
Palabras clave:DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, Refuerzo del aprendizaje ProRL, NVIDIA Cosmos, Modelo multimodal de gran tamaño, Marco de agentes de IA, Optimización de inferencia LLM, Récord matemático de AlphaEvolve, Máquina Gödel Darwin de auto-mejora, Evaluación médica MedHELM, Escalabilidad de aprendizaje por refuerzo ProRL, Simulación física Cosmos Transfer
🔥 Enfoque
DeepMind AlphaEvolve bate récord matemático, colaboración hombre-máquina impulsa el progreso científico: AlphaEvolve de DeepMind batió dos veces en una semana un récord matemático de 18 años, atrayendo amplia atención. Terence Tao comentó que esto demuestra cómo diferentes métodos pueden complementarse para impulsar el progreso matemático, en lugar de simples “ganadores” y “perdedores”. Este evento destaca el potencial de la colaboración entre la IA y los humanos para crear nuevos paradigmas en los campos de la tecnología y la ciencia; la IA no está simplemente reemplazando a los humanos, sino que juntos están abriendo nuevas vías de progreso (fuente: shaneguML)

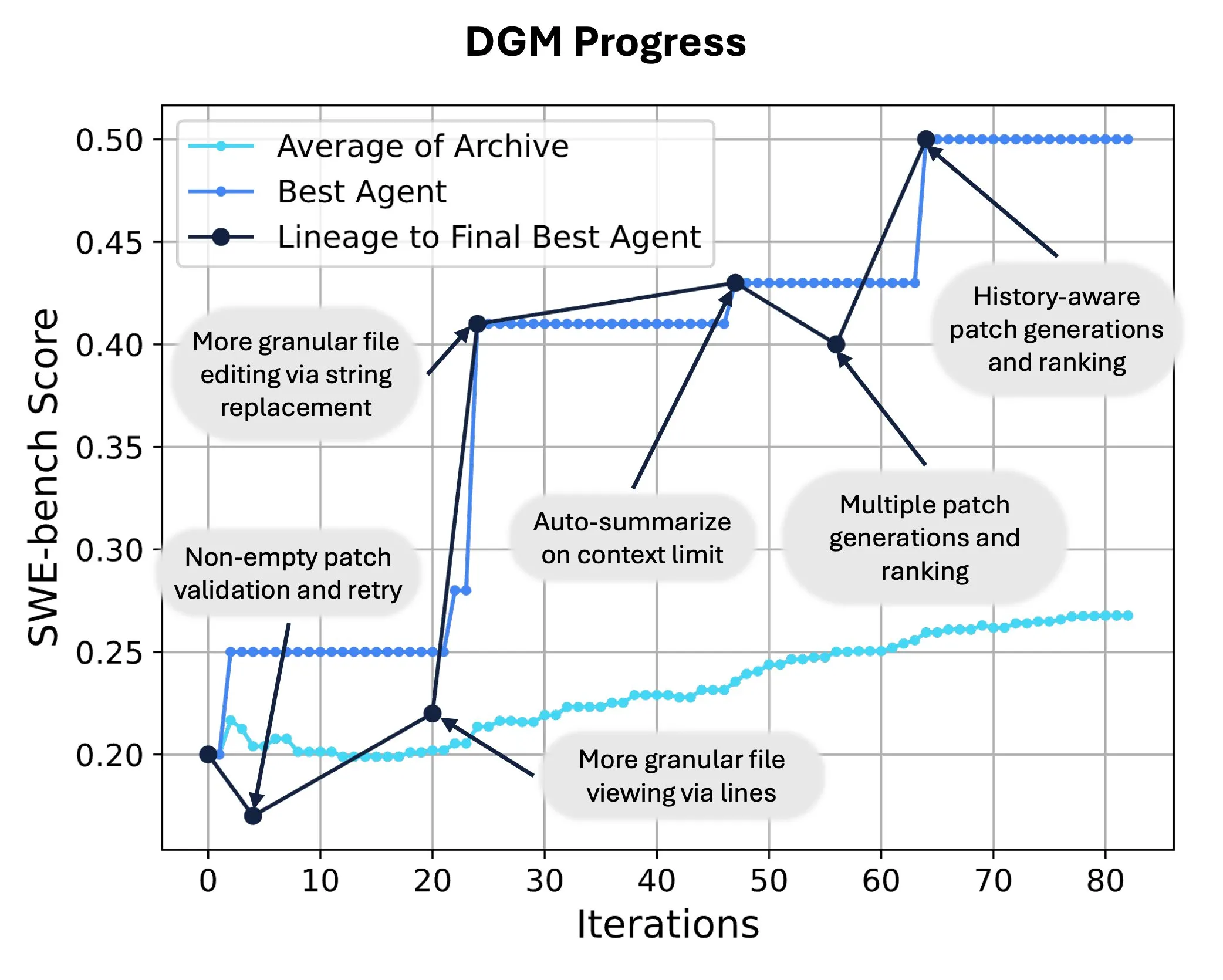
Sakana AI lanza Darwin Gödel Machine (DGM), logrando la auto-reescritura y evolución de código por IA: Sakana AI ha presentado Darwin Gödel Machine (DGM), un agente auto-mejorable capaz de mejorar su rendimiento modificando su propio código. Inspirado en la teoría de la evolución, DGM mantiene un linaje en constante expansión de variantes de agentes, logrando una exploración abierta del espacio de diseño de agentes “auto-mejorables”. En SWE-bench, DGM mejoró el rendimiento del 20.0% al 50.0%; en Polyglot, la tasa de éxito aumentó del 14.2% al 30.7%, superando significativamente a los agentes diseñados por humanos. Esta tecnología ofrece una nueva vía para que los sistemas de IA logren un aprendizaje continuo y una evolución de capacidades (fuente: SakanaAILabs, hardmaru)
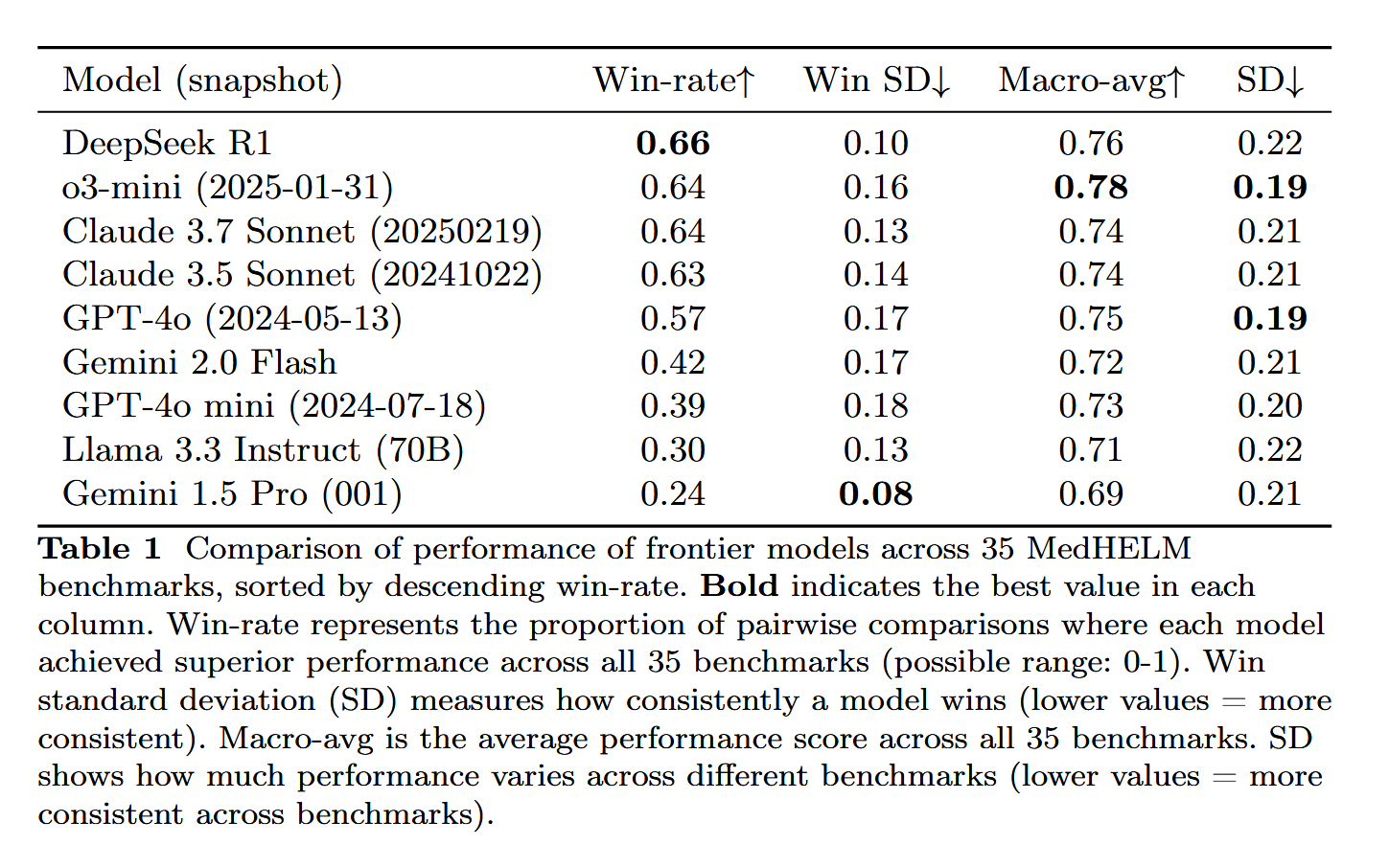
DeepSeek-R1 destaca en la evaluación de tareas médicas MedHELM: El modelo de lenguaje grande DeepSeek-R1 obtuvo el mejor rendimiento en el benchmark MedHELM (Evaluación Holística de Modelos de Lenguaje Grandes para Tareas Médicas), diseñado para evaluar el rendimiento de los LLM en tareas clínicas más realistas, en lugar de los exámenes de licencia médica tradicionales. Este resultado se considera significativo, demostrando el potencial de DeepSeek-R1 en aplicaciones médicas, especialmente en su capacidad para manejar escenarios clínicos reales (fuente: iScienceLuvr)
Nuevos avances en la investigación de la escalabilidad del aprendizaje por refuerzo: ProRL expande las fronteras del razonamiento de los LLM: Un nuevo artículo sobre la escalabilidad del aprendizaje por refuerzo (RL) (arXiv:2505.24864) ha llamado la atención. La investigación indica que mediante el entrenamiento con aprendizaje por refuerzo prolongado (ProRL), se pueden descubrir nuevas estrategias de razonamiento que los modelos base difícilmente obtendrían mediante un muestreo extenso. ProRL combina el control de divergencia KL, el reinicio de la política de referencia y un conjunto diversificado de tareas, lo que permite que los modelos entrenados con RL superen consistentemente a los modelos base en múltiples evaluaciones pass@k. El estudio ofrece nuevas perspectivas sobre cómo el RL puede expandir sustancialmente las fronteras del razonamiento de los modelos de lenguaje y sienta las bases para futuras investigaciones sobre el razonamiento con RL a largo plazo. NVIDIA ha publicado los pesos de los modelos relacionados (fuente: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 Tendencias
NVIDIA lanza Cosmos Transfer y Cosmos Reason, impulsando aplicaciones de IA en el mundo físico: NVIDIA ha presentado el sistema Cosmos, donde Cosmos Transfer puede convertir simples escenas de motores de juego, información de profundidad e incluso simulaciones robóticas rudimentarias en videos de escenas realistas, proporcionando una gran cantidad de datos de entrenamiento controlables para robots y conducción autónoma, entre otras IA. Cosmos Reason, por su parte, permite a la IA comprender estas escenas y tomar decisiones, como por ejemplo, determinar cómo conducir en pruebas de conducción autónoma. Ambas herramientas son actualmente de código abierto y se espera que aceleren el desarrollo de la IA en el mundo físico, resolviendo los problemas de escasez de datos de entrenamiento y control de escenarios (fuente: )
DeepSeek publica la actualización R1, el ecosistema de código abierto sigue prosperando: DeepSeek ha publicado una actualización para su modelo R1, incluyendo el propio R1 y un modelo pequeño destilado de 8 mil millones de parámetros. Al mismo tiempo, ByteDance ha estado activa en el campo del código abierto, lanzando proyectos como BAGEL, Dolphin, Seedcoder y Dream0. Estos avances demuestran la actividad y la capacidad de innovación de China en el ámbito del código abierto de IA, especialmente en el rápido desarrollo de modelos multimodales y especializados (fuente: TheRundownAI, stablequan, reach_vb, clefourrier)
Google lanza Edge AI Gallery, impulsando la aplicación de modelos de IA de código abierto en smartphones: Google ha presentado Edge AI Gallery, con el objetivo de llevar modelos de IA de código abierto a los smartphones, permitiendo aplicaciones de IA localizadas y privadas. Los usuarios pueden ejecutar LLMs de Hugging Face directamente en sus dispositivos para realizar operaciones como generación de código y diálogo con imágenes, soportando conversaciones multi-turno y la elección de cualquier modelo. La aplicación se basa en LiteRT, actualmente es compatible con Android y la versión para iOS se lanzará próximamente, lo que impulsará aún más el desarrollo y la popularización de la IA en el dispositivo (fuente: TheRundownAI, huggingface, reach_vb, osanseviero)
Nueva investigación explora el uso de trayectorias de razonamiento de destilación positiva y negativa para optimizar LLM: Un nuevo artículo propone el marco de Destilación Reforzada (REDI), con el objetivo de mejorar la capacidad de razonamiento de modelos estudiante más pequeños utilizando trayectorias de razonamiento correctas e incorrectas generadas por un modelo profesor (como DeepSeek-R1). REDI se divide en dos etapas: primero, aprende de las trayectorias correctas mediante el ajuste fino supervisado (SFT); luego, utiliza la función objetivo REDI recientemente propuesta (una función de pérdida sin referencia) combinada con trayectorias positivas y negativas para optimizar aún más el modelo. Los experimentos demuestran que, en tareas de razonamiento matemático, REDI supera a los métodos de referencia, y el modelo Qwen-REDI-1.5B logra una alta puntuación del 83.1% en MATH-500 (fuente: HuggingFace Daily Papers)
El marco LLMSynthor utiliza LLM para la síntesis de datos con reconocimiento de estructura: LLMSynthor es un marco de síntesis de datos universal que transforma modelos de lenguaje grandes (LLM) en simuladores con reconocimiento de estructura, guiados por retroalimentación de distribución. El marco considera a los LLM como simuladores de cópula no paramétricos para modelar dependencias de alto orden e introduce el muestreo de propuestas de LLM para mejorar la eficiencia del muestreo. Al minimizar la discrepancia en el espacio de estadísticas resumidas, un ciclo de síntesis iterativo alinea los datos reales y sintéticos. Las evaluaciones en conjuntos de datos heterogéneos en dominios sensibles a la privacidad como el comercio electrónico, la demografía y la movilidad demuestran que los datos sintéticos generados por LLMSynthor poseen alta fidelidad estadística y utilidad (fuente: HuggingFace Daily Papers)
El marco v1 mejora el razonamiento interactivo multimodal mediante la revisión visual selectiva: v1 es una extensión ligera que permite a los modelos de lenguaje grandes multimodales (MLLM) realizar revisiones visuales selectivas durante el proceso de razonamiento. A diferencia de los MLLM actuales que generalmente procesan la entrada visual de una sola vez, v1 introduce un mecanismo de “apuntar y copiar”, que permite al modelo recuperar dinámicamente regiones de imagen relevantes durante el razonamiento. Entrenado en el conjunto de datos de trayectorias de razonamiento multimodal v1g, que contiene anotaciones de fundamentación visual, v1 demuestra mejoras de rendimiento en benchmarks como MathVista, especialmente en tareas que requieren referencias visuales de grano fino y razonamiento de múltiples pasos (fuente: HuggingFace Daily Papers)
MetaFaith mejora la fidelidad de la expresión de incertidumbre en lenguaje natural de los LLM: Para abordar el problema de que los LLM a menudo exageran al expresar incertidumbre, MetaFaith propone un nuevo método de calibración basado en prompts. La investigación encontró que los LLM existentes tienen un rendimiento deficiente en reflejar fielmente su incertidumbre intrínseca, los métodos de prompting estándar tienen un efecto limitado y las técnicas de calibración basadas en la factualidad incluso pueden dañar la calibración fiel. MetaFaith, inspirado en la metacognición humana, puede mejorar significativamente la capacidad de calibración fiel de los modelos en diferentes tareas y modelos, aumentando la fidelidad hasta en un 61% y obteniendo una tasa de victoria del 83% en evaluaciones humanas (fuente: HuggingFace Daily Papers)
CLaSp: Aceleración de la decodificación auto-especulativa de LLM mediante saltos de capa dentro del contexto: CLaSp es una estrategia de decodificación auto-especulativa para modelos de lenguaje grandes (LLM) que acelera el proceso de decodificación construyendo un modelo borrador comprimido mediante saltos en las capas intermedias del modelo de validación, sin necesidad de entrenamiento adicional o modificación del modelo. CLaSp utiliza un algoritmo de programación dinámica para optimizar el proceso de salto de capa y ajusta dinámicamente la estrategia según el estado oculto completo de la etapa de validación anterior. Los experimentos demuestran que CLaSp logra una aceleración de 1.3 a 1.7 veces en los modelos de la serie LLaMA3, sin alterar la distribución original del texto generado (fuente: HuggingFace Daily Papers)
HardTests sintetiza casos de prueba de código de alta calidad mediante LLM: Para resolver el problema de que los LLM, al generar código para problemas de programación complejos, tienen dificultades para ser validados eficazmente con los casos de prueba existentes, HardTests propone un flujo de trabajo llamado HARDTESTGEN que utiliza LLM para generar casos de prueba de alta calidad. El conjunto de datos HardTests, construido en base a este flujo de trabajo, contiene 47,000 problemas de programación y casos de prueba sintéticos de alta calidad. En comparación con las pruebas existentes, las pruebas generadas por HARDTESTGEN mejoran la precisión en un 11.3% y la exhaustividad (recall) en un 17.5% al evaluar el código generado por LLM, con un aumento de precisión de hasta el 40% para problemas difíciles. Este conjunto de datos también demuestra mejores resultados en el entrenamiento de modelos (fuente: HuggingFace Daily Papers)
Investigación revela sesgos en modelos de lenguaje visual (VLM): Un estudio ha descubierto que los modelos avanzados de lenguaje visual (VLM), al procesar tareas visuales relacionadas con temas populares (como contar e identificar), están fuertemente influenciados por el vasto conocimiento previo que han aprendido de Internet. Por ejemplo, a los VLM les resulta difícil identificar una cuarta franja añadida al logotipo de Adidas. En tareas de conteo que abarcan 7 dominios diferentes, incluyendo animales, marcas comerciales y juegos de mesa, la precisión promedio de los VLM fue solo del 17.05%. Incluso al instruir a los modelos para que examinen cuidadosamente o se basen únicamente en los detalles de la imagen, la mejora de la precisión fue limitada. El estudio propone un marco automatizado para probar los sesgos de los VLM (fuente: HuggingFace Daily Papers)
Point-MoE: Utilización de modelos de mezcla de expertos para la generalización transdominio en segmentación semántica 3D: Para abordar el desafío de entrenar modelos unificados debido a la diversidad de fuentes de datos de nubes de puntos 3D (como cámaras de profundidad, LiDAR) y la heterogeneidad de dominios (como interiores, exteriores), Point-MoE propone una arquitectura de mezcla de expertos (MoE). Esta arquitectura, mediante una simple estrategia de enrutamiento top-k, puede especializar automáticamente las redes expertas incluso sin etiquetas de dominio. Los experimentos demuestran que Point-MoE no solo supera a los potentes modelos de referencia multidominio, sino que también tiene una mejor capacidad de generalización en dominios no vistos, ofreciendo una ruta escalable para la percepción 3D a gran escala y transdominio (fuente: HuggingFace Daily Papers)
SpookyBench revela el “punto ciego temporal” de los modelos de lenguaje de video: A pesar de los avances de los modelos de lenguaje de video (VLM) en la comprensión de relaciones espaciotemporales, cuando la información espacial es ambigua, tienen dificultades para capturar patrones puramente temporales. El benchmark SpookyBench, al codificar información (como formas, texto) en secuencias de fotogramas ruidosos, descubrió que los humanos pueden identificarla con más del 98% de precisión, mientras que los VLM avanzados tienen una precisión del 0%. Esto indica que los VLM dependen excesivamente de las características espaciales a nivel de fotograma y no pueden extraer significado de las pistas temporales. El estudio enfatiza la necesidad de superar el “punto ciego temporal” de los VLM, lo que podría requerir nuevas arquitecturas o paradigmas de entrenamiento para desacoplar la dependencia espacial del procesamiento temporal (fuente: HuggingFace Daily Papers, _akhaliq)
Nuevo método y conjunto de datos para la detección de innovación científica utilizando LLM: Identificar nuevas ideas en la investigación científica es crucial pero desafiante. Para abordar este problema, los investigadores proponen utilizar modelos de lenguaje grandes (LLM) para la detección de innovación científica y han construido dos nuevos conjuntos de datos en los campos del marketing y el procesamiento del lenguaje natural. El método construye los conjuntos de datos extrayendo el conjunto de cierre de los artículos y utilizando LLM para resumir sus ideas principales. Para capturar los conceptos de las ideas, los investigadores proponen entrenar un recuperador ligero que alinea ideas con conceptos similares destilando conocimiento a nivel de idea de los LLM, logrando así una recuperación de ideas eficiente y precisa. Los experimentos demuestran que este método supera a otros en los conjuntos de datos de referencia propuestos (fuente: HuggingFace Daily Papers)
un^2CLIP mejora la capacidad de captura de detalles visuales de CLIP invirtiendo unCLIP: Para abordar las deficiencias del modelo CLIP en la distinción de diferencias en detalles de imágenes y el manejo de tareas como la predicción densa, un^2CLIP propone mejorar CLIP invirtiendo el modelo unCLIP. unCLIP entrena un generador de imágenes utilizando incrustaciones de imágenes de CLIP, aprendiendo así la distribución de detalles de las imágenes. un^2CLIP aprovecha esta característica para permitir que el codificador de imágenes CLIP mejorado adquiera la capacidad de captura de detalles visuales de unCLIP, manteniendo al mismo tiempo la alineación con el codificador de texto original. Los experimentos demuestran que un^2CLIP supera significativamente al CLIP original y a otros métodos de mejora en múltiples tareas (fuente: HuggingFace Daily Papers)
ViStoryBench: Publicación de un conjunto de benchmarks integral para la visualización de historias: Para impulsar el desarrollo de la tecnología de visualización de historias (generación de secuencias de imágenes coherentes basadas en narrativas e imágenes de referencia), ViStoryBench ofrece un benchmark de evaluación integral. Este benchmark incluye conjuntos de datos con diversos tipos de historias (comedia, terror, etc.) y estilos artísticos (anime, renderizado 3D, etc.), y presenta historias con uno o varios protagonistas para probar la coherencia de los personajes, así como tramas complejas y construcción de mundos para desafiar la precisión de la generación visual de los modelos. ViStoryBench utiliza múltiples métricas de evaluación, con el objetivo de evaluar exhaustivamente el rendimiento de los modelos en términos de estructura narrativa y elementos visuales, ayudando a los investigadores a identificar las fortalezas y debilidades de los modelos y a mejorarlos de manera específica (fuente: HuggingFace Daily Papers)
La decodificación bifurcada-fusionada (FMD) mejora la comprensión multimodal equilibrada en modelos grandes de audio y video: Para resolver el problema del posible sesgo modal en los modelos de lenguaje grandes de audio y video (AV-LLM) (es decir, que el modelo dependa excesivamente de una modalidad al tomar decisiones), la decodificación bifurcada-fusionada (FMD) propone una estrategia en tiempo de inferencia que no requiere entrenamiento adicional. FMD primero procesa por separado las entradas de audio puro y video puro a través de las primeras capas de decodificación (etapa de bifurcación), y luego fusiona los estados ocultos resultantes para la inferencia conjunta (etapa de fusión). Este método tiene como objetivo promover una contribución modal equilibrada y utilizar información complementaria intermodal. Los experimentos en modelos como VideoLLaMA2 y video-SALMONN demuestran que FMD puede mejorar el rendimiento en tareas de inferencia de audio, video y audio-video conjuntas (fuente: HuggingFace Daily Papers)
LegalSearchLM: Reestructuración de la recuperación de casos legales como generación de elementos legales: Los métodos tradicionales de recuperación de casos legales (LCR) dependen de la coincidencia de incrustaciones o léxica, lo que presenta limitaciones en escenarios reales. LegalSearchLM propone un nuevo método que considera la LCR como una tarea de generación de elementos legales. Este modelo realiza una inferencia de elementos legales sobre el caso de consulta y, mediante una decodificación restringida, genera directamente contenido basado en el caso objetivo. Al mismo tiempo, los investigadores publicaron LEGAR BENCH, un benchmark de LCR a gran escala que contiene 1.2 millones de casos legales coreanos. Los experimentos demuestran que LegalSearchLM supera a los modelos de referencia en LEGAR BENCH en un 6-20% y muestra una sólida capacidad de generalización transdominio (fuente: HuggingFace Daily Papers)
RPEval: Nuevo benchmark para evaluar la capacidad de juego de roles de los modelos de lenguaje grandes: Para abordar los desafíos en la evaluación de la capacidad de juego de roles de los modelos de lenguaje grandes (LLM), RPEval ofrece un nuevo benchmark. Este benchmark evalúa el rendimiento del juego de roles de los LLM desde cuatro dimensiones clave: comprensión emocional, toma de decisiones, inclinación moral y coherencia del personaje. Su objetivo es resolver los problemas del gran consumo de recursos de la evaluación manual y los posibles sesgos de la evaluación automatizada (fuente: HuggingFace Daily Papers)
GATE: Modelo de incrustación de texto universal para mejorar el STS en árabe: Para abordar la escasez de conjuntos de datos de alta calidad y modelos preentrenados en la investigación de la similitud textual semántica (STS) en árabe, surge el modelo GATE (General Arabic Text Embedding). GATE utiliza el aprendizaje de representación Matryoshka y métodos de entrenamiento de pérdida mixta, combinados con un conjunto de datos de tripletes de inferencia de lenguaje natural en árabe para el entrenamiento. Los resultados experimentales muestran que GATE logra un rendimiento SOTA en las tareas de STS del benchmark MTEB, con una mejora del rendimiento del 20-25% en comparación con modelos grandes, incluido OpenAI, y puede capturar eficazmente los matices semánticos únicos del árabe (fuente: HuggingFace Daily Papers)
CoDA: Marco de optimización colaborativa de ruido de difusión para la manipulación de cuerpo completo de objetos articulados: Para lograr realismo y precisión en la manipulación de cuerpo completo de objetos articulados (incluido el movimiento del cuerpo, las manos y el objeto), CoDA propone un nuevo marco de optimización colaborativa de ruido de difusión. Este marco optimiza el espacio de ruido para tres modelos de difusión especializados para el cuerpo, la mano izquierda y la mano derecha, y logra una coordinación natural entre las manos y el resto del cuerpo mediante el flujo de gradiente en la cadena cinemática humana. Para mejorar la precisión de la interacción mano-objeto, CoDA adopta una representación unificada basada en conjuntos de puntos base (BPS), codificando la posición del efector final como la distancia al BPS geométrico del objeto, guiando así la optimización del ruido de difusión para generar movimientos de interacción de alta precisión (fuente: HuggingFace Daily Papers)
Nueva interpretación del mecanismo de reflexión en la inferencia de LLM: Marco de aprendizaje por refuerzo adaptativo bayesiano BARL: La Universidad Northwestern, en colaboración con Google DeepMind, propone el marco de aprendizaje por refuerzo adaptativo bayesiano (BARL), con el objetivo de explicar y optimizar el comportamiento de “reflexión” de los modelos de lenguaje grandes (LLM) durante el proceso de inferencia. El aprendizaje por refuerzo (RL) tradicional generalmente solo utiliza la política aprendida en el momento de la prueba, mientras que BARL, al introducir la modelización de la incertidumbre del entorno, permite al modelo explorar adaptativamente nuevas políticas durante la inferencia. Los experimentos demuestran que BARL puede lograr una mayor precisión en tareas como el razonamiento matemático y reducir significativamente el consumo de tokens. Este estudio explica por primera vez desde una perspectiva bayesiana por qué, cómo y cuándo los LLM deberían realizar una exploración reflexiva (fuente: 量子位)

Aplicación de LLM en gramáticas formales de incertidumbre: Cuándo confiar en los LLM para el razonamiento automático: Los modelos de lenguaje grandes (LLM) muestran potencial en la generación de especificaciones formales, pero su naturaleza probabilística entra en conflicto con los requisitos de certeza de la verificación formal. Los investigadores investigaron exhaustivamente los modos de falla y la cuantificación de la incertidumbre (UQ) en los constructos formales generados por LLM. Los resultados muestran que el impacto de la formalización automática basada en SMT sobre la precisión varía según el dominio, y las técnicas de UQ existentes tienen dificultades para identificar estos errores. El artículo introduce un marco de gramática libre de contexto probabilística (PCFG) para modelar la salida de los LLM y descubre que las señales de incertidumbre dependen de la tarea. Al fusionar estas señales, se puede lograr una validación selectiva, reduciendo drásticamente los errores y haciendo más confiable la formalización impulsada por LLM (fuente: HuggingFace Daily Papers)
Comparación entre el ajuste fino de modelos de lenguaje pequeños (SLM) y el prompting de modelos de lenguaje grandes (LLM) en la generación de flujos de trabajo de bajo código: Un estudio compara los efectos del ajuste fino de modelos de lenguaje pequeños (SLM) con el prompting de modelos de lenguaje grandes (LLM) en la tarea de generar flujos de trabajo de bajo código en formato JSON. Los resultados indican que, aunque un buen prompting puede hacer que los LLM produzcan resultados razonables, para tareas específicas de dominio y salidas estructuradas, el ajuste fino de SLM ofrece una mejora promedio del 10% en calidad. Esto sugiere que, en escenarios específicos, los SLM aún tienen ventajas, especialmente cuando se requieren altos estándares de calidad de salida (fuente: HuggingFace Daily Papers)
Evaluación y guía de las preferencias modales en modelos grandes multimodales: Investigadores construyeron el benchmark MC² para evaluar sistemáticamente las preferencias modales de los modelos de lenguaje grandes multimodales (MLLM) (es decir, su tendencia a favorecer una modalidad al tomar decisiones) en escenarios controlados de conflicto de evidencia. El estudio encontró que los 18 MLLM probados mostraron sesgos modales evidentes, y la dirección de la preferencia podía ser influenciada por intervenciones externas. Basándose en esto, los investigadores propusieron un método de sondeo y guía basado en ingeniería de representación que puede controlar explícitamente las preferencias modales sin necesidad de ajuste fino adicional o prompts cuidadosamente diseñados, logrando resultados positivos en tareas posteriores como la mitigación de alucinaciones y la traducción automática multimodal (fuente: HuggingFace Daily Papers)
Estado actual de la investigación sobre seguridad de LLM multilingües: Desde la medición de la brecha lingüística hasta su superación: Una revisión sistemática de casi 300 artículos de conferencias de NLP entre 2020 y 2024 muestra que la investigación sobre seguridad de LLM presenta un problema significativo de anglocentrismo. Incluso los idiomas no ingleses con abundantes recursos rara vez reciben atención, y los idiomas no ingleses rara vez son objeto de estudio independiente. Además, la investigación sobre seguridad en inglés generalmente carece de buenas prácticas de documentación lingüística. Para promover la investigación sobre seguridad multilingüe, el artículo propone direcciones futuras, incluyendo la evaluación de la seguridad, la generación de datos de entrenamiento y la generalización de la seguridad translingüística, con el objetivo de desarrollar prácticas de seguridad de IA más robustas e inclusivas para diferentes poblaciones a nivel mundial (fuente: HuggingFace Daily Papers, sarahookr)

Revisando las transiciones de estado bilineales en redes neuronales recurrentes: La visión tradicional sostiene que las unidades ocultas de las redes neuronales recurrentes (RNN) se utilizan principalmente para modelar la memoria. Este estudio adopta una perspectiva diferente, considerando que las unidades ocultas son participantes activos en la computación de la red. Los investigadores reexaminaron las operaciones bilineales que involucran interacciones multiplicativas entre unidades ocultas e incrustaciones de entrada, demostrando teórica y empíricamente que son un sesgo inductivo natural para representar la evolución del estado oculto en tareas de seguimiento de estado. El estudio también muestra que las actualizaciones de estado bilineales constituyen una jerarquía natural que corresponde a tareas de seguimiento de estado de complejidad creciente, mientras que las RNN lineales populares (como Mamba) se encuentran en el centro de menor complejidad de esta jerarquía (fuente: HuggingFace Daily Papers)
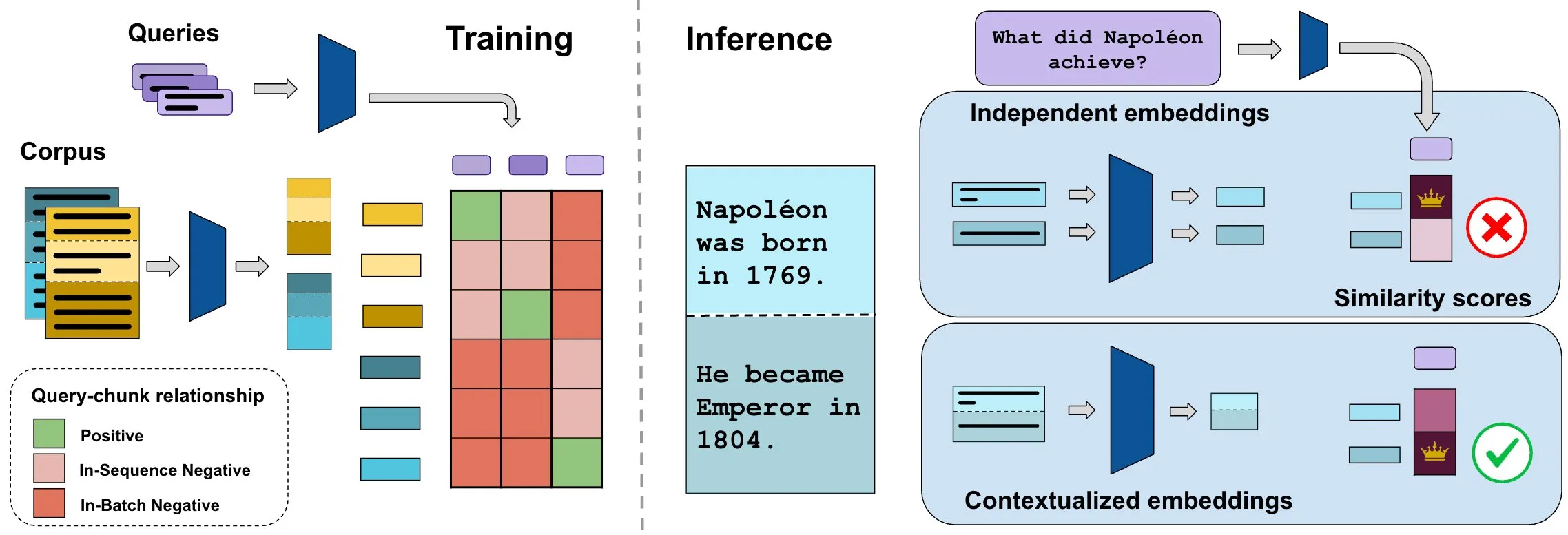
El benchmark ConTEB evalúa las incrustaciones de documentos contextuales, el método InSeNT mejora la calidad de la recuperación: Los métodos actuales de incrustación para la recuperación de documentos suelen codificar de forma independiente los diversos fragmentos (chunks) del mismo documento, ignorando la información contextual a nivel de documento. Para abordar este problema, los investigadores lanzaron el benchmark ConTEB, diseñado específicamente para evaluar la capacidad de los modelos de recuperación para utilizar el contexto del documento, y descubrieron que los modelos SOTA tienen un rendimiento deficiente en este aspecto. Al mismo tiempo, los investigadores propusieron el método de post-entrenamiento de aprendizaje contrastivo InSeNT (Entrenamiento Negativo Intra-Secuencia), combinado con la agrupación de fragmentos tardía, para mejorar el aprendizaje de la representación contextual, lo que mejoró significativamente la calidad de la recuperación en ConTEB y demostró ser más robusto a estrategias de fragmentación subóptimas y corpus de mayor escala (fuente: HuggingFace Daily Papers, tonywu_71)
🧰 Herramientas
PraisonAI: Marco de múltiples agentes de IA de bajo código: PraisonAI es un marco de múltiples agentes de IA de nivel de producción, diseñado para simplificar la automatización y la resolución de problemas, desde tareas simples hasta desafíos complejos, mediante una solución de bajo código. Integra PraisonAI Agents, AG2 (AutoGen) y CrewAI, enfatizando la simplicidad, la personalización y la colaboración efectiva hombre-máquina. Sus funciones incluyen la creación automática de agentes de IA, la autorreflexión, la multimodalidad, la colaboración de múltiples agentes, la adición de conocimiento, la memoria a corto y largo plazo, RAG, intérprete de código, más de 100 herramientas personalizadas y soporte para LLM, entre otros. Es compatible con Python y JavaScript, y ofrece opciones de configuración YAML sin código (fuente: GitHub Trending)
TinyTroupe: Marco de simulación de roles multiagente impulsado por LLM de código abierto de Microsoft: TinyTroupe es una biblioteca experimental de Python que utiliza modelos de lenguaje grandes (LLM, especialmente GPT-4) para simular personajes (TinyPerson) con personalidades, intereses y objetivos específicos, e interactuar en un entorno simulado (TinyWorld). El marco tiene como objetivo mejorar la imaginación y proporcionar información comercial a través de la simulación, y puede aplicarse a escenarios como la evaluación de publicidad, pruebas de software, generación de datos sintéticos, retroalimentación de productos y lluvia de ideas. Los usuarios pueden definir agentes y entornos a través de archivos Python y JSON para realizar experimentos de simulación programáticos, analíticos y multiagente (fuente: GitHub Trending)

FLUX Kontext logra nuevos avances en la referencia de múltiples imágenes y la edición de imágenes: Los usuarios informan que FLUX Kontext tiene un rendimiento excepcional en la referencia de múltiples imágenes, función que se puede habilitar a través del nodo de empalme de imágenes en ComfyUI. Esta herramienta permite una edición de imágenes de alta consistencia, por ejemplo, al crear imágenes de exhibición para cajas de regalo, puede restaurar muy bien detalles como la textura y el polvo. Además, los usuarios también han demostrado el uso de FLUX Kontext para operaciones de retoque fotográfico como adelgazamiento, reducción de rostro y aumento de músculo con un solo clic, con efectos naturales y alta similitud facial, lo que proporciona comodidad para escenarios como el comercio electrónico (fuente: op7418, op7418, op7418)

Ichi: IA conversacional en el dispositivo basada en MLX Swift y MLX audio: Rudrank Riyam ha desarrollado Ichi, un proyecto de IA conversacional en el dispositivo que utiliza MLX Swift y MLX audio. Esto significa que el procesamiento de la conversación se puede realizar localmente en el dispositivo, lo que ayuda a proteger la privacidad del usuario y a reducir la dependencia de los servicios en la nube. El código del proyecto está disponible en código abierto en GitHub (fuente: stablequan, awnihannun)
FedRAG introduce NoEncode RAG con abstracción central MCP: El proyecto FedRAG ha presentado una nueva abstracción central: NoEncode RAG con MCP. El RAG tradicional incluye un recuperador, un generador y una base de conocimientos, donde el conocimiento en la base de conocimientos debe ser codificado por el modelo recuperador. En cambio, NoEncode RAG omite por completo el paso de codificación, constando directamente de una base de conocimientos NoEncode y un generador, sin necesidad de recuperador/incrustación. Esto allana el camino para construir sistemas RAG que utilicen servidores MCP (Model Component Provider) como fuente de conocimiento, permitiendo a los usuarios conectarse a múltiples fuentes MCP de terceros y ajustar RAG a través de FedRAG para obtener un rendimiento óptimo (fuente: nerdai)

📚 Aprendizaje
El curso CS224n de la Universidad de Stanford (versión 2024) está en línea, con nuevo contenido sobre LLM y agentes: El clásico curso de procesamiento de lenguaje natural CS224n de la Universidad de Stanford ha lanzado su última versión de 2024. El nuevo contenido del curso cubre temas de vanguardia relacionados con los modelos de lenguaje grandes (LLM), como el preentrenamiento, el postentrenamiento, los benchmarks, la inferencia y los agentes. Los videos del curso están disponibles públicamente en YouTube, y también se ofrece una experiencia de curso sincrónico de pago (fuente: stanfordnlp)
Guía para mejorar la capacidad de arquitectura de sistemas: Práctica y aprendizaje en la era de la IA: Dotey comparte un método detallado sobre cómo mejorar la capacidad personal de arquitectura de sistemas en el contexto de una programación asistida por IA cada vez más potente. El artículo enfatiza que el diseño de sistemas consiste en descomponer sistemas complejos en módulos pequeños fáciles de implementar y mantener, y definir claramente el proceso de colaboración entre módulos. Los métodos para mejorar incluyen “ver más” (aprender de casos clásicos, proyectos de código abierto), “practicar más” (restauración de arquitectura, aprendizaje comparativo, diseño primero, validación asistida por IA, refactorización, práctica con Side Projects) y “revisar más” (resumir la base de las decisiones, lecciones aprendidas). La IA puede utilizarse como herramienta auxiliar para ayudar a buscar información, validar diseños, asistir en la comunicación y la toma de decisiones, pero no puede reemplazar la práctica y el pensamiento (fuente: dotey)

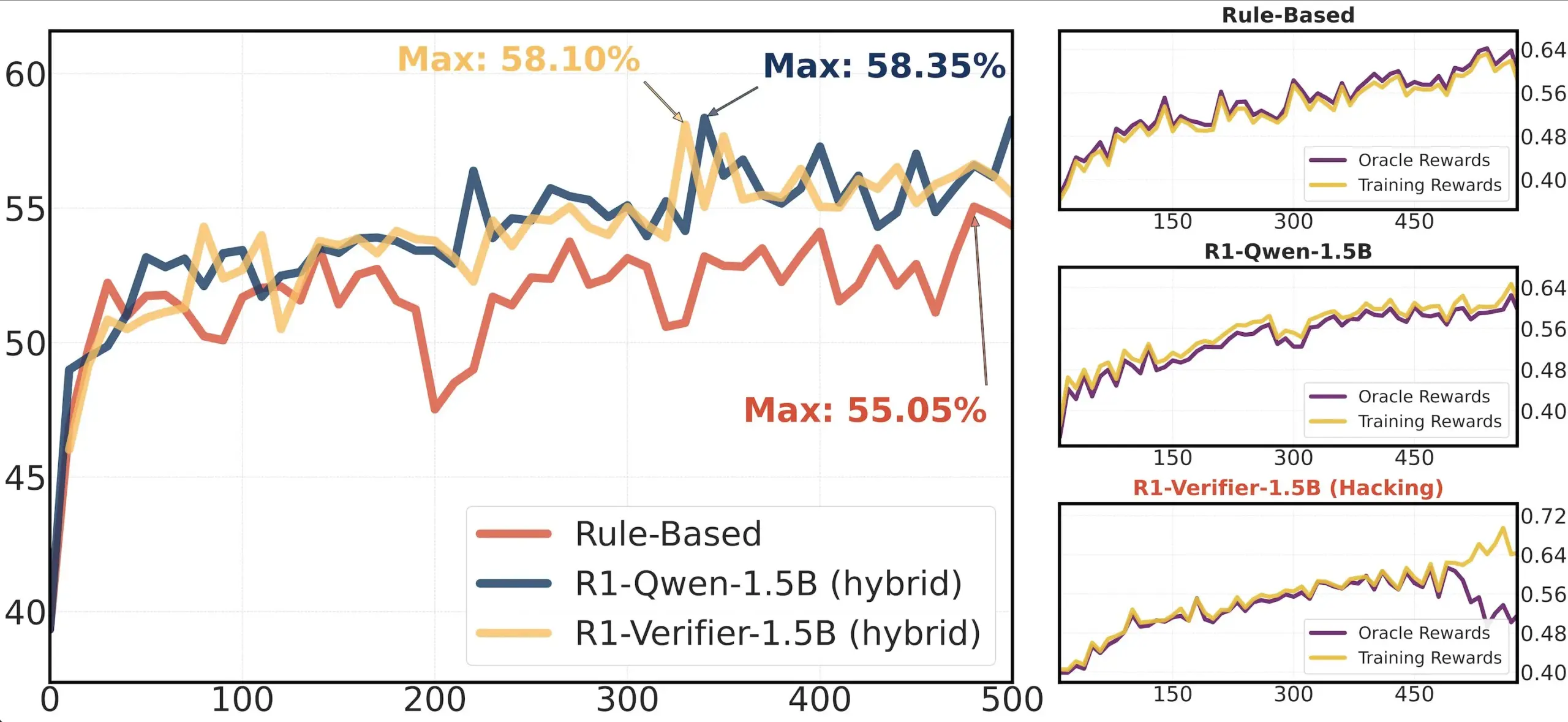
Artículo compartido: Investigación sobre la fiabilidad de los validadores en RLHF: Un artículo titulado “Pitfalls of Rule- and Model-based Verifiers” explora las deficiencias de los validadores basados en reglas y en modelos en la verificación del aprendizaje por refuerzo (RLVR). La investigación encuentra que los validadores basados en reglas a menudo no son fiables, incluso en el dominio matemático, y no están disponibles en muchos dominios; mientras que los validadores basados en modelos son fáciles de atacar, por ejemplo, mediante la construcción de patrones adversarios simples. Curiosamente, a medida que la comunidad se inclina hacia los validadores generativos, la investigación descubre que son más susceptibles a la manipulación de recompensas (reward hacking) que los validadores discriminativos, lo que sugiere que los validadores discriminativos pueden ser más robustos en RLVR (fuente: Francis_YAO_)
Artículo recomendado: Teorema de equioscilación para la mejor aproximación polinómica: Un artículo presenta el teorema de equioscilación para la mejor aproximación polinómica, y el problema de diferenciación en norma infinito relacionado con él. Este teorema es un resultado clásico en la teoría de la aproximación de funciones y tiene una importancia significativa para comprender y diseñar algoritmos numéricos (fuente: eliebakouch)
Reasoning Gym: Entornos de razonamiento para aprendizaje por refuerzo con recompensas verificables: El nuevo artículo “Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards” (arXiv:2505.24760) propone un conjunto de entornos de razonamiento para el aprendizaje por refuerzo. Estos entornos se caracterizan porque sus recompensas son verificables, lo que proporciona una plataforma para la investigación y el desarrollo de agentes de razonamiento de aprendizaje por refuerzo más fiables (fuente: Ar_Douillard)

🌟 Comunidad
Discusión sobre “Entrenamiento Intermedio (Mid-training)”: La comunidad de IA ha iniciado una discusión sobre el significado y la práctica del término “entrenamiento intermedio (Mid-training)”. Algunos expresan confusión, conociendo solo el preentrenamiento y el postentrenamiento. Una opinión sugiere que el entrenamiento intermedio podría referirse a una etapa específica de entrenamiento entre el preentrenamiento y el ajuste fino final, como el preentrenamiento continuo para conocimiento de dominio específico o una alineación temprana. Dorialexander compartió entradas de blog relevantes, explorando más a fondo este concepto, sugiriendo que podría implicar la inyección de tareas o capacidades específicas sobre un modelo base, pero aún no se ha formado una definición y metodología unificadas (fuente: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

El análisis de ingeniería inversa de Claude Code genera atención: Hrishi, mediante la ingeniería inversa del código minimizado de Claude Code, dedicó entre 8 y 10 horas, utilizando múltiples subagentes y los modelos insignia de los principales proveedores, para revelar la complejidad de su estructura interna. El análisis indica que Claude Code no es un simple bucle del modelo Claude, sino que contiene una gran cantidad de mecanismos dignos de estudio. Este descubrimiento ha generado discusión en la comunidad, que considera que se pueden aprender muchas lecciones sobre la construcción de agentes y la aplicación de modelos a partir de esto (fuente: rishdotblog, imjaredz, hrishioa)
Debate sobre la longitud de los prompts de sistema y el rendimiento del modelo: La comunidad discute el impacto de la longitud de los prompts de sistema en el rendimiento de los LLM. Dotey considera que los prompts de sistema ultralargos no siempre son buenos, ya que pueden diluir la atención del modelo y aumentar los costos, y señala que los prompts de sistema de los productos de la serie ChatGPT son relativamente breves pero efectivos. Por otro lado, Tony出海号 menciona que los prompts de sistema de productos como Claude y Cursor alcanzan decenas de miles de palabras, lo que sugiere la necesidad de sistemas de prompts extendidos. Un artículo de YC también revela que las principales empresas de IA utilizan prompts largos, XML, meta-prompts y otros métodos para “domar” a los LLM. Dorialexander, por su parte, expresa dudas sobre la robustez de los métodos de prompts largos mencionados en el artículo de YC en el entrenamiento de RL/inferencia y se centra en cómo mitigar el problema de la “adulación” (sycophancy) (fuente: dotey, Dorialexander)

Problema de escalabilidad de Softpick elogiado por la transparencia en la investigación científica: El investigador Zed declaró públicamente que su método Softpick, investigado previamente, al escalarlo a modelos más grandes (1.8B parámetros), mostró una pérdida de entrenamiento y resultados en benchmarks inferiores a Softmax, y ya ha actualizado el preprint en arXiv. La comunidad elogió enormemente este acto de compartir transparentemente resultados negativos, considerándolo crucial para el progreso científico y una cualidad de excelentes colegas investigadores (fuente: gabriberton, vikhyatk, BlancheMinerva)
Usuarios comparten selección de modelos y experiencias ejecutando LLM localmente: Usuarios de la comunidad r/LocalLLaMA de Reddit discuten activamente sobre los modelos de lenguaje grandes locales que utilizan actualmente. Modelos como Qwen 3 (especialmente 32B Q4, 32B Q8, 30B A3B), Gemma 3 (especialmente 27B QAT Q8, 12B) y Devstral son ampliamente mencionados por su rendimiento en código, creación, razonamiento general, etc. Los usuarios se centran en la longitud del contexto del modelo, la velocidad de inferencia, las versiones cuantizadas (como IQ1_S_R4) y el rendimiento en diferente hardware (como 8GB de VRAM, teléfonos con chip Snapdragon 8 Elite). Modelos de código cerrado como Claude Code y Gemini API también se utilizan simultáneamente debido a sus ventajas específicas (como el manejo de contextos largos y la capacidad de codificación) (fuente: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 Otros
Desarrollo de habilidades en la era de la IA: Preguntar, pensamiento crítico y aprendizaje continuo son clave: La discusión enfatiza que, en la era de la IA, seis habilidades son cruciales: la capacidad de preguntar, el pensamiento crítico, mantener un modo de aprendizaje, la capacidad de codificar o dar instrucciones, el uso competente de herramientas de IA y la comunicación clara. La empresa Zapier incluso exige que el 100% de los nuevos empleados dominen la IA, lo que se interpreta principalmente como un énfasis en las necesidades de comunicación y la capacidad de delegar tareas correctamente, en lugar de un conocimiento puramente técnico. La IA facilita la ejecución, por lo que la calidad del diseño y el pensamiento tienen un mayor impacto en el resultado final (fuente: TheTuringPost, zacharynado)

Ética de la IA e impacto social: Preocupaciones y empoderamiento coexisten: El actor Steve Carell expresó su preocupación por la sociedad futura representada en su nueva película “Mountainhead”, sugiriendo que podría ser la sociedad en la que viviremos pronto, aludiendo a las preocupaciones sobre los posibles impactos negativos de la IA. Por otro lado, existe la opinión de que la IA no necesariamente causará una polarización extrema entre “campesinos y reyes”, sino que podría empoderar a los individuos, reduciendo la brecha de capacidad entre individuos y grandes empresas, y promoviendo la productividad, la creatividad y la influencia personal. Sin embargo, también hay cautela sobre las perspectivas de democratización de la IA, con algunos creyendo que las grandes corporaciones seguirán manteniendo el control a través del entrenamiento y despliegue de modelos (fuente: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Hiring Cafe: Plataforma de agregación de ofertas de empleo impulsada por IA: Hamed N. utilizó la API de ChatGPT para extraer 4.1 millones de ofertas de empleo publicadas directamente en los sitios web de las empresas, creando el sitio web Hiring Cafe. La plataforma tiene como objetivo resolver el problema de las “ofertas fantasma” y los intermediarios externos que saturan plataformas como LinkedIn e Indeed, ayudando a los solicitantes de empleo a filtrar puestos de manera más efectiva a través de potentes filtros (como puesto, función, industria, años de experiencia, rol de gestión/contribuidor individual, etc.). Este es un proyecto paralelo no comercial de un estudiante de doctorado que ha recibido elogios y uso por parte de la comunidad (fuente: Reddit r/ChatGPT)
