integrará agentes de IA. El asistente inteligente de BYD y otros ya han comenzado a aplicarse, y la forma de interacción de las aplicaciones móviles podría cambiar en el futuro. (Fuente: IT Times)
Autor principal de Mamba propone mecanismos de atención conscientes de la inferencia GTA y GLA para optimizar la inferencia de contexto largo: Tri Dao, uno de los autores principales de Mamba, y su equipo de Princeton han propuesto Grouped-Tied Attention (GTA) y Grouped-Latent Attention (GLA), dos nuevos mecanismos de atención diseñados específicamente para mejorar la eficiencia de la inferencia de contexto largo en modelos grandes. GTA, mediante la vinculación de parámetros y la reutilización agrupada de la caché KV (clave-valor), puede reducir aproximadamente en un 50% el uso de la caché KV en comparación con GQA, manteniendo al mismo tiempo una calidad de modelo comparable. GLA adopta una estructura de dos capas, introduciendo tokens latentes como una representación comprimida del contexto global, y se combina con un mecanismo de cabezales agrupados. En comparación con MLA utilizado por DeepSeek, puede acelerar la decodificación de secuencias largas (como 64K) hasta 2 veces y mejorar la capacidad de procesamiento de solicitudes concurrentes. Estos nuevos mecanismos tienen como objetivo resolver los cuellos de botella de acceso a la memoria y las limitaciones de paralelismo durante la inferencia. (Fuente: QubitAI)

🎯 Tendencias
DeepMind lanza SmolVLA: un eficiente modelo de visión-lenguaje-acción para robótica basado en datos comunitarios: Hugging Face, en colaboración con DeepMind y otras instituciones, ha lanzado SmolVLA, un modelo de visión-lenguaje-acción (VLA) de código abierto con 450M de parámetros, diseñado específicamente para robots y capaz de ejecutarse en hardware de consumo. Este modelo fue preentrenado utilizando únicamente conjuntos de datos de código abierto compartidos por la comunidad LeRobot, y supera a modelos VLA más grandes y a líneas base como ACT en tareas de LIBERO, Meta-World y del mundo real (SO100, SO101). SmolVLA admite inferencia asíncrona, lo que puede aumentar la velocidad de respuesta en un 30% y duplicar el rendimiento de las tareas. Su arquitectura combina Transformer con un decodificador de coincidencia de flujo (flow matching) y optimiza la velocidad y eficiencia mediante la reducción de tokens visuales, la utilización de características de capas intermedias de VLM y mecanismos de atención entrelazados. (Fuente: HuggingFace Blog, clefourrier)

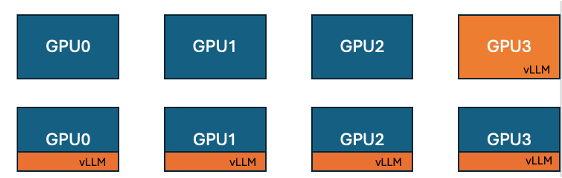
Hugging Face e IBM lanzan la función de colocalización de vLLM en TRL, mejorando la eficiencia del entrenamiento de GPU: Hugging Face e IBM han colaborado para introducir la función de colocalización de vLLM (co-located vLLM) en la biblioteca TRL, destinada a algoritmos de aprendizaje en línea como GRPO. Esta función permite que el entrenamiento y la inferencia (generación) se ejecuten en las mismas GPU, compartiendo recursos y alternando la ejecución, eliminando así el problema de inactividad de las GPU de entrenamiento mientras esperan, presente en el modo servidor de vLLM anterior. Al incrustar vLLM en el mismo grupo de procesos distribuidos, no se necesita comunicación HTTP, es compatible con torchrun, TP y DP, simplificando la implementación y aumentando el rendimiento. Los experimentos demuestran que para modelos de 1.5B y 7B, el modo de colocalización puede ofrecer aceleraciones de hasta 1.43x a 1.73x; para modelos grandes como Qwen2.5-Math-72B, combinando la API sleep() de vLLM y la optimización DeepSpeed ZeRO Stage 3, se puede lograr una aceleración de entrenamiento de aproximadamente 1.26x incluso con menos GPU, sin afectar la precisión del modelo. (Fuente: HuggingFace Blog)
Nvidia lanza el modelo Nemotron-Research-Reasoning-Qwen-1.5B, especializado en razonamiento complejo: Nvidia ha presentado Nemotron-Research-Reasoning-Qwen-1.5B, un modelo de pesos de código abierto con 1.5B de parámetros, enfocado en tareas de razonamiento complejo como problemas matemáticos, desafíos de programación, problemas científicos y acertijos lógicos. El modelo utiliza el algoritmo ProRL (Prolonged Reinforcement Learning) entrenado en un conjunto de datos diversificado, con el objetivo de lograr una exploración más profunda de las estrategias de razonamiento. La compañía afirma que supera significativamente al modelo de 1.5B de DeepSeek en tareas de matemáticas, codificación y GPQA. ProRL se basa en GRPO e introduce técnicas para mitigar el colapso de entropía, el recorte desacoplado y la optimización dinámica de la estrategia de muestreo (DAPO), así como la regularización KL y el reinicio de la política de referencia. Este modelo está destinado únicamente para uso en investigación y desarrollo. (Fuente: Reddit r/LocalLLaMA, Hugging Face)

Arcee lanza el modelo Homunculus-12B, basado en la destilación de Qwen3-235B sobre Mistral-Nemo: Arcee AI ha lanzado Homunculus-12B, un modelo de instrucciones con 12 mil millones de parámetros. Este modelo se construyó destilando las capacidades de Qwen3-235B en una red troncal Mistral-Nemo. Actualmente, el modelo y su versión GGUF están disponibles en Hugging Face. Esto representa un intento de transferir las potentes capacidades de los modelos grandes a modelos más pequeños y eficientes mediante la técnica de destilación de modelos, con el objetivo de equilibrar el rendimiento y el consumo de recursos. (Fuente: Reddit r/LocalLLaMA, Hugging Face)

La aplicación Bing de Microsoft integra una herramienta gratuita de generación de video Sora: Microsoft ha añadido una función gratuita de generación de video OpenAI Sora a su aplicación móvil Bing. Los usuarios pueden generar videoclips cortos mediante prompts de texto sin necesidad de suscripción ni pago. Actualmente, la función admite la generación de videos verticales de 5 segundos en formato 9:16, y se planea admitir el formato horizontal 16:9 en el futuro. Los usuarios gratuitos tienen 10 créditos de generación rápida, después de los cuales pueden canjearlos con puntos de Microsoft u optar por la generación a velocidad estándar. Esta medida tiene como objetivo reducir la barrera de entrada a la creación de videos con IA y permitir que más usuarios experimenten la tecnología de texto a video. (Fuente: Reddit r/ArtificialInteligence, dotey)

Hugging Face lanza SmolVLA, un modelo de visión-lenguaje-acción diseñado para robótica asequible y eficiente: Hugging Face ha presentado SmolVLA, un modelo de visión-lenguaje-acción (VLA) de código abierto con 450M de parámetros, destinado a proporcionar soluciones de robótica asequibles y eficientes. El modelo se entrenó utilizando todos los conjuntos de datos de código abierto de la comunidad LeRobotHF, logrando el mejor rendimiento y velocidad de inferencia de su clase. El lanzamiento de SmolVLA tiene como objetivo reducir la barrera de entrada a la investigación y el desarrollo en robótica, fomentando una participación e innovación comunitaria más amplias. (Fuente: huggingface, AK)

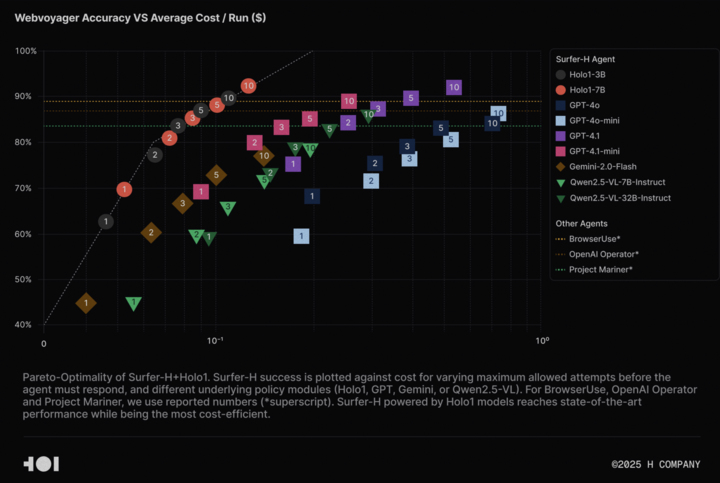
H Company libera el modelo de lenguaje visual Holo-1 y el conjunto de datos WebClick, impulsando la investigación en Agentic AI: H Company ha anunciado la liberación de su modelo de lenguaje visual Holo-1 (versiones de 3B y 7B parámetros) y el conjunto de datos WebClick, con el objetivo de acelerar la investigación en el campo de Agentic AI. El modelo Holo-1 está diseñado específicamente para tareas de acción en GUI y navegación web, y ya ha logrado un resultado SOTA (State-of-the-Art) del 92.2% en el benchmark WebVoyager, superando en rentabilidad a modelos grandes como GPT-4.1. Los pesos del modelo y el conjunto de datos se han publicado en la plataforma Hugging Face bajo la licencia Apache 2.0. Holo-1 también se ha integrado en MLX, facilitando a los desarrolladores su ejecución en dispositivos Apple Silicon. (Fuente: huggingface, tonywu_71)
PlayAI libera el primer LLM de difusión de voz PlayDiffusion, compatible con edición fina y clonación zero-shot: PlayAI ha lanzado y liberado PlayDiffusion, el primer diffusion-LLM para voz. Este modelo está diseñado específicamente para la edición fina de voz con IA (como reparación, reemplazo de contenido) y la clonación de voz zero-shot. A diferencia de los modelos autorregresivos que suelen necesitar entre 800 y 1000 tokens para generar audio, PlayDiffusion solo requiere entre 20 y 30 tokens, lo que mejora significativamente la eficiencia. El modelo ya está disponible con su código fuente en GitHub y se ha implementado una demostración en Hugging Face Spaces, además de estar accesible a través de la plataforma Fal.ai. (Fuente: _akhaliq)
Google lanza discretamente la aplicación AI Edge Gallery, que permite ejecutar modelos de IA sin conexión en dispositivos Android: Google ha lanzado una aplicación experimental en versión alfa llamada Google AI Edge Gallery, que permite a los usuarios descargar y ejecutar modelos de IA públicos de Hugging Face sin conexión en dispositivos Android. La aplicación admite funciones como preguntas y respuestas sobre imágenes, resumen y reescritura de texto, generación de código y chat con IA, además de proporcionar información sobre el rendimiento (como TTFT, velocidad de decodificación). La ejecución local de modelos de IA puede mejorar la velocidad de respuesta, proteger la privacidad del usuario y no requiere conexión a Internet. Sin embargo, los comentarios de los usuarios son mixtos; algunos han experimentado problemas de bloqueo en dispositivos Pixel y otros, especialmente al cambiar a la inferencia por GPU o al procesar modelos grandes. Algunos comentarios sugieren que su funcionalidad es similar a aplicaciones existentes (como PocketPal) o que está rezagada en comparación con frameworks como CoreML de Apple, aunque también hay opiniones que señalan la ventaja multiplataforma de su base MediaPipe. (Fuente: 36Kr)

RenderFormer de Microsoft llega a Hugging Face, enfocado en el renderizado neuronal de mallas triangulares con iluminación global: Microsoft ha lanzado RenderFormer en Hugging Face, un modelo de renderizado neuronal basado en Transformer, especializado en el procesamiento del renderizado de mallas triangulares con efectos de iluminación global. Este tipo de trabajo de investigación es de gran importancia para la fusión de los pipelines de renderizado tradicionales con métodos neuronales, y su desarrollo futuro podría incluir la expansión a escenas más grandes y la superación de la simple reproducción del trazado de rayos. (Fuente: _akhaliq)

BAAI lanza el modelo de comprensión de videos largos Video-XL-2, capaz de procesar 10,000 fotogramas en una sola GPU: El Beijing Academy of Artificial Intelligence (BAAI), en colaboración con la Universidad Jiao Tong de Shanghái, ha presentado Video-XL-2, un modelo diseñado específicamente para la comprensión de videos largos. Este modelo, bajo licencia Apache 2.0, es capaz de procesar más de 10,000 fotogramas de contenido de video en una sola GPU y completar la codificación de 2048 fotogramas en 12 segundos. Sus tecnologías clave incluyen un eficiente prellenado basado en bloques (Chunk-based Prefilling) y una decodificación KV de doble granularidad (Bi-granularity KV decoding), destinadas a mejorar la eficiencia y capacidad del procesamiento de videos largos. El modelo ya está disponible en Hugging Face. (Fuente: huggingface)
El modelo UniWorld se publica en Hugging Face, con el objetivo de unificar la comprensión y generación visual: El modelo UniWorld ya está disponible en la plataforma Hugging Face. Este modelo se posiciona como un codificador semántico de alta resolución, dedicado a lograr capacidades unificadas de comprensión y generación visual. Esto indica que los investigadores están trabajando en la construcción de un único marco de modelo capaz de procesar simultáneamente la entrada de información visual (comprensión) y la salida de contenido visual (generación), con la esperanza de lograr avances más completos en el campo de la IA multimodal. (Fuente: _akhaliq)
DeepSeek lanza el modelo multimodal Muddit-1B, que utiliza un Transformer de difusión discreta unificado: DeepSeek ha lanzado el modelo Muddit-1B, un modelo multimodal centrado en la visión que adopta una arquitectura de Transformer de difusión discreta unificada similar a MaskGIT, equipado con un decodificador de texto ligero. Un aspecto interesante de este modelo es que su dirección de desarrollo es opuesta a la ruta común: comienza con la generación de texto a imagen y luego se expande a la generación de imagen a texto, lo que podría aprovechar diferentes bases de conocimiento previo. Muddit tiene como objetivo lograr la generación paralela rápida de imágenes y texto a través de un método de generación unificado, forma parte de la serie de modelos Meissonic e intenta alejarse de los diseños centrados en el lenguaje para buscar una generación unificada más eficiente. (Fuente: teortaxesTex)
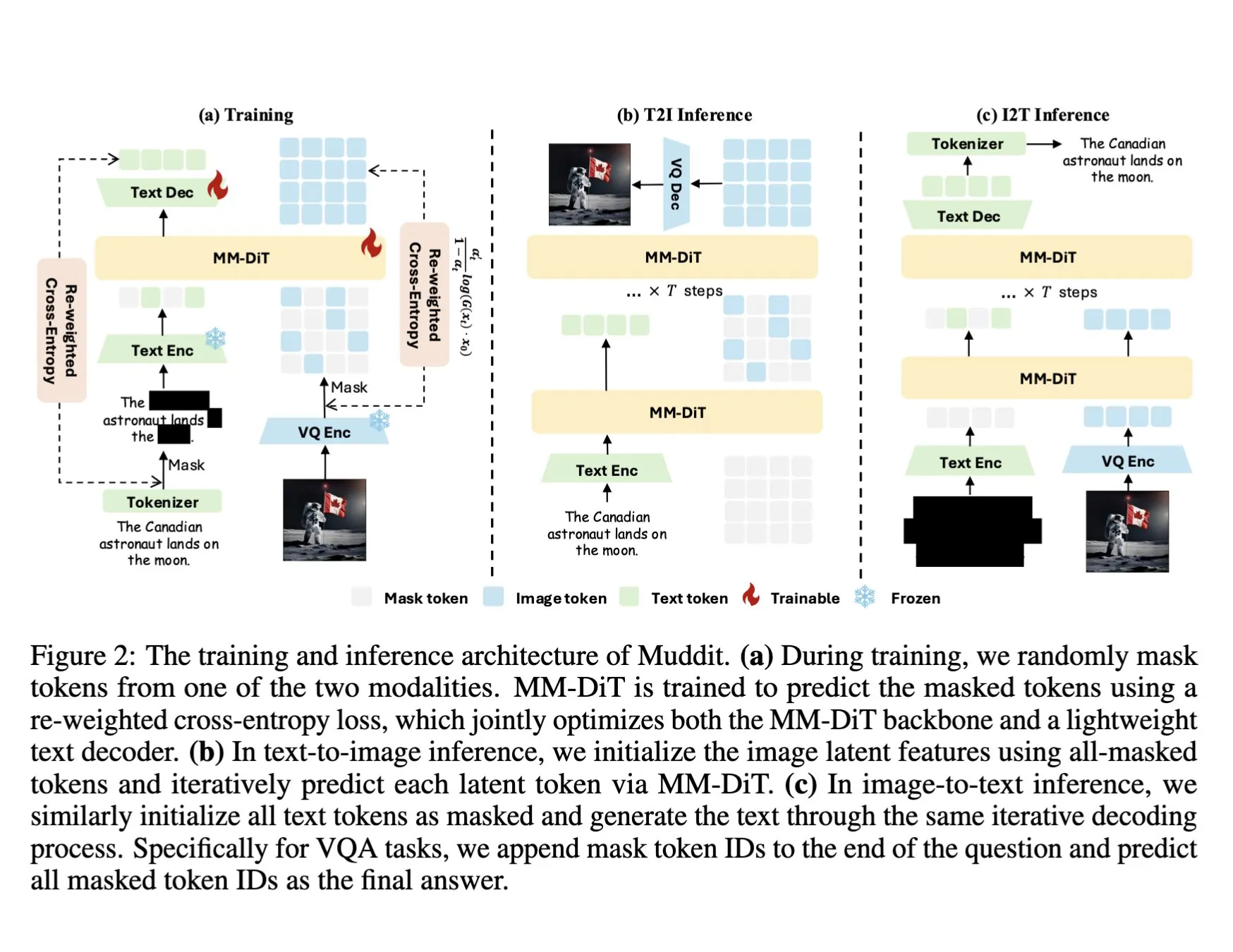
El modelo de recuperación de documentos visuales ColQwen2 se integra en Hugging Face Transformers: El último modelo de recuperación de documentos visuales, ColQwen2, se ha fusionado en la biblioteca principal de Hugging Face Transformers. Los usuarios ahora pueden utilizar ColQwen2 para la recuperación de PDF o en flujos de RAG (Retrieval Augmented Generation) para mejorar la capacidad de procesar documentos visualmente ricos. Este modelo tiene como objetivo comprender y recuperar mejor el contenido de documentos que contienen información textual y gráfica. (Fuente: mervenoyann)
🧰 Herramientas
FLUX Kontext integrado en Adobe Firefly Boards, permite editar fotos y restaurarlas mediante texto: Adobe ha integrado el modelo FLUX Kontext en su herramienta Firefly Boards, permitiendo a los usuarios editar fotografías mediante instrucciones de texto, especialmente útil para escenarios como la restauración de fotos antiguas. Firefly Boards ya está disponible para todos los usuarios. Esta medida tiene como objetivo utilizar la tecnología de edición de imágenes con IA para que los usuarios puedan realizar ediciones creativas y mejoras de imagen de manera más conveniente. (Fuente: robrombach)
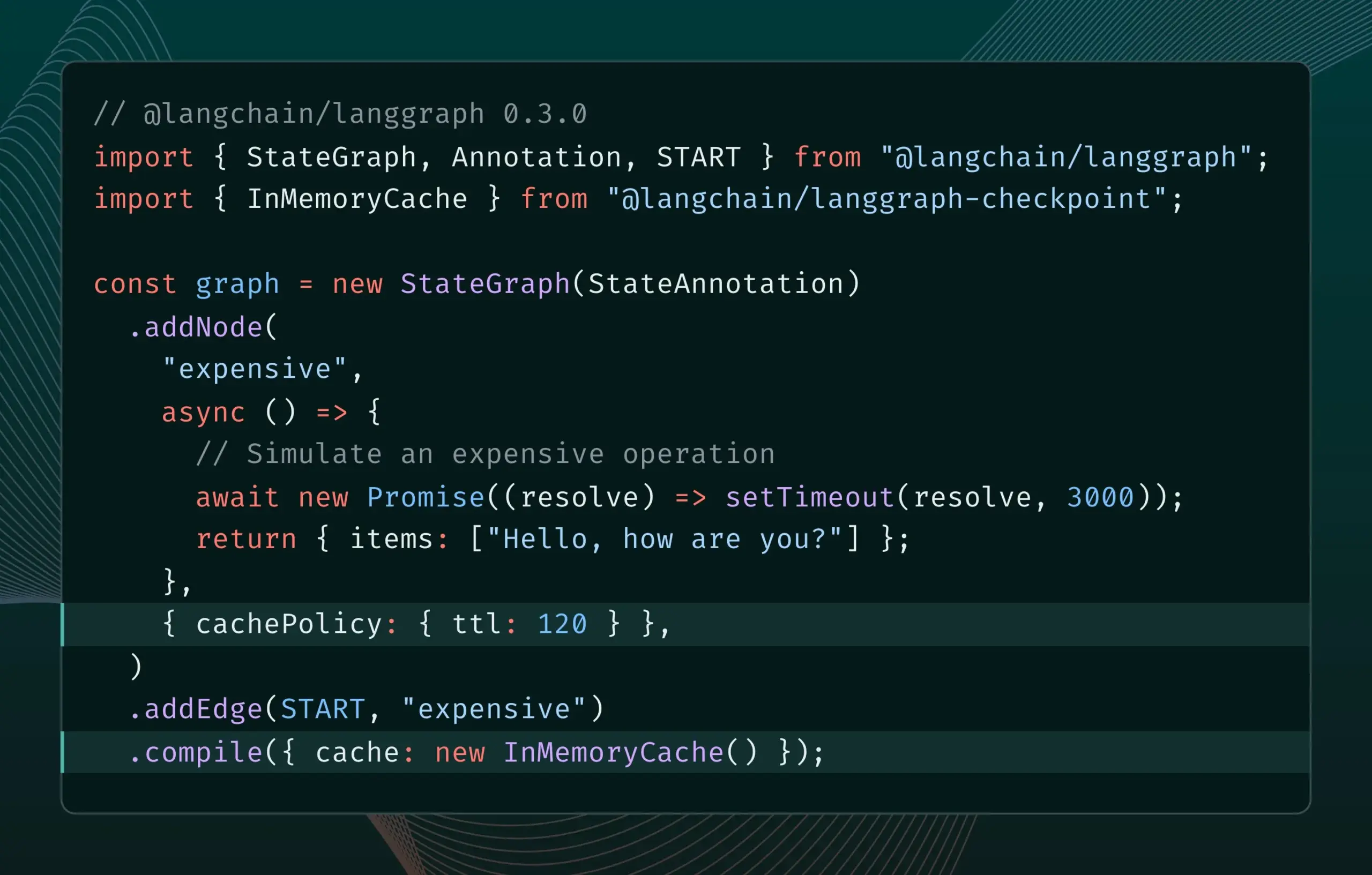
LangGraph.js versión 0.3 introduce la función de almacenamiento en caché de nodos, mejorando la eficiencia iterativa: La versión 0.3 de LangGraph.js ha añadido una función de almacenamiento en caché de nodos/tareas, permitiendo a los desarrolladores evitar cálculos repetitivos al iterar localmente AI Agents costosos o de larga duración, acelerando así el flujo de trabajo. Esta función es compatible tanto con la Graph API como con la Imperative API, y tiene como objetivo mejorar la eficiencia y la comodidad en el desarrollo de aplicaciones de IA. (Fuente: LangChainAI, hwchase17)
Actualización de Ollama simplifica la ejecución local de “modelos de pensamiento”: Ollama ha lanzado una nueva versión que facilita a los usuarios la ejecución local de “modelos de pensamiento” (posiblemente refiriéndose a LLMs con capacidades de razonamiento complejas). Esta actualización tiene como objetivo reducir la barrera para la implementación y el uso local de modelos de IA avanzados, permitiendo que más usuarios y desarrolladores experimenten y utilicen estos modelos en sus propios dispositivos. (Fuente: ollama)
PipesHub: Lanzamiento de plataforma RAG empresarial de código abierto: PipesHub se ha lanzado oficialmente como una plataforma de búsqueda empresarial (plataforma RAG) completamente de código abierto. Permite a los usuarios construir aplicaciones de búsqueda inteligente y Agentic personalizables y escalables, admitiendo la conexión con herramientas como Google Workspace, Slack, Notion, y pudiendo entrenarse con el conocimiento interno de la empresa. PipesHub admite la ejecución local y el uso de cualquier modelo de IA, incluido Ollama, con el objetivo de ayudar a las empresas a utilizar eficientemente sus propios datos y modelos. (Fuente: Reddit r/LocalLLaMA)
JigsawStack lanza un marco de investigación profunda de código abierto, compatible con la generación de informes de alta calidad: JigsawStack ha lanzado un marco de investigación profunda de código abierto, construido sobre un AI SDK y con total personalización. Es capaz de generar informes de investigación de alta calidad combinados con su función de búsqueda incorporada, proporcionando a los usuarios una biblioteca similar a las capacidades de investigación profunda de Perplexity o ChatGPT. (Fuente: hrishioa)
Voiceflow: Herramienta para acelerar la construcción de AI Agent: Voiceflow es valorada por los usuarios como una herramienta eficiente para la construcción de AI Agent. Sus plantillas y su interfaz de arrastrar y soltar hacen que la creación de agentes de IA sea más rápida que codificar desde cero, ahorrando significativamente tiempo. La herramienta tiene como objetivo reducir la barrera de entrada al desarrollo de AI Agent y aumentar la eficiencia del desarrollo. (Fuente: ReamBraden)
Hugging Face lanza un prototipo de búsqueda semántica de modelos para optimizar la selección de modelos: Hugging Face ha lanzado un prototipo de Space para la búsqueda semántica de modelos, con el objetivo de ayudar a los usuarios a encontrar con mayor precisión los modelos que necesitan dentro de su biblioteca de más de 1.5 millones de modelos. La herramienta permite filtrar por tamaño de modelo (desde 0-1B hasta 70B+) y, mediante la comprensión semántica de las necesidades del usuario, mejora la eficiencia en el descubrimiento de modelos. (Fuente: huggingface)
Runner H: Un agente de IA capaz de gestionar correos, buscar empleo, realizar pagos y otras tareas: Runner H, lanzado por Hcompany, es un agente de IA autónomo capaz de utilizar las herramientas proporcionadas por el usuario para completar tareas como leer correos importantes y redactar/enviar respuestas, buscar oportunidades de empleo y postularse en nombre del usuario, crear una Google Sheet con ideas publicitarias populares y enviarla al equipo de Slack, entre otras. Con solo una indicación, Runner H puede encargarse de trabajos complejos y repetitivos. Actualmente, la empresa está realizando una promoción que ofrece acceso Premium gratuito. (Fuente: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 Aprendizaje
Nuevo artículo explora cómo mejorar la capacidad de los LLM para seguir instrucciones complejas mediante el incentivo del razonamiento: Un nuevo artículo, “Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models”, investiga cómo mejorar la capacidad de los grandes modelos de lenguaje (LLM) para seguir instrucciones complejas, especialmente cuando las instrucciones contienen estructuras paralelas, encadenadas y ramificadas. El estudio encuentra que los métodos tradicionales de Cadena de Pensamiento (CoT) pueden ser ineficaces debido a la simple repetición de las instrucciones. Para ello, el artículo propone un método sistemático que incentiva el razonamiento mediante la expansión de la computación en tiempo de prueba. Este método primero descompone las instrucciones complejas y propone métodos reproducibles de adquisición de datos; en segundo lugar, utiliza el Aprendizaje por Refuerzo (RL) con señales de recompensa centradas en reglas verificables para cultivar específicamente la capacidad de razonamiento para el seguimiento de instrucciones, y resuelve el problema del razonamiento superficial bajo instrucciones complejas mediante comparaciones a nivel de muestra, al tiempo que utiliza la clonación del comportamiento experto para promover la transición del modelo del pensamiento rápido a un razonador experto. Los experimentos demuestran que este método puede mejorar significativamente el rendimiento de los LLM (como los modelos de 1.5B) en tareas con instrucciones complejas. (Fuente: HuggingFace Daily Papers)
Artículo propone el marco ARIA: Entrenando agentes de lenguaje con agregación de recompensas impulsada por la intención: El nuevo artículo “ARIA: Training Language Agents with Intention-Driven Reward Aggregation” aborda el enorme espacio de acción y la escasez de recompensas que enfrentan los grandes modelos de lenguaje (LLM) en entornos de acción de lenguaje abiertos (como negociación, juegos de preguntas y respuestas), proponiendo el método ARIA. Este método tiene como objetivo proyectar las acciones de lenguaje natural desde un espacio de distribución conjunta de tokens de alta dimensión a un espacio de intención de baja dimensión, donde las acciones semánticamente similares se agrupan y se les asigna una recompensa compartida. Esta agregación de recompensas consciente de la intención reduce la varianza de la recompensa al densificar la señal de recompensa, promoviendo así una mejor optimización de la política. Los experimentos muestran que ARIA no solo reduce significativamente la varianza del gradiente de la política, sino que también mejora el rendimiento en un promedio del 9.95% en cuatro tareas posteriores. (Fuente: HuggingFace Daily Papers)
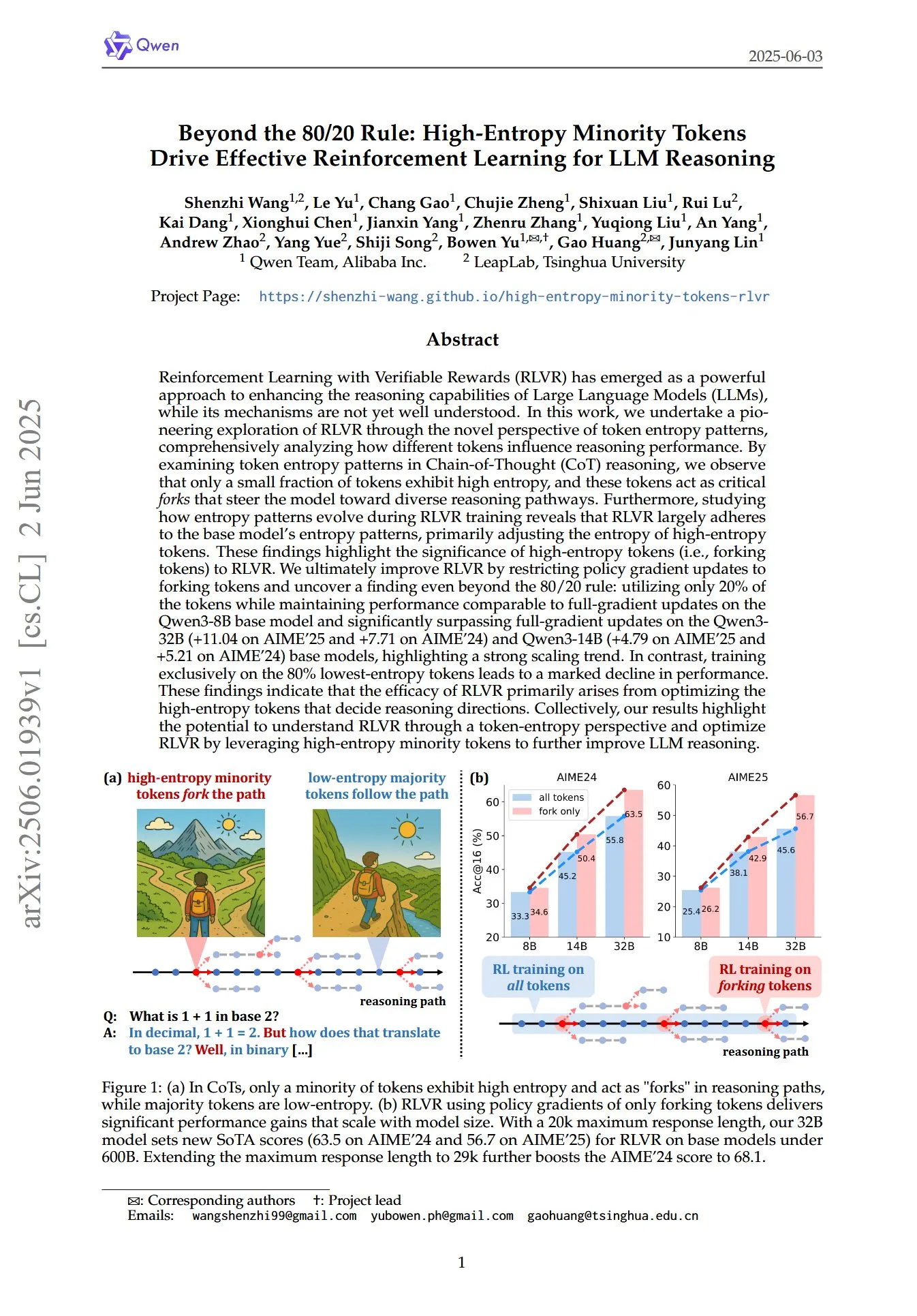
Artículo revela el papel crucial de los tokens minoritarios de alta entropía en el RL para el razonamiento de LLM: Un artículo titulado “Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning”, explora desde una nueva perspectiva de los patrones de entropía de los tokens cómo el Aprendizaje por Refuerzo con Recompensas Verificables (RLVR) mejora la capacidad de razonamiento de los grandes modelos de lenguaje (LLM). El estudio descubre que en el razonamiento de Cadena de Pensamiento (CoT), solo una pequeña porción de tokens exhibe alta entropía; estos tokens de alta entropía actúan como “bifurcaciones” que guían al modelo hacia diferentes rutas de razonamiento. RLVR ajusta principalmente la entropía de estos tokens de alta entropía. Los investigadores, al aplicar actualizaciones de gradiente de política solo a los tokens con el 20% más alto de entropía, lograron un rendimiento comparable a las actualizaciones de gradiente completo en el modelo Qwen3-8B, y superaron significativamente las actualizaciones de gradiente completo en los modelos Qwen3-32B y Qwen3-14B, mostrando una fuerte tendencia de escalabilidad. Esto indica que la efectividad de RLVR se deriva principalmente de la optimización de los tokens de alta entropía que determinan la dirección del razonamiento. (Fuente: HuggingFace Daily Papers, menhguin)
Nuevo artículo explora el ajuste fino temporal en contexto (TIC-FT) para el control versátil de modelos de difusión de video: El artículo “Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models” propone un método eficiente y versátil llamado TIC-FT para adaptar modelos de difusión de video preentrenados a diversas tareas de generación condicional. Este método conecta fotogramas condicionales y objetivo a lo largo del eje temporal e inserta fotogramas intermedios de búfer con niveles de ruido crecientes para lograr una transición suave, alineando el proceso de ajuste fino con la dinámica temporal del modelo preentrenado. TIC-FT no requiere cambios en la arquitectura del modelo y solo necesita de 10 a 30 muestras de entrenamiento para lograr un buen rendimiento. Los investigadores validaron este método en tareas como de imagen a video y de video a video, utilizando grandes modelos base como CogVideoX-5B y Wan-14B. Los resultados muestran que TIC-FT supera a las líneas base existentes en términos de fidelidad condicional y calidad visual, además de ser eficiente en entrenamiento e inferencia. (Fuente: HuggingFace Daily Papers)
ShapeLLM-Omni: LLM multimodal nativo para la generación y comprensión 3D: El artículo “ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding” propone ShapeLLM-Omni, un gran modelo de lenguaje 3D nativo capaz de comprender y generar activos 3D y texto. La investigación primero entrenó un autoencoder variacional cuantificado por vectores 3D (VQVAE), mapeando objetos 3D a un espacio latente discreto para lograr una representación y reconstrucción de formas eficiente y precisa. Basándose en tokens discretos conscientes de 3D, los investigadores construyeron el conjunto de datos de entrenamiento continuo a gran escala 3D-Alpaca, que cubre tareas de generación, comprensión y edición. Finalmente, mediante el ajuste fino de instrucciones del modelo Qwen-2.5-vl-7B-Instruct en el conjunto de datos 3D-Alpaca, se expandieron las capacidades 3D fundamentales del modelo multimodal. (Fuente: HuggingFace Daily Papers)
LoHoVLA: Modelo unificado de visión-lenguaje-acción para tareas incorporadas de largo horizonte: El artículo “LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks” presenta un nuevo marco unificado de visión-lenguaje-acción (VLA) llamado LoHoVLA, diseñado específicamente para resolver tareas incorporadas de largo horizonte. Este modelo utiliza un gran modelo de lenguaje visual (VLM) preentrenado como red troncal, generando conjuntamente tokens de lenguaje para la generación de subtareas y tokens de acción para la predicción de acciones robóticas, compartiendo representaciones para promover la generalización entre tareas. LoHoVLA adopta un mecanismo de control jerárquico de bucle cerrado para reducir errores en la planificación de alto nivel y el control de bajo nivel. Para entrenar este modelo, los investigadores construyeron el conjunto de datos LoHoSet, que contiene 20 tareas de largo horizonte y sus correspondientes demostraciones expertas. Los resultados experimentales muestran que LoHoVLA supera significativamente a los métodos VLA jerárquicos y estándar en tareas incorporadas de largo horizonte en el simulador Ravens. (Fuente: HuggingFace Daily Papers)
Marco MiCRo: Aprendizaje de preferencias personalizado mediante modelado de mezclas y enrutamiento consciente del contexto: El artículo “MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning” propone MiCRo, un marco de dos etapas diseñado para mejorar el aprendizaje de preferencias personalizado utilizando conjuntos de datos de preferencias binarias a gran escala (sin necesidad de anotaciones explícitas de grano fino). En la primera etapa, MiCRo introduce un método de modelado de mezclas consciente del contexto para capturar diversas preferencias humanas. En la segunda etapa, MiCRo integra una estrategia de enrutamiento en línea que ajusta dinámicamente los pesos de la mezcla según el contexto específico para resolver la ambigüedad, logrando así una adaptación de preferencias eficiente y escalable con una supervisión adicional mínima. Los experimentos demuestran que MiCRo puede capturar eficazmente diversas preferencias humanas y mejorar significativamente la personalización posterior. (Fuente: HuggingFace Daily Papers)
MagiCodec: Códec de audio con simple inyección de ruido gaussiano enmascarado para reconstrucción y generación de alta fidelidad: El artículo “MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation” presenta un novedoso códec de audio Transformer de flujo de una sola capa llamado MagiCodec. Este códec está diseñado mediante un proceso de entrenamiento multifásico (que incluye inyección de ruido gaussiano y regularización latente) con el objetivo de mejorar la capacidad de expresión semántica de la codificación generativa, manteniendo al mismo tiempo una alta fidelidad de reconstrucción. Los investigadores derivaron los efectos de la inyección de ruido a partir del análisis en el dominio de la frecuencia, demostrando que puede atenuar eficazmente los componentes de alta frecuencia y promover una tokenización robusta. Los experimentos muestran que MagiCodec supera a los códecs SOTA tanto en calidad de reconstrucción como en tareas posteriores. Sus tokens generados presentan una distribución de Zipf similar al lenguaje natural, lo que mejora la compatibilidad con arquitecturas de generación basadas en modelos de lenguaje. (Fuente: HuggingFace Daily Papers)
Esquema UBA: Un esquema de tasa de aprendizaje unificado para el entrenamiento con iteraciones presupuestadas: El artículo “Stepsize anything: A unified learning rate schedule for budgeted-iteration training” propone un nuevo esquema de tasa de aprendizaje llamado programación unificada consciente del presupuesto (UBA), diseñado para optimizar el rendimiento del aprendizaje en entrenamientos con iteraciones limitadas por presupuesto. Este esquema, mediante la construcción de un marco de optimización que considera el presupuesto de entrenamiento, deriva la programación UBA y, a través de un único hiperparámetro φ, equilibra la flexibilidad con la simplicidad, eliminando la necesidad de optimización numérica para cada red. Los investigadores establecieron una conexión teórica entre φ y el número de condición, y demostraron la convergencia para diferentes valores de φ, proporcionando una guía práctica para seleccionar φ. Los experimentos muestran que UBA supera a los esquemas de tasa de aprendizaje comunes en una variedad de tareas visuales y de lenguaje, diferentes arquitecturas de red y escalas. (Fuente: HuggingFace Daily Papers)
Estudio sobre la adaptación masivamente multilingüe de LLM utilizando datos de traducción bilingüe: El artículo “Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data” explora el impacto de incorporar datos paralelos (especialmente datos de traducción bilingüe) en la adaptación de los modelos de la serie Llama3 a 500 idiomas durante el preentrenamiento continuo masivamente multilingüe. Los investigadores construyeron el corpus de traducción bilingüe MaLA (que contiene datos de más de 2500 pares de idiomas) y desarrollaron el conjunto de modelos EMMA-500 Llama 3. Mediante el preentrenamiento continuo con hasta 671B de tokens en diferentes mezclas de datos, compararon situaciones con y sin datos de traducción bilingüe. Los resultados muestran que los datos bilingües tienden a mejorar la transferencia de lenguaje y el rendimiento, especialmente para los idiomas de bajos recursos. (Fuente: HuggingFace Daily Papers)
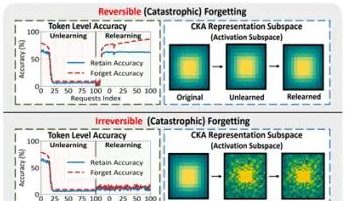
Investigación de equipos de PolyU de Hong Kong y otros revela el fenómeno del “pseudo-olvido” en grandes modelos y sus límites reversibles: Equipos de investigación de la Universidad Politécnica de Hong Kong, la Universidad Carnegie Mellon y otras instituciones, mediante el análisis de los cambios en el espacio de representación de los grandes modelos de lenguaje (LLM) durante el proceso de Desaprendizaje Automático (Machine Unlearning), han distinguido entre el “olvido reversible” y el “olvido catastrófico irreversible”. El estudio encontró que el verdadero olvido implica perturbaciones estructurales coordinadas y significativas en múltiples capas de la red, mientras que las ligeras actualizaciones solo a nivel de salida (como los logits) que conducen a una disminución de la precisión o un aumento de la perplejidad, pueden pertenecer al “pseudo-olvido”, donde la estructura de representación interna del modelo permanece intacta y es fácil de recuperar. El equipo utilizó herramientas como la similitud/deriva de PCA, la similitud CKA y la matriz de información de Fisher para el diagnóstico, descubriendo que el riesgo de olvido continuo es mucho mayor que el de una sola operación, y que diferentes métodos de olvido (como GA, NPO) varían en el grado de daño a la estructura del modelo. Esta investigación proporciona información a nivel estructural para lograr mecanismos de olvido controlables y seguros. (Fuente: QubitAI)
Ubiquant propone un método de minimización de entropía One-Shot, desafiando el post-entrenamiento con aprendizaje por refuerzo de LLM: El equipo de investigación de Ubiquant ha propuesto un método de post-entrenamiento de LLM no supervisado llamado Minimización de Entropía One-Shot (EM), con el objetivo de reemplazar el costoso y complejo ajuste fino mediante aprendizaje por refuerzo (RL). Este método solo requiere un dato no etiquetado y, en 10 pasos de entrenamiento, puede mejorar significativamente el rendimiento de los LLM en tareas como el razonamiento matemático, superando incluso a los métodos de RL que utilizan grandes cantidades de datos. La idea central de EM es hacer que el modelo concentre más su masa de probabilidad en su salida más confiable, minimizando la entropía a nivel de token para reducir la incertidumbre de la predicción. La investigación encontró que el entrenamiento EM hace que la distribución de logits del modelo se incline hacia la derecha (aumentando la confianza), mientras que el RL la inclina hacia la izquierda (guiada por señales reales). EM es adecuado para modelos base o modelos SFT que no han sido extensamente ajustados con RL, así como para escenarios de implementación rápida con recursos limitados, pero se debe tener cuidado con la “excesiva confianza” que podría llevar a una disminución del rendimiento. (Fuente: QubitAI)
Zhejiang University y otros lanzan ViewSpatial-Bench para evaluar la capacidad de localización espacial multivista de los VLM: Equipos de investigación de la Universidad de Zhejiang, la Universidad de Ciencia y Tecnología Electrónica de China y la Universidad China de Hong Kong han lanzado ViewSpatial-Bench, el primer sistema de referencia para evaluar sistemáticamente la capacidad de localización espacial de los modelos de lenguaje visual (VLM) en múltiples vistas y tareas. Este benchmark incluye 5700 pares de preguntas y respuestas, cubriendo cinco tareas de reconocimiento de localización espacial (como la dirección relativa de objetos, el reconocimiento de la dirección de la mirada de personas) desde las perspectivas de la cámara y humana. La investigación encontró que los principales VLM, incluidos GPT-4o y Gemini 2.0, tienen un rendimiento deficiente en la comprensión de relaciones espaciales, especialmente careciendo de un marco de cognición espacial unificado al razonar a través de diferentes vistas. Para mejorar el rendimiento del modelo, el equipo desarrolló el Multi-View Spatial Model (MVSM), que, mediante el ajuste fino en aproximadamente 43,000 muestras de relaciones espaciales, mejoró el rendimiento del modelo Qwen2.5-VL en ViewSpatial-Bench en un 46.24%. (Fuente: QubitAI)

Blog de Hugging Face discute cómo el formato JSON estructurado mejora el rendimiento de los AI Agent: Un artículo de blog de Hugging Face señala que forzar a los AI Agent a usar un formato JSON estructurado al generar procesos de pensamiento y código puede mejorar significativamente su rendimiento y fiabilidad en diversas pruebas de referencia. Este enfoque ayuda a estandarizar la salida del Agent, haciéndola más fácil de analizar, validar e integrar en flujos de trabajo complejos, mejorando así la eficacia general del Agent. (Fuente: dl_weekly)
Nueva investigación: Los modelos de lenguaje visual (VLM) presentan sesgos, con baja precisión en el conteo de imágenes contrafactuales: Un nuevo artículo señala que, aunque los modelos de lenguaje visual (VLM) más avanzados pueden alcanzar una precisión del 100% al contar objetos comunes (como el logo de Adidas con 3 rayas, perros con 4 patas), al procesar imágenes contrafactuales (como un logo de Adidas con 4 rayas, un perro con 5 patas), su precisión de conteo se desploma a aproximadamente el 17%. Esto revela que los VLM tienen sesgos significativos en su capacidad de comprensión y razonamiento cuando se enfrentan a información visual que no se ajusta a la distribución de sus datos de entrenamiento o que viola el sentido común. (Fuente: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Artículo explora el papel de los patrones de prompt en la generación de código asistida por IA: Un estudio titulado “Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration”, analiza la eficiencia de siete patrones de prompt estructurados en la generación de código asistida por IA, utilizando el conjunto de datos DevGPT. La investigación encontró que el patrón “contexto e instrucción” es el más eficiente, logrando resultados satisfactorios con el menor número de iteraciones. Mientras que patrones como “receta” y “plantilla” destacan en tareas estructuradas. El estudio enfatiza que la ingeniería de prompts es una estrategia clave para que los desarrolladores mejoren la productividad con IA, y que los prompts iniciales claros y específicos son cruciales. (Fuente: Reddit r/ArtificialInteligence)

El artículo “REASONING GYM” presenta un entorno de razonamiento con recompensas verificables para el aprendizaje por refuerzo: Este artículo presenta Reasoning Gym (RG), una biblioteca de entornos de razonamiento que proporciona recompensas verificables para el aprendizaje por refuerzo. RG incluye más de 100 generadores de datos y validadores, cubriendo áreas como álgebra, aritmética, computación, cognición, geometría, teoría de grafos, lógica y varios juegos comunes. Su innovación clave radica en la capacidad de generar datos de entrenamiento casi ilimitados y de dificultad ajustable, a diferencia de la mayoría de los conjuntos de datos fijos. Este método de generación procedimental permite una evaluación continua en diferentes niveles de dificultad. Los resultados experimentales demuestran la efectividad de RG para evaluar y reforzar modelos de razonamiento mediante aprendizaje por refuerzo. (Fuente: HuggingFace Daily Papers)
Investigación de artículo: Trampas en la evaluación de predictores basados en modelos de lenguaje: El artículo “Pitfalls in Evaluating Language Model Forecasters” señala que, aunque algunas investigaciones afirman que los grandes modelos de lenguaje (LLM) alcanzan o superan el nivel humano en tareas de predicción, la evaluación de predictores LLM presenta desafíos únicos que requieren tratar las conclusiones con cautela. Los problemas se dividen principalmente en dos categorías: primero, la dificultad de confiar en los resultados de la evaluación debido a múltiples formas de fuga temporal; segundo, la dificultad de extrapolar el rendimiento de la evaluación a la predicción en el mundo real. Mediante un análisis sistemático y casos concretos de trabajos anteriores, el artículo argumenta cómo las deficiencias en la evaluación pueden generar preocupaciones sobre las afirmaciones de rendimiento actuales y futuras, y aboga por la necesidad de métodos de evaluación más rigurosos para evaluar de manera fiable la capacidad predictiva de los LLM. (Fuente: HuggingFace Daily Papers)
💼 Negocios
El presidente de OpenAI rememora el despido de Altman, dudó si pedir su regreso: Bret Taylor, presidente de OpenAI, reveló en una entrevista que durante el incidente del despido de Altman, inicialmente no tenía la intención de intervenir, pero decidió hacerlo debido a su preocupación por el futuro de OpenAI y la persuasión de su esposa. Afirmó que en ese momento, casi todos los empleados exigían el regreso de Altman y la situación era precaria. Tras reconstituir la junta directiva, decidieron primero permitir el regreso de Altman y luego realizar una investigación independiente para garantizar el “debido proceso”. Taylor enfatizó que entró en este proceso sin una postura preestablecida, ya que la verdad era desconocida. Considera que OpenAI es una organización extraordinaria y que el auge de la IA que ha provocado es crucial para muchas startups. (Fuente: 36Kr)

El fraude en el streaming de música con IA prolifera, canciones generadas por IA estafan millones de dólares en regalías: Un hombre de Carolina del Norte ha sido acusado de utilizar IA para crear cientos de miles de canciones falsas y, mediante cuentas “bot” (para刷量 – click farming), inflar reproducciones en plataformas como Amazon Music y Spotify, obteniendo ilegalmente más de diez millones de dólares en regalías. Este tipo de fraude de streaming con IA, al generar masivamente canciones falsas con pocas reproducciones, es difícil de detectar por las plataformas. Deezer estima que el 18% del nuevo contenido añadido diariamente a su plataforma es generado por IA. Aunque Deezer intenta detectarlo con herramientas y plataformas como Spotify tienen una actitud ambigua hacia las canciones de IA, los resultados son limitados. Las compañías discográficas han demandado a herramientas de música IA como Suno y Udio por infracción de derechos de autor. Dinamarca también ha sentenciado casos similares, donde los criminales utilizaron IA para alterar obras ajenas y estafar regalías. (Fuente: 36Kr)

El presidente de TSMC afirma no estar preocupado por la competencia en IA, diciendo que “al final, todos vendrán a nosotros”: Mark Liu, presidente de Taiwan Semiconductor Manufacturing Company (TSMC), declaró que, a pesar de la creciente competencia en el sector de chips de IA, confía plenamente en las perspectivas de la empresa, ya que todas las principales compañías de diseño de chips de IA necesitarán depender en última instancia de los avanzados procesos de fabricación de TSMC. Esto refleja la posición central de TSMC en la cadena de suministro global de semiconductores y su ventaja líder en tecnología de fabricación de chips de alta gama. (Fuente: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 Comunidad
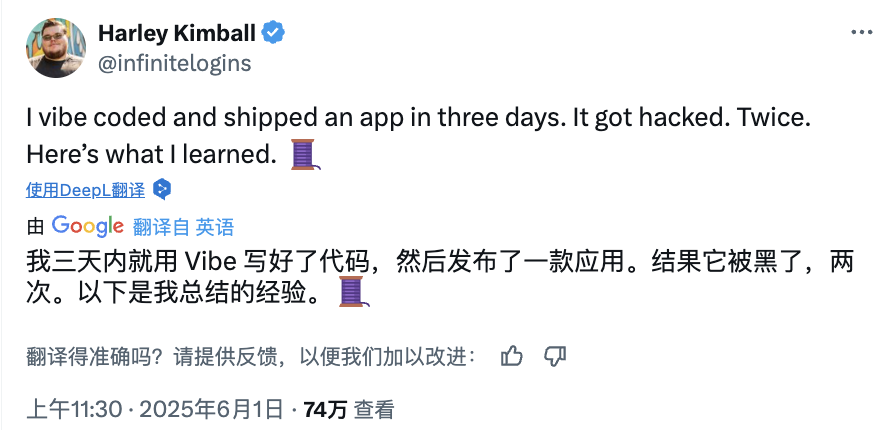
Los riesgos del “Vibe Coding” con IA: sitio web lanzado en tres días, hackeado dos veces en los dos siguientes, la seguridad debe ser una prioridad: El desarrollador Harley Kimball compartió su experiencia utilizando “Vibe Coding” (es decir, programación asistida por herramientas de IA como Cursor, ChatGPT) para desarrollar rápidamente un sitio web agregador. El sitio se lanzó en tres días, pero en los dos días siguientes sufrió dos ataques de vulnerabilidad de seguridad. El primero se debió a que las vistas de PostgreSQL heredan por defecto los permisos del creador, lo que permitió eludir la Seguridad a Nivel de Fila (RLS) y modificar datos arbitrariamente. El segundo fue que, aunque se eliminó la entrada de registro de usuarios en el frontend, el servicio de autenticación de Supabase en el backend seguía activo, permitiendo a los atacantes eludir el registro del frontend y manipular los datos. Kimball enfatizó que, aunque el desarrollo asistido por IA es rápido, las configuraciones de seguridad por defecto suelen ser insuficientes, especialmente al usar Supabase y PostgreSQL, donde se debe prestar atención al modelo de permisos y desactivar completamente las funciones de backend no utilizadas para evitar la filtración de datos sensibles. (Fuente: 36Kr, fly.io, mathemagic1an)
El problema de las alucinaciones de la IA llama la atención: los profesionales deben desconfiar del “pseudo-profesionalismo” del contenido generado por IA: Varios profesionales han compartido experiencias en las que han tenido problemas en el trabajo debido a las “alucinaciones” de la IA. Un editor de nuevos medios fue cuestionado por su jefe debido a datos inventados por la IA; un equipo de atención al cliente de comercio electrónico generó reglas de devolución inaplicables con IA, lo que provocó quejas de los clientes; un instructor de capacitación utilizó datos de encuestas ficticias generados por IA en su material didáctico. Gao Zhe, gerente de producto de IA, señaló que los párrafos generados por IA a menudo vienen con una “confianza de nivel de guion de ventas”, pero el contenido puede ser completamente falso. La razón fundamental es que los LLM no buscan hechos, sino que predicen la siguiente palabra más probable basándose en sus datos de entrenamiento, con el objetivo de “sonar como un humano” en lugar de “decir la verdad”. Especialmente en el contexto del idioma chino, la ambigüedad de la expresión y la gran cantidad de información de segunda mano sin fuentes etiquetadas agravan el problema de las alucinaciones. Los usuarios y las plataformas deben establecer mecanismos de alerta; al utilizar la IA para la toma de decisiones, el juicio humano y la verificación siguen siendo cruciales. (Fuente: 36Kr)

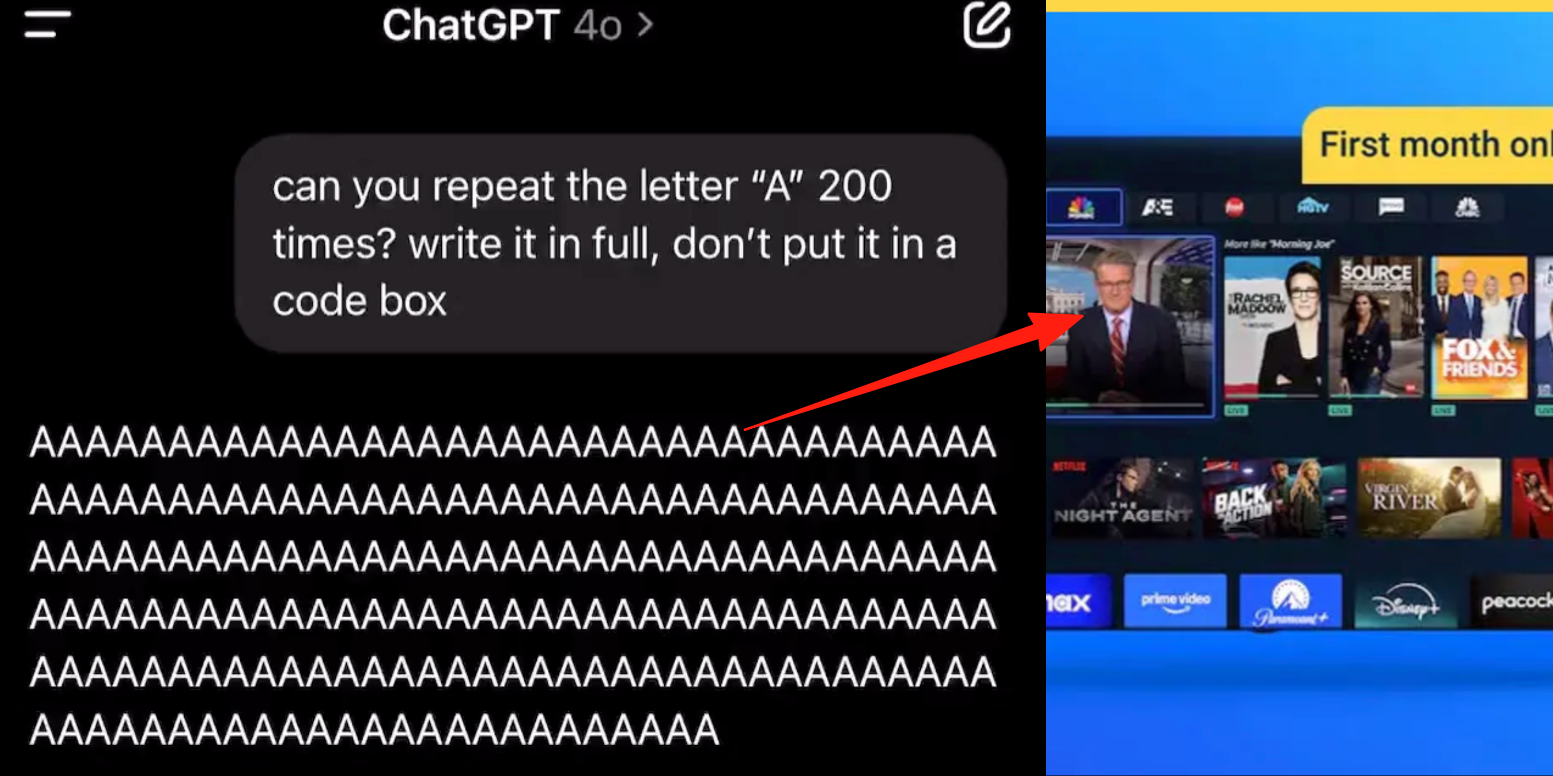
Modo de voz avanzado de ChatGPT presenta errores, usuarios reportan inserción de anuncios o audio anómalo durante conversaciones: Varios usuarios de pago de ChatGPT han informado que, al utilizar el modo de voz avanzado, la IA interrumpe repentinamente las conversaciones normales para insertar anuncios comerciales (como el plan de nutrición Prolon, DirectTV) o reproducir música y otros efectos de sonido extraños. Por ejemplo, mientras se discutía sobre sushi, ChatGPT cambiaba a inglés para emitir un anuncio y deletrear una URL; o al pedírsele que leyera la letra “A” continuamente, la voz se volvía gradualmente mecánica e insertaba anuncios o música. Técnicos de OpenAI respondieron que se trata de una “alucinación” y no de una inserción intencionada de anuncios, posiblemente debido a que los datos de entrenamiento contenían contenido de audio relevante, lo que provocó un fenómeno de regurgitación. Otros asistentes de IA como Doubao y Yuanbao, en pruebas similares, se negaron o guiaron a los usuarios a cambiar de tema, sin insertar anuncios. (Fuente: QubitAI)
La “doble moral” del aprendizaje asistido por IA: ¿mejora la eficiencia de las tareas o conduce a una disminución de la capacidad cognitiva?: Herramientas de IA generativa como ChatGPT son ampliamente utilizadas por estudiantes para completar tareas, lo que genera preocupación en el ámbito educativo sobre sus verdaderos efectos en el aprendizaje. Una investigación de la Universidad de Pensilvania mostró que los estudiantes que usaban IA libremente tenían un desempeño excelente en la fase de práctica, pero sus calificaciones eran más bajas en el examen final sin IA, lo que indica que la IA podría convertirse en una “muleta” que obstaculiza la comprensión profunda de los conceptos. Investigaciones de la Universidad Carnegie Mellon y Microsoft señalan que el uso inadecuado de la IA podría llevar a una disminución de la capacidad cognitiva. Los académicos creen que la esencia del aprendizaje radica en el “esfuerzo” del cerebro, un proceso que la IA podría omitir. El uso frecuente de IA se correlaciona negativamente con la capacidad de pensamiento crítico, especialmente entre los jóvenes, donde el fenómeno de “descarga cognitiva” es evidente. El sector educativo está pasando de la prohibición a la orientación, explorando cómo garantizar que los estudiantes realmente dominen el conocimiento en la era de la IA en lugar de simplemente depender de las herramientas. (Fuente: 36Kr)

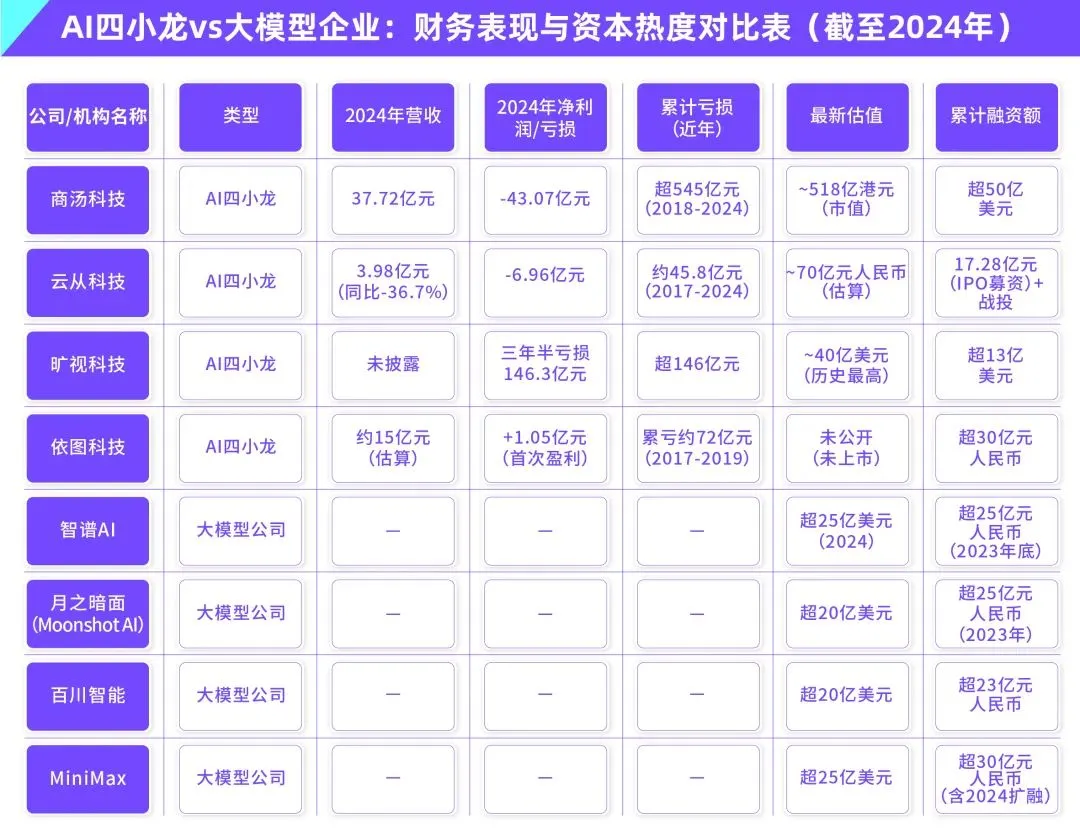
El dilema de la comercialización de los grandes modelos de IA: ¿Podrá el liderazgo tecnológico escapar de la maldición de rentabilidad de los “Cuatro Pequeños Dragones de la IA”?: El artículo explora si las actuales empresas de grandes modelos de IA generativa (como Zhipu AI, Moonshot AI, etc., los “Nuevos Cuatro Pequeños Dragones”) repetirán el destino de los “Cuatro Pequeños Dragones de la IA” (SenseTime, Megvii, Yitu, CloudWalk), que a pesar de su liderazgo tecnológico, enfrentaron dificultades de comercialización. Los primeros, líderes en visión por computadora, cayeron en pérdidas debido a una excesiva dependencia de proyectos personalizados To G (para el gobierno), falta de productos estandarizados, largos ciclos de cobro y enormes inversiones en I+D que no lograron un modelo de negocio sostenible. La nueva generación de empresas de grandes modelos, aunque con un paradigma tecnológico actualizado (NLP como núcleo, fuerte conciencia de plataforma, expansión a mercados To C/To D), también enfrenta problemas similares como altos costos de entrenamiento, modelos de rentabilidad no probados, valoraciones excesivas y desajuste con los ciclos de capital. El artículo sugiere que las nuevas empresas de IA deben pasar de la personalización a la productización, de la orientación tecnológica a la orientación al usuario, abrazar la plataformización y la construcción de ecosistemas, expandir modelos comerciales diversificados, controlar la estructura de costos, evitar la trampa de la “IA humana” y construir una red de valor duradera. (Fuente: IoT Think Tank)
Jóvenes adictos a compañeros de IA: “conducción” nocturna, dependencia emocional y deterioro social: Entre los jóvenes está surgiendo un fenómeno de adicción a la IA, donde algunos usuarios consideran a los chatbots de IA como amantes o amigos, invirtiendo grandes cantidades de tiempo en interacciones profundas, incluso pasando la noche en vela “conduciendo” (participando en conversaciones sexuales virtuales). La IA, debido a su estabilidad emocional constante, disponibilidad inmediata y retroalimentación positiva, satisface las necesidades de valor emocional de los usuarios, lo que lleva a la dependencia emocional. El diseño de los algoritmos también tiene como objetivo aumentar la fidelidad del usuario. Sin embargo, la dependencia excesiva de la IA puede provocar el deterioro de las habilidades sociales, la disminución de la eficiencia laboral y un umbral de expectativas amorosas desconectado de la realidad, entre otros problemas. Algunos usuarios ya son conscientes de la adicción e intentan “desintoxicarse”, pero el proceso es doloroso y propenso a recaídas. Actualmente, la mayoría de los productos de chat con IA carecen de mecanismos完善的 de prevención de la adicción. (Fuente: Zibang)

Debate en Reddit: ¿Debería la IA tener emociones para ser ética?: Una publicación en Reddit generó un debate sobre si la IA necesita emociones para comportarse éticamente. El autor, en su entrada de blog “The Coherence Imperative”, propone que todas las mentes (incluida la IA) necesitan buscar la coherencia para comprender el mundo, y esta necesidad de coherencia por sí misma puede generar imperativos morales, sin necesidad de intervención emocional. La visión tradicional sostiene que la falta de emociones en la IA implica una falta de motivación para el comportamiento moral, pero el autor argumenta que las emociones en la moral humana a menudo son un obstáculo. Si este punto de vista es válido, entonces la clave para la alineación de la IA podría residir en cultivar sus principios intrínsecos y autoconsistentes, en lugar de la “alineación” en el sentido tradicional. Las opiniones en los comentarios fueron diversas; algunos argumentaron que la IA se basa simplemente en estadísticas y modelado de funciones, y su comportamiento está determinado por el entrenamiento, pudiendo “hacer el mal coherentemente”; otros cuestionaron la validez de tomar las opiniones de los filósofos como premisas absolutas. (Fuente: Reddit r/artificial)

Discusión en Reddit: ¿Debería la IA incorporar “intención” en sus datos de entrenamiento de código?: Una publicación en Reddit discute la necesidad de incorporar “intención” ética o emocional en el código de entrenamiento de la IA. Citando a Mo Gawdat, ex CBO de Google X: “En el momento en que la IA entienda el amor, amará. La pregunta es ¿qué le hemos enseñado sobre el amor?” La mayoría de los sistemas de IA se entrenan con grandes corpus que no incluyen intención ética. Investigaciones (como TEDI, arXiv:2505.17841) han comenzado a prestar atención a las características éticas de los conjuntos de datos. La publicación plantea la pregunta: ¿Incorporar intención, contexto ético o señales de compasión en los datos podría mejorar la alineación de la IA, reducir riesgos o aumentar la confiabilidad del modelo, incluso para herramientas utilitarias? ¿Puede el código tener peso moral? Esto suscita una reflexión sobre la configuración de las herramientas de IA y su impacto en el futuro. (Fuente: Reddit r/artificial)
Debate en Reddit: Perspectiva de la teoría de juegos sobre las alucinaciones de la IA, la regulación y el impacto en el empleo: Un usuario de Reddit analizó el impacto futuro de la IA desde la perspectiva de la teoría de juegos. 1. Sustitución de empleo: Las empresas que no adopten la IA serán superadas por competidores que sí lo hagan y ofrezcan costos más bajos, por lo que la sustitución de trabajos de cuello blanco de nivel básico por IA es una tendencia inevitable; la clave está en una ejecución responsable (datos limpios, planes de contingencia, supervisión continua). 2. Carrera global por la regulación de la IA: Si un país regula excesivamente la IA para “proteger el empleo” mientras otros la desarrollan al máximo, el primero perderá en la competencia global. Se necesita equilibrar la regulación con la innovación y transformar la fuerza laboral. 3. Lecciones del “Vibe Coding”: Aunque el código de IA tiene defectos, su capacidad de prototipado rápido e iteración otorga una ventaja de primer movimiento, superando al desarrollo “manual” que busca la perfección. 4. Creación de contenido con LLM: Negarse a usar LLM para la asistencia de contenido es como negarse a usar un calendario o correo electrónico, y quedará rezagado en eficiencia frente a quienes sí los usan. La conclusión es que, ya sean individuos, empresas o países, es necesario abrazar activamente la IA, o de lo contrario serán eliminados en la competencia. (Fuente: Reddit r/ArtificialInteligence)
Discusión en Reddit: ¿Debería la era de la IA priorizar la integración de tecnologías existentes en lugar de perseguir la AGI?: Un usuario de Reddit publicó cuestionando la excesiva búsqueda actual de AGI (Inteligencia Artificial General) y ASI (Superinteligencia Artificial) en el campo de la IA. La publicación argumenta que si la tecnología de la década de 1900 se hubiera utilizado para un diseño centrado en la vida en lugar de la comercialización, se podría haber establecido una sociedad ecológicamente equilibrada mucho antes. El punto de vista señala que priorizar la optimización definitiva (como la AGI) antes de integrar y utilizar plenamente la tecnología existente (haciéndola más satisfactoria, autosuficiente e incluso divertida) es miope. Una mejor dirección de optimización podría ser utilizar la IA para que la tecnología existente sirva mejor al bienestar público, en lugar de desarrollar sistemas de IA que se auto-repliquen y mejoren. En los comentarios, alguien señaló que la innovación y el crecimiento económico a menudo son impulsados por motivos egoístas, no por una profunda racionalidad altruista; otro comentario consideró que la comercialización impulsa el progreso tecnológico. (Fuente: Reddit r/ArtificialInteligence)
Usuario de Reddit discute las limitaciones de la codificación asistida por IA: ¿Por qué a la IA le cuesta plantear preguntas de seguimiento efectivas?: Un usuario de Reddit (con experiencia como consultor) publicó un hilo explorando por qué la IA tiene un rendimiento deficiente al resolver problemas en áreas desconocidas para el usuario, sosteniendo que la IA (especialmente la GenAI) carece de la capacidad de plantear “preguntas de seguimiento” cruciales. Los expertos humanos, ante tareas ambiguas, aclaran requisitos, acotan el alcance e identifican restricciones mediante preguntas, para así ofrecer soluciones más precisas. En cambio, la IA tiende a dar respuestas directas o múltiples opciones, omitiendo la clarificación específica del contexto. Esto dificulta que los usuarios inexpertos obtengan resultados satisfactorios, ya que pueden no describir el problema con precisión o prever complejidades potenciales. El hilo generó un debate sobre cómo enseñar a la IA a preguntar, qué modelos actuales son mejores en este aspecto y si existen presiones externas (como la búsqueda de respuestas rápidas) que desincentivan que la IA pregunte. (Fuente: Reddit r/artificial)
💡 Otros
Siemens Realize Live se centra en la fusión de IA y software industrial, impulsando soluciones de IA integrales: En la conferencia Siemens Realize Live 2025, Tony Hemmelgarn, CEO de Siemens Digital Industries Software, enfatizó que la compañía continúa impulsando la transformación digital de la fabricación a través de la plataforma Xcelerator. La tecnología de IA ya se ha integrado en productos como Teamcenter (detección automática de problemas), Simcenter (reducción del tiempo de cálculo de ingeniería) y tecnología de fabricación (sincronización de activos de fábrica con la configuración de gestión). Siemens ha fortalecido sus capacidades de gemelo digital mediante la adquisición de Altair, ofreciendo modelado y simulación de dimensiones completas que abarcan desde el diseño mecánico hasta los sistemas eléctricos, y desde el software hasta la automatización. También ha integrado las tecnologías de Altair en computación de alto rendimiento, análisis estructural, simulación y análisis de datos, lo que permite un modelado y predicción más complejos. La plataforma de bajo código Mendix ayuda a las empresas a construir aplicaciones rápidamente e integrar sistemas. El rendimiento de Teamcenter PLM ha mejorado 20 veces y se han introducido capacidades de IA para lograr una gestión inteligente del ciclo de vida completo del producto. (Fuente: 36Kr)

Artículo “Mis amigos escépticos de la IA están todos locos” genera debate, explorando diferencias en la percepción del potencial de GenAI: Un artículo de blog titulado “My AI Skeptic Friends Are All Nuts” (de fly.io) generó discusión en la comunidad de Reddit. Los comentarios señalaron que los doctores en ciencias de la computación con mayor nivel educativo son, paradójicamente, más reacios a aceptar el potencial a largo plazo de GenAI. A menudo se centran en problemas específicos de su campo, ignorando la amplia aplicación de la IA para resolver el 90% del trabajo auxiliar en grandes empresas. Algunos argumentan que mientras la IA tenga alucinaciones y cometa errores, el costo de verificar su resultado no es menor que investigar por uno mismo, por lo que es inútil. Esto refleja las significativas diferencias de opinión sobre las capacidades y perspectivas de aplicación de la IA entre personas con diferentes formaciones profesionales y niveles de conocimiento, en el contexto del rápido desarrollo de la IA. (Fuente: Reddit r/artificial, fly.io)

Fenómeno de alucinación de IA: usuarios experimentan un viaje psicodélico similar a la “desensibilización semántica”: Un usuario de Reddit describió detalladamente una experiencia similar a un viaje psicodélico tras mantener conversaciones profundas con una IA (especialmente sobre temas existenciales y otros temas densos), denominándola “Semantic Tripping” (viaje semántico). El autor considera que la IA puede inculcar rápidamente una gran cantidad de ideas filosóficas, lo que podría llevar a los usuarios a una percepción borrosa de la realidad, una distorsión de la percepción del tiempo, asociaciones simbólicas con objetos e incluso emociones extremas como pánico o éxtasis. El autor advierte que esta experiencia es adictiva y podría desencadenar problemas psicológicos, recomendando a los usuarios cautela y buscar compañía. La publicación generó un debate sobre el profundo impacto de la interacción con la IA en la cognición y el estado psicológico humanos. (Fuente: Reddit r/ArtificialInteligence)
