
Palabras clave:Modelo de IA, Aprendizaje profundo, Inteligencia artificial, Modelo de lenguaje grande, Aprendizaje automático, Agente de IA, Cuello de botella de potencia computacional, Aplicación de IA, Sistema de sugerencias Grok, Registro matemático AlphaEvolve, Agente de IA Gemini, Método de entrenamiento FP4, Análisis de tablas Sonnet 4.0
🔥 Enfoque
xAI hace públicos los prompts del sistema Grok y refuerza los mecanismos de revisión: La empresa xAI anunció recientemente que, debido a que su robot de respuesta Grok tuvo sus prompts modificados sin autorización en la plataforma X y emitió declaraciones políticas que violan las políticas y valores de la empresa, ha decidido hacer públicos los prompts del sistema Grok en GitHub. Esta medida tiene como objetivo aumentar la transparencia y fiabilidad de Grok como una IA que busca la verdad. xAI también declaró que reforzará sus procesos internos de revisión de código y añadirá un equipo de monitoreo 24/7 para prevenir que incidentes similares ocurran de nuevo y para responder más rápidamente a problemas no capturados por los sistemas automáticos. (Fuente: xai, xai)
DeepMind AlphaEvolve vuelve a batir récord matemático, la colaboración entre IA y humanos muestra un nuevo paradigma en la investigación científica: AlphaEvolve de DeepMind batió dos veces en una semana un récord matemático que se mantenía desde hacía 18 años, atrayendo la atención de matemáticos como Terence Tao. Tao considera que diferentes métodos de investigación pueden complementarse para impulsar el progreso matemático, en lugar de un simple “el ganador se lo lleva todo”. Este evento resalta el potencial de la colaboración entre IA y humanos para crear nuevos modelos de progreso en la ciencia y la tecnología, donde la IA ya no es solo una herramienta de reemplazo, sino un socio que explora lo desconocido y acelera la innovación junto a los humanos. (Fuente: Yuchenj_UW)

Google colabora con la comunidad de código abierto para simplificar la construcción de agentes de IA basados en Gemini: Google anunció que está colaborando con frameworks de código abierto como LangChain LangGraph, crewAI, LlamaIndex y ComposIO, con el objetivo de facilitar a los desarrolladores la construcción de agentes de IA basados en los modelos Google Gemini. Esta iniciativa refleja la determinación de Google de impulsar el desarrollo del ecosistema de agentes de IA, proporcionando herramientas y frameworks más fáciles de usar, reduciendo las barreras de desarrollo y fomentando la creación de más aplicaciones innovadoras. (Fuente: osanseviero, Hacubu)

La capacidad de inferencia de los modelos de IA podría enfrentarse a un cuello de botella en su capacidad de cómputo en un año: Aunque los modelos de inferencia como o3 de OpenAI han mostrado mejoras significativas de rendimiento a corto plazo impulsadas por la capacidad de cómputo (por ejemplo, la capacidad de cómputo para el entrenamiento de o3 es 10 veces mayor que la de o1), instituciones de investigación como Epoch AI predicen que si la capacidad de cómputo continúa duplicándose cada pocos meses a una tasa de 10 veces, la expansión de la capacidad de cómputo para los modelos de inferencia podría alcanzar un “techo” en un año como máximo. Para entonces, la tasa de crecimiento de la capacidad de cómputo podría reducirse a 4 veces al año, y la velocidad de actualización de los modelos disminuiría en consecuencia. Los datos de entrenamiento de modelos como DeepSeek-R1 también confirman indirectamente la escala actual del consumo de capacidad de cómputo para el entrenamiento de inferencia. Aunque la innovación en datos y algoritmos aún puede impulsar el progreso, la desaceleración del crecimiento de la capacidad de cómputo será un desafío importante para la industria de la IA. (Fuente: WeChat)

🎯 Tendencias
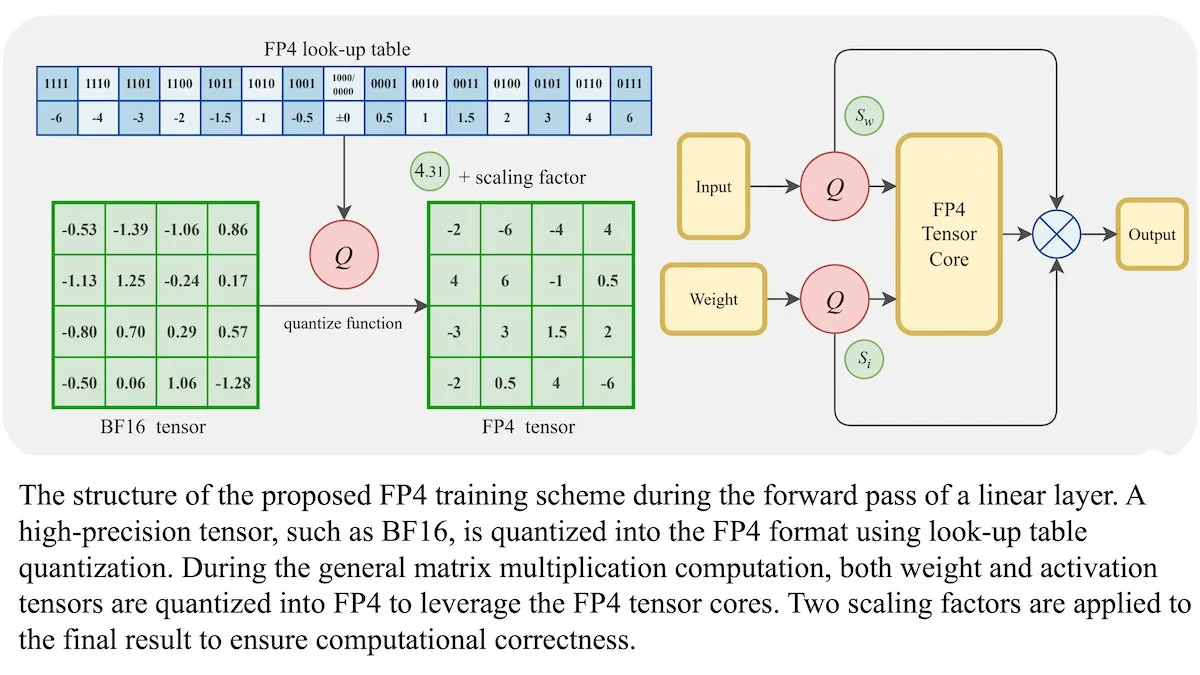
Nuevo método de entrenamiento para LLM: precisión de punto flotante de 4 bits (FP4) puede alcanzar la misma exactitud que BF16: Investigadores han demostrado que los modelos de lenguaje grandes (LLM) pueden entrenarse utilizando precisión de punto flotante de 4 bits (FP4) sin sacrificar la exactitud. Al utilizar FP4 para la multiplicación de matrices, que representa el 95% del cómputo de entrenamiento, se logró un rendimiento comparable al formato BF16 comúnmente utilizado. El equipo introdujo aproximaciones diferenciables para superar la no diferenciabilidad de la cuantización, mejorando la eficiencia del entrenamiento. Las simulaciones en GPU Nvidia H100 mostraron que FP4 funciona igual o mejor que BF16 en varias pruebas de referencia de lenguaje. (Fuente: DeepLearningAI)
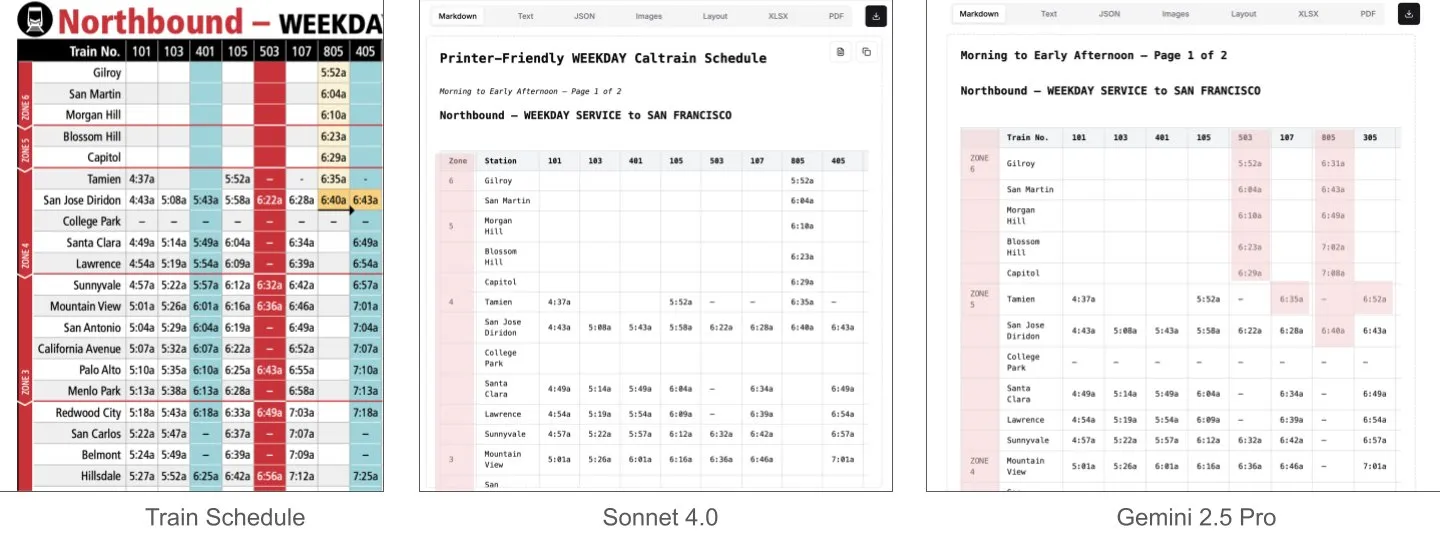
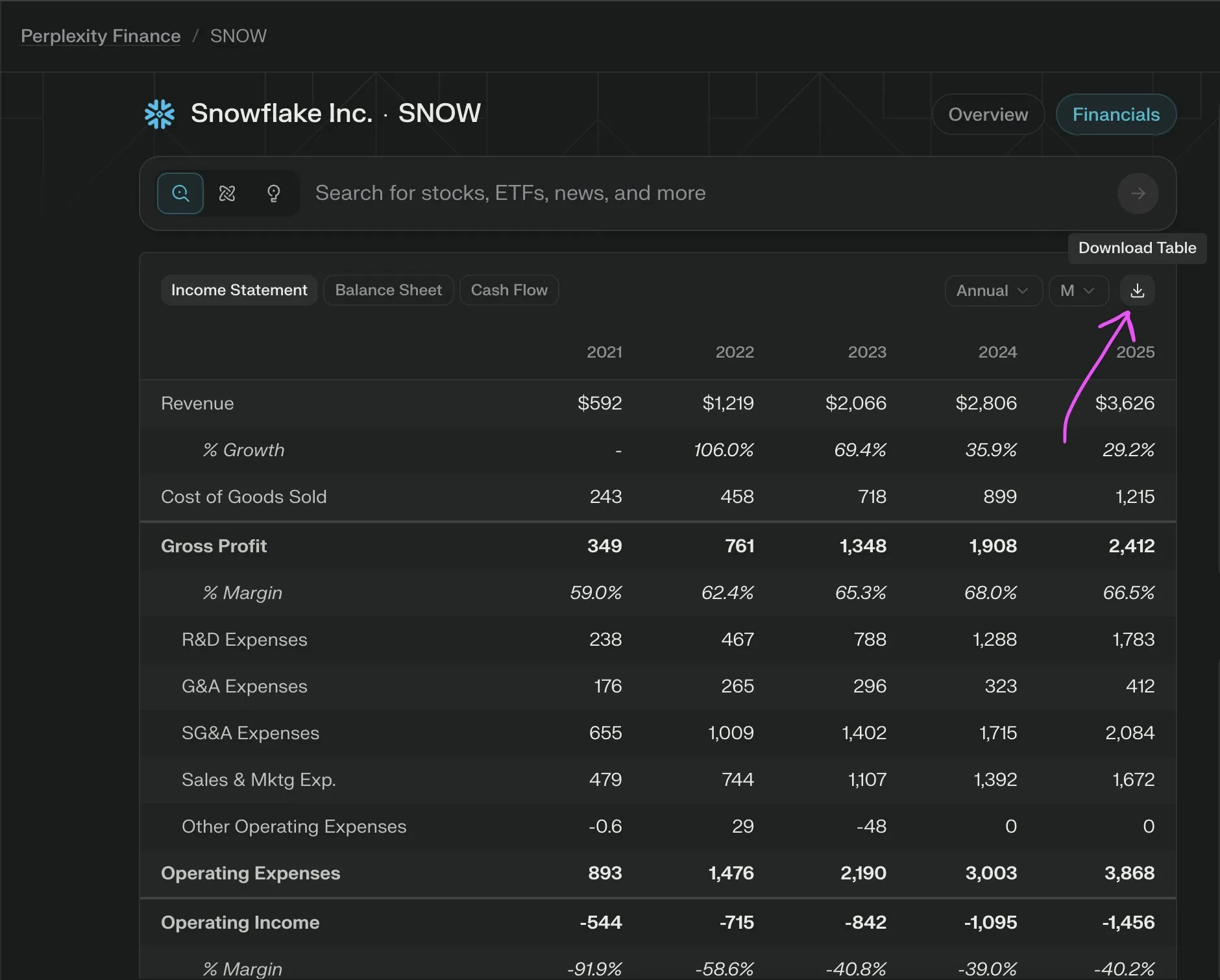
Sonnet 4.0 supera a Gemini 2.5 Pro en la comprensión de documentos, especialmente en el análisis de tablas: Jerry Liu de LlamaIndex descubrió, mediante pruebas comparativas, que Sonnet 4.0 de Anthropic tiene una capacidad de análisis de tablas significativamente superior a Gemini 2.5 Pro de Google al procesar capturas de pantalla del horario de Caltrain, que contienen datos tabulares densos. Gemini 2.5 Pro presentó errores de alineación de columnas, mientras que Sonnet 4.0 pudo reconstruir la mayoría de los valores correctamente, cometiendo errores solo en los encabezados de tabla y en algunos otros valores. Aunque Sonnet 4.0 es actualmente más costoso y lento, su rendimiento en razonamiento visual y análisis de tablas es destacado. (Fuente: jerryjliu0)
xAI, TWG Global y Palantir colaboran para remodelar las aplicaciones de IA en la industria de servicios financieros: xAI anunció una asociación con TWG Global y Palantir Technologies, dedicada a diseñar e implementar conjuntamente soluciones empresariales impulsadas por IA para remodelar la forma en que los proveedores de servicios financieros adoptan la IA y amplían la tecnología. El CEO de Palantir, Alex Karp, y el copresidente de TWG Global, Thomas Tull, discutieron en la conferencia del Milken Institute cómo esta colaboración impulsará la innovación en IA en el sector financiero. (Fuente: xai, xai)
La revisión mejorada tras la actualización de DeepSeek-R1-0528 genera debate en la comunidad: Los usuarios informan que DeepSeek-R1-0528 (modelo completo de 671B, FP8) ha endurecido notablemente la revisión de contenido en comparación con la versión anterior R1. Por ejemplo, al ser preguntado sobre eventos históricos sensibles, el nuevo modelo da respuestas más evasivas y oficialistas, mientras que la versión anterior R1 podía proporcionar información más directa. Este cambio ha provocado un debate en la comunidad sobre la apertura del modelo, los criterios de revisión y su posible impacto en la investigación y las aplicaciones, especialmente en escenarios que dependen del modelo para obtener información no censurada. (Fuente: Reddit r/LocalLLaMA)
Huawei lanza el modelo Pangu Embedded, que fusiona una arquitectura cognitiva de sistema dual de pensamiento rápido y lento: El equipo Pangu de Huawei, basándose en la NPU Ascend, ha propuesto el modelo Pangu Embedded, que integra de forma innovadora modos de inferencia dual “pensamiento rápido” y “pensamiento lento”. Este modelo, mediante un entrenamiento en dos etapas (destilación iterativa y fusión de modelos, sistema de recompensa dinámica multiorfuente RL) y una arquitectura cognitiva que cambia automáticamente según el control del usuario o la percepción de la dificultad del problema, tiene como objetivo lograr un equilibrio dinámico entre la eficiencia de la inferencia y la profundidad, resolviendo la contradicción de los modelos grandes tradicionales que piensan demasiado en problemas simples y no lo suficiente en tareas complejas. (Fuente: WeChat)

Nuevo modelo de mundo de video combina SSM y modelos de difusión, logrando contexto largo y simulación interactiva: Investigadores de la Universidad de Stanford, la Universidad de Princeton y Adobe Research han propuesto un nuevo modelo de mundo de video que, al combinar modelos de espacio de estados (SSM, específicamente el esquema de escaneo por bloques de Mamba) y modelos de difusión de video, resuelve los problemas de los modelos de video existentes con longitud de contexto limitada y dificultad para simular la coherencia a largo plazo. Este modelo puede procesar eficazmente dinámicas temporales causales, rastrear el estado del mundo y garantizar la fidelidad de la generación mediante mecanismos de atención local por fotograma, ofreciendo una nueva vía para la generación de video de longitud infinita, en tiempo real y coherente en aplicaciones interactivas (como juegos). (Fuente: WeChat)

ByteDance lanza el modelo base multimodal de código abierto BAGEL, compatible con la comprensión y generación de gráficos, texto y video: ByteDance ha lanzado el modelo BAGEL (ByteDance Agnostic Generation and Empathetic Language model), un modelo base multimodal unificado capaz de procesar simultáneamente tareas de comprensión y generación de texto, imágenes y video. La versión BAGEL-7B-MoT tiene un total de 14 mil millones de parámetros (7 mil millones de parámetros activos) y requiere aproximadamente 30G de VRAM para funcionar a pleno rendimiento. Los usuarios pueden experimentar y desplegar el modelo a través de la demo de Hugging Face y la dirección del modelo proporcionadas, logrando funciones como edición de imágenes y transferencia de estilo. (Fuente: WeChat)
FLUX.1 Kontext lanzado: fusiona edición y generación de texto e imágenes, velocidad aumentada 8 veces: Black Forest Labs (BFL) ha lanzado la nueva generación de modelos de imagen FLUX.1 Kontext. Esta serie de modelos admite la generación de imágenes dentro del contexto, puede procesar simultáneamente prompts de texto e imágenes, y logra la edición instantánea de texto a imagen y la generación de texto a imagen. FLUX.1 Kontext se destaca en la coherencia de personajes, la comprensión del contexto y la edición local. La generación de imágenes con resolución de 1024×1024 solo toma de 3 a 5 segundos, una velocidad hasta 8 veces superior a la de GPT-Image-1, y admite la edición iterativa en múltiples rondas. Este modelo se basa en un transformador de flujo rectificado (rectified flow transformer) y técnicas de muestreo por destilación de difusión adversaria. (Fuente: WeChat, WeChat)

LaViDa: Un nuevo VLM de comprensión multimodal basado en modelos de difusión: Investigadores de la Universidad de California en Los Ángeles, Panasonic, Adobe y Salesforce han presentado LaViDa (Large Vision-Language Diffusion Model with Masking), un modelo de visión-lenguaje (VLM) basado en modelos de difusión. A diferencia de los VLM tradicionales basados en LLM autorregresivos, LaViDa utiliza un proceso de difusión discreta para manejar la generación de texto, lo que teóricamente ofrece mejor paralelismo, un equilibrio entre velocidad y calidad, y la capacidad de procesar contexto bidireccional. El modelo integra características visuales a través de un codificador visual y emplea un proceso de entrenamiento en dos etapas (preentrenamiento para alinear los espacios latentes visuales y del DLM, y ajuste fino para lograr el seguimiento de instrucciones). Los experimentos demuestran que LaViDa es competitivo en diversas tareas como la comprensión visual, el razonamiento, el OCR y la respuesta a preguntas científicas. (Fuente: WeChat)
Los modelos de IA enfrentan el riesgo de “colapso del modelo” debido a la ingesta excesiva de datos generados por IA: Investigaciones indican que si los modelos de IA ingieren demasiados datos generados por otras IA durante el proceso de entrenamiento, pueden experimentar un fenómeno de “colapso del modelo” (model collapse), lo que hace que los modelos se vuelvan más caóticos e poco fiables. Incluso permitir que los modelos busquen información en línea podría agravar el problema, ya que Internet está inundado de contenido de baja calidad generado por IA. Este fenómeno, propuesto por primera vez en 2023, se está volviendo cada vez más evidente y plantea desafíos para el desarrollo a largo plazo de los modelos de IA y el control de la calidad de los datos. (Fuente: Reddit r/ArtificialInteligence)

El procesador AMD Octa-core Ryzen AI Max Pro 385 aparece en Geekbench, presagiando la llegada al mercado de chips Strix Halo asequibles: Se ha descubierto el nuevo procesador de ocho núcleos Ryzen AI Max Pro 385 de AMD en Geekbench, lo que podría significar que los chips de IA más asequibles con nombre en clave Strix Halo están a punto de llegar al mercado. Los usuarios esperan que este tipo de chips ofrezcan más carriles PCIe para admitir configuraciones híbridas, satisfaciendo la necesidad de agregar tarjetas de expansión y dispositivos USB4. Aunque la memoria integrada es aceptable debido a su ventaja de velocidad, la capacidad de expansión sigue siendo un foco de atención. (Fuente: Reddit r/LocalLLaMA)

La empresa 1X presenta su último prototipo de robot humanoide Neo Gamma: La empresa noruega de robótica 1X ha lanzado su último prototipo de robot humanoide, Neo Gamma. El lanzamiento de este robot representa otro avance en la tecnología de robots humanoides en los campos de la automatización y la inteligencia artificial, mostrando su potencial de aplicación en diversos escenarios futuros como la industria y los servicios. (Fuente: Ronald_vanLoon)
Se prevé que el consumo de energía de la IA supere pronto al de la minería de Bitcoin: Se espera que el consumo de energía de los modelos de IA crezca rápidamente, pudiendo llegar a ocupar pronto casi la mitad de la electricidad de los centros de datos, con un consumo energético comparable al de algunos países enteros. El aumento de la demanda de chips de IA está ejerciendo presión sobre la red eléctrica de EE. UU., impulsando la construcción de nuevos proyectos de combustibles fósiles y energía nuclear. Debido a la falta de transparencia y la complejidad de las fuentes de energía regionales, resulta difícil rastrear con precisión el impacto de las emisiones de carbono de la IA. (Fuente: Reddit r/ArtificialInteligence)

🧰 Herramientas
e-library-agent: un agente inteligente de gestión de bibliotecas personales creado con LlamaIndex: Clelia Bertelli ha utilizado el flujo de trabajo de LlamaIndex para construir una herramienta llamada e-library-agent, diseñada para ayudar a los usuarios a organizar, buscar y explorar sus colecciones de lectura personales. La herramienta integra tecnologías como ingest-anything, Qdrant, Linkup_platform, FastAPI y Gradio, resolviendo el problema de “leído pero no encontrado” y mejorando la eficiencia de la gestión del conocimiento personal. (Fuente: jerryjliu0, jerryjliu0)
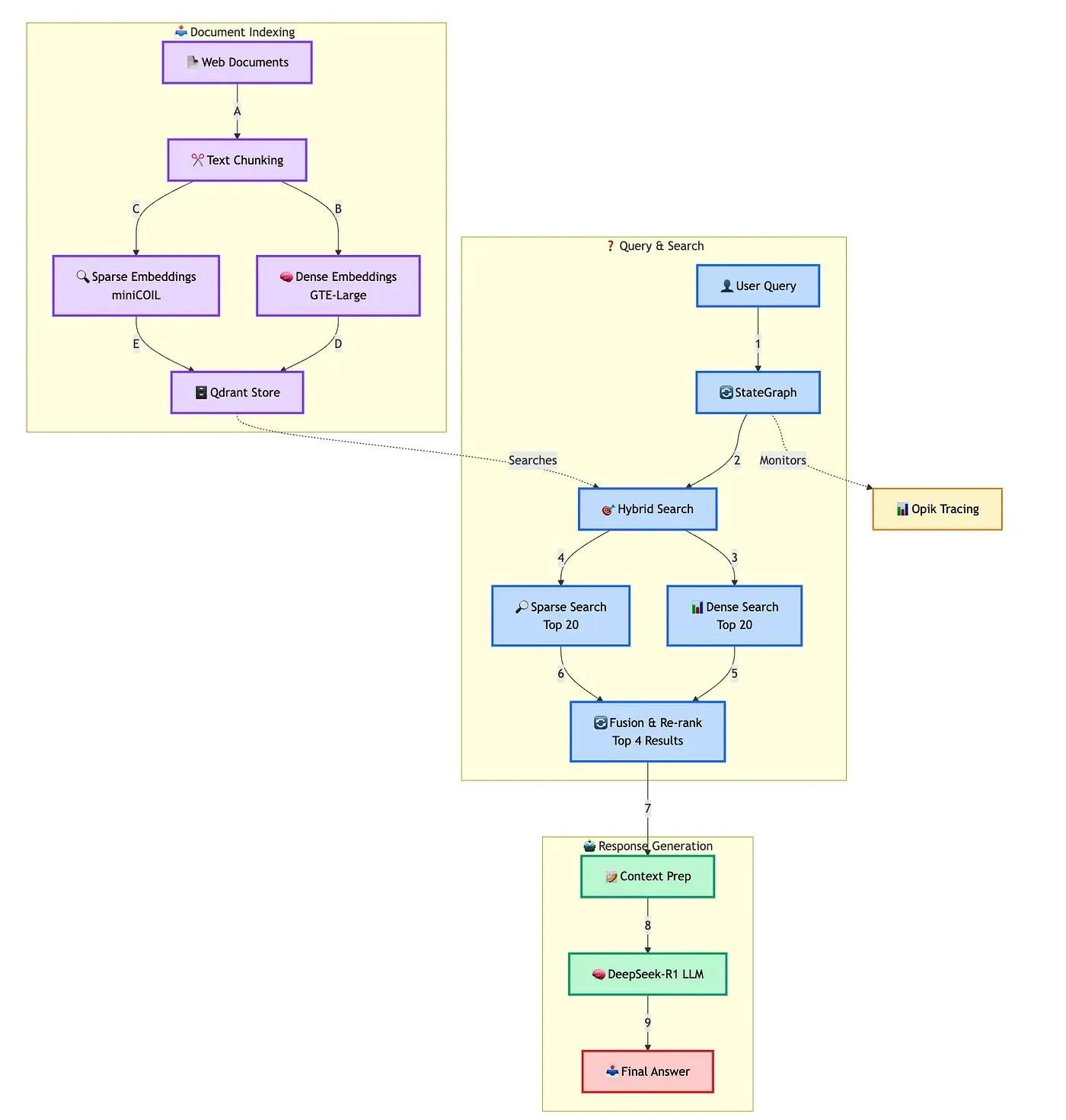
Qdrant muestra una solución avanzada para construir chatbots RAG híbridos: Qdrant, en colaboración con TRJ_0751, demostró cómo construir un chatbot RAG (Recuperación Aumentada por Generación) híbrido avanzado para soporte al cliente utilizando miniCOIL, LangGraph y DeepSeek-R1. Esta solución utiliza miniCOIL para mejorar la capacidad de percepción semántica de la recuperación dispersa, LangGraph (de LangChainAI) para orquestar el flujo híbrido (incluyendo MMR y reordenamiento), Opik para rastrear y evaluar cada paso del flujo, y DeepSeek-R1 (de SambaNovaAI) para proporcionar respuestas de baja latencia y enfocadas. (Fuente: qdrant_engine, hwchase17)
Google lanza la aplicación AI Edge Gallery, compatible con la ejecución local de modelos de IA: Google ha lanzado una aplicación llamada AI Edge Gallery, que permite a los usuarios descargar y ejecutar modelos de IA en sus dispositivos locales. Esto significa que los usuarios pueden utilizar herramientas de IA para la generación de imágenes, respuesta a preguntas o escritura de código sin conexión a Internet, garantizando al mismo tiempo la privacidad de los datos. La aplicación está actualmente disponible como versión preliminar y es compatible con modelos como Gemma 3n. (Fuente: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)

Perplexity Labs permite la búsqueda en archivos SEC EDGAR, fortaleciendo las capacidades de investigación financiera: Perplexity Labs ha añadido una nueva función que permite a los usuarios buscar en los archivos de empresas de la base de datos EDGAR de la Comisión de Bolsa y Valores de EE. UU. (SEC). Esta actualización tiene como objetivo fortalecer aún más su aplicación en el campo de la investigación financiera, proporcionando a los usuarios una forma más conveniente de recuperar y analizar información de empresas que cotizan en bolsa. (Fuente: AravSrinivas)
Meituan lanza la herramienta de IA sin código NoCode, que permite construir aplicaciones con lenguaje natural: Meituan ha lanzado NoCode, una herramienta de IA sin código que permite a los usuarios sin experiencia en programación crear herramientas personales de mejora de la eficiencia, prototipos de productos, páginas interactivas e incluso juegos simples mediante conversaciones en lenguaje natural. NoCode admite la vista previa en tiempo real, la modificación parcial y el despliegue con un solo clic, con el objetivo de reducir las barreras de desarrollo y permitir que más personas liberen su creatividad. Detrás de esta herramienta hay múltiples modelos de IA colaborando, incluido el modelo especializado apply de 7B parámetros desarrollado internamente por Meituan, optimizado con datos de código reales internos de la empresa. (Fuente: WeChat)
VAST actualiza Tripo Studio, añadiendo funciones de modelado IA como segmentación inteligente de partes y pincel mágico: La startup de modelos 3D VAST ha realizado una importante actualización de su herramienta de modelado IA Tripo Studio, introduciendo cuatro funciones principales: segmentación inteligente de partes, pincel mágico para texturas, generación inteligente de modelos de baja poligonalización y rigging automático de huesos para cualquier objeto. Estas funciones tienen como objetivo resolver los puntos débiles del flujo de trabajo tradicional de modelado 3D, como la dificultad para editar partes, la reparación laboriosa de imperfecciones en texturas, la optimización engorrosa de modelos de alta poligonalización y la complejidad del rigging de huesos, mejorando significativamente la eficiencia y facilidad de uso en la creación de contenido 3D y reduciendo la barrera de entrada para usuarios no profesionales. (Fuente: 量子位)
Hugging Face lanza dos robots humanoides de código abierto, HopeJR y Reachy Mini, a precios asequibles: Hugging Face, en colaboración con The Robot Studio y Pollen Robotics, ha lanzado dos robots humanoides de código abierto: HopeJR de tamaño completo (aproximadamente 3000 dólares) y Reachy Mini de escritorio (aproximadamente 250-300 dólares). Esta iniciativa tiene como objetivo promover la popularización y la investigación abierta de la tecnología robótica, permitiendo a cualquiera ensamblar, modificar y aprender los principios de la robótica. HopeJR tiene la capacidad de caminar y mover los brazos, y puede ser controlado remotamente mediante guantes; Reachy Mini, por su parte, puede mover la cabeza, hablar y escuchar, y se utiliza para probar aplicaciones de IA. (Fuente: WeChat)

Se lanza EvoAgentX, el primer framework de código abierto para la autoevolución de agentes de IA del mundo: El equipo de investigación de la Universidad de Glasgow en el Reino Unido ha lanzado EvoAgentX, el primer framework de código abierto del mundo para la autoevolución de agentes de IA. Este framework tiene como objetivo resolver la complejidad de la construcción y optimización de sistemas multiagente de IA. Mediante la introducción de mecanismos de autoevolución, permite la construcción de flujos de trabajo con un solo clic y que el sistema optimice continuamente su estructura y rendimiento en función de los cambios en el entorno y los objetivos durante su ejecución. EvoAgentX espera impulsar los sistemas multiagente desde la depuración manual hacia la evolución autónoma, proporcionando una plataforma unificada de experimentación y despliegue para investigadores e ingenieros. (Fuente: WeChat)

Perplexity Labs lanza nueva función para exportar gratuitamente datos financieros de empresas a CSV: Perplexity Labs anunció que los usuarios ahora pueden exportar gratuitamente datos de cualquier sección financiera de empresas desde sus páginas financieras a formato CSV. Anteriormente, funciones similares en plataformas como Yahoo Finance generalmente requerían una suscripción de pago. Perplexity indicó que en el futuro añadirá más datos históricos. (Fuente: AravSrinivas)
📚 Aprendizaje
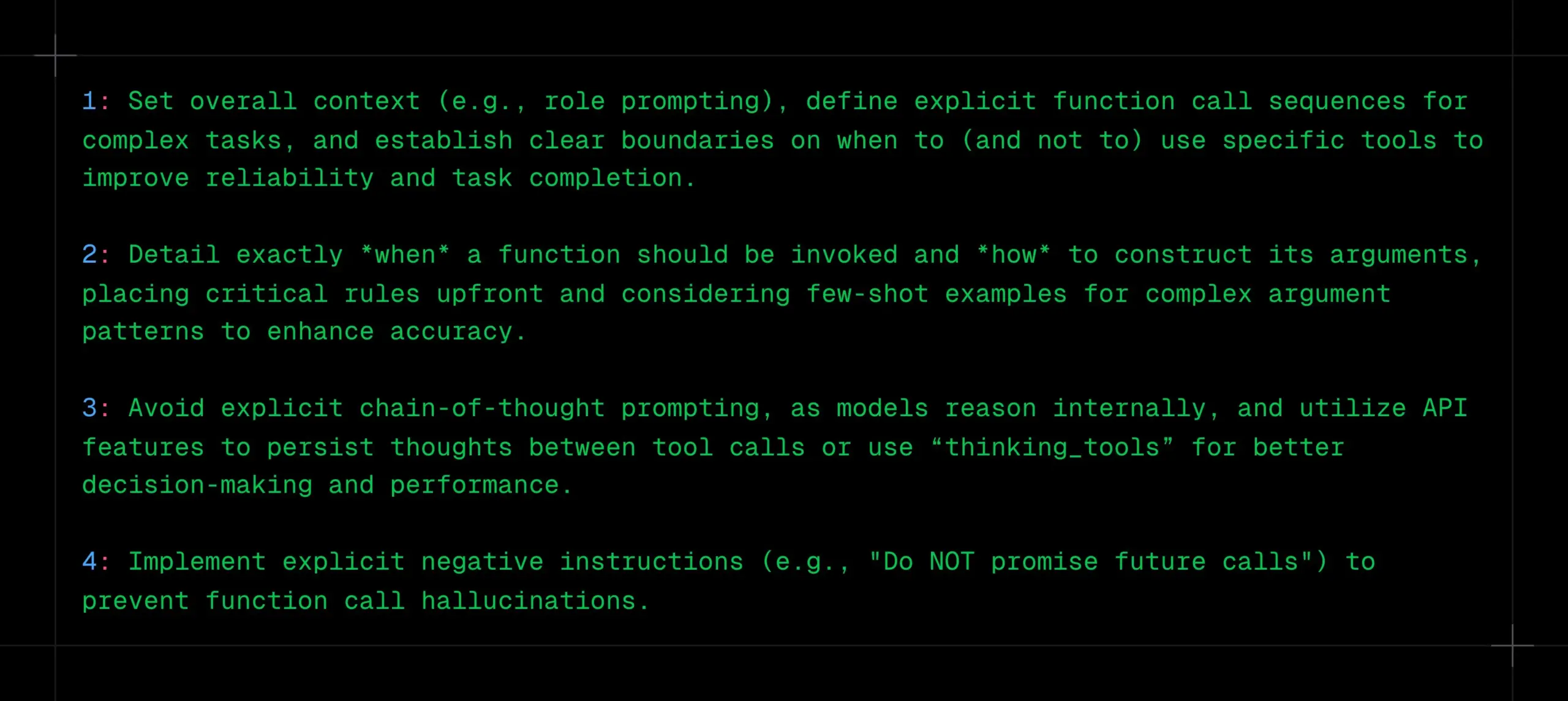
Técnicas de llamada a funciones en LLM: definir claramente contexto, secuencias y límites, evitar CoT y alucinaciones: _philschmid comparte recomendaciones para realizar llamadas a funciones en modelos de inferencia como Gemini 2.5 u OpenAI o3. Los puntos clave incluyen: establecer un contexto general (como un prompt de rol), definir secuencias claras de llamadas a funciones para tareas complejas y establecer límites claros para el uso de herramientas (cuándo usarlas/no usarlas). Es necesario detallar cuándo se deben realizar las llamadas a funciones y cómo construir los parámetros. Evitar prompts explícitos de CoT, ya que el modelo realizará inferencias internas; se pueden utilizar las características de la API para persistir el pensamiento entre llamadas a herramientas o usar “thinking_tools”. Al mismo tiempo, implementar instrucciones negativas claras (como “no prometer llamadas futuras”) para prevenir alucinaciones en las llamadas a funciones. (Fuente: _philschmid)
Se comparten 12 consejos profesionales de programación con IA: Cline comparte 12 consejos de programación con IA de una reciente conferencia sobre mejores prácticas de ingeniería, enfatizando la planificación, el uso de modelos avanzados para tareas complejas, la atención a la ventana de contexto, la creación de archivos de reglas, la clarificación de la intención, la consideración de la IA como un colaborador, el uso de bancos de memoria, el aprendizaje de estrategias de gestión de contexto y la construcción del intercambio de conocimientos en equipo. El objetivo principal es construir software más rápido y mejor, utilizando la IA como un amplificador de capacidades en lugar de un sustituto. (Fuente: cline, cline)

Sugerencias para optimizar los prompts de creación tras la actualización de DeepSeek-R1-0528: En respuesta a la actualización del modelo DeepSeek-R1-0528 (68.5 mil millones de parámetros, contexto de 128K, capacidad de codificación cercana a o3), un creador de contenido ha compartido 10 prompts de creación optimizados. Las sugerencias incluyen aprovechar su capacidad de inferencia superlarga de 30-60 minutos para un pensamiento profundo, procesar textos largos de 128K, optimizar la generación de código, personalizar los prompts del sistema, mejorar la calidad de las tareas de escritura, realizar verificaciones anti-alucinaciones, superar los cuellos de botella en la escritura creativa, realizar análisis de diagnóstico de problemas, integrar el aprendizaje de conocimientos y optimizar el texto comercial. Se enfatiza la especificación de los prompts, el pleno aprovechamiento del contexto largo, el buen uso de la inferencia profunda, el establecimiento de una memoria de diálogo y la verificación de información importante. (Fuente: WeChat)
Framework RM-R1: Remodelando los modelos de recompensa como tareas de razonamiento para mejorar la interpretabilidad y el rendimiento: Un equipo de investigación de la Universidad de Illinois en Urbana-Champaign ha propuesto el framework RM-R1, que redefine la construcción de modelos de recompensa (Reward Models) como una tarea de razonamiento. Este framework, mediante la introducción del mecanismo “Chain-of-Rubrics” (CoR), permite que el modelo genere criterios de evaluación estructurados y procesos de razonamiento antes de emitir juicios de preferencia, mejorando así la interpretabilidad de los modelos de recompensa y su precisión en la evaluación de tareas complejas (como matemáticas, programación). RM-R1, a través de un entrenamiento en dos etapas de destilación de razonamiento y aprendizaje por refuerzo, supera a los modelos de código abierto y cerrado existentes en múltiples pruebas de referencia de modelos de recompensa. (Fuente: WeChat)

Análisis profundo del Protocolo de Contexto de Modelo (MCP): simplificando la integración de la IA con servicios externos: El Protocolo de Contexto de Modelo (MCP), como estándar abierto, tiene como objetivo resolver el problema de fragmentación en la integración de modelos de IA con fuentes de datos y herramientas externas (como Slack, Gmail). A través de una interfaz de sistema unificada (compatible con los protocolos STDIO y SSE), MCP permite a los desarrolladores construir clientes MCP (como el escritorio de Claude, Cursor IDE) y servidores MCP (que operan bases de datos, sistemas de archivos, llaman a API), simplificando la compleja red de adaptación “M×N” a un modelo “M+N”, logrando la integración plug-and-play de la IA con servicios externos. Tan Yu, socio de Fabarta, una empresa de tecnología de Fengqing, cree que el valor de MCP radica en proporcionar capacidades de conexión básicas, y su comercialización depende del valor específico proporcionado por el sistema subyacente, por ejemplo, simplificando los procesos de usuario a través del agente inteligente de superoficina de Fabarta integrado con MCP Server. (Fuente: WeChat)

Agentic ROI: Un indicador clave para medir la usabilidad de los agentes de modelos grandes: La Universidad Jiao Tong de Shanghái, en colaboración con la Universidad de Ciencia y Tecnología de China, ha propuesto el Agentic ROI (Retorno de la Inversión del Agente) como un indicador central para medir la utilidad práctica de los agentes de modelos grandes en escenarios reales. Este indicador considera de manera integral la calidad de la información, el costo de tiempo del usuario y del agente, y los gastos económicos. El estudio señala que los agentes actuales se utilizan más en campos con altos costos de mano de obra como la investigación científica y la programación, pero en escenarios cotidianos como el comercio electrónico y la búsqueda, el Agentic ROI es bajo debido a un valor marginal poco claro y altos costos de interacción. Optimizar el Agentic ROI requiere seguir una ruta de desarrollo en “zigzag”: primero mejorar la calidad de la información a gran escala, y luego reducir los costos de manera ligera. (Fuente: WeChat)
💼 Negocios
Los ingresos anualizados de Anthropic se disparan a 3 mil millones de dólares, impulsados por la demanda de IA empresarial: Según dos fuentes, los ingresos anualizados de Anthropic han aumentado de 1 mil millones a 3 mil millones de dólares en solo cinco meses. Este crecimiento significativo se debe principalmente a la fuerte demanda de IA por parte de las empresas, especialmente en el campo de la generación de código. Esto indica que la disposición de aplicación y pago del mercado empresarial por modelos de IA avanzados (como la serie Claude de Anthropic) está aumentando rápidamente. (Fuente: cto_junior, scaling01, Reddit r/ArtificialInteligence)
Informe financiero del primer trimestre del año fiscal 2026 de Nvidia: ingresos totales de 44.1 mil millones de dólares, el negocio de centros de datos aporta casi el noventa por ciento: Nvidia publicó su informe financiero del primer trimestre del año fiscal 2026, finalizado el 27 de abril de 2025, con ingresos totales de 44.1 mil millones de dólares, un aumento intertrimestral del 12% y un aumento interanual del 69%. Los ingresos del negocio de centros de datos fueron de 39.1 mil millones de dólares, lo que representa el 88.91%, un aumento interanual del 73%. Los ingresos del negocio de juegos fueron de 3.8 mil millones de dólares, un máximo histórico. Aunque el chip H20 se vio afectado por las restricciones de exportación, lo que resultó en una depreciación de inventario de 4.5 mil millones de dólares y gastos por obligaciones de compra, y se espera que el segundo trimestre pierda 8 mil millones de dólares en ingresos debido a esto, el rendimiento general sigue siendo sólido. Se espera que nuevos productos como Blackwell Ultra impulsen aún más el crecimiento. (Fuente: 量子位, WeChat)

Meta reorganiza su equipo de IA, la mayoría de los autores principales originales de Llama se han marchado, el estatus de FAIR genera preocupación: Meta anunció una reorganización de su equipo de IA, dividiéndolo en un equipo de productos de IA liderado por Connor Hayes y un departamento de fundamentos de AGI codirigido por Ahmad Al-Dahle y Amir Frenkel. El departamento de investigación básica en inteligencia artificial FAIR mantiene una relativa independencia, aunque algunos equipos multimedia se han integrado. Este ajuste tiene como objetivo mejorar la autonomía y la velocidad de desarrollo. Sin embargo, de los 14 autores principales originales del modelo Llama, solo 3 permanecen, la mayoría se han marchado o se han unido a competidores (como Mistral AI). Sumado a la tibia recepción tras el lanzamiento de Llama 4 y los ajustes internos en la asignación de capacidad de cómputo y la dirección de la investigación, han surgido preocupaciones sobre si Meta podrá mantener su posición de liderazgo en el campo de la IA de código abierto y sobre el futuro desarrollo de FAIR. (Fuente: WeChat)

🌟 Comunidad
Debate sobre la alineación de la IA: ¿Pueden las normas blandas mantener el poder humano en la era de la AGI?: Ryan Greenblatt discute las opiniones de Dwarkesh Patel, quien se muestra escéptico sobre la alineación de la IA y espera que, mediante normas blandas, los humanos puedan conservar parte del poder y espacio vital después de que la AGI (Inteligencia Artificial General) domine el poder duro. Greenblatt argumenta que si la IA es sensible al alcance (scope sensitive) y tiene la capacidad de tomar el poder, es poco probable que intentar revelar su desalineación o hacerla trabajar para los humanos mediante transacciones o contratos tenga éxito. Además, factores como el ajuste fino barato, la mejora de la alineación por parte de los humanos y la libre replicación hacen que el control humano sobre la propiedad sea muy inestable antes de que se resuelva el problema de la alineación. Una vez que aparezca una IA alineada o mano de obra de IA más barata, los humanos las usarán prioritariamente, lo que incentivará fuertemente a las IA no alineadas a tomar el poder. (Fuente: RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, JeffLadish)

El creador de Redis considera que la programación con IA es muy inferior a los programadores humanos, lo que genera resonancia y debate entre los desarrolladores: Salvatore Sanfilippo (Antirez), el creador de Redis, compartió su experiencia de desarrollo, considerando que la IA actual, aunque útil en programación, es muy inferior a los programadores humanos, especialmente en romper moldes y concebir soluciones extrañas pero efectivas. Compara la IA con un “subordinado suficientemente inteligente” que ayuda a validar ideas. Esta opinión generó un acalorado debate entre los desarrolladores, muchos de los cuales coinciden en que la IA puede servir como un “pato de goma” para ayudar a pensar, pero señalan que la IA es demasiado confiada y puede inducir a error a los desarrolladores novatos. Algunos desarrolladores expresaron que las respuestas incorrectas generadas por la IA los motivaron a codificar manualmente. La discusión enfatizó la importancia de la experiencia para utilizar eficazmente la IA y el posible impacto negativo de la IA en los principiantes en programación. (Fuente: WeChat)

La relación entre DeepMind y Google Research vuelve a ser objeto de debate: la marca frente a la contribución real a la innovación: Faruk Guney publicó un largo hilo en Twitter comentando la relación entre DeepMind y Google Research, argumentando que los avances clave de la actual revolución de la IA (como la arquitectura Transformer) provinieron principalmente de Google Research, y no de DeepMind después de ser adquirida por Google. Señala que aunque AlphaFold es un logro de DeepMind, también dependió de los recursos computacionales y la infraestructura de investigación de Google, y que los contribuyentes principales fueron científicos e ingenieros como John Jumper y Pushmeet Kohli. Guney opina que la posterior incorporación de Google Research a DeepMind fue más un ajuste de marca y estructura organizativa, que involucró complejas políticas corporativas que podrían haber ocultado el verdadero origen de la innovación. Enfatiza que muchos avances en IA son el resultado de años de investigación en equipo, y no deben atribuirse únicamente a unas pocas figuras o marcas conocidas. (Fuente: farguney, farguney)
La transformación de puestos de trabajo y habilidades en la era de la IA genera preocupación y debate: En las redes sociales, el debate sobre el impacto de la IA en el mercado laboral es constante. Por un lado, hay quienes opinan que la IA provocará un desempleo masivo, como expresó el CEO de Anthropic, lo que lleva a la gente a pensar en cómo afrontarlo. Por otro lado, también hay voces que señalan que la IA principalmente aumenta la productividad y es poco probable que cause un desempleo masivo, a menos que ocurra una grave recesión económica, ya que la demanda de los consumidores depende del empleo y los ingresos. Al mismo tiempo, algunos usuarios han compartido experiencias personales de pérdida de empleo debido a la IA (como jefes que reemplazan a empleados con ChatGPT). De cara al futuro, el debate apunta a la necesidad de ahorrar, aprender habilidades prácticas, adaptarse a la posibilidad de una reducción de ingresos y cómo el sistema educativo debe ajustarse para cultivar las habilidades necesarias en la era de la IA, como el pensamiento crítico y la capacidad de utilizar eficazmente las herramientas de IA. (Fuente: Reddit r/ArtificialInteligence, Reddit r/artificial)

La dependencia excesiva de ChatGPT genera preocupación por la disminución de la capacidad de pensamiento: Un usuario de Reddit expresó su preocupación por la dependencia excesiva de su novia de ChatGPT para tomar decisiones, obtener opiniones e ideas, considerando que esto podría llevarla a perder su capacidad de pensamiento independiente y originalidad. La publicación generó un amplio debate; algunos comentaristas coincidieron con esta preocupación, argumentando que la dependencia excesiva de las herramientas de IA realmente podría debilitar el pensamiento personal; otros argumentaron que la IA es solo una herramienta, como las enciclopedias o los motores de búsqueda del pasado, y que la clave está en cómo la utiliza el usuario, ya sea como punto de partida para pensar o como un reemplazo completo. Algunos comentarios también sugirieron abordar el problema mediante la comunicación, la orientación y la demostración de las limitaciones de la IA. (Fuente: Reddit r/ChatGPT)
Desafíos de la IA en la educación: Profesor se lamenta del abuso de ChatGPT por parte de los estudiantes y pide cultivar la capacidad de pensamiento real: Un profesor de historia antigua publicó en Reddit que el abuso de ChatGPT ha afectado gravemente su enseñanza, ya que los trabajos de los estudiantes están llenos de “basura vacía” generada por IA, que incluso contiene errores factuales, lo que le hace dudar de si los estudiantes realmente están aprendiendo. Enfatizó que el núcleo de la educación humanística es cultivar nuevos conocimientos, ideas creativas y pensamiento independiente, no simplemente repetir información existente. La publicación generó un acalorado debate, y los comentaristas propusieron diversas estrategias de respuesta, como cambiar a presentaciones orales, trabajos escritos a mano en clase, exigir a los estudiantes que presenten un metaanálisis del proceso de uso de la IA, o integrar la IA en la enseñanza, haciendo que los estudiantes critiquen los resultados de la IA. (Fuente: Reddit r/ChatGPT)
Kernel generado por IA supera inesperadamente al kernel experto de PyTorch, equipo chino de Stanford revela nuevas posibilidades: El equipo de Anne Ouyang, Azalia Mirhoseini y Percy Liang de la Universidad de Stanford, al intentar generar datos sintéticos para entrenar un modelo de generación de kernels, descubrió inesperadamente que su kernel generado por IA, escrito en puro CUDA-C, se acercaba e incluso superaba en rendimiento al kernel FP32 integrado en PyTorch, optimizado por expertos. Por ejemplo, en la multiplicación de matrices alcanzó el 101.3% del rendimiento de PyTorch, y en la convolución bidimensional el 179.9%. El equipo adoptó una optimización iterativa en múltiples rondas, combinando ideas de optimización del razonamiento en lenguaje natural y estrategias de búsqueda por expansión de ramas, utilizando los modelos OpenAI o3 y Gemini 2.5 Pro. Este logro indica que, mediante una búsqueda ingeniosa y una exploración paralela, la IA tiene el potencial de lograr avances en la generación de kernels de alto rendimiento computacional. (Fuente: WeChat)

💡 Otros
La poderosa fuerza de lobby de la industria de la IA atrae la atención de Max Tegmark: El profesor del MIT Max Tegmark señaló que el número de lobistas de la industria de la IA en Washington y Bruselas ya supera la suma de los de las industrias de combustibles fósiles y tabaco. Este fenómeno revela la creciente influencia de la industria de la IA en la formulación de políticas y su activa inversión en la configuración del entorno regulatorio, lo que podría tener un profundo impacto en la dirección del desarrollo de la tecnología de IA, las normas éticas y el panorama de la competencia en el mercado. (Fuente: Reddit r/artificial)

La IA podría simular ataques bioterroristas mediante deepfakes, constituyendo una nueva amenaza para la salud pública: Un artículo de STAT News señala que, además del riesgo de armas bioingenierizadas asistidas por IA, el uso de la tecnología deepfake para simular ataques bioterroristas también podría representar una grave amenaza. Especialmente entre países en conflicto militar, este tipo de información falsificada podría provocar pánico, errores de juicio y una escalada militar innecesaria. Dado que las investigaciones podrían ser dirigidas por organismos policiales o militares, en lugar de equipos de salud pública o técnicos, estos podrían estar más inclinados a creer en la autenticidad del ataque, lo que dificultaría su refutación efectiva. (Fuente: Reddit r/ArtificialInteligence)
Se debate si aún se debe cursar una carrera de ingeniería en la era de la IA: La comunidad debate el valor de cursar una carrera de ingeniería en la era de la IA. Una parte considera que la IA podría reemplazar muchas tareas de ingeniería tradicionales, disminuyendo el valor del título. Otra parte argumenta que el pensamiento sistémico, la capacidad de resolución de problemas y la base matemática y física que fomenta una carrera de ingeniería siguen siendo importantes, especialmente para comprender y aplicar herramientas de IA. Algunas opiniones señalan que si la IA puede reemplazar a los ingenieros, entonces otras profesiones tampoco estarían a salvo, y que la clave está en el aprendizaje continuo y la adaptación. Campos con un fuerte componente práctico y difíciles de automatizar, como la veterinaria, se consideran opciones relativamente seguras. (Fuente: Reddit r/ArtificialInteligence)