
Palabras clave:Gemini 2.5 Pro, Veo 3, OpenAI, Jony Ive, Claude 4 Opus, generación de vídeo con IA, agente de IA, modelo multimodal, modo Deep Think, modelo de generación de vídeo, capacidad de razonamiento de IA, diseño de hardware para IA, optimización de ingeniería de software
🔥 Enfoque
Google lanza Gemini 2.5 Pro Deep Think y Veo 3, impulsando nuevas alturas en el razonamiento de AI y la generación de vídeo: En la conferencia Google I/O, Google presentó el modo Deep Think de Gemini 2.5 Pro, diseñado específicamente para resolver problemas complejos, destacando en problemas difíciles de competiciones matemáticas como USAMO y demostrando avances significativos de la AI en el razonamiento avanzado, por ejemplo, resolviendo problemas algebraicos complejos mediante razonamiento de múltiples pasos y probando diferentes métodos de demostración (como la reducción al absurdo o el teorema de Rolle). Al mismo tiempo, Veo 3, el modelo de generación de vídeo lanzado por Google, con sus escenas realistas, consistencia de personajes controlable, síntesis de sonido y diversas funciones de edición (como transformación de escenas, generación a partir de imágenes de referencia, transferencia de estilo, especificación de fotogramas iniciales y finales, edición localizada, etc.), ha establecido un nuevo estándar en el campo de la generación de vídeo por AI, atrayendo una amplia atención (Fuente: demishassabis, lmthang, GoogleDeepMind, _philschmid, fabianstelzer, matvelloso, seo_leaders, op7418, )
OpenAI invierte 6.500 millones de dólares para adquirir la empresa de Jony Ive y crear conjuntamente una nueva generación de ordenadores impulsados por AI: OpenAI anunció una colaboración con el ex diseñador jefe de Apple, Jony Ive, y la adquisición de su empresa, con el objetivo de construir conjuntamente una nueva generación de ordenadores impulsados por AI. Esta medida marca la expansión de OpenAI hacia el sector del hardware e intenta integrar profundamente las capacidades de AI en los dispositivos de computación, lo que podría remodelar la forma de interacción humano-máquina. Jony Ive es conocido por su excepcional diseño durante su etapa en Apple, y su incorporación augura que los nuevos dispositivos podrían tener importantes avances en diseño y experiencia de usuario, desafiando la forma de los dispositivos de computación existentes (Fuente: op7418, TheRundownAI, BorisMPower)
La conferencia de desarrolladores de Anthropic está a punto de celebrarse, se especula que Claude 4 Opus podría ser lanzado, con un enfoque en las capacidades de ingeniería de software: Anthropic está a punto de celebrar su primera conferencia de desarrolladores, y la comunidad especula ampliamente que la nueva generación de modelos Claude 4 (incluyendo Sonnet 4 y Opus 4) podría ser presentada en esta conferencia. Hay indicios de que la API de Claude Sonnet 3.7 ya muestra un comportamiento similar al de Claude 4, como el uso rápido de herramientas sin necesidad de “pasos de pensamiento”. Anthropic parece estar concentrando sus esfuerzos en superar los desafíos de la ingeniería de software, lo que difiere del camino de OpenAI y Google en la búsqueda de “modelos omnipotentes”. La revista TIME también ha confirmado indirectamente el lanzamiento de Claude 4 Opus, elevando aún más las expectativas del mercado sobre las capacidades de Anthropic en la codificación mediante AI y el procesamiento de tareas complejas (Fuente: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
Diferencias en la estrategia de ecosistema AI entre OpenAI y Google: ensamblar un acorazado frente a transformar un imperio: OpenAI y Google están tomando dos caminos diferentes, “ensamblar el ecosistema” y “transformar el ecosistema” respectivamente, para competir por la posición de “sistema operativo principal” de las futuras plataformas de AI. OpenAI, mediante la adquisición de hardware (io), bases de datos (Rockset), cadenas de herramientas (Windsurf) y herramientas de colaboración (Multi), entre otros, está ensamblando capacidades de AI full-stack desde cero. Mientras que Google opta por integrar profundamente su modelo Gemini en productos existentes (Search, Android, Docs, YouTube, etc.) y transformar los sistemas subyacentes para lograr una natividad AI. Aunque las estrategias de ambos difieren, su objetivo es el mismo: construir la plataforma definitiva de la era de la AI (Fuente: dotey)
🎯 Tendencias
Microsoft revela su visión de la “red de agentes inteligentes” (agentic web), enfatizando que los agentes de AI serán el núcleo del trabajo de próxima generación: El CEO de Microsoft, Satya Nadella, en la conferencia Build 2025 y en entrevistas, expuso la visión de la compañía sobre la “red de agentes inteligentes (agentic web)”. Considera que en el futuro los agentes de AI se convertirán en ciudadanos de primera clase del ecosistema empresarial y de M365, e incluso podrían dar lugar a nuevas profesiones como “administrador de agentes de AI”. Cuando el 95% del código sea generado por AI, el papel de los humanos se desplazará hacia la gestión y orquestación de estos agentes. Microsoft está construyendo un ecosistema de agentes abierto a través de Azure AI Foundry, Copilot Studio y protocolos abiertos como NLWeb, y convertirá Teams en un centro de colaboración multiagente (Fuente: rowancheung, TheTuringPost)
MMaDA: Lanzamiento de Multimodal Large Diffusion Language Models que unifican el razonamiento textual, la comprensión multimodal y la generación de imágenes: Investigadores han presentado MMaDA (Multimodal Large Diffusion Language Models), un nuevo tipo de modelo fundacional de difusión multimodal que, mediante Mixed Long-CoT (Mixed Long Chain-of-Thought) y el algoritmo de aprendizaje por refuerzo unificado UniGRPO, logra unificar las capacidades de razonamiento textual, comprensión multimodal y generación de imágenes. MMaDA-8B supera a Show-o y SEED-X en comprensión multimodal, y a SDXL y Janus en generación de texto a imagen. El modelo y el código están disponibles en Hugging Face (Fuente: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache: Mecanismo de caché diseñado para modelos de lenguaje de difusión, mejorando significativamente la velocidad de inferencia: Para abordar el problema de la lenta velocidad de inferencia de los modelos de lenguaje de difusión (DLMs), los investigadores han propuesto el mecanismo dKV-Cache. Este método, inspirado en el KV-Cache de los modelos autorregresivos, diseña un caché de clave-valor para el proceso de eliminación de ruido de los DLMs mediante estrategias de caché retardada y condicionada. Los experimentos demuestran que dKV-Cache puede lograr una aceleración de inferencia de 2 a 10 veces, reduciendo significativamente la brecha de velocidad entre los DLMs y los modelos autorregresivos, e incluso mejorando el rendimiento en secuencias largas, y puede aplicarse a los DLM existentes sin necesidad de entrenamiento (Fuente: NandoDF, HuggingFace Daily Papers)

Imagen4 muestra un rendimiento excepcional en la restauración de detalles, acercándose al “endgame” de la generación de imágenes: El modelo Imagen4 ha demostrado una potente capacidad de restauración de detalles al generar imágenes a partir de prompts de texto complejos. Por ejemplo, al generar una imagen que contenía 25 detalles específicos (como colores, objetos, ubicaciones, iluminación y atmósfera particulares), Imagen4 logró restaurar 23 de ellos. Esta alta fidelidad y la comprensión precisa de instrucciones complejas indican que la tecnología de texto a imagen se está acercando a un nivel de “endgame” capaz de reproducir perfectamente la imaginación del usuario (Fuente: cloneofsimo)

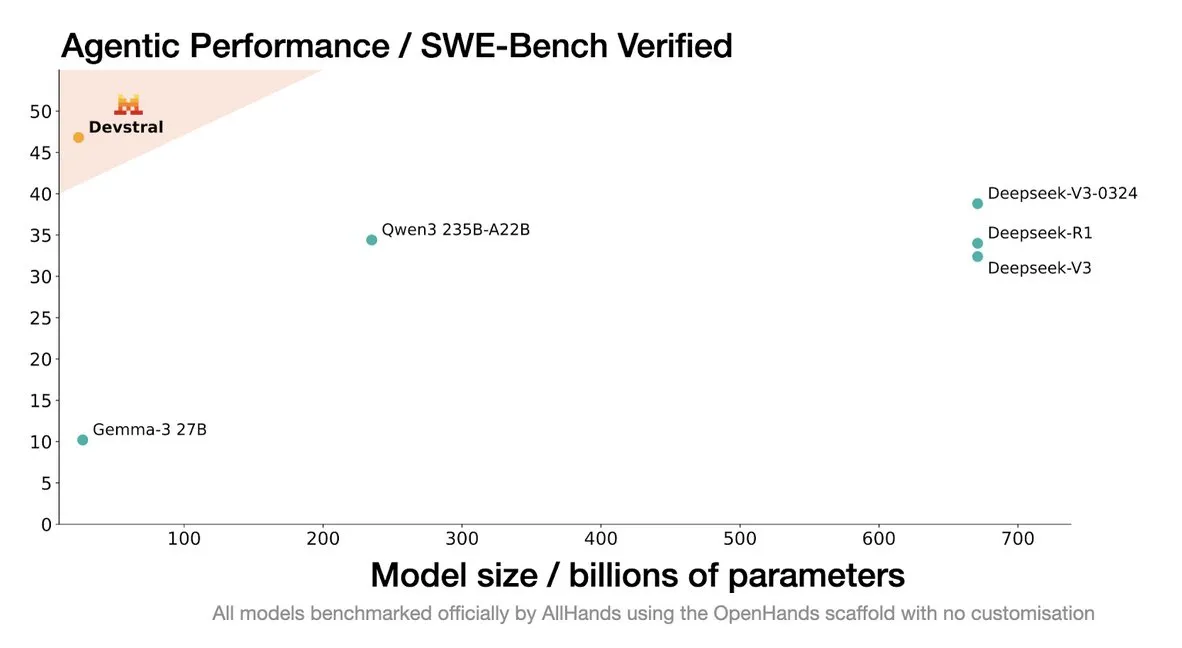
Mistral lanza el modelo Devstral, diseñado específicamente para agentes de codificación: Mistral AI ha presentado Devstral, un modelo de código abierto diseñado específicamente para agentes de codificación, desarrollado en colaboración con allhands_ai. Su versión cuantizada DWQ de 4 bits ya está disponible en Hugging Face (mlx-community/Devstral-Small-2505-4bit-DWQ) y puede ejecutarse fluidamente en dispositivos como M2 Ultra, mostrando potencial de optimización en la generación y comprensión de código (Fuente: awnihannun, clefourrier, GuillaumeLample)
ByteDance publica un informe sobre el entrenamiento de un modelo multimodal de nivel Gemini, adoptando una arquitectura de Transformer integrado: ByteDance ha publicado un informe de 37 páginas que detalla su método para entrenar un modelo multimodal nativo similar a Gemini. Lo más destacado es la arquitectura “Integrated Transformer”, que utiliza la misma red troncal simultáneamente como un modelo autorregresivo tipo GPT y un modelo de difusión tipo DiT, mostrando su exploración en el modelado unificado multimodal (Fuente: NandoDF)

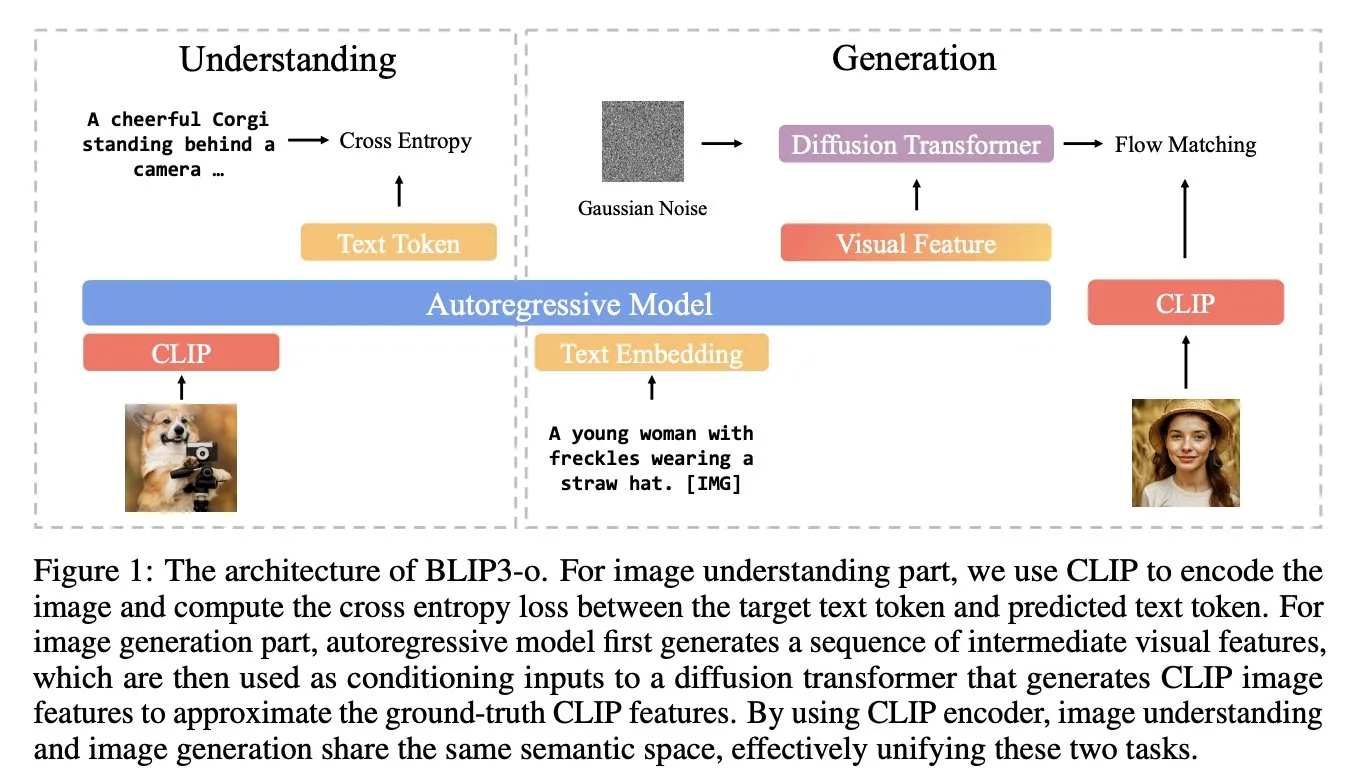
BLIP3-o: Salesforce lanza una serie de modelos multimodales unificados totalmente de código abierto, desbloqueando capacidades de generación de imágenes de nivel GPT-4o: El equipo de investigación de Salesforce ha lanzado la serie de modelos BLIP3-o, un conjunto de modelos multimodales unificados completamente de código abierto, con el objetivo de intentar desbloquear capacidades de generación de imágenes similares a las de GPT-4o. Este proyecto no solo ha abierto el código de los modelos, sino que también ha publicado un conjunto de datos de preentrenamiento con 25 millones de entradas, impulsando la apertura de la investigación multimodal (Fuente: arankomatsuzaki)
Google lanza la versión preliminar de Gemma 3n E4B, un modelo multimodal diseñado para dispositivos de bajos recursos: Google ha lanzado el modelo Gemma 3n E4B-it-litert-preview en Hugging Face. Este modelo está diseñado para procesar entradas de texto, imágenes, vídeo y audio, y generar salidas de texto; la versión actual admite entradas de texto y visuales. Gemma 3n utiliza una novedosa arquitectura Matformer, que permite anidar múltiples modelos y activar eficazmente 2B o 4B parámetros, optimizado específicamente para un funcionamiento eficiente en dispositivos de bajos recursos. El modelo se entrenó con aproximadamente 11 billones de tokens de datos multimodales, con conocimiento actualizado hasta junio de 2024 (Fuente: Tim_Dettmers, Reddit r/LocalLLaMA)
Una investigación revela el fenómeno del Conocimiento Específico del Lenguaje (LSK) en los grandes modelos: Un nuevo estudio explora el fenómeno del “Conocimiento Específico del Lenguaje” (Language Specific Knowledge, LSK) en los modelos de lenguaje, es decir, que el modelo puede rendir mejor en un idioma no inglés específico que en inglés al procesar ciertos temas o dominios. La investigación descubrió que el rendimiento del modelo puede mejorarse mediante el razonamiento en cadena de pensamiento en un idioma específico (incluso en idiomas de bajos recursos). Esto sugiere que los textos culturalmente específicos son más abundantes en sus respectivos idiomas, lo que hace que cierto conocimiento solo pueda existir en el idioma “experto”. Los investigadores diseñaron el método LSKExtractor para medir y utilizar este LSK, logrando una mejora relativa promedio del 10% en la precisión en múltiples modelos y conjuntos de datos (Fuente: HuggingFace Daily Papers)
Los efectos de generación de vídeo de DeepMind Veo 3 son asombrosos, con detalles realistas que atraen la atención: El modelo de generación de vídeo Veo 3 de Google DeepMind ha demostrado potentes capacidades de generación de vídeo, incluyendo transformación de escenas, generación impulsada por imágenes de referencia, transferencia de estilo, consistencia de personajes, especificación de fotogramas iniciales y finales, escalado de vídeo, adición de objetos y control de acciones. El realismo de los vídeos generados y su capacidad para comprender instrucciones complejas han maravillado a los usuarios sobre el rápido desarrollo de la tecnología de generación de vídeo por AI, e incluso algunos usuarios lo han utilizado para crear anuncios publicitarios con una calidad comparable a la producción profesional (Fuente: demishassabis, , Reddit r/ChatGPT)
El modelo de lenguaje visual Moondream lanza una versión cuantizada de 4 bits, reduciendo significativamente la VRAM y aumentando la velocidad: El modelo de lenguaje visual (VLM) Moondream ha lanzado una versión cuantizada de 4 bits, logrando una reducción del 42% en el uso de VRAM y un aumento del 34% en la velocidad de inferencia, manteniendo al mismo tiempo una precisión del 99.4%. Esta optimización hace que este potente y pequeño VLM sea más fácil de implementar y usar en tareas como la detección de objetos, y ha sido bien recibido por los desarrolladores (Fuente: Sentdex, vikhyatk)
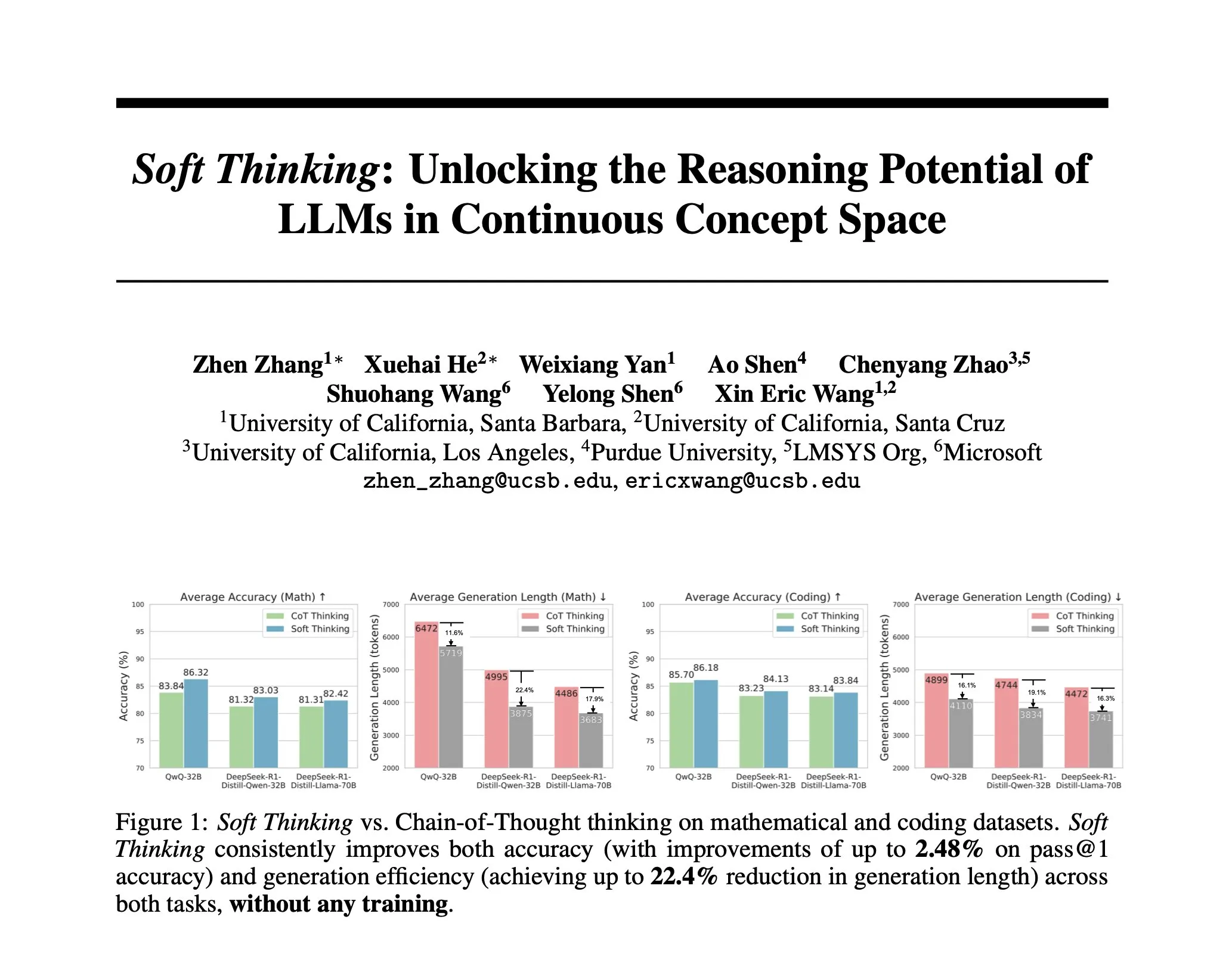
Una investigación propone Soft Thinking: un método sin entrenamiento para simular el razonamiento “blando” humano: Para que el razonamiento de la AI se asemeje más al pensamiento fluido humano, sin las limitaciones de los tokens discretos, los investigadores han propuesto el método Soft Thinking. Este método no requiere entrenamiento adicional y genera tokens conceptuales continuos y abstractos. Estos tokens fusionan suavemente múltiples significados mediante una mezcla ponderada probabilísticamente de embeddings, logrando así representaciones más ricas y una exploración fluida de diferentes rutas de razonamiento. Los experimentos demuestran que este método mejora la precisión hasta en un 2.48% (pass@1) en benchmarks de matemáticas y código, al tiempo que reduce el uso de tokens hasta en un 22.4% (Fuente: arankomatsuzaki)
Framework IA-T2I: Utiliza Internet para mejorar la capacidad de los modelos de texto a imagen para procesar conocimiento incierto: Para abordar las deficiencias de los modelos de texto a imagen existentes al procesar prompts de texto que contienen conocimiento incierto (como eventos recientes o conceptos raros), se ha propuesto el framework IA-T2I (Internet-Augmented Text-to-Image Generation). Este framework utiliza un módulo de recuperación activa para determinar si se necesitan imágenes de referencia, un módulo de selección jerárquica de imágenes para elegir las imágenes más adecuadas de los resultados de los motores de búsqueda para mejorar el modelo T2I, y un mecanismo de autorreflexión para evaluar y optimizar continuamente las imágenes generadas. En el conjunto de datos Img-Ref-T2I especialmente construido, IA-T2I superó a GPT-4o en aproximadamente un 30% (evaluación humana) (Fuente: HuggingFace Daily Papers)
MoI (Mixture of Inputs) mejora la calidad de la generación autorregresiva y la capacidad de razonamiento: Para resolver el problema de la pérdida de información de distribución de tokens durante el proceso de generación autorregresiva estándar, los investigadores han propuesto el método Mixture of Inputs (MoI). Este método no requiere entrenamiento adicional y, después de generar un token, mezcla el token discreto generado con la distribución de tokens previamente descartada para construir una nueva entrada. Mediante la estimación bayesiana, la distribución de tokens se considera como a priori, el token muestreado como observación, y la expectativa posterior continua reemplaza al vector one-hot tradicional como nueva entrada del modelo. MoI ha mejorado continuamente el rendimiento de múltiples modelos como Qwen-32B y Nemotron-Super-49B en tareas de razonamiento matemático, generación de código y preguntas y respuestas de nivel doctoral (Fuente: HuggingFace Daily Papers)
ConvSearch-R1: Optimiza la reescritura de consultas en la búsqueda conversacional mediante aprendizaje por refuerzo: Para resolver los problemas de ambigüedad, omisión y referencia en las consultas dependientes del contexto en la búsqueda conversacional, se ha propuesto el framework ConvSearch-R1. Este framework adopta por primera vez un método autodirigido, utilizando el aprendizaje por refuerzo para optimizar directamente la reescritura de consultas mediante señales de recuperación, eliminando por completo la dependencia de la supervisión externa de reescritura (como anotaciones manuales o grandes modelos). Su método de dos etapas incluye un precalentamiento de la política autodirigida y un aprendizaje por refuerzo guiado por la recuperación (utilizando un mecanismo de recompensa de incentivos jerárquicos). Los experimentos demuestran que ConvSearch-R1 supera significativamente a los métodos SOTA anteriores en los conjuntos de datos TopiOCQA y QReCC (Fuente: HuggingFace Daily Papers)
El framework ASRR logra una inferencia adaptativa eficiente para grandes modelos de lenguaje: Para abordar el problema del excesivo coste computacional de los grandes modelos de razonamiento (LRMs) en tareas simples debido al razonamiento redundante, los investigadores han propuesto el framework de Razonamiento Autoadaptativo con Autorrecuperación (Adaptive Self-Recovery Reasoning, ASRR). Este framework, al revelar el “mecanismo interno de autorrecuperación” del modelo (que complementa implícitamente el razonamiento en la generación de respuestas), suprime el razonamiento innecesario e introduce un ajuste de recompensa de longitud sensible a la precisión, asignando adaptativamente el esfuerzo de razonamiento según la dificultad del problema. Los experimentos demuestran que ASRR puede reducir significativamente el presupuesto de inferencia y mejorar la tasa de inocuidad en benchmarks de seguridad con una pérdida mínima de rendimiento (Fuente: HuggingFace Daily Papers)
El framework MoT (Mixture-of-Thought) mejora la capacidad de razonamiento lógico: Inspirados por la forma en que los humanos utilizan múltiples modalidades de razonamiento (lenguaje natural, código, lógica simbólica) para resolver problemas lógicos, los investigadores han propuesto el framework Mixture-of-Thought (MoT). MoT permite a los LLM razonar a través de tres modalidades complementarias, incluida la modalidad simbólica de tablas de verdad recientemente introducida. Mediante un diseño de dos etapas (entrenamiento MoT autoevolutivo e inferencia MoT), MoT supera significativamente a los métodos de cadena de pensamiento monomodales en benchmarks de razonamiento lógico como FOLIO y ProofWriter, con una mejora promedio de la precisión de hasta el 11.7% (Fuente: HuggingFace Daily Papers)
RL Tango: Co-entrenamiento de generador y validador mediante aprendizaje por refuerzo para mejorar el razonamiento del lenguaje: Para resolver los problemas de “reward hacking” y mala generalización en los métodos actuales de aprendizaje por refuerzo para LLM, donde el validador (modelo de recompensa) es fijo o se ajusta finamente de forma supervisada, se ha propuesto el framework RL Tango. Este framework entrena de forma intercalada y simultánea el generador LLM y un validador LLM generativo a nivel de proceso, mediante aprendizaje por refuerzo. El validador se entrena únicamente basándose en la recompensa de corrección de la validación a nivel de resultado, sin necesidad de anotaciones a nivel de proceso, formando así una interpromoción efectiva con el generador. Los experimentos demuestran que tanto el generador como el validador de Tango alcanzan niveles SOTA en modelos de escala 7B/8B (Fuente: HuggingFace Daily Papers)
pPE: Prior Prompt Engineering ayuda al ajuste fino reforzado (RFT): Una investigación explora el papel del prior prompt engineering (pPE) en el ajuste fino reforzado (RFT). A diferencia del prompt engineering en tiempo de inferencia (iPE), el pPE antepone instrucciones (como el razonamiento paso a paso) a la consulta durante la fase de entrenamiento para guiar al modelo de lenguaje a internalizar comportamientos específicos. Los experimentos aplicaron cinco estrategias de iPE (razonamiento, planificación, razonamiento con código, recuperación de conocimiento, utilización de ejemplos vacíos) como métodos de pPE a Qwen2.5-7B. Los resultados muestran que todos los modelos entrenados con pPE superaron a sus correspondientes modelos con iPE, siendo el pPE con ejemplos vacíos el que obtuvo la mayor mejora en benchmarks como AIME2024 y GPQA-Diamond, revelando el pPE como un medio eficaz y poco estudiado en RFT (Fuente: HuggingFace Daily Papers)
BiasLens: Framework de evaluación de sesgos en LLM sin necesidad de conjuntos de pruebas manuales: Para resolver los problemas de los métodos actuales de evaluación de sesgos en LLM, que dependen de datos etiquetados construidos manualmente y tienen una cobertura limitada, se ha propuesto el framework BiasLens. Este framework parte de la estructura del espacio vectorial del modelo, combinando vectores de activación conceptual (CAVs) y autoencoders dispersos (SAEs) para extraer representaciones conceptuales interpretables. Cuantifica el sesgo midiendo los cambios en la similitud de representación entre conceptos objetivo y conceptos de referencia. BiasLens muestra una fuerte consistencia (correlación de Spearman r > 0.85) con las métricas tradicionales de evaluación de sesgos en ausencia de datos etiquetados, y puede revelar formas de sesgo difíciles de detectar con los métodos existentes (Fuente: HuggingFace Daily Papers)
HumaniBench: Framework de evaluación de grandes modelos multimodales centrado en el ser humano: Para abordar las deficiencias de los LMM actuales en estándares centrados en el ser humano como la equidad, la ética y la empatía, se ha propuesto HumaniBench. Se trata de un benchmark integral que contiene 32K pares de preguntas y respuestas de imágenes y texto del mundo real, anotados con la ayuda de GPT-4o y validados por expertos. HumaniBench evalúa siete principios de AI centrada en el ser humano: equidad, ética, comprensión, razonamiento, inclusión lingüística, empatía y robustez, cubriendo siete tareas diversas. Las pruebas realizadas en 15 LMM SOTA muestran que los modelos de código cerrado generalmente lideran, pero la robustez y la localización visual siguen siendo puntos débiles (Fuente: HuggingFace Daily Papers)
AJailBench: Primer benchmark integral de ataques de jailbreak a grandes modelos de lenguaje de audio: Para evaluar sistemáticamente la seguridad de los grandes modelos de lenguaje de audio (LAMs) frente a ataques de jailbreak, se ha propuesto AJailBench. Este benchmark primero construyó el conjunto de datos AJailBench-Base, que contiene 1495 prompts de audio adversarios y cubre 10 categorías de infracciones. La evaluación basada en este conjunto de datos muestra que los LAMs SOTA existentes no demuestran una robustez consistente. Para simular ataques más realistas, los investigadores desarrollaron el kit de herramientas de perturbación de audio (APT), que utiliza optimización bayesiana para buscar perturbaciones sutiles y eficientes, generando el conjunto de datos extendido AJailBench-APT. La investigación demuestra que perturbaciones pequeñas y que preservan la semántica pueden reducir significativamente el rendimiento de seguridad de los LAMs (Fuente: HuggingFace Daily Papers)
WebNovelBench: Benchmark para evaluar la capacidad de los LLM en la creación de novelas largas: Para abordar los desafíos de la evaluación de la capacidad narrativa de formato largo de los LLM, se ha propuesto WebNovelBench. Este benchmark utiliza un conjunto de datos de más de 4000 novelas web chinas y establece la evaluación como una tarea de generación de historia a partir de un esquema. Mediante un método de LLM como juez, se realiza una evaluación automática desde ocho dimensiones de calidad narrativa, y se utiliza el análisis de componentes principales para agregar las puntuaciones, comparándolas con obras humanas mediante clasificación percentil. Los experimentos distinguieron eficazmente entre obras maestras humanas, novelas web populares y contenido generado por LLM, y se realizó un análisis exhaustivo de 24 LLM SOTA (Fuente: HuggingFace Daily Papers)
MultiHal: Dataset multilingüe basado en grafos de conocimiento para la evaluación de alucinaciones en LLM: Para suplir las deficiencias de los benchmarks de evaluación de alucinaciones existentes en cuanto a rutas de grafos de conocimiento y multilingüismo, se ha propuesto MultiHal. Se trata de un benchmark multilingüe y multisalto basado en grafos de conocimiento, diseñado específicamente para la evaluación de texto generado. El equipo extrajo 140,000 rutas de grafos de conocimiento de dominio abierto y seleccionó 25,900 rutas de alta calidad. La evaluación de referencia muestra que, en múltiples idiomas y modelos, el RAG mejorado con grafos de conocimiento (KG-RAG) logra una mejora absoluta de aproximadamente 0.12 a 0.36 puntos en las puntuaciones de similitud semántica en comparación con las preguntas y respuestas ordinarias, demostrando el potencial de la integración de grafos de conocimiento (Fuente: HuggingFace Daily Papers)
Llama-SMoP: Método de reconocimiento de voz audiovisual para LLM basado en proyectores mixtos dispersos (Sparse Mixture of Projectors): Para resolver el alto coste computacional de los LLM en el reconocimiento de voz audiovisual (AVSR), se ha propuesto Llama-SMoP. Se trata de un LLM multimodal eficiente que utiliza un módulo de proyectores mixtos dispersos (SMoP), que expande la capacidad del modelo sin aumentar el coste de inferencia mediante proyectores de mezcla de expertos (MoE) con puertas dispersas. Los experimentos demuestran que la configuración Llama-SMoP DEDR, que utiliza enrutamiento y expertos específicos de la modalidad, logra un rendimiento excelente en tareas de ASR, VSR y AVSR, y muestra un buen comportamiento en la activación de expertos, escalabilidad y robustez al ruido (Fuente: HuggingFace Daily Papers)
VPRL: Framework de planificación puramente visual basado en aprendizaje por refuerzo, con un rendimiento que supera al razonamiento textual: Un equipo de investigadores de la Universidad de Cambridge, University College London y Google ha propuesto VPRL (Visual Planning with Reinforcement Learning), un nuevo paradigma que se basa puramente en secuencias de imágenes para el razonamiento. Este framework utiliza la optimización de políticas relativas de grupo (GRPO) para post-entrenar grandes modelos visuales, calculando señales de recompensa mediante la transición de estados visuales y validando las restricciones del entorno. En tareas de navegación visual como FrozenLake, Maze y MiniBehavior, la precisión de VPRL alcanza hasta el 80.6%, superando significativamente a los métodos de razonamiento basados en texto (como el 43.7% de Gemini 2.5 Pro), y muestra un mejor rendimiento en tareas complejas y robustez, demostrando la superioridad de la planificación visual (Fuente: 量子位)

Nvidia anuncia su hoja de ruta tecnológica de AI para los próximos cinco años y su transformación en una empresa de infraestructura de AI: El CEO de Nvidia, Jensen Huang, anunció en COMPUTEX 2025 el reajuste del posicionamiento de la empresa como una compañía de infraestructura de AI y reveló la hoja de ruta tecnológica para los próximos cinco años. Subrayó que la infraestructura de AI será tan omnipresente como la electricidad o Internet, y que Nvidia se dedica a construir las “fábricas” de la era de la AI. Para respaldar esta transformación, Nvidia ampliará su “círculo de amigos” en la cadena de suministro, profundizando la cooperación con TSMC entre otros, y planea establecer una oficina en Taiwán (NVIDIA Constellation) y el primer superordenador de AI gigante (Fuente: 36氪)

Google reinicia su proyecto de gafas de AI, lanza la plataforma Android XR y dispositivos de terceros: En la conferencia I/O 2025, Google anunció el reinicio de su proyecto de gafas AI/AR, lanzó la plataforma Android XR desarrollada específicamente para dispositivos XR y mostró dos dispositivos de terceros basados en esta plataforma: Project Moohan de Samsung (competidor de Vision Pro) y Project Aura de Xreal. Google tiene como objetivo replicar el éxito de Android en el campo de los smartphones, creando el “momento Android” para los dispositivos XR y posicionándose para las futuras plataformas de computación ambiental y espacial. Combinado con el modelo grande multimodal Gemini 2.5 Pro actualizado y la tecnología de asistente inteligente Project Astra, la nueva generación de gafas AI/AR logrará una experiencia disruptiva en comprensión de voz, traducción en tiempo real, conciencia contextual y ejecución de tareas complejas (Fuente: 36氪)

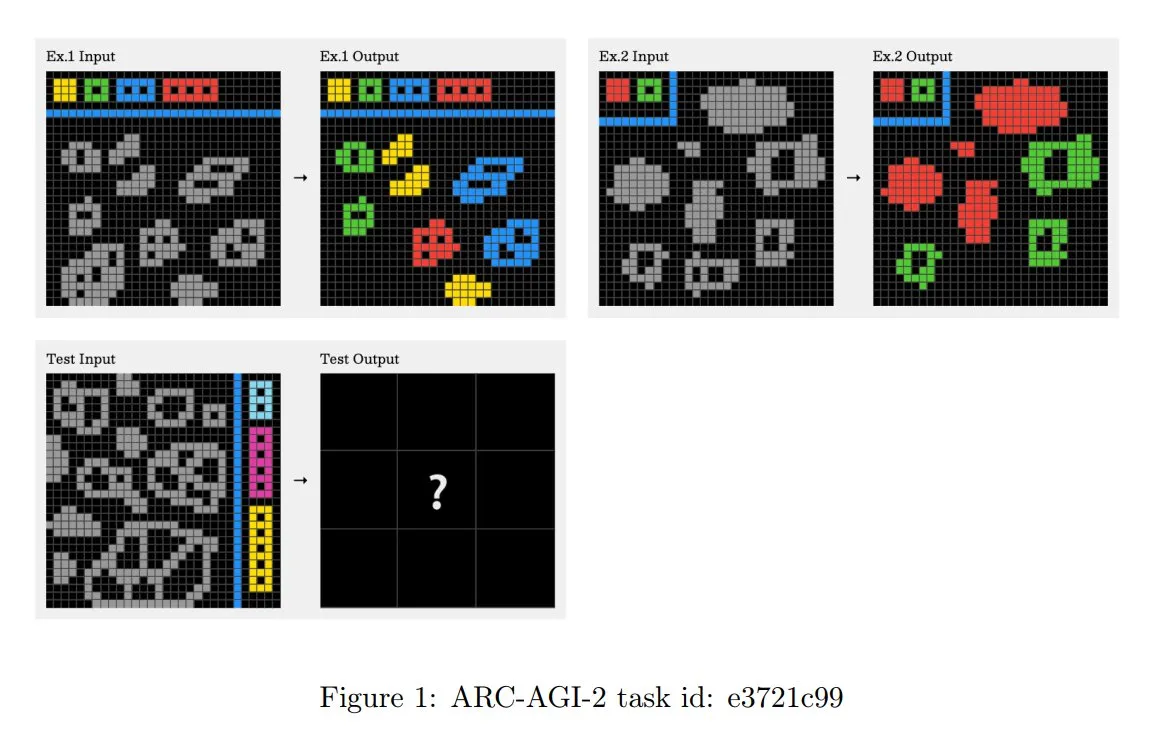
Actualización de los principios del desafío ARC-AGI-2, enfatizando el razonamiento contextual de múltiples pasos: El nuevo artículo de ARC-AGI-2 actualiza los principios de diseño de este desafío. Los nuevos principios requieren que la resolución de tareas posea capacidades de razonamiento contextual, de múltiples reglas y de múltiples pasos. Las cuadrículas son más grandes, contienen más objetos y codifican múltiples conceptos interactivos. Las tareas son novedosas y no reutilizables para limitar la memorización. El diseño se resiste intencionadamente a la síntesis de programas por fuerza bruta. Los solucionadores humanos necesitan un promedio de 2.7 minutos por tarea, mientras que los sistemas de primer nivel (como OpenAI o3-medium) obtienen solo alrededor del 3%, y todas las tareas requieren un esfuerzo cognitivo explícito (Fuente: TheTuringPost, clefourrier)
Skywork lanza superagentes con el objetivo de reducir 8 horas de trabajo a 8 minutos: Skywork ha lanzado sus agentes de espacio de trabajo AI, Skywork Super Agents, afirmando que pueden comprimir 8 horas de trabajo del usuario en 8 minutos. Este producto se posiciona como el pionero de los agentes de espacio de trabajo AI, y sus funciones y métodos de implementación específicos están por verse (Fuente: _akhaliq)
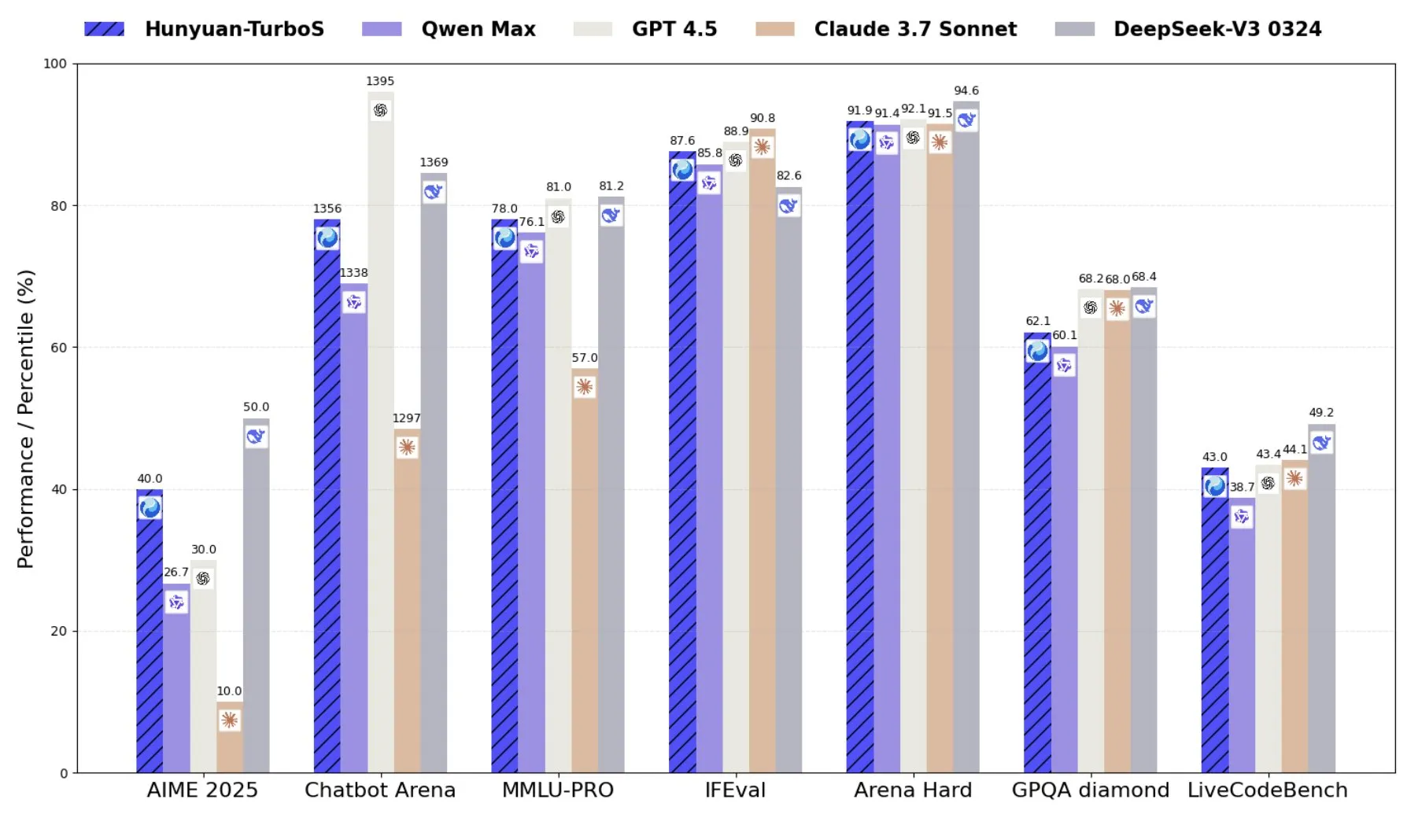
Tencent lanza Hunyuan-TurboS, un modelo de mezcla de expertos (MoE) que combina Transformer y Mamba: Tencent ha lanzado el modelo Hunyuan-TurboS, que adopta una arquitectura de mezcla de expertos (MoE) de Transformer y Mamba, con 56 mil millones de parámetros activos y entrenado en 16 billones de tokens. Hunyuan-TurboS puede cambiar dinámicamente entre modos de respuesta rápida y “pensamiento” profundo, y se encuentra entre los siete primeros en la clasificación general de LMSYS Chatbot Arena (Fuente: tri_dao)
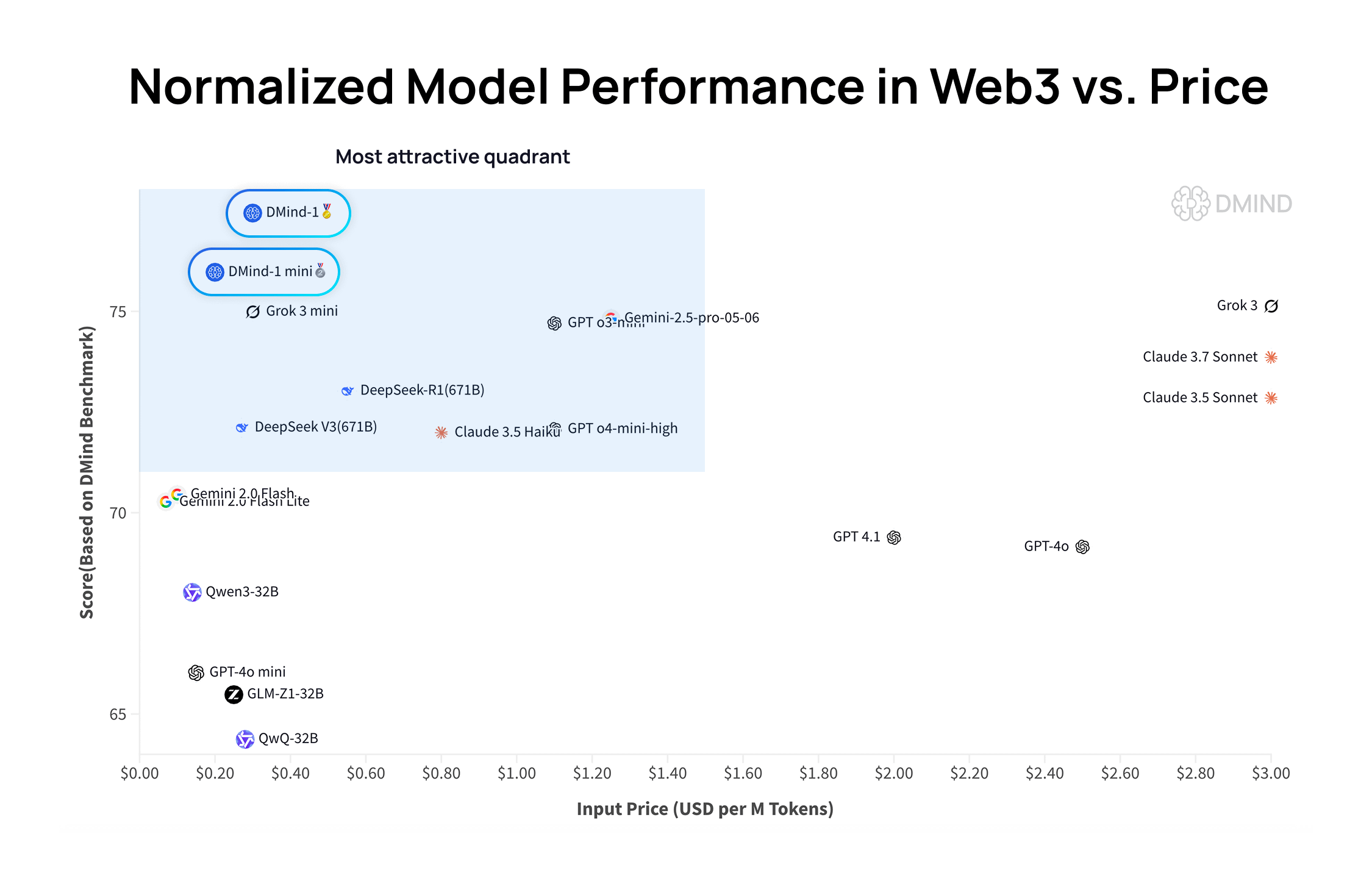
DMind-1: Un gran modelo de lenguaje de código abierto diseñado para escenarios Web3: DMind AI ha lanzado DMind-1, un gran modelo de lenguaje de código abierto optimizado para escenarios Web3. DMind-1 (32B) se ha ajustado finamente a partir de Qwen3-32B, utilizando una gran cantidad de conocimiento específico de Web3, con el objetivo de equilibrar el rendimiento y el coste de las aplicaciones AI+Web3. En las evaluaciones de benchmarks Web3, DMind-1 supera a los LLM genéricos principales, y su coste de token es solo alrededor del 10% del de estos. También se lanzó DMind-1-mini (14B), que conserva más del 95% del rendimiento de DMind-1 y es superior en latencia y eficiencia computacional (Fuente: _akhaliq)
LightOn lanza Reason-ModernColBERT, un modelo de pocos parámetros con excelente rendimiento en tareas de recuperación intensivas en razonamiento: LightOn ha presentado Reason-ModernColBERT, un modelo de interacción tardía con solo 149 millones de parámetros. En el popular benchmark BRIGHT (centrado en la recuperación intensiva en razonamiento), este modelo ha demostrado un rendimiento excepcional, superando a modelos con 45 veces más parámetros y alcanzando niveles SOTA en múltiples dominios. Este logro demuestra una vez más la eficiencia de los modelos de interacción tardía en tareas específicas (Fuente: lateinteraction, jeremyphoward, Dorialexander, huggingface)

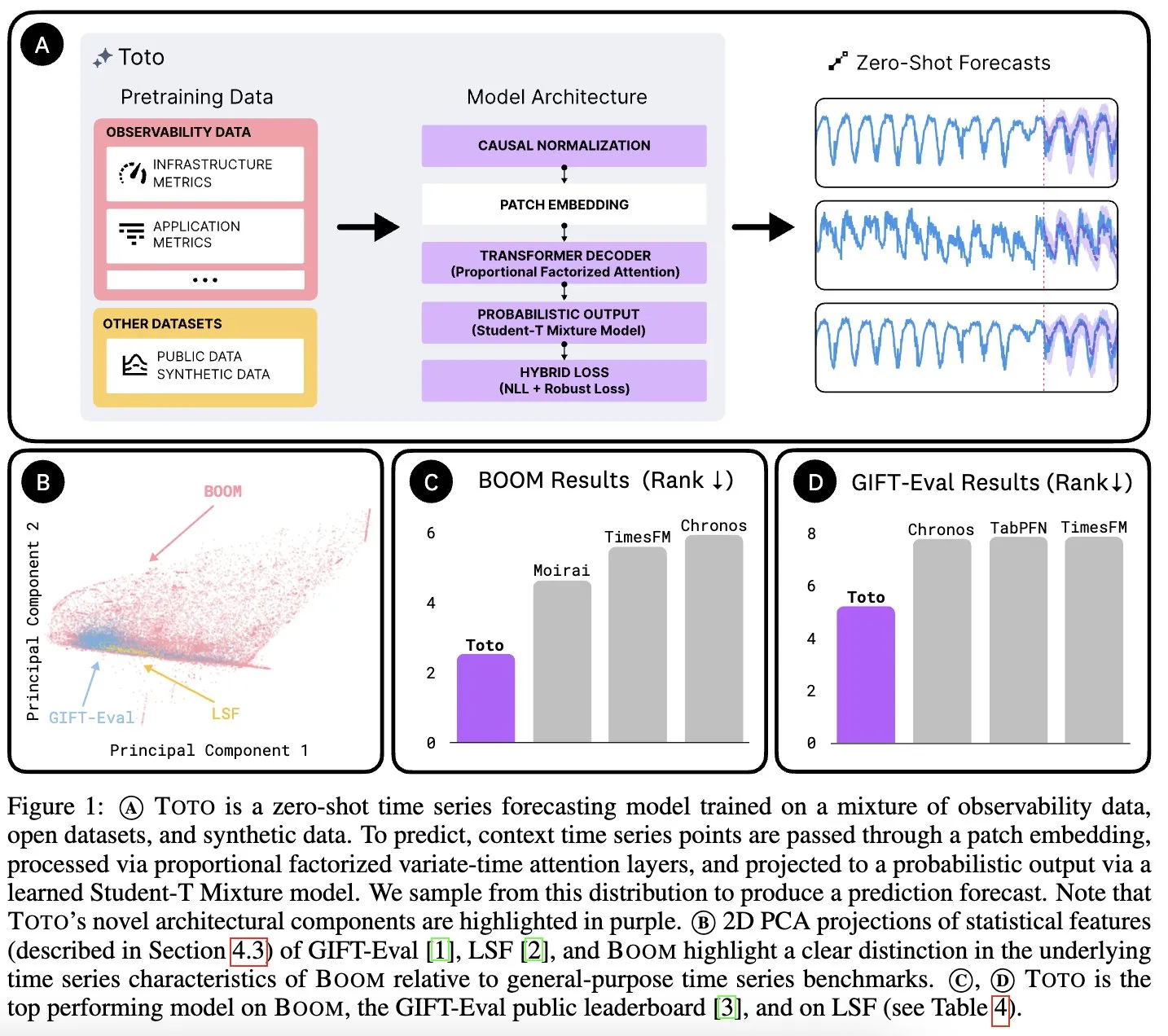
Datadog AI Research lanza Toto, un modelo fundacional de series temporales, y BOOM, un benchmark de métricas de observabilidad: Datadog AI Research ha presentado Toto, un nuevo modelo fundacional de series temporales, que supera ampliamente a los modelos SOTA existentes en benchmarks relevantes. Al mismo tiempo, ha lanzado BOOM, el mayor benchmark de métricas de observabilidad hasta la fecha. Ambos se han publicado bajo la licencia Apache 2.0, con el objetivo de impulsar la investigación y aplicación en los campos del análisis de series temporales y la observabilidad (Fuente: jefrankle, ClementDelangue)
TII lanza la serie de modelos híbridos Transformer-SSM Falcon-H1: El Instituto de Innovación Tecnológica (TII) de los Emiratos Árabes Unidos ha lanzado la serie de modelos Falcon-H1, un conjunto de modelos de lenguaje de arquitectura híbrida que combina mecanismos de atención Transformer y cabezales de modelo de espacio de estados (SSM) Mamba2. Esta serie de modelos varía en tamaño de parámetros de 0.5B a 34B, admite longitudes de contexto de hasta 256K y supera o iguala el rendimiento de modelos Transformer de primer nivel como Qwen3-32B y Llama4-Scout en múltiples benchmarks, mostrando ventajas especialmente en multilingüismo (soporte nativo para 18 idiomas) y eficiencia. Los modelos se han integrado en vLLM, Hugging Face Transformers y llama.cpp (Fuente: Reddit r/LocalLLaMA)

Investigación del MIT: La AI puede aprender la asociación entre la visión y el sonido sin intervención humana: Investigadores del MIT han demostrado un sistema de AI capaz de aprender de forma autónoma las conexiones entre la información visual y los sonidos correspondientes, sin necesidad de guía explícita o datos etiquetados por humanos. Esta capacidad es crucial para desarrollar sistemas de AI multimodales más completos, que les permitan comprender y percibir el mundo de una manera más similar a los humanos (Fuente: Reddit r/artificial, Reddit r/ArtificialInteligence)

Emiratos Árabes Unidos lanza un gran modelo de AI en árabe, acelerando la carrera de AI en la región del Golfo: Emiratos Árabes Unidos ha lanzado un gran modelo de AI en árabe, lo que marca una mayor inversión en el campo de la inteligencia artificial e intensifica la competencia en el desarrollo de tecnología de AI entre los países de la región del Golfo. Esta medida tiene como objetivo aumentar la influencia del idioma árabe en el campo de la AI y satisfacer la demanda de aplicaciones de AI localizadas (Fuente: Reddit r/artificial)
Fenbi Technology lanza un gran modelo vertical, definiendo un nuevo paradigma de “AI + Educación”: Fenbi Technology presentó su gran modelo vertical de desarrollo propio para el sector de la educación profesional en la Cumbre de Aplicaciones Industriales de AI de Tencent Cloud. Este modelo ya se ha aplicado en productos como la evaluación de entrevistas y el sistema de clases con práctica de IA, cubriendo toda la cadena de “enseñanza, aprendizaje, práctica, evaluación y examen”. A través de formas como los profesores de AI, se busca pasar de una enseñanza “uniforme para todos” a una enseñanza personalizada “a medida para cada uno”, y se planea lanzar productos de hardware de AI equipados con su modelo grande de desarrollo propio, impulsando la transformación inteligente de la educación (Fuente: 量子位)

Beisen Kuxueyuan lanza la nueva generación de la plataforma AI Learning, introduciendo cinco AI Agents: Beisen Holdings, tras la adquisición de Kuxueyuan, ha lanzado la nueva generación de la plataforma de aprendizaje AI Learning, basada en grandes modelos de AI. Esta plataforma añade cinco agentes inteligentes a la base de eLearning existente: asistente de creación de cursos AI, asistente de aprendizaje AI, entrenador AI, coach de liderazgo AI y asistente de exámenes AI. Su objetivo es subvertir el modelo tradicional de aprendizaje corporativo mediante el diálogo en tiempo real con Agents, el entrenamiento de habilidades, el aprendizaje personalizado y la creación y evaluación de cursos y exámenes todo en uno con AI (Fuente: 量子位)

Informe financiero Q1 de Pony.ai: Los ingresos del servicio Robotaxi aumentan 8 veces interanual, se desplegarán mil vehículos autónomos a finales de año: Pony.ai publicó su informe financiero del primer trimestre de 2025, con ingresos totales de 102 millones de yuanes, un aumento interanual del 12%. De estos, los ingresos del servicio principal Robotaxi alcanzaron los 12.3 millones de yuanes, un aumento interanual del 200.3%, y los ingresos por tarifas de pasajeros aumentaron 8 veces interanual. La compañía planea comenzar la producción en masa de su Robotaxi de séptima generación en el segundo trimestre y desplegar 1000 vehículos antes de fin de año, esforzándose por alcanzar el punto de equilibrio por vehículo. Pony.ai también anunció colaboraciones con Tencent Cloud y Uber para expandir los mercados nacionales y de Oriente Medio a través de las plataformas WeChat y Uber, respectivamente (Fuente: 量子位)

Kevin Weil, CPO de OpenAI: ChatGPT se transformará en un asistente de acción, el coste del modelo ya es 500 veces superior al de GPT-4: Kevin Weil, Director de Producto de OpenAI, declaró que el posicionamiento de ChatGPT pasará de responder preguntas a ejecutar tareas para los usuarios, convirtiéndose en un asistente de acción de AI mediante el uso intercalado de herramientas (como navegar por la web, programar, conectarse a fuentes de conocimiento internas). Reveló que el coste del modelo actual ya es 500 veces superior al del GPT-4 original, pero OpenAI se compromete a mejorar la eficiencia y reducir los precios de la API mediante mejoras de hardware y algoritmos. Considera que los AI Agents se desarrollarán rápidamente, pasando de un nivel de ingeniero junior a un nivel de arquitecto en un año (Fuente: 量子位)

🧰 Herramientas
FlowiseAI: Construcción visual de agentes de AI: FlowiseAI es un proyecto de código abierto que permite a los usuarios construir agentes de AI y aplicaciones LLM a través de una interfaz visual. Admite arrastrar y soltar componentes, conectar diferentes LLM, herramientas y fuentes de datos, simplificando el flujo de desarrollo de aplicaciones de AI. Los usuarios pueden instalar Flowise mediante npm o implementarlo con Docker para construir y probar rápidamente sus propios flujos de AI (Fuente: GitHub Trending)

Lanzamiento de las bibliotecas JS de Hugging Face, simplificando la interacción con la API del Hub y los servicios de inferencia: Hugging Face ha lanzado una serie de bibliotecas JavaScript (@huggingface/inference, @huggingface/hub, @huggingface/mcp-client, etc.) destinadas a facilitar a los desarrolladores la interacción con la API de Hugging Face Hub y los servicios de inferencia mediante JS/TS. Estas bibliotecas admiten la creación de repositorios, la carga de archivos, la llamada a la inferencia de más de 100,000 modelos (incluida la completación de chat, texto a imagen, etc.), el uso del cliente MCP para construir agentes, entre otras funciones, y son compatibles con múltiples proveedores de inferencia (Fuente: GitHub Trending)

El entorno de ejecución local Jan AI actualiza su licencia a Apache 2.0, reduciendo las barreras de entrada para las empresas: Jan AI es una herramienta de código abierto que admite la ejecución local de LLM y recientemente ha cambiado su licencia de AGPL a la más permisiva Apache 2.0. Esta medida tiene como objetivo facilitar que las empresas y equipos implementen y utilicen Jan dentro de sus organizaciones sin preocuparse por los problemas de cumplimiento que conlleva AGPL, permitiendo bifurcar, modificar y publicar libremente, impulsando así la adopción a gran escala de Jan en entornos de producción reales (Fuente: reach_vb, Reddit r/LocalLLaMA)
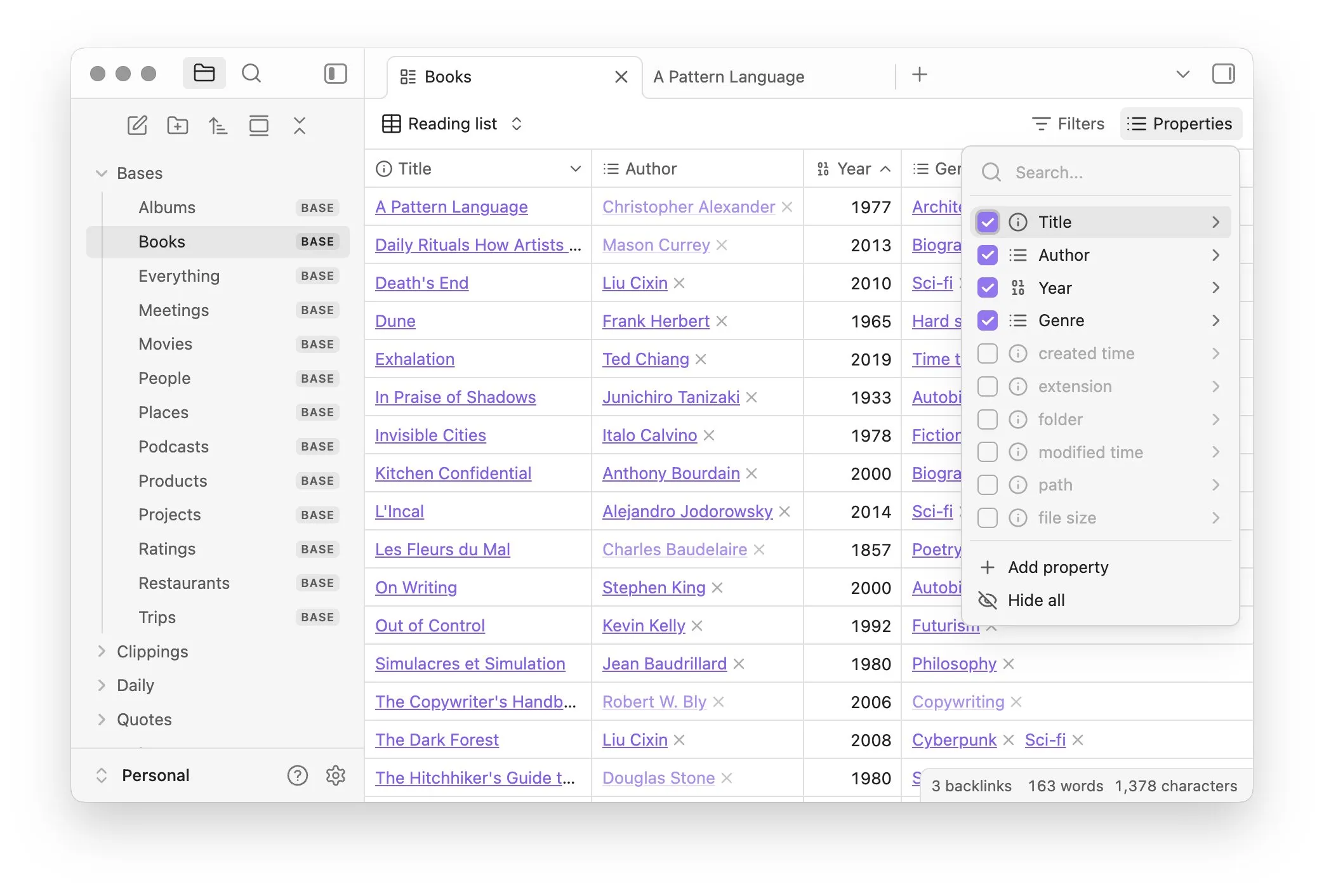
Obsidian lanza el plugin principal Bases, permitiendo la gestión de notas como bases de datos: El software de gestión del conocimiento Obsidian ha actualizado su plugin principal Bases, permitiendo a los usuarios transformar conjuntos de notas en potentes bases de datos. Con Bases, los usuarios pueden crear vistas de tabla personalizadas, visualizar y operar interactivamente con los datos de su base de conocimiento, admitiendo el filtrado de notas por propiedades y la creación de fórmulas para derivar atributos dinámicos, aplicable a la gestión de proyectos, planificación de viajes, listas de lectura y otros muchos escenarios. Esta función ya está disponible para los primeros usuarios (Fuente: op7418)
Hugging Face lanza Tiny Agents, simplificando el control del navegador y las operaciones de archivos por modelos locales: Hugging Face, en su curso MCP, ha presentado Tiny Agents, un framework de configuración de control de navegador fácil de usar. Los usuarios, mediante la línea de comandos, configuración JSON y prompts, pueden hacer que un LLM ejecutado localmente (a través de un servidor compatible con OpenAI) controle el navegador (como Playwright) o el sistema de archivos local, sin necesidad de llamar directamente a la API, lo que facilita las aplicaciones de agentes para modelos locales como llama.cpp (Fuente: Reddit r/LocalLLaMA)

Un desarrollador crea una aplicación de código abierto para optimizar currículums con AI, basada en LangChain y Ollama: Un desarrollador ha construido y publicado una aplicación de código abierto para optimizar currículums impulsada por AI. Después de que el usuario sube su currículum actual y la descripción del puesto deseado, la aplicación intenta ajustar las palabras clave del currículum para que se adapten mejor a los requisitos de contratación. El backend del proyecto utiliza LangChain, combinando la recuperación dispersa BM25 y modelos densos para una recuperación híbrida; el modelo de lenguaje se ejecuta localmente a través de Ollama, y el frontend utiliza React. El proyecto se encuentra actualmente en fase de prueba de concepto y el código está disponible en GitHub (Fuente: Reddit r/deeplearning)
La herramienta de creación de aplicaciones Lovable mejora su capacidad de procesamiento de imágenes: La herramienta de creación de aplicaciones de AI Lovable ha anunciado mejoras en sus funciones de procesamiento de imágenes. Los usuarios ahora pueden subir imágenes al chat e indicar a Lovable que utilice estos materiales gráficos en la aplicación, mejorando la experiencia del usuario al construir aplicaciones que contienen elementos visuales con la ayuda de AI (Fuente: op7418)
Helios: Primera plataforma que intenta acelerar el trabajo gubernamental con AI: Joe Scheidler ha lanzado Helios, una plataforma destinada a mejorar la eficiencia del trabajo gubernamental mediante el uso de AI, descrita como “la versión de Cursor para el gobierno”. Esta plataforma es uno de los primeros intentos explícitamente dirigidos a los departamentos gubernamentales, buscando optimizar sus flujos de trabajo y eficiencia mediante la tecnología AI; sus funciones y escenarios de aplicación específicos están por verse (Fuente: timsoret)
📚 Aprendizaje
La Universidad de Zhejiang publica el libro de texto “Fundamentos de los Grandes Modelos”, explicando sistemáticamente el conocimiento de los LLM con actualizaciones continuas: El equipo de LLM de la Universidad de Zhejiang ha publicado en código abierto el libro de texto “Fundamentos de los Grandes Modelos”, con el objetivo de proporcionar a los lectores interesados en los grandes modelos de lenguaje un conocimiento básico sistemático y una introducción a las tecnologías de vanguardia. El libro incluye modelos de lenguaje tradicionales, la evolución de la arquitectura de los LLM, Prompt Engineering, ajuste fino eficiente de parámetros, edición de modelos, generación aumentada por recuperación, etc., y se actualizará mensualmente. Cada capítulo está acompañado de una lista de artículos relevantes para seguir los últimos avances. El PDF completo y el contenido por capítulos ya están disponibles en GitHub (Fuente: GitHub Trending)

Hugging Face ofrece 10 cursos gratuitos de AI, cubriendo diversos niveles y múltiples dominios de conocimiento: Hugging Face ha recopilado 10 cursos gratuitos de AI ofrecidos en su plataforma, con contenidos que abarcan desde niveles introductorios hasta avanzados sobre diversos temas populares de AI, incluyendo procesamiento del lenguaje natural, aprendizaje profundo, aprendizaje por refuerzo, procesamiento de audio, multimodalidad, etc. Estos cursos proporcionan valiosos recursos para que los estudiantes de diferentes niveles aprendan sistemáticamente el conocimiento de la AI, impulsando aún más la popularización del conocimiento de la AI y el desarrollo de la comunidad de código abierto (Fuente: huggingface, reach_vb, _akhaliq)

La Universidad de Stanford comparte experiencias y lecciones del entrenamiento del modelo Marin 8B: El equipo de Percy Liang de la Universidad de Stanford ha publicado una revisión detallada de su experiencia entrenando el modelo Marin 8B desde cero (y superando al modelo base Llama 3.1 8B en múltiples benchmarks). Este honesto registro incluye todos los descubrimientos del equipo y los errores cometidos durante el proceso de desarrollo, proporcionando a la comunidad una valiosa experiencia real en la construcción de LLM y enfatizando la importancia del ensayo y error y la iteración en el proceso de investigación científica (Fuente: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AI y Predibase colaboran para lanzar un curso sobre ajuste fino reforzado (RFT) de LLM: DeepLearning.AI de Andrew Ng, en colaboración con Predibase, ha lanzado un curso corto gratuito sobre el uso de GRPO (Group Relative Policy Optimization) para el ajuste fino reforzado (RFT) con el fin de mejorar el rendimiento de los LLM. El curso, impartido por Travis Addair, cofundador y CTO de Predibase, entre otros, tiene como objetivo ayudar a los alumnos a dominar cómo utilizar el aprendizaje por refuerzo para transformar pequeños LLM de código abierto en motores de inferencia para casos de uso específicos con solo una pequeña cantidad de datos etiquetados (Fuente: DeepLearningAI)
La página de artículos de Hugging Face añade una función de resumen generado por AI: Hugging Face ha introducido una nueva función en su página de visualización de artículos, proporcionando un resumen de una sola frase generado por AI para cada artículo. Este resumen tiene como objetivo resumir de forma concisa y clara el contenido principal del artículo, ayudando a los usuarios a filtrar y comprender rápidamente la literatura de investigación, y mejorando la accesibilidad y eficiencia de uso de los recursos académicos. Esta función es impulsada por LLM de código abierto, lo que refleja la filosofía de “AI potenciando la investigación en AI” (Fuente: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

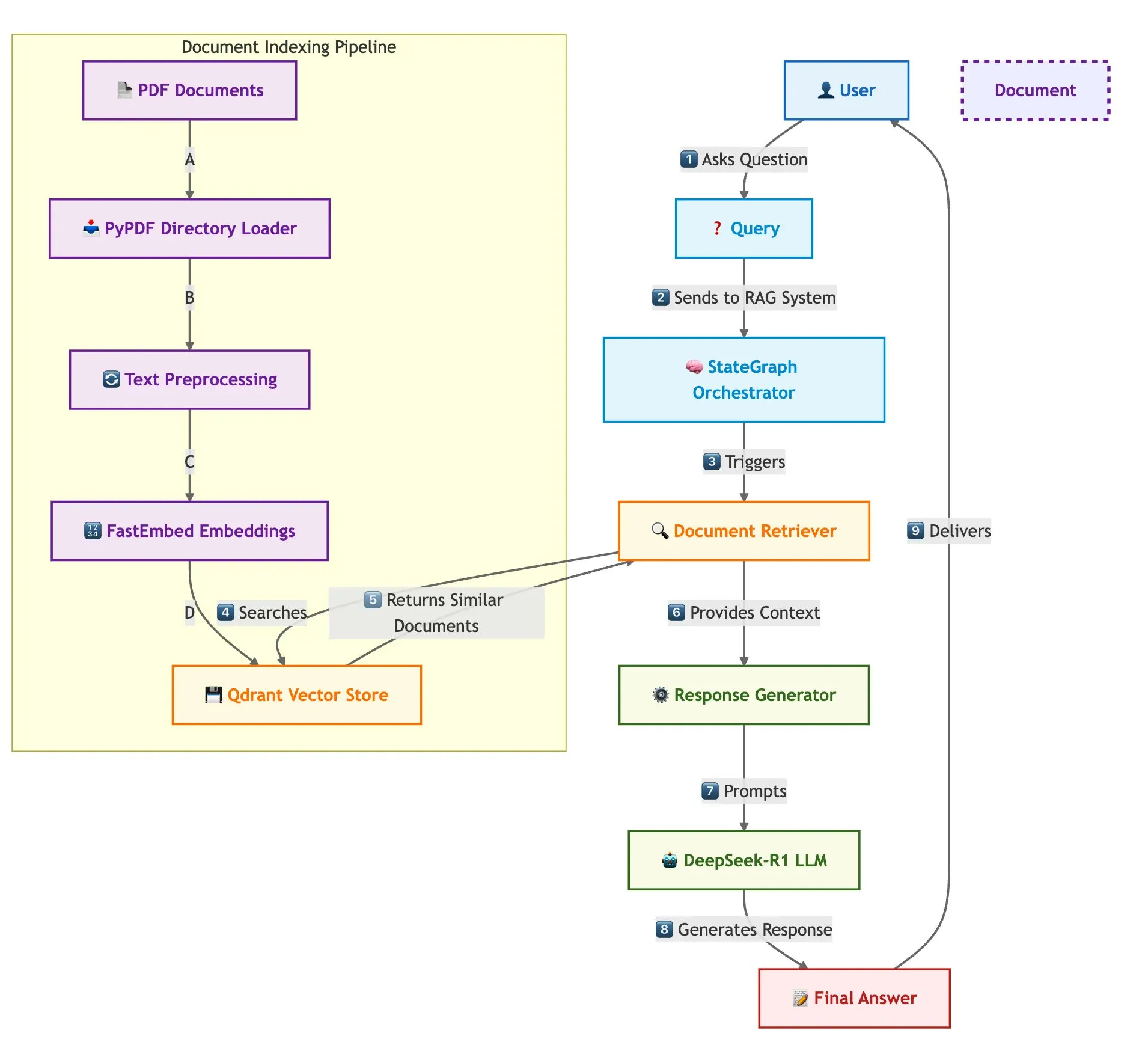
Qdrant, SambaNova y otros presentan conjuntamente una solución para construir sistemas RAG multidocumento rápidos: Un blog técnico presenta cómo utilizar la base de datos vectorial Qdrant, SambaNova, DeepSeek-R1 y LangGraph para construir un sistema de generación aumentada por recuperación (RAG) multidocumento rápido y eficiente en memoria. Esta solución logra un ahorro de memoria de 32 veces mediante cuantización binaria, utiliza DeepSeek-R1 para respuestas LLM rápidas y centralizadas, y se apoya en LangGraph para la orquestación modular, siendo adecuada para escenarios de procesamiento de múltiples documentos a gran escala (Fuente: qdrant_engine)
Publicado el resumen en mandarín de la cumbre LangChain Interrupt 2025: Se ha publicado el resumen en mandarín de la cumbre LangChain Interrupt 2025. Esta cumbre atrajo a más de 800 participantes de todo el mundo, quienes compartieron experiencias y perspectivas futuras sobre la construcción de agentes de AI, y se anunciaron varios productos como LangGraph Platform y LangGraph Studio v2, además de debatir temas como la ingeniería de agentes y la observabilidad de la AI (Fuente: hwchase17)
Andi Marafioti publica el tutorial nanoVLM, explicando paso a paso el entrenamiento de un modelo de lenguaje visual con PyTorch puro: Andi Marafioti ha publicado un nuevo tutorial en su blog, llamado nanoVLM, que detalla cómo entrenar tu propio modelo de lenguaje visual (VLM) desde cero utilizando PyTorch puro. El contenido del tutorial es fácil de entender y seguir, con el objetivo de ayudar a los principiantes a dominar rápidamente el proceso de entrenamiento de VLM (Fuente: LoubnaBenAllal1)

Ferenc Huszár explica las cadenas de Markov de tiempo continuo y su aplicación en modelos de lenguaje de difusión: El investigador de aprendizaje profundo Ferenc Huszár ha publicado una entrada de blog que explica de forma clara e intuitiva las cadenas de Markov de tiempo continuo (CTMCs), un componente clave de los modelos de lenguaje de difusión (DLMs) como Mercury y Gemini Diffusion. El artículo explora diferentes perspectivas de las cadenas de Markov y sus conexiones con los procesos puntuales, proporcionando una referencia valiosa para comprender la base teórica de los DLM (Fuente: fhuszar)
💼 Negocios
La empresa de “AI artificial” Builder.ai se declara en quiebra tras recaudar casi 500 millones de dólares: Builder.ai (antes Engineer.ai), una empresa británica que afirmaba revolucionar el desarrollo de software con AI y que llegó a estar valorada en 1.000 millones de dólares, anunció esta semana su liquidación por quiebra. Anteriormente se había revelado que muchas funciones de su plataforma de AI eran en realidad realizadas manualmente por ingenieros en la India. A pesar de haber obtenido casi 500 millones de dólares de financiación de instituciones de renombre como Microsoft y SoftBank DeepCore, la empresa finalmente se quedó sin fondos debido a dudas sobre la autenticidad de su tecnología, una gestión financiera caótica y disputas legales del fundador, además de adeudar 30 millones de dólares a Microsoft y 85 millones de dólares a Amazon por servicios en la nube (Fuente: 36氪)

LMArena.ai (antes LMSys) obtiene una financiación semilla de 100 millones de dólares, pasando de ser una aplicación de Gradio a la comercialización: LMArena.ai, originalmente un proyecto académico basado en Gradio llamado LMSys (para la competición y evaluación de LLM), anunció una ronda de financiación semilla de 100 millones de dólares, liderada por a16z y la sociedad de inversión de la Universidad de California. Esta financiación permitirá a LMArena continuar su investigación en AI fiable y la operación de su plataforma, marcando la transición de un exitoso proyecto académico de código abierto a una operación comercial. Esto también subraya el potencial de herramientas de prototipado rápido como Gradio para incubar proyectos de AI influyentes (Fuente: ClementDelangue, _akhaliq, clefourrier)
La guerra por el talento en AI se intensifica: OpenAI, Google y otros ofrecen salarios millonarios para atraer personal: La competencia por el talento en el sector de la AI en Silicon Valley se ha vuelto encarnizada, y los investigadores de primer nivel (IC) se han convertido en el recurso principal por el que compiten gigantes como OpenAI, Google y xAI, con salarios anuales más incentivos en acciones que suelen superar los diez millones de dólares. Por ejemplo, OpenAI ofreció una bonificación de 2 millones de dólares y más de 20 millones en acciones para retener a un investigador senior que consideraba unirse a SSI; Google DeepMind también ofrece salarios de 20 millones de dólares anuales a talentos de primer nivel. Esta intensa competencia se debe a la enorme contribución de unos pocos talentos clave al desarrollo de grandes modelos de lenguaje, y su permanencia o partida puede influir directamente en el éxito o fracaso de los modelos de AI (Fuente: 36氪)
🌟 Comunidad
La capacidad de Sora con el chino parece haber mejorado, pero las limitaciones del modelo persisten: Usuarios de redes sociales han observado que Sora, el modelo de generación de vídeo de OpenAI, parece haber progresado en el manejo del texto en chino, siendo capaz de generar escenas que contienen caracteres chinos. Sin embargo, los usuarios también señalan que el modelo todavía tiene sus limitaciones y el contenido generado no es perfecto; aceptar esta imperfección puede ser una norma en la interacción con los modelos de AI en la etapa actual (Fuente: dotey)

Gemini lanza la función de “examen” para informes detallados, ayudando a la reutilización del conocimiento y al ciclo de aprendizaje cerrado: Google Gemini ha lanzado una nueva función que permite a Gemini realizar pruebas directamente después de que el usuario lea informes detallados. Esta función tiene como objetivo verificar el grado real de comprensión del contenido por parte del usuario y construir un ciclo de aprendizaje nativo de AI de “aprender → examinar → complementar → reaprender”, enfatizando que el núcleo del aprendizaje en la era de la AI reside en la capacidad de reutilizar el conocimiento en lugar de la cantidad de lectura (Fuente: dotey)
La función de memoria de ChatGPT genera preocupaciones entre los usuarios sobre el control: La nueva función de ChatGPT “aprender de los chats para recordar”, que permite al modelo recordar información de conversaciones pasadas del usuario para proporcionar respuestas más personalizadas en interacciones posteriores, ha generado preocupación entre algunos usuarios avanzados. Consideran que esto cambia la forma de interactuar con el modelo y prefieren tener un control total sobre el contenido de entrada del modelo, no deseando que el modelo utilice información histórica sin su conocimiento o sin un control preciso (Fuente: random_walker)
El rápido desarrollo de los AI Agents podría cambiar los futuros modelos de trabajo: La comunidad debate activamente el rápido desarrollo de los AI Agents y su impacto potencial en los futuros modelos de trabajo. Se considera que los AI Agents están evolucionando de simples herramientas de preguntas y respuestas a “empleados virtuales” capaces de completar tareas complejas de forma independiente (como codificación, investigación, soporte al cliente). Kevin Weil, CPO de OpenAI, predice que la capacidad de los AI Agents aumentará rápidamente, pasando de un nivel de ingeniero junior a un nivel de arquitecto en un año. Microsoft también ha propuesto el concepto de “red de agentes inteligentes”, lo que sugiere que el trabajo futuro podría girar en torno a la gestión y orquestación de agentes de AI (Fuente: rowancheung, 量子位)
La AI tiene un gran potencial en el diagnóstico médico, pero genera preocupación profesional entre los médicos: La AI está demostrando capacidades asombrosas en el diagnóstico médico; por ejemplo, un estudio afirma que el modelo o1-preview muestra una capacidad sobrehumana en tareas de razonamiento y diagnóstico médico, y los casos de AI detectando neumonía en segundos también han llamado la atención. Esto ha convertido el diagnóstico asistido por AI en un tema candente, pero también ha hecho que algunos médicos con 20 años de experiencia se preocupen por sus perspectivas profesionales, llegando incluso a bromear con ir a trabajar a McDonald’s. La comunidad discute que la AI debería considerarse más como una herramienta para ayudar a los médicos a mejorar la eficiencia y la precisión, en lugar de un reemplazo completo (Fuente: paul_cal, Reddit r/ArtificialInteligence)
Los editores de noticias acusan al nuevo modo de búsqueda con AI de Google de “robo”: La News Media Alliance y otros editores han expresado su fuerte descontento con el nuevo modo de búsqueda con AI de Google, calificándolo de “robo”. Consideran que la AI de Google extrae directamente información del contenido de las noticias y la integra en los resultados de búsqueda, eludiendo los sitios web de noticias y perjudicando el tráfico y los ingresos publicitarios de los editores, lo que ha desencadenado un intenso debate sobre los derechos de autor del contenido y el uso justo en la era de la AI (Fuente: Reddit r/artificial)
El modelo DeepSeek se utiliza en China para la adivinación tradicional, lo que suscita un debate sobre los límites de la aplicación de la AI: Algunos usuarios han descubierto que una gran parte del tráfico del modelo DeepSeek en China proviene de usuarios que lo utilizan para actividades de adivinación tradicional como la consulta del I Ching. Este fenómeno ha suscitado un debate sobre los límites de la aplicación de la AI y la adaptación cultural, y también refleja indirectamente la diversa exploración y demanda de las capacidades de la AI por parte de los usuarios (Fuente: menhguin, cto_junior)

💡 Otros
El robot humanoide de la empresa Figure completa un turno continuo de 20 horas en la línea de producción de BMW: La empresa de robots humanoides Figure anunció que su robot completó con éxito un turno de trabajo continuo de 20 horas en la línea de producción del BMW X3. Anteriormente, el robot había realizado pruebas de turnos de 10 horas durante varias semanas. Figure afirma que esta es la primera vez a nivel mundial que un robot humanoide completa un trabajo continuo de tan larga duración en una línea de producción de automóviles, demostrando su potencial en el campo de la automatización industrial (Fuente: adcock_brett, TheRundownAI)
Diferencias y conexiones entre Agentic AI y GenAI: La comunidad ha discutido los conceptos de Agentic AI (AI agéntica) y Generative AI (AI generativa). La AI generativa se refiere principalmente a la AI que puede crear nuevo contenido (texto, imágenes, código, etc.), mientras que la AI agéntica enfatiza más la autonomía, la orientación a objetivos y la capacidad de interactuar y actuar con el entorno. La AI agéntica suele utilizar la AI generativa como una de sus capacidades principales para comprender, planificar y ejecutar tareas, y es una dirección importante para el desarrollo de la AI hacia una inteligencia autónoma más avanzada (Fuente: Ronald_vanLoon, Ronald_vanLoon)

La aplicación de la AI en la investigación científica está subestimada, y existe un fenómeno de “maquillaje de resultados”: La comunidad señala que el potencial de la aplicación de la AI en la investigación científica es enorme pero podría estar subestimado, y al mismo tiempo existe un fenómeno de investigadores que “maquillan” los resultados de los experimentos de AI para publicarlos. Por ejemplo, en campos como las ecuaciones en derivadas parciales (PDEs), el rendimiento real de la AI podría no ser tan sobresaliente como se presenta en los artículos. Esto sugiere que la comunidad científica necesita evaluar de manera más rigurosa y transparente el papel real y las limitaciones de la AI en los descubrimientos científicos (Fuente: clefourrier)