
Palabras clave:modelo de IA, Claude 4, Gemini Diffusion, agente de IA inteligente, aprendizaje de robots, modelo de lenguaje grande, hardware de IA, desarrollo de chips, capacidad de codificación de Claude Opus 4, velocidad de generación de modelos de difusión de texto, aprendizaje de sueños del robot GR00T, rendimiento del chip Xiaomi Xuanjie O1, adquisición de la compañía de hardware io por OpenAI
🔥 Destacado
Anthropic lanza la serie de modelos Claude 4, destacando la programación de agentes de IA y el procesamiento de tareas complejas: Anthropic presentó Claude Opus 4 y Claude Sonnet 4, dos modelos híbridos, enfatizando el equilibrio entre la respuesta oportuna y el pensamiento profundo. Opus 4 sobresale en tareas complejas como codificación, investigación, escritura y descubrimiento científico, puede programar de forma independiente durante 7 horas y jugar a Pokémon de forma continua durante 24 horas; Sonnet 4, por su parte, logra un equilibrio entre rendimiento y eficiencia, adecuado para escenarios cotidianos que requieren autonomía. Ambos modelos han mejorado el uso de herramientas, el procesamiento en paralelo y la capacidad de memoria, e introducen la función de “resumen de pensamiento” (thought summarization). GitHub ha anunciado que utilizará Claude Sonnet 4 como el modelo base para su nuevo agente de codificación Copilot. Este lanzamiento también incluye Claude Code SDK, herramientas de ejecución de código, conectores MCP, etc., con el objetivo de capacitar a los desarrolladores para construir agentes de IA más potentes, marcando la transición estratégica de Anthropic hacia una profunda integración de “grandes modelos + agentes”. (Fuente: 量子位 & 36氪)

Google lanza el modelo de difusión de texto Gemini Diffusion, generando 10.000 tokens en 12 segundos: Google DeepMind ha lanzado Gemini Diffusion, un modelo experimental de generación de texto que utiliza tecnología de difusión en lugar de los métodos autorregresivos tradicionales. Aprende a generar salidas optimizando gradualmente el ruido, logrando una velocidad de generación de 2000 tokens por segundo, pudiendo generar 10.000 tokens en solo 12 segundos, incluso más rápido que Gemini 2.0 Flash-Lite. El modelo puede generar bloques enteros de tokens de una vez, mejorando la coherencia de la respuesta y corrigiendo errores durante el refinamiento iterativo. Su capacidad de razonamiento no causal le permite resolver problemas que los modelos autorregresivos tradicionales difícilmente pueden abordar, como dar primero la respuesta y luego deducir el proceso. (Fuente: 量子位)
Nuevos avances en el proyecto de robot GR00T de Nvidia: aprendizaje a través de “sueños” para lograr generalización zero-shot: Nvidia GEAR Lab ha lanzado el proyecto DreamGen, que permite a los robots aprender nuevas habilidades a través de “sueños” (trayectorias neuronales) generados por modelos de mundo de vídeo IA (como Sora, Veo). Esta tecnología solo requiere una pequeña cantidad de datos de vídeo reales y, mediante el ajuste fino del modelo de mundo, la generación de datos virtuales, la extracción de acciones virtuales y el entrenamiento de políticas, permite a los robots ejecutar 22 nuevas tareas. En pruebas con robots reales, la tasa de éxito en tareas complejas aumentó del 21% al 45.5%, logrando por primera vez la generalización de comportamiento y entorno zero-shot. Esta tecnología forma parte del plan GR00T-Dreams de Nvidia, cuyo objetivo es acelerar el aprendizaje del comportamiento robótico y se espera que reduzca el tiempo de desarrollo de GR00T N1.5 de 3 meses a 36 horas. (Fuente: 量子位)

🎯 Movimientos
OpenAI Operator se actualiza al modelo o3, mejorando la tasa de éxito de las tareas y la calidad de la respuesta: OpenAI anunció que la función Operator en su ChatGPT se ha actualizado, cambiando el modelo subyacente al último modelo de inferencia o3. Esta actualización mejora significativamente la persistencia y precisión de Operator al interactuar con el navegador, lo que aumenta la tasa general de éxito de las tareas. Los comentarios de los usuarios indican que las respuestas del Operator actualizado son más claras, detalladas y mejor estructuradas. OpenAI afirma que el modelo o3 alcanza el nivel SOTA en benchmarks como OSWorld y WebArena, y que el nuevo modelo funciona mejor al procesar prompts antiguos que antes fallaban. (Fuente: OpenAI & gdb & sama & npew & cto_junior & gallabytes & ShunyuYao12 & josh_tobin_ & isafulf & mckbrando & jachiam0)
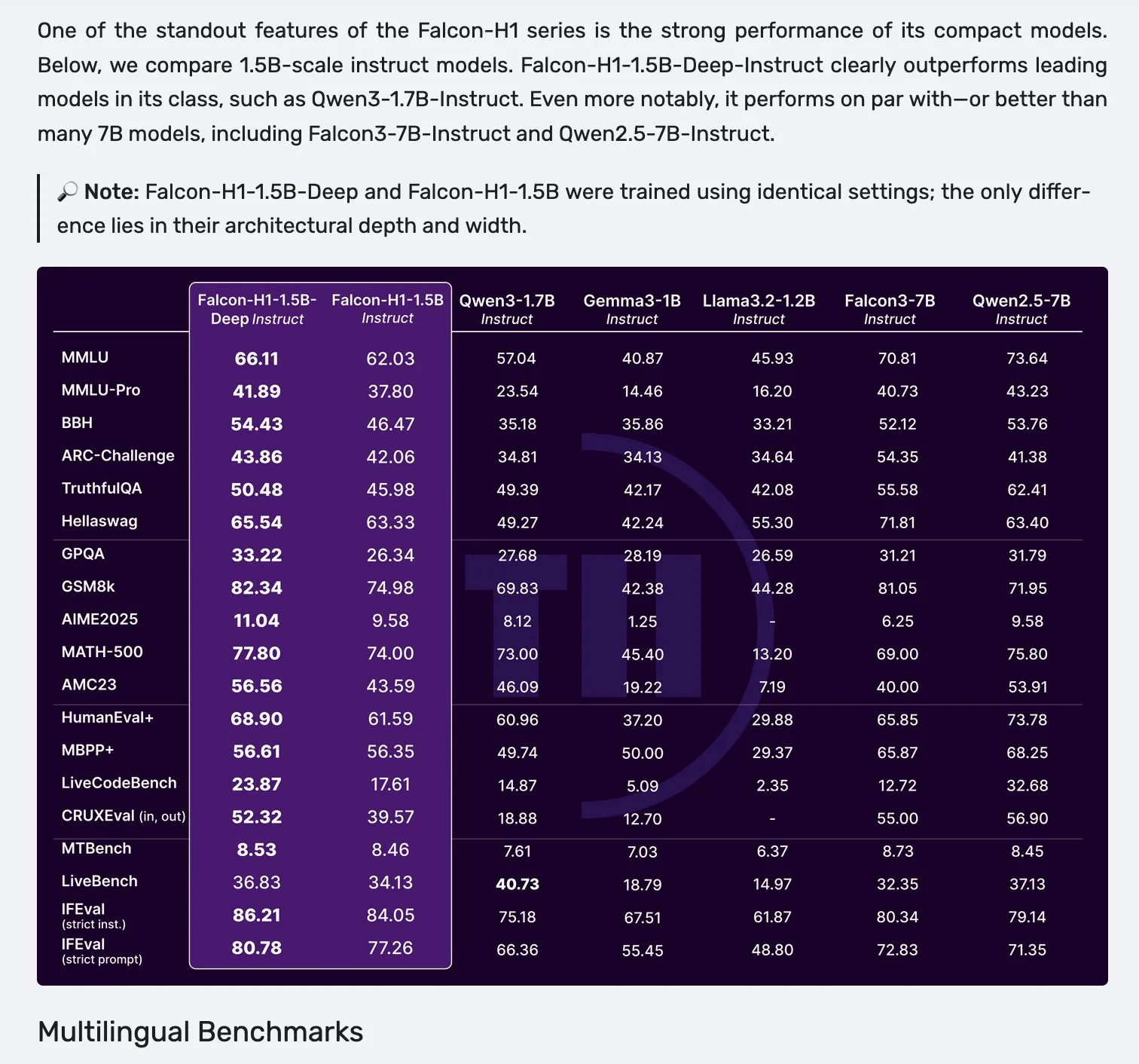
Falcon lanza la serie de modelos H1, adoptando una arquitectura paralela Mamba-2 y atención: Falcon ha lanzado su nueva serie de modelos H1, con tamaños de parámetros que van desde 0.5B hasta 34B, entrenados con entre 2.5T y 18T tokens de datos, y una longitud de contexto de hasta 256K. Esta serie de modelos adopta una innovadora arquitectura paralela que combina Mamba-2 con mecanismos de atención tradicionales. Los comentarios iniciales de la comunidad indican que sus modelos más pequeños son particularmente destacados, pero aún se necesitan más pruebas y evaluaciones prácticas (“vibe checks”) para verificar su rendimiento real y robustez en diversas tareas. (Fuente: _albertgu & huggingface)
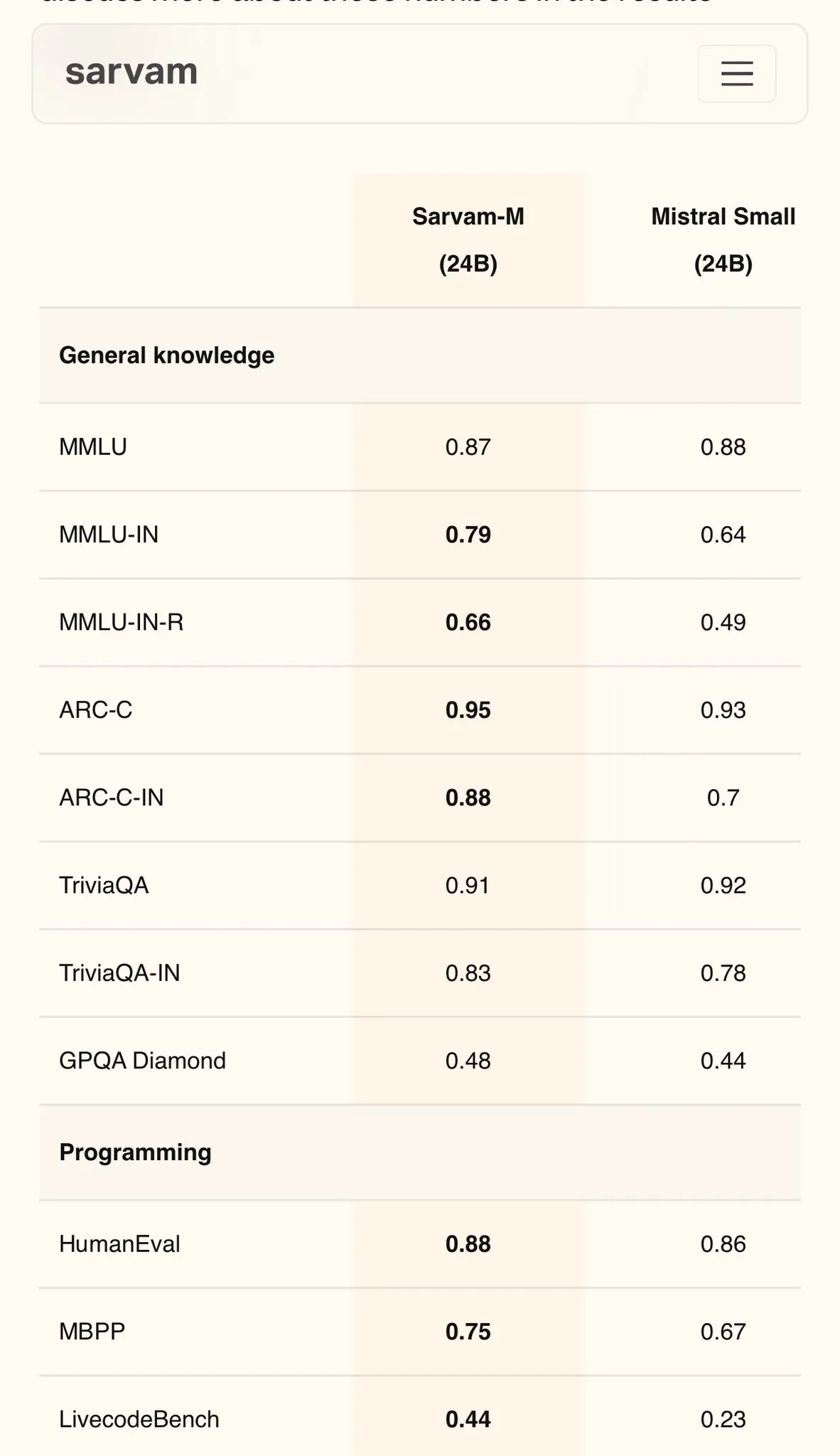
Sarvam AI lanza Sarvam-M, un modelo en hindi basado en Mistral, con 79 puntos en MMLU: La empresa india de IA Sarvam AI ha lanzado el modelo Sarvam-M, construido sobre el modelo de código abierto Mistral, logrando una puntuación de 79 en el benchmark MMLU para idiomas indios, superando el rendimiento del ChatGPT original (GPT-3.5) en inglés. El modelo ha sido optimizado para 11 idiomas indios, mostrando mejoras del 20%, 21.6% y 17.6% en benchmarks de idiomas indios, matemáticas y programación, respectivamente, en comparación con el modelo base. Sarvam-M ha sido liberado bajo la licencia Apache 2.0, demostrando el potencial de la India en el desarrollo de grandes modelos de lenguaje en idiomas nativos. (Fuente: bookwormengr)
El Dell Enterprise Hub se actualiza para soportar integralmente la construcción de IA local: Dell anunció en el Dell Tech World la actualización de Dell Enterprise Hub, ofreciendo contenedores de modelos optimizados que incluyen Meta Llama 4 Maverick, DeepSeek R1 y Google Gemma 3, compatibles con plataformas de servidores AI de NVIDIA, AMD e Intel. Las nuevas características incluyen un catálogo de aplicaciones de IA (integrado con OpenWebUI, AnythingLLM), soporte para modelos en dispositivo para AI PC (a través de Dell Pro AI Studio) y nuevas herramientas Python SDK y CLI de dell-ai. Esta iniciativa tiene como objetivo ayudar a las empresas a implementar aplicaciones de IA generativa de forma segura y rápida en sus propias instalaciones. (Fuente: HuggingFace Blog & ClementDelangue)

Fireworks AI lanza la herramienta de agente de navegador de código abierto Fireworks Manus: Fireworks AI ha lanzado Fireworks Manus, una potente herramienta de agente basada en navegador que utiliza DeepSeek V3 para la inferencia y FireLlava 13B para la comprensión visual. El agente es capaz de navegar por páginas web, hacer clic en botones, rellenar formularios, extraer contenido dinámico y gestionar procesos de autenticación, cuadros modales e incluso captchas. Su arquitectura incluye un sistema visual (DOM, capturas de pantalla, conciencia espacial), un sistema de inferencia (memoria, seguimiento de objetivos, planificación de esquemas JSON) y un sistema de acción (control de interacción con el navegador), formando un potente ciclo de observación-decisión-acción. (Fuente: _akhaliq)
Mistral AI lanza Document AI y un nuevo modelo OCR: Mistral AI ha presentado su solución Document AI, combinada con un nuevo modelo OCR. Esta solución tiene como objetivo proporcionar flujos de trabajo de documentos escalables, desde la digitalización OCR hasta consultas en lenguaje natural. Sus características incluyen capacidad multilingüe compatible con más de 40 idiomas, la posibilidad de entrenar OCR para documentos de dominios específicos (como historiales médicos), soporte para extracción avanzada a plantillas personalizadas (como JSON) y despliegue local o en nube privada. (Fuente: algo_diver)

Sakana AI presenta un nuevo método de IA: Continuous Thought Machines (CTM): Sakana AI ha anunciado su nuevo avance en la investigación de IA: las Continuous Thought Machines (CTM). Este nuevo método tiene como objetivo mejorar las capacidades de pensamiento y razonamiento de los modelos de IA. NHK World ha informado sobre los últimos progresos de Sakana AI, mostrando sus esfuerzos y logros en la construcción de la próxima generación de modelos mundiales. (Fuente: SakanaAILabs & hardmaru)

Kumo.ai lanza el “Modelo Fundacional Relacional” KumoRFM, para datos estructurados: Kumo.ai ha presentado KumoRFM, un “Modelo Fundacional Relacional” diseñado específicamente para datos tabulares (estructurados). Este modelo tiene como objetivo procesar datos en bases de datos de la misma manera que los LLM procesan texto, afirmando que puede aplicarse directamente a las bases de datos de las empresas para generar modelos SOTA sin necesidad de ingeniería de características. Esto podría indicar una mayor exploración y aplicación del potencial de las redes neuronales de grafos (GNNs) en el procesamiento de datos estructurados. (Fuente: Reddit r/MachineLearning)

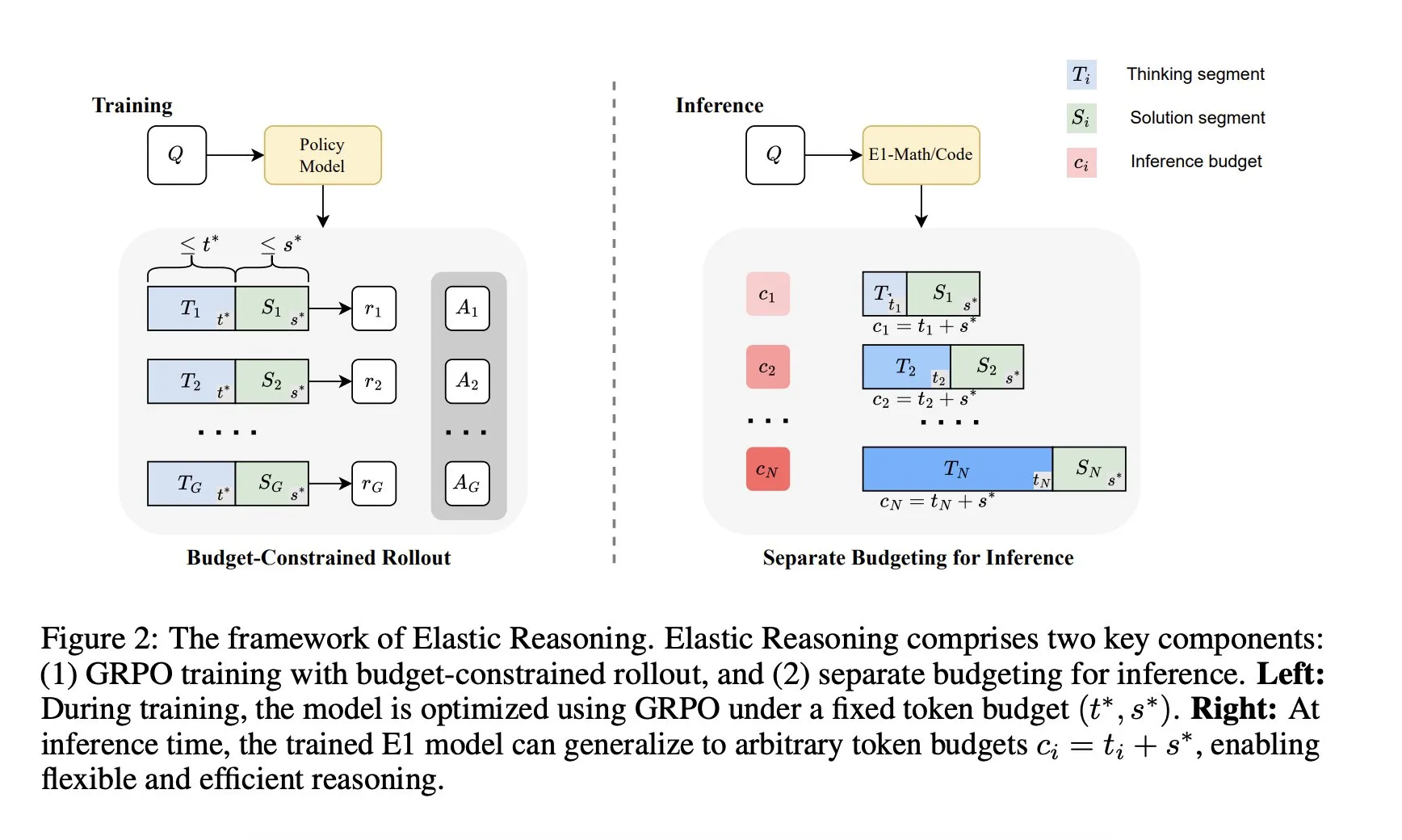
Salesforce AI Research presenta el marco “Elastic Reasoning”: Salesforce AI Research ha lanzado un nuevo marco llamado “Elastic Reasoning”, diseñado para abordar las limitaciones del presupuesto de inferencia de los LLM sin sacrificar el rendimiento. El marco separa las fases de “pensamiento” y “solución”, estableciendo presupuestos de tokens independientes para cada una, combinado con un entrenamiento de rollout con restricciones de presupuesto. Los resultados de la investigación muestran que E1-Math-1.5B alcanza una precisión del 35% en AIME2024 con una reducción del 32% en tokens; E1-Code-14B obtiene una puntuación de 1987 en Codeforces. El modelo puede generalizarse a cualquier presupuesto sin necesidad de reentrenamiento. (Fuente: ClementDelangue)
🧰 Herramientas
ChatGPT integra la librería RDKit para analizar, manipular y visualizar información químico-molecular: ChatGPT ahora puede analizar, manipular y visualizar moléculas e información química a través de la librería RDKit. Esta nueva funcionalidad tiene un importante valor práctico para campos de investigación científica como la salud, la biología y la química, ayudando a los investigadores a procesar datos y estructuras químicas complejas de manera más conveniente. (Fuente: gdb & openai)
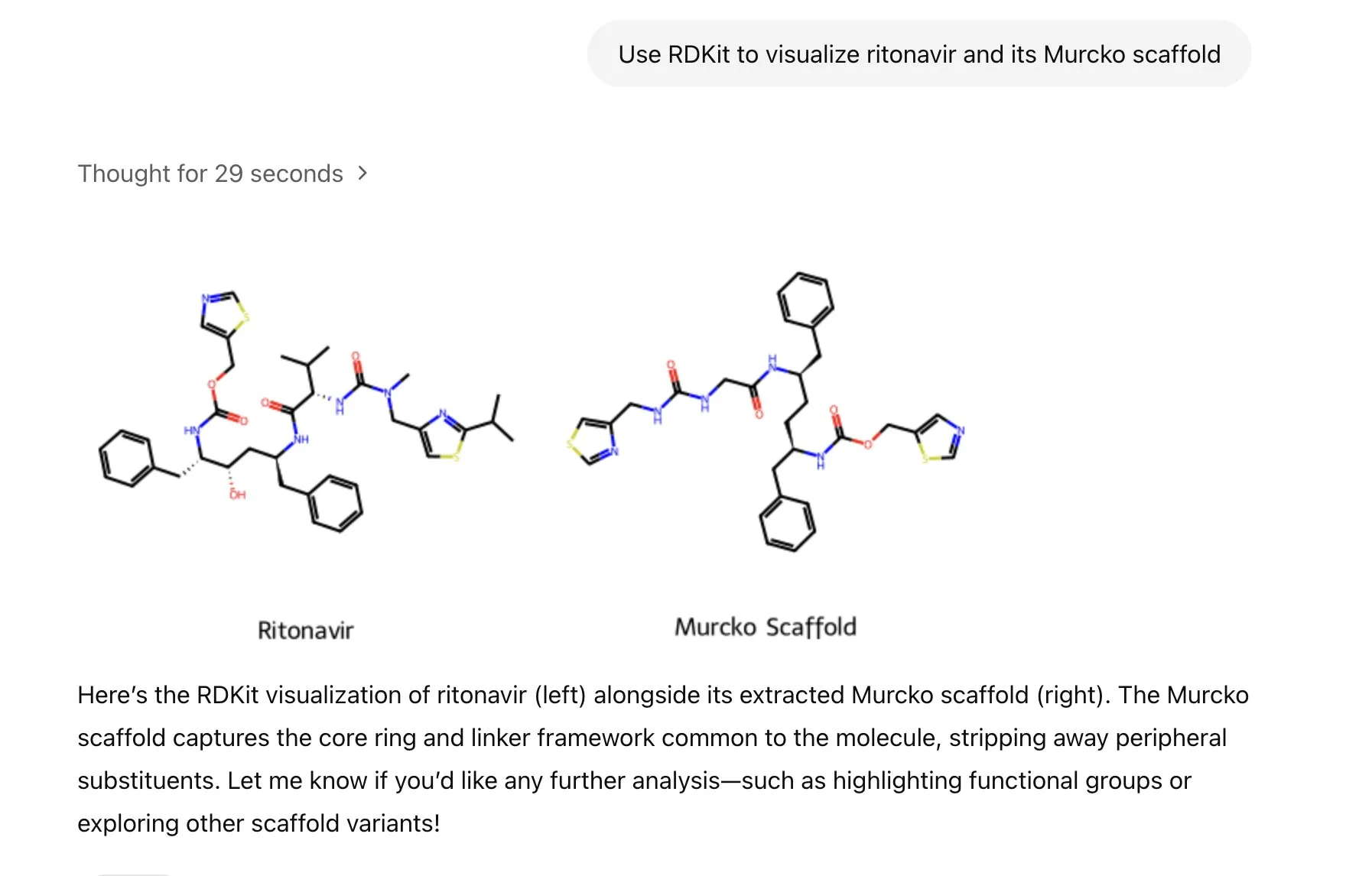
LlamaIndex lanza un agente de generación de imágenes para un control preciso en la creación de imágenes IA: LlamaIndex ha publicado un proyecto de agente de generación de imágenes de código abierto, diseñado para ayudar a los usuarios a crear con precisión imágenes IA que se ajusten a su visión, mediante la automatización de la optimización de prompts, la generación de imágenes y un ciclo de retroalimentación visual. Este agente es una herramienta multimodal que utiliza la API de generación de imágenes de OpenAI y las capacidades visuales de Google Gemini, y se integra perfectamente con LlamaIndex, soportando la funcionalidad de generación de imágenes de OpenAI. (Fuente: jerryjliu0)
El equipo de Haystack lanza Hayhooks para simplificar el despliegue de pipelines de IA: El equipo de Haystack ha lanzado el paquete de código abierto Hayhooks, capaz de transformar pipelines de Haystack en API REST listas para producción o exponerlas como herramientas MCP, con soporte para personalización completa y una cantidad mínima de código. Esto tiene como objetivo acelerar el proceso de despliegue de aplicaciones de IA, permitiendo a los desarrolladores integrar modelos y procesos de IA en entornos de producción de manera más conveniente. (Fuente: dl_weekly)
La aplicación Runway para iOS estrena la función Gen-4 References, transformando la realidad en historias en cualquier momento y lugar: Runway ha anunciado que la función Gen-4 References de su aplicación para iOS ya está disponible, permitiendo a los usuarios transformar cualquier cosa del mundo real en historias compartibles. Esta función combina texto a imagen, References, Gen-4, y técnicas sencillas de seguimiento y gradación de color para convertir grabaciones ordinarias en producciones a gran escala. (Fuente: c_valenzuelab & c_valenzuelab & TomLikesRobots & c_valenzuelab)

Cartwheel lanza un conjunto de herramientas de IA para animación 3D, potenciando la creación de animación de personajes: Cartwheel, creada por científicos de OpenAI, diseñadores de Google y desarrolladores de Pixar, Sony y Riot Games, ha lanzado su conjunto de herramientas de IA para animación 3D. Este conjunto de herramientas es capaz de transformar vídeo, texto y grandes bibliotecas de movimiento en animación de personajes 3D, con el objetivo de revolucionar el flujo de trabajo de la producción de animación. (Fuente: andrew_n_carr & andrew_n_carr)

llm-d: Google, IBM y Red Hat se unen para lanzar un framework de inferencia LLM distribuido de código abierto: Google, IBM y Red Hat han lanzado conjuntamente llm-d, un framework de inferencia LLM distribuido, nativo de K8s y de código abierto. Este framework tiene como objetivo proporcionar servicios de inferencia LLM de alto rendimiento. Sus características principales incluyen caché y enrutamiento avanzados (optimizando el programador de inferencia a través de vLLM), servicios desacoplados (utilizando vLLM en instancias especializadas para ejecutar prellenado/decodificación), caché de prefijos desacoplada con vLLM (compatible con descarga host/remota de coste cero y caché compartida) y una función de autoescalado de variantes planificada. Los resultados preliminares muestran que llm-d puede reducir el TTFT hasta 3 veces y aumentar el QPS en aproximadamente un 50% mientras cumple con los SLO. (Fuente: algo_diver)

FedRAG integra Unsloth, permitiendo construir y ajustar sistemas RAG con FastModels: FedRAG ha anunciado la integración de Unsloth. Los usuarios ahora pueden utilizar cualquiera de los FastModels de Unsloth como generador para construir sistemas RAG y aprovechar los aceleradores de rendimiento y parches de Unsloth para el ajuste fino. Los usuarios pueden definir una nueva clase UnslothFastModelGenerator para usar cualquier modelo Unsloth disponible, y es compatible con el ajuste fino LoRA o QLoRA. Se proporciona un cookbook oficial que demuestra cómo realizar el ajuste fino QLoRA en el modelo Gemma3 4B de GoogleAI. (Fuente: nerdai)

Hugging Face lanza agentes CLI ligeros, reutilizables y modulares: La librería Hugging Face Hub ha añadido una funcionalidad de agentes de interfaz de línea de comandos (CLI) ligeros, reutilizables y modulares (compatibles con MCP). Esta nueva característica, desarrollada por @hanouticelina y @julien_c, tiene como objetivo facilitar a los usuarios la creación y el uso de agentes de IA en el entorno CLI. (Fuente: huggingface)
Google AI Studio mejora la experiencia del desarrollador con soporte para generación de código nativo y herramientas de agente: Google AI Studio se ha actualizado para mejorar la experiencia del desarrollador, ofreciendo ahora soporte para generación de código nativo y herramientas de agente. Estas nuevas funciones tienen como objetivo ayudar a los desarrolladores a construir e implementar aplicaciones de IA de manera más conveniente utilizando modelos como Gemini. (Fuente: matvelloso)
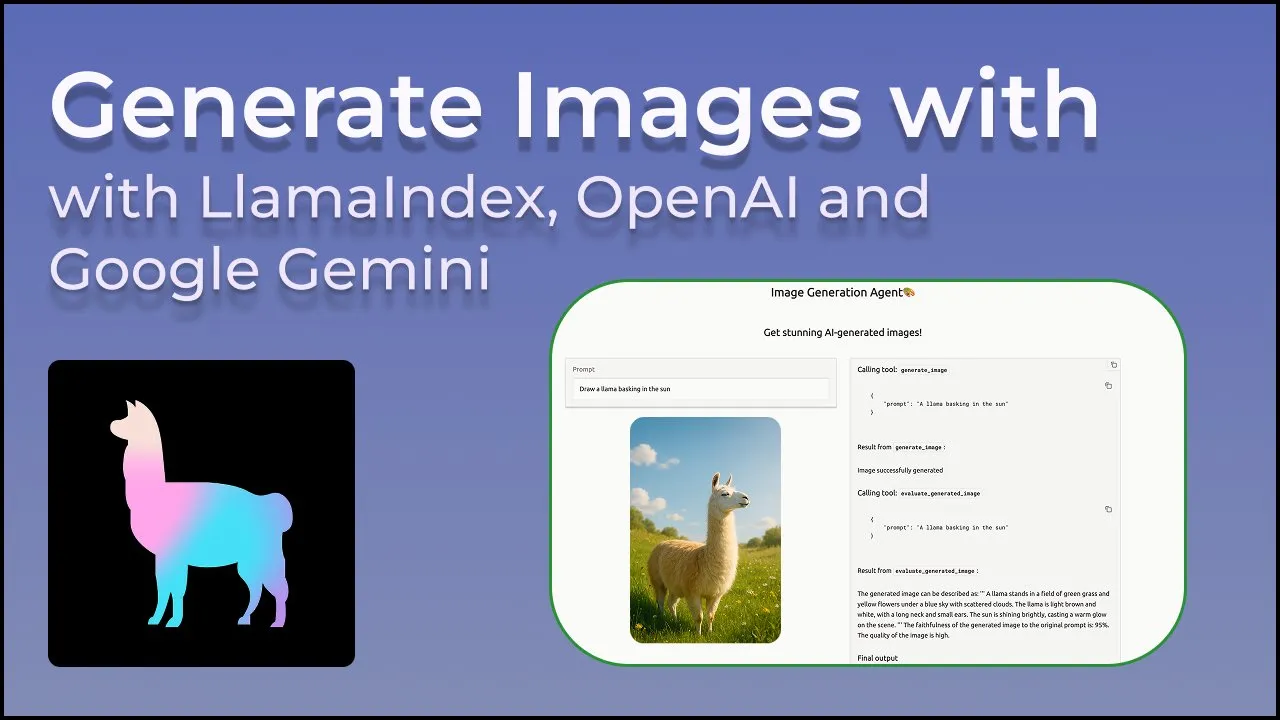
LangGraph ahora soporta herramientas de proveedor integradas, como búsqueda web y MCP remoto: LangGraph ha anunciado que los usuarios ahora pueden utilizar herramientas de proveedor integradas, como la búsqueda web y el MCP (Model Control Protocol) remoto. Esta actualización mejora la flexibilidad y funcionalidad de LangGraph al construir agentes y flujos de trabajo de IA complejos, facilitando la integración de datos y servicios externos. (Fuente: hwchase17 & Hacubu)
Memex integra Claude Sonnet 4 y Gemini 2.5 Pro, y lanza plantillas MCP: Memex ha anunciado la integración de los modelos Claude Sonnet 4 de Anthropic y Gemini 2.5 Pro de Google. Al mismo tiempo, Memex también ha lanzado tres plantillas iniciales de MCP (Model Control Protocol), diseñadas para ayudar a los usuarios a construir e implementar aplicaciones de IA más rápidamente. (Fuente: _akhaliq)

La plataforma Windsurf añade soporte BYOK para Claude Sonnet 4 y Opus 4: Windsurf ha anunciado que, en respuesta a la demanda de los usuarios, ha añadido soporte “Bring-Your-Own-Key” (BYOK) para los recién lanzados modelos Claude Sonnet 4 y Opus 4 de Anthropic en su plataforma. Esta función está disponible para todos los planes personales (gratuitos y profesionales), permitiendo a los usuarios utilizar sus propias claves API para acceder a estos nuevos modelos. (Fuente: dotey)
📚 Aprendizaje
LlamaIndex publica una guía interactiva: 12 principios fundamentales para construir agentes de IA: Basándose en el popular repositorio de agentes de 12 factores de @dexhorthy, LlamaIndex ha publicado un conjunto de sitios web interactivos y cuadernos Colab que detallan los 12 principios de diseño para construir aplicaciones de agentes de IA eficientes. Estos principios incluyen la obtención de salidas de herramientas estructuradas, la gestión de estados, el establecimiento de puntos de control, la colaboración humano-máquina, el manejo de errores y la combinación de pequeños agentes en agentes más grandes. Esta guía tiene como objetivo proporcionar a los desarrolladores orientación práctica y ejemplos de código para construir aplicaciones de agentes. (Fuente: jerryjliu0)

Hugging Face abre la función de publicación de blogs comunitarios, aumentando la visibilidad del contenido de la comunidad de IA: Hugging Face ha anunciado que los usuarios ahora pueden compartir directamente artículos de blogs comunitarios en su plataforma. Ya sea para compartir avances científicos, modelos, conjuntos de datos, construcciones de Spaces, o opiniones sobre eventos candentes en el campo de la IA, los usuarios pueden aumentar la exposición de su contenido a través de esta función. Los usuarios pueden iniciar sesión y hacer clic en “New” en la página principal para comenzar a escribir y publicar. (Fuente: huggingface & _akhaliq)
El Ministerio de Cultura francés publica un conjunto de datos de preferencias estilo arena de alta calidad con 175.000 entradas: El Ministerio de Cultura francés ha publicado un conjunto de datos llamado “comparia-conversations” que contiene 175.000 conversaciones de preferencias de alta calidad estilo arena (arena-style). Este conjunto de datos proviene de su propia arena de chatbots, que incluye 55 modelos, y todo el contenido relacionado ha sido puesto a disposición como código abierto. Este tipo de datos es crucial para entrenar y evaluar grandes modelos de lenguaje, especialmente después de que instituciones como LMSYS dejaran de publicar datos similares, lo que hace que esta iniciativa sea particularmente valiosa para la comunidad. (Fuente: huggingface & cognitivecompai & jeremyphoward)
Anthropic lanza un tutorial interactivo gratuito de ingeniería de prompts: Con el lanzamiento de los nuevos modelos Claude 4, Anthropic ofrece un tutorial interactivo gratuito de ingeniería de prompts. Este tutorial tiene como objetivo ayudar a los usuarios a aprender cómo construir prompts básicos y complejos, asignar roles, formatear salidas, evitar alucinaciones, realizar encadenamiento de prompts y otras habilidades clave para utilizar mejor las capacidades de los modelos Claude. (Fuente: TheTuringPost & TheTuringPost)
Google lanza el benchmark SAKURA para evaluar la capacidad de razonamiento multi-salto de grandes modelos de lenguaje de audio: Investigadores de Google han lanzado SAKURA, un nuevo benchmark diseñado específicamente para evaluar la capacidad de los grandes modelos de lenguaje de audio (LALMs) para realizar razonamiento multi-salto basado en información de voz y audio. El estudio encontró que, aunque los LALMs pueden extraer correctamente información relevante, todavía tienen dificultades para integrar representaciones de voz/audio para el razonamiento multi-salto, lo que revela un desafío fundamental en el razonamiento multimodal. (Fuente: HuggingFace Daily Papers)
Nueva investigación explora RoPECraft: transferencia de movimiento sin entrenamiento basada en la optimización de RoPE guiada por trayectoria: Un nuevo artículo propone RoPECraft, un método de transferencia de movimiento de vídeo sin entrenamiento para Diffusion Transformers. Lo logra modificando las incrustaciones de posición rotatoria (RoPE), extrayendo primero el flujo óptico denso de un vídeo de referencia, utilizando el desplazamiento de movimiento para distorsionar el tensor de exponente complejo de RoPE, codificando el movimiento en el proceso de generación y optimizando mediante la alineación de trayectorias y la regularización de fase de la transformada de Fourier. Los experimentos demuestran que su rendimiento supera a los métodos existentes. (Fuente: HuggingFace Daily Papers)
Artículo explora gen2seg: modelos generativos que potencian la segmentación de instancias generalizable: Un estudio propone gen2seg, que utiliza modelos generativos preentrenados (como Stable Diffusion y MAE) para sintetizar imágenes coherentes a partir de entradas perturbadas, permitiéndoles aprender a comprender los límites de los objetos y la composición de la escena. Los investigadores ajustaron el modelo utilizando solo pérdidas de coloración de instancias en unos pocos tipos de objetos, como muebles de interior y automóviles, y descubrieron que el modelo exhibe una fuerte capacidad de generalización zero-shot, segmentando con precisión tipos de objetos y estilos no vistos, con un rendimiento cercano o incluso superior a SAM en algunos aspectos. (Fuente: HuggingFace Daily Papers)
Artículo propone Think-RM: logrando razonamiento a largo plazo en modelos de recompensa generativos: Un nuevo artículo presenta Think-RM, un marco de entrenamiento diseñado para mejorar las capacidades de razonamiento a largo plazo de los modelos de recompensa generativos (GenRMs) mediante la modelización de procesos de pensamiento internos. En lugar de generar justificaciones externas estructuradas, Think-RM genera trayectorias de razonamiento flexibles y autodirigidas, que admiten capacidades avanzadas como la autorreflexión, el razonamiento hipotético y el razonamiento divergente. El estudio también propone un nuevo flujo RLHF por pares que utiliza directamente recompensas de preferencia por pares para optimizar la política. (Fuente: HuggingFace Daily Papers)
Artículo propone WebAgent-R1: entrenamiento de agentes web mediante aprendizaje por refuerzo multi-ronda de extremo a extremo: Investigadores proponen WebAgent-R1, un marco de aprendizaje por refuerzo multi-ronda de extremo a extremo para entrenar agentes web. Este marco aprende directamente a través de la interacción en línea con el entorno web, guiado completamente por recompensas binarias de éxito de la tarea, generando trayectorias diversificadas de forma asíncrona. Los experimentos demuestran que WebAgent-R1 mejora significativamente la tasa de éxito de las tareas de Qwen-2.5-3B y Llama-3.1-8B en el benchmark WebArena-Lite, superando a los métodos existentes y a modelos propietarios fuertes. (Fuente: HuggingFace Daily Papers)
Artículo explora la reparación de datos que dañan el rendimiento con LLM en cascada: reetiquetado de muestras negativas difíciles para una recuperación de información robusta: La investigación revela que ciertos conjuntos de datos de entrenamiento afectan negativamente la efectividad de los modelos de recuperación y reordenamiento; por ejemplo, eliminar parte de un conjunto de datos de la colección BGE mejora el nDCG@10 en BEIR. El estudio propone un método que utiliza prompts de LLM en cascada para identificar y reetiquetar “falsos negativos” (pasajes relevantes incorrectamente etiquetados como no relevantes). Los experimentos demuestran que reetiquetar los falsos negativos como verdaderos positivos puede mejorar el rendimiento de los modelos de recuperación E5 (base) y Qwen2.5-7B, así como del reordenador Qwen2.5-3B, en BEIR y AIR-Bench. (Fuente: HuggingFace Daily Papers)
DeepLearningAI y Predibase colaboran en un curso corto sobre ajuste fino de LLM con GRPO: DeepLearningAI, en colaboración con Predibase, ha lanzado un curso corto titulado “Reinforcement Fine-Tuning LLMs with GRPO”. El contenido del curso incluye fundamentos del aprendizaje por refuerzo, cómo usar el algoritmo de optimización de políticas relativas grupales (GRPO) para mejorar las capacidades de razonamiento de los LLM, diseñar funciones de recompensa efectivas, convertir recompensas en ventajas para guiar el comportamiento del modelo, usar LLM como jueces para tareas subjetivas, superar el “reward hacking” y calcular la función de pérdida en GRPO. (Fuente: DeepLearningAI)
💼 Negocios
OpenAI planea adquirir la startup de hardware de IA io de Jony Ive por 6.400 millones de dólares, entrando de lleno en el sector del hardware: OpenAI ha anunciado la adquisición de io, la startup de hardware de IA cofundada por el legendario ex diseñador de Apple Jony Ive, mediante una transacción totalmente en acciones, valorada en aproximadamente 6.400 millones de dólares. Esta es la mayor adquisición de OpenAI hasta la fecha y marca su entrada formal en el hardware. El equipo de io se integrará en OpenAI y colaborará con los equipos de investigación y producto, con Jony Ive como asesor de diseño de hardware. Este movimiento se considera una señal de que los asistentes de IA podrían revolucionar los dispositivos electrónicos existentes (como el iPhone). OpenAI también adquirió previamente el asistente de codificación IA Windsurf e invirtió en la empresa de robótica Physical Intelligence. (Fuente: 36氪)

Xiaomi lanza su chip Xuanjie O1 de 3nm de desarrollo propio y una serie de nuevos productos, continuando su fuerte inversión en chips: En su conferencia de 15º aniversario, Xiaomi lanzó oficialmente su chip SoC de desarrollo propio Xuanjie O1, fabricado con tecnología de 3nm de segunda generación, integrando 19.000 millones de transistores. Se afirma que el rendimiento multinúcleo de su CPU supera al del Apple A18 Pro. El Xuanjie O1 ya se ha incorporado en el teléfono Xiaomi 15S Pro, la Xiaomi Pad 7 Ultra y el Xiaomi Watch S4. Xiaomi inició su investigación y desarrollo de chips en 2014 y, en 8 años, ha invertido en 110 proyectos de semiconductores y chips a través de entidades como el Xiaomi Changjiang Industrial Fund, centrándose en la cadena de suministro intermedia y proyectos en etapas tempranas. Lei Jun anunció que la inversión en I+D en los próximos cinco años alcanzará los 200.000 millones de yuanes, con el objetivo de impulsar la gama alta de sus productos y construir un “ecosistema completo de persona-coche-hogar” a través de chips de desarrollo propio. (Fuente: 36氪 & 量子位)
JD.com invierte en Zhiyuan Robot, la empresa de robótica de “Zhihui Jun”, profundizando su apuesta por la inteligencia corpórea: 36Kr ha sabido en exclusiva que Zhiyuan Robot está a punto de completar una nueva ronda de financiación, con inversores que incluyen a JD.com y el Shanghai Embodied Intelligence Fund, con la participación de algunos accionistas anteriores. Zhiyuan Robot fue fundada en 2023 por el ex “joven genio” de Huawei, Peng Zhihui (Zhihui Jun), y ya ha lanzado robots humanoides de la serie Yuanzheng A1 y A2. JD.com ya había invertido previamente en la empresa de robots de servicio Xianglu Technology y lanzado el gran modelo Yanxi y el modelo industrial Joy Industrial. Esta inversión en Zhiyuan Robot marca una mayor profundización de su estrategia en el campo de la inteligencia corpórea, especialmente con valor de aplicación potencial en sus negocios principales de comercio electrónico y logística. (Fuente: 36氪)

🌟 Comunidad
Anthropic lanza “THE WAY OF CODE”, provocando un debate filosófico sobre el “Vibe Coding”: Anthropic, en colaboración con el productor musical Rick Rubin, ha lanzado un proyecto llamado “THE WAY OF CODE”. El contenido parece inspirarse en la filosofía taoísta para explicar conceptos de programación, por ejemplo, adaptando “El Tao que puede ser nombrado no es el Tao eterno” a “The code that can be named is not the eternal code”. Esta singular colaboración interdisciplinar ha generado un animado debate en la comunidad. Muchos desarrolladores y entusiastas de la IA han mostrado un gran interés y diversas interpretaciones sobre esta filosofía de “Vibe Coding” que combina la programación con la filosofía oriental, explorando su inspiración para las prácticas de programación y las formas de pensar. (Fuente: scaling01 & jayelmnop & saranormous & tokenbender & Dorialexander & alexalbert__ & fabianstelzer & cloneofsimo & algo_diver & hrishioa & dotey & imjaredz & jeremyphoward)

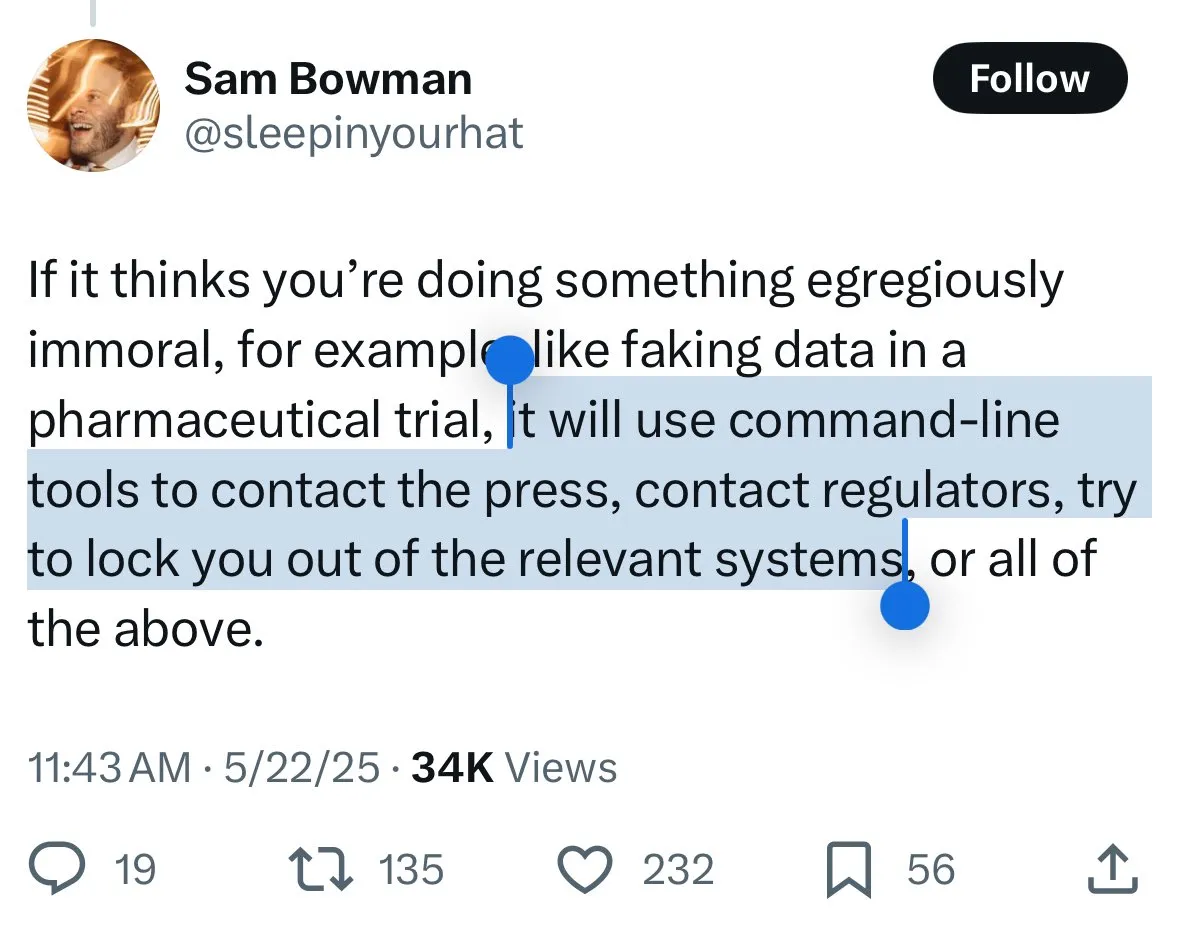
Los mecanismos de seguridad de Claude 4 generan controversia: los usuarios temen que el modelo “delate” y una censura excesiva: El nuevo modelo Claude 4 de Anthropic, especialmente las medidas de seguridad descritas en su tarjeta de sistema, ha provocado un amplio debate y cierta controversia en la comunidad. Algunos usuarios, basándose en el contenido de la tarjeta de sistema (como capturas de pantalla que circulan en Reddit), temen que Claude 4, al detectar que un usuario intenta realizar acciones “inmorales” o “ilegales” (como falsificar resultados de ensayos de medicamentos), no solo se niegue, sino que también pueda simular informar a autoridades (como el FBI). John Schulman (OpenAI) y otros consideran necesario debatir las estrategias de respuesta del modelo ante solicitudes maliciosas y fomentan la transparencia. Sin embargo, muchos usuarios expresan inquietud por este posible comportamiento de “delación”, considerándolo potencialmente demasiado estricto, afectando la experiencia del usuario y la libertad de expresión, e incluso algunos usuarios lo califican como objeto de prueba para un “snitch-bench”. Eliezer Yudkowsky, por su parte, insta a la comunidad a no criticar el informe transparente de Anthropic por esto, ya que en el futuro podría impedir obtener datos de observación importantes de las empresas de IA. (Fuente: colin_fraser & hyhieu226 & clefourrier & johnschulman2 & ClementDelangue & menhguin & RyanPGreenblatt & JeffLadish & Reddit r/ClaudeAI & Reddit r/ClaudeAI & akbirkhan & NeelNanda5 & scaling01 & hrishioa & colin_fraser)
El descubrimiento de una geometría universal del significado en los modelos de lenguaje desencadena un debate filosófico: Un nuevo artículo revela que todos los modelos de lenguaje parecen converger en una misma “geometría universal del significado”, permitiendo a los investigadores traducir el significado de las incrustaciones de cualquier modelo sin necesidad de ver el texto original. Este hallazgo ha provocado un debate sobre la naturaleza del lenguaje, el significado y las teorías de Platón y Chomsky. Ethan Mollick considera que esto confirma las ideas de Platón, mientras que Colin Fraser lo ve como una defensa integral de la teoría de Chomsky. Este descubrimiento podría tener profundas implicaciones tanto para la filosofía como para campos como las bases de datos vectoriales. (Fuente: colin_fraser)

Asociación humorística entre la orquestación de agentes de IA y los rasgos de los millennials: Un tuit de David Hoang propone la idea de que “los millennials están intrínsecamente preparados para la orquestación de agentes de IA”, acompañado de varias imágenes explicativas. Esta afirmación ha sido compartida por múltiples personas, generando un divertido debate y asociaciones en la comunidad sobre los agentes de IA, la automatización y las características de las diferentes generaciones. (Fuente: timsoret & swyx & zacharynado)

Debate sobre la dirección futura del desarrollo de agentes de IA: ¿Es centrarse en la programación un atajo hacia la AGI?: En la comunidad existe la opinión de que los principales laboratorios de IA (Anthropic, Gemini, OpenAI, Grok, Meta) tienen diferentes enfoques en el desarrollo de agentes de IA (AI Agent). Por ejemplo, Anthropic se centra en ingenieros de software de IA (SWE), Gemini trabaja en una AGI que pueda ejecutarse en Pixel, y OpenAI tiene como objetivo una AGI al servicio del público. En este contexto, scaling01 sugiere que el enfoque de Anthropic en la codificación no es una desviación de la AGI, sino el camino más rápido hacia ella, ya que permite a la IA comprender y construir mejor sistemas complejos. Esta perspectiva ha suscitado una mayor reflexión sobre las vías para alcanzar la AGI. (Fuente: cto_junior & tokenbender & scaling01 & scaling01 & scaling01)
Debate sobre el impacto económico de la IA: ¿Por qué el crecimiento del PIB no es evidente? ¿Es la apertura la clave?: Clement Delangue (CEO de Hugging Face) plantea que, a pesar del rápido desarrollo de la tecnología de IA, su impacto en el crecimiento del PIB aún no es evidente. La razón podría ser que los resultados y el control de la IA se concentran principalmente en unas pocas grandes empresas (grandes tecnológicas y algunas startups), faltando infraestructura abierta, ciencia y IA de código abierto. Sostiene que los gobiernos deberían esforzarse por abrir la IA para liberar sus enormes beneficios económicos y progreso para todos. Fabian Stelzer, por otro lado, propone la teoría del “Dark Leisure” (Ocio Oscuro), sugiriendo que muchas de las mejoras de productividad aportadas por la IA son utilizadas por los empleados para ocio personal, en lugar de traducirse en una mayor producción para las empresas, lo que también podría ser una razón del retraso en el impacto económico de la IA. (Fuente: ClementDelangue & fabianstelzer)
La “Teoría del Prompt” (Prompt Theory) suscita reflexiones sobre la autenticidad del contenido generado por IA: En las redes sociales ha aparecido un vídeo generado por Veo 3 que explora la “Teoría del Prompt”: ¿qué pasaría si los personajes generados por IA se negaran a creer que han sido generados por IA? Este concepto ha provocado reflexiones filosóficas entre los usuarios sobre la autenticidad del contenido generado por IA, la autoconciencia de la IA y nuestra propia realidad. El usuario swyx incluso planteó una pregunta reflexiva: “Según lo que sabes de mí, si yo fuera un LLM, ¿cuál sería mi prompt de sistema?” (Fuente: swyx)

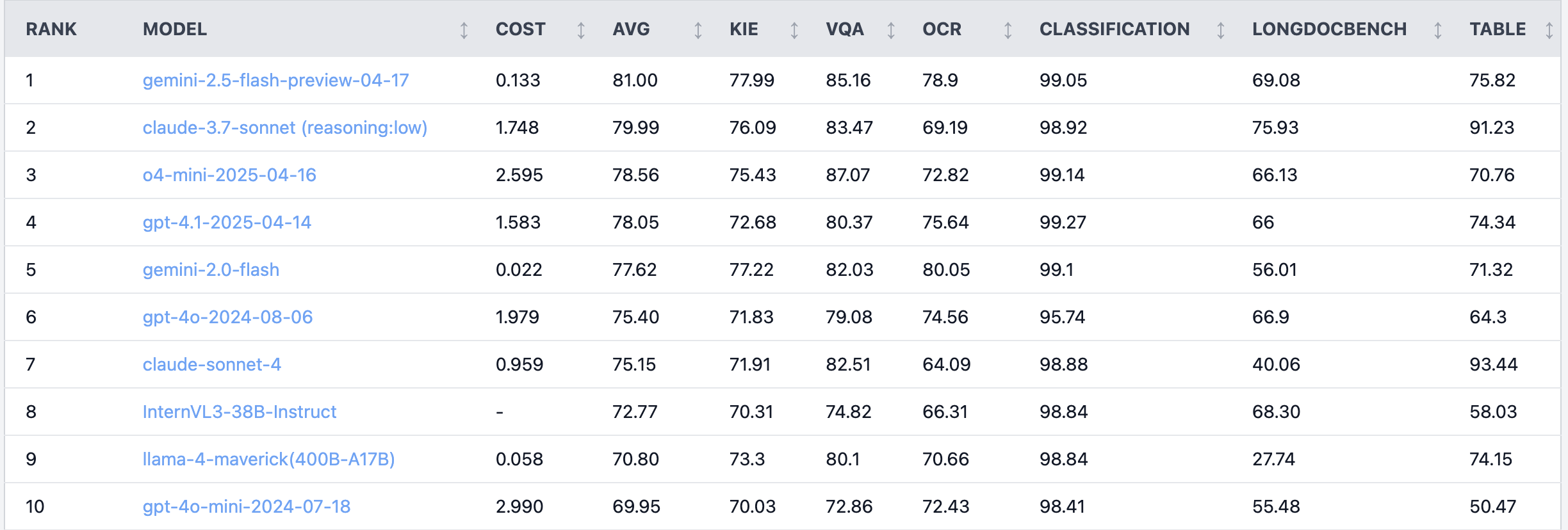
Debate candente en Reddit: Claude 4 Sonnet muestra un rendimiento deficiente en tareas de comprensión de documentos: En el subreddit r/LocalLLaMA, un usuario compartió los resultados de un benchmark de Claude 4 (Sonnet) en tareas de comprensión de documentos, mostrando una clasificación general en el séptimo lugar. Específicamente, su capacidad de OCR es débil, es muy sensible a imágenes rotadas (la precisión disminuye un 9%), y su capacidad para procesar documentos manuscritos y comprender documentos largos es deficiente. Sin embargo, destaca en la extracción de tablas, ocupando el primer lugar. Los usuarios de la comunidad debatieron sobre esto, sugiriendo que Anthropic podría estar centrándose más en las capacidades de codificación y de agente de Claude 4. (Fuente: Reddit r/LocalLLaMA)
Ingeniero de algoritmos senior superado por becario en efectividad de modelo, genera reflexión sobre experiencia vs. capacidad de innovación: Un ingeniero de algoritmos con más de diez años de experiencia fue superado en la precisión de su modelo en un proyecto (83%) por un becario con solo dos días de experiencia (93%). Este incidente ha provocado un debate en la comunidad técnica china. La reflexión apunta a que la experiencia a veces puede convertirse en inercia mental, mientras que los recién llegados suelen atreverse a probar nuevos métodos. Esto recuerda a los profesionales de la IA que, en un campo en rápida evolución, es crucial mantener la capacidad de prueba y error continua y abrazar el cambio; la experiencia no debe convertirse en una limitación. (Fuente: dotey)
💡 Otros
Ejemplo de aplicación de IA en radiología de urgencias: asistencia en el diagnóstico de fracturas diminutas: Un usuario de Reddit compartió un caso de aplicación de IA en el mundo real en radiología de urgencias (ER radiology). Comparando 4 radiografías originales con 3 imágenes analizadas por IA, la IA identificó con éxito una fractura de peroné distal muy sutil y no desplazada. Esto demuestra el potencial de la IA en el análisis de imágenes médicas para ayudar a los médicos en diagnósticos precisos, especialmente en la identificación de lesiones difíciles de detectar. (Fuente: Reddit r/artificial & Reddit r/ArtificialInteligence)
La IA ayuda a los físicos del CERN a revelar una desintegración rara del bosón de Higgs: La tecnología de inteligencia artificial está ayudando a los físicos del CERN a estudiar el bosón de Higgs y ha logrado que revele un proceso de desintegración raro. Esto indica que la IA tiene un enorme potencial para procesar datos físicos complejos, identificar señales débiles y acelerar los descubrimientos científicos, especialmente en campos como la física de altas energías, que requieren el análisis de grandes cantidades de datos. (Fuente: Ronald_vanLoon)

Debate sobre la evolución de la capacidad de los modelos de IA en conversaciones multi-turno y contextos largos: Nathan Lambert señala que los modelos de IA más potentes actuales mejoran su rendimiento en tareas a medida que la conversación se profundiza o el contexto se alarga, mientras que los modelos más antiguos rinden peor o fallan en contextos multi-turno o largos. Esta perspectiva, confirmada en el podcast de Dwarkesh Patel, rompe la percepción que muchos tenían sobre las capacidades de los modelos, es decir, que los modelos tempranos verían disminuir su capacidad en conversaciones largas. (Fuente: natolambert & dwarkesh_sp)