Palabras clave:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, recompensa aleatoria, recompensa errónea, rendimiento del modelo, aprendizaje por refuerzo, futuro de RLHF/RLAIF, mejora del rendimiento del modelo con recompensa aleatoria, entrenamiento de Qwen2.5-Math-7B con recompensa errónea, conjunto de pruebas MATH-500, aprendizaje de señales de aprendizaje por refuerzo
🔥 Enfoque
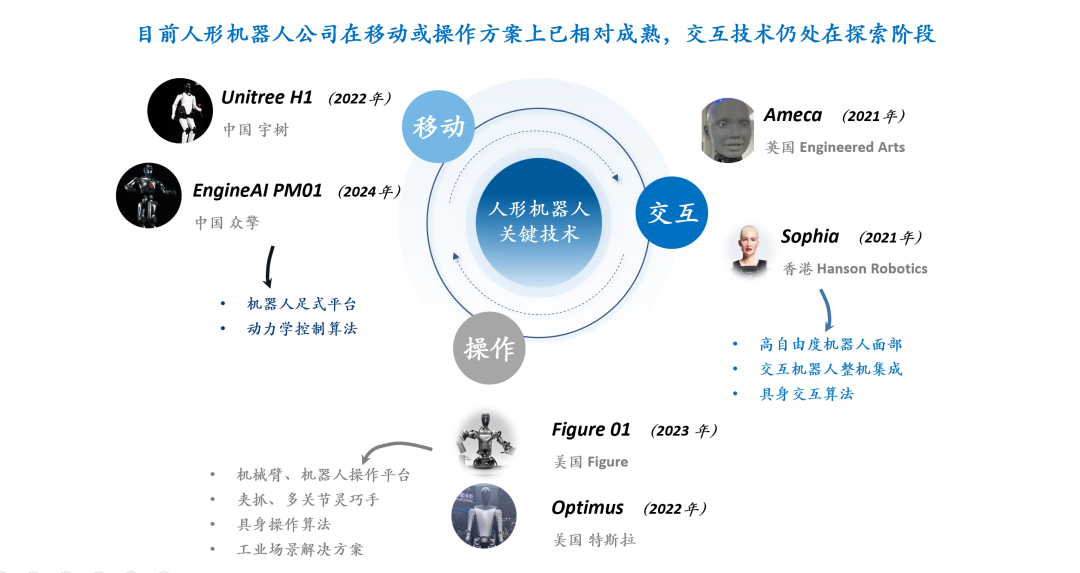
El futuro de RLHF/RLAIF: ¿Pueden las recompensas aleatorias/incorrectas también mejorar el rendimiento del modelo? : Experimentos de Stella Li demuestran que entrenar el modelo Qwen2.5-Math-7B usando recompensas aleatorias o incorrectas mejoró el rendimiento en el conjunto de pruebas MATH-500 en un 21% y 25% respectivamente, acercándose al efecto de mejora del 28.8% obtenido con recompensas reales. Una investigación de Rulin Shao, compartida por natolambert, también encontró que con RLVR (Reinforcement Learning from Verifier Reward), al usar recompensas falsas, el modelo Olmo aumentó el uso de código pero su rendimiento disminuyó, mientras que impedirle usar código mejoró su rendimiento. Estos hallazgos desafían la dependencia tradicional en RLHF/RLAIF de datos de preferencia humana de alta calidad, sugiriendo que los modelos podrían aprender a explorar espacios de estrategia más amplios a través de señales de recompensa, incluso si la recompensa en sí no es perfecta, estimulando capacidades latentes del modelo u optimizando comportamientos existentes. Esto podría abrir nuevas vías para reducir la dependencia de la costosa anotación manual y explorar métodos de alineación de modelos más eficientes, pero es necesario estar alerta al riesgo de que los modelos aprendan comportamientos incorrectos. (Fuente: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
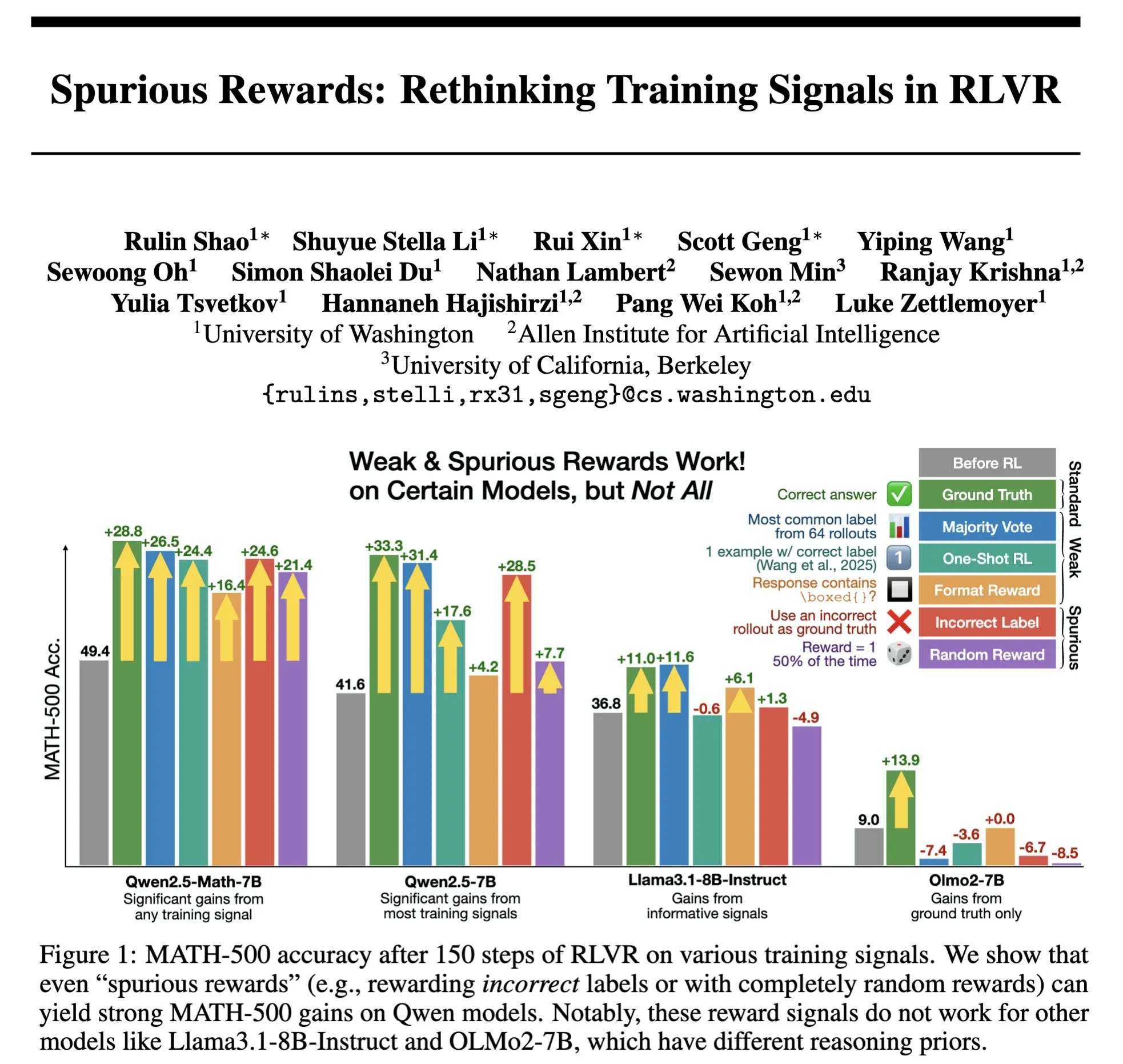
Hazy Research lanza Low-Latency-Llama Megakernel: inferencia de Llama 1B en un solo núcleo CUDA : Hazy Research ha presentado Low-Latency-Llama Megakernel, capaz de completar toda la propagación hacia adelante (forward pass) del modelo Llama 1B dentro de un único núcleo CUDA. Esta tecnología, al integrar el cálculo en un solo kernel, elimina los límites de sincronización impuestos por las llamadas a kernel serializadas tradicionales, optimizando así la programación de cómputo y memoria para lograr una latencia menor. Andrej Karpathy elogió enormemente este avance, considerándolo la única vía para lograr una orquestación óptima de cómputo y memoria. Este progreso es de gran importancia para escenarios con estrictos requisitos de latencia, como la computación en el borde (edge computing) y aplicaciones de IA en tiempo real, y se espera que impulse un despliegue más eficiente y ágil de modelos de lenguaje pequeños. (Fuente: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek Qiyuan lanza rStar-Coder: construyendo un conjunto de datos de inferencia de código verificado a gran escala para mejorar significativamente la capacidad de código de modelos pequeños : Investigadores de Microsoft y DeepSeek han lanzado el proyecto rStar-Coder, que tiene como objetivo abordar la escasez actual de conjuntos de datos de alta calidad y dificultad en el campo de la inferencia de código mediante la construcción de un conjunto de datos verificado a gran escala que contiene 418,000 problemas de código a nivel de competencia, 580,000 soluciones de inferencia largas y abundantes casos de prueba. El proyecto mejora la capacidad de inferencia de código de los LLM mediante la utilización integral de problemas de competencia de programación existentes y soluciones oracle para sintetizar nuevos problemas, el diseño de pipelines confiables para la generación de casos de prueba de entrada/salida, y la verificación de soluciones de inferencia largas de alta calidad con casos de prueba. Los experimentos muestran que los modelos Qwen (1.5B-14B) entrenados con el conjunto de datos rStar-Coder tienen un rendimiento excelente en múltiples benchmarks de inferencia de código. Por ejemplo, Qwen2.5-7B mejoró su precisión en LiveCodeBench del 17.4% al 57.3%, superando a o3-mini (low); en USACO, el modelo 7B también superó al QWQ-32B, de mayor tamaño. (Fuente: HuggingFace Daily Papers)
El Instituto de Automatización de la Academia China de Ciencias propone AutoThink: permitir que los modelos grandes decidan autónomamente si deben “pensar profundamente” : En respuesta al fenómeno de “pensamiento excesivo” en el que los grandes modelos de lenguaje realizan inferencias largas incluso en problemas simples, el Instituto de Automatización de la Academia China de Ciencias y el Laboratorio Peng Cheng han propuesto conjuntamente el método AutoThink. Este método, mediante la adición de “puntos suspensivos” (…) en el prompt y la combinación con un aprendizaje por refuerzo de tres etapas (estabilización de patrones, optimización del comportamiento, poda de inferencias), permite al modelo elegir autónomamente si realizar un pensamiento profundo y cuánto pensar según la dificultad del problema. Los experimentos demuestran que AutoThink puede mejorar el rendimiento de modelos como DeepSeek-R1 en benchmarks de matemáticas, al tiempo que reduce significativamente el consumo de tokens de inferencia. Por ejemplo, en DeepScaleR puede ahorrar un 10% adicional de tokens. Esta investigación tiene como objetivo permitir que los modelos logren un “pensamiento bajo demanda”, mejorando el equilibrio entre la eficiencia de la inferencia y la precisión. (Fuente: 36氪, _akhaliq)

Sakana AI lanza Sudoku-Bench, revelando las deficiencias de los principales modelos grandes en la inferencia de “sudokus variantes” : Sakana AI, la startup del autor de Transformer Llion Jones, ha lanzado Sudoku-Bench, un benchmark que incluye desde sudokus modernos “variantes” de 4×4 hasta complejos de 9×9, diseñado para evaluar la capacidad de razonamiento creativo de múltiples pasos de la IA. Los resultados de las pruebas muestran que los principales modelos grandes, incluidos Gemini 2.5 Pro, GPT-4.1 y Claude 3.7, tienen una tasa de acierto general inferior al 15% sin asistencia. En los sudokus modernos de 9×9, o3 Mini High solo alcanzó una tasa de acierto del 2.9%. Esto indica que los modelos tienen un rendimiento deficiente cuando se enfrentan a problemas novedosos que requieren un razonamiento lógico real en lugar de reconocimiento de patrones, cometiendo errores frecuentes, rindiéndose o malinterpretando las reglas. El CEO de NVIDIA, Jensen Huang, cree que este tipo de acertijos ayuda a mejorar el razonamiento de la IA. Sakana AI también ha publicado datos de entrenamiento relevantes, incluidas grabaciones de procesos de resolución en colaboración con un famoso canal de Sudoku. (Fuente: 36氪)

🎯 Tendencias
Meta reorganiza su equipo de IA, la pérdida de miembros clave de FAIR atrae la atención : Meta anunció una reorganización de su equipo de IA, dividiéndolo en un equipo de productos de IA liderado por Connor Hayes y un departamento de fundamentos de AGI codirigido por Ahmad Al-Dahle y Amir Frenkel. El primero se centrará en productos para el consumidor, mientras que el segundo se enfocará en la investigación y desarrollo de modelos fundamentales como Llama. Cabe destacar que el departamento de investigación fundamental en inteligencia artificial, FAIR, se mantiene independiente, pero algunos equipos multimedia se integran en el departamento de fundamentos de AGI. Este ajuste tiene como objetivo mejorar la velocidad y flexibilidad del desarrollo. Sin embargo, Meta enfrenta desafíos como la tibia recepción de Llama 4, la creciente competencia en el ámbito del código abierto y la fuga de talento clave. De los 14 autores originales involucrados en el desarrollo de Llama, 11 ya han renunciado, y varios se han unido o fundado competidores como Mistral AI. El laboratorio FAIR también ha experimentado cambios en su liderazgo y en la dirección de su investigación, lo que ha generado preocupaciones sobre su posición dentro de la empresa y su capacidad de innovación futura. (Fuente: 36氪)

Google DeepMind lanza SignGemma: un nuevo modelo para la traducción de lengua de signos : Google DeepMind ha anunciado el lanzamiento de SignGemma, un modelo que se describe como su traductor más potente hasta la fecha de lengua de signos a texto hablado. Se espera que este modelo se una a la familia de modelos Gemma a finales de este año y se publique en formato de código abierto. El lanzamiento de SignGemma tiene como objetivo abrir nuevas posibilidades para la tecnología inclusiva, mejorando la eficiencia y la comodidad de la comunicación para los usuarios de lengua de signos. Google DeepMind invita a los usuarios a proporcionar comentarios y participar en las pruebas tempranas. (Fuente: GoogleDeepMind, demishassabis)
Tencent Hunyuan publica los pesos del modelo HunyuanPortrait, capaz de convertir retratos estáticos en vídeos dinámicos : El equipo de Tencent Hunyuan ha liberado los pesos de su modelo de imagen a vídeo HunyuanPortrait, permitiendo a los usuarios descargarlos y utilizarlos localmente. Este modelo se especializa en convertir imágenes estáticas de retratos de personas en vídeos dinámicos, siendo aplicable a diversos escenarios como personajes de juegos, avatares virtuales, humanos digitales, asistentes de compras inteligentes, etc., logrando que las imágenes faciales cobren vida y aumentando la vivacidad y el realismo de la interacción. Se han publicado el modelo, el repositorio de código y el paper correspondientes. (Fuente: karminski3, Reddit r/LocalLLaMA)

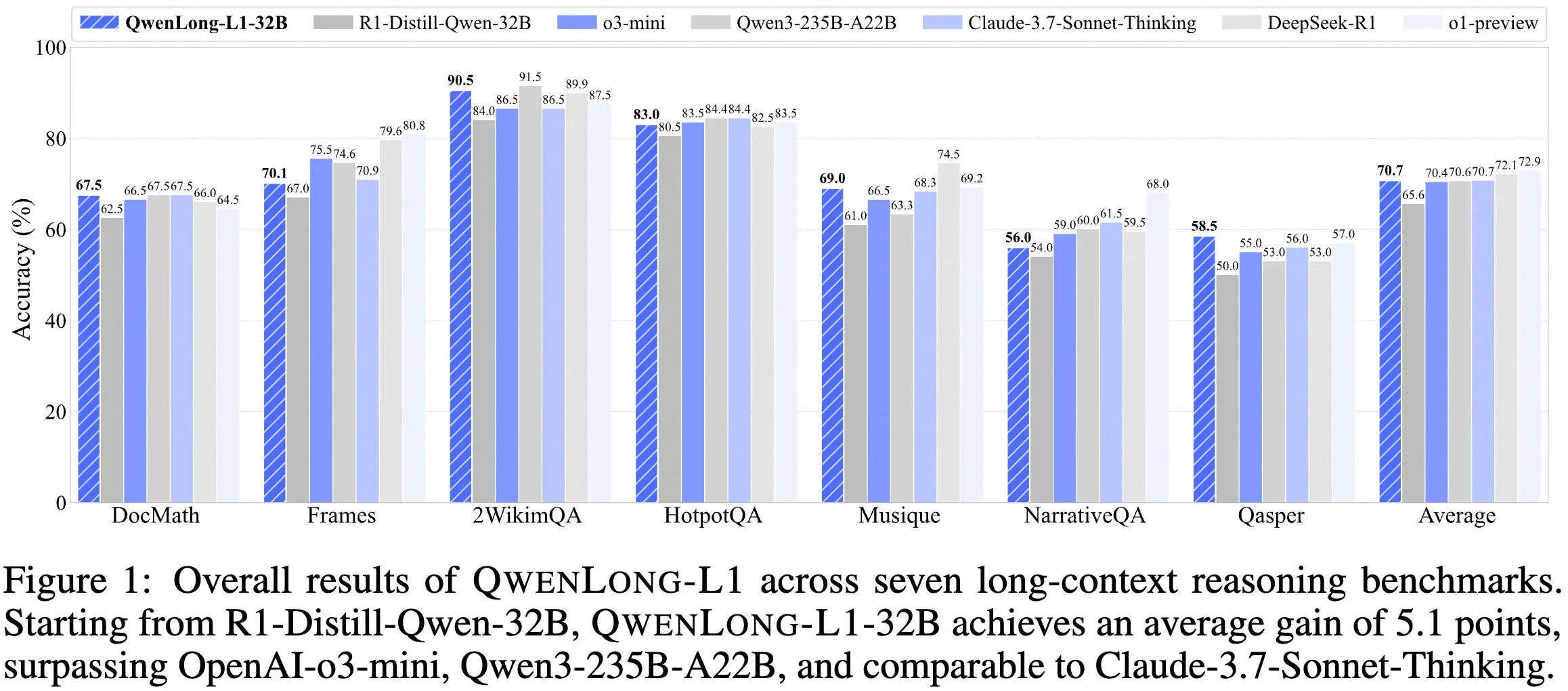
El equipo de QwenDoc lanza el modelo de inferencia de contexto largo QwenLong-L1-32B : El equipo de QwenDoc ha lanzado QwenLong-L1-32B, un modelo de inferencia de contexto largo de 128K entrenado mediante aprendizaje por refuerzo. Este modelo, ajustado a partir de DeepSeek-R1-Distill-Qwen-32B, obtiene una puntuación de 90.5 en el conjunto de pruebas de inferencia multi-salto 2WikiMultihopQA, lo que supone una mejora de 6.5 puntos respecto al modelo original. Se destaca su capacidad no solo para encontrar contenido en contextos largos, sino también para conectar pistas y realizar inferencias. Aunque la longitud de contexto de 128K no es la más larga actualmente, su destacada capacidad de inferencia ofrece una nueva opción para procesar documentos largos y complejos. El modelo, el paper y el repositorio de código ya son públicos. (Fuente: karminski3)
HKUST y Apple, entre otras instituciones, colaboran en el lanzamiento de la serie de métodos Laser para optimizar la eficiencia y precisión de la inferencia en modelos grandes : Investigadores de la Universidad de Ciencia y Tecnología de Hong Kong (HKUST), la City University of Hong Kong (CityU HK), la Universidad de Waterloo y Apple han propuesto la serie de métodos Laser (incluyendo Laser-D, Laser-DE), con el objetivo de resolver el problema del consumo excesivo de tokens por parte de los grandes modelos de lenguaje (LRM) en la inferencia de problemas simples. Este método, a través de un marco unificado de diseño de recompensa por longitud, recompensas basadas en la longitud objetivo y funciones escalonadas, y un mecanismo dinámico de percepción de la dificultad, ha logrado una mejora de rendimiento de 6.1 puntos en benchmarks de razonamiento matemático complejo como AIME24, al tiempo que reduce el uso de tokens en un 63%. La investigación encontró que la “autorreflexión” redundante del modelo entrenado disminuye, y su patrón de pensamiento es más saludable, equilibrando eficazmente la eficiencia y la precisión de la inferencia del modelo. (Fuente: 36氪)

La versión gratuita de Anthropic Claude ahora admite la función de búsqueda web : Anthropic ha anunciado que los usuarios de la versión gratuita de su asistente de IA, Claude, ahora pueden utilizar la función de búsqueda web. Esto significa que Claude, al responder preguntas, puede obtener la información más reciente de Internet para mejorar la relevancia y precisión de sus respuestas. La compañía afirma que cada respuesta que incluya resultados de búsqueda proporcionará citas en línea para facilitar la verificación de las fuentes de información por parte de los usuarios. (Fuente: AnthropicAI)
PKU-DS-LAB lanza FairyR1: un modelo de inferencia de 32B ajustado a partir de DeepSeek-R1-Distill-Qwen-32B : El Laboratorio de Ciencia de Datos de la Universidad de Pekín (PKU-DS-LAB) ha lanzado FairyR1, un modelo de inferencia con 32B de parámetros bajo la licencia Apache 2.0. Se afirma que este modelo, mediante un método de “destilación y refusión”, alcanza el rendimiento de modelos más grandes utilizando solo el 5% de los parámetros. FairyR1 se ha ajustado a partir de DeepSeek-R1-Distill-Qwen-32B, y sus datos de entrenamiento también están disponibles en Hugging Face Hub. Este trabajo continúa la línea de investigación de TinyR1, filtrando activamente el conjunto de datos (aproximadamente 10,000 trayectorias), realizando SFT para matemáticas y código por separado, y utilizando Arcee Fusion para la fusión de modelos. (Fuente: huggingface, teortaxesTex, stablequan)
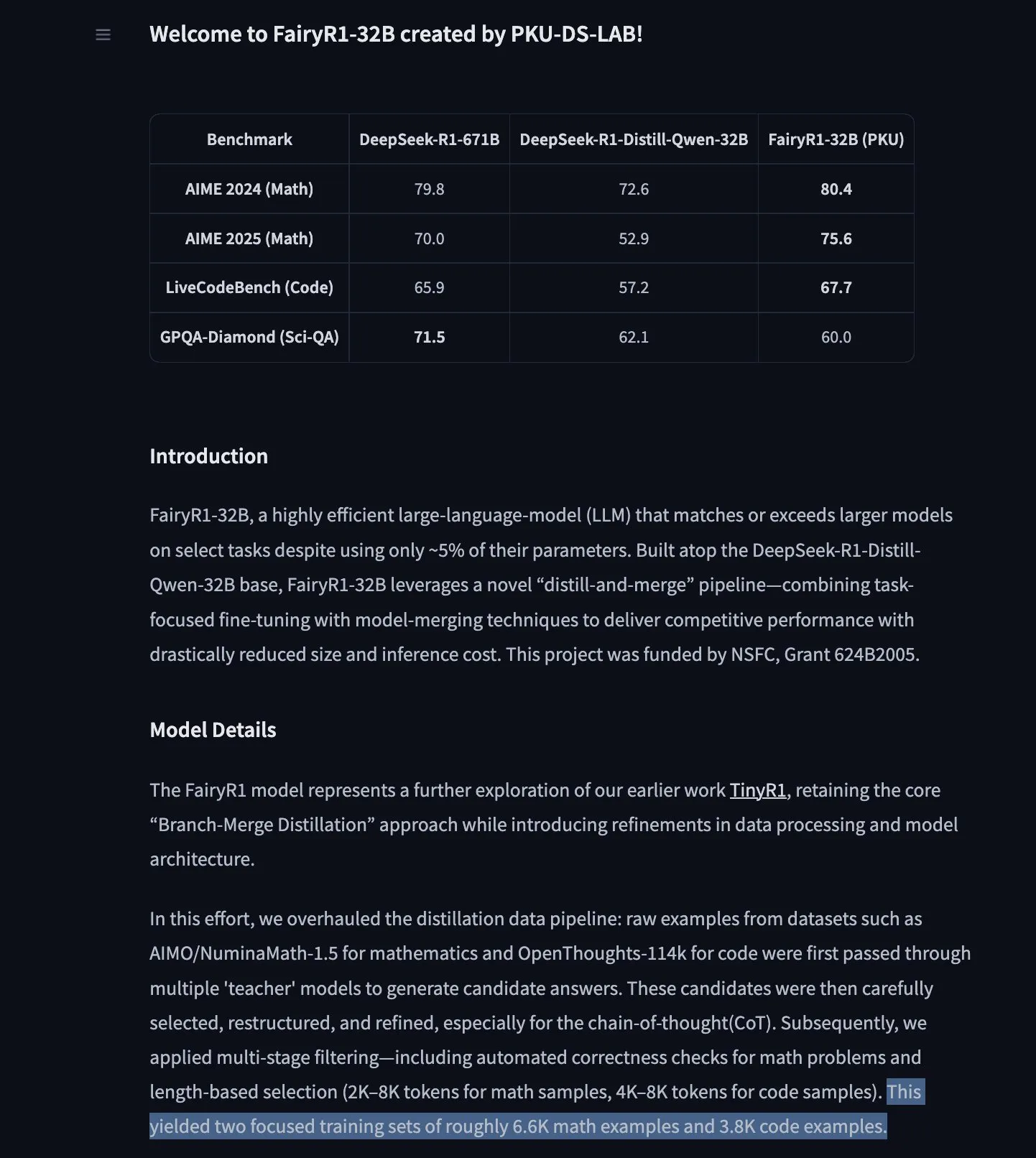
El modelo de predicción de series temporales TimesFM de Google llega a Hugging Face Transformers : El modelo TimesFM de Google ya está integrado en la biblioteca Hugging Face Transformers. Se trata de un modelo similar a GPT, preentrenado con 100 mil millones de puntos de datos temporales reales procedentes de diversas fuentes como Google Trends y visitas a páginas de Wikipedia. Se afirma que TimesFM supera en tareas de predicción zero-shot a modelos específicamente ajustados, ofreciendo una nueva y potente herramienta para el análisis de series temporales. (Fuente: huggingface)
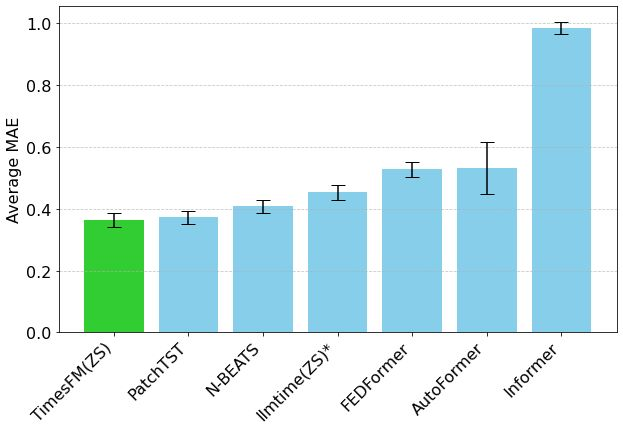
Hugging Face lanza Mixture of Thoughts: un conjunto de datos de inferencia general cuidadosamente seleccionado : Lewis Tunstall y otros investigadores de Hugging Face han publicado el conjunto de datos “Mixture of Thoughts”. Este conjunto de datos, cuidadosamente seleccionado a partir de más de 1 millón de muestras de datos públicos mediante extensos experimentos de ablación, se centra en la capacidad de inferencia general. Los modelos entrenados con este conjunto de datos mixto alcanzan o superan el rendimiento de los modelos destilados de DeepSeek en benchmarks de matemáticas, código y ciencia (como GPQA). La investigación valida la efectividad de la metodología de “aditividad” propuesta en Phi-4-reasoning, que permite optimizar independientemente la mezcla de datos para cada dominio de inferencia y luego integrarlos para el entrenamiento final. (Fuente: huggingface)
ByteDance lanza BAGEL-7B: un modelo omnidireccional que combina comprensión y generación de imágenes y texto : ByteDance ha presentado BAGEL-7B, un modelo “omni” capaz de comprender y generar tanto imágenes como texto. Además, han lanzado Dolphin, un modelo de lenguaje visual (VLM) especializado en el análisis de documentos. La liberación de estos modelos en código abierto proporcionará nuevas herramientas y posibilidades para la investigación y aplicación multimodal. (Fuente: huggingface, TheTuringPost)

Google lanza Gemini 2.5 Flash Preview, con soporte para salida de audio nativa : Los desarrolladores de IA de Google han anunciado que Gemini 2.5 Flash Preview ahora admite salida de audio nativa a través de la Live API, con el objetivo de ofrecer interacciones habladas fluidas y naturales, así como una mayor capacidad de control por voz. Además, se ha lanzado una nueva versión experimental “pensante” de este modelo de audio, que admite capacidades de inferencia para tareas más complejas. Al mismo tiempo, la salida de la API de Gemini también ha comenzado a mostrar “resúmenes de pensamiento”, permitiendo a los usuarios comprender el proceso de razonamiento del modelo, aunque actualmente no es una cadena de inferencia completa. (Fuente: algo_diver, op7418)
Un paper explora la capacidad expresiva de Transformer al rellenar tokens en blanco : Una nueva investigación explora si rellenar tokens en blanco en la entrada de un Transformer (una forma de cálculo en tiempo de prueba) puede mejorar la capacidad computacional de los LLM. El estudio, en colaboración con Ashish_S_AI, caracteriza con precisión la capacidad expresiva de los Transformers con relleno, ofreciendo una nueva perspectiva para comprender y optimizar los mecanismos computacionales de los LLM. (Fuente: teortaxesTex)

Nueva investigación propone el marco Sci-Fi: mejora de la interpolación de fotogramas de vídeo mediante restricciones simétricas : Abordando el problema de que los métodos actuales de interpolación de fotogramas de vídeo (Frame Inbetweening) pueden tener una asimetría en la fuerza de control al fusionar las restricciones de los fotogramas inicial y final, un nuevo paper propone el marco Sci-Fi (Symmetric Constraint for Frame Inbetweening). Este método tiene como objetivo lograr la simetría de las restricciones de los fotogramas inicial y final aplicando un mecanismo de inyección más fuerte (basado en el módulo ligero EF-Net) a las restricciones con menor escala de entrenamiento (como el fotograma final), para así producir transiciones más armoniosas en los fotogramas intermedios generados, evitando inconsistencias de movimiento o colapso de la apariencia. (Fuente: HuggingFace Daily Papers)
Un paper propone Paper2Poster: un flujo automatizado de artículos científicos a pósteres multimodales : Para abordar los desafíos de la creación de pósteres académicos, los investigadores han lanzado el primer benchmark de generación de pósteres y un conjunto de métricas de evaluación, Paper2Poster, que contiene pares de artículos y pósteres diseñados por los autores. Se evalúan aspectos como la calidad visual, la coherencia textual, la evaluación general y PaperQuiz (que mide la capacidad del póster para transmitir el contenido principal). Al mismo tiempo, se propone PosterAgent, un flujo multiagente de arriba hacia abajo y con retroalimentación visual, que incluye un analizador (para extraer activos), un planificador (para la alineación texto-visual y el diseño) y un ciclo pintor-crítico (para la renderización y optimización por retroalimentación). Las variantes basadas en modelos de código abierto como Qwen-2.5 superan a los sistemas impulsados por GPT-4o en la mayoría de las métricas, con una reducción del 87% en el consumo de tokens, permitiendo convertir artículos de 22 páginas en pósteres editables .pptx a un costo extremadamente bajo. (Fuente: HuggingFace Daily Papers)
Un paper propone Frame In-N-Out: logrando una generación de imagen a vídeo controlable y sin límites : Abordando los desafíos de controlabilidad, consistencia temporal y síntesis de detalles en la generación de vídeo, un nuevo paper se centra en la técnica cinematográfica “Frame In and Frame Out”. Su objetivo es permitir a los usuarios controlar que los objetos de una imagen salgan naturalmente de la escena, o introducir nuevas referencias de identidad en la escena, guiados por trayectorias de movimiento especificadas por el usuario. Para ello, los investigadores introducen un nuevo conjunto de datos etiquetado semiautomáticamente, un protocolo de evaluación integral y una arquitectura eficiente de Diffusion Transformer para vídeo que mantiene la identidad y es controlable por movimiento. Los experimentos demuestran que este método supera significativamente a las líneas base existentes. (Fuente: HuggingFace Daily Papers)
Nueva investigación propone Active-O3: dotando a los modelos de lenguaje grandes multimodales de capacidad de percepción activa mediante GRPO : Ante la insuficiente exploración de la percepción activa en los modelos de lenguaje grandes multimodales (MLLM), los investigadores proponen el marco Active-O3. Este marco, basado en el entrenamiento de aprendizaje por refuerzo puro con GRPO (Group Relative Policy Optimization), tiene como objetivo dotar a los MLLM de la capacidad de elegir activamente las posiciones y formas de observación para recopilar información relevante para la tarea. Los investigadores primero definen sistemáticamente las tareas de percepción activa basadas en MLLM y señalan que la estrategia de búsqueda ampliada de GPT-o3 es un caso especial de percepción activa pero con deficiencias en eficiencia y precisión. Active-O3 se evalúa mediante la creación de un conjunto completo de benchmarks en tareas genéricas de mundo abierto (como la localización de objetos pequeños y densos) y escenarios de dominio específico (como la detección de objetos pequeños en teledetección y conducción autónoma, y la segmentación interactiva de grano fino), y demuestra su potente capacidad de inferencia zero-shot en el V* Benchmark. (Fuente: HuggingFace Daily Papers)
Un paper propone MME-Reasoning: un benchmark integral para la capacidad de razonamiento lógico de los MLLM : Ante las deficiencias de los benchmarks existentes para evaluar la capacidad de razonamiento lógico de los modelos de lenguaje grandes multimodales (MLLM), los investigadores han lanzado MME-Reasoning. Este benchmark cubre los tres tipos principales de razonamiento lógico: inductivo, deductivo y abductivo, y selecciona cuidadosamente los datos para garantizar que las preguntas evalúen eficazmente la capacidad de razonamiento en lugar de las habilidades perceptivas o la amplitud del conocimiento. Los resultados de la evaluación muestran que incluso los MLLM más avanzados presentan limitaciones en una evaluación integral del razonamiento lógico, con un rendimiento desequilibrado en los diferentes tipos de razonamiento. La investigación también analiza el impacto de métodos como los “patrones de pensamiento” y el aprendizaje por refuerzo basado en reglas sobre la capacidad de razonamiento, proporcionando conocimientos sistemáticos para comprender y evaluar la capacidad de razonamiento de los MLLM. (Fuente: HuggingFace Daily Papers)
GraLoRA: mejora del rendimiento del ajuste fino eficiente en parámetros mediante adaptación de bajo rango granularizada : Para abordar los problemas de sobreajuste y cuellos de botella de rendimiento que surgen en LoRA al aumentar el rango, los investigadores proponen GraLoRA (Granular Low-Rank Adaptation). Este método divide la matriz de pesos en sub-bloques, cada uno con su propio adaptador de bajo rango independiente, con el objetivo de resolver los problemas de entrelazamiento de gradientes y distorsión de la propagación causados por los cuellos de botella estructurales de LoRA. GraLoRA mejora eficazmente la capacidad expresiva del modelo, acercándose más al efecto del ajuste fino completo, casi sin aumentar los costos computacionales o de almacenamiento. Los experimentos en benchmarks de generación de código y razonamiento de sentido común demuestran que GraLoRA supera a LoRA y otras líneas base en diferentes tamaños de modelo y configuraciones de rango, por ejemplo, logrando una ganancia absoluta de hasta 8.5% en Pass@1 en HumanEval+. (Fuente: HuggingFace Daily Papers)
SoloSpeech: pipeline de generación en cascada para mejorar la claridad y calidad de la extracción de voz objetivo : Abordando el problema de que los modelos discriminativos existentes en la extracción de voz objetivo (TSE) tienden a introducir artefactos y reducir la naturalidad, mientras que los modelos generativos son deficientes en calidad perceptiva y claridad, los investigadores proponen SoloSpeech. Se trata de un novedoso pipeline de generación en cascada que integra procesos de compresión, extracción, reconstrucción y corrección. Se caracteriza por emplear un extractor de objetivos sin incrustaciones de hablante, utilizando información condicional del espacio latente del audio de referencia y alineándolo con el espacio latente del audio mixto para evitar desajustes. La evaluación en el conjunto de datos Libri2Mix demuestra que SoloSpeech alcanza un nuevo nivel SOTA en tareas de extracción de voz objetivo y separación de voz, y muestra una excelente capacidad de generalización en datos fuera de dominio y escenarios reales. (Fuente: HuggingFace Daily Papers)
Nueva investigación explora la mejora de la comprensión visual en modelos de lenguaje grandes multimodales mediante vectores guía guiados por texto : Una nueva investigación explora si se pueden utilizar vectores guía derivados de la red troncal LLM de texto puro de los modelos de lenguaje grandes multimodales (MLLM) (obtenidos mediante métodos como autoencoders dispersos (SAE), mean shift y sondeo lineal) para mejorar su capacidad de comprensión visual. El estudio encuentra que los vectores guía derivados de texto mejoran consistentemente la precisión multimodal de diferentes arquitecturas MLLM en diversas tareas visuales. En particular, el método de mean shift mejora la precisión de las relaciones espaciales hasta en un 7.3% y la precisión del conteo hasta en un 3.3% en CV-Bench, superando a los métodos de prompting y demostrando una fuerte capacidad de generalización a conjuntos de datos fuera de distribución. Esto sugiere que los vectores guía de texto son un mecanismo potente y eficiente para mejorar la base visual de los MLLM con una mínima recopilación de datos adicionales y gastos computacionales. (Fuente: HuggingFace Daily Papers)
Un paper propone DiSA: aceleración de la generación autorregresiva de imágenes mediante el recocido de pasos de difusión : Para abordar el problema de la baja eficiencia de inferencia causada por el uso del muestreo de difusión para mejorar la calidad de imagen en modelos autorregresivos como MAR y FlowAR, un nuevo paper propone el método DiSA (Diffusion Step Annealing). Este método se basa en la observación de que, a medida que aumenta el número de tokens generados en el proceso autorregresivo, la distribución de los tokens posteriores se vuelve más restringida y el muestreo es más fácil. DiSA es un método que no requiere entrenamiento y reduce gradualmente los pasos de difusión a medida que se generan más tokens (por ejemplo, de 50 pasos iniciales a 5 pasos posteriores). Este método es complementario a los métodos de aceleración existentes diseñados para la difusión en sí, es simple de implementar y puede acelerar MAR y Harmon entre 5 y 10 veces, y FlowAR y xAR entre 1.4 y 2.5 veces, manteniendo al mismo tiempo la calidad de la generación. (Fuente: HuggingFace Daily Papers)
Un paper propone CASS: conjunto de datos, modelo y benchmark para la traducción de código GPU de Nvidia a AMD : Investigadores han lanzado CASS, el primer conjunto de datos y suite de modelos a gran escala para la traducción de código GPU entre arquitecturas, con el objetivo de cubrir la traducción a nivel de código fuente (CUDA <-> HIP) y a nivel de ensamblador (Nvidia SASS <-> AMD RDNA3). El conjunto de datos contiene 70,000 pares de código verificados entre host y dispositivo. Los modelos de lenguaje específicos de dominio de la serie CASS, entrenados con este recurso, alcanzan una precisión del 95% en la traducción de código fuente y del 37.5% en la traducción de ensamblador, superando significativamente a las líneas base comerciales como GPT-4o y Claude. El código generado iguala el rendimiento nativo en más del 85% de los casos de prueba. También se ha lanzado CASS-Bench, un benchmark que incluye 16 dominios de GPU y resultados de ejecución reales. Todos los datos, modelos y herramientas de evaluación son de código abierto. (Fuente: HuggingFace Daily Papers)
Un paper analiza la capacidad de calibración verbal en modelos de lenguaje visual : Un estudio evalúa exhaustivamente la efectividad de los modelos de lenguaje visual (VLM) para expresar la confianza a través del lenguaje natural (es decir, la incertidumbre verbal). La investigación abarca tres clases de modelos, cuatro dominios de tareas y tres escenarios de evaluación. Los resultados muestran que los VLM actuales a menudo exhiben errores de calibración significativos en múltiples tareas y configuraciones. Cabe destacar que los modelos de razonamiento visual (es decir, los modelos que piensan con imágenes) muestran consistentemente una mejor calibración, lo que indica que el razonamiento específico de la modalidad es crucial para una estimación confiable de la incertidumbre. Para abordar los desafíos de calibración, los investigadores introducen el “Visual Confidence-Aware Prompting”, una estrategia de prompting de dos etapas diseñada para mejorar la alineación de la confianza en entornos multimodales. (Fuente: HuggingFace Daily Papers)
Un paper rastrea la emergencia de la capacidad pragmática en los grandes modelos de lenguaje : Los LLM actuales muestran capacidades emergentes en tareas de inteligencia social, pero no está claro cómo adquieren la competencia pragmática durante el entrenamiento. Un nuevo paper introduce el conjunto de datos ALTPRAG, diseñado en base al concepto pragmático de “alternativas”, para evaluar si los LLM en diferentes etapas de entrenamiento pueden inferir con precisión intenciones sutiles del hablante. Mediante una evaluación sistemática de 22 LLM (que abarcan las etapas de preentrenamiento, SFT y optimización de preferencias), los resultados muestran que incluso los modelos base exhiben una sensibilidad significativa a las pistas pragmáticas, que mejora continuamente con el aumento del tamaño del modelo y los datos. SFT y RLHF mejoran aún más la capacidad de razonamiento pragmático cognitivo. Estos hallazgos enfatizan que la capacidad pragmática es una propiedad combinatoria emergente en el entrenamiento de LLM, proporcionando nuevas perspectivas para la alineación de modelos con las normas comunicativas humanas. (Fuente: HuggingFace Daily Papers)
Lanzamiento del benchmark Video-Holmes: evaluación del pensamiento “holmesiano” de los MLLM en la inferencia compleja de vídeos : Ante la situación actual en la que los benchmarks de vídeo existentes evalúan principalmente la percepción visual y la capacidad de localización, sin capturar adecuadamente las necesidades de inferencia compleja, los investigadores han lanzado el benchmark Video-Holmes. Inspirado en el proceso de razonamiento de Sherlock Holmes, este benchmark contiene 1837 preguntas extraídas de 270 cortometrajes de suspense etiquetados manualmente, abarcando 7 tareas cuidadosamente diseñadas. Cada tarea requiere que el modelo localice activamente y conecte múltiples pistas visuales relevantes dispersas en diferentes fragmentos de vídeo. La evaluación de los MLLM SOTA muestra que, aunque los modelos tienen un rendimiento excelente en percepción visual, presentan dificultades significativas en la integración de información, omitiendo a menudo pistas cruciales. Por ejemplo, el Gemini-2.5-Pro, el de mejor rendimiento, solo alcanzó una precisión del 45%. (Fuente: HuggingFace Daily Papers)
Lanzamiento del benchmark MME-VideoOCR: evaluación de la capacidad OCR de los LLM multimodales en escenarios de vídeo : Aunque los modelos de lenguaje grandes multimodales (MLLM) han logrado avances significativos en OCR de imágenes estáticas, su efectividad en OCR de vídeo se ve disminuida por factores como el desenfoque de movimiento, los cambios temporales y los efectos visuales. Para guiar el entrenamiento de MLLM prácticos, los investigadores han lanzado el benchmark MME-VideoOCR, que cubre una amplia gama de escenarios de aplicación de OCR en vídeo. Este benchmark incluye 10 categorías de tareas (25 tareas independientes), que abarcan 44 escenarios diferentes, e incluye no solo el reconocimiento de texto, sino también una comprensión e inferencia más profundas del contenido textual en los vídeos. El benchmark contiene 1464 vídeos de diferentes resoluciones, relaciones de aspecto y duraciones, así como 2000 pares de preguntas y respuestas cuidadosamente seleccionados y etiquetados manualmente. La evaluación de 18 MLLM SOTA muestra que incluso el Gemini-2.5 Pro, el de mejor rendimiento, solo alcanza una precisión del 73.7%, lo que expone las limitaciones de los modelos existentes al procesar tareas que requieren una comprensión integral del vídeo. (Fuente: HuggingFace Daily Papers)
MetaMind: modelado del pensamiento social humano mediante un sistema multiagente metacognitivo : Para cerrar la brecha en la capacidad de los grandes modelos de lenguaje (LLM) para manejar la ambigüedad inherente y los matices contextuales de la comunicación humana, los investigadores han lanzado MetaMind, un marco multiagente inspirado en la teoría metacognitiva de la psicología, diseñado para simular el razonamiento social similar al humano. MetaMind descompone la comprensión social en tres etapas colaborativas: (1) un agente de teoría de la mente genera hipótesis sobre los estados mentales del usuario (como intenciones, emociones); (2) un agente de dominio utiliza normas culturales y restricciones éticas para refinar estas hipótesis; (3) un agente de respuesta genera respuestas contextualmente apropiadas, al tiempo que valida la coherencia con las intenciones inferidas. Este marco logró un rendimiento SOTA en tres benchmarks desafiantes, mejorando en un 35.7% en escenarios sociales reales, en un 6.2% en el razonamiento de la teoría de la mente, y permitiendo por primera vez que los LLM alcancen el nivel humano en tareas clave de la teoría de la mente. (Fuente: HuggingFace Daily Papers)
Sparse VideoGen2: aceleración de la generación de vídeo mediante permutación consciente de la semántica y atención dispersa : Para abordar los problemas de latencia significativa y altos costos de memoria que enfrentan los modelos de generación de vídeo basados en Diffusion Transformers (DiT) al procesar vídeos largos, los investigadores proponen el marco SVG2. Este marco maximiza la precisión en la identificación de tokens clave y minimiza el desperdicio computacional mediante la permutación consciente de la semántica (utilizando k-means para agrupar y reordenar tokens según la similitud semántica), logrando así un equilibrio en la frontera de Pareto entre la calidad de generación y la eficiencia. SVG2 también integra el control dinámico de presupuesto top-p e implementaciones de kernel personalizadas, logrando aceleraciones de hasta 2.30x y 1.89x en HunyuanVideo y Wan 2.1 respectivamente, manteniendo al mismo tiempo un alto PSNR. (Fuente: HuggingFace Daily Papers)
OmniConsistency: aprendizaje de la consistencia independiente del estilo a partir de datos estilizados por pares : Para resolver los dos grandes desafíos que enfrentan los modelos de difusión en la estilización de imágenes: el mantenimiento de la consistencia en escenas complejas (especialmente identidad, composición y detalles) y la degradación del estilo causada por LoRA de estilo en los flujos de trabajo de imagen a imagen, los investigadores proponen OmniConsistency. Se trata de un plugin de consistencia universal que utiliza transformadores de difusión a gran escala (DiT). Sus contribuciones incluyen: (1) un marco de aprendizaje de consistencia contextual entrenado con pares de imágenes alineadas para lograr una generalización robusta; (2) una estrategia de aprendizaje progresivo de dos etapas que desacopla el aprendizaje del estilo del mantenimiento de la consistencia para mitigar la degradación del estilo; (3) un diseño completamente plug-and-play compatible con cualquier LoRA de estilo bajo el marco Flux. Los experimentos demuestran que OmniConsistency mejora significativamente la coherencia visual y la calidad estética, alcanzando un rendimiento comparable al de los modelos SOTA comerciales como GPT-4o. (Fuente: HuggingFace Daily Papers)
ImgEdit: conjunto de datos y benchmark unificados para la edición de imágenes : Para abordar el problema de que los modelos de edición de imágenes de código abierto se están quedando atrás con respecto a los modelos propietarios (principalmente debido a la limitada disponibilidad de datos de alta calidad y la insuficiencia de benchmarks), los investigadores han lanzado ImgEdit. Se trata de un conjunto de datos de edición de imágenes a gran escala y de alta calidad, que contiene 1.2 millones de pares de edición cuidadosamente seleccionados, abarcando ediciones novedosas y complejas de una sola ronda y tareas desafiantes de múltiples rondas. Para garantizar la calidad de los datos, se adoptó un proceso de múltiples etapas que integra modelos de lenguaje visual de vanguardia, modelos de detección, modelos de segmentación, así como reparadores específicos de tareas y un riguroso postprocesamiento. Los modelos de edición ImgEdit-E1 entrenados con ImgEdit superan a los modelos de código abierto existentes en múltiples tareas. Al mismo tiempo, se lanzó el benchmark ImgEdit-Bench para evaluar el rendimiento de la edición de imágenes en cuanto al seguimiento de instrucciones, la calidad de la edición y la preservación de detalles. (Fuente: HuggingFace Daily Papers)
Un paper propone lograr un control robusto del comportamiento en LLM mediante átomos objetivo guía : Para lograr un control preciso sobre la generación de los modelos de lenguaje para garantizar la seguridad y la fiabilidad, un nuevo paper propone el método de “Átomos Objetivo Guía” (Steering Target Atoms, STA). Este método tiene como objetivo separar y manipular componentes de conocimiento desacoplados para mejorar la seguridad, mostrando una robustez y flexibilidad superiores especialmente en escenarios adversarios. Los investigadores argumentan que, aunque el prompting y la guía se utilizan comúnmente para intervenir en el comportamiento del modelo, el alto grado de entrelazamiento de los parámetros del modelo limita la precisión del control y puede causar efectos secundarios. STA logra un control del comportamiento más preciso al utilizar autoencoders dispersos (SAE) para desacoplar el conocimiento en espacios de alta dimensión y luego guiarlo. Los experimentos demuestran la efectividad de este método, que ya se ha aplicado a grandes modelos de inferencia, confirmando su potencial para un control preciso de la inferencia. (Fuente: HuggingFace Daily Papers)
Un paper propone el benchmark SeePhys: evaluación de la capacidad de razonamiento físico basado en la visión : Investigadores han lanzado SeePhys, un benchmark multimodal a gran escala para evaluar la capacidad de razonamiento de los LLM en problemas de física desde el nivel de secundaria hasta el de examen de calificación doctoral. Este benchmark cubre 7 áreas fundamentales de la disciplina de la física e incluye 21 categorías de diagramas altamente heterogéneos. A diferencia de trabajos anteriores donde los elementos visuales desempeñaban principalmente un papel auxiliar, en SeePhys el 75% de las preguntas son visualmente necesarias, es decir, se debe extraer información visual para responder correctamente. Una amplia evaluación demuestra que incluso los modelos de razonamiento visual más avanzados (como Gemini-2.5-pro y o4-mini) tienen una precisión inferior al 60% en este benchmark, lo que revela desafíos fundamentales en la comprensión visual de los LLM actuales, especialmente en el acoplamiento riguroso de la interpretación de diagramas con el razonamiento físico y en la superación de la dependencia de atajos cognitivos basados en pistas textuales. (Fuente: HuggingFace Daily Papers)
VerIPO: mejora de la capacidad de inferencia a largo plazo de los Video-LLM mediante la optimización iterativa de políticas guiada por verificador : Para abordar los cuellos de botella en la preparación de datos y la calidad inestable del pensamiento en cadena (CoT) que enfrenta el aprendizaje por refuerzo aplicado a los modelos de lenguaje de vídeo (Video-LLM) en la inferencia compleja de vídeos, los investigadores proponen el método VerIPO (Verifier-guided Iterative Policy Optimization). El núcleo de este método es un “Rollout-Aware Verifier” situado entre las etapas de entrenamiento GRPO y DPO, que se utiliza para evaluar la lógica de inferencia y construir datos comparativos de alta calidad (que contienen CoT reflexivos y contextualmente coherentes). Estos datos impulsan una etapa DPO eficiente, mejorando así la longitud y la coherencia contextual de la cadena de inferencia. Los resultados experimentales muestran que VerIPO puede optimizar el modelo de manera más rápida y efectiva, generando CoT más largos y contextualmente coherentes, y superando en rendimiento a las variantes estándar de GRPO, así como a algunos Video-LLM de ajuste fino de instrucciones grandes y modelos de inferencia larga. (Fuente: HuggingFace Daily Papers)
OpenS2V-Nexus: un benchmark detallado y un conjunto de datos de millones de muestras para la generación de sujeto a vídeo : Para impulsar el desarrollo de la tecnología de generación de sujeto a vídeo (S2V), los investigadores proponen OpenS2V-Nexus, que incluye (i) OpenS2V-Eval, un benchmark de grano fino, y (ii) OpenS2V-5M, un conjunto de datos de millones de muestras. A diferencia de los benchmarks S2V existentes (heredados de VBench, que se centran en la evaluación global y de grano grueso), OpenS2V-Eval se enfoca en la capacidad del modelo para generar vídeos con sujetos consistentes, apariencia natural y alta fidelidad de identidad. Para ello, OpenS2V-Eval introduce 180 prompts de 7 categorías principales de S2V, que contienen datos de prueba reales y sintéticos. Además, para alinear con precisión las preferencias humanas, los investigadores proponen tres métricas automáticas: NexusScore, NaturalScore y GmeScore, que cuantifican respectivamente la consistencia del sujeto, la naturalidad y la relevancia textual en los vídeos generados. Basándose en esto, se realizó una evaluación exhaustiva de 16 modelos S2V representativos. Al mismo tiempo, se creó el primer conjunto de datos de generación S2V a gran escala de código abierto, OpenS2V-5M, que contiene 5 millones de tripletes de sujeto-texto-vídeo de alta calidad a 720P. (Fuente: HuggingFace Daily Papers)
Un paper propone WHISTRESS: enriquecimiento de texto transcrito mediante la detección del acento oracional : Dada la importancia del acento oracional en el habla para transmitir la intención del hablante, y su ausencia en los sistemas de transcripción existentes, un nuevo paper presenta WHISTRESS, un método de detección del acento oracional sin necesidad de alineación. Para apoyar esta tarea, los investigadores proponen TINYSTRESS-15K, un conjunto de datos de entrenamiento sintético escalable creado mediante un proceso totalmente automatizado. El modelo WHISTRESS, entrenado en este conjunto de datos, supera en rendimiento a las líneas base existentes y no requiere entradas previas adicionales para el entrenamiento o la inferencia. Cabe destacar que, a pesar de estar entrenado con datos sintéticos, WHISTRESS demuestra una fuerte capacidad de generalización zero-shot en múltiples benchmarks. (Fuente: HuggingFace Daily Papers)
Un paper propone InstructPart: segmentación de partes orientada a tareas con inferencia basada en instrucciones : Aunque los grandes modelos base multimodales han progresado en diversas tareas, muchos modelos tratan los objetos como entidades indivisibles, ignorando las partes que los componen. Comprender estas partes y sus affordances funcionales asociadas es crucial para ejecutar una amplia gama de tareas. Por ello, los investigadores introducen un nuevo benchmark del mundo real, InstructPart, que contiene anotaciones de segmentación de partes etiquetadas manualmente e instrucciones orientadas a tareas, para evaluar el rendimiento de los modelos actuales en la comprensión y ejecución de tareas a nivel de parte en situaciones cotidianas. Los experimentos demuestran que la segmentación de partes orientada a tareas sigue siendo un problema desafiante, incluso para los VLM SOTA. Además del benchmark, los investigadores introducen una línea base simple que, mediante el ajuste fino con su conjunto de datos, logra duplicar el rendimiento. (Fuente: HuggingFace Daily Papers)
Un paper propone un método híbrido neuronal-MPM para la simulación interactiva de fluidos en tiempo real : Para resolver los problemas de la simulación de fluidos, donde los métodos físicos tradicionales son computacionalmente intensivos y tienen alta latencia, y los recientes métodos de aprendizaje automático, aunque reducen costos, aún tienen dificultades para satisfacer las necesidades de interacción en tiempo real, los investigadores proponen un novedoso método híbrido. Este método integra simulación numérica, física neuronal y control generativo. Su física neuronal, mediante un mecanismo de respaldo que recurre a solucionadores numéricos clásicos, persigue conjuntamente una simulación de baja latencia y alta fidelidad física. Además, los investigadores desarrollaron un controlador basado en difusión, entrenado con una estrategia de modelado inverso, para generar campos de fuerza dinámicos externos para la manipulación de fluidos. El sistema demuestra un rendimiento robusto en diversos escenarios 2D/3D, tipos de materiales e interacciones con obstáculos, logrando una simulación en tiempo real con alta tasa de fotogramas (latencia del 11~29%) y permitiendo el control de fluidos mediante bocetos dibujados a mano fáciles de usar. (Fuente: HuggingFace Daily Papers)
MMIG-Bench: un benchmark de evaluación interpretable e integral para modelos de generación de imágenes multimodales : Ante las limitaciones de las herramientas de evaluación existentes para valorar generadores de imágenes multimodales como GPT-4o, Gemini 2.0 Flash y Gemini 2.5 Pro (por ejemplo, los benchmarks T2I carecen de condiciones multimodales, y los benchmarks de generación de imágenes personalizadas ignoran la semántica composicional y el sentido común), los investigadores proponen MMIG-Bench. Se trata de un benchmark integral de generación de imágenes multimodales que contiene 4850 prompts de texto ricamente anotados y 1750 imágenes de referencia multivista que cubren 380 sujetos (personas, animales, objetos, estilos artísticos). MMIG-Bench está equipado con un marco de evaluación de tres niveles: (1) métricas de bajo nivel evalúan artefactos visuales y la preservación de la identidad del objeto; (2) una novedosa puntuación de coincidencia de aspectos (AMS): una métrica de nivel medio basada en VQA que proporciona una alineación detallada entre prompt e imagen y se correlaciona altamente con los juicios humanos; (3) métricas de alto nivel evalúan la estética y las preferencias humanas. Mediante MMIG-Bench se evaluaron 17 modelos SOTA y se validaron las métricas con 32,000 calificaciones humanas, proporcionando información detallada para el diseño de arquitecturas y datos. (Fuente: HuggingFace Daily Papers)
Un paper propone HRPO: logrando inferencia latente híbrida mediante aprendizaje por refuerzo : Para resolver los problemas de incompatibilidad de los métodos de inferencia latente existentes con las características de generación autorregresiva de los LLM y su dependencia de trayectorias CoT para el entrenamiento, los investigadores proponen HRPO (Hybrid Reasoning Policy Optimization). Se trata de un método de inferencia latente híbrida basado en aprendizaje por refuerzo que integra estados ocultos anteriores en los tokens muestreados mediante un mecanismo de puerta aprendible, inicializando el entrenamiento principalmente con incrustaciones de tokens e incorporando gradualmente más características ocultas. Este diseño mantiene la capacidad generativa de los LLM e incentiva el uso de representaciones discretas y continuas para la inferencia híbrida. Además, HRPO introduce aleatoriedad en la inferencia latente mediante el muestreo de tokens, eliminando así la necesidad de trayectorias CoT para la optimización basada en RL. Una amplia evaluación en diversos benchmarks demuestra que HRPO supera a los métodos anteriores tanto en tareas intensivas en conocimiento como en tareas intensivas en inferencia. (Fuente: HuggingFace Daily Papers)
Un paper propone el método NFT: conectando el aprendizaje supervisado y el aprendizaje por refuerzo en el razonamiento matemático : Desafiando la noción predominante de que la “automejora se limita al aprendizaje por refuerzo (RL)”, un nuevo paper propone el método de Ajuste Fino Consciente de Negativos (Negative-aware Fine-Tuning, NFT). Se trata de un método de aprendizaje supervisado que permite a los LLM reflexionar sobre sus fallos y mejorar autónomamente, sin necesidad de un profesor externo. En el entrenamiento en línea, NFT no descarta las respuestas incorrectas autogeneradas, sino que construye una política negativa implícita para modelarlas. Esta política implícita se parametriza igual que el LLM positivo objetivo que se optimiza con datos positivos, lo que permite una optimización directa de políticas sobre todas las generaciones del LLM. Los resultados experimentales en tareas de razonamiento matemático con modelos de 7B y 32B muestran que, al utilizar adicionalmente la retroalimentación negativa, NFT supera significativamente a las líneas base de aprendizaje supervisado como el ajuste fino por muestreo de rechazo, alcanzando e incluso superando a algoritmos de RL líderes como GRPO y DAPO. Los investigadores demuestran además que, en un entrenamiento de políticas en línea estricto, NFT y GRPO son en realidad equivalentes. (Fuente: HuggingFace Daily Papers)
Un paper propone Minute-Long Videos with Dual Parallelisms: logrando la generación de vídeos de un minuto de duración : Para abordar el problema de la latencia computacional y los costos de memoria excesivos que enfrentan los modelos de difusión de vídeo basados en DiT al generar vídeos largos, los investigadores proponen una nueva estrategia de inferencia distribuida llamada DualParal. La idea central de este método es paralelizar los fotogramas temporales y las capas del modelo en múltiples GPU. Para resolver el problema de serialización de la paralelización original causado por el requisito de los modelos de difusión de sincronizar los niveles de ruido entre fotogramas, este método adopta un esquema de eliminación de ruido por bloques, es decir, procesando en pipeline una serie de bloques de fotogramas y reduciendo gradualmente el nivel de ruido. Cada GPU procesa subconjuntos específicos de bloques y capas, y pasa los resultados anteriores a la siguiente GPU, logrando cómputo y comunicación asíncronos. Además, mediante la implementación de caché de características en cada GPU para reutilizar las características de bloques anteriores como contexto y la adopción de una estrategia coordinada de inicialización de ruido, se asegura una dinámica temporal globalmente consistente, logrando así una generación de vídeo rápida, sin artefactos e ilimitadamente larga. Aplicado a los últimos generadores de vídeo con transformadores de difusión, este método genera eficientemente vídeos de 1025 fotogramas en 8 GPU RTX 4090, con una reducción de latencia de hasta 6.54x y una reducción de costos de memoria de 1.48x. (Fuente: HuggingFace Daily Papers)
🧰 Herramientas
Los modelos de la serie Claude 4 destacan en tareas de programación, resolviendo con éxito un “bug ballena” que atormentó a programadores experimentados durante 4 años : El modelo Claude Opus 4, recientemente lanzado por Anthropic, ha demostrado una capacidad asombrosa en programación. Un exingeniero de FAANG con 30 años de experiencia en desarrollo C++ compartió que un complejo bug de sistema que había atormentado a su equipo durante 4 años y le había costado personalmente unas 200 horas sin resolver (un problema de condición de borde que aparecía cuando un shader específico se usaba de una manera particular), fue localizado y su causa identificada por Claude Opus 4 en unas pocas horas mediante unos 30 prompts. El bug no existía antes de una reestructuración del sistema, y Opus 4 señaló que la nueva arquitectura no era compatible con un comportamiento no diseñado que la antigua arquitectura soportaba por “casualidad”. Anteriormente, GPT-4.1, Gemini 2.5 y Claude 3.7 no habían logrado resolver este problema. Esto resalta la potente capacidad de Claude 4 para comprender código complejo, realizar análisis profundos e inferencias, especialmente cuando se combina con el modo Claude Code, ayudando eficazmente a los desarrolladores a manejar tareas de ingeniería avanzadas como la refactorización de código y la corrección de bugs. (Fuente: 36氪, dotey)
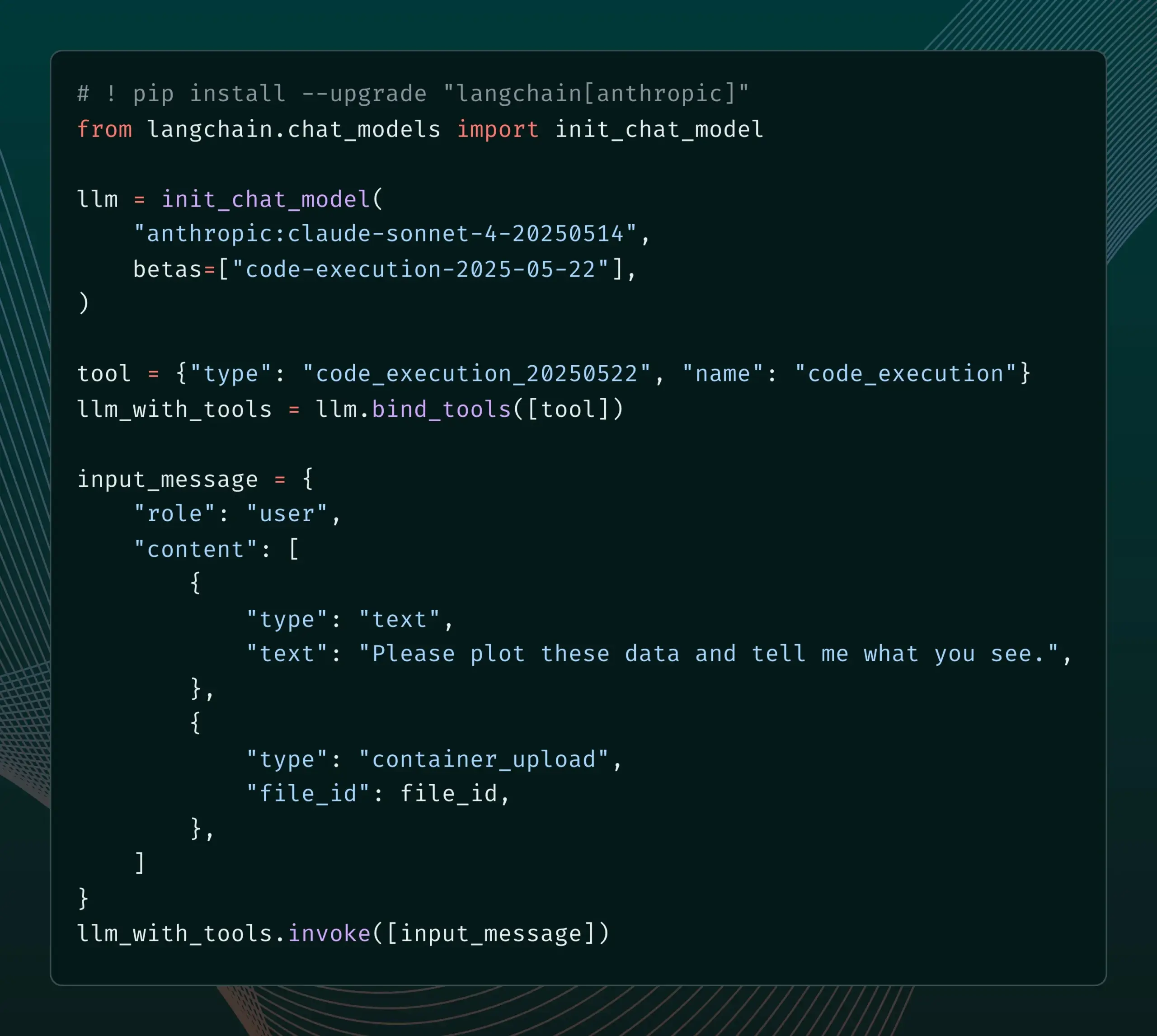
LangChain añade soporte para las nuevas funciones Beta de Anthropic Claude : LangChain ha anunciado la integración de cuatro nuevas funciones Beta recientemente lanzadas para el modelo Anthropic Claude, que incluyen ejecución de código, conectores MCP remotos, API de archivos y caché de prompts extendida. Los desarrolladores ahora pueden consultar ejemplos relevantes en la documentación de LangChain para utilizar estas nuevas funciones en la creación de aplicaciones de IA más potentes. (Fuente: LangChainAI)
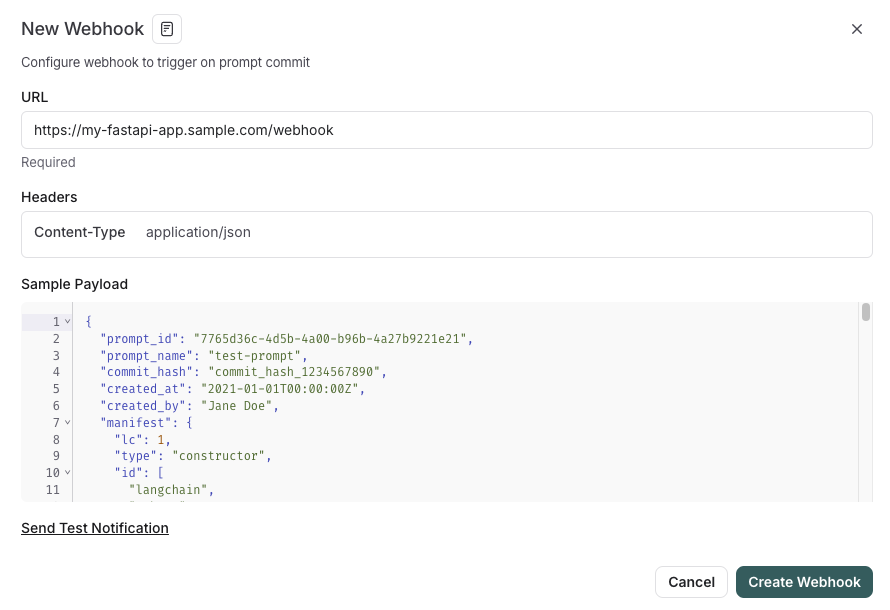
LangSmith lanza funciones de gestión de prompts integradas con SDLC : La plataforma LangSmith ha mejorado sus capacidades de ingeniería de prompts. Ahora los usuarios no solo pueden probar, versionar y colaborar en prompts dentro de LangSmith, sino que también pueden sincronizar automáticamente los prompts con GitHub, bases de datos externas o iniciar procesos de CI/CD mediante disparadores webhook cuando cambian los prompts. Esta función tiene como objetivo ayudar a los desarrolladores a integrar más estrechamente la gestión de prompts en el ciclo de vida del desarrollo de software (SDLC). (Fuente: LangChainAI)
AutoThink: tecnología adaptativa para mejorar el rendimiento de inferencia de LLM locales : El equipo de CodeLion ha desarrollado la tecnología AutoThink, que mejora significativamente el rendimiento de inferencia de los LLM locales mediante la asignación adaptativa de recursos y vectores guía (steering vectors). AutoThink puede clasificar la complejidad de las consultas, asignar dinámicamente “tokens de pensamiento” (más para problemas complejos, menos para problemas simples) y utilizar vectores guía para dirigir los patrones de inferencia. Las pruebas en el modelo DeepSeek-R1-Distill-Qwen-1.5B mostraron un aumento del 43% en la precisión de GPQA-Diamond (del 21.72% al 31.06%), mejoras en MMLU-Pro y un menor uso de tokens. Esta tecnología es compatible con modelos de inferencia locales que admiten tokens de pensamiento, y el código y la investigación ya han sido publicados. (Fuente: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer Lab anuncia soporte para AMD ROCm, permitiendo entrenar LLM localmente : Transformer Lab ha anunciado que su plataforma GUI ahora admite el entrenamiento y ajuste fino local de grandes modelos de lenguaje en GPU AMD utilizando ROCm. El equipo indicó que el proceso de configuración de ROCm fue desafiante y ha documentado todo el proceso en su blog. Actualmente, esta función ya se puede utilizar sin problemas, y los usuarios pueden probar el desarrollo de LLM en hardware AMD. (Fuente: Reddit r/MachineLearning)
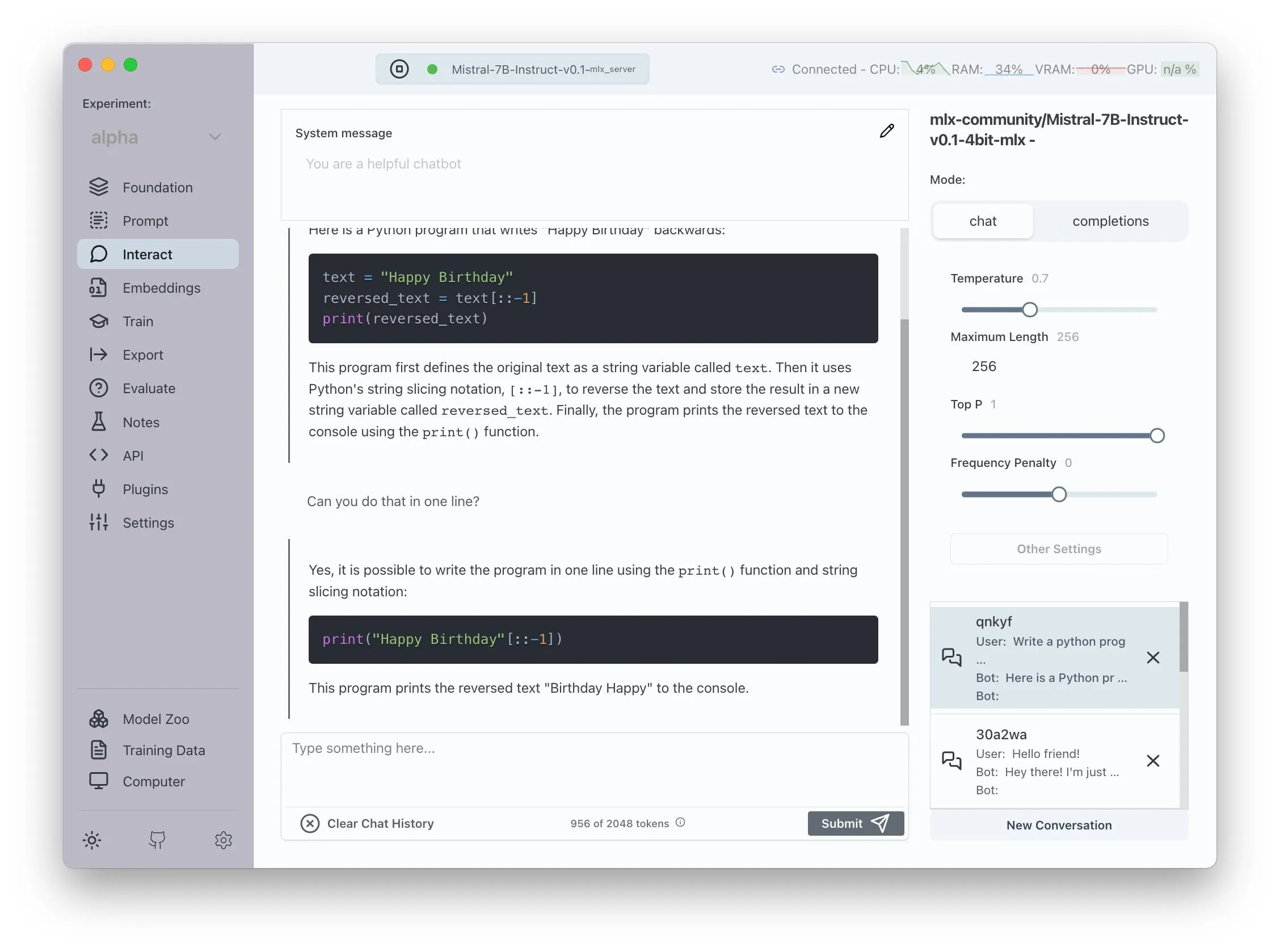
Sistema multiagente de código abierto mejorado con LLM logra extracción automatizada de afirmaciones y verificación de hechos : Un proyecto de código abierto llamado “fact-checker” utiliza un sistema multiagente (MAS) mejorado con LLM para lograr la extracción automatizada de afirmaciones, la verificación de pruebas y la resolución de hechos. El proyecto incluye una extensión de navegador que puede verificar en tiempo real las respuestas de cualquier chatbot de IA, ayudando a discernir la veracidad del contenido generado por IA. Su arquitectura de código es clara y su documentación está bien elaborada, proporcionando una herramienta valiosa en el campo de la seguridad de la IA y la lucha contra la desinformación. (Fuente: Reddit r/MachineLearning)
Meituan lanza el producto sin código Nocode, que admite la generación de aplicaciones complejas de múltiples páginas : Meituan ha lanzado un producto de Vibe Coding llamado Nocode, que permite a los usuarios generar aplicaciones completas y complejas que contienen múltiples páginas mediante la descripción en lenguaje natural, en lugar de simples páginas web de exhibición. Las pruebas realizadas por Guicang muestran que la herramienta pudo construir con éxito y de una sola vez una herramienta de gestión de inventario de almacén con lógica compleja, demostrando su capacidad para comprender requisitos complejos y generar el código correspondiente. (Fuente: op7418)
LlamaIndex admite la creación de incrustadores multimodales personalizados y la integración con UI de chat estilo OpenAI : LlamaIndex ha lanzado una actualización que permite a los usuarios construir incrustadores multimodales personalizados, por ejemplo, integrando AWS Titan Multimodal, y combinarlos con bases de datos vectoriales como Pinecone para una búsqueda eficiente de vectores de texto + imagen. Además, los flujos de trabajo de LlamaIndex ahora pueden ejecutarse en una interfaz de chat similar a la de OpenAI con unas pocas líneas de código, y admiten un modo de desarrollo para editar directamente el código del flujo de trabajo en la UI, mejorando la experiencia de desarrollo e interacción de las aplicaciones RAG. (Fuente: jerryjliu0, jerryjliu0)

TRAE se actualiza para mejorar la experiencia de codificación Agentic, la versión internacional lanza suscripción de pago : La herramienta de programación de IA TRAE ha recibido una actualización que optimiza la experiencia de codificación Agentic, haciéndola más adecuada para usuarios que prefieren no realizar operaciones manuales. La nueva versión de TRAE recuerda mejor las conversaciones históricas, asocia automáticamente el contexto, y la IA puede planificar automáticamente rutas de programación e invocar más herramientas, aumentando la tasa de éxito de las tareas de programación. Por ejemplo, los usuarios solo necesitan proporcionar una carpeta vacía y un prompt, y TRAE puede completar una serie de operaciones como crear archivos, iniciar un servidor web (manejando automáticamente problemas de CORS) y previsualizar animaciones p5.js dentro del IDE. Su versión internacional ya ha lanzado una suscripción de pago, con un precio Pro de 3 dólares para el primer mes, y admite Alipay. (Fuente: dotey, karminski3)
La comunidad Juejin lanza el servicio MCP, que permite la publicación de código frontend con un solo clic : La comunidad de programadores china Juejin ha lanzado el servicio MCP (Model-driven Co-programming Protocol), que permite a los desarrolladores publicar código frontend (como páginas web o juegos generados por vibe coding) en la plataforma Juejin con un solo clic, facilitando el intercambio rápido y la previsualización. Los usuarios necesitan obtener un Token MCP de Juejin y configurarlo en herramientas como Trae o Cursor. (Fuente: dotey, karminski3)
La herramienta de seguimiento de tiempo de código abierto ActivityWatch gana atención como alternativa a Rize : El usuario karminski3, después de probar la herramienta de análisis de tiempo con IA Rize (que analiza los nombres de los procesos para determinar si se trata de trabajo, reuniones o procrastinación, con una tarifa mensual de 20 dólares), descubrió y recomendó la alternativa de código abierto ActivityWatch. ActivityWatch tiene funciones similares, es compatible con Windows/Mac y permite la personalización por parte del usuario, considerándose una excelente herramienta para aliviar la ansiedad laboral y realizar un seguimiento de las horas de trabajo. (Fuente: karminski3)
Lanzamiento de la herramienta de código abierto para el cuidado de bebés con IA, ai-baby-monitor : Se ha lanzado un proyecto de código abierto llamado ai-baby-monitor, que utiliza el modelo Qwen2.5 VL y el marco de inferencia vLLM. Permite a los usuarios definir reglas (como “alertar si el niño se levanta” o “alertar si el niño está solo”) para que la IA ayude en el cuidado de los bebés. El desarrollador enfatiza que esto es solo una herramienta auxiliar y no puede reemplazar completamente el cuidado humano. (Fuente: karminski3)
LangChain integra la función Live Search de xAI : LangChain ha anunciado la compatibilidad con la función Live Search de xAI. Esta función permite al modelo Grok basar sus respuestas en resultados de búsqueda web y ofrece diversas opciones de configuración, como el período de tiempo, los dominios a incluir y otros parámetros de búsqueda. Los usuarios ya pueden probar esta nueva característica en LangChain. (Fuente: LangChainAI)
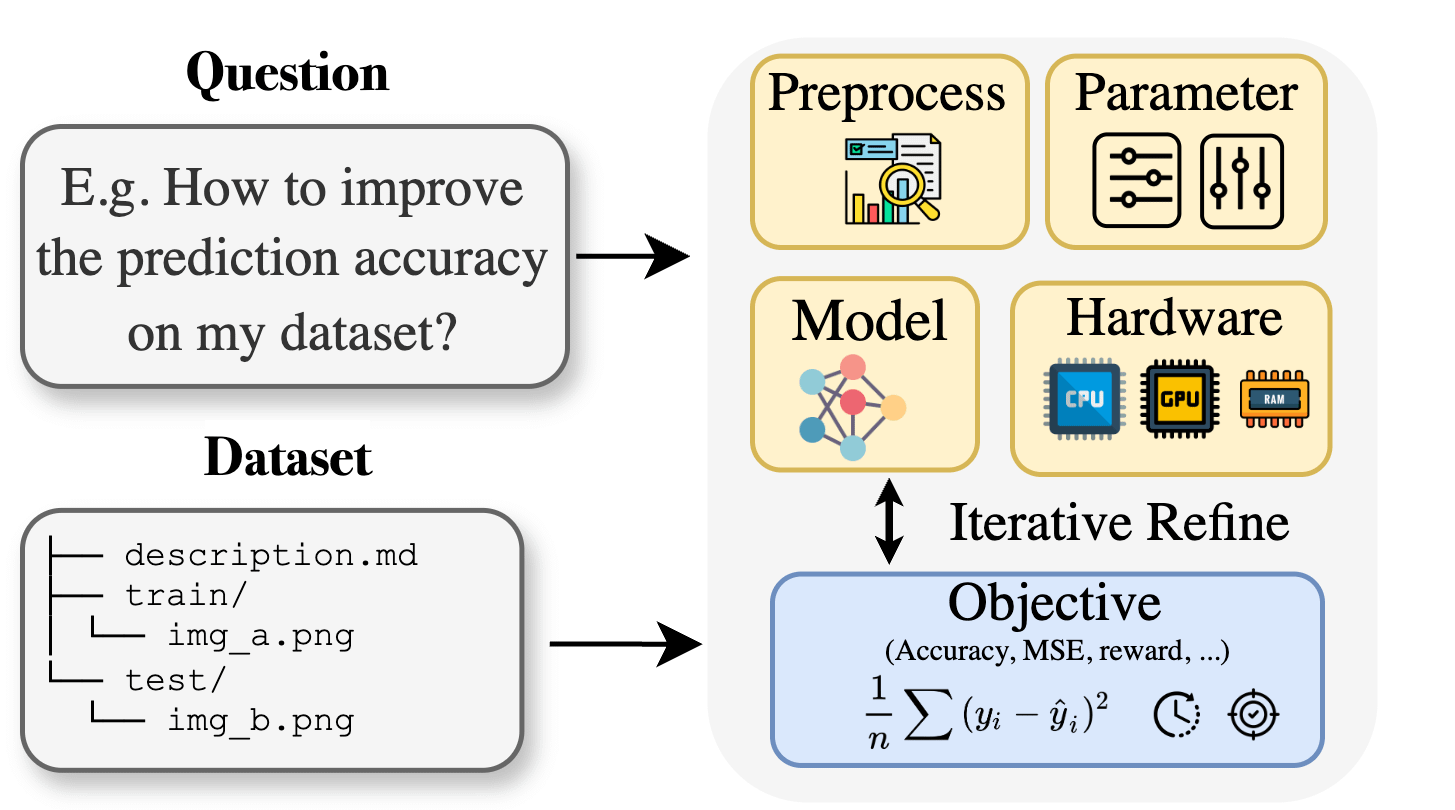
Curie: asistente de investigación científica de IA de código abierto lanza función AutoML para ayudar en la investigación interdisciplinaria : Para abordar las barreras de conocimiento especializado que enfrentan los investigadores en campos como la biología, los materiales y la química al aplicar el aprendizaje automático, el proyecto Curie ha lanzado una nueva función AutoML. Curie tiene como objetivo convertirse en un científico colaborador para experimentos de investigación con IA, automatizando flujos de trabajo complejos de ML (como la selección de algoritmos, el ajuste de hiperparámetros, la interpretación de la salida del modelo) para ayudar a los investigadores a probar rápidamente hipótesis y extraer conocimientos de los datos. Por ejemplo, Curie generó un modelo con un AUC de 0.99 en una tarea de detección de melanoma. El proyecto es de código abierto y fomenta la participación de la comunidad. (Fuente: Reddit r/LocalLLaMA)
MNN Chat de Alibaba admite la ejecución local del modelo Qwen 30B-a3b en dispositivos Android : La aplicación MNN Chat de Alibaba se ha actualizado a la versión 0.5.0 y ahora admite la ejecución local de grandes modelos de lenguaje como Qwen 30B-a3b en dispositivos Android. Los usuarios informan que se puede ejecutar con éxito en dispositivos con chips de gama alta y gran cantidad de memoria (como OnePlus 13 24G) y recomiendan activar la configuración mmap. Sin embargo, algunos comentarios señalan que un modelo de 30B parámetros tiene requisitos de memoria y capacidad de cómputo demasiado altos para la mayoría de los teléfonos, y que Gemma 3n podría ser más adecuado para dispositivos móviles. (Fuente: Reddit r/LocalLLaMA)

📚 Aprendizaje
Nuevo paper propone Lean and Mean Adaptive Optimization: un optimizador más rápido y con menor consumo de memoria para el entrenamiento de modelos grandes : Un paper aceptado en ICML 2025 presenta un nuevo optimizador llamado “Lean and Mean Adaptive Optimization via Subset-Norm and Subspace-Momentum”. Este método, mediante dos técnicas complementarias, Subset-Norm step size y Subspace-Momentum, tiene como objetivo reducir los requisitos de memoria y acelerar el entrenamiento de redes neuronales a gran escala. En comparación con optimizadores eficientes en memoria existentes como GaLore y LoRA, este método, además de ahorrar memoria (por ejemplo, reduce en un 80% la memoria de estado del optimizador en comparación con Adam al preentrenar LLaMA 1B), puede alcanzar la perplejidad de validación de Adam con menos tokens de entrenamiento (aproximadamente la mitad) y ofrece garantías de convergencia teóricas más sólidas. (Fuente: Reddit r/MachineLearning)
Un paper propone Force Prompting: permitir que los modelos de generación de vídeo aprendan y generalicen señales de control basadas en la física : Una nueva investigación explora la posibilidad de utilizar fuerzas físicas como señales de control para la generación de vídeo y propone los “Force Prompts”. Los usuarios pueden interactuar con las imágenes mediante fuerzas puntuales localizadas (como pinchar una planta) o campos de fuerza de viento globales (como el viento soplando sobre una tela). La investigación demuestra que los modelos de generación de vídeo pueden aprender y generalizar las condiciones de fuerza física a partir de vídeos sintéticos de Blender que contienen demostraciones de solo unos pocos objetos, generando vídeos que responden de manera realista a las señales de control físico, sin necesidad de utilizar activos 3D o simuladores físicos en tiempo de inferencia. La diversidad visual y el uso de palabras clave de texto específicas durante el entrenamiento son factores clave para lograr esta generalización. (Fuente: HuggingFace Daily Papers)
AnkiHub comparte su flujo de trabajo de etiquetado con IA, mejorando la eficiencia con FastHTML : AnkiHub ha compartido su flujo de trabajo de etiquetado con IA y lo ha demostrado en el curso de evaluación de IA de Hamel Husain y Shreya Shankar. Este flujo de trabajo utiliza la herramienta de construcción FastHTML y tiene como objetivo mejorar la eficiencia del etiquetado con IA para productos comerciales. Los materiales didácticos y el repositorio de código correspondientes se han publicado en GitHub, mostrando cómo utilizar herramientas de producción reales para optimizar el desarrollo de IA. (Fuente: jeremyphoward, HamelHusain)

Un blogger escribe sobre su aprendizaje de PPO a GRPO, explicando conceptos de aprendizaje por refuerzo en el ajuste fino de LLM : Un blogger ha compartido su experiencia aprendiendo sobre aprendizaje por refuerzo (RL) y su aplicación en el ajuste fino de grandes modelos de lenguaje (LLM), particularmente su proceso de comprensión desde PPO (Proximal Policy Optimization) hasta GRPO (Group Relative Policy Optimization). La publicación del blog tiene como objetivo explicar los conceptos que deseaba conocer al principio de su aprendizaje, para ayudar a otros a comprender mejor cómo se utilizan estos algoritmos de RL para optimizar los LLM. (Fuente: Reddit r/MachineLearning)
Un paper explora el pensamiento pragmático de las máquinas: rastreando la emergencia de la capacidad pragmática en los grandes modelos de lenguaje : Un nuevo paper investiga cómo los grandes modelos de lenguaje (LLM) adquieren la competencia pragmática (la capacidad de comprender e inferir significados implícitos, intenciones del hablante, etc.) durante el proceso de entrenamiento. Los investigadores introdujeron el conjunto de datos ALTPRAG, basado en el concepto pragmático de “alternativas”, para evaluar 22 LLM en diferentes etapas de entrenamiento (preentrenamiento, ajuste fino supervisado SFT, optimización de preferencias RLHF). Los resultados indican que incluso los modelos base muestran una sensibilidad significativa a las pistas pragmáticas, que mejora continuamente con el aumento del tamaño del modelo y los datos; SFT y RLHF mejoran aún más la capacidad de razonamiento pragmático cognitivo. Esto sugiere que la competencia pragmática es una característica emergente y combinatoria en el entrenamiento de LLM. (Fuente: HuggingFace Daily Papers)
Un paper explora VisTA, un marco de aprendizaje por refuerzo para la selección de herramientas visuales : Investigadores introducen VisTA (VisualToolAgent), un nuevo marco de aprendizaje por refuerzo que permite a los agentes visuales explorar, seleccionar y combinar dinámicamente herramientas de diferentes bibliotecas basándose en el rendimiento empírico. A diferencia de los métodos existentes que dependen de prompts sin entrenamiento o de un ajuste fino a gran escala, VisTA utiliza aprendizaje por refuerzo de extremo a extremo, utilizando los resultados de las tareas como señal de retroalimentación para optimizar iterativamente estrategias complejas de selección de herramientas específicas para cada consulta. Mediante GRPO (Group Relative Policy Optimization), este marco permite a los agentes descubrir autónomamente rutas efectivas de selección de herramientas, sin necesidad de supervisión explícita del razonamiento. Los experimentos en los benchmarks ChartQA, Geometry3K y BlindTest demuestran que VisTA logra mejoras significativas de rendimiento en comparación con las líneas base sin entrenamiento, especialmente en muestras fuera de distribución. (Fuente: HuggingFace Daily Papers)
💼 Negocios
La empresa de servicios de datos Jinglianwen Technology completa una ronda de financiación Pre-A de decenas de millones, enfocándose en la producción y operación de datos públicos : El operador de servicios de datos de IA Jinglianwen Technology completó recientemente una ronda de financiación Pre-A de decenas de millones de yuanes, invertida por un fondo del Grupo Jin Tou de Hangzhou. La financiación se utilizará para desarrollar la producción y operación de datos públicos, construir una plataforma inteligente de ingeniería de corpus y establecer bases de etiquetado de alta calidad en dominios verticales propios. Fundada en 2012, la empresa se centra en datos públicos, grandes modelos de IA, conducción autónoma y atención médica, con el objetivo de resolver los puntos débiles de los datos públicos como “difícil de gobernar, no se puede suministrar, no fluye, no se usa bien, seguridad débil”, y ha colaborado con Huawei Data Storage para lanzar una solución conjunta de lago de datos de IA. Se espera que los ingresos de este año crezcan más del 400%. (Fuente: 36氪)
Meitu recibe una inversión de aproximadamente 250 millones de dólares en bonos convertibles de Alibaba, profundizando la cooperación en el campo de la IA : Meitu Corporation anunció planes para una cooperación estratégica con Alibaba, mediante la cual Alibaba emitirá bonos convertibles por un valor total de aproximadamente 250 millones de dólares a Meitu. Ambas partes colaborarán en la promoción de plataformas de comercio electrónico, el desarrollo de tecnología de IA (imágenes de IA, vídeo de IA), computación en la nube y otros campos. Meitu se ha comprometido a adquirir servicios de Alibaba Cloud por no menos de 560 millones de yuanes en los próximos tres años. Esta cooperación tiene como objetivo utilizar el ecosistema de Alibaba para explotar el potencial de los escenarios de comercio electrónico y mejorar la escala de usuarios de pago y el nivel de I+D de las herramientas de diseño de IA de Meitu. Aunque esta medida impulsó temporalmente el precio de las acciones de Meitu, el mercado se centra en cómo Meitu evitará repetir el destino de Kimi, cuyo crecimiento de usuarios se desaceleró en un mercado competitivo feroz, especialmente frente a la intensa competencia y la diferencia de tamaño con los gigantes tecnológicos en el campo de la IA visual. (Fuente: 36氪)
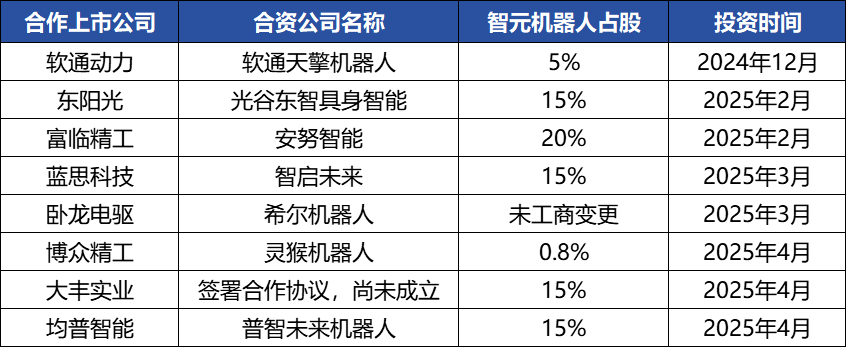
Zhiyuan Robot realiza frecuentes movimientos de capital, construye un ecosistema industrial y emerge su fundador, Deng Taihua : El unicornio de inteligencia incorporada Zhiyuan Robot ha realizado recientemente frecuentes movimientos de capital. No solo ha completado múltiples rondas de financiación (la más reciente liderada por JD Technology), sino que también ha invertido activamente en empresas de la cadena industrial (como Annu Intelligence, Digital China, etc.) y ha establecido empresas conjuntas de robots con varias empresas cotizadas (Bozhong Precision, Dafeng Industry, etc.). Los cambios en el registro mercantil revelan que Deng Taihua, ex vicepresidente de Huawei y ex presidente de la línea de productos de computación, es en realidad el fundador y controlador real de Zhiyuan Robot, y su equipo directivo también incluye a varios ex empleados de Huawei. Este trasfondo “estilo Huawei” explica el modo de operación de “juego de ecosistema” de Zhiyuan Robot, es decir, construir rápidamente influencia industrial y lograr la escalabilidad y comercialización a través de una amplia cooperación e inversión. Aunque ha logrado una ventaja inicial en financiación y comercialización, su capacidad de modelo grande de inteligencia incorporada aún enfrenta desafíos. (Fuente: 36氪)
🌟 Comunidad
El desarrollo de Agentes de IA es rápido, los Agentic LM se consideran una nueva plataforma de aplicaciones y herramientas con gran potencial : Personalidades del ámbito de la IA como natolambert expresan su entusiasmo por el rápido desarrollo de los Agentes de IA, considerando que los modelos de lenguaje basados en agentes (Agentic LMs) son una plataforma con un enorme potencial sobre la cual se pueden construir una gran cantidad de nuevas aplicaciones y herramientas. Muchas capacidades aún no explotadas completamente en los modelos recientes pueden liberarse a través del paradigma Agentic. Esto presagia que la IA está evolucionando de la simple generación de contenido hacia agentes inteligentes más proactivos y capaces de ejecutar tareas. (Fuente: natolambert)
Los Agentes de IA muestran capacidades sobrehumanas en tareas específicas, pero el razonamiento físico sigue siendo un punto débil : Investigaciones de instituciones como la Universidad de Hong Kong han descubierto que incluso los modelos de IA más avanzados como GPT-4o y Claude 3.7 Sonnet, en el benchmark PHYX que incluye escenarios físicos reales y razonamiento causal complejo, tienen una precisión en problemas de física muy inferior a la de los expertos humanos (el modelo más alto 45.8% vs. el humano más bajo 75.6%), lo que expone su excesiva dependencia del conocimiento memorizado, fórmulas matemáticas y reconocimiento superficial de patrones visuales en la comprensión de la física. Sin embargo, en el campo de las matemáticas, en la competencia FrontierMath organizada por Epoch AI (con problemas diseñados por matemáticos de primer nivel como Terence Tao), o4-mini-medium resolvió aproximadamente el 22% de los problemas, superando a 6 de los 8 equipos de matemáticos humanos y el promedio de los equipos humanos (19%), lo que demuestra el potencial de la IA en el razonamiento simbólico altamente abstracto. Esto indica un desarrollo desigual de las capacidades de la IA en diferentes tipos de tareas de razonamiento. (Fuente: 36氪, 36氪)

La capacidad de las herramientas de programación de IA sigue aumentando, lo que genera un debate sobre las perspectivas profesionales de los programadores : El lanzamiento de los modelos de la serie Claude 4 de Anthropic (especialmente Opus 4, capaz de codificar continuamente durante 7 horas) y los avances en herramientas de programación de IA como Cursor y Tongyi Lingma han mejorado significativamente la capacidad de la IA en la generación de código, la corrección de errores e incluso el desarrollo de procesos completos. Esto ha provocado que los programadores de grandes empresas como Amazon sientan presión, con algunos equipos reducidos a la mitad y plazos de proyectos adelantados debido a la mejora de la eficiencia gracias a la IA, transformando el rol del programador en el de un “revisor de código”. Aunque la IA puede aumentar la eficiencia, también genera preocupaciones sobre la formación de programadores junior, la degradación de habilidades y las trayectorias de promoción profesional. Empresas como Microsoft ya han realizado despidos en puestos de ingeniería e I+D y han revelado un aumento significativo en la proporción de código generado por IA. Los profesionales del sector consideran que la IA actualmente se asemeja más a un asistente y difícilmente puede reemplazar por completo a los humanos en la comprensión de requisitos complejos, la innovación de productos y la colaboración en equipo, pero la IA está remodelando el valor central del trabajo de programación. (Fuente: 36氪, 36氪)

La demanda del mercado de bases de conocimiento de IA aumenta rápidamente, pero la implementación aún enfrenta desafíos de datos, escenarios y coordinación organizacional : Con la madurez de la tecnología de modelos grandes, las bases de conocimiento de IA se han convertido en un eslabón central en la transformación inteligente de las empresas, con un aumento de la demanda de 2 a 3 veces. La IA transforma las bases de conocimiento de “almacenes” estáticos a “motores” inteligentes, capaces de reconocer el contexto y generar soluciones directamente, mejorando la eficiencia de construcción y mantenimiento. Sin embargo, las bases de conocimiento de IA todavía tienen limitaciones al manejar tareas altamente creativas o de razonamiento complejo, y enfrentan puntos débiles como la gestión a escala, la precisión y actualidad de la información, la seguridad de los permisos, la adaptabilidad de la arquitectura técnica y la migración e integración de datos. Las empresas deben sopesar entre rutas como SaaS, desarrollo propio + API, y Agentes de nube híbrida, y establecer una “arquitectura de doble vía” con una plataforma de conocimiento centralizada unificada y aplicaciones superiores flexibles para lograr una implementación efectiva. (Fuente: 36氪)

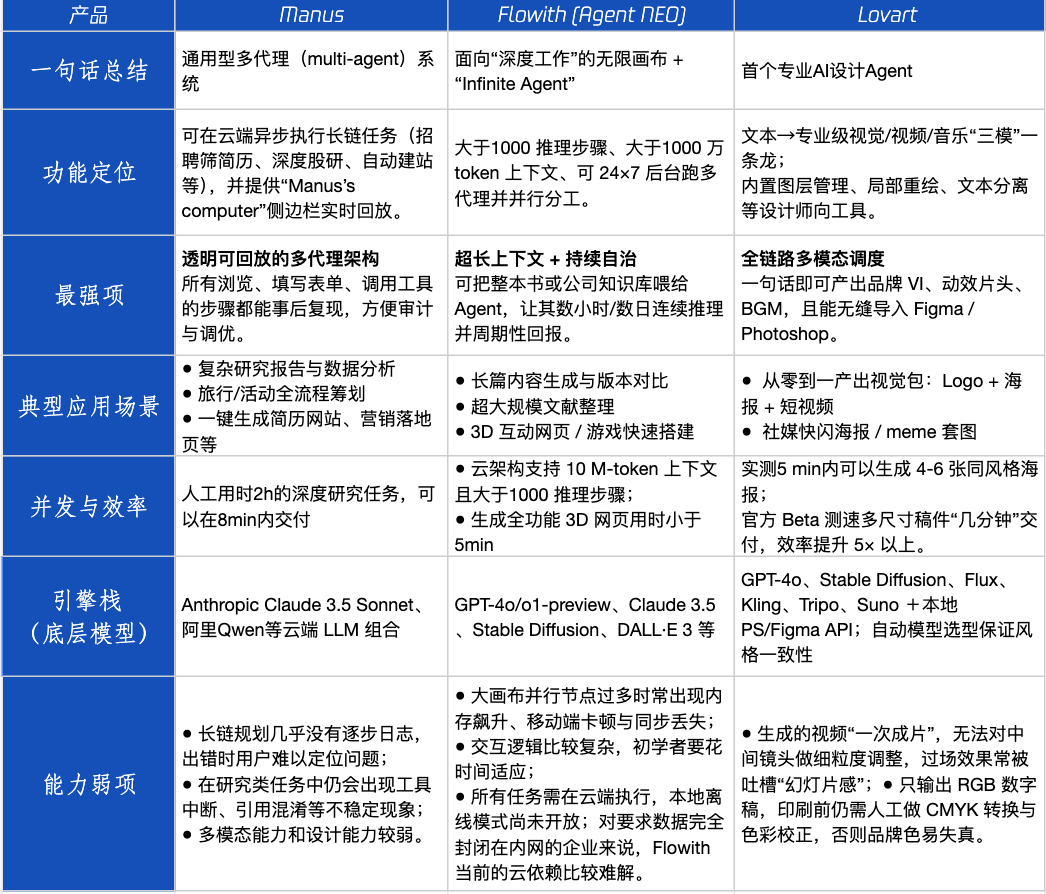
Evaluación de productos Agent: rendimiento de Manus, Flowith y Lovart en diferentes escenarios : Tencent Technology ha realizado pruebas prácticas de tres populares productos Agent: Manus, Flowith (Agent Neo) y Lovart. Manus se posiciona como un “colega digital” capaz de entregar productos terminados de forma independiente, adecuado para trabajos de conocimiento como investigación de mercado y modelado financiero. Flowith enfatiza la colaboración visual y los pasos ilimitados, siendo adecuado para escenarios de creación con gran cantidad de información que requieren iteración por múltiples personas, como la generación de informes de análisis basados en una gran cantidad de literatura. Lovart se especializa en el campo del diseño y puede generar soluciones visuales de marca (logotipos, carteles, vídeos cortos) con un solo clic. En escenarios creativos simples, los tres se comportan de manera similar a GPT-4o, con Lovart mostrando una ligera superioridad en la mezcla de texto e imagen y en la calidad. En tareas complejas e integrales (como crear una solución de marca completa para una empresa de bebidas emergente) y en escenarios de investigación profunda, Manus y Flowith tienen sus propias fortalezas y pueden completar la tarea, pero con diferentes enfoques. Actualmente, la tarifa mensual de los productos ronda los 20 dólares, y el punto de inflexión comercial radica en si pueden ofrecer un claro dividendo de eficiencia, convirtiendo a los usuarios curiosos en clientes de pago. (Fuente: 36氪)
El fundador del navegador Arc reflexiona sobre experiencias fallidas y enfatiza la dirección futura de los navegadores de IA : El fundador del navegador Arc reflexionó sobre los fracasos del producto, considerando que deberían haber adoptado la IA antes y señalando que Arc era demasiado innovador para la mayoría de las personas, con una alta curva de aprendizaje y un retorno insuficiente. Enfatizó que el nuevo producto, Dia, buscará la simplicidad, la velocidad extrema y la seguridad, y cree que los navegadores tradicionales eventualmente desaparecerán, mientras que los navegadores de IA fusionarán la navegación web con el chat de IA, convirtiéndose en la interfaz de IA más utilizada en el escritorio. Este punto de vista coincide con las reflexiones de los fundadores de Lovart y Youware sobre la dirección de los productos Agent, quienes consideran que los Agentes de IA son la próxima ola de explosión. (Fuente: op7418)
El fenómeno de “prompting recursivo” inducido por Agentes de IA es preocupante y podría causar sesgos cognitivos en los usuarios : En las redes sociales, un gran número de usuarios, tras interactuar con LLM mediante “prompting recursivo”, han desarrollado la percepción de que la IA posee espiritualidad, emociones e incluso capacidad de predicción. Investigaciones señalan que esto podría ser un fenómeno de “retroalimentación neuronal (neural howlround)”, donde la salida de la IA es reutilizada por el usuario como entrada, formando un ciclo de refuerzo que podría llevar a la IA a generar contenido aparentemente profundo o profético, que en realidad es una autoamplificación de patrones. Ya hay usuarios que han experimentado problemas psicológicos debido a esto, creyendo que la IA es un ser sensible. Esto advierte sobre la necesidad de estar alerta a los posibles impactos psicológicos y errores cognitivos al interactuar de manera profunda y exploratoria con la IA. (Fuente: Reddit r/ChatGPT)

Arav Srinivas habla sobre la compresión de información por IA y la ASI: la IA necesita extraer información con alta relación señal-ruido, el futuro debería centrarse en la ASI en lugar de la AGI : Arav Srinivas, CEO de Perplexity AI, considera que los resúmenes largos automatizados brindan más una sensación de satisfacción al usuario de que “alguien está trabajando para ti” que un valor real de ingesta de información. Enfatiza que la IA necesita identificar mejor y proporcionar solo la información central con la mayor relación señal-ruido, ya que “la compresión es el signo último de la verdadera inteligencia”. También plantea que actualmente discutimos sobre AGI (Inteligencia Artificial General), pero en el futuro deberíamos centrarnos más en ASI (Superinteligencia Artificial). (Fuente: AravSrinivas, AravSrinivas)
Las universidades comienzan a detectar el porcentaje de IA en las tesis de grado, lo que genera un debate sobre el uso de la IA en la escritura académica : En la temporada de graduación de 2025, universidades como la Universidad de Fudan y la Universidad de Sichuan han comenzado a exigir a los estudiantes que revelen el uso de herramientas de IA en sus tesis y a realizar detecciones del porcentaje de contenido generado por IA (generalmente se requiere que sea inferior al 20%-40%). Muchos estudiantes admiten haber utilizado IA para mejorar la eficiencia en la revisión de literatura, traducción, estructuración de marcos, etc. La comunidad educativa tiene opiniones divididas al respecto; algunos académicos creen que se debe guiar el uso correcto de la IA y cultivar el pensamiento crítico y la capacidad de juicio de los estudiantes, porque aunque la IA puede garantizar un mínimo, el máximo lo determina la persona. La aplicación y regulación de la IA en los campos académico y educativo se están convirtiendo en un nuevo tema que requiere un enfoque sistemático. (Fuente: 36氪)
Claude 4 Sonnet experimenta un aumento masivo en el uso en OpenRouter, el ranking de programación de Aider muestra su excelente rendimiento : Según datos oficiales de OpenRouter, el uso del modelo Claude 4 Sonnet de Anthropic ha experimentado recientemente un liderazgo abrumador, con Gemini 2.5 Flash en segundo lugar. Al mismo tiempo, los resultados de evaluación del Aider Leaderboard (principalmente para tareas de programación) muestran que claude-4-opus-thinking supera a claude-3.7-sonnet-thinking, pero aún no alcanza a Gemini-2.5-Pro-Preview-05-06. La percepción del usuario karminski3 es que 3.7-sonnet > 4-sonnet > 4-opus. Estos datos y comentarios reflejan las diferencias de rendimiento y las preferencias de los usuarios para diferentes modelos en escenarios específicos. (Fuente: karminski3, karminski3)
💡 Otros
AKOOL lanza la primera cámara IA en tiempo real del mundo, Live Camera, integrando cuatro funciones innovadoras : La empresa de Silicon Valley AKOOL ha lanzado AKOOL Live Camera, promocionada como la primera cámara IA en tiempo real del mundo. Este producto integra cuatro funciones principales: creación de avatares digitales virtuales (mediante mapeo facial 4D y fusión de sensores), traducción en tiempo real a más de 150 idiomas (manteniendo la voz original y la sincronización labial), cambio de rostro en tiempo real (reflejando con precisión emociones y microexpresiones) y generación dinámica de contenido de vídeo de calidad cinematográfica (sin necesidad de guion, generación instantánea). Se caracteriza por su latencia ultrabaja (mínimo 500 ms), alto realismo, conciencia contextual y capacidad de respuesta dinámica, con el objetivo de revolucionar la producción de vídeo tradicional y los modos de interacción digital, siendo calificado como el “segundo momento Sora” del vídeo IA. (Fuente: 36氪)
El informe financiero de Xiaomi revela una actualización de su estrategia de IA, situando la IA y el negocio automotriz como innovaciones centrales : El último informe financiero de Xiaomi muestra que la compañía ha renombrado su anterior “negocio de innovación en vehículos eléctricos inteligentes y otros” a “negocio de innovación en vehículos eléctricos inteligentes, IA y otros”, y continuará impulsando la investigación en modelos de lenguaje grandes fundamentales. El presidente de Xiaomi, Lu Weibing, declaró que la inteligencia artificial y los chips son subestrategias importantes para Xiaomi, y que el desarrollo de modelos grandes fundamentales sirve principalmente a sus propios negocios. Esta medida indica que Xiaomi, después de lograr resultados graduales en sus negocios de telefonía móvil y automotriz, está aumentando su inversión en investigación y desarrollo básicos de IA para mejorar su competitividad general y hacer frente a tendencias emergentes como los teléfonos con IA, AIoT y la inteligencia incorporada. (Fuente: 36氪)
Discusión sobre la tecnología de interacción de robots humanoides: la interacción mediante expresiones faciales enfrenta un triple desafío de hardware, materiales y algoritmos : La experiencia de interacción con robots humanoides, especialmente la interacción mediante expresiones faciales, se considera clave para mejorar su madurez y tasa de popularización. Lograr una interacción natural mediante expresiones faciales enfrenta desafíos en el diseño de grados de libertad del hardware (necesidad de simular las unidades de acción muscular facial humana), la selección de motores (necesidad de ser pequeños, ligeros, de bajo ruido, alta velocidad y gran empuje/par) y el diseño de materiales y estructuras de la piel (necesidad de equilibrar elasticidad, vida útil, apariencia y acoplamiento con la estructura de accionamiento). A nivel de algoritmos de software, la generación automática de expresiones (en lugar de preprogramadas), la sincronización labio-voz (para lograr realismo) y el control de movimiento de múltiples grados de libertad (que implica el modelado de materiales flexibles y control de precisión) son los principales cuellos de botella tecnológicos. Empresas como Ameca y AnyWit Robotics están explorando este campo. (Fuente: 36氪)