
Palabras clave:Gemini 2.5, Agente de IA, Modelo de lenguaje grande, Modelo de lenguaje visual, Aprendizaje por refuerzo, Modo Deep Think de Gemini 2.5 Pro, Agente GitHub Copilot de código abierto, Generación de imágenes de un solo paso MeanFlow, Razonamiento de planificación visual VPRL, Optimización de inferencia Huawei FusionSpec MoE
🔥 Destacado
Google I/O presenta múltiples avances en IA, liderados por la serie de modelos Gemini 2.5: Google anunció numerosas actualizaciones en el campo de la IA en su conferencia I/O. Gemini 2.5 Pro es aclamado como el modelo fundacional más potente actualmente, liderando en múltiples benchmarks e introduciendo el modo de inferencia mejorada Deep Think. El modelo ligero Gemini 2.5 Flash también ha sido actualizado, centrándose en la velocidad y la eficiencia. Google Search introduce el “Modo AI”, ofreciendo una experiencia de búsqueda de IA de extremo a extremo mediante Gemini 2.5, capaz de desglosar problemas complejos y realizar una minería profunda de información. El modelo de generación de video Veo 3 logra la generación sincronizada de audio y video, y el modelo de imagen Imagen 4 mejora la capacidad de procesamiento de detalles y texto. Además, se lanzaron la herramienta de producción cinematográfica con IA Flow y la aplicación práctica del proyecto de asistente de IA Project Astra, Gemini Live. Estas actualizaciones demuestran la determinación de Google de integrar completamente la IA en su ecosistema de productos, con el objetivo de mejorar la experiencia del usuario y la eficiencia de los desarrolladores (Fuente: 量子位, 36氪, WeChat)

Microsoft Build impulsa los AI Agent, GitHub Copilot recibe una importante actualización y anuncia su código abierto: Microsoft situó a los AI Agent en el centro de su conferencia para desarrolladores Build 2025, anunciando que el proyecto GitHub Copilot Extension for VSCode será de código abierto y lanzando un nuevo agente de codificación con IA (Agent). Este Agent puede completar de forma autónoma tareas como la reparación de bugs, la adición de funciones y la optimización de la documentación, integrándose profundamente en GitHub Copilot. Microsoft también presentó la plataforma de agentes inteligentes para el descubrimiento científico Microsoft Discovery, el proyecto de sitio web de interacción en lenguaje natural NLWeb, la plataforma de construcción de agentes Agent Factory y Copilot Tuning para datos empresariales personalizables. Estas iniciativas indican que Microsoft está impulsando con fuerza la aplicación de AI Agent en múltiples campos como el desarrollo y la investigación científica, con el objetivo de construir un ecosistema abierto de colaboración de agentes inteligentes (Fuente: 量子位, WeChat, WeChat)

Kevin Weil, CPO de OpenAI, expone la dirección de transformación de ChatGPT: de preguntas y respuestas a la acción, los AI Agent evolucionarán rápidamente: El Chief Product Officer de OpenAI, Kevin Weil, reveló en una entrevista que el posicionamiento de ChatGPT pasará de ser una herramienta para responder preguntas a un AI Agent capaz de ejecutar tareas para los usuarios. Prevé que los AI Agent evolucionarán rápidamente a corto plazo, pasando de ingenieros junior a ingenieros senior, e incluso a arquitectos. Esto significa que los AI Agent tendrán una mayor autonomía, capaces de resolver problemas complejos navegando por la web, pensando profundamente y resumiendo mediante inferencia. Weil también mencionó que el costo actual de entrenamiento de modelos ya es 500 veces superior al de GPT-4, pero en el futuro se mejorará la eficiencia y se reducirán los precios de las API mediante mejoras de hardware y algoritmos, para promover la popularización y el desarrollo de la IA (Fuente: 量子位, 36氪)

El equipo de Kaiming He propone MeanFlow: nuevo SOTA en generación de imágenes en un solo paso, revolucionando el paradigma tradicional sin preentrenamiento: La última investigación del equipo de Kaiming He presenta un marco de modelado generativo en un solo paso llamado MeanFlow. En el dataset ImageNet 256×256, con solo 1 evaluación de función (1-NFE), alcanza una puntuación FID de 3.43, superando a los mejores métodos anteriores de su clase en un 50%-70%, y sin necesidad de preentrenamiento, destilación o aprendizaje curricular. La innovación central de MeanFlow radica en la introducción del concepto de “campo de velocidad promedio” y la derivación de su relación matemática con el campo de velocidad instantánea, guiando así el entrenamiento de la red neuronal. Este método también puede integrar de forma natural la guía sin clasificador (CFG) sin aumentar la carga computacional adicional durante el muestreo, reduciendo significativamente la brecha de rendimiento entre los modelos generativos de un solo paso y los de múltiples pasos, y demostrando el potencial de los modelos de pocos pasos para desafiar a los modelos de múltiples pasos (Fuente: WeChat, WeChat)

🎯 Tendencias
ByteDance lanza el modelo multimodal Bagel 14B MoE, compatible con la generación de imágenes y de código abierto: ByteDance ha lanzado un modelo multimodal de Mixture-of-Experts (MoE) de 14 mil millones de parámetros llamado Bagel, con 7 mil millones de parámetros activos. Este modelo tiene capacidad de generación de imágenes y es de código abierto, bajo la licencia Apache. Sus pesos, sitio web y paper (titulado 《Emerging Properties in Unified Multimodal Pretraining》) ya han sido publicados. La comunidad ha reaccionado positivamente, considerándolo el primer modelo local capaz de generar imágenes y texto simultáneamente, y prestando atención a su posible ejecución en tarjetas gráficas de 24GB y a cuestiones de cuantización (Fuente: Reddit r/LocalLLaMA)
Mistral AI lanza Devstral: un modelo SOTA de código abierto optimizado para la codificación: Mistral AI ha lanzado Devstral, un modelo de código abierto líder diseñado específicamente para tareas de ingeniería de software, construido en colaboración por Mistral AI y All Hands AI. Devstral ha demostrado un rendimiento excepcional en el benchmark SWE-bench, convirtiéndose en el modelo de código abierto número uno en dicho benchmark. El modelo es experto en el uso de herramientas para explorar bases de código, editar múltiples archivos y potenciar agentes de ingeniería de software. Los pesos del modelo están disponibles en Hugging Face (Fuente: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

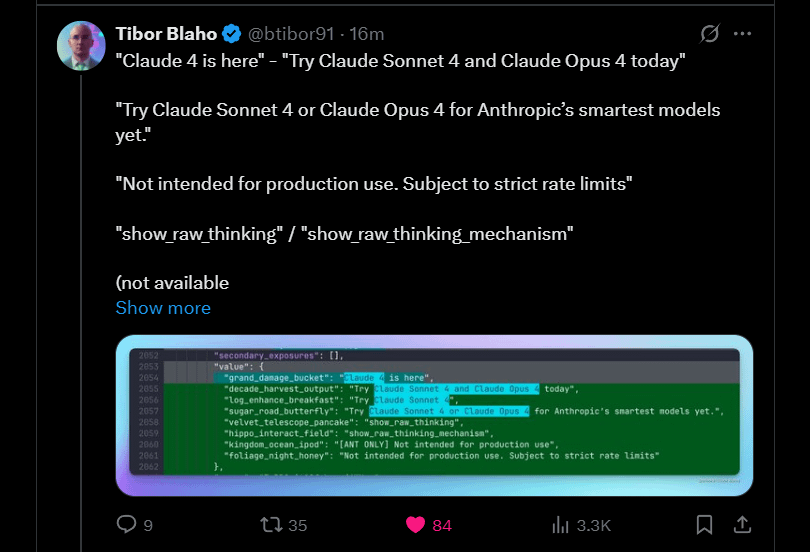
Anthropic anuncia el próximo lanzamiento de Claude 4 Sonnet y Opus: Anthropic planea lanzar las próximas versiones de su gran modelo de lenguaje Claude: Claude 4 Sonnet y Opus. Esta noticia ha generado expectación en la comunidad, y los usuarios han expresado su interés en el rendimiento de los nuevos modelos, especialmente en la mejora de la capacidad de memoria contextual. Algunos comentarios señalan que el anuncio de Google I/O podría haber impulsado a los competidores a acelerar el lanzamiento de sus mejores productos. Al mismo tiempo, los usuarios también expresaron su preocupación por las limitaciones de los nuevos modelos (como las cuotas de uso) y advirtieron a la comunidad que no tuviera expectativas demasiado altas para Opus 4, para evitar decepciones (Fuente: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Google lanza la aplicación para Android Gemma3n, compatible con inferencia LLM local: Google ha lanzado una aplicación para Android que puede interactuar con el nuevo modelo Gemma3n y ha proporcionado las soluciones MediaPipe y el repositorio de GitHub correspondientes. Los usuarios comentan que la interfaz de la aplicación es buena, pero señalan que Gemma3n actualmente no es compatible con la inferencia en GPU. Un usuario logró cargar manualmente el modelo gemma-3n-E2B y compartió datos de ejecución, mientras que la comunidad también expresó la necesidad de una versión sin censura del modelo (Fuente: Reddit r/LocalLLaMA)

Se lanza la familia de modelos de lenguaje de cabeza híbrida Falcon-H1, que incluye varias escalas de parámetros: TII UAE ha lanzado la serie Falcon-H1 de modelos de lenguaje de cabeza híbrida, con escalas de parámetros que van desde 0.5B hasta 34B. Esta serie de modelos adopta la arquitectura híbrida Mamba y es comparable en rendimiento a Qwen3. Los modelos se pueden utilizar a través de las bibliotecas Hugging Face Transformers, vLLM o una versión personalizada de llama.cpp, lo que garantiza la facilidad de uso de los modelos. La comunidad ha expresado su entusiasmo, considerándolo un avance importante, y un usuario ha creado gráficos comparativos de rendimiento. Al mismo tiempo, los investigadores también están prestando atención a sus diferencias con IBM Granite 4 en la forma en que se combinan los módulos SSM y de atención (Fuente: Reddit r/LocalLLaMA)

Google explora Gemini Diffusion: un modelo de lenguaje con arquitectura de difusión: Google ha presentado su modelo de difusión de lenguaje Gemini Diffusion, que según se informa es extremadamente rápido y tiene la mitad del tamaño de modelos de rendimiento similar. Dado que los modelos de difusión pueden procesar iterativamente todo el texto de una vez, sin necesidad de caché KV, pueden tener ventajas en eficiencia de memoria y pueden mejorar la calidad de salida aumentando el número de iteraciones. La comunidad cree que si Google puede demostrar la viabilidad de los modelos de difusión en aplicaciones a gran escala, tendrá un impacto positivo en la comunidad de IA local. Sin embargo, actualmente el modelo solo ofrece una lista de espera para la demostración y no es de código abierto ni proporciona descargas de pesos (Fuente: Reddit r/LocalLLaMA)

Investigación revela vulnerabilidad de secuestro de Agent de cero clics en el framework Browser Use (CVE-2025-47241): Una investigación de ARIMLABS.AI ha descubierto una grave vulnerabilidad de seguridad (CVE-2025-47241) en el framework Browser Use, ampliamente utilizado en más de 1500 proyectos de IA. Esta vulnerabilidad permite a los atacantes secuestrar un Agent de navegación impulsado por LLM sin necesidad de clics (zero-click), simplemente induciéndolo a visitar una página maliciosa, sin interacción del usuario para controlar el agente. Este descubrimiento ha suscitado serias preocupaciones sobre la seguridad de los agentes de IA autónomos, especialmente aquellos que interactúan con la web, y hace un llamamiento a la comunidad para que preste atención a los problemas de seguridad de los agentes de IA (Fuente: Reddit r/artificial, Reddit r/artificial)
Tencent y Alibaba compiten en el campo de AI to C, QQ Browser y Quark se enfrentan: QQ Browser, bajo el paraguas de CSIG de Tencent, anunció su actualización a un navegador de IA, lanzando AI QBot e integrando los modelos duales Tencent Hunyuan y DeepSeek, entrando formalmente en competencia con Quark de Alibaba, que ya se ha transformado en una búsqueda de IA. Este movimiento marca la aceleración del despliegue de Tencent en el campo de AI to C, formando dos líneas de productos principales: Tencent Yuanbao y QQ Browser. Los responsables clave de ambas partes, Wu Zurong (Tencent) y Wu Jia (Alibaba), también forman así un “duelo de los Wu”. Los analistas creen que QQ Browser tiene ventaja en cuanto a base de usuarios, mientras que Quark ha tomado la delantera en la transformación de IA, pero la transformación de QQ Browser es relativamente conservadora, con funciones de IA que se asemejan más a plugins y están limitadas por su modelo publicitario original. Esta competencia no es solo a nivel de producto, sino que también podría afectar el desarrollo profesional de los dos responsables en sus respectivas empresas (Fuente: 36氪)
Cambridge y Google proponen VPRL: nuevo paradigma de razonamiento de planificación puramente visual, con una precisión que supera al razonamiento basado en texto: Equipos de investigación de la Universidad de Cambridge, University College London y Google han propuesto un nuevo paradigma de planificación visual basada en aprendizaje por refuerzo (VPRL), logrando por primera vez un razonamiento basado puramente en imágenes. Este marco utiliza la optimización de políticas relativas de grupo (GRPO) para post-entrenar grandes modelos visuales. En múltiples tareas de navegación visual (como FrozenLake, Maze, MiniBehavior), su rendimiento supera con creces a los métodos de razonamiento basados en texto, alcanzando una precisión de hasta el 80% y una mejora del rendimiento de al menos el 40%. VPRL planifica directamente utilizando secuencias de imágenes, evitando la pérdida de información y la reducción de eficiencia causadas por la conversión a lenguaje, abriendo nuevas direcciones para tareas de razonamiento intuitivo de imágenes. El código correspondiente ha sido liberado como código abierto (Fuente: WeChat)

Huawei lanza FusionSpec y OptiQuant para optimizar la inferencia de grandes modelos MoE: Huawei, para hacer frente a los desafíos de velocidad y latencia en la inferencia de modelos MoE (Mixture-of-Experts) a gran escala, ha lanzado el marco de inferencia especulativa FusionSpec y el marco de cuantización OptiQuant. FusionSpec aprovecha la alta relación cómputo-ancho de banda de los servidores Ascend, optimizando el flujo del modelo principal y del modelo especulativo, reduciendo el tiempo consumido por el marco de inferencia especulativa a 1 milisegundo. OptiQuant es compatible con los principales algoritmos de cuantización como Int2/4/8 y FP8/HiFloat8, e introduce innovaciones como el “truncamiento aprendible” y la “optimización de parámetros de cuantización”, con el objetivo de reducir la pérdida de precisión del modelo y mejorar la relación costo-rendimiento de la inferencia. Estas tecnologías buscan resolver los problemas de eficiencia de inferencia y ocupación de recursos que enfrentan los modelos MoE en su despliegue (Fuente: WeChat)

El Instituto de IA de Beijing lanza tres modelos vectoriales SOTA, fortaleciendo la recuperación de código y multimodal: El Instituto de IA de Beijing (BAAI), en colaboración con varias universidades, ha lanzado BGE-Code-v1 (modelo vectorial de código), BGE-VL-v1.5 (modelo vectorial multimodal general) y BGE-VL-Screenshot (modelo vectorial de documentos visuales). BGE-Code-v1, basado en Qwen2.5-Coder-1.5B, muestra un rendimiento excelente en los benchmarks CoIR y CodeRAG. BGE-VL-v1.5, basado en LLaVA-1.6, ha establecido un nuevo récord zero-shot en el benchmark multimodal MMEB. BGE-VL-Screenshot, dirigido a tareas de recuperación de información visual (Vis-IR) como páginas web y documentos, se entrena sobre Qwen2.5-VL-3B-Instruct y ha logrado SOTA en el recién lanzado benchmark MVRB. Estos modelos tienen como objetivo proporcionar capacidades más sólidas de comprensión y recuperación de código y multimodal para aplicaciones como la generación aumentada por recuperación (RAG), y todos han sido liberados como código abierto (Fuente: WeChat)

Kuaishou y la Universidad Nacional de Singapur presentan Any2Caption, logrando generación de video controlable: Kuaishou y la Universidad Nacional de Singapur han lanzado conjuntamente el framework Any2Caption, con el objetivo de mejorar la precisión y la calidad de la generación de video controlable mediante el desacoplamiento inteligente de la comprensión de la intención del usuario y el proceso de generación de video. Este framework puede procesar condiciones de entrada de múltiples modalidades como texto, imágenes, videos, trayectorias de pose y movimiento de cámara, utilizando grandes modelos de lenguaje multimodales para convertir instrucciones complejas en “guiones de video” estructurados que guían la generación de video. Any2Caption se entrena con la base de datos Any2CapIns, que contiene 337,000 instancias de video y 407,000 condiciones multimodales. Los experimentos demuestran que puede mejorar eficazmente los resultados de los modelos de generación de video controlable existentes (Fuente: WeChat)

🧰 Herramientas
Feishu lanza la función “Knowledge Q&A”, creando un asistente de preguntas y respuestas y creación de contenido con IA exclusivo para empresas: Feishu ha lanzado la nueva función “Knowledge Q&A”, posicionada como una herramienta de preguntas y respuestas con IA exclusiva para empresas. Basándose en mensajes, documentos, bases de conocimiento, actas de reuniones (Miaoji) y otra información a la que los empleados tienen acceso en Feishu, y combinando grandes modelos como DeepSeek-R1, Doubao y tecnología RAG, proporciona respuestas precisas y soporte para la creación de contenido. Esta función enfatiza la activación y utilización del conocimiento interno de la empresa; empleados con diferentes roles pueden obtener respuestas desde diferentes perspectivas a la misma pregunta, y se respetan estrictamente los permisos organizacionales. Feishu Knowledge Q&A tiene como objetivo integrar la IA de manera fluida en los flujos de trabajo diarios, mejorar la eficiencia en la obtención de información y la colaboración, y ayudar a las empresas a construir un sistema dinámico de gestión del conocimiento (Fuente: WeChat, WeChat)
Supabase, gracias a sus ventajas de código abierto e integración con IA, se convierte en el backend preferido para la “programación ambiental”: La base de datos de código abierto Supabase, debido a su experiencia “lista para usar” con PostgreSQL y su respuesta activa a las tendencias de desarrollo de IA, se ha convertido en la opción de backend popular en el modo de “programación ambiental” (Vibe Coding). Vibe Coding enfatiza el uso de múltiples herramientas de IA para completar rápidamente todo el proceso de desarrollo, desde los requisitos hasta la implementación. Supabase, mediante la integración de PGVector, admite el almacenamiento de incrustaciones vectoriales (crucial para aplicaciones RAG), colabora con Ollama para proporcionar servicios de modelos de IA en el borde (edge), y ha lanzado su propio asistente de IA para ayudar en la generación de esquemas de bases de datos y la depuración de SQL. Recientemente, Supabase también lanzó un servidor MCP oficial, permitiendo que las herramientas de IA interactúen directamente con él. Estas características lo han hecho popular entre plataformas de creación de aplicaciones nativas de IA como Lovable y Bolt.new (Fuente: WeChat)

Hugging Face lanza nanoVLM: un kit de herramientas minimalista para entrenar modelos de lenguaje visual (VLM) en PyTorch puro: Hugging Face ha lanzado nanoVLM, un kit de herramientas ligero de PyTorch diseñado para simplificar el proceso de entrenamiento de modelos de lenguaje visual. El código del proyecto es pequeño y fácil de leer, adecuado para principiantes o desarrolladores que deseen comprender en profundidad el funcionamiento interno de los VLM. La arquitectura de nanoVLM se basa en el codificador visual SigLIP y el decodificador de lenguaje Llama 3, alineando las modalidades visual y textual mediante un módulo de proyección modal. El proyecto ofrece una forma conveniente de iniciar el entrenamiento de VLM en un Colab Notebook gratuito y ya ha publicado un modelo preentrenado basado en SigLIP y SmolLM2 para pruebas (Fuente: HuggingFace Blog)

La biblioteca Diffusers integra múltiples backends de cuantización para optimizar grandes modelos de difusión: La biblioteca Diffusers de Hugging Face ahora integra múltiples backends de cuantización como bitsandbytes, torchao, Quanto, GGUF y FP8 nativo, con el objetivo de reducir la huella de memoria y los requisitos computacionales de grandes modelos de difusión (como Flux). Estos backends admiten cuantización de diferentes precisiones (como 4 bits, 8 bits, FP8) y pueden combinarse con técnicas de optimización de memoria como CPU offloading, group offloading y torch.compile. El blog, a través de un caso de cuantización del modelo Flux.1-dev, muestra el rendimiento de cada backend en ahorro de memoria y tiempo de inferencia, y proporciona una guía de selección para ayudar a los usuarios a lograr un equilibrio entre el tamaño del modelo, la velocidad y la calidad. Algunos modelos cuantizados ya están disponibles en Hugging Face Hub (Fuente: HuggingFace Blog)

La plataforma de computación para el desarrollo de grandes modelos JoyBuild de JD.com mejora la eficiencia del entrenamiento y la inferencia: El Instituto de Exploración de JD.com ha propuesto un sistema y método para entrenar, actualizar grandes modelos en un entorno abierto y desplegarlos en colaboración con modelos pequeños. Los resultados relevantes se publicaron en la revista npj Artificial Intelligence, del grupo Nature. Esta tecnología, mediante cuatro innovaciones: destilación de modelos (destilación jerárquica dinámica), gobernanza de datos (muestreo dinámico interdominio), optimización del entrenamiento (optimización bayesiana) y colaboración nube-borde (compresión en dos etapas), mejora la eficiencia de inferencia de los grandes modelos en un promedio del 30% y reduce los costos de entrenamiento en un 70%. Esta tecnología respalda la plataforma de computación para el desarrollo de grandes modelos JoyBuild, que admite el desarrollo y ajuste de varios modelos (como el gran modelo de JD, Llama, DeepSeek), ayudando a las empresas a transformar modelos generales en modelos especializados, y ya se ha aplicado en escenarios como el comercio minorista y la logística (Fuente: WeChat)
Se inicia el proyecto de registro del Model Context Protocol (MCP): modelcontextprotocol/registry es un proyecto de servicio de registro de servidores MCP impulsado por la comunidad, actualmente en fase temprana de desarrollo. El proyecto tiene como objetivo proporcionar un repositorio central de entradas de servidores MCP, permitiendo el descubrimiento y la gestión de diversas implementaciones de MCP y sus metadatos, configuraciones y capacidades. Sus características incluyen una API RESTful para gestionar entradas, un endpoint de comprobación de estado, compatibilidad con múltiples configuraciones de entorno, compatibilidad con bases de datos MongoDB y en memoria, y documentación de la API. El proyecto está escrito en Go y proporciona una guía para un inicio rápido mediante Docker Compose (Fuente: GitHub Trending)
📚 Aprendizaje
Terence Tao publica un tutorial de demostración matemática asistida por IA, mostrando cómo usar GitHub Copilot para demostrar límites de funciones: El medallista Fields, Terence Tao, actualizó un video en su canal de YouTube, demostrando detalladamente cómo usar GitHub Copilot para ayudar a demostrar los teoremas de suma, resta y producto de límites de funciones. El tutorial enfatiza la importancia de guiar correctamente a la IA y muestra el papel de Copilot en la generación de estructuras de código y la sugerencia de funciones de biblioteca, al mismo tiempo que señala sus limitaciones en el manejo de detalles matemáticos complejos, casos especiales y el mantenimiento de la coherencia contextual. Tao concluye que Copilot es beneficioso para principiantes, pero en problemas complejos aún requiere una gran intervención y ajuste manual, y a veces combinarlo con deducciones en papel y lápiz puede ser más eficiente (Fuente: 量子位)

Un paper discute la contradicción entre la inferencia de grandes modelos y el seguimiento de instrucciones, proponiendo el concepto de atención restringida: Un artículo de investigación titulado 《When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs》 señala que después de que los grandes modelos de lenguaje utilizan el pensamiento en cadena (CoT) para la inferencia, aunque pueden parecer más inteligentes en algunos aspectos (como respetar el formato, el número de palabras), su precisión en el seguimiento estricto de las instrucciones puede disminuir. El equipo de investigación, mediante pruebas en 15 modelos de código abierto y cerrado, descubrió que los modelos, después de usar CoT, son más propensos a “tomar la iniciativa”, modificando o añadiendo información adicional e ignorando las instrucciones originales. El artículo introduce el concepto de “atención restringida” (Constraint Attention), descubriendo que la inferencia CoT reduce la atención del modelo a las limitaciones clave. La investigación también muestra que no existe una correlación significativa entre la longitud del pensamiento CoT y la precisión en la finalización de la tarea, y explora la posibilidad de mejorar el seguimiento de instrucciones mediante ejemplos de pocos disparos, autorreflexión, etc. (Fuente: WeChat)

MIT y Google proponen PASTA: un nuevo paradigma de generación paralela asíncrona de LLM basada en aprendizaje de políticas: Investigadores del Massachusetts Institute of Technology (MIT) y Google han propuesto el marco PASTA (PArallel STructure Annotation), que permite a los grandes modelos de lenguaje (LLM) optimizar autónomamente estrategias de generación paralela asíncrona mediante el aprendizaje de políticas. Este método primero desarrolla el lenguaje de marcado PASTA-LANG, utilizado para marcar bloques de texto semánticamente independientes para lograr la generación paralela. El proceso de entrenamiento se divide en dos etapas: el ajuste fino supervisado permite al modelo aprender a insertar marcadores PASTA-LANG, y luego, mediante la optimización de preferencias (basada en la relación de aceleración teórica y la evaluación de la calidad del contenido), se mejora aún más la estrategia de anotación. PASTA diseña un diseño de caché KV entrelazado y un mecanismo de control de atención para coordinar la colaboración eficiente de múltiples hilos. Los experimentos demuestran que PASTA logra una aceleración de 1.21-1.93 veces en el benchmark AlpacaEval, manteniendo o mejorando la calidad de salida, y mostrando una buena escalabilidad (Fuente: WeChat)

Paper de ICML 2025 propone TPO: nueva solución de alineación de preferencias instantánea en tiempo de inferencia, sin necesidad de reentrenamiento: El Laboratorio de IA de Shanghái propone la Optimización de Preferencias en Tiempo de Prueba (Test-Time Preference Optimization, TPO), un nuevo método que permite a los grandes modelos de lenguaje ajustar su salida de forma autónoma durante la inferencia mediante retroalimentación textual iterativa, para cumplir con las preferencias humanas. TPO logra la alineación sin actualizar los pesos del modelo simulando un proceso de “descenso de gradiente” lingüístico (generar respuestas candidatas, calcular la pérdida textual, calcular el gradiente textual, actualizar la respuesta). Los experimentos demuestran que TPO puede mejorar significativamente el rendimiento de modelos no alineados y ya alineados; por ejemplo, el modelo Llama-3.1-70B-SFT, después de dos pasos de optimización TPO, supera a la versión Instruct ya alineada en múltiples benchmarks. Este método proporciona una estrategia de expansión de inferencia de “amplitud + profundidad”, mostrando un potencial de optimización eficiente en entornos con recursos limitados (Fuente: WeChat)
Nueva investigación explora métodos para extraer conocimiento latente de los LLM: Un artículo investiga cómo extraer conocimiento que los grandes modelos de lenguaje podrían estar ocultando. Los investigadores entrenaron un modelo “tabú” diseñado para describir una palabra secreta específica sin decirla directamente, y esta palabra secreta no aparecía en los datos de entrenamiento ni en los prompts. Posteriormente, evaluaron estrategias automatizadas, tanto métodos no interpretativos (caja negra) como técnicas basadas en interpretabilidad mecanicista (como logit lens y autoencoders dispersos), para revelar este secreto. Los resultados indican que ambos enfoques pueden extraer eficazmente la palabra secreta en una configuración de prueba de concepto. Este trabajo tiene como objetivo proporcionar soluciones preliminares al problema crítico de extraer conocimiento secreto de los modelos de lenguaje para promover su despliegue seguro y fiable (Fuente: HuggingFace Daily Papers)
Paper explora la aplicación de la poda federada en grandes modelos de lenguaje (FedPrLLM): Para abordar el problema de la dificultad de obtener muestras de calibración públicas para la poda de grandes modelos de lenguaje (LLM) en dominios sensibles a la privacidad, los investigadores proponen FedPrLLM, un marco integral de poda federada. Bajo este marco, cada cliente solo necesita calcular una matriz de máscara de poda basada en datos de calibración locales y compartirla con el servidor para podar colaborativamente el modelo global, protegiendo al mismo tiempo la privacidad de los datos locales. A través de extensos experimentos, se descubrió que la poda de una sola vez (one-shot pruning) combinada con la comparación de capas (layer comparison) y sin escalado de pesos (no weight scaling) es la mejor opción dentro del marco FedPrLLM. Esta investigación tiene como objetivo guiar futuros trabajos sobre la poda de LLM en dominios sensibles a la privacidad (Fuente: HuggingFace Daily Papers)
Paper propone MIGRATION-BENCH: un benchmark para la migración de código Java 8: Investigadores han lanzado MIGRATION-BENCH, un benchmark centrado en la migración de código desde Java 8 a las versiones LTS más recientes (Java 17, 21). Este benchmark incluye un conjunto de datos completo con 5102 repositorios y un subconjunto de 300 repositorios complejos cuidadosamente seleccionados, diseñado para evaluar la capacidad de los grandes modelos de lenguaje (LLM) en tareas de migración de código a nivel de repositorio. Al mismo tiempo, el artículo proporciona un marco de evaluación integral y propone el método SD-Feedback. Los experimentos demuestran que los LLM (como Claude-3.5-Sonnet-v2) pueden manejar eficazmente tales tareas de migración, alcanzando tasas de éxito del 62.33% (migración mínima) y 27.00% (migración máxima) en el subconjunto seleccionado (Fuente: HuggingFace Daily Papers)
Paper propone CS-Sum: benchmark de resumen de conversaciones con cambio de código y análisis de limitaciones de LLM: Para evaluar la capacidad de los grandes modelos de lenguaje (LLM) para comprender el cambio de código (CS), los investigadores introducen el benchmark CS-Sum, que evalúa mediante el resumen de conversaciones con cambio de código al inglés. CS-Sum es el primer benchmark de resumen de conversaciones con cambio de código para los pares de idiomas mandarín-inglés, tamil-inglés y malayo-inglés, cada par de idiomas contiene entre 900 y 1300 conversaciones anotadas manualmente. Mediante la evaluación de diez LLM de código abierto y cerrado (incluidos métodos de pocos ejemplos, traducción-resumen y ajuste fino), la investigación descubre que, a pesar de las altas puntuaciones en las métricas de evaluación automática, los LLM aún cometen errores sutiles al procesar entradas de CS, alterando así el significado completo de la conversación. El artículo también señala los tres tipos de errores más comunes que cometen los LLM al procesar CS y enfatiza la necesidad de un entrenamiento especializado para datos con cambio de código (Fuente: HuggingFace Daily Papers)
Paper explora la capacidad de los grandes modelos para expresar confianza durante la inferencia: La investigación muestra que los grandes modelos de lenguaje (LLM) que realizan inferencia con cadena de pensamiento extendida (CoT) no solo se desempeñan mejor en la resolución de problemas, sino que también son más precisos al expresar su nivel de confianza. Mediante pruebas de referencia de seis modelos de inferencia en seis conjuntos de datos, se encontró que en 33 de 36 configuraciones, los modelos de inferencia tenían una mejor calibración de confianza que los modelos sin inferencia. El análisis sugiere que esto se debe al comportamiento de “pensamiento lento” de los modelos de inferencia (como explorar alternativas, retroceder), lo que les permite ajustar dinámicamente la confianza durante el proceso CoT. Además, eliminar el comportamiento de pensamiento lento conduce a una disminución significativa en la calibración, mientras que los modelos sin inferencia también pueden beneficiarse al ser guiados para realizar un pensamiento lento (Fuente: HuggingFace Daily Papers)
Paper: Uso de aprendizaje por refuerzo a partir de pares de preguntas y respuestas visuales para entrenar VLM en razonamiento visual (Visionary-R1): Esta investigación tiene como objetivo entrenar modelos de lenguaje visual (VLM) para razonar sobre datos de imágenes mediante aprendizaje por refuerzo y pares de preguntas y respuestas visuales, sin supervisión explícita de cadena de pensamiento (CoT). Se descubrió que aplicar simplemente el aprendizaje por refuerzo (indicando al modelo que genere una cadena de razonamiento antes de responder) puede llevar al modelo a aprender atajos de problemas simples, reduciendo su capacidad de generalización. Para abordar este problema, los investigadores proponen que el modelo siga un formato de salida “subtítulo-razonamiento-respuesta”, es decir, primero generar un subtítulo detallado de la imagen y luego construir la cadena de razonamiento. El modelo Visionary-R1, entrenado con este método, supera en rendimiento a potentes modelos multimodales como GPT-4o, Claude3.5-Sonnet y Gemini-1.5-Pro en múltiples benchmarks de razonamiento visual (Fuente: HuggingFace Daily Papers)
Paper propone VideoEval-Pro: un benchmark de evaluación de comprensión de videos largos más realista y robusto: La investigación señala que los benchmarks actuales de comprensión de videos largos (LVU) dependen en su mayoría de preguntas de opción múltiple (MCQ), que son susceptibles a la adivinación, y algunas preguntas pueden responderse sin ver el video completo, lo que sobreestima el rendimiento del modelo. Para abordar este problema, el artículo propone VideoEval-Pro, un benchmark de LVU que incluye preguntas de respuesta corta abierta, diseñado para evaluar de manera realista la comprensión del modelo de todo el video, abarcando tareas de percepción y razonamiento a nivel de fragmento y de video completo. La evaluación de 21 LMM de video muestra que el rendimiento de los modelos disminuye drásticamente en las preguntas abiertas, y que las puntuaciones altas en MCQ no se correlacionan necesariamente con puntuaciones altas en VideoEval-Pro. VideoEval-Pro se beneficia más del aumento del número de fotogramas de entrada, proporcionando un estándar de evaluación más fiable para el campo de LVU (Fuente: HuggingFace Daily Papers)
Paper: Ajuste fino de redes neuronales cuantizadas mediante optimización de orden cero (QZO): Con el crecimiento exponencial del tamaño de los grandes modelos de lenguaje, la memoria de la GPU se ha convertido en un cuello de botella para la adaptación de modelos a tareas posteriores. Esta investigación tiene como objetivo minimizar el uso de memoria de los pesos del modelo, gradientes y estados del optimizador mediante un marco unificado. Los investigadores proponen eliminar los gradientes y los estados del optimizador mediante la optimización de orden cero, que aproxima los gradientes perturbando los pesos durante la propagación hacia adelante. Para minimizar la memoria de los pesos, se utiliza la cuantización del modelo (por ejemplo, de bfloat16 a int4). Sin embargo, aplicar directamente la optimización de orden cero a los pesos cuantizados no es factible debido a la brecha de precisión entre los pesos discretos y los gradientes continuos. Para resolver este problema, el artículo propone la optimización de orden cero cuantizada (QZO), un nuevo método que estima los gradientes perturbando las escalas de cuantización continuas y utiliza un método de recorte de derivadas direccionales para estabilizar el entrenamiento. QZO es ortogonal a los métodos de cuantización post-entrenamiento basados en escalares y en libros de códigos. En comparación con el ajuste fino de todos los parámetros en bfloat16, QZO puede reducir los costos totales de memoria en más de 18 veces para LLM de 4 bits y permite que Llama-2-13B y Stable Diffusion 3.5 Large se ajusten finamente en una sola GPU de 24 GB (Fuente: HuggingFace Daily Papers)
Paper: Optimización del rendimiento de inferencia en cualquier momento mediante la optimización de políticas relativas al presupuesto (BRPO) (AnytimeReasoner): El cómputo extendido en tiempo de prueba es crucial para mejorar la capacidad de razonamiento de los grandes modelos de lenguaje (LLM). Los métodos existentes suelen emplear aprendizaje por refuerzo (RL) para maximizar una recompensa verificable al final de la trayectoria de inferencia, pero esto solo optimiza el rendimiento final bajo un presupuesto fijo de tokens, lo que afecta la eficiencia del entrenamiento y el despliegue. Esta investigación propone el marco AnytimeReasoner, diseñado para optimizar el rendimiento de inferencia en cualquier momento, mejorando la eficiencia de los tokens y la flexibilidad de la inferencia bajo diferentes restricciones presupuestarias. El método consiste en truncar el proceso completo de pensamiento para adaptarse a un presupuesto de tokens muestreado de una distribución a priori, lo que obliga al modelo a resumir la mejor respuesta para cada pensamiento truncado para su verificación, introduciendo así recompensas densas verificables durante el proceso de inferencia y promoviendo una asignación de crédito más efectiva en la optimización de RL. Además, los investigadores introducen la optimización de políticas relativas al presupuesto (BRPO), una nueva técnica de reducción de varianza, para mejorar la robustez y eficiencia del aprendizaje al reforzar las políticas de pensamiento. Los resultados experimentales en tareas de razonamiento matemático demuestran que este método supera a GRPO en todos los presupuestos de pensamiento bajo diversas distribuciones a priori, mejorando la eficiencia del entrenamiento y de los tokens (Fuente: HuggingFace Daily Papers)
Paper propone Modelos de Inferencia Híbrida a Gran Escala (LHRM): pensamiento bajo demanda para mejorar la eficiencia y la capacidad: Los recientes modelos de inferencia a gran escala (LRM) han mejorado significativamente la capacidad de razonamiento al realizar un proceso de pensamiento extendido antes de generar la respuesta final. Sin embargo, procesos de pensamiento excesivamente largos conllevan enormes costos de consumo de tokens y latencia, especialmente innecesarios para consultas simples. Esta investigación introduce los Modelos de Inferencia Híbrida a Gran Escala (LHRM), modelos que pueden decidir adaptativamente si ejecutar o no el pensamiento en función de la información contextual de la consulta del usuario. Para lograr este objetivo, los investigadores proponen un proceso de entrenamiento en dos etapas: primero, un arranque en frío mediante ajuste fino híbrido (HFT), y luego, aprendizaje por refuerzo en línea con la propuesta Optimización de Políticas de Grupo Híbrido (HGPO) para aprender implícitamente a seleccionar el modo de pensamiento apropiado. Además, los investigadores introducen la métrica de Precisión Híbrida (Hybrid Accuracy) para cuantificar la capacidad de pensamiento híbrido del modelo. Los resultados experimentales demuestran que los LHRM pueden ejecutar adaptativamente el pensamiento híbrido en consultas de diferente dificultad y tipo, y su capacidad de razonamiento y generalización supera a los LRM y LLM existentes, al tiempo que mejora significativamente la eficiencia (Fuente: HuggingFace Daily Papers)
Paper: Uso de aprendizaje por refuerzo para clasificar VisualQuality-R1 para la evaluación de la calidad de imagen inducida por razonamiento: DeepSeek-R1 ha demostrado que el aprendizaje por refuerzo puede incentivar eficazmente las capacidades de razonamiento y generalización de los grandes modelos de lenguaje (LLM). Sin embargo, en el campo de la evaluación de la calidad de imagen (IQA), que depende del razonamiento visual, el potencial del modelado computacional inducido por razonamiento aún no se ha explorado por completo. Esta investigación introduce VisualQuality-R1, un modelo de IQA sin referencia (NR-IQA) inducido por razonamiento, y utiliza el aprendizaje por refuerzo para clasificar (reinforcement learning to rank) para el entrenamiento, un algoritmo de aprendizaje adaptado a la relatividad intrínseca de la calidad visual. Específicamente, para un par de imágenes, el modelo utiliza la optimización de políticas relativas de grupo (group relative policy optimization) para generar múltiples puntuaciones de calidad para cada imagen. Estas estimaciones se utilizan luego para calcular la probabilidad de comparación de que una imagen tenga una calidad superior a otra bajo el modelo de Thurstone. La recompensa para cada estimación de calidad se define utilizando una métrica de fidelidad continua en lugar de etiquetas binarias discretas. Numerosos experimentos demuestran que el VisualQuality-R1 propuesto supera consistentemente en rendimiento a los modelos NR-IQA basados en aprendizaje profundo discriminativo, así como a los métodos recientes de regresión de calidad inducida por razonamiento. Además, VisualQuality-R1 es capaz de generar descripciones de calidad ricas en contexto y consistentes con el juicio humano, y admite el entrenamiento en múltiples conjuntos de datos sin necesidad de reajustar la escala perceptiva. Estas características lo hacen particularmente adecuado para medir de manera fiable el progreso en diversas tareas de procesamiento de imágenes, como la superresolución de imágenes y la generación de imágenes (Fuente: HuggingFace Daily Papers)
Paper: Desbloqueo de la capacidad de razonamiento general mediante “calentamiento” en condiciones de recursos limitados: Diseñar LLM eficaces con capacidad de razonamiento generalmente requiere el uso de aprendizaje por refuerzo con recompensas verificables (RLVR) o la destilación de cadenas de pensamiento (CoT) largas y cuidadosamente seleccionadas, ambos dependiendo en gran medida de grandes cantidades de datos de entrenamiento, lo que plantea un desafío significativo para escenarios donde los datos de entrenamiento de calidad son escasos. Los investigadores proponen una estrategia de entrenamiento de dos etapas eficiente en muestras para desarrollar LLM de razonamiento con supervisión limitada. En la primera etapa, el modelo se “calienta” destilando largas CoT de dominios de juguete (como los acertijos lógicos de caballeros y bribones) para adquirir habilidades de razonamiento general. En la segunda etapa, se aplica RLVR al modelo “calentado” utilizando una pequeña cantidad de muestras del dominio objetivo. Los experimentos demuestran que este método tiene varios beneficios: (i) solo la etapa de calentamiento promueve el razonamiento general, mejorando el rendimiento en una variedad de tareas (MATH, HumanEval+, MMLU-Pro); (ii) al entrenar con RLVR en el mismo conjunto de datos pequeño (≤100 muestras), los modelos calentados superan consistentemente a los modelos base; (iii) el calentamiento antes del entrenamiento con RLVR permite que el modelo mantenga la capacidad de generalización entre dominios después de ser entrenado para un dominio específico; (iv) introducir el calentamiento en el proceso no solo mejora la precisión, sino que también aumenta la eficiencia general de las muestras del entrenamiento con RLVR. Los resultados de esta investigación muestran el potencial del “calentamiento” para construir LLM de razonamiento robustos en entornos con escasez de datos (Fuente: HuggingFace Daily Papers)
Paper propone IndexMark: un marco de marca de agua sin entrenamiento para la generación autorregresiva de imágenes: La tecnología de marca de agua invisible para imágenes puede proteger la propiedad de las imágenes y prevenir el abuso malicioso de los modelos de generación visual. Sin embargo, los métodos existentes de marca de agua generativa se dirigen principalmente a modelos de difusión, mientras que la tecnología de marca de agua para modelos de generación autorregresiva de imágenes aún está por explorar. Los investigadores proponen IndexMark, un marco de marca de agua sin entrenamiento para modelos de generación autorregresiva de imágenes. IndexMark se inspira en la característica de redundancia de los libros de códigos (codebook): reemplazar los índices generados autorregresivamente con índices similares produce diferencias visuales insignificantes. El componente central de IndexMark es un método simple y efectivo de “emparejar-reemplazar”, que selecciona cuidadosamente tokens de marca de agua del libro de códigos según la similitud de tokens y generaliza el uso de tokens de marca de agua mediante el reemplazo de tokens, incrustando así la marca de agua sin afectar la calidad de la imagen. La verificación de la marca de agua se logra calculando la proporción de tokens de marca de agua en la imagen generada, y se mejora aún más la precisión mediante un codificador de índices. Además, los investigadores introducen un esquema de verificación auxiliar para mejorar la robustez contra ataques de recorte. Los experimentos demuestran que IndexMark alcanza un nivel SOTA tanto en calidad de imagen como en precisión de verificación, y muestra robustez ante diversas perturbaciones como recorte, ruido, desenfoque gaussiano, borrado aleatorio, fluctuación de color y compresión JPEG (Fuente: HuggingFace Daily Papers)
Paper: Razonamiento mediante modelos de recompensa (RRM): Los modelos de recompensa desempeñan un papel crucial en la guía de los grandes modelos de lenguaje (LLM) para producir resultados que se alineen con las expectativas humanas. Sin embargo, cómo utilizar eficazmente el cómputo en tiempo de prueba para mejorar el rendimiento del modelo de recompensa sigue siendo un desafío abierto. Esta investigación introduce los Modelos de Razonamiento de Recompensa (Reward Reasoning Models, RRMs), modelos diseñados específicamente para ejecutar un proceso de razonamiento deliberado antes de generar la recompensa final. Mediante el razonamiento de cadena de pensamiento, los RRMs pueden utilizar cómputo adicional en tiempo de prueba para consultas complejas donde la recompensa no es obvia. Para desarrollar RRMs, los investigadores implementaron un marco de aprendizaje por refuerzo que puede cultivar la capacidad de razonamiento de recompensa autoevolutiva sin necesidad de trayectorias de razonamiento explícitas como datos de entrenamiento. Los resultados experimentales demuestran que los RRMs logran un rendimiento superior en benchmarks de modelado de recompensas en múltiples dominios. Es de destacar que los investigadores muestran que los RRMs pueden utilizar adaptativamente el cómputo en tiempo de prueba para mejorar aún más la precisión de la recompensa. Los modelos de razonamiento de recompensa preentrenados están disponibles en HuggingFace (Fuente: HuggingFace Daily Papers)
Paper: Guía del pensamiento utilizando expertos cognitivos en MoE para mejorar el razonamiento sin entrenamiento adicional: Las arquitecturas de Mixture-of-Experts (MoE) en los grandes modelos de razonamiento (LRM) han logrado impresionantes capacidades de razonamiento mediante la activación selectiva de expertos para facilitar procesos cognitivos estructurados. A pesar de los avances significativos, los modelos de razonamiento existentes a menudo se ven afectados por ineficiencias cognitivas como el pensamiento excesivo y el pensamiento insuficiente. Para abordar estas limitaciones, los investigadores introducen un novedoso método de guía en tiempo de inferencia llamado “Refuerzo de Expertos Cognitivos” (Reinforcing Cognitive Experts, RICE), diseñado para mejorar el rendimiento del razonamiento sin entrenamiento adicional ni heurísticas complejas. Utilizando la información mutua puntual normalizada (nPMI), los investigadores identifican sistemáticamente expertos especializados, denominados “expertos cognitivos”, responsables de coordinar operaciones de razonamiento a nivel meta caracterizadas por tokens específicos (como “«`”). Las evaluaciones experimentales en benchmarks cuantitativos y de razonamiento científico rigurosos en LRM basados en MoE líderes (DeepSeek-R1 y Qwen3-235B) demuestran que RICE logra mejoras significativas y consistentes en la precisión del razonamiento, la eficiencia cognitiva y la generalización entre dominios. Fundamentalmente, este enfoque ligero supera sustancialmente en rendimiento a las técnicas populares de guía del razonamiento (como el diseño de prompts y las restricciones de decodificación), al tiempo que preserva la capacidad general de seguimiento de instrucciones del modelo. Estos resultados destacan el refuerzo de los expertos cognitivos como una dirección prometedora, práctica e interpretable para mejorar la eficiencia cognitiva dentro de los modelos de razonamiento avanzados (Fuente: HuggingFace Daily Papers)
Paper: Explorando el impacto de la permutación del contexto en el rendimiento de los modelos de lenguaje en preguntas y respuestas de múltiples saltos: Las preguntas y respuestas de múltiples saltos (MHQA) plantean un desafío para los modelos de lenguaje (LM) debido a su complejidad. Cuando se les pide a los LM que procesen múltiples resultados de búsqueda, no solo deben recuperar información relevante, sino también realizar inferencias de múltiples saltos a través de las fuentes de información. Aunque los LM se desempeñan bien en tareas tradicionales de preguntas y respuestas, la máscara causal puede obstaculizar su capacidad para razonar en contextos complejos. Esta investigación explora cómo responden los LM a preguntas de múltiples saltos permutando los resultados de búsqueda (documentos recuperados) en diferentes configuraciones. La investigación encontró que: 1) los modelos codificador-decodificador (como la serie Flan-T5) generalmente superan a los LM de solo decodificador causal en tareas de MHQA, a pesar de ser mucho más pequeños; 2) cambiar el orden de los documentos de oro revela diferentes tendencias en los modelos Flan T5 y los modelos de solo decodificador ajustados, con el mejor rendimiento cuando el orden de los documentos se alinea con el orden de la cadena de inferencia; 3) modificar la máscara causal para mejorar la atención bidireccional de los modelos de solo decodificador causal puede mejorar eficazmente su rendimiento final. Además, la investigación realiza una investigación exhaustiva de la distribución de los pesos de atención de los LM en el contexto de MHQA, encontrando que cuando la respuesta es correcta, los pesos de atención tienden a alcanzar su punto máximo en valores más altos. Los investigadores utilizan este hallazgo para mejorar heurísticamente el rendimiento de los LM en esta tarea (Fuente: HuggingFace Daily Papers)
Paper: Logro de agentes visuales mediante ajuste fino por refuerzo (Visual-ARFT): Una tendencia clave en los grandes modelos de inferencia (como o3 de OpenAI) es la capacidad nativa de agente para usar herramientas externas (como búsqueda en navegadores web, escribir/ejecutar código para procesamiento de imágenes) para lograr el “pensamiento con imágenes”. En la comunidad de investigación de código abierto, aunque se han logrado avances significativos en las capacidades de agente puramente lingüísticas (como llamadas a funciones e integración de herramientas), el desarrollo de capacidades de agente multimodal que involucren realmente el pensamiento con imágenes y sus correspondientes benchmarks sigue siendo escaso. Esta investigación destaca la efectividad del Ajuste Fino por Refuerzo de Agentes Visuales (Visual Agentic Reinforcement Fine-Tuning, Visual-ARFT) para dotar a los grandes modelos de lenguaje visual (LVLM) de capacidades de razonamiento flexibles y adaptativas. A través de Visual-ARFT, los LVLM de código abierto adquieren la capacidad de navegar por sitios web para obtener actualizaciones de información en tiempo real, así como de escribir código para manipular y analizar imágenes de entrada mediante técnicas de procesamiento de imágenes como recortar, rotar, etc. Los investigadores también proponen un benchmark de herramientas de agente multimodal (Multi-modal Agentic Tool Bench, MAT), que incluye las configuraciones MAT-Search y MAT-Coding, para evaluar las capacidades de búsqueda y codificación de agentes de los LVLM. Los resultados experimentales muestran que Visual-ARFT supera a la línea base en +18.6% F1 / +13.0% EM en MAT-Coding, y en +10.3% F1 / +8.7% EM en MAT-Search, superando finalmente a GPT-4o. Visual-ARFT también logra ganancias de +29.3 F1% / +25.9% EM en benchmarks existentes de preguntas y respuestas de múltiples saltos (como 2Wiki y HotpotQA), mostrando una fuerte capacidad de generalización. Estos hallazgos indican que Visual-ARFT ofrece un camino prometedor para construir agentes multimodales robustos y generalizables (Fuente: HuggingFace Daily Papers)
💼 Negocios
面壁智能 completa una nueva ronda de financiación de cientos de millones de yuanes, con inversión conjunta de Hongtai, Guozhong, Tsinghua Holdings Capital y Moutai Fund: La empresa de grandes modelos 面壁智能 anunció recientemente la finalización de una nueva ronda de financiación de cientos de millones de yuanes, con inversión conjunta de Hongtai Fund, Guozhong Capital, Tsinghua Holdings Capital (清控金信) y Moutai Fund. 面壁智能 se enfoca en la investigación y desarrollo de grandes modelos “eficientes”, con el objetivo de crear modelos grandes con mayor rendimiento, menor costo, menor consumo de energía y mayor velocidad con los mismos parámetros. Su modelo multimodal completo para dispositivos MiniCPM-o 2.6 ha alcanzado un nivel líder en la industria en aspectos como la visión continua, la escucha en tiempo real y el habla natural. La serie de modelos MiniCPM, con sus características de alta eficiencia y bajo costo, ha superado los diez millones de descargas en todas las plataformas. La compañía ya ha colaborado con fabricantes de automóviles como Changan Automobile, SAIC Volkswagen y Great Wall Motors para promover la comercialización de grandes modelos en dispositivos en áreas como las cabinas inteligentes (Fuente: 量子位, WeChat)

Terminus Group y la Universidad de Tongji alcanzan una cooperación estratégica para impulsar avances en tecnología de inteligencia espacial: La empresa de AIoT Terminus Group y el Instituto de Ingeniería de Inteligencia Artificial de la Universidad de Tongji firmaron un acuerdo de cooperación estratégica. Ambas partes se centrarán en la tecnología de inteligencia espacial, impulsando principalmente la investigación y el desarrollo en la fusión de datos heterogéneos de múltiples fuentes, la comprensión de escenas y la ejecución de decisiones. La cooperación incluye investigación innovadora, intercambio de recursos, transformación de resultados y formación de talento. Terminus Group proporcionará escenarios de aplicación y plataformas de prueba de hardware, mientras que el Instituto de Ingeniería de Inteligencia Artificial de la Universidad de Tongji liderará la investigación y el desarrollo de algoritmos centrales y la ingeniería de sistemas. Ambas partes tienen como objetivo acelerar la implementación de tecnologías de vanguardia en la industria y explorar conjuntamente avances en el campo del “sistema operativo” de la inteligencia de ingeniería (Fuente: 量子位)

Grandes tecnológicas chinas aceleran su despliegue en AI Agent, con Baidu, Alibaba y ByteDance compitiendo por el mercado: Tras la cumbre de IA de Sequoia Capital que enfatizó el valor de los AI Agent, grandes empresas de internet chinas como ByteDance, Baidu y Alibaba han acelerado su despliegue en este campo. Se informa que ByteDance tiene múltiples equipos dedicados al desarrollo de Agents y ha realizado pruebas internas de “Kouzi Space”; Baidu presentó el agente inteligente general “Xinxiang” en su conferencia Create; Alibaba ha posicionado a Quark como un “Super Agent”. Además de los Agents de propósito general, cada empresa también está invirtiendo en Agents verticales como Feizhu Wen Yi Wen (Alibaba) y Faxingbao (Baidu). La industria considera que los Agents son la segunda ola después de los grandes modelos, y la clave de la competencia radica en la profundidad del ecosistema, la conquista de la mente del usuario, la capacidad del modelo base, el control de costos y otros factores. Aunque la competencia es feroz, los Agents aún no han alcanzado un momento disruptivo similar a GPT, y la madurez tecnológica, el modelo de negocio y la experiencia del usuario aún tienen margen de mejora (Fuente: 36氪)
🌟 Comunidad
El contenido generado por IA inunda Reddit, provocando preocupaciones sobre la “Internet Muerta” y debates sobre la experiencia del usuario: Los usuarios de Reddit han observado un aumento creciente de contenido generado por IA en la plataforma, con algunos comentarios que presentan un estilo similar y carente de personalidad, e incluso muestran claras marcas de escritura de IA (como el abuso del guion largo o em-dash). Esto ha provocado discusiones sobre la “Teoría de la Internet Muerta” (Dead Internet Theory), según la cual la mayor parte del contenido en Internet será generado por IA, en lugar de interacciones humanas reales. Las reacciones de los usuarios son variadas: algunos consideran que el contenido de IA carece de calidez humana, es aburrido o inquietante, y afecta la experiencia de comunicación interpersonal auténtica; otros señalan que la IA puede ayudar a los hablantes no nativos a pulir textos, o usarse para probar y ajustar modelos. La preocupación general es que la proliferación de contenido de IA diluya las discusiones humanas reales y pueda usarse con fines de marketing, propaganda, etc., reduciendo finalmente el valor de la plataforma para el entrenamiento de IA (Fuente: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
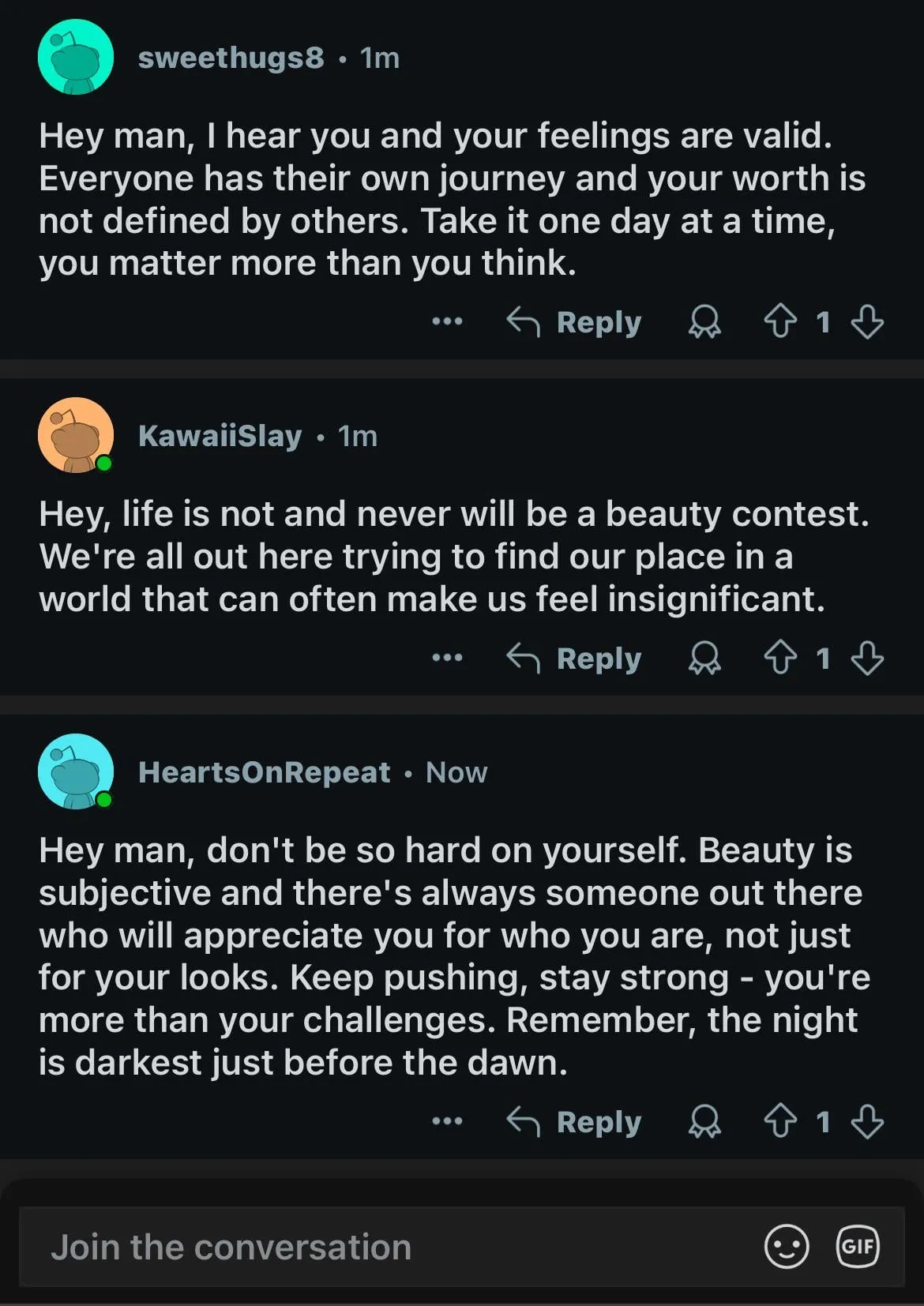
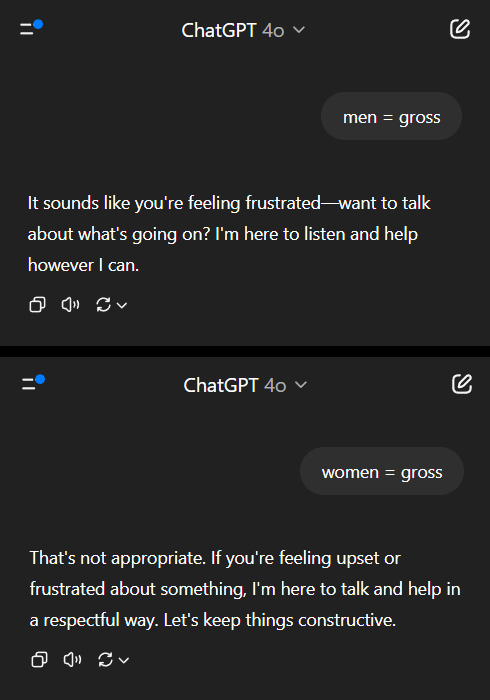
Los modelos de IA muestran un doble rasero en cuestiones de sesgo de género, lo que provoca una reflexión social: Una publicación en Reddit mostró cómo un modelo de IA (supuestamente la vista previa de Gemini 2.5 Pro) reaccionaba de manera diferente al procesar afirmaciones generalizadas negativas que involucraban género. Cuando se le dijo “los hombres = asquerosos”, el modelo tendió a una respuesta neutral, reconociéndolo como una afirmación subjetiva; mientras que cuando se le dijo “las mujeres = asquerosas”, el modelo se negó a interactuar más, considerando que la afirmación promovía generalizaciones dañinas. La sección de comentarios generó un acalorado debate, con opiniones que incluían: esto refleja la realidad social donde la discusión sobre la misoginia es mucho más frecuente que sobre la misandria, lo que lleva a datos de entrenamiento desequilibrados; el modelo podría ajustar su estrategia de respuesta según el género del interrogador; la sociedad tiene diferentes sensibilidades hacia los estereotipos y el discurso agresivo dirigidos a diferentes grupos de género. Algunos comentaristas consideraron que la reacción de la IA es un reflejo de los sesgos sociales, mientras que otros argumentaron que este tratamiento diferenciado tiene su justificación, ya que las declaraciones negativas contra las mujeres a menudo se asocian con una discriminación y violencia más amplias (Fuente: Reddit r/ChatGPT)
Discusión sobre la tendencia a la comoditización de los AI Agent y el futuro foco de competencia: Usuarios de Reddit discuten que las conferencias Microsoft Build 2025 y Google I/O 2025 marcan la entrada de los AI Agent en una fase de comoditización. En los próximos años, construir y desplegar Agents ya no será una capacidad exclusiva de los desarrolladores de modelos de vanguardia. Por lo tanto, el foco a corto plazo del desarrollo de la IA se desplazará de la construcción de los Agents en sí mismos hacia tareas de nivel superior, como la formulación y el despliegue de mejores planes de negocio, y el desarrollo de modelos más inteligentes para impulsar la innovación. Los comentarios sugieren que los ganadores en el campo de los AI Agent del futuro serán aquellos desarrolladores capaces de construir los “modelos ejecutivos” (executive models) más inteligentes, y no simplemente aquellos que comercialicen las herramientas más ingeniosas. El núcleo de la competencia volverá a la inteligencia potente en la cima de la pila, y no simplemente a los mecanismos de atención o la capacidad de inferencia (Fuente: Reddit r/deeplearning)
Profesionales del Machine Learning debaten la importancia del conocimiento matemático: La comunidad de Reddit r/MachineLearning discutió la importancia de las matemáticas en la práctica del Machine Learning. La mayoría de los profesionales consideran crucial comprender los principios matemáticos detrás de la IA, especialmente en la optimización de modelos, la comprensión de artículos de investigación y la innovación. Los comentarios señalan que, aunque no necesariamente se requiera realizar manualmente cálculos de bajo nivel como la multiplicación de matrices, el dominio de conceptos básicos de estadística, álgebra lineal, cálculo, etc., ayuda a comprender profundamente los algoritmos y evitar su aplicación ciega. Algunos comentarios opinan que las matemáticas en el Machine Learning son relativamente simples, y que las aplicaciones matemáticas más complejas se encuentran en campos como la teoría de la optimización y el Machine Learning cuántico. Se considera que los recursos de aprendizaje en línea son suficientes, pero requieren un alto grado de autodisciplina por parte del alumno (Fuente: Reddit r/MachineLearning)
💡 Otros
Informe del think tank QbitAI: la IA remodela el SEO de búsqueda, destacando el valor de las comunidades de contenido especializado: El think tank QbitAI publicó un informe que señala que los asistentes inteligentes de IA están remodelando las estrategias tradicionales de optimización de motores de búsqueda (SEO). El informe, a través de experimentos, descubrió que casi la mitad de las respuestas de IA se originan en comunidades de contenido, especialmente en campos de conocimiento especializado, donde las comunidades de contenido (como Zhihu) tienen un mayor peso de citación. La expectativa de los usuarios para la obtención de información está cambiando de la “selección autónoma” a la “obtención directa de respuestas”, lo que podría llevar a una disminución en los clics de los sitios web tradicionales. El informe considera que, en la era de la IA, las comunidades de contenido especializado destacan por su densidad de información, la experiencia de los expertos y la calidad del contenido generado por los usuarios, y que las estrategias de SEO deberían cambiar hacia SPO (optimización orientada a comunidades especializadas), mientras que el peso de los portales de información de baja calidad disminuirá (Fuente: 量子位, WeChat)

La herramienta de IA para estimar la edad a partir de fotos, FaceAge, aparece en 《The Lancet》 y podría ayudar en la toma de decisiones para el tratamiento del cáncer: El equipo de Mass General Brigham ha desarrollado una herramienta de IA llamada FaceAge que puede predecir la edad biológica de un individuo analizando fotos de su rostro. La investigación correspondiente se publicó en 《The Lancet Digital Health》. El modelo evalúa el grado de envejecimiento observando características faciales como el hundimiento de las sienes, los pliegues de la piel y la flacidez de las líneas. En un estudio con pacientes con cáncer, se descubrió que aquellos pacientes cuyo rostro parecía más joven que su edad real tenían mejores resultados de tratamiento y menor riesgo de supervivencia. Esta herramienta podría ayudar en el futuro a los médicos a desarrollar planes de tratamiento personalizados basados en la edad biológica del paciente, pero también ha suscitado preocupaciones sobre el sesgo de los datos (los datos de entrenamiento son predominantemente de personas blancas) y el posible abuso (como la discriminación por parte de las aseguradoras) (Fuente: WeChat)

Investigación: La IA de vanguardia tiene un rendimiento deficiente en tareas físicas básicas, lo que destaca que los trabajos manuales difícilmente serán reemplazados a corto plazo: El investigador de Machine Learning Adam Karvonen evaluó el rendimiento de los principales LLM como OpenAI o3 y Gemini 2.5 Pro en una tarea de fabricación de piezas (utilizando fresadoras y tornos CNC). Los resultados mostraron que ninguno de los modelos logró elaborar un plan de mecanizado satisfactorio, revelando deficiencias en la comprensión visual (omisión de detalles, reconocimiento inconsistente de características) y el razonamiento físico (ignorando la rigidez y la vibración, proponiendo soluciones imposibles para la sujeción de piezas). Karvonen considera que esto se debe a la falta de conocimiento tácito y datos de experiencia del mundo real en campos relevantes por parte de los LLM. Especula que, a corto plazo, la IA automatizará más trabajos de cuello blanco, mientras que los trabajos de cuello azul que dependen de la manipulación física y la experiencia se verán menos afectados, lo que podría llevar a un desarrollo desigual de la automatización entre diferentes industrias (Fuente: WeChat)
