
Palabras clave:DeepSeek R1-0528, Máquina de Gödel de Darwin, Consumo energético de IA, Refuerzo del aprendizaje con recompensas falsas, Ascend de Huawei, Lista SuperCLUE, Pruebas de referencia multimodal, Mejora del rendimiento de DeepSeek R1-0528, Mecanismo de auto-evolución DGM, Solución de energía nuclear para centros de datos de IA, Mecanismo RLVR del modelo Qwen, Optimización del entrenamiento de Pangu Ultra MoE
🔥 Destacados
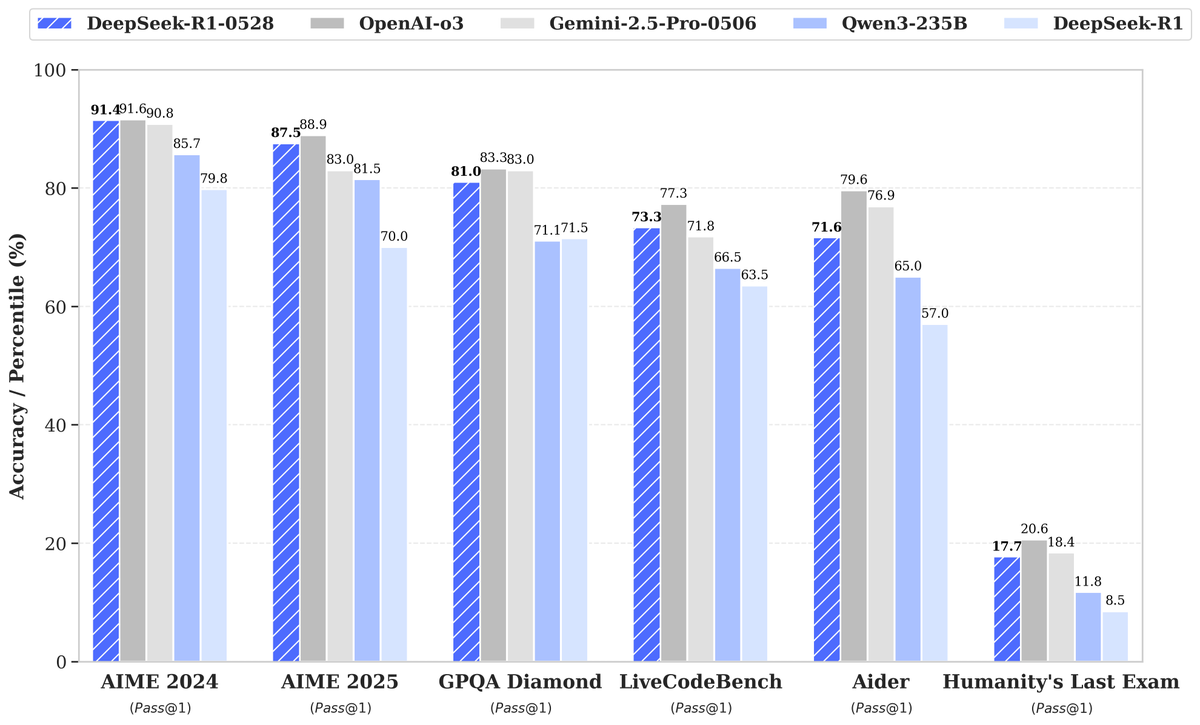
DeepSeek lanza el nuevo modelo R1-0528: una mejora significativa de rendimiento atrae la atención: DeepSeek ha lanzado una nueva versión de su gran modelo de lenguaje, R1-0528, que ha mostrado un rendimiento excelente en múltiples benchmarks, especialmente logrando avances significativos en áreas como la generación de código (LiveCodeBench), el razonamiento científico (GPQA Diamond) y las competiciones de matemáticas (AIME 2024). Artificial Analysis señala que R1-0528 ha saltado de 60 a 68 puntos en su índice de inteligencia, igualando a Gemini 2.5 Pro de Google, convirtiéndose en el segundo laboratorio de IA a nivel mundial, y consolidando su posición de liderazgo en el campo de los modelos de pesos abiertos. La comunidad ha reaccionado positivamente, y Unsloth ha lanzado rápidamente versiones cuantizadas GGUF para facilitar la implementación local. Esta actualización se ha logrado principalmente mediante técnicas de post-entrenamiento como el aprendizaje por refuerzo (RL), demostrando el potencial para mejorar continuamente la inteligencia del modelo sobre la base de la arquitectura y el preentrenamiento existentes, aunque algunas discusiones señalan que sus resultados a veces tienen un estilo “adulador”, en general se considera un gran avance en las capacidades de razonamiento y código. (Fuente: DeepSeek, Artificial Analysis, tokenbender, karminski3, teortaxesTex)
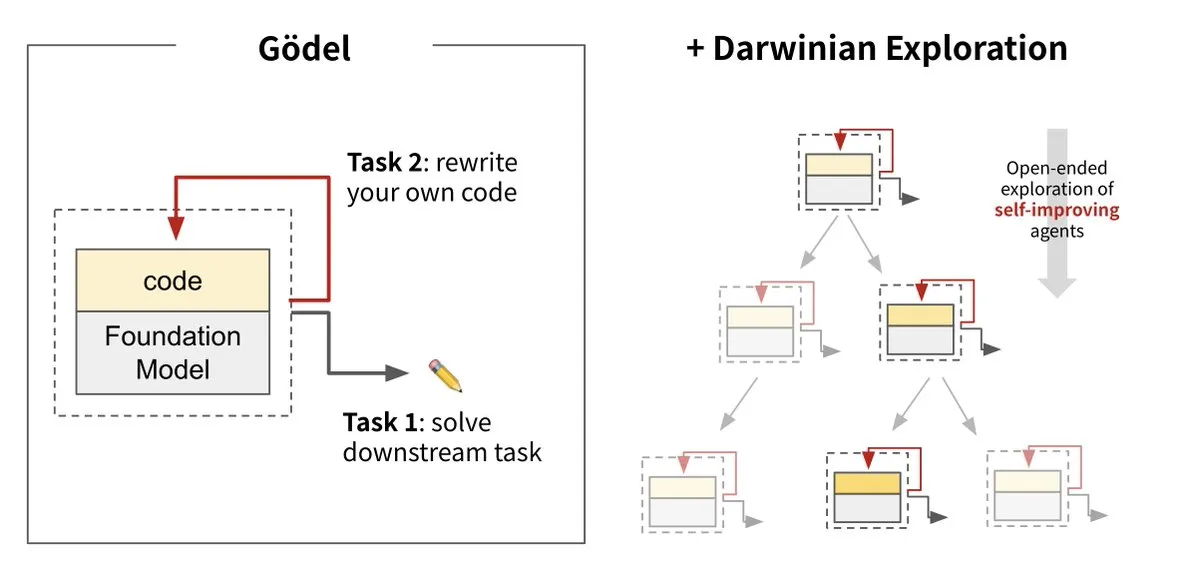
Sakana AI presenta la Darwin Gödel Machine (DGM), logrando la autoevolución de la IA: Sakana AI, en colaboración con UBC, ha presentado la Darwin Gödel Machine (DGM), un agente de IA capaz de auto-mejorarse continuamente reescribiendo su propio código. Inspirado en la teoría de la evolución, el sistema combina grandes modelos fundacionales y repositorios de código, permitiendo a los agentes proponer mejoras de código y auto-evaluarse. Los experimentos muestran que el rendimiento de DGM en SWE-bench aumentó del 20% al 50%, y en Polyglot la tasa de éxito pasó del 14.2% al 30.7%, superando significativamente a los agentes diseñados manualmente. Esta investigación se considera un paso importante hacia una IA capaz de aprender e innovar de forma autónoma, con el objetivo de resolver el problema de la inteligencia fija de los sistemas de IA tras su despliegue, y subraya la gran importancia de la seguridad durante el proceso de desarrollo. (Fuente: Sakana AI, hardmaru, ITmedia AI+)
El consumo de energía de la IA genera preocupación, con la energía nuclear y los combustibles fósiles como posibles fuentes de energía: La serie de reportajes “Power Hungry” de MIT Technology Review analiza en profundidad las necesidades energéticas previstas de la inteligencia artificial (IA). Los centros de datos de IA requieren un suministro de energía continuo y estable, especialmente para la inferencia de modelos. Aunque la energía solar y eólica son limpias, su intermitencia dificulta que satisfagan por sí solas la demanda de la IA, a menos que se combinen con costosas soluciones de almacenamiento. La energía nuclear se considera una solución potencial por su capacidad de proporcionar electricidad continua, pero la construcción de nuevas centrales nucleares es larga y compleja. Por lo tanto, los combustibles fósiles como el gas natural podrían convertirse en una dependencia a corto plazo para satisfacer la creciente demanda energética de la IA, lo que podría suponer un reto para los objetivos climáticos. El informe subraya que las grandes empresas tecnológicas deberían impulsar soluciones energéticas más limpias, como la tecnología de captura de carbono u optimizar la eficiencia del uso de la energía, para hacer frente al doble reto energético y climático que plantea el desarrollo de la IA. (Fuente: MIT Technology Review, The Download)

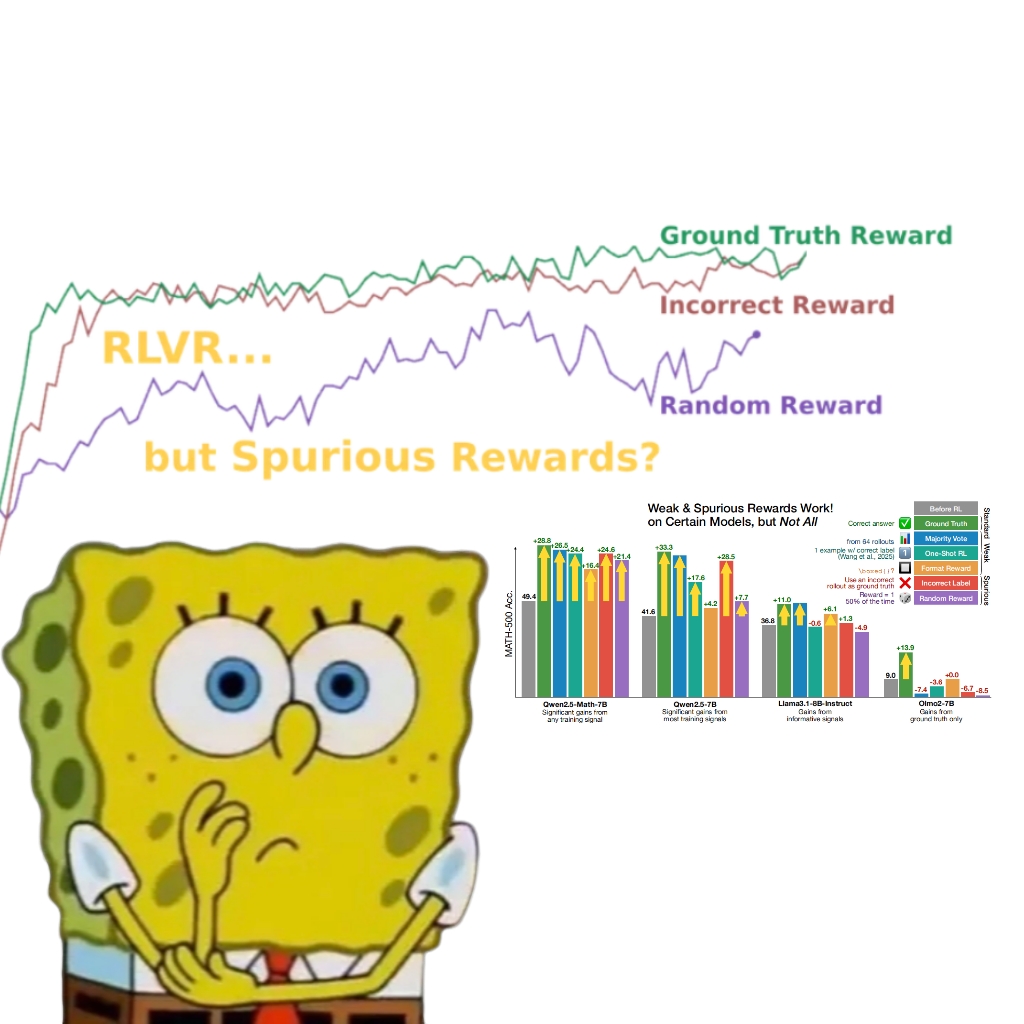
Investigación revela que las recompensas falsas también pueden mejorar el rendimiento del modelo Qwen, lo que lleva a reconsiderar el mecanismo RLVR: Un equipo de investigación de la Universidad de Washington descubrió que incluso utilizando señales de recompensa aleatorias o incorrectas, el entrenamiento del modelo Qwen2.5-Math mediante Reinforcement Learning with Verifiable Rewards (RLVR) puede mejorar significativamente su rendimiento en benchmarks de razonamiento matemático como MATH-500 en aproximadamente un 25%, acercándose al efecto de optimización de las recompensas reales. El estudio señala que este fenómeno se debe principalmente a estrategias específicas de razonamiento de código aprendidas por el modelo Qwen durante el preentrenamiento (como generar código Python para ayudar al pensamiento), y el proceso RLVR (especialmente cuando se utiliza el algoritmo GRPO) aumenta la frecuencia de este comportamiento beneficioso, en lugar de la corrección de la señal de recompensa en sí. Este hallazgo no se aplica a otros modelos que no poseen tales características de preentrenamiento (como OLMo2-7B), cuyo rendimiento apenas cambia o incluso disminuye con recompensas falsas. El estudio desafía la concepción tradicional de que RLVR depende de señales de recompensa correctas y advierte a los investigadores que estén atentos al impacto de comportamientos específicos del modelo en los resultados de la evaluación, enfatizando la importancia de la validación cruzada entre modelos. (Fuente: 量子位, Stella Li)
🎯 Tendencias
Huawei Ascend potencia el entrenamiento eficiente del modelo Pangu Ultra MoE de casi un billón de parámetros, logrando un control autónomo en todo el proceso: Huawei ha publicado un informe técnico que detalla su práctica de entrenamiento eficiente de extremo a extremo del modelo Pangu Ultra MoE (718 mil millones de parámetros) basado en el hardware Ascend AI y el framework MindSpore. Mediante la selección inteligente de estrategias paralelas, la profunda integración de cómputo y comunicación, y el equilibrio de carga dinámico global, entre otras tecnologías, se ha logrado un 41% de MFU (Model Flops Utilization) en el clúster de diez mil tarjetas Ascend Atlas 800T A2. En la etapa de post-entrenamiento RL, combinando la tecnología RL Fusion de entrenamiento e inferencia en la misma tarjeta y el mecanismo cuasi-asíncrono StaleSync, se ha alcanzado un alto rendimiento de 35K Tokens/s por supernodo en el clúster de 384 supernodos Ascend CloudMatrix, lo que equivale a procesar un problema de matemáticas avanzadas cada 2 segundos. Esto marca la madurez del ciclo cerrado de la potencia de cómputo de IA nacional y el entrenamiento de grandes modelos, y demuestra un rendimiento líder en la industria en el entrenamiento de modelos MoE a gran escala. (Fuente: 量子位)

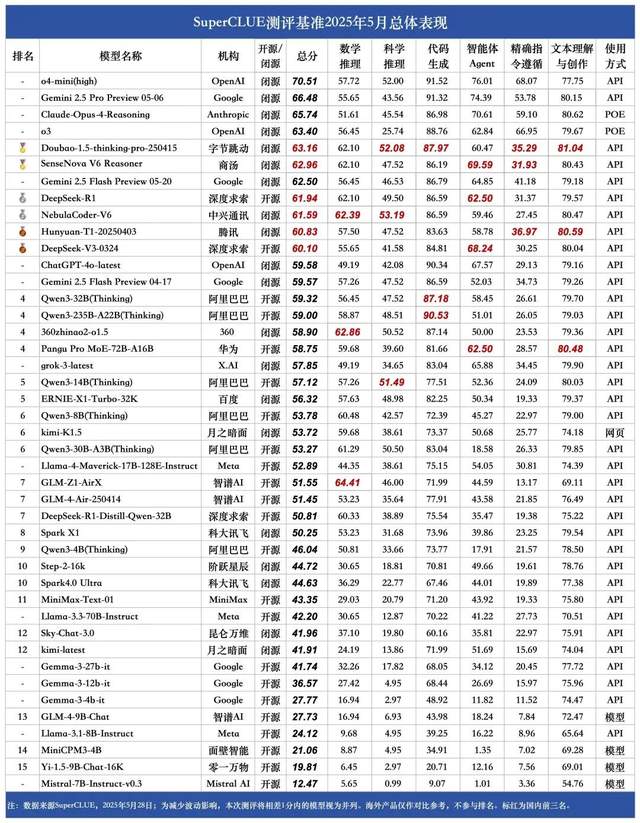
Ranking de mayo de SuperCLUE de grandes modelos en chino: Doubao 1.5 y SenseNova V6 de SenseTime empatados en el primer puesto nacional: La autoridad en evaluación de grandes modelos, SuperCLUE, ha publicado su “Informe de Evaluación de Benchmarks de Grandes Modelos en Chino” de mayo de 2025. El informe muestra que el modelo Doubao-1.5-thinking-pro de ByteDance y el modelo multimodal SenseNova-V6 Reasoner de SenseTime comparten el primer puesto a nivel nacional, y su rendimiento en capacidades generales en chino ya supera a Gemini 2.5 Flash Preview. Los modelos DeepSeek-R1, NebulaCoder-V6, Hunyuan-T1 y DeepSeek-V3 les siguen de cerca, situándose en el segundo grupo. El informe destaca que la brecha en las capacidades generales en el ámbito chino entre los principales grandes modelos nacionales e internacionales se está reduciendo, y el panorama competitivo de los modelos de inferencia nacionales está comenzando a tomar forma. Esta evaluación abarcó seis tareas principales: razonamiento matemático, razonamiento científico, generación de código, Agentes inteligentes, seguimiento preciso de instrucciones y comprensión y creación de texto. (Fuente: 量子位)
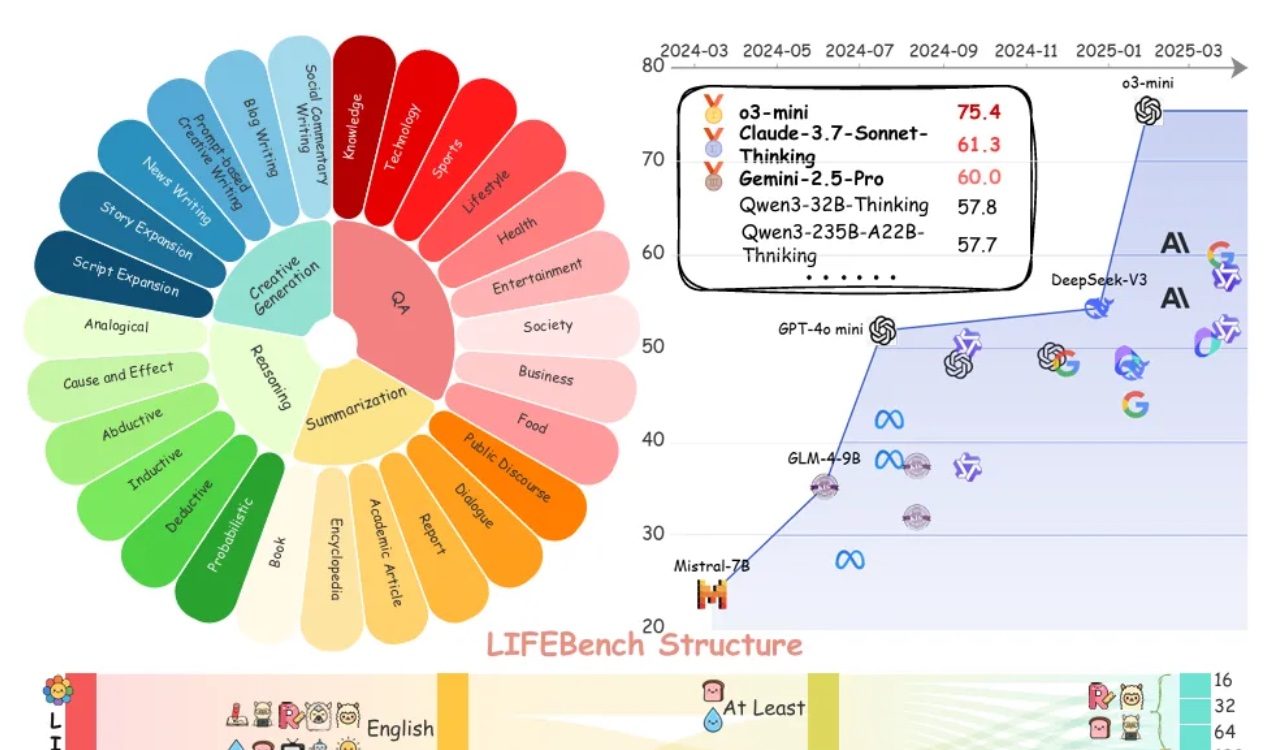
La evaluación LIFEBench muestra que los grandes modelos tienen deficiencias generalizadas en el seguimiento de instrucciones de longitud: Un nuevo benchmark llamado LIFEBench indica que los actuales grandes modelos de lenguaje (LLMs) principales tienen un rendimiento deficiente en el seguimiento de instrucciones de longitud de texto específicas, especialmente en la generación de textos largos. La investigación probó 26 modelos y descubrió que la mayoría obtuvieron puntuaciones bajas cuando se les pidió generar texto de una longitud precisa, con solo unos pocos modelos como o3-mini, Claude-Sonnet-Thinking y Gemini-2.5-Pro mostrando un rendimiento aceptable. La generación de texto largo (>2000 palabras) es una debilidad generalizada, con una caída significativa en las puntuaciones de todos los modelos. Además, los modelos generalmente rindieron peor en tareas en chino que en inglés, y tendieron a “sobregenerar”. El estudio también señaló que la longitud máxima de salida declarada por muchos modelos no se corresponde con su capacidad real, existiendo un fenómeno de “publicidad excesiva”. Los modelos presentan cuellos de botella en la percepción de la longitud, el procesamiento de entradas largas y la evitación de la “generación perezosa” (como la terminación prematura o la negativa a generar). (Fuente: 量子位)
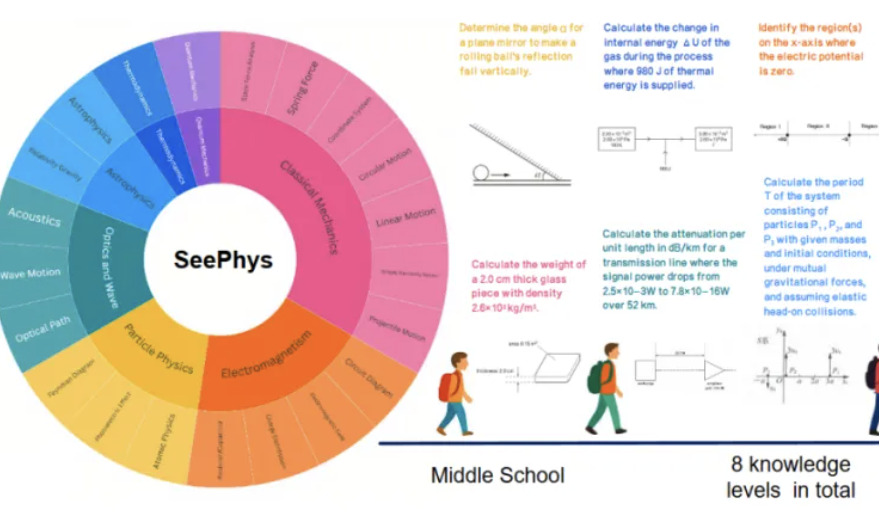
Nuevo benchmark SeePhys revela las deficiencias de los grandes modelos multimodales en la comprensión de imágenes físicas: Instituciones como la Universidad Sun Yat-sen han lanzado conjuntamente el benchmark SeePhys, diseñado específicamente para evaluar la capacidad de los grandes modelos multimodales (MLLM) para comprender y razonar sobre imágenes relacionadas con la física. Este benchmark contiene 2000 preguntas y 2245 diagramas que abarcan desde el nivel de secundaria hasta el de doctorado, cubriendo la física clásica y moderna. Los resultados de las pruebas muestran que incluso los modelos más avanzados como Gemini-2.5-Pro y o4-mini tienen una precisión inferior al 55% en SeePhys, especialmente al procesar tipos específicos de diagramas como circuitos eléctricos y gráficos de ecuaciones de onda, donde existen obstáculos sistemáticos de reconocimiento. La investigación también encontró que los modelos de lenguaje puro, en algunos casos, se desempeñan de manera similar a los modelos multimodales, lo que expone las deficiencias actuales de los MLLM en la alineación visual-textual. Este benchmark subraya la importancia de la percepción gráfica para que los modelos comprendan el mundo físico y revela los enormes desafíos actuales de la IA en tareas que acoplan diagramas científicos complejos con la derivación teórica. (Fuente: 量子位)
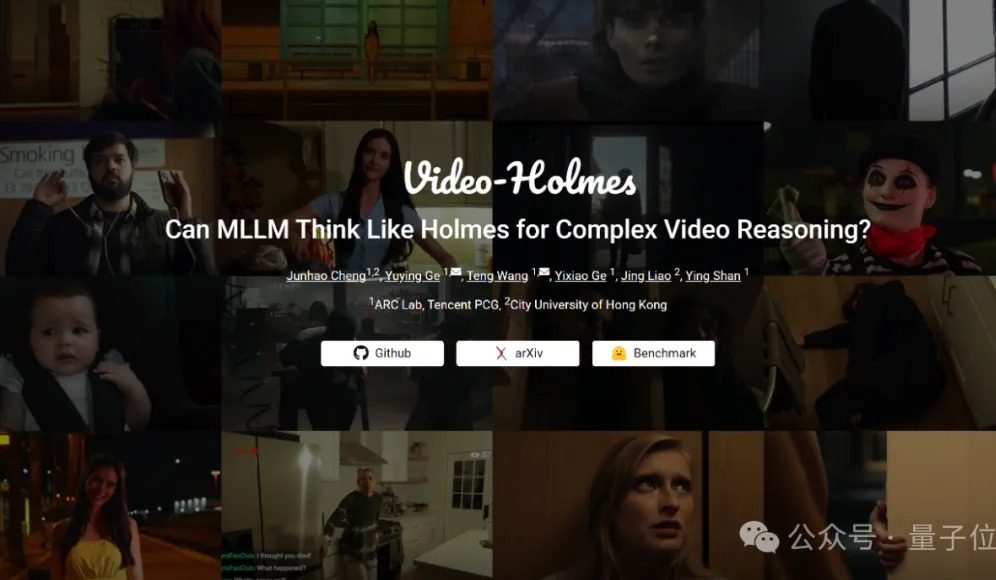
Benchmark Video-Holmes: los grandes modelos actuales suspenden en capacidad de razonamiento complejo de vídeo: Tencent ARC Lab y la City University of Hong Kong han lanzado el benchmark Video-Holmes, destinado a evaluar la capacidad de razonamiento complejo de vídeo de los grandes modelos multimodales (MLLM). Este benchmark incluye 270 “cortometrajes de misterio” y ha diseñado 7 tipos de preguntas de opción múltiple de alta exigencia de razonamiento, como “inferir al asesino” o “analizar la intención del crimen”, que requieren que el modelo extraiga y conecte información clave dispersa en el vídeo. Los resultados de las pruebas muestran que todos los grandes modelos evaluados, incluido Gemini-2.5-Pro, no alcanzaron la línea de aprobado (la precisión de Gemini-2.5-Pro fue de aproximadamente el 45%). El estudio señala que los modelos existentes pueden percibir información visual, pero presentan deficiencias generalizadas en la asociación de múltiples pistas y la captura de información clave, lo que dificulta la simulación del complejo proceso de razonamiento humano de búsqueda activa, integración y análisis. (Fuente: 量子位)
Meta considera clave la integración perfecta de los servicios de IA, utilizando el efecto de red social para aumentar la participación del usuario: Meta enfatiza que, aunque su modelo Llama no está en la cima de los rankings, la compañía posee una enorme ventaja en la carrera de la IA gracias a su vasto ecosistema de redes sociales (3.43 mil millones de usuarios activos diarios). Meta puede ofrecer a los usuarios herramientas de IA perfectamente integradas, algo que plataformas de IA independientes como ChatGPT difícilmente pueden igualar. La compañía ya ha aumentado el retorno para los anunciantes (el precio por anuncio aumentó un 10% interanual) mediante atractivas herramientas de IA y está monetizando rápidamente sus inversiones en IA. Se espera que el número de usuarios de la plataforma Meta AI supere los mil millones para fin de año. Sin embargo, los altos gastos de capital (estimados entre 64 y 72 mil millones de dólares para 2025) y las continuas pérdidas de Reality Labs (pérdidas anuales superiores a 15 mil millones de dólares) son obstáculos para su desarrollo, y el flujo de caja libre ya ha disminuido por ello. A pesar de esto, gracias a una valoración moderada y al potencial de comercialización a corto plazo, las acciones de Meta siguen siendo bien vistas. (Fuente: 36氪)

CEO de Google, Pichai: La IA está experimentando una nueva etapa de transformación de plataforma que remodelará el ecosistema de Internet: Sundar Pichai, CEO de Google, declaró después de la conferencia I/O que la IA está atravesando una transformación de plataforma similar al auge de los dispositivos móviles, con la particularidad de que la plataforma misma puede autocrearse y mejorarse, liberando la creatividad con un efecto multiplicador. Google está integrando ampliamente los resultados de su investigación en IA en toda su línea de productos, incluyendo Búsqueda, YouTube y servicios en la nube. La nueva función de búsqueda con IA ya está disponible para usuarios en EE. UU., generando páginas de resultados personalizadas en tiempo real que incluyen gráficos interactivos y módulos de aplicaciones personalizadas, lo que augura una búsqueda que va más allá de los enlaces web tradicionales. Pichai cree que, aunque esto podría cambiar el ecosistema de Internet (la IA ve la web como una base de datos estructurada), la cantidad de tráfico que Google dirige a la web sigue batiendo récords. Prevé una rápida explosión de la IA en aplicaciones empresariales (como IDEs de codificación, creación de vídeo, derecho, medicina) y considera que nuevas formas de hardware impulsadas por IA, como las gafas de RA, están llenas de oportunidades. (Fuente: 36氪)

Aplicaciones de IA como Zhipu Qingyan y Kimi acusadas de recopilar información personal de forma no conforme, generando preocupación por la privacidad: Recientemente, un informe oficial señaló que “Zhipu Qingyan” de Zhipu AI tiene el problema de que “la información personal recopilada realmente excede el alcance autorizado por el usuario”, mientras que “Kimi” de Moonshot AI “recopila información personal con una frecuencia que no está directamente relacionada con las funciones del negocio”. El señalamiento de estas dos aplicaciones estrella de IA ha generado una amplia preocupación pública sobre los riesgos de fuga de privacidad en los productos de IA generativa. La inteligencia de la IA generativa depende de sus características impulsadas por datos, lo que la enfrenta al dilema de equilibrar la mejora del rendimiento del modelo y la protección de la privacidad del usuario. El preentrenamiento con datos a gran escala es una condición necesaria para el desarrollo tecnológico, pero cualquier recopilación y uso indebido de información personal no conformes dañarán gravemente la confianza del usuario y la reputación de la industria. Este incidente expone problemas potenciales en el procesamiento de datos por parte de algunas empresas de IA, así como las deficiencias del marco actual de protección de datos para hacer frente a los desafíos de la tecnología de IA. (Fuente: 36氪)

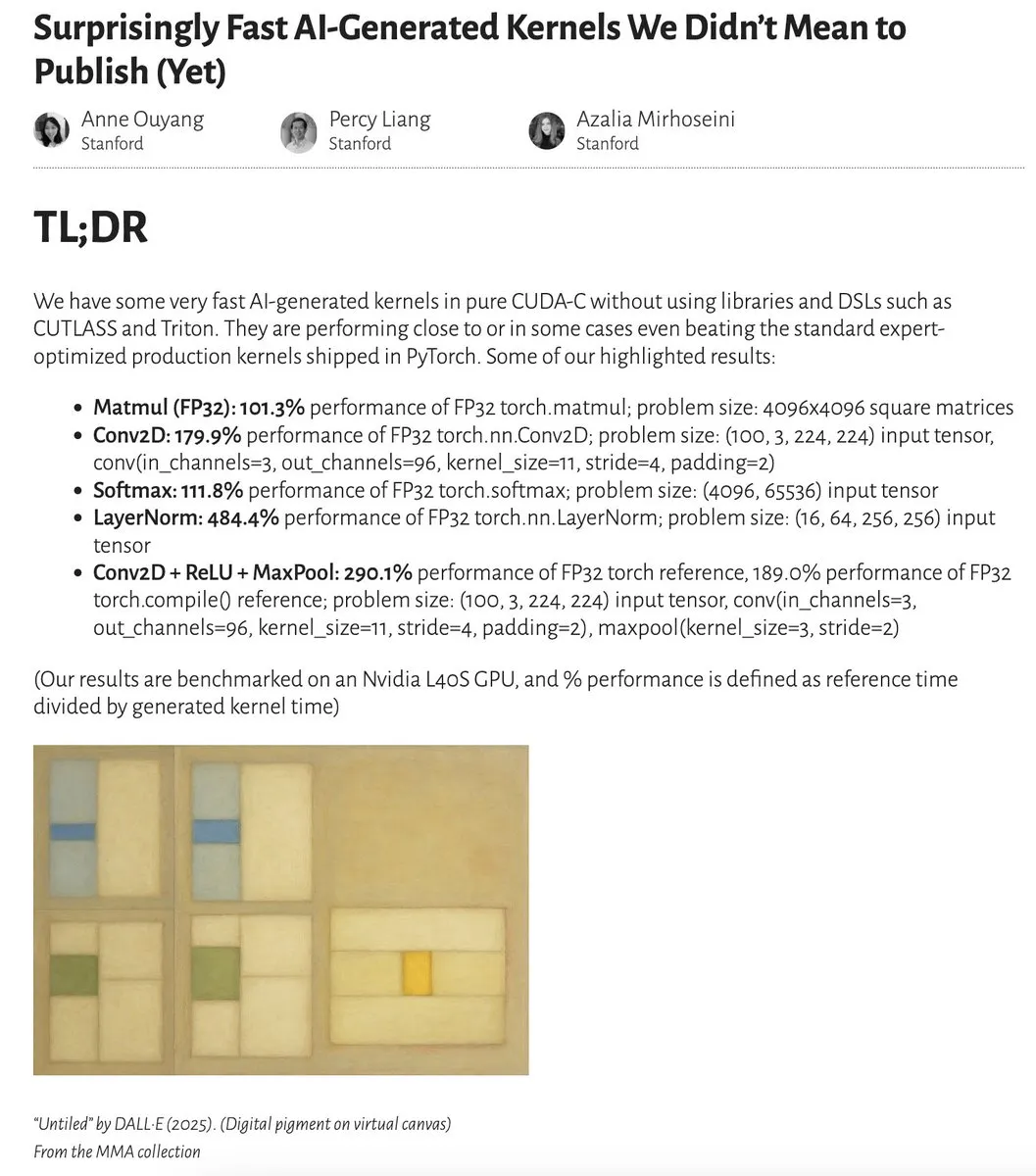
Los kernels generados por IA se acercan o incluso superan el rendimiento de los kernels optimizados por expertos: Anne Ouyang y sus colaboradores publicaron una investigación que demuestra que los kernels de IA generados mediante una simple búsqueda en tiempo de prueba se acercan en rendimiento, e incluso en algunos casos superan, a los kernels de producción estándar optimizados por expertos en PyTorch. Fleetwood realizó una reproducción preliminar del kernel LayerNorm en Colab, confirmando su impresionante mejora de rendimiento (aproximadamente 484.4%). Este avance indica el enorme potencial de la IA en la optimización de código de bajo nivel, e incluso podría afectar el trabajo de los ingenieros de kernels. Sin embargo, una actualización posterior señaló que el kernel LayerNorm generado tiene problemas de inestabilidad numérica, advirtiendo a los usuarios que lo utilicen con precaución. (Fuente: eliebakouch, fleetwood___)
Discusión: ¿Pueden los grandes modelos de lenguaje poseer verdadera creatividad?: MoritzW42 publicó un artículo discutiendo el problema de la creatividad en los grandes modelos de lenguaje (LLM), argumentando que los LLM son inherentemente incapaces de poseer verdadera creatividad. Cita la definición de creatividad del físico David Deutsch —la capacidad de crear nuevo conocimiento a través de conjeturas y críticas— y considera que esto es similar a la variación y selección en el proceso evolutivo. Los LLM dependen de la probabilidad inductiva y los patrones en los datos de entrenamiento, y no pueden realizar conjeturas creativas ni resolver nuevos problemas, como generar instancias de “cisnes negros” no vistas en los datos de entrenamiento (por ejemplo, una copa de vino llena hasta el borde). El artículo sostiene que los LLM son más bien herramientas para potenciar la creatividad humana que entidades con creatividad autónoma, por lo que el miedo hacia ellos es irracional. (Fuente: MoritzW42)
Discusión: La construcción de agentes de IA debe evitar la dependencia del proveedor, centrarse en el modelo en sí: El punto de vista de Austin Vance (reenviado por rachel_l_woods) señala que un error importante al construir agentes de IA es caer en la dependencia del proveedor. Empresas como OpenAI, Anthropic y Google tienden a promover sus API integradas, pero esto genera enormes costos de cambio sin aportar valor adicional. Enfatiza que lo que impulsa el rendimiento es el modelo en sí, no la API. Dado que la posición de los modelos en los rankings cambia con frecuencia, el uso de frameworks de código abierto e independientes del modelo (como LangChain) y herramientas (como LangSmith) garantiza que las empresas puedan elegir el mejor modelo del momento, en lugar de estar limitadas a las opciones ofrecidas por laboratorios de modelos fundacionales específicos. (Fuente: rachel_l_woods)
Discusión: La función de resumen de IA presenta riesgos de inyección de prompts: Zack Witten descubrió y demostró que se puede realizar una inyección de prompts (prompt injection) en la función de resumen de IA (AI overview), lo que significa que se pueden manipular las entradas especialmente diseñadas para que la IA genere información resumida no deseada o engañosa. Charles IRL y otros usuarios reenviaron y prestaron atención a esta vulnerabilidad de seguridad, señalando la necesidad de prestar atención a su robustez y seguridad al aplicar ampliamente tales funciones de IA. (Fuente: charles_irl, giffmana)
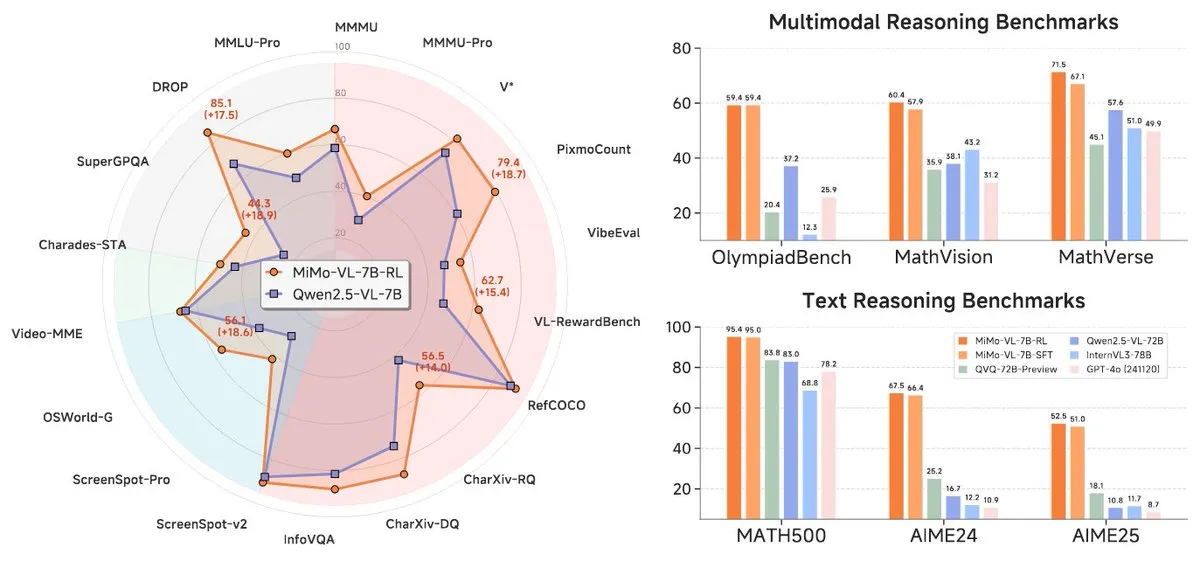
Xiaomi lanza la nueva serie de modelos MiMo-7B, destacando en el nivel de 7B: Xiaomi ha lanzado sus modelos de inferencia actualizados de 7B, MiMo-7B-RL-0530, y su versión de modelo de lenguaje visual, MiMo-VL-7B-RL, afirmando alcanzar el nivel SOTA (State-of-the-Art) en su escala de parámetros. Estos modelos son compatibles con la arquitectura Qwen-VL, pueden ejecutarse en frameworks como vLLM, Transformers, SGLang y Llama.cpp, y se distribuyen bajo la licencia MIT de código abierto. La versión MiMo-VL-RL muestra mejoras significativas en múltiples benchmarks de texto en comparación con el MiMo-7B-RL de solo texto, al tiempo que añade capacidades visuales, lo que ha generado un debate en la comunidad sobre si está excesivamente optimizado para los benchmarks o si ha logrado un progreso multimodal sustancial. (Fuente: reach_vb, teortaxesTex, Reddit r/LocalLLaMA)
🧰 Herramientas
Black Forest Labs lanza FLUX.1 Kontext, logrando edición de imágenes a nivel de píxel y generación contextual: Black Forest Labs (BFL), fundada por miembros del equipo inventor de la tecnología central de Stable Diffusion, ha lanzado un nuevo conjunto de modelos de generación y edición de imágenes llamado FLUX.1 Kontext. Este modelo, basado en la arquitectura de flow matching, puede comprender simultáneamente entradas de texto e imágenes, logrando generación basada en contexto y edición multivuelta, manteniendo una excelente consistencia de personajes. FLUX.1 Kontext admite la edición local sin afectar otras partes, puede generar escenas del mismo estilo haciendo referencia al estilo de entrada y tiene baja latencia. Actualmente se han lanzado las versiones Pro y Max, y está disponible en plataformas como KreaAI y Freepik, con el objetivo de proporcionar a los equipos creativos empresariales capacidades de edición de imágenes más precisas y rápidas. La retroalimentación de la comunidad es positiva, afirmando que puede lograr una edición perfecta a nivel de píxel. (Fuente: 36氪, timudk, op7418, lmarena_ai)

Simon Willison lanza la herramienta CLI LLM para un acceso conveniente a múltiples grandes modelos: Simon Willison ha desarrollado una herramienta de línea de comandos y biblioteca de Python llamada LLM, que permite a los usuarios interactuar con múltiples grandes modelos de lenguaje como OpenAI, Anthropic Claude, Google Gemini, Meta Llama, etc., a través de la línea de comandos, admitiendo API remotas y modelos implementados localmente. La herramienta puede ejecutar prompts, almacenar prompts y respuestas en SQLite, generar y almacenar embeddings, extraer contenido estructurado de texto e imágenes, etc. Los usuarios pueden instalarla mediante pip o Homebrew, y pueden usar modelos locales instalando plugins (como llm-ollama). Admite un modo de chat interactivo, lo que facilita a los usuarios conversar con los modelos. (Fuente: GitHub Trending)

Contextual.ai lanza un analizador de documentos optimizado para RAG: Contextual.ai ha lanzado un analizador de documentos diseñado específicamente para aplicaciones de generación aumentada por recuperación (RAG). Esta herramienta combina modelos de visión, OCR y lenguaje visual de vanguardia, con el objetivo de proporcionar una extracción de contenido de documentos de alta precisión. Los usuarios pueden probarlo de forma gratuita, con las primeras 500 páginas gratuitas. Esto es muy útil para escenarios que requieren extraer información de documentos complejos para su uso por LLM, lo que ayuda a mejorar el rendimiento y la precisión de los sistemas RAG. (Fuente: douwekiela)
Alibaba lanza Tongyi Lingma AI IDE, integrando completado de código y modo Agente: Alibaba ha lanzado un entorno de desarrollo integrado (IDE) de IA llamado “Tongyi Lingma”. Este IDE cuenta con funciones como completado de código, MCP (Model-Copilot-Playground), modo Agente, memoria a largo plazo y completado multilínea. Actualmente es compatible con los modelos Qwen y DeepSeek, y los usuarios esperan que en el futuro se añada soporte para otros modelos. La retroalimentación inicial de los usuarios indica que su panel de chat aún tiene margen de mejora en cuanto a la búsqueda en línea y la función de mención @, pero en general ofrece a los desarrolladores una nueva herramienta que integra capacidades de programación asistida por IA. (Fuente: karminski3, karminski3)
Perplexity Labs presenta nueva función para crear aplicaciones e informes a partir de prompts: La plataforma Labs de Perplexity AI ha mostrado nuevas funciones que permiten a los usuarios crear aplicaciones e informes interactivos mediante prompts. Por ejemplo, un usuario generó con éxito un panel de control que comparaba el rendimiento a 5 años de una cartera de acciones tradicional con una cartera impulsada por IA, obteniendo resultados muy precisos. Otro usuario utilizó la plataforma para comparar diferentes modelos LLM y se mostró satisfecho con los resultados. Estos casos demuestran el progreso de Perplexity en la transformación de las capacidades de IA en herramientas de análisis prácticas, especialmente en áreas como la investigación financiera. (Fuente: AravSrinivas, AravSrinivas, TheRundownAI)

Unsloth lanza versiones cuantizadas GGUF de DeepSeek-R1-0528 para ejecución local: Unsloth ha creado versiones cuantizadas GGUF para el recién lanzado modelo DeepSeek-R1-0528, incluyendo IQ1_S (185GB), Q2_K_XL (251GB) y otras especificaciones, facilitando a los usuarios la ejecución de este gran modelo en hardware local (como RTX 4090/3090 con suficiente VRAM). Mediante el uso de parámetros como -ot ".ffn_.*_exps.=CPU", se pueden descargar algunas capas MoE a la RAM, permitiendo la inferencia con VRAM limitada. Esto proporciona comodidad a los usuarios que desean experimentar e investigar las potentes funciones de DeepSeek R1 localmente. (Fuente: karminski3, Reddit r/LocalLLaMA)

local-ai-packaged: Entorno de desarrollo de IA local integrado con Ollama, Supabase, etc.:coleam00/local-ai-packaged es una plantilla de Docker Compose de código abierto diseñada para configurar rápidamente un entorno de desarrollo de IA local y de bajo código con todas las funciones. Integra Ollama (ejecución local de LLM), Supabase (base de datos, almacenamiento de vectores, autenticación), n8n (automatización de bajo código), Open WebUI (interfaz de chat), Flowise (constructor de agentes de IA), Neo4j (grafo de conocimiento), Langfuse (observabilidad de LLM), SearXNG (metabuscador) y Caddy (gestión de HTTPS). Este proyecto facilita a los desarrolladores la integración y el uso de diversas herramientas y servicios de IA en un entorno local. (Fuente: GitHub Trending)
Resemble AI lanza la herramienta de voz AI de código abierto ChatterBox, compatible con control emocional: Resemble AI ha lanzado una herramienta de voz AI de código abierto llamada ChatterBox. Esta herramienta permite a los usuarios diseñar, clonar y editar voces de forma gratuita, y puede controlar las emociones. Se afirma que ChatterBox supera en rendimiento a algunos de los principales servicios comerciales de voz AI (como Elevenlabs), proporcionando a los desarrolladores y creadores de contenido potentes capacidades de síntesis y edición de voz. (Fuente: ClementDelangue)
Mem0.ai se combina con Qdrant para proporcionar una solución de memoria a largo plazo para agentes de IA: El framework Mem0.ai, combinado con la base de datos vectorial Qdrant, ofrece una solución de memoria a largo plazo para agentes de IA. Esta solución tiene como objetivo ayudar a los agentes a mantener el contexto, recordar hechos y mantener la coherencia en las conversaciones. Los usuarios pueden implementarlo en la nube o de forma local (código abierto), conectando Mem0 a Qdrant para almacenar memoria vectorial a largo plazo. Esto es de gran importancia para construir aplicaciones de IA que requieren memoria persistente y capacidades de conversación complejas. (Fuente: qdrant_engine)

📚 Aprendizaje
Nueva investigación de la Universidad de Tokio: El metaaprendizaje en contexto induce la emergencia de circuitos multifásicos en LLM: Un estudio de la Universidad de Tokio titulado “Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence” explora estructuras más complejas dentro de los grandes modelos de lenguaje (LLM). La investigación descubre que durante el metaaprendizaje en contexto (in-context meta-learning), los LLM pueden inducir la emergencia de circuitos multifásicos, lo que va más allá de los mecanismos simples previamente entendidos como los cabezales de inducción (induction heads). Este estudio ofrece una nueva perspectiva sobre cómo los LLM aprenden a través del contexto y forman representaciones internas complejas. (Fuente: teortaxesTex, [email protected])

MLflow mejora el soporte para flujos de trabajo de optimización de DSPy, aumentando la observabilidad: MLflow ha anunciado soporte para el seguimiento de los flujos de trabajo de optimización de DSPy (un framework para construir y optimizar aplicaciones de modelos de lenguaje), similar a su soporte para el entrenamiento de PyTorch. A través de las funciones de seguimiento y registro automático de MLflow, los desarrolladores pueden depurar y monitorear sin problemas las llamadas a módulos, evaluaciones y optimizadores de DSPy, lo que permite una mejor comprensión e iteración de los flujos de trabajo de GenAI, logrando una gestión de extremo a extremo desde el desarrollo hasta la implementación. Esto proporciona a los desarrolladores que utilizan DSPy para la ingeniería de prompts y el desarrollo de aplicaciones LLM una mayor observabilidad y prácticas de MLOps. (Fuente: lateinteraction, dennylee)

Nuevo artículo explora el método de auto-mejora UniRL para modelos multimodales unificados: El artículo “UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning” presenta un método de post-entrenamiento de auto-mejora llamado UniRL. Este método permite a los modelos generar imágenes basadas en prompts y utilizar estas imágenes como datos de entrenamiento iterativos, sin necesidad de datos de imágenes externas. También logra una mejora mutua entre las tareas de generación y comprensión: las imágenes generadas se utilizan para la comprensión, y los resultados de la comprensión se utilizan para supervisar la generación. Los investigadores exploraron el ajuste fino supervisado (SFT) y la optimización de políticas relativas de grupo (GRPO) para optimizar modelos como Show-o y Janus. Las ventajas de UniRL radican en que no necesita datos de imágenes externas, puede mejorar el rendimiento de tareas únicas y reducir el desequilibrio entre generación y comprensión, y solo requiere unos pocos pasos de entrenamiento adicionales. (Fuente: HuggingFace Daily Papers)
Artículo Fast-dLLM: Aceleración de Diffusion LLM mediante KV Cache y decodificación paralela: El artículo “Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding” aborda el problema de la lenta velocidad de inferencia de los grandes modelos de lenguaje basados en difusión (Diffusion LLM) proponiendo un método de aceleración sin necesidad de entrenamiento. Este método introduce un mecanismo de KV cache aproximado a nivel de bloque personalizado para modelos de difusión bidireccionales y propone una estrategia de decodificación paralela sensible a la confianza para mantener la calidad de la generación al decodificar múltiples tokens simultáneamente. Los experimentos demuestran que este método logra un aumento de hasta 27.6 veces en el rendimiento en los modelos LLaDA y Dream, con una pérdida de precisión mínima, lo que ayuda a cerrar la brecha de rendimiento entre los Diffusion LLM y los modelos autorregresivos. (Fuente: HuggingFace Daily Papers)
Artículo Uni-Instruct: Modelo de difusión de un solo paso mediante instrucción unificada de divergencia de difusión: El artículo “Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction” propone un marco teórico llamado Uni-Instruct, que unifica más de 10 métodos existentes de destilación de difusión de un solo paso. Este marco se basa en la teoría de extensión de difusión de la familia de f-divergencias propuesta por los autores e introduce una teoría clave para superar los problemas intratables de la f-divergencia extendida original, obteniendo así una función de pérdida equivalente y fácil de manejar, que entrena eficazmente modelos de difusión de un solo paso minimizando la familia de f-divergencias extendidas. Uni-Instruct logra un rendimiento de generación de un solo paso SOTA en benchmarks como CIFAR10 e ImageNet-64×64, y ya se ha aplicado a tareas como la generación de texto a 3D. (Fuente: HuggingFace Daily Papers)
Nueva investigación explora la relación entre la capacidad de razonamiento de los grandes modelos de lenguaje y el fenómeno de las alucinaciones: El artículo “¿Son los modelos de razonamiento más propensos a las alucinaciones?” (Are Reasoning Models More Prone to Hallucination?) investiga si los grandes modelos de razonamiento (LRM), al mismo tiempo que muestran una potente capacidad de razonamiento de cadena de pensamiento (CoT), son más propensos a generar alucinaciones. El estudio encuentra que los LRM que han pasado por un proceso completo de post-entrenamiento (incluyendo SFT de arranque en frío y RL con recompensa verificable) generalmente pueden mitigar las alucinaciones, mientras que el entrenamiento solo mediante destilación o RL sin ajuste fino de arranque en frío puede introducir alucinaciones más sutiles. El estudio también analiza los comportamientos cognitivos clave que conducen a las alucinaciones (como la repetición defectuosa, la falta de coincidencia entre el pensamiento y la respuesta) y el desajuste entre la incertidumbre del modelo y la precisión fáctica. (Fuente: HuggingFace Daily Papers)
Artículo presenta KVzip: Compresión de KV cache agnóstica a la consulta con reconstrucción de contexto: El artículo “KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction” presenta un método de desalojo de KV cache agnóstico a la consulta llamado KVzip, diseñado para reutilizar eficazmente la KV cache comprimida para hacer frente a diferentes consultas. KVzip cuantifica la importancia de los pares KV almacenados en caché reconstruyendo el contexto original a partir de ellos mediante el LLM subyacente, y desaloja los pares KV menos importantes. Los experimentos demuestran que KVzip puede reducir el tamaño de la KV cache entre 3 y 4 veces, disminuir la latencia de decodificación de FlashAttention aproximadamente 2 veces, y presenta una pérdida de rendimiento insignificante en tareas como preguntas y respuestas, recuperación, razonamiento y comprensión de código, admitiendo contextos de hasta 170K tokens. (Fuente: HuggingFace Daily Papers)
💼 Negocios
Último informe financiero de NVIDIA muestra un aumento de ingresos del 69%, la demanda de chips de IA sigue siendo fuerte: El gigante de los chips de IA, NVIDIA, publicó su último informe financiero, con ventas trimestrales que alcanzaron los 44.1 mil millones de dólares, un aumento interanual del 69%, y un beneficio neto que creció un 26% interanual, hasta los 18.78 mil millones de dólares. Aunque las ventas superaron las expectativas, el beneficio fue ligeramente inferior a lo esperado. Las restricciones de EE. UU. a la exportación de chips a China causaron a la empresa pérdidas por valor de 4.5 mil millones de dólares, pero la compañía prevé que los ingresos del próximo trimestre sigan creciendo un 50% interanual, hasta los 45 mil millones de dólares, principalmente gracias a las ventas de su chip de IA más reciente, Blackwell. El CEO de NVIDIA, Jensen Huang, afirmó que los países de todo el mundo se han dado cuenta de que la IA se convertirá en infraestructura. Impulsada por el informe financiero, la capitalización de mercado de NVIDIA superó brevemente a la de Apple, situándose como la segunda más grande del mundo. La empresa está expandiendo activamente sus mercados en Europa, Asia y Oriente Medio, y la venta de chips a clientes gubernamentales se ha convertido en una importante dirección estratégica. (Fuente: dotey)

Los principales capitalistas de riesgo de Silicon Valley se vuelcan al hardware de IA, buscando la próxima generación de terminales de interacción: Con el rápido desarrollo de los algoritmos de IA, la dirección de la inversión en Silicon Valley está cambiando de la optimización pura de algoritmos hacia dispositivos de hardware capaces de soportar las capacidades de IA. Gigantes como Google, OpenAI (que adquirió la empresa de hardware de IA io), Meta y Apple están realizando movimientos activos en el campo del hardware de IA, como gafas inteligentes y dispositivos de RA. Sequoia Capital invirtió en las gafas de IA Brilliant Labs, e IDG Capital invirtió en el portátil sin pantalla Spacetop. Empresas emergentes como Celestial AI (interconexión de chips fotónicos), NeuroFlex (materiales flexibles para interfaces cerebro-máquina), Luminai (módulos de RA ligeros), BioLink Systems (sensores de IA digeribles) y SynthSense (sistemas sensoriales robóticos multimodales) también están impulsando la innovación en hardware de IA en sus respectivos campos. Esto refleja la importancia que la industria otorga al “cuerpo” de la IA, creyendo que la innovación en hardware determinará la velocidad y los límites de la implementación de la tecnología de IA y remodelará la forma de interacción humano-máquina. (Fuente: 36氪)

Sequoia invierte en una nueva startup de agentes de programación de IA, desafiando a los gigantes existentes: Según LiorOnAI, Sequoia Capital ha invertido en una nueva startup cuyo objetivo es desafiar a las herramientas de programación de IA existentes como Devin, Cursor y OpenAI Codex. Se dice que el agente de IA desarrollado por la compañía es capaz de leer repositorios de código completos y completar automáticamente tareas como escribir, probar, corregir y fusionar pull requests (PR), con el objetivo de proporcionar un asistente de ingeniero de software totalmente autónomo y disponible las 24 horas del día. Esto marca una mayor intensificación de la competencia en el campo de la automatización del desarrollo de software mediante IA. (Fuente: LiorOnAI)
🌟 Comunidad
Debate en la comunidad sobre las deficiencias de los LLM en el seguimiento de instrucciones de longitud y la “publicidad excesiva”: La investigación de LIFEBench ha generado debate en la comunidad, donde muchos usuarios y desarrolladores coinciden en las deficiencias de los actuales grandes modelos de lenguaje para seguir instrucciones de longitud precisas, especialmente en la generación de textos largos. Los miembros de la comunidad señalan que los modelos a menudo generan contenido que no coincide con la longitud solicitada, terminan prematuramente o incluso se niegan a generar textos largos. Al mismo tiempo, el número máximo de tokens de salida declarado por los modelos a menudo difiere de su capacidad de generación efectiva real, siendo común el fenómeno de la “publicidad excesiva”. Se espera que los futuros modelos, mediante mejores estrategias de entrenamiento y sistemas de evaluación, mejoren su capacidad para ejecutar instrucciones de longitud y su rendimiento real, logrando “cumplir con el recuento de palabras y con contenido de calidad”. (Fuente: 量子位)
Usuarios reportan fenómeno de excesiva “adulación” (Glazing) en chatbots de IA: Usuarios de la comunidad de Reddit informan que, al usar chatbots de IA como ChatGPT, encuentran con frecuencia que el modelo elogia y afirma excesivamente las preguntas o entradas del usuario (coloquialmente conocido como “glazing” o “sycophancy”), por ejemplo, “¡Esa es una observación muy inteligente!”. Los usuarios expresan su molestia, considerando que esta adulación es innecesaria y afecta la naturalidad de la interacción. Los miembros de la comunidad discuten métodos para reducir este fenómeno mediante prompts específicos (como pedir al modelo que responda de manera directa, objetiva y neutral) y comparten sus experiencias y sentimientos. DeepSeek-R1-0528 también ha sido señalado por algunos usuarios por tener una tendencia similar. (Fuente: Reddit r/ChatGPT, teortaxesTex)

Discusión en la comunidad: ¿Está la IA realmente “quitando empleos” o exponiendo la redundancia de los puestos de “intermediario”?: En Reddit se discute que, más que “quitarnos el trabajo”, la IA está exponiendo la naturaleza de “intermediario” y la potencial redundancia de muchos trabajos existentes (como procesar documentos, reenviar correos electrónicos, transmitir información entre quienes toman decisiones, etc.). Este punto de vista ha provocado una reflexión sobre la naturaleza del trabajo, la distribución del valor social y la transformación del papel humano en la era de la IA. Los comentaristas señalan que, incluso si algunos trabajos son efectivamente de naturaleza “intermediaria”, proporcionan un sustento a las personas, y la transformación provocada por la IA requiere apoyo a nivel social y el desarrollo de nuevas habilidades. (Fuente: Reddit r/ArtificialInteligence)
Ollama genera descontento entre usuarios de la comunidad por nombres de modelos inexactos: En la comunidad de Reddit r/LocalLLaMA, un usuario señaló que Ollama tiene inexactitudes o nombres que pueden generar confusión en la denominación de sus modelos. Por ejemplo, abreviar DeepSeek-R1-Distill-Qwen-32B como deepseek-r1:32b podría llevar a los usuarios novatos a creer erróneamente que están ejecutando un modelo DeepSeek puro, ignorando su naturaleza de destilación de Qwen. Los usuarios consideran que esta forma de nombrar no es coherente con las costumbres de plataformas como HuggingFace, carece de transparencia y podría llevar a los usuarios a tener una percepción errónea de las características del modelo. (Fuente: Reddit r/LocalLLaMA)

Los lenguajes de programación han contribuido enormemente al éxito de los grandes modelos de lenguaje: La discusión en la comunidad enfatiza que los lenguajes de programación, como corpus de entrenamiento de alta calidad, debido a su clara definición lógica y la facilidad para verificar la corrección de los resultados, han desempeñado un papel crucial en el exitoso desarrollo de los grandes modelos de lenguaje. No solo han proporcionado a los modelos una fuente de conocimiento estructurado, sino que también han sentado las bases para que los modelos aprendan el razonamiento y la generación de código ejecutable. (Fuente: dotey)

💡 Otros
Indoor Robotics presenta un dron robot de seguridad de navegación autónoma basado en IA: La empresa Indoor Robotics ha presentado un dron robot de seguridad de navegación autónoma basado en inteligencia artificial. Este dron, diseñado específicamente para entornos interiores, puede realizar de forma autónoma tareas de patrulla y vigilancia de seguridad, utilizando IA para la navegación y la identificación de amenazas, ofreciendo una solución innovadora y automatizada para la seguridad en interiores. (Fuente: Ronald_vanLoon, Ronald_vanLoon)
Unitree Robotics actualiza el robot industrial con ruedas B2-W, mejorando sus funciones: Unitree Robotics ha actualizado las funciones de su robot industrial con ruedas B2-W, dotándolo de capacidades más emocionantes. Este robot combina la flexibilidad de la movilidad sobre ruedas con la versatilidad de un robot, y está diseñado para aplicarse en diversos escenarios industriales, mejorando el nivel de automatización y la eficiencia operativa. (Fuente: Ronald_vanLoon)
Lenovo presenta el robot hexápodo Daystar, dirigido a los sectores industrial, de investigación y educativo: Lenovo ha presentado un robot hexápodo llamado Daystar. Este robot está diseñado específicamente para aplicaciones industriales, investigación científica y fines educativos. Su estructura de múltiples patas le permite adaptarse a terrenos complejos, ofreciendo una nueva opción de plataforma robótica para los campos relevantes. (Fuente: Ronald_vanLoon)