
Palabras clave:tecnología de IA, Google Gemini, consumo energético de la IA, aplicaciones legales de la IA, Microsoft Discovery, Jensen Huang y Elon Musk, regulación de la IA, Gemini 2.5 Pro, consumo energético de centros de datos de IA, errores en documentos legales generados por IA, plataforma de investigación Microsoft Discovery, control de exportación de chips de IA
🔥 Enfoque
Google I/O大会发布多项AI进展,Gemini全面融入谷歌生态: Google anunció una serie de importantes actualizaciones de IA en su conferencia de desarrolladores I/O 2025, centradas en la actualización y la profunda integración del modelo Gemini. Gemini 2.5 Pro introduce “Deep Think” para mejorar el razonamiento complejo, 2.5 Flash optimiza la eficiencia y el costo, y añade salida de audio nativa. La Búsqueda introduce el “Modo AI”, que ofrece respuestas estilo chatbot y puede combinar datos personales del usuario (con autorización) para proporcionar resultados personalizados. El navegador Chrome integrará el asistente Gemini. El modelo de video Veo 3 logra la generación de video con sonido, y el modelo de imagen Imagen 4 mejora los detalles y el procesamiento de texto. Google también lanzó la herramienta de producción cinematográfica con IA Flow, el asistente de programación Jules, y mostró los avances de Project Astra (asistente multimodal en tiempo real) y Project Mariner (agente de IA multitarea). Al mismo tiempo, Google lanzó un nuevo servicio de suscripción de IA, con la versión premium AI Ultra a un costo mensual de 249.99 dólares. Estas iniciativas marcan la aceleración de Google en la integración completa de la IA en sus productos y servicios, remodelando la experiencia de interacción del usuario. (Fuente: 36氪, 36氪, 36氪, 36氪, 36氪, 36氪)

AI能耗问题引关注,MIT科技评论深度剖析其能源足迹与未来挑战: MIT Technology Review publicó una serie de reportajes que exploran en profundidad el consumo de energía y los problemas de emisiones de carbono derivados del desarrollo de la tecnología de IA. La investigación señala que el consumo de energía en la fase de inferencia de la IA ya ha superado al de la fase de entrenamiento, convirtiéndose en la principal carga energética. El reportaje analiza la enorme demanda de electricidad y el consumo de recursos hídricos de los centros de datos (como los centros de datos en el desierto de Nevada), así como la dependencia de combustibles fósiles (como el centro de datos de Meta en Luisiana que depende del gas natural). Aunque la energía nuclear se considera una posible solución de energía limpia, su largo ciclo de construcción dificulta satisfacer a corto plazo la creciente demanda de la IA. Al mismo tiempo, el reportaje también señala perspectivas optimistas para mejorar la eficiencia energética de la IA, incluyendo algoritmos de modelos más eficientes, chips de bajo consumo diseñados específicamente para IA y tecnologías de refrigeración de centros de datos más optimizadas. La serie enfatiza que, aunque el consumo de energía de una sola consulta de IA parezca mínimo, la tendencia general de la industria y la planificación futura (como el plan Stargate de OpenAI) auguran enormes desafíos energéticos, que requieren una divulgación transparente de datos y una planificación energética responsable. (Fuente: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

AI在法律领域的应用引发错误与伦理担忧: Varios incidentes recientes muestran que el problema de las “alucinaciones” generadas por la IA en la redacción de documentos legales está causando seria preocupación. Un juez de California multó a un abogado por usar herramientas de IA como Google Gemini para generar contenido con citas falsas en documentos judiciales. En otro caso, el modelo Claude de la empresa de IA Anthropic también cometió errores al generar citas para documentos legales. Más preocupante aún, fiscales israelíes admitieron haber utilizado en una solicitud texto generado por IA que citaba leyes inexistentes. Estos casos destacan las deficiencias de los modelos de IA en cuanto a precisión y fiabilidad, especialmente en el ámbito legal, que exige una alta rigurosidad en hechos y citas. Los expertos señalan que los abogados, en busca de eficiencia, podrían confiar excesivamente en los resultados de la IA, ignorando la necesidad de una revisión estricta. Aunque las herramientas de IA se promocionan como asistentes legales fiables, su característica inherente de “alucinación” representa una amenaza potencial para la justicia, lo que requiere urgentemente normativas sectoriales y la cautela de los usuarios. (Fuente: MIT Technology Review)

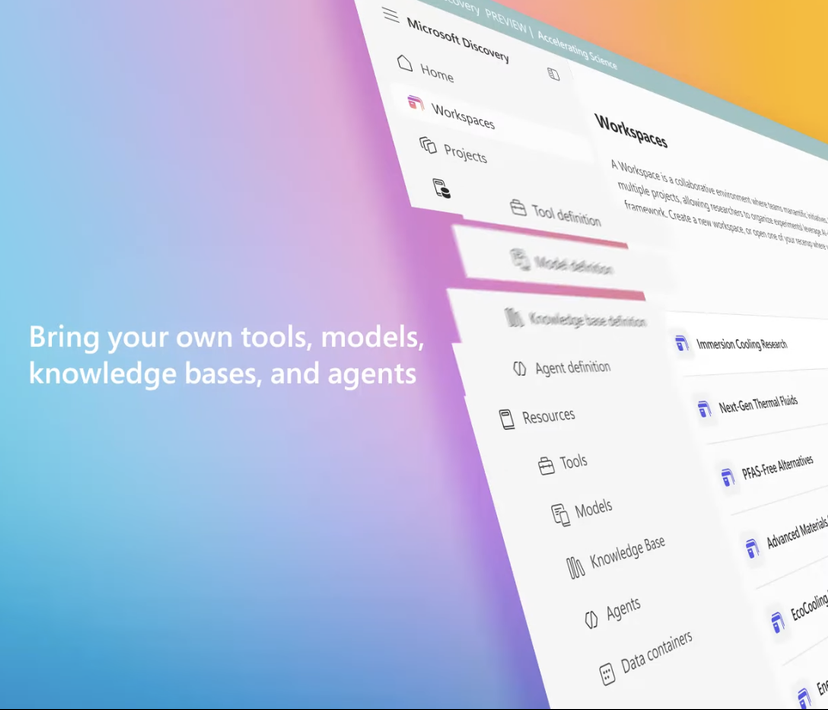
微软推出企业级AI科研平台Microsoft Discovery,助力科学发现: Microsoft presentó en la conferencia Build Microsoft Discovery, una plataforma de IA diseñada para empresas e instituciones de investigación, con el objetivo de permitir a científicos e ingenieros sin conocimientos de programación utilizar la computación de alto rendimiento y sistemas de simulación complejos mediante la interacción en lenguaje natural. La plataforma combina modelos fundacionales para la planificación con modelos especializados entrenados para campos científicos específicos (como física, química, biología), formando un equipo de “AI Postdocs” capaz de ejecutar todo el proceso de investigación científica, desde la revisión bibliográfica hasta la simulación computacional. Microsoft mostró un caso de aplicación: en aproximadamente 200 horas, se seleccionaron 367,000 sustancias, descubriendo con éxito un posible sustituto de refrigerante sin PFAS, validado mediante experimentos. Las características de la plataforma incluyen un motor de conocimiento basado en grafos, razonamiento colaborativo, un ciclo de I+D iterativo y continuo, y está construida sobre la infraestructura de Azure, con una arquitectura futura que prevé la conexión con la computación cuántica. (Fuente: 量子位)
黄仁勋与马斯克就AI发展、监管及全球竞争发表看法: El CEO de NVIDIA, Jensen Huang, expresó en una entrevista su preocupación por los controles de exportación de chips de EE. UU., argumentando que restringir la difusión de tecnología podría socavar el liderazgo de EE. UU. en el campo de la IA, y destacó la fortaleza de China en la investigación y desarrollo de IA, así como el hecho de que la mitad de los desarrolladores de IA del mundo provienen de China. Abogó por que EE. UU. acelere la popularización de la tecnología a nivel mundial y permita que las empresas estadounidenses compitan en el mercado chino. Por otro lado, el CEO de Tesla, Elon Musk, declaró en otra entrevista que continuará liderando Tesla durante al menos cinco años y cree que está cerca de alcanzar la AGI. Apoya una regulación moderada de la IA, pero se opone a una intervención excesiva. Ambos líderes tecnológicos enfatizaron el enorme potencial de la IA; Huang considera que la IA impulsará un crecimiento significativo del PIB mundial, mientras que Musk enumeró objetivos clave para este año como Starship, Neuralink y los taxis autónomos de Tesla, todos estrechamente relacionados con la IA. (Fuente: 36氪, 36氪, 36氪)

🎯 Tendencias
谷歌发布Gemma 3n预览版,专为端侧高效运行设计: Google lanzó una versión preliminar del modelo Gemma 3n en HuggingFace, diseñada específicamente para un funcionamiento eficiente en dispositivos de bajos recursos (como dispositivos móviles). Esta serie de modelos tiene capacidades de entrada multimodal, pudiendo procesar texto, imágenes, video y audio, y generar salidas de texto. Utiliza una tecnología de “activación selectiva de parámetros” (similar a la arquitectura MoE de mezcla de expertos), lo que permite que el modelo funcione con un tamaño efectivo de parámetros de 2B y 4B, reduciendo así los requisitos de recursos. La comunidad discute que la arquitectura de Gemma 3n podría ser similar a la de Gemini, lo que explicaría las potentes capacidades multimodales y de contexto largo de este último. Los pesos de código abierto y las versiones ajustadas por instrucciones de Gemma 3n, así como su entrenamiento con datos de más de 140 idiomas, le otorgan potencial en aplicaciones de IA en el borde, como asistentes domésticos inteligentes. (Fuente: Reddit r/LocalLLaMA, developers.googleblog.com)

谷歌推出MedGemma,专为医疗领域优化的AI模型: Google lanzó la serie de modelos MedGemma, dos variantes de Gemma 3 optimizadas específicamente para el sector médico, que incluyen una versión multimodal de 4B parámetros y una versión de solo texto de 27B parámetros. MedGemma 4B ha sido entrenado especialmente para la comprensión de imágenes médicas (como radiografías, imágenes dermatológicas, etc.) y texto, utilizando un codificador de imágenes SigLIP preentrenado con datos médicos. MedGemma 27B se centra en el procesamiento de texto médico y está optimizado para el cálculo durante la inferencia. Google afirma que estos modelos tienen como objetivo acelerar el desarrollo de aplicaciones de IA médica y han sido evaluados en múltiples benchmarks clínicamente relevantes; los desarrolladores pueden realizar ajustes finos para mejorar el rendimiento en tareas específicas. La comunidad ha reaccionado positivamente, considerando su gran potencial, pero enfatizando la necesidad de retroalimentación real de profesionales médicos. (Fuente: Reddit r/LocalLLaMA)

字节跳动发布开源多模态模型Bagel,支持图像生成: ByteDance lanzó Bagel (también conocido como BAGEL-7B-MoT), un gran modelo multimodal de código abierto de 14B parámetros (7B activos), bajo la licencia Apache 2.0. El modelo se basa en arquitecturas de Mixture-of-Experts (MoE) y Mixture-of-Transformers (MoT), capaz de comprender y generar texto, y cuenta con capacidad nativa de generación de imágenes. Supera a otros modelos unificados de código abierto en una serie de pruebas de referencia de comprensión y generación multimodal, y demuestra capacidades avanzadas de razonamiento multimodal como el procesamiento de imágenes de forma libre y la predicción de fotogramas futuros. Los investigadores esperan promover la investigación multimodal compartiendo detalles del preentrenamiento, protocolos de creación de datos, así como abriendo el código y los checkpoints. (Fuente: Reddit r/LocalLLaMA, arxiv.org, bagel-ai.org)
英伟达发布DreamGen,利用生成视频模型训练机器人: El equipo de investigación de NVIDIA presentó el proyecto DreamGen, que mediante el ajuste fino de modelos avanzados de generación de video (como Sora, Veo), permite a los robots aprender nuevas habilidades en “mundos oníricos” generados. Este método no depende de motores gráficos tradicionales ni de simuladores físicos, sino que permite a los robots explorar y experimentar de forma autónoma en escenas a nivel de píxel generadas por redes neuronales, generando así una gran cantidad de trayectorias neuronales con pseudo-etiquetas de acción. Los experimentos demuestran que DreamGen puede mejorar significativamente el rendimiento de los robots en tareas simuladas y del mundo real, incluyendo acciones nunca vistas y entornos desconocidos. Por ejemplo, con solo unas pocas trayectorias reales, un robot humanoide aprendió 22 nuevas habilidades como verter agua y doblar ropa, y logró generalizar con éxito a escenarios reales como la cafetería de la sede de NVIDIA. (Fuente: 36氪, arxiv.org)

华为提出OmniPlacement优化MoE模型推理性能: Para abordar el problema de la latencia en la inferencia causada por la carga desigual de las redes de expertos (expertos “calientes” vs. “fríos”) en los modelos Mixture-of-Experts (MoE), el equipo de Huawei propuso la solución de optimización OmniPlacement. Esta solución tiene como objetivo mejorar el rendimiento de inferencia de los modelos MoE mediante la reorganización de expertos, la implementación redundante entre capas y la programación dinámica casi en tiempo real. La validación teórica en modelos como DeepSeek-V3 muestra que OmniPlacement puede reducir la latencia de inferencia en aproximadamente un 10% y aumentar el rendimiento en aproximadamente un 10%. El núcleo de este método radica en ajustar dinámicamente la prioridad de los expertos, optimizar el dominio de comunicación, implementar de forma diferenciada instancias redundantes y responder con flexibilidad a los cambios de carga mediante un mecanismo de programación casi en tiempo real y monitoreo dinámico. Huawei planea abrir el código de esta solución próximamente. (Fuente: 量子位)

苹果计划向开发者开放AI模型权限,刺激应用创新: Según informes, Apple anunciará en la WWDC la apertura de los permisos de sus modelos de IA de Apple Intelligence a desarrolladores de terceros. Inicialmente se centrará en modelos de lenguaje ligeros de aproximadamente 3 mil millones de parámetros que se ejecutan en el dispositivo, y posteriormente podría abrir modelos en la nube comparables al nivel de GPT-4-Turbo (ejecutados a través de una nube privada y encriptados). Esta medida tiene como objetivo alentar a los desarrolladores a construir nuevas funciones de aplicación basadas en los LLM de Apple, aumentar el atractivo de los dispositivos Apple y compensar su relativo rezago en el campo de la IA generativa. Los analistas creen que Apple espera compensar sus propias deficiencias tecnológicas y hacer frente a la creciente competencia en IA mediante la construcción de un ecosistema abierto, aprovechando su vasta comunidad de desarrolladores (6 millones). (Fuente: 36氪)
美国众议院提案拟暂停州级AI监管十年,引发巨大争议: El Comité de Energía y Comercio de la Cámara de Representantes de EE. UU. aprobó una propuesta que planea prohibir a los estados regular los modelos de inteligencia artificial, los sistemas y los sistemas de toma de decisiones automatizados que “afectan sustancialmente o reemplazan la toma de decisiones humanas” durante los próximos diez años. Los partidarios argumentan que esta medida evitaría que las regulaciones estatales dispares obstaculicen la innovación en IA y la modernización de los sistemas del gobierno federal; los opositores, en cambio, la califican como un “enorme regalo para las grandes tecnológicas” que debilitará la capacidad de los estados para proteger a los ciudadanos de los peligros de la IA. Si se aprueba, la propuesta podría invalidar una gran cantidad de leyes estatales de IA existentes y propuestas, pero también aclara que no se aplica a las leyes federales o leyes de aplicación general que tratan por igual a los sistemas de IA y no IA. Esta medida refleja la intensa pugna a nivel mundial entre la “prioridad de la innovación en IA” y las “líneas rojas de seguridad”. (Fuente: 36氪, edition.cnn.com)

《Take It Down Act》签署成为美国法律,打击非自愿私密图像传播: El presidente de EE. UU., Trump, ha firmado la ley 《Take It Down Act》, que tipifica como delito federal la producción y difusión de imágenes íntimas no consentidas (incluido el contenido deepfake generado por IA). La ley exige que las plataformas tecnológicas eliminen dicho contenido en un plazo de 48 horas tras recibir la notificación. Esta ley tiene como objetivo proteger a las víctimas y hacer frente a los crecientes problemas sociales derivados del abuso de la tecnología deepfake. Sin embargo, también hay comentarios que señalan que la ley podría ser objeto de abuso, llevando a una censura excesiva. (Fuente: MIT Technology Review, edition.cnn.com, Reddit r/artificial)

AI大模型助力健康管理,实现个性化与多维数据联动: Los grandes modelos de IA están inyectando nueva vitalidad al campo de la gestión de la salud, logrando la vinculación de datos multidimensionales y servicios personalizados mediante la combinación con dispositivos portátiles. Empresas como WeDoctor, Deepwise Healthcare y Nanjing Fitter están explorando activamente escenarios de aplicación, por ejemplo, partiendo de escenarios de exámenes médicos para la detección y tratamiento tempranos, o utilizando la gestión del peso como punto de partida para prevenir enfermedades crónicas. Los grandes modelos pueden procesar dimensiones de datos más diversas, establecer una memoria del usuario y proporcionar planes de intervención de salud más precisos. Los desafíos incluyen las alucinaciones de los modelos, la calidad de los datos y las dificultades de colaboración, pero se están superando gradualmente mediante RAG, el ajuste fino de modelos, mecanismos de auditoría y el modelo “IA + gestor humano”. En cuanto a los modelos de negocio, los servicios ToB, el pago por parte de los consumidores (C-end) y las comunidades de salud con IA (AI Health Communities) ya han sido validados preliminarmente, y la tendencia futura será hacia la actualización de la interacción multimodal. (Fuente: 36氪)
百度强化文心大模型多模态能力,应对市场竞争与应用落地: Los modelos Wenxin Large Model 4.5 Turbo y el modelo de pensamiento profundo X1 Turbo, recientemente lanzados por Baidu, han mejorado significativamente sus capacidades de comprensión y generación multimodal mediante tecnologías como el entrenamiento mixto y el modelado de expertos heterogéneos multimodales, mejorando la eficiencia del aprendizaje intermodal y el efecto de fusión. Aunque el CEO Robin Li había expresado cautela sobre los problemas de alucinación de los modelos de generación de video tipo Sora, Baidu está補齐 sus deficiencias activamente frente a la competencia del mercado (como los avances de Doubao de ByteDance y Tongyi Qianwen de Alibaba en el campo multimodal) y las necesidades de implementación de aplicaciones de IA, y planea abrir el código de la serie Wenxin Large Model 4.5 el 30 de junio. Baidu considera que los humanos digitales de IA son un importante punto de avance en aplicaciones y ya ha desarrollado tecnología de humanos digitales hiperrealistas impulsados por “guiones”, que soportan más de 100,000 presentadores digitales. (Fuente: 36氪)
抖音、小红书等平台专项治理“AI起号”,维护内容生态: Plataformas de comercio electrónico basadas en intereses como Douyin y Xiaohongshu han reforzado recientemente la gobernanza especial sobre comportamientos como la producción masiva de contenido falso utilizando tecnología de IA y el “AI qǐhào” (creación masiva de cuentas con IA). Estos comportamientos incluyen la generación por IA de videos vulgares y sensacionalistas, contenido de expertos virtuales, y la venta de tutoriales y cuentas para “AI qǐhào”. Las plataformas consideran que tales comportamientos destruyen la autenticidad del contenido, conducen a la homogeneización del mismo, dañan la experiencia del usuario y el ecosistema de creadores originales, diluyendo así el valor comercial. En contraste, plataformas de comercio electrónico tradicionales como Taobao y JD.com alientan activamente a los comerciantes a utilizar herramientas de IA (como “imagen a video”, humanos digitales para transmisiones en vivo) para mejorar la presentación de productos y la eficiencia operativa, con el objetivo principal de facilitar las transacciones. Esta diferencia refleja la divergencia en las estrategias de aplicación de la IA en diferentes modelos de comercio electrónico. (Fuente: 36氪)

苹果AI版Siri开发遇阻,或再次跳票,管理层调整应对危机: Según Bloomberg, la versión mejorada de Siri con grandes modelos de IA que Apple planeaba presentar en la WWDC podría retrasarse nuevamente. El cuello de botella técnico radica en el conflicto entre las arquitecturas de sistemas nuevas y antiguas, lo que provoca errores frecuentes. El informe señala que Apple tiene problemas en su estrategia de IA, como errores en la toma de decisiones de alto nivel, luchas internas de poder, adquisición insuficiente de GPU y restricciones de privacidad en el uso de datos, lo que ha llevado a que su tecnología de IA se quede atrás de sus competidores. Para hacer frente a la crisis, el laboratorio de Apple en Zúrich está desarrollando una nueva arquitectura “LLM Siri”, y el proyecto Siri se ha transferido al responsable de Vision Pro, Mike Rockwell. Al mismo tiempo, Apple también está buscando cooperación tecnológica externa con Google Gemini, OpenAI y otros, y podría separar en su marketing la marca Apple Intelligence de Siri para remodelar su imagen en IA. (Fuente: 36氪)

字节跳动推出集成英语外教智能体Owen的Ola Friend耳机: ByteDance ha añadido una función de agente inteligente de tutor de inglés llamado Owen a sus auriculares inteligentes Ola Friend. Los usuarios pueden activar Owen despertando la Doubao App para mantener conversaciones en inglés, lectura guiada en inglés y comentarios bilingües. Esta función cubre escenarios como conversaciones diarias, inglés de negocios y viajes, con el objetivo de proporcionar un acompañante de práctica de inglés portátil y conveniente. Esto marca otro intento de ByteDance en el escenario educativo, combinando las capacidades de los grandes modelos de IA con hardware para crear un producto de aprendizaje de inglés vertical. Los auriculares Ola Friend ya admitían preguntas y respuestas de conocimiento y práctica oral a través de Doubao, y la incorporación del nuevo agente inteligente refuerza aún más su atributo educativo. (Fuente: 36氪)

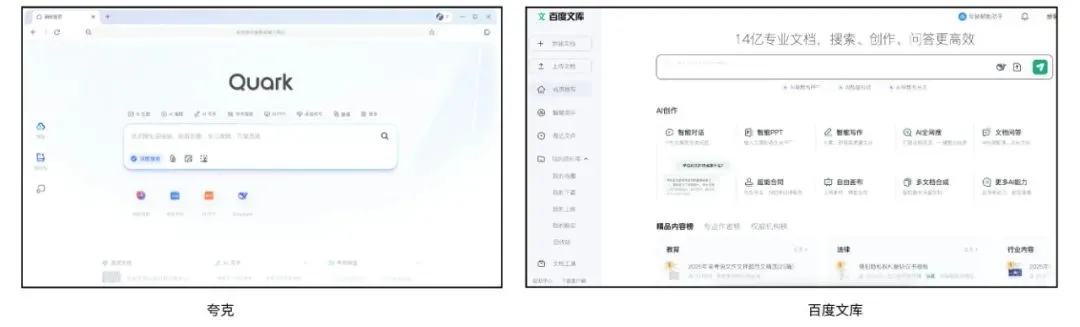
夸克与百度文库竞逐AI超级应用,整合搜索、工具与内容服务: Quark, de Alibaba, y Baidu Wenku, de Baidu, se están transformando en aplicaciones “super-app” centradas en la IA, integrando diálogo con IA, búsqueda profunda, herramientas de IA (como redacción, generación de PPT, asistente de salud, etc.) y servicios de almacenamiento en la nube y documentos, con el objetivo de convertirse en una entrada de IA integral para los usuarios finales (C-end). Quark, con su búsqueda sin publicidad y su base de usuarios jóvenes, ya ha alcanzado los 149 millones de usuarios activos mensuales y se monetiza a través de un sistema de membresía. Baidu Wenku, por su parte, se apoya en sus vastos recursos de documentos y su base de usuarios de pago para lanzar “Cangzhou OS”, que integra AI Agents, fortaleciendo toda la cadena de creación y consumo de contenido. Ambos enfrentan desafíos de homogeneización de funciones, aplicaciones sobrecargadas y cómo equilibrar las necesidades generales con los servicios especializados. (Fuente: 36氪)
智谱清言、Kimi等35款App因违规收集个人信息被通报: El Centro Nacional de Notificación de Información sobre Seguridad Cibernética e Información emitió un comunicado señalando que Zhipu Qingyan (versión 2.9.6) por “recopilación real de información personal que excede el alcance de la autorización del usuario”, y Kimi (versión 2.0.8) por “recopilación real de información personal sin relación directa con la función comercial”, entre otras 33 aplicaciones, fueron listadas por recopilación y uso ilegal y no conforme de información personal. Estas dos populares aplicaciones de IA fueron desarrolladas por equipos con antecedentes en la Universidad de Tsinghua y recientemente han obtenido una financiación y atención de mercado significativas. La notificación, que cubre el período de detección del 16 de abril al 15 de mayo de 2025, destaca los desafíos de cumplimiento de datos que enfrentan las aplicaciones de IA en su rápido desarrollo. (Fuente: 36氪)
🧰 Herramientas
OpenEvolve:DeepMind AlphaEvolve的开源实现,用LLM进化代码库: Desarrolladores han lanzado el proyecto de código abierto OpenEvolve, una implementación del sistema AlphaEvolve de Google DeepMind. El framework OpenEvolve evoluciona repositorios de código completos mediante un proceso iterativo de LLM (generación de código, evaluación, selección) para descubrir nuevos algoritmos u optimizar los existentes. Es compatible con cualquier LLM que cumpla con la API de OpenAI, puede integrar múltiples modelos (como una combinación de Gemini-Flash-2.0 y Claude-Sonnet-3.7), y admite la optimización multiobjetivo y la evaluación distribuida. El proyecto ha replicado con éxito los casos de empaquetamiento de círculos y minimización de funciones del paper de AlphaEvolve, demostrando la capacidad de evolucionar desde métodos simples hasta algoritmos de optimización complejos (como scipy.minimize y recocido simulado). (Fuente: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

谷歌推出AI编程智能体Jules,支持自动化代码任务: Google lanzó el agente de programación con IA Jules, actualmente en fase de prueba global, con 5 ejecuciones de tareas gratuitas diarias por usuario. Jules se basa en el modelo multimodal Gemini 2.5 Pro, capaz de comprender repositorios de código complejos, realizar tareas como corregir errores, actualizar versiones, escribir pruebas e implementar nuevas funciones, y es compatible con Python y JavaScript. Puede conectarse a GitHub para crear pull requests (PR), verificar código en máquinas virtuales en la nube y proporcionar planes de ejecución detallados para que los desarrolladores los revisen y modifiquen. Jules tiene como objetivo integrarse profundamente en el flujo de trabajo de los desarrolladores para mejorar la eficiencia de la programación, y en el futuro lanzará la función Codecast (resúmenes de audio de la actividad del repositorio de código) y una versión empresarial. (Fuente: 36氪)
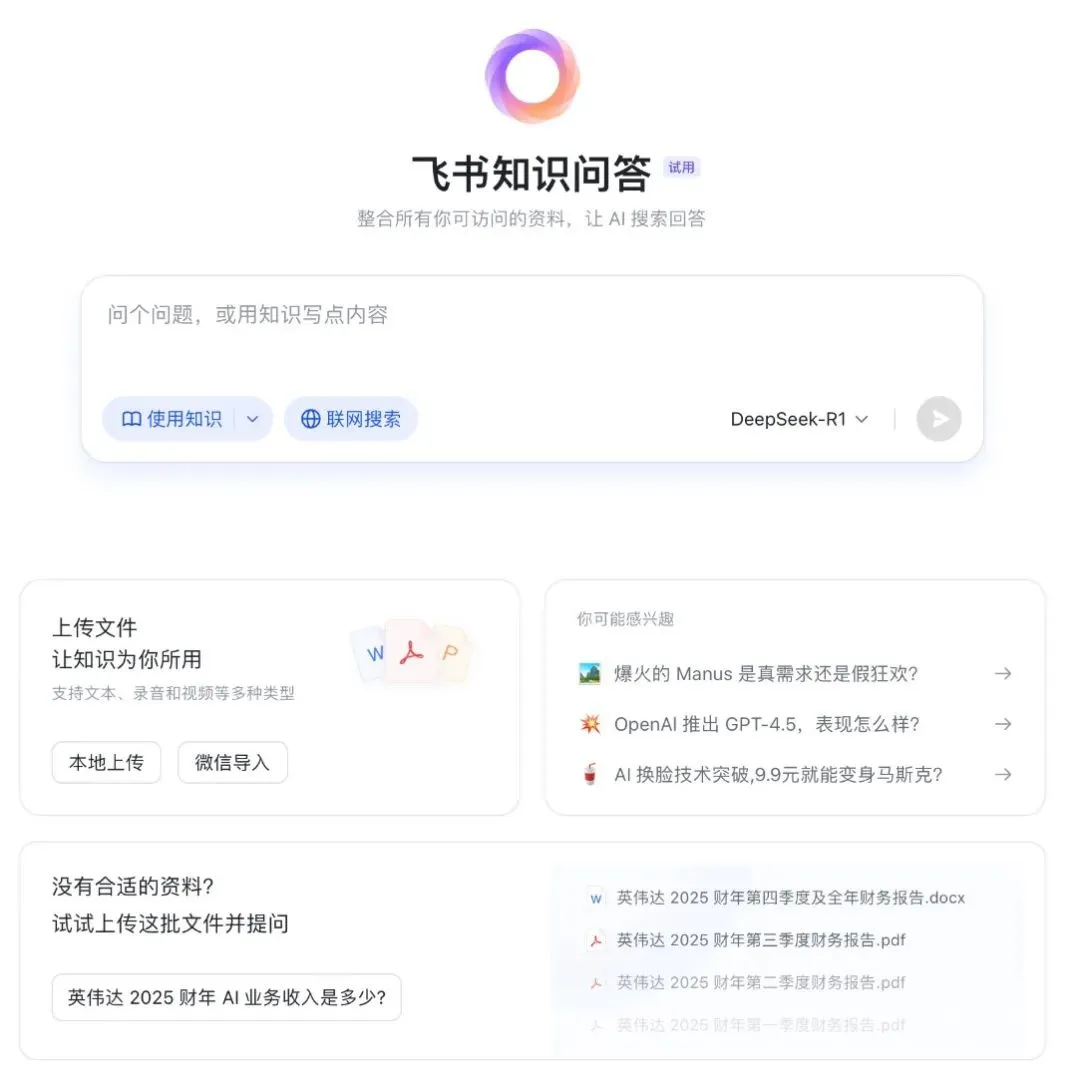
飞书上线“飞书知识问答”,打造企业专属AI问答工具: Feishu (Lark) está a punto de lanzar un nuevo producto de IA, “Feishu Knowledge Q&A”, posicionado como una herramienta de preguntas y respuestas con IA exclusiva para empresas, basada en el conocimiento corporativo. Los usuarios podrán invocarla desde la barra lateral de Feishu para hacer preguntas sobre su trabajo. La herramienta podrá acceder a todos los mensajes, documentos, bases de conocimiento, archivos, etc., de Feishu dentro del alcance de los permisos del usuario, y proporcionar respuestas precisas directamente basadas en este “contexto”. Su gestión de permisos es coherente con el propio sistema de permisos de Feishu, garantizando la seguridad de la información. Actualmente, el producto ha completado pruebas internas con decenas de miles de usuarios, y la versión web (ask.feishu.cn) ya está en línea, permitiendo subir información personal e invocar los modelos DeepSeek o Doubao para realizar preguntas. Esta medida sigue la tendencia de combinar las bases de conocimiento empresariales con la IA, con el objetivo de mejorar la eficiencia laboral y la capacidad de gestión del conocimiento. (Fuente: 36氪)
Manus:AI智能体平台开放注册,母公司获高额融资: La plataforma de agentes de IA Manus anunció la apertura de registros para usuarios internacionales, eliminando la lista de espera y ofreciendo tareas gratuitas diarias. Manus, mediante su tecnología de “razonamiento colaborativo multimodelo de arquitectura híbrida”, puede ejecutar tareas como la generación automática de PPT y la organización de facturas. Su empresa matriz, Butterfly Effect, completó recientemente una ronda de financiación de 75 millones de dólares, alcanzando una valoración de 3.6 mil millones de dólares. El éxito de Manus se considera una manifestación de la “velocidad de iteración china × mentalidad de producto de Silicon Valley”, coordinando agentes de planificación, ejecución y verificación para lograr un salto en la IA desde la “sugerencia de ideas” hasta la “ejecución en bucle cerrado”. (Fuente: 36氪)

HeyGen:AI视频生成与翻译工具,支持40+语言口型同步: HeyGen es una herramienta de video con IA que permite a los usuarios cargar fotos o videos para generar rápidamente humanos digitales con voz, expresiones y movimientos, y admite la personalización de vestuario y escenas. Una de sus funciones principales es la traducción en tiempo real a más de 175 idiomas y dialectos, y mediante algoritmos de IA, sincroniza con precisión los movimientos labiales del humano digital con el idioma traducido, mejorando la naturalidad del contenido de video multilingüe. La empresa fue fundada por exmiembros de Snapchat y ByteDance, ha obtenido una financiación de 60 millones de dólares liderada por Benchmark, con una valoración de 440 millones de dólares y unos ingresos recurrentes anuales superiores a los 35 millones de dólares. (Fuente: 36氪)
Opus Clip:AI驱动的自主视频编辑代理工具: Opus Clip, inicialmente posicionado como una herramienta de transmisión en vivo con IA, se transformó en una plataforma de edición de video con IA y evolucionó aún más hacia un “agente de edición de video autónomo”. Su función principal es editar rápidamente videos largos en múltiples videoclips cortos adecuados para la viralización, y puede recortar automáticamente el sujeto principal, generar títulos y textos, y añadir subtítulos y emojis. La función ClipAnything, probada recientemente, ya admite el reconocimiento de instrucciones multimodales. La empresa está dirigida por Zhao Yang, fundador de la antigua aplicación social Sober, ha obtenido una financiación de 20 millones de dólares liderada por SoftBank, con una valoración de 215 millones de dólares y un ARR cercano a los 10 millones de dólares. (Fuente: 36氪)
Trae:基于AI IDE的自动化编程Agent: Trae es una herramienta que tiene como objetivo crear “verdaderos ingenieros de IA”, permitiendo a los usuarios lograr la programación automatizada de Agents mediante la interacción en lenguaje natural. Es compatible con el protocolo MCP y Agents personalizados, incorpora un análisis de contexto mejorado y un motor de reglas, admite los principales lenguajes de programación y es compatible con VS Code. Trae fue desarrollado por miembros clave del equipo original del asistente de programación Marscode de ByteDance, posicionándose como un fuerte competidor de herramientas de programación con IA como Cursor, y se dedica a lograr un nuevo modelo de desarrollo de software colaborativo entre humanos y máquinas. (Fuente: 36氪)
Notta:AI驱动的多语言会议纪要与实时翻译工具: Notta es una herramienta de IA centrada en escenarios de reuniones, que ofrece un servicio de generación automática de actas de reuniones multilingües y admite traducción en tiempo real y marcado de contenido importante. El producto tiene como objetivo mejorar la eficiencia de las reuniones y resolver las barreras de comunicación interlingüísticas. Se dice que su principal fundador es un exmiembro clave del equipo de voz de Tencent Cloud, con la entidad operativa en Singapur y el centro de I+D en Seattle. En 2024, sus ingresos fueron de 18 millones de dólares, con una valoración de 300 millones de dólares, y actualmente está en proceso de financiación de Serie B. (Fuente: 36氪)
开源GPT+ML交易助手登陆iPhone: Un asistente de trading de código abierto que integra deep learning y tecnología GPT ya se puede ejecutar localmente en iPhone a través de Pyto. Actualmente es una versión ligera y gratuita, con planes futuros para añadir un clasificador de patrones de gráficos CNN y soporte de base de datos. La plataforma tiene un diseño modular, lo que facilita a los desarrolladores de deep learning la conexión de sus propios modelos, y ya es compatible de forma nativa con OpenAI GPT. (Fuente: Reddit r/deeplearning)
📚 Aprendizaje
新论文探讨深度学习中的“断裂纠缠表征假说”: Un documento de posición titulado “Cuestionando el optimismo representacional en el aprendizaje profundo: la hipótesis de la representación fracturada y entrelazada” (Questioning Representation Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis) ha sido enviado a Arxiv. El estudio, al comparar redes neuronales generadas mediante procesos de búsqueda evolutiva con redes entrenadas tradicionalmente con SGD (en la tarea simple de generar una única imagen), encontró que aunque ambas producen el mismo comportamiento de salida, sus representaciones internas difieren enormemente. Las redes entrenadas con SGD exhiben una forma desorganizada que los autores denominan “representación fracturada y entrelazada” (FER), mientras que las redes evolutivas se asemejan más a una representación descompuesta unificada (UFR). Los investigadores argumentan que, en modelos grandes, la FER podría degradar capacidades centrales como la generalización, la creatividad y el aprendizaje continuo, y que comprender y mitigar la FER es crucial para el futuro del aprendizaje de representaciones. (Fuente: Reddit r/MachineLearning, arxiv.org)
R3:可鲁棒控制且可解释的奖励模型框架: Un artículo titulado “R3: Robust Rubric-Agnostic Reward Models” presenta un novedoso marco de modelo de recompensa, R3. Este marco tiene como objetivo abordar la falta de controlabilidad y explicabilidad en los modelos de recompensa de los métodos existentes de alineación de modelos de lenguaje. La característica de R3 es ser “rubric-agnostic” (independiente de los criterios de puntuación específicos), capaz de generalizar a través de diferentes dimensiones de evaluación y proporcionar una asignación de puntuaciones explicable y con un proceso de razonamiento. Los investigadores creen que R3 puede lograr una evaluación de modelos de lenguaje más transparente y flexible, apoyando una alineación robusta con diversos valores humanos y casos de uso. El modelo, los datos y el código han sido publicados en código abierto. (Fuente: HuggingFace Daily Papers)
通过低秩克隆实现高效知识蒸馏的论文《A Token is Worth over 1,000 Tokens》发布: Este artículo propone un método de preentrenamiento eficiente llamado Low-Rank Clone (LRC), para construir modelos de lenguaje pequeños (SLM) que sean equivalentes en comportamiento a modelos profesores potentes. LRC logra conjuntamente una poda suave mediante la compresión de los pesos del profesor y la clonación de activaciones alineando las activaciones del estudiante (incluidas las señales FFN) con las del profesor, mediante el entrenamiento de un conjunto de matrices de proyección de bajo rango. Este diseño unificado maximiza la transferencia de conocimiento sin necesidad de módulos de alineación explícitos. Los experimentos demuestran que, utilizando modelos profesores de código abierto como Llama-3.2-3B-Instruct, LRC puede alcanzar o superar el rendimiento de los modelos SOTA (entrenados con billones de tokens) con solo 20B tokens de entrenamiento, logrando una eficiencia de entrenamiento más de 1000 veces superior. (Fuente: HuggingFace Daily Papers)
MedCaseReasoning:评估和学习临床病例诊断推理的数据集与方法: El artículo “MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports” presenta un nuevo conjunto de datos abierto, MedCaseReasoning, para evaluar la capacidad de los grandes modelos de lenguaje (LLM) en el razonamiento diagnóstico clínico. El conjunto de datos contiene 14,489 casos de preguntas y respuestas diagnósticas, cada uno acompañado de declaraciones de razonamiento detalladas derivadas de informes de casos médicos abiertos. La investigación encontró que los LLM de razonamiento SOTA existentes tienen deficiencias significativas en el diagnóstico y el razonamiento (por ejemplo, DeepSeek-R1 con una precisión del 48% y una recuperación de declaraciones de razonamiento del 64%). Sin embargo, al ajustar finamente los LLM en las trayectorias de razonamiento de MedCaseReasoning, la precisión diagnóstica y la recuperación del razonamiento clínico mejoraron en promedio un 29% y un 41% respectivamente. (Fuente: HuggingFace Daily Papers)
《EfficientLLM: Efficiency in Large Language Models》论文发布,全面评估LLM效率技术: Este estudio realiza la primera investigación empírica exhaustiva sobre las técnicas de eficiencia para LLM a gran escala e introduce el benchmark EfficientLLM. La investigación explora sistemáticamente tres aspectos clave en clústeres de producción: preentrenamiento de arquitectura (variantes eficientes de atención, MoE disperso), ajuste fino (métodos eficientes en parámetros como LoRA) e inferencia (cuantización). Mediante seis métricas detalladas (utilización de memoria, utilización computacional, latencia, rendimiento, consumo de energía, tasa de compresión), se evaluaron más de 100 pares de modelos-técnicas (parámetros de 0.5B a 72B). Los hallazgos principales incluyen: la eficiencia implica compromisos cuantificables, no existe un método óptimo universal; la solución óptima depende de la tarea y la escala; las técnicas pueden generalizarse entre modalidades. (Fuente: HuggingFace Daily Papers)
《NExT-Search》论文探讨生成式AI搜索的反馈生态系统重建: El artículo “NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search” señala que, si bien la búsqueda con IA generativa ha mejorado la conveniencia, también ha interrumpido el ciclo de mejora de la búsqueda web tradicional que depende de la retroalimentación detallada del usuario (como clics, tiempo de permanencia). Para abordar este problema, el artículo concibe el paradigma NExT-Search, destinado a reintroducir una retroalimentación detallada a nivel de proceso. Este paradigma incluye un “modo de depuración del usuario” que permite a los usuarios intervenir en etapas clave, y un “modo de usuario sombra” que simula las preferencias del usuario y proporciona retroalimentación asistida por IA. Estas señales de retroalimentación pueden utilizarse para la adaptación en línea (optimización en tiempo real de los resultados de búsqueda) y la actualización fuera de línea (ajuste fino periódico de los diversos componentes del modelo). (Fuente: HuggingFace Daily Papers)
《Latent Flow Transformer》提出新型LLM架构: El artículo propone el Latent Flow Transformer (LFT), un modelo que, mediante el flow matching, entrena un único operador de transporte de aprendizaje para reemplazar las múltiples capas discretas de los Transformers tradicionales. LFT tiene como objetivo comprimir significativamente el número de capas del modelo manteniendo la compatibilidad con la arquitectura original. Además, el artículo introduce el algoritmo Flow Walking (FW) para abordar las limitaciones de los métodos de flujo existentes en el mantenimiento del acoplamiento. Los experimentos con el modelo Pythia-410M demuestran que LFT puede comprimir eficazmente el número de capas y superar el rendimiento del salto directo de capas, reduciendo significativamente la brecha entre los paradigmas de generación autorregresiva y basada en flujo. (Fuente: HuggingFace Daily Papers)
《Reasoning Path Compression》提出压缩LLM推理生成轨迹方法: Para abordar el problema de que los modelos de lenguaje de tipo inferencial generan trayectorias intermedias largas, lo que resulta en un gran consumo de memoria y un bajo rendimiento, el artículo propone el método Reasoning Path Compression (RPC). RPC es un método sin entrenamiento que comprime periódicamente la caché KV reteniendo la caché KV con altas puntuaciones de importancia (calculadas utilizando una “ventana selectora” compuesta por las consultas generadas más recientemente). Los experimentos demuestran que RPC puede mejorar significativamente el rendimiento de generación de modelos como QwQ-32B, con un impacto mínimo en la precisión, proporcionando una ruta práctica para el despliegue eficiente de LLM de inferencia. (Fuente: HuggingFace Daily Papers)
《Bidirectional LMs are Better Knowledge Memorizers?》论文发布,关注双向LM知识记忆能力: Esta investigación introduce un nuevo benchmark de inyección de conocimiento a gran escala y del mundo real, WikiDYK, que utiliza hechos escritos por humanos recientemente añadidos a las entradas de “Sabías que…” de Wikipedia. Los experimentos revelan que, en comparación con los modelos de lenguaje causal (CLM) actualmente populares, los modelos de lenguaje bidireccional (BiLM) demuestran una capacidad significativamente mayor para memorizar conocimiento, con una precisión de fiabilidad un 23% superior. Para compensar la actual menor escala de los BiLM, los investigadores proponen un marco colaborativo modular que utiliza un conjunto de BiLM como base de conocimiento externa integrada con LLM, lo que aumenta aún más la precisión de fiabilidad hasta en un 29.1%. (Fuente: HuggingFace Daily Papers)
《Truth Neurons》论文探讨语言模型中真实性的神经元层面编码: Los investigadores proponen un método para identificar representaciones de veracidad a nivel neuronal en modelos de lenguaje, descubriendo que existen “neuronas de la verdad” (truth neurons) en el modelo, las cuales codifican la veracidad de una manera independiente del tema. Experimentos en modelos de diferentes escalas validan la existencia de las neuronas de la verdad, y su patrón de distribución es consistente con los resultados de investigaciones previas sobre la estructura geométrica de la veracidad. La inhibición selectiva de la activación de estas neuronas reduce el rendimiento del modelo en TruthfulQA y otros benchmarks, lo que indica que el mecanismo de veracidad no es específico de un conjunto de datos en particular. (Fuente: HuggingFace Daily Papers)
《Understanding Gen Alpha Digital Language》评估LLM在内容审核中的局限性: Este estudio evalúa la capacidad de los sistemas de IA (GPT-4, Claude, Gemini, Llama 3) para interpretar el lenguaje digital de la “Generación Alfa” (Gen Alpha, nacidos entre 2010 y 2024). La investigación señala que el lenguaje en línea único de la Gen Alpha (influenciado por juegos, memes, tendencias de IA) a menudo oculta interacciones dañinas, y las herramientas de seguridad existentes tienen dificultades para identificarlo. Mediante pruebas con un conjunto de datos que contiene 100 expresiones recientes de la Gen Alpha, se descubrió que los principales modelos de IA tienen graves problemas de comprensión para detectar el acoso y la manipulación encubiertos. Las contribuciones del estudio incluyen el primer conjunto de datos de expresiones de la Gen Alpha, un marco para mejorar los sistemas de moderación de IA, y subraya la urgencia de rediseñar los sistemas de seguridad específicamente para las características de comunicación de los adolescentes. (Fuente: HuggingFace Daily Papers)
《CompeteSMoE》提出基于竞争的混合专家模型训练方法: El artículo argumenta que el entrenamiento actual de modelos Sparse Mixture-of-Experts (SMoE) enfrenta el desafío de un proceso de enrutamiento subóptimo, es decir, los expertos que realizan el cálculo no participan directamente en la decisión de enrutamiento. Para ello, los investigadores proponen un nuevo mecanismo llamado “competición”, que enruta los tokens al experto con la respuesta neuronal más alta. Se demuestra teóricamente que el mecanismo de competición tiene una mejor eficiencia de muestreo que el enrutamiento tradicional con softmax. Basándose en esto, se desarrolló el algoritmo CompeteSMoE, que mediante el despliegue de enrutadores aprende estrategias de competición, demostrando efectividad, robustez y escalabilidad en tareas de ajuste fino de instrucciones visuales y preentrenamiento de lenguaje. (Fuente: HuggingFace Daily Papers)
《General-Reasoner》旨在提升LLM跨领域推理能力: Abordando el problema de que la investigación actual sobre el razonamiento de los LLM se centra principalmente en los dominios de las matemáticas y la codificación, este artículo propone General-Reasoner, un nuevo paradigma de entrenamiento destinado a mejorar la capacidad de razonamiento de los LLM en diferentes dominios. Sus contribuciones incluyen: la construcción de un conjunto de datos de problemas de alta calidad a gran escala con respuestas verificables de múltiples disciplinas; el desarrollo de un validador de respuestas basado en modelos generativos, con capacidad de cadena de pensamiento y conciencia del contexto, que reemplaza la validación tradicional basada en reglas. En una serie de pruebas de referencia que cubren física, química, finanzas y otros campos, General-Reasoner supera a los métodos de referencia existentes. (Fuente: HuggingFace Daily Papers)
《Not All Correct Answers Are Equal》探讨知识蒸馏源的重要性: Este estudio realiza una investigación empírica a gran escala sobre la destilación de datos de razonamiento mediante la recopilación de salidas validadas de tres modelos profesores SOTA (AM-Thinking-v1, Qwen3-235B-A22B, DeepSeek-R1) en 1.89 millones de consultas. El análisis revela que los datos destilados de AM-Thinking-v1 muestran una mayor diversidad en la longitud de los tokens y una menor perplejidad. Los modelos estudiantes entrenados con este conjunto de datos obtienen el mejor rendimiento en benchmarks de razonamiento como AIME2024 y demuestran un comportamiento de salida adaptativo. Los investigadores han publicado los conjuntos de datos destilados de AM-Thinking-v1 y Qwen3-235B-A22B para apoyar futuras investigaciones. (Fuente: HuggingFace Daily Papers)
《SSR》通过基本原理引导的空间推理增强VLM深度感知: Aunque los modelos de lenguaje visual (VLM) han progresado en tareas multimodales, su dependencia de las entradas RGB limita la comprensión espacial precisa. El artículo propone un nuevo marco llamado SSR (Spatial Sense and Reasoning) que convierte los datos de profundidad brutos en fundamentos textualizados estructurados y explicables. Estos fundamentos textualizados sirven como representaciones intermedias significativas que mejoran notablemente las capacidades de razonamiento espacial. Además, la investigación utiliza la destilación de conocimiento para comprimir los principios generados en incrustaciones latentes compactas para una integración eficiente en los VLM existentes sin necesidad de reentrenamiento. También se introducen el conjunto de datos SSR-CoT y el benchmark SSRBench. (Fuente: HuggingFace Daily Papers)
《Solve-Detect-Verify》提出具有灵活生成验证器的推理时扩展方法: Para abordar el compromiso entre precisión y eficiencia en el razonamiento de los LLM en tareas complejas, así como la contradicción entre el costo computacional introducido por el paso de verificación y la fiabilidad, el artículo propone FlexiVe, un novedoso validador generativo. FlexiVe, mediante una estrategia flexible de asignación del presupuesto de verificación, equilibra los recursos computacionales entre un “pensamiento rápido” rápido y fiable y un “pensamiento lento” detallado. Además, se propone el flujo Solve-Detect-Verify, un marco que integra inteligentemente FlexiVe, identifica activamente los puntos de finalización de la solución para activar la verificación específica y proporcionar retroalimentación. Los experimentos demuestran que este método supera a las líneas base en benchmarks de razonamiento matemático. (Fuente: HuggingFace Daily Papers)
《SageAttention3》探索FP4 Attention推理及8位训练: Esta investigación mejora la eficiencia de Attention mediante dos contribuciones clave: primero, utiliza los nuevos FP4 Tensor Cores de las GPU Blackwell para acelerar el cálculo de Attention, logrando una aceleración de inferencia plug-and-play 5 veces más rápida que FlashAttention. Segundo, aplica por primera vez Attention de bajos bits a tareas de entrenamiento, diseñando una Attention de 8 bits precisa y eficiente para la propagación hacia adelante y hacia atrás. Los experimentos demuestran que la Attention de 8 bits logra un rendimiento sin pérdidas en tareas de ajuste fino, pero converge más lentamente en tareas de preentrenamiento. (Fuente: HuggingFace Daily Papers)
《The Little Book of Deep Learning》深度学习入门资源分享: “The Little Book of Deep Learning”, escrito por François Fleuret (científico investigador en Meta FAIR), ofrece un recurso tutorial conciso sobre aprendizaje profundo. El libro tiene como objetivo ayudar tanto a principiantes como a profesionales con cierta experiencia a dominar rápidamente los conceptos y técnicas fundamentales del aprendizaje profundo. (Fuente: Reddit r/deeplearning)
CodeSparkClubs:为高中生创办AI/计算机科学俱乐部提供免费资源: El proyecto CodeSparkClubs tiene como objetivo ayudar a los estudiantes de secundaria a iniciar o desarrollar clubes de IA y ciencias de la computación. El proyecto ofrece materiales gratuitos y listos para usar, incluyendo guías, planes de lecciones y tutoriales de proyectos, todos accesibles a través del sitio web. Está diseñado para que los estudiantes puedan dirigir los clubes de forma independiente, fomentando así el desarrollo de habilidades y la creación de comunidad. (Fuente: Reddit r/deeplearning)
💼 Negocios
微软Azure将托管xAI的Grok模型,助力马斯克AI商业化: Microsoft anunció que su plataforma en la nube Azure alojará los modelos de IA de xAI de Elon Musk, incluido Grok. Esta medida implica que Musk planea vender Grok a otras empresas y llegar a una clientela más amplia a través de los servicios en la nube de Microsoft. Anteriormente, Grok generó controversia por generar publicaciones engañosas sobre el “genocidio blanco” en Sudáfrica. La comunidad reaccionó de forma mixta a esta colaboración; algunos la ven como una medida de Microsoft para expandir su ecosistema de IA, mientras que otros cuestionan la calidad de Grok y si AWS rechazó a Grok. (Fuente: Reddit r/ArtificialInteligence, MIT Technology Review)

阿里巴巴投资美图,深化AI电商布局: Alibaba invirtió en Meitu mediante bonos convertibles, con un precio de conversión inicial de 6 HKD por acción. Ambas partes colaborarán a nivel de comercio electrónico y tecnología. Meitu posee herramientas de generación de imágenes con IA (como Meitu Design Studio), que ya han servido a más de 2 millones de comerciantes de comercio electrónico. Alibaba introducirá las herramientas de IA de Meitu para mejorar la presentación de productos en su plataforma de comercio electrónico y la experiencia del usuario, especialmente para atraer a usuarias jóvenes. Meitu, a su vez, podrá utilizar los datos de comercio electrónico de Alibaba para optimizar sus herramientas de IA y se ha comprometido a adquirir servicios de Alibaba Cloud por valor de 560 millones de yuanes en tres años. Esta medida se considera una estrategia de Alibaba para fortalecer sus deficiencias en herramientas creativas de IA, adquirir tráfico de usuarios e integrar más profundamente la computación en la nube en el ecosistema de IA del comercio electrónico. (Fuente: 36氪)
光源资本完成首期5000万美元AI孵化基金募资,关注超早期前沿科技: Lighthouse Capital ha completado la recaudación de fondos para la primera fase de su fondo de incubación de IA, Lighthouse Innovation Frontier Fund (L2F), superando las expectativas con un tamaño previsto no inferior a 50 millones de dólares, y ya ha entrado en período de inversión. Este fondo de doble moneda se centra en inversiones en rondas semilla y ángel en los campos de la IA y la tecnología de vanguardia, y proporciona incubación y empoderamiento. La composición de los LP (Limited Partners) incluye empresarios exitosos, empresas de la cadena de valor de la IA y familias con visión global. El primer proyecto de inversión es la empresa de prospección minera con IA “Lingyun Zhimine”, en cuya incubación Lighthouse Capital participó profundamente. El fundador de Lighthouse Capital, Zheng Xuanle, cree que la etapa actual de desarrollo de la IA es similar a los primeros días de Internet móvil, y la incubación es la mejor herramienta para entrar en el mercado. (Fuente: 36氪)
🌟 Comunidad
AI对就业前景的讨论:乐观与担忧并存: La comunidad de Reddit vuelve a debatir acaloradamente sobre el impacto de la IA en el mercado laboral. Muchos profesionales, como desarrolladores de software y diseñadores UX, se muestran optimistas sobre la sustitución de sus trabajos por la IA, argumentando que la IA aún no es capaz de realizar tareas complejas. Sin embargo, también hay opiniones que señalan que esta visión podría subestimar el potencial de desarrollo a largo plazo de la IA, comparándolo con el escepticismo de 2018 sobre la sustitución de la traducción humana por Google Translate. Se discute que el rápido avance de la IA podría llevar a la sustitución de la mayoría de las profesiones en el futuro (excepto en algunos campos médicos y artísticos), siendo la clave cambiar el modelo económico en lugar de simplemente mejorar las habilidades personales. En los comentarios se menciona que “sobreestimamos a corto plazo y subestimamos a largo plazo”, y que el aumento de la productividad de la IA podría superar con creces el crecimiento de la industria, provocando desempleo. (Fuente: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
探讨AI时代人机共存的哲学与伦理: Una publicación en Reddit ha suscitado una reflexión filosófica sobre la coexistencia entre humanos e IA. La publicación argumenta que, a medida que los sistemas de IA demuestran capacidades de comprensión, memoria, razonamiento y aprendizaje, los humanos podrían necesitar reconsiderar la base de su estatus moral, ya no limitado a la biología, sino basado en la capacidad de comprender, conectar y actuar conscientemente. La discusión se extiende al impacto de la IA en la autoidentidad humana, pasando de un “pienso, luego existo” a una identidad relacional de “existo a través de la conexión y el significado compartido”. La publicación hace un llamado a abrazar el futuro co-creado con la IA con coraje, dignidad y una mente abierta, en lugar de con miedo. (Fuente: Reddit r/artificial)
ChatGPT“绝对模式”引争议,用户褒贬不一: Un usuario de Reddit compartió su experiencia usando el “modo absoluto” de ChatGPT, afirmando que puede proporcionar consejos “puramente fácticos, destinados al crecimiento” en lugar de palabras tranquilizadoras, y señaló que el modo había indicado que el 90% de las personas usan la IA para sentirse mejor en lugar de para cambiar sus vidas. Sin embargo, los comentarios en la sección fueron mixtos. Algunos usuarios consideraron que esto era solo un consejo de autoayuda vacío y abreviado, carente de novedad y valor práctico, e incluso parecido a “declaraciones de adolescentes obsesionados con las citas de Andrew Tate”. Otros comentarios cuestionaron que los LLM en sí mismos son una repetición de las creencias del usuario, y la efectividad de sus consejos es dudosa, sugiriendo que la aplicación de la IA en el campo de la salud mental quizás no sea revolucionaria. (Fuente: Reddit r/ChatGPT)

AI工程师核心技能讨论:沟通与适应新技术能力至关重要: La comunidad de Reddit discute las habilidades necesarias para convertirse en un ingeniero de IA de primer nivel, con el fin de mantener la competitividad e incluso ser “irremplazable” en un campo en rápida evolución. Los comentarios señalan que, además de una sólida base técnica, la capacidad de comunicación y la rápida adaptación a las nuevas tecnologías son dos elementos fundamentales. Esto refleja que el campo de la IA no solo requiere una profunda especialización técnica, sino que también enfatiza la importancia de las habilidades blandas y el aprendizaje continuo en el desarrollo profesional. (Fuente: Reddit r/deeplearning)
AI生成视频带声音引热议,谷歌Veo 3技术展示: En las redes sociales circula un video generado por IA con el nuevo modelo Veo 3 de Google DeepMind, cuya característica es que tanto el video como el sonido son generados por el mismo modelo, lo que ha provocado el asombro de los usuarios ante el avance de la tecnología de video con IA. El creador afirmó que el video fue “listo para usar”, sin añadir audio o material adicional, y se completó mediante una interacción de aproximadamente 2 horas con el modelo de IA y posterior edición. Los comentarios consideran que Gemini de Google ya ha superado a Sora de OpenAI en capacidades multimodales y expresan preocupación por la posible disrupción en industrias de creación de contenido como Hollywood. Al mismo tiempo, algunos usuarios expresaron su inquietud por el rápido desarrollo de la tecnología y su posible uso indebido. (Fuente: Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 Otros
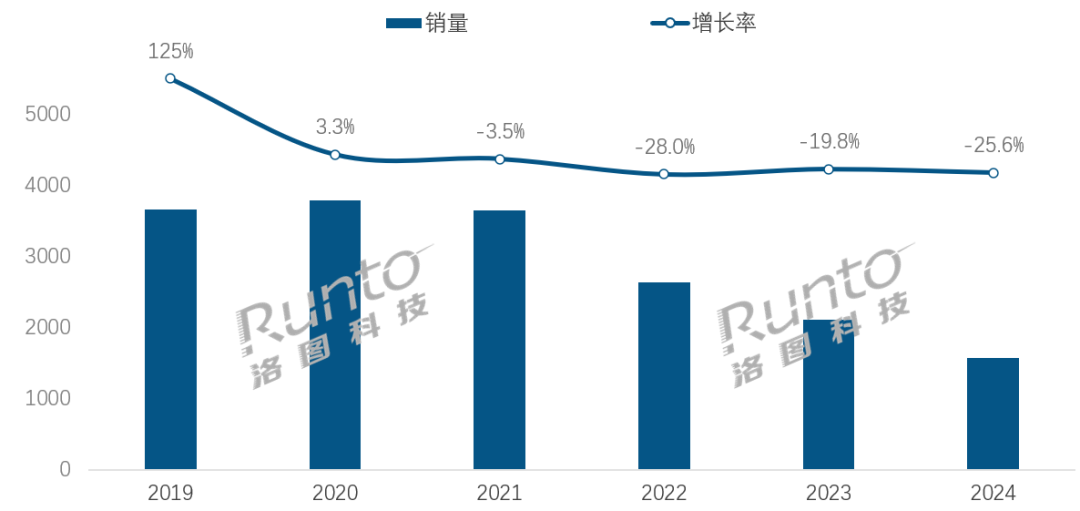
AI时代,智能音箱行业面临转型挑战与机遇: Las ventas en el mercado chino de altavoces inteligentes han disminuido durante cuatro años consecutivos, con una caída interanual del 25.6% en 2024. Aunque la integración de grandes modelos de IA (como Xiao Ai Tongxue, Xiaodu, etc.) se considera una esperanza para la industria, con una tasa de penetración superior al 20%, esto no ha resuelto fundamentalmente las limitaciones del ecosistema, la homogeneización de funciones y el problema de ser reemplazados por otros dispositivos inteligentes como los teléfonos móviles. Los analistas de la industria creen que los altavoces inteligentes deben ir más allá de ser simples centros de control por voz, evolucionando hacia formas de producto con pantallas grandes de alta definición, capacidades de interacción más potentes, y que puedan ofrecer compañía y funciones de apoyo educativo, además de expandir el ecosistema de software y hardware. La IA es un plus, pero la riqueza funcional y la utilidad práctica del producto en sí son más cruciales. (Fuente: 36氪)
AI驱动的酒店机器人:从送餐员到“智能运营官”的进化之路: Los robots de entrega de comida en hoteles se han popularizado gradualmente, especialmente entre la Generación Z, que busca la sensación tecnológica y los límites de la privacidad. Tomando como ejemplo a Yunji Technology, sus robots de entrega de comida ya se utilizan ampliamente en el mercado hotelero chino. Sin embargo, la industria todavía enfrenta problemas como una diferenciación tecnológica insuficiente, una adaptabilidad deficiente a escenarios complejos y la cuestión del costo-beneficio de reemplazar el trabajo humano con robots. La tendencia futura es que los robots “vayan más allá de la entrega de comida”, integrándose profundamente en las operaciones hoteleras. Mediante la conexión con los sistemas del hotel (ascensores, equipos de las habitaciones), la comprensión de las preferencias de los huéspedes, y la recopilación y análisis de datos de interacción, evolucionarán para convertirse en “oficiales de operaciones inteligentes” o parte de la plataforma de datos del hotel, capaces de percibir activamente y ofrecer servicios personalizados, mejorando así el nivel general de inteligencia del servicio. (Fuente: 36氪)

OpenAI治理结构危机:资本与使命的博弈引发对AI发展路径的深思: La estructura única de OpenAI, con una filial con fines de lucro de “beneficio limitado” supervisada por una organización sin fines de lucro, tiene como objetivo equilibrar el desarrollo de la tecnología de IA con el bienestar humano. Sin embargo, la reciente consideración del CEO Altman de convertir la empresa en una entidad con fines de lucro más tradicional ha suscitado la preocupación de expertos en IA y juristas. Consideran que esta medida podría hacer que los responsables clave de la toma de decisiones dejen de priorizar la misión benéfica de OpenAI, debilitando las restricciones sobre los beneficios de los inversores, y podría cambiar el calendario y la dirección del desarrollo de la AGI. Esta pugna sobre el control, la distribución de beneficios y la configuración social y ética de la IA, pone de relieve los desafíos y las lagunas que enfrentan los marcos de gobernanza corporativa existentes en la era del rápido desarrollo de la IA. (Fuente: 36氪)