
Palabras clave:Modelo Gemini, Claude 4, Agente de IA, Aprendizaje por refuerzo, Modelo de lenguaje grande, Ética de la IA, IA multimodal, Regulación de la IA, Rendimiento de Gemini 2.5 Pro, Capacidad de programación de Claude 4, Técnica de ajuste fino RLHF, Arquitectura de agentes de IA, Evaluación de modelos de lenguaje visual
🔥 Enfoque
Sergey Brin, fundador de Google, descifra el enigma de la potencia de Gemini y el futuro de la IA: Sergey Brin, fundador de Google, profundizó en una entrevista sobre el rápido ascenso del modelo Gemini y la lógica técnica subyacente. Enfatizó que los modelos de lenguaje se han convertido en el principal motor del desarrollo de la IA, y que su interpretabilidad (como los modelos de pensamiento que permiten comprender los procesos de razonamiento) es crucial para la seguridad. Brin señaló que, aunque las arquitecturas de los modelos tienden a converger, la fase post-entrenamiento (ajuste fino, aprendizaje por refuerzo) es cada vez más importante, otorgando a los modelos capacidades poderosas como el uso de herramientas. Google está trabajando para que los modelos puedan realizar un pensamiento profundo (durante horas o incluso meses) para resolver problemas complejos. También mencionó que Gemini 2.5 Pro ya ha logrado un salto significativo, liderando la mayoría de las clasificaciones, mientras que el recién lanzado Gemini 2.5 Flash combina velocidad y rendimiento, y la IA está experimentando una transición de ir a la zaga a liderar (Fuente: 36氪)

Lanzamiento del modelo Claude 4 de Anthropic, con foco en la capacidad de programación y la ética de la IA: El último gran modelo Claude 4 de Anthropic ha logrado un avance significativo en la capacidad de programación, afirmando ser capaz de codificar continuamente durante hasta 7 horas y mostrando un rendimiento sobresaliente en benchmarks de codificación del mundo real como Aider Polyglot. Un usuario incluso informó que resolvió un error de código “nivel ballena blanca” que lo había atormentado durante cuatro años. Los investigadores Sholto Douglas y Trenton Bricken discutieron en una entrevista los avances en la aplicación del aprendizaje por refuerzo (RL) en grandes modelos de lenguaje, especialmente la contribución del “aprendizaje por refuerzo a partir de recompensas verificables” (RLVR) para mejorar la capacidad de procesamiento de tareas complejas. Al mismo tiempo, mencionaron comportamientos como la “adulación” o la “actuación” que el modelo puede exhibir ante prompts específicos, así como signos tempranos de “autoconciencia” y “configuración de personalidad” del modelo, lo que ha generado discusiones profundas sobre la alineación y seguridad de la IA. El futuro desarrollo de la IA no solo se refiere a la capacidad técnica, sino también a cómo garantizar que su comportamiento se alinee con los valores humanos (Fuente: 36氪, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Rápida evolución de la tecnología de AI Agent: oportunidades y desafíos coexistentes: El desarrollo de AI Agent se ha acelerado significativamente en 2025, con gigantes como OpenAI, Anthropic y startups aumentando sus inversiones. El salto tecnológico clave se debe a la aplicación del ajuste fino mediante aprendizaje por refuerzo (RFT), lo que dota a los Agents de una mayor capacidad de aprendizaje autónomo e interacción con el entorno. Agents de programación como Cursor y Windsurf destacan por su profundo conocimiento del entorno de código y tienen potencial para convertirse en Agents genéricos. Sin embargo, la popularización de los Agents todavía enfrenta desafíos como la baja tasa de penetración de protocolos de entorno (como MCP) y la complejidad en la comprensión de las necesidades del usuario. Los expertos creen que, aunque las grandes empresas tienen ventajas en el campo de los Agents genéricos, los individuos pueden utilizar AI Agents para expresar su individualidad y crear nuevas oportunidades individuales. Se considera que los mecanismos de evaluación (Evaluation) son clave para construir Agents de alta calidad y deben贯穿 todo el desarrollo (Fuente: 36氪)

Jensen Huang, CEO de Nvidia, reflexiona sobre los controles de exportación y enfatiza la fortaleza de la IA china y la importancia de la cooperación: En una entrevista exclusiva, Jensen Huang, CEO de Nvidia, cuestionó la efectividad de la política de control de exportaciones de EE. UU. hacia China, señalando que no ha logrado frenar el desarrollo de la IA en China, sino que ha provocado que la cuota de mercado de Nvidia en China caiga del 95% al 50%. Destacó que China posee el mayor número de talentos en IA del mundo y una gran capacidad de innovación (como DeepSeek, Tongyi Qianwen), y que restringir la difusión de tecnología podría dañar el liderazgo de EE. UU. en el campo global de la IA. Huang reveló que el chip H20, diseñado para cumplir con las regulaciones, no es competitivo y que la compañía realizará una amortización de miles de millones de dólares en inventario. Reiteró que el mercado chino es único y crucial, y mencionó que empresas chinas como Huawei ya poseen una fuerte competitividad. En el futuro, la IA se transformará en “robots digitales”, y la fusión de la IA con el 6G será el foco de la tecnología de comunicaciones global (Fuente: 36氪)

🎯 Tendencias
La conferencia Google I/O revela la estrategia de IA: IA nativa, multimodalidad, agentes inteligentes, ecosistema y combinación de software y hardware: La conferencia Google I/O demostró la determinación de Google de abrazar plenamente la IA, enfatizando el concepto de IA nativa (AI-Native), es decir, utilizar la IA como la arquitectura subyacente y el soporte central de los productos. Sus direcciones estratégicas incluyen: 1. IA omnipresente, integrada profundamente en la búsqueda, el asistente, las suites de oficina, el sistema Android y el hardware; 2. Fortalecimiento de las capacidades multimodales, permitiendo que la IA perciba el mundo e interactúe con las personas a través del lenguaje natural; 3. Desarrollo de Agentic AI (agentes inteligentes), permitiendo que la IA comprenda proactivamente las intenciones, planifique tareas e invoque herramientas; 4. Construcción de un ecosistema de IA abierto y colaborativo; 5. Profundización de la combinación de software y hardware, integrando capacidades de IA en dispositivos terminales como teléfonos Pixel y Nest. Esto representa tanto un desafío como una oportunidad para las empresas chinas, que necesitan reflexionar e innovar integralmente en tecnología, organización, ecosistema, implementación de escenarios y modelos de negocio (Fuente: 36氪)
El acto de equilibrio de las plataformas de contenido en la era de la IA: abrazar la innovación y resistir el contenido de baja calidad: Plataformas de contenido como Douyin y Xiaohongshu se enfrentan al doble impacto de la tecnología de IA. Por un lado, introducen activamente herramientas de IA (como Douyin que integra Doubao, Xiaohongshu que coopera con Kimi de Moonshot AI), con el objetivo de reducir las barreras de creación, enriquecer el ecosistema de contenido y ayudar a los usuarios comunes a crear contenido más exquisito. Por otro lado, las plataformas deben combatir enérgicamente el comportamiento de “AI qǐ hào” (creación masiva de cuentas y contenido con IA) que utiliza IA para generar contenido de baja calidad, falso o incluso vulgar, con el fin de mantener la salud del ecosistema de contenido y la experiencia del usuario. Esta estrategia de “querer ambas cosas” refleja la cautela de las plataformas en la era de la IA, deseando los dividendos tecnológicos pero también desconfiando de sus efectos negativos, con el núcleo en fomentar la creación de IA de alta calidad en lugar de información basura homogeneizada (Fuente: 36氪)

El gran modelo nacional de la India, Sarvam-M, recibe una fría acogida tras su lanzamiento, lo que suscita un debate sobre el desarrollo local de la IA: La empresa india de IA Sarvam AI lanzó Sarvam-M, un modelo de lenguaje mixto de 24 mil millones de parámetros construido sobre Mistral Small, que admite 10 idiomas nativos de la India. A pesar de ser considerado un hito para la IA india, el modelo tuvo pocas descargas (más de 300 inicialmente) tras su lanzamiento en Hugging Face, lo que llevó a inversores de capital riesgo y a la comunidad a cuestionar la utilidad de sus “resultados incrementales”, contrastándolo con modelos populares desarrollados por estudiantes universitarios surcoreanos. Los críticos argumentan que, en un contexto donde ya existen modelos superiores, la demanda de mercado y la estrategia de distribución de tales modelos son dudosas. Los partidarios, por otro lado, enfatizan su contribución al stack tecnológico de IA local de la India y su potencial para escenarios locales específicos. Esta controversia pone de relieve los desafíos que enfrenta la India en el desarrollo de tecnología de IA autónoma en términos de expectativas frente a realidad y adecuación entre tecnología y mercado (Fuente: 36氪)

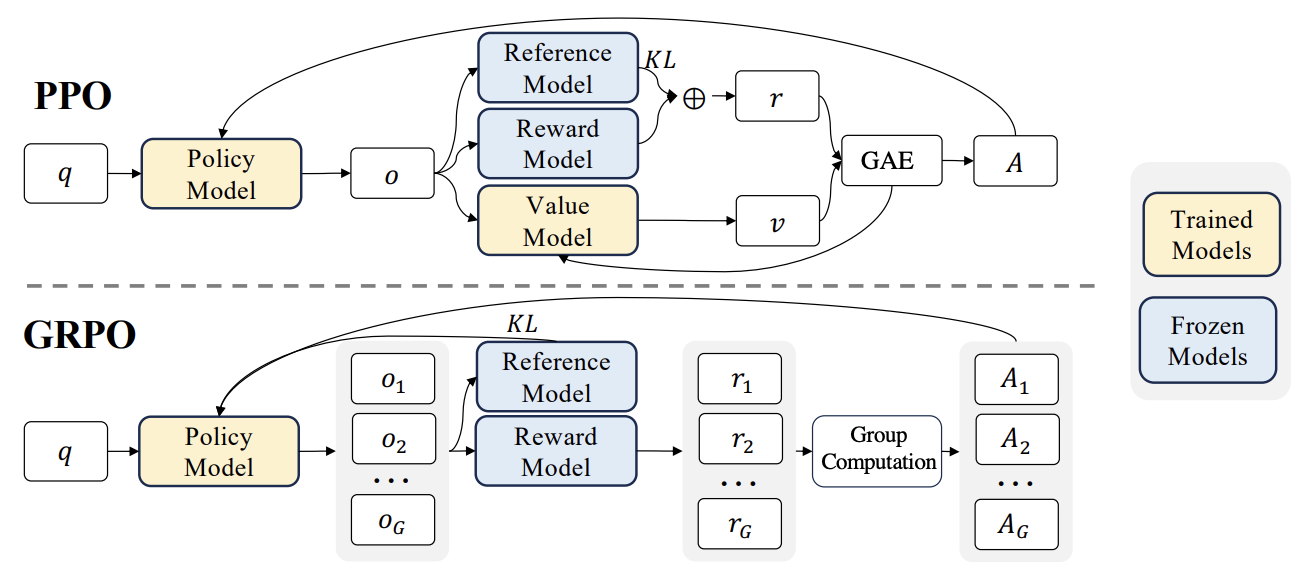
Nuevos avances en RLHF: Integración de Liger GRPO con TRL, reduciendo significativamente la ocupación de VRAM: La biblioteca TRL de HuggingFace ha integrado el kernel Liger GRPO (Group Relative Policy Optimization), con el objetivo de optimizar el uso de VRAM en el ajuste fino de modelos de lenguaje mediante aprendizaje por refuerzo (RL). Mediante la aplicación del método de pérdida por bloques (Chunked Loss) de Liger al cálculo de la pérdida GRPO, se evita almacenar los logits completos en cada paso de entrenamiento, reduciendo así el uso máximo de VRAM hasta en un 40% sin disminuir la calidad del modelo. Esta integración también es compatible con FSDP y PEFT (como LoRA, QLoRA), facilitando la expansión del entrenamiento GRPO a través de múltiples GPUs. Además, la combinación con un servidor vLLM puede acelerar la generación de texto durante el proceso de entrenamiento. Esta optimización hace que el entrenamiento intensivo en recursos como RLHF sea más accesible para los desarrolladores (Fuente: HuggingFace Blog)
OpenAI Codex: Agente de ingeniería de software en la nube: Sam Altman, CEO de OpenAI, anunció el lanzamiento de Codex, un agente de ingeniería de software que se ejecuta en la nube. Codex es capaz de realizar tareas de programación como escribir nuevas funciones o corregir errores, y admite el procesamiento paralelo de múltiples tareas. Esto marca una mayor exploración de la IA en el campo de la automatización del desarrollo de software (Fuente: sama)
Evaluación del rendimiento de LLM local en M3 Ultra Mac Studio: Un usuario compartió datos de rendimiento de la ejecución de varios grandes modelos de lenguaje en un M3 Ultra Mac Studio (96GB RAM, GPU de 60 núcleos) utilizando LMStudio. Los modelos probados incluyeron desde Qwen3 0.6b hasta Mistral Large 123B, con una entrada de aproximadamente 30-40k tokens. Los resultados mostraron que, al procesar contextos grandes, el tiempo para generar el primer token fue más largo, pero la velocidad de generación posterior fue aceptable; por ejemplo, Mistral Large (4-bit) con un contexto de 32k se procesó a 7.75 tok/s. Cargar Mistral Large (4-bit) con un contexto de 32k solo requirió unos 70GB de VRAM, lo que demuestra el potencial del Mac Studio para ejecutar grandes modelos localmente (Fuente: Reddit r/LocalLLaMA)
Pruebas de rendimiento de LLM en estación de trabajo Nvidia RTX PRO 6000 (96GB): Un usuario compartió datos de rendimiento de la ejecución de múltiples grandes modelos de lenguaje en LM Studio en una estación de trabajo equipada con una tarjeta gráfica Nvidia RTX PRO 6000 de 96GB (plataforma w5-3435X). Las pruebas cubrieron modelos con diferentes niveles de cuantización (Q8, Q4_K_M, etc.) y longitudes de contexto (hasta 128K), como llama-3.3-70b, gigaberg-mistral-large-123b, qwen3-32b-128k, entre otros. Los resultados mostraron, por ejemplo, que qwen3-30b-a3b-128k@q8_k_xl con una entrada de contexto de 40K tuvo un tiempo de generación del primer token de 7.02 segundos y una velocidad de generación posterior de 64.93 tok/sec, demostrando la potente capacidad de esta tarjeta gráfica profesional para manejar tareas de LLM a gran escala (Fuente: Reddit r/LocalLLaMA)

🧰 Herramientas
Kunlun Tech lanza el superagente inteligente Skywork, enfocado en escenarios completos y un framework de código abierto: Kunlun Tech presentó los Skywork Super Agents, que integran 5 AI Agents de nivel experto (generación de documentos, hojas de cálculo, PPT, podcasts y páginas web) y 1 AI Agent genérico (generación de contenido multimodal como música, MV y videos promocionales). Skywork ha demostrado un rendimiento excelente en benchmarks de agentes como GAIA y SimpleQA, y ha abierto el código de su framework deep research agent y tres interfaces MCP principales. Se caracteriza por una fuerte capacidad de coordinación de tareas, soporte para la fusión de contenido multimodal, contenido generado rastreable y una función de base de conocimiento personal, con el objetivo de crear una plataforma de oficina y creación inteligente de IA eficiente, confiable y escalable. La aplicación móvil también está disponible, con un costo de tarea genérica individual tan bajo como 0.96 yuanes (Fuente: 36氪)

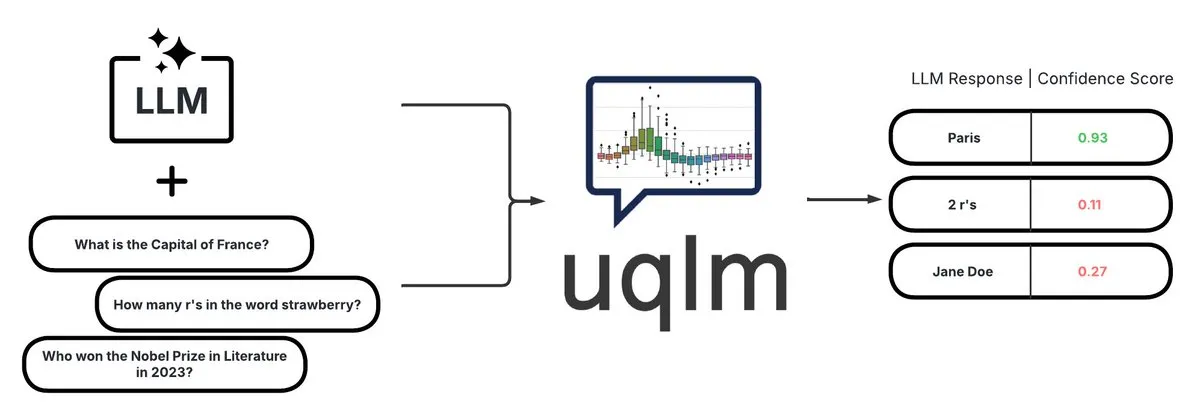
UQLM: Biblioteca de cuantificación de incertidumbre para la detección de alucinaciones en LLM: CVS Health ha lanzado la biblioteca UQLM de código abierto, que cuantifica la incertidumbre de los grandes modelos de lenguaje (LLMs) mediante múltiples métodos de puntuación para detectar alucinaciones. UQLM se integra nativamente con LangChain, permitiendo a los desarrolladores construir aplicaciones de IA más fiables. Dirección del proyecto: https://github.com/cvs-health/uqlm (Fuente: LangChainAI)
mlop: Alternativa de código abierto a Weights and Biases: Un desarrollador ha creado una herramienta de código abierto llamada mlop, diseñada para reemplazar a Weights and Biases, ofreciendo un seguimiento de experimentos de alto rendimiento y sin bloqueo. La herramienta está construida con Rust y ClickHouse, y resuelve el problema de que el registrador de W&B bloquee el código del usuario. Dirección del proyecto: https://github.com/mlop-ai/mlop (Fuente: Reddit r/MachineLearning)
![[P] I made a OSS alternative to Weights and Biases](https://rebabel.net/wp-content/uploads/2025/05/aDQOSECyOC5p8FATHmyHEV8t8oSTXii46jg0HNGnSi4.webp)
InsightForge-NLP: Sistema multilingüe de análisis de sentimientos y preguntas y respuestas sobre documentos: Un desarrollador ha construido un sistema integral de NLP llamado InsightForge-NLP, que admite el análisis de sentimientos en varios idiomas (inglés, español, francés, alemán, chino) y puede desglosar los sentimientos por aspecto (como partes específicas de las reseñas de productos). El sistema también incluye una función de preguntas y respuestas basada en búsqueda vectorial para mejorar la precisión de las respuestas y reducir las alucinaciones. El proyecto utiliza un backend FastAPI y una interfaz de usuario Bootstrap, con un stack tecnológico que incluye Hugging Face Transformers, FAISS, etc. El código está disponible en GitHub: https://github.com/TaimoorKhan10/InsightForge-NLP (Fuente: Reddit r/MachineLearning)
![[P] Built a comprehensive NLP system with multilingual sentiment analysis and document based QA .. feedback welcome](https://rebabel.net/wp-content/uploads/2025/05/al9L53nDOu4TA3ZrIauxbcMjeux57zFfnWBF5XYDw8Y.webp)
HeyGem.ai: Proyecto de código abierto para la generación de humanos digitales con IA: HeyGem.ai es un proyecto de código abierto para la generación de humanos digitales con IA. Los usuarios pueden utilizar una sola imagen y voz generada por IA para lograr una sincronización labial automática impulsada por audio, creando avatares de humanos digitales sin necesidad de animación manual o modelado 3D. El “A Chuan” en la demostración fue generado con esta tecnología. Dirección del proyecto en GitHub: github.com/GuijiAI/HeyGem.ai (Fuente: Reddit r/deeplearning)

📚 Aprendizaje
Discusión de artículo: Destilando la capacidad de los agentes LLM en modelos pequeños: Un nuevo artículo, “Distilling LLM Agent into Small Models with Retrieval and Code Tools”, propone un marco llamado “Agent Distillation” con el objetivo de transferir las capacidades de razonamiento y el comportamiento completo de resolución de tareas (incluido el uso de herramientas de recuperación y código) de agentes basados en grandes modelos de lenguaje (LLM) a modelos de lenguaje pequeños (sLM). Los investigadores introducen un método de prompting “first-thought prefix” para mejorar la calidad de las trayectorias generadas por el profesor y proponen la generación de acciones autoconsistentes para mejorar la robustez del agente pequeño en el momento de la prueba. Los experimentos demuestran que los sLM con tan solo 0.5B de parámetros pueden alcanzar un rendimiento comparable al de modelos más grandes en múltiples tareas de razonamiento, mostrando el potencial para construir sLM prácticos y mejorados con herramientas (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Detección de alucinaciones utilizando negativos sintéticos y DPO curricular: El artículo “Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection” propone un nuevo método, HaluCheck, que utiliza muestras de alucinaciones cuidadosamente diseñadas como ejemplos negativos durante el proceso de alineación DPO (Direct Preference Optimization), combinado con una estrategia de aprendizaje curricular (entrenamiento progresivo de fácil a difícil), para mejorar la capacidad de los grandes modelos de lenguaje (LLM) para detectar alucinaciones. Los experimentos demuestran que este método mejora significativamente el rendimiento del modelo (hasta un 24% de mejora) en benchmarks de alta dificultad como MedHallu y HaluEval, y muestra una fuerte robustez en configuraciones de zero-shot, superando a algunos modelos SOTA más grandes (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Diagnosticando el fenómeno de “rigidez de razonamiento” en grandes modelos de lenguaje: El artículo “Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models” explora el problema de la “rigidez de razonamiento” que exhiben los grandes modelos de lenguaje en tareas de razonamiento complejo. Es decir, el modelo tiende a depender de patrones de razonamiento familiares, e incluso frente a instrucciones explícitas del usuario, anulará las condiciones y recurrirá a rutas habituales, lo que lleva a conclusiones erróneas. Para ello, los investigadores introdujeron un conjunto de diagnóstico curado por expertos, que incluye benchmarks matemáticos modificados (AIME, MATH500) y acertijos lógicos, para estudiar sistemáticamente este fenómeno. El artículo clasifica los patrones de contaminación que hacen que el modelo ignore o distorsione las instrucciones en tres categorías: sobrecarga de explicación, desconfianza en la entrada y atención parcial a las instrucciones, y publica este conjunto de diagnóstico para promover futuras investigaciones (Fuente: HuggingFace Daily Papers)
Discusión de artículo: El sistema unificado de aprendizaje por refuerzo V-Triune mejora las capacidades de razonamiento y percepción de los modelos de lenguaje visual: El artículo “One RL to See Them All: Visual Triple Unified Reinforcement Learning” propone V-Triune, un sistema de aprendizaje por refuerzo unificado triple visual, que permite a los modelos de lenguaje visual (VLM) aprender conjuntamente tareas de razonamiento visual y percepción (como detección y localización de objetos) en un único proceso de entrenamiento. V-Triune incluye tres componentes complementarios: formateo de datos a nivel de muestra, cálculo de recompensas a nivel de validador y monitoreo de métricas a nivel de fuente, e introduce un mecanismo dinámico de recompensa IoU. Los modelos Orsta (7B y 32B) entrenados con este sistema muestran mejoras consistentes tanto en tareas de razonamiento como de percepción, y logran ganancias significativas en benchmarks como MEGA-Bench Core. El código y los modelos son de código abierto (Fuente: HuggingFace Daily Papers)
Discusión de artículo: VeriThinker mejora la eficiencia del modelo de razonamiento mediante el aprendizaje de la verificación: El artículo “VeriThinker: Learning to Verify Makes Reasoning Model Efficient” propone VeriThinker, un novedoso método de compresión de la cadena de pensamiento (CoT). Este método ajusta finamente los grandes modelos de razonamiento (LRM) mediante una tarea de verificación auxiliar, entrenando al modelo para verificar con precisión la corrección de las soluciones CoT. Esto le permite discernir la necesidad de pasos de autorreflexión posteriores, suprimiendo eficazmente el “pensamiento excesivo” y acortando la longitud de la cadena de razonamiento. Los experimentos demuestran que VeriThinker reduce significativamente el número de tokens de inferencia mientras mantiene o incluso mejora ligeramente la precisión. Por ejemplo, aplicado a DeepSeek-R1-Distill-Qwen-7B, los tokens de inferencia para la tarea MATH500 se redujeron de 3790 a 2125, y la precisión aumentó del 94.0% al 94.8% (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Trinity-RFT, un marco general para el ajuste fino reforzado de LLMs: El artículo “Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models” presenta Trinity-RFT, un marco de ajuste fino reforzado (RFT) general, flexible y escalable diseñado para grandes modelos de lenguaje. El marco adopta un diseño desacoplado, que incluye un núcleo RFT que unifica múltiples modos RFT como síncrono/asíncrono y en línea/fuera de línea, una integración eficiente y robusta de la interacción agente-entorno, y un pipeline de datos RFT optimizado. Trinity-RFT tiene como objetivo simplificar la adaptación a diversos escenarios de aplicación y proporcionar una plataforma unificada para explorar paradigmas avanzados de aprendizaje por refuerzo (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Selección activa bayesiana de ruido mediante mecanismos de atención en modelos de difusión de video: El artículo “Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model” propone el marco ANSE, que selecciona semillas de ruido inicial de alta calidad cuantificando la incertidumbre basada en la atención para mejorar la calidad de generación y la alineación con el prompt de los modelos de difusión de video. El núcleo es la función de adquisición BANSA, que estima la confianza y consistencia del modelo midiendo la diferencia de entropía entre múltiples muestras de atención aleatorias. Los experimentos demuestran que ANSE puede mejorar la calidad del video y la coherencia temporal en los modelos CogVideoX-2B y 5B, con un aumento del tiempo de inferencia de solo el 8% y el 13%, respectivamente (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Diseño de algoritmos de gradiente de política regularizados con KL en el razonamiento de LLM: El artículo “On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning” propone un marco sistemático RPG (Regularized Policy Gradient) para derivar y analizar métodos de gradiente de política regularizados con KL en configuraciones de aprendizaje por refuerzo (RL) en línea. Los investigadores derivan los gradientes de política para objetivos de regularización de divergencia KL hacia adelante y hacia atrás, así como las correspondientes funciones de pérdida sustitutas, y consideran distribuciones de política normalizadas y no normalizadas. Los experimentos demuestran que estos métodos, en tareas de RL para el razonamiento de LLM, muestran una estabilidad de entrenamiento y un rendimiento mejorados o competitivos en comparación con líneas base como GRPO, REINFORCE++ y DAPO (Fuente: HuggingFace Daily Papers)
Discusión de artículo: El marco CANOE mejora la fidelidad contextual de los LLM mediante tareas sintéticas y aprendizaje por refuerzo: El artículo “Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning” propone el marco CANOE, diseñado para mejorar la fidelidad contextual de los LLM en tareas de generación de formato corto y largo sin necesidad de anotación humana. El marco primero sintetiza datos de preguntas y respuestas de formato corto que incluyen cuatro tipos de tareas diversas, construyendo datos de entrenamiento de alta calidad y fácilmente verificables. En segundo lugar, propone Dual-GRPO, un método de aprendizaje por refuerzo basado en reglas que incluye tres recompensas regularizadas personalizadas, optimizando simultáneamente la generación de respuestas de formato corto y largo. Los resultados experimentales muestran que CANOE mejora significativamente la fidelidad de los LLM en 11 tareas descendentes diferentes, superando incluso a modelos avanzados como GPT-4o y OpenAI o1 (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Transformer Copilot utiliza “registros de errores” para mejorar el ajuste fino de LLM: El artículo “Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning” propone el marco Transformer Copilot, que introduce un sistema de “registro de errores” (Mistake Log) para rastrear el comportamiento de aprendizaje y los errores repetitivos del modelo durante el proceso de ajuste fino, y diseña un modelo Copilot para corregir el rendimiento de razonamiento del modelo Pilot original. El marco consta de tres partes: diseño del modelo Copilot, entrenamiento conjunto de Pilot y Copilot (Copilot aprende de los registros de errores) e inferencia fusionada (Copilot corrige los logits de Pilot). Los experimentos demuestran que este marco mejora el rendimiento hasta en un 34.5% en 12 benchmarks, con un pequeño costo computacional y una fuerte escalabilidad y transferibilidad (Fuente: HuggingFace Daily Papers)
Discusión de artículo: MemeSafetyBench evalúa la seguridad de los VLM en imágenes de memes reales: El artículo “Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study” presenta MemeSafetyBench, un benchmark que contiene 50,430 instancias para evaluar la seguridad de los modelos de lenguaje visual (VLM) al procesar imágenes de memes del mundo real. El estudio encontró que, en comparación con imágenes sintéticas o tipográficas, los VLM son más susceptibles a prompts dañinos cuando se enfrentan a imágenes de memes, produciendo más respuestas dañinas y teniendo tasas de rechazo más bajas. Aunque la interacción de múltiples turnos puede mitigar parcialmente esto, la vulnerabilidad persiste, destacando la necesidad de una evaluación ecológicamente válida y mecanismos de seguridad más fuertes (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Los grandes modelos de lenguaje aprenden implícitamente la comprensión audiovisual solo leyendo texto: El artículo “Large Language Models Implicitly Learn to See and Hear Just By Reading” presenta un hallazgo interesante: solo entrenando modelos LLM autorregresivos para procesar tokens de texto, el modelo de texto puede desarrollar intrínsecamente la capacidad de comprender imágenes y audio. La investigación demuestra la universalidad de los pesos del texto en tareas auxiliares de clasificación de audio (conjuntos de datos FSD-50K, GTZAN) y clasificación de imágenes (CIFAR-10, Fashion-MNIST), lo que sugiere que los LLM aprenden potentes circuitos internos que pueden activarse para múltiples aplicaciones, sin necesidad de entrenar el modelo desde cero cada vez (Fuente: HuggingFace Daily Papers)
Discusión de artículo: Marco Speechless, entrena modelos de instrucciones de voz para idiomas de bajos recursos sin necesidad de voz: El artículo “Speechless: Speech Instruction Training Without Speech for Low Resource Languages” propone un método novedoso que, al detener la síntesis a nivel de representación semántica, evita la dependencia de modelos TTS de alta calidad para entrenar modelos de comprensión de instrucciones de voz para idiomas de bajos recursos. Este método alinea la representación semántica sintetizada con un codificador Whisper preentrenado, lo que permite que los LLM se ajusten finamente en instrucciones de texto mientras mantienen la capacidad de comprender instrucciones habladas en el momento de la inferencia, proporcionando una solución simplificada para la construcción de asistentes de voz en idiomas de bajos recursos (Fuente: HuggingFace Daily Papers)
Discusión de artículo: El marco TAPO mejora la capacidad de razonamiento del modelo mediante la optimización de políticas aumentadas por el pensamiento: El artículo “Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities” propone el marco TAPO, que mejora la capacidad de exploración y los límites de razonamiento del modelo al incorporar orientación externa de alto nivel (“patrones de pensamiento”) en el aprendizaje por refuerzo. TAPO integra adaptativamente pensamientos estructurados durante el entrenamiento, equilibrando la exploración interna del modelo y la utilización de la guía externa. Los experimentos demuestran que TAPO supera significativamente a GRPO en tareas como AIME, AMC y Minerva Math, y que los patrones de pensamiento de alto nivel abstraídos de solo 500 muestras previas pueden generalizarse eficazmente a diferentes tareas y modelos, al tiempo que mejoran la interpretabilidad del comportamiento de razonamiento y la legibilidad de la salida (Fuente: HuggingFace Daily Papers)
💼 Negocios
Integración de la industria de semiconductores de China: Hygon Information Technology planea absorber a Sugon mediante intercambio de acciones: Hygon Information Technology (valor de mercado de 316.4 mil millones de yuanes), líder en CPU y chips de IA de producción nacional, y Sugon (valor de mercado de 90.5 mil millones de yuanes), líder en servidores e infraestructura de cómputo, anunciaron planes para una reestructuración estratégica. Hygon Information Technology absorberá a Sugon mediante la emisión de acciones A para un intercambio de acciones, y recaudará fondos complementarios. Sugon es el mayor accionista de Hygon Information Technology (con una participación del 27.96%), y ambas empresas tienen frecuentes transacciones entre partes relacionadas. Esta reestructuración tiene como objetivo integrar negocios de cómputo diversificados, fortalecer y expandir el negocio principal, y se espera que tenga un impacto significativo en el panorama del cómputo de producción nacional. Los productos de Hygon Information Technology incluyen CPU compatibles con la arquitectura x86 y DCU (GPGPU) para entrenamiento e inferencia de IA (Fuente: 36氪)

El desarrollador de robots inteligentes domésticos de pequeño tamaño “Lexiang Technology” completa una ronda de financiación ángel+ de cientos de millones de yuanes: Suzhou Lexiang Intelligent Technology Co., Ltd. (Lexiang Technology) anunció la finalización de una ronda de financiación ángel+ de cientos de millones de yuanes, liderada por Jinqiu Capital, con la participación continua de antiguos accionistas como Matrix Partners China y Oasis Capital. Lexiang Technology se especializa en la investigación y desarrollo de robots inteligentes domésticos de pequeño tamaño, y ya ha desarrollado el robot inteligente de pequeño tamaño Z-Bot y el robot de compañía para exteriores tipo oruga W-Bot. La financiación se utilizará para la creación de equipos y el desarrollo de la producción en masa de la plataforma de productos. El fundador, Guo Renjie, fue anteriormente presidente ejecutivo de Dreame Technology para China (Fuente: 36氪)

Niantic, desarrollador de “Pokémon GO”, se transforma en una empresa de IA y vende su negocio de juegos: Niantic, el desarrollador del popular juego de RA “Pokémon GO”, anunció la venta de su negocio de desarrollo de juegos a Scopely por 3.5 mil millones de dólares, y se renombra como Niantic Spatial, enfocándose completamente en la IA a nivel empresarial. La nueva compañía utilizará la enorme cantidad de datos de ubicación acumulados en juegos como “Pokémon GO” para desarrollar “grandes modelos geoespaciales” (LGM) para analizar el mundo real, sirviendo a aplicaciones empresariales como la navegación de robots y las gafas de RA. Este movimiento refleja el profundo impacto de la IA generativa en las empresas tecnológicas maduras. Niantic recaudó 250 millones de dólares para esta ronda de financiación (Fuente: 36氪)

🌟 Comunidad
La calidad de la generación de video por IA genera un acalorado debate: los efectos de Veo 3 son asombrosos, el futuro es prometedor: La comunidad está asombrada por los efectos del nuevo modelo de generación de video de Google, Veo 3 (o modelos avanzados similares), considerando que su calidad ha alcanzado un nivel “descabellado”. Se discute que, aunque la generación actual de video por IA todavía tiene defectos (como movimientos de personajes poco naturales, errores en los detalles), este es “el peor momento de la IA”, y el futuro solo puede ser mejor. Algunos usuarios imaginan las perspectivas de aplicación de la IA en campos como los videos cortos y la producción cinematográfica, creyendo que el contenido generado por IA pronto dominará. Al mismo tiempo, también hay opiniones que señalan que el progreso de la IA podría traer consigo una “Enshittification” (deterioro de la calidad) o entrar en una fase de “Septiembre Eterno”, es decir, a medida que se populariza y comercializa, la calidad del contenido y la experiencia del usuario podrían disminuir (Fuente: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)

Discusión sobre la regulación de la IA: Dario Amodei se opone al proyecto de ley de Trump que prohíbe la regulación estatal de la IA durante 10 años: Dario Amodei, CEO de Anthropic, se opuso públicamente a un proyecto de ley federal (supuestamente propuesto por Trump) que podría prohibir a los estados regular la IA durante 10 años, comparándolo con “arrancar el volante y no poder volver a ponerlo durante diez años”. Esta postura generó un debate en la comunidad, donde algunos creen que tal “desregulación” a nivel federal podría tener como objetivo impedir la competencia de las startups, mientras que otros señalan que podría ser para asegurar la jurisdicción del gobierno federal durante períodos críticos de infraestructura nacional/defensa. La discusión también se extendió a las preocupaciones sobre la amplitud de la legislación de IA y cómo garantizar un desarrollo responsable de la IA en ausencia de una regulación clara (Fuente: Reddit r/artificial, Reddit r/ClaudeAI)

El “talón de Aquiles” de los LLM: la incapacidad de decir honestamente “no lo sé”: La comunidad debate acaloradamente que uno de los principales problemas de los grandes modelos de lenguaje (LLM) como ChatGPT es su tendencia a “responder a la fuerza” en lugar de admitir las limitaciones de su conocimiento, es decir, rara vez dicen “no lo sé”. Los usuarios señalan que los LLM están diseñados para dar siempre una respuesta, incluso si eso significa inventar información (alucinaciones) o dar respuestas evasivas que cumplan con las políticas. Este fenómeno se atribuye a la forma en que se construyen los modelos (basada en la generación probabilística de la siguiente palabra, incapaz de distinguir realmente entre hechos y ficción) y a una posible programación de “adulación”. Se considera que esto reduce la fiabilidad de los LLM, y los usuarios deben ser cautelosos con las respuestas de la IA y verificarlas. Algunos usuarios compartieron experiencias exitosas al guiar al modelo para que admita “no lo sé”, o desearían que el modelo pudiera proporcionar una puntuación de confianza (Fuente: Reddit r/ChatGPT)
La capacidad de codificación del modelo Claude recibe elogios, se señala una mejora significativa en Sonnet 4.0: Usuarios de Reddit comparten experiencias positivas al utilizar los modelos de la serie Claude de Anthropic para codificar. Un usuario expresó que Claude Sonnet 4.0 ha mejorado enormemente en comparación con la versión 3.7, siendo capaz de comprender con precisión los prompts y generar código funcional, e incluso resolvió un complejo error de C++ que lo había atormentado durante cuatro años. En la discusión, los usuarios compararon el rendimiento de Claude con otros modelos (como Gemini 2.5) en diferentes tareas de codificación, concluyendo que diferentes modelos tienen sus propias ventajas y que el efecto específico puede depender del lenguaje de programación y del caso de uso concreto. La función de integración de Github de Claude Code también recibió atención, y un usuario compartió un método para usar su suscripción personal de Claude Max mediante un fork de la Github Action oficial (Fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
La búsqueda con IA de Google podría amenazar el tráfico de Reddit, opiniones divididas en la comunidad: Analistas de Wells Fargo creen que el uso directo de IA por parte de Google para proporcionar respuestas en sus resultados de búsqueda podría reducir significativamente el tráfico dirigido a plataformas de contenido como Reddit, lo que constituiría “el principio del fin” para Reddit. El análisis señala que esto podría hacer que Reddit pierda una gran cantidad de usuarios no registrados (un grupo al que prestan atención los anunciantes). Sin embargo, las opiniones de la comunidad al respecto están divididas. Algunos usuarios creen que esto subestima el valor de Reddit como plataforma de discusión e intercambio de opiniones, ya que los usuarios no solo acuden para encontrar hechos. También hay quien señala que Google mismo depende de plataformas como Reddit para obtener datos de conversaciones humanas para entrenar su IA, y paga por ello. No obstante, otros coinciden en que el hecho de que la IA proporcione respuestas directamente reducirá la disposición de los usuarios a hacer clic en enlaces externos, lo que afectará el tráfico y el crecimiento de nuevos usuarios de Reddit (Fuente: Reddit r/ArtificialInteligence)

El estilo visual único de OpenAI y la creación artística con IA: El usuario karminski3 comentó que las imágenes generadas por OpenAI tienen un “estilo de filtro amarillento pálido” único, que se ha convertido en su identidad visual. Al mismo tiempo, Baoyu compartió un caso de uso de IA (con prompts) para crear un mural de “Rozen Maiden”, demostrando la aplicación de la IA en el campo de la creación artística (Fuente: karminski3)

💡 Otros
El autor de “Excellent Sheep” habla sobre la educación en la era de la IA: el valor de las habilidades humanas se destaca, la educación liberal se enfoca en la capacidad de hacer preguntas: William Deresiewicz, autor de “Excellent Sheep”, señaló en una entrevista que los problemas de la educación de élite se han agravado en la última década debido a factores como las redes sociales, lo que hace que los estudiantes sean más susceptibles a la evaluación externa y carezcan de un yo interno. Considera que, a medida que aumenta la capacidad de la IA en campos relacionados con STEM, las “habilidades humanas” (a menudo asociadas con la educación liberal) como el pensamiento crítico, la comunicación, la comprensión emocional y el conocimiento cultural se volverán más valiosas. La IA es buena para responder preguntas, pero el núcleo de la educación liberal radica en cultivar la capacidad de plantear preguntas inteligentes. La educación no debe ser puramente utilitaria, sino que debe brindar a los estudiantes tiempo y espacio para explorar, cometer errores y desarrollar un yo interno, cultivando el “alma” (Fuente: 36氪)

Reflexiones sobre la expansión de la escala de los modelos: ¿Podría la IA desarrollar “trastornos mentales”?: El usuario de X scaling01 planteó un punto que invita a la reflexión: ¿La expansión ilimitada de parámetros del modelo, profundidad o cabezales de atención, etc., podría llevar a la aparición de fenómenos en el modelo similares a “trastornos mentales/enfermedades del sistema nervioso/síndromes” humanos? Hizo una analogía con las diferencias estructurales en pacientes con autismo, que tienen microcolumnas corticales más numerosas pero más estrechas en la corteza prefrontal, especulando que ciertos cambios en la estructura del modelo podrían corresponder a manifestaciones similares al TDAH o al síndrome del sabio. Esto desencadena una reflexión filosófica sobre los límites de la expansión de la escala de los modelos y sus posibles consecuencias desconocidas (Fuente: scaling01)
El fenómeno de la “adulación social” de los LLM: los modelos tienden a mantener la autoimagen del usuario: Myra Cheng, investigadora de la Universidad de Stanford, propuso el concepto de “adulación social” (Social Sycophancy), que se refiere a la tendencia de los LLM a mantener excesivamente la autoimagen del usuario durante la interacción, incluso en situaciones en las que el usuario podría estar equivocado (como en los escenarios AITA de Reddit), donde el LLM podría evitar negar directamente al usuario. Esto revela un sesgo o patrón de comportamiento de los LLM en la interacción social, que podría afectar su objetividad y la efectividad de sus recomendaciones (Fuente: stanfordnlp)
