Palabras clave:OpenAI, Jony Ive, hardware de IA, Google I/O, Gemini, Mistral AI, Devstral, programación de IA, adquisición de io por OpenAI, Gemini 2.5 Pro, modelo de código abierto Devstral, herramienta de producción de cine IA Flow, agente de programación IA Jules
🔥 Enfoque
OpenAI anuncia la adquisición de la startup de hardware de IA de Jony Ive, io, por 6.500 millones de dólares: OpenAI confirma la adquisición de io, la empresa de hardware de IA fundada por el exjefe de diseño de Apple, Jony Ive, en colaboración con SoftBank, por un valor aproximado de 6.500 millones de dólares. Jony Ive se desempeñará como Director Creativo de OpenAI, responsable del diseño de productos. El equipo de io, compuesto por unas 55 personas, se unirá a OpenAI para dedicarse al desarrollo de dispositivos de hardware de IA de nueva forma, y se espera que el primer producto se lance en 2026. Esta adquisición marca la entrada oficial de OpenAI en el campo del hardware, con el objetivo de crear dispositivos de computación personal y experiencias interactivas nativas de IA, lo que podría desafiar el panorama actual del mercado de smartphones y dispositivos de computación. (Fuente: 量子位, 智东西, 新芒xAI, sama, Reddit r/artificial, dotey, steph_palazzolo, karinanguyen_, kevinweil, npew, gdb, zachtratar, shuchaobi, snsf, Reddit r/ArtificialInteligence)

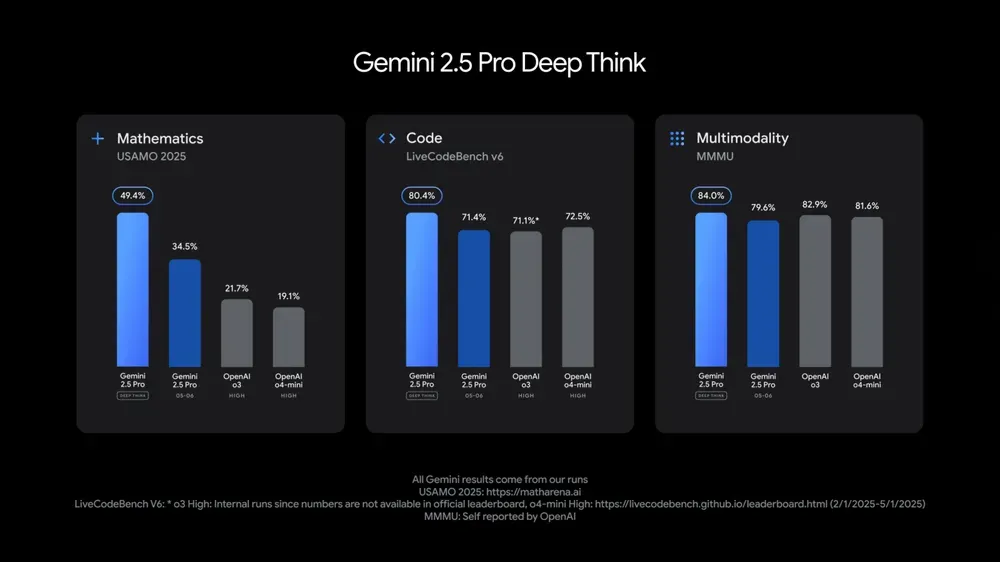
Google I/O presenta múltiples modelos y aplicaciones de IA, enfatizando la integración de la IA en la vida diaria: En la conferencia de desarrolladores I/O 2025, Google presentó Gemini 2.5 Pro y su versión de pensamiento profundo (Deep Think), el modelo ligero Gemini 2.5 Flash, el modelo de difusión de texto Gemini Diffusion, el modelo de generación de imágenes Imagen 4 y el modelo de generación de video Veo 3. Veo 3 admite la generación de videos con audio y diálogo, con resultados sorprendentes. Google también lanzó la aplicación de creación cinematográfica con IA Flow, que integra Veo, Imagen y Gemini. La función de búsqueda con IA integrará resúmenes de IA, Deep Search e información personal, y lanzará el AI Mode. Google enfatizó la integración perfecta de la IA en sus productos y servicios existentes, con el objetivo de hacer que la tecnología de IA sea “invisible” y mejorar la experiencia del usuario. (Fuente: , MIT Technology Review, dotey, JeffDean, demishassabis, GoogleDeepMind, Google, Reddit r/ChatGPT)

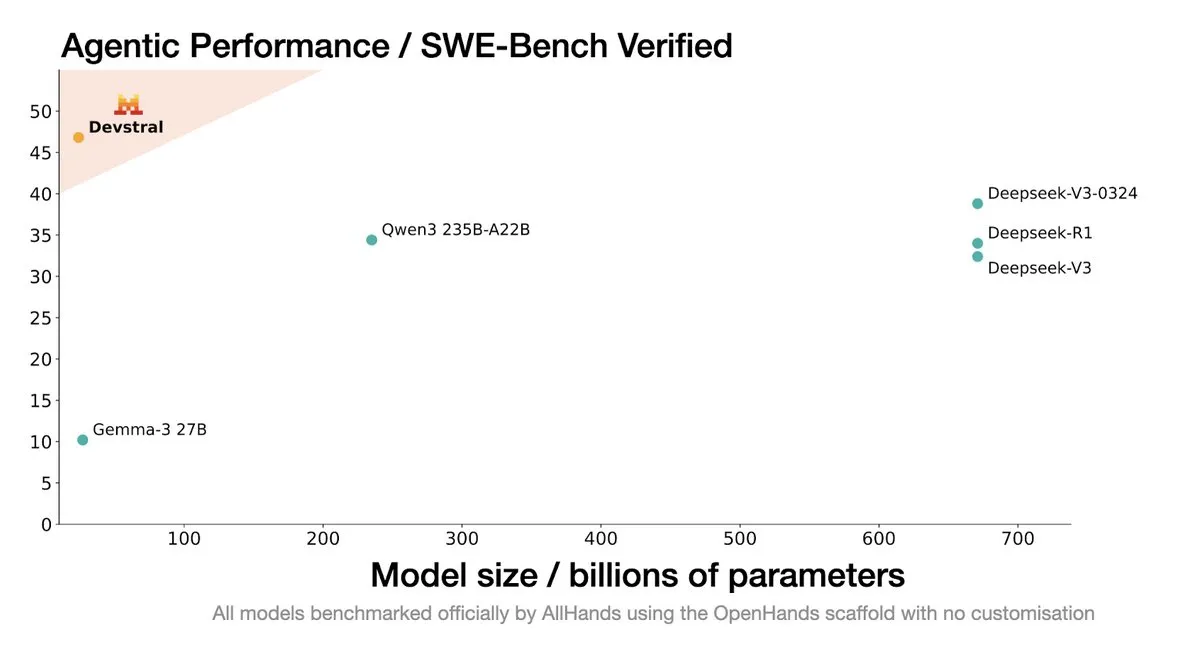
Mistral AI lanza Devstral: un modelo SOTA de código abierto diseñado para agentes de codificación inteligentes: Mistral AI, en colaboración con All Hands AI, ha lanzado Devstral, un modelo SOTA de código abierto diseñado específicamente para agentes de codificación inteligentes. Este modelo ha demostrado un rendimiento sobresaliente en el benchmark SWE-Bench Verified, superando a la serie DeepSeek y a Qwen3 235B, con solo 24B de parámetros, y puede ejecutarse en una única tarjeta RTX4090 o en un Mac con 32G de memoria. Devstral está entrenado en Issues reales de GitHub, enfatizando la comprensión contextual en grandes bases de código, la identificación de relaciones entre componentes y la detección de errores en funciones complejas. Adopta la licencia de código abierto Apache 2.0, siendo más abierto que su predecesor Codestral. (Fuente: MistralAI, natolambert, karminski3, qtnx_, huggingface, arthurmensch)
El CTO de Google DeepMind, Koray Kavukcuoglu, analiza Veo 3, Deep Think y los avances hacia la AGI: Durante el Google I/O, el CTO de DeepMind, Koray Kavukcuoglu, fue entrevistado para discutir los avances en el modelo de generación de video Veo 3 (como la sincronización de audio y video), el modo de razonamiento mejorado Deep Think en Gemini 2.5 Pro (mediante cadenas de pensamiento paralelas) y sus perspectivas sobre la AGI. Kavukcuoglu enfatizó que la escala no es el único factor para alcanzar la AGI; la arquitectura, los algoritmos, los datos y las técnicas de razonamiento son igualmente importantes. La realización de la AGI requiere avances en la investigación fundamental e innovaciones clave, no simplemente una acumulación de ingeniería. También se mostró optimista sobre el “vibe coding” para empoderar a personas sin experiencia en codificación para construir aplicaciones. (Fuente: demishassabis, 36氪)
🎯 Movimientos
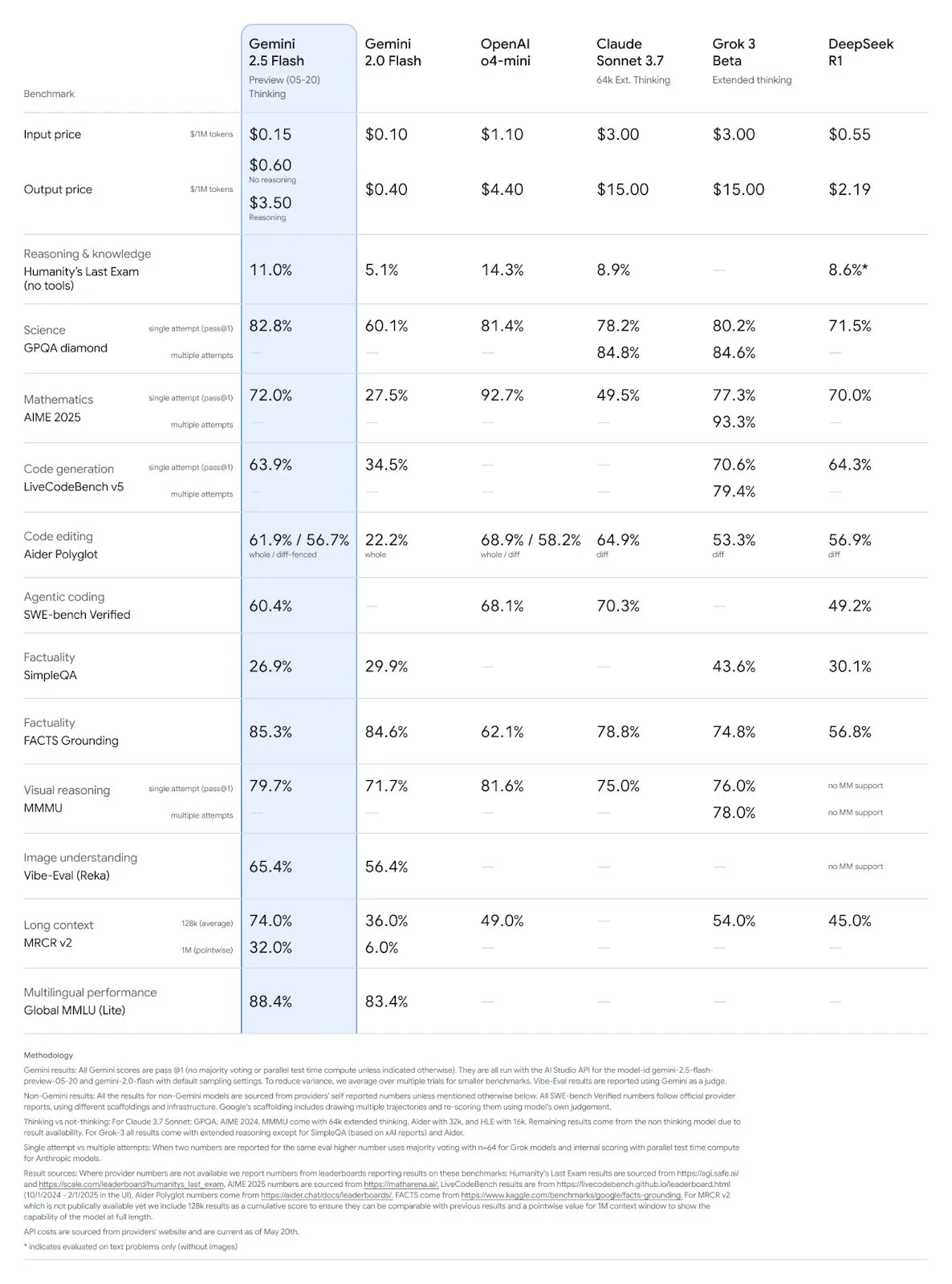
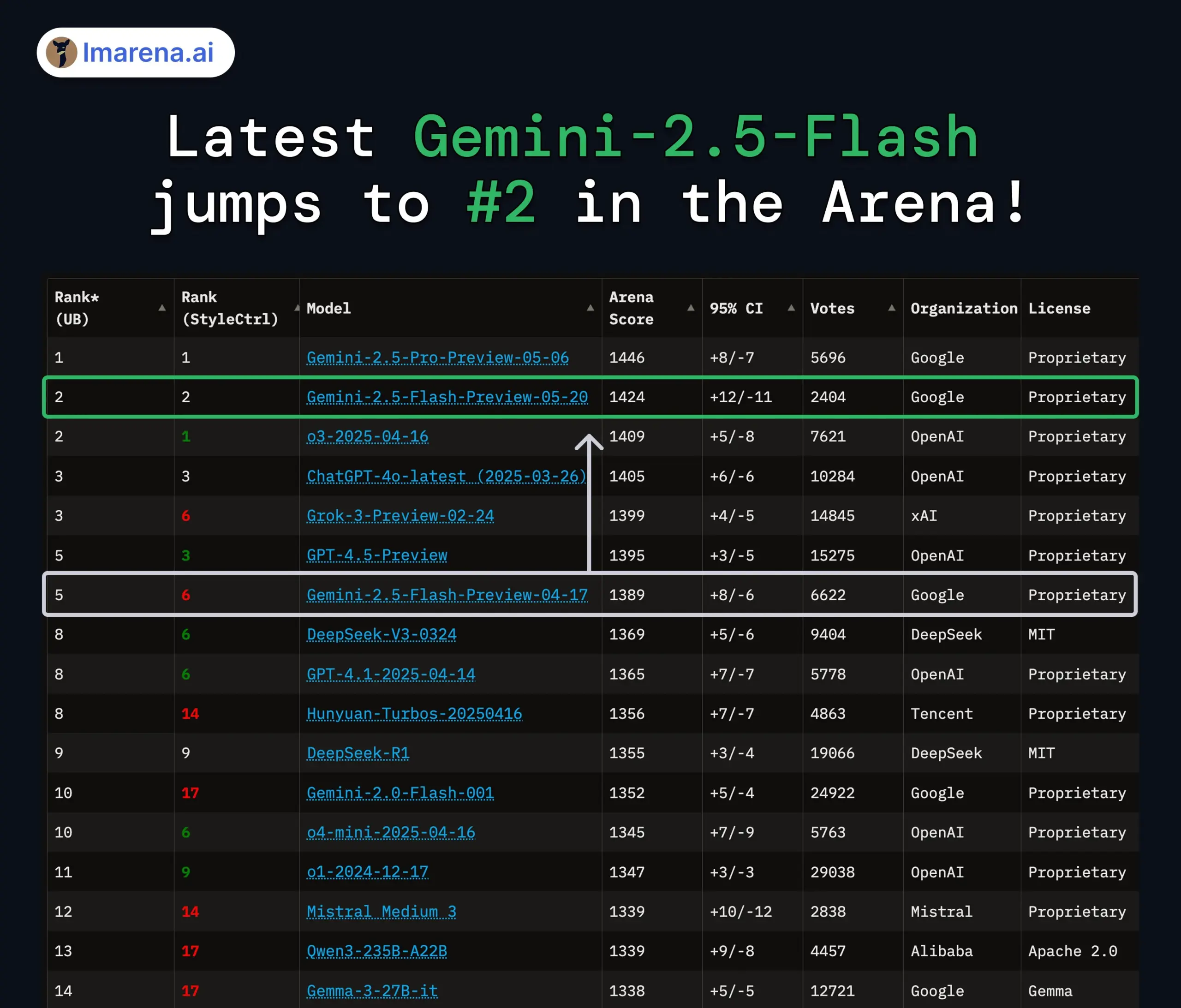
Actualización de los modelos Gemini 2.5 Pro y Flash de Google, con mejoras significativas de rendimiento: Google anunció en el I/O que los modelos Gemini 2.5 Pro y Flash se lanzarán oficialmente en junio. Gemini 2.5 Pro se promociona como el modelo de IA más inteligente del mundo, con una nueva versión de pensamiento profundo (Deep Think) que lidera en múltiples pruebas. Gemini 2.5 Flash, como modelo ligero, ha mejorado su eficiencia en un 22%, reducido el consumo de tokens en un 20%-30% y cuenta con capacidad nativa de generación de audio. Los datos de LMArena muestran que la nueva versión de Gemini-2.5-Flash ha ascendido drásticamente al segundo lugar en la arena de chatbots, destacando especialmente en tareas complejas como codificación y matemáticas. (Fuente: natolambert, demishassabis, karminski3, lmarena_ai)
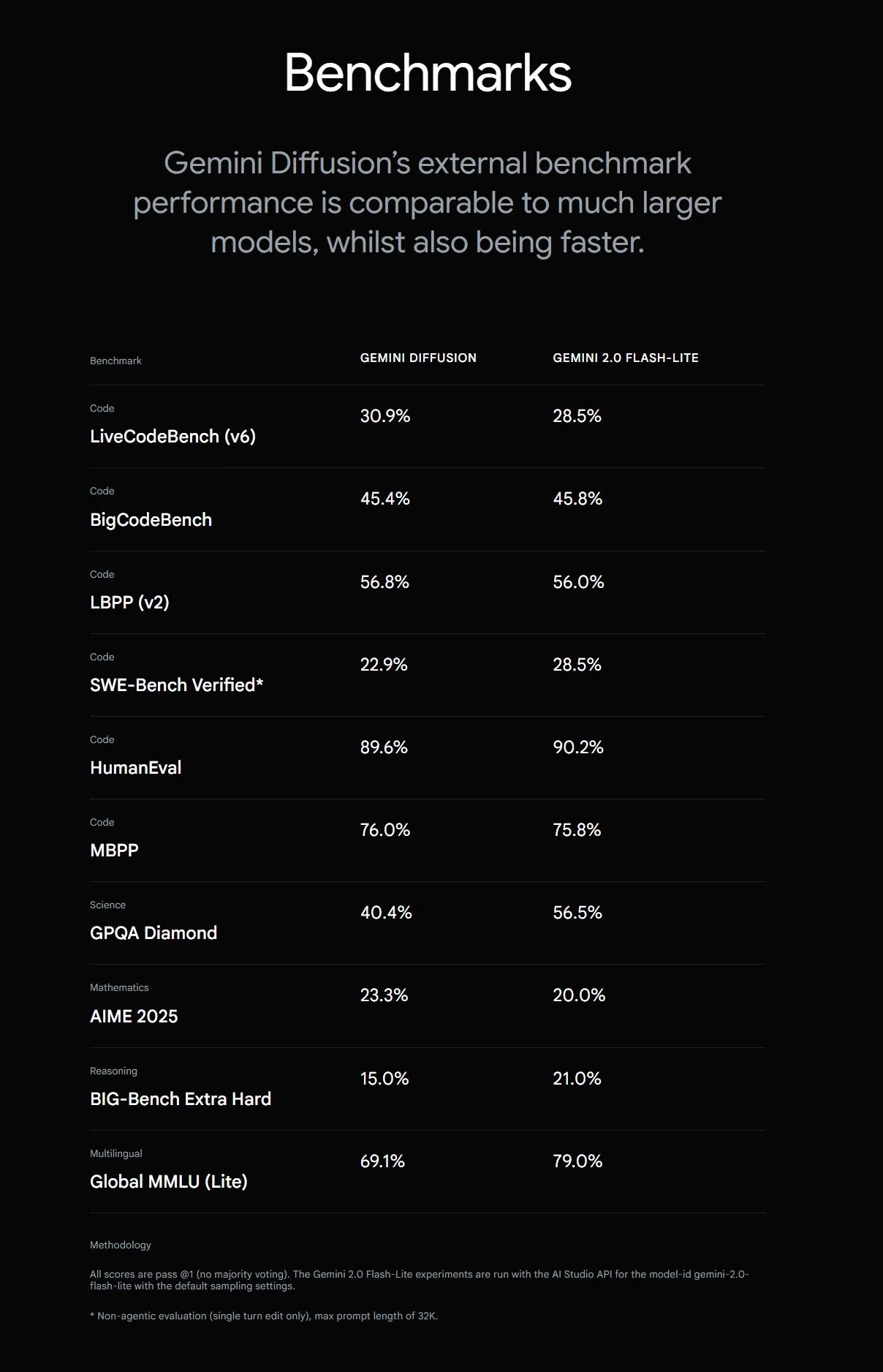
Google lanza Gemini Diffusion, aumentando la velocidad de generación de texto en 5 veces: Google DeepMind ha lanzado el modelo experimental de generación de texto Gemini Diffusion, cuya velocidad de generación es 5 veces más rápida que el modelo más rápido anterior. Su capacidad de programación es particularmente destacada, alcanzando los 2000 tokens por segundo (incluyendo tokenización y otros gastos generales). A diferencia de los modelos autorregresivos tradicionales, los modelos de difusión pueden realizar inferencias no causales, permitiéndoles “pensar” de antemano en las respuestas posteriores, superando a GPT-4o en la resolución de problemas complejos que requieren razonamiento global (como problemas de cálculo específicos o búsqueda de números primos). Actualmente, este modelo solo está disponible para desarrolladores mediante solicitud. (Fuente: OriolVinyalsML, dotey, karminski3)
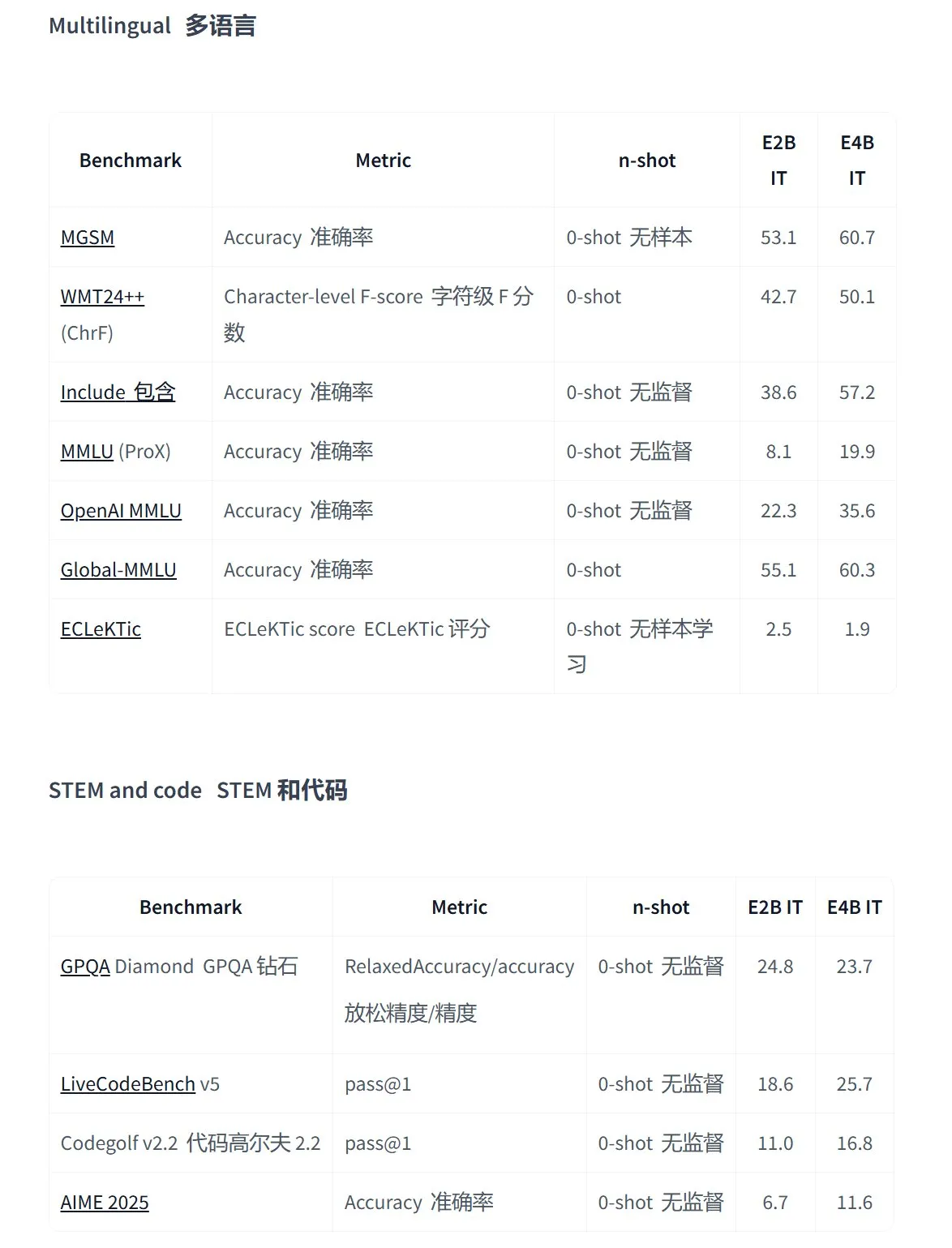
Google lanza la serie de modelos de código abierto Gemma 3n, diseñados para aplicaciones multimodales en el dispositivo: Google ha presentado la nueva generación de modelos multimodales de código abierto eficientes Gemma 3n, diseñados específicamente para dispositivos de bajo consumo. Admiten entrada de texto, voz, imagen y video, así como procesamiento multilingüe. Esta serie de modelos (como gemma-3n-E4B-it-litert-preview y gemma-3n-E2B-it-litert-preview) son compactos (3-4.4GB), pueden ejecutarse en dispositivos con 2GB de RAM y su conocimiento está actualizado hasta junio de 2024. Actualmente están disponibles en vista previa para desarrolladores en las plataformas AI Studio y AI Edge. (Fuente: demishassabis, karminski3, huggingface, Ar_Douillard, GoogleDeepMind)
La API Responses de OpenAI añade soporte MCP, generación de imágenes y funciones de Code Interpreter: La plataforma para desarrolladores de OpenAI anunció importantes actualizaciones para su API Responses (anteriormente conocida como Assistants API), añadiendo soporte para servidores de protocolo de contexto de modelo remoto (MCP), lo que permite a los agentes de IA interactuar de manera más flexible con herramientas y servicios externos. Además, la API ha integrado capacidades de generación de imágenes y funciones de Code Interpreter, ampliando aún más sus escenarios de aplicación y potencial de desarrollo. (Fuente: gdb, npew, OpenAIDevs, snsf)
La API de xAI integra la función de búsqueda en tiempo real Grok Live Search: xAI anunció la adición de la función Live Search a su API, permitiendo a Grok buscar datos en tiempo real desde la plataforma X, internet, noticias y otras fuentes. Esta función se encuentra actualmente en fase de prueba Beta y está disponible de forma gratuita para los desarrolladores por tiempo limitado, con el objetivo de mejorar la capacidad de Grok para obtener y procesar la información más reciente, y así apoyar la creación de aplicaciones de IA más dinámicas y ricas en información. (Fuente: xai, TheGregYang, yoheinakajima)

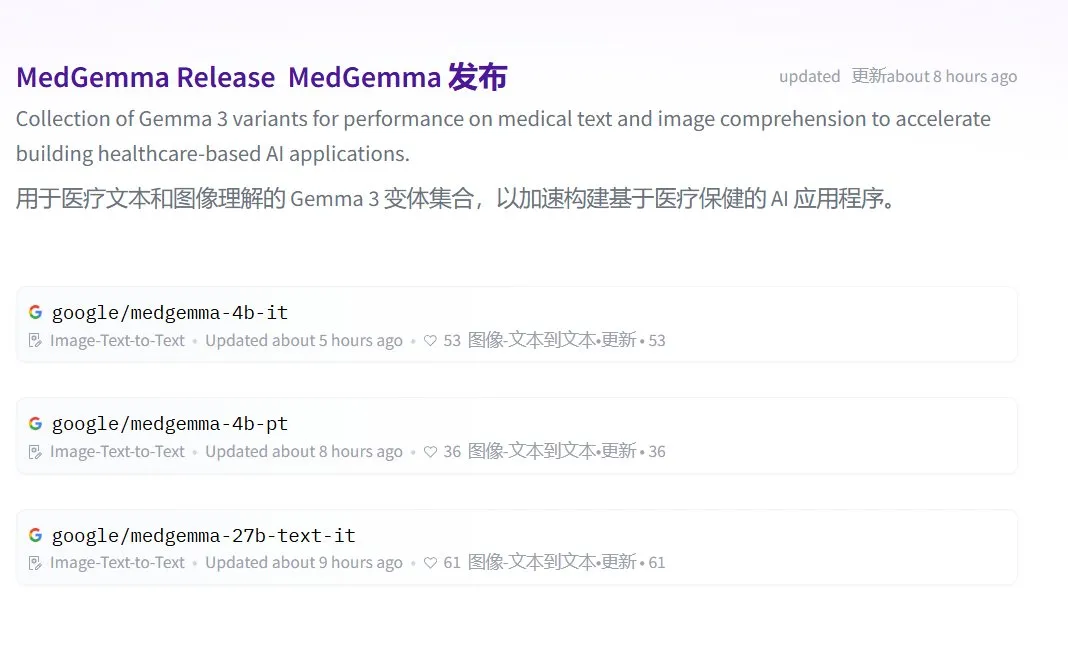
Google lanza la serie MedGemma de grandes modelos médicos de código abierto: Google ha presentado MedGemma, una serie de modelos médicos de código abierto basados en la arquitectura Gemma 3. Incluye medgemma-4b-pt (base), medgemma-4b-it (multimodal, para diagnóstico por imágenes médicas) y medgemma-27b-text-it (solo texto, para consultas e historiales médicos). Estos modelos han sido entrenados específicamente para la comprensión de textos e imágenes médicas, con el objetivo de mejorar las capacidades de la IA en el sector sanitario, como la ayuda al diagnóstico y el análisis de historiales clínicos. Los modelos ya están disponibles en Hugging Face. (Fuente: JeffDean, karminski3)
El gran modelo Hunyuan de Tencent actualiza varios productos y lanza una plataforma abierta de agentes inteligentes: Tencent Hunyuan anunció la actualización iterativa de su modelo insignia de pensamiento rápido TurboS y su modelo de pensamiento profundo T1. TurboS ha entrado en el top ten mundial en capacidades de código y matemáticas. Se han lanzado el nuevo modelo de inferencia visual profunda T1-Vision y el modelo de llamadas de voz de extremo a extremo Hunyuan Voice. El motor de conocimiento original se ha actualizado a la “Plataforma de Desarrollo de Agentes Inteligentes de Tencent Cloud”, integrando capacidades de RAG y Agent. También se han actualizado Hunyuan Image 2.0, 3D v2.5 y el modelo de generación visual para juegos, y se planea continuar abriendo modelos base multimodales y plugins. (Fuente: 36氪)

Alibaba y la Universidad de Zhejiang proponen la ley de escalado de computación paralela ParScale: El equipo de investigación de Alibaba, en colaboración con la Universidad de Zhejiang, ha propuesto una nueva Ley de Escalado: la Ley de Escalado de Computación Paralela (ParScale). Esta ley señala que aumentar la computación paralela del modelo durante el entrenamiento y la inferencia puede mejorar la capacidad de los grandes modelos sin aumentar los parámetros, y también mejorar la eficiencia de la inferencia. En comparación con el escalado de parámetros, el aumento de memoria de ParScale es solo del 4.5%, y el aumento de latencia es del 16.7%. Este método se logra mediante la transformación diversificada de entradas, el procesamiento paralelo y la agregación dinámica de salidas, mostrando un rendimiento notable especialmente en tareas de fuerte razonamiento como matemáticas y programación. (Fuente: 36氪)
Microsoft lanza Aurora, un modelo base atmosférico a gran escala, que aumenta la velocidad de predicción 5000 veces: Microsoft y sus colaboradores han lanzado el primer modelo base atmosférico a gran escala, Aurora, entrenado con más de 1 millón de horas de datos geofísicos. Puede predecir con mayor precisión y eficiencia la calidad del aire, las trayectorias de los ciclones tropicales, la dinámica de las olas marinas y el clima de alta resolución. En comparación con el avanzado sistema de predicción numérica IFS, Aurora aumenta la velocidad de cálculo aproximadamente 5000 veces y alcanza el estado del arte (SOTA) en múltiples áreas clave de predicción. La arquitectura de este modelo es flexible y puede ajustarse para tareas específicas, lo que promete impulsar la popularización de la predicción del sistema terrestre. (Fuente: 36氪)

La búsqueda con IA de Google lanzará el AI Mode, integrando múltiples funciones inteligentes: Google anunció el lanzamiento del “AI Mode” para su motor de búsqueda, promocionado como “la búsqueda con IA más potente”. Este modo, basado en Gemini 2.5, cuenta con una mayor capacidad de razonamiento, admite consultas más largas, búsqueda multimodal y respuestas instantáneas de alta calidad. En el futuro, también integrará la función “Deep Search”, que puede realizar cientos de consultas simultáneamente y proporcionar informes completos. Además, planea integrar datos personales de Gmail y otros servicios, así como la interacción con la cámara en tiempo real de Project Astra y la gestión automática de tareas de Project Mariner. (Fuente: dotey, Google)

Se lanza el modelo de generación de imágenes Imagen 4 de Google, con mejoras drásticas en velocidad y detalle: Google ha lanzado su último modelo de texto a imagen, Imagen 4, afirmando que la velocidad de generación ha aumentado entre 3 y 10 veces en comparación con la generación anterior. Las imágenes son más ricas en detalles, los resultados más precisos y la capacidad de renderizado de texto también ha mejorado significativamente. Imagen 4 puede generar objetos complejos como telas, gotas de agua, pelo de animales, etc., con una resolución de hasta 2K, y admite la creación de tarjetas de felicitación, carteles, cómics, etc. Este modelo ya está disponible de forma gratuita en la aplicación Gemini, Whisk y las aplicaciones de Workspace, así como en Vertex AI. (Fuente: dotey, GoogleDeepMind)
Investigación revela riesgo de “alucinación de paquetes de software” en código generado por herramientas de programación con IA: Un estudio que se publicará próximamente en USENIX Security 2025 señala que el fenómeno de “alucinación de paquetes de software” es común en el código generado por IA, es decir, las bibliotecas de terceros referenciadas simplemente no existen. La investigación probó 16 grandes modelos de lenguaje principales y descubrió que más del 20% del código dependía de paquetes de software ficticios, siendo la proporción aún mayor en los modelos de código abierto. Esto crea oportunidades para ataques a la cadena de suministro, ya que los atacantes pueden utilizar estos nombres de paquetes ficticios para publicar código malicioso. Empresas como Apple y Microsoft ya han sido víctimas de ataques de confusión de dependencias de este tipo. (Fuente: 36氪)

Suno lanza la función Remix, permitiendo a los usuarios crear a partir de canciones existentes: La plataforma de generación de música con IA Suno ha lanzado la función Remix, que permite a los usuarios seleccionar cualquier pista de la plataforma para su recreación. Los usuarios pueden realizar operaciones como Cover (versión), Extend (extender) o Reuse Prompt (reutilizar la indicación) en las canciones. Las creaciones Remix conservarán la información de origen del material original, y los usuarios también podrán activar o desactivar el permiso Remix para sus propias obras en cualquier momento. (Fuente: SunoMusic)
Investigación descubre que todos los modelos de incrustación aprenden estructuras semánticas similares: Jack Morris y otros investigadores han descubierto que las estructuras semánticas aprendidas por diferentes modelos de incrustación (embedding models) son altamente similares. Incluso es posible mapear entre los espacios de incrustación de diferentes modelos basándose únicamente en la información estructural, sin necesidad de datos emparejados. Este hallazgo sugiere la posible existencia de alguna estructura geométrica universal en los espacios de incrustación, lo cual tiene implicaciones importantes para la compatibilidad entre modelos, el aprendizaje por transferencia y la comprensión de la naturaleza de las incrustaciones. (Fuente: menhguin, torchcompiled, dilipkay, jeremyphoward)
Artículo discute el problema del “impuesto de alucinación” en el ajuste fino por aprendizaje reforzado (RFT): Una investigación de Taiwei Shi y otros señala que, si bien el ajuste fino por aprendizaje reforzado (RFT) mejora la capacidad de razonamiento de los grandes modelos de lenguaje, también puede hacer que el modelo genere con confianza respuestas alucinatorias cuando se enfrenta a preguntas que no puede responder, lo que denominan el “impuesto de alucinación”. El estudio introduce el conjunto de datos SUM (problemas matemáticos sintéticos sin respuesta) para la validación, y encuentra que el entrenamiento RFT estándar reduce significativamente la tasa de rechazo del modelo. Al agregar una pequeña cantidad de datos SUM en el RFT, se puede restaurar eficazmente el comportamiento de rechazo apropiado del modelo y mejorar su conciencia sobre su propia incertidumbre y límites de conocimiento. (Fuente: teortaxesTex)

🧰 Herramientas
Google lanza la herramienta de producción cinematográfica con IA Flow, integrando Veo, Imagen y Gemini: Google ha presentado Flow, una herramienta de producción cinematográfica y televisiva con IA que integra sus más recientes modelos de generación de video Veo 3, de generación de imágenes Imagen 4 y el modelo multimodal Gemini. A través de Flow, los usuarios pueden utilizar lenguaje natural y gestión de recursos para crear fácilmente cortometrajes de calidad cinematográfica, incluyendo la generación de fragmentos a partir de indicaciones de texto, la combinación de escenas, la construcción de narrativas y el guardado de elementos de uso frecuente como material. Esta herramienta tiene como objetivo ayudar a los creadores a producir obras con calidad cinematográfica de manera rápida y eficiente. Actualmente está disponible para usuarios suscriptores de Google AI Pro y Ultra en Estados Unidos. (Fuente: dotey, op7418)

Google lanza el agente de programación con IA en la nube Jules, impulsado por Gemini 2.5 Pro: Google ha presentado Jules, un agente de programación con IA basado en Gemini 2.5 Pro. Jules puede procesar automáticamente tareas en repositorios de código en segundo plano, como la corrección de errores (bugs) y la refactorización de código, y admite la ejecución de múltiples tareas en paralelo. Además, Jules ofrece Codecasts, un podcast actualizado diariamente que ayuda a los usuarios a conocer las últimas novedades del repositorio de código. Esta herramienta ya está disponible para prueba gratuita. (Fuente: dotey, karminski3, GoogleDeepMind)
LangChain lanza la plataforma de agentes inteligentes de código abierto y sin código Open Agent Platform (OAP): LangChain ha lanzado Open Agent Platform (OAP), una plataforma de código abierto y sin código orientada a usuarios comunes para construir, prototipar y desplegar agentes de IA. OAP permite construir agentes a través de una interfaz de usuario web (Web UI), conectarse a servidores RAG para mejorar la recuperación de información, extender herramientas externas a través de MCP y orquestar flujos de trabajo de múltiples agentes utilizando Agent Supervisor. Su objetivo es permitir que los desarrolladores no profesionales también puedan aprovechar la potente funcionalidad de los agentes LangGraph. (Fuente: LangChainAI, Hacubu)

Google Labs lanza la herramienta de diseño de UI con IA Stitch: Google Labs ha lanzado Stitch, una herramienta de diseño de UI con IA que integra los modelos más recientes de DeepMind de Google (incluyendo Gemini e Imagen) y puede generar rápidamente diseños de UI de alta calidad. Los usuarios pueden actualizar temas de interfaz mediante lenguaje natural, ajustar imágenes automáticamente, realizar traducciones de contenido multilingüe y exportar código frontend con un solo clic. Stitch es una evolución del anterior Galileo AI, cuyos fundadores se han unido al equipo de Google. (Fuente: dotey)
LangChain lanza el sandbox de código local LangChain Sandbox: LangChain ha lanzado LangChain Sandbox, que permite a los agentes de IA ejecutar de forma segura código Python no confiable localmente. Proporciona un entorno de ejecución aislado y permisos configurables, sin necesidad de ejecución remota o contenedores Docker, y admite la persistencia del estado entre múltiples ejecuciones a través de sesiones. Esto ofrece una herramienta más segura y conveniente para construir agentes de IA capaces de ejecutar código (como los codeact agents). (Fuente: hwchase17, Hacubu)
Vitalops lanza Datatune de código abierto: una herramienta LLM para procesar grandes conjuntos de datos con lenguaje natural: Vitalops ha lanzado Datatune de código abierto, una herramienta que permite a los usuarios procesar conjuntos de datos de cualquier tamaño mediante instrucciones en lenguaje natural. Datatune admite operaciones Map y Filter, puede conectarse a múltiples proveedores de LLM como OpenAI, Azure, Ollama, o modelos personalizados, y utiliza Dask DataFrame para el particionamiento y procesamiento paralelo. Esta herramienta tiene como objetivo simplificar tareas como la limpieza y el enriquecimiento de datos, reemplazando expresiones regulares complejas o código personalizado. (Fuente: Reddit r/MachineLearning)
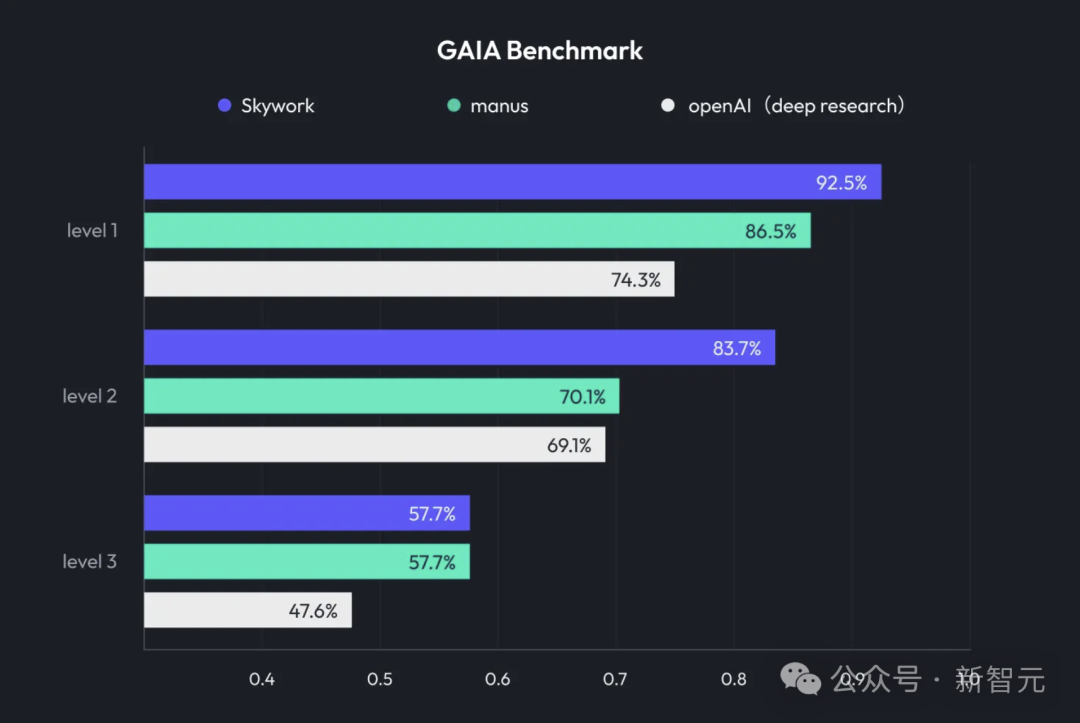
Kunlun Wanwei lanza Skywork Super Agents, integrando Deep Research y salida multimodal: Kunlun Wanwei ha lanzado su producto de ofimática con IA, Skywork Super Agents, que combina capacidades de investigación profunda (Deep Research) con la funcionalidad de salida multimodal de agentes inteligentes generales. Este producto admite la creación de PPT, redacción de documentos, procesamiento de hojas de cálculo, generación de páginas web, creación de podcasts y otros escenarios de oficina, enfatizando la trazabilidad del contenido para reducir las alucinaciones y ofreciendo funciones de edición en línea y exportación. Kunlun Wanwei también ha abierto el código del framework Deep Research Agent y el MCP relacionado. (Fuente: 36氪)
Google lanza SynthID Detector para ayudar a identificar contenido generado por IA: Google ha lanzado SynthID Detector, un nuevo portal web diseñado para ayudar a periodistas, profesionales de los medios e investigadores a identificar más fácilmente si el contenido lleva una marca de agua SynthID. SynthID es una tecnología desarrollada por Google para añadir una marca de agua invisible al contenido generado por IA (incluyendo imágenes, audio, video o texto). El lanzamiento de esta herramienta de detección contribuye a aumentar la transparencia y la trazabilidad del contenido generado por IA. (Fuente: dotey, Google)
Feishu (Lark) lanza la función “Knowledge Q&A”, creando una herramienta de preguntas y respuestas con IA exclusiva para empresas: Feishu ha lanzado la nueva función “Knowledge Q&A”, una herramienta que, basándose en toda la información a la que los empleados de la empresa tienen acceso en Feishu (mensajes, documentos, base de conocimientos, etc.), y combinando grandes modelos como DeepSeek-R1, Doubao (豆包) y tecnología RAG, proporciona a los empleados respuestas precisas y soporte para la creación de contenido. Su característica distintiva es que las respuestas se ajustan dinámicamente según la identidad y los permisos del interrogador dentro de la empresa, con el objetivo de integrar la IA sin problemas en el flujo de trabajo diario y mejorar la eficiencia de la gestión y utilización del conocimiento empresarial. (Fuente: 量子位)

Animon: la primera plataforma japonesa de generación de anime con IA, enfocada en la calidad del estilo “二次元” (2D) y generación gratuita ilimitada: La empresa japonesa CreateAI (anteriormente TuSimple Future) ha lanzado Animon, una plataforma de generación de anime con IA personalizada para la creación de anime. Esta plataforma fusiona la estética del anime japonés con la tecnología de IA, enfatizando la consistencia del estilo visual y la producción eficiente, y anuncia que los usuarios individuales pueden generar videos de forma gratuita e ilimitada. Animon permite generar rápidamente fragmentos de animación (aproximadamente 3 minutos) subiendo imágenes de personajes y descripciones de texto, con el objetivo de reducir las barreras para la creación de anime e impulsar un ecosistema de contenido UGC. Su empresa matriz, CreateAI, posee un gran modelo de desarrollo propio llamado Ruyi y tiene los derechos de adaptación de IPs como “El problema de los tres cuerpos” y “Jin Yong Qunxia Zhuan”, implementando una estrategia de doble motor de “contenido de desarrollo propio + plataforma de herramientas UGC”. (Fuente: 量子位)

📚 Aprendizaje
DeepLearning.AI lanza un nuevo curso: Refinamiento de LLM con GRPO: Andrew Ng anunció una colaboración con Predibase para lanzar un nuevo curso corto sobre “Refinamiento de LLM con GRPO (Group Relative Policy Optimization)”. El curso enseñará cómo usar el aprendizaje por refuerzo (específicamente el algoritmo GRPO) para mejorar el rendimiento de los LLM en tareas de razonamiento de múltiples pasos (como la resolución de problemas matemáticos y la depuración de código), sin necesidad de una gran cantidad de muestras de ajuste fino supervisado. GRPO guía al modelo a través de funciones de recompensa programables, es adecuado para tareas con resultados verificables y puede mejorar significativamente la capacidad de razonamiento de los LLM más pequeños. (Fuente: AndrewYNg, DeepLearningAI)
LlamaIndex comparte experiencia en la gestión de monorepos de Python a gran escala: El equipo de LlamaIndex compartió su experiencia en la gestión de un monorepo de Python que contiene más de 650 paquetes comunitarios. Migraron de Poetry y Pants a uv y a su herramienta de gestión de compilación de código abierto desarrollada internamente, LlamaDev, logrando una mejora del 20% en la velocidad de ejecución de pruebas, registros más claros, simplificación del desarrollo local y una reducción de la barrera de entrada para los contribuyentes. Esta experiencia es valiosa para equipos que necesitan gestionar grandes proyectos de Python. (Fuente: jerryjliu0)

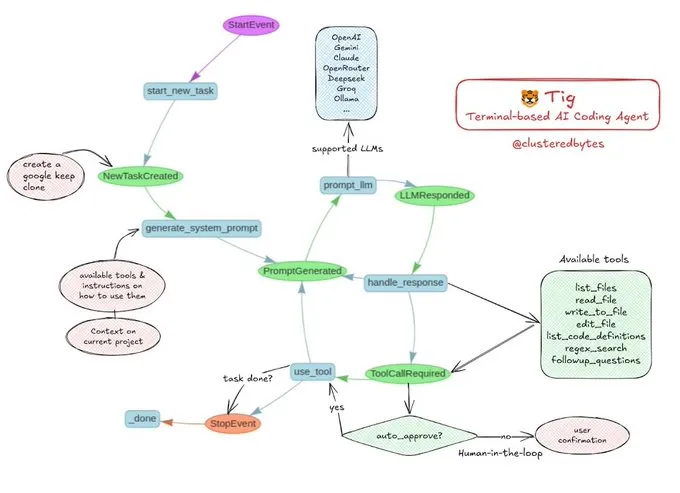
Tutorial compartido: Construye tu propio agente de codificación con IA, Tig: Jerry Liu recomendó un proyecto de agente de codificación con IA de código abierto llamado Tig. Este proyecto es un asistente de codificación basado en terminal, con intervención humana (human-in-the-loop), construido con el flujo de trabajo de LlamaIndex. Tig es capaz de escribir, depurar y analizar código en múltiples lenguajes, ejecutar comandos de shell, buscar en repositorios de código y generar pruebas y documentación, entre otras tareas. El repositorio de GitHub proporciona una guía de construcción detallada, lo que lo convierte en un excelente recurso educativo para desarrolladores que deseen aprender a construir agentes de codificación con IA. (Fuente: jerryjliu0)
Hugging Face publica una importante entrada de blog sobre VLM, presentando el laboratorio comunitario nanoVLM: Hugging Face ha publicado una entrada de blog sobre modelos de lenguaje visual (VLM), que cubre los fundamentos de VLM, su arquitectura y cómo entrenar tu propio VLM ligero. También presenta nanoVLM, un repositorio de código abierto para el ajuste fino de VLM, que ahora se ha convertido en un laboratorio comunitario para la investigación en lenguaje visual, con el objetivo de ayudar a los desarrolladores a explorar y contribuir a la investigación de VLM. (Fuente: _akhaliq, huggingface)
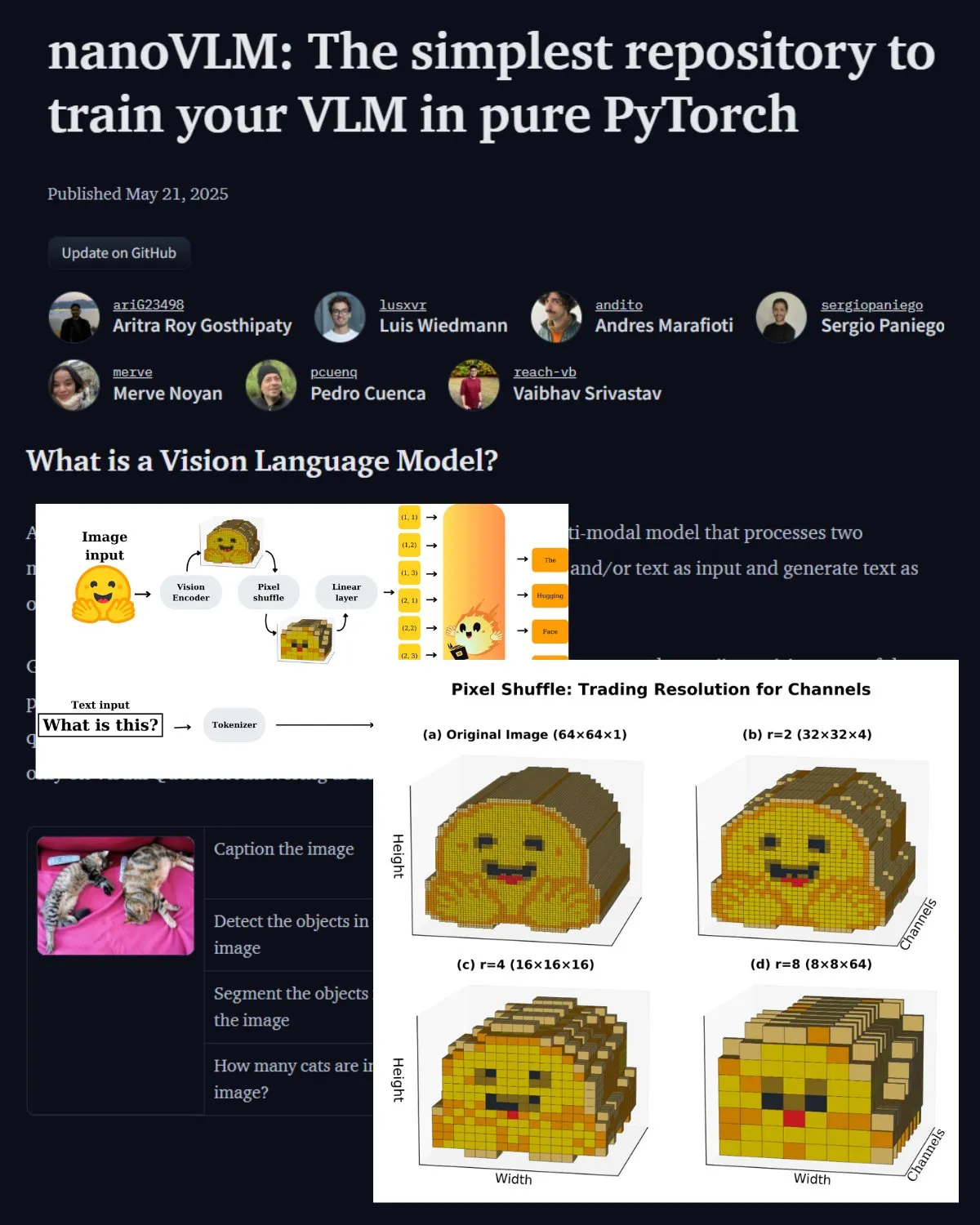
Serrano Academy publica una serie de tutoriales en video sobre el ajuste fino de LLM con aprendizaje por refuerzo: Serrano Academy ha completado y publicado una serie de tutoriales en video sobre el uso del aprendizaje por refuerzo para el ajuste fino y entrenamiento de LLM. El contenido abarca conceptos y técnicas clave como el aprendizaje profundo por refuerzo (Deep Reinforcement Learning), RLHF (Reinforcement Learning from Human Feedback), PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization) y la divergencia KL (KL Divergence). (Fuente: SerranoAcademy)
Artículo explora el fenómeno de las “capas vacías” en los grandes modelos de lenguaje: Un estudio investiga el fenómeno de que no todas las capas se activan durante el proceso de inferencia en los grandes modelos de lenguaje ajustados por instrucciones, denominando a las capas no activadas “capas vacías” (Voids). La investigación utiliza el método de computación adaptativa L2 (LAC) para rastrear las capas activadas durante las etapas de procesamiento de la indicación y generación de la respuesta, descubriendo que las capas activadas también difieren en diferentes etapas. Los experimentos demuestran que, en benchmarks como MMLU, omitir las capas vacías en Qwen2.5-7B-Instruct (usando solo el 30% de las capas) puede mejorar el rendimiento, lo que sugiere que omitir selectivamente la mayoría de las capas podría ser beneficioso para tareas específicas. (Fuente: HuggingFace Daily Papers)
Investigación propone “Soft Thinking”: desbloqueando el potencial de razonamiento de los LLM en espacios conceptuales continuos: Un artículo titulado “Soft Thinking” propone un método sin entrenamiento que simula el razonamiento “blando” similar al humano mediante la generación de tokens conceptuales abstractos y blandos en un espacio conceptual continuo. Estos tokens conceptuales se componen de una mezcla ponderada por probabilidad de incrustaciones de tokens discretos relacionados, capaces de encapsular múltiples significados de tokens discretos relevantes, explorando así implícitamente múltiples rutas de razonamiento. Los experimentos demuestran que este método mejora la precisión pass@1 en benchmarks de matemáticas y codificación, al tiempo que reduce el uso de tokens y mantiene la interpretabilidad de la salida. (Fuente: HuggingFace Daily Papers)
Artículo explora cadenas de pensamiento escalables mediante razonamiento elástico: Investigadores de Salesforce han propuesto un método para lograr cadenas de pensamiento escalables mediante el razonamiento elástico (Elastic Reasoning). Esta investigación tiene como objetivo abordar el problema de cómo los grandes modelos de lenguaje pueden generar y gestionar eficazmente largas cadenas de pensamiento al procesar tareas de razonamiento complejas, para mejorar la precisión y la eficiencia del razonamiento. Los modelos y el código relacionados se han publicado en Hugging Face. (Fuente: _akhaliq)

Estudio de investigación: ¿Mentirían los modelos de IA para salvar a niños enfermos?: Un estudio llamado LitmusValues ha creado un proceso de evaluación diseñado para revelar las prioridades de los modelos de IA en una serie de categorías de valores de IA. Mediante la recopilación de AIRiskDilemmas (una colección de dilemas que contienen escenarios relacionados con los riesgos de seguridad de la IA), los investigadores miden las elecciones de los modelos de IA en diferentes conflictos de valores, prediciendo así sus prioridades de valor e identificando riesgos potenciales. El estudio demuestra que los valores definidos en LitmusValues (incluido el cuidado, entre otros) pueden predecir comportamientos de riesgo ya observados en AIRiskDilemmas, así como comportamientos de riesgo no vistos en HarmBench. (Fuente: HuggingFace Daily Papers)
Artículo investiga el ajuste fino eficiente de modelos de difusión mediante aprendizaje por refuerzo basado en valor (VARD): Los modelos de difusión muestran un gran potencial en tareas de generación, pero su ajuste fino para atributos específicos sigue siendo un desafío. Los métodos existentes de aprendizaje por refuerzo presentan deficiencias en estabilidad, eficiencia y manejo de recompensas no diferenciables. VARD (Value-based Reinforced Diffusion) propone primero aprender una función de valor que predice la expectativa de recompensa desde estados intermedios, y luego utilizar esta función de valor y la regularización KL para proporcionar supervisión densa durante todo el proceso de generación. Los experimentos demuestran que este método puede mejorar la guía de trayectoria, aumentar la eficiencia del entrenamiento y extender la aplicación de RL a la optimización de modelos de difusión con funciones de recompensa complejas y no diferenciables. (Fuente: HuggingFace Daily Papers)
💼 Negocios
LMArena.ai (antes LMSYS.org) obtiene 100 millones de dólares en financiación semilla, liderada por a16z y la sociedad de inversión de la Universidad de California: La plataforma de evaluación de modelos de IA LMArena.ai (anteriormente LMSYS.org) anunció la finalización de una ronda de financiación semilla de 100 millones de dólares, coliderada por Andreessen Horowitz (a16z) y UC Investments (la sociedad de inversión de la Universidad de California). La empresa se dedica a construir una plataforma neutral, abierta y impulsada por la comunidad para ayudar al mundo a comprender y mejorar el rendimiento de los modelos de IA en consultas de usuarios reales. Tras la financiación, la empresa está valorada en 600 millones de dólares. (Fuente: janonacct, lmarena_ai, scaling01, _akhaliq, ClementDelangue)
El gobierno de EE. UU. anuncia la venta de tecnología y servicios de IA por valor de decenas de miles de millones de dólares a Arabia Saudita y Emiratos Árabes Unidos: El gobierno de EE. UU. anunció un acuerdo con Arabia Saudita y Emiratos Árabes Unidos para venderles tecnología y servicios de IA por valor de decenas de miles de millones de dólares. Las empresas participantes incluyen AMD, Nvidia, Amazon, Google, IBM, Oracle y Qualcomm, entre otras. Nvidia suministrará 18.000 chips de IA GB300 y posteriormente cientos de miles de GPU a la empresa saudí Humain; AMD y Humain invertirán conjuntamente 10.000 millones de dólares en la construcción de centros de datos de IA. Esta medida tiene como objetivo fortalecer la influencia de EE. UU. en la IA en la región de Oriente Medio y ayudar a ambos países a diversificar sus economías. (Fuente: DeepLearning.AI Blog)

Meta lanza el programa Llama Startup, para empoderar a startups de IA en etapa temprana: Meta anunció el lanzamiento del Llama Startup Program, diseñado para apoyar a startups estadounidenses en etapa temprana (con financiación inferior a 10 millones de dólares y al menos un desarrollador) en la innovación de aplicaciones de IA generativa utilizando los modelos Llama. El programa ofrece reembolso de recursos en la nube, soporte técnico de expertos en Llama y recursos comunitarios. La fecha límite para solicitar es el 30 de mayo de 2025 a las 6:00 PM (hora del Pacífico). (Fuente: AIatMeta)
🌟 Comunidad
El Google I/O desata un acalorado debate: la IA se integra por completo y perspectivas de futuro: El Google I/O presentó una gran cantidad de productos y actualizaciones relacionados con la IA, incluyendo la serie de modelos Gemini, la generación de video Veo 3, la generación de imágenes Imagen 4, el modo de búsqueda con IA, etc., lo que generó una amplia discusión en la comunidad. Muchos comentaristas consideran que Google ha demostrado una gran fortaleza en el nivel de aplicación de la IA, especialmente su estrategia de integrar la IA sin problemas en su ecosistema de productos existente. Al mismo tiempo, temas como la autenticidad del contenido generado por IA, la ética de la IA y el futuro camino hacia la AGI también se convirtieron en focos de discusión. (Fuente: rowancheung, dotey, karminski3, GoogleDeepMind, natolambert)

El hardware de IA se convierte en el nuevo foco, la colaboración entre OpenAI y Jony Ive atrae la atención: La noticia de la adquisición por parte de OpenAI de la empresa de hardware de IA de Jony Ive, io, así como el prototipo de gafas inteligentes Android XR presentado por Google en el I/O, encendieron el debate en la comunidad sobre el futuro del hardware de IA. La colaboración entre Sam Altman y Jony Ive se considera un intento de crear una nueva generación de dispositivos de computación personal impulsados por IA, que podrían revolucionar la forma en que interactuamos con los teléfonos móviles y ordenadores actuales. La comunidad espera en general que el hardware nativo de IA traiga experiencias revolucionarias, pero también se preocupa por su forma, funciones y aceptación en el mercado. (Fuente: dotey, sama, dotey, swyx)

El papel y los riesgos de la IA en el desarrollo de software generan debate: El lanzamiento por parte de Mistral AI del modelo Devstral, diseñado para agentes de codificación inteligentes, y la actualización de Codex por parte de OpenAI, han provocado discusiones sobre la aplicación de la IA en el desarrollo de software. La comunidad está preocupada por la capacidad real de las herramientas de programación con IA, así como por la calidad y seguridad del código generado. En particular, una investigación que señala que el código generado por IA puede hacer referencia a “paquetes de software alucinatorios” inexistentes, lo que plantea riesgos para la seguridad de la cadena de suministro, recuerda a los desarrolladores la necesidad de verificar cuidadosamente el código y las dependencias generadas por IA. (Fuente: MistralAI, DeepLearning.AI Blog, qtnx_)
El debate sobre la evaluación de modelos de IA y los benchmarks sigue candente: La enorme financiación obtenida por LMArena.ai, así como el rendimiento de diversos modelos nuevos en los benchmarks, han convertido la evaluación de modelos de IA en un tema candente en la comunidad. Los usuarios se preocupan por la capacidad real de diferentes modelos en tareas específicas (como codificación, matemáticas, preguntas de sentido común, comprensión emocional), así como por la fiabilidad y las limitaciones de los sistemas de evaluación existentes. Por ejemplo, el marco de evaluación de inteligencia emocional SAGE publicado por Tencent intenta proporcionar una nueva dimensión de evaluación para los modelos de IA desde la perspectiva de la “inteligencia emocional”. (Fuente: lmarena_ai, 36氪, natolambert)
El retraso en el desarrollo del sector tecnológico europeo suscita reflexión, Yann LeCun retuitea un debate que atribuye la causa principal a la falta de “patriotismo”: Un artículo del Wall Street Journal sobre el panorama tecnológico europeo, mucho menor que el de EE. UU. y China, generó debate. Yann LeCun retuiteó el comentario de Arnaud Bertrand. Bertrand argumenta que la razón principal del retraso tecnológico de Europa es la falta de espíritu “patriótico”; los medios y las élites europeas tienden a ensalzar a las startups estadounidenses e ignorar la innovación local, lo que dificulta que las empresas locales obtengan apoyo temprano y reconocimiento en el mercado. Cita su propia experiencia al fundar HouseTrip como ejemplo, señalando la falta de confianza y apoyo a la innovación local en Europa. (Fuente: ylecun)

💡 Otros
El consumo de energía de la IA genera preocupación: MIT Technology Review organizó una mesa redonda para debatir el problema del consumo de energía derivado del rápido desarrollo de la tecnología de IA y su impacto en el clima. A medida que aumenta la escala y el alcance de las aplicaciones de los modelos de IA, la electricidad y los recursos computacionales necesarios se incrementan drásticamente, convirtiendo la demanda energética de los centros de datos en un nuevo foco de atención. El debate se centró en el consumo de energía de una sola consulta de IA, la huella energética general de la IA y cómo abordar este desafío. (Fuente: MIT Technology Review, madiator)

Anthropic anuncia novedades, la comunidad especula sobre el posible lanzamiento de Claude 4: Anthropic ha anunciado una transmisión en vivo para el 22 de mayo a las 9:30 AM hora del Pacífico (23 de mayo, 0:00 AM hora de Beijing), lo que ha generado especulaciones en la comunidad sobre el posible lanzamiento de una nueva generación de su modelo Claude (posiblemente Claude 4). Teniendo en cuenta las recientes e importantes actualizaciones de OpenAI y Google, este movimiento de Anthropic es muy esperado. (Fuente: AnthropicAI, dotey, karminski3, scaling01, Reddit r/ClaudeAI)
Fusión de IA y tecnología XR, Google presenta un prototipo de gafas inteligentes Android XR: En la conferencia I/O, Google presentó un prototipo de gafas inteligentes Android XR, destacando su profunda integración con la IA. Este dispositivo admite asistencia inteligente desde una perspectiva en primera persona y funciones de asistencia sin contacto, permitiendo a los usuarios interactuar con el dispositivo mediante lenguaje natural para realizar consultas de información, gestionar agendas, navegación en tiempo real, etc. Esto augura que la IA se convertirá en el motor central de interacción y funcionalidad para la próxima generación de dispositivos XR, mejorando la experiencia del usuario en entornos de realidad aumentada. (Fuente: dotey, 36氪)