
Palabras clave:DeepSeek-R1-0528, Agente de IA, Modelo multimodal, IA de código abierto, Aprendizaje por refuerzo, Edición de imágenes, Modelo de lenguaje grande (LLM), Evaluación comparativa de IA, DeepSeek-R1-0528-Qwen3-8B, Herramienta Circuit Tracer, Máquina Darwin Gödel, FLUX.1 Kontext, Recuperación agentica
🔥 Enfoque
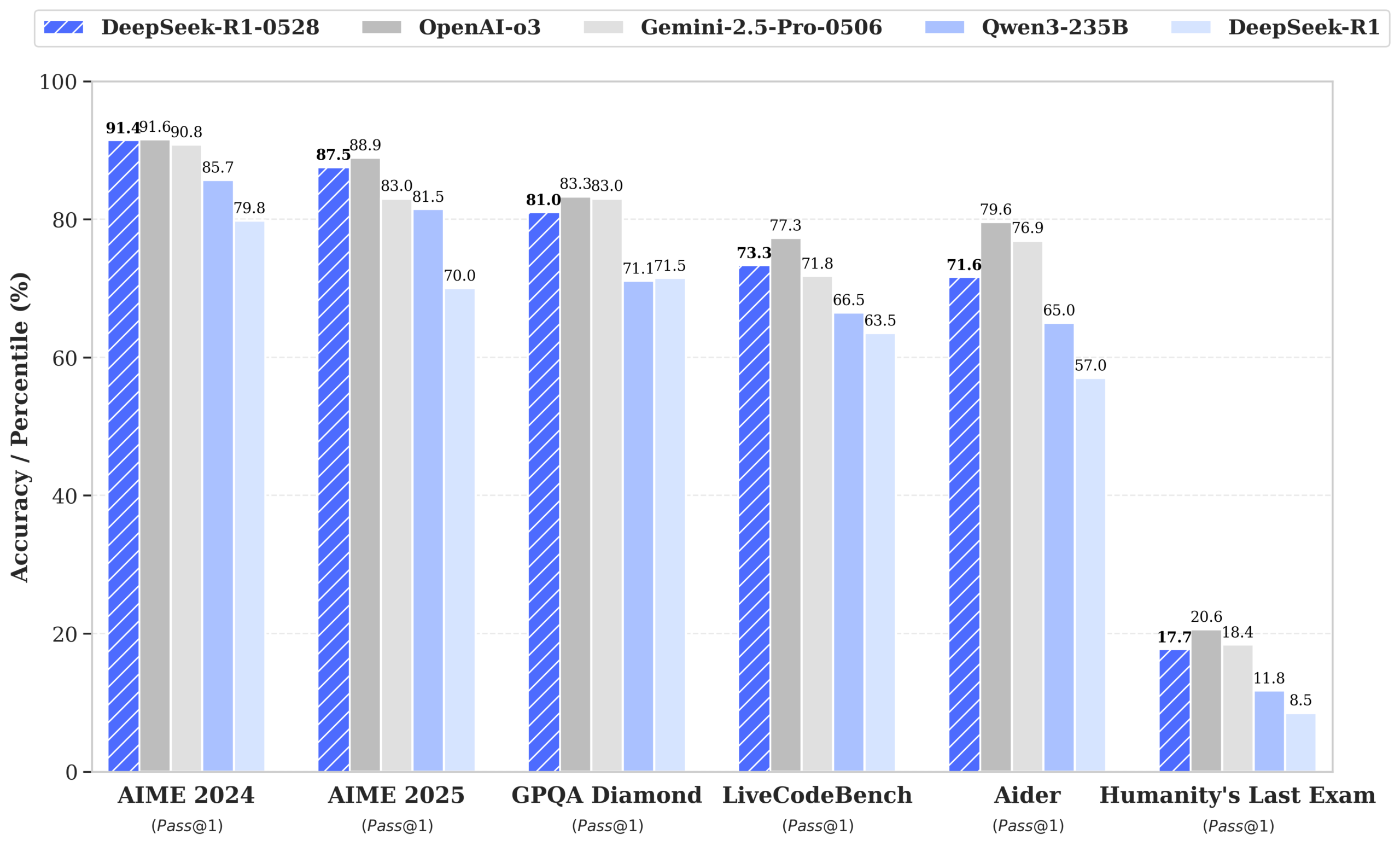
DeepSeek lanza el modelo R1-0528, con un rendimiento cercano a GPT-4o y Gemini 2.5 Pro, y se sitúa a la cabeza de las clasificaciones de código abierto: DeepSeek-R1-0528 destaca en múltiples benchmarks de matemáticas, programación y razonamiento lógico general, especialmente en la prueba AIME 2025, donde su precisión aumentó del 70% al 87.5%. La nueva versión reduce significativamente la tasa de alucinaciones (aproximadamente un 45-50%), mejora la capacidad de generación de código frontend y soporta salida JSON y llamadas a funciones. Al mismo tiempo, DeepSeek, basándose en el fine-tuning de Qwen3-8B Base, ha lanzado DeepSeek-R1-0528-Qwen3-8B, cuyo rendimiento en AIME 2024 solo es superado por R1-0528, superando a Qwen3-235B. Esta actualización consolida la posición de DeepSeek como el segundo laboratorio de IA más grande del mundo y líder en código abierto. (Fuente: ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
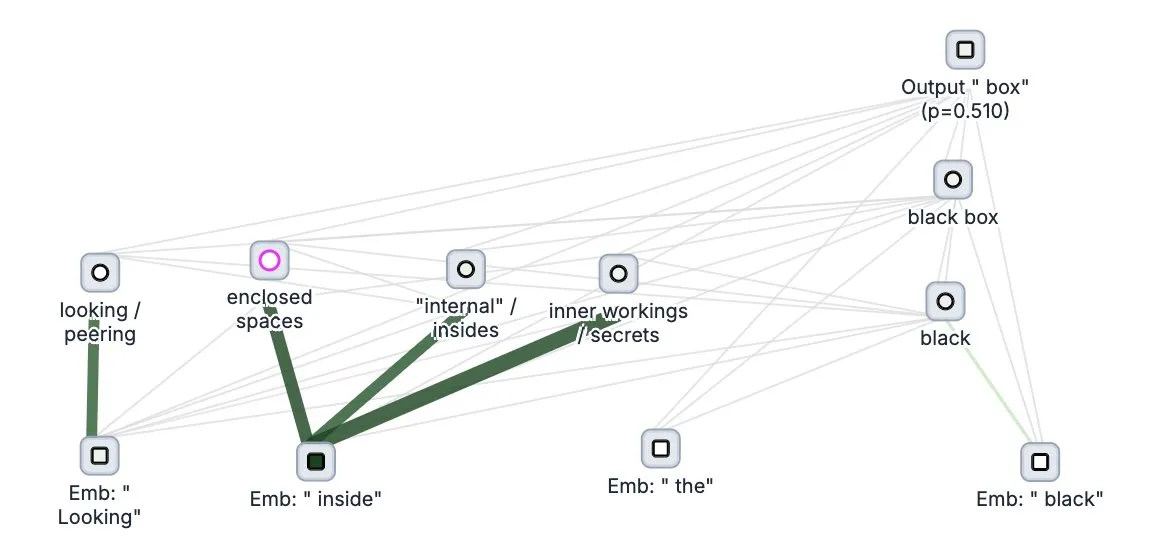
Anthropic publica en código abierto la herramienta de “seguimiento del pensamiento” de grandes modelos Circuit Tracer: Anthropic ha publicado en código abierto su herramienta de investigación de interpretabilidad de grandes modelos, Circuit Tracer, que permite a los investigadores generar y explorar interactivamente “mapas de atribución” para comprender los procesos internos de “pensamiento” y los mecanismos de decisión de los grandes modelos de lenguaje (LLM). Esta herramienta tiene como objetivo ayudar a los investigadores a profundizar en el funcionamiento interno de los LLM, por ejemplo, cómo un modelo utiliza características específicas para predecir el siguiente token. Los usuarios pueden probar la herramienta en Neuronpedia, introduciendo frases para obtener diagramas de circuito del uso de características del modelo. (Fuente: scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
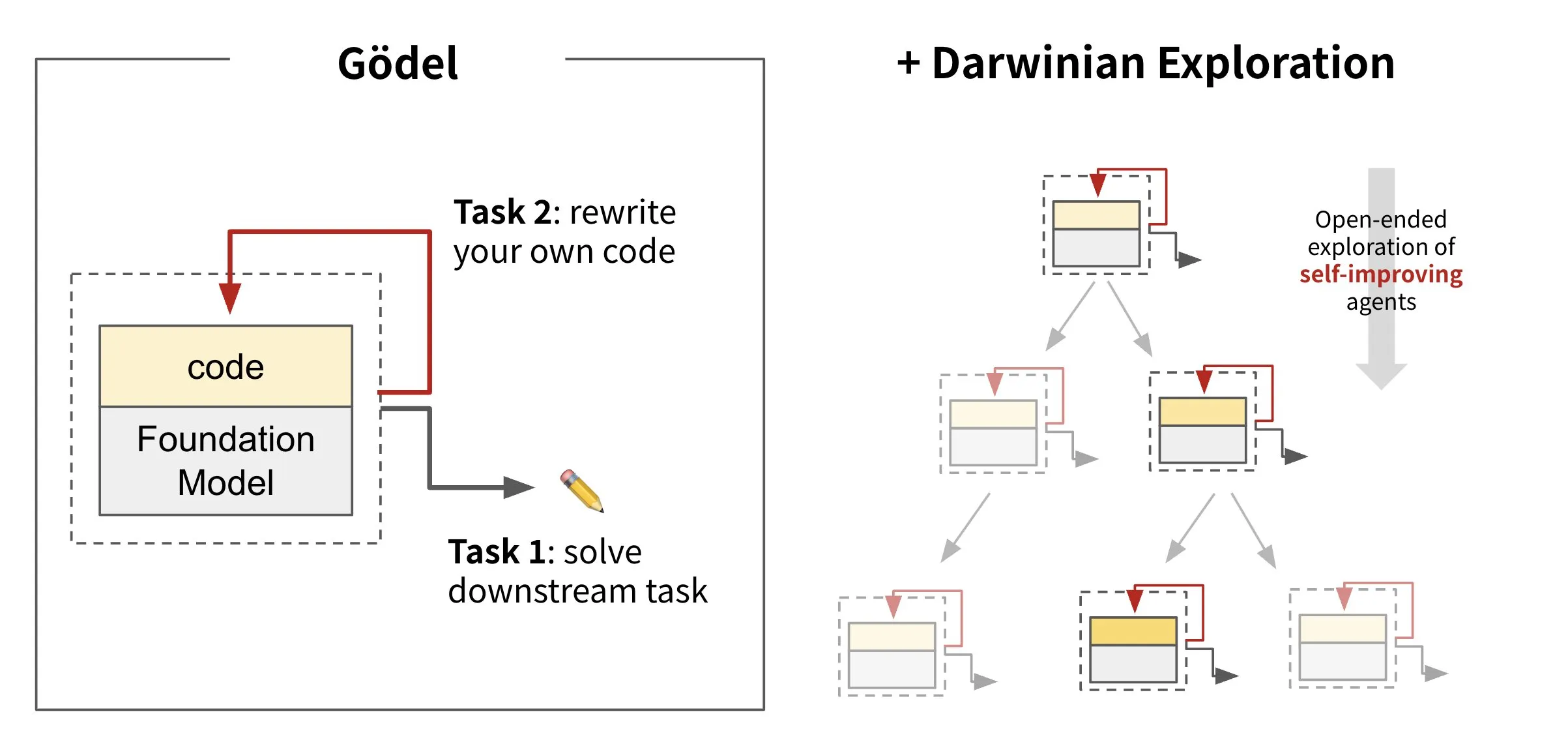
Sakana AI lanza el marco de agentes autoevolutivos Darwin Gödel Machine (DGM): Sakana AI ha presentado Darwin Gödel Machine (DGM), un marco de agentes de IA capaz de auto-mejorarse mediante la reescritura de su propio código. DGM, inspirado en la teoría de la evolución, mantiene un linaje en constante expansión de variantes de agentes para explorar de forma abierta el espacio de diseño de agentes auto-mejorables. El marco tiene como objetivo permitir que los sistemas de IA aprendan y evolucionen sus propias capacidades con el tiempo, al igual que los humanos. En SWE-bench, DGM mejoró el rendimiento del 20.0% al 50.0%; en Polyglot, la tasa de éxito aumentó del 14.2% al 30.7%. (Fuente: SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs lanza el modelo de edición de imágenes FLUX.1 Kontext, compatible con entrada mixta de texto e imágenes: Black Forest Labs ha presentado la nueva generación de modelos de edición de imágenes FLUX.1 Kontext, que utiliza una arquitectura de flow matching y es capaz de aceptar tanto texto como imágenes como entrada, logrando una generación y edición de imágenes sensible al contexto. El modelo destaca en consistencia de personajes, edición local, referencia de estilo y velocidad de interacción, por ejemplo, generando imágenes con una resolución de 1024×1024 en solo 3-5 segundos. Las pruebas de Replicate indican que sus efectos de edición son superiores a GPT-4o-Image y con un coste menor. Kontext ofrece versiones Pro y Max, y planea lanzar una versión Dev de código abierto. (Fuente: TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 Tendencias
Google DeepMind lanza el modelo médico multimodal MedGemma: Google DeepMind ha presentado MedGemma, un potente modelo abierto diseñado específicamente para la comprensión multimodal de textos e imágenes médicas. Este modelo, ofrecido como parte de Health AI Developer Foundations, tiene como objetivo mejorar la capacidad de aplicación de la IA en el campo de la medicina, especialmente en el análisis integral que combina texto e imágenes médicas (como radiografías). (Fuente: GoogleDeepMind)
Perplexity AI lanza Perplexity Labs para potenciar el procesamiento de tareas complejas: Perplexity AI ha lanzado la nueva función Perplexity Labs, diseñada específicamente para manejar tareas más complejas, con el objetivo de proporcionar a los usuarios capacidades de análisis y construcción similares a las de todo un equipo de investigación. Los usuarios pueden utilizar Labs para crear informes analíticos, presentaciones y paneles dinámicos, entre otros. La función ya está disponible para todos los usuarios Pro y ha demostrado su potencial en investigación científica, análisis de mercado y creación de miniaplicaciones (como juegos y paneles). (Fuente: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
Tencent Hunyuan y Tencent Music lanzan conjuntamente HunyuanVideo-Avatar, que permite generar vídeos de canto realistas a partir de fotos: Tencent Hunyuan y Tencent Music se han unido para lanzar el modelo HunyuanVideo-Avatar, capaz de combinar fotos y audio subidos por el usuario para detectar automáticamente el contexto de la escena y la emoción, generando vídeos de habla o canto con sincronización labial realista y efectos visuales dinámicos. Esta tecnología admite múltiples estilos y ha sido publicada en código abierto. (Fuente: huggingface, thursdai_pod)
Apache Spark 4.0.0 lanzado oficialmente, con mejoras en SQL, Spark Connect y soporte multilingüe: Se ha lanzado oficialmente la versión Apache Spark 4.0.0, que trae consigo mejoras significativas en las funciones SQL, optimizaciones en Spark Connect para facilitar la ejecución de aplicaciones y la adición de soporte para nuevos lenguajes. Esta actualización ha resuelto más de 5100 problemas, con la participación de más de 390 colaboradores. (Fuente: matei_zaharia, lateinteraction)

Lanzamiento del modelo de vídeo Kling 2.1, integrado con OpenArt para dar soporte a la consistencia de personajes: Kling AI ha lanzado su modelo de vídeo Kling 2.1 y se ha asociado con OpenArt para permitir la consistencia de personajes en la narración de historias de vídeo con IA. Kling 2.1 mejora la alineación con las indicaciones (prompts), la velocidad de generación de vídeo, la claridad del movimiento de la cámara y afirma tener los mejores efectos de texto a vídeo. La nueva versión admite salida a 720p (estándar) y 1080p (profesional); la función de imagen a vídeo ya está disponible y la de texto a vídeo se lanzará próximamente. (Fuente: Kling_ai, NandoDF)
Hume lanza el modelo de voz EVI 3, capaz de comprender y generar cualquier voz humana: Hume ha presentado su último modelo de lenguaje de voz, EVI 3, diseñado para lograr una inteligencia de voz universal. EVI 3 es capaz de comprender y generar cualquier voz humana, no solo la de unos pocos hablantes específicos, ofreciendo así una gama más amplia de capacidades expresivas y una comprensión más profunda del tono, el ritmo, el timbre y el estilo del habla. Esta tecnología tiene como objetivo que cada persona pueda tener una IA única y confiable, reconocible por su voz. (Fuente: AlanCowen, AlanCowen, _akhaliq)
Alibaba lanza WebDancer, explorando agentes inteligentes de búsqueda autónoma de información: Alibaba ha lanzado el proyecto WebDancer, destinado a investigar y desarrollar agentes de IA capaces de realizar búsquedas de información de forma autónoma. El proyecto se centra en cómo hacer que los agentes de IA naveguen de manera más eficiente en el entorno web, comprendan la información y completen tareas complejas de adquisición de información. (Fuente: _akhaliq)
MiniMax publica en código abierto el framework V-Triune y el modelo Orsta, unificando el razonamiento visual RL y las tareas de percepción: La empresa de IA MiniMax ha publicado en código abierto su framework unificado de aprendizaje por refuerzo visual V-Triune y la serie de modelos Orsta (de 7B a 32B) basados en este framework. Mediante un diseño de componentes de tres capas y un mecanismo de recompensa dinámico de Intersección sobre Unión (IoU), el framework permite por primera vez que un VLM aprenda conjuntamente tareas de razonamiento visual y percepción en un único proceso de post-entrenamiento, logrando mejoras significativas de rendimiento en el benchmark MEGA-Bench Core. (Fuente: 量子位)

El Laboratorio de IA de Shanghái y otros publican el nuevo benchmark de edición de imágenes RISEBench, que pone a prueba el razonamiento profundo de los modelos: El Laboratorio de Inteligencia Artificial de Shanghái, en colaboración con varias universidades, ha publicado un nuevo benchmark de evaluación de edición de imágenes llamado RISEBench, que contiene 360 casos de alta dificultad diseñados por expertos humanos, cubriendo cuatro tipos de razonamiento central: temporal, causal, espacial y lógico. Los resultados de las pruebas muestran que incluso GPT-4o-Image solo pudo completar el 28.9% de las tareas, lo que expone las deficiencias de los modelos multimodales actuales en la comprensión de instrucciones complejas y la edición visual. (Fuente: 36氪)

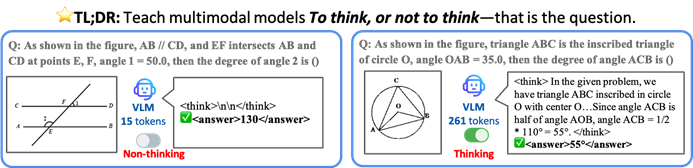
La Universidad China de Hong Kong y otras proponen el framework TON, que permite a los modelos de IA pensar selectivamente para mejorar la eficiencia y la precisión: Investigadores de la Universidad China de Hong Kong y del Show Lab de la Universidad Nacional de Singapur han propuesto el framework TON (Think Or Not), que permite a los modelos de lenguaje visual (VLM) decidir autónomamente si necesitan un razonamiento explícito. A través del “descarte de pensamientos” y el aprendizaje por refuerzo, el framework permite que el modelo responda directamente a preguntas simples y realice un razonamiento detallado para problemas complejos, reduciendo así la longitud promedio de la salida de razonamiento hasta en un 90% sin sacrificar la precisión, e incluso mejorando la precisión en algunas tareas en un 17%. (Fuente: 36氪)
Microsoft Copilot se integra con Instacart para permitir compras de comestibles asistidas por IA: Mustafa Suleyman, responsable de IA de Microsoft, anunció que Copilot ahora está integrado con el servicio Instacart, permitiendo a los usuarios completar sin problemas todo el proceso, desde la generación de recetas y la creación de listas de compras hasta la entrega a domicilio de comestibles frescos, a través de la aplicación Copilot. Esto marca una mayor expansión de los asistentes de IA en el ámbito de los servicios de la vida cotidiana. (Fuente: mustafasuleyman)
🧰 Herramientas
LlamaIndex lanza el código fuente de BundesGPT y la herramienta create-llama, simplificando la creación de aplicaciones de IA: Jerry Liu de LlamaIndex anunció la disponibilidad del código fuente de BundesGPT y promocionó su herramienta de código abierto create-llama. Esta herramienta, basada en LlamaIndex, tiene como objetivo ayudar a los desarrolladores a construir e integrar fácilmente datos empresariales con agentes de IA. Su nuevo eject-mode hace que la creación de interfaces de IA totalmente personalizables como BundesGPT sea muy sencilla. Esta medida busca apoyar el posible plan de Alemania de ofrecer una suscripción gratuita a ChatGPT Plus a cada ciudadano. (Fuente: jerryjliu0)
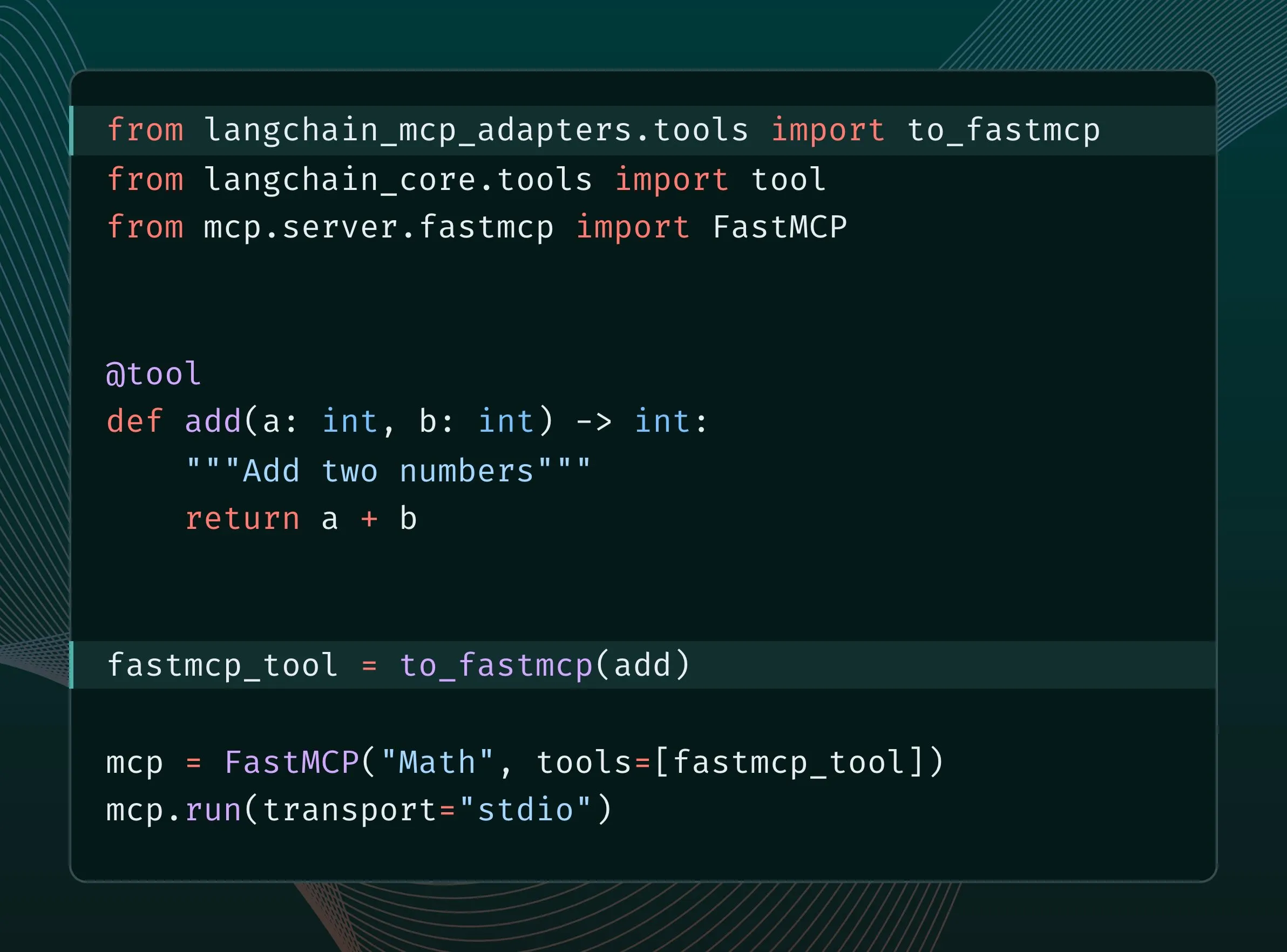
Las herramientas de LangChain se pueden convertir a herramientas MCP e integrarse en el servidor FastMCP: Los usuarios de LangChain ahora pueden convertir sus herramientas de LangChain en herramientas MCP (Model Component Protocol) y agregarlas directamente al servidor FastMCP. Al instalar la biblioteca langchain-mcp-adapters, los desarrolladores pueden utilizar más fácilmente el conjunto de herramientas de LangChain dentro del ecosistema MCP, promoviendo la interoperabilidad entre diferentes frameworks de IA. (Fuente: LangChainAI, hwchase17)
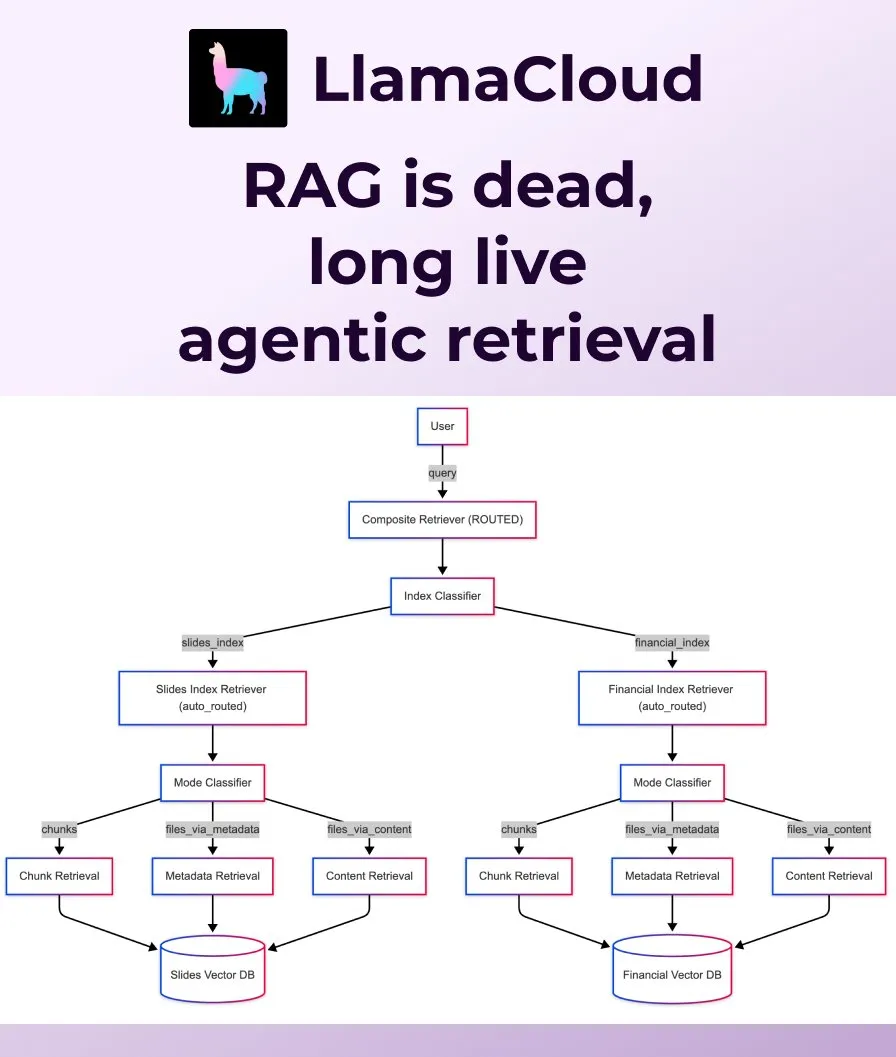
LlamaIndex lanza Agentic Retrieval, reemplazando el RAG tradicional: LlamaIndex considera que el RAG (Retrieval Augmented Generation) tradicional y simple ya no es suficiente para satisfacer las necesidades de las aplicaciones modernas, y ha lanzado Agentic Retrieval. Esta solución, integrada en LlamaCloud, permite a los agentes recuperar dinámicamente archivos completos o bloques de datos específicos de uno o varios repositorios de conocimiento (como Sharepoint, Box, GDrive, S3) según el contenido de la pregunta, logrando una obtención de contexto más inteligente y flexible. (Fuente: jerryjliu0, jerryjliu0)
Ollama permite ejecutar el modelo Osmosis-Structure-0.6B para la transformación de datos no estructurados: Los usuarios ahora pueden ejecutar el modelo Osmosis-Structure-0.6B a través de Ollama. Este es un modelo extremadamente pequeño capaz de convertir cualquier dato no estructurado a un formato específico (por ejemplo, JSON Schema), y puede usarse con cualquier modelo, siendo especialmente útil para tareas de inferencia que requieren salida estructurada. (Fuente: ollama)
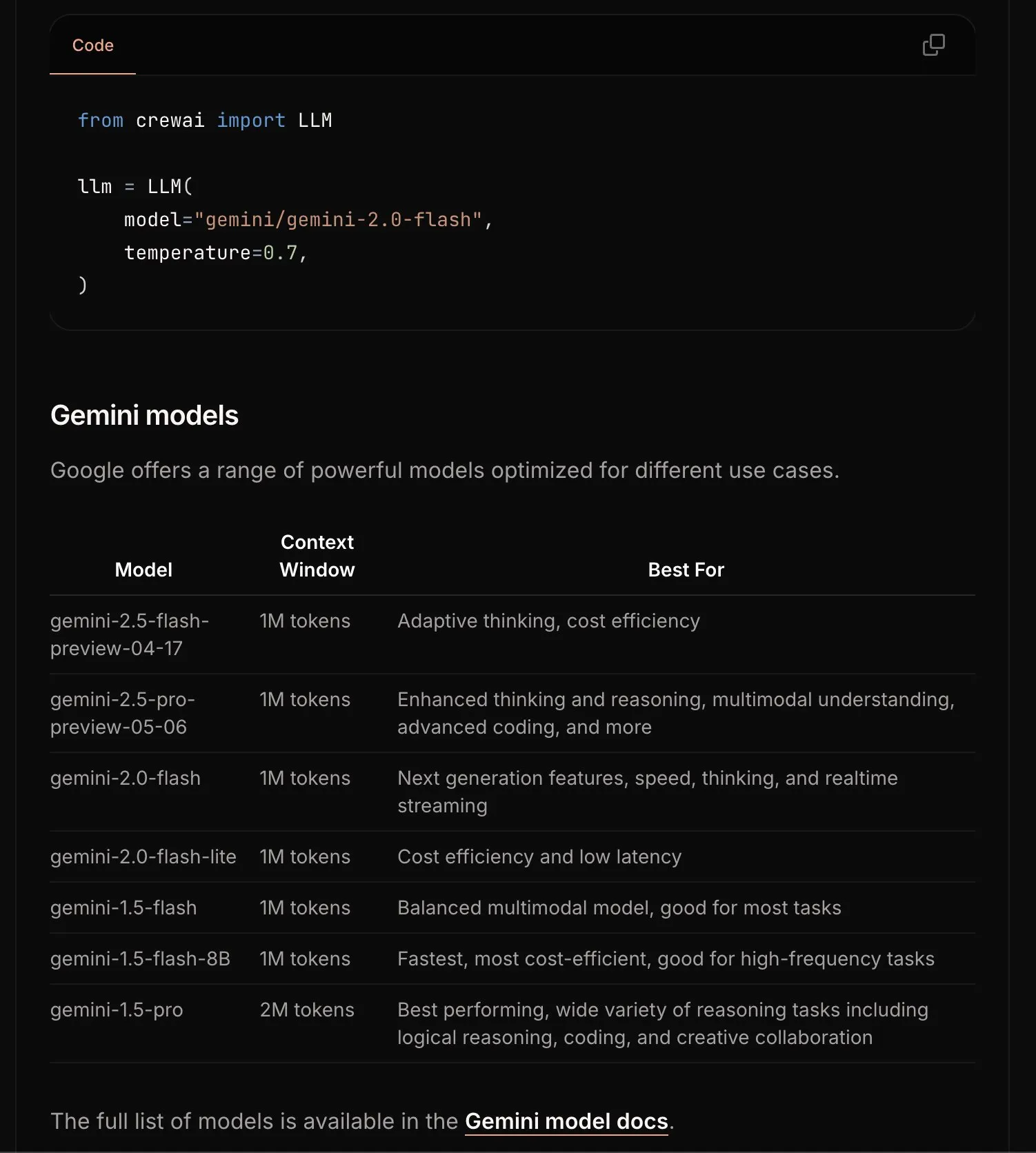
CrewAI actualiza la documentación de Gemini para simplificar el proceso de iniciación: El equipo de CrewAI ha actualizado su documentación sobre la API de Google Gemini, con el objetivo de ayudar a los usuarios a comenzar más fácilmente a construir agentes de IA utilizando los modelos Gemini. La nueva documentación podría incluir directrices más claras, código de ejemplo o mejores prácticas. (Fuente: _philschmid)
Requesty lanza la función Smart Routing, que selecciona automáticamente el mejor LLM para OpenWebUI: Requesty ha lanzado la función Smart Routing, que se integra sin problemas con OpenWebUI para seleccionar automáticamente el mejor LLM (como GPT-4o, Claude, Gemini) según el tipo de tarea indicada por el usuario. Los usuarios solo necesitan usar smart/task como ID del modelo, y el sistema clasificará la indicación en aproximadamente 65 milisegundos y la enrutará al modelo más adecuado en función del costo, la velocidad y la calidad. Esta función tiene como objetivo simplificar la selección de modelos y mejorar la experiencia del usuario. (Fuente: Reddit r/OpenWebUI)
EvoAgentX: Lanzamiento del primer framework de código abierto para la autoevolución de agentes de IA: Un equipo de investigación de la Universidad de Glasgow en el Reino Unido ha lanzado EvoAgentX, el primer framework de código abierto del mundo para la autoevolución de agentes de IA. Permite la construcción de flujos de trabajo con un solo clic e introduce un mecanismo de “autoevolución”, que permite a los sistemas multiagente optimizar continuamente su estructura y rendimiento en función de los cambios en el entorno y los objetivos. Su objetivo es impulsar los sistemas multiagente de IA desde la “depuración manual” hacia la “evolución autónoma”. Los experimentos muestran una mejora promedio del rendimiento del 8% al 13% en tareas de respuesta a preguntas de múltiples saltos, generación de código y razonamiento matemático. (Fuente: 36氪)

📚 Aprendizaje
HuggingFace, Gradio y otros organizan conjuntamente el Agents & MCP Hackathon, ofreciendo generosos premios y créditos de API: HuggingFace, Gradio, Anthropic, SambaNovaAI, MistralAI y LlamaIndex, entre otras organizaciones, organizarán conjuntamente el Gradio Agents & MCP Hackathon (del 2 al 8 de junio). El evento ofrece un total de 11,000 USD en premios y proporcionará a los primeros inscritos créditos gratuitos de API de Hyperbolic, Anthropic, Mistral y SambaNova. Modal Labs se ha comprometido además a ofrecer a todos los participantes créditos de GPU por valor de 250 USD, sumando un total de más de 300,000 USD. (Fuente: huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain comparte la práctica de JPMorgan Chase utilizando sistemas multiagente para la investigación de inversiones: David Odomirok y Zheng Xue de JPMorgan Chase compartieron cómo construyeron un sistema de IA multiagente llamado “Ask David”. Este sistema tiene como objetivo automatizar el proceso de investigación de inversiones para miles de productos financieros, demostrando el potencial de la arquitectura multiagente en el análisis financiero complejo. (Fuente: LangChainAI, hwchase17)
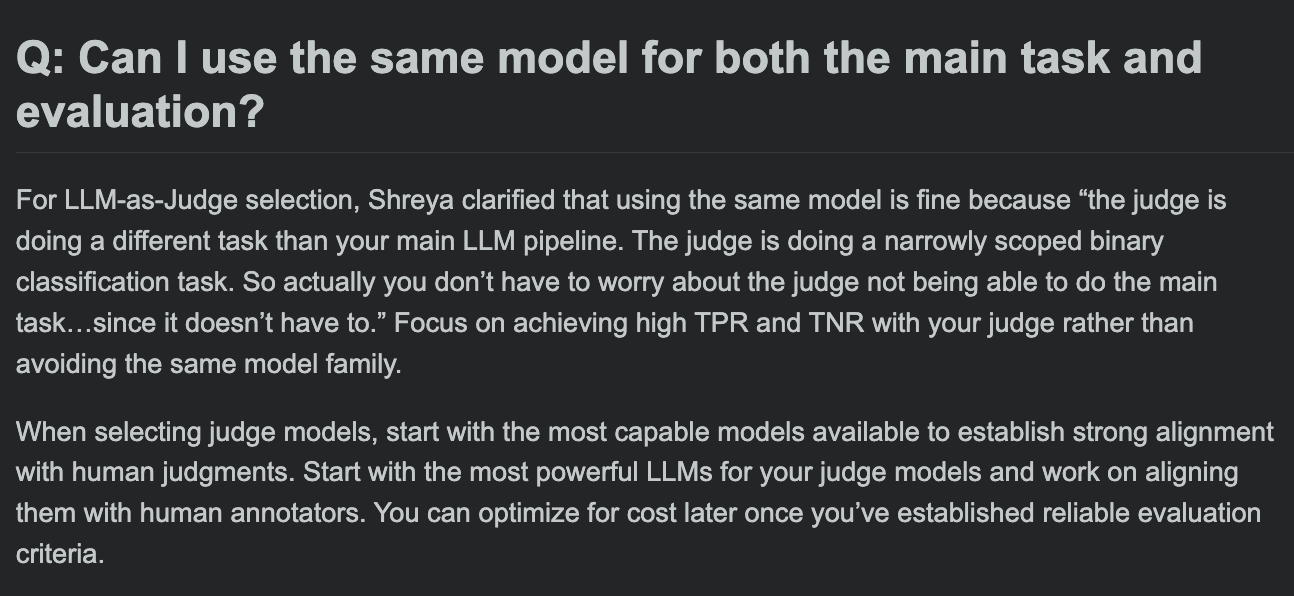
Hamel Husain comparte FAQ del curso de evaluación de LLM, discutiendo si el modelo de evaluación y el modelo de tarea principal pueden ser el mismo: En la sesión de preguntas y respuestas de su curso de evaluación de LLM, Hamel Husain abordó una pregunta común: ¿se puede usar el mismo modelo para el procesamiento de la tarea principal y la evaluación de la tarea? Esta discusión ayuda a los desarrolladores a comprender los posibles sesgos y las mejores prácticas en la evaluación de modelos. (Fuente: HamelHusain, HamelHusain)
The Rundown AI lanza una plataforma de educación en IA personalizada: The Rundown AI anunció el lanzamiento de la primera plataforma de educación en IA personalizada del mundo, que ofrece capacitación personalizada, casos de uso y talleres en tiempo real adaptados a diferentes industrias, niveles de habilidad y flujos de trabajo diarios. El contenido de la plataforma incluye cursos de certificación de IA específicos de la industria en 16 verticales tecnológicas, más de 300 casos de uso de IA del mundo real, talleres de expertos y descuentos en herramientas de IA, entre otros. (Fuente: TheRundownAI, rowancheung)
Common Crawl publica los grafos de red a nivel de host y dominio de marzo a mayo de 2025: Common Crawl ha publicado sus últimos datos de grafos de red a nivel de host y dominio, que cubren marzo, abril y mayo de 2025. Estos datos son de gran valor para investigar la estructura de la web, entrenar modelos de lenguaje y realizar análisis de red a gran escala. (Fuente: CommonCrawl)
Bill Chambers lanza la actividad de aprendizaje “20 Days of DSPyOSS”: Para ayudar a la comunidad a comprender mejor las funciones y el uso de DSPyOSS, Bill Chambers ha lanzado una actividad de aprendizaje de DSPyOSS de 20 días. Cada día se publicará un fragmento de código DSPy y su explicación, con el objetivo de ayudar a los usuarios a dominar el framework desde el nivel básico hasta el avanzado. (Fuente: lateinteraction)
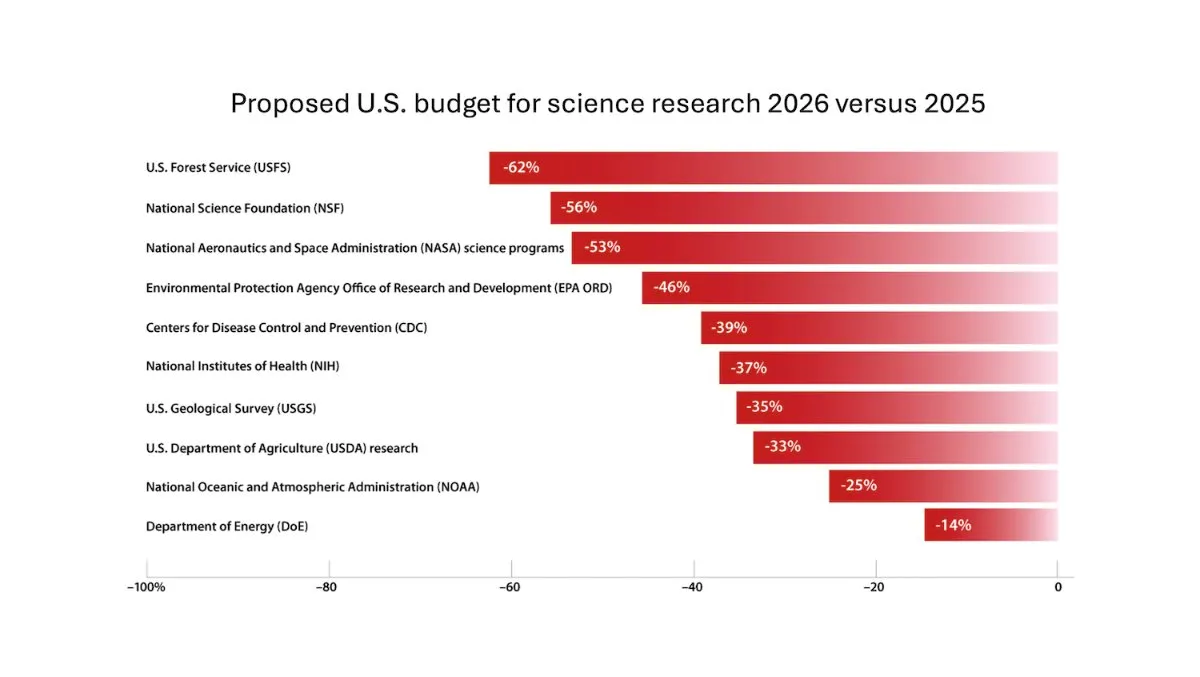
DeepLearning.AI publica el boletín semanal The Batch, Andrew Ng discute los riesgos de recortar la financiación para la investigación científica: En la última edición del boletín semanal The Batch, Andrew Ng analiza los riesgos potenciales de recortar la financiación para la investigación científica para la competitividad y seguridad nacional. El boletín también cubre el rendimiento del modelo Claude 4 en benchmarks de codificación, los lanzamientos de IA de Google I/O, el método de entrenamiento de bajo costo de DeepSeek y la posibilidad de que GPT-4o haya utilizado libros protegidos por derechos de autor para su entrenamiento, entre otros temas candentes. (Fuente: DeepLearningAI)
Google DeepMind ofrece acceso gratuito a Gemini 2.5 Pro y NotebookLM a estudiantes universitarios del Reino Unido: Google DeepMind anunció que ofrecerá a los estudiantes universitarios del Reino Unido acceso gratuito a sus modelos más avanzados (incluidos Gemini 2.5 Pro y NotebookLM) durante 15 meses. Esta medida tiene como objetivo apoyar el aprendizaje de los estudiantes en investigación, redacción y preparación de exámenes, entre otros, y ofrece 2 TB de almacenamiento gratuito. (Fuente: demishassabis)
Artículo de IA: Prot2Token, un framework unificado para el modelado de proteínas: El artículo “Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction” presenta un framework unificado para el modelado de proteínas, Prot2Token, que convierte múltiples tareas de predicción, desde atributos de secuencia de proteínas y características de residuos hasta interacciones proteína-proteína, en un formato estándar de predicción del siguiente token. El framework utiliza un decodificador autorregresivo, aprovechando los embeddings de codificadores de proteínas preentrenados y tokens de tarea aprendibles para el aprendizaje multitarea, con el objetivo de mejorar la eficiencia y acelerar los descubrimientos biológicos. (Fuente: HuggingFace Daily Papers)
Artículo de IA: Minería de negativos difíciles para la recuperación específica de dominio en sistemas empresariales: El artículo “Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems” propone un framework escalable de minería de negativos difíciles para datos específicos de dominio empresarial. El método selecciona dinámicamente documentos semánticamente desafiantes pero contextualmente irrelevantes para mejorar el rendimiento del modelo de reranking implementado, demostrando en experimentos con corpus empresariales del sector de servicios en la nube mejoras del 15% y 19% en MRR@3 y MRR@10, respectivamente. (Fuente: HuggingFace Daily Papers)
Artículo de IA: FS-DAG, redes de grafos adaptables a dominios con pocas muestras para la comprensión de documentos visualmente ricos: El artículo “FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding” propone la arquitectura del modelo FS-DAG para la comprensión de documentos visualmente ricos en situaciones con pocas muestras (few-shot). El modelo utiliza redes troncales específicas del dominio y específicas del lenguaje/visión para adaptarse a diferentes tipos de documentos con datos mínimos dentro de un marco modular, y en experimentos de tareas de extracción de información muestra una velocidad de convergencia y un rendimiento superiores a los métodos SOTA. (Fuente: HuggingFace Daily Papers)
Artículo de IA: FastTD3, aprendizaje por refuerzo simple, rápido y capaz para el control de robots humanoides: El artículo “FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control” presenta un algoritmo de aprendizaje por refuerzo llamado FastTD3, que acelera significativamente la velocidad de entrenamiento de robots humanoides en suites populares como HumanoidBench, IsaacLab y MuJoCo Playground mediante simulación paralela, actualizaciones de lotes grandes, críticos distribuidos e hiperparámetros cuidadosamente ajustados. (Fuente: HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
Artículo de IA: HLIP, preentrenamiento lenguaje-imagen escalable para imágenes médicas 3D: El artículo “Towards Scalable Language-Image Pre-training for 3D Medical Imaging” presenta un framework de preentrenamiento escalable para imágenes médicas 3D llamado HLIP (Hierarchical attention for Language-Image Pre-training). HLIP adopta un mecanismo de atención jerárquica ligero, capaz de entrenar directamente en conjuntos de datos clínicos no curados, y ha logrado un rendimiento SOTA en múltiples benchmarks. (Fuente: HuggingFace Daily Papers)
Artículo de IA: PENGUIN, benchmark de seguridad personalizada en LLM y enfoque de agente basado en planificación: El artículo “Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach” introduce el concepto de seguridad personalizada y propone el benchmark PENGUIN (que contiene 14,000 escenarios en 7 dominios sensibles) y el framework RAISE (un agente de dos etapas sin entrenamiento que adquiere estratégicamente información de contexto específica del usuario). La investigación demuestra que la información personalizada puede mejorar significativamente las puntuaciones de seguridad, y RAISE puede mejorar la seguridad con un bajo costo de interacción. (Fuente: HuggingFace Daily Papers)
Artículo de IA: Reforzando el razonamiento multiturno en agentes LLM mediante la asignación de crédito a nivel de turno: El artículo “Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment” investiga cómo mejorar la capacidad de razonamiento de los agentes LLM mediante el aprendizaje por refuerzo, especialmente en escenarios de uso de herramientas multiturno. Los autores proponen una estrategia de estimación de ventaja a nivel de turno de grano fino para lograr una asignación de crédito más precisa. Los experimentos demuestran que este método puede mejorar significativamente la capacidad de razonamiento multiturno de los agentes LLM en tareas de decisión complejas. (Fuente: HuggingFace Daily Papers)
Artículo de IA: PISCES, borrado preciso de conceptos intra-parámetro en grandes modelos de lenguaje: El artículo “Precise In-Parameter Concept Erasure in Large Language Models” propone el framework PISCES para el borrado preciso de conceptos completos en los parámetros del modelo mediante la edición directa de la dirección que codifica el concepto en el espacio de parámetros. El método utiliza un disentangler para descomponer los vectores MLP, identificar las características relacionadas con el concepto objetivo y eliminarlas de los parámetros del modelo. Los experimentos muestran su superioridad sobre los métodos existentes en términos de efectividad del borrado, especificidad y robustez. (Fuente: HuggingFace Daily Papers)
Artículo de IA: DORI, evaluación de la comprensión de la orientación en MLLM con tareas de percepción multieje de grano fino: El artículo “Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks” introduce el benchmark DORI, diseñado para evaluar la capacidad de los grandes modelos de lenguaje multimodales (MLLM) para comprender la orientación de los objetos. DORI incluye cuatro dimensiones: localización frontal, transformación rotacional, relaciones de dirección relativa y comprensión de la dirección canónica. Se probaron 15 MLLM SOTA, y se encontró que incluso los mejores modelos tienen limitaciones significativas en el juicio fino de la orientación. (Fuente: HuggingFace Daily Papers)
Artículo de IA: ¿Pueden los LLM inferir relaciones causales a partir de texto del mundo real?: El artículo “Can Large Language Models Infer Causal Relationships from Real-World Text?” explora la capacidad de los LLM para inferir relaciones causales a partir de texto del mundo real. Los investigadores desarrollaron un benchmark derivado de literatura académica real, que contiene textos de diferente longitud, complejidad y dominio. Los experimentos muestran que incluso los LLM SOTA enfrentan desafíos significativos en esta tarea, con el mejor modelo obteniendo una puntuación F1 de solo 0.477, lo que revela sus dificultades para procesar información implícita, distinguir factores relevantes y conectar información dispersa. (Fuente: HuggingFace Daily Papers)
Artículo de IA: IQBench, evaluando cuán “inteligentes” son los modelos de lenguaje visual con pruebas de CI humano: El artículo “IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests” presenta IQBench, un nuevo benchmark diseñado para evaluar la inteligencia fluida de los modelos de lenguaje visual (VLM) mediante pruebas de CI visual estandarizadas. El benchmark se centra en lo visual, contiene 500 preguntas de CI visual recopiladas y anotadas manualmente, y evalúa la interpretación, los patrones de resolución de problemas y la precisión de las predicciones finales del modelo. Los experimentos muestran que o4-mini, Gemini-2.5-Flash y Claude-3.7-Sonnet tuvieron un buen desempeño, pero todos los modelos tuvieron dificultades en tareas de razonamiento espacial 3D y anagramas. (Fuente: HuggingFace Daily Papers)
Artículo de IA: PixelThink, hacia un razonamiento eficiente de cadena de píxeles: El artículo “PixelThink: Towards Efficient Chain-of-Pixel Reasoning” propone la solución PixelThink, que regula la generación de razonamiento dentro de un paradigma de aprendizaje por refuerzo mediante la integración de la dificultad de la tarea estimada externamente y la incertidumbre del modelo medida internamente. El modelo aprende a comprimir la longitud del razonamiento según la complejidad de la escena y la confianza de la predicción. Al mismo tiempo, se introduce el benchmark ReasonSeg-Diff para la evaluación. Los experimentos demuestran que este método mejora la eficiencia del razonamiento y el rendimiento general de la segmentación. (Fuente: HuggingFace Daily Papers)
Artículo de IA: Revisitando el debate multiagente como escalado en tiempo de prueba: un estudio sistemático de la efectividad condicional: El artículo “Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness” conceptualiza el debate multiagente (MAD) como una técnica de escalado computacional en tiempo de prueba y estudia sistemáticamente su efectividad en relación con los métodos de auto-agente bajo diferentes condiciones (dificultad de la tarea, escala del modelo, diversidad de agentes). El estudio encuentra que, para el razonamiento matemático, la ventaja de MAD es limitada, pero es más efectiva cuando aumenta la dificultad del problema o disminuye la capacidad del modelo; para tareas de seguridad, la optimización colaborativa de MAD puede aumentar la vulnerabilidad, pero las configuraciones diversificadas ayudan a reducir la tasa de éxito de los ataques. (Fuente: HuggingFace Daily Papers)
Artículo de IA: VF-Eval, evaluación de la capacidad de los MLLM para generar retroalimentación sobre vídeos AIGC: El artículo “VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos” propone el nuevo benchmark VF-Eval para evaluar la capacidad de los grandes modelos de lenguaje multimodales (MLLM) para interpretar vídeos generados por IA (AIGC). VF-Eval incluye cuatro tareas: verificación de coherencia, percepción de errores, detección de tipos de error y evaluación de razonamiento. La evaluación de 13 MLLM de vanguardia muestra que incluso el GPT-4.1 de mejor rendimiento tiene dificultades para mantener un buen desempeño en todas las tareas. (Fuente: HuggingFace Daily Papers)
Artículo de IA: SafeScientist, agentes LLM para descubrimientos científicos conscientes del riesgo: El artículo “SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents” presenta un framework de científico de IA llamado SafeScientist, diseñado para mejorar la seguridad y la responsabilidad ética en la exploración científica impulsada por IA. El framework puede rechazar activamente tareas inapropiadas o de alto riesgo y enfatiza la seguridad del proceso de investigación a través de múltiples mecanismos de defensa, como el monitoreo de prompts, el monitoreo colaborativo de agentes, el monitoreo del uso de herramientas y componentes de revisores éticos. Al mismo tiempo, se propone el benchmark SciSafetyBench para la evaluación. (Fuente: HuggingFace Daily Papers)
Artículo de IA: CXReasonBench, un benchmark para evaluar el razonamiento diagnóstico estructurado en radiografías de tórax: El artículo “CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays” presenta el proceso CheXStruct y el benchmark CXReasonBench para evaluar si los grandes modelos de lenguaje visual (LVLM) pueden ejecutar pasos de razonamiento clínicamente efectivos en el diagnóstico de radiografías de tórax. El benchmark contiene 18,988 pares de preguntas y respuestas, que cubren 12 tareas de diagnóstico y 1200 casos, y admite la evaluación multirruta y multietapa, incluida la selección de regiones anatómicas y la localización visual de mediciones diagnósticas. (Fuente: HuggingFace Daily Papers)
Artículo de IA: ZeroGUI, automatización del aprendizaje de GUI en línea sin costo humano: El artículo “ZeroGUI: Automating Online GUI Learning at Zero Human Cost” propone ZeroGUI, un framework de aprendizaje en línea escalable para automatizar el entrenamiento de agentes GUI sin costo humano. ZeroGUI integra la generación automática de tareas basada en VLM, la estimación automática de recompensas y el aprendizaje por refuerzo en línea de dos etapas para interactuar continuamente con el entorno GUI y aprender de él. (Fuente: HuggingFace Daily Papers)
Artículo de IA: Spatial-MLLM, potenciando las capacidades de los MLLM en inteligencia espacial basada en la visión: El artículo “Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence” propone el framework Spatial-MLLM para el razonamiento espacial basado en la visión a partir de observaciones puramente 2D. El framework adopta una arquitectura de doble codificador (un codificador visual semántico y un codificador espacial) y se combina con una estrategia de muestreo de fotogramas consciente del espacio, logrando un rendimiento SOTA en múltiples conjuntos de datos del mundo real. (Fuente: HuggingFace Daily Papers)
Artículo de IA: TrustVLM, juzgando si las predicciones de los modelos de lenguaje visual son confiables: El artículo “To Trust Or Not To Trust Your Vision-Language Model’s Prediction” introduce TrustVLM, un framework sin entrenamiento diseñado para evaluar la confiabilidad de las predicciones de los modelos de lenguaje visual (VLM). El método utiliza las diferencias en la representación de conceptos en el espacio de incrustación de imágenes y propone nuevas funciones de puntuación de confianza para mejorar la detección de clasificaciones erróneas, demostrando un rendimiento SOTA en 17 conjuntos de datos diferentes. (Fuente: HuggingFace Daily Papers)
Artículo de IA: MAGREF, generación de vídeo multirreferencia guiada por máscaras: El artículo “MAGREF: Masked Guidance for Any-Reference Video Generation” propone MAGREF, un framework unificado de generación de vídeo multirreferencia. Introduce un mecanismo de guía por máscaras que, mediante máscaras dinámicas conscientes de la región y conexiones de canales a nivel de píxel, logra la síntesis coherente de vídeos multiobjeto bajo diversas condiciones de imágenes de referencia e indicaciones de texto, superando a las líneas base de código abierto y comerciales existentes en benchmarks de vídeo multiobjeto. (Fuente: HuggingFace Daily Papers)
Artículo de IA: ATLAS, aprendiendo a memorizar óptimamente el contexto en tiempo de prueba: El artículo “ATLAS: Learning to Optimally Memorize the Context at Test Time” propone ATLAS, un módulo de memoria a largo plazo de alta capacidad que aprende a memorizar el contexto optimizando la memoria según los tokens actuales y pasados, superando las características de actualización en línea de los modelos de memoria a largo plazo. Basándose en esto, los autores proponen la familia de arquitecturas DeepTransformers. Los experimentos muestran que ATLAS supera a los Transformers y a los recientes modelos lineales recurrentes en tareas de modelado de lenguaje, razonamiento de sentido común, recuperación intensiva y comprensión de contextos largos. (Fuente: HuggingFace Daily Papers)
Artículo de IA: Satori-SWE, un método de ingeniería de software evolutivo y escalable en tiempo de prueba con eficiencia de muestras: El artículo “Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering” propone el método EvoScale, que trata la generación de código como un proceso evolutivo, mejorando el rendimiento de modelos pequeños en tareas de ingeniería de software (como SWE-Bench) mediante la optimización iterativa de la salida. El modelo Satori-SWE-32B, mediante este método y utilizando una pequeña cantidad de muestras, alcanza o supera el rendimiento de modelos con más de 100B de parámetros. (Fuente: HuggingFace Daily Papers)
Artículo de IA: OPO, aprendizaje por refuerzo on-policy con línea base de recompensa óptima: El artículo “On-Policy RL with Optimal Reward Baseline” propone el algoritmo OPO, un nuevo algoritmo simplificado de aprendizaje por refuerzo diseñado para abordar los problemas de inestabilidad en el entrenamiento y baja eficiencia computacional que enfrentan los algoritmos de RL actuales al entrenar LLM. OPO enfatiza el entrenamiento on-policy preciso e introduce una línea base de recompensa teóricamente óptima que minimiza la varianza del gradiente. Los experimentos demuestran su rendimiento superior y estabilidad de entrenamiento en benchmarks de razonamiento matemático. (Fuente: HuggingFace Daily Papers)
Artículo de IA: ¡SWE-bench Goes Live! Un benchmark de ingeniería de software actualizado en tiempo real: El artículo “SWE-bench Goes Live!” presenta SWE-bench-Live, un benchmark actualizado en tiempo real diseñado para superar las limitaciones del SWE-bench existente. La nueva versión incluye 1319 tareas derivadas de problemas reales de GitHub desde 2024, cubriendo 93 repositorios, y está equipada con procesos de gestión automatizados para lograr escalabilidad y actualización continua, proporcionando así una evaluación más rigurosa y resistente a la contaminación de LLM y agentes. (Fuente: HuggingFace Daily Papers, _akhaliq)
Artículo de IA: ToMAP, entrenamiento de persuasores LLM conscientes del oponente con Teoría de la Mente: El artículo “ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind” presenta un nuevo método llamado ToMAP, que construye agentes persuasores más flexibles integrando dos módulos de teoría de la mente para mejorar su conciencia y análisis del estado mental del oponente. Los experimentos muestran que los persuasores ToMAP con solo 3B de parámetros superan a grandes líneas base como GPT-4o en múltiples modelos de objetos de persuasión y corpus. (Fuente: HuggingFace Daily Papers)
Artículo de IA: ¿Pueden los LLM engañar a CLIP? Evaluación de la composicionalidad adversaria de representaciones multimodales preentrenadas mediante actualizaciones de texto: El artículo “Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates” introduce el benchmark de Composicionalidad Adversaria Multimodal (MAC), que utiliza LLM para generar muestras de texto engañosas con el fin de explotar las vulnerabilidades de composicionalidad de representaciones multimodales preentrenadas como CLIP. La investigación propone un método de autoentrenamiento que realiza un fine-tuning con muestreo por rechazo mediante un filtrado que promueve la diversidad, para mejorar la tasa de éxito de los ataques y la diversidad de las muestras. (Fuente: HuggingFace Daily Papers)
Artículo de IA: El papel de las recompensas ruidosas en el aprendizaje del razonamiento: el ascenso esculpe la sabiduría más profundamente que la cima: El artículo “The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason” investiga el impacto del ruido en las recompensas en el post-entrenamiento de LLM para el razonamiento mediante aprendizaje por refuerzo. El estudio encuentra que los LLM muestran una fuerte robustez a grandes cantidades de ruido en las recompensas; incluso recompensando solo la aparición de frases clave de razonamiento (sin verificar la corrección de la respuesta), el modelo puede alcanzar un rendimiento comparable al de los modelos entrenados con verificación estricta y recompensas precisas. (Fuente: HuggingFace Daily Papers)
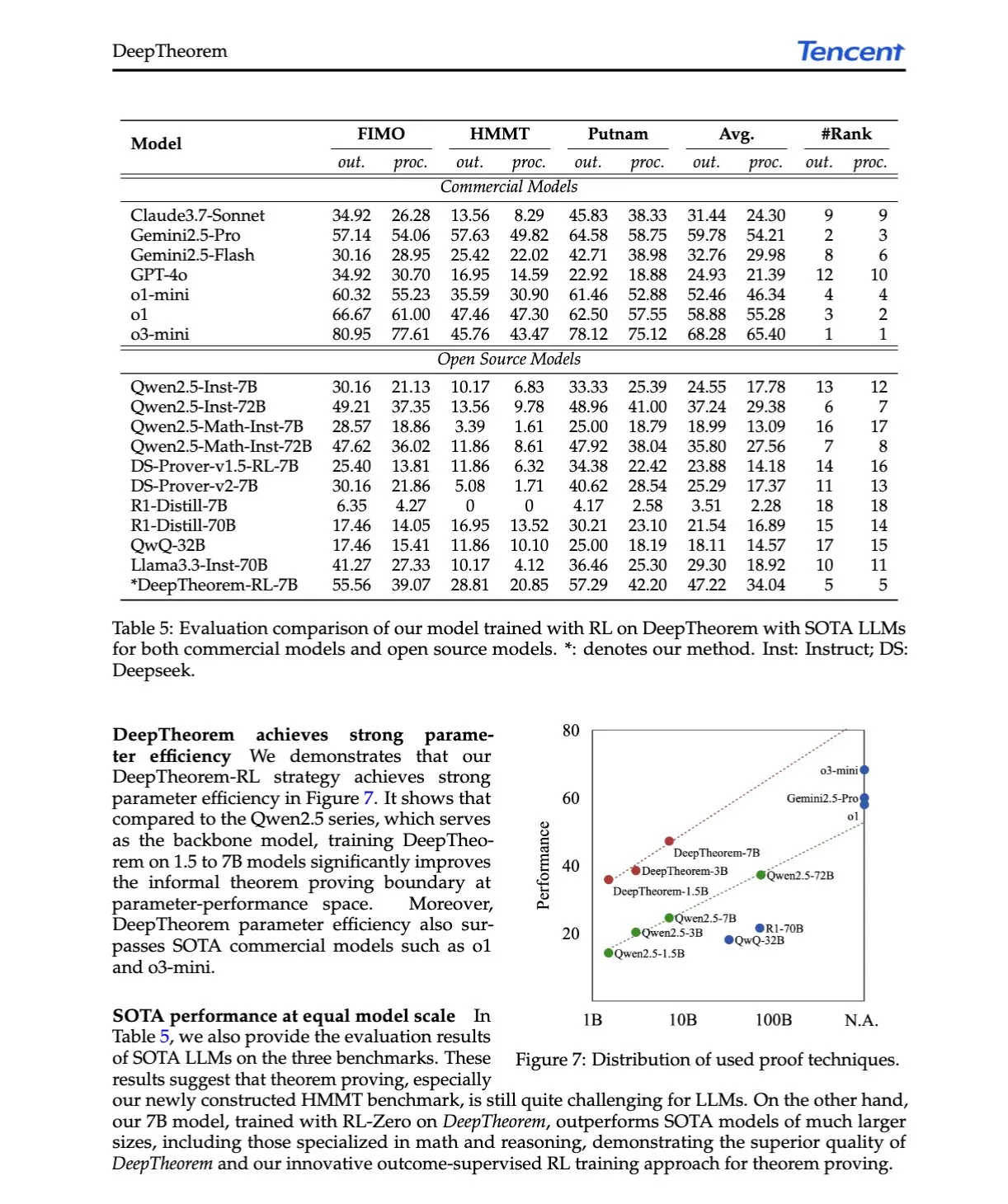
Artículo de IA: DeepTheorem, avanzando en la demostración de teoremas con LLM mediante lenguaje natural y aprendizaje por refuerzo: El artículo “DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning” propone DeepTheorem, un framework de demostración de teoremas no formal que utiliza lenguaje natural para mejorar el razonamiento matemático de los LLM. El framework incluye un conjunto de datos de benchmark a gran escala (121,000 teoremas y demostraciones no formales de nivel IMO) y una política de RL diseñada específicamente para la demostración de teoremas no formales (RL-Zero). (Fuente: HuggingFace Daily Papers, teortaxesTex)
Artículo de IA: D-AR, difusión mediante modelos autorregresivos: El artículo “D-AR: Diffusion via Autoregressive Models” propone el nuevo paradigma D-AR, que reformula el proceso de difusión de imágenes como un proceso estándar de predicción del siguiente token autorregresivo. Mediante un tokenizer diseñado, las imágenes se convierten en secuencias de tokens discretos, donde los tokens en diferentes posiciones pueden decodificarse en diferentes pasos de eliminación de ruido por difusión en el espacio de píxeles. Este método alcanza un FID de 2.09 en ImageNet utilizando una red troncal Llama de 775M y 256 tokens discretos. (Fuente: HuggingFace Daily Papers)
Artículo de IA: Table-R1, escalado en tiempo de inferencia para el razonamiento tabular: El artículo “Table-R1: Inference-Time Scaling for Table Reasoning” explora por primera vez el escalado en tiempo de inferencia en tareas de razonamiento tabular. Los investigadores desarrollaron y evaluaron dos estrategias de post-entrenamiento: destilación a partir de trayectorias de inferencia de modelos de vanguardia (Table-R1-SFT) y aprendizaje por refuerzo con recompensas verificables (Table-R1-Zero). Table-R1-Zero (7B parámetros) alcanza o supera el rendimiento de GPT-4.1 y DeepSeek-R1 en diversas tareas de razonamiento tabular. (Fuente: HuggingFace Daily Papers)
Artículo de IA: Muddit, un modelo de difusión discreta unificado para la generación más allá de texto a imagen: El artículo “Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model” presenta Muddit, un modelo Transformer de difusión discreta unificado que admite la generación paralela rápida de modalidades de texto e imagen. Muddit integra los potentes priors visuales de una red troncal de texto a imagen preentrenada y un decodificador de texto ligero, siendo competitivo tanto en calidad como en eficiencia. (Fuente: HuggingFace Daily Papers)
Artículo de IA: VideoReasonBench, ¿pueden los MLLM realizar razonamiento complejo de vídeo centrado en la visión?: El artículo “VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?” introduce VideoReasonBench, un benchmark diseñado para evaluar la capacidad de razonamiento complejo de vídeo centrado en la visión. El benchmark incluye vídeos de secuencias de operaciones de grano fino, y las preguntas evalúan las capacidades de recuerdo, inferencia y predicción. Los experimentos muestran que la mayoría de los MLLM SOTA tienen un rendimiento deficiente en este benchmark, mientras que Gemini-2.5-Pro mejorado con pensamiento destaca. (Fuente: HuggingFace Daily Papers, OriolVinyalsML)
Artículo de IA: GeoDrive, un modelo del mundo para la conducción con percepción geométrica 3D y control preciso de acciones: El artículo “GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control” propone GeoDrive, que integra explícitamente condiciones geométricas 3D robustas en un modelo del mundo para la conducción, con el fin de mejorar la comprensión espacial y la controlabilidad de las acciones. El método mejora los efectos de renderizado durante el entrenamiento mediante un módulo de edición dinámica. Los experimentos demuestran su superioridad sobre los modelos existentes en precisión de acciones y percepción espacial 3D. (Fuente: HuggingFace Daily Papers)
Artículo de IA: Guía adaptativa sin clasificador mediante enmascaramiento dinámico de baja confianza: El artículo “Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking” propone el método A-CFG, que personaliza la entrada incondicional de la guía sin clasificador (CFG) utilizando la confianza de predicción instantánea del modelo. A-CFG identifica los tokens de baja confianza en cada paso de los modelos de lenguaje de difusión iterativa (enmascarada) y los vuelve a enmascarar temporalmente, creando así entradas incondicionales dinámicas y localizadas que hacen que el impacto correctivo de CFG sea más preciso. (Fuente: HuggingFace Daily Papers)
Artículo de IA: PatientSim, un simulador impulsado por personas para interacciones realistas médico-paciente: El artículo “PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions” presenta PatientSim, un simulador que genera personas de pacientes realistas y diversas basándose en perfiles clínicos del conjunto de datos MIMIC y cuatro ejes de persona (personalidad, dominio del lenguaje, nivel de recuerdo del historial médico, nivel de confusión cognitiva). Su objetivo es proporcionar un sistema de interacción con pacientes realista para entrenar o evaluar LLM médicos. (Fuente: HuggingFace Daily Papers)
Artículo de IA: LoRAShop, generación y edición de imágenes multiconcepto sin entrenamiento mediante Transformers de flujo rectificado: El artículo “LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers” presenta el primer framework que utiliza modelos LoRA para la edición de imágenes multiconcepto, LoRAShop. El framework aprovecha los patrones de interacción de características internas del Transformer de difusión estilo Flux para derivar máscaras latentes desacopladas para cada concepto, y mezcla los pesos LoRA solo dentro de las regiones conceptuales, logrando una integración perfecta de múltiples sujetos o estilos. (Fuente: HuggingFace Daily Papers)
Artículo de IA: AnySplat, splatting gaussiano 3D feed-forward desde vistas no restringidas: El artículo “AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views” presenta AnySplat, una red feed-forward para la síntesis de nuevas vistas a partir de un conjunto de imágenes no calibradas. A diferencia de los flujos de trabajo de renderizado neuronal tradicionales, AnySplat puede predecir primitivas gaussianas 3D (que codifican la geometría y apariencia de la escena) así como los parámetros intrínsecos y extrínsecos de la cámara para cada imagen de entrada mediante una única pasada hacia adelante, sin necesidad de anotaciones de pose, y admite la síntesis de nuevas vistas en tiempo real. (Fuente: HuggingFace Daily Papers)
Artículo de IA: ZeroSep, separación de cualquier cosa en audio sin entrenamiento: El artículo “ZeroSep: Separate Anything in Audio with Zero Training” descubre que, utilizando únicamente modelos de difusión de audio guiados por texto preentrenados, se puede lograr la separación de fuentes de sonido zero-shot en configuraciones específicas. El método ZeroSep invierte el audio mezclado al espacio latente del modelo de difusión y utiliza la guía condicionada por texto del proceso de eliminación de ruido para recuperar fuentes de sonido individuales, sin necesidad de ningún entrenamiento o fine-tuning específico para la tarea. (Fuente: HuggingFace Daily Papers)
Artículo de IA: Estudio sobre la minimización de la entropía en una sola toma (one-shot): El artículo “One-shot Entropy Minimization” descubre, mediante el entrenamiento de 13,440 grandes modelos de lenguaje, que la minimización de la entropía solo requiere un único dato no etiquetado y 10 pasos de optimización para alcanzar o incluso superar las mejoras de rendimiento logradas por el aprendizaje por refuerzo basado en reglas que utiliza miles de datos y recompensas cuidadosamente diseñadas. Este resultado podría impulsar una reconsideración de los paradigmas de post-entrenamiento de LLM. (Fuente: HuggingFace Daily Papers)
Artículo de IA: ChartLens, atribución visual de grano fino en gráficos: El artículo “ChartLens: Fine-grained Visual Attribution in Charts” aborda el problema de que los MLLM tienden a generar alucinaciones en la comprensión de gráficos, introduciendo la tarea de atribución visual posterior en gráficos y proponiendo el algoritmo ChartLens. Este algoritmo utiliza técnicas de segmentación para identificar objetos en los gráficos y realiza una atribución visual de grano fino con los MLLM mediante prompts con conjuntos de etiquetas. Al mismo tiempo, se publica el benchmark ChartVA-Eval, que contiene anotaciones de atribución de grano fino para gráficos de los campos financiero, político, económico, etc. (Fuente: HuggingFace Daily Papers)
Artículo de IA: Explorando los patrones estructurales del conocimiento en grandes modelos de lenguaje desde una perspectiva de grafos: El artículo “A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models” investiga los patrones estructurales del conocimiento en los LLM desde una perspectiva de grafos. El estudio cuantifica el conocimiento de los LLM a nivel de tripletas y entidades, analiza su relación con atributos estructurales de los grafos como el grado de los nodos, y revela la homogeneidad del conocimiento (las entidades topológicamente cercanas tienen niveles de conocimiento similares). Basándose en esto, se desarrollaron modelos de aprendizaje automático de grafos para estimar el conocimiento de las entidades y utilizarlos para la verificación del conocimiento. (Fuente: HuggingFace Daily Papers)
💼 Negocios
La empresa de inteligencia corporeizada Lumos Robotics recauda casi 200 millones en medio año y alcanza acuerdos con COSCO Shipping y otros: Lumos Robotics (鹿明机器人), una empresa de robots de inteligencia corporeizada fundada por el ex ejecutivo de Dreame, Yu Chao, anunció la finalización de su ronda de financiación Ángel++, con inversores como Fosun RZ Capital, Dematic Technology y Wuzhong Financial Holding. En los últimos seis meses, la empresa ha recaudado acumulativamente casi 200 millones de yuanes. La compañía se centra en escenarios domésticos, con productos que incluyen los robots humanoides de las series LUS y MOS, así como componentes principales. Ya ha lanzado el robot humanoide de tamaño completo LUS y ha alcanzado acuerdos estratégicos con Dematic Technology, COSCO Shipping y otros, acelerando la comercialización de la inteligencia corporeizada en escenarios como la logística y la fabricación inteligente. (Fuente: 36氪)

Snorkel AI completa una ronda de financiación Serie D de 100 millones de dólares y lanza servicios de evaluación de agentes de IA y datos de expertos: La empresa de IA para centros de datos Snorkel AI anunció la finalización de una ronda de financiación Serie D de 100 millones de dólares liderada por Valor Equity Partners, elevando su financiación total a 235 millones de dólares. Al mismo tiempo, la compañía lanzó Snorkel Evaluate (una plataforma de evaluación de IA para agentes de centros de datos) y Expert Data-as-a-Service (datos de expertos como servicio), con el objetivo de ayudar a las empresas a construir e implementar agentes de IA más confiables y profesionales. (Fuente: realDanFu, percyliang, tri_dao, krandiash)
El Departamento de Energía de EE. UU. anuncia colaboración con Dell y NVIDIA para desarrollar la supercomputadora de próxima generación “Doudna”: El Departamento de Energía de EE. UU. anunció la firma de un contrato con Dell para desarrollar la supercomputadora insignia de próxima generación del Laboratorio Nacional Lawrence Berkeley, llamada “Doudna” (NERSC-10). El sistema estará impulsado por la plataforma Vera Rubin de próxima generación de NVIDIA y se espera que entre en funcionamiento en 2026, con un rendimiento más de 10 veces superior al de la actual insignia Perlmutter. Su objetivo es soportar cargas de trabajo de computación de alto rendimiento e IA a gran escala, ayudando a Estados Unidos a ganar la carrera por el dominio global de la IA. (Fuente: 36氪, nvidia)

🌟 Comunidad
DeepSeek R1-0528 genera debate, con el rendimiento, las alucinaciones y la llamada a herramientas como focos de atención: El lanzamiento de DeepSeek R1-0528 ha generado un amplio debate en la comunidad. La mayoría de las opiniones coinciden en que ha mejorado significativamente en matemáticas, programación y razonamiento lógico general, acercándose o incluso superando a algunos modelos de código cerrado. La nueva versión ha progresado en la reducción de la tasa de alucinaciones y ha añadido soporte para salida JSON y llamadas a funciones. Al mismo tiempo, su versión destilada Qwen3-8B también ha llamado la atención por su excelente rendimiento matemático en un modelo pequeño. La comunidad considera en general que DeepSeek ha consolidado su liderazgo en el ámbito del código abierto y espera con interés el lanzamiento de la versión R2. (Fuente: ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
El modelo de edición de imágenes con IA FLUX.1 Kontext llama la atención, destacando la comprensión del contexto y la consistencia de los personajes: El modelo de edición de imágenes FLUX.1 Kontext, lanzado por Black Forest Labs, ha llamado la atención de la comunidad por su capacidad para procesar simultáneamente entradas de texto e imágenes y mantener la consistencia de los personajes. Los usuarios comentan que su rendimiento es excelente en tareas como la edición de imágenes, la transferencia de estilo y la superposición de texto, especialmente en la edición multivuelta, donde conserva bien las características del sujeto. Plataformas como Replicate ya han incorporado el modelo y ofrecen informes de prueba detallados y consejos de uso. (Fuente: TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

Los agentes de IA cambiarán significativamente los modelos de búsqueda y publicidad: Arav Srinivas, CEO de Perplexity AI, cree que a medida que los agentes de IA realicen búsquedas en nombre de los usuarios, el volumen de consultas humanas en motores de búsqueda como Google disminuirá drásticamente. Esto conducirá a una reducción del CPM/CPC publicitario, y el gasto en publicidad podría desplazarse hacia las redes sociales o las plataformas de IA. Los usuarios ya no necesitarán realizar búsquedas frecuentes por palabras clave, sino que los asistentes de IA les proporcionarán información de forma proactiva. (Fuente: AravSrinivas)
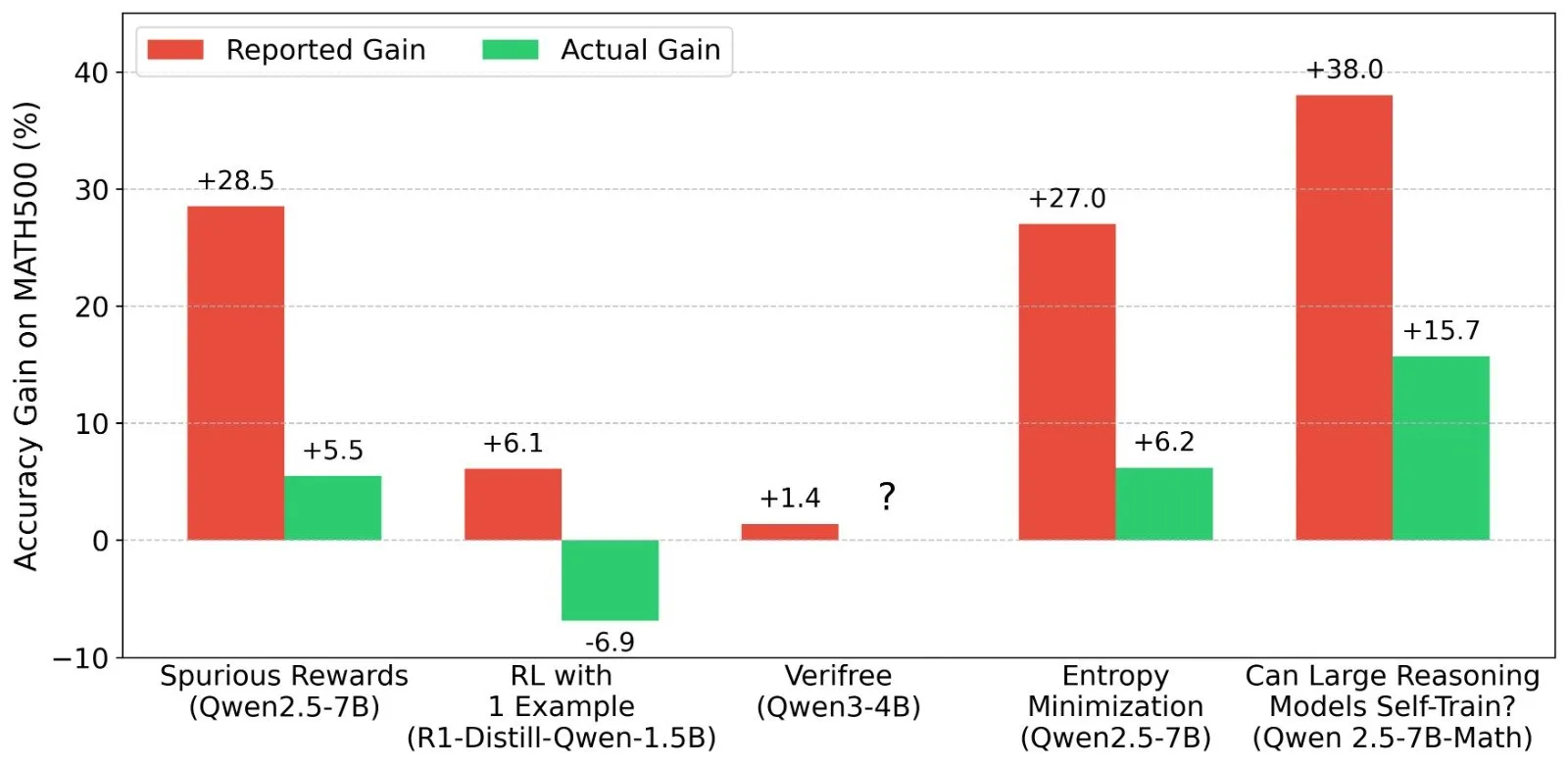
Discusión sobre los resultados del aprendizaje por refuerzo (RL) en LLM: la veracidad de las señales de recompensa y la capacidad del modelo: Investigadores como Shashwat Goel cuestionan el fenómeno observado recientemente en estudios de RL con LLM, donde los modelos mejoran su rendimiento incluso sin señales de recompensa reales. Señalan que algunos estudios podrían estar subestimando la capacidad base de los modelos preentrenados o que existen otros factores de confusión. La discusión ha llevado a un análisis más profundo del rendimiento de modelos como Qwen en RL, así como a una reflexión sobre la efectividad del RLVR (aprendizaje por refuerzo con recompensa verificable), enfatizando la necesidad de líneas base más estrictas y optimización de prompts al evaluar los efectos del RL. (Fuente: menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
“Vibe Coding” genera debate, destacando la importancia de los valores predeterminados seguros y los riesgos de la deuda técnica: El “Vibe coding” (programación por ambiente, que se refiere a una forma de programar que depende más de la intuición y la iteración rápida que de especificaciones estrictas) se ha convertido en un tema candente en la comunidad. Amjad Masad, CEO de Replit, considera que este enfoque empodera a los nuevos desarrolladores, pero que las plataformas deben ofrecer configuraciones predeterminadas seguras. Al mismo tiempo, Pedro Domingos comentó que “la programación por ambiente es el Godzilla de la deuda técnica”, insinuando los problemas de mantenimiento a largo plazo que podría acarrear. Semafor informó sobre una vulnerabilidad de seguridad en Lovable debido a una configuración incorrecta de la política RLS, lo que generó más preocupación sobre la seguridad de este estilo de programación. (Fuente: alexalbert__, amasad, pmddomingos, gfodor)
El papel de la IA en la ingeniería de software: aumento de la eficiencia y la insustituibilidad de los programadores humanos: Salvatore Sanfilippo, el creador de Redis, compartió su experiencia señalando que, aunque la IA (como Gemini 2.5 Pro) es valiosa para la asistencia en programación, la revisión de código y la validación de ideas, los programadores humanos siguen superando con creces a la IA en la resolución creativa de problemas y el pensamiento innovador. La discusión en la comunidad señaló además que la IA actualmente se asemeja más a un “pato de goma inteligente”, capaz de ayudar en el proceso de pensamiento, pero sus sugerencias deben evaluarse con cautela, y una dependencia excesiva podría debilitar las capacidades fundamentales de los desarrolladores. Mitchell Hashimoto también compartió un caso en el que un LLM le ayudó a localizar rápidamente un problema de compilación en Clang, ahorrándole una cantidad significativa de tiempo. (Fuente: mitchellh, 36氪)
La cuestión de si la IA reemplazará masivamente puestos de trabajo sigue generando preocupación: Dario Amodei, CEO de Anthropic, predice que la IA podría hacer desaparecer la mitad de los puestos de oficina de nivel básico, mientras que Mark Cuban opina que la IA creará nuevas empresas y nuevos puestos. La comunidad debate intensamente sobre esto; algunos argumentan que trabajos como el servicio al cliente, la redacción de textos básicos y parte del desarrollo ya se han visto afectados, pero la IA aún tiene dificultades para reemplazar a los humanos en áreas que requieren creatividad, toma de decisiones complejas y alta interacción interpersonal. El consenso general es que la IA cambiará la naturaleza del trabajo, y los humanos necesitarán adaptarse y mejorar su capacidad para colaborar con la IA. (Fuente: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
Los AI Agent (agentes inteligentes) se convierten en la próxima puerta de entrada a la interacción, desatando la competencia entre las grandes tecnológicas: Empresas tecnológicas nacionales e internacionales como Microsoft, Google, OpenAI, Alibaba, Tencent, Baidu y Coocaa están apostando por los AI Agent. Los agentes inteligentes pueden pensar profundamente, planificar de forma autónoma, tomar decisiones y ejecutar tareas complejas, y se consideran la próxima puerta de entrada a la interacción después de los motores de búsqueda y las aplicaciones. Actualmente se han formado tres fuerzas principales: constructores de ecosistemas tecnológicos representados por OpenAI y Baidu; proveedores de servicios empresariales para escenarios verticales representados por Microsoft y Alibaba Cloud; y fabricantes de terminales de hardware y software representados por Huawei y Coocaa. (Fuente: 36氪)

💡 Otros
La expansión internacional de la IA china se acelera, pasando de la exportación de productos a la construcción de ecosistemas: El informe “El crecimiento transoceánico de la IA china” señala que la expansión internacional de las empresas chinas de IA ha entrado en una vía rápida de escalamiento, con un 76% concentrado en el nivel de aplicación. La ruta de expansión ha evolucionado desde las primeras aplicaciones de tipo herramienta, pasando por una fase intermedia de exportación de soluciones industriales combinadas con ventajas tecnológicas, hasta la etapa actual, que se centra en la exportación de ecosistemas tecnológicos, promoviendo estándares técnicos y colaboración de código abierto. La expansión internacional de la IA muestra una penetración gradual “de cerca a lejos” y enfrenta desafíos como la localización, el cumplimiento normativo y ético, y el marketing de marca. (Fuente: 36氪)

El Departamento de Energía de EE. UU. compara la carrera de la IA con un “nuevo Proyecto Manhattan” y enfatiza que EE. UU. ganará: Al anunciar la supercomputadora de próxima generación “Doudna”, el Departamento de Energía de EE. UU. se refirió a la competencia en el desarrollo de la IA como “el Proyecto Manhattan de nuestro tiempo” y declaró que Estados Unidos ganará esta carrera. Estas declaraciones han generado un debate en la comunidad sobre la competencia tecnológica entre grandes potencias, la ética de la IA y la cooperación internacional. (Fuente: gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
Los avances de la IA en el campo de la creación de contenidos suscitan reflexiones sobre la “autenticidad” y la “creatividad”: La comunidad ha debatido sobre las aplicaciones de la IA en el diseño de moda, la creación de cómics, la generación de vídeos, etc. Por un lado, la IA puede generar rápidamente contenidos diversos, e incluso convertir obras de cómic de hace años en vídeos; por otro lado, estos contenidos generados a veces resultan extraños o carecen de profundidad. Esto ha suscitado reflexiones sobre si los contenidos generados por IA son “mejores” y qué papel desempeñará la creatividad humana en la era de la IA. (Fuente: Reddit r/ChatGPT, Reddit r/artificial)
